Анализ больших объемов данных | BaseGroup Labs
Обычно, когда говорят о серьезной аналитической обработке, особенно если используют термин Data Mining, подразумевают, что данных огромное количество. В общем случае это не так, т. к. довольно часто приходится обрабатывать небольшие наборы данных, и находить в них закономерности ничуть не проще, чем в сотнях миллионов записей. Хотя нет сомнений, что необходимость поиска закономерностей в больших базах данных усложняет и без того нетривиальную задачу анализа.
Такая ситуация особенно характерна для бизнеса, связанного с розничной торговлей, телекоммуникациями, банками, интернетом. В их базах данных аккумулируется огромное количество информации, связанной с транзакциями: чеки, платежи, звонки, логи и т.п.
Не существует универсальных способов анализа или алгоритмов, пригодных для любых случаев и любых объемов информации. Методы анализа данных существенно отличаются друг от друга по производительности, качеству результатов, удобству применения и требованиям к данным.
Конечно, можно увеличить скорость обработки данных за счет более производительного оборудования, тем более, что современные сервера и рабочие станции используют многоядерные процессоры, оперативную память значительных размеров и мощные дисковые массивы. Однако, есть множество других способов обработки больших объемов данных, которые позволяют повысить масштабируемость и не требуют бесконечного обновления оборудования.
Возможности СУБД
Современные базы данных включают различные механизмы, применение которых позволит значительно увеличить скорость аналитической обработки:
- Предварительный обсчет данных. Сведения, которые чаще всего используются для анализа, можно заранее обсчитать (например, ночью) и в подготовленном для обработки виде хранить на сервере БД в виде многомерных кубов, материализованных представлений, специальных таблиц.

- Кэширование таблиц в оперативную память. Данные, которые занимают немного места, но к которым часто происходит обращение в процессе анализа, например, справочники, можно средствами базы данных кэшировать в оперативную память. Так во много раз сокращаются обращения к более медленной дисковой подсистеме.
- Разбиение таблиц на разделы и табличные пространства. Можно размещать на отдельных дисках данные, индексы, вспомогательные таблицы. Это позволит СУБД параллельно считывать и записывать информацию на диски. Кроме того, таблицы могут быть разбиты на разделы (partition) таким образом, чтобы при обращении к данным было минимальное количество операций с дисками. Например, если чаще всего мы анализируем данные за последний месяц, то можно логически использовать одну таблицу с историческими данными, но физически разбить ее на несколько разделов, чтобы при обращении к месячным данным считывался небольшой раздел и не было обращений ко всем историческим данным.

Это только часть возможностей, которые предоставляют современные СУБД. Повысить скорость извлечения информации из базы данных можно и десятком других способов: рациональное индексирование, построение планов запросов, параллельная обработка SQL запросов, применение кластеров, подготовка анализируемых данных при помощи хранимых процедур и триггеров на стороне сервера БД и т.п. Причем многие из этих механизмов можно использовать с применением не только «тяжелых» СУБД, но и бесплатных баз данных.
Повысить скорость извлечения информации из базы данных можно и десятком других способов: рациональное индексирование, построение планов запросов, параллельная обработка SQL запросов, применение кластеров, подготовка анализируемых данных при помощи хранимых процедур и триггеров на стороне сервера БД и т.п. Причем многие из этих механизмов можно использовать с применением не только «тяжелых» СУБД, но и бесплатных баз данных.
Комбинирование моделей
Возможности повышения скорости не сводятся только к оптимизации работы базы данных, многое можно сделать при помощи комбинирования различных моделей. Известно, что скорость обработки существенно связана со сложностью используемого математического аппарата. Чем более простые механизмы анализа используются, тем быстрее данные анализируются.
Возможно построение сценария обработки данных таким образом, чтобы данные «прогонялись» через сито моделей. Тут применяется простая идея: не тратить время на обработку того, что можно не анализировать.
Вначале используются наиболее простые алгоритмы. Часть данных, которые можно обработать при помощи таких алгоритмов и которые бессмысленно обрабатывать с использованием более сложных методов, анализируется и исключается из дальнейшей обработки. Оставшиеся данные передаются на следующий этап обработки, где используются более сложные алгоритмы, и так далее по цепочке. На последнем узле сценария обработки применяются самые сложные алгоритмы, но объем анализируемых данных во много раз меньше первоначальной выборки. В результате общее время, необходимое для обработки всех данных, уменьшается на порядки.
Приведем практический пример использования этого подхода. При решении задачи прогнозирования спроса первоначально рекомендуется провести XYZ-анализ, который позволяет определить, насколько стабилен спрос на различные товары. Товары группы X продаются достаточно стабильно, поэтому применение к ним алгоритмов прогнозирования позволяет получить качественный прогноз. Товары группы Y продаются менее стабильно, возможно для них стоит строить модели не для каждого артикула, а для группы, это позволяет сгладить временной ряд и обеспечить работу алгоритма прогнозирования.
По статистике около 70 % ассортимента составляют товары группы Z. Еще около 25 % — товары группы Y и только примерно 5 % — товары группы X. Таким образом, построение и применение сложных моделей актуально максимум для 30 % товаров. Поэтому применение описанного выше подхода позволит сократить время на анализ и прогнозирование в 5-10 раз.
Параллельная обработка
Еще одной эффективной стратегией обработки больших объемов данных является разбиение данных на сегменты и построение моделей для каждого сегмента по отдельности, с дальнейшим объединением результатов. Чаще всего в больших объемах данных можно выделить несколько отличающихся друг от друга подмножеств. Это могут быть, например, группы клиентов, товаров, которые ведут себя схожим образом и для которых целесообразно строить одну модель.
В этом случае вместо построения одной сложной модели для всех можно строить несколько простых для каждого сегмента. Подобный подход позволяет повысить скорость анализа и снизить требования к памяти благодаря обработке меньших объемов данных в один проход. Кроме того, в этом случае аналитическую обработку можно распараллелить, что тоже положительно сказывается на затраченном времени. К тому же модели для каждого сегмента могут строить различные аналитики.
Помимо повышения скорости этот подход имеет и еще одно важное преимущество – несколько относительно простых моделей по отдельности легче создавать и поддерживать, чем одну большую. Можно запускать модели поэтапно, получая таким образом первые результаты в максимально сжатые сроки.
Репрезентативные выборки
При наличии больших объемов данных можно использовать для построения модели не всю информацию, а некоторое подмножество – репрезентативную выборку. Корректным образом подготовленная репрезентативная выборка содержит в себе информацию, необходимую для построения качественной модели.
Процесс аналитической обработки делится на 2 части: построение модели и применение построенной модели к новым данным. Построение сложной модели – ресурсоемкий процесс. В зависимости от применяемого алгоритма данные кэшируются, сканируются тысячи раз, рассчитывается множество вспомогательных параметров и т.п. Применение же уже построенной модели к новым данным требует ресурсов в десятки и сотни раз меньше. Очень часто это сводится к вычислению нескольких простых функций.
Таким образом, если модель будет строиться на относительно небольших множествах и применяться в дальнейшем ко всему набору данных, то время получения результата сократится на порядки по сравнению с попыткой полностью переработать весь имеющийся набор данных.
Для получения репрезентативных выборок существуют специальные методы, например, сэмплинг. Их применение позволяет повышать скорость аналитической обработки, не жертвуя качеством анализа.
Резюме
Описанные подходы – это только небольшая часть методов, которые позволяют анализировать огромные объемы данных.
Анализ огромных баз данных – это нетривиальная задача, которая в большинстве случаев не решается «в лоб», однако современные базы данных и аналитические платформы предлагают множество методов решения этой задачи. При разумном их применении системы способны перерабатывать терабайты данных с приемлемой скоростью.
| Согласуйте цели изучения данных с бизнес-задачами | Более обширные наборы данных позволяют совершать новые открытия. Поэтому важно планировать вложения в специалистов, организацию и инфраструктуру исходя из четко поставленных бизнес-задач, чтобы гарантировать постоянное привлечение инвестиций и финансирование. Чтобы понять, на верном ли Вы пути, спросите себя, каким образом большие данные поддерживают приоритеты бизнеса и ИТ и способствуют достижению важнейших целей. Например, речь может идти о фильтрации веб-журналов для понимания тенденций в интернет-торговле, анализе отзывов заказчиков в социальных сетях и взаимодействия со службой поддержки, а также изучении методов статистической корреляции и их сопоставлении с данными о заказчиках, продукции, производстве и проектировании. Например, речь может идти о фильтрации веб-журналов для понимания тенденций в интернет-торговле, анализе отзывов заказчиков в социальных сетях и взаимодействия со службой поддержки, а также изучении методов статистической корреляции и их сопоставлении с данными о заказчиках, продукции, производстве и проектировании.
|
| Используйте стандарты и руководства, чтобы компенсировать недостаток квалификации | Нехватка навыков является одним из наиболее существенных препятствий на пути к извлечению выгоды из больших данных. Этот риск можно снизить, если внести технологии, планы и решения, связанные с большими данными, в программу управления ИТ. Стандартизация подхода позволит эффективнее управлять расходами и ресурсами. При внедрении решений и стратегий, имеющих отношение к большим данным, необходимо заранее оценить необходимый уровень компетенции и принять меры по устранению недостатков в навыках. Речь может идти об обучении или переобучении существующего персонала, найме новых специалистов или обращении в консалтинговые фирмы. |
| Оптимизируйте передачу знаний с помощью центров повышения квалификации | Используйте центры повышения квалификации для обмена знаниями, наблюдения и управления проектной коммуникацией. Независимо от того, начинаете ли Вы работу с большими данными или продолжаете, расходы на оборудование и ПО следует распределить по всем подразделениям организации. Такой структурированный и систематизированный подход помогает расширить возможности больших данных и повысить уровень зрелости информационной архитектуры в целом. |
| Согласование структурированных и неструктурированных данных приносит наибольшие преимущества | Анализ больших данных сам по себе ценен. Однако Вы сможете извлечь еще большее количество полезных сведений за счет сопоставления и интеграции больших данных низкой плотности с уже используемыми структурированными данными. Неважно, какие данные Вы собираете — данные о заказчиках, продукции, оборудовании или окружающей среде — цель состоит в том, чтобы добавить больше релевантных единиц информации в эталонные и аналитические сводки и обеспечить более точные выводы. Не забывайте, что процессы и модели больших данных могут выполняться и разрабатываться как человеком, так и машинами. Аналитические возможности больших данных включают статистику, пространственный анализ, семантику, интерактивное изучение и визуализацию. Использование аналитических моделей позволяет соотносить различные типы и источники данных, чтобы устанавливать связи и извлекать полезные сведения. |
| Обеспечение производительности лабораторий по изучению данных |
Обнаружение полезных сведений в данных не всегда обходится без сложностей. Иногда мы даже не знаем, что именно ищем. Это нормально. Руководство и специалисты по ИТ должны с пониманием относиться к отсутствию четкой цели или требований. В то же время специалисты по анализу и изучению данных должны тесно сотрудничать с коммерческими подразделениями, чтобы ясно представлять, в каких областях имеются пробелы и каковы требования бизнеса. Чтобы обеспечить интерактивное исследование данных и возможность экспериментов со статистическими алгоритмами, необходимы высокопроизводительные рабочие среды. Убедитесь, что в тестовых средах есть доступ ко всем необходимым ресурсам и что они надлежащим образом контролируются. |
| Согласование с облачной операционной моделью | Технологии больших данных требуют доступа к широкому набору ресурсов для итеративных экспериментов и текущих производственных задач. Решения для больших данных охватывают все области деятельности, включая транзакции, основные, эталонные и сводные данные. Тестовые среды для анализа должны создаваться по требованию. Управление распределением ресурсов играет критически важную роль в обеспечении контроля за всем потоком данных, включая предварительную и последующую обработку, интеграцию, обобщение в базе данных и аналитическое моделирование. Правильно спланированная стратегия предоставления ресурсов для частных и общедоступных облаков и обеспечения безопасности имеет ключевое значение при поддержке этих меняющихся требований. Правильно спланированная стратегия предоставления ресурсов для частных и общедоступных облаков и обеспечения безопасности имеет ключевое значение при поддержке этих меняющихся требований. |
 Например, важно различать отношение всех заказчиков от отношения наиболее ценных заказчиков. Именно поэтому многие организации рассматривают большие данные как неотъемлемую часть существующего набора средств бизнес-анализа, платформ хранения данных и информационной архитектуры.
Например, важно различать отношение всех заказчиков от отношения наиболее ценных заказчиков. Именно поэтому многие организации рассматривают большие данные как неотъемлемую часть существующего набора средств бизнес-анализа, платформ хранения данных и информационной архитектуры.
Принципы работы с большими данными, парадигма MapReduce / Хабр
Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
И даже такие:
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро./2016-02/01_16/13182899/Direktor_informacionnoj_sluzhby_(CIO.RU)_Bez_imeni-1_(8747).jpg)
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Решение:
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1]), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Второй пример взят из реальной практики Data-Centric Alliance.
Задача: имеется csv-лог рекламной системы вида:
<user_id>,<country>,<city>,<campaign_id>,<creative_id>,<payment></p>
11111,RU,Moscow,2,4,0. 3
22222,RU,Voronezh,2,3,0.2
13413,UA,Kiev,4,11,0.7
…
 3
22222,RU,Voronezh,2,3,0.2
13413,UA,Kiev,4,11,0.7
…
3
22222,RU,Voronezh,2,3,0.2
13413,UA,Kiev,4,11,0.7
…
Необходимо рассчитать среднюю стоимость показа рекламы по городам России.
Решение:
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Резюме
В статье мы рассмотрели несколько вводных моментов про большие данные:
· Что такое Big Data и откуда берётся;
· Каким основным принципам следуют все средства и парадигмы работы с большими данными;
· Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена.
Первая статья была больше теоретической, во второй статье мы перейдем к практике, рассмотрим Hadoop – одну из самых известных технологий для работы с большими данными и покажем, как запускать MapReduce-задачи на Hadoop.
В последующих статьях цикла мы рассмотрим более сложные задачи, решаемые при помощи MapReduce, расскажем об ограничениях MapReduce и о том, какими инструментами и техниками можно обходить эти ограничения.
Спасибо за внимание, готовы ответить на ваши вопросы.
Youtube-Канал автора об анализе данных
Ссылки на другие части цикла:
Часть 2: Hadoop
Часть 3: Приемы и стратегии разработки MapReduce-приложений
Часть 4: Hbase
Обзор технологии «большие данные» (Big Data) и программно-аппаратных средств, применяемых для их анализа и обработки Текст научной статьи по специальности «Компьютерные и информационные науки»
3. Сашурин А.Д. Формирование центров техногенных катастроф в зоне интенсивной добычи полезных ископаемых // Горнодобывающая промышленность Арктики, Тронхейм, Норвегия, 1996. С. 201-206. (Формирование техногенных катастроф в районах интенсивной добычи полезных ископаемых).
