Найти повторяющиеся значения (дубли, повторы) в диапазоне Excel
Поиск дубликатов в Excel осложняется множеством факторов. Это могут быть лишние пробелы, знаки препинания, перестановки слов. К тому же, часто хочется ограничиться только поиском дублей без их удаления. Если же вы спокойны и готовы избавиться от дублей в 1 шаг, не проверяя их, вам в раздел «удалить дубликаты«.
Иногда дубли хочется найти внутри колонки, другой раз интересует поиск значений, повторяющихся в другой колонке.
Ситуаций множество, но ключевых моментов всего три:
1. Какие ячейки мы готовы считать дубликатами — все кроме первого или включая его?
2. Считаем ли дублями строки, отличающиеся только пробелами до, после слов или лишними пробелами между словами?
3. Где мы будем искать дубли — внутри текущего диапазона, или производим сравнение с другим диапазоном?
Итак, обо всем по порядку
Выделить повторяющиеся значения в Excel цветом
Зачастую под словом «найти» рядовой пользователь Excel подразумевает «найти и выделить цветом», когда дело заходит о повторяющихся значениях.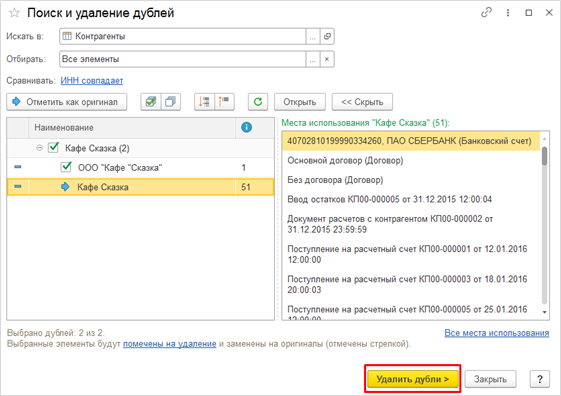
Идеальным кандидатом для решения задачи в таком случае выступает условное форматирование. В Excel для условного форматирования уже вшиты готовые правила, в том числе и для отбора повторяющихся значений.
Процедура находится на вкладке «Главная»:
Вызов процедуры условного форматирования для подсветки повторяющихся значенийПроцедура интуитивно понятна:
- выделяем диапазон, в котором хотим найти дубликаты,
- вызываем процедуру,
- выбираем форматирование для отобранных ячеек, есть заготовленные форматы, можно выбрать свой вариант
Данное поведение является неочевидным, и об этом факте часто забывают.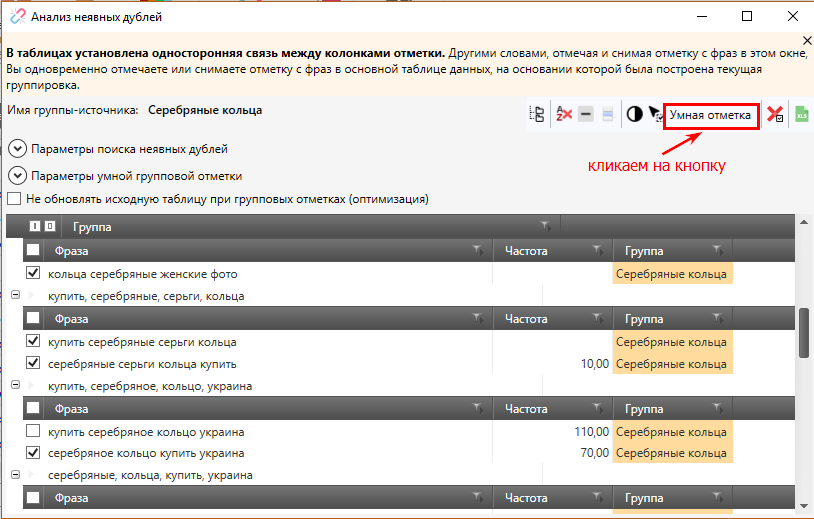 Если дальше вы планируете удалять повторы, можете потерять оба варианта в одном столбце.
Если дальше вы планируете удалять повторы, можете потерять оба варианта в одном столбце.
Как избежать подобной ситуации, если хочется найти именно дубли в другом столбце? Простейшее решение — удалить дубли внутри каждого столбца перед применением условного форматирования.
Но есть и другие решения — о них дальше.
Формула проверки наличия дублей в диапазонах
Использование собственной формулы для проверки дубликатов в списке или диапазоне имеет ряд преимуществ, единственная задача — составление такой формулы. Но её я возьму на себя.
Внутри диапазона
Чтобы проверить, есть ли в диапазоне повторяющиеся значения, можно использовать такую формулу массива:
=СУММПРОИЗВ(СЧЁТЕСЛИ(диапазон;тот-же-диапазон)-1)>0
Так выглядит на практике применение формулы:
Формула возвращает ИСТИНА, если в адресованном диапазоне появляется дубликатВ чем же преимущество такой формулы, ведь она полностью дублирует опцию условного форматирования? — Спросите вы.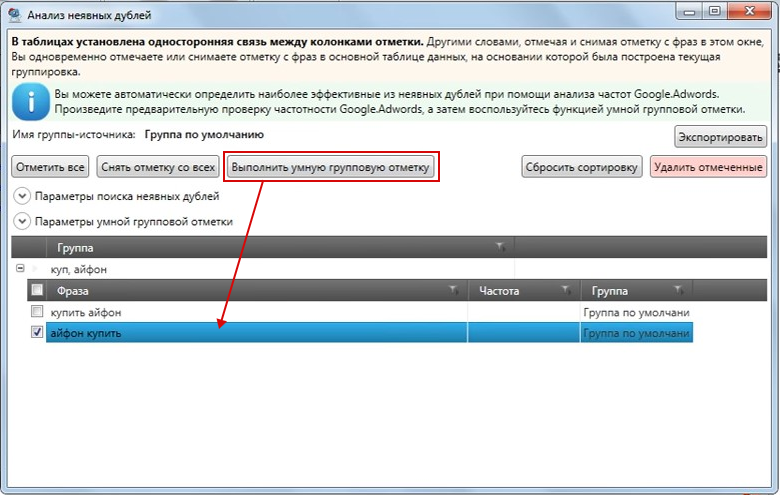
А дело все в том, что формулу несложно видоизменить и улучшить.
Например, можно улучшить эффективность формулы, добавив в нее функцию СЖПРОБЕЛЫ — это позволит находить дубликаты, отличающиеся незаметными лишними пробелами:
=СУММПРОИЗВ(--(СЖПРОБЕЛЫ(ячейка)=СЖПРОБЕЛЫ(диапазон)))>1
Эта формула слегка отличается, так как проверяет встречаемость в диапазоне значения одной ячейки.
Если внести ее как правило отбора условного форматирования, она позволит выявлять неявные дубли. Ниже наглядная демонстрация:
Обратите внимание на пару моментов этой демонстрации:
- диапазон закреплен ($A$1:$B$4), а искомая ячейка — нет (A1).
- именно это позволяет условному форматированию находить все дубликаты в диапазоне
Выделить цветом совпадения из другого столбца/диапазона
Поиск дубликатов с !SEMTools
В свое время я много намаялся с перечисленными выше методами поиска повторяющихся значений, как внутри столбца, так и при сравнении столбцов, и все они мне не нравились.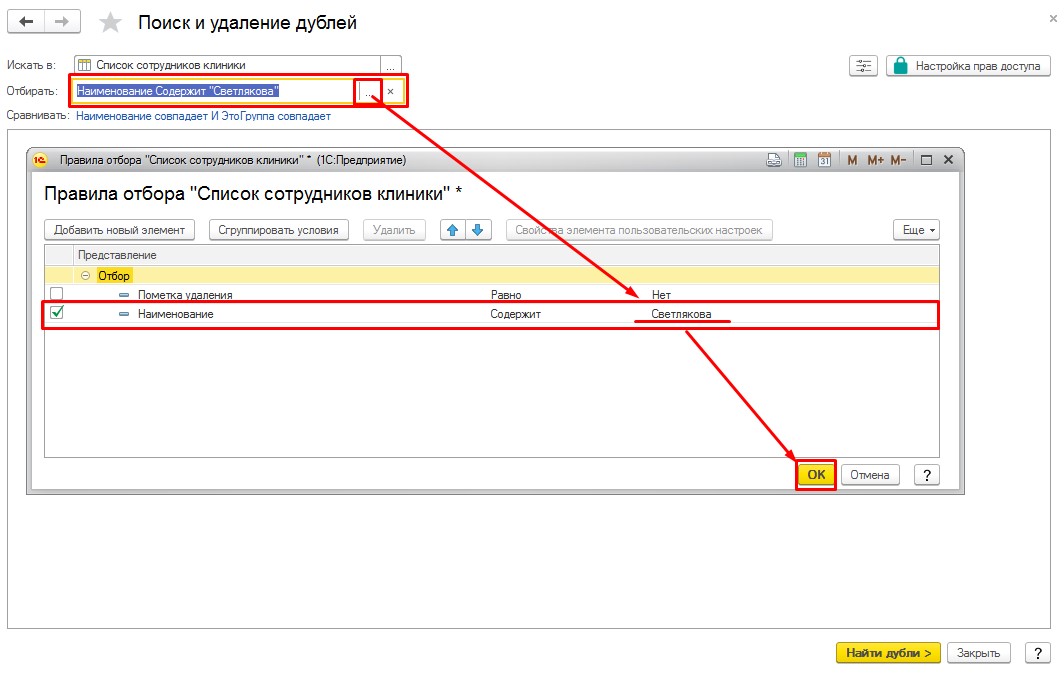 Основная причина — это попросту долго.
Основная причина — это попросту долго.
Поэтому я пришел к тому, чтобы сделать процесс удаления дубликатов максимально быстрым и удобным — сделал для этого отдельные процедуры в своей надстройке. Далее покажу, как они работают.
Найти дубли ячеек внутри диапазона, кроме первого
Найти в диапазоне дубли ячеек, включая первый
Найти дубли без учета лишних пробелов
Если мы считаем дубликатами фразы, отличающиеся количеством пробелов между словами или после — наша задача сначала избавиться от лишних пробелов, и далее — произвести тот же поиск пробелов.
Для первой операции есть отдельный макрос — удалить лишние пробелы
Как найти дубли ячеек, не учитывая лишние пробелыСмотрите также:
Удалить дубли без смещения строк
Удалить неявные дубли
Найти повторяющиеся слова в Excel
Удалить повторяющиеся слова внутри ячеек
Найти повторы в тексте Online. Сервис тавтологий «Свежий Взгляд»
Вы ведь знаете, что и ПС и читатели сегодня ценят качество текста, как никогда? А тавтология – это один из признаков плохого контента. Тексты с повторами однокоренных слов в соседних предложениях плохо воспринимаются и вызывают сомнения в профессионализме автора.
Тексты с повторами однокоренных слов в соседних предложениях плохо воспринимаются и вызывают сомнения в профессионализме автора.
Чтобы ваш профессионализм никто не ставил под вопрос, мы создали сервис поиска тавтологии онлайн. Он станет отличным помощником для:
- копирайтеров;
- переводчиков;
- журналистов;
- редакторов;
- блогеров;
- всех, кто имеет дело с текстами.
