Как распознать текст в PDF
ABBYY- Контакты
- Интернет-магазин
-
Выберите регион
Global
Global Web Site EnglishNorth America
Canada English Mexico Español United States EnglishSouth America
Brazil Português South America EspañolEurope
Africa and Asia
China 中文 India and SEA Countries English Israel עברית Japan 日本語 Middle East English South Korea 한국어 Turkey TürkçeAustralia
Как распознать текст в формате pdf 🚩 Программное обеспечение
Электронные документы, созданные текстовым редактором, легко распознает бесплатная программа Adobе Rеadеr. Откройте в программе нужный PDF файл, зайдите в меню «редактировать», в выпадающем окне выберите строку «копировать в буфер обмена». Создайте в «ворде» новый документ, вставьте в него из буфера обмена текс и редактируйте, затем сохраните в нужном формате.
Также конвертировать и редактировать пдф-файлы можете при помощи многофункциональной утилиты Acrobat Reader DC. Программный продукт располагает большим количеством инструментов для работы с электронными документами.
Это хорошие программы, но они не смогут распознать текст, если pdf-документы защищены от редактирования или отсканированы с бумажного носителя. В этом случае нужна специальная программа оптического распознавания символов.
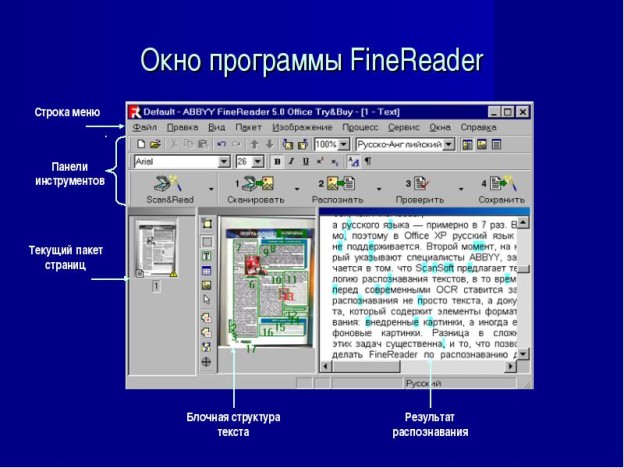
Безусловным лидером является ABBYY FineReader, программа распознает и отдельные страницы, и работает в пакетном режиме. Обработанный текст можно сохранить в txt, doc, html и других форматах. Программа довольно качественно распознает текст pdf. Возможен небольшой процент неправильно распознаных символов и документу потребуется ручная доработка, результат зависит от качества сканов. У этой программы один недостаток – она платная.
Существуют и другие платные, а также бесплатные программы, позволяющие распознать и конвертировать текст из pdf в word: бесплатные – CuneiForm, Freemore OCR, FreeOCR; платные – Readiris Pro, Nitro PDF Professional.
Если не каждый день преобразовываете электронные документы, просто возникла необходимость один раз поработать с форматом пдф, в этом случае нет смысла устанавливать на компьютер программу. Для таких эпизодов существуют онлайн сервисы. Также удобно пользоваться ими на работе, в путешествии, когда нет рядом компьютера с установленной программой. Онлайн сервисы позволяют распознать текст бесплатно и быстро. Вот некоторые:
— Online OCR — www.onlineocr.net
— NewOCR — www.newocr.com
— Free-OCR — www.free-ocr.com
— OCRConvert — www.ocrconvert.com
В распознавании текста онлайн много положительных моментов, но есть и минусы: на сервисе надо зарегистрироваться; не все сервисы имею функцию экспорта, надо самому распознанный текс копировать с веб-страницы; на некоторых сервисах установлен лимит на количество обрабатываемых документов; качество конечного результата зависит от скорости интернета.
Как выяснилось, распознать текст pdf несложно, существуют разные програмы, можите выбирать любую.
7 инструментов для распознавания текста онлайн и офлайн
1. Office Lens
- Платформы: Android, iOS, Windows.
- Распознаёт: снимки камеры.
- Сохраняет: DOCX, PPTX, PDF.
Этот сервис от компании Microsoft превращает камеру смартфона или ПК в бесплатный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы доступны для редактирования в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens. К сожалению, с русским языком программа справляется не так хорошо, как с английским.

Цена: Бесплатно


Разработчик: Microsoft Corporation
Цена: Бесплатно
2. Adobe Scan
- Платформы: Android, iOS.
- Распознаёт: снимки камеры.
- Сохраняет: PDF.
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Приложение полностью бесплатно. Результаты удобно экспортировать в кросс‑платформенный сервис Adobe Acrobat, который позволяет редактировать PDF‑файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.
Разработчик:
AdobeЦена: Бесплатно
Цена: Бесплатно
3. FineReader
- Платформы: веб, Android, iOS, Windows.
- Распознаёт: JPG, TIF, BMP, PNG, PDF, снимки камеры.
- Сохраняет: DOC, DOCX, XLS, XLSX, ODT, TXT, RTF, PDF, PDF/A, PPTX, EPUB, FB2.

