5 способов избавится от дубликатов страниц на вашем сайте
В данном обзоре рассмотрим как найти и навсегда удалить дубли страниц.
Как возникают дубликаты страниц
Какие бывают дубли страниц
Какую опасность несут в себе дубли страниц
Как обнаружить дубликаты на сайте
5 способов удалить дубликаты страниц
Как возникают дубликаты страниц
Основные причины появления дублей — несовершенство CMS сайта, практически все современные коммерческие и некоммерческие CMS генерируют дубли страниц. Другой причиной может быть низкий профессиональный уровень разработчика сайтов, который допустил появление дублей.
Какие бывают дубли страниц
1. Главная страница сайта, которая открывается с www и без www
пример www.site.ua и site.ua
site.ua/home.html и site.ua/
2. Динамическое содержание сайта с идентификаторами ?, index.php, &view
site.ua/index.php?option=com_k2&Itemid=141&id=10&lang=ru&task=category&view=itemlist
site.ua/index.php?option=com_k2&Itemid=141&id=10&lang=ru&layout=category&task=category&view=itemlist
3. Со слешем в конце URL и без
site.ua/cadok/
site.ua/cadok
4. Фильтры в интернет-магазине (пример VirtueMart)
site.ua//?Itemid=&product_book&
5. Странички печати
site.ua/cadok/?tmpl=component&print=1&layout=default&page=»
Какую опасность несут в себе дубли страниц
Представьте себе что вы читаете книгу где на страничках одинаковый текст, или очень похожий. Насколько полезна для вас такая информация? В таком же положении оказываются и поисковые машины, ища среди дубликатов вашего сайта то полезное содержимое которое необходимо пользователю.
Поисковые машины не любят такие сайты, следовательно ваш сайт не займет высокие позиции в поиске, и это несет для него прямую угрозу.
Как обнаружить дубликаты на сайте
1. С помощью команды site:site.ua можете проверить какие именно дубли попали в индекс поисковой машины.
2. Введите отрывки фраз с вашего сайте в поиск, таким образом обнаружите страницы на которых она присутствует
3. Инструменты для веб-мастеров Google, в разделе Вид в поиске → Оптимизация HTML, можете увидеть страницы, на которых есть повторяющееся метаописание или заголовки.
5 способов удалить дубликаты страниц
1. С помощью файла robots.txt
Пример
Disallow: /*?
Disallow: /index.php?*
Таким образом, дадим знать поисковой машине, что странички, которые содержат параметры ?, index.php?, не должны индексироваться.
Есть одно «но»: файл robots — это только рекомендация для поисковых машин, а не правило, которому они абсолютно следуют. Если, например, на такую страничку поставлена ссылка то она попадет в индекс.
2. Файл .htaccess, позволяет решить проблему с дублями на уровне сервера.
.htaccess — это файл конфигурации сервера Apache, находится в корне сайта. Позволяет настраивать конфигурацию сервера для отдельно взятого сайта.
Склеить странички сайта 301 редиректом.
Пример
Redirect 301 /home.html http://site.ua/ (для статических страниц cайта)
RewriteCond %{QUERY_STRING} ^id=45454
RewriteRule ^index.php$ http://site.ua/news.html? [L,R=301] (редирект для динамических страничек)
Использовать 410 редирект (полное удаление дубля)
Он сообщает что такой странички нет на сервере.
Пример
Redirect 410 /tag/video.html
Настроить домен с www и без www
Пример с www
Options +FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} ^site\.ua
RewriteRule ^(.*)$ http://www.site.ua/$1 [R=permanent,L]
Без www
Options +FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www.site.ua$ [NC]
RewriteRule ^(.*)$ http://site.ua/$1 [R=301,L]
Добавляем слеш в конце URL
RewriteCond %{REQUEST_URI} (.*/[^/.]+)($|\?) RewriteRule .* %1/ [R=301,L]
Для сайтов с большим количеством страниц будет довольно трудозатратно искать и склеивать дубли.
3. Инструменты для веб-мастеров
Функция Параметры URL позволяют запретить Google сканировать странички сайта с определенными параметрами
Или вручную удалить
Удаление страничек возможно только в случае если страничка:
— запрещена для индексации в файле robots.txt
— возвращает ответ сервера 404
— запрещена тегом noindex
4. Мета тег noindex — это самый действенный способ удаления дубликатов. Удаляет навсегда и бесповоротно.
По заявлению Google наличие тега noindex полностью исключает страничку из индекса.
Пример
<meta name=»robots» content=»noindex»>
Важно. Для того что бы робот смог удалить страничку, он должен ее проиндексировать, то есть она не должна быть закрыта от индексации в файле robots.txt.
Реализовать можно через регулярные выражения PHP, используя функцию preg_match().
5. Атрибут rel=»canonical»
Атрибут rel=»canonical» дает возможность указать рекомендуемую (каноническую) страничку для индексации поисковыми машинами, таким образом дубликаты не попадают в индекс.
rel=»canonical» указывается двома способами
1. С помощью атрибута link в в HTTP-заголовке
Пример
Link: <http://site.ua/do/white>; rel=»canonical»
2. В раздел <head> добавить rel=»canonical» для неканонических версий страниц
Пример
<link rel=»canonical» href=»http://site.ua/product.php?book»/>
В некоторые популярные CMS атрибут rel=»canonical» внедрен автоматически — например, Joomla! 3.0 (почитайте об отличии версии Joomla! 2.5 и Joomla! 3.0). У других CMS есть специальные дополнения.
Подведем итог. При разработке сайта учитывайте возможности появления дублей и заранее определяйте способы борьбы с ними. Создавайте правильную структуру сайта (подробнее здесь).
Проверяйте периодически количество страниц в индексе, и используйте возможности панели Инструментов для веб-мастеров.
При написании использовались материалы
https://support.google.com/webmasters/topic/2371375?hl=ru&ref_topic=1724125
Зберегти
Зберегти
Зберегти
blog.mcsite.ua
Как найти и удалить дубли страниц на сайте
Многих людей на каком-то этапе начинает беспокоить вопрос поиска дублей страниц на их сайте. Данной проблеме особенно подвержены интернет-магазины, особенно старые и на самописных движках (да, такие ещё встречаются). В принципе это не удивительно, поскольку любая работа над сайтом в итоге сопровождается появлением дублей.
В этой статье я не буду пичкать вас бесполезной теорией. В этом нет нужды ибо именно теории посвящены тысячи статей. Сейчас я вам расскажу о том, как определить наличие или отсутствие проблем и их характер. Полное отсутствие проблем конечно же может констатировать только SEO-специалист. Вы же сможете только понять есть ли серьезные проблемы у сайта или нет. В этой статье мы определим есть ли проблемы у сайта с дублями страниц и со страницами низкого качества.
Беглый осмотр
Чтобы понять каково текущее состояние сайта, достаточно зайти в Яндекс.Вебмастер в раздел «Страницы в индексе».
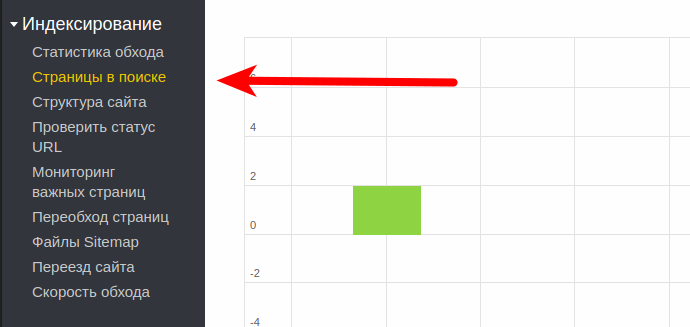
После этого мы попадем на страницу, где собрана вся информация касаемо процесса индексации нашего сайта. Первым делом смотрим на график, если видим примерно вот такую картину:

Зеленые столбики без синих означают что серьезных проблем у сайта нет. Но если же мы видим примерно вот такую картину:
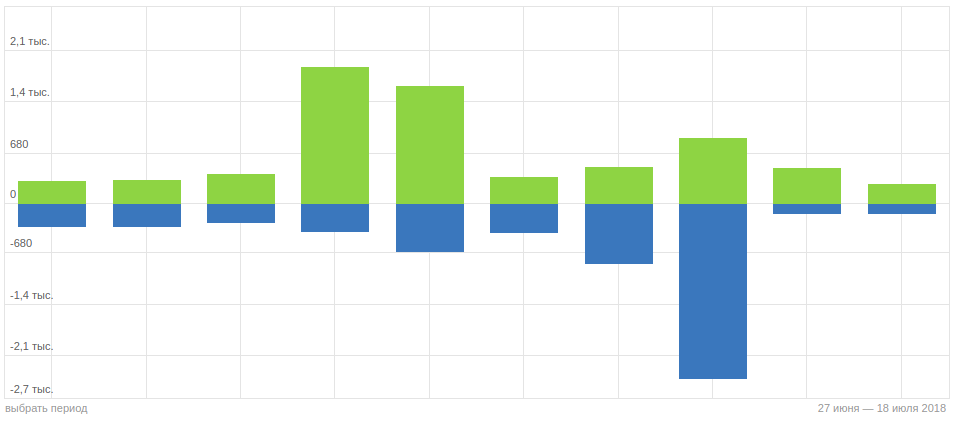
То начинаем ерзать на стуле, поскольку это говорит о явных проблемах. Чуть ниже под графиком кликаем кнопку «Исключенные страницы» и смотрим с каким комментарием удаляются страницы.
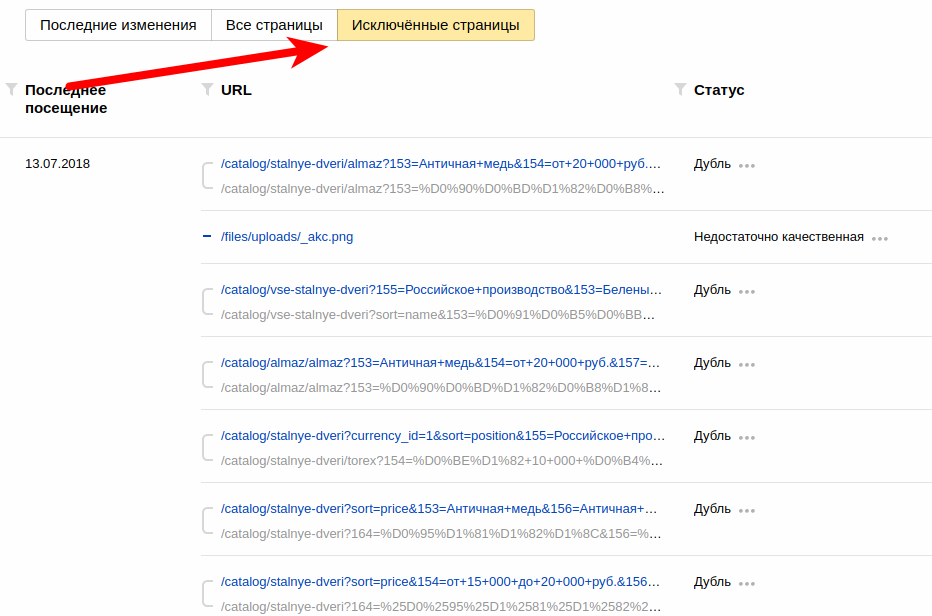
Как видите в поле «Статус» финурируют понятия «Дубль», «Недостаточно качественная». Это очень плохо. Если же в колонке «Статус» фигурируют «Редирект», «Ошибка 404», «Запрешщено тем-то», то можете спать спокойно, у вашего сайта нет серьезных проблем. Спускаемся в конец страницы и смотрим количество страниц с исключенными страницами.