Конечно, главный советник в деле борьбы за качество текста – это голова. Но бывают случаи, когда она не справляется и нуждается в помощнике.
Например, 5 ситуаций, когда сервис поиска тавтологии может вам помочь:
- Нет времени. В идеале, чтобы избавиться от дублей нужно несколько вычиток. Но на это нужно время. А если дедлайн уже стучится в окно монитора, то быстрее и удобнее использовать сервис.
- Борьба с переспамом. Читатель может закрыть глаза на пару однокоренных слов рядышком или просто не заметить их. А вот ПС не закроют и обязательно заметят.

- Замылился глаз. Когда вы пишете или редактируете уже 25 статью за день, то волей-неволей перестаёте замечать повторы. Сдавать текст с тавтологией заказчику нельзя. И на свой сайт тоже выкладывать нежелательно. Поэтому быстренько прогоняете контент через сервис поиска дублей и всё. Вредитель (он же тавтология) выявлен и истреблён.
- Мало опыта. Начинающие авторы зачастую просто не замечают повторы слов. А потом получают тексты на бесконечные правки от заказчиков. Чтобы быстрее набить руку и начать замечать тавтологию, можно посмотреть, как это делает онлайн сервис.
- Экономия сил. Зачем ломать голову над поисками повторов слов, если можно заняться чем-то более важным или отдохнуть? Правильно, незачем. Доверьте тексты сервису и идите пить чай.
В сервисе «Свежий взгляд» вы можете самостоятельно настроить «строгость» проверки. Это очень просто. Или можете оставить настройки по умолчанию и получить усредненный оптимальный вариант.
Не переживайте, ваши тексты будете видеть только вы. Мы не сохраняем их и ни в коем случае не используем в своих целях.
Размер текста не имеет значения. Вы можете загрузить любой объём, и всё равно проверка будет моментальной. И ещё, сервис бесплатный. И это навсегда.
Так что, ищите повторы, экономьте время и повышайте качество текстов с помощью сервиса поиска тавтологии «Свежий взгляд»
Онлайн удаление дубликатов строк
- – Автор: Игорь (Администратор)
Удаление дубликатов строк — это один из полезных и востребованных инструментов для обработки текста. Его применение найдут полезным не только SEO специалисты и копирайтеры, но и обычные пользователи, которые встречаются с простой задачей фильтрацией дублей.
Онлайн удаление дубликатов строк:
Учитывать регистр?
Привести к нижнему регистру?
Очистить
Если в SEO индустрии этот инструмент, в основном, применяется для очистки списка ссылок, анкоров или ключей, то в повседневной жизни обычных пользователей удаление дубликатов применяется для решения простых аналитических задач. И примеров тому масса. Хаотичное составление списка музыкальных композиций. Составление подборки фотографий. Любые списки вещей, которые состоят из большого числа пунктов. И многое многое другое.
Однако, в отличии от копирайтеров и оптимизаторов, которые используют этот инструмент для решения однотипных задач, простые пользователи намного реже встречаются с такого рода задачей, а если и встречаются, то в разных ее вариантах. Из-за чего в последствии появляется множество различных решений, построенных чуть ли не на запросах к базе данных.
Примечание: Как факт. Зная простейшие базовые конструкции любой базы данных, можно относительно быстро создать подобного рода инструмент. Однако, пользоваться таким инструментом будет не удобно, да и назвать его «всегда под рукой» нельзя. Тем не менее, факт есть факт.
Однако, пользоваться таким инструментом будет не удобно, да и назвать его «всегда под рукой» нельзя. Тем не менее, факт есть факт.
Поэтому, если у вас возникла необходимость очистить список или текст от повторяющихся слов, фраз или абзацев, не торопитесь открывать офисные пакеты и искать функции очистки от дубликатов. Лучше воспользуйтесь данным инструментом.
Примечание: Как факт №2. Если у вас есть сомнения или же вы обрабатываете конфиденциальные данные (переживаете из-за возможного распространения), то вы можете сохранить эту страницу у себя на диске. И в последствии открывать ее у себя в браузере, даже с отключенным интернетом. Инструмент будет продолжать чистить дубликаты строк, так как код полностью выполнен на JavaScript и не посылает никаких запросов на этот или другие сайты.
☕ Хотите выразить благодарность автору? Поделитесь с друзьями!
- Онлайн генератор паролей с русским языком
- Онлайн конвертер HTML в BBCode и обратно
Добавить комментарий / отзыв
Поиск дубликатов фото и удаление одинаковых изображений
Находите дубликаты и похожие картинки по фактическому содержанию изображения
Удалите лишние фото, и пусть ваша РС коллекция фотографий будет безупречной.
Image Comparer™ представляет собой программу поиска дубликатов для любого фото-коллектора. Как только вы установите программу на компьютер, она автоматически отыщет копии фотографий или фотографии с различной степенью схожести. Все, что вам нужно, это выбрать папку для сканирования и начать поиск. Используя инновационную технологию сравнения фотографий на основе содержания, Image Comparer™ произведет анализ каждого фото в выбранной папке и
найдет точные копии или близкие соответствия по фактическому содержанию изображения. Получив результаты, просто поставьте отметку рядом с нежелательными файлами и удалите их все, лишь кликнув мышкой. Вот и все. Вам не нужно просматривать папки и запоминать то, что вы увидели. Программа Image Comparer™ поставит весь процесс на автопилот, так что вам не нужно будет беспокоиться. В качестве дополнительного преимущества, программа Image Comparer™ предлагает встроенную систему просмотра изображений, чтобы вы были уверены, что удалили то, что действительно хотели.
Программа Image Comparer™ работает на Windows 2000 / XP / Vista / 7 / 8 / 10 и имеет бесплатную ознакомительную 30-дневную версию.
Что умеет программа:
- Поиск фото дубликатов и похожих изображений по фактическому содержанию изображений
- Сканирование на предмет дубликатов внутри одной папки или сравнение между двумя папками
- Определение фото дубликатов в различных форматах: RAW, JPEG, J2K, BMP, GIF, PNG, TIFF, TGA
- Выбор индивидуального порога схожести для фильтрации похожих соответствий
- Предварительный просмотр фотографий во встроенной системе просмотра изображений
- Классификация и сортировка файлов изображений по различным критериям: название, дата, размер, ширина, высота
- Удаление, копирование, перемещение файлов одним кликом
- Автоматическая отметка изображений с высоким или низким качеством для последующих операций над ними
- Программа имеет русскоязычный интерфейс (среди десятков других доступных языков)
Обзор программы Image Comparer
Image Comparer™ представляет совершенно новую технологию того, как пользователи могут находить дубликаты фото. В отличие от большинства программ поиска дубликатов, которые выполняют поиск дубликатов по имени файла, его размеру и не способны находить похожие файлы, Image Comparer™ может находить похожие файлы с любой степенью схожести, которая может быть задана пользователем. Более того, программа Image Comparer™ способна
анализировать и распознавать изображения по содержанию,
независимо от имени файла, формата, размера изображения, битовой глубины и расположения объекта. Программа распознает даже повернутые или перевернутые фото или фотографии с разными условиями съемки. Инновационный алгоритм сравнения фотографий, основанный на содержании, обеспечивает феноменальную точность.
В отличие от большинства программ поиска дубликатов, которые выполняют поиск дубликатов по имени файла, его размеру и не способны находить похожие файлы, Image Comparer™ может находить похожие файлы с любой степенью схожести, которая может быть задана пользователем. Более того, программа Image Comparer™ способна
анализировать и распознавать изображения по содержанию,
независимо от имени файла, формата, размера изображения, битовой глубины и расположения объекта. Программа распознает даже повернутые или перевернутые фото или фотографии с разными условиями съемки. Инновационный алгоритм сравнения фотографий, основанный на содержании, обеспечивает феноменальную точность.
Находите дубликаты фотографий или похожие изображения с легкостью
Image Comparer™ позволяет находить дубликаты фотографий в компьютерной коллекции и без труда удалять лишние фотографии. Чтобы начать поиск, просто запустите Мастер сравнения, уточните, необходим ли поиск внутри одной папки, или сравнение двух папок, и выберите целевой каталог для сканирования.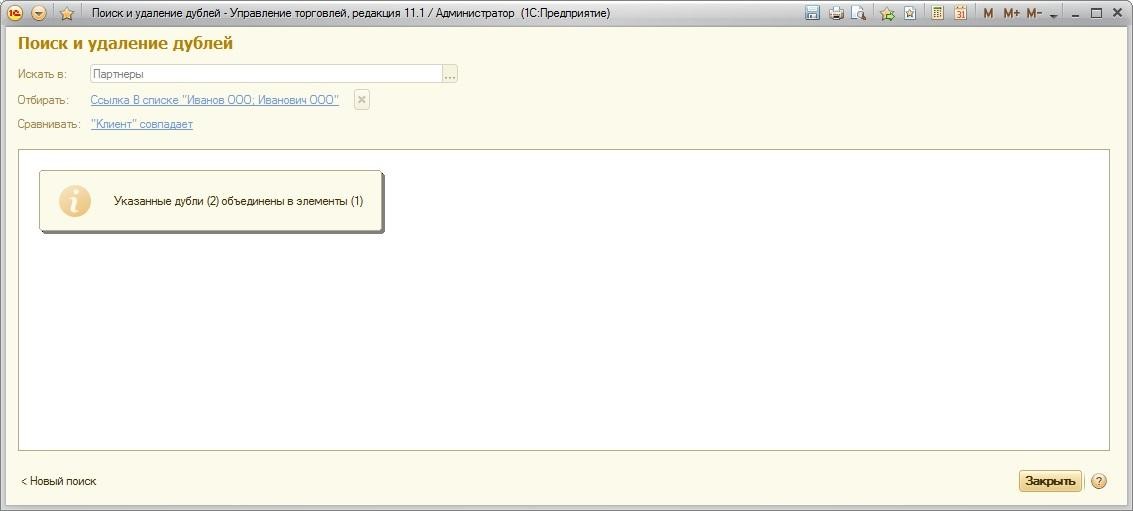 Можно также задать собственный уровень схожести изображений, который определяет, с какой точность Image Comparer™ будет искать сходства в файлах. По умолчанию, этот параметр устанавливается на уровне 95%. Наконец, нужно выбрать папку сохранения результатов и кликнуть на кнопке «Старт», чтобы запустить поиск.
Можно также задать собственный уровень схожести изображений, который определяет, с какой точность Image Comparer™ будет искать сходства в файлах. По умолчанию, этот параметр устанавливается на уровне 95%. Наконец, нужно выбрать папку сохранения результатов и кликнуть на кнопке «Старт», чтобы запустить поиск.