FineReader славится высокой точностью распознавания. Увы, бесплатные возможности инструмента ограниченны: после регистрации вам позволят отсканировать всего 10 страниц. Зато каждый месяц будут начислять ещё по пять страниц в качестве бонуса. Подписка стоимостью 129 евро позволяет сканировать до 5 000 страниц в год, а также открывает доступ к десктопному редактору PDF‑файлов.
Перейти на сайт FineReader →
4. Online OCR
- Платформы: веб.
- Распознаёт: JPG, GIF, TIFF, BMP, PNG, PCX, PDF.
- Сохраняет: TXT, DOC, DOCX, XLSX, PDF.

Веб‑сервис для распознавания текстов и таблиц. Без регистрации Online OCR позволяет конвертировать до 15 документов в час — бесплатно. Создав аккаунт, вы сможете отсканировать 50 страниц без ограничений по времени и разблокируете все выходные форматы. За каждую дополнительную страницу сервис просит от 0,8 цента: чем больше покупаете, тем ниже стоимость.
Перейти на сайт Online OCR →
5. img2txt
- Платформы: веб.
- Распознаёт: JPEG, PNG, PDF.
- Сохраняет: PDF, TXT, DOCX, ODF.

Бесплатный онлайн‑конвертер, существующий за счёт рекламы. img2txt быстро обрабатывает файлы, но точность распознавания не всегда можно назвать удовлетворительной. Сервис допускает меньше ошибок, если текст на загруженных снимках написан на одном языке, расположен горизонтально и не прерывается картинками.
Перейти на сайт img2txt →
6. Microsoft OneNote
- Платформы: Windows, macOS.
- Распознаёт: популярные форматы изображений.
- Сохраняет: DOC, PDF.

В настольной версии популярного блокнота OneNote тоже есть функция распознавания текста, которая работает с загруженными в заметки изображениями. Если кликнуть правой кнопкой мыши по снимку документа и выбрать в появившемся меню «Копировать текст из рисунка», то всё текстовое содержимое окажется в буфере обмена. Программа доступна бесплатно.
Скачать Microsoft OneNote →
7. Readiris 17
- Платформы: Windows, macOS.
- Распознаёт: JPEG, PNG, PDF и другие.
- Сохраняет: PDF, TXT, PPTX, DOCX, XLSX и другие.

Мощная профессиональная программа для работы с PDF и распознавания текста. С высокой точностью конвертирует документы на разных языках, включая русский. Но и стоит Readiris 17 соответственно — от 49 до 199 евро в зависимости от количества функций. Вы можете установить пробную версию, которая будет работать бесплатно 10 дней. Для этого нужно зарегистрироваться на сайте Readiris, скачать программу на компьютер и ввести в ней данные от своей учётной записи.
Скачать Readiris 17 →
Читайте также 💻📎🖌
Как распознать PDF файл онлайн

Извлечь текст из PDF-файла методом обычного копирования можно далеко не всегда. Часто страницы подобных документов представляют собой отсканированное содержимое их бумажных вариантов. Для преобразования таких файлов в полностью редактируемые текстовые данные используются специальные программы с функцией Optical Character Recognition (OCR).
Такие решения являются весьма сложными в реализации и, следовательно, стоят немалых денег. Если потребность в распознавании текста с PDF у вас возникает регулярно, вполне целесообразно будет приобрести соответствующую программу. Для редких же случаев более логичным будет воспользоваться одним из доступных онлайн-сервисов с подобными функциями.
Как распознать текст с PDF онлайн
Конечно, набор возможностей онлайн-сервисов OCR, в сравнении с полноценными десктопными решениями, более ограничен. Но и работать с такими ресурсами можно либо же совсем бесплатно, либо за символическую плату. Главное, что с основной своей задачей, а именно с распознаванием текста, соответствующие веб-приложения справляются так же хорошо.
Способ 1: ABBYY FineReader Online
Компания-разработчик сервиса — одна из лидеров в области оптического распознавания документов. ABBYY FineReader для Windows и Mac является мощным решением для преобразования PDF в текст и дальнейшей работы с ним.
Веб-аналог программы, конечно же, уступает ей по функционалу. Тем не менее сервис умеет распознавать текст со сканов и фотографий на более чем 190 языках. Поддерживается преобразование PDF-файлов в документы Word, Excel и т.п.
Онлайн-сервис ABBYY FineReader Online
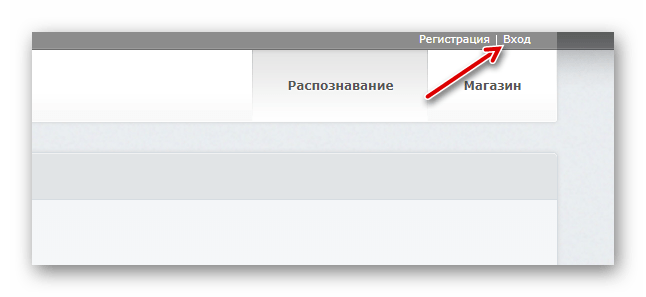
- Прежде чем приступить к работе с инструментом, создайте аккаунт на сайте или войдите при помощи учетной записи Facebook, Google или Microsoft.

