Как долго личные данные хранятся в Интернете?
Как долго данные остаются доступными в Интернете? Ответы и пути решения связанных с этим вопросов могут поразить вас.
Как долго хранятся личные данные в сети ИнтернетКак долго личные данные хранятся в сети Интернет, каков срок хранения цифровых данных? Этими вопросами ежедневно задаются пользователи, компании и организации. Ответ прост – очень долго, бесконечно долго, целую вечность. В действительности же дела часто обстоят иначе, так как существуют определённые ограничения, касающиеся данных, их хранения и поиска, которые часто определяют тот или иной срок хранения для цифровых данных. В вопросах данных, их сбора, хранения и использования третьими лицами реальную проблему представляет переходный характер информации. Данные, собранные и хранящиеся в одном месте, могут иметь срок действия в отношении к этому конкретному месту, но если эти данные переданы, утеряны или украдены, и хранятся с этого момента в новом месте, срок их хранения увеличивается.
- Продолжительность времени, в течение которого бит информации может оставаться доступным онлайн, полностью зависит от того, что это за информация и где она хранится. Случайный бит информации, не имеющей ценности в перспективе, может быть стёрт из памяти и утерян из сети очень быстро. Материал же, специально загруженный на такой сайт, как YouTube, Facebook или в другую социальную сеть, может всегда отражаться в поиске.
Ответы на эти вопросы, представляющиеся любопытными в философском смысле, в перспективе крайне важны для нас и будущих пользователей Интернета. The Cloud («Облако») дало толчок к развитию онлайн-хранения данных, которое означает, что данные, которые вы загружаете, храните, используете и к которым получаете доступ, будут в какой-то момент времени использоваться, храниться и сохраняться сервером некой третьей стороны. Это означает, что в будущем, возможно, данные не будут храниться локально.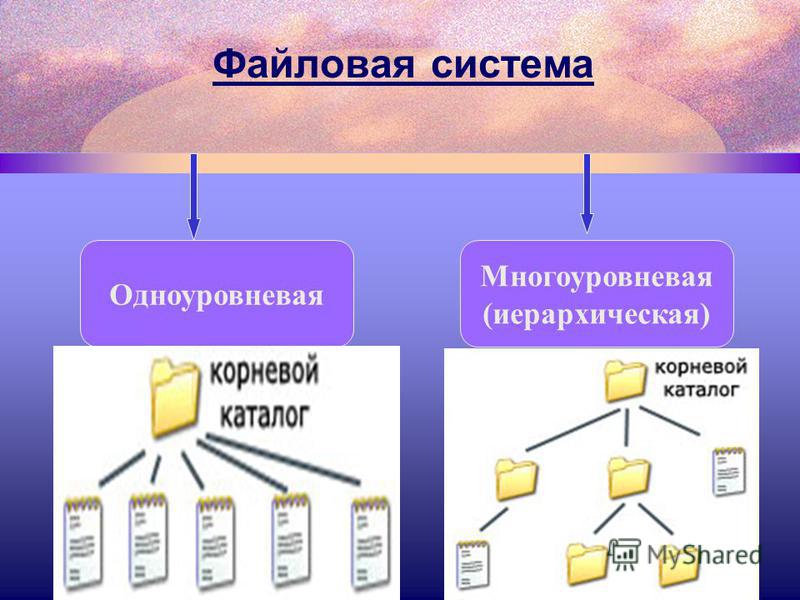
«Облаку» сложно дать определение. Хотя оно включает в себя и онлайн-хранение данных, оно также включает и почти все виды услуг SaaS и PaaS, доступные в сети Интернет. Вообще, «облако» (и не одно, а целое их множество) представляет собой сеть серверов, созданную для выполнения функций. Как правило, функцией является запуск и работа приложения или предоставление услуги по Интернету. Пользователям не требуется загружать или устанавливать какое-либо ПО, так как все функции выполняются облачной сетью…которая сохраняет ваши данные и информацию о вас.
- «Облако» – это не предмет, а термин, обозначающий серверные веб-приложения, работающие по Интернету; любая серверная сеть, созданная по этому принципу, является «облачной». Стоимость хранения данных является низкой относительно их ценности. Пока данные являются ценными, их будут собирать и хранить.
- В декабре 2010 года администрация президента США Барака Обамы предложила политику «Cloud First», подтолкнув компании к извлечению максимальной пользы из технологий «облачных» вычислений, тем самым увеличив свою эффективность и повысив производительность.
Часто вы пользуетесь «облаками», даже не подозревая об этом и не давая своего согласия на это. Задумайтесь о вашем мобильном телефоне. Я точно знаю, что я никогда не регистрировался в сервисах для онлайн-хранения фотографий, но все мои изображения каким-то образом оказались в «облачном» хранилище. Хорошими примерами могут также служить такие файлообменные сервисы, как Google Drive и Dropbox. Timeline на Facebook запоминает, что вы делали в прошлом, благодаря всё тому же «облаку».
Сколько могут храниться цифровые данные? Evernote, организация, предоставляющая услуги по обмену файлами и онлайн-хранению данных, гарантирует своим клиентам доступ к их данным в течение 100 лет. Для выполнения этого обещания руководители компании основали трастовый фонд, чтобы обеспечить работу серверов хранения в случае, если компания закончит свою деятельность или будет поглощена.
В некоторых случаях срок хранения информации регулируется законодательством. В Австралии был принят и введён в силу закон о сроке хранения данных, обязывающий телекоммуникационные компании и операторов телекоммуникационных услуг записывать и хранить все метаданные пользователей в течение 2 лет. Закон, рассматривавшийся как средство защиты населения, вызвал возмущения и негодование в Австралии, так как его восприняли и как грубое вторжение в частную жизнь. Данные потребуются для использования правоохранительными органами в ходе расследований и судебных разбирательств, что легко превращает телекоммуникационные компании и операторов телекоммуникационных услуг в правительственных шпионов. Digital Rights Watch, организация, контролирующая наблюдение за соблюдением прав на цифровую информацию, объявила день принятия данного закона
Настоящей проблемой в Австралии является то, что 2 500 отдельных компаний имеют доступ к данным и ответственность за их мониторинг, что означает, что серверы по всей стране будут обмениваться данными и хранить их. Собираемая информация включает имя владельца аккаунта, номер телефона/IP-адрес, исходящий трафик, даты звонков, данные о получателях и данные email-сообщений. Используя эту информацию, программа-шпион может получить подробную картину личной жизни любого австралийца, включая информацию о его финансовом положении, состоянии здоровья и политических взглядах.
Упоминание срока хранения телекоммуникационных данных в статье об онлайн-хранении информации может показаться несколько странным, но позвольте мне напомнить вам кое о чём. Современные компьютеры, компьютерные сети и Интернет – это ответвления телефонных систем. Компьютеры были созданы, чтобы справляться с трафиком и маршрутизацией звонков, когда система стала слишком сложной для того, чтобы ею управляли люди. В современном мире мы редко пользуемся тем, что теперь называется «городским/стационарным телефоном», но, тем не менее, наши мобильные, Wi-Fi и компьютерные соединения всё равно проходят через телефонную систему в тот или иной момент их передачи. И на каждом этапе они записываются.
Законность хранения данных являлась проблемой для многих стран. В Европейском союзе был принят закон о хранении данных, и предпосылкой к этому была необходимость борьбы с преступностью, но позже данный закон был объявлен недействительным в связи с нарушением основных прав человека. В Соединённом Королевстве был принят закон с поправками, на волне признания недействительным закона, принятого в ЕС, но и он «попал в опалу» за нарушение прав человека. Его окрестили «хартией ищеек», объявив его попыткой правительства шпионить за населением, или, хуже, посягательством на источники информации, которая может использоваться в незаконных целях, например, с целью мошенничества.
США не удалось принять законы о хранении данных, обязательные к исполнению телекоммуникационными компаниями и операторами телекоммуникационных услуг, однако многие частные и коммерческие организации активно осуществляют сбор данных, к чему их может принуждать правительство. ФБР может защищать данные с помощью Письма Национальной Безопасности, которое в действительности является секретным ордером, выдаваемым без какого-либо судебного надзора. Аргумент: данные могут быть использованы для борьбы с преступностью и терроризмом, но цена за это – конфиденциальность, гражданская свобода и основные права человека.
Существует множество причин, по которым данные могут быть утеряны из сети Интернет. Ниже представлены несколько ограничений в онлайн-хранении данных.
- Ограничения оборудования
Даже у современных мощных компьютеров существуют пределы их возможностей. Серверы хранения имеют лимит, превышение которого может привести к утере старой или наименее используемой информации. Возможны также перебои в питании сервера или достижение предела его возможностей, что приведёт к нарушению его правильной работы и утере данных.
Данные хранятся, так как они имеют ценность. Данные, сохраняемые пользователями, могут включать пароли, данные учётной записи, медицинские карточки, информацию о кредитах, финансовую и другую информацию, важную для человека и потому имеющую ценность. Компании могут хранить в «облаке» свою документацию и информацию. Когда данные утрачивают свою ценность, они могут быть удалены.
Если данные устаревают или же их место, способ хранения или ответственная за него компания больше не являются необходимыми, весь пакет данных может быть утерян навсегда. Риск для нашего поколения, забившего свои шкафы CD-дисками, заключается в том, что, если мы перейдём к новой форме онлайн-хранения данных, информация, хранящаяся нынешними способами, будет утеряна.
Многие данные, хранящиеся в Интернете, привязаны к учётным записям. Если вы ищете статью или изображение и не можете найти, велик шанс, что учётная запись была удалена. Это могло быть сделано и намеренно, но обычно так происходит в связи с заморозкой аккаунта по причине несанкционированного использования.
- Намеренное удаление
Часто контент удаляется из Интернета намеренно, и становится утерянным навсегда, если только он не хранится где-то ещё. Обратной стороной является проблема удаления контента по вашему желанию. Если контент был распространён вирусным или любым другим способом, найти и удалить весь этот контент может быть крайне сложно.
- Изменение ссылки
Иногда контент теряется, так как изменяется ссылка на него. Если ссылка была изменена и это не было зафиксировано, может быть трудно или вовсе невозможно найти контент, который, таким образом, теряется.
Как долго хранятся личные данные в Интернете?Если вы задаётесь этим вопросом, беспокоясь из-за того, что вы что-то запостили в прошлом, то вы можете быть уверены, что та информация всё ещё доступна там же. Думайте, Прежде Чем Постить – этот совет остаётся наиболее полезным для всех Интернет-пользователей: сохраняйте свою личную жизнь личной, и эта головная боль вам не грозит. Как уже было сказано, для уничтожения всех «следов» прошлой жизни могут потребоваться немалые усилия. Обучаясь некоторым профессиям, студенты усваивают, что нельзя отправлять подробную информацию в социальные сети, так как их могут выследить, и это правило должны выучить все студенты, в самом раннем возрасте.
Попытаться вспомнить и стереть все «ошибки прошлого» – это грандиозная задача, которая не всегда может быть выполнена. Конечно, вы можете удалить пост из Facebook или Instagram, но удастся ли вам удалить упоминания о каждом, кто лайкнул, сохранил или репостнул ваш пост? Если речь идёт об удалении информации, вам нужно связаться с владельцами всех веб-сайтов, где может быть ваша информация, и попросить их удалить её, а также поверить им, что они выполнили вашу просьбу. Проблема в том, что невозможно знать все серверы, на которых могут храниться ваши данные или всё, что известно о вас в Интернете, чтобы найти все «следы» и «стереть» себя из Всемирной паутины.
Достоинства и недостатки онлайн-хранения данныхОнлайн-хранение данных – это проблема для компаний и организаций, которые осуществляют сбор данных, а также для тех, чьи данные собираются. Когда вы начинаете осуществлять сбор и хранение данных, вы должны учесть правовые и коммерческие требования, касающиеся этики, конфиденциальности и экономической эффективности. Хранение данных и политика их хранения становятся ключевыми словами в деловом мире, и менеджеры обсуждают политику, утверждающую принцип служенной необходимости, сроки хранения, правила архивации, форматы хранения, шифрование и доступ. Целью хранения данных является защита прав, конфиденциальности и этичности при сохранении и организации полезной и необходимой информации для последующего её использования.
Хранение данных и политика их хранения становятся ключевыми словами в деловом мире, и менеджеры обсуждают политику, утверждающую принцип служенной необходимости, сроки хранения, правила архивации, форматы хранения, шифрование и доступ. Целью хранения данных является защита прав, конфиденциальности и этичности при сохранении и организации полезной и необходимой информации для последующего её использования.
Важным пунктом любой политики хранения данных является протокол по «необратимому удалению». Все мы знаем, что удалённый контент никогда не является действительно удалённым до тех пор, пока он не стёрт с жёсткого диска, на котором он находится. Простое удаление может стереть путь к месту, где хранятся данные, и освободить место для новых данных, что необязательно подразумевает полное удаление данных. Смекалистые компьютерные техники могут с лёгкостью обойти операционные системы и найти данные, хранящиеся на жёстких дисках, если они не были физически повреждены. Протокол «необратимого удаления» может требовать хранения данных в зашифрованном виде. В таком случае, файл может быть найден после удаления, но без ключа шифрования открыть его будет невозможно. Для повышения эффективности данного протокола ключи шифрования также должны удаляться для гарантии того, что доступ к оригиналу и любым его копиям будет невозможен.
В онлайн-хранении данных существуют и физические ограничения. Серверы устаревают и изнашиваются, требуется их замена. Огромные группы серверов, управляющие «облаками», активно генерируют тепло, и для их работы необходимы гигантские вентиляторы и системы охлаждения. Ещё одной проблемой является влажность, которая может ускорить процесс окисления и химического разрушения оборудования, как и данных, хранящихся в электронном виде, которые представляют собой не что иное, как очень сложные цепочки магнитных единиц и нулей. Всё это требует множества усилий, пространства и денег.
Аргумент и ответСреди многих аргументов против массового хранения данных телекоммуникационными компаниями и провайдерами есть и тот аргумент, что террористы и преступники очень легко могут скрываться в Интернете, что приведёт к неэффективности политики хранения. К множеству способов, которыми может воспользоваться Интернет-пользователь, чтобы скрыть своё присутствие в Интернете, относятся Интернет-кафе, файлообменники P2P, сеть TOR, цифровые тайники и анонимные прокси. Ирония заключается в том, что многие средства, которыми пользуются преступники, – это те же самые средства, которые используют и огромные корпорации, и правительство, чтобы защитить свои соединения, а также пользователи, не желающие оставлять «цифровые улики» своих действий в Интернете.
К множеству способов, которыми может воспользоваться Интернет-пользователь, чтобы скрыть своё присутствие в Интернете, относятся Интернет-кафе, файлообменники P2P, сеть TOR, цифровые тайники и анонимные прокси. Ирония заключается в том, что многие средства, которыми пользуются преступники, – это те же самые средства, которые используют и огромные корпорации, и правительство, чтобы защитить свои соединения, а также пользователи, не желающие оставлять «цифровые улики» своих действий в Интернете.
Одним из самых эффективных средств защиты ваших данных и информации о вас от сбора и хранения третьими сторонами – веб-сайтами, отдельными лицами и организациями – является VPN. VPN, виртуальная частная сеть, представляет собой сложный протокол элементов безопасности, разрабатывавшийся во время создания Интернета таким, каким мы знаем его сегодня. Они объединяют технологию IP-маскирования и шифрование для создания безопасных соединений, которые сложно найти, сложно взломать и невозможно прочесть. Доступные изначально только тем, кто обладал богатством, ресурсами или знаниями, сегодня VPN, как и всё что угодно в Интернете, доступны буквально по одному клику мышки, через электронную подписку.
Среднестатистический незащищённый компьютер транслирует свой IP-адрес и IP-адрес своего роутера серверам провайдеров, а также сетевым серверам всего Интернета. Эта трансляция, словно маяк, светит любому, кто достаточно умён, чтобы отслеживать Интернет-траффик, и, поверьте мне, это не так сложно. Это означает, что любой может наблюдать за вами, следить за вами, записывать и сохранять данные о вас, даже проследовать за вами до вашего дома, в прямом и переносном смысле. VPN решает все эти проблемы.
VPN цифровым способом «переупаковывает» ваши данные и запросы соединения, направляя их затем на специальные серверы. Он выполняет две функции. Во-первых, маскирует ваш первоначальный IP-адрес, заменяя его новым, анонимным, который выдаётся VPN-сервером. Во-вторых, VPN обходит серверы вашего провайдера, соединяясь напрямую со специальным VPN-сервером, надёжно скрывая вас от любопытных глаз. Теперь все соединения анонимны и скрыты, дополнительная защита – шифрование определёнными протоколами. Это значит, что только веб-сайты, которые вы посещаете, будут знать, что вы в сети, они не будут знать кто вы, и вы будете давать им напрямую лишь ту конфиденциальную информацию, сбор которой они могут осуществлять.
Теперь все соединения анонимны и скрыты, дополнительная защита – шифрование определёнными протоколами. Это значит, что только веб-сайты, которые вы посещаете, будут знать, что вы в сети, они не будут знать кто вы, и вы будете давать им напрямую лишь ту конфиденциальную информацию, сбор которой они могут осуществлять.
Le VPN является ведущим провайдером VPN-технологии для клиентов и представителей малого бизнеса. В отличие от бесплатных VPN, которые осуществляют сбор, хранение и имеют дело с тем же объёмом данных, как и любой другой веб-сайт, платный сервис Le VPN гарантирует обеспечение высшего возможного уровня анонимности и безопасности при пользовании Интернетом. Сервис является недорогим относительно того, что вы с его помощью получаете: вы платите менее $5 в месяц при 12-месячном обслуживании, получая доступ к 4 протоколам и серверам, доступным в более чем 120+ странах. Хотя VPN не может помочь с данными, которые уже сохранены, он может существенно сократить новый сбор данных, повышая вашу безопасность в Интернете. Не ждите, пока будет слишком поздно что-либо предпринимать. Будьте аккуратны с тем, что и куда вы отправляете и постите, и скрывайте ваши «цифровые улики» с помощью Le VPN.
Подпишитесь сегодня!
Купите Le VPN с гарантией возврата денег на 7 дней и начните использовать Интернет по Вашим правилам прямо сейчас!
НИКАКИХ ЛОГОВ
СЕРВЕРЫ В 120 СТРАНАХ
P2P РАЗРЕШЁН
ЛЕГКОСТЬ ИСПОЛЬЗОВАНИЯ
ГАРАНТИЯ ВОЗВРАТА 7 ДНЕЙ
ДРУЖЕЛЮБНАЯ ПОДДЕРЖКА
ОПЛАТА БИТКОЙНАМИ
ВЫСОКИЕ СКОРОСТИ
Как будут храниться данные переписки россиян по закону Яровой
Через несколько месяцев в России вступит в силу положение из пакета законов Яровой-Озерова, касающееся временного хранения данных о переговорах граждан и их действиях в Интернете. Правила хранения этой информации были разработаны Минкомсвязи и 12 апреля утверждены постановлением Правительства. «Парламентская газета» разобралась, что и как будут беречь операторы и в каких случаях эти данные получит Федеральная служба безопасности (ФСБ).
«Парламентская газета» разобралась, что и как будут беречь операторы и в каких случаях эти данные получит Федеральная служба безопасности (ФСБ).
Закон и порядок
С 1 июля операторы связи, в том числе Интернет, начнут сохранять данные абонентов — записи разговоров по телефону и смс-сообщения. Позднее, с 1 октября 2018 года, сохранению будет подлежать весь интернет-трафик: голосовые сообщения, переписка, пересланные картинки и видео.
Каждое сообщение или разговор будут беречь на специальных серверах в течение полугода с момента их приёма или доставки. Затем данные автоматически удалятся.
Ёмкость серверов каждый оператор связи или провайдер определит самостоятельно. Для этого ему нужно будет подсчитать весь объём информации, которой обменивались абоненты за месяц до ввода хранилища в эксплуатацию. Акт о вводе сервера подписывают Роскомнадзор и ФСБ. После этого в течение пяти лет его ёмкость должна ежегодно увеличиваться на 15 процентов.
Защищать серверы от несанкционированного доступа обязан сам оператор связи. К слову, он сможет воспользоваться также техникой другой компании, но только при согласии ФСБ.
Итак, оператор связи или провайдер будет основным объектом, который владеет сервером, а также сохраняет и удаляет с него данные, которыми обмениваются абоненты. ФСБ может получить доступ к этой информации только в рамках оперативно-разыскных мероприятий.
Добавим, что «антитеррористический» пакет поправок в сфере услуг связи также предполагает, что операторы обязаны хранить информацию о фактах приёма, передачи и обработки данных в течение трёх лет.
Только по решению суда
Ранее глава Министерства связи и массовых коммуникаций РФ Николай Никифоров сообщал, что в России насчитывается около 35 тысяч операторов. Он отмечал, что ФСБ будет работать с ними точечно: «По сути, с каждым оператором, исходя из того, какая у него сеть, ФСБ будет обсуждать этот план внедрения («антитеррористического закона» — Прим.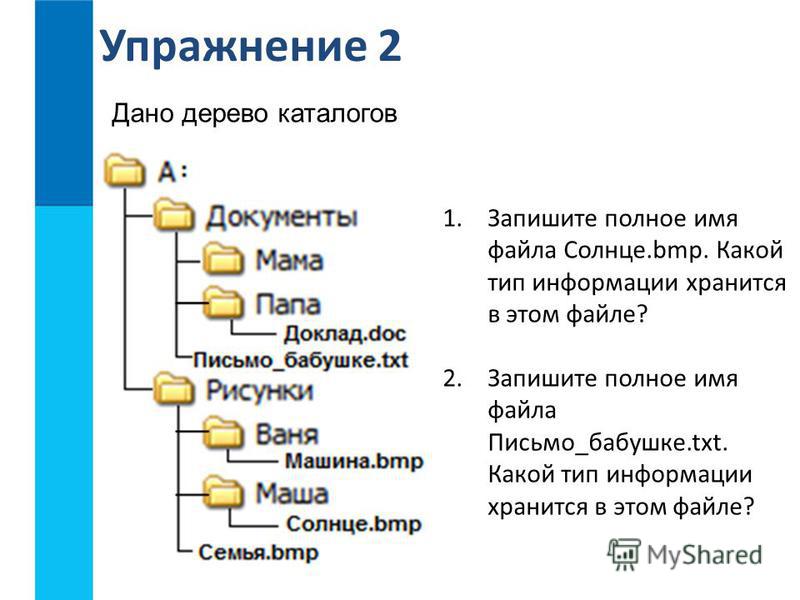 ред.) отдельно, потому что есть операторы федеральные, есть региональные, есть совсем маленькие, которые работают вообще, так сказать, в трёх сёлах».
ред.) отдельно, потому что есть операторы федеральные, есть региональные, есть совсем маленькие, которые работают вообще, так сказать, в трёх сёлах».
Президент Владимир Путин в июле прошлого года положительно оценил идею о временном сохранении информации, которой обмениваются россияне по телефону и Интернету. По его мнению, это обоснованно с точки зрения борьбы с терроризмом. Успокаивая граждан, которые переживали о тотальном доступе спецслужб к их личной жизни, глава государства подчеркнул: «Сущностная, личная информация может быть получена спецслужбой или правоохранительными органами только по решению суда».
К слову, подобный механизм сохранения данных о переговорах и переписке граждан, сегодня действует в США, Канаде, Австралии и во многих других странах.
Антитеррористический пакет поправок был принят летом 2016 года. Он получил неофициальное название «пакет Яровой» или «пакет Яровой-Озерова» — по именам одних из авторов документов.
Как хранится информация?. Microsoft Office
Как хранится информация?
Теперь, если вас спросят, как хранится информация на вашем компьютере, вы можете ответить так:
? Где именно? – на дорожках и секторах жесткого диска (или, на логическом уровне – в виде кластеров на логических дисках).
? Как именно? – в виде логических нулей и единиц (битов), а также их групп (байтов).
Все это правильно… Но все равно непонятно. Компьютеру так, может, и проще, ведь ему абсолютно безразлично, чем именно мы забиваем винчестер – документами ли, музыкой или картинками. Для него все это – информация, которую нужно лишь разбить на определенные кусочки – и в любой момент знать, где именно находится тот или иной кусочек. Но нам, пользователям, придется иметь дело не с битами и байтами. И уж тем более – не с кластерами и секторами. Нам же интересно другое деление информации – логическое. Содержательное. Следовательно, нам нужно принять новую единицу, новую точку отсчета. Такими единицами и станут для нас файл и папка.
Содержательное. Следовательно, нам нужно принять новую единицу, новую точку отсчета. Такими единицами и станут для нас файл и папка.
Файлы
Файл (File) в переводе с английского – лист, на котором может быть записана некая информация. Неважно, что это – код программы или созданный вами текст. Важно другое – каждый такой листок является чем-то логически завершенным, законченным.
Файл может хранить в себе любую информацию – текст, графическую информацию, программный код и так далее (хотя бывают и некие комбинированные файлы, включающие, к примеру, картинку, текст и элемент программы). Главное, чтобы мы, пользователи, всегда могли отличить один «кусочек информации» от другого и знали, как именно нам работать с каждым типом файлов.
Как это делается? Очень просто: каждый файл, подобно человеку, имеет собственное «имя» и «фамилию» (ее называют «типом» файла).
Имя файла чаще всего может быть выбрано произвольно самим пользователем. Скажем, вы создали файл-документ с текстом своего договора с фирмой – его можно назвать «Договор», «Документ 4155» или вообще «Апрельские тезисы». Раньше, в эпоху DOS, имена файлов могли состоять максимум из восьми букв латинского алфавита – сегодня их может быть до 256 и никаких языковых ограничений не осталось. Работая с русской версией Windows, мы можем давать нашим документам-файлам русские имена, а китайцы, к примеру, могут с легкостью использовать свои иероглифы. Другой вопрос, что такой документ не всегда можно открыть на других компьютерах – «американская» Windows может не понять китайское имя, ну а наша, российская версия частенько спотыкается на западноевропейских символах.
Тип файла показывает, какого рода начинка хранится в каждом информационном «контейнере» – рисунок ли это, текст или программа.
О типе файла рассказывает его расширение – часть имени из трех (редко – из четырех) букв, отделенное от основной части названия точкой. Например, файл, в котором хранится эта книга, называется Compbook.doc.
В компьютерном мире существует бесчисленное множество расширений – запомнить все просто нереально.
Однако основных расширений не так уж много:
? ехе – обозначает «исполняемый» файл, хранящий в себе программу. Например, winword.exe;
? com – другой тип программного файла. Обычно файлы.com соответствуют небольшим (до сотни килобайт) программкам. Часто встречались в эпоху DOS, однако сегодня практически сошли со сцены;
? bat – так называемый пакетный файл, предназначенный для последовательного запуска нескольких программ (или команд). По сути дела, это обычный текстовый файл, в котором набраны названия программных файлов, которые вы хотите выполнить в необходимом вам порядке. Пример – файл autoexec.bat, автоматически выполняющийся в момент загрузки компьютера;
? cfg – конфигурационный файл, в котором программа указывает параметры своей работы;
? dll – так называемая динамически подключающаяся библиотека данных, к которой могут обратиться по мере надобности сразу несколько программ;
? hlp – файл справки, в котором хранятся «подсказки», а иногда и полное руководство по той или иной программе;
? txt, doc – текстовые файлы;
? htm, html – гипертекстовый документ Интернета;
? xls – электронная таблица;
? dat – файл данных;
? wav, mp3 – звук в цифровом формате;
? bmp, jpg – графическая информация, картинки;
? arj, zip, rar, 7z – файлы архивов, то есть сжатой с помощью специальных программ «архиваторов» информации. В одном архивном файле на самом деле может храниться множество файлов. И так далее.
В одном архивном файле на самом деле может храниться множество файлов. И так далее.
Работая в Windows, вы чаще всего будете видеть не расширение файла, а соответствующий ему графический значок. Например, лист с текстом и буквой W покажет, что перед вами – документ, созданный в программе Microsoft Word. Это, конечно, удобно – но только не забывайте, что значки могут меняться в зависимости от того, к какой именно программе привязан тот или иной тип файла. К тому же одним значком могут обозначаться файлы сразу нескольких типов. Расширение же во всех случаях остается неизменным. Есть у файла и еще один признак, называемый атрибутом. Однако, в отличие от имени и расширения (а в Windows – значка определенного типа) его-то пользователь как раз и не видит. Зато великолепно видит и понимает компьютер.
Вот лишь некоторые из этих атрибутов:
Скрытый (Hidden). Файлы с этими атрибутами обычно не видны пользователю. Для перестраховки – как правило, файлы эти весьма важные для функционирования системы. Хотя опытному юзеру не составит труда настроить программу просмотра файлов (файловый менеджер) таким образом, что все скрытые файлы будут видны как на ладони.
Только для чтения (Read-Only). А вот эти файлы всегда открыты любопытному взору… Но и только. Изменить их содержание нельзя – по крайней мере, без специальной команды пользователя, дабы последний был полностью уверен в том, что именно он делает.
Системный (System). Этим атрибутом, как особым знаком отличия, отмечены самые важные файлы в операционной системе, отвечающие за загрузку компьютера. Их повреждение или удаление всегда влечет за собой самые тяжкие последствия, поэтому щедрый компьютер, не скупясь, «награждает» их заодно и двумя предыдущими атрибутами – «только для чтения» и «скрытый».
Архивный (Archive). Этот атрибут устанавливается обычно во время работы с файлом, при его изменении. По окончании сеанса работы он, как правило, снимается.
Этот атрибут устанавливается обычно во время работы с файлом, при его изменении. По окончании сеанса работы он, как правило, снимается.
Папки
Если мы сравнили файлы с листиками, то почему бы нам не продолжить аналогию дальше? Где же те деревья, на которых растут такие полезные листики? Сравнение с деревом тут не случайно. Ведь расположение файлов на жестком диске и называется именно древовидной структурой. Есть листья. Они растут на веточках. Веточки в свою очередь растут на ветках. Ветки… Ну, скажем, на сучьях. А уж сучья… И так до бесконечности. Понятно, что держать совершенно разные файлы в одной куче нельзя. Их надо упорядочивать. Каждому сверчку – свой шесток, каждой семье – отдельную квартиру… Ну и так далее.
Файлы объединены в особые структуры – папки. Или – каталоги. Или – директории. Или – фолдеры. Совершенно непонятно, зачем понадобилось создавать такую кучу терминов для одного-единственного предмета. Папка – самый поздний термин и, на мой взгляд, самый удачный. Именно в папке лежат листочки-файлы. Папка, которую в любой момент можно открыть и отыскать нужный листок. Папка, в которую, кстати говоря, можно вложить другую папку…
Обычно каждый программный пакет, установленный на вашем компьютере, занимает свою, отдельную папку. Однако бывает и так, что программа, словно хитрая птица-кукушка, раскидывает свои файлы по многим папкам. Особенно это любят делать программные пакеты, работающие под операционной системой Windows.
Как отличить папку от файла? Не так уж и сложно. Во-первых, папки не имеют расширения и обозначаются в Windows особыми значками – как раз в виде открывающейся папки. Во-вторых, в отношении папки нельзя применить операции редактирования. Переименовать, перенести, удалить – пожалуйста. И, конечно же, папку можно открыть, чтобы посмотреть, что в ней находится. Для этого достаточно просто щелкнуть по ней дважды левой кнопкой мыши.
Для этого достаточно просто щелкнуть по ней дважды левой кнопкой мыши.
Ну а теперь разберемся, как выглядит логический адрес любого файла или папки на нашем жестком диске. Первый элемент этого адреса – имя диска. Состоит оно из одной буквы, двоеточия и обратной косой черты, называемой на компьютерном жаргоне бэк-слэш:
А: С: D: Е:
Диском А: чаще всего называется дисковод и, пока вы не вставите в него дискету, этого диска у вас как бы и не будет. И бог с ним: и без него дисков хватает.
Диск С: – главный жесткий диск вашего компьютера (либо логический диск в основном разделе). Именно с этого диска производится загрузка системы, именно на нем «живет» большинство ваших программ и документов.
Если в вашей системе больше одного жесткого диска или единственный жесткий диск разбит на несколько разделов, эти разделы будут носить имена, соответствующие следующим буквам латинского алфавита. А последняя буква-имя обычно обозначает дисковод CD-ROM.
С дисками разобрались. Дальше следуют директории – папки и подпапки. Например, адрес папки, в которой установлена ваша операционная система Windows, обычно выглядит так:
C:WINDOWS.
Ну а третий элемент адреса – имя самого файла. Например, адрес
C:WINDOWS egedit.exe
соответствует программе для редактирования системного реестра Windows, которая находится на диске C: в папке Windows.
Файловая система
Что ж, теперь мы с вами поняли, как компьютеру удобнее хранить данные и в каком виде предпочитаем видеть их мы. Осталось за кадром лишь одно – каким же образом секторы и кластеры, забитые под завязку битами и байтами, превращаются в удобные для нас файлы и папки! Мистика, волшебство? Ничуть. Просто, рассказывая о логической структуре жесткого диска, мы намеренно пропустили очень важный этап – создание файловой системы. А именно она позволяет окончательно упорядочить данные на нашем жестком диске и в любой момент извлекать из этой информационной кладовой нужный кусочек.
А именно она позволяет окончательно упорядочить данные на нашем жестком диске и в любой момент извлекать из этой информационной кладовой нужный кусочек.
Когда мы записываем на винчестер файлы и папки, компьютер разбивает их на привычные ему кластеры и раскидывает по всему пространству жесткого диска. Файл, конечно же, в одном кластере не помещается. Проживает он сразу в нескольких, причем совершенно не обязательно, что кластеры эти будут жить рядышком, как горошины в стручке. Чаще случается наоборот: файл хранится на диске в раздробленном виде – «голова» в одном участке диска, «ноги» в другом… Чтобы не заблудиться в собственных «закромах», компьютер создает в самом начале жесткого диска специальный «путеводитель» по его содержанию – FAT, таблицу размещения файлов. Именно в FAT хранятся все сведения о том, какие именно кластеры занимает тот или иной файл или папка, а также – их заголовки. С одной стороны, это удобно: при таком способе размещения компьютер не должен лихорадочно искать на жестком диске кусок именно такого размера, который подходит для конкретного файла. Пиши куда вздумается! Да и удалять файлы и папки становится проще – не нужно стирать содержимое принадлежащих им кластеров, достаточно просто объявить их свободными, изменив пару байт в FAT. Да и у пользователя остается возможность быстро их восстановить с помощью все той же пары байт…
Таблица размещения файлов – это часть файловой – системы, ответственной за хранение данных на нашем компьютере. Файловая система создается на жестком диске на заключительном этапе форматирования, и именно от нее зависят такие важные параметры, как размер кластера, количество (или вид) символов в имени файла, возможности работы с папками и многое другое – вплоть до максимального размера жесткого диска…
Существует несколько стандартных файловых систем, привязанных к конкретным операционным системам.
Например, древняя DOS и первые версии Windows использовали 16-разрядную файловую систему FAT16, в которой отсутствовала поддержка длинных имен, а объем логического диска не мог превышать 4 Гб (65536 кластеров по 64 кб). В частности, именно этот фактор заставлял владельцев винчестеров большой емкости «разбивать» его на несколько разделов – иначе работать с диском было невозможно.
Для Windows 95 была создана новая модификация файловой системы – 32-битная FAT32, которая позволяла использовать так полюбившиеся нам длинные имена. Уменьшился максимальный размер кластера – до 16 кб (стандартный же размер составлял 4 кб). А главное, увеличился максимальный размер жесткого диска – до 4 Тб! Впрочем, довольно скоро выяснилось, что и FAT32 работает небезупречно: несмотря на декларированную поддержку до 4 Тб дисковой памяти, стандартные утилиты позволяли создавать логические разделы объемом лишь до 32 Гб. К тому же размер файла в FAT32 не мог превышать 4 Гб, что крайне осложняло работу любителям цифрового видео (ведь оцифрованный фильм может занять на диске сотни гигабайт!). Так что задуматься о смене файловой системы пришлось довольно скоро, хотя и сегодня FAT32 используется, например, при создании DVD-дисков. А семь лет назад мир потихоньку начал переходить на файловую систему нового типа – NTFS, количественные изменения в который были куда менее интересны, чем качественные. Да, благодаря NTFS удалось снять ограничения на объем файла – теперь он может занимать хоть весь жесткий диск целиком – а максимальный размер дискового раздела увеличился до 12 Тб. Однако куда интереснее были новые возможности: помимо привычных логических дисков фиксированного размера NTFS позволяет создавать еще и динамические жесткие диски, поддерживает шифрование и защиту паролем отдельных разделов и папок.
Главное качество новой системы – надежность хранения данных: если «уронить» жесткий диск с FAT32 было легче легкого, то под защитой NTFS ваши данные будут чувствовать себя гораздо увереннее. NTFS ведет свой собственный журнал операций, который позволяет защитить данные в случае сбоя.
NTFS ведет свой собственный журнал операций, который позволяет защитить данные в случае сбоя.
Попробуйте внезапно выключить компьютер при копировании или удалении файла в FAT32 – и, скорее всего, вы поплатитесь за такую вольность потерей данных. Ведь изменения в таблице размещения файлов не будут сохранены, и ваш документ превратится в кучу «потерянных кластеров». Поэтому FAT всегда хранится в 2-х экземплярах! NTFS же вносит изменения в таблицу лишь тогда, когда операция успешно завершена, а «журнал» помогает застраховать файлы от преждевременной кончины.
Увы – ради надежности приходится жертвовать совместимостью:
Если жесткие диски, отформатированные в FAT16 и FAT32, способны увидеть практически все версии Windows (а также операционные системы семейства Linux), то при использовании NTFS вы намертво привязаны к линейке Windows 2000 —ХР —Vista.
Если на вашем компьютере уместилось две операционные системы – старая Windows ME и новая Windows ХР (с файловой системой NTFS), – то содержимое «икспишного» раздела или целого диска останется невидимым для ME. Более того – вы теряете возможность работать с диском, загружаясь в режиме «командной строки» с компакт-диска или «загрузочной» дискеты – для DOS файловая система NTFS тоже как бы не существует.
Наконец, если преобразовать файловую систему FAT32 в NTFS не составит никакого труда даже с помощью штатных программ Windows, причем с полным сохранением всей информации, то выполнить обратное преобразование в большинстве случаев просто невозможно без форматирования диска. И, как следствие, утраты всей информации…
Конечно, существуют специальные программы для работы с разделами и файловыми системами – например Partition Magic, которая умеет конвертировать диск NTFS в FAT32 без потери информации. Но их использование сопряжено с немалыми трудностями – в особенности для новичков… И все же, несмотря на все недостатки, использование NTFS сегодня дает куда больше преимуществ, чем неудобств. Поэтому уверенно отвечайте «Да!» на вопрос о переводе в NTFS – и окончательно прощайтесь с прошлым.
Но их использование сопряжено с немалыми трудностями – в особенности для новичков… И все же, несмотря на все недостатки, использование NTFS сегодня дает куда больше преимуществ, чем неудобств. Поэтому уверенно отвечайте «Да!» на вопрос о переводе в NTFS – и окончательно прощайтесь с прошлым.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРесГде хранятся данные сайта — выделенный сервер?
Когда человек вводит определенный адрес какого-либо веб-сайта в браузере, то зачастую не знает, откуда взялся текстовый контент, картинки и дизайнерское решение. Страница начинает грузиться, так как где-то работает ПК (сервер).
На сервере находятся все файлы сайта и загружаются только тогда, когда пользователи начинают на него заходить. Чем крупнее сайт, тем больше он требует ресурсов.
Хостинг и его виды
Хостинг является услугой, в которую входит аренда серверного пространства и его мощностей. Многочисленные компании, предоставляющие хостинг, именуют провайдерами или хостерами. Одной из таких компаний является Hostzealot.ru, которая предлагает выделенный сервер по самым доступным ценам. Цель компании – создание круглосуточного доступа пользователей к вашему сайту.
Хостинг необходим для того чтобы хранящиеся на нем файлы сайта были доступны пользователям 24 часа в сутки, а также для того чтобы его владелец мог самостоятельно управлять ними и при необходимости конфигурировать. Для этого существуют панели управления.
В настоящее время существует 5 типов хостинга, которые пользуются большим спросом среди пользователей всемирной сети.
· Виртуальный хостинг. В этом случае один сервер делится не определенное количество частей и сдается в аренду, поэтому на одном сервере может находиться сразу множество сайтов. Все арендаторы используют мощности одного сервера, поэтому он подходит для размещения небольших веб-сайтов.
Все арендаторы используют мощности одного сервера, поэтому он подходит для размещения небольших веб-сайтов.
· Виртуальный сервер. В этом случае реальный сервер делится на несколько отдельных частей и сдается в аренду также частями. Один «железный» сервер может быть разделен на множество виртуальных серверов, каждый из которых пользователь может настраивать под конкретный проект, независимо от соседей.
· Выделенный сервер. В этом случае только один пользователь управляет реальным сервером и не зависит от своих соседей. В настоящее время аренда выделенного сервера является наиболее выгодной, так как его администратор получает полный доступ к его ресурсам. Компания Hostzealot.ru предлагает выделенные серверы по самым доступным ценам для размещения крупных высоконагруженных проектов.
· Облачный хостинг. В этом случае пользователь платит только за количество ресурсов, а провайдер делит их между другими серверами. Таким образом, сайт может храниться на нескольких различных серверах, с которых берется ОП, мощность процессора и прочие ресурсы.
· Колокейшн. В этом случае пользователь располагает свои сервера у провайдера и оплачивает их профессиональное обслуживание. Такой хостинг подойдет людям, которые имеют высоконагруженные сайты.
Таким образом, владельцы сайтов могут выбрать для себя наиболее оптимальный вид хостинга, обратившись на сайт компании Hostzealot.ru.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Что такое файлы cookie, зачем они нужны, как очистить куки в браузерах
Cookies (в переводе с английского – печенька) или как мы их называем в российском сегменте Интернета «куки» — это текстовые файлы небольшого объема со служебной информацией для браузера. Иными словами сервер обменивается с веб-обозревателем на ПК или мобильном гаджете данными о сайтах, которые посещал пользователь. Информация в куках может быть самой разной. Например, часто в таких файлах хранится статистика посещений, логин и пароль от сайтов или сервисов, индивидуальные настройки пользователя (регион, дизайн оформления и прочее).
Например, часто в таких файлах хранится статистика посещений, логин и пароль от сайтов или сервисов, индивидуальные настройки пользователя (регион, дизайн оформления и прочее).
Чтобы разобраться, что такое куки в браузере понадобится ввести понятие сессии. Обмен данными между обозревателем и сервером происходит с помощью протокола HTTP. Некоторые данные могут храниться временно, то есть в течение одной сессии, и удаляться после закрытия программы. Другая информация может храниться в течение долгого времени в специальном файле на компьютере — cookies.txt. Обычно этот документ размещается в директории используемого браузера.
Когда пользователь очередной раз заходит на сайт, посещает сервис или личный аккаунт в соцсети, браузер подгружает регистрационные данные и прочие сохраненные настройки из куки. Так снижается нагрузка на сервер, а значит, сайты быстрее открываются. Пользователю также одни плюсы: не нужно каждый раз вводит логин и пароль, настраивать сайт под себя и прочее. Всё быстро подгружается из cookies.txt.
Самые распространенные мифы относительно куки:
- Файлы cookies – это вредоносные программы, которые следует удалять после каждого посещения интернета. Это не так. Документы в формате .txt никоим образом не смогут навредить вашему компьютеру или гаджету. В них прописывается только информация о тех сайтах, которые вы посещали и ваши настройки. Заразиться вирусами через куки невозможно.
- Куки как то связаны с рекламными баннерами и всплывающими pop-up окнами. Навязчивая реклама в браузере отключается с помощью установки специальных плагинов или расширений. Например, AdBlock, AdGuard и прочих. Информация в куках может использоваться браузерами для показа релевантных сообщений, но только с согласия пользователя. Вы вправе отключить рекламу.
- Куки «воруют» личные данные. Файл cookies создали для комфортной работы сервера и браузера, а не для слежки за пользователями.
 То есть в куках хранятся данные обозревателя. Например, вы зарегистрировались на сайте с Хрома. При следующем входе на эту страницу данные посещения сохраняются в файл. Если вы войдете на этот же сайт с Opera, придется заново вводить данные. Это нужно для того, чтобы создать cookies.txt. для другого обозревателя.
То есть в куках хранятся данные обозревателя. Например, вы зарегистрировались на сайте с Хрома. При следующем входе на эту страницу данные посещения сохраняются в файл. Если вы войдете на этот же сайт с Opera, придется заново вводить данные. Это нужно для того, чтобы создать cookies.txt. для другого обозревателя.
 То есть в куках хранятся данные обозревателя. Например, вы зарегистрировались на сайте с Хрома. При следующем входе на эту страницу данные посещения сохраняются в файл. Если вы войдете на этот же сайт с Opera, придется заново вводить данные. Это нужно для того, чтобы создать cookies.txt. для другого обозревателя.
То есть в куках хранятся данные обозревателя. Например, вы зарегистрировались на сайте с Хрома. При следующем входе на эту страницу данные посещения сохраняются в файл. Если вы войдете на этот же сайт с Opera, придется заново вводить данные. Это нужно для того, чтобы создать cookies.txt. для другого обозревателя.Для чего нужны куки?
Основная задача cookies состоит в том, чтобы сделать серфинг в Интернете более комфортным. Пользователю не нужно постоянно вводить регистрационные данные на сайтах, которые он регулярно посещает. При этом снижается нагрузка не сервер и повышается скорость открытия страниц.
То есть сегодня множество сайтов не смогут нормально работать без куки. В лучшем случае они смогут открываться, но потеряют большую часть своих возможностей.
Приведем несколько примеров необходимости cookies:
- Автоматическая авторизация. 90% сайтов и сервисов в сети предлагают пользователям пройти регистрацию, а после входить на сайт под своим логином и паролем. Если бы браузер не мог запоминать и хранить информацию, то юзерам приходилось бы каждый сеанс начинать с авторизации. Это муторно. Куки позволяют передавать сохраненные данные в фоновом режиме. Пользователь просто заходит на сайт уже авторизованным юзером.
- Коммерция в интернете. Без куки невозможно ни сравнить товары, ни купить их. Корзина в онлайн-магазине использует сохраненные данные активности посетителей из cookies.txt. для запоминания выбранной продукции. Даже если вы покинете сайт, отложенные товары сохранятся в корзине.
- Личные настройки соцсетей, поисковых систем. Куки помогают сохранить в настройках браузера регион проживания, язык, стиль оформления страницы и многое другое. В противном случае настройки сбивались бы при каждом закрытии браузера.
Что такое сторонние и постоянные куки?
К постоянным cookies относится информация, хранящаяся в текстовом файле в директории браузера, который используется для серфинга в Интернете. Период хранения постоянных куки устанавливается владельцами сайтов, сервисов и прочих ресурсов в сети. По окончании установленного отрезка, данные автоматически удаляются.
Период хранения постоянных куки устанавливается владельцами сайтов, сервисов и прочих ресурсов в сети. По окончании установленного отрезка, данные автоматически удаляются.
Например, вы в течение месяца ежедневно посещали личный аккаунт во Вконтакте через браузер Хром. В файле кукис сохранились регистрационные данные, настройки. Потом вы 1-2 месяца не посещали соцсеть. Зайдя снова после длительного периода бездействия, сервис попросит вас авторизоваться, так как сохраненные куки уже автоматически очистились.
Сторонние cookies – файлы, которые не находятся на вашем компьютере, а размещаются на сторонних серверах. Например, счетчики Яндекс.Метрики и Гугл Аналитики, LiveInternet, различные браузерные скрипты. Они обмениваются данными с вашим интернет обозревателем. Сторонние куки нужны владельцам сайтов для анализа посещаемости и прочих метрик.
Где хранятся куки?
Выше мы разобрались, что такое файлы Cookie. Теперь посмотрим, в каком месте на компьютере они хранятся. Мы писали, что cookies.txt располагается в директории обозревателя, который используется для серфинга в Интернете. Укажем точное местоположение файла в популярных браузерах:
Google Chrome
Opera
Mozilla Firefox
Яндекс Браузер
Internet Explorer 11
Как очистить, запретить или блокировать куки в браузерах?
Несмотря на огромную пользу сохраненной информации о посещении сайтов, иногда необходимо отключить опцию сбора cookies или полностью стереть «все следы» активности на конкретном ресурсе. Вот несколько ситуаций, когда можно блокировать сбор и хранение данных о пользователе:
Зашли на сайт или в аккаунт соцсети с чужого компьютера, авторизовались. Чтобы ваш логин и пароль не прописался в текстовом хранилище браузера, нужно после сеанса почистить куки. Есть и другой вариант «не наследить» – заходить в режиме инкогнито (специальная опция на современных браузерах, которая исключает запись сеанса и вводимых данных). Активируется режим нажатием комбинации клавиш Сtrl+Shift+N.
Активируется режим нажатием комбинации клавиш Сtrl+Shift+N.
Проблемы с входом на страницу в сети. Что такое куки на сайте? Это информация о посещениях пользователей и личные настройки для конкретного ресурса. Если сохраненные данные вовремя не очищаются автоматически, то происходит их наслоение друг на друга. В итоге сбои в работе страницы – долго грузится, не открывается и прочее. В этом случае рекомендуется очистить кэш браузера или же почистить файл cookies.
Рассмотрим пошагово, как очистить историю посещений и сохраненную информация в популярных браузерах.
Google Chrome и Яндекс Браузер (алгоритм идентичен для двух программ)
- Открываем браузер.
- Нажимаем комбинацию клавиш Ctrl+Shift+Delete.
- В открывшемся окне выбираем временной период из выпадающего списка, отмечаем пункт «файлы cookie и другие данные сайтов». После чего жмем «Удалить данные».
- Всё.
Чтобы сайтам запретить собирать и хранить информацию, заходим в «Настройки» и кликаем на «Дополнительные».
В разделе «Конфиденциальность и безопасность» выбираем «Настройки сайта» и далее «Файлы cookie».
Отключаем «разрешить сайтам сохранять и читать файлы». Всё.
Можно также активировать опцию блокировки сторонних куки или задать отдельные сайты, с которых не будут собираться данные.
Mozilla Firefox
- Открываем браузер.
- Нажимаем комбинацию клавиш Ctrl+Shift+Delete.
- В окне выбираем период, отмечаем нужный чек-бокс и нажимает стереть историю.
- Всё.
Блокируется сбор данных следующим образом. Заходим в «Настройки», переходим на вкладку «Приватность и защита». Далее настраиваем опции хранения куки, запоминания историй посещений.
Opera
- Открываем браузер.
- Нажимаем комбинацию клавиш Ctrl+Shift+Delete.
- В открывшемся окне выбираем временной период и опцию удалить кукис, нажимаем «Удалить».
- Всё.

Для запрета сбора и хранения данных с сайтов переходим в «Настройки», далее в «Безопасность» и справа открываем раздел «Настройки сайта».
Далее выбираем «Файлы cookie» и настраиваем по своему усмотрению.
Internet Explorer
- Открываем браузер.
- Нажимаем комбинацию клавиш Ctrl+Shift+Delete.
- В открывшемся окне активируем чек-бокс «Файлы cookie и данные web-сайтов», и нажимаем «Удалить».
- Всё.
Чтобы блокировать сбор данных о посещениях, заходим в настройки браузера. Далее переходим на вкладку «Безопасность» и выбираем «Включить защиту от слежения». В открывшемся окне выбираем «Ваш настроенный список» и жмём «Параметры».
Далее выбираем «Блокировать автоматически» и нажимаем «ОК».
Резюме
Мы подробно изучили, что такое куки. Узнали, зачем нужны эти текстовые файлы, где они хранятся на компьютере. Также мы рассмотрели способы очистки сохраненных данных в пяти популярных браузерах. Научились блокировать сбор информации о посещениях сайтов пользователями.
В любом случае, куки – это полезные текстовые данные, с помощью которых ускоряется загрузка страниц и повышается комфорт серфинга в Интернете.
Где хранится информация, которую производят люди
Еще пять лет назад люди произвели 4,4 зеттабайта (4,4 миллиарда террабайт) данных за год, но уже к 2025 году этот показатель достигнет 160 зеттабайт. Если объем информации продолжит расти такими же темпами, то к 2040 году человечеству будет негде брать достаточное количество кремния для создания микрочипов в требуемом объеме.
В том, что информации меньше не станет, не сомневается никто, грядущий интернет вещей с непрерывным обменом данными между всей домашней техникой, автомобилями и даже одеждой приведет лишь к ускорению этой лавины. Прогнозируется, что к концу XXI века объем данных будет измеряться уже следующей по порядку величиной – иоттабайтами.
Пока для обычных пользователей проблем нет: когда их файлы перестают помещаться на облаке, они просто меняют тариф, но на самом деле эти хранилища не бездонны.
Сегодня ученые видят будущее хранения информации в ДНК. Если в каждой клетке человека хранится столько генетической информации, то почему бы не использовать аналогичную систему на базе специально созданных клеток и в качестве банка цифровых данных?
Это уже давно не фантастика. На ДНК еще несколько лет назад в качестве эксперимента записывали клипы и книги, а в 2020 году Microsoft планирует создать первый прототип ДНК-облака на базе одного из своих центров обработки данных. Главный плюс – компактность такой системы. Все данные человечества можно сохранить в ДНК-хранилище размером с обычный шкаф. К тому же в ДНК срок хранения данных измеряется не десятилетиями, как на жестких дисках, а тысячами лет. Но есть и минусы.
На данный момент технологии быстрой записи и обмена данными с ДНК-системами не изобретено. Все процессы завязаны на тот же самый секвенатор ДНК, которым расшифровывается генетическая информация человека. Однако даже в сегодняшнем своем виде ДНК-хранилища будут востребованы – они подходят для данных, которые не требуются нам каждый день и которые при этом нужно сохранить надолго. Такие архивы нужны и государствам, и крупным компаниям. Что же касается более бытовых решений, то их создание – дело времени.
Вероятно, вам также будет интересно:
Как технологии изменят нашу жизнь к 2030 году
Второй подкаст GQ Tech посвящен искусственному интеллекту
Искусственный интеллект угрожает музыкантам и художникам
Управление паролями с использованием связок ключей на Mac
Связки ключей в macOS помогают Вам хранить и защищать пароли, учетные записи и другую конфиденциальную информацию, которую Вы ежедневно используете на компьютерах Mac и устройствах iOS и iPadOS.
Вы можете использовать приложение «Связка ключей» на компьютере Mac для просмотра связок ключей и управления ими. При помощи Связки ключей iCloud можно синхронизировать пароли и другую конфиденциальную информацию на всех Ваших устройствах.
Что такое связка ключей?
Связка ключей — это зашифрованный контейнер, в котором безопасно хранятся имена учетных записей и пароли от Mac, от приложений, серверов и веб-сайтов, а также конфиденциальная информация, например номера кредитных карт или PIN-коды от банковских счетов.
При подключении к веб-сайту, учетной записи электронной почты, сетевому серверу или другому защищенному паролем ресурсу Вы решаете, что делать: сохранить пароль в связке ключей, чтобы не нужно было его запоминать, или вводить пароль каждый раз вручную.
У каждого пользователя на Mac есть связка ключей входа. Пароль от связки ключей входа совпадает с паролем, который Вы используете для входа в Mac. Если администратор Mac сбросит Ваш пароль для входа в систему, Вам нужно будет самостоятельно сбросить пароль от связки ключей входа.
Связка ключей
Приложение «Связка ключей» на Mac используется для управления связкой ключей входа, другими связками ключей, а также объектами, которые безопасно хранятся в связках, например ключами, сертификатами, паролями, данными учетных записей и заметками. Если Вы забыли пароль, его можно посмотреть в приложении «Связка ключей». Подробнее о Связке ключей.
Связка ключей iCloud
Если Вы используете iCloud, в Связке ключей iCloud можно безопасно хранить информацию для входа на веб-сайты и данные кредитных карт, используемые функцией автозаполнения в Safari, а также информацию о сетях Wi-Fi. Связка ключей iCloud автоматически синхронизирует эту информацию на всех Ваших Mac и устройствах iOS и iPadOS. В Связке ключей iCloud также хранится информация для входа в учетные записи, которые используются в Почте, Контактах, Календаре и Сообщениях, чтобы они были доступны на всех Ваших устройствах. Подробнее о Связке ключей iCloud.
Совет. Когда Вы в Интернете используете пароли или кредитные карты, Вы можете разрешить Safari сохранять их в связке ключей и автоматически вводить их на сайтах. Если Вы используете Связку ключей iCloud на Mac и устройствах iOS и iPadOS, Safari может автоматически подставлять сохраненную информацию на всех этих устройствах. См. раздел Автозаполнение данных платежных карт, контактов и паролей.
Что такое сервер Интернет-центра обработки данных и как он работает? | Малый бизнес
Хотя люди часто думают об Интернете как о нематериальном объекте, данные, из которых состоит Интернет, на самом деле хранятся в очень физическом месте: на серверах данных. Компании иногда используют свои собственные серверы или сдают серверы в аренду в центрах обработки данных, что позволяет им хранить онлайн-файлы — например, те, которые составляют веб-сайт, — и делать их глобально доступными. По сути, сервер Интернет-центра обработки данных — это место для хранения файлов, доступных из Интернета.
Сервер данных
Сервер данных — это, по сути, компьютер без периферийных устройств, таких как мониторы и клавиатуры. Сервер полностью работает как хранилище и подключен к сети, чтобы сделать эти данные доступными для компьютеров. В случае Интернет-сервера устройство подключено к Интернету, так что любой компьютер, подключенный к Интернету, может получить доступ к файлам, хранящимся на сервере. Серверы хранят и обрабатывают данные так же, как компьютер, и подключены к Интернету через проводные или беспроводные соединения.
Дата-центр
Дата-центр состоит из множества серверов данных, размещенных в одном комплексе. Как и компьютеры, серверам требуются определенные условия окружающей среды, такие как умеренный уровень тепла и влажности, а также сетевые подключения для доступа в Интернет. Крупные центры обработки данных с огромными объемами хранения на жестких дисках позволяют компаниям, которые их эксплуатируют, извлекать выгоду из эффекта масштаба, экономя больше данных при аналогичных затратах на обслуживание объектов и инфраструктуру подключения.Многие крупные интернет-компании имеют собственные выделенные центры обработки данных, а некоторые центры обработки данных предлагают услуги хранения для нескольких клиентов.
Как это работает
Так же, как два компьютера, подключенные к локальной сети, Интернет-серверы отправляют информацию в веб-браузеры через сетевые соединения. Данные, хранящиеся на сервере, делятся на пакеты для передачи и отправляются через специальные компьютеры, называемые маршрутизаторами, которые определяют наилучший путь передачи этих данных — через серию проводных и беспроводных сетей — до поставщика услуг Интернета и, в конечном итоге, компьютер.Каждый раз, когда вы вводите веб-адрес в браузере, вы запрашиваете информацию с сервера, и процесс просто обратный, когда вы хотите загрузить информацию на Интернет-сервер.
Данные и безопасность
Как и любой тип компьютерных данных, данные сервера уязвимы для повреждения, ошибок передачи, потери и взлома. Хотя протоколы безопасности различаются для разных компаний и центров обработки данных, большинство центров обработки данных реализуют комплексные меры безопасности, которые включают шифрование данных во время передачи, несколько мест сохранения в случае отключения одного сервера, одновременное сохранение в двух или более местах, чтобы файлы можно было согласовывать и создавать резервные копии в случае, если они не сохраняются должным образом в одном месте, и полная очистка данных с диска, когда сервер исчерпал свой срок службы.
Ссылки
Ресурсы
Биография писателя
Эдвард Мерсер начал профессионально писать в 2009 году, участвуя в нескольких онлайн-публикациях по темам, включая путешествия, технологии, финансы и питание. Он получил степень бакалавра литературы в Йельском университете в 2006 году.
Ваши онлайн-данные хранятся в этих удивительных местах
Что бы мы делали без всемирной паутины? В наши дни мы используем его практически для всего.От поиска информации до направления и даже встречи с друзьями — возможности, которые он предлагает, кажутся безграничными. Действительно, в наши дни мы очень много делаем в Интернете. Как вы уже поняли, многие веб-сайты предлагают пользователям возможность создавать учетные записи.
Стойки дисков со всеми вашими данными | ShutterstockПри использовании таких сервисов, как Facebook, у вас, вероятно, есть много изображений и видео, загруженных в вашу учетную запись. Более того, у вас, вероятно, будет несколько файлов, хранящихся в любой облачной службе, на которую вы подписались.
Если вам интересно, к чему это я веду, суть в том, что каждое онлайн-действие генерирует данные. Это то, о чем мы можем не думать, поскольку все, кажется, волшебным образом загружается, когда мы в сети. Это происходит, несмотря на то, что данные, к которым мы получаем доступ, не хранятся локально на наших персональных компьютерах. Однако эти данные не могут быть воображаемыми, ведь они ведь должны где-то храниться?
Каждый день создается 2,5 квинтиллиона байтов данных. Это 2 500 000 000 000 000 000 байтов данных.
Прелесть Интернета в том, что он позволяет нам получать доступ к огромным объемам информации во всемирной паутине с устройства, общая внутренняя память которого бледнеет по сравнению с общим размером сети.
Примечание: Чтобы внести ясность, Интернет — это гигантская сеть компьютеров. С другой стороны, всемирная паутина представляет собой хранилище мультимедиа в форме веб-страниц. Вам нужен доступ в Интернет, чтобы пользоваться всемирной паутиной. Подробнее об этом можно узнать здесь.Так где же хранятся эти данные? Есть физические места, называемые центрами обработки данных, разбросанные по всему миру, где находится всемирная паутина.
Это довольно интригующе, и вы, наверное, согласитесь, что заслуживает более внимательного рассмотрения. Итак, приступим!
Обзор центра обработки данных
Центр обработки данных — это, по сути, совокупность серверов и другого соответствующего вычислительного оборудования, где информация хранится и управляется в относительно большом масштабе. Некоторые организации имеют такие помещения только для внутреннего пользования.
Однако центры обработки данных, на которых мы сосредоточимся, ориентированы на поддержку частей всемирной паутины.
Центр обработки данных — это, по сути, совокупность серверов и другого соответствующего вычислительного оборудования, где информация хранится и управляется в относительно большом масштабе.
Основные компоненты центра обработки данных можно разделить на четыре основных компонента, а именно:
- Оборудование информационных технологий (ИТ)
- Электрическая система
- Система охлаждения
- Физический завод или здание
ИТ-оборудование
ИТ-оборудование в центре обработки данных состоит из четырех основных компонентов.Это серверы, оборудование для хранения данных, такое как жесткие диски, сетевое оборудование, такое как сетевые коммутаторы, и стойки, на которых это оборудование установлено.
Серверы по сути такие же, как и ваш персональный компьютер. Но они более мощные. Они запускают программное обеспечение, необходимое для работы наших веб-сайтов и обработки огромного потока данных. Взгляните на некоторые из серверов в центре обработки данных округа Дуглас, штат Джорджия, компании Google.
Серверы, установленные в стойках в центре обработки данных округа Дуглас, штат Джорджия, Google | GoogleТакие вещи, как фотографии, загруженные на веб-сайт, можно найти на устройствах хранения.Это очень похоже на то, что происходит, когда вы сохраняете фотографию на своем компьютере. Однако в этом случае вы, вероятно, не знаете, где находится жесткий диск с вашей онлайн-фотографией! Резервные копии важных данных также делаются на цифровую ленту.
Цифровое резервное копирование на магнитную ленту в округе Беркли, Южная Каролина | Сетевое оборудование Googleконтролирует передачу информации между серверами, а также за пределы центра обработки данных.
Коммутаторы Ethernet в центре обработки данных в Беркли | GoogleНаконец, есть стойки, на которых монтируются серверы, сетевое оборудование и складское оборудование.Стойки обеспечивают легкий доступ и обслуживание других компонентов ИТ-оборудования, а также гарантируют, что все будет аккуратно организовано, что позволяет максимально использовать пространство.
Электрооборудование
Центру обработки данных требуется электричество для работы. Электричество обеспечивает бесперебойную работу центра обработки данных даже в случае отключения электроэнергии. Это необходимо для того, чтобы данные всегда были доступны. Для этого необходимо создать надлежащую основу.
Распределение электроэнергии по стальным балкам в центре обработки данных Google’s Council Bluffs, штат Айова | GoogleЭлектроэнергия обычно предоставляется коммунальным предприятием. В случае отключения электроэнергии обязанности по обеспечению электроэнергией автоматически переключаются на резервные генераторы благодаря автоматическому переключателю (АВР).
Однако существует задержка между полным включением генераторов после сбоя. Чтобы компенсировать это, источники бесперебойного питания обеспечивают подачу электроэнергии в этот переходный период.
Как вы понимаете, энергетические потребности центров обработки данных весьма значительны из-за их масштаба и работы в режиме 24/7.
Cooling Framework
Требования к охлаждению для центра обработки данных огромны. ИТ-оборудование в центре обработки данных выделяет огромное количество тепла, поэтому охлаждение необходимо для эффективной работы центра обработки данных. Сложные системы охлаждения отвечают за регулирование температуры в центре обработки данных.
Одним из наиболее важных и видимых компонентов самого центра обработки данных является кондиционер воздуха компьютерного зала (CRAC).CRAC циркулирует холодный воздух, который он производит, вокруг горячего ИТ-оборудования центра обработки данных. После прохождения холодного воздуха вокруг оборудования оно становится горячим. Поток воздуха в центре обработки данных регулируется таким образом, что горячий воздух возвращается в блоки CRAC, которые затем охлаждают горячий воздух.
Этот цикл продолжается и гарантирует, что температура в центре обработки данных остается оптимальной для правильной работы оборудования.
Такие резервуары вмещают до 240 000 галлонов воды, используемой для охлаждения центра обработки данных | GooglePhysical Plant
Здание, в котором находится оборудование центра обработки данных, не следует воспринимать как должное.Здание центра обработки данных должно быть конструктивно прочным и безопасным. Это необходимо для защиты оборудования в случае непогоды.
Безопасность данных также важна не только с точки зрения защиты программного обеспечения. Персонал службы безопасности всегда присутствует в центрах обработки данных, чтобы защитить здание и его содержимое.
Кроме того, в центры обработки данных в первую очередь допускаются только лица с высоким уровнем допуска.
Известные центры обработки данных
Поскольку мы говорим об известных центрах обработки данных, лучше всего начать с самого большого центра обработки данных в мире.На фото ниже Технологический центр Lakeside, расположенный по адресу 350 East Cermak Road в Чикаго.
Он принадлежит Digital Realty Trust и обслуживает широкий круг клиентов. Его общая площадь составляет 1,1 миллиона квадратных футов. Щелкните здесь, если хотите узнать больше об этом центре обработки данных.
Центр обработки данных Lakeside Technology в Чикаго — крупнейший центр обработки данных в мире | Global DotsТехнологический центр Lakeside может быть крупнейшим центром обработки данных, но совокупность центров обработки данных Google также впечатляет.Google использует ряд новых методов, чтобы их центры обработки данных работали как хорошо смазанные машины. Благодаря этому у нас есть беспрепятственный доступ к сервисам Google 24/7.
Коллекция центров обработки данных Google впечатляет.
Центры обработки данных Google
Google строит свои серверы по индивидуальному заказу в соответствии с конкретными потребностями компании.
Один из специально разработанных серверов Google | CNETЦентры обработки данных Google рассчитаны на эффективную работу при более высоких температурах, чем другие центры обработки данных.Это позволяет им сократить количество энергии, расходуемой на охлаждение.
Сотни вентиляторов направляют горячий воздух из серверных стоек в охлаждающее устройство | GoogleПрограммное обеспечение, разработанное Google для управления их невероятным набором серверов, настолько динамично, что позволяет им действовать как одна система. Одно изменение, сделанное в одной области, видно по всем направлениям.
Следует также отметить, что у Google есть замечательная команда инженеров по надежности сайтов (SRE), которые работают в кампусах Google по всему миру, которые подвергают центры обработки данных тщательному тестированию, чтобы убедиться в их устойчивости и надежности.
Инженеры Google за работой в Санкт-Гислене, Бельгия | GoogleЕсли вас интересуют более подробные сведения о центрах обработки данных Google, вы можете узнать о них больше здесь.
Центры обработки данных Facebook тоже довольно хороши.
Последние мысли
Онлайн-данные из Интернета хранятся в центрах обработки данных, разбросанных по всему миру. Эти центры становятся все более важными, особенно в последние годы, когда население мира все больше и больше полагается на Интернет.
Дата-центры будут только улучшаться. Особенно важно повышение энергоэффективности центра обработки данных. Несколько центров обработки данных также внедрили решения в области возобновляемых источников энергии.
Это необходимо для снижения воздействия этих центров на окружающую среду. Однако такие инициативы, как Google, в которых центры обработки данных работают чуть более горячими, чем обычно, уже помогают экономить электроэнергию. Важность центров обработки данных неоспорима, и они будут продолжать оставлять свой след в нашей личной жизни еще долгие годы.
ТАКЖЕ ПРОЧИТАЙТЕ: 5 влиятельных людей в мире науки и техники выступают против AI
Вышеупомянутая статья может содержать партнерские ссылки, которые помогают поддерживать Guiding Tech. Однако это не влияет на нашу редакционную честность. Содержание остается непредвзятым и достоверным.
Где в мире живет Интернет? на WhoIsHostingThis.com
Раскрытие информации: Ваша поддержка помогает поддерживать работу сайта! Мы зарабатываем реферальный сбор за некоторые услуги, которые мы рекомендуем на этой странице.Узнать большеМиллиарды людей во всем мире пользуются Интернетом каждый день, но, скорее всего, мало кто за пределами ИТ-индустрии может дать окончательный ответ на вопрос: «Где же Интернет?». Это вопрос, который многие, возможно, никогда не смогут даже заинтересовать большинство пользователей Интернета, помимо исследования хостинг-провайдера или расплывчатых представлений о «киберпространстве» или воспоминаний о дискетах AOL из 90-х.
Тем не менее, несмотря на его эфемерный характер, у Интернета действительно есть физический дом — тот, который окружает земной шар.Распространенная на почти 75 миллионов взаимосвязанных серверов, сеть, которую мы сейчас называем Интернетом, соединяет более пяти миллиардов (по некоторым оценкам, приближается к десяти миллиардам) компьютеров, смартфонов и других устройств. Это далеко от его предка, проекта ARPANET 1960-х годов, который начинался как соединение со скоростью 2,4 кбит / с между двумя огромными университетскими компьютерами.
Сегодня соединения, которые питают магистраль Интернета, передают данные со скоростью, близкой к скорости света, по подводному кабелю протяженностью более полумиллиона миль.Этого кабеля достаточно, чтобы облететь Землю более 22 раз или добраться от Земли до Луны и обратно. Однако даже при такой огромной мощности и охвате эксперты из Международного союза электросвязи (ITU) прогнозируют, что к концу 2013 года только 40% всего населения Земли будут подключены к Интернету. Это число, вероятно, будет намного выше, чем через спутниковый Интернет. технологии становятся более практичными, а покрытие распространяется на районы, в настоящее время недоступные для традиционных стационарных телефонов.
Будь то под водой, излучение со спутника или полет через Wi-Fi соседа, соединения и данные, составляющие Интернет, затрагивают практически все аспекты нашей жизни.Эта гигантская — и в значительной степени невидимая — инфраструктура делает большую часть современной жизни возможной (или, по крайней мере, более удобной). Поскольку мир становится все более взаимосвязанным, ответ на вопрос «Где находится Интернет?» может со временем стать простым «Везде».
Где Интернет?
Основы Интернета были заложены Министерством обороны США в 1960-х годах. Это включало процесс подключения компьютеров для более быстрой передачи данных. Этот процесс продолжается и по сей день.
В настоящее время Интернет состоит из не менее 30 миллионов серверов по всему миру по состоянию на 2008 год, которые, по оценкам, на сегодняшний день закрыты до 75 миллионов.
550 000 миль подводного кабеля, передающего данные со скоростью 186 000 миль в секунду.
1 миллиард подключенных компьютеров, рост до 5 миллиардов, включая все устройства с выходом в Интернет. К 2020 году эта цифра достигнет 22 миллиардов.
Без учета серверов и кабелей вес Интернета был подсчитан в 0,2 миллионных долей унции.Вес песчинки.
Google оценивает размер Интернета примерно в 5 миллионов терабайт данных. Они контролируют крупнейший в мире индекс Интернета, но он составляет всего 0,004% всех данных.
Подводные кабели, соединяющие мир, могут показаться чем-то новым, но на самом деле они были там с 1860-х годов.
6 основных подводных кабельных станций:
- Токио
- Сингапур
- Нью-Йорк / Нью-Джерси
- Корнуолл
- Южная Флорида
- Гонконг
Местные хосты:
- Apollo Submarine Cable Systems — Лондон
- Управляет самой современной трансатлантической кабельной системой, соединяющей США с Великобританией и Европой.
- Пересечение Тихого океана — Токио и Калифорния
- Управляет основной транстихоокеанской кабельной системой, соединяющей США и Азию.
- Reach — Hong Kong
- Управляет основной азиатско-тихоокеанской кабельной системой, соединяющей большую часть Азии и, кроме того, Австралию.
- FLAG Telecom — Лондон
- Управляет крупнейшей кабельной сетью Европа-Африка-Азия.
- PIPE Networks — Брисбен
- Управляет основной кабельной сетью, соединяющей Австралию с Азией и США.
5 самых загруженных интернет-узлов:
- Франкфурт — 2,5 терабит в секунду
- Амстердам — 2,4 терабит в секунду
- Лондон — 1,8 терабит в секунду
- Москва — 1,1 терабит в секунду
- Ashburn — 610 Гигабит в секунду
3 страны с наибольшим количеством интернет-узлов:
- США — 97
- Бразилия — 23
- Франция — 21
Компании с наибольшим количеством серверов:
- Microsoft — более 1 миллиона серверов
- Google — 900 000
- OVH.com — 150 000
- Akamai — 127 000
- Softlayer — 100 000
- Intel — 75 000
Более 1 миллиона домов в некоторых районах Великобритании не могут подключиться к Интернету, поскольку это не принесет пользы поставщикам услуг чтобы подключить их. Спутниковый Интернет скоро решит эту проблему, так как он сможет подключиться к любому месту по всему миру.
Интернет не один, а несколько. Существуют различные параллельные формы, известные как Darknets. Они используются, чтобы избежать обнаружения системами наблюдения, и в основном используются военными, а также группами, занимающимися преступной деятельностью.
Население мира составляет более 7 миллиардов человек. В 2000 году к Интернету было подключено более 300 миллионов пользователей. В 2013 году во всем мире насчитывалось почти 3 миллиарда пользователей.
Мы создадим цивилизацию Разума в Киберпространстве. Пусть он будет более гуманным и справедливым, чем мир, созданный вашими правительствами раньше. — Джон Перри Барлоу
Источники
Где хранятся все информационные данные в Интернете?
Ответ:
Интернет — это огромный лабиринт.Это невероятно сложно дать количественную оценку, а иногда почти невозможно по-настоящему ориентироваться. Сложный набор оборудования, кодирования и вычислительной мощности необходим для работы даже одного компьютера, не говоря уже о таком чудовище, как Интернет.
Обмен информацией в Интернете осуществляется посредством пакетов данных, отправляемых компьютерами друг другу. Файл или запрос информации делятся на эти пакеты, чтобы сделать загрузку управляемой для компьютера и подключения к Интернету, через которое он перемещается.Каждый пакет может содержать до 1500 байтов информации. Каждый байт состоит из восьми битов данных. Каждый бит может быть либо нулем, либо единицей. Система байтов позволяет передавать то, что люди читают как слова или числа, а также логические процессы в компьютерных приложениях из одного места в другое в двоичном формате. Двоичный — это язык, полностью состоящий из единиц и нулей. Один представляет истину, а ноль — ложь. Компьютер на своем базовом уровне считывает эти единицы и нули и может выполнять любую функцию, которую ему велят делать.По сути, двоичный файл действует как набор инструкций, которым должен следовать компьютер.
Хотя все это не кажется сложным, все становится сложным, когда компьютер должен учитывать миллиарды байтов. Звучит нереально? Средний размер файла сегодня составляет около 3 мегабайт, что соответствует 3 миллионам байтов данных. К счастью, современные технологии позволяют передавать файлы такого размера за считанные секунды. Но при учете миллиардов и миллиардов файлов возникает вопрос: где хранится вся эта информация?
В конце концов, все эти файлы и приложения нельзя использовать одновременно.Так где же они хранятся, когда не используются? Наверняка не существует какого-то центрального узла, где хранятся все данные в Интернете. Это предположение верно. Следует помнить, что Интернет — это не что-то особенное. Это сложная сеть взаимосвязанных машин по всему миру.
Из-за этого данные хранятся на жестких дисках многочисленных веб-серверов по всему миру. Веб-сервер — это компьютер, как и любой другой. Фактически, любой компьютер можно преобразовать в сервер, на котором будут размещаться и храниться данные после преобразования.Но средний сервер полностью посвящен своей задаче. Он часто имеет значительно большую вычислительную мощность и объем памяти, чем средний компьютер, для эффективного выполнения своей задачи.
Серверы часто организованы в огромные сетевые узлы, здания, заполненные множеством стоек компьютеров. Эти стойки часто подключены друг к другу, а также к Интернету, поэтому они могут обмениваться, обрабатывать и хранить больше данных. Эти базы данных легко хранят непристойное количество данных, стоимостью тысячи энциклопедий.Подводя итог, можно сказать, что информация, представленная в Интернете, хранится там, где расположен сервер конкретного веб-сайта или сервера приложения.
Как это работает?
Для доступа к данным, не хранящимся на персональном компьютере, необходимы веб-браузеры. Если вы хотите транслировать видео на YouTube, вы вводите веб-адрес YouTube. Этот адрес обрабатывается вашим компьютером и отправляется через довольно сложный процесс через Интернет-маршрутизатор в «Интернет». По сути, после того, как запрос покидает ваш маршрутизатор, он переходит от маршрутизатора к маршрутизатору на пути к серверу YouTube.Он знает, куда идти, на основе процесса, который связывает имя веб-адреса с его IP-адресом сервера и MAC-адресом (его Интернет и физическое местоположение). Как только он достигает сервера YouTube, запрос на доступ к его веб-сайту обрабатывается и принимается с данными, необходимыми для отображения страницы, к которой обращается ваш компьютер. Если вы хотите найти видео, этот процесс повторяется. Фактически, этот процесс используется практически для всего, что используется и доступно в Интернете.
Интернет в культуре:
Само собой разумеется, что Интернет является неотъемлемой и вездесущей частью общества.Иногда к нему трудно получить доступ. Это может быть связано с плохим подключением к Интернету, что часто случается. Но столь же банальной проблемой является используемый компьютер. Если вычислительная мощность компьютера недостаточно высока для удовлетворения требований пользователя, последует медленный, утомительный и разочаровывающий опыт. Для борьбы с этим постоянно создаются новые мощные компьютеры. Вот несколько вариантов ниже:
Где на Земле фактически находятся данные об облаках?
Подумайте об облачных вычислениях, и первое, что приходит на ум, — это обычные приложения, такие как Google Drive , Dropbox или iCloud , но это гораздо больше, чем вы думаете.
Во-первых, нам нужно понять, что такое облачные вычисления. Вкратце, облачные вычисления — это хранение и извлечение ваших личных (или корпоративных) данных из вашей небольшой области в Интернете. На вашем локальном жестком диске ничего не хранится, и к нему можно получить доступ из любого места, с любого устройства и в любое время.
Если все это звучит немного неправдоподобно, подумайте об услуге электронной почты, которую вы уже используете, например Gmail, Yahoo, Hotmail и т. Д. Ни одно из этих писем, которые вы отправляете и получаете, на самом деле не занимает места на вашем локальном жестком диске, они хранятся на серверах провайдеров электронной почты: это форма облачных вычислений.
Чтобы продолжить этот пример, помните, что вы можете войти в систему и получить доступ к своей электронной почте с любого компьютера, любого ноутбука и любого смартфона. Это стало возможным только благодаря облаку.
Однако многие люди не осознают, что, несмотря на то, что ваши данные хранятся в «облаке», их все же необходимо физически хранить где-то на устройстве. Будь то флэш-память или традиционное хранилище на жестких дисках , компаниям, предлагающим эту услугу, по-прежнему необходимо иметь огромные серверы, предназначенные для хранения ваших данных.Эти места часто называют «фермами серверов » и представляют собой, по сути, огромные склады, заполненные серверами, которые работают круглосуточно, 7 дней в неделю, 365 дней в году.
Это вызывает ряд вопросов: где на самом деле хранятся мои данные? У кого есть доступ к моим данным и в безопасности ли они?
Где на самом деле хранятся мои данные?
С точки зрения , где хранятся ваши данные, можно с уверенностью сказать, что вы никогда не узнаете по-настоящему, если не покопаетесь. Провайдер может находиться в США (например), но его серверы могут находиться в Китае, Великобритании или в любой другой точке мира.Многие компании передают свои серверные фермы сторонним поставщикам, чтобы сократить расходы. Таким образом, очень сложно узнать, где на самом деле находятся ваши данные, и поставщик облачных услуг не обязательно раскрывает это.
Кто имеет доступ к моим данным?
У кого есть доступ к вашим данным — еще один момент, который следует учитывать. Авторитетные компании испытали и протестировали системы безопасности, чтобы гарантировать, что только у вас есть доступ к вашим данным. Существуют безликие компании, предлагающие одинаковый объем хранилища и функциональность, независимо от того, доверяете вы им или нет, это важное решение.Кроме того, вы также должны узнать о мерах безопасности, которые обеспечивают безопасность и постоянный доступ к вашим данным. Наиболее авторитетные поставщики облачных хранилищ будут реплицировать ваши данные несколько раз на разных серверах, чтобы в случае катастрофы ваши файлы были в безопасности. Это не означает, что ваши данные когда-либо будут на 100% безопасными: стихийные бедствия, пожары и злонамеренный ущерб (например) — это все события, которые вы можете запланировать, но не обязательно избегать.
Помните…
Важно помнить, что, хотя ваши данные физически не хранятся на вашем локальном жестком диске, они все еще хранятся где-то , и с учетом этого они могут быть подвержены тем же сбоям и проблемам, что и жесткий диск в ваш ноутбук или компьютер.Серверные фермы не непобедимы; носители данных могут выйти из строя, крупные корпорации могут быть взломаны, а данные могут быть удалены на сервере так же легко, как и на вашем компьютере, поэтому будьте осторожны с хранением всех ваших важных и конфиденциальных файлов в облаке.
Интернет вещей: куда деваются данные?
Интернет вещей означает разные вещи для разных людей. Для поставщиков это последняя из множества крупномасштабных тенденций, влияющих на их корпоративных клиентов, и последний маркетинговый ход, который им следует учитывать.Для корпоративных организаций это все еще смесь технических стандартов, противоречивых мнений и большого потенциала. Для разработчиков это отличная возможность собрать правильное сочетание инструментов и технологий, и, вероятно, то, что они уже делают под другим именем. Понимание того, как эти технологии работают вместе на техническом уровне, становится важным и откроет больше возможностей для использования дизайна программного обеспечения как части общего бизнеса.
По мере того, как проекты Интернета вещей переходят от концепций к реальности, одна из самых больших проблем заключается в том, как данные, созданные устройствами, будут проходить через систему.Сколько устройств будет создавать информацию? Как они отправят эту информацию обратно? Будете ли вы собирать эти данные в режиме реального времени или партиями? Какую роль будет играть аналитика в будущем?
Эти вопросы необходимо задать на этапе проектирования. В организациях, с которыми я разговаривал, этот подготовительный этап важен для того, чтобы вы с самого начала использовали правильные инструменты.
Отправка данных
Полезно рассматривать данные, создаваемые устройством, в три этапа.Первый этап — это первоначальное создание, которое происходит на устройстве, а затем отправляется через Интернет. Второй этап — это то, как центральная система собирает и систематизирует эти данные. Третий этап — постоянное использование этих данных в будущем.
Для интеллектуальных устройств и датчиков каждое событие может и будет создавать данные. Затем эту информацию можно отправить по сети обратно в центральное приложение. На этом этапе необходимо решить, в каком стандарте будут создаваться данные и как они будут отправляться по сети.Для обратной доставки этих данных наиболее распространенными стандартными протоколами являются MQTT, HTTP и CoAP. У каждого из них есть свои преимущества и варианты использования.
HTTP предоставляет подходящий метод для обмена данными между устройствами и центральными системами. Первоначально разработанный для вычислительной модели клиент-сервер, сегодня он поддерживает ежедневный просмотр веб-страниц, а также более специализированные службы, связанные с устройствами Интернета вещей. Несмотря на то, что он отвечает требованиям к функциональности для отправки данных, HTTP включает в себя гораздо больше данных вокруг сообщения в своих заголовках.Когда вы работаете в условиях низкой пропускной способности, это может сделать HTTP менее подходящим.
MQTT был разработан как протокол для межмашинного развертывания и Интернета вещей. Он основан на модели публикации / подписки для доставки сообщений с устройства обратно в центральную систему, которая действует как брокер, где они затем могут быть доставлены обратно во все другие системы, которые будут их использовать. Новые устройства или службы могут просто подключаться к брокеру, если им нужны сообщения. MQTT легче HTTP с точки зрения размера сообщения, поэтому он более полезен для реализаций, где пропускная способность является потенциальной проблемой.Однако он не включает шифрование в качестве стандарта, поэтому его следует рассматривать отдельно.
CoAP — еще один стандарт, разработанный для сред с низким энергопотреблением и низкой пропускной способностью. Вместо того, чтобы быть разработанным для брокерской системы, такой как MQTT, CoAP больше нацелен на индивидуальные соединения. Он разработан для удовлетворения требований дизайна REST, обеспечивая способ взаимодействия с HTTP, но при этом удовлетворяет требованиям устройств и сред с низким энергопотреблением.
Каждый из этих протоколов поддерживает получение информации или обновлений от отдельного устройства и отправку их в центральное место.Однако более широкие возможности заключаются в том, как эти данные затем хранятся и используются в будущем. Здесь есть две основные проблемы: как данные обрабатываются, когда они поступают в приложение, и как они хранятся для будущего использования.
Хранение данных
В Интернете вещей устройства создают данные, которые отправляются в основное приложение для отправки, использования и использования. В зависимости от устройства, сети и ограничений энергопотребления данные можно отправлять в режиме реального времени или пакетами в любое время.Однако реальное значение определяется порядком создания точек данных.
Эти данные временного ряда должны быть точными для приложений Интернета вещей. Если нет, то это ставит под угрозу сами цели самих приложений. Снимайте телеметрические данные с автомобилей. Если порядок данных не полностью согласован и не точен, это указывает на потенциально разные результаты при анализе. Если определенная деталь начинает выходить из строя в определенных условиях — например, при падении температуры одновременно с определенным уровнем износа — тогда эти условия должны быть точно отражены в получаемых данных, иначе это приведет к ложным полученные результаты.
Данные временного ряда могут быть созданы по мере того, как события происходят вокруг устройства, а затем отправлены. Такое использование информации в реальном времени обеспечивает полную запись для каждого устройства, как это происходит. В качестве альтернативы, их можно сопоставить, поскольку данные пересылаются пакетами — историческая запись данных будет там, но она просто недоступна в реальном времени. Это характерно для устройств, где срок службы батареи является ключевым требованием по сравнению с необходимостью доставки данных в режиме реального времени. В любом случае, фундаментальное требование состоит в том, чтобы каждая транзакция на каждом устройстве имела правильную временную метку для сортировки и выравнивания.Если вы хотите делать это в реальном времени с сотнями тысяч или потенциально миллионами устройств, то скорость записи на уровне базы данных является важным фактором.
Каждая запись должна приниматься по мере получения от самого устройства и помещаться в базу данных. Для более традиционных технологий реляционных баз данных это может быть ограничивающим фактором, поскольку запросы на запись могут выходить за рамки того, для чего была создана база данных. Когда вам нужно получить все данные с устройств для создания точной и полезной информации, эта потенциальная потеря может иметь большое влияние.Для организаций, с которыми я разговаривал по проектам Интернета вещей, платформы NoSQL, такие как Cassandra, лучше подходят для их требований.
Частично это связано с огромным объемом писем, на которые способна что-то вроде Кассандры; даже с миллионами устройств, которые постоянно создают данные, база данных предназначена для приема такого количества данных по мере их создания. Однако это также связано с тем, как спроектированы сами базы данных. Традиционные базы данных имеют структуру первичной реплики, при которой ведущий сервер базы данных будет обрабатывать все транзакции и синхронно передавать их другим серверам, если это необходимо.Это приводит к проблемам в случае сбоя или отказа сервера, поскольку необходимо установить новый первичный сервер, что может привести к потере данных.
Для правильно настроенных систем распределенных баз данных, таких как Cassandra, нет «основного» сервера, который бы отвечал за них; каждый узел в кластере может обрабатывать транзакции по мере их поступления, а полная запись сохраняется с течением времени. Даже если сервер выходит из строя или узел удаляется из-за потери сетевого подключения, остальная часть кластера может продолжать обрабатывать данные по мере их поступления.Для данных временных рядов это особенно ценно, поскольку это означает, что не должно происходить потери данных в списке транзакций с течением времени.
Анализ данных
Когда у вас есть это хранилище данных временных рядов, следующая возможность — искать тенденции во времени. Анализ данных временных рядов дает возможность повысить ценность для владельцев задействованных устройств или выполнять автоматизированные задачи на основе определенного набора условий. Типичный пример — подключенный к Интернету холодильник, который понимает, что в нем нет молока; однако данные Интернета вещей более ценны, когда они связаны с более крупными частными или общественными выгодами и с более сложными наборами условий, которые необходимо соблюдать.Анализ трафика, инженерные сети и использование электроэнергии в разных местах недвижимого имущества — все это связано с потреблением данных с нескольких устройств для выявления тенденций и экономии денег или времени.
В этой среде полезно подумать о том, когда потребуются результаты аналитики: существует ли немедленная потребность в анализе в режиме, близком к реальному времени, или это историческое требование? Популярность Apache Spark для анализа больших данных и потоковой передачи Spark в режиме, близком к реальному времени, продолжает расти, и в сочетании с такими приложениями, как Cassandra, он может предоставить разработчикам возможность обрабатывать и анализировать большие, быстро меняющиеся наборы данных. друг друга.
Однако дело не только в том, что происходит сейчас. Значение из данных временных рядов также может поступать со временем. Например, компания i2O Water в Великобритании рассматривает информацию о давлении воды, полученную с устройств, встроенных в водопроводные сети по всему миру. Эти данные собирались в течение двух лет и хранятся в кластере Cassandra. Компания использует эту информацию для своей аналитики и для оповещения клиентов о том, где может потребоваться техническое обслуживание.
Эти данные имеют для компании отдельную ценность. В нем есть готовый источник информации о моделировании и аналитике для клиентов, который также можно использовать для новых продуктов. Это связано с тем, что компания разработала модульную архитектуру своих приложений; когда добавляется новый модуль или услуга, данные временного ряда могут быть «воспроизведены» в системе, как если бы данные создавались. Затем это можно использовать для аналитики и показать, как устройства в водопроводной сети отреагировали бы на изменения давления или других данных датчиков в течение этого времени.
Для i2O Water здесь есть возможность добавить услуги, которые демонстрируют большую ценность для коммунальных компаний, которые являются ее клиентами. Ценность воды будет только расти по мере того, как все больше людей будет нуждаться в доступе, что, в свою очередь, сделает точные и своевременные данные более ценными. Это хороший пример того, как подключение устройств и данных может улучшить жизнь, а также создать новые возможности для вовлеченных компаний.
Возможность просматривать данные временных рядов имеет самые далеко идущие последствия для Интернета вещей в целом.Независимо от того, идет ли речь о выгодах частного или государственного сектора, важно понимать структуру приложения и то, как эти данные хранятся с течением времени. При проектировании для Интернета вещей также важна роль распределенных систем, которые могут справляться с огромным объемом создаваемых данных.
Патрик Макфадин — главный евангелист Apache Cassandra.
Вернуться к началу. Перейти к: Начало статьи.«Где на самом деле находится облачное хранилище? И это безопасно? »
Спросите The Times, Times Insider , опираясь на опыт New York Times, чтобы ответить на вопросы о текущих событиях, науке, спорте, культуре и всем остальном, о чем пишут заголовки.
Читатель спрашивает: «Где на самом деле находится облачное хранилище? И это безопасно? »
Квентин Харди , заместитель редактора The Times по технологиям, рассматривает этот вопрос.
_____
«Облачные» данные хранятся на жестких дисках (почти так же, как обычно хранятся данные). И да, это, вероятно, более безопасно, чем данные, хранящиеся обычным способом.
Чем отличается облачное хранилище? Вместо того, чтобы храниться непосредственно на вашем личном устройстве (например, на жестком диске вашего ноутбука или вашего телефона), облачные данные хранятся в другом месте — обычно на серверах, принадлежащих крупным компаниям — и становятся доступными вам через интернет.
Когда люди думают об облачных вычислениях, они часто думают о подключенных к Интернету общедоступных облаках, управляемых такими компаниями, как Amazon, Microsoft и Google. (Если вы используете Gmail, Dropbox или Microsoft Office 365, вы используете облачную службу.) Существуют также потребительские облака, в которых, например, хранятся ваши изображения и сообщения в социальных сетях (например, Facebook или Twitter), или хранится ваша музыка и электронная почта (подумайте об Apple или Google).
У каждой из этих компаний есть облачные вычислительные системы — компьютерные серверы и устройства хранения, связанные с компьютерным сетевым оборудованием, — которые охватывают весь земной шар.(Системы Facebook могут позволить более чем одному миллиарду людей взаимодействовать с ними.) Ваши данные хранятся на их компьютерах, обычно хранятся в региональном центре обработки данных, расположенном поблизости от вашего места жительства.
Отдельные компании также могут иметь свои собственные облака, называемые частными облаками, к которым сотрудники и клиенты получают доступ, как правило, через Интернет и в их собственных частных сетях.
Помимо хранения, вычислительные облака также могут обрабатывать информацию по-разному; у них есть специальное программное обеспечение, которое позволяет распределять рабочие нагрузки между разными машинами.Например, ваши фотографии в Facebook не привязаны к конкретному чипу, но могут перемещаться между компьютерами.
Это большое дело. Когда рабочие нагрузки разделены, компьютеры могут работать почти на полную мощность при одновременном запуске нескольких программ. Это намного эффективнее, чем автономные компьютеры, выполняющие одно задание за раз.
Для людей, управляющих компьютерами, на самом деле не имеет значения, где находятся данные или программы в любой момент: все работает внутри «облака» вычислительных возможностей.В идеале, если одна машина выходит из строя, операция переносится на другую часть системы с минимальным временем простоя.
В наши дни вычислительные облака повсюду — это одна из причин, по которой люди беспокоятся о своей безопасности. Мы все чаще слышим о хакерах, которые выходят через Интернет и крадут данные тысяч людей.
Однако большинство этих атак поражают традиционные серверы. Ни один из самых катастрофических взломов не применялся в больших публичных облаках.
Точно так же, как ваши деньги, вероятно, безопаснее смешивать с деньгами других людей в банковском хранилище, чем лежать в одиночестве в вашем ящике комода, ваши данные могут быть в большей безопасности в облаке: оно лучше защищено от злоумышленников.
В случае больших публичных облаков защита — это работа некоторых из лучших компьютерных ученых мира, нанятых из таких мест, как Агентство национальной безопасности и Стэнфордский университет, чтобы серьезно подумать о безопасности, шифровании данных и новейших онлайн-мошенничествах.