Удаляйте, копируйте, перемещайте файлы одним кликом
Image Comparer™ позволяет выполнять различные действия с найденными дубликатами. Когда сканирование закончено, программа отображает результат сравнения — перечень фотографий в галерее вместе с десятью самыми похожими изображениями для каждого выбранного фото. Можно также просматривать предполагаемые дубликаты парами, рядом друг с другом. Запись каждого фото-файла содержит подробные данные о формате изображения, разрешении и размере файла. Лишние файлы можно выделить, поставив отметку, и выполнить действия по ним — копировать, перемещать их в отдельную папку, или просто удалять. Также есть опция, позволяющая автоматически отмечать фото-файлы с высоким и низким качеством.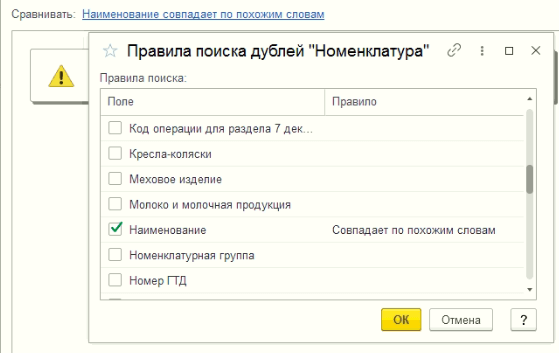
Сканируйте файлы в различных графических форматах
Image Comparer™ способен находить дубликаты и похожие изображения различных форматов, таких как RAW, JPEG, J2K, BMP, GIF, PNG, TIFF, TGA и многих других. Список поддерживаемых файлов изображений регулярно обновляется при появлении новых форматов. Независимо от типа файла, программа находит дубликат невероятно быстро.
Просматривайте фотографии прямо из Image Comparer™
Программа Image Comparer™ имеет встроенную систему просмотра фотографий, позволяющую просматривать миниатюры фотографий, поэтому нет необходимости выходить из программы и запускать внешнее приложение просмотра фотографий. Система просмотра фотографий поможет вам убедиться, что вы собираетесь удалить правильные файлы, а не просто две версии одной картинки, обе из которых вы хотели бы сохранить.
Начните прямо сейчас!
Сделайте вашу фото-коллекцию безупречной! Скачайте испытательную версию программы Image Comparer™ и составьте собственное мнение, и вы увидите, как это просто — находить дубликаты фото и похожие файлы с помощью специальной программы поиска дубликатов фотографий.
Кому Image Comparer™ наиболее полезен?
Image Comparer™ может быть полезен каждому, кто хранит фотографии в компьютере. Вот некоторые примеры.
- Профессиональные фотографы. Будучи фотографом, вы сможете автоматически выделить серии фотографий и выбрать в каждой лучшие изображения. Специально для фотографов, мы добавили поддержку формата изображений RAW.
- Веб-мастера. Веб-мастера, сайты которых содержат много фотографий и графики, могут использовать Image Comparer™, чтобы упорядочить изображения и удалить дубликаты фото, которые занимают место на жестком диске.
- Коллекционеры фотографий. Люди, которые собирают фотографии, цифровые изображения и обои для рабочего стола могут положиться на Image Comparer™ — он удалит лишние или слегка измененные файлы и сделает коллекцию уникальной.
Как найти одинаковые значения в столбце Excel
Поиск дублей в Excel – это одна из самых распространенных задач для любого офисного сотрудника.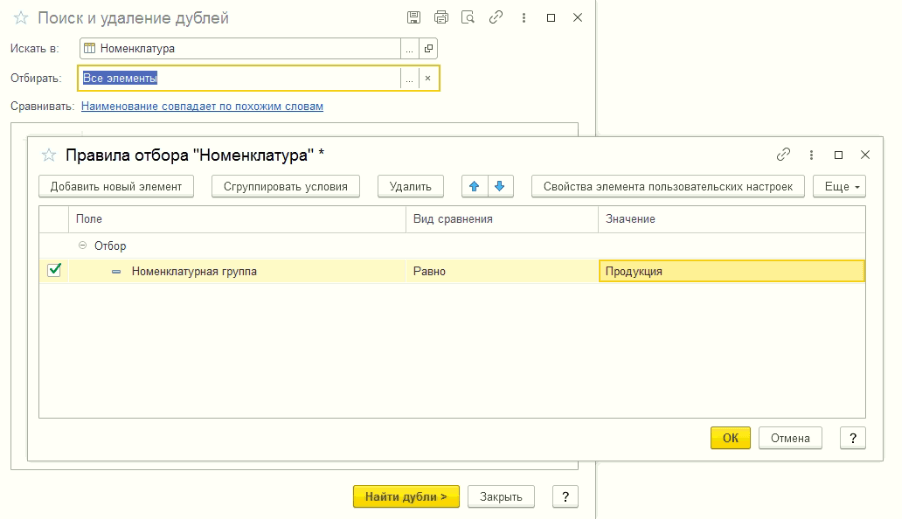 Для ее решения существует несколько разных способов. Но как быстро как найти дубликаты в Excel и выделить их цветом? Для ответа на этот часто задаваемый вопрос рассмотрим конкретный пример.
Для ее решения существует несколько разных способов. Но как быстро как найти дубликаты в Excel и выделить их цветом? Для ответа на этот часто задаваемый вопрос рассмотрим конкретный пример.
Как найти повторяющиеся значения в Excel?
Допустим мы занимаемся регистрацией заказов, поступающих на фирму через факс и e-mail. Может сложиться такая ситуация, что один и тот же заказ поступил двумя каналами входящей информации. Если зарегистрировать дважды один и тот же заказ, могут возникнуть определенные проблемы для фирмы. Ниже рассмотрим решение средствами условного форматирования.
Чтобы избежать дублированных заказов, можно использовать условное форматирование, которое поможет быстро найти одинаковые значения в столбце Excel.
Пример дневного журнала заказов на товары:
Чтобы проверить содержит ли журнал заказов возможные дубликаты, будем анализировать по наименованиям клиентов – столбец B:
- Выделите диапазон B2:B9 и выберите инструмент: «ГЛАВНАЯ»-«Стили»-«Условное форматирование»-«Создать правило».
- Вберете «Использовать формулу для определения форматируемых ячеек».
- Чтобы найти повторяющиеся значения в столбце Excel, в поле ввода введите формулу: =СЧЁТЕСЛИ($B$2:$B$9; B2)>1.
- Нажмите на кнопку «Формат» и выберите желаемую заливку ячеек, чтобы выделить дубликаты цветом. Например, зеленый. И нажмите ОК на всех открытых окнах.
Скачать пример поиска одинаковых значений в столбце.
Как видно на рисунке с условным форматированием нам удалось легко и быстро реализовать поиск дубликатов в Excel и обнаружить повторяющиеся данные ячеек для таблицы журнала заказов.
Пример функции СЧЁТЕСЛИ и выделение повторяющихся значений
Принцип действия формулы для поиска дубликатов условным форматированием – прост. Формула содержит функцию =СЧЁТЕСЛИ(). Эту функцию так же можно использовать при поиске одинаковых значений в диапазоне ячеек. В функции первым аргументом указан просматриваемый диапазон данных. Во втором аргументе мы указываем что мы ищем.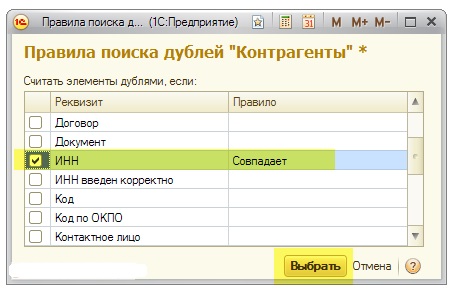 Первый аргумент у нас имеет абсолютные ссылки, так как он должен быть неизменным. А второй аргумент наоборот, должен меняться на адрес каждой ячейки просматриваемого диапазона, потому имеет относительную ссылку.
Первый аргумент у нас имеет абсолютные ссылки, так как он должен быть неизменным. А второй аргумент наоборот, должен меняться на адрес каждой ячейки просматриваемого диапазона, потому имеет относительную ссылку.
Самые быстрые и простые способы: найти дубликаты в ячейках.
После функции идет оператор сравнения количества найденных значений в диапазоне с числом 1. То есть если больше чем одно значение, значит формула возвращает значение ИСТЕНА и к текущей ячейке применяется условное форматирование.
Автоматический поиск дублей в сервисе Fasta
При ручном вводе первичных документов в 1С не исключено повторное заведение документов, то есть будут созданы дубли. При загрузке первички с помощью сервиса Fasta процесс поиска дублирующихся документов в базе 1С автоматизирован.
После нажатия кнопки Загрузить в 1С в главном окне программы или в окне верификации документа сервис проверит наличие ранее созданных документов с такими же параметрами. Если такие документы есть, выводится уведомление о найденных дублях загружаемых документов.
Если такие документы есть, выводится уведомление о найденных дублях загружаемых документов.
В открывшимся окне отображаются все найденные дублирующие документы, а также их статус: проведен, не проведен или помечен на удаление.
Сервис Fasta проводит поиск дублей загружаемых документов по следующим реквизитам:
- контрагент;
- номер\дата входящего документа;
- вид операции.
В случае, если Fasta нашла дублирующие документы, будет предложено несколько вариантов дальнейших действий для пользователя:
- перезаписать существующий документ новыми данными
- создать новый документ
- отменить действие.
Пользователь также может открыть найденные дублирующиеся документы для их просмотра, редактирования, проведения. Для этого необходимо выполнить двойной клик на документе из списка и нажать кнопку Открыть.
Кроме того, если в процессе загрузки документа в базу 1С были внесены изменения, то можно провести еще раз поиск дублирующих документов, нажав на кнопку Повторный поиск дублей в верхней части окна.
Таким образом, сервис Fasta контролирует наличие дублей документов в 1С и обеспечивает порядок в вашей базе 1С.
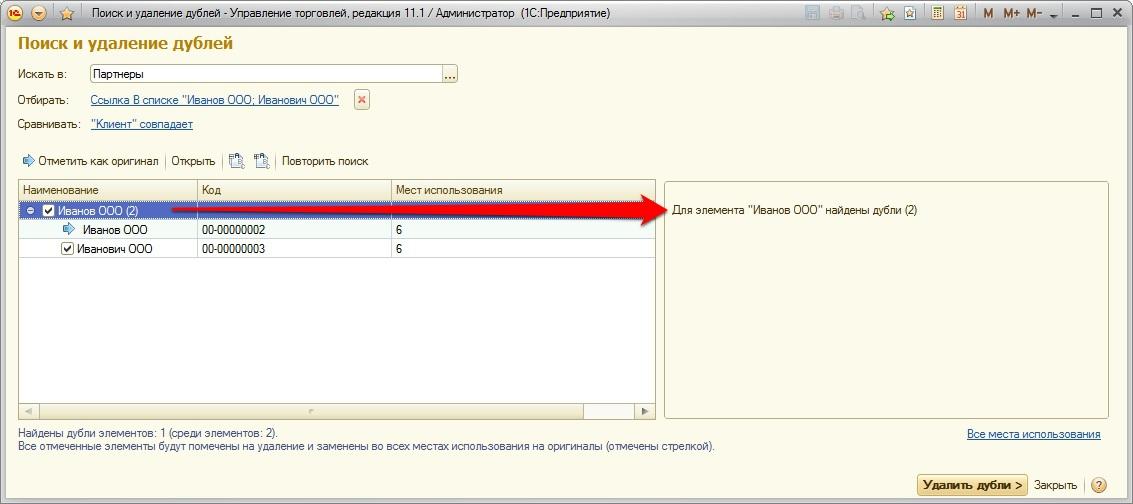
Поиск и удаление дублей клиентов и контактных лиц
Своевременный контроль за клиентской базой, а также удаление дублей клиентов и контактных лиц является неотъемлемой задачей для поддержания актуальности наработанной базы. При этом важно, чтобы вся информация из объекта дубля полностью переносилась в объект оригинал, так как потеря контактной информации, интереса или активного взаимодействия ведет к финансовым и репутационным потерям.