TECHNOLOGY REVIEW «BIG DATA» AND SOFTWARE FACILITIES APPLICABLE FOR IT ANALYSIS AND PROCESSING Nazarenko Yu.L. (Russian Federation) Email: Nazarenko431 @scientifictext.ru
Nazarenko Yuri Leonidovich — Student, DEPARTMENT OF INFORMATICS AND COMPUTER SCIENCE, DON STATE TECHNICAL UNIVERSITY, ROSTOV-ON-DON
Abstract: the article is devoted to the review of the technology of large data (Big Data) and its features. The main characteristics that allow to distinguish this technology among others, the principles of working with it, allowing to conduct the analysis as efficiently as possible are presented. The necessity of using and promising application of Big Data technologies is grounded, the results of using this technology are considered. The analysis of existing software and hardware used for analysis and processing of large data such as Hadoop, MadReduce and NoSQL is carried out, their advantages and features are highlighted.
The main characteristics that allow to distinguish this technology among others, the principles of working with it, allowing to conduct the analysis as efficiently as possible are presented. The necessity of using and promising application of Big Data technologies is grounded, the results of using this technology are considered. The analysis of existing software and hardware used for analysis and processing of large data such as Hadoop, MadReduce and NoSQL is carried out, their advantages and features are highlighted.
Keywords: large data, big data, Hadoop, MapReduce, NoSQL, statistical analysis, scalability.
ОБЗОР ТЕХНОЛОГИИ «БОЛЬШИЕ ДАННЫЕ» (BIG DATA) И ПРОГРАММНО-АППАРАТНЫХ СРЕДСТВ, ПРИМЕНЯЕМЫХ ДЛЯ ИХ АНАЛИЗА И ОБРАБОТКИ Назаренко Ю.Л. (Российская Федерация)
Назаренко Юрий Леонидович — студент, факультет информатики и вычислительной техники, Донской государственный технический университет, г. Ростов-на-Дону
Ростов-на-Дону
Аннотация: статья посвящена обзору технологии «большие данные» (Big Data) и её особенностей. Приведены основные характеристики, позволяющие выделить эту технологию среди прочих, принципы работы с ней, позволяющие проводить анализ максимально эффективно. Обоснованы необходимость использования и перспективность применения технологий Big Data, рассмотрены результаты применения этой технологии. Проведен анализ существующих программно-аппаратных средств, использующихся для анализа и обработки больших данных, таких как Hadoop, MapReduce и NoSQL, выделены их преимущества и особенности. Ключевые слова: большие данные, Big Data, Hadoop, MapReduce, NoSQL, статистический анализ, масштабируемость.
Введение. Большие данные (англ. big data) — совокупность подходов, инструментов и методов обработки структурированных неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста,
распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence [1].
В широком смысле о «больших данных» говорят как о социально-экономическом феномене, связанном с появлением технологических возможностей анализировать огромные массивы данных, в некоторых проблемных областях — весь мировой объём данных, и вытекающих из этого трансформационных последствий.
Что такое Big Data. Цифровые технологии присутствуют во всех областях жизни человека. Объем записываемых в мировые хранилища данных ежесекундно растет, а это означает, что такими же темпами должны изменяться условия хранения информации и появляться новые возможности для наращивания ее объема.
Согласно исследованию IDC Digital Universe, в ближайшие пять лет объем данных на планете вырастет до 40 зеттабайтов, то есть к 2020 году на каждого живущего на Земле человека будет приходиться по 5200 Гб. График роста показан на рисунке 1.
Известно, что основной поток информации генерируют не люди. Источником служат роботы, находящиеся в постоянном взаимодействии друг с другом. Это приборы для мониторинга, сенсоры, системы наблюдения, операционные системы персональных устройств, смартфоны, интеллектуальные системы, датчики и прочее. Все они задают бешеный темп роста объема данных, что приводит к появлению потребности наращивать количество рабочих серверов (и реальных, и виртуальных) — как следствие, расширять и внедрять новые data-центры.
Источником служат роботы, находящиеся в постоянном взаимодействии друг с другом. Это приборы для мониторинга, сенсоры, системы наблюдения, операционные системы персональных устройств, смартфоны, интеллектуальные системы, датчики и прочее. Все они задают бешеный темп роста объема данных, что приводит к появлению потребности наращивать количество рабочих серверов (и реальных, и виртуальных) — как следствие, расширять и внедрять новые data-центры.
По сути, большие данные — довольно условное и относительное понятие. Самое распространенное его определение — это набор информации, по объему превосходящей жесткий диск одного персонального устройства и не поддающейся обработке классическими инструментами, применяемыми для меньших объемов.
Рис. 1. Рост Big Data к 2020 году, прогноз IDC Digital Universe от 2012 года
Характеристики больших данных. Есть характеристики, которые позволяют отнести информацию и данные именно к Big Data. То есть не все данные могут быть пригодны для аналитики. В этих характеристиках как раз и заложено ключевое понятие биг дата. Все они умещаются в три V.
Есть характеристики, которые позволяют отнести информацию и данные именно к Big Data. То есть не все данные могут быть пригодны для аналитики. В этих характеристиках как раз и заложено ключевое понятие биг дата. Все они умещаются в три V.
1. Объем (от англ. volume). Данные измеряются в величине физического объема «документа», подлежащего анализу;
2. Скорость (от англ. velocity). Данные не стоят в своем развитии, а постоянно прирастают, именно поэтому и требуется их быстрая обработка для получения результатов;
3.Многообразие (от англ. variety). Данные могут быть не одноформатными. То есть могут быть разрозненными, структурированным или структурированными частично.
Однако периодически к VVV добавляют и четвертую V (veracity — достоверность/правдоподобность данных) и даже пятую V (в некоторых вариантах это — viability — жизнеспособность, в других же это — value — ценность).
Принципы работы с большими данными. Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много — любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных — в 2 раза увеличили количество железа в кластере и всё продолжило работать [2].
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин. Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом — расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных — по возможности обрабатываем данные на той же машине, на которой их храним.
Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом — расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных — по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того чтобы им следовать — необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных.
Техники и методы анализа, применимые к Big Data:
• Data Mining;
• Краудсорсинг;
• Смешение и интеграция данных;
• Машинное обучение;
• Искусственные нейронные сети;
• Распознавание образов;
• Прогнозная аналитика;
• Имитационное моделирование;
• Пространственный анализ;
• Статистический анализ;
• Визуализация аналитических данных.
Горизонтальная масштабируемость, которая обеспечивает обработку данных — базовый принцип обработки больших данных. Данные распределены на вычислительные узлы, а обработка происходит без деградации производительности. Таблица эффективности работы с технологией Big Data изображена на рисунке 2.
Степень использования низкая Q средняя Ц высокая
Ввдео Изображения Текст’чнолд
Банковский сектор
Страхование
Ценные бумаги и инвестиции
Производство
Розничная торговля
Оптовая торговля
Профессиональные услуги
Развлекательные услуги
Здравоохранение
Транспортные услуги
СМИ
Коммунальные услуги
Рис.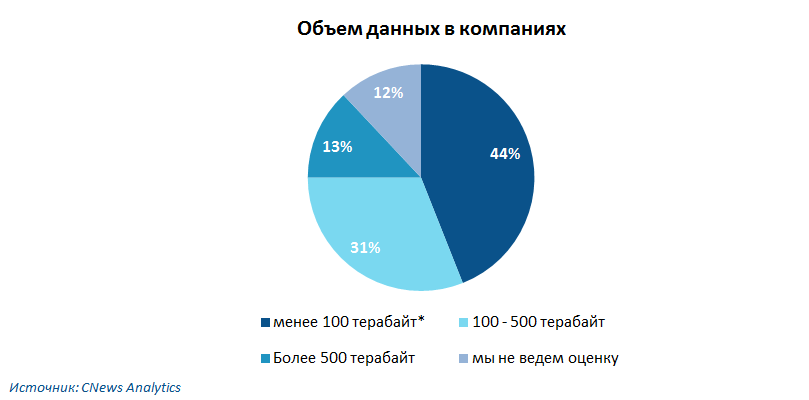 2. Превалирующие типы информации для разных сфер деятельности
2. Превалирующие типы информации для разных сфер деятельности
Технологии анализа и работы с большими данными. Большинство аналитиков относит к технологиям обработки и анализа больших данных следующие средства:
• MapReduce •Hadoop
• NoSQL
MapReduce — это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах.
Мар{) Shuffle ReduceQ
Рис. 3. Общая схема работы MapReduce
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map./big-data-1667184-06573145744d4f44b5ad83ba779ec86a.jpg) На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в
На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в
предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования — пользовательская функция применяется к каждой входной записи.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» — каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce(). Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.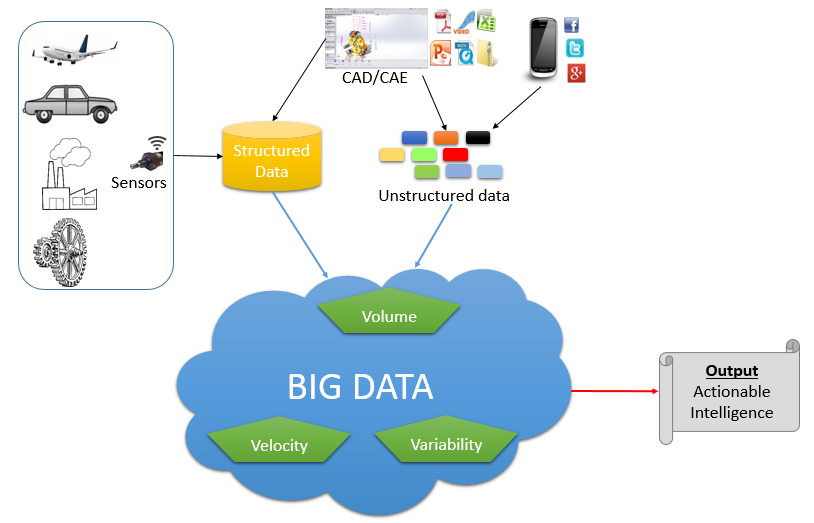
Hadoop. Главные задачи платформы Hadoop — хранение, обработка и управление данными [3].
Основными составляющими платформы Hadoop являются:
• отказоустойчивая распределенная файловая система Hadoop Distributed File System (HDFS), при помощи которой осуществляется хранение;
• программный интерфейс Map Reduce, который является основой для написания приложений, обрабатывающих большие объемы структурированных и неструктурированных данных параллельно на кластере, состоящем из тысяч машин;
• Apache Hadoop YARN, выполняющий функцию управления данными.
Впервые о технологии Hadoop заговорили в 2007 г. и с каждым годом интерес к
ней все больше возрастает. Это отражает индекс цитируемости Google.
Это отражает индекс цитируемости Google.
Преимущества решения на базе Hadoop
• Снижение времени на обработку данных.
• Снижение стоимости оборудования.
• Повышение отказоустойчивости. Технология позволяет построить отказоустойчивое решение.
• Линейная масштабируемость.
• Работа с неструктурированными данными.
NoSQL. Традиционные СУБД ориентируются на требования ACID к транзакционной системе: атомарность, согласованность, изолированность (англ. isolation), надёжность (англ. durability), тогда как в NoSQL вместо ACID может рассматриваться набор свойств BASE:
• базовая доступность (англ. basic availability) — каждый запрос гарантированно завершается (успешно или безуспешно).
basic availability) — каждый запрос гарантированно завершается (успешно или безуспешно).
• гибкое состояние (англ. soft state) — состояние системы может изменяться со временем, даже без ввода новых данных, для достижения согласования данных.
• согласованность в конечном счёте (англ. eventual consistency) — данные могут быть некоторое время рассогласованы, но приходят к согласованию через некоторое время.
Решения NoSQL отличаются не только проектированием с учётом масштабирования. Другими характерными чертами NoSQL-решений являются:
• Применение различных типов хранилищ.
• Возможность разработки базы данных без задания схемы.
• Линейная масштабируемость (добавление процессоров увеличивает производительность).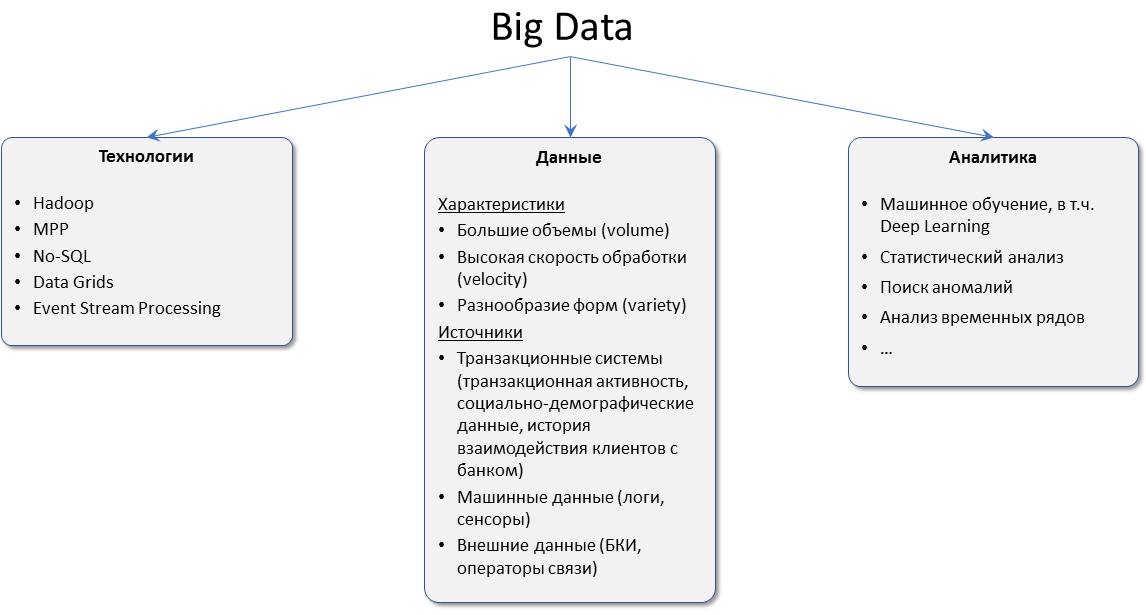
• Инновационность: «не только SQL» открывает много возможностей для хранения и обработки данных.
Критика Big Data
Хранение Big Data не всегда приводит к получению выгоды.
Хранение огромного количества данных, описывающих некоторые легко наблюдаемые события, не всегда приводит к выгодному пониманию реальности.
Это в равной мере относится к анализу акций, каналов twitter, медицинских данных, данных CRM, или мониторингу комплекса оборудования для диагностического обслуживания.
Например, достоверный список потенциальных покупателей товаров, наряду с демографической информацией, а также информацией о чистой стоимости товаров, могут быть гораздо более ценными для поставщиков, чем массивное хранилище данных о кликах на различных сайтах онлайн-магазинов.