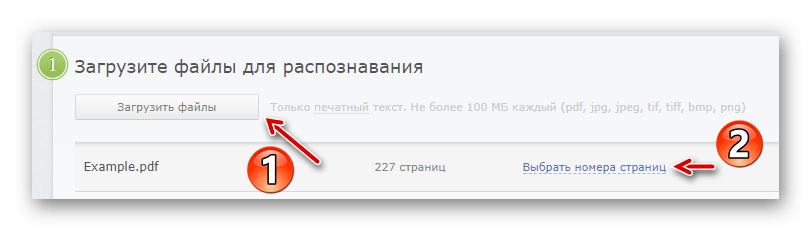
Чтобы перейти к окну авторизации, щелкните по кнопке «Вход» в верхней панели меню. - Осуществив вход, импортируйте нужный PDF-документ в FineReader, воспользовавшись кнопкой «Загрузить файлы».
Затем нажмите «Выбрать номера страниц» и укажите желаемый промежуток для распознавания текста. - Далее выберите языки, присутствующие в документе, формат итогового файла и нажмите на кнопку «Распознать».
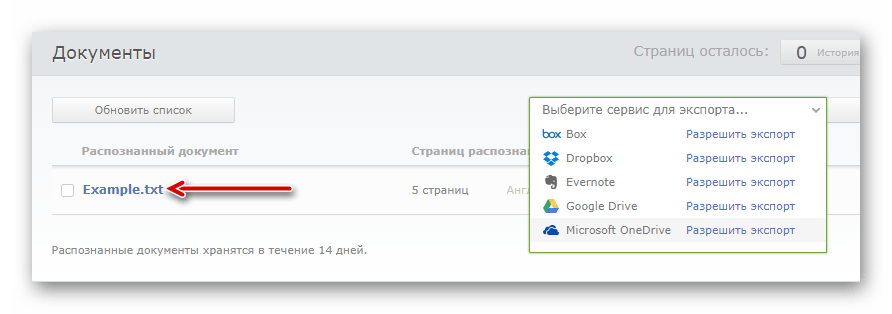
- После обработки, длительность которой полностью зависит от объема документа, вы можете скачать готовый файл с текстовыми данными просто щелкнув по его названию.
Либо же экспортируйте его в один из доступных облачных сервисов.

Сервис отличается, вероятно, наиболее точными алгоритмами распознавания текста на изображениях и PDF-файлах. Но, к сожалению, его бесплатное использование ограничено пятью обрабатываемыми страницами в месяц. Чтобы работать с более объемными документами, придется купить годовую подписку.
Тем не менее, если функция OCR нужна совсем уж редко, ABBYY FineReader Online — отличный вариант для извлечения текста из небольших PDF-файлов.
Способ 2: Free Online OCR
Простой и удобный сервис для оцифровки текста. Без необходимости регистрации ресурс позволяет распознавать 15 полных PDF-страниц в час. Free Online OCR полноценно работает с документами на 46 языках и без авторизации поддерживает три формата экспорта текста — DOCX, XLSX и TXT.
При регистрации пользователь получает возможность обрабатывать многостраничные документы, однако бесплатное количество этих самых страниц ограничено 50 единицами.
Онлайн-сервис Free Online OCR
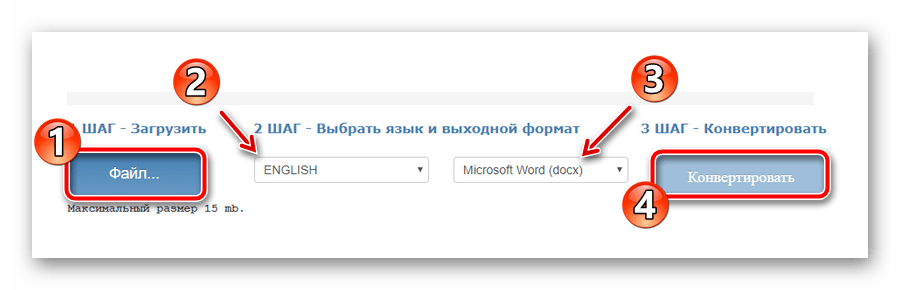
- Чтобы распознать текст из PDF как «гость», без авторизации на ресурсе, воспользуйтесь соответствующей формой на главной странице сайта.
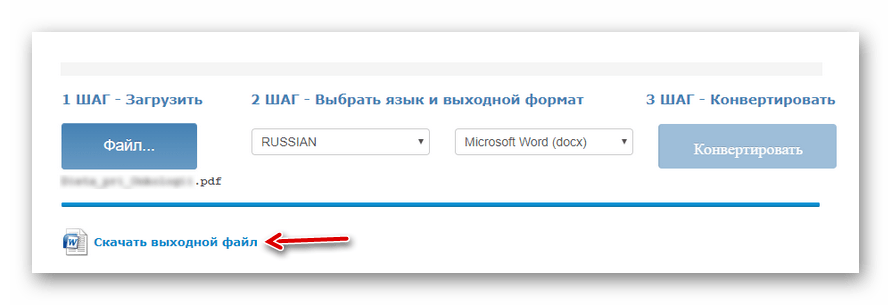
Выберите нужный документ с помощью кнопки «Файл», укажите основной язык текста, выходной формат, затем дождитесь загрузки файла и нажмите «Конвертировать». - По окончании процесса оцифровки нажмите «Скачать выходной файл» для сохранения готового документа с текстом на компьютере.
Для авторизованных же пользователей последовательность действий несколько иная.
- Воспользуйтесь кнопкой «Регистрация» или «Вход» в верхней панели меню, чтобы, соответственно, создать учетную запись Free Online OCR либо зайти в нее.
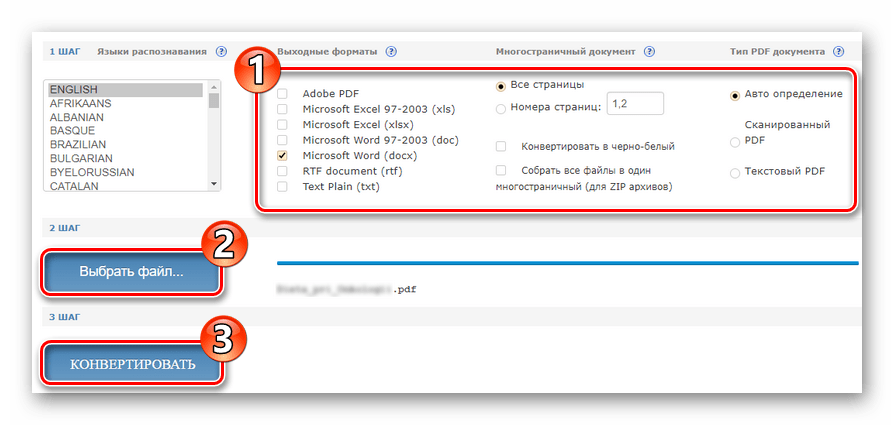
- После авторизации в панели распознавания, удерживая клавишу «CTRL», выберите до двух языков исходного документа из предложенного списка.
- Укажите дальнейшие параметры извлечения текста из PDF и нажмите кнопку «Выбрать файл» для загрузки документа в сервис.
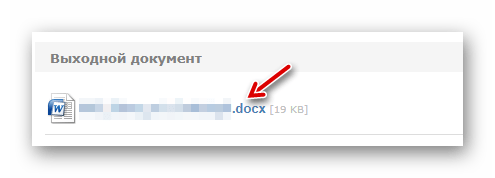
Затем, чтобы приступить к распознаванию, щелкните «Конвертировать». - По окончании обработки документа нажмите на ссылку с названием выходного файла в соответствующей колонке.
Результат распознавания сразу же будет сохранен в памяти вашего компьютера.


При необходимости извлечь текст из небольшого PDF-документа можно смело прибегать к использованию вышеописанного инструмента. Для работы же с объемными файлами придется купить дополнительные символы во Free Online OCR либо же прибегнуть к другому решению.
Способ 3: NewOCR
Полностью бесплатный OCR-сервис, позволяющий извлекать текст практически из любых графических и электронных документов вроде DjVu и PDF. Ресурс не накладывает ограничений на размер и количество распознаваемых файлов, не требует регистрации и предлагает широкий набор сопутствующих функций.
NewOCR поддерживает 106 языков и умеет корректно обрабатывать даже низкокачественные сканы документов. Есть возможность вручную выбирать область для распознавания текста на странице файла.
Онлайн-сервис NewOCR
- Так, приступить к работе с ресурсом вы можете сразу, без необходимости выполнения лишних действий.
Прямо на главной странице размещена форма для импорта документа на сайт. Чтобы загрузить файл в NewOCR, воспользуйтесь кнопкой «Выберите файл» в разделе «Select your file». Затем в поле «Recognition language(s)» укажите один или более языков исходного документа, после чего нажмите «Upload + OCR». - Задайте предпочитаемые настройки распознавания, выберите нужную страницу для извлечения текста и щелкните по кнопке «OCR».
- Прокрутите страницу немного ниже и найдите кнопку «Download».
Щелкните по ней и в выпадающем списке выберите необходимый формат документа для скачивания. После этого готовый файл с извлеченным текстом будет загружен на ваш компьютер.

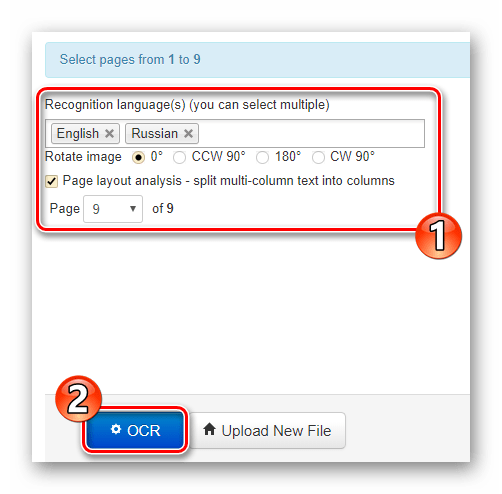
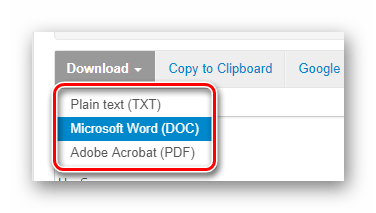
Инструмент удобный и достаточно качественно распознает все символы. Впрочем, обработку каждой страницы импортированного PDF-документа нужно запускать самостоятельно и выводится она в отдельный файл. Можно, конечно, сразу копировать результаты распознавания в буфер обмена и объединять их с другими.
Тем не менее, учитывая вышеописанный нюанс, большие объемы текста с помощью NewOCR извлекать весьма затруднительно. С малыми же файлами сервис справляется «на ура».
Способ 4: OCR.Space
Простой и понятный ресурс для оцифровки текста, позволяет распознавать PDF-документы и выводить результат в TXT-файл. Никаких лимитов по количеству страниц не предусмотрено. Единственное ограничение — размер входного документа не должен превышать 5 мегабайт.
Онлайн-сервис OCR.Space
- Регистрироваться для работы с инструментом не нужно.
Просто перейдите по ссылке выше и загрузите PDF-документ на сайт с компьютера при помощи кнопки «Выберите файл» либо из сети — по ссылке. - В выпадающем списке «Select OCR language» выберите язык импортированного документа.
Затем запустите процесс распознавания текста, щелкнув по кнопке «Start OCR!». - По окончании обработки файла ознакомьтесь с результатом в поле «OCR’ed Result» и нажмите «Download», чтобы скачать готовый TXT-документ.


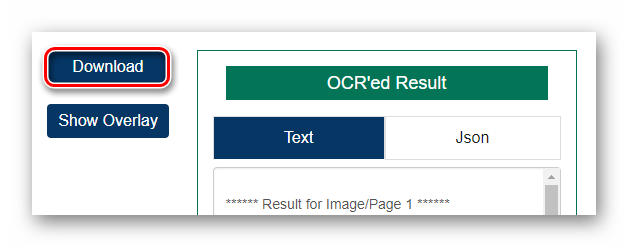
Если вам нужно просто извлечь текст из PDF и при этом финальное его форматирование совсем не важно, OCR.Space — хороший выбор. Единственное, документ должен быть «одноязычным», так как распознавание двух и более языков одновременно в сервисе не предусмотрено.
Читайте также: Бесплатные аналоги FineReader
Оценивая онлайн-инструменты, представленные в статье, следует отметить, что наиболее точно и качественно с функцией OCR справляется FineReader Online от ABBYY. Если для вас важна именно максимальная точность распознавания текста, лучше всего рассмотреть конкретно этот вариант. Но и заплатить за него, скорее всего, также придется.
Если же нужна оцифровка небольших документов и вы готовы самостоятельно исправлять ошибки за сервисом, целесообразно использовать NewOCR, OCR.Space или Free Online OCR.
 Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Мы рады, что смогли помочь Вам в решении проблемы.Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.Помогла ли вам эта статья?
ДА НЕТКак распознать текст из pdf?
Графический формат pdf является не только одним из самых популярных форматов в котором читают всевозможные книжки, журналы и т.д., но и так же, пожалуй, самым удобным форматов в котором можно отсканировать всевозможные тексты для их дальнейшего распознания и работы с ними. Тем более что большинство современных сканеров и мобильных приложений преобразуют сканированные копии текстов сразу в PDF формат.
Для того, чтобы распознать текст из pdf легко и быстро, можно воспользоваться бесплатной программой PDF-XChange Viewer. Сама по себе программа предназначена для просмотра файлов в pdf формате, однако у нее есть одна очень полезная функция, которая отличает эту программу от своих собратьев, это возможность распознавать текст.
И так, чтобы распознать текст из pdf следует после установки и запуска программы, на верхней панели инструментов нажать на кнопку OCR. Открывается окно настройки распознавания текста.
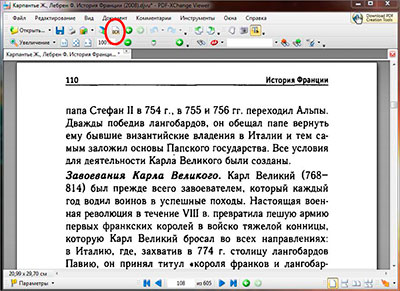
Первоначально в PDF-XChange Viewer русского языка для распознавания текста не установлено и поэтому, его надо дополнительно установить из дополнительного языкового пакета. Языковой пакет запускается из .exe файла двойным кликом по нему, в появившемся установочном окне следует выбрать нужным нам язык (естественно ставим галочку на против русского, ну или какого ни будь другого европейского языка если угодно) и устанавливаем пакет языков на компьютер.

После установки пакета перезагружаем программу и уже в меню «основной язык» устанавливаем русский язык.
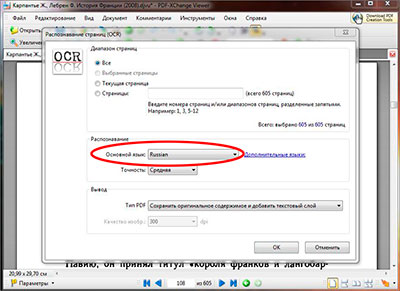
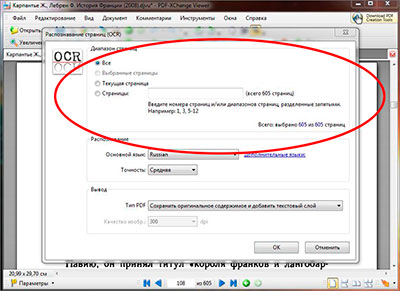
После того как основной язык выбран, там же в настройках распознавания текста, так же можно выбрать сколько будет распознано страниц файл. Если страниц в pdf файле не много, то его можно распознать целиком, если же станиц очень много и они все не нужны, то для сохранения времени можно выбрать отдельные страницы для распознавания указав с какой по какую надо распознать. Так же можно распознать текст из pdf на текущей открытой странице выбрав соответствующий пункт в настройках.
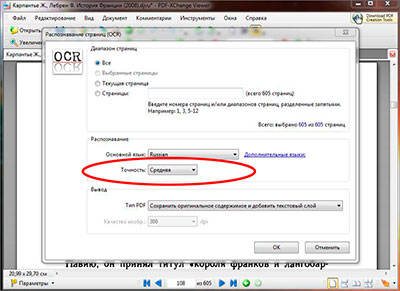
После того как выбран основной язык распознавания и нужные страницы файла, следует указать точность распознавания текста из pdf, их в программе PDF-XChange Viewer три степени: низкая, средняя и высокая. И соответственно, чем выше степень тем лучше будет распознавание, но и времени на обработку в высоком качестве будет потрачено больше чем в низком.
После того как нужный текст из pdf файла распознан, для того что бы его скопировать, следует на панели инструментов нажать на кнопку выделение (она выглядит как квадрат с буквой «Т») и выделить нужные фрагмент текста, а после нажать правой кнопкой мыши и выбрать строку копировать.
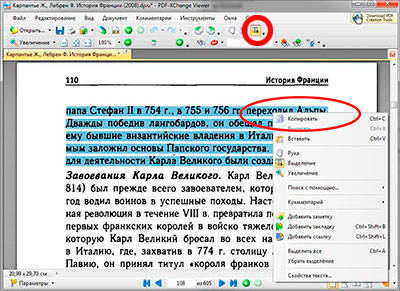
Сама же программа PDF-XChange Viewer является вполне хорошим и удобным просмотрщиком pdf файлов с возможностью вставлять комментарии в нужном месте текста, импортом и экспортом файлов данных, настройкой вида текста и окна программы и широкой панелью инструментов.
Распространение: бесплатное.
Операционная система: Windows XP, Windows Vista, Windows 7, Windows 8, Windows 10.
Сайт программы tracker-software.com/product/pdf-xchange-viewer-activex-sdk
Оптическое распознавание текста (OCR) | Яндекс.Облако
В этом разделе описано, как работает возможность распознавание текста (Optical Character Recognition, OCR).
Подготовка запроса на распознавание
В запросе вы указываете список возможностей для анализа, которые необходимо применить к изображению. Чтобы распознать текст, используйте тип TEXT_DETECTION и задайте список языков в конфигурации.
Конфигурация запроса
В конфигурации указывается:
список языков, на основе которого будет определена языковая модель для распознавания.
Если вы не знаете язык текста, укажите
"*", чтобы сервис выбрал наиболее подходящую модель автоматически.модель, которая будет использована для поиска текста на изображении. Доступные модели:
page(по умолчанию) — подходит для изображений с любым количеством строк текста.line— подходит для распознавания одной строки текста. Например, если вы не хотите передавать изображение целиком, вы можете вырезать строку и отправить на распознавание только ее.На изображении должна быть только одна строка текста, а высота текста должна быть не меньше 80% от высоты изображения, иначе результаты распознавания с моделью
lineбудут непредсказуемы. Пример правильного изображения:

Определение языковой модели
Для распознавания текста в сервисе используется языковая модель, обученная на определенном наборе языков. Модель выбирается автоматически на основе списка языков, который вы указываете в конфигурации.
При каждом распознавании текста используется только одна модель. Например, если на изображении текст на китайском и японском, то распознан будет только один из этих языков. Чтобы распознать оба этих языка, укажите в запросе несколько возможностей для анализа с разными списками языков.
Совет
Для текста на русском и английском лучше всего работает англо-русская модель. Чтобы использовать ее, укажите один из этих языков или оба в text_detection_config, но не указывайте другие языки.
Требования к изображению
Изображение в запросе должно соответствовать следующим требованиям:
Поддерживаемые форматы файлов: JPEG, PNG, PDF.
MIME-тип файла вы указываете в свойстве
mime_type. По умолчаниюimage.Максимальный размер файла: 1 МБ.
Размер изображения не должен превышать 20 мегапикселей (длина x ширина).
Ответ с результатами распознавания
Сервис выделяет найденный текст на изображении и группирует его по уровням: слова группируются в строки, строки в блоки, блоки в страницы.

В результате сервис возвращает объект, где для каждого из уровней дополнительно указывается:
- страницы (
pages[]) — размер страницы; - блоки текста (
blocks[]) — расположение текста на странице; - строки (
lines[]) — расположение и достоверность распознавания; - слова (
words[]) — расположение, достоверность, текст и язык, использованный при распознавании.
Чтобы показать расположение текста, сервис возвращает координаты прямоугольника, обрамляющего текст. Координаты — количество пикселей от левого верхнего угла на изображении.
Координаты прямоугольника считаются от левого верхнего угла и указываются против часовой стрелки:
Пример распознанного слова с координатами:
{
"boundingBox": {
"vertices": [{
"x": "410",
"y": "404"
},
{
"x": "410",
"y": "467"
},
{
"x": "559",
"y": "467"
},
{
"x": "559",
"y": "404"
}
]
},
"languages": [{
"languageCode": "en",
"confidence": 0.9412244558
}],
"text": "you",
"confidence": 0.9412244558
}
Достоверность распознавания
Достоверность распознавания показывает уверенность сервиса в результате. Например, значение "confidence": 0.9412244558 для строки we like you
означает, что с вероятностью в 94% текст распознан корректно.
Сейчас достоверность считается только для строк. В значение confidence для слов и языка подставляется значение для confidence строки.
Что дальше
Распознавание текста онлайн — ТОП-9 сервисов
Распознавание текста с картинки, OCR (optical character recognition), то есть превращение картинки в текст доступно бесплатно на многих сайтах в режиме онлайн. Но везде свое качество и свои ограничения на количество распознаваемых картинок.
Я проверила с десяток онлайн-сервисов и составила рейтинг лучших.
Для примера распознавала фотографию документа, который есть у каждого – свидетельство ИНН физического лица (разрешением 1275×1750 пикселей).
В Google можно распознавать неограниченное количество картинок, лишь бы они поместились на Google Drive. Нужно просто открыть картинку с Google диска с помощью Google Документов, и она автоматически распознается.
| Входные форматы | PDF , JPEG, PNG, GIF |
| Выходные форматы | Word, Open Document, RTF, Adobe PDF, HTML, Text Plain, Epub (но форматирование исчезает – нарушается компоновка картинок с текстом) |
| Размер файла | До 2 Мб |
| Ограничения | Ограничено только размером хранилищ Google. Качество исходника рекоменовано не меньше 10 пикселей по высоте для строки. |
| Качество | Так себе – качество распознавания свидетельства инн хуже, чем с Finereader. И ФИО, и номер инн полностью потеряны. |
Как пользоваться
У вас должен быть Google-аккаунт для пользования сервисом, если есть почта gmail – подойдет аккаунт от нее.
- Загрузите файл на страницу drive.google.com или выберите там уже загруженную картинку
- Нажмите правой кнопкой мыши на нужный файл.
- Выберите “Открыть с помощью” –> “Google Документы”.
- Картинка преобразуется в документ Google и откроется на вкладке https://docs.google.com


Abbyy Finereader
В Abbyy Finereader Online самый удобный интерфейс, хорошее качество, но доступна только ознакомительная версия – можно распознать не более 10 страниц за две недели. (200 страниц в месяц стоят 299р). Для использования сервиса нужно зарегистрироваться (можно войти через аккаунты социальных сетей). Кроме того, полученный текст можно там же перевести на другой язык с помощью машинного перевода.
Бесплатно доступно не более 10 страниц в две недели.
| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG |
| Выходные форматы | Word, Excel, Power Point, Open Document, RTF, Adobe PDF, Text Plain, Fb2, Epub |
| Размер файла | До 100Мб |
| Ограничения | 10 картинок на две недели |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Online OCR – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
 Результат распознавания Finereader. (ФИО и город распознаны, но стерты вручную)
Результат распознавания Finereader. (ФИО и город распознаны, но стерты вручную)Как пользоваться
- Загрузите файлы
- Выберите язык
- Выберите выходной формат
- Щелкните кнопку «Распознать»


Распознавание текста онлайн без регистрации
Online OCR
Online OCR http://www.onlineocr.net/ – единственный наряду с Abbyy Finereader сервис, который позволяет сохранять в выходном формате картинки вместе с текстом. Вот как выглядит распознанный вариант с выходным форматом Word:
 Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)
Результат распознавания в Online OCR (ФИО и дата распознаны, но стерты вручную)| Входные форматы | PDF, TIF, JPEG, BMP, PCX, PNG, GIF |
| Выходные форматы | Word, Excel, Adobe PDF, Text Plain |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Распознает не более 15 картинок в час без регистрации |
| Качество | Качество распознавания свидетельства инн оказалось хорошее. Примерно как у Abbyy Finereader – какие-то части документа лучше распознались тем сервисом, а какие-то – этим. |
Как пользоваться
- Загрузите файл (щелкните «Select File»)
- Выберите язык и выходной формат
- Введите капчу и щелкните «Convert»

Внизу появится ссылка на выходной файл (текст с картинками) и окно с текстовым содержимым
Free Online OCR
Free Online OCR https://www.newocr.com/ позволяет выделить часть изображения. Выдает результат в текстовом формате (картинки не сохраняются).
| Входные форматы | PDF, DjVu JPEG, PNG, GIF, BMP, TIFF |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 5Мб без регистрации и до 100Мб с ней |
| Ограничения | Ограничения на количество нет |
| Качество | Качество распознавания свидетельства инн плохое. |
Можно распознавать как все целиком, так и выделить часть изображения для распознавания.
Как пользоваться
- Выберите файл или вставьте url файла и щелкните «Preview» – картинка загрузится и появится в окне браузера Не забудьте правильно указать язык.
- Выберите область сканирования (можно оставить целиком как есть)
- Выберите языки, на которых написан текст на картинке и щелкните кнопку «OCR»
- Внизу появится окно с текстом
 Не забудьте правильно указать язык.
Не забудьте правильно указать язык.

OCR Convert
OCR Convert http://www.ocrconvert.com/ txt
| Входные форматы | Многостраничные PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 5Мб общий размер файлов за один раз. |
| Ограничения | Одновременно до 5 файлов. Сколько угодно раз. |
| Качество | Качество распознавания свидетельства инн среднее. (ФИО распознано частично). Лучше, чем Google, хуже, чем Finereader |
Как пользоваться
- Загрузите файл, выберите язык и щелкните кнопку «Process»

- Появится ссылка на файл с распознанным текстом

Free OCR
Free OCR www.free-ocr.com распознал документ хуже всех.
| Входные форматы | PDF, JPG, PNG, BMP, GIF, TIFF |
| Выходные форматы | Text Plain |
| Размер файла | До 6Мб |
| Ограничения | У PDF-файла распознается только первая страница |
| Качество | Качество распознавания свидетельства инн низкое – правильно распознано только три слова. |
Как пользоваться
- Выберите файл
- Выберите языки на картинке
- Щелкните кнопку “Start”

I2OCR
I2OCR http://www.i2ocr.com/ неплохой сервис со средним качеством выходного файла. Отличается приятным дизайном, отсутствием ограничений на количество распознаваемых картинок. Но временами зависает.
| Входные форматы | JPG, PNG, BMP, TIF, PBM, PGM, PPM |
| Выходные форматы | Text Plain (PDF и Word тоже можно загрузить, но внутри них все равно текст без форматирования и картинок). |
| Размер файла | До 10Мб |
| Ограничения | нет |
| Качество | Качество распознавания свидетельства инн среднее – сравнимо с OCR Convert. Замечено, что сервис временами не работает. |
Как пользоваться
- Выберите язык
- Загрузите файл
- Введите капчу
- Щелкните кнопку «Extract text»
- По кнопке «Download» можно загрузить выходной файл в нужном формате

Яндекс OCR
Недавно обнаружила этот сервис, и он мне очень понравился качеством и простотой использования. Вообще то он предназначен для перевода загруженной картинки, но его можно использоваться и для распознавания текста с картинки. Регистрации не требует, ограничений на количество изображений нет. В данный момент находится в стадии бета-тестирования.
Просто перейдите на https://translate.yandex.ru/ocr, загрузите картинку (можно перетащить) и щелкните “Открыть в Переводчике”. Откроется как текст с картинки, так и перевод в правом поле.
 Перетащите картинку
Перетащите картинку Результат распознавания
Результат распознаванияConvertio
Convertio hhttps://convertio.co/ru/ocr/ работает своеобразно, поэтому сравнивать его тяжело. В целом не понравился. Свидетельство ИНН, загруженное целиком, он не распознал совсем, так как плохо выделяет текст среди картинок. Не распозналось ни одного слова! Для его проверки я вырезала текстовый кусочек из ИНН и распознала его – это удалось сделать.
К тому же временами он зависает в попытках что-либо распознать.
| Входные форматы | pdf, jpg, bmp, gif, jp2, jpeg, pbm, pcx, pgm, png, ppm, tga, tiff, wbmp, webp |
| Выходные форматы | Text Plain, PDF, Word , Excel, Pptx, Djvu, Epub, Fb2, Csv |
| Размер файла | ?, зависит от тарифа |
| Ограничения | 10 страниц бесплатно, дальше тарифы от 7 долларов. |
| Качество | Сложно оценить – файл с картинками (ИНН) не распознал совсем, отдельно вырезанный кусок текста распознал. Замечено, что при распознавании сервис временами зависает, возможно ваши картинки ставятся в большую очередь на бесплатном тарифе. |
Как пользоваться
- Загрузите файл
- Выберите язык
- Выберите выходной формат
- Введите капчу
- Щелкните “Преобразовать”
- Чтобы увидеть результат, промотайте наверх к форме загрузки файлов. Там же можно будет и скачать результат.
 Интерфейс Convertio
Интерфейс ConvertioВырезанный и распознанный кусок (целиком не распознается):
 Результат работы Convertio
Результат работы ConvertioЗаключение
Лучше всего документ распознал Abbyy Finereader и Online OCR. Кроме того, эти сервисы сохраняют форматирование файла: где нет текста, оставляют картинки и компонуют их с распознанным текстом. Из новых сервисов хорош Яндекс OCR.
Хуже всего сработал Free OCR – он распознал всего три слова.