Полное руководство по файлу robots.txt для WordPress
WordPress
access_time25 июля, 2018
hourglass_empty6мин. чтения
Чтобы быть уверенным, что ваш сайт хорошо ранжируется в результатах поисковых систем (Search Engine Result Pages – SERPs), вам нужно сделать его наиболее важные страницы удобным для поиска и индексирования «роботоми» («ботами») поисковых движков. Хорошо структурированный файл robots.txt поможет направить этих ботов на страницы, которые вы хотите проиндексировать (и пропустить другие).
В этой статье мы собираемся раскрыть такие вопросы:
- Что такое файл robots.txt и почему он важен
- Где находится robots.txt для WordPress
- Как создать файл robots.txt
- Какие правила должны быть в файле robots.txt для WordPress
- Как проверить файл robots.txt и отправить его в консоль Google Search.


К концу нашего обсуждения у вас будет всё необходимое для настройки отличного файла robots.txt для вашего сайт на WordPress. Начнём!
Что такое файл
robots.txt для WordPress и зачем он нуженКогда вы создаёте новый сайт, поисковые движки будут отправлять своих миньонов (или роботов) для сканирования и создания карты всех его страниц. Таким образом, они будут знать, какие страницы показывать как результат, когда кто-либо ищет по относящимся ключевым словам. На базовом уровне это достаточно просто.
Проблема состоит в том, что современные сайты содержат множество других элементом, кроме страниц. WordPress позволяет вам устанавливать, например, плагины, которые часто имеют свои каталоги. Вы не хотите показывать это в результатах поисковой выдачи, поскольку они не соответствуют содержимому.
Что делает файл robots.txt, так это обеспечивает ряд указаний для поисковых роботов. Он говорит им: «Посмотрите здесь, но не заходите в эти области!». Этот файл может настолько подробным, на сколько вы захотите и его очень просто создавать, даже если вы не технический волшебник.
Этот файл может настолько подробным, на сколько вы захотите и его очень просто создавать, даже если вы не технический волшебник.
На практике, поисковые движки всё равно будут сканировать ваш сайт, даже если вы не создадите файл robots.txt. Однако, не создавать его является весьма нерациональным шагом. Без этого файла вы оставите роботам для индексации весь контент вашего сайта и они решать, что можно показывать все части вашего сайта, даже те, которые бы вы хотели скрыть от общего доступа.
Более важный момент, без файла robots.txt, у вас будет очень много обращений для сканирования ботами вашего сайта. Это негативно скажется на его производительности. Даже если посещаемость вашего сайта ещё невелика, скорость загрузки страницы – это то, что всегда должно быть в приоритете и на высшем уровне. В конце концов, есть всего несколько моментов, которые люди не любят больше, чем медленная загрузка сайтов.
Где находится файл robots.txt для WordPress
Когда вы создаёте сайт на WordPress, файл robots. txt создаётся автоматически и располагается в вашем главном каталоге на сервере. Например, если ваш сайт расположен здесь: yourfakewebsite.com, вы сможете найти его по адресу yourfakewebsite.com/robots.txt и увидеть примерно такой файл:
txt создаётся автоматически и располагается в вашем главном каталоге на сервере. Например, если ваш сайт расположен здесь: yourfakewebsite.com, вы сможете найти его по адресу yourfakewebsite.com/robots.txt и увидеть примерно такой файл:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/
Это пример самого простого базового файла robots.txt. Переводя на понятный человеку язык, правая часть после User-agent: объявляет, для каких роботов предназначены правила ниже. Звёздочка означает, что правило универсальное и применяется для всех ботов. В данном случае файл говорит ботам, что им нельзя сканировать каталоги wp-admin и wp-includes
Конечно же, вы можете добавить больше правил в свой файл. Прежде чем вы это сделаете, вам нужно понять, что это виртуальный файл. Обычно, WordPress robots.txt находится в корневом(root) каталоге, который часто называется public_html или www (или по названию имени вашего сайта):
Обычно, WordPress robots.txt находится в корневом(root) каталоге, который часто называется public_html или www (или по названию имени вашего сайта):
Надо отметить, что файл robots.txt для WordPress, устанавливаемый по умолчанию, не доступен для вас ни из какого каталога. Он работает, но если вы захотите внести изменения, вам нужно создать ваш собственный файл и загрузить его в
Мы рассмотрим несколько способов создания файла robots.txt для WordPress за минуту. А сейчас давайте обсудим, как определить, какие правила нужно включить в файл.
Какие правила нужно включить в файл robots.txt для WordPress
В предыдущем разделе мы видели пример генерируемого WordPress файла robots.txt. Он включает в себя только два коротких правила, но для большинства сайтов их достаточно. Давайте взглянем на два разных файла robots.
Вот наш первый пример файла robots.txt WordPress:
User-agent: * Allow: / # Disallowed Sub-Directories Disallow: /checkout/ Disallow: /images/ Disallow: /forum/
Этот файл robots.txt создан для форума. Поисковые системы обычно индексируют каждое обсуждение на форуме. В зависимости от того, какая тематика вашего форума, вы можете захотеть запретить индексацию. Так, например, Google не будет индексировать сотни коротких обсуждения пользователей. Вы также можете установить правила, указывающие на конкретную ветвь форума, чтобы исключить её, и позволить поисковым системам обходить остальные.
Вы также заметили строку, которая начинается с Allow: / вверху файла. Эта строка говорит ботам, что они могут сканировать все страницы вашего сайта, кроме установленных ниже ограничений. Также вы заметили, что мы установили эти правила как универсальные (со звёздочкой), как было в виртуальном файле WordPress robots. txt.
txt.
Давайте проверим другой пример файла WordPress robots.txt:
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/ User-agent: Bingbot Disallow: /
В этом файле мы устанавливаем те же правила, что идут в WordPress по умолчанию. Хотя мы также добавляем новый набор правил, которые блокируют поисковых роботов Bing от сканирования нашего сайта. Bingbot, как можно понять, это имя робота.
Вы можете совершенно конкретно задавать поисковых роботов отдельного движка для ограничения/разрешения их доступа. На практике, конечно, Bingbot очень хороший (даже если не такой хороший, как Googlebot). Однако, есть и много вредоносных роботов.
Плохой новостью является то, что они далеко не всегда следуют инструкциям из файла robots.txt (они же всё же работают как террористы). Следует иметь в виду, что, хотя большинство роботов будут использовать указания, представленные в этом файле, но вы не можете принудить их это делать.
Если глубже вникнуть в тему, вы найдёте много предложений того, что разрешать и что блокировать на своём сайте WordPress. Хотя, из нашего опыта, меньше правил часто лучше. Вот пример рекомендованного вида вашего первого файла robots.txt:
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/
Традиционно WordPress любит закрывать каталоги wp-admin и
Что содержится в вашем файле robots.txt будет зависеть от особенностей и потребностей вашего сайта. Поэтому смело проводите больше исследований!
Как создать файл robots.txt для WordPress (3 способа)
Как только вы решили сделать свой файл robots. txt, всё что осталось – это найти способ его создать. Вы можете редактировать robots.txt в WordPress, используя плагин или вручную. В этом разделе мы обучим вас применению двух наиболее популярных плагинов для выполнения этой задачи и обсудим, как создать и загрузить файл вручную. Поехали!
txt, всё что осталось – это найти способ его создать. Вы можете редактировать robots.txt в WordPress, используя плагин или вручную. В этом разделе мы обучим вас применению двух наиболее популярных плагинов для выполнения этой задачи и обсудим, как создать и загрузить файл вручную. Поехали!
1. Использование плагина Yoast SEO
Yoast SEO вряд ли требует представления. Это наиболее известный SEO-плагин для WordPress, он позволяет вам улучшать ваши записи и страницы для лучшего использования ключевых слов. Кроме этого, он также оценит ваш контент с точки зрения удобности чтения, а это повысит аудиторию поклонников.
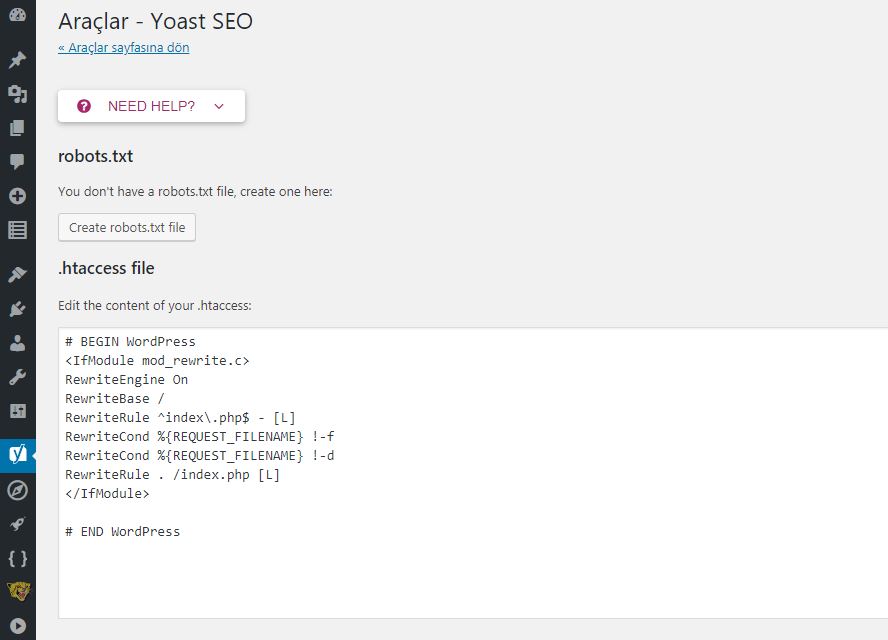
Наша команда является почитателями плагина Yoast SEO благодаря его простоте и удобству. Это относится и к вопросу создания файла robots.txt. Как только вы установите и активируете свой плагин, перейдите во вкладку SEO › Инструменты в своей консоли и найдите настройку Редактор файлов:
Нажав на эту ссылку, вы можете редактировать файл . htaccess не покидая админ консоль. Здесь же есть кнопка Создать файл robots.txt:
htaccess не покидая админ консоль. Здесь же есть кнопка Создать файл robots.txt:
После нажатия на кнопку во вкладке будет отображён новый редактор, где вы можете напрямую редактировать ваш файл robots.txt. Обратите внимание, что Yoast SEO устанавливает свои правила по умолчанию, которые перекрывают правила существующего виртуального файла robots.txt.
После удаления или добавления правил нажимайте кнопку Сохранить изменения в robots.txt для вступления их в силу:
Это всё! Давайте теперь посмотрим на другой популярный плагин, который позволит нам выполнить эту же задачу.
2. Применение плагина All in One SEO Pack
Плагин All in One SEO Pack – ещё один прекрасный плагин WordPress для настройки SEO. Он включает в себя большинство функций плагина Yoast SEO, но некоторые предпочитают его потому что он более легковесный. Что касается файла robots.txt, его создать в этом плагине также просто.
После установки плагина, перейдите на страницу All in One SEO > Управление модулями в консоли. Внутри вы найдёте опцию Robots.txt с хорошо заметной кнопкой Activate внизу справа. Нажмите на неё:
Теперь в меню All in One SEO будет отображаться новая вкладка Robots.txt. Если вы нажмёте на этот пункт меню, вы увидите настройки для добавления новых правил в ваш файл, сохраните внесённые изменения или удалите всё:
Обратите внимание, что вы не можете напрямую изменять файл robots.txt при помощи этого плагина. Содержимое файла будет неактивным, что видно по серому фону поля, в отличие от Yoast SEO, который позволяет вам вводить всё, что вы хотите:
Но, так как добавление новых правил очень простая процедура, то этот факт не должен расстроить вас. Более важный момент, что All in One SEO Pack также включает функцию, которая поможет вам блокировать «плохих» ботов, её вы можете найти во вкладке All in One SEO:
Это всё, что вам нужно сделать, если вы выбрали этот способ. Теперь давайте поговорим о том, как вручную создать файл robots.txt, если вы не хотите устанавливать дополнительный плагин только для этой задачи.
Теперь давайте поговорим о том, как вручную создать файл robots.txt, если вы не хотите устанавливать дополнительный плагин только для этой задачи.
3. Создание и загрузка файла
robots.txt для WordPress по FTPЧто может быть проще, чем создание текстового файла txt. Всё, что вам нужно сделать, открыть свой любимый редактор (как, например, Notepad или TextEdit) и ввести несколько строк. Потом вы сохраняете файл, используя любое имя и расширение txt. Это буквально займёт несколько секунд, поэтому вы вполне можете захотеть создать robots.txt для WordPress без использования плагина.
Вот быстрый пример такого файла:
Мы сохранили этот файл локально на компьютере. Как только вы сделали свой собственный файл вам нужно подключиться к своему сайту по FTP. Если вы не совсем понимаете, как это сделать, у нас есть руководство, посвящённое этому – использование удобного для новичков клиента FileZilla.
После подключения к своему сайту перейдите в каталог public_html. Теперь, всё что вам нужно сделать это загрузить файл robots.txt со своего компьютера на сервер. Вы можете это сделать либо нажав правой кнопкой мыши на файле в локальной FTP навигаторе или простым перетаскиванием мышью:
Это займёт всего несколько секунд. Как вы видите, этот способ не сложнее использования плагина.
Как проверит WordPress robots.txt и отправить его в Консоль Google Search
Теперь, когда ваш файл WordPress robots.txt создан и загружен на сайт, вы можете проверить его на ошибки в Консоли Google Search. Search Console – это набор инструментов Google, призванных помочь вам отслеживать то, как ваш контент появляется в результатах поиска. Один из таких инструментов проверяет robots.txt, его вы можете использовать перейдя в своей консоли в раздел Инструмент проверки файла robots.txt:
Здесь вы найдёте поле редактора, где вы можете добавить код своего файла WordPress robots. txt, и нажать Отправить в правом нижнем углу. Консоль Google Search спросит вас, хотите ли вы использовать новый код или загрузить файл с вашего сайта. Выберите опцию, которая говорит Ask Google to Update для публикации вручную:
txt, и нажать Отправить в правом нижнем углу. Консоль Google Search спросит вас, хотите ли вы использовать новый код или загрузить файл с вашего сайта. Выберите опцию, которая говорит Ask Google to Update для публикации вручную:
Теперь платформа проверит ваш файл на ошибки. Если будет найдена ошибка, информация об этом будет показана вам.
Вы ознакомились с несколькими примерами файл robots.txt WordPress, и теперь у вас есть ещё больше шансов создать свой идеальный!
Заключение
Чтобы быть уверенным, что ваш сайт представлен наилучшим образом для поисковых роботов стоит позаботиться о том, чтобы для них был открыт необходимый контент. Как мы увидели, хорошо настроенный файл robots.txt WordPress поможет показать роботам, каким образом лучше взаимодействовать с вашим сайтом. Таким образом, они помогут тем, кто ищет получить более релевантный и полезный контент.
У вас остались вопросы о том, как редактировать robots. txt в WordPress? Напишите нам в разделе комментариев ниже!
txt в WordPress? Напишите нам в разделе комментариев ниже!
Правильный robots.txt для WordPress
Относительно того, что должно быть внутри файла robots.txt до сих пор возникает куча споров. Вообще, на мой взгляд, этот файл должен содержать две обязательные вещи:
Скрывать в нём все функциональные PHP-файлы (как делают некоторые вебмастера) я не вижу смысла. А уж страницы сайта тем более. Я проводил эксперимент со скрытием страниц через
Для скрытия от индексации страниц сайта используйте метатег:
<meta name="robots" content="noindex, follow" />
Функция do_robots()
Выводит несколько директив для файла robots.txt, рекомендуемые для WordPress.
Параметров не имеет, зато имеет 1 хук и 1 фильтр.
Рассмотрим по порядку, как работает функция:
- В первую очередь функция устанавливает
Content-Typetext/plain(с кодировкой UTF-8). - Затем запускается экшен
do_robotstxt(без параметров). - Третьим шагом идёт проверка, отмечена ли галочка «Попросить поисковые системы не индексировать сайт» в настройках чтения:
- Если отмечена, содержимое
robots.txtбудет:User-agent: * Disallow: /
Если не отмечена:
User-agent: * Disallow: /wp-admin/
- Непосредственно перед выводом срабатывает фильтр
robots_txt(WordPress 3.0+) с двумя параметрами —robots.txt) и$public(отмечена ли галочка в пункте 3).
Готовый robots.txt
К результату функции do_robots() добавим еще то, о чем я говорил в начале поста и получим вот такой robots.txt для WordPress:
User-agent: * Disallow: /wp-admin/ User-agent: Yandex Disallow: /wp-admin/ Host: truemisha.ru Sitemap: https://misha.agency/sitemap.xml
Создать его вы можете при помощи любого текстового редактора. Сохраните его там же, где находятся директории
Сохраните его там же, где находятся директории wp-admin
wp-content.Миша
Недавно я осознал, что моя миссия – способствовать распространению WordPress. Ведь WordPress – это лучший движок для разработки сайтов – как для тех, кто готов использовать заложенную структуру этой CMS, так и для тех, кто предпочитает headless решения.
Сам же я впервые познакомился с WordPress в 2009 году. Организатор WordCamp. Преподаватель в школах Epic Skills и LoftSchool.
Если вам нужна помощь с вашим сайтом или может даже разработка с нуля на WordPress / WooCommerce — пишите. Я и моя команда сделаем вам всё на лучшем уровне.
Что такое robots.txt и как его настроить
Знание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.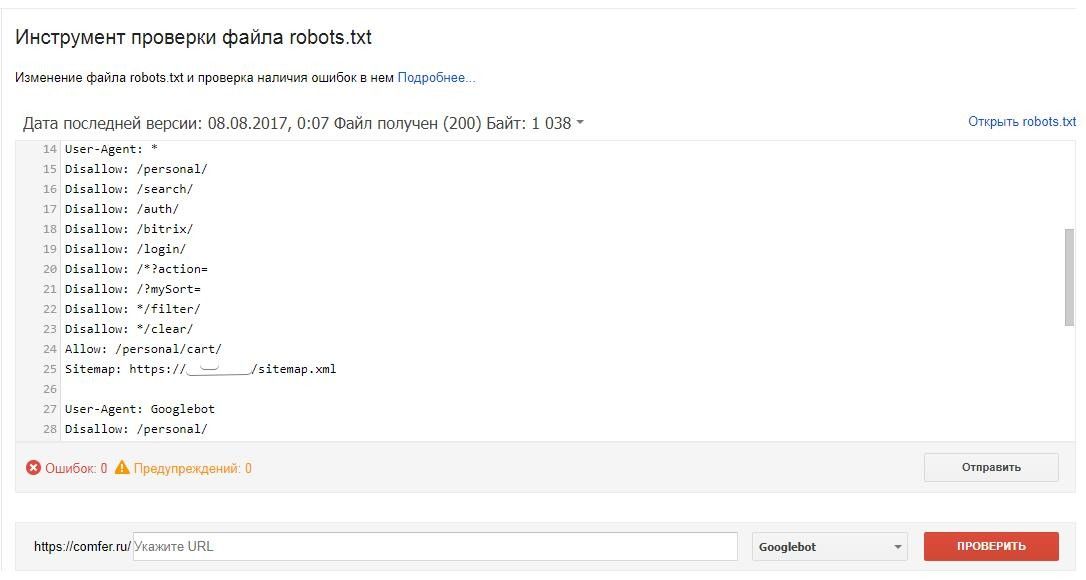
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на хостинге.
Что такое robots.txt
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно.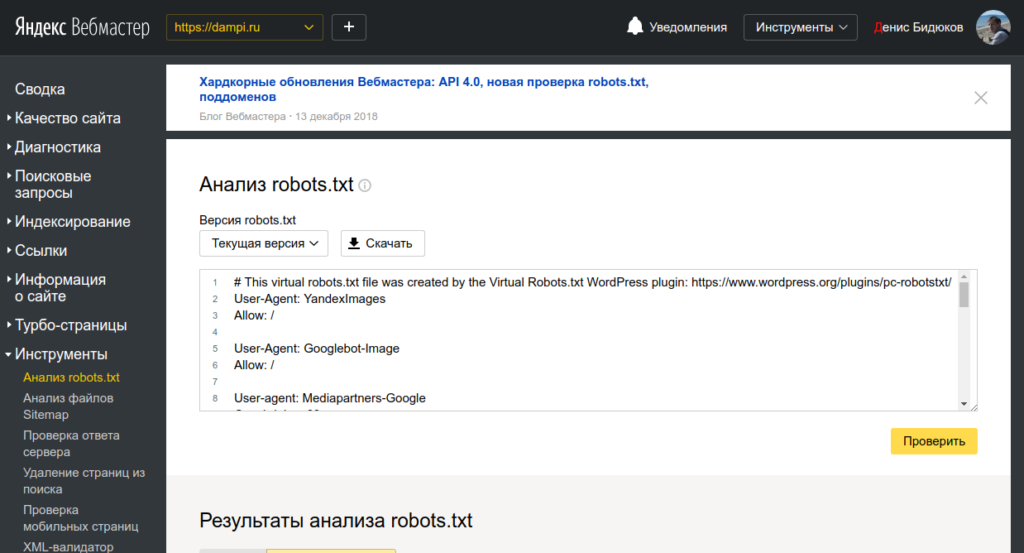 robots.txt скрывает от индексации:
robots.txt скрывает от индексации:
- дубли страниц;
- служебные файлы;
- файлы, которые бесполезны для посетителей;
- страницы с неуникальным контентом.
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Главное правило называется User-agent. В нем мы создаем кодовое слово для роботов. Если робот видит такое слово, он понимает, что это правило для него.
Пример:
User-agent: Yandex
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
User-agent: *
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Allow: /category/
Даем рекомендацию, чтобы индексировались категории.
Disallow: /
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
- * – звездочка означает любую последовательность символов (либо отсутствие символов).
- $ – знак доллара является своеобразной точкой, которая прерывает последовательность символов.
Disallow: /category/$ # закрываем только страницу категорий Disallow: /category/* # закрываем все страницы в папке категории
Sitemap
Данная директива нужна для того, чтобы сориентировать робота, если он заплутает. Мы показываем роботу дорогу к Sitemap.
Пример:
Sitemap: http://site.ru/sitemap.xml
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Crawl-delay: 10
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
User-agent: * Disallow: /
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots. txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
Есть потрясающий инструмент, который позволит вам включиться в творческую работу с директивами и прописать правильный robots.txt – инструмент от Яндекс.Вебмастера.
Переходим в инструмент, вводим домен и содержимое вашего файла.
Нажимаем «Проверить» и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
Вводим список адресов, которые нас интересуют, и нажимаем «Проверить». Инструмент сообщит нам, разрешены ли для индексации данные адреса страниц, а в столбце «Результат» будет видно, почему страница индексируется или не индексируется.
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
User-agent: * Disallow: /cgi-bin # папка на хостинге Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ # Все служебные файлы можно закрыть другим образом: Disallow: /wp- Disallow: /xmlrpc.php # файл WordPress API Disallow: /*? # поиск Disallow: /?s= # поиск Allow: /*.css # стили Allow: /*.js # скрипты Sitemap: https://site.ru/sitemap.xml # путь к карте сайта (надо прописать свой сайт)
Правильный robots.txt для Joomla
User-agent: * Disallow: /administrator/ Disallow: /bin/ Disallow: /cache/ Disallow: /cli/ Disallow: /components/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /layouts/ Disallow: /libraries/ Disallow: /logs/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Sitemap: https://site.
 ru/sitemap.xml
ru/sitemap.xmlЗдесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.
Правильно настроенный файл robots.txt способен оказать позитивное влияние на продвижение сайта. Если вы хотите избавиться от мусора и навести порядок на сайте, файл robots.txt готов прийти на помощь.
правильный пример на WordPress для Яндекса и Google
Всем привет! Сегодня я бы хотел Вам рассказать про файл robots.txt. Да, про него очень много чего написано в интернете, но, если честно, я сам очень долгое время не мог понять, как же создать правильный robots.txt. В итоге я сделал один и он стоит на всех моих блогах. Проблем с индексацией сайта я не замечаю, robots.txt работает просто великолепно.
Robots.txt для WordPress
А зачем, собственно говоря, нужен robots.txt? Ответ все тот же – продвижение сайта в поисковых системах. То есть составление robots. txt – это одно из частей поисковой оптимизации сайта (кстати, очень скоро будет урок, который будет посвящен всей внутренней оптимизации сайта на WordPress. Поэтому не забудьте подписаться на RSS, чтобы не пропустить интересные материалы.).
txt – это одно из частей поисковой оптимизации сайта (кстати, очень скоро будет урок, который будет посвящен всей внутренней оптимизации сайта на WordPress. Поэтому не забудьте подписаться на RSS, чтобы не пропустить интересные материалы.).
Одна из функций данного файла – запрет индексации ненужных страниц сайта. Также в нем задается адрес карты сайта sitemap.xml и прописывается главное зеркало сайта (сайт с www или без www).
Примечание: для поисковых систем один и тот же сайт с www и без www совсем абсолютно разные сайты. Но, поняв, что содержимое этих сайтов одинаковое, поисковики “склеивают” их. Поэтому важно прописать главное зеркало сайта в robots.txt. Чтобы узнать, какое главное (с www или без www), просто наберите адрес своего сайта в браузере, к примеру, с www, если Вас автоматически перебросит на тот же сайт без www, значит главное зеркало Вашего сайта без www. Надеюсь правильно объяснил.
Было:
Стало (после перехода на сайт, www автоматически удалились, и сайт стал без www):
Так вот, этот заветный, по-моему, правильный robots. txt для WordPress Вы можете увидеть ниже.
txt для WordPress Вы можете увидеть ниже.
Правильный Robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: wpnew.ru
Sitemap: https://wpnew.ru/sitemap.xml.gz
Sitemap: https://wpnew.ru/sitemap.xml
Все что дано выше, Вам нужно скопировать в текстовой документ с расширением . txt, то есть, чтобы название файла было robots.txt. Данный текстовой документ Вы можете создать, к примеру, с помощью программы Notepad++. Только, не забудьте, пожалуйста, изменить в последних трех строчках адрес wpnew.ru на адрес своего сайта. Файл robots.txt должен располагаться в корне блога, то есть в той же папке, где находятся папки wp-content, wp-admin и др. .
txt, то есть, чтобы название файла было robots.txt. Данный текстовой документ Вы можете создать, к примеру, с помощью программы Notepad++. Только, не забудьте, пожалуйста, изменить в последних трех строчках адрес wpnew.ru на адрес своего сайта. Файл robots.txt должен располагаться в корне блога, то есть в той же папке, где находятся папки wp-content, wp-admin и др. .
Те, кому же лень создавать данный текстовой файл, можете просто скачать robots.txt и также там подкорректировать 3 строчки.
Хочу отметить, что в техническими частями, о которых речь пойдет ниже, себя сильно загружать не нужно. Привожу их для “знаний”, так сказать общего кругозора, чтобы знали, что и зачем нужно.
Итак, строка:
User-agent
задает правила для какого-то поисковика: к примеру “*” (звездочкой) отмечено, что правила для всех поисковиков, а то, что ниже
User-agent: Yandex
означает, что данные правила только для Яндекса.
Disallow
Здесь же Вы “засовываете” разделы, которые НЕ нужно индексировать поисковикам. К примеру, на странице https://wpnew.ru/tag/seo у меня идет дубль статей (повторение) с обычными статьями, а дублирование страниц отрицательно сказывается на поисковом продвижении, поэтому, крайне желательно, данные секторы нужно закрыть от индексации, что мы и делаем с помощью этого правила:
К примеру, на странице https://wpnew.ru/tag/seo у меня идет дубль статей (повторение) с обычными статьями, а дублирование страниц отрицательно сказывается на поисковом продвижении, поэтому, крайне желательно, данные секторы нужно закрыть от индексации, что мы и делаем с помощью этого правила:
Disallow: /tag
Так вот, в том robots.txt, который дан выше, от индексации закрыты почти все ненужные разделы сайта на WordPress, то есть просто оставьте все как есть.
Host
Здесь мы задаем главное зеркало сайта, о котором я рассказывал чуть выше.
Sitemap
В последних двух строчках мы задаем адрес до двух карт сайта, созданные с помощью плагина Google XML Sitemaps.
Возможные проблемы
Если у Вас на блоге не стоит ЧПУ (именно так у меня происходит с тем сайтом, которого я занимаюсь продвижением), то с тем robots.txt, который дан выше, могут быть проблемы. Напомню, что без ЧПУ ссылки на сайте на посты выглядят примерно следующим образом:
А вот из-за этой строчки в robots. txt, у меня перестали индексироваться посты сайта:
txt, у меня перестали индексироваться посты сайта:
Disallow: /*?*
Как видите, эта самая строка в robots.txt запрещает индексирование статей, что естественно нам нисколько не нужно. Чтобы исправить это, просто нужно удалить эти 2 строчки (в правилах для всех поисковиков и для Яндекса) и окончательный правильный robots.txt для WordPress сайта без ЧПУ будет выглядеть следующим образом:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
Host: wpnew. ru
ru
Sitemap: https://wpnew.ru/sitemap.xml.gz
Sitemap: https://wpnew.ru/sitemap.xml
Анализ robots.txt
Чтобы проверить, правильно ли мы составили файл robots.txt я рекомендую Вам воспользоваться сервисом Яндекс Вебмастер (как регистрироваться в данном сервисе я рассказывал тут).
Заходим в раздел Настройки индексирования –> Анализ robots.txt:
Уже там нажимаете на кнопку “Загрузить robots.txt с сайта”, а затем нажимаете на кнопку “Проверить”:
Если Вы увидите примерно следующее сообщение, значит у Вас правильный robots.txt для Яндекса:
Также Вы можете в “Список URL” добавить адрес любой статьи сайта, чтобы проверить не запрещает ли robots.txt индексирование данной страницы:
Как видите, никакого запрета на индексирование страницы со стороны robots.txt мы не видим, значит все в порядке :).
Надеюсь больше вопросов, типа: как составить robots.txt или как сделать правильным данный файл у Вас не возникнет. В этом уроке я постарался показать Вам правильный пример robots.txt:
В этом уроке я постарался показать Вам правильный пример robots.txt:
Вы можете посмотреть другие варианты, как еще можно составлять robots.txt.
До скорой встречи!
P.s. Совсем недавно я добавил блог в Яндекс Каталог, что же интересного произошло? 🙂
Как оптимизировать Robots.txt для SEO в WordPress
Вы хотите оптимизировать свой файл robots.txt в WordPress? Не уверены, почему и каким образом файл robots.txt имеет важное значение для вашего SEO? В этой статье расскажем вам, как оптимизировать ваш файл robots.txt на сайте WordPress для SEO и поможем вам понять важность файла robots.txt.В последнее время, пользователи спрашивают нас, нуждаются ли сайт в файле robots.txt и какова важность его? Файл robots.txt для вашего сайта играет важную роль в общей производительности и seo оптимизации вашего сайта. Это в основном позволяет вам общаться с поисковыми системами и дают им знать, какие части вашего сайта они должны индексировать.
Нужен ли файл robots.txt?
Отсутствие файла robots.txt не остановит поисковых систем от сканирования и индексирования вашего сайта. Тем не менее, настоятельно рекомендуется создать один. Если вы хотите представить на вашем сайте в XML карту сайта для поисковых систем, то в файле поисковые системы будут искать ваш XML Sitemap, если вы не указали его в Yandex webmaster или Google Webmaster Tools.
Мы настоятельно рекомендуем, если у вас нет файла robots.txt на вашем сайте, то вы должны сразу же создать.
Где находится файл robots.txt? Как создать файл robots.txt?
Файл robots.txt, как правило, находится в корневой папке вашего сайта. Вам нужно будет подключиться к вашему сайту с использованием клиента FTP или с помощью файлового менеджера CPanel для его просмотра.
Он такой же, как любой обычный текстовый файл, и вы можете открыть его с помощью обычного текстового редактора как Блокнота.
Если у вас нет файла robots.txt в корневом каталоге вашего сайта, то вы всегда можете создать. Все, что вам нужно сделать, это создать новый текстовый файл на вашем компьютере и сохранить его в файле robots.txt. Далее, просто загрузите его в корневую папку вашего сайта.
Все, что вам нужно сделать, это создать новый текстовый файл на вашем компьютере и сохранить его в файле robots.txt. Далее, просто загрузите его в корневую папку вашего сайта.
Как использовать файл robots.txt?
Формат файла robots.txt на самом деле довольно прост. Первая строка обычно называет User-Agent. Агент пользователя на самом деле имя бота поисковой системы, которые пытаются прочитать ваш сайт. Например, Googlebot или Yandexbot. Вы можете использовать звездочку *, чтобы проинструктировать всех ботов.
В следующей строке следует разрешить или запретить инструкции для поисковых систем, чтобы они знали, какие части вы хотите, чтобы индексировались, и какие из них вы не хотите индексировать.
Смотрите пример файла robots.txt:
User-Agent: * Allow: /wp-content/uploads/ Disallow: /wp-content/plugins/ Disallow: /readme.html
В этом примере файл robots.txt для WordPress, мы поручили всем ботам индексировать наш каталог загрузки изображения.
В следующих двух строках мы им запрещаем индексировать наш каталог плагинов WordPress и файл readme.html.
Оптимизация файла Robots.txt для SEO
В руководстве для веб-мастеров, Google советует веб-мастерам, не использовать файл robots.txt, чтобы скрыть содержание низкого качества. Если вы думаете об использовании файла robots.txt, чтобы остановить Google индексировать категории, даты и другие архивные страницы, то это не может быть мудрым выбором.
Помните, что цель robots.txt является поручить ботам, что делать с содержанием, когда они сканируют ваш сайт. Это не помешает ботам сканировать ваш сайт.
Есть и другие плагины для WordPress, которые позволяют добавлять мета-теги, как NOFOLLOW и мета тег noindex в ваших страницах архива. Плагин WordPress SEO также позволяет сделать это. Мы не говорим, что вы должны иметь ваши архивные страницы deindexed, но если вы хотите сделать это, то, что правильный способ сделать это.
Вам не нужно добавлять страницу логина, каталога администратора или страницу регистрации в robots. txt, потому что логин и регистрационные страницы имеют теги NOINDEX, которые уже добавлены как мета-тег с помощью WordPress.
txt, потому что логин и регистрационные страницы имеют теги NOINDEX, которые уже добавлены как мета-тег с помощью WordPress.
Он рекомендуется запретить readme.html файл в файле robots.txt. Этот файл readme может быть использован кем-то, кто пытается выяснить, какую версию WordPress вы используете. Если бы это было физическое лицо, то они могут легко получить доступ к файлу, просто просматривая его.
С другой стороны, если кто-то работает с вредоносными запросами, чтобы найти сайты на WordPress с использованием конкретной версии, то этот тег Disallow может защитить вас от этих массовых атак.
Вы также можете запретить ваш каталог плагинов WordPress. Это будет способствовать укреплению безопасности вашего сайта, если кто-то ищет конкретный уязвимый плагин, чтобы использовать его для массовой атаки.
Добавление вашей XML Sitemap в файл robots.txt
Если вы используете плагин Йоаст в WordPress SEO или какой – либо другой плагин для генерации XML Sitemap , то ваш плагин будет пытаться автоматически добавлять связанные строки в вашем файле Sitemap в файл robots. txt.
txt.
Однако, если это не удается, то ваш плагин покажет вам ссылку на XML Sitemaps, который вы можете добавить в свой файл robots.txt вручную следующим образом:
Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xml
Как должен выглядеть идеальный файл robots.txt?
Честно говоря, многие популярные блоги используют очень простые файлы robots.txt. Их содержание варьируются в зависимости от потребностей конкретного сайта:
User-agent: * Disallow: Sitemap: http://www.example.com/post-sitemap.xml Sitemap: http://www.example.com/page-sitemap.xml
Этот файл robots.txt просто сообщает всем ботам индексировать все содержание и предоставляет ссылки на XML Sitemaps сайта.
Вот еще один пример файла robots.txt, на этот раз это тот, который мы используем здесь на AndreyEx.ru:
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback Disallow: */feed Disallow: */comments Disallow: /wp-login.
 php
Disallow: /login.php
Disallow: /wp-register.php
Host: https://AndreyEx.ru
User-agent: Googlebot
Allow: /wp-content/plugins
Allow: /wp-content/cache
Sitemap: https://AndreyEx.ru/sitemap_index.xml
php
Disallow: /login.php
Disallow: /wp-register.php
Host: https://AndreyEx.ru
User-agent: Googlebot
Allow: /wp-content/plugins
Allow: /wp-content/cache
Sitemap: https://AndreyEx.ru/sitemap_index.xmlЭто все. Мы надеемся , что эта статья помогла вам узнать , как оптимизировать ваш файл robots.txt для SEO. Вы также можете увидеть наш путеводитель по 9 лучшим WordPress SEO плагинам и инструментам, которые вы должны использовать.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Что такое robots.txt [Основы для новичков]
Успешная индексация нового сайта зависит от многих слагаемых. Один из них — файл robots.txt, с правильным заполнением которого должен быть знаком любой начинающий веб-мастер. Обновили материал для новичков.
Подробно о правилах составления файла в полном руководстве «Как составить robots.txt самостоятельно».
А в этом материале основы для начинающих, которые хотят быть в курсе профессиональных терминов.
Что такое robots.txt
Файл robots.txt — это документ в формате .txt, содержащий инструкции по индексации конкретного сайта для поисковых ботов. Он указывает поисковикам, какие страницы веб-ресурса стоит проиндексировать, а какие не нужно допустить к индексации.
Поисковый робот, придя к вам на сайт, первым делом пытается отыскать robots.txt. Если робот не нашел файл или он составлен неправильно, бот будет изучать сайт по своему собственному усмотрению. Далеко не факт, что он начнет с тех страниц, которые нужно вводить в поиск в первую очередь (новые статьи, обзоры, фотоотчеты и так далее). Индексация нового сайта может затянуться. Поэтому веб-мастеру нужно вовремя позаботиться о создании правильного файла robots.txt.
На некоторых конструкторах сайтов файл формируется сам. Например, Wix автоматически создает robots.txt. Чтобы посмотреть файл, добавьте к домену «/robots. txt». Если вы увидите там странные элементы типа «noflashhtml» и «backhtml», не пугайтесь: они относятся к структуре сайтов на платформе и не влияют на отношение поисковых систем.
txt». Если вы увидите там странные элементы типа «noflashhtml» и «backhtml», не пугайтесь: они относятся к структуре сайтов на платформе и не влияют на отношение поисковых систем.
Зачем нужен robots.txt
Казалось бы, зачем запрещать индексировать какое-то содержимое сайта? Далеко не весь контент, из которого состоит сайт, нужен поисковым роботам. Есть системные файлы, есть дубликаты страниц, есть рубрики ключевых слов и много чего еще есть, что вовсе не обязательно индексировать. Есть одно но:
Содержимое файла robots.txt — это рекомендации для ботов, а не жесткие правила. Рекомендации боты могут проигнорировать.
Google предупреждает, что через robots.txt нельзя заблокировать страницы для показа в Google. Даже если вы закроете доступ к странице в robots.txt, если на какой-то другой странице будет ссылка на эту, она может попасть в индекс. Лучше использовать и ограничения в robots, и другие методы запрета:
Запрет индексирования сайта, Яндекс
Блокировка индексирования, Google
Тем не менее, без robots. txt больше вероятность, что информация, которая должна быть скрыта, попадет в выдачу, а это бывает чревато раскрытием персональных данных и другими проблемами.
txt больше вероятность, что информация, которая должна быть скрыта, попадет в выдачу, а это бывает чревато раскрытием персональных данных и другими проблемами.
Из чего состоит robots.txt
Файл должен называться только «robots.txt» строчными буквами и никак иначе. Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Внутри все должно быть на латинице, все русские названия нужно перевести с помощью любого Punycode-конвертера. Каждый префикс URL нужно писать на отдельной строке.
В robots.txt с помощью специальных терминов прописываются директивы (команды или инструкции). Кратко о директивах для поисковых ботах:
«Us-agent:» — основная директива robots.txt
Используется для конкретизации поискового робота, которому будут давать указания. Например, User-agent: Googlebot или User-agent: Yandex.
В файле robots.txt можно обратиться ко всем остальным поисковым системам сразу. Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
После основной директивы «User-agent:» следуют конкретные команды.
Команда «Disallow:» — запрет индексации в robots.txt
При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение у нее будет.
User-agent: Yandex Disallow: /
Такого рода запись в файле robots.txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
User-agent: Yandex Disallow: /wp-admin
На этот раз уточнения имеются и касаются они системной папки wp-admin в CMS WordPress. То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
Команда «Allow:» — разрешение индексации в robots.txt
Антипод предыдущей директивы. При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
User-agent: * Allow: /catalog Disallow: /
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено.
На практике «Allow:» используется не так уж и часто. В ней нет надобности, поскольку она применяется автоматически. В robots «разрешено все, что не запрещено». Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
Директива «Sitemap:» — указание на карту сайта
«Sitemap:» указывает индексирующему роботу правильный путь к так Карте сайта — файлам sitemap. xml и sitemap.xml.gz в случае с CMS WordPress.
xml и sitemap.xml.gz в случае с CMS WordPress.
User-agent: * Sitemap: http://pr-cy.ru/sitemap.xml Sitemap: http://pr-cy.ru/sitemap.xml.gz
Прописывание команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это ускорит процесс попадания страниц ресурса в выдачу.
Файл robots.txt готов — что дальше
Итак, вы создали текстовый документ robots.txt с учетом особенностей вашего сайта. Его можно сделать автоматически, к примеру, с помощью нашего инструмента.
Что делать дальше:
- проверить корректность созданного документа, например, посредством сервиса Яндекса;
- при помощи FTP-клиента закачать готовый файл в корневую папку своего сайта. В ситуации с WordPress речь обычно идет о системной папке Public_html.
Дальше остается только ждать, когда появятся поисковые роботы, изучат ваш robots.txt, а после возьмутся за индексацию вашего сайта.
Как посмотреть robots.txt чужого сайта
Если вам интересно сперва посмотреть на готовые примеры файла robots.txt в исполнении других, то нет ничего проще. Для этого в адресной строке браузера достаточно ввести site.ru/robots.txt. Вместо «site.ru» — название интересующего вас ресурса.
Полезное и интересное » Как правильно составить Robots.txt
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots. txt.
txt.
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Подробнее об исключениях:
Исключения Яндекса
Стандарт исключений для роботов (Википедия)
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:User-agent: *
Для конкретного бота:User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс. Картинки Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
Mail. Ru Ru |
|
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
Во-первых, нужно знать дополнительные операторы и понимать, как они используются — это *, $ и #.
* — это любое количество символов, в том числе и их отсутствие. При этом в конце строки звездочку можно не ставить, подразумевается, что она там находится по умолчанию.
$ — показывает, что символ перед ним должен быть последним.
# — комментарий, все что после этого символа в строке роботом не учитывается.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Следующие ссылки будут закрыты от индексации:
http://site.ru/?s=
http://site.ru/?s=keyword
http://site.ru/page/?s=keyword
http://site.ru/category/
Следующие ссылки будут открыты для индексации:
http://site.ru/category/cat1/
http://site.ru/category-folder/
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
http://site.ru/template/ — закрыто от индексирования
http://site.ru/template/style.css — закрыто от индексирования
http://site. ru/style.css — открыто для индексирования
ru/style.css — открыто для индексирования
http://site.ru/theme/style.css — открыто для индексирования
Если нужно, чтобы все файлы .css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Например,
Sitemap: http://site.ru/sitemap.xml
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Host
Директива для указания главного зеркала сайта (в большинстве случаев: с www или без www). Обратите внимание, что главное зеркало указывается БЕЗ http://, но С https://. Также если необходимо, то указывается порт.
Директива поддерживается только ботами Яндекса и Mail.Ru. Другими роботами, в частности GoogleBot, команда не будет учтена. Host прописывается только один раз!
Пример 1:Host: site.ru
Пример 2:Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Пример 1:Crawl-delay: 3
Пример 2:Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Пример 1:
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Пример 2:
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Смысл директив:
Request-rate: 1/5 — загружать не более одной страницы за пять секунд
Visit-time: 0600-0845 — загружать страницы только в промежуток с 6 утра до 8:45 по Гринвичу.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
User-agent: * Disallow: /
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots. txt воспользуйтесь следующим алгоритмом:
txt воспользуйтесь следующим алгоритмом:
- Закройте от индексирования админку сайта
- Закройте от индексирования личный кабинет, авторизацию, регистрацию
- Закройте от индексирования корзину, формы заказа, данные по доставке и заказам
- Закройте от индексирования ajax, json-скрипты
- Закройте от индексирования папку cgi
- Закройте от индексирования плагины, темы оформления, js, css для всех роботов, кроме Яндекса и Google
- Закройте от индексирования функционал поиска
- Закройте от индексирования служебные разделы, которые не несут никакой ценности для сайта в поиске (ошибка 404, список авторов)
- Закройте от индексирования технические дубли страниц, а также страницы, на которых весь контент в том или ином виде продублирован с других страниц (календари, архивы, RSS)
- Закройте от индексирования страницы с параметрами фильтров, сортировки, сравнения
- Закройте от индексирования страницы с параметрами UTM-меток и сессий
- Проверьте, что проиндексировано Яндексом и Google с помощью параметра «site:» (в поисковой строке наберите «site:site. ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt
- Укажите Sitemap и Host
- По необходимости пропишите Crawl-Delay и Clean-Param
- Проверьте корректность robots.txt через инструменты Google и Яндекса (описано ниже)
- Через 2 недели перепроверьте, появились ли в поисковой выдаче новые страницы, которые не должны индексироваться. В случае необходимости повторить выше перечисленные шаги.
 ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt
ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txtПример robots.txt
# Пример файла robots.txt для настройки гипотетического сайта https://site.ru User-agent: * Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Crawl-Delay: 5 User-agent: GoogleBot Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Allow: /plugins/*.
 css
Allow: /plugins/*.js
Allow: /plugins/*.png
Allow: /plugins/*.jpg
Allow: /plugins/*.gif
User-agent: Yandex
Disallow: /admin/
Disallow: /plugins/
Disallow: /search/
Disallow: /cart/
Disallow: */?s=
Disallow: *sort=
Disallow: *view=
Allow: /plugins/*.css
Allow: /plugins/*.js
Allow: /plugins/*.png
Allow: /plugins/*.jpg
Allow: /plugins/*.gif
Clean-Param: utm_source&utm_medium&utm_campaign
Crawl-Delay: 0.5
Sitemap: https://site.ru/sitemap.xml
Host: https://site.ru
css
Allow: /plugins/*.js
Allow: /plugins/*.png
Allow: /plugins/*.jpg
Allow: /plugins/*.gif
User-agent: Yandex
Disallow: /admin/
Disallow: /plugins/
Disallow: /search/
Disallow: /cart/
Disallow: */?s=
Disallow: *sort=
Disallow: *view=
Allow: /plugins/*.css
Allow: /plugins/*.js
Allow: /plugins/*.png
Allow: /plugins/*.jpg
Allow: /plugins/*.gif
Clean-Param: utm_source&utm_medium&utm_campaign
Crawl-Delay: 0.5
Sitemap: https://site.ru/sitemap.xml
Host: https://site.ruКак добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
Типичные ошибки в robots.txt
В конце статьи приведу несколько типичных ошибок файла robots. txt
txt
- robots.txt отсутствует
- в robots.txt сайт закрыт от индексирования (Disallow: /)
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий
- в файле указаны только директивы
Allow: *.css
Allow: *.js
Allow: *.png
Allow: *.jpg
Allow: *.gif
при этом файлы css, js, png, jpg, gif закрыты другими директивами в ряде директорий - директива Host прописана несколько раз
- в Host не указан протокол https
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта
P.S.
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях.
Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots. txt для WordPress».
txt для WordPress».
P.S.2
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
WordPress Руководство Robots.txt — что это такое и как его использовать
Вы когда-нибудь слышали термин robots.txt и задавались вопросом, как он применим к вашему веб-сайту? На большинстве веб-сайтов есть файл robots.txt, но это не значит, что большинство веб-мастеров его понимают. В этом посте мы надеемся изменить это, предложив более подробное описание файла robots.txt WordPress, а также того, как он может контролировать и ограничивать доступ к вашему сайту. К концу вы сможете ответить на такие вопросы, как:
Есть много чего рассказать, так что приступим!
Что такое роботы WordPress.текст?
Прежде чем мы сможем говорить о файле robots.txt WordPress, важно определить, что в данном случае представляет собой «робот». Роботы — это любой тип «бота», который посещает веб-сайты в Интернете. Самый распространенный пример — сканеры поисковых систем. Эти боты «ползают» по сети, чтобы помочь поисковым системам, таким как Google, индексировать и ранжировать миллиарды страниц в Интернете.
Роботы — это любой тип «бота», который посещает веб-сайты в Интернете. Самый распространенный пример — сканеры поисковых систем. Эти боты «ползают» по сети, чтобы помочь поисковым системам, таким как Google, индексировать и ранжировать миллиарды страниц в Интернете.
Итак, боты есть, вообще , вещь для интернета хорошая… или хотя бы необходимая вещь. Но это не обязательно означает, что вы или другие веб-мастера хотите, чтобы боты работали без ограничений.Желание контролировать взаимодействие веб-роботов с веб-сайтами привело к созданию стандарта исключения роботов в середине 1990-х годов. Robots.txt — это практическая реализация этого стандарта — , он позволяет вам контролировать, как участвующие боты взаимодействуют с вашим сайтом. . Вы можете полностью заблокировать ботов, ограничить их доступ к определенным областям вашего сайта и многое другое.
Эта «участвующая» часть, тем не менее, важна. Robots.txt не может заставить бота следовать его директивам. А вредоносные боты могут и будут игнорировать файл robots.txt. Кроме того, даже авторитетные организации игнорируют и некоторые команды , которые вы можете поместить в Robots.txt. Например, Google проигнорирует любые правила, которые вы добавляете в свой robots.txt, о том, как часто заходят его сканеры. Если у вас много проблем с ботами, вам может пригодиться такое решение безопасности, как Cloudflare или Sucuri.
А вредоносные боты могут и будут игнорировать файл robots.txt. Кроме того, даже авторитетные организации игнорируют и некоторые команды , которые вы можете поместить в Robots.txt. Например, Google проигнорирует любые правила, которые вы добавляете в свой robots.txt, о том, как часто заходят его сканеры. Если у вас много проблем с ботами, вам может пригодиться такое решение безопасности, как Cloudflare или Sucuri.
Почему вам следует заботиться о своем файле Robots.txt?
Для большинства веб-мастеров преимущества хорошо структурированного файла robots.txt можно разделить на две категории:
- Оптимизация ресурсов сканирования поисковых систем путем указания им не тратить время на страницы, которые вы не хотите индексировать. Это помогает гарантировать, что поисковые системы сосредоточатся на сканировании наиболее важных для вас страниц.
- Оптимизация использования вашего сервера за счет блокировки ботов, тратящих ресурсы впустую.
Robots.
 txt конкретно не о контроле того, какие страницы индексируются в поисковых системах
txt конкретно не о контроле того, какие страницы индексируются в поисковых системахRobots.txt не является надежным способом контролировать, какие страницы индексируются поисковыми системами.Если ваша основная цель — предотвратить включение определенных страниц в результаты поисковых систем, правильным подходом будет использование метатега noindex или другого аналогичного прямого метода.
Это связано с тем, что ваш файл Robots.txt напрямую не говорит поисковым системам не индексировать контент — он просто говорит им не сканировать его. Хотя Google не будет сканировать отмеченные области внутри вашего сайта, сам Google заявляет, что если внешний сайт ссылается на страницу, которую вы исключаете с помощью файла Robots.txt, Google все равно может проиндексировать эту страницу.
Джон Мюллер, аналитик Google для веб-мастеров, также подтвердил, что, если на странице есть ссылки, указывающие на нее, даже если она заблокирована файлом robots.txt, все равно может проиндексироваться. Вот что он сказал на видеовстрече в Центре веб-мастеров:
Вот что он сказал на видеовстрече в Центре веб-мастеров:
Здесь следует иметь в виду одну вещь: если эти страницы заблокированы файлом robots.txt, то теоретически может случиться так, что кто-то случайно сделает ссылку на одну из этих страниц. И если они это сделают, то может случиться так, что мы проиндексируем этот URL без какого-либо контента, потому что он заблокирован роботами.текст. Таким образом, мы не узнаем, что вы не хотите, чтобы эти страницы действительно индексировались.
Если они не заблокированы файлом robots.txt, вы можете разместить на этих страницах метатег noindex. И если кто-то будет ссылаться на них, и мы просканируем эту ссылку и подумаем, что, может быть, здесь есть что-то полезное, тогда мы будем знать, что эти страницы не нужно индексировать, и мы можем просто полностью пропустить их из индексации.
Итак, в связи с этим, если у вас есть что-то на этих страницах, что вы не хотите индексировать, не запрещайте их, используйте вместо этого noindex .

Как создать и отредактировать файл WordPress Robots.txt
По умолчанию WordPress автоматически создает виртуальный файл robots.txt для вашего сайта. Таким образом, даже если вы не пошевелите пальцем, на вашем сайте уже должен быть файл robots.txt по умолчанию. Вы можете проверить, так ли это, добавив «/robots.txt» в конец своего доменного имени. Например, «https://kinsta.com/robots.txt» вызывает файл robots.txt, который мы используем здесь, в Kinsta:
Пример файла Robots.txt
Поскольку этот файл виртуальный, вы не можете его редактировать.Если вы хотите отредактировать файл robots.txt, вам нужно будет фактически создать физический файл на своем сервере, которым вы можете управлять по мере необходимости. Вот три простых способа сделать это…
Как создать и отредактировать файл Robots.txt с помощью Yoast SEO
Если вы используете популярный плагин Yoast SEO, вы можете создать (а позже отредактировать) файл robots.txt прямо из интерфейса Yoast. Однако, прежде чем вы сможете получить к нему доступ, вам необходимо включить расширенные функции Yoast SEO, перейдя в SEO → Dashboard → Features и переключившись на страницы дополнительных настроек :
Однако, прежде чем вы сможете получить к нему доступ, вам необходимо включить расширенные функции Yoast SEO, перейдя в SEO → Dashboard → Features и переключившись на страницы дополнительных настроек :
Как включить расширенные функции Yoast
После активации вы можете перейти к SEO → Инструменты и нажать Редактор файлов :
Как получить доступ к редактору файлов Yoast
Если у вас еще нет физического робота.txt, Yoast даст вам возможность Создать файл robots.txt :
Как создать Robots.txt в Yoast
И как только вы нажмете эту кнопку, вы сможете редактировать содержимое своего файла Robots.txt прямо из того же интерфейса:
Как редактировать Robots.txt в Yoast
По мере чтения мы подробнее рассмотрим, какие типы директив следует добавлять в файл robots.txt WordPress.
Как создать и отредактировать файл Robots.txt с помощью универсального SEO
Если вы используете почти такой же популярный, как Yoast All in One SEO Pack плагин, вы также можете создавать и редактировать свои роботы WordPress. txt прямо из интерфейса плагина. Все, что вам нужно сделать, это перейти к All in One SEO → Feature Manager и Активировать файл Robots.txt feature:
txt прямо из интерфейса плагина. Все, что вам нужно сделать, это перейти к All in One SEO → Feature Manager и Активировать файл Robots.txt feature:
Как создать Robots.txt в All In One SEO
Затем вы сможете управлять своим файлом Robots.txt, перейдя в All in One SEO → Robots.txt:
Как редактировать Robots.txt в All In One SEO
Как создать и отредактировать файл Robots.txt через FTP
Если вы не используете плагин SEO, который предлагает robots.txt, вы по-прежнему можете создавать файл robots.txt и управлять им через SFTP. Сначала с помощью любого текстового редактора создайте пустой файл с именем «robots.txt»:
Как создать свой собственный файл Robots.txt
Затем подключитесь к своему сайту через SFTP и загрузите этот файл в корневую папку вашего сайта. Вы можете внести дополнительные изменения в свой файл robots.txt, отредактировав его через SFTP или загрузив новые версии файла.
Что помещать в файл robots.txt
Хорошо, теперь у вас есть физический робот.txt на вашем сервере, который вы можете редактировать по мере необходимости. Но что вы на самом деле делаете с этим файлом? Как вы узнали из первого раздела, robots.txt позволяет вам контролировать, как роботы взаимодействуют с вашим сайтом. Вы делаете это с помощью двух основных команд:
- User-agent — позволяет настраивать таргетинг на определенных ботов. Пользовательские агенты — это то, что боты используют для идентификации себя. С их помощью вы можете, например, создать правило, которое применяется к Bing, но не к Google.
- Запретить — позволяет запретить роботам доступ к определенным областям вашего сайта.
Существует также команда Allow , которую вы будете использовать в нишевых ситуациях. По умолчанию все на вашем сайте помечено как Allow , поэтому нет необходимости использовать команду Allow в 99% случаев. Но он пригодится, если вы хотите Запретить доступ к папке и ее дочерним папкам, но Разрешить доступ к одной конкретной дочерней папке.
Но он пригодится, если вы хотите Запретить доступ к папке и ее дочерним папкам, но Разрешить доступ к одной конкретной дочерней папке.
Вы добавляете правила, сначала указывая, к какому User-agent должно применяться правило, а затем перечисляя, какие правила применять, используя Disallow и Allow .Есть также некоторые другие команды, такие как Crawl-delay и Sitemap , но это либо:
- Игнорируется большинством основных поисковых роботов или интерпретируется совершенно по-разному (в случае задержки сканирования)
- Изменилось с помощью таких инструментов, как Google Search Console (для карт сайта)
Давайте рассмотрим некоторые конкретные примеры использования, чтобы показать вам, как все это сочетается.
Как использовать Robots.txt для блокировки доступа ко всему сайту
Допустим, вы хотите заблокировать всем поисковым роботам доступ к вашему сайту. На живом сайте это вряд ли произойдет, но для сайта разработки это пригодится. Для этого вы должны добавить этот код в свой файл robots.txt WordPress:
На живом сайте это вряд ли произойдет, но для сайта разработки это пригодится. Для этого вы должны добавить этот код в свой файл robots.txt WordPress:
Агент пользователя: *
Disallow: / Что происходит в этом коде?
Звездочка * рядом с User-agent означает «все пользовательские агенты». Звездочка — это подстановочный знак, означающий, что он применяется к каждому пользовательскому агенту. / косая черта рядом с Disallow означает, что вы хотите запретить доступ к всем страницам , которые содержат «yourdomain.com / ”(т.е. каждая страница вашего сайта).
Как использовать Robots.txt, чтобы заблокировать доступ одного бота к вашему сайту
Давайте изменим ситуацию. В этом примере мы сделаем вид, что вам не нравится, что Bing сканирует ваши страницы. Вы полностью работаете в команде Google и даже не хотите, чтобы Bing просматривал ваш сайт. Чтобы заблокировать сканирование вашего сайта только Bing, замените подстановочный знак * звездочку на Bingbot:
Чтобы заблокировать сканирование вашего сайта только Bing, замените подстановочный знак * звездочку на Bingbot:
Подпишитесь на информационный бюллетень
Мы увеличили наш трафик на 1187% с помощью WordPress.
Мы покажем вам, как это сделать.
Присоединяйтесь к более чем 20 000 других людей, которые получают нашу еженедельную рассылку с инсайдерскими советами по WordPress!
Пользовательский агент: Bingbot
Disallow: / По сути, приведенный выше код говорит , что только применяет правило Disallow к ботам с пользовательским агентом «Bingbot» . Теперь вы вряд ли захотите блокировать доступ к Bing, но этот сценарий действительно пригодится, если есть конкретный бот, которому вы не хотите получать доступ к своему сайту.На этом сайте есть хороший список известных имен User-agent большинства сервисов.
Как использовать Robots.txt для блокировки доступа к определенной папке или файлу
В этом примере предположим, что вы хотите заблокировать доступ только к определенному файлу или папке (и всем ее подпапкам). Чтобы применить это к WordPress, допустим, вы хотите заблокировать:
- Вся папка wp-admin
- wp-login.php
Вы можете использовать следующие команды:
Агент пользователя: *
Запретить: / wp-admin /
Запретить: / wp-login.php Как использовать Robots.txt для разрешения доступа к определенному файлу в запрещенной папке
Хорошо, теперь допустим, что вы хотите заблокировать всю папку, но все же хотите разрешить доступ к определенному файлу внутри этой папки. Здесь вам пригодится команда Allow . И это действительно очень применимо к WordPress. Фактически, виртуальный файл robots.txt WordPress прекрасно иллюстрирует этот пример:
Агент пользователя: *
Запретить: / wp-admin /
Разрешить: / wp-admin / admin-ajax. php  php
php Этот фрагмент блокирует доступ ко всей папке / wp-admin / , за исключением файла /wp-admin/admin-ajax.php .
Как использовать Robots.txt, чтобы запретить ботам сканировать результаты поиска WordPress
Одна специальная настройка WordPress, которую вы, возможно, захотите сделать, — это запретить поисковым роботам сканировать ваши страницы результатов поиска. По умолчанию WordPress использует параметр запроса «? S =». Итак, чтобы заблокировать доступ, все, что вам нужно сделать, это добавить следующее правило:
Агент пользователя: *
Запретить: /? S =
Disallow: / search / Это также может быть эффективным способом остановить мягкие ошибки 404, если вы их получаете.Обязательно прочтите наше подробное руководство о том, как ускорить поиск в WordPress.
Как создать разные правила для разных ботов в robots.txt
До сих пор все примеры касались одного правила за раз. Но что, если вы хотите применить разные правила к разным ботам? Вам просто нужно добавить каждый набор правил в объявление User-agent для каждого бота. Например, если вы хотите создать одно правило, которое применяется к , все боты , а другое правило, которое применяется к , только Bingbot , вы можете сделать это следующим образом:
Но что, если вы хотите применить разные правила к разным ботам? Вам просто нужно добавить каждый набор правил в объявление User-agent для каждого бота. Например, если вы хотите создать одно правило, которое применяется к , все боты , а другое правило, которое применяется к , только Bingbot , вы можете сделать это следующим образом:
Агент пользователя: *
Запретить: / wp-admin /
Пользовательский агент: Bingbot
Disallow: / В этом примере всем ботам будет заблокирован доступ к / wp-admin /, но Bingbot будет заблокирован от доступа ко всему вашему сайту.
Тестирование файла Robots.txt
Вы можете проверить свой файл robots.txt WordPress в консоли поиска Google, чтобы убедиться, что он правильно настроен. Просто нажмите на свой сайт и в разделе «Сканирование» нажмите «Тестер robots.txt». Затем вы можете отправить любой URL, включая вашу домашнюю страницу. Вы должны увидеть зеленый Разрешено , если все доступно для сканирования. Вы также можете проверить URL-адреса, которые вы заблокировали, чтобы убедиться, что они действительно заблокированы, или Disallowed .
Вы должны увидеть зеленый Разрешено , если все доступно для сканирования. Вы также можете проверить URL-адреса, которые вы заблокировали, чтобы убедиться, что они действительно заблокированы, или Disallowed .
Тестовый файл robots.txt
Остерегайтесь спецификации UTF-8
BOM обозначает отметку порядка байтов и, по сути, является невидимым символом, который иногда добавляется к файлам старыми текстовыми редакторами и т.п.Если это произойдет с вашим файлом robots.txt, Google может неправильно его прочитать. Вот почему так важно проверять файл на наличие ошибок. Например, как показано ниже, в нашем файле был невидимый символ, и Google жалуется на непонимание синтаксиса. Это по существу делает недействительной первую строку нашего файла robots.txt, что не очень хорошо! У Гленна Гейба есть отличная статья о том, как бомба UTF-8 может убить вашего SEO.
Спецификация UTF-8 в вашем файле robots.txt
Робот Googlebot находится в основном в США.

Также важно не блокировать Googlebot из США, даже если вы нацеливаетесь на регион за пределами США.Иногда они выполняют локальное сканирование, но робот Google в основном находится в США.
Робот Googlebot в основном находится в США, но иногда мы также выполняем локальное сканирование. https://t.co/9KnmN4yXpe
— Центр поиска Google (@googlesearchc) 13 ноября 2017 г.
Что популярные сайты WordPress помещают в свой файл Robots.txt
Чтобы предоставить некоторый контекст для перечисленных выше пунктов, вот как некоторые из самых популярных сайтов WordPress используют своих роботов.txt файлы.
TechCrunch
TechCrunch Файл Robots.txt
Помимо ограничения доступа к ряду уникальных страниц, TechCrunch, в частности, запрещает поисковым роботам:
Еще они установили особые ограничения для двух ботов:
Если вам интересно, IRLbot — это сканер из исследовательского проекта Техасского университета A&M. Это странно!
Это странно!
Фонд Обамы
Файл Robots.txt Фонда Обамы
Фонд Обамы не делал никаких специальных дополнений, предпочитая ограничивать доступ исключительно к / wp-admin /.
Angry Birds
Angry Birds Файл Robots.txt
Angry Birds имеет те же настройки по умолчанию, что и The Obama Foundation. Ничего особенного не добавлено.
Дрифт
Drift Robots.txt Файл
Наконец, Drift решает определить свои карты сайта в файле Robots.txt, но в остальном оставляет те же ограничения по умолчанию, что и The Obama Foundation и Angry Birds.
Правильно используйте Robots.txt
Завершая наше руководство по robots.txt, мы хотим еще раз напомнить вам, что использование команды Disallow в вашем файле robots.txt — это не то же самое, что использовать тег noindex . Robots.txt блокирует сканирование, но не обязательно индексацию. Вы можете использовать его для добавления определенных правил, определяющих, как поисковые системы и другие боты взаимодействуют с вашим сайтом, но он не будет явно контролировать, индексируется ваш контент или нет.
Для большинства обычных пользователей WordPress нет особой необходимости изменять виртуальный файл robots.txt по умолчанию. Но если у вас возникли проблемы с конкретным ботом или вы хотите изменить способ взаимодействия поисковых систем с определенным плагином или темой, которую вы используете, вы можете добавить свои собственные правила.
Мы надеемся, что вам понравилось это руководство, и обязательно оставьте комментарий, если у вас возникнут дополнительные вопросы об использовании файла robots.txt в WordPress.
Если вам понравилась эта статья, то вам понравится хостинговая платформа Kinsta WordPress. Ускорьте свой сайт и получите круглосуточную поддержку от нашей опытной команды WordPress. Наша инфраструктура на базе Google Cloud ориентирована на автоматическое масштабирование, производительность и безопасность. Позвольте нам показать вам разницу Kinsta! Ознакомьтесь с нашими тарифами
Передовой пример для SEO • Yoast
Джоно Алдерсон Джоно — цифровой стратег, технолог по маркетингу и разработчик полного цикла. Он занимается техническим SEO, новыми технологиями и стратегией бренда.
Он занимается техническим SEO, новыми технологиями и стратегией бренда.
Файл robots.txt — мощный инструмент при работе над поисковой оптимизацией веб-сайта, но с ним следует обращаться осторожно. Он позволяет запрещать поисковым системам доступ к различным файлам и папкам, но часто не лучший способ оптимизировать ваш сайт. Здесь мы объясним, как, по нашему мнению, веб-мастера должны использовать свой файл robots.txt, и предложим «передовой» подход, подходящий для большинства веб-сайтов.
Ниже на этой странице вы найдете пример robots.txt, который работает для подавляющего большинства веб-сайтов WordPress. Если вы хотите узнать больше о том, как работает ваш файл robots.txt, вы можете прочитать наше полное руководство по robots.txt.
Как выглядит «лучшая практика»?
Поисковые системы постоянно улучшают способы сканирования Интернета и индексации контента. Это означает, что то, что считалось оптимальным несколько лет назад, больше не работает или даже может нанести вред вашему сайту.
Сегодня лучшая практика означает как можно меньше полагаться на файл robots.txt. Фактически, действительно необходимо блокировать URL-адреса в файле robots.txt только тогда, когда у вас есть сложные технические проблемы (например, большой веб-сайт электронной коммерции с фасетной навигацией) или когда нет другого выхода.
Блокировка URL-адресов через robots.txt — это метод «грубой силы», который может вызвать больше проблем, чем решить.
Для большинства сайтов WordPress рекомендуется следующий пример:
# Это поле намеренно оставлено пустым
# Если вы хотите узнать, почему наш robots.txt выглядит так, прочтите этот пост: https://yoa.st/robots-txt
Пользовательский агент: * Мы даже используем этот подход в нашем собственном файле robots.txt.
Что делает этот код?
- Инструкция
User-agent: *гласит, что все следующие инструкции применимы ко всем поисковым роботам. - Поскольку мы не предоставляем никаких дополнительных инструкций, мы говорим, что «все сканеры могут свободно сканировать этот сайт без ограничений».
- Мы также предоставляем некоторую информацию людям, просматривающим файл (ссылаясь на эту самую страницу), чтобы они понимали, почему файл «пуст».

Если вам нужно запретить URL-адреса
Если вы хотите запретить поисковым системам сканировать или индексировать определенные части вашего сайта WordPress, почти всегда лучше сделать это, добавив мета-теги или заголовки HTTP для роботов.
В нашем полном руководстве по метатегам роботов объясняется, как «правильно» управлять сканированием и индексированием, а наш плагин Yoast SEO предоставляет инструменты, которые помогут вам реализовать эти теги на своих страницах.
Если у вашего сайта есть проблемы со сканированием или индексированием, которые нельзя устранить с помощью метатегов или HTTP-заголовков , или если вам необходимо предотвратить доступ сканеров по другим причинам, вам следует прочитать наше полное руководство по роботам.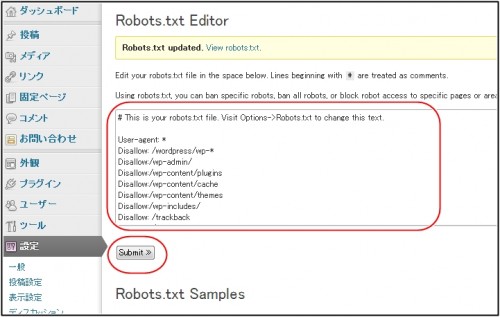 текст.
текст.
Обратите внимание, что WordPress и Yoast SEO уже автоматически предотвращают индексацию некоторых конфиденциальных файлов и URL-адресов, например, вашей административной области WordPress (через HTTP-заголовок x-robots).
Почему этот «минимализм» лучше всего подходит?
Robots.txt создает тупики
Прежде чем вы сможете соревноваться за видимость в результатах поиска, поисковые системы должны обнаружить, сканировать и проиндексировать ваши страницы. Если вы заблокировали определенные URL-адреса с помощью robots.txt, поисковые системы больше не смогут сканировать эти страницы с по в поисках других.Это может означать, что ключевые страницы не будут обнаружены.
Robots.txt запрещает ссылкам их значение
Одно из основных правил SEO заключается в том, что ссылки с других страниц могут влиять на вашу эффективность. Если URL-адрес заблокирован, поисковые системы не только не будут его сканировать, но и не будут распространять «значение ссылки», указывающее на этот URL-адрес или с по на другие страницы сайта.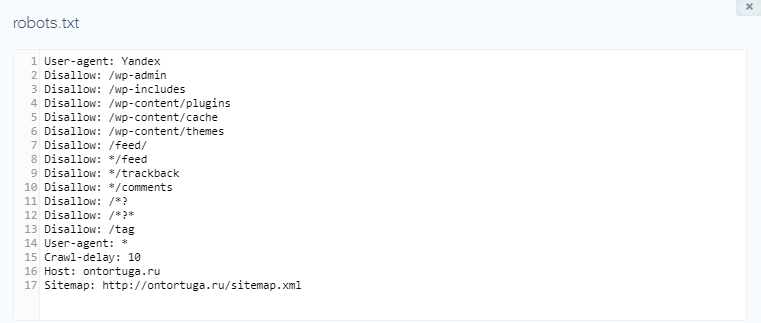
Google полностью отображает ваш сайт
Люди раньше блокировали доступ к файлам CSS и JavaScript, чтобы поисковые системы фокусировались на этих важнейших содержательных страницах.
В настоящее время Google извлекает все ваши стили и JavaScript и полностью отображает ваши страницы. Понимание макета и представления вашей страницы является ключевой частью оценки качества. Таким образом, Google совсем не нравится , когда вы запрещаете ему доступ к вашим файлам CSS или JavaScript.
Предыдущая передовая практика блокировки доступа к вашему каталогу wp-includes и каталогу ваших плагинов через файл robots.txt больше не действует, поэтому мы работали с WordPress, чтобы удалить правило disallow по умолчанию для wp-includes в версии 4.0.
Многие темы WordPress также используют асинхронные запросы JavaScript — так называемый AJAX — для добавления содержимого на веб-страницы. WordPress раньше блокировал это для Google по умолчанию, но мы исправили это в WordPress 4.4.
WordPress раньше блокировал это для Google по умолчанию, но мы исправили это в WordPress 4.4.
Вам (обычно) не нужно ссылаться на карту сайта
Стандарт robots.txt поддерживает добавление в файл ссылки на ваши XML-карты сайта. Это помогает поисковым системам обнаруживать местонахождение и содержание вашего сайта.
Нам всегда казалось, что это лишнее; вы должны уже добавить карту сайта в свои учетные записи Google Search Console и Bing для веб-мастеров, чтобы получить доступ к аналитике и данным о производительности.Если вы это сделали, то ссылка в файле robots.txt вам не понадобится.
Подробнее: Предотвращение индексации вашего сайта: правильный путь »
Как редактировать robots.txt через Yoast SEO • Yoast
Файл robots.txt сообщает поисковой системе, куда разрешено переходить на вашем веб-сайте. Вы можете редактировать файл robots.txt с помощью Yoast SEO и Yoast SEO Premium. В этой статье мы покажем вам, как это сделать!
Хотите узнать больше о том, что такое robots. txt есть и что он делает? Ознакомьтесь с нашим полным руководством по robots.txt.
txt есть и что он делает? Ознакомьтесь с нашим полным руководством по robots.txt.
WordPress по умолчанию
По умолчанию WordPress создает файл robots.txt со следующим содержанием:
Агент пользователя: * Запретить: / wp-admin / Разрешить: /wp-admin/admin-ajax.php
Это содержимое заменяется при создании или настройке файла robots.txt.
Создайте или отредактируйте robots.txt в панели управления WordPress
Самый простой способ создать или отредактировать файл robots.txt через Yoast SEO на панели инструментов WordPress. Для этого выполните следующие действия.
- Войдите на свой сайт WordPress.
Когда вы войдете в систему, вы окажетесь в «Личном кабинете».
- Нажмите «SEO».
Слева вы увидите меню. В этом меню нажмите «SEO».
- Щелкните «Инструменты».
Настройки «SEO» расширятся, предоставляя вам дополнительные возможности.
Щелкните «Инструменты». - Щелкните «Редактор файлов».
Это меню не появится, если ваша установка WordPress отключила редактирование файлов. Пожалуйста, разрешите редактирование файла или отредактируйте файл через FTP. Если вы не знаете, как использовать FTP, ваш хост-провайдер может помочь.
- Внесите изменения в свой файл.
- Сохраните изменения.
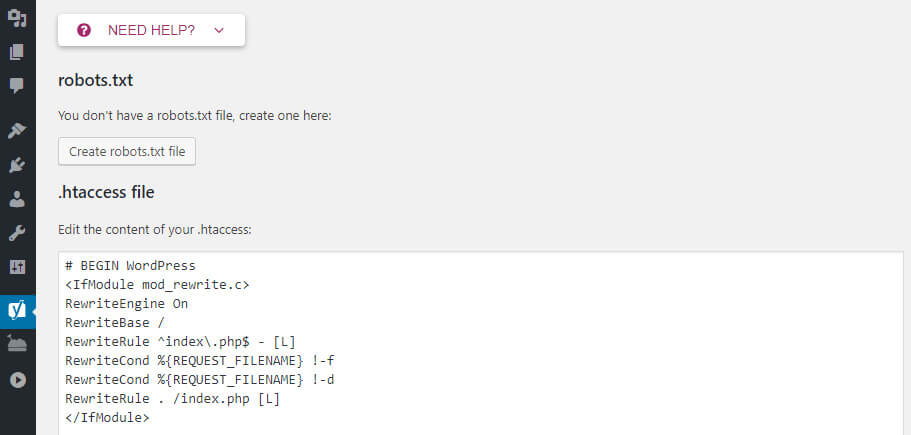 Щелкните «Инструменты».
Щелкните «Инструменты».Создайте или отредактируйте на своем сервере
Если файл robots.txt недоступен для записи или ваша установка WordPress отключила редактирование файла, создание или редактирование файла robots.txt через панель управления WordPress может завершиться ошибкой. В этом случае вы можете редактировать на уровне сервера. WordPress создает виртуальный файл robots.txt , если корень сайта не содержит физического файла. Чтобы переопределить виртуальный файл, выполните следующие действия, чтобы создать физический файл robots.. txt
txt
- Используйте свой любимый текстовый редактор и создайте текстовый файл.
- Сохраните пустой файл с именем
robots.txt. - Загрузите файл на свой сервер.Если вы не знаете, где на вашем сервере загрузить файл, обратитесь к своему хостингу.
Если WordPress блокировал доступ к виртуальному файлу, вы должны иметь возможность редактировать физический файл из нашего плагина. Если нет, вы всегда можете отредактировать robots.txt прямо на своем сервере, используя FTP или файловый менеджер сервера.
Если у вас возникли проблемы с загрузкой или редактированием файлов на сервере, обратитесь за помощью к своему веб-хосту.
Robots.txt и WordPress | WP Engine®
Поддержание поисковой оптимизации (SEO) вашего сайта имеет решающее значение для привлечения органического трафика.Однако есть некоторые страницы, такие как дублированный контент или промежуточные области, которые вы не можете захотеть, чтобы пользователи находили через поисковые системы. К счастью, есть способ запретить таким системам, как Google, получать доступ к определенным страницам и отображать их для поисковиков. Редактируя файл robots.txt своего сайта, вы можете контролировать, какой контент будет отображаться на страницах результатов поиска (SERP).
К счастью, есть способ запретить таким системам, как Google, получать доступ к определенным страницам и отображать их для поисковиков. Редактируя файл robots.txt своего сайта, вы можете контролировать, какой контент будет отображаться на страницах результатов поиска (SERP).
ПРИМЕЧАНИЕ. По умолчанию WP Engine ограничивает трафик поисковых систем на любой сайт с помощью установки .wpengine.com домен. Это означает, что поисковые системы не смогут посещать сайты , а не , которые в настоящее время находятся в разработке, с использованием личного домена.
О
Robots.txtФайл robots.txt содержит инструкции для поисковых систем о том, как находить и извлекать информацию с вашего веб-сайта. Этот процесс называется «сканированием». После того, как страница просканирована, она будет проиндексирована, чтобы поисковая система могла быстро найти и отобразить ее позже.
Первое, что делает сканер поисковой системы, когда попадает на сайт, — это ищет файл robots. txt . Если его нет, он продолжит сканирование остальной части сайта как обычно. Если он найдет этот файл, поисковый робот будет искать в нем какие-либо команды, прежде чем продолжить.
txt . Если его нет, он продолжит сканирование остальной части сайта как обычно. Если он найдет этот файл, поисковый робот будет искать в нем какие-либо команды, прежде чем продолжить.
В файле robots.txt есть четыре общие команды:
- Disallow запрещает сканерам поисковых систем проверять и индексировать указанные файлы сайта.Это может помочь вам предотвратить появление дублированного контента, промежуточных областей или других личных файлов в результатах поиска.
- Разрешить разрешает доступ к подпапкам, в то время как родительские папки запрещены.
- Задержка сканирования предписывает поисковым роботам подождать определенное время перед загрузкой файла.
- Sitemap указывает расположение любых файлов Sitemap, связанных с вашим сайтом.
Файлы Robots.txt всегда форматируются одинаково, чтобы их директивы были понятны:
Каждая директива начинается с определения «агента пользователя», которым обычно является сканер поисковой системы. Если вы хотите, чтобы команда применялась ко всем потенциальным пользовательским агентам, вы можете использовать звездочку (*). Чтобы вместо этого настроить таргетинг на определенный пользовательский агент, вы можете добавить его имя. Например, мы можем заменить звездочку выше на «Googlebot», чтобы запретить Google сканирование страницы администратора.
Если вы хотите, чтобы команда применялась ко всем потенциальным пользовательским агентам, вы можете использовать звездочку (*). Чтобы вместо этого настроить таргетинг на определенный пользовательский агент, вы можете добавить его имя. Например, мы можем заменить звездочку выше на «Googlebot», чтобы запретить Google сканирование страницы администратора.
Понимание того, как использовать и редактировать файл robots.txt , жизненно важно. Включенные вами в него директивы будут определять, как поисковые системы взаимодействуют с вашим сайтом. Они могут помочь вам, скрывая контент, от которого вы хотите отвлечь пользователей, что улучшит общее SEO вашего сайта.
Протестируйте файл
Robots.txtВы можете проверить, есть ли у вас файл robots.txt и , добавив «/robots.txt» в конец URL-адреса вашего сайта в браузере. Это вызовет файл, если он существует. Однако наличие вашего файла не обязательно означает, что он работает правильно.
К счастью, проверить файл robots. txt просто. Вы можете просто скопировать и вставить свой файл в тестер robots.txt .Инструмент выделит все ошибки в файле. Важно отметить, что изменения, внесенные вами в редактор тестера robots.txt , не будут применяться к фактическому файлу — вам все равно придется редактировать файл на своем сервере.
txt просто. Вы можете просто скопировать и вставить свой файл в тестер robots.txt .Инструмент выделит все ошибки в файле. Важно отметить, что изменения, внесенные вами в редактор тестера robots.txt , не будут применяться к фактическому файлу — вам все равно придется редактировать файл на своем сервере.
Среди распространенных ошибок — запрет на использование файлов CSS или JavaScript, неправильное использование подстановочных знаков, таких как * и $, и случайное запрещение важных страниц. Также важно помнить, что сканеры поисковых систем чувствительны к регистру, поэтому все URL-адреса в вашем файле robots.txt должен появиться так же, как и в вашем браузере.
Создание файла
Robots.txt с подключаемым модулем Если на вашем сайте отсутствует файл robots.txt , вы можете легко добавить его в WordPress с помощью плагина Yoast SEO. Это избавит вас от необходимости создавать простой текстовый файл и вручную загружать его на сервер. Если вы предпочитаете создать его вручную, перейдите к разделу «Создание файла Robots.txt вручную» ниже.
Если вы предпочитаете создать его вручную, перейдите к разделу «Создание файла Robots.txt вручную» ниже.
Перейдите к инструментам Yoast SEO
Для начала вам необходимо установить и активировать плагин Yoast SEO.Затем вы можете перейти на панель администратора WordPress и выбрать SEO > Tools на боковой панели :
Это приведет вас к списку полезных инструментов, к которым пользователи Yoast могут получить доступ для эффективного улучшения своего SEO.
Используйте редактор файлов для создания файла
Robots.txtОдним из инструментов, доступных в списке, является редактор файлов. Это позволяет вам редактировать файлы, связанные с SEO вашего сайта, включая файл robots.txt :
Поскольку на вашем сайте его еще нет, выберите «Создать роботов».txt файл:
Откроется редактор файлов, в котором вы сможете редактировать и сохранять новый файл.
Отредактируйте файл Robots.txt
по умолчанию и сохраните его По умолчанию новый файл robots. txt , созданный с помощью Yoast, включает директиву, скрывающую вашу папку wp-admin и разрешающую доступ к вашему файлу admin-ajax.php для всех пользовательских агентов. Рекомендуется оставить эту директиву в файле:
txt , созданный с помощью Yoast, включает директиву, скрывающую вашу папку wp-admin и разрешающую доступ к вашему файлу admin-ajax.php для всех пользовательских агентов. Рекомендуется оставить эту директиву в файле:
Перед сохранением файла вы также можете добавить любые другие директивы, которые хотите включить.В этом примере мы запретили поисковым роботам Bing доступ ко всем нашим файлам, добавили задержку сканирования в десять миллисекунд для поискового робота Yahoo (Slurp) и направили поисковые роботы в расположение нашей карты сайта. Когда вы закончите вносить свои изменения, не забудьте их сохранить!
Руководство
Robots.txt Создание файлаЕсли вам нужно создать файл robots.txt вручную, процесс так же прост, как создание и загрузка файла на ваш сервер.
- Создайте файл с именем
robots.txt- Убедитесь, что имя написано в нижнем регистре.
- Убедитесь, что расширение —
., а не txt .html
- Добавьте в файл любые необходимые директивы и сохраните
- Загрузите файл с помощью SFTP или SSH-шлюз в корневой каталог вашего сайта
 txt
txt ПРИМЕЧАНИЕ : Если в корне вашего сайта есть физический файл с именем robots.txt , он перезапишет любой динамически сгенерированный файл robots.txt , созданный с помощью плагин или тема.
Использование файла robots.txt
Файл robots.txt разбит на блоки пользовательским агентом. Внутри блока каждая директива указывается в новой строке. Например:
Агент пользователя: * Запретить: / Пользовательский агент: Googlebot Запретить: Пользовательский агент: bingbot Запретить: / no-bing-crawl / Disallow: wp-admin.
Пользовательские агенты обычно сокращаются до более общего имени, но это не требуется .
Значения директивы чувствительны к регистру.
- URL-адреса
no-bing-crawlиNo-Bing-Crawl— это разных .

Глобализация и регулярные выражения не поддерживаются полностью .
-
*в поле User-agent — это специальное значение, означающее «любой робот».
Ограничить доступ ботов к вашему сайту
(Все сайты в среде URL .wpengine.com имеют следующие robots.txt применяется автоматически.)
Агент пользователя: * Disallow: /
Ограничить доступ одного робота ко всей площадке
Агент пользователя: BadBotName Disallow: /
Ограничить доступ бота к определенным каталогам и файлам
Пример запрещает ботов на всех страницах wp-admin и wp-login.php . Это хороший файл robots.txt по умолчанию или начальный файл .
Агент пользователя: * Запретить: / wp-admin / Запретить: / wp-login.php
Ограничить доступ бота ко всем файлам определенного типа
В примере используется тип файла .  pdf
pdf
Агент пользователя: * Disallow: /*.pdf$
Ограничить конкретную поисковую систему
Пример использования Googlebot-Image в / wp-content / загружает каталог
User-Agent: Googlebot-Image Запретить: / wp-content / uploads /
Ограничить всех ботов, кроме одного
Пример разрешает только Google
User-agent: Google Запретить: Пользовательский агент: * Disallow: /
Добавление правильных комбинаций директив может быть сложным.К счастью, есть плагины, которые также создают (и тестируют) файл robots.txt за вас. Примеры плагинов:
Если вам нужна дополнительная помощь в настройке правил в файле robots.txt, мы рекомендуем посетить Google Developers или The Web Robots Pages для получения дополнительных инструкций.
Задержка сканирования
Если вы видите слишком высокий трафик ботов и это влияет на производительность сервера, задержка сканирования может быть хорошим вариантом.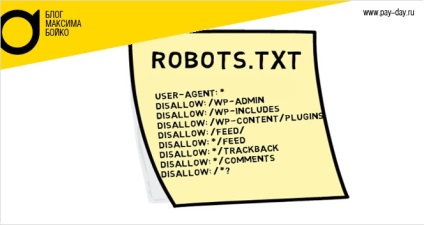 Задержка сканирования позволяет ограничить время, которое должен пройти бот перед сканированием следующей страницы.
Задержка сканирования позволяет ограничить время, которое должен пройти бот перед сканированием следующей страницы.
Для настройки задержки сканирования используйте следующую директиву, значение настраивается и указывается в секундах:
задержка сканирования: 10
Например, чтобы запретить сканирование всем ботам wp-admin , wp-login.php и установить задержку сканирования для всех ботов на 600 секунд (10 минут):
Агент пользователя: * Запретить: /wp-login.php Запретить: / wp-admin / Задержка сканирования: 600
ПРИМЕЧАНИЕ : Службы обхода контента могут иметь свои собственные требования для установки задержки обхода.Как правило, лучше всего связаться со службой напрямую для получения требуемого метода.
Отрегулируйте задержку сканирования для SEMrush
- SEMrush - отличный сервис, но сканирование может оказаться очень тяжелым, что в конечном итоге ухудшит производительность вашего сайта. По умолчанию боты SEMrush игнорируют директивы задержки сканирования в файле robots.txt, поэтому обязательно войдите в их панель управления и включите Уважение задержки сканирования robots.txt .
- Дополнительную информацию о SEMrush можно найти здесь.
 По умолчанию боты SEMrush игнорируют директивы задержки сканирования в файле robots.txt, поэтому обязательно войдите в их панель управления и включите Уважение задержки сканирования robots.txt .
По умолчанию боты SEMrush игнорируют директивы задержки сканирования в файле robots.txt, поэтому обязательно войдите в их панель управления и включите Уважение задержки сканирования robots.txt . Регулировка задержки сканирования Bingbot
- Bingbot должен соблюдать директивы
crawl-delay, однако они также позволяют вам установить шаблон управления сканированием.
Настройте задержку сканирования для Google
Дополнительную информацию см. В документации поддержки Google)
Откройте страницу настроек скорости сканирования вашего ресурса.
- Если ваша скорость сканирования описана как , рассчитанная как оптимальная , единственный способ уменьшить скорость сканирования - это подать специальный запрос.Вы не можете увеличить скорость сканирования .
- В противном случае выберите нужный вариант и затем ограничьте скорость сканирования по желанию. Новая скорость сканирования будет действовать в течение 90 дней.

ПРИМЕЧАНИЕ : Хотя эта конфигурация запрещена на нашей платформе, стоит отметить, что задержка сканирования Googlebot не может быть изменена для сайтов, размещенных в подкаталогах, таких как domain.com/blog
Лучшие Лрактики
Прежде всего следует помнить о следующем: непроизводственные сайты должны запрещать использование всех пользовательских агентов.WP Engine автоматически делает это для любых сайтов, использующих домен environmentname .wpengine.com. Только когда вы будете готовы «запустить» свой сайт, вы можете добавить файл robots.txt.
Во-вторых, если вы хотите заблокировать определенного User-Agent, помните, что роботы не обязаны следовать правилам, установленным в вашем файле robots.txt. Лучше всего использовать брандмауэр, например Sucuri WAF или Cloudflare, который позволяет блокировать злоумышленников до того, как они попадут на ваш сайт. Или вы можете обратиться в службу поддержки за дополнительной помощью по блокировке трафика.
Или вы можете обратиться в службу поддержки за дополнительной помощью по блокировке трафика.
Наконец, если у вас очень большая библиотека сообщений и страниц на вашем сайте, Google и другие поисковые системы, индексирующие ваш сайт, могут вызвать проблемы с производительностью. Увеличение срока действия кеша или ограничение скорости сканирования поможет компенсировать это влияние.
СЛЕДУЮЩИЙ ШАГ: устранение ошибок 504
Как оптимизировать файл WordPress Robots.txt для улучшения SEO
Если вам интересно, как оптимизировать файл robots.txt WordPress для улучшения SEO, вы попали в нужное место.
В этом кратком руководстве я объясню, что такое файл robots.txt, почему так важно улучшить ваш поисковый рейтинг и как внести в него изменения и отправить в Google.
Давайте нырнем!
Что такое файл robots.txt WordPress и нужно ли мне о нем беспокоиться?
Файл robots.txt - это файл на вашем сайте, который позволяет запрещать поисковым системам доступ к определенным файлам и папкам. Вы можете использовать его, чтобы запретить роботам Google (и других поисковых систем) сканировать определенные страницы вашего сайта.Вот пример файла:
Вы можете использовать его, чтобы запретить роботам Google (и других поисковых систем) сканировать определенные страницы вашего сайта.Вот пример файла:
Итак, как отказ в доступе к поисковым системам на самом деле улучшает ваше SEO? Кажется нелогичным…
Это работает так: чем больше страниц на вашем сайте, тем больше страниц Google должен сканировать.
Например, если в вашем блоге много страниц с категориями и тегами, эти страницы имеют низкое качество и не нуждаются в сканировании поисковыми системами; они просто расходуют бюджет сканирования вашего сайта (выделенное количество страниц, которые Google будет сканировать на вашем сайте в любой момент времени).
Бюджет сканирования важен, поскольку он определяет, насколько быстро Google улавливает изменения на вашем сайте и, следовательно, насколько быстро вы занимаетесь рейтингом. Это может особенно помочь в SEO электронной коммерции!
Просто будьте осторожны, делая это правильно, так как это может навредить вашему SEO, если все будет сделано плохо.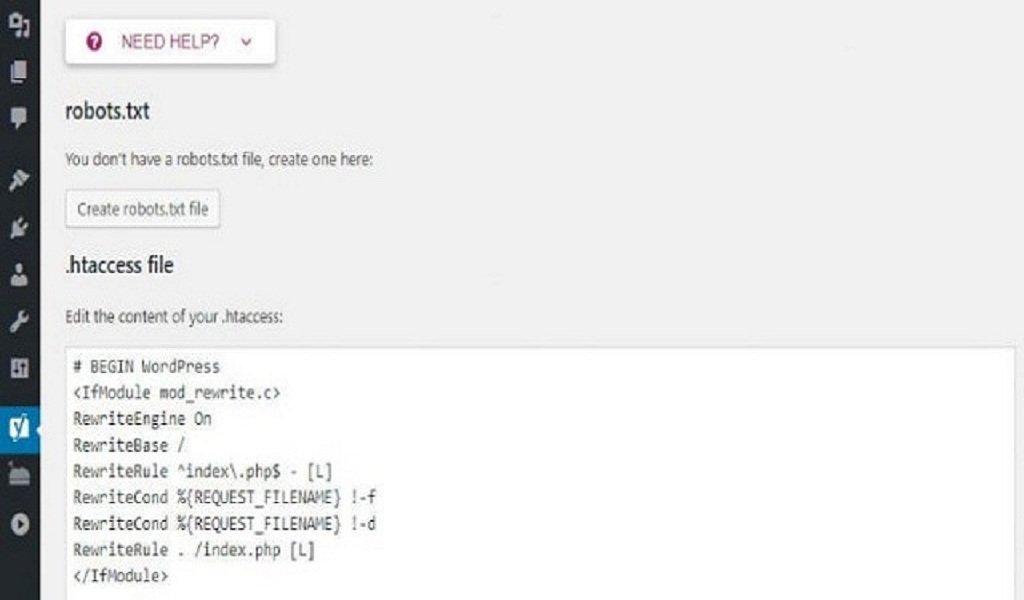 Для получения дополнительной информации о том, как правильно не индексировать нужные страницы, ознакомьтесь с этим руководством DeepCrawl.
Для получения дополнительной информации о том, как правильно не индексировать нужные страницы, ознакомьтесь с этим руководством DeepCrawl.
Итак, вам нужно возиться с файлом robots.txt в WordPress?
Если вы находитесь в высококонкурентной нише с большим сайтом, возможно.Однако если вы только начинаете свой первый блог, создание ссылок на ваш контент и создание множества высококачественных статей являются более важными приоритетами.
Как оптимизировать файл robots.txt WordPress для улучшения SEO
Теперь давайте обсудим, как на самом деле получить (или создать) и оптимизировать файл robots.txt WordPress.
Robots.txt обычно находится в корневой папке вашего сайта. Вам нужно будет подключиться к своему сайту с помощью FTP-клиента или с помощью файлового менеджера cPanel, чтобы просмотреть его.Это обычный текстовый файл, который затем можно открыть в Блокноте.
Если у вас нет файла robots.txt в корневом каталоге вашего сайта, вы можете его создать. Все, что вам нужно сделать, это создать новый текстовый файл на вашем компьютере и сохранить его как robots.txt. Затем просто загрузите его в корневую папку своего сайта.
Все, что вам нужно сделать, это создать новый текстовый файл на вашем компьютере и сохранить его как robots.txt. Затем просто загрузите его в корневую папку своего сайта.
Как выглядит идеальный файл robots.txt?
Формат файла robots.txt очень прост. В первой строке обычно указывается пользовательский агент. Пользовательский агент - это имя поискового бота, с которым вы пытаетесь связаться.Например, Googlebot или Bingbot . Вы можете использовать звездочку * , чтобы проинструктировать всех ботов.
Следующая строка следует с инструкциями Allow или Disallow для поисковых систем, чтобы они знали, какие части вы хотите, чтобы они индексировали, а какие - нет.
Вот пример:
Пользовательский агент: *
Разрешить: /? Display = wide
Разрешить: / wp-content / uploads /
Запретить: /readme.html
Запретить: / ссылаться /
Карта сайта: http: // www.codeinwp.com/post-sitemap.xml
Карта сайта: http://www. codeinwp.com/page-sitemap.xml
Карта сайта: http://www.codeinwp.com/deals-sitemap.xml
Карта сайта: http://www.codeinwp.com/hosting-sitemap.xml  codeinwp.com/page-sitemap.xml
Карта сайта: http://www.codeinwp.com/deals-sitemap.xml
Карта сайта: http://www.codeinwp.com/hosting-sitemap.xml
codeinwp.com/page-sitemap.xml
Карта сайта: http://www.codeinwp.com/deals-sitemap.xml
Карта сайта: http://www.codeinwp.com/hosting-sitemap.xml Обратите внимание: если вы используете такой плагин, как Yoast или All in One SEO, вам может не понадобиться добавлять раздел карты сайта, поскольку они пытаются сделать это автоматически. Если это не удается, вы можете добавить его вручную, как в примере выше.
Что мне запретить или noindex?
В руководстве для веб-мастеров Google советуют веб-мастерам не использовать своих роботов.txt, чтобы скрыть некачественный контент. Таким образом, использование файла robots.txt для предотвращения индексации Google вашей категории, даты и других страниц архива может быть неразумным выбором.
Помните, что цель файла robots.txt - указать ботам, что делать с содержимым, которое они сканируют на вашем сайте. Это не мешает им сканировать ваш сайт.
Кроме того, вам не нужно добавлять страницу входа в WordPress, каталог администратора или страницу регистрации в robots. txt, потому что страницы входа и регистрации содержат тег noindex, автоматически добавляемый WordPress.
txt, потому что страницы входа и регистрации содержат тег noindex, автоматически добавляемый WordPress.
Однако я рекомендую вам запретить использование файла readme.html в вашем файле robots.txt. Этот файл readme может использоваться кем-то, кто пытается выяснить, какую версию WordPress вы используете. Если это человек, он может легко получить доступ к файлу, просто перейдя к нему. Кроме того, установка тега запрета может блокировать вредоносные атаки.
Как мне отправить файл robots.txt WordPress в Google?
После обновления или создания файла robots.txt вы можете отправить его в Google с помощью консоли поиска Google.
Однако я рекомендую сначала протестировать его с помощью инструмента тестирования Google robots.txt.
Если вы не видите здесь созданную версию, вам придется повторно загрузить файл robots.txt, который вы создали, на свой сайт WordPress. Вы можете сделать это с помощью Yoast SEO.
Заключение
Теперь вы знаете, как оптимизировать файл robots. txt WordPress для улучшения SEO.
txt WordPress для улучшения SEO.
Не забывайте проявлять осторожность при внесении каких-либо серьезных изменений в ваш сайт через robots.txt. Хотя эти изменения могут улучшить ваш поисковый трафик, они также могут принести больше вреда, чем пользы, если вы не будете осторожны.
И если вы очень хотите узнать больше, ознакомьтесь с нашим полным обзором руководств по WordPress!
Дайте нам знать в комментариях; у вас есть вопросы по оптимизации файла robots.txt WordPress? Какое влияние это оказало на ваш поисковый рейтинг?
Бесплатный гид
5 основных советов по ускорению работы вашего сайта на WordPress
Сократите время загрузки даже на 50-80%
, просто следуя простым советам.
Файл Robots.txt [Примеры 2021] - Moz
Что такое файл robots.txt?
Robots.txt - это текстовый файл, который веб-мастера создают, чтобы проинструктировать веб-роботов (обычно роботов поисковых систем), как сканировать страницы на своем веб-сайте. Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя директивы, такие как мета-роботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «следовать» или «nofollow»).
Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя директивы, такие как мета-роботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «следовать» или «nofollow»).
На практике файлы robots.txt указывают, могут ли определенные пользовательские агенты (программное обеспечение для веб-сканирования) сканировать части веб-сайта. Эти инструкции сканирования определяются как «запрещающие» или «разрешающие» поведение определенных (или всех) пользовательских агентов.
Базовый формат:User-agent: [user-agent name] Disallow: [URL-строка не должна сканироваться]
Вместе эти две строки считаются полным файлом robots.txt, хотя один файл robots может содержат несколько строк пользовательских агентов и директив (т. е.е., запрещает, разрешает, задержки сканирования и т. д.).
е.е., запрещает, разрешает, задержки сканирования и т. д.).
В файле robots.txt каждый набор директив пользовательского агента отображается как дискретный набор , разделенных разрывом строки:
В файле robots.txt с несколькими директивами пользовательского агента, каждое запрещающее или разрешающее правило только применяется к агентам-пользователям, указанным в этом конкретном наборе, разделенном разрывом строки. Если файл содержит правило, которое применяется более чем к одному пользовательскому агенту, поисковый робот будет только обратить внимание (и следовать директивам в) наиболее конкретной группе инструкций.
Вот пример:
Msnbot, discobot и Slurp все вызываются специально, поэтому эти пользовательские агенты будут только обращать внимание на директивы в своих разделах файла robots.txt. Все остальные пользовательские агенты будут следовать директивам в группе user-agent: *.
Пример robots.txt:
Вот несколько примеров использования robots.txt для сайта www.example.com:
URL файла Robots.txt: www.example.com/robots.txt Блокирование доступа всех поисковых роботов к содержимомуАгент пользователя: * Disallow: /
Использование этого синтаксиса в файле robots.txt укажет всем поисковым роботам не сканировать никакие страницы на www.example .com, включая домашнюю страницу.
Разрешение всем поисковым роботам доступа ко всему контентуUser-agent: * Disallow:
Использование этого синтаксиса в файле robots.txt указывает поисковым роботам сканировать все страницы на www.example.com, включая домашнюю страницу.
Блокировка определенного поискового робота из определенной папкиUser-agent: Googlebot Disallow: / example-subfolder /
Этот синтаксис сообщает только поисковому роботу Google (имя агента пользователя Googlebot) не сканировать страницы, которые содержат строку URL www. example.com/example-subfolder/.
example.com/example-subfolder/.
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Этот синтаксис сообщает только сканеру Bing (имя агента пользователя Bing) избегать сканирование конкретной страницы www.example.com/example-subfolder/blocked-page.html.
Как работает robots.txt?
Поисковые системы выполняют две основные задачи:
- Сканирование Интернета для обнаружения контента;
- Индексирование этого контента, чтобы его могли обслуживать искатели, ищущие информацию.
Чтобы сканировать сайты, поисковые системы переходят по ссылкам с одного сайта на другой - в конечном итоге просматривая многие миллиарды ссылок и веб-сайтов. Такое ползание иногда называют «пауками».”
После перехода на веб-сайт, но перед его сканированием поисковый робот будет искать файл robots.txt. Если он найдет его, сканер сначала прочитает этот файл, прежде чем продолжить просмотр страницы. Поскольку файл robots.txt содержит информацию о , как должна сканировать поисковая система, найденная там информация будет указывать дальнейшие действия поискового робота на этом конкретном сайте. Если файл robots.txt не содержит , а не содержит директив, запрещающих действия пользовательского агента (или если на сайте нет файла robots.txt), он перейдет к сканированию другой информации на сайте.
Поскольку файл robots.txt содержит информацию о , как должна сканировать поисковая система, найденная там информация будет указывать дальнейшие действия поискового робота на этом конкретном сайте. Если файл robots.txt не содержит , а не содержит директив, запрещающих действия пользовательского агента (или если на сайте нет файла robots.txt), он перейдет к сканированию другой информации на сайте.
Другой быстрый файл robots.txt, который необходимо знать:
(более подробно обсуждается ниже)
Чтобы его можно было найти, файл robots.txt должен быть помещен в каталог верхнего уровня веб-сайта.
Robots.txt чувствителен к регистру: файл должен называться «robots.txt» (не Robots.txt, robots.TXT и т. Д.).
Некоторые пользовательские агенты (роботы) могут игнорировать ваших роботов.txt файл. Это особенно характерно для более гнусных поисковых роботов, таких как вредоносные роботы или парсеры адресов электронной почты.
Файл /robots.txt является общедоступным: просто добавьте /robots.txt в конец любого корневого домена, чтобы увидеть директивы этого веб-сайта (если на этом сайте есть файл robots.txt!). Это означает, что любой может видеть, какие страницы вы просматриваете или не хотите сканировать, поэтому не используйте их для сокрытия личной информации пользователя.
Каждый субдомен в корневом домене использует отдельных роботов.txt файлы. Это означает, что и blog.example.com, и example.com должны иметь свои собственные файлы robots.txt (по адресу blog.example.com/robots.txt и example.com/robots.txt).
Обычно рекомендуется указывать расположение любых карт сайта, связанных с этим доменом, в нижней части файла robots.txt. Вот пример:

Технический синтаксис robots.txt
Синтаксис robots.txt можно рассматривать как «язык» файлов robots.txt. Есть пять общих терминов, которые вы, вероятно, встретите в файле robots. К ним относятся:
К ним относятся:
User-agent: Определенный веб-сканер, которому вы даете инструкции для сканирования (обычно это поисковая система). Список большинства пользовательских агентов можно найти здесь.
Disallow: Команда, указывающая агенту пользователя не сканировать определенный URL. Для каждого URL разрешена только одна строка «Disallow:».
Разрешить (применимо только для робота Googlebot): команда, указывающая роботу Googlebot, что он может получить доступ к странице или подпапке, даже если его родительская страница или подпапка могут быть запрещены.
Crawl-delay: Сколько секунд сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что робот Googlebot не принимает эту команду, но скорость сканирования можно установить в консоли поиска Google.
Карта сайта: Используется для вызова местоположения любых XML-файлов Sitemap, связанных с этим URL.
Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
 Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.Сопоставление с шаблоном
Когда дело доходит до фактических URL-адресов для блокировки или разрешения, robots.txt могут быть довольно сложными, поскольку они позволяют использовать сопоставление с образцом для охвата диапазона возможных вариантов URL. И Google, и Bing соблюдают два регулярных выражения, которые можно использовать для идентификации страниц или подпапок, которые SEO хочет исключить. Эти два символа - звездочка (*) и знак доллара ($).
- * - это подстановочный знак, который представляет любую последовательность символов.
- $ соответствует концу URL-адреса
Google предлагает здесь большой список возможных синтаксисов и примеров сопоставления с образцом.
Где находится файл robots.txt на сайте?
Каждый раз, когда они заходят на сайт, поисковые системы и другие роботы, сканирующие Интернет (например, сканер Facebook Facebot), знают, что нужно искать файл robots. txt. Но они будут искать этот файл в только в одном конкретном месте : в основном каталоге (обычно это корневой домен или домашняя страница). Если пользовательский агент посещает www.example.com/robots.txt и не находит там файла роботов, он будет считать, что на сайте его нет, и продолжит сканирование всего на странице (и, возможно, даже на всем сайте. ).Даже если страница robots.txt действительно существует, например, по адресу example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не будет обнаружена пользовательскими агентами и, следовательно, сайт будет обрабатываться так, как если бы он вообще не имел файла robots.
txt. Но они будут искать этот файл в только в одном конкретном месте : в основном каталоге (обычно это корневой домен или домашняя страница). Если пользовательский агент посещает www.example.com/robots.txt и не находит там файла роботов, он будет считать, что на сайте его нет, и продолжит сканирование всего на странице (и, возможно, даже на всем сайте. ).Даже если страница robots.txt действительно существует, например, по адресу example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не будет обнаружена пользовательскими агентами и, следовательно, сайт будет обрабатываться так, как если бы он вообще не имел файла robots.
Чтобы гарантировать, что ваш файл robots.txt найден, всегда включайте его в свой основной каталог или корневой домен.
Зачем нужен robots.txt?
Файлы Robots.txt управляют доступом поискового робота к определенным областям вашего сайта.Хотя это может быть очень опасно, если вы случайно запретите роботу Google сканировать весь ваш сайт (!!), в некоторых ситуациях файл robots. txt может оказаться очень полезным.
txt может оказаться очень полезным.
Некоторые распространенные варианты использования включают:
- Предотвращение появления дублированного контента в результатах поиска (обратите внимание, что мета-роботы часто являются лучшим выбором для этого)
- Сохранение конфиденциальности целых разделов веб-сайта (например, промежуточного сайта вашей группы инженеров)
- Предотвращение показа страниц результатов внутреннего поиска в общедоступной поисковой выдаче
- Указание местоположения карты (карт) сайта
- Предотвращение индексирования поисковыми системами определенных файлов на вашем веб-сайте (изображений, PDF-файлов и т. Д.))
- Указание задержки сканирования для предотвращения перегрузки ваших серверов, когда сканеры загружают сразу несколько частей контента
Если на вашем сайте нет областей, к которым вы хотите контролировать доступ пользовательского агента, вы не можете вообще нужен файл robots.txt.
Проверка наличия файла robots.
 txt
txtНе уверены, есть ли у вас файл robots.txt? Просто введите свой корневой домен и добавьте /robots.txt в конец URL-адреса. Например, файл роботов Moz находится по адресу moz.ru / robots.txt.
Если страница .txt не отображается, значит, у вас нет (активной) страницы robots.txt.
Как создать файл robots.txt
Если вы обнаружили, что у вас нет файла robots.txt или вы хотите изменить свой, создание его - простой процесс. В этой статье от Google рассматривается процесс создания файла robots.txt, и этот инструмент позволяет вам проверить, правильно ли настроен ваш файл.
Хотите попрактиковаться в создании файлов роботов? В этом сообщении блога рассматриваются некоторые интерактивные примеры.
Рекомендации по поисковой оптимизации
Убедитесь, что вы не блокируете какой-либо контент или разделы своего веб-сайта, которые нужно просканировать.
Ссылки на страницах, заблокированных файлом robots.txt, переходить не будут.
Это означает 1.) Если на них также не ссылаются другие страницы, доступные для поисковых систем (т. Е. Страницы, не заблокированные с помощью robots.txt, мета-роботов или иным образом), связанные ресурсы не будут сканироваться и не могут быть индексированы. 2.) Никакой ссылочный капитал не может быть передан с заблокированной страницы на место назначения ссылки.Если у вас есть страницы, на которые вы хотите передать средства, используйте другой механизм блокировки, отличный от robots.txt.Не используйте robots.txt для предотвращения появления конфиденциальных данных (например, личной информации пользователя) в результатах поисковой выдачи. Поскольку другие страницы могут напрямую ссылаться на страницу, содержащую личную информацию (таким образом, в обход директив robots.txt в вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или метадирективу noindex.
Некоторые поисковые системы имеют несколько пользовательских агентов. Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений. Большинство пользовательских агентов из одной и той же поисковой системы следуют одним и тем же правилам, поэтому нет необходимости указывать директивы для каждого из нескольких сканеров поисковой системы, но такая возможность позволяет вам точно настроить способ сканирования содержания вашего сайта.
Поисковая машина кэширует содержимое robots.txt, но обычно обновляет кэшированное содержимое не реже одного раза в день.Если вы изменили файл и хотите обновить его быстрее, чем это происходит, вы можете отправить свой URL-адрес robots.txt в Google.
 Это означает 1.) Если на них также не ссылаются другие страницы, доступные для поисковых систем (т. Е. Страницы, не заблокированные с помощью robots.txt, мета-роботов или иным образом), связанные ресурсы не будут сканироваться и не могут быть индексированы. 2.) Никакой ссылочный капитал не может быть передан с заблокированной страницы на место назначения ссылки.Если у вас есть страницы, на которые вы хотите передать средства, используйте другой механизм блокировки, отличный от robots.txt.
Это означает 1.) Если на них также не ссылаются другие страницы, доступные для поисковых систем (т. Е. Страницы, не заблокированные с помощью robots.txt, мета-роботов или иным образом), связанные ресурсы не будут сканироваться и не могут быть индексированы. 2.) Никакой ссылочный капитал не может быть передан с заблокированной страницы на место назначения ссылки.Если у вас есть страницы, на которые вы хотите передать средства, используйте другой механизм блокировки, отличный от robots.txt.
Robots.txt vs meta robots vs x-robots
Так много роботов! В чем разница между этими тремя типами инструкций для роботов? Во-первых, robots.txt - это фактический текстовый файл, тогда как мета и x-роботы - это метадирективы. Помимо того, чем они являются на самом деле, все три выполняют разные функции. Robots.txt определяет поведение сканирования сайта или всего каталога, тогда как мета и x-роботы могут определять поведение индексации на уровне отдельной страницы (или элемента страницы).
Помимо того, чем они являются на самом деле, все три выполняют разные функции. Robots.txt определяет поведение сканирования сайта или всего каталога, тогда как мета и x-роботы могут определять поведение индексации на уровне отдельной страницы (или элемента страницы).
Продолжайте учиться
Используйте свои навыки на практике
Moz Pro может определить, блокирует ли ваш файл robots.txt наш доступ к вашему веб-сайту. Попробуйте >>
Как оптимизировать файл WordPress Robots.txt для SEO | от Visualmodo | visualmodo
Вы оптимизировали свой файл WordPress Robots.txt для SEO? Если вы этого не сделали, вы игнорируете важный аспект SEO. Файл robots.txt играет важную роль в поисковой оптимизации вашего сайта. Вам повезло, что WordPress автоматически создает файл Robots.txt для вас. Наличие этого файла - половина дела. Вы должны убедиться, что файл Robots.txt оптимизирован для получения всех преимуществ.
Файл Robots.txt сообщает роботам поисковых систем, какие страницы сканировать, а какие избегать. В этом посте я покажу вам, как редактировать и оптимизировать файл Robots.txt в WordPress.
В этом посте я покажу вам, как редактировать и оптимизировать файл Robots.txt в WordPress.
Что такое файл Robots.txt?
Начнем с основного. Файл Robots.txt - это текстовый файл, который инструктирует ботам поисковых систем, как сканировать и индексировать сайт.Всякий раз, когда на ваш сайт приходит какой-либо робот поисковой системы, он читает файл robots.txt и следует инструкциям. Используя этот файл, вы можете указать ботам, какую часть вашего сайта сканировать, а какую - избегать. Однако отсутствие robots.txt не помешает роботам поисковых систем сканировать и индексировать ваш сайт.
Редактирование и понимание Robots.txt в WordPress
Я уже сказал, что на каждом сайте WordPress есть файл robots.txt по умолчанию в корневом каталоге. Вы можете проверить свой robots.txt, перейдя на http://yourdomain.com/robots.txt. Например, вы можете проверить наш файл robots.txt здесь: https://roadtoblogging.com/robots.txt
. Если у вас нет файла robots.txt, вам придется его создать. Сделать это очень просто. Просто создайте текстовый файл на своем компьютере, сохраните его как robots.txt и загрузите в корневой каталог. Вы можете загрузить его через FTP Manager или cPanel File Manager.
Если у вас нет файла robots.txt, вам придется его создать. Сделать это очень просто. Просто создайте текстовый файл на своем компьютере, сохраните его как robots.txt и загрузите в корневой каталог. Вы можете загрузить его через FTP Manager или cPanel File Manager.
Теперь давайте посмотрим, как отредактировать файл robots.txt.
Вы можете редактировать файл robots.txt с помощью FTP Manager или cPanel File Manager. Но это отнимает много времени и немного сложно.
Наилучший способ редактировать файл Robots.txt - использовать плагин. Есть несколько плагинов для WordPress robots.txt. Я предпочитаю Yoast SEO. Это лучший плагин SEO для WordPress. Я уже рассказывал, как настроить Yoast SEO.
Yoast SEO позволяет изменять файл robots.txt из админки WordPress. Однако, если вы не хотите использовать плагин Yoast, вы можете использовать другие плагины, например WP Robots Txt.
После того, как вы установили и активировали плагин Yoast SEO, перейдите в панель администратора WordPress> SEO> Инструменты.
Затем щелкните «Редактор файлов».
Затем вам нужно нажать на «Создать файл robots.txt».
Тогда вы получите редактор файла Robots.txt. Здесь вы можете настроить файл robots.txt.
Перед редактированием файла вам необходимо понять команды файла. В основном есть три команды.
- User-agent - определяет имя ботов поисковых систем, таких как Googlebot или Bingbot.Вы можете использовать звездочку (*) для обозначения всех роботов поисковых систем.
- Disallow - Указывает поисковым системам не сканировать и не индексировать некоторые части вашего сайта.
- Разрешить - указывает поисковым системам сканировать и индексировать, какие части вы хотите проиндексировать.
Вот образец файла Robots.txt.
User-agent: *
Disallow: / wp-admin /
Allow: /
Этот файл robots.txt предписывает всем роботам поисковых систем сканировать сайт. Во второй строке он сообщает ботам поисковых систем не сканировать / wp-admin / part. В третьей строке он инструктирует роботов поисковых систем сканировать и индексировать весь сайт.
В третьей строке он инструктирует роботов поисковых систем сканировать и индексировать весь сайт.
Настройка и оптимизация файла Robots.txt для SEO
Простая неправильная конфигурация файла Robots.txt может полностью деиндексировать ваш сайт поисковыми системами. Например, если вы используете команду «Disallow: /» в файле Robots.txt, ваш сайт будет деиндексирован поисковыми системами. Так что будьте осторожны при настройке.
Еще один важный момент - оптимизация файла Robots.txt для SEO.Прежде чем перейти к лучшим методам SEO-оптимизации Robots.txt, я хотел бы предупредить вас о некоторых плохих методах.
- Не используйте файл Robots.txt для скрытия некачественного содержания. Лучше всего использовать метатеги noindex и nofollow. Вы можете сделать это с помощью плагина Yoast SEO.
- Не используйте файл Robots.txt для остановки поисковых систем для индексации ваших категорий, тегов, архивов, страниц авторов и т. Д. Вы можете добавить метатеги nofollow и noindex на эти страницы с помощью плагина Yoast SEO.
- Не используйте роботов.txt для обработки дублированного содержимого. Есть и другие способы.
Теперь давайте посмотрим, как можно сделать файл Robots.txt дружественным для поисковых систем.
- Сначала вам нужно определить, какие части вашего сайта вы не хотите, чтобы роботы поисковых систем сканировали. Я предпочитаю запретить / wp-admin /, / wp-content / plugins /, /readme.html, / trackback /.
- Добавление производных «Allow: /» в файл Robots.txt не так важно, поскольку боты все равно будут сканировать ваш сайт. Но вы можете использовать его для конкретного бота.
- Добавление карты сайта в файл Robots.txt также является хорошей практикой. Читайте: Как создать карту сайта
Вот пример идеального файла Robots.txt для WordPress.
User-agent: *
Disallow: / wp-admin /
Disallow: / wp-content / plugins /
Disallow: /readme.html
Disallow: / trackback /
Disallow: / go /
Allow: / wp- admin / admin-ajax.
Разрешить: / wp-content / uploads /
Карта сайта: https://roadtoblogging.com/post-sitemap.xml
Карта сайта: https: // roadtoblogging.com / page-sitemap.xml
 php
php Вы можете проверить файл RTB Robots.txt здесь: https://roadtoblogging.com/robots.txt
Тестирование файла Robots.txt в Инструментах Google для веб-мастеров
После обновления ваших роботов. txt необходимо протестировать файл Robots.txt, чтобы проверить, не повлияло ли обновление на какой-либо контент.
Вы можете использовать Google Search Console, чтобы проверить наличие «ошибок» или «предупреждений» для вашего файла Robots.txt. Просто войдите в Google Search Console и выберите сайт. Затем перейдите в Сканирование> роботы.txt Tester и нажмите кнопку «Отправить».
Появится окно. Просто нажмите кнопку «Отправить».
Затем перезагрузите страницу и проверьте, обновлен ли файл. Обновление файла Robots.txt может занять некоторое время.
Если он еще не обновлен, вы можете ввести код файла Robots.