При мониторинге работы электростанций, было установлено, что обращение внимания именно на определенные фрагменты информации и на изменения, которые происходят в некоторых параметрах (или их комбинациях), более информативны для последующего представления, чем мониторинг тысячи параметров потоков данных за каждую секунду.
Скорость обновления данных и «актуальный» временной интервал. Например, для поставщиков домашней фурнитуры, было бы важнее получить «сигнал» за месяц или два перед тем, как осуществится покупка жилья, вместо информации в режиме реального времени уже после покупки, когда потенциальный клиент просматривает различные Интернет-сайты в поисках фурнитуры.
Выводы. Анализ и обработка больших данных — непростая и комплексная задача, требующая для решения особых инструментов и больших вычислительных возможностей. В их основе лежат математические алгоритмы, теория вероятностей и многие другие инструменты, которые при применении к большим данным могут принести больше плоды тем, кто не обошёл вниманием это относительно новое явление в информационном интернет -пространстве. Учитывая стремительный рост объёма больших данных, можно с достаточной уверенностью предполагать, что направления науки, связанные с их анализом, не потеряют актуальность в обозримом будущем.
Учитывая стремительный рост объёма больших данных, можно с достаточной уверенностью предполагать, что направления науки, связанные с их анализом, не потеряют актуальность в обозримом будущем.
Список литературы /References
1. Большие данные // Википедия, 2017. [Электронный ресурс]. Режим доступа: http://ru.wikipedia.org/?oldid=87934960/ (дата обращения: 29.09.2017).
2. Медетов А.А. Термин Big Data и способы его применения // Молодой ученый,
2016. № 11. С. 207-210.
3. Иванов П.Д., Вампилов В.Ж. Технологии Big Data и их применение на современном промышленном предприятии. Инженерный журнал: Наука и инновации, 2014. Вып. 8.
Список литературы на английском языке /References in English
1. Big data, 2017, October 13. In Wikipedia. The Free Encyclopedia. Retrieved October 29,
Big data, 2017, October 13. In Wikipedia. The Free Encyclopedia. Retrieved October 29,
2017. [Electronic resource]. URL: https://en.wikipedia.org/w/index.php?title=Big_data& oldid=805135614/ (date of access: 29.09.2017).
2. Medetov A.A. The term Big Data and the methods of its application // Young scientist, 2016. № 11. P. 07-210.
3. Ivanov P.D., Vampilov V.Zh. Big Data technologies and their application to modern industrial enterprise. Engineering Journal: Science and innovation, 2014. Vol. 8.
Большие Данные = большая проблема?
Рис. 1. Работа данных в rDBMS-системе
Термин NoSQL расшифровывается как Not Only SQL (не только SQL). На сегодняшний момент существует большое количество таких систем, но все они, как правило, обладают следующими характеристиками:
- гибкость использования: у подобных систем отсутствуют требования к наличию схемы данных, а в качестве модели хранения выступает JSON1;
- встроенные возможности горизонтального масштабирования и параллельной обработки;
- возможность быстрого получения первых результатов.

Сравним типичный сценарий работы с данными в RDBMS (Relational Database Management System, реляционная СУБД) и в NoSQL-системе. В случае с RDBMS необходимо разработать схему хранения данных. Кроме того, перед загрузкой в СУБД данные должны быть очищены и преобразованы в требуемые форматы, только после этого ими можно будет воспользоваться через язык SQL-запросов. Таким образом, необходимо пройти как минимум шесть этапов (причем трансформация и загрузка данных могут быть весьма длительными и трудоемкими процессами), прежде чем появятся первые результаты (см. рис. 1).
Рис. 2. Работа данных в noSqL-системе
В случае с NoSQL ситуация выглядит значительно проще: после поступления данных в хранилище система уже готова к работе, конечно, при условии что у вас есть готовая программа обработки (см. рис. 2).
Все NoSQL-системы при всем их многообразии можно разделить на два больших класса. Во-первых, это различные виды NoSQL Key/Value Database, или NoSQL базы данных. Типичными представителями этого класса систем являются такие проекты, как MongoDB, Cassandra или HBase. Все они представляют собой разновидность баз данных, хранящих информацию в виде пар «ключ–значение» и не имеющих жесткой схемы данных. Как правило, подобные продукты горизонтально масштабируются (объединяются в кластер из однотипных недорогих узлов) и имеют встроенные средства защиты от выхода из строя отдельных компонент
Типичными представителями этого класса систем являются такие проекты, как MongoDB, Cassandra или HBase. Все они представляют собой разновидность баз данных, хранящих информацию в виде пар «ключ–значение» и не имеющих жесткой схемы данных. Как правило, подобные продукты горизонтально масштабируются (объединяются в кластер из однотипных недорогих узлов) и имеют встроенные средства защиты от выхода из строя отдельных компонент
кластера. Их удобно использовать в условиях постоянно изменяющейся (или вообще неопределенной) структуры данных.
Постепенно пришло осознание того, что реляционные СУБД не являются оптимальным решением для ряда ситуаций, а это привело к появлению семейства решений, которые можно классифицировать одним словом – NoSQL-системы
Например, БД NoSQL часто используют для сбора и хранения информации в социальных сетях. Поскольку приложения, с которыми работают пользователи, очень быстро меняются, структуру данных делают максимально простой: вместо того чтобы разрабатывать схему данных со связями между сущностями, создают структуры, содержащие основной ключ для идентификации данных и привязанное к нему содержимое. Такие оптимизированные и динамические структуры позволяют проводить изменения, не выполняя сложную и дорогую реорганизацию на уровне хранилища.
Такие оптимизированные и динамические структуры позволяют проводить изменения, не выполняя сложную и дорогую реорганизацию на уровне хранилища.
Более подробно о базах данных NoSQL и особенностях работы с ними мы расскажем в отдельной статье этого номера, поэтому здесь на них останавливаться не будем. Следует лишь отметить, что эти решения хорошо подходят для систем, нагрузка на которые схожа с OLTP.
Вторым большим классом NoSQL-систем являются проекты, обеспечивающие горизонтально масштабируемую платформу для хранения и параллельной обработки данных. Они больше подходят для задач с «тяжелыми» запросами, свойственными DWH (Data Warehouse) или бизнес-аналитике. Наиболее популярным и известным проектом является Apache Hadoop, состав и принципы работы которого мы рассмотрим более подробно.
Маленький «слон» для Больших Данных
Не вдаваясь глубоко в технические подробности, можно сказать, что Hadoop состоит из двух основных компонент: распределенной кластерной системы Hadoop Distributed File System (HDFS) и программного интерфейса Map/Reduce. На основе HDFS и Map/Reduce разработан ряд продуктов (см. рис. 3).
На основе HDFS и Map/Reduce разработан ряд продуктов (см. рис. 3).
Чтобы оценить достоинства, которыми обладает Hadoop, необходимо хорошо понимать принципы работы его компонент. Рассмотрим архитектуру решения более подробно.
HDFS представляет собой распределенную, линейно-масштабируемую и устойчивую к отказам кластерную файловую систему. Фактически это кластер из множества однотипных узлов хранения данных с внутренними дисками, объединенных общей LAN. Кроме узлов хранения (Data Nodes), в кластере присутствует специальный узел, ответственный за управление и хранение метаинформации о HDFS (Name Node).
Запись в HDFS осуществляется блоками по 64 MБ. Такой большой размер обусловлен тем, что HDFS изначально спроектирована для хранения и обработки весьма значительного объема данных. Запись блоков данных по узлам кластера происходит равномерно, причем каждый блок имеет, как минимум, одну копию данных на другом узле (см. рис. 4).
Рис. 3. Семейство продуктов Hadoop
3. Семейство продуктов Hadoop
Таким образом, HDFS защищена от выхода из строя любого из узлов кластера (за исключением Name Node, который надо резервировать). Количество резервных копий блоков данных можно увеличивать, тем самым добиваясь отказоустойчивости двух или более узлов кластера одновременно. При добавлении нового узла в HDFS-кластер происходит автоматическое перераспределение блоков данных с учетом новой топологии, при этом емкость HDFS также увеличивается автоматически, не требуя каких-либо действий со стороны администратора.
Как следует из вышесказанного, HDFS сама по себе не представляет ничего революционного. Самое интересное начинается при использовании связки HDFS и программного интерфейса Map/Reduce.
Рис. 4. Hadoop HDfS
При разработке Map/Reduce предполагалось создать технологию, способную за ограниченное время обрабатывать огромные объемы данных. Дело в том, что классическая парадигма сервера(-ов), имеющих совместный доступ к центральному хранилищу данных, перестает работать при их неограниченном объеме, поскольку вертикальное масштабирование серверов, массивов и каналов передачи данных ограничено. Была необходима система, масштабируемая горизонтально и не требующая передачи всех данных счетным узлам. Именно таким образом и спроектирован Map/Reduce.
Была необходима система, масштабируемая горизонтально и не требующая передачи всех данных счетным узлам. Именно таким образом и спроектирован Map/Reduce.
Основные принципы, заложенные в программный интерфейс Map/Reduce, можно сформулировать следующим образом:
- не данные передаются программе обработки, а программа – данным;
- данные всегда обрабатываются параллельно;
- параллельность обработки заложена архитектурно в программном интерфейсе Map/Reduce и не требует дополнительного кодирования от разработчика.
В этой системе запрос на обработку данных представляет собой небольшую программу. По умолчанию она написана на языке Java, но фактически можно использовать любой язык программирования.
Своим названием программный интерфейс Map/Reduce обязан двум основным задачам, которые всегда выполняются при запуске в нем любого задания. Для того чтобы наглядно представить принципы его работы, рассмотрим задачу тарификации абонентов вымышленного оператора сотовой связи MR Telecom. Предположим, что все данные о разговорах абонентов наш сотовый оператор помещает в директорию /calls, куда также попадают сообщения об ошибках и прочая информация. Для выставления счетов абонентам надо подсчитать общее время исходящих звонков для каждого номера. Таким образом, оператора интересуют записи вида «001 1234567 7654321 00:05:14», где первое поле – внутренний номер, второе – номер звонившего абонента, третье – номер вызываемого абонента и, наконец, четвертое – длительность разговора.
Предположим, что все данные о разговорах абонентов наш сотовый оператор помещает в директорию /calls, куда также попадают сообщения об ошибках и прочая информация. Для выставления счетов абонентам надо подсчитать общее время исходящих звонков для каждого номера. Таким образом, оператора интересуют записи вида «001 1234567 7654321 00:05:14», где первое поле – внутренний номер, второе – номер звонившего абонента, третье – номер вызываемого абонента и, наконец, четвертое – длительность разговора.
Рис. 5. Принцип работы Map/Reduce
Для решения этой задачи создается небольшая программа, реализующая два метода. Первый – метод Map, который из потока данных на входе выбирает нужные записи и производит агрегацию значений по ключу. В нашем случае ключом служит номер звонившего абонента, а значением – длительность разговора. После работы Map оператор получает ряд ключей с массивом значений для каждого из них (см. рис. 5).
После этого данные обрабатываются методом Reduce. Он выполняет агрегацию значений ключа, в нашем случае просто суммируя время разговоров по каждому номеру. На выходе оператор имеет список абонентов с суммарным временем разговора (см. рис. 5).
Он выполняет агрегацию значений ключа, в нашем случае просто суммируя время разговоров по каждому номеру. На выходе оператор имеет список абонентов с суммарным временем разговора (см. рис. 5).
Самое интересное, что программный интерфейс Map/Reduce самостоятельно передает и одновременно запускает эту программу на узлах кластера, хранящих обрабатываемые данные. Так как HDFS равномерно распределяет данные по всем узлам, скорее всего, будут задействованы все доступные серверы кластера. Далее результаты работы от всех узлов агрегируются методом Reduce и передаются пользователю.
Таким образом, вместо привычной концепции «база данных и сервер» у нас имеется кластер из множества недорогих узлов, каждый узел которого является и хранилищем, и обработчиком данных, а само понятие «база данных» отсутствует.
Стоит отметить, что подобная система обладает двумя важными характеристиками. Во-первых, любой сколь угодно сложный анализ большого объема данных сводится к их обработке на локальных дисках сервера, поэтому максимально возможное время реакции хорошо прогнозируемо. Во-вторых, система масштабируется симметрично и линейно – при добавлении новых узлов возрастают и вычислительная мощность, и дисковая емкость, поэтому время обработки данных не зависит от их объема.
Во-вторых, система масштабируется симметрично и линейно – при добавлении новых узлов возрастают и вычислительная мощность, и дисковая емкость, поэтому время обработки данных не зависит от их объема.
Табл. 1. Сравнение rDBMS с Hadoop
Как видно из описания, система на базе Hadoop выглядит очень привлекательно, и идея заменить дорогие серверы с не менее дорогими прикладным обеспечением и системой хранения данных на доступный кластер со свободно распространяемым ПО возникла у многих специалистов. Но, разумеется, все не так радужно, как выглядит на первый взгляд, иначе бы мы наблюдали повсеместное внедрение Hadoop-систем во всех DWH-проектах.
Тест на сообразительность
По сравнению с RDBMS (особенно с параллельными) Hadoop имеет два недостатка. Первый очевиден: интерфейс Map/Reduce не совместим с SQL1, поэтому приложение для работы с Hadoop придется переписывать. Второй проблемой является то, что, несмотря на все возможности параллельной обработки данных, по производительности Hadoop проигрывает существующим решениям на базе параллельных RDBMS. Этот вопрос долгое время был предметом жарких дискуссий между сторонниками и противниками RDBMS, пока группа известных специалистов по базам данных во главе с Майклом Стоунбрейкером и Дэвидом Девиттом не провела ряд испытаний, результаты которых были приведены в статье «A Comparison of Approaches to Large-Scale Data Analysis».
Этот вопрос долгое время был предметом жарких дискуссий между сторонниками и противниками RDBMS, пока группа известных специалистов по базам данных во главе с Майклом Стоунбрейкером и Дэвидом Девиттом не провела ряд испытаний, результаты которых были приведены в статье «A Comparison of Approaches to Large-Scale Data Analysis».
Результаты тестов были довольно неутешительны для сторонников новых технологий. Система Hadoop сравнивалась с параллельными RDBMS Vertica и СУБД-Х, которые по итогам продемонстрировали существенное превосходство в производительности над Hadoop при выполнении ряда тестовых задач анализа данных большого объема. В среднем для всех пяти задач на кластере из 100 узлов СУБД-X оказалась в 3,2 раза быстрее Hadoop, а Vertica – в 2,3 раза быстрее СУБД-X.
По мнению авторов тестов, преимущество в производительности, свойственное обеим системам баз данных, является результатом применения ряда технологий, разработанных в последние 25 лет. Это индексы в виде B-деревьев, ускоряющие выполнение операций выборки, новые механизмы хранения данных (например, поколоночное хранение), эффективные методы сжатия данных с возможностью выполнять операции прямо над ними и сложные параллельные алгоритмы для выполнения запросов над большими объемами реляционных данных.