Подробнее о контроле наличия дубликатов клиентов и контактных лиц можно прочитать в статье «Контроль наличия дубликатов клиентов и контактных лиц».
Механизм «Поиск и замена дублей клиентов и контактов» находится в разделе Клиенты → Сервис.
Поиск и замена дублей клиентов и контактов
По умолчанию форма «Поиск и замена дублей клиентов и контактов» предзаполнена следующим образом: поиск дублей будет осуществляться по одинаковому наименованию клиентов, также будут выводиться сопоставленные дубли клиентов и контактов.
Предзаполнение формы «Поиск и замена дублей клиентов и контактов»
Важно!
Не рекомендуется отключать опции «Выводить сопоставленных клиентов»/«Выводить сопоставленные контакты», т.к. может быть утеряна информация о ранее сопоставленных дублях.
Сопоставленными клиентами и контактами являются те объекты, которые пользователи предложили как дубли.
Также перейти к механизму «Поиск и замена дублей клиентов и контактов» можно из форм Клиенты и Контактные лица клиентов. Для этого на формах списков в меню «Еще» выбрать команду «Поиск и замена дублей».
Переход к механизму «Поиск и замена дублей» из формы Контактные лица клиентов
При переходе к механизму «Поиск и замена дублей» из формы списка Клиенты по умолчанию механизм предзаполнен опцией «Выводить сопоставленных клиентов».
При переходе к механизму «Поиск и замена дублей» из формы списка Контактные лица клиентов по умолчанию механизм предзаполнен опцией «Выводить сопоставленные контакты».
Механизм «Поиск и замена дублей клиентов и контактов» позволяет искать дубли клиентов по следующим параметрам:
- по наименованию;
- по публичному наименованию;
- по телефону;
- по эл. почте.
По умолчанию поиск по параметрам «по наименованию» и «по публичному наименованию» осуществляется по полному совпадению слов. Это указано в настройке рядом с параметром «одинаковые».
Поиск дублей клиентов по полному совпадению слов
Для того, чтобы найти дубли клиентов по похожему «наименованию»/«публичному наименованию» необходимо изменить настройку напротив нужного поля на «похожие».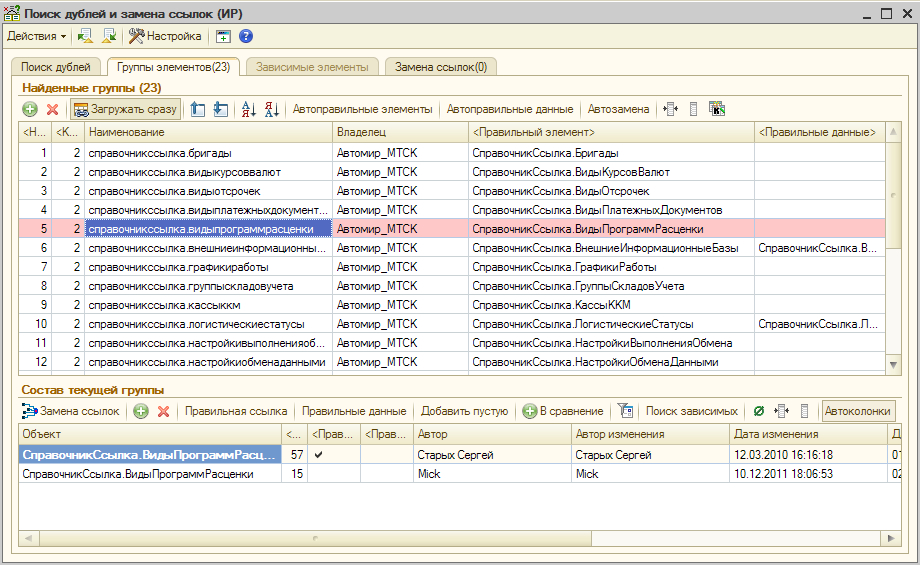
Поиск дублей клиентов по полному похожим словам
При переключении настройки поиска по «похожим», становится доступна настройка уровня сходства слов. Настройка варьируется от поиска не отличающихся наименований до отличающихся значительно.
Настройка уровня сходства слов
Поиск дублей клиентов по e-mail
В настройках () на форме «Поиск и замена дублей клиентов и контактов» можно выбрать те домены, которые будут игнорироваться при поиске дублей по эл. почте. По умолчанию настройка предзаполнена распространенными общедоступными доменными именами. Для изменения списка предзаполненных доменов необходимо нажать на гиперссылку с доменами и в открывшемся окне удалить уже имеющийся домен или добавить новый.
Настройка доменов для поиска дублей
Устанавливая настройки для поиска дублей можно воспользоваться отбором для поиска и сравнением по реквизитам.
Отбор для поиска дублей
Чтобы осуществить отбор, необходимо нажать напротив поля «Отбор для поиска» на команду «Без условий». В открывшемся окне «Установка параметров проверки условий» с помощью команды «Добавить новый элемент» добавить новый отбор. После его заполнения, нажать кнопку «ОК».
Отбор для поиска
Для того, чтобы найти дубли клиентов с учетом сравнения реквизитов в карточке клиента, необходимо нажать напротив поля «Сравнивать по» на команду «Выберите реквизиты». В открывшемся окне выбрать требуемый реквизит, после закрыть окно, нажав на крестик.
Настройка «Сравнивать по»
Важно!
Функция «Сравнивать по» ищет дубли по И, если в остальных настройках поиска стоит поиск «Одинаковые». Функция «Сравнивать по» ищет дубли по ИЛИ, если в остальных настройках поиска стоит поиск «Похожие» (при этом настройка уровня сходства слов может оставаться в статусе «не отличается»).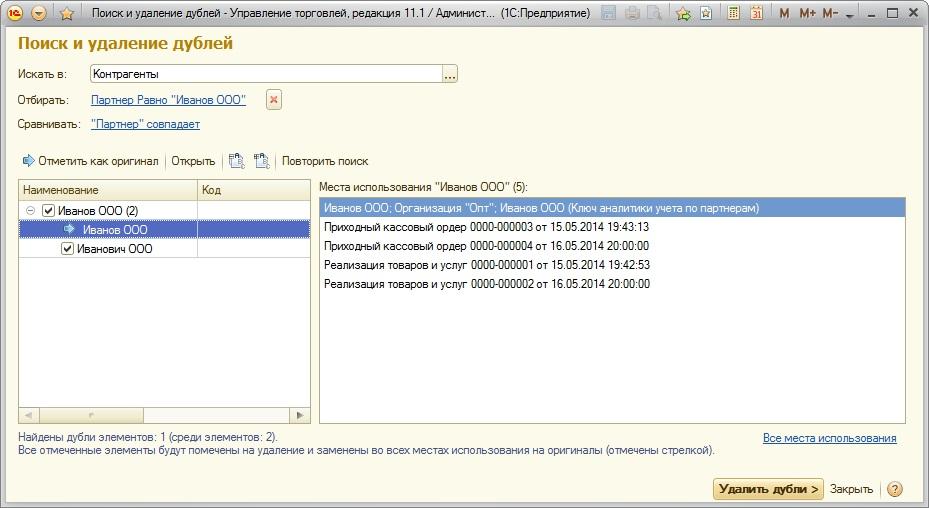
Если по факту поиска дубли не были найдены, система выведет сообщение «Дубли не найдены».
Сообщение «Дубли не найдены»
Аналогично клиентам, осуществляется поиск дублей по контактам.
Настройка поиска дублей по контактам
Важно!
При необходимости искать дубли контактных лиц по фамилии и имени, поиск настраивается следующим образом: поиск по фамилии, в настройке «Сравнивать по» требуется выбрать «Имя» (аналогично, если нужен поиск и по отчеству).
Поиск контактов по фамилии и имени
Результат поиска дублей отображается в правой части экрана.
Отображение найденных дублей
Важно!
Контакты или клиенты, уже помеченные на удаление, будут отображаться зачеркнутыми.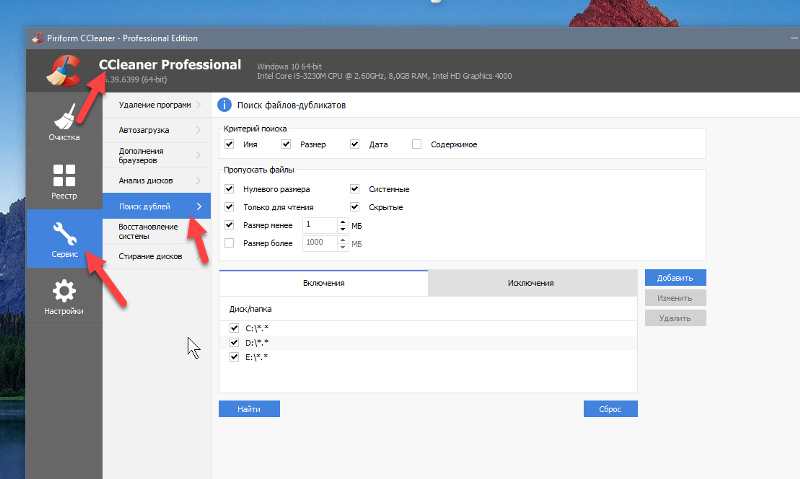
К дублям, найденным системой автоматически, добавляется комментарий «Дубль найден автоматически». Напротив дублей, которые нашли пользователи, будет отображаться комментарий, который написал пользователь. Если пользователь не оставил комментарий, тогда поле останется пустым.
Для того, чтобы сопоставить найденные дубли, необходимо проверить их на корректность. Для этого требуется выбрать нужный дубль и открыть гиперссылку «Показать найденные ссылки». В открывшемся окне будет указана вся информация по выбранному объекту. На основании этих данных администратор принимает решение об удалении дубля.
Отображение найденных ссылок
Неверно найденные дубли можно удалить из списка. Для этого необходимо выбрать ошибочный дубль и выполнить команду Исключить. Чтобы изменить оригинал в ветке дублей, необходимо выбрать нужный контакт (или нужного клиента) и выполнить команду Отметить как оригинал. После того, как была произведена проверка найденных дублей, необходимо выбрать команду Сопоставить дубли.
После того, как была произведена проверка найденных дублей, необходимо выбрать команду Сопоставить дубли.
Команды для коррекции списка найденных дублей
Для удаления дублей необходимо отметить галочками в столбце «Заменить» те дубли, которые будут впоследствии удалены и нажать на кнопку «Перейти к удалению».
Заменить дубли
На форме удаления дублей также можно исключить те дубли, которые в дальнейшем будут удалены или помечены на удаление.
Форма удаления дублей
Чтобы пометить дубли на удаление, необходимо удостовериться, что снята галочка «Непосредственно удалять объекты». После чего все дубли, отмеченные как «Заменить», после нажатия на команду Пометить на удаление будут помечены на удаление.
Пометить на удаление
Чтобы удалить дубли необходимо поставить галочку в поле «Непосредственно удалять объекты». И выполнить команду Удалить дубли.
Удаление дублей
После осуществления операции удаления дублей или пометки их на удаление можно вернуться к окну поиска дублей. Для этого нажимаем на кнопку «Перейти к поиску».
Для просмотра помеченных на удаление дублей в окне поиска дублей выполняется команда Показать помеченные на удаление.
Просмотр дублей, помеченных на удаление
Помеченные на удаление объекты можно удалить либо с помощью команды Удаление помеченных объектов или выбрав команду Показать помеченные на удаление, возле необходимых дублей поставить галочку «Заменить», после чего — «Перейти к удалению», поставить галочку напротив поля «Непосредственно удалять объекты» и нажать на кнопку «Удалить дубли».
Вернуться к списку статейКак найти и удалить дубликаты в Google Таблицах
Если вы являетесь постоянным пользователем Google Таблиц, вы, вероятно, столкнулись с проблемой, когда вы случайно добавили повторяющиеся записи в свою электронную таблицу. Эта ситуация может испортить набор данных, над созданием которого вы так усердно работали. Вы можете не знать, что это произошло, особенно когда ваш компьютер выходит из строя или когда вы ударяете трекпадом на своем ноутбуке.
В любом случае слишком легко что-то упустить, когда в вашей электронной таблице имеется большой объем данных.Типичные результаты включают ошибки вычислений и повторяющиеся ячейки, которые трудно идентифицировать при поиске источника проблемы.
К счастью, существует несколько различных методов выделения дубликатов в ваших таблицах.
- Используйте встроенную функцию удаления дубликатов.
- Используйте выделение для поиска дубликатов.
- Скопируйте уникальные ячейки и переместите их на новый лист.
- Воспользуйтесь сторонним средством поиска дубликатов.
- Создайте сводную таблицу, в которой учитываются дубликаты на индивидуальной основе.
Вышеупомянутые процессы упрощают поиск этих повторяющихся записей, так что вы можете удалить их или игнорировать, если они совпадают, но не являются дубликатами. Вот ваши варианты.
Используйте функцию удаления дубликатов в Google Таблицах
Если вы пытаетесь найти дубликаты в одном столбце, двух столбцах или на всем листе, функция удаления дубликатов точно удаляет ячейки с одинаковыми данными. Однако следует помнить, что удаляет все дубликаты, даже если они не связаны с одними и теми же данными.
- Выделите столбцы, которые нужно проверить на наличие повторяющихся данных.
- В меню вверху выберите «Данные», , а затем выберите
«Удалить дубликаты». - Появится всплывающее диалоговое окно. Установите флажки рядом с каждым столбцом в списке, который вы хотите проверить, или вы можете отметить «Выбрать все», , а затем щелкнуть «Удалить дубликаты». “
- В Google Таблицах показано, сколько копий было найдено и удалено, чтобы вы могли убедиться, что процесс прошел должным образом.
Использование встроенной функции «Найти и удалить дубликаты» в Google Таблицах — самый простой способ удалить дубликаты, но иногда вам может потребоваться просмотреть копии перед их удалением. Отличный способ сделать это — выделить цветом.
Выделение дубликатов с помощью цветов для легкого удаления
Когда дело доходит до выявления ошибок в электронных таблицах, использование цветного выделения для выделения неверной информации — лучший способ.
- Откройте файл Google Таблиц и выберите столбец или столбцы, которые нужно отсортировать.
- В строке меню вверху выберите «Формат».
- В раскрывающемся меню выберите «Условное форматирование».
- Выберите нужный диапазон в появившемся новом меню.
- В разделе «Правила форматирования» измените раскрывающийся раздел с заголовком «Форматировать ячейки, если…» на «Пользовательская формула».
- Вставьте следующую формулу в поле, расположенное под опцией «Пользовательская формула»:
= counttif (A: A, A1)> 1. - В разделе «Стиль форматирования» выберите «Значок цвета заливки» , чтобы выделить содержимое желтым (или любым другим цветом) фоном ячейки.
- Нажмите « Готово» , чтобы сохранить изменения.
Ваша электронная таблица теперь будет выделять повторяющиеся ячейки выбранным вами цветом, и вы можете сканировать выделение на предмет любых дубликатов.
Примечание. Лучше выделить ячейки столбца, начинающиеся со строки 1, а не выбирать ячейки посередине.Формула не любит использовать строку 2 в качестве первого столбца. Он пропустил пару дубликатов в выбранном поле (A2: B9). После добавления строки 1 (A1: B9) были обнаружены все дублирования. Смотрите два изображения ниже.
Изображение №1: показывает пропущенные дубликаты при выборе ячеек строки 2 в качестве первых ячеек (A2 и B2):
Изображение №2: показывает все дубликаты при выборе ячеек строки 1 в качестве первых ячеек (A1 и B1):
Убедитесь, что все существующие дубликаты верны, так как некоторые копии вообще не являются копиями.Они могут быть одинаковыми для двух разных учетных записей, пользователей, сотрудников или чего-либо еще. Как только вы подтвердите, что ячейки-подражатели вам не нужны, удалите их. Наконец, вы можете закрыть меню форматирования и восстановить стандартный цвет для своих ячеек.
Копирование уникальных ячеек в Google Таблицы для легкого удаления дубликатов
Если вы предпочитаете автоматически сортировать необработанные данные, лучше скопировать все уникальные ячейки, а не дублировать. Этот процесс обеспечивает более быструю сортировку и фильтрацию .Если вы уверены, что ваша информация верна, и вместо этого предпочитаете удалить дубликаты, попробуйте метод, описанный ниже.
- Откройте документ Таблиц, который нужно отсортировать, и выделите столбец, который нужно отредактировать. Этот процесс запишет диапазон столбцов для следующего шага.
- Выделив столбец, щелкните пустой столбец, в котором должны отображаться уникальные записи. Вставьте следующую формулу в поле ввода формулы вверху документа:
= UNIQUE () - Введите координаты ячейки исходного столбца в скобках, например:
(A3: A9). - Нажмите «введите» , чтобы переместить новые данные в столбец, который вы указали ранее.
По завершении вы можете либо проверить записи вручную, либо импортировать данные в свою рабочую электронную таблицу.
Использование сторонних надстроек для поиска и удаления дубликатов в таблицах
Существуют онлайн-надстройки, доступные для использования с Google Таблицами. Вы найдете надстройки в Google Workspace Marketplace, включая инструменты для автоматического удаления повторяющихся записей.
Удаление дубликатов по Ablebits
Подходящий инструмент, известный как Удаление дубликатов по Ablebits, позволяет быстро находить дубликаты по всему листу информации или путем поиска до двух столбцов одновременно.
Результаты можно перемещать, удалять и выделять. Инструмент включает две настройки мастера: поиск и удаление дубликатов и поиск уникальных ячеек или качеств в документе. Эти две опции позволяют легко отслеживать информацию по ходу дела.
В целом использование мастера для поиска информации может окупиться в долгосрочной перспективе.Это утверждение в первую очередь предназначено для пользователей, которые постоянно ищут дубликаты в своих таблицах и предпочитают тратить свое время на что-то другое.
Использование сводной таблицы для поиска повторяющихся строк в листах
Сводная таблица — удобный инструмент для более внимательного изучения данных. Сводная таблица не удаляет автоматически повторяющиеся ячейки или строки; он предоставляет разбивку того, какие столбцы имеют дубликаты, чтобы вы могли вручную просмотреть свои данные и увидеть, что вам нужно удалить, если что-то нужно.
Создание сводной таблицы немного сложнее, чем другие методы, показанные в этой статье. Вы должны добавить сводную таблицу для каждого столбца, чтобы обеспечить единообразие результатов и точное определение дубликатов.
Примечание. Если у вас нет имен столбцов в вашей электронной таблице, сводные таблицы не будут работать точно для поиска дубликатов. Попробуйте временно добавить новую строку, а затем назовите столбцы, используя эту новую строку.
Вот шаги по использованию сводной таблицы для выявления повторяющихся ячеек или строк.
- Выберите все данные таблицы, затем перейдите к «Данные-> Сводная таблица».
- При необходимости отрегулируйте диапазон ячеек, затем нажмите «Создать».
- Выберите «Добавить» рядом с «Строки». На этом шаге будет выбран столбец для поиска дубликатов. Да, вы правильно прочитали. Выберите нужный столбец из раскрывающегося меню. Если вы потеряете редактор сводной таблицы, щелкните заполненную ячейку, чтобы вернуть ее.
- Выберите «Добавить» рядом с полем «Значения» и выберите тот же столбец, что и выше, но установите для него суммирование с помощью «COUNT» или «COUNTA». Он уже должен быть по умолчанию.
- Новая сводная таблица идентифицирует дубликаты, как показано ниже.
- Если вы, , хотите просмотреть другой столбец , вы можете повторить описанные выше шаги (чтобы сохранить предыдущие результаты) или повторно открыть редактор сводной таблицы, а затем изменить существующую таблицу.
- Сводная таблица изменится, чтобы отобразить новые настройки.
Как упоминалось ранее, метод сводной таблицы немного сложнее. Тем не менее, он дает вам конкретный отчет о местонахождении ваших повторяющихся записей, который может быть очень полезен для анализа данных. Дополнительные сведения об использовании сводных таблиц см. В руководстве TechJunkie по созданию, редактированию и обновлению сводных таблиц в Google Таблицах.
В целом, повторяющаяся ячейка в Google Таблицах может вызвать проблемы с вашими данными, если вы не будете осторожны, особенно при попытке отсортировать финансовую информацию в полезную электронную таблицу.
Наиболее частые причины дублирования:
- Несколько человек добавили одного и того же клиента, счет-фактуру, категорию, элемент и т. Д.
- Импорт данных добавляется к уже существующим данным во второй раз.
- При копировании / вставке добавлены повторяющиеся записи.
К счастью, идентификация, удаление и удаление идентичных ячеек данных в Google Таблицах на удивление легко, что положительно, если вы постоянно имеете дело с электронными таблицами в своем повседневном рабочем процессе.Если вы ищете что-то для лучшей сортировки вашего контента, вы всегда можете использовать надстройку, например Remove Duplicates by Ablebits, чтобы убедиться, что ваша информация хорошо отсортирована и хорошо организована.
Duplicate Finder — Плагины электронной коммерции для интернет-магазинов — Shopify App Store
Найдите и удалите повторяющиеся названия продуктов в вашем магазине.
С помощью этого приложения вы можете найти повторяющиеся названия товаров в вашем магазине. Он может удалить повторяющиеся названия продуктов за несколько очень простых шагов.
Найдите и удалите повторяющиеся артикулы из продуктов вашего магазина.
С помощью этого приложения вы можете найти одинаковые артикулы в одном продукте или в разных продуктах в вашем магазине. Он может удалить повторяющиеся SKU продуктов за несколько очень простых шагов.
Найдите и удалите повторяющиеся штрих-коды из продуктов вашего магазина.
С помощью этого приложения вы можете найти повторяющиеся штрих-коды в одном продукте или в разных продуктах в вашем магазине. Он может удалить повторяющиеся штрих-коды продуктов за несколько очень простых шагов.
Почему вам следует использовать это приложение?
Позвольте мне объяснить, что это приложение может для вас сделать. Допустим, вы импортируете товары в свой магазин, но по какой-то причине может случиться так, что вы загрузили одни и те же товары несколько раз. В этом случае одни и те же продукты могут быть загружены более одного раза. Другой случай дублирования может произойти из-за того, что вы, возможно, по ошибке добавили повторяющийся SKU или дублированный штрих-код более одного раза. На этом этапе наше приложение поможет вам найти и удалить эти дубликаты.Вы сможете найти повторяющиеся названия продуктов, повторяющиеся артикулы и повторяющиеся штрих-коды. И тогда вы сможете удалить эти дубликаты, просто установив флажки. Шаги очень простые, как указано ниже:
- Установите наше приложение и активируйте заряд.
- Синхронизируйте все свои продукты с нашим приложением.
- Установите флажки и из массового действия удалите выбранные дубликаты.
Мы создали это приложение, потому что знаем, что иногда по ошибке могут быть загружены повторяющиеся данные.После этого вам может быть сложно найти все дубликаты с помощью ручного поиска. Это создает проблему, которая может привести к потере времени и денег. С помощью этого приложения вы сможете удалять дубликаты прямо в вашем магазине, просто устанавливая флажки эффективно и быстро. Он также очень прост и удобен в использовании. Процесс может начаться, как только вы установите приложение, и никаких знаний в области программирования не требуется. Это так же просто, как открыть приложение и установить флажки.
Запросы функций
Мы постоянно улучшаем функциональность нашего приложения. Мы открыты для ваших предложений. Не стесняйтесь связаться с нами. Наилучшие пожелания Администратор
Поиск повторяющихся посетителей и их объединение
Вы можете попросить менеджера театра найти повторяющихся посетителей в двух местах:- Окно списка посетителей — которое позволяет сканировать текущий отображаемый список — или — сканировать всю базу данных, чтобы предложить повторяющихся посетителей
- Окно «Подробная информация о списке рассылки» — вкладка whos ‘in позволяет искать пользователей в списке (которые на самом деле являются постоянными посетителями в списке рассылки), чтобы увидеть, не дублируются ли какие-либо из них.Это может быть полезно, если Arts Management составила для вас список постоянных клиентов с повторяющимися адресами электронной почты.
В этих двух окнах есть кнопка «Дубликаты». При нажатии на нее будут показаны некоторые поля, которые можно использовать для поиска возможных повторяющихся посетителей в базе данных, которые можно использовать для объединения посетителей. Это полезно, если:
- Вы недавно выполнили импорт посетителей, и у вас есть несколько дубликатов.
- Вам необходимо идентифицировать людей, которые добавляли себя несколько раз в Интернете, используя разные адреса электронной почты и нуждающихся в объединении в одну запись о постоянном посетителе.
Процесс поиска дубликатов также имеет функцию автоматического объединения посетителей, найденных по различным критериям.Поскольку слияние постоянных клиентов не может быть отменено, функцию слияния следует использовать только в том случае, если вы действительно знаете, что делаете, и:
- Планирование слияния множества постоянных клиентов -и-
- Сделали резервную копию базы данных на всякий случай
Процесс поиска дубликатов / слияния
Если вы собираетесь объединить постоянных пользователей, мы рекомендуем сделать это в два этапа, а именно:
- Используйте процедуру поиска дубликатов для выявления возможных дубликатов (но не слияния)
- Посмотрите список постоянных посетителей вручную.Если есть какие-либо очевидные покровители, которые необходимо удалить (которые обнаруживают дублирующий процесс), то «удалите» их вручную из списка, выбрав строки, щелкнув правой кнопкой мыши и выбрав «удалить из списка».
- Повторно запустите процесс дубликатов и выполните поиск в списке (не в базе данных) и выполните слияние с именами в списке. Это намного безопаснее
- В качестве альтернативы, если у вас есть только несколько совпадений для слияния, вы можете использовать функцию «подсказки» в автоматическом слиянии, чтобы определить до 25 совпадений за один раз.
Поиск в базе данных с использованием полей, повторяющихся адресов электронной почты или списка
У вас есть выбор поиска:
- текущее содержимое списка клиентов для дубликатов с использованием указанных вами полей.
- база данных для повторяющихся посетителей, также с использованием полей, которые вы указываете База данных
- для постоянных посетителей, которые используют один и тот же адрес электронной почты, но находятся в разных домохозяйствах . Два посетителя с одним и тем же адресом электронной почты не допускаются, но это могло произойти, если данные были импортированы из нескольких систем, и это все еще требует согласования.
После этого вы можете выполнить поиск в списке и добавить дополнительные поля, чтобы уточнить критерии соответствия. Вы также можете выполнить поиск по списку, если вы только что обратились к большому кругу людей, например, ко всем тем, чья фамилия начинается с буквы «S».
Выберите желаемый вариант и нажмите «Шаг 2».
Выберите поля для соответствия
Следующим шагом является выбор некоторых полей базы данных, которые вы хотите использовать для фактического соответствия постоянным посетителям.Вы можете использовать один или несколько. Например, вы можете использовать фамилию, имя и адрес для создания совпадений — и игнорировать компанию, если вы не считаете поле компании важным для этого конкретного поиска.
Поля выше используются для ОПРЕДЕЛЕНИЯ возможных групп посетителей. Они появятся в списке как выделенные.
Когда закончите, щелкните шаг 3.
Укажите, хотите ли вы объединиться (или нет)
Если вы не хотите объединяться, нажмите «Вручную».Вы можете выбрать эту опцию в первый раз, чтобы определить записи, которые могут быть дубликатами, и просмотреть их. Даже если вы идентифицируете только возможные дубликаты, вы можете использовать кнопку «объединить» в списке клиентов, чтобы объединить их вручную.
Однако, если вы хотите автоматически объединять посетителей, которые ИДЕНТИФИЦИРОВАНЫ как совпадающие с использованием полей на шаге 3, вы можете нажать «Автоматическое объединение после идентификации записей». Если вы выберете эту опцию, нижняя часть экрана изменится, и вы сможете указать другие опции, которые будут использоваться для сопоставления записей, прежде чем слияние станет возможным.
Важно то, что шаг 2 ИДЕНТИФИКАЕТ записи, которые МОГУТ совпадать (скажем, с использованием фамилии и адреса), а шаг 3 указывает из тех, что на шаге, что слияние может произойти только в том случае, если последний, первый, адрес, почтовый индекс, тип покровителя и номер телефона совпадают. Шаг 3 обычно должен указывать БОЛЬШЕ полей, чем шаг 2.
После выбора полей для сопоставления (или игнорирования) внизу укажите, хотите ли вы, чтобы TM
- запрашивать у вас каждое совпадение (этот процесс может открывать не более 23 окон) из-за ограничений памяти) -или-
- вы можете настроить Theater Manager, который автоматически объединяет совпадающие данные, и может выполнять множество записей.Используйте эту опцию, если у вас достаточно консервативные критерии соответствия (т. Е. Вы используете много полей) и у вас есть много данных, которые вы, возможно, только что импортировали.
Если вы хотите, чтобы TM автоматически сливалась, укажите, как вы хотите, чтобы TM выбирал номер патрона для слияния. Общие правила объединения группы возможных дубликатов:
- TM всегда будет объединяться в сотрудника, если он входит в группу -или-
- Если ни один сотрудник не существует, TM будет искать любого покровителя, помеченного как «не удалять», и попытается слиться с этим покровителем.
- Если ни один из вышеперечисленных сценариев не существует, то TM сольется с самым низким, самым высоким или покровителем с самым последним изменением, в зависимости от того, что вы выбрали.
Просмотрите запрошенные вами действия
Наконец, TM покажет вам точное описание того, что он собирается делать, включая:
- Если вы ищете в базе данных или списке
- Последняя известная дата резервного копирования
- Поля, используемые для ИДЕНТИФИКАЦИИ возможных повторяющихся записей
- Какие поля используются для объединения патронов вместе -и-
- Как TM решит, какой патрон использовать для слияния с
Обзор фактических результатов
Результаты поиска-дубликата могут отличаться в зависимости от того, выполняли ли вы поиск:
Ошибки в процессе слияния
| Иногда в процессе слияния могут возникать ошибки, которые не позволяют завершить слияние.Внимательно ознакомьтесь с сообщением и сравните его с некоторыми из приведенных ниже. |
- Вы получаете сообщение об ошибке, что корзину нельзя объединить из-за проблемы с предыдущей корзиной покупок, которая не была заполнена правильно. Обратитесь к закрытию тележек, чтобы сбросить статус, а затем снова войти.
Как найти дубликаты в Excel
Чтобы найти дубликаты в Microsoft Excel, вам понадобится несколько уловок в рукаве.
Примечание редактора: В видео Брэндон Вильяроло использует Microsoft Office 365 и проходит через этапы поиска, идентификации и удаления повторяющихся данных в Excel.Следующий учебник Сьюзан Харкинс был первоначально опубликован в январе 2009 года.
В дублированном мире определение означает все. Это потому, что дубликат субъективен для контекста связанных с ним данных. Дубликаты могут встречаться в одном столбце, в нескольких столбцах или в полных записях. Нет ни одной функции или техники, которые позволили бы найти дубликаты в каждом случае.
ПОДРОБНЕЕ: цены и возможности Office 365 для потребителей
Чтобы найти повторяющиеся записи, воспользуйтесь простой в использовании функцией фильтра Excel, как показано ниже:
- Выберите любую ячейку в наборе записей.
- В меню «Данные» выберите «Фильтр», а затем выберите «Расширенный фильтр», чтобы открыть диалоговое окно «Расширенный фильтр».
- Выберите «Копировать в другое место» в разделе «Действие».
- Введите диапазон копирования в поле «Копировать в».
- Отметьте только уникальные записи и нажмите OK.
Excel скопирует отфильтрованный список уникальных записей в диапазон, указанный в поле «Копировать в». На этом этапе вы можете заменить исходный набор записей отфильтрованным списком (скопированным списком), если хотите удалить дубликаты.
Найти дубликаты в одном или нескольких столбцах немного сложнее. Используйте условное форматирование, чтобы выделить дубликаты в одном столбце, как показано ниже:
- Используя пример рабочего листа, выберите ячейку A2. При применении этого к собственному рабочему листу выберите первую ячейку данных в списке (столбце).
- Выберите «Условное форматирование» в меню «Формат».
- Выберите Formula Is в раскрывающемся списке первого элемента управления.
- В элементе управления формулой введите = СЧЁТЕСЛИ (A: A, A2)> 1 .
- Нажмите кнопку «Формат» и укажите соответствующий формат. Например, щелкните вкладку «Шрифт», выберите «Красный» в элементе управления «Цвет» и нажмите «ОК». На этом этапе диалоговое окно «Условное форматирование» должно напоминать следующий рисунок:
- Нажмите «ОК», чтобы вернуться на рабочий лист.
- Не снимая выделения с ячейки A2, нажмите «Формат по образцу».
- Выберите оставшиеся ячейки в списке (ячейки A3: A5 на листе примера).
Условный формат выделяет любое повторяющееся значение в столбце A.Если вы хотите, чтобы Excel выделял только копии, оставляя первое вхождение значения неизменным, введите формулу = СЧЁТЕСЛИ ($ A $ 2: $ A2, A2)> 1 на шаге 4.
Условный формат отлично подходит для один столбец. Чтобы найти дубликаты в нескольких столбцах, используйте два выражения: одно для объединения сравниваемых столбцов; секунду для подсчета дубликатов. Например, если вы хотите найти дубликаты имени и фамилии на листе примера, вы должны ввести следующую формулу в ячейку D2, чтобы объединить значения имени и фамилии:
= A2 & B2
Вы можете вставить пробел символ между двумя именами, если хотите, но это не обязательно.Скопируйте формулу, чтобы разместить оставшиеся элементы списка.
Затем в ячейке E2 введите следующую формулу и скопируйте ее, чтобы разместить оставшийся список:
= ЕСЛИ (СЧЁТЕСЛИ (D $ 2: D $ 7, D2)> 1, «Дублировано», «»)
Обратите внимание, что на листе появилась новая запись (строка 6). Эта запись дублирует имя Сьюзен, но не фамилию. Условный формат выделяет имя, поскольку оно дублируется в столбце A. Однако формула в столбце E не идентифицирует объединенные значения в столбцах A и B как дубликаты, поскольку имя и фамилия вместе не дублируются.
Еженедельный бюллетень Microsoft
Будьте инсайдером Microsoft в своей компании, прочитав эти советы, рекомендации и шпаргалки по Windows и Office. Доставка по понедельникам и средам.
Зарегистрироваться СегодняСм. Также
В объявлениях о вакансиях в Интернете много дубликатов.Но как их обнаружить, если они не являются точными копиями друг друга?
Для Jobfeed, базы данных Textkernel в режиме реального времени для анализа рынка труда, мы сканируем Интернет в поисках онлайн-объявлений о вакансиях. Конечно, обеспечение высокого качества этой базы данных сопряжено с множеством технических проблем. Одна из них — обнаружение дубликатов объявлений о вакансиях. В этом сообщении блога Валентин Джийкун, руководитель группы веб-майнинга, объясняет, как Textkernel решает эту проблему.Валентин Джийкун
В среднем онлайн-вакансии повторяются
Когда вы работаете с большими объемами веб-данных, рано или поздно вы сталкиваетесь с проблемой дублирования контента.Многие веб-страницы не уникальны: в документе Google говорится, что около 30% веб-страниц практически дублируются.
В Jobfeed, где мы размещаем объявления о вакансиях в Интернете в восьми странах, эта проблема становится еще более заметной: мы выяснили, что в среднем объявление о вакансии публикуется повторно от 2 до 5 раз (в зависимости от страны), что делает долю дубликатов столь же высокой. как 50–80%. Это неудивительно: компании максимально широко рекламируют свои вакансии, чтобы привлечь больше хороших соискателей: на корпоративных сайтах, на общих и специализированных досках вакансий, через кадровые агентства и т. Д.Это делает выявление и группировку повторяющихся объявлений важным шагом в нашей обработке данных.
Почти идентичные объявления о вакансиях редко бывают идентичными: при размещении объявления на другом сайте текст часто реструктурируется, укорачивается или расширяется, а метаданные часто изменяются в соответствии с моделью данных сайта. Рассмотрим две публикации одной и той же вакансии, показанные ниже:
Щелкните для просмотра версии Jobfeed Щелкните, чтобы просмотреть версию JobfeedЗаявление о равных возможностях трудоустройства от aerotek.com перемещен в начало публикации на сайте thingamajob.com. Метаданные имеют разные поля («Компания:», «Категория:»), и значения записываются по-разному. Полный адрес компании добавлен в сообщение на сайте thingamajob.com. Шаблонный текст (верхние и нижние колонтитулы, блоки навигации) также зависит от веб-сайта.
Тем не менее, как мы можем сказать, что эти два объявления относятся к одной и той же работе?
- Aerotek (кадровое агентство) упоминает «Идентификатор публикации», который совпадает с «Идентификатором ссылки на вакансию» на thingamajob.com (доска объявлений).
- Названия должностей и описания должностей очень похожи.
- Имя рекламодателя похоже: Aerotek vs. Aerotek Scientific.
- Аналогичный тип контракта, диапазон заработной платы и место работы.
- То же контактное лицо (имя, номер телефона и адрес электронной почты).
Эти наблюдения позволяют предположить, что мы имеем дело с одной и той же вакансией. Однако одного из наблюдений недостаточно.Рассмотрим два идентичных объявления о вакансиях, в которых различается только местоположение вакансии (например, название города, одно слово!): Эти объявления явно не дублируются и должны рассматриваться как отдельные вакансии.
В Jobfeed мы подходим к этому как к проблеме машинного обучения: мы обучаем статистический классификатор, который предсказывает, относятся ли две публикации к одному и тому же заданию, на основе ряда характеристик (таких как «наблюдения» выше).
В такой большой стране, как США, мы ежедневно рассылаем сотни тысяч новых объявлений о вакансиях.Поскольку было бы непрактично сравнивать каждое новое сообщение с каждым из миллионов сообщений, которые мы видели ранее, мы ограничиваем сравнение подмножеством текстуально похожих объявлений. Выявление этого подмножества — это то место, где традиционное текстовое обнаружение почти дубликатов оказывается очень полезным.
Текстовое сходство
Эффективные методы поиска похожих веб-страниц почти так же стары, как и сама сеть: основополагающая статья «Синтаксическая кластеризация сети» А. Бродера и др. появился в 1997 году.В Jobfeed мы используем классический подход, основанный на использовании черепицы и минимальных перестановок.
Как мы покажем ниже, относительно простая реализация может легко работать с десятками миллионов документов. Для наборов данных с миллиардами документов необходима более сложная реализация и / или другой метод: см. Статью в блоге «Обнаружение близких к дубликатам» для обзора и статью «Обнаружение близких к дубликатам для веб-сканирования» для подробностей. С помощью shingling мы конвертируем каждый текстовый документ в набор всех последовательностей (shingles) последовательных слов в том виде, в каком они встречаются в документе.
Например, если мы рассмотрим последовательности из 6 слов для текста «Хорошо организованная и уважаемая адвокатская контора в центре Бейкерсфилда нуждается во временном помощнике по правовым вопросам…», черепица будет включать:
- «Хорошо зарекомендовавшая себя и уважаемая адвокатская контора»
- «Основанная и уважаемая адвокатская контора в»
- «и уважаемая адвокатская контора в центре города» и т. Д.
Мы можем измерить текстовое сходство между двумя документами как перекрытие между их наборами черепицы.В нашем примере объявлений «Юридический секретарь» на два документа приходится 179 из 484 черепиц, что дает нам сходство в 37%. Это может показаться заниженным, учитывая, что описания должностей практически идентичны: в основном это связано с разным форматированием метаданных (местоположение, название компании, телефон) и отсутствием текста о равных возможностях трудоустройства. Понятно, что для объявлений о вакансиях использования простого порога схожести для определения того, являются ли два объявления дубликатами, недостаточно.
Эффективный поиск похожих документов
Чтобы избежать хранения и сравнения сотен черепиц для каждого документа, мы применяем схему хеширования с учетом местоположения, как показано ниже.Сначала мы сопоставляем каждый кусок документа с 64-битным целым числом, используя хорошую хеш-функцию. Назовем эти целые числа галькой. Мы берем фиксированную случайную целочисленную перестановку, применяем ее ко всем хешам черепицы из документа и берем наименьшее значение — это первое значение, которое мы будем хранить. Мы повторяем это M раз с различными фиксированными случайными перестановками, чтобы получить список из M целых чисел: мы называем это эскизом документа. Оказывается, чтобы оценить сходство двух документов, достаточно подсчитать количество совпадающих целых чисел в их эскизах.Это означает, что нам нужно хранить только M целых чисел для каждого документа. Выбирая соответствующее значение для M, мы можем найти хороший компромисс между точностью оценки и требованиями к хранению.
Как мы храним эскизы документов для быстрого поиска похожих документов? Мы используем обычную технику: перевернутый индекс. Мы вычисляем эскизы для всех документов в нашем наборе данных, и для каждого наблюдаемого целого числа мы сохраняем список документов, эскизы которых содержат это целое число. Чтобы найти похожие документы для нового ввода, нам нужно только объединить списки документов для M целых чисел в его скетче.Elasticsearch очень хорош в управлении такими индексами с эффективным использованием времени и памяти, поэтому мы используем его для индексации наших эскизов и получения возможных почти дубликатов. Мы постоянно обновляем индекс по мере появления новых документов в Jobfeed.
Особенности дедупликации объявлений о вакансиях
Как я уже говорил выше, мы используем шинглинг, хеширование с минимальными перестановками и инвертированное индексирование, чтобы найти объявления о вакансиях, текстуально похожие на новый входной документ. Для общего обнаружения почти дублирования часто бывает достаточно: простого порогового значения схожести текста между вводом и кандидатами достаточно, чтобы решить, является ли ввод дубликатом.Для объявлений о вакансиях такого подхода, основанного на пороге, недостаточно: как мы видели в нашем примере, истинные дубликаты могут иметь сходство до 37%.
В Jobfeed мы дополняем текстовый поиск еще несколькими уловками:
- Мы применяем машинное обучение и методы на основе правил для удаления нерелевантного контента (шаблонный текст, навигация, баннеры, реклама и т. Д.)
- Мы используем наш семантический синтаксический анализатор, специально обученный для объявлений о вакансиях, чтобы определять текстовые разделы, содержащие описание должности и требования к кандидату (в отличие от общего описания рекламной компании, которое часто повторяется во многих несвязанных объявлениях о вакансиях компании)
- Для каждого нового объявления о вакансии мы используем черепицу, как описано выше, чтобы найти кандидатов со значительным перекрытием текста.
- Мы обучаем классификатор предсказывать, действительно ли заданный ввод и выбранный кандидат являются объявлениями об одной и той же вакансии. Классификатор полагается на перекрытие текста и соответствие между другими свойствами сообщений, извлеченными нашим семантическим анализатором: название организации, категория профессии, контактная информация и т. Д.
Насколько точна система, которую я описал выше? Находит ли все дубликаты? Сгруппированы ли сообщения, которые не являются дубликатами? Если коротко, то система «довольно хороша, на 90% хороша».Более подробный ответ потребует обсуждения многих возможных способов оценки такой системы — что я сделаю в следующем посте.
Полезные ссылки
- xxhash: хорошая библиотека хеширования для Python
- Целочисленные хэш-функции: смешивание обратимых хэш-функций Томаса Ванга, которые могут использоваться для построения псевдослучайных перестановок
Об авторе
Вам интересно узнать о Textkernel и команде веб-майнинга? Мы растем и ищем инженера-программиста — Python и большие данные!
dupeGuru | находит повторяющиеся файлы
dupeGuru — это кроссплатформенный (Linux, OS X, Windows) инструмент с графическим интерфейсом для поиска повторяющихся файлов в системе.Он написан в основном на Python 3 и имеет особенность использования нескольких наборов инструментов с графическим интерфейсом, использующих один и тот же базовый код Python. В OS X уровень пользовательского интерфейса написан на Objective-C и использует какао. В Linux и Windows он написан на Python и использует Qt5.
dupeGuru — это инструмент для поиска дубликатов файлов на вашем компьютере. Он может сканировать либо имена файлов, либо содержимое. При сканировании файлов используется алгоритм нечеткого сопоставления, который может находить повторяющиеся имена файлов, даже если они не совсем совпадают.dupeGuru работает в Mac OS X и Linux.
dupeGuru работоспособен. Найдите дубликаты файлов за считанные минуты благодаря алгоритму быстрого нечеткого сопоставления. dupeGuru не только находит одинаковые имена файлов, но также находит похожие имена файлов.
dupeGuru хорошо с музыкой. Он имеет специальный музыкальный режим, который может сканировать теги и отображать информацию о музыке в окне повторяющихся результатов.
dupeGuru хорош с картинками. Он имеет специальный режим изображения, который может сканировать изображения нечетко, , что позволяет находить похожие, но не совсем одинаковые изображения.
dupeGuru настраивается. Вы можете настроить его механизм сопоставления, чтобы найти именно те дубликаты, которые вы хотите найти. На странице настроек файла справки перечислены все настройки модуля сканирования, которые вы можете изменить.
dupeGuru безопасен. Его двигатель был специально разработан с учетом требований безопасности. Его справочная система каталогов, а также система группировки не позволяют вам удалять файлы, которые вы не собирались удалять.
Делайте с дубликатами все, что хотите.Вы можете не только удалять дубликаты файлов, которые находит DupeGuru, но также перемещать или копировать их в другое место. Существует также несколько способов фильтрации и сортировки результатов, чтобы легко отсеивать ложные дубликаты (для сканирования с низким порогом).
Поддерживаемые языки: английский, французский, немецкий, китайский (упрощенный), чешский, итальянский, армянский, русский, украинский, бразильский, вьетнамский.
Как удалить дубликаты Google Фото в 2021 году
Google Фото — один из лучших сервисов для загрузки изображений в облако, и это простой способ синхронизации нескольких устройств.Однако ваш диск может быстро заполниться идентичными фотографиями, особенно после того, как вы загрузили и отредактировали тысячи изображений. В этой статье мы рассмотрим лучшие способы удаления дубликатов Google Фото.
Самый быстрый способ очистить ваш Google Диск — это программное обеспечение, которое может автоматически сканировать похожие фотографии. Хотя встроенная система «обнаружения дубликатов» поможет вам избежать прямых копий во время загрузки, стороннее средство поиска дубликатов — лучший способ обнаружить любые отредактированные файлы или близкие совпадения, которые вы, возможно, захотите удалить.
Однако, если вы хотите удалить дубликаты фотографий с Google Диска, лучше всего просто сделать это самостоятельно. Вы сможете сохранить определенные дубликаты или удалить старые фотографии, которые вам больше не нужны, и это можно сделать на любом компьютере или мобильном устройстве с помощью приложения Google Фото или веб-сайта.
- Как удалить дубликаты фотографий на Google Диске?
Точные дубликаты должны автоматически удаляться Google, а стороннее программное обеспечение может найти любые почти идентичные фотографии.Однако вам следует удалить дубликаты фотографий вручную, чтобы получить максимальный контроль над пространством для хранения.
- Как очистить мои Google Фото?
Лучший способ очистить диск — это найти и удалить дубликаты из Google Фото. Просто пролистайте фотоальбом и удалите любое изображение с идентичной копией. Это освободит место, особенно если вы регулярно редактируете фотографии.
- Как удалить синхронизированные фотографии из Google?
В опции «Настройки» для функции «Резервное копирование и синхронизация» вы можете изменить действия Google при удалении файлов с вашего диска.Вы можете удалить сразу и локальную, и облачную версию, оставить ту, которую вы не выбрали, или настроить ее так, чтобы она запрашивала каждый раз. Затем вы можете удалить фотографию, не удаляя ее со своего компьютера.
Проблема: дубликаты фотографий Google
Обнаружение дубликатов в Google Фото — не редкость, особенно если вы храните много изображений. Однако большинству людей не нужны дублированные фотографии каждого события, занимающие их ограниченное облачное хранилище. К счастью, есть способ удалить повторяющиеся файлы, даже если вы их редактировали и их слишком много для поиска вручную.
Некоторые причины дублирования фотографий
Самая большая причина дублирования фотографий в том, что пользователь загрузил их дважды. Часто это происходит потому, что вы не знали, что изображение уже загружено. Вы также можете случайно создать копии при редактировании фотографии, и в зависимости от изменений новый файл может быть практически идентичен оригиналу.
Ошибки и сбои также могут создавать дубликаты фотографий на вашем Google Диске. Иногда, когда вы добавляете новое устройство в свои Google Фото или включаете функцию «резервного копирования и синхронизации», оно загружает файл, который уже находится в облаке, потому что два изображения имеют несколько разные метаданные.
1. Используйте обнаружение идентичных дубликатов с помощью Google Фото
Google действительно пытается предотвратить появление точных дубликатов с помощью функции «обнаружения идентичных дубликатов». Будет выполнено сканирование содержимого и метаданных любого изображения, которое вы загружаете в облако, и проверка, чтобы убедиться, что вы его еще не загрузили.
Это действительно просто в использовании, так как оно включается автоматически и удаляет дубликаты без какого-либо вмешательства пользователя. Однако у него есть ограничения на то, что он удаляет, и есть несколько шагов, которые вы можете выполнить, чтобы повысить эффективность этой функции.
- Используйте Google Фото, а не Google Диск
Можно загружать файлы изображений либо на ваш основной Google Диск, либо на Google Фото. Однако вам следует использовать только последнее, поскольку обнаружение дубликатов нельзя сравнивать между разными приложениями в Google Workspace, а Google Фото может обнаруживать идентичные изображения с разными именами.
Обнаружение дубликатов не синхронизируется между Google Диском и Google Фото.
- Убедитесь, что обнаружение дубликатов работает на вашем устройстве
Выберите изображение, которое было загружено в вашу учетную запись, и попробуйте загрузить его снова.Вы увидите всплывающее окно «элемент загружен» в правом нижнем углу, но Google Диск не добавит его в вашу папку или альбом. Если он появится, вам придется обратиться в службу поддержки Google, так как вы не можете вручную переключить обнаружение дубликатов.
Несмотря на удаление дубликатов, Google все равно сообщит вам, что он их загрузил.
2. Используйте сторонние приложения для удаления дубликатов в Google Фото
Несмотря на то, что собственное обнаружение Google было довольно посредственным, существуют бесплатные сторонние решения для удаления дубликатов из вашего облачного хранилища.Хотя вы можете найти в Интернете множество программ, которые могут это сделать, например, «Поиск дубликатов файлов, Очиститель для Диска» или «Очиститель дубликатов фотографий», все они следуют аналогичному процессу.
1. Загрузите программу
Независимо от того, какое приложение вы выберете, первым делом необходимо его загрузить и установить. Убедитесь, что вы получили его из надежного источника и у вас есть хороший антивирус, чтобы обезопасить свой компьютер.
Найдите сервис, который может удалить дубликаты фото в гугле, и скачайте его.
2. Предоставьте программе доступ к вашим фотографиям
В зависимости от того, какую программу вы используете, предоставьте ей доступ к своей учетной записи Google или загрузите папку Google Фото в приложение.
Добавьте все свои фотографии, чтобы можно было найти дубликаты.
3. Проверьте свои фотографии на наличие дубликатов
Найдите в папке с фотографиями дубликаты. Программа должна выдать все идентичные изображения, которые она найдет, но вам может потребоваться уменьшить порог сходства , чтобы удалить все.
Просмотрите изображения, отмеченные приложением, и выберите удаление дубликатов.
4. Удалите дубликаты
Чтобы программа не могла случайно удалить изображения, которые вы хотите сохранить, она попросит вас удалить найденные дубликаты. Обязательно отметьте их все, чтобы предотвратить случайное удаление изображения, которое не является дубликатом.
Выберите удаление дубликатов фотографий или перемещение их в корзину.
3. Худший случай: как вручную удалить повторяющиеся фотографии из Google
Если вы обнаружите, что ни встроенное программное обеспечение, ни сторонние приложения не могут удалить все ваши дубликаты, то лучший вариант — просто пройти и удалить их вручную.Это займет некоторое время, но не обязательно делать это очень часто.
1. Найдите повторяющиеся изображения
Просмотрите все свои фотографии и найдите идентичную пару . Поскольку Google сортирует их по дате, они, скорее всего, будут рядом друг с другом, и вам не придется много двигаться вперед и назад.
Вы должны просмотреть все свои фотографии, чтобы найти дубликаты.
2. Откройте фотографию и найдите значок корзины
Вы можете щелкнуть изображение, чтобы увидеть его более подробно и получить различные варианты.В правом верхнем углу будет значок корзины, который нужно выбрать, чтобы удалить изображение.
Щелкните дубликат изображения, чтобы найти кнопку удаления.
3. Удалите дубликаты
Нажмите кнопку «Переместить в корзину» , чтобы удалить изображение. Если вы удалите не ту, изображение будет оставаться в папке для мусора в течение 60 дней, но по истечении этого срока оно будет безвозвратно.
Подтвердите, что вы хотите удалить изображения из Google Фото.
Как избежать дублирования Google Фото
Самый быстрый, простой и надежный способ избежать дублирования — это вообще предотвратить их создание. Лучший способ сделать это — сохранить все свои изображения в одной учетной записи Google или связать их через MultCloud, что увеличивает вероятность того, что встроенное обнаружение удалит ваши дубликаты.
Вам также следует удалить исходный файл, если вы его редактировали. Создание обычных копий при редактировании — отличный способ предотвратить ошибку, которая может испортить вашу фотографию, но она также быстро заполнит ваше хранилище.
Другой вариант — отключить такие функции, как «резервное копирование и синхронизация», и вместо этого вручную загружать фотографии в свою учетную запись Google. Это позволит вам контролировать изображения, которые перемещаются с жесткого диска в облачное хранилище, и вы можете защитить их, пока они находятся на вашем компьютере, с помощью любого хорошего поставщика резервного копирования в Интернете.
Однако, если вы меньше заботитесь о существовании дубликатов и просто хотите вернуть пространство, вам следует переключиться с «оригинала» на «высокое качество». Это даст вам доступ к неограниченному хранилищу изображений за счет снижения качества до 16MP.
Последние мысли
Хотя очистка вашей учетной записи Google Фото может быть медленной, если вы хотите сэкономить место на вашем диске, не полагаясь на компьютер для хранения лишних данных, это возможно. С помощью бесплатного стороннего приложения или надстройки вы можете загружать, синхронизировать и редактировать файлы, не тратя все свое время или хранилище.
Однако Google Фото — не единственное облачное хранилище изображений. В других сервисах, таких как Flickr и Amazon Drive, есть разные способы поиска и удаления фотографий, которые вы, возможно, загрузили дважды.Вы даже можете обнаружить, что они работают лучше, чем параметры Google Диска и Google Фото (ознакомьтесь с нашим списком лучших альтернатив Google Фото).
У вас есть картинки, сохраненные в облаке? Вы пробовали удалить дубликаты в Google Фото этими методами? Сообщите нам свои мысли в разделе комментариев ниже. Спасибо за прочтение.
Сообщите нам, понравился ли вам пост. Это единственный способ стать лучше.
да Нет
.