Значение в 2500 максимальное и говорит о том, что как минимум на вашем сайте 50 000 проблемных страниц. На самом деле это число может быть в десятки раз выше. На одном сайте с 800 товарами Яндекс загрузил свыше 4 миллионов страниц. Это было самым большим количеством загруженных страниц, которое попадалось мне за мою практику. Из этого количества только 1 000 страниц является уникальными, все остальное дубли. Зато, со слов владельца сайта, этот самописный сайт очень удобный. Честно говоря в одно место такое удобство. Разработчикам таких, с позволения сказать, CMS хочется оторвать руки. Две недели я буду просто удалять ссылки.
Но это ерунда, перед этим ко мне обратились одни товарищи с интернет-магазином на ViartShop, вот где полный атас. Там карточка товара может иметь до трех дублей без возможности установить хотя бы rel canonical. тут только на удаление мусорных ссылок мне потребовалось бы от 40 до 50 дней, при том, что договор заключался всего на 60 календартный дней и за это время я должен был показать результаты в виде увеличения продаж. Само собой пришлось с товарищами расстаться. Загадят сайт, а потом жесткие условия ставят.
Первый шаг: определяем характерные особенности «мусорных» ссылок\
Для этого нам потребуется изучить ссылки исключенных страниц. Поскольку частая причина возникновения дублей – это фильтрация, то как правило общим признаком таких страниц является наличие знака вопроса «?» в URL. По идее мы можем закрыть их все всего лишь одной директивой «DisallowL *?*», но эта директива закроет вообще все страницы где есть знак «?». Если на сайте нет важных страниц с параметрами, то можно использовать эту директиву. Но не всегда есть возможность разобраться с сайтом, а действовать надо прямо сейчас, то проще сначала закрыть от индексации страницы с конкретными параметрами.
Второй, по популярности, причиной появления дублей является пагинация. Эти страницы также необходимо закрывать от индексации. Хорошо если в URL этих страниц имеются явные признаки в виде «?page=6» или «/page/6», но бывают случаи когда такие признаки отсутствуют, например пагинация имеет в URL просто цифру «blog/5», такие страницы будет сложно закрыть от индексации без «хирургического» вмешательства в движок.
Но в случае с моим подопытным таких проблем не было. Все ссылки с параметрами являются бесполезными и их можно смело закрывать от индексации. Остается только определить их ключевые признаки:
- /catalog/dveri-iz-massiva?158=***
- /mezhkomnatnye-dveri?sort=price&162=***
- /catalog/stalnye-dveri/torex?156=***
- /catalog/mezhkomnatnye-dveri?162=***&161=***
- /products?page=23
- /catalog/mezhkomnatnye-dveri/sibir-profil?162=***&sort=name
- /catalog/dveri-s-plenkoj-pvh/?162=***
Если бы разработчики движка, на котором работает подопытный сайт, хоть чуть-чуть разбирались в SEO, то сделали бы параметры в виде массива:
- /catalog/mezhkomnatnye-dveri/sibir-profil?filter[162]=***&filter[sort]=name
Или каждый параметр снабжали бы префиксом:
- /catalog/mezhkomnatnye-dveri/sibir-profil?filter_162=***&filter_sort=name
В обоих случаях можно было бы прикрыть все страницы фильтрации всего лишь одной директивой «Disalow: *filter*». Но увы, криворукие программисты в данном случае забили на все что связано в SEO и иными «бесполезными» вещами, которые так или иначе связаны с SEO, и не оставили мне другого выхода кроме как закрывать от индексации страницы фильтрации путем указания параметров. Конечно же я мог внести изменения и устранить этот недостаток, но самописный движок всегда ящик Пандоры, стоит начать его ковырять и ошибки начинают выскакивать пачками. По этой причине я решил избежать действий, которые могли привести к непредвиденным последствиям..
В итоге у меня получился примерно вот такой список директив:
- Disallow: *sort=*
- Disallow: *page=*
- Disallow: *153=*
- Disallow: *154=*
- Disallow: *155=*
- Disallow: *156=*
Правильность директив можно проверить на странице «Инструменты -> Анализ robots.txt». Там в самом низу есть поле, копируем туда ссылку и жмем кнопку «Проверить».
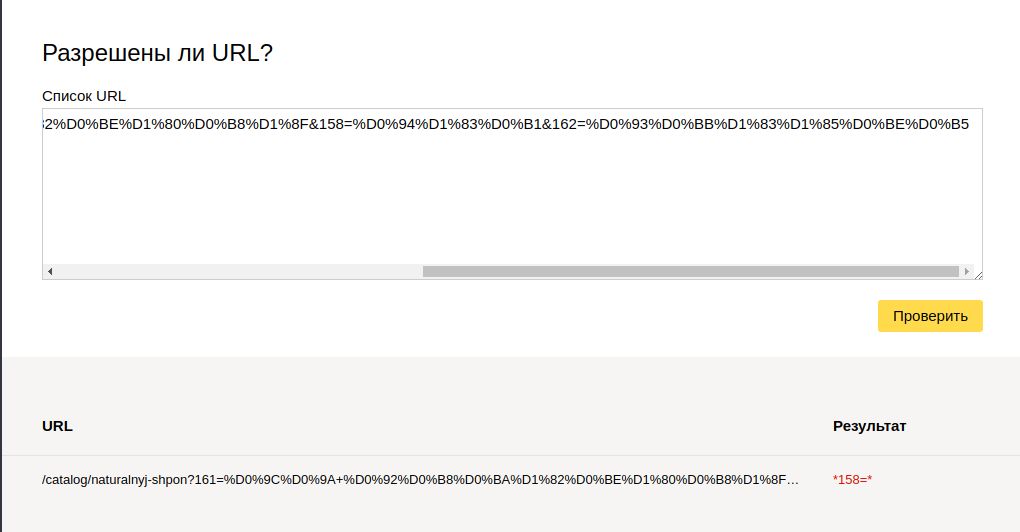
Если под надписью «Результат» мы видим параметр одной из диркектив, выделенный красным, значит ссылка запрещена, если же там зеленая галка, значит ссылка не запрещена к индексации. Необходимо корректировать параметр директивы, отвечающий за запрет к индексации подобных страниц.
Самое главное – это соблюдать осторожность в формировании параметров директив. Можно таких дров наломать, что мама дорогая. Я однажды в погоне за «хвостами» от переноса сайта с Wix закрыл от индексации весь сайт клиента. Приятным бонусом было таки исчезновение этих «хвостов» из индекса.
Второй шаг: удаление «мусора»
Тут у нас с вами два пути:
- Забить и ждать пока Яндекс сам все удалит из индекса.
- Ускорить этот процесс путем использования инструмента «Удаление страниц из поиска».
Первый вариант может затянуться на месяцы и если вы никуда не спешите, то можно в принципе не заморачиваться. Второй вариант тоже не самый быстрый, но побыстрее чем первый. Единственный его минус – это возможность удаления страниц из поиска до 500 в сутки.
Когда с этой проблемой я столкнулся на своем сайте, то там я не стал заморачиваться автоматизацией, поскольку надо было удалить всего 400 с лишним URL. Но даже на это у меня ушло два дня. Сидеть и вручную копипастом перебивать ссылки то ещё занятие. Но для удаления нескольких тысяч я решил все-таки написать скрипт на PHP, который выворачивает весь индекс сайта и выбирает из него страницы, которые необходимо удалить. Эти страницы он складывает в файлик. После этого нам остается «вырезать» из этого файла ссылки и вставлять в поле на странице «Удаление страниц из поиска».
К сожалению и в случае со скриптом есть одно «но», для работы со скриптом необходима регистрация и настройка Яндекс XML, поскольку скрипт работает на основе этого сервиса. Перед использованием необходимо со своего аккаунта в Яндекс получить ключ и вставить его в скрипт. После этого скрипт будет готов к работе. Ключ необходимо скопировать из ссылки , которая указана в верхней части страницы с настройками(см. фото).
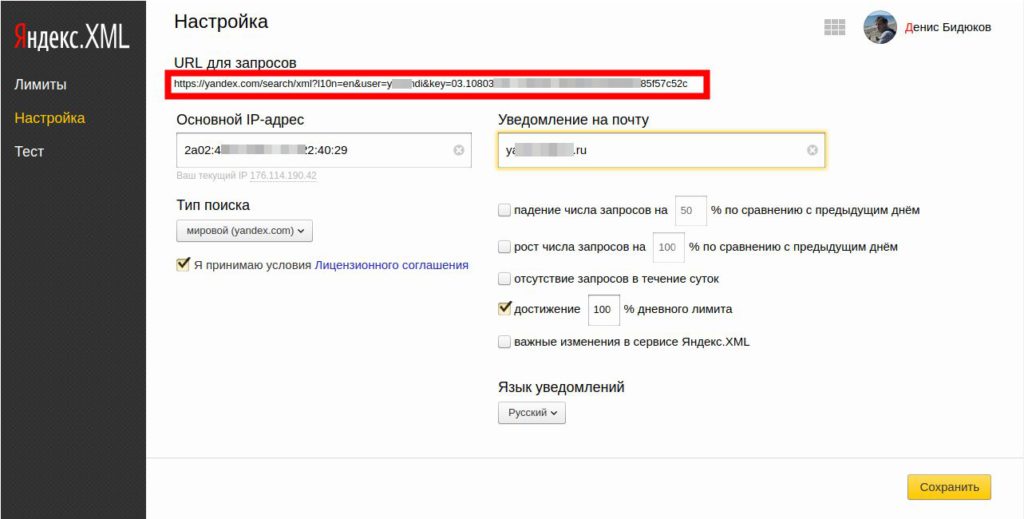
Обратите внимание на лимиты, прежде чем приступать к работе со скриптом. Необходимо убедиться что лимит запросов к сервису достаточно велик. Ни в коем случае не запускайте скрипт на хостинге, ничего хорошего это не даст.
Получив файл со списком ссылок, нам остается только раз в день открывать Яндекс.Вебмастер и Google Console, и в разделах «Удаление URL» копипастить ссылки пачками.
Скрипт тут: https://yadi.sk/d/d3IRM_vv3ZQkww
P.S. Больше всего повезло обладателям сайтов (интернет-магазинам) на Битриксе, поскольку там разработчики отличаются большей сообразительностью и там уже искаропки идет robots.txt заполненный как надо. Как пример сайт buldoors.ru, из 17к страниц в индексе, мусорных у него всего 60+. Казалось бы можно расслабиться, но увы, большое количество страниц говорит явно о каких-то проблемах, выяснение которых требует более глубокого анализа.
dampi.ru
Как убрать дубли страниц на сайте

Что такое дубли страниц — это страницы с абсолютно одинаковым содержанием и разными URL адресами.
Причин возникновения дублей страниц на сайте может быть несколько, однако почти все они так или иначе связаны с системой управления содержимым сайта. Лучше всего принять меры, предотвращающие появление страниц-дублей еще на стадии создания сайта. Если Ваш сайт уже функционирует — обязательно проверьте наличие на нем повторяющихся страниц, иначе серьёзных проблем с индексацией и SEO не избежать.
Существует несколько способов избавления от дублей страниц сайта. Одни могут помочь в борьбе с уже появившимися копиями страниц, другие помогут избежать их появления в будущем.
Как найти дубли страниц на сайте?
Но для начала необходимо проверить — есть ли вообще повторяющиеся страницы на Вашем ресурсе и, если да, то какого типа эти страницы. Как это сделать?
- Способ 1. Запрос в поиске «site:»
Можно воспользоваться командой «site:». Эта команда выдает результаты поиска по определенному сайту. Введя site:www.yoursite.com/page1, Вы увидите, есть ли в поиске дубли этой страницы.
- Способ 2. Поиск по отрывку из статьи
Выделяем небольшой отрывок текста со страницы, для которой мы ищем дубли, и вставляем в поиск. Результаты поиска сразу покажут все проиндексированные дубли нужной страницы.
Как бороться с дублями страниц?
301 редирект
Одним из самых эффективных, но в то же время и самых непростых методов борьбы с дублями является 301-редирект, он склеивает указанные страницы и дубли со временем исчезают из индекса поисковых систем.
При попадании поискового робота на дубликат страницы, на которой прописан 301 редирект, веб-сервер автоматически перенаправит его на страницу-оригинал. Прописываются все перенаправления в файле .htaccess, который находится в корневом каталоге сайта. Не стоит использовать 301 перенаправление (постоянный редирект), если вы планируете в дальнейшем как-то использовать страницу-копию. Для этого можно использовать 302 перенаправление (временное). Тогда склеивания страниц не произойдет.
При использовании 301 редиректа для удаления дублей страниц из индекса прежде всего надо определиться с главным зеркалом сайта. Для примера в качестве главного зеркала укажем http://site.ru Вам останется только поменять на адрес своего сайта
- 301 Редирект с www.site.ru на site.ru
Для этого надо в файле .htaccess (файл находится в корне сайта) добавить следующие строки сразу после RewriteEngine On:
RewriteCond %{HTTP_HOST} ^www.site.ru$ [NC]RewriteRule ^(.*)$ http://site.ru/$1 [R=301,L]
- 301 редирект с site.ru/index.php на site.ru
RewriteCond %{THE_REQUEST} ^[A-Z]{3,9}\ /index\.php\ HTTP/
RewriteRule ^index\.php$ http://site.ru/ [R=301,L]
Аналогичным образом можно избавиться от дублей типа:
http://site.ru/index
http://site.ru/index.html
http://site.ru/index.htm
Если Вы, к примеру, хотите склеить страницы http://site.ru и http://site.ru/page123, то в файле .htaccess следует прописать следующее:
Redirect 301 /page123 http://site.ru
Теперь при попытке зайти на страницу http://site.ru/page123 будет срабатывать перенаправление на главную.
Канонические ссылки
Другой способ указать оригинал — прописывать на страницах-дублях т.н. канонические ссылки. Это ссылки с атрибутом rel=canonical, иными словами в блоке head такой страницы прописано:
<link rel=»canonical» href=»http://site.ru/load» />
Если поисковые системы сталкиваются с такой ссылкой, то понимают какая из многочисленных копий страниц является оригиналом и индексируют её.
Например, в примере выше на сайте были 2 страницы-дубля:
http://site.ru/load
http://site.ru/load/
Указав на странице http://site.ru/load атрибут rel=canonical мы покажем поисковым системам, что эта страница является главной и именно ее надо индексировать.
Некоторые CMS (например, Joomla!) могут автоматически создавать такие ссылки, на других эта операция выполняется различными плагинами. Однако, даже если все новосозданные дубли страниц Вашего сайта будут с каноническими ссылками, это не поможет решить проблему уже существующих дублей.
robots.txt
Частично проблему дублей страниц решает файл robots.txt в котором содержатся рекомендации поисковым системам с перечнем файлов и папок, которые не должны быть проиндексированы. Почему частично? Потому что этот файл содержит именно рекомендации, а не правила и некоторые поисковые системы игнорируют эти рекомендации.
Например, чтобы Яндекс удалил из индекса старые дубли страниц, достаточно прописать соответствующие запрещающие их индексацию правила в robots.txt. С Google ситуация немного сложнее. Те же правила придется вносить в особый инструментарий от Google, разработанный специально для веб-мастеров. В Google вебмастер понадобится задать необходимые нам параметры ссылок в разделе «Сканирование».
При создании же robots.txt нам понадобится воспользоваться запрещающей директивой Disallow.
- Правильный robots.txt для Joomla
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Sitemap: http://site.ru/sitemap.xml
User-agent: Yandex
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /xmlrpc/
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
- Правильный robots.txt для WordPress
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Sitemap: http://site.ru/sitemap.xml
User-agent: Yandex
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: site.ru
Sitemap: http://site.ru/sitemap.xml
Что означают эти строки:
- User-agent: * — правила описанные в ниже этой строки будут действовать для всех поисковых роботов
- User-agent: Yandex — правила действуют только для робота Яндекса
- Allow: — разрешить индексирование (обычно не пишут)
- Disallow: запрещено индексировать страницы в адресе котроых есть то что описано в строке.
- Host: site.ru — Основное зеркало сайта
- Sitemap: — ссылка на XML-карту сайта
- «*» — любая последовательность символов в адресе страницы
Борьба с дублями страниц в WordPress
Каким должен быть файл robots.txt для WordPress мы уже рассмотрели выше. А теперь поговорим о плагинах, которые позволяют бороться с дублями и вообще незаменимы для оптимизатора сайтов на этом движке.
Yoast SEO — Один из самых популярных плагинов для WordPress, позволяющим бороться с проблемой дублей. С его помощью можно заставить WordPress прописывать канонические ссылки, запретить индексацию страниц с постраничным разбиением (рубрики), скрыть архивы автора, удалить /category/ из URL и многое другое.
All in One Seo Pack — Аналогичный плагин, не менее популярный и выполняющий похожие функции. Какой из них использовать — решать вам.
Как убрать дубли страниц в Joomla
Несмотря на то, что Joomla! поддерживает автоматическое создание канонических ссылок, некоторые дубли все равно могут попадать в индекс поисковых машин. Для борьбы с дублями в Joomla! можно использовать robots.txt и 301редирект. Правильный файл rorbots.txt описан выше.
Ну, а чтобы включить ЧПУ (человеко понятные урлы) в Joomla достаточно переименовать htaccess.txt в .htaccess и добавить туда сразу после RewriteEngine On:
RewriteCond %{HTTP_HOST} ^www.site.ru$ [NC]
RewriteRule ^(.*)$ http://site.ru/$1 [R=301,L]
RewriteCond %{THE_REQUEST} ^[A-Z]{3,9}\ /index\.php\ HTTP/
RewriteRule ^index\.php$ http://site.ru/ [R=301,L]
А также в настройках сайта поставить галочки следующим образом:

Таким образом мы избавимся от дублей типа www.site.ru и site.ru/index.php, потому что в этой CMS возникает такая проблема с дублями. И поисковики часто индескируют страницы типа site.ru/index.php. Теперь после всех манипуляций при попытке зайти на страницу, например, www.site.ru посетителя перекинет на главную, т.е. site.ru.
Из плагинов для Джумлы могу посоветовать JL No Doubles — плагин убирает дубли страниц в компоненте com_content. Возможен 301 редирект на правильную страницу, либо вывод 404 ошибки.
Специальные сервисы для создания robots.txt и .htaccess
Если Вы только начинаете осваивать сайтостроение — попробуйте воспользоваться услугами специализированных сервисов, которые помогут Вам сгенерировать валидные файлы robots.txt и .htaccess:
seolib.ru — На нем можно не только создать, но и протестировать Ваш robots.txt
htaccess.ru — один из наиболее популярных сервисов, на котором можно создать и выбрать различные параметры генерируемого файла .htaccess
aff1.ru
Как найти и удалить дубли страниц на сайте?
В данной статье я напишу о том, как найти дубли страниц на сайте в также как удалить их. Я покажу на примере этого блога, как я находил дубликаты и удалял.

Если на вашем ресурсе присутствуют проблемы с индексацией, то советую прочитать этот пост внимательно и до конца.
Не секрет, что если на блоге есть дубликаты документов, то это плохо. Во-первых, дублируется сам контент на странице и таким образом он получается уже не уникальным. Во-вторых, бывает такое, что внутренние ссылки проставлены не на продвигаемые страницы, а на их дубликаты. Таким образом важные документы не получают тот вес, который они бы могли получить.
Перед тем, как перейти к поиску дублирующих документов, нужно прикинуть, сколько на сайте есть полезных для посетителя страниц. На моем блоге опубликована 81 статья, создано 7 категорий, и присутствует 12 страниц навигации + главная. Категории запрещены к индексации в robots.txt. Получается, что поисковики должны индексировать примерно 94 страницы. Теперь наша задача узнать, сколько документов проиндексировано на самом деле. И в этом нам поможет, конечно, RDS Bar:

Мы видим, что Яндекс индексирует 74 документа, а Гугл 400. Учитывая то, что Яндекс еще не успел проиндексировать несколько последних постов, а также некоторые страницы навигации он не индексирует, то можно сделать вывод, что в индексе Яндекса точно нет дубликатов. Теперь что касается Гугла. Мы видим, что он индексирует 400 страниц, но в основном индексе только 24%. Получается, что 97 страниц присутствуют в основном индексе, а 303 документа – это «сопли». Моя задача определить дубли страниц и удалить их с поиска Гугла. Но я также покажу, как находить дубликаты в Яндексе, возможно у вас, наоборот, с Гуглом все нормально, а Яндекс индексирует ненужные документы.
Итак, как определить дубли страниц на сайте
1. Для того, чтобы узнать, какие страницы присутствуют в основном индексе Гугла не включая «сопли», достаточно ввести вот такой адрес: site:vachevskiy.ru/
А если нужно найти все страницы вместе с «соплями», нужно ввести вот так: site:vachevskiy.ru
В моем случае необходимо вводить как раз последний вариант. Ввожу site:vachevskiy.ru, дальше перехожу на самую последнюю страницу и нажимаю на ссылку «Показать скрытые результаты»:

Мне прекрасно видно, что Гугл включает в дополнительный поиск даже те документы, которые запрещены в файле robots.txt:
Вот, например, адрес страницы, которая разрешена к индексированию выглядит так:
Как создать группу в контакте и получить посетителей на сайт?
А вот эта страница появляется тогда, когда нажать на кнопку «Ответить», на последний комментарий:
Как создать группу в контакте и получить посетителей на сайт?
Почему закрытая страница вообще появляется в результатах поиска, для меня остается загадкой

Как видим, вместо сниппета пишет: «описание веб-страницы недоступно из-за ограничений в файле robots.txt». То есть Гугл и не скрывает, что страница закрыта от индексации, но, с поиска ее почему-то не удаляет. Значит, будем искать другие варианты ее удаления, об этом я напишу немного позже.
С Яндексом все гораздо проще, там нет никаких «соплей», он или индексирует страницу или не индексирует. Причем, если документ запрещен в robots.txt, то он его индексировать не будет. Для того, чтобы узнать, какие страницы присутствуют в индексе Яндекса, достаточно ввести вот такой запрос: site:vachevskiy.ru
Если страниц на сайте немного, то можно пробежаться по заголовкам и легко определить дубликаты.
2. Найти дубли страниц на сайте можно также с помощью текста. Для этого откройте расширенный поиск в Яндексе, укажите в кавычках любой кусочек текста со станицы, которая уже проиндексировалась, и нажмите «найти»:

Если на вашем блоге есть дубликат страницы, с которой был взять кусочек текста и эта страница также индексируется Яндексом, то вы увидите ее в результатах поиска. В моем случае дубликата нет, поэтому Яндекс показал мне только один документ:

Точно также можно найти дубли страниц на сайте и в поисковой системе Google.
3. Определить дубли страниц можно и с помощью программы Xenu. О ней я уже писал в статье: «Как найти и удалить битые ссылки на сайте?» Сначала скачиваем программу, запускаем ее и выбираем в левом верхнем углу «File» — «Check URL». Дальше вводим адрес своего сайта и нажимаем «ОК»:

После анализа программа предложит создать карту сайта, лучше нажать нет и сохранить результаты на компьютер. Для этого нажмите «File» — «Export to TAB separated file». Программа нейдет все страницы, в том числе и с ошибками 404. Вам достаточно перейти на них и посмотреть, какие индексируются, а какие нет.
Как удалить дубли страниц
1) Файл robots.txt.
Этот файл предназначен исключительно для поискового бота, и с его помощью можно легко запретить индексировать отдельный документ, категорию или целый сайт. Советую вам прочитать статью о том, как создать файл robots.txt.
Для того чтобы увидеть, запрещена ли страница от индексации в файле robots.txt, достаточно открыть ее исходный код (Ctrl+U) и проверить наличие такой строчки:
meta name=’robots’ content=’noindex,nofollow’
Если есть, значит, она индексироваться не должна, по крайней мере, Яндексом точно :smile:.
2. Параметры URL.
Помните, я писал выше, что Гугл индексирует на моем блоге вот эту страницу:
Как создать группу в контакте и получить посетителей на сайт?
Удалить ее с индекса Google можно с помощью параметров URL, для этого нужно, чтобы ваш ресурс был добавлен в Google Webmaster. Заходим в раздел «сканирование» и выбираем пункт «параметры URL». По умолчанию Google предложит вам параметры, которые желательно исключить с индекса.

Если нужного параметра нет, то вы можете его создать. Для этого нажмите на кнопку «Добавление параметра», укажите параметр, который не должен присутствовать в URL. Для того чтобы убрать все ссылки, которые содержат параметр replytocom, нужно сделать вот так:

Теперь через некоторое время эти ссылки должны перестать индексироваться Гуглом.
3. Удалить URL-адреса;
В Google webmaster также есть возможность удалить ненужные страницы вручную. Для этого переходим в раздел «Индекс Google» и выбираем «удалить URL-адреса». Потом нажимаем «Создать новый запрос на удаление», вводим дубликат страницы и нажимаем «Продолжить»:

Но эта страница обязательно должна быть заблокирована в файле robots.txt или недоступна, иначе она может через некоторое время вновь появиться в результатах поиска.
Точно также документ можно удалить и с Яндекса. Для этого переходим в раздел «мои сайты» и справа внизу выбираем «удалить URL»:

4. Атрибут rel=”canonical”.
Если на сайте присутствуют дубликаты страниц, то с помощью rel=”canonical” можно указать поисковикам, какой документ основной и должен участвовать в ранжировании.
Например, у меня есть основная страница такая:
Как создать группу в контакте и получить посетителей на сайт?
а это ее дубликат:
Как создать группу в контакте и получить посетителей на сайт?
Мне нужно открыть эти две страницы и прописать там следующее:
link href=
Таким образом, робот будет понимать, какая страница должна получить вес и ранжироваться в поиске. Если у вас блог на движке wordpress, то в плагине all in one seo pack достаточно поставить галочку напротив надписи «Канонические URL’ы:». А если страницы созданы вручную, то нужно открыть их код и прописать канонический адрес. Или даже просто удалить дубли страниц вручную.
5. 301-редирект.
С помощью редиректа можно перенаправить как пользователя, так и поискового бота с одного документа на другой, таким образом, происходит склеивания документов. На моем блоге сделано перенаправление с www.vachevskiy.ru на vachevskiy.ru.
На этом все на сегодня. Теперь вы знаете, как найти и удалить дубли на сайте. Всем пока ;-).
vachevskiy.ru
Как удалить дубли страниц

Здравствуйте уважаемые читатели и подписчики. Как проходит лето? Надеюсь, более чем насыщенно. В сегодняшнем посте мы опять поговорим о продвижении сайта, а если быть более точным, то уделим внимание поиску и устранению дублей страниц.
Прежде чем начать, хотелось бы рассказать новичкам, что вообще такое дубли и как они могут препятствовать продвижению. Дубли страниц возникают из-за того, что один тот же контент доступен по разным адресам. Например: sayt.ru/statja и www.sayt.ru/statja. Это приводит к тому, что контент на сайте становится неуникальным и позиции в поисковых системах падают. Чаще всего дубли возникают из-за особенности той или иной CMS (движка блога), а также из-за неопытности и невнимательности вебмастера.
Дубли можно разделить на 2 категории: полные и не полные. В перовом случае дублируется вся страница, во втором, только ее часть, например, после анонса в RSS.
Если на своем сайте Вы обнаружили дубли контента, то вот с какими проблемами Вы можете столкнуться при продвижении:
- Потеря внутреннего ссылочного веса. Это может произойти из-за того, что ссылки ведут на дублированные страницы, вместо того чтобы увеличивать вес продвигаемой. Простой пример: при внутренней перелинковке, Вы можете случайно ошибиться и сослаться на дублированную страницу, в таком случае вес страницы пропадает в пустую.
- Подмена основной страницы в индексе. Дублированная страница может быть расценена поисковиками как оригинальная и свободно попасть в основной индекс. Если такое произойдет, то все усилия по ее продвижению будут напрасны и соответственно позиции по нужным запросам просядут.
- Если дублей очень много, то есть риск попадания под фильтр Яндекса АГС.
Теперь, когда мы узнали определение и последствия дублей, можно приступать к их поиску и устранению. Устранение сводиться к тому, чтобы запретить дублям индексироваться
Устранение самых распространенных дублей
Сайт доступен с www и без www
Откройте главную страницу сайта. У меня это life-webmaster.ru (без www, но у Вас может быть наоборот). Теперь уберите или допишите к адресу www. Если дубля нет, то Вас будет автоматически перебрасывать на основное зеркало. Если сайт доступен и с www и без него – это дубль и от него нужно избавляться.
Делается это очень просто. Если вы хотите сделать сайт доступным без www, то в конец файла .htaccess пишем этот код:
Options +FollowSymLinks
RewriteEngine On
RewriteCond %{HTTP_HOST} ^www.domain\.com$ [NC]
RewriteRule ^(.*)$ http://domain.com/$1 [R=301,L] |
Options +FollowSymLinks RewriteEngine On RewriteCond %{HTTP_HOST} ^www.domain\.com$ [NC] RewriteRule ^(.*)$ http://domain.com/$1 [R=301,L]
Если с www, этот:
RewriteEngine On
RewriteCond %{HTTP_HOST} !^www\.(.*) [NC]
RewriteRule ^(.*)$ http://www.%1/$1 [R=301,L] |
RewriteEngine On RewriteCond %{HTTP_HOST} !^www\.(.*) [NC] RewriteRule ^(.*)$ http://www.%1/$1 [R=301,L]
В индексе присутствуют страницы с параметрами page=1; .php и т.д.
Эта проблема наблюдается в основном у тех, кто использовал движок WordPress для создания своего сайта. Дело в том, что URL, который использует данный движок для записей, выглядит следующим образом: sayt.ru/?p=1. Это не очень хорошо, но решается тегом rel=”canonical”, который есть в любом seo плагине. Если у Вас другая CMS, то зайдите в файл index.php и добавьте этот тег вручную. Если тег rel=”canonical” уже прописан на Вашем сайте, this is хорошо.
Дубли со слешами на конце
Суть в том, что страница доступна по ссылке со слешем (/) и без него. Проверяется следующим образом:
- Открываем статью сайта
- Например, у меня открылась sayt.ru/statja/ (т.е. со слешем)
- Теперь убираем слеш, получиться sayt.ru/statja
Если одни и те же страницы будут открываться со слешем и без него, то это дубль:
- sayt.ru/statja
- sayt.ru/statja/
Устранить эту проблему можно прописав в конец файла .htaccess следующее правило:
RewriteBase /
RewriteCond %{HTTP_HOST} (.*)
RewriteCond %{REQUEST_URI} /$ [NC]
RewriteRule ^(.*)(/)$ $1 [L,R=301] |
RewriteBase / RewriteCond %{HTTP_HOST} (.*) RewriteCond %{REQUEST_URI} /$ [NC] RewriteRule ^(.*)(/)$ $1 [L,R=301]
Оно уберет слеш на конце ссылки и будет перенаправлять пользователя на правильную страницу. Например, человек ввел в адресную строку адрес sayt.ru/statja/ и его тут же перебросит на sayt.ru/statja
Этими действиями мы предотвратили появление в индексе дублированного контента, но что делать, если таковой уже имеется в выдаче? В таком случае нужно отыскать, и избавится от него вручную.
Поиск дублированного контента в индексе
Есть множество способов найти дублированный контент, давайте рассмотрим самые основные:
Расширенный поиск Яндекса. Заходим в этот поисковик и жмем “расширенный поиск”:

Берем кусок текста из старого поста, заключаем его в кавычки и вставляем в строку поиска. Далее вводим адрес блога и жмем “Найти”:

Если по таким запросам показывается несколько страниц, то это дубли. Заметьте, что нужно брать текст из середины или конца поста, потому как первые предложения могут встречаться на главной странице или в рубриках блога.
Если найдены дубли, то удалите их с помощью инструмента из Яндекс Вебмастера.
Конечно, если на Вашем сайте тысячи страниц то проверять его ручками можно вечно, поэтому для упрощения работы придумана программа XENU.
Проверка с помощью программы Xenu. Эта программа проанализирует все ссылки Вашей площадки и укажет на возможные ошибки. Программка на английском, но разобраться в ней несложно.
Итак, скачиваем ее отсюда (жмем кнопку Download) и устанавливаем на компьютер. После установки запустите программу, перейдите в раздел “file” и выберите подраздел “check URL”:

Здесь введите адрес нужного сайта и нажмите ok. Начнется процесс проверки ссылок. Прошу заметить, что полная проверка может длиться достаточно долго, поэтому не переживаем.
Все ошибки будут подсвечены красным цветом, поэтому распознать проблемные страницы будет несложно. После анализа, программа предложить сделать карту сайта, но этого делать не нужно.
Еще одним удобным способом проверки дублированных страниц является инструмент в Google Webmaster. Если Ваш сайт добавлен туда, то перейдите в раздел “оптимизация”, а затем в “оптимизация html”. Здесь будут показаны одинаковые тайтлы и description, что говорит о дублированном контенте. Если все good, то ы увидите следующие:

После нахождения дублей анализируйте их появление, и устраняйте вышеперечисленными способами. Если найдены дубли с непонятными адресами, то закрывайте их от индексации через robots.txt. Также если на Вашем сайте есть архив записей, то его тоже лучше закрыть от индексации в robots.txt либо через All in One Seo Pack.
На этом все, надеюсь, Вы выявили все проблемные страницы Вашего сайта и с успехом удалили их. Если возникли вопросы по поводу дублей, не стесняйтесь, я всегда открыт для общения.
Песенка на закуску
Буду благодарен за подписку и за репост в социальных сетях. Удачного лета друзья.
p.s. Стал писать реже, потому что уехал в Крым :3
 Загрузка…
Загрузка…Подпишитесь на обновления блога Life-Webmaster.ru и получайте в числе первых новые статьи про создание блога, раскрутку и заработок на нем!
life-webmaster.ru
Удаляем дубли страниц на сайте

Когда пользователь вводит поисковые слова и начинает поиск, поисковая система в свою очередь, по определённому алгоритму начинает искать страницу, в соответствии заданным словам. В любом случае поисковой системой будет выдан конечный результат, но вот какую именно выберет система, при наличии дубликата страницы сайта, сразу узнать проблематично. Таким образом, разные поисковые системы, например как Яндекс и Google, могут выдавать различные результаты по поиску одних и тех же ключевых слов, что в свою очередь может привести к негативным результатам для владельца ресурса, у которого есть на сайте дубликаты страниц.
Основные негативные последствия для владельца сайта с дублями страниц следующие:
Происходит уменьшение семантического соответствия заданного запроса к главной странице сайта, что в свою очередь ухудшает оптимизационные свойства всего ресурса.
Позиции ключевых cлов для ресурса постоянно изменяются, всё это происходит благодаря тому, что поисковые системы выдают в результате, то одну страницу, то её дубликат.
- Ухудшается уровень ранжирования, а вместе с ним и все показатели, связанные с ним. Именно все выше перечисленные негативные последствия заставляют разработчиков и оптимизаторов веб сайтов предусмотреть их, когда происходит раскрутка ресурса и оптимизация, удалить дубликаты страниц.
Какими бывают дубликаты
Дубликаты страниц сайта бывают двух видов:
- полный. Такой вид в точности повторяет одну из страниц ресурса и находиться под другим адресом, причём количество таких страниц не ограниченно и может быть любым.
- частичный. В таком виде дубли содержат часть контента дублируемой страницы, но не являются её точной копией.
Для каждого вида дубля, процесс их поиска и удаления не много отличается.
Как появляются полные дубликаты страниц сайта
- При создании сайта не было выбрано главное зеркало сайта. В таком случае дубль страницы может быть открыт по интернет адресу без www, или с ним.
- Главная страница ресурса не была чётка заданна в параметрах хостинга или движка, на котором разрабатывался сайт.
- Разработчики ресурса не учли автоматический переход на адрес без параметра, при запросе пользователя данной страницы с параметром.
- При разработке сайта, разработчики не правильно прописали иерархические адреса страниц ресурса.
- Не правильно настроена страница с ошибкой 404, что в свою очередь приводит к появлению огромного количества дублей страниц.
Как появляются частичные дубли страниц сайта?
Частичные дубли страниц возникают также как и в случае с полными, в основном из-за различных возможностей каждого взятого движка, на котором строится ресурс. Такие дубли на много тяжелей обнаруживать, чем полные, а также тяжелей их удалять.
Приведём наиболее распространённые случаи:
- Страницы ресурса, которые содержат формы для различного рода поиска, сортировки, вывода информации по различным видам водимых параметров и тому подобное. Такое часто происходит, когда при разработке этих алгоритмов, были использованы другие возможности, отличные от скриптов.
- Страницы сайта, на которых пользователи могут оставить на ресурсе, свою информацию.
- Страницы ресурса, предоставляющие возможность пользователю увидеть определённые страницы в версии для печати, а также содержащие документы в формате *.pdf, доступные для скачивания.
- При разработке html страницы, использовалась технология AJAX.
Если полные дубли страниц сайта приводят к быстрому ухудшению ранжирования сайта по времени, то частичные дубли действуют более медленно, и создают очень много проблем оптимизаторам сайтов, в течении относительно долгого времени.
Как найти дубли страниц?
Если изучаемый ресурс содержит в себе, не большое количество страниц, то нахождение дублей можно провести в ручную.
Для ресурсов содержащих большое количество страниц, можно использовать следующие основные методы обнаружения.
C помощью специального программного обеспечения, функциональные возможности которых, позволяют выявлять дубли страниц ресурса. Основной принцип работы таких программ, состоит в том, чтобы про сканировать весь ресурс и найти на нём все ссылки. Таким образом программа находит все ссылки и потом уже легко можно будет найти дубликаты страниц.
Проверить сайт на дубли страниц онлайн можно в поисковой системе Google, в поисковой консоли(Google search console), нужно выбрать пункт меню «Оптимизация html», таким образом будут найдены страницы с повторяющимся контентом. Эти страницы и будут потенциальными дублями исследуемого ресурса.
Как предупреждать и удалять, уже имеющиеся дубли, и как происходит удаление неявных дублей ?
- Если дубли страниц находятся на статистических адресах, то у владельца ресурса, как правило имеется доступ к управлению сайтом и значит есть возможность, при обнаружении дубля на хосте, его удалить.
- В файле robots.txt запретить индексацию страниц ресурса.
- Правильная настройка и конфигурация перехода, при пере направлении 301. В зависимости от движка сайта, нужно использовать редирект страницы со слешем и без.
- Для страниц сайта, содержащих формы поиска, фильтрации и тому подобное, применить правильную установку необходимых тегов. Тоже самое относится к страницам, содержащие печатные версии, просматриваемых страниц.
- Удалить из индекса страницы, которые были про индексированы ранее поисковыми системами, но оказались дублями, достаточно просто. Так для поисковой системы Яндекс, необходимо зайти на данный адрес —
https://webmaster.yandex.ru/tools/del-url/, и с помощью инструмента для веб мастеров, удалить дублируемую страницу. Другие поисковые системы содержат подобные средства, и принцип удаления дублей аналогичен.

webshake.ru
Как убрать дубликаты страниц — Академия SEO (СЕО)
Как избавиться от дублей страниц
После того как были обнаружены копии страничек веб-ресурса, нужно решить, как убрать дублирование. Ведь даже если подобных повторений немного, это все равно негативно скажется на рейтингах Вашего веб-ресурса – поисковики могут наказать Вас снижением позиций. Поэтому важно убрать дубликаты страниц независимо от их количества.
С чего начать удаление дублей страниц
Для начала рекомендуется выявить причину, по которой появилось дублирование контента. Чаще всего это:
- Ошибки при формировании структуры веб-ресурса.
- «Проделки» некоторых современных движков для сайтов, которые при неправильных настройках довольно часто автоматически генерируют копии и хранят их под разными адресами.
- Неправильные настройки фильтров поиска по сайту.
Способы решения выявленных проблем
После выяснения причины, по которой появилось дублирование, и ее устранения нужно принять решение касательно того, как убрать дубли страниц. В большинстве случаев подойдет один из этих методов:
- Удалить дубли страниц вручную. Этот метод подойдет для небольших веб-ресурсов, содержащих до 100–150 страничек, которые вполне можно перебрать самому.
- Настроить robots.txt. Подойдет, чтобы скрыть дубликаты страниц, индексирование которых еще не проводилось. Использование директивы Disallow запрещает ботам заходить на ненужные страницы. Чтобы указать боту Яндекса на то, что ему не следует индексировать странички, содержащие в URL «stranitsa», нужно в robots.txt добавить:

- Использовать мета-тег «noindex». Это не поможет удалить дубли страниц, но скроет их от индексирования, как и в предыдущем способе. Прописывается в HTML-коде странички (в разделе head), про которую должны «забыть» поисковики, в таком виде:
При этом есть один нюанс – если страница-дубликат уже появляется в результатах выдачи, то она будет продолжать это делать до повторной индексации, которая могла быть заблокирована в файле robots.txt.
- Удаление дублей страниц, используя перенаправление 410. Неплохой вариант вместо предыдущих двух способов. Уведомляет зашедшего в гости робота поисковика о том, что странички не существует и отсутствуют данные об альтернативном документе. Вставляется в файл конфигурирования сервера .htaccess в виде:
В результате при попытке зайти по адресу страницы-дубля Вы увидите:
- Указать каноническую страничку для индексации. Для этой цели используется атрибут rel=”canonical”. Добавляется в head HTML-кода страничек, которые являются ненужными копиями.
Это не поможет физически избавиться от дублей страниц, а лишь укажет ботам поисковых систем каноническую (исходную), которой нужна индексация.
- Склеивание страниц. Для этого используется перенаправление 301. Подобный вариант также не поможет убрать дубликаты страниц, но позволит передать нужной страничке до 99% внешнего и внутреннего ссылочного веса. Пример:


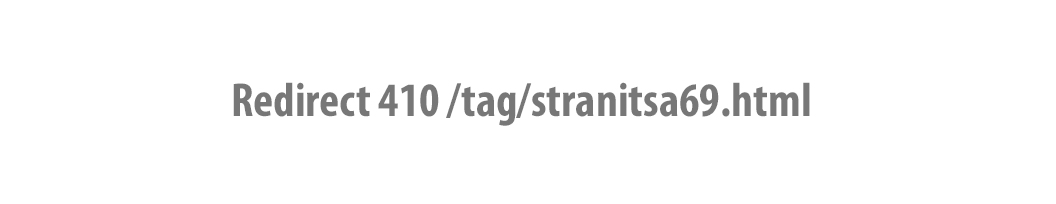



Если нет возможности убрать дубли страниц…
… или же Вы не хотите их удалять, можно хотя бы обезопасить странички, которые при помощи внутренней перелинковки связаны с ними. Для этого используется атрибут rel=«nofollow». Если прописать его в ссылках, они больше не будут передавать вес.

Теперь Вы знаете достаточно способов того, как убрать дубли страниц. Если умело их комбинировать, Вы сможете добиться, чтобы не осталось ни единого прецедента дублирования контента. Только после этого можно рассчитывать на максимальную эффективность продвижения Вашего сайта.
Если остались вопросы по данной теме, не забудьте их задать в комментариях!
seo-akademiya.com