Табл. 2. Сравнение rDBMS с noSqL-системами
В случае Hadoop система вынуждена всегда начинать выполнение запроса с просмотра всего входного набора данных, реализуя задачу, схожую с ETL-процессом (Extract, Transform and Load), которая в RDBMS уже выполнена. Но, хотя авторы не были удивлены относительным превосходством в производительности двух параллельных систем баз данных, на них произвела впечатление сравнительная простота установки и использования Hadoop.
После спада шумихи вокруг Hadoop стало ясно, что «серебряной пули» все-таки нет, и новые технологии имеют не только преимущества, но и недостатки. Краткий перечень «за» и «против» использования Hadoop приведен в табл. 1, и ИТ-специалисты должны сами решить, в каком случае применять (или не применять) Hadoop.
Большое будущее
Несмотря на множество проблем, которые могут возникнуть при применении NoSQL-технологий, одно можно сказать совершенно определенно – реляционные СУБД теперь не являются единственным средством работы с данными.
Множество решений, связанных с обработкой больших объемов данных, в ближайшее время будут использовать как реляционные СУБД, так и NoSQL-технологии, которые дополняют возможности друг друга
Это не значит, что СУБД вдруг устарели и будут вытеснены новыми прогрессивными NoSQL-системами. Более того, реляционные СУБД будут оставаться доминирующей технологией в OLTP-системах и во всех небольших и средних DWH-решениях в обозримом будущем. В то же время множество решений, связанных с обработкой больших объемов данных, в ближайшее время будут использовать как реляционные СУБД, так и NoSQL-технологии, которые дополняют возможности друг друга (см. табл. 2).
Со временем более отчетливо будет видна та ниша, где применение NoSQL является наиболее эффективным и органичным. Уже сейчас есть несколько областей, где использование этой технологии имеет вполне радужные перспективы. Специалисты, которые проводили сравнительное тестирование Hadoop с параллельными СУБД, в 2010 году опубликовали статью с красноречивым названием «MapReduce and Parallel DBMSs: Friends or Foes?» («MapReduce и параллельные СУБД: друзья или враги?»), где отметили как минимум пять таких областей.
ETL и наборы данных, читаемые только единожды
Каноническое использование Hadoop характеризуется шаблоном из пяти операций:
- чтение журнальной информации из нескольких разных источников;
- разбор и очистка журнальных данных;
- выполнение сложных преобразований;
- принятие решения о том, какие атрибутивные данные следует сохранить;
- загрузка информации в СУБД или другую СХД.
Эти шаги аналогичны фазам извлечения, преобразования и загрузки в системах ETL. Hadoop, по сути, создает из необработанных данных полезную информацию, которая потребляется другой системой хранения. Поэтому решение можно считать параллельной системой ETL общего назначения. Она является хорошей унифицированной заменой различным подсистемам очистки и загрузки данных, зачастую разрабатываемым компаниями самостоятельно.
Несмотря на проблемы, которые могут возникнуть при применении NoSQL-технологий, ясно одно – реляционные СУБД не являются единственным средством работы с данными
Сложная аналитика. Во многих приложениях интеллектуального анализа (Data Mining) и кластеризации данных программе приходится производить несколько проходов по данным. Для этого требуется сложная программа обработки потоков информации, в которой выходные данные одной части приложения являются входными данными другой его части. Hadoop является хорошим кандидатом для реализации таких приложений.
Во многих приложениях интеллектуального анализа (Data Mining) и кластеризации данных программе приходится производить несколько проходов по данным. Для этого требуется сложная программа обработки потоков информации, в которой выходные данные одной части приложения являются входными данными другой его части. Hadoop является хорошим кандидатом для реализации таких приложений.
Работа с частично структурированными данными
В отличие от СУБД, NoSQL-системам не требуется, чтобы пользователи определяли схемы своих данных. Поэтому они легко сохраняют и обрабатывают так называемые частично структурированные данные. В этом ключе потенциальными пользователями NoSQL-технологий являются различные интернет-проекты, специфика которых, как правило, подразумевает работу именно с такой информацией.
Анализ на скорую руку
Одним из недостатков многих современных параллельных СУБД является то, что их трудно должным образом устанавливать и конфигурировать. Пользователи часто сталкиваются с мириадами параметров настройки, которые необходимо корректно установить, чтобы добиться эффективной работы системы. После установки и правильного конфигурирования СУБД программисты должны определить схему своих данных (если она еще не существует), а затем загрузить данные в систему. Этот процесс длится значительно дольше, чем в Hadoop, потому что СУБД должна разобрать и проверить в загружаемых кортежах каждый элемент данных. NoSQL- программисты же по умолчанию (значит, чаще всего) загружают свои данные путем их простого копирования в распределенную блочную систему хранения, на которой основывается система Map/Reduce. Соответственно, если вам нужно выполнить единичный анализ текущих данных, предпочтительнее модель NoSQL со своим небольшим временем раскрутки.
Пользователи часто сталкиваются с мириадами параметров настройки, которые необходимо корректно установить, чтобы добиться эффективной работы системы. После установки и правильного конфигурирования СУБД программисты должны определить схему своих данных (если она еще не существует), а затем загрузить данные в систему. Этот процесс длится значительно дольше, чем в Hadoop, потому что СУБД должна разобрать и проверить в загружаемых кортежах каждый элемент данных. NoSQL- программисты же по умолчанию (значит, чаще всего) загружают свои данные путем их простого копирования в распределенную блочную систему хранения, на которой основывается система Map/Reduce. Соответственно, если вам нужно выполнить единичный анализ текущих данных, предпочтительнее модель NoSQL со своим небольшим временем раскрутки.
Производственная эксплуатация при ограниченном бюджете
Eще одним достоинством систем NoSQL является то, что почти все они созданы в проектах Open Source и доступны бесплатно. СУБД, в частности параллельные, стоят недешево. И если корпоративные пользователи с высоким уровнем потребностей и большим бюджетом могут позволить себе коммерческую систему и все инструментальные средства, то бизнес с более умеренными бюджетом и уровнем требований зачастую предпочитает системы с открытыми исходными текстами. Поэтому для компаний так называемого среднего уровня вариант аналитической системы на базе NoSQL выглядит достаточно привлекательно.
СУБД, в частности параллельные, стоят недешево. И если корпоративные пользователи с высоким уровнем потребностей и большим бюджетом могут позволить себе коммерческую систему и все инструментальные средства, то бизнес с более умеренными бюджетом и уровнем требований зачастую предпочитает системы с открытыми исходными текстами. Поэтому для компаний так называемого среднего уровня вариант аналитической системы на базе NoSQL выглядит достаточно привлекательно.
Что такое Big Data и почему их называют «новой нефтью» :: РБК Тренды
Big Data Analytics — как анализируют большие данные?
Благодаря высокопроизводительным технологиям — таким, как грид-вычисления или аналитика в оперативной памяти, компании могут использовать любые объемы больших данных для анализа. Иногда Big Data сначала структурируют, отбирая только те, что нужны для анализа. Все чаще большие данные применяют для задач в рамках расширенной аналитики, включая искусственный интеллект.
Выделяют четыре основных метода анализа Big Data [4]:
1. Описательная аналитика (descriptive analytics) — самая распространенная. Она отвечает на вопрос «Что произошло?», анализирует данные, поступающие в реальном времени, и исторические данные. Главная цель — выяснить причины и закономерности успехов или неудач в той или иной сфере, чтобы использовать эти данные для наиболее эффективных моделей. Для описательной аналитики используют базовые математические функции. Типичный пример — социологические исследования или данные веб-статистики, которые компания получает через Google Analytics.
Антон Мироненков, управляющий директор «X5 Технологии»:
«Есть два больших класса моделей для принятия решений по ценообразованию. Первый отталкивается от рыночных цен на тот или иной товар. Данные о ценниках в других магазинах собираются, анализируются и на их основе по определенным правилам устанавливаются собственные цены.
Второй класс моделей связан с выстраиванием кривой спроса, которая отражает объемы продаж в зависимости от цены. Это более аналитическая история. В онлайне такой механизм применяется очень широко, и мы переносим эту технологию из онлайна в офлайн».
2. Прогнозная или предикативная аналитика (predictive analytics) — помогает спрогнозировать наиболее вероятное развитие событий на основе имеющихся данных. Для этого используют готовые шаблоны на основе каких-либо объектов или явлений с аналогичным набором характеристик. С помощью предикативной (или предиктивной, прогнозной) аналитики можно, например, просчитать обвал или изменение цен на фондовом рынке. Или оценить возможности потенциального заемщика по выплате кредита.
3. Предписательная аналитика (prescriptive analytics) — следующий уровень по сравнению с прогнозной. С помощью Big Data и современных технологий можно выявить проблемные точки в бизнесе или любой другой деятельности и рассчитать, при каком сценарии их можно избежать их в будущем.
Сеть медицинских центров Aurora Health Care ежегодно экономит $6 млн за счет предписывающей аналитики: ей удалось снизить число повторных госпитализаций на 10% [5].
4. Диагностическая аналитика (diagnostic analytics) — использует данные, чтобы проанализировать причины произошедшего. Это помогает выявлять аномалии и случайные связи между событиями и действиями.
Например, Amazon анализирует данные о продажах и валовой прибыли для различных продуктов, чтобы выяснить, почему они принесли меньше дохода, чем ожидалось.
Данные обрабатывают и анализируют с помощью различных инструментов и технологий [6] [7]:
- Cпециальное ПО: NoSQL, MapReduce, Hadoop, R;
- Data mining — извлечение из массивов ранее неизвестных данных с помощью большого набора техник;
- ИИ и нейросети — для построения моделей на основе Big Data, включая распознавание текста и изображений. Например, оператор лотерей «Столото» сделал большие данные основой своей стратегии в рамках Data-driven Organization. С помощью Big Data и искусственного интеллекта компания анализирует клиентский опыт и предлагает персонифицированные продукты и сервисы;
- Визуализация аналитических данных — анимированные модели или графики, созданные на основе больших данных.
 С помощью Big Data и искусственного интеллекта компания анализирует клиентский опыт и предлагает персонифицированные продукты и сервисы;
С помощью Big Data и искусственного интеллекта компания анализирует клиентский опыт и предлагает персонифицированные продукты и сервисы;Примеры визуализации данных (data-driven animation)
Как отметил в подкасте РБК Трендов менеджер по развитию IoT «Яндекс.Облака» Александр Сурков, разработчики придерживаются двух критериев сбора информации:
- Обезличивание данных делает персональную информацию пользователей в какой-то степени недоступной;
- Агрегированность данных позволяет оперировать лишь со средними показателями.

Чтобы обрабатывать большие массивы данных в режиме онлайн используют суперкомпьютеры: их мощность и вычислительные возможности многократно превосходят обычные. Подробнее — в материале «Как устроены суперкомпьютеры и что они умеют».
Big Data и Data Science — в чем разница?
Data Science или наука о данных — это сфера деятельности, которая подразумевает сбор, обработку и анализ данных, — структурированных и неструктурированных, не только больших. В ней используют методы математического и статистического анализа, а также программные решения. Data Science работает, в том числе, и с Big Data, но ее главная цель — найти в данных что-то ценное, чтобы использовать это для конкретных задач.
Большие данные (Big Data) – одна из ключевых технологий будущего
Big Data или по-русски «большие данные», — термин, появившийся совсем недавно – всего шесть лет назад. Но это не значит, что само явление появилось тогда же. Большими данными принято называть огромные массивы информации со сложной неоднородной и\или неопределенной структурой. Иногда о Big Data говорят, как о неструктурированной информации, но это неверно – большие данные всегда имеют структуру, она может быть сложной из-за того, что данные поступают из разных источников и содержат совершенно различные сведения или вовсе неизвестной. То есть, как правило, привести это нагромождение в единую таблицу не представляется возможным.
Большими данными принято называть огромные массивы информации со сложной неоднородной и\или неопределенной структурой. Иногда о Big Data говорят, как о неструктурированной информации, но это неверно – большие данные всегда имеют структуру, она может быть сложной из-за того, что данные поступают из разных источников и содержат совершенно различные сведения или вовсе неизвестной. То есть, как правило, привести это нагромождение в единую таблицу не представляется возможным.
Большие данные хотя и существуют уже несколько лет, ранее не представляли большой ценности, т.к. их обработка и анализ были затруднены – для этого требовались существенные вычислительные мощности, продолжительное временя и финансовые затраты. Все изменилось, когда появилась технология обработки многогигабайтных массивов информации в быстрой оперативной памяти. Прорыв в этой области связывают с выходом на рынок свободно распространяемой платформы Hadoop, включающей библиотеки, утилиты и фреймворки для работы с Big Data. Компоненты Hadoop используются сегодня в большинстве коммерческих платформ и систем таких компаний, как SAP, Oracle, IBM и так далее.
Компоненты Hadoop используются сегодня в большинстве коммерческих платформ и систем таких компаний, как SAP, Oracle, IBM и так далее.
Сегодня термин Big Data, как правило, используется для обозначения не только самих массивов данных, но также инструментов для их обработки и потенциальной пользы, которая может быть получена в результате кропотливого анализа. Главные характеристики, отличающие Big Data от другого рода данных – три V: volume, velocity, variety. Первая – большие объемы, вторая – необходимость в быстрой обработке и высокая скорость накопления этих данных, третье – разнообразие.
Большие данные в ритейле могут состоять из различных сведений о потребителях, истории их покупок, детальной информации с каждого чека, привлекших внимание скидках, фактов посещении разных магазинов и т.д. Банки и страховые компании также обладают возможностью собирать информацию о клиентах, их действиях, финансовых транзакциях и даже перемещениях как по городу, так и по миру. Банк может определить даты важных событий в жизни своих клиентов – свадьба, рождение ребенка, смена работы, переезд и т. д. Эти сведения можно использовать для увеличения продаж и работы над лояльностью клиентов.
д. Эти сведения можно использовать для увеличения продаж и работы над лояльностью клиентов.
Большие данные определяют развитие и коммунальной отрасли. Возможность собирать и анализировать информацию, поступающую со счетиков учета воды, газа и электроэнергии – это первый и главный шаг на пути к умного потрублению ресурсов как на уровне домохозяйств, так и в масштабе ЖКХ-компаний. Так, например, применение больших данных позволило эстонской распределительной компании Elektrilevi, совместно с Ericsson реализующей запуск интеллектуальной системы учета электроэнергии, всего за первые два года проекта повысить эффективность на 20%, сократить OPEX и CAPEX, и избегать дорогостоящих ошибок за счет оперативного обнаружения неисправностей.
В телекоме большие данные – это вся служебная информация с подключенных устройств, история использования сервисов, геолокационные сведения и даже весь трафик, который может быть проанализирован, вплоть до текстов SMS. У операторов есть доступ к такого рода информации, но по закону «О персональных данных», они не могут использовать ее без согласия владельца устройства. Но могут производить, например, полнотекстовый анализ трафика, очищенного от персональных сведений. Такого рода инструменты пока не используются операторами (разве что только при участии Роскомнадзора, который эксплуатирует систему, позволяющую обнаруживать отдельные ключевые слова и фразы).
Но могут производить, например, полнотекстовый анализ трафика, очищенного от персональных сведений. Такого рода инструменты пока не используются операторами (разве что только при участии Роскомнадзора, который эксплуатирует систему, позволяющую обнаруживать отдельные ключевые слова и фразы).
Главное, для чего используются большие данные в телекоме – более точная сегментация клиентов по типам, в соответствии с их потребительским поведением и предпочтениями. Маркетологи оператора, зная больше о клиентах, могут делать им более точные предложения, вовлекать их в использование дополнительных услуг, поддерживать лояльность, и тем самым больше на них зарабатывать. Общемировая тенденция такова, что размеры этих клиентских сегментов, которые помогает выявлять Big Data, становятся все точнее и меньше, вплоть до обращения с каждым отдельным клиентом, как с полноценным сегментом. Такой персонифицированный маркетинг – дело будущего, не только для российских операторов, но и для самых передовых иностранных.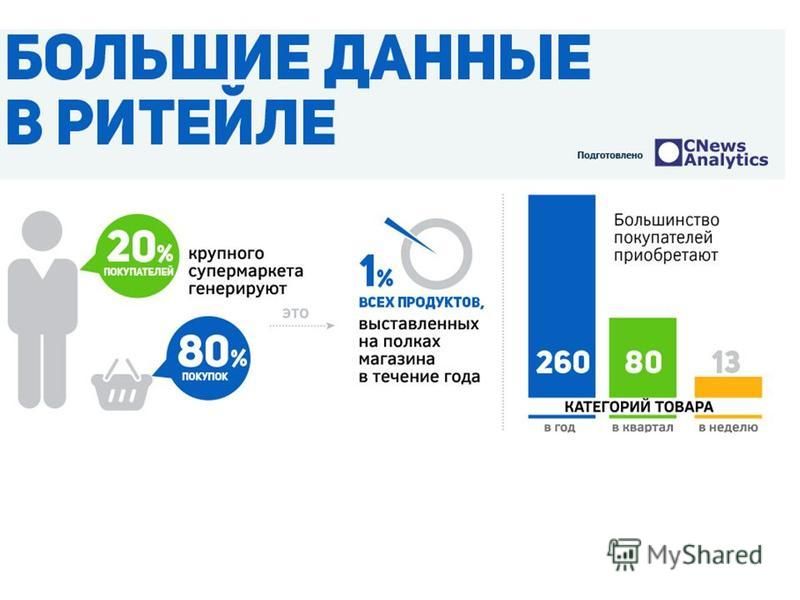 Но мышление маркетологов, подкрепляемое технологиями, движется именно в этом направлении, т.к. борьба за клиентов усиливается, и выигрывают те, кто умеет наладить личное взаимодействие с каждым потребителем.
Но мышление маркетологов, подкрепляемое технологиями, движется именно в этом направлении, т.к. борьба за клиентов усиливается, и выигрывают те, кто умеет наладить личное взаимодействие с каждым потребителем.
Важность инструментов для повышения эффективности работы с клиентами демонстрирует тот факт, что сегмент Big Data растет на фоне спада в ИТ-индустрии в целом. По данным CNews в 2014 году этот рынок вырастет в РФ на 20-25%. Эксперты отмечают, что лишь около 10% компаний в России начали пробовать эти инструменты, тогда как, согласно исследованию Gartner, в мире таких примерно 30%.
Согласно опросу CNews Analytics, проведенному в первом полугодии 2014 года среди представителей банковского сектора, ритейла и телекома 44% компаний не применяют технологии больших данных, 31% применяют, 25% — планируют начать использовать. Аналитики опрашивали только представителей компаний, которые входят в сотню крупнейших в своей отрасли.
Помимо использования Big Data в маркетинговых целях, телеком-операторы (впрочем, как и банки) могут применять такие технологии для обнаружения и предотвращения случаев фрода (мошеннические действия киберпреступников, направленные на воровство финансовых средств). Кроме того, операторы, как обладатели огромного количества информации о потребителях, потенциально могут стать центром экономической экосистемы, предоставляя партнерским компаниям из других сфер доступ к клиентам. В самом простом случае оператор может стать каналом маркетинговых коммуникаций, то есть попросту рассылать рекламу компании-партнера. Но делать это не массово, а адресно, точно направляя сообщение тем людям, которые могут быть в нем заинтересованы. К примеру, скидки на покупки в новом магазине косметики будут предлагаться только женщинам, живущим неподалеку. Тем, кто тратит часы, простаивая в пробках на дорогах, может прийти реклама аудиокниг.
Кроме того, операторы, как обладатели огромного количества информации о потребителях, потенциально могут стать центром экономической экосистемы, предоставляя партнерским компаниям из других сфер доступ к клиентам. В самом простом случае оператор может стать каналом маркетинговых коммуникаций, то есть попросту рассылать рекламу компании-партнера. Но делать это не массово, а адресно, точно направляя сообщение тем людям, которые могут быть в нем заинтересованы. К примеру, скидки на покупки в новом магазине косметики будут предлагаться только женщинам, живущим неподалеку. Тем, кто тратит часы, простаивая в пробках на дорогах, может прийти реклама аудиокниг.
«Большая тройка» операторов мобильной связи – в числе первопроходцев, осваивающих технологии больших данных. По сведениям CNews, «Вымпелком» использует Big Data для повышения качества обслуживания, оптимизации каналов коммуникации с клиентами, аналитики и отчетности, анализа данных для развития сети, анализа М2М-данных, борьбы с мошенничеством и спамом, персонализации услуг. Мегафон – для геоаналитики, в маркетинге и продажах. МТС – в маркетинговых целях и для повышения продаж, для сегментации абонентской базы, персонализации услуг.
Мегафон – для геоаналитики, в маркетинге и продажах. МТС – в маркетинговых целях и для повышения продаж, для сегментации абонентской базы, персонализации услуг.
Сергей Федечкин, ведущий эксперт систем отчетности оператора «ВымпелКом» сообщает, что компания занимается бизнес-аналитикой уже около 10 лет, однако инструменты Big Data были освоены ею пару лет назад. «Применение технологий Big Data позволяет нам решать несколько задач, в том числе управлять и измерять качество оказания услуг на уровне каждого абонента, бороться со спамом и мобильным мошенничеством, формировать индивидуальные предложения продуктов и услуг, планировать развитие инфраструктуры связи, а также развивать розничную сеть и многое другое. Для работы с «большими данными» мы используем решение компании HortonWorks Data Platform (HDP)», — говорит Сергей Федечкин.
В будущем телекоммуникационным компаниям придется иметь дело с большими данными все чаще – распространение технологий М2М приведет к тому, что к 2020 году на планете будет гораздо больше подключенных устройств, чем людей. Согласно видению компании Ericsson К 2020 году в мире будет насчитываеться более 50 млрд подклбченных устройств. Каждое из таких устройств будет генерировать данные, и ежемесячный трафик только лишь мобильных данных превысит 25 ЭБ. В итоге объемы информации, созданной машинами и людьми, достигнет к 2020 году, по прогнозам IDC, 44 зеттабайт (Зеттабайт = десять в степени 21 байт). И проблемой станет даже их хранение, не говоря уж об обработке. Аналитики IDC считают, что хранилищ данных хватит лишь на 15% от всего объема информации. К апрелю текущего года Россия сгенерировала лишь 155 экзабайт в совокупности, или 2,4% от всего объема мировых данных. И в ближайшие семь лет, по мнению аналитиков, это соотношение сохранится.
Согласно видению компании Ericsson К 2020 году в мире будет насчитываеться более 50 млрд подклбченных устройств. Каждое из таких устройств будет генерировать данные, и ежемесячный трафик только лишь мобильных данных превысит 25 ЭБ. В итоге объемы информации, созданной машинами и людьми, достигнет к 2020 году, по прогнозам IDC, 44 зеттабайт (Зеттабайт = десять в степени 21 байт). И проблемой станет даже их хранение, не говоря уж об обработке. Аналитики IDC считают, что хранилищ данных хватит лишь на 15% от всего объема информации. К апрелю текущего года Россия сгенерировала лишь 155 экзабайт в совокупности, или 2,4% от всего объема мировых данных. И в ближайшие семь лет, по мнению аналитиков, это соотношение сохранится.
Светлана Рагимова
Выборслов — Когда использовать «количество» против «количества»?
Оба грамматически правильные, и в каждом есть тонкое различие. Слово сумма используется в единственном числе для обозначения единственного количества:
.
существительное
1.0 Количество чего-либо, особенно общая вещь или предметы по количеству, размеру, стоимости или размеру:
спорт приносит огромное количество удовольствия многим людям
вещество безвредно, если принимать его вместе с небольшие суммы1.1 Денежная сумма:
они потратили колоссальную сумму перестроить стадион
ODO выделено добавлено
Поскольку количества обычно измеряются со ссылкой на контент, источник, время и пространство, разнородное количество часто представляется как множественного числа , чтобы передать сложность контента, источника, времени или пространства. Рассмотрим выражение большие объемы данных , где различные типы данных поступают из разных источников с разным умножением на и хранятся в разных местах , но они рассматриваются вместе:
Другими словами, это два типа данных, предназначенные для хранения действительно большие объемы данных .
Программирование баз данных с помощью JDBC и Java Джорджа Риза, выделение добавлено
 Большие двоичные объекты, представленные типом данных BLOB, содержат больших объемов двоичных данных . Аналогично клобуки, представленные
по типу данных CLOB, хранить больших объемов текстовых данных ..
Большие двоичные объекты, представленные типом данных BLOB, содержат больших объемов двоичных данных . Аналогично клобуки, представленные
по типу данных CLOB, хранить больших объемов текстовых данных .. Все эти больших объемов данных можно было бы объединить в один большой объем данных , но множественное число передает ощущение сложности внутри этого единственного большого количества .
Такое же восприятие сложности верно и для крупных сумм денег:
Так или иначе, крупные суммы денег уезжают с Запада домочадцев почти каждый день, но так было всегда, и Ричард достаточно внимательно отслеживает расходы каждого человека. Фандрайзинг Кен Бернетт, выделено добавлено
Большая сумма расходов каждого отдельного человека может быть объединена в одну большую сумму денег, но множественное число выражает ощущение сложности. Даже большая сумма индивидуальных расходов может быть выражена во множественном числе для обозначения различных статей бюджета или операций в рамках расходов:
Даже большая сумма индивидуальных расходов может быть выражена во множественном числе для обозначения различных статей бюджета или операций в рамках расходов:
Он потратил больших денег на сам дом, готизируя его внешний вид с горгульями, башенками и панелями.
Бульвер Литтон: Взлет и падение викторианского литератора Лесли Митчел, выделение добавлено
В отношении OP, в частности, единичное большое количество пота будет фокусироваться на потном теле в целом в один момент времени.Выражение во множественном числе добавило бы сложности: различные потные места на теле или, возможно, даже различные причины пота с течением времени.
Конечно, люди не всегда строго помнят об этих тонкостях, когда говорят или пишут, поэтому вполне возможно, что выражение множественного числа просто добавляет чувство акцента к крайнему состоянию пота.
Одиннадцать советов по работе с большими наборами данных
Большие данные исследуются повсюду, и наборы данных становятся только больше — и работать с ними становится все сложнее.К сожалению, говорит Трейси Тил, это такая работа, которую слишком часто не учитывают в научной подготовке.
«Это образ мышления, — говорит Тил, — относиться к данным как к первоклассному гражданину». Она должна знать: Тил до прошлого месяца был исполнительным директором The Carpentries, организации в Окленде, штат Калифорния, которая обучает исследователей по всему миру навыкам программирования и обработки данных. По ее словам, в исследовательском сообществе существует тенденция игнорировать время и усилия, необходимые для управления данными и обмена ими, и не рассматривать их как реальную часть науки.Но, по ее мнению, «мы можем изменить свое мышление на оценку этой работы как части исследовательского процесса», а не рассматривать ее как нечто второстепенное.
Вот 11 советов, как максимально эффективно использовать большие наборы данных.
Берегите свои данные
«Храните необработанные данные в сыром виде: не изменяйте их, не имея копии», — говорит Тил. Она рекомендует хранить ваши данные там, где создаются автоматические резервные копии и к которым могут получить доступ другие сотрудники лаборатории, при соблюдении правил вашего учреждения о согласии и конфиденциальности данных.
Поскольку вам не нужно часто получать доступ к этим данным, говорит Тил, «вы можете использовать варианты хранения, где доступ к данным может стоить дороже, но затраты на хранение низкие» — например, сервис Amazon Glacier. Вы даже можете хранить необработанные данные на дублированных жестких дисках, хранящихся в разных местах. Затраты на хранение больших файлов данных могут увеличиваться, поэтому выделяйте соответствующий бюджет.
Визуализируйте информацию
По мере того, как массивы данных становятся больше, появляются новые морщины, говорит Титус Браун, биоинформатик из Калифорнийского университета в Дэвисе. «На каждом этапе вы будете сталкиваться с новым и захватывающим беспорядочным поведением». Его совет: «Делайте много графиков и ищите выбросы». В апреле прошлого года один из студентов Брауна проанализировал транскриптомы — полный набор молекул РНК, продуцируемых клеткой или организмом — из 678 морских микроорганизмов, таких как планктон (Л. К. Джонсон, и др. GigaScience 8 , giy158; 2019). Когда Браун и его ученик составили график средних значений длины транскрипта, охвата и содержания гена, они заметили, что некоторые значения были нулевыми, показывая, где вычислительный рабочий процесс дал сбой и должен был быть запущен повторно.
«На каждом этапе вы будете сталкиваться с новым и захватывающим беспорядочным поведением». Его совет: «Делайте много графиков и ищите выбросы». В апреле прошлого года один из студентов Брауна проанализировал транскриптомы — полный набор молекул РНК, продуцируемых клеткой или организмом — из 678 морских микроорганизмов, таких как планктон (Л. К. Джонсон, и др. GigaScience 8 , giy158; 2019). Когда Браун и его ученик составили график средних значений длины транскрипта, охвата и содержания гена, они заметили, что некоторые значения были нулевыми, показывая, где вычислительный рабочий процесс дал сбой и должен был быть запущен повторно.
Покажите свой рабочий процесс
Когда физик элементарных частиц Питер Элмер помогает своему 11-летнему сыну с домашним заданием по математике, он должен напомнить ему, чтобы он задокументировал свои шаги. «Он просто хочет записать ответ», — говорит Элмер, исполнительный директор Института исследований и инноваций в области программного обеспечения для физики высоких энергий в Принстонском университете в Нью-Джерси. Исследователи, работающие с большими наборами данных, могут извлечь пользу из того же совета, который Элмер дал своему сыну: «Продемонстрировать свою работу так же важно, как добраться до конца.”
Исследователи, работающие с большими наборами данных, могут извлечь пользу из того же совета, который Элмер дал своему сыну: «Продемонстрировать свою работу так же важно, как добраться до конца.”
Это означает запись всего рабочего процесса с данными — какую версию данных вы использовали, шаги очистки и проверки качества, а также любой код обработки, который вы выполняли. Такая информация бесценна для документирования и воспроизведения ваших методов. Эрик Лайонс, компьютерный биолог из Аризонского университета в Тусоне, использует инструмент видеозахвата asciinema для записи того, что он вводит в командную строку, но могут работать и менее технологичные решения. Он вспоминает, что группа его коллег сфотографировала экран своих компьютеров и разместила их в группе лаборатории на платформе обмена мгновенными сообщениями Slack.
Использование контроля версий
Системы контроля версий позволяют исследователям точно понять, как файл изменился с течением времени и кто внес эти изменения. Но некоторые системы ограничивают размер файлов, которые вы можете использовать. Harvard Dataverse (который открыт для всех исследователей) и Zenodo можно использовать для контроля версий больших файлов, говорит Алисса Гудман, астрофизик и специалист по визуализации данных из Гарвардского университета в Кембридже, штат Массачусетс. Другой вариант — Dat, бесплатная одноранговая сеть для совместного использования и управления версиями файлов любого размера.По словам Эндрю Ошероффа, основного разработчика программного обеспечения в Dat в Копенгагене, система ведет журнал с защитой от несанкционированного доступа, в который записываются все операции, которые вы выполняете с файлом. По словам менеджера по продуктам Dat Кариссы МакКелви, которая живет в Окленде, штат Калифорния, пользователи могут указать системе архивировать копию каждой версии файла. Dat в настоящее время является утилитой командной строки, но «мы активно модернизируем», — говорит МакКелви; команда надеется выпустить более удобный интерфейс в конце этого года.
Но некоторые системы ограничивают размер файлов, которые вы можете использовать. Harvard Dataverse (который открыт для всех исследователей) и Zenodo можно использовать для контроля версий больших файлов, говорит Алисса Гудман, астрофизик и специалист по визуализации данных из Гарвардского университета в Кембридже, штат Массачусетс. Другой вариант — Dat, бесплатная одноранговая сеть для совместного использования и управления версиями файлов любого размера.По словам Эндрю Ошероффа, основного разработчика программного обеспечения в Dat в Копенгагене, система ведет журнал с защитой от несанкционированного доступа, в который записываются все операции, которые вы выполняете с файлом. По словам менеджера по продуктам Dat Кариссы МакКелви, которая живет в Окленде, штат Калифорния, пользователи могут указать системе архивировать копию каждой версии файла. Dat в настоящее время является утилитой командной строки, но «мы активно модернизируем», — говорит МакКелви; команда надеется выпустить более удобный интерфейс в конце этого года.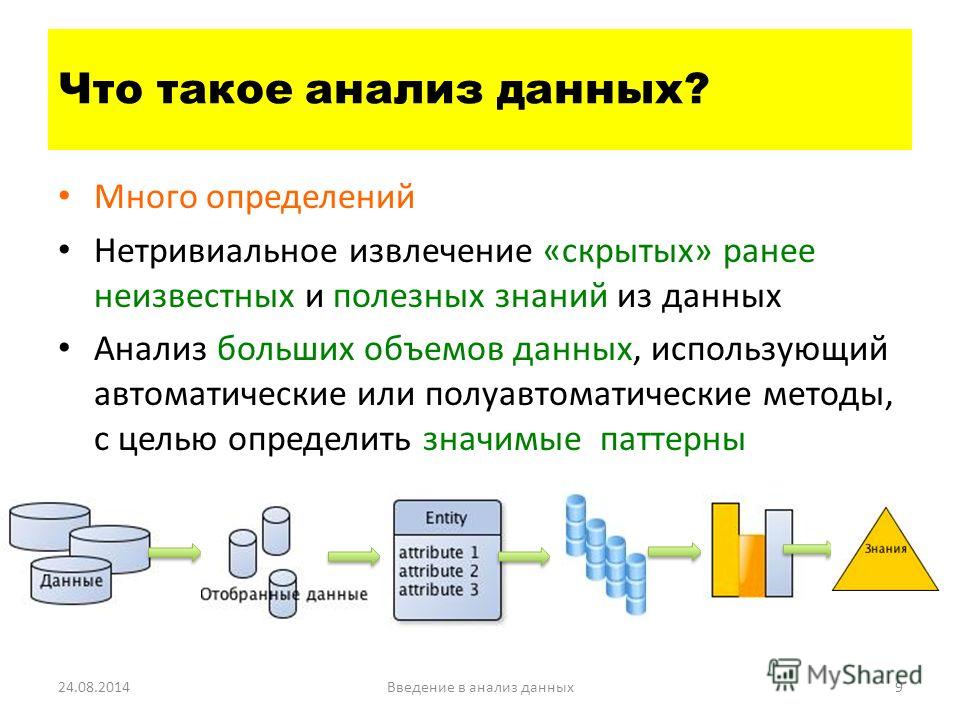
Метаданные записи
«Ваши данные бесполезны, если люди — и« вы в будущем »- не знают, что они собой представляют», — говорит Тил.Это задача метаданных, которые описывают, как были собраны, отформатированы и организованы наблюдения. Подумайте, какие метаданные следует записывать, прежде чем начинать сбор, советует Лайонс, и сохраните эту информацию вместе с данными — либо в программном средстве, используемом для сбора наблюдений, либо в README или другом специальном файле. Проект Open Connectome, возглавляемый Джошуа Фогельштейном, нейростатистом из Университета Джона Хопкинса в Балтиморе, штат Мэриленд, регистрирует свои метаданные в структурированном текстовом формате под названием JSON.Какова бы ни была ваша стратегия, старайтесь думать о долгосрочной перспективе, говорит Лайонс: однажды вы можете захотеть интегрировать свои данные с данными других лабораторий. Если вы будете активно использовать метаданные, интеграция будет проще в будущем.
Автоматизируйте, автоматизируйте, автоматизируйте
Наборы больших данных слишком велики, чтобы их можно было прочесать вручную, поэтому автоматизация является ключевым моментом, говорит Шоаиб Муфти, старший директор по данным и технологиям Института исследований мозга Аллена в Сиэтле, штат Вашингтон. По словам Муфти, группа нейроинформатиков института, например, использует шаблон для данных о клетках мозга и генетике, который принимает информацию только в правильном формате и типе.Когда приходит время интегрировать эти данные в более крупную базу данных или коллекцию, шаги по обеспечению качества данных автоматизируются с использованием Apache Spark и Apache Hbase, двух инструментов с открытым исходным кодом, для проверки и исправления данных в реальном времени. «Весь наш набор программных инструментов для проверки и приема данных работает в облаке, что позволяет нам легко масштабироваться», — говорит он. По словам Фогельштейна, проект Open Connectome также обеспечивает автоматическую проверку качества — это создает визуализацию сводной статистики, которую пользователи могут проверить, прежде чем приступить к анализу.
По словам Муфти, группа нейроинформатиков института, например, использует шаблон для данных о клетках мозга и генетике, который принимает информацию только в правильном формате и типе.Когда приходит время интегрировать эти данные в более крупную базу данных или коллекцию, шаги по обеспечению качества данных автоматизируются с использованием Apache Spark и Apache Hbase, двух инструментов с открытым исходным кодом, для проверки и исправления данных в реальном времени. «Весь наш набор программных инструментов для проверки и приема данных работает в облаке, что позволяет нам легко масштабироваться», — говорит он. По словам Фогельштейна, проект Open Connectome также обеспечивает автоматическую проверку качества — это создает визуализацию сводной статистики, которую пользователи могут проверить, прежде чем приступить к анализу.
Учет времени вычислений
Для больших наборов данных требуются высокопроизводительные вычисления (HPC), и многие исследовательские институты теперь имеют свои собственные средства HPC. Национальный научный фонд США поддерживает национальную сеть высокопроизводительных вычислений XSEDE, которая включает в себя сеть облачных вычислений Jetstream и центры высокопроизводительных вычислений по всей стране. Исследователи могут запросить выделение ресурсов на xsede.org и создать пробные учетные записи на go.nature.com/36ufhgh. Другие варианты включают базирующуюся в США сеть ACI-REF, NCI Australia, Партнерство по передовым вычислениям в Европе и сети ELIXIR, а также коммерческих поставщиков, таких как Amazon, Google и Microsoft.
Национальный научный фонд США поддерживает национальную сеть высокопроизводительных вычислений XSEDE, которая включает в себя сеть облачных вычислений Jetstream и центры высокопроизводительных вычислений по всей стране. Исследователи могут запросить выделение ресурсов на xsede.org и создать пробные учетные записи на go.nature.com/36ufhgh. Другие варианты включают базирующуюся в США сеть ACI-REF, NCI Australia, Партнерство по передовым вычислениям в Европе и сети ELIXIR, а также коммерческих поставщиков, таких как Amazon, Google и Microsoft.
Но когда дело касается вычислений, время — деньги. Чтобы максимально использовать свое вычислительное время в кластерах GenomeDK и Computerome в Дании, Гоцзе Чжан, исследователь геномики из Копенгагенского университета, говорит, что его группа обычно проводит мелкомасштабные тесты перед переносом своих анализов в сеть HPC. Чжан является участником проекта «Геномы позвоночных», который стремится собрать геномы около 70 000 видов позвоночных. «Нам нужны миллионы или даже миллиарды компьютерных часов», — говорит он.
Захватите окружающую среду
Чтобы воспроизвести анализ позже, вам не понадобится только та же версия инструмента, который вы использовали, — говорит Бенджамин Хейб-Кейнс, специалист по компьютерной фармако-геномике из Онкологического центра принцессы Маргарет в Торонто, Канада. Вам также понадобится та же операционная система и все те же программные библиотеки, которые требуются для этого инструмента. По этой причине он рекомендует работать в автономной вычислительной среде — контейнере Docker, который можно собрать где угодно.Хайбе-Каинс и его команда используют онлайн-платформу Code Ocean (основанную на Docker) для захвата и совместного использования своих виртуальных сред; другие варианты включают Binder, Gigantum и Nextjournal. «Через десять лет вы по-прежнему сможете управлять этим трубопроводом точно так же, если вам нужно», — говорит Хайбе-Каинс.
Не загружать данные
Загрузка и хранение больших наборов данных нецелесообразны. По словам Брауна, исследователи должны проводить анализ удаленно, недалеко от места хранения данных. Многие проекты с большими данными используют Jupyter Notebook, который создает документы, сочетающие программный код, текст и рисунки.По словам Брауна, исследователи могут «развернуть» такие документы на серверах данных или рядом с ними для удаленного анализа, изучения данных и многого другого. По словам Брауна, Jupyter Notebook не особенно доступен для исследователей, которым может быть неудобно использовать командную строку, но существуют более удобные платформы, которые могут восполнить пробел, в том числе Terra и Seven Bridges Genomics.
Многие проекты с большими данными используют Jupyter Notebook, который создает документы, сочетающие программный код, текст и рисунки.По словам Брауна, исследователи могут «развернуть» такие документы на серверах данных или рядом с ними для удаленного анализа, изучения данных и многого другого. По словам Брауна, Jupyter Notebook не особенно доступен для исследователей, которым может быть неудобно использовать командную строку, но существуют более удобные платформы, которые могут восполнить пробел, в том числе Terra и Seven Bridges Genomics.
Начать рано
Управление данными имеет решающее значение даже для молодых исследователей, поэтому начинайте обучение как можно раньше. «Людям кажется, что у них никогда не бывает времени для инвестиций, — говорит Элмер, — но в конечном итоге вы экономите свое время».По его словам, начните с основ командной строки, а также с языка программирования, такого как Python или R, в зависимости от того, что более важно для вашей области. Лайонс соглашается: «Шаг первый: ознакомьтесь с данными из командной строки». В ноябре у некоторых из его сотрудников, которые плохо владели командной строкой, возникли проблемы с геномными данными, потому что имена хромосом не совпадали во всех их файлах, говорит Лайонс. «Обладая базовыми навыками работы с командной строкой и программированием, я мог быстро исправить имена хромосом.”
В ноябре у некоторых из его сотрудников, которые плохо владели командной строкой, возникли проблемы с геномными данными, потому что имена хромосом не совпадали во всех их файлах, говорит Лайонс. «Обладая базовыми навыками работы с командной строкой и программированием, я мог быстро исправить имена хромосом.”
Получить справку
Справка доступна как в интерактивном, так и в автономном режиме. Начните с онлайн-форума Stack Overflow. Проконсультируйтесь с библиотекарями вашего учреждения о необходимых вам навыках и доступных ресурсах, — советует Тил. Не сбрасывайте со счетов обучение на месте, говорит Лайонс: «Столярные изделия — отличное место для начала».
Совместное использование, хранение и вычисление огромных объемов данных | by Alibaba Cloud
Данные имеют решающее значение для работы любого бизнеса. Компании часто собирают большое количество журналов, чтобы лучше понимать свои собственные службы и людей, которые их используют.
Со временем количество и активность пользователей постоянно увеличивается, равно как и скорость генерации данных, накопленный объем данных, а также количество измерений и типов данных. В результате мы получаем все больше и больше островов данных.
В результате мы получаем все больше и больше островов данных.
Мы достигли точки, когда островки данных стали тяжелым бременем для ИТ-отдела компании, увеличивая расходы без увеличения прибыли.
Хранение и обработка больших объемов данных создает серьезные проблемы для предприятий, например:
- Серьезная проблема островков данных (без облачной платформы больших данных)
- Неточная оценка затрат, трата ресурсов при изменении размера вычислительной мощности
- Важное место проблема избыточности данных
- Высокая стоимость хранения
- Локальное оборудование сложно масштабировать, а стоимость обслуживания высока
- Размер данных слишком велик для резервного копирования.
- Обширные потребности бизнеса приводят к разным типам данных и высоким расходам на анализ и разработку
В этой статье обсуждаются некоторые возможные решения проблем при работе с большими объемами данных для конкретных отраслей.
1.
 Логистика
ЛогистикаПакеты генерируют множество данных отслеживания от сбора до отгрузки, транспортировки, перевалки и распределения. Каждый раз, когда пакет достигает контрольной точки, он будет сканироваться, и его статус будет записан.
В процессе транспортировки отслеживается транспортное средство, связанное с посылкой, включая записи транспортного средства, маршрут, расход топлива, статус транспортного средства и статус водителя. В процессе распространения будет отслеживаться как информация о местонахождении курьера, так и статус доставки посылки, что также генерирует большой объем данных.
Транспортное средство может создавать десятки тысяч записей отслеживания за день. Курьер также может создавать десятки тысяч записей отслеживания в день.Даже небольшая посылка может генерировать сотни записей отслеживания!
Одним из потенциальных решений для логистической отрасли является динамическое планирование пути. Благодаря динамическому планированию пути мы можем получать информацию о ближайших курьерах в режиме реального времени в соответствии с их позиционной информацией.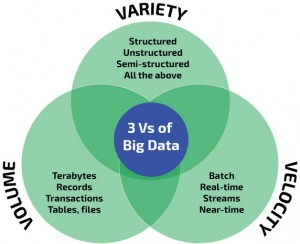 Затем эту информацию можно использовать для создания оптимального пути с наименьшими затратами для быстрой доставки. Если вам интересно, вы можете обратиться к «Технологии, использованные на фестивале шоппинга Double 11 — логистика и динамическое планирование пути» (статья на китайском языке).
Затем эту информацию можно использовать для создания оптимального пути с наименьшими затратами для быстрой доставки. Если вам интересно, вы можете обратиться к «Технологии, использованные на фестивале шоппинга Double 11 — логистика и динамическое планирование пути» (статья на китайском языке).
2. Финансы
Финансовая индустрия — еще один генератор массовых данных. Данные финансовой отрасли в основном включают данные об операциях пользователей, корпоративных операциях и ценных бумагах. Что еще хуже, большинство транзакций в финансовой индустрии требуют вычислений в реальном времени и использования широкого спектра различных функций статистического анализа.
Кроме того, данные, собранные в финансовой сфере, должны быть защищены. Я поделился анализом потребностей системы моделирования торговли ценными бумагами.Если вам интересно, см. Анализ и применение PostgreSQL в базах данных в индустрии ценных бумаг (статья на китайском языке).
3. Интернет вещей (IoT)
Данные, генерируемые IoT, являются последовательными и поэтому требуют StreamCompute (например, запускается при достижении порогового значения) и анализа после события. Поскольку размер данных огромен, их также необходимо сжать.
Поскольку размер данных огромен, их также необходимо сжать.
Еще одна особенность IoT заключается в том, что данные, передаваемые датчиками, всегда содержат числовые диапазоны (например, диапазон температур), географическое положение, изображения и т. Д.Как мы можем эффективно хранить и искать такие разные типы данных? Я также проанализировал особенности баз данных приложений IoT в нескольких статьях (статьях на китайском языке).
Rise of StreamCompute — PostgreSQL объединяет усилия с PipelineDB для поддержки IoT
Реализация алгоритма сжатия данных вращающейся двери в PostgreSQL — применение потокового сжатия в сценариях IoT, мониторинга и датчиков
Передовая технология PostgreSQL для IoT — создание индекса (индекс BRIN), составляющий часть обычного размера
Простой алгоритм, помогающий пользователям Интернета вещей и финансов сократить расходы на хранение данных на 98%
Приложение потоковой передачи в Интернете вещей — обработка в реальном времени (триллионы записей данных на day) с использованием передовой технологии PostgreSQL
PostgreSQL — тип диапазона и индексы Gist ускоряют развитие в IoT
4.
 Мониторинг
МониторингМониторинг включает в себя наблюдение за бизнес-операциями и состояниями ИТ-инфраструктуры, такими как состояние сервера, состояние сети и состояние хранилища. Мониторинг широко используется во всех видах бизнеса, но потребности в мониторинге и типы данных различаются в зависимости от отрасли.
Например, в некоторых отраслях может потребоваться позиционный мониторинг, такой как отслеживание местоположения автобуса и отправка предупреждений, когда он выходит за пределы геозоны или когда водитель демонстрирует необычное поведение при вождении.
5. Общественная безопасность
Данные общественной безопасности поступают из различных областей, включая записи сообщений и записи о поездках.
Данные общественной безопасности могут быть невероятно большими. Типичным вариантом использования может быть контроль рисков или поимка подозреваемых в совершении преступлений. Он в значительной степени полагается на анализ хронологической и географической информации о местоположении (поиск изображений).
Как можно удовлетворить эти потребности?
Проблемы ведения бизнеса с большими объемами данных можно резюмировать с помощью следующего списка вопросов:
- Как мы можем решить проблему островков данных и открыть каналы обмена данными?
- Как мы можем эффективно записывать журналы, поведенческие треки, финансовые данные и данные о траектории?
- Как мы можем быстро и эффективно обрабатывать данные, отправлять пороговые предупреждения и проводить анализ в реальном времени?
- Как решить проблемы с отказоустойчивостью и резервным копированием, с которыми сталкиваются большие данные?
- Как решить проблемы сжатия и эффективности для больших данных?
- Как мы можем решить проблемы, связанные с многомерными данными, разнообразными типами данных и сложными вычислениями?
- Как мы можем помочь компаниям улучшить масштабируемость их ИТ-архитектур?
Мы рассмотрим три компонента:
1.RDS PostgreSQL
RDS PostgreSQL поддерживает хронологические данные, индексы диапазона блоков, инвертированные индексы, многоядерные параллельные вычисления, JSON, хранилище массивов, внешнее чтение / запись OSS_FDW и другие функции.
RDS PostgreSQL решает проблемы OLTP, приложений ГИС, сложных запросов, обработки пространственных данных, многомерного анализа и разделения горячих и холодных данных.
2.HybridDB PostgreSQL
HybridDB PostgreSQL поддерживает хранение массивов, горизонтальное расширение, сжатие блоков, расширенные типы данных, библиотеку машинного обучения, PLPYTHON, PLJAVA и программирование PLR, внешнее чтение и запись OSS_FDW и т. Д.
Он полностью решает проблему вычисления больших объемов данных.
3. Служба хранилища объектов (OSS)
Данные могут совместно использоваться несколькими экземплярами RDS через OSS_FDW. OSS поддерживает множественное копирование и межрегиональную репликацию.
OSS решает проблемы островков данных, хранения больших объемов данных, устойчивости к сбоям между центрами обработки данных, массивного резервного копирования данных и т. Д.
1. Запись
Данные записываются тремя способами:
- Запись в реальном времени в режиме онлайн реализован через интерфейс RDS SQL, что позволяет одному экземпляру достичь скорости записи более 1 миллиона строк в секунду.
- Пакетная запись в квазиреальном времени, реализованная через интерфейс HybridDB SQL, который позволяет одному экземпляру достичь скорости записи более 1 миллиона строк в секунду.
- Пакетная запись в квази-реальном времени, например запись в файл, реализованная через интерфейс OSS, который поддерживает автоматическое масштабирование полосы пропускания.
2. Совместное использование
Данные могут совместно использоваться несколькими экземплярами RDS через OSS_FDW.
Предположим, что у нас есть два предприятия, и мы использовали два экземпляра базы данных RDS, но есть часть данных, которые необходимо разделить между ними.Традиционный метод требует использования ETL, но теперь мы можем эффективно обеспечить совместное использование данных между несколькими экземплярами с помощью OSS_FDW.
Функция параллельного чтения / записи RDS PostgreSQL OSS_FDW (позволяющая нескольким рабочим процессам читать и писать в один и тот же файл таблицы) обеспечивает высокоэффективный процесс чтения / записи для общих данных.
Параллельная функция воплощена в трех функциях: параллельное чтение / запись OSS, многоядерные параллельные вычисления RDS PostgreSQL, параллельные вычисления на нескольких компьютерах RDS PostgreSQL или HybridDB.
3. Хранилище
Локальные RDS PostgreSQL и HybridDB используются для хранения данных в реальном времени. Когда хранимые данные необходимо проанализировать или поделиться ими, мы сохраняем их в OSS.
Когда мы сравниваем объем хранилища с используемыми вычислительными ресурсами, стоимость OSS намного ниже, что снижает затраты компании на ИТ без отрицательного влияния на гибкость.
OSS решает проблемы предприятий по избыточности данных и высокой стоимости, а также отвечает требованиям по резервному копированию данных и устойчивости к сбоям.
4. Вычисления
Используя RDS PostgreSQL, HybridDB и OSS, мы можем разделить наши вычислительные ресурсы и ресурсы хранения.
Поскольку мы можем хранить меньше данных на вычислительных узлах (большая часть данных хранится в OSS), изменение размера, уменьшение, отказоустойчивость и резервное копирование компьютерных узлов намного проще./database-157334670-5c29939d46e0fb0001edf766.jpg)
Вычислительные методы можно разделить на следующие типы
1. Потоковые вычисления
StreamCompute можно разделить на два подтипа: вычисления в реальном времени и предупреждения о пороге в реальном времени.
И то, и другое можно реализовать с помощью конвейераb (на основе postgresql).
Преимущества:
Стандартный интерфейс SQL и широкий спектр различных встроенных функций поддерживают сложные требования StreamCompute. Разнообразные типы данных (включая ГИС, JSON и т. Д.) Поддерживают еще больше бизнес-сценариев StreamCompute. Этот механизм на основе асинхронных сообщений поддерживает потребности второго типа StreamCompute.
pipelinedb в настоящее время корректируется и может использоваться как расширение PostgreSQL в будущем.
https://github.com/pipelinedb/pipelinedb/issues?q=is%3Aissue+is%3Aopen+label%3A%22extension+refactor%22
Если взять в качестве примера отрасль мониторинга, асинхронные сообщения на основе Механизм StreamCompute позволяет эффективно избежать бесполезности традиционных методов мониторинга активных запросов.
2. Взаимодействие в режиме реального времени
Мы можем использовать RDS PostgreSQL для удовлетворения традиционных требований OLTP.
Возможности PostgreSQL включают: ГИС, JSON, массивы, разделение горячих и холодных данных, горизонтальное разделение базы данных, тип K-V, многоядерные параллельные вычисления, индексы BRIN, индексы GIN и т. Д.
Сценарии, поддерживаемые PostgreSQL, включают: StreamCompute, поиск изображений, хронологические данные, планирование пути, нечеткий поиск, полнотекстовый поиск, поиск сходства, отслеживание аукционов, генетику, финансы, химию, приложение ГИС, сложный поиск, BI, многомерный анализ, поиск пространственных данных и т. д.
Он охватывает широкий спектр отраслей, включая банковское дело, страхование, ценные бумаги, Интернет вещей, Интернет, игры, астрономию, издательское дело, электронную коммерцию, традиционные предприятия и т. д.
3. Квази-анализ в реальном времени
При использовании в сочетании с OSS и RDS PostgreSQL, и HybridDB могут выполнять анализ в квази-реальном времени.
Одни и те же данные OSS также могут совместно использоваться несколькими экземплярами и иметь к ним одновременный доступ.
4. Офлайн-анализ данных и интеллектуальный анализ данных
При использовании в сочетании с OSS и RDS PostgreSQL, и HybridDB могут использоваться для анализа и добычи офлайн-данных.
RDS PostgreSQL поддерживает многоядерные параллельные вычисления на одном компьютере, а HybridDB для PostgreSQL поддерживает многоядерные параллельные вычисления на нескольких компьютерах.Пользователи могут делать выбор в зависимости от вычислительной мощности.
Требуемые вычислительные мощности
Суть вычислений — это работа с разными типами данных.
- PostgreSQL поддерживает широкий спектр различных встроенных типов данных, включая числа, строки, время, логическое значение, перечисление, массив, диапазон, ГИС, полнотекстовый поиск, байт, большой объект, геометрию, бит, XML, UUID , JSON, составные типы и т. Д. , А также типы данных, настраиваемые пользователями. PostgreSQL поддерживает практически все бизнес-сценарии.
- Операторы. Чтобы удовлетворить потребности в обработке данных, PostgreSQL предлагает множество операций для каждого из поддерживаемых типов данных.
- PostgreSQL имеет обширные встроенные функции, включая статистические, тригонометрические, ГИС и функции машинного обучения MADlib.
- Индивидуальная вычислительная логика. Пользователи могут использовать различные языки программирования, включая C, python, java и R, для настройки этих функций обработки данных и расширения возможностей обработки данных PostgreSQL и HybridDB для PostgreSQL.
- Имеются обширные встроенные агрегатные функции для поддержки статистического анализа.
- Функции оконного запроса.
- Рекурсивные запросы.
- Многомерный аналитический синтаксис.
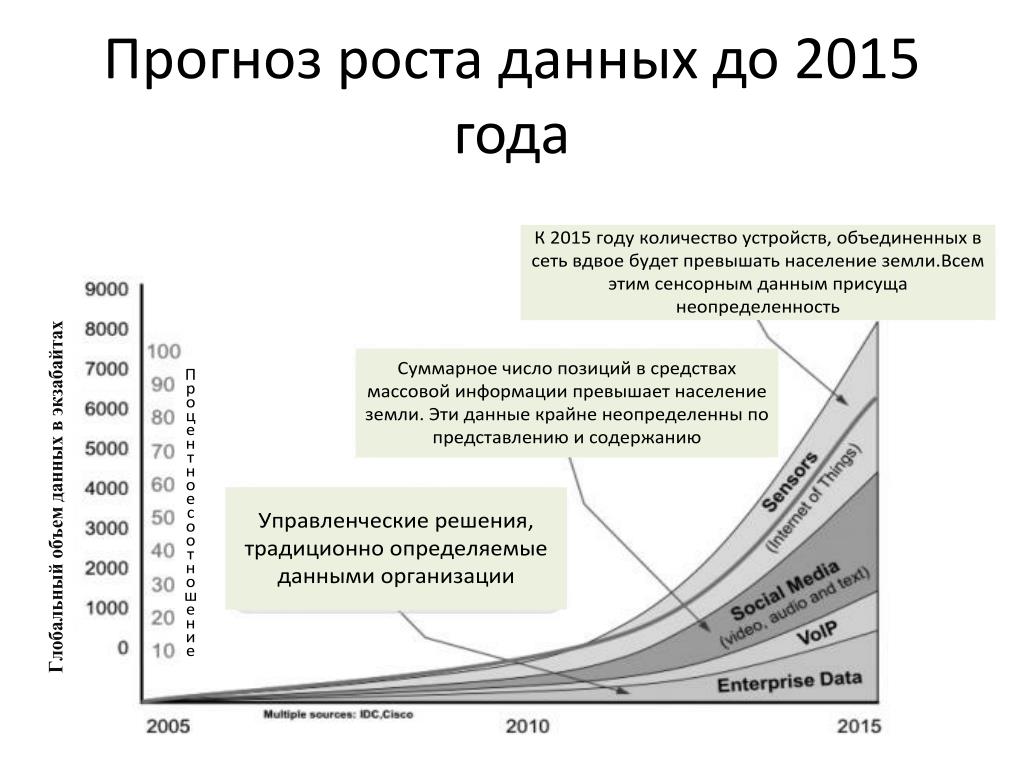 , А также типы данных, настраиваемые пользователями. PostgreSQL поддерживает практически все бизнес-сценарии.
, А также типы данных, настраиваемые пользователями. PostgreSQL поддерживает практически все бизнес-сценарии.Преимущества RDS PostgreSQL
в основном представлены в следующих аспектах:
1. Производительность
Производительность
RDS PostgreSQL в основном обрабатывает онлайн-транзакции и небольшой объем квази-анализа в реальном времени.
Производительность PostgreSQL OLTP на уровне коммерческих баз данных.Подробнее см. В этой статье:
Оценка производительности в базе данных industry_tpc.org
Многоядерные параллельные вычисления, JIT, повторное использование операторов и другие функции PostgreSQL позволяют ему оставлять другие СУБД далеко позади с точки зрения емкости OLAP . Подробнее об аналитических возможностях PostgreSQL OLAP см. В этой статье:
Анализ передовых технологий ускорительных движков — откройте сундук с сокровищами PostgreSQL с помощью комбинации LLVM, хранилища массивов, многоядерных параллельных вычислений и повторное использование оператора
PostgreSQL 10 также имеет много улучшений в аспекте HTAP.
2. Возможности
Возможности — главная сила PostgreSQL. Вы можете найти подробное описание в предыдущем разделе «Требуемые вычислительные мощности».
3. Масштабируемость
Производительность сложных вычислений можно повысить за счет добавления дополнительных процессоров.
Емкость хранилища RDS PG может быть увеличена, а ограничение хранилища может быть нарушено с помощью хранилища OSS и расширения OSS_FDW.
4. Стоимость
Поскольку большая часть данных, которые необходимо разделить, хранится в OSS, пользователям не нужно беспокоиться об отказоустойчивости и резервном копировании этой части данных.По сравнению с хранением в базах данных затраты на хранение значительно снижаются.
И RDS PG, и HybridDB PG поддерживают широкий спектр стандартных интерфейсов SQL, которые также используются для доступа к данным, хранящимся в OSS (интерфейс таблицы). Сочетание всех этих функций приводит к значительному сокращению затрат на разработку.
Стоимость обслуживания: при использовании облачных сервисов затраты на эксплуатацию и техническое обслуживание практически отсутствуют.
5. Охватываемые отрасли
Он охватывает широкий спектр отраслей, включая банковское дело, страхование, ценные бумаги, IoT, Интернет, игры, астрономию, издательское дело, электронную коммерцию, традиционные предприятия и т. Д.
Д.
Преимущества HybridDB PostgreSQL
1. Производительность
HybridDB PostgreSQL является архитектурой MPP и, следовательно, обладает выдающейся вычислительной производительностью.
2.Features
Вы можете найти подробное описание в предыдущем разделе «Требуемые вычислительные мощности».
3. Масштабируемость
Производительность сложных вычислений можно повысить за счет добавления дополнительных вычислительных узлов.
Емкость хранилища RDS PG может быть увеличена, а ограничение хранилища может быть нарушено с помощью хранилища OSS и расширения OSS_FDW.
4. Стоимость
Поскольку большая часть данных, которые необходимо разделить, хранится в OSS, пользователям не нужно беспокоиться об отказоустойчивости и резервном копировании этой части данных. По сравнению с хранением в базах данных затраты на хранение значительно снижаются.
И RDS PG, и HybridDB PG поддерживают широкий спектр стандартных интерфейсов SQL, которые также используются для доступа к данным, хранящимся в OSS (интерфейс таблицы). Сочетание всех этих функций приводит к значительному сокращению затрат на разработку.
Сочетание всех этих функций приводит к значительному сокращению затрат на разработку.
Стоимость обслуживания: при использовании облачных сервисов затраты на эксплуатацию и техническое обслуживание практически отсутствуют.
5. Охватываемые отрасли
Он охватывает широкий спектр отраслей, включая банковское дело, страхование, ценные бумаги, IoT, Интернет, игры, астрономию, издательское дело, электронную коммерцию, традиционные предприятия и т. Д.
RDS PostgreSQL: используйте oss_fdw для чтение / запись OSS
HybridDB PostgreSQL: используйте oss_fdw для чтения / записи OSS
https://www.alibabacloud.com/blog/Sharing-Storing-and-Computing-Massive-Amounts-of-Data_p28092041?spm=a2c.11187713.0.0
Как начать использовать большие объемы данных быстрее и эффективнее
На вашем предприятии имеется большой объем данных, и их количество каждый день становится все больше и больше.
Вам сложно, а то и невозможно сохранить все эти данные организованными и управляемыми, особенно с учетом всех приложений и инструментов, требующих доступа.
Добро пожаловать в так называемую «гравитацию данных».
Что такое гравитация данных?Придуманный автором Дэйвом МакКрори, гравитация данных — это идея о том, что : чем больше данных поступает в местоположение, тем больше приложений будет направлено к нему.
Хотя цель состоит в том, чтобы приложения могли получить доступ к данным, одна из проблем с гравитацией данных заключается в том, что могут быть более эффективные места для выполнения анализа данных, но часто проще рассчитаться с ресурсом, который находится рядом с ними. Кроме того, чем выше серьезность данных, тем сложнее передать данные в другое место или сделать их доступными для других приложений.
Загрузить сейчас: Навигация по наводнению: повышение ценности за счет снижения сложности данных и правильного управления данными
Это не только ограничивает гибкость предприятия, но также может привести к неорганизованности больших наборов данных, поскольку гравитация данных затрудняет фактическое управление данными.
Главное — правильно хранить ваши данные с самого начала.
Или, если этот конкретный поезд уже покинул станцию, вам нужно переосмыслить и реорганизовать все свои данные таким образом, чтобы были введены правила, чтобы все было управляемым.
С этой целью хранилище данных позволяет вам брать большие объемы данных из разных мест и решений для хранения и помещать их в централизованное хранилище данных, где они могут быть агрегированы, а аналитика может выполняться в одном месте. .
Это решает многие проблемы гравитации данных. Это также заставляет вас установить надлежащие руководящие принципы для будущего агрегирования и управления по мере поступления новых данных.
Что произойдет, если вы не примете меры, чтобы избежать гравитации данных? Прежде всего, вы упустите возможности в понимании бизнеса и ценности для бизнеса.
Без использования таких решений, как хранилища данных, вы в конечном итоге достигнете точки с вашими данными, когда ваши инженеры или аналитические группы столкнутся с препятствиями, решая проблемы, потому что необходимые им данные — и разрешения на доступ к ним — будут отдельными мест, с отдельными ИТ-организациями.
Это, в конце концов, отнимает уйму времени и ресурсов, поскольку те, кому нужен доступ к данным, тратят больше времени на их поиск и организацию, чем фактически работают с ними.
Не попадитесь в черную дыру гравитацией данных. Загрузите нашу бесплатную техническую документацию Navigating the Flood: Повышение ценности за счет снижения сложности данных и правильного управления данными .
стратегий для эффективного отображения больших объемов данных в веб-приложениях
В блоге «Технический подход к большим наборам данных объектов» мы продемонстрировали методы быстрого отображения больших объемов данных без ошибок рисования слоев. Хотя доступны инструменты для быстрого рисования миллиарда объектов в сети, позволяет ли отображение каждой отдельной функции визуализировать данные в доступной для понимания форме?
Хотя доступны инструменты для быстрого рисования миллиарда объектов в сети, позволяет ли отображение каждой отдельной функции визуализировать данные в доступной для понимания форме?
В приложении ниже сравнивается векторный слой и слой листов с 95 039 точками, представляющими землетрясения, произошедшие в период с 2014 по 2017 год. Карты используются для понимания геопространственных явлений. Хотя картография светлячков выглядит великолепно (спасибо Джону Нельсону), какое понимание можно получить о глобальном распределении землетрясений с помощью этих карт?
Распределение землетрясений 2014-2017
* Примечание автора.Ладно, это не совсем миллиард баллов, но их достаточно, чтобы Точка … понять … Точечные характеристики …
- Где произошло больше всего землетрясений?
- Где произошли самые сильные землетрясения?
- Где землетрясения относительно редки?
- Сколько землетрясений произошло в Канаде?
- Были вызваны майнингом?
С точки зрения визуализации очень сложно ответить на эти вопросы, основываясь на приведенном выше приложении. Есть много перекрывающихся элементов, и трудно визуально понять плотность точек. Вы заметили, что на правой карте в три раза больше объектов, чем на левой? Мудрый и благородный волшебник, Альбус Дамблдор однажды сказал, : «Это наш выбор, Гарри, показывает, кто мы есть на самом деле, гораздо больше, чем наши способности». Хотя использование тайлового слоя позволяет отображать на карте миллиард * точек, в этом блоге будут рассмотрены четыре других стратегии для отображения больших наборов данных — например, те, которые используются в этом примере землетрясения, — которые помогут вашим пользователям легко понять с ваших карт.
Есть много перекрывающихся элементов, и трудно визуально понять плотность точек. Вы заметили, что на правой карте в три раза больше объектов, чем на левой? Мудрый и благородный волшебник, Альбус Дамблдор однажды сказал, : «Это наш выбор, Гарри, показывает, кто мы есть на самом деле, гораздо больше, чем наши способности». Хотя использование тайлового слоя позволяет отображать на карте миллиард * точек, в этом блоге будут рассмотрены четыре других стратегии для отображения больших наборов данных — например, те, которые используются в этом примере землетрясения, — которые помогут вашим пользователям легко понять с ваших карт.
Примечание автора. Для приведенных ниже стратегий набор данных с 17 358 точками отображает землетрясения, произошедшие в 2017 году. Этот меньший набор данных позволяет легче увидеть различия между примерами, но концепции могут применяться к более крупным наборам данных.
Стратегия 1. Отображение важных данных
Используйте фильтр для отображения функций, которые вы хотите, чтобы ваши пользователи просматривали и изучали.
Это приложение отображает землетрясения с магнитудой более 6 баллов.5. Пользователи могут визуально идентифицировать и исследовать сильные землетрясения, произошедшие в 2017 году, не отвлекаясь на более мелкие землетрясения на дисплее.
Стратегия 2: агрегирование данных в шестиугольники одинакового размера (шестиугольники) для визуализации шаблонов
Используйте инструмент анализа «Сводные точки», чтобы создать новый слой с подсчетом всех объектов землетрясений в пределах шестиугольного многоугольника. Это отображает кластеры землетрясений по регионам в равных областях, которые можно использовать для тематического картирования.
Слева каждый шестиугольник представляет количество землетрясений, произошедших в пределах гексабина 250 км. Также была рассчитана средняя магнитуда землетрясений в пределах шестиугольника. Это показывает скопления многих землетрясений в Индонезии и Японии. На карте справа показаны данные о землетрясениях, которые не были агрегированы.
Стратегия 3. Используйте масштабную видимость и / или многомасштабную визуализацию, чтобы отображать информацию, когда она визуально полезна.
Установите видимый диапазон для отображения соответствующих данных в соответствующих масштабах.Отображайте подробные данные в большом масштабе, позволяя рисовать, когда функции можно визуально идентифицировать. Сделайте подробные данные невидимыми в малых масштабах, чтобы исключить возможность просмотра сильно перекрывающихся данных. Рассмотрите возможность использования агрегированных данных для предоставления контекста вашей аудитории в небольших масштабах.
Мультимасштабный рендеринг
Это приложение использует шестнадцатеричные биты 100 км для определения местоположения кластеров землетрясений. Увеличивайте темно-фиолетовые шестиугольники, пока точечные объекты не появятся в Оклахоме.
Стратегия 4. Использование кластеризации для группировки точек в один символ и применения стилей интеллектуального сопоставления
Кластеризация — это новая функция, доступная для наборов данных, содержащих до 50 000 объектов (скоро появятся более крупные наборы данных). Включение кластеризации группирует точки, находящиеся на расстоянии друг от друга на экране, в один символ. По мере увеличения пользователем масштаба кластеры динамически обновляются, чтобы отображать соответствующие кластеры в текущем представлении приложения. Интеллектуальное сопоставление может применяться для отображения преобладающего типа для категориальных атрибутов и усредненных значений для числовых атрибутов.
Включение кластеризации группирует точки, находящиеся на расстоянии друг от друга на экране, в один символ. По мере увеличения пользователем масштаба кластеры динамически обновляются, чтобы отображать соответствующие кластеры в текущем представлении приложения. Интеллектуальное сопоставление может применяться для отображения преобладающего типа для категориальных атрибутов и усредненных значений для числовых атрибутов.
Например, карта слева показывает, где произошло много землетрясений, представленных большими кластерами, и преобладающие типы землетрясений в каждом кластере. На карте в правом приложении показаны места распространения землетрясений и их тип. Продолжайте увеличивать кластеры Mining Explosion, чтобы узнать больше о типах землетрясений в кластере.
Что дальше?
Используйте эти четыре стратегии и службы плиток, чтобы быстро и информативно показать множество функций, которые подходят для передачи вашего сообщения пользователям.
Ознакомьтесь с этими полезными блогами, чтобы получить более подробную информацию о вышеуказанных стратегиях:
Использование техники биннинга для точечных многомасштабных веб-карт
Как создать смарт-карту с кластеризацией
Создание тематических карт с шестиугольниками
Быстрое отображение красивых символов в ArcGIS Online
Картография светлячков
Как отобразить миллиард функций в Интернете
Каталог данных о землетрясениях USGS
Об авторе
Келли Герроу-Уилкокс
Келли — менеджер по продукту в команде ArcGIS Online. Она работает в Esri с 2012 года и любит вести блог, пользоваться веб-приложениями и приключениями на природе!
Она работает в Esri с 2012 года и любит вести блог, пользоваться веб-приложениями и приключениями на природе!
Анализ больших наборов данных с помощью Power Pivot в Microsoft Excel
Анализ больших наборов данных с помощью Power Pivot в Microsoft Excel
Контекст для Power Pivot… Если вы часто пользуетесь Excel, то, вероятно, знакомы со сводными таблицами.Они используются для быстрого получения информации из небольших объемов данных, а также могут быть преобразованы в простые для понимания графики. Но даже у Excel есть свои ограничения. При объединении таблиц, манипулировании большими наборами данных, превышающими один миллион строк, или при выборе данных из нескольких источников Excel будет испытывать трудности. Может быть неприятно, когда Excel неожиданно завершает работу, работает очень медленно или по истечении времени ожидания и требуется принудительное завершение работы!
Итак, что произойдет, если у вас есть более миллиона строк (1 048 576, если быть точным) данных? Вы используете Power Pivots.
В 2010 году Microsoft добавила Power Pivots в Excel, чтобы помочь в анализе больших объемов данных. Power Pivot может обрабатывать сотни миллионов строк данных, что делает его лучшей альтернативой Microsoft Access, который до Excel был единственным способом для этого. Думайте о Power Pivot как о способе использования сводных таблиц для очень больших наборов данных.
Это также полезно, когда данные поступают из нескольких источников. С помощью Power Pivot вы можете импортировать эти данные только в одну книгу без необходимости использования нескольких исходных листов, что может сбивать с толку и расстраивать.
Power Pivot был создан для импорта и анализа данных из нескольких источников. В качестве источников данных в Power Pivot можно использовать все, что угодно, от баз данных Microsoft SQL, Oracle или Access до данных списков SharePoint и текстовых документов.
Доступ к Power Pivot
Power Pivot — это бесплатный инструмент надстройки в Excel и постоянная встроенная функция в Excel 2016 и 365. Первый шаг в использовании Power Pivot — это добавление его на ленту Excel.В последние версии Microsoft Excel (13-17 дюймов) Power Pivot встроен, но вам может потребоваться его активировать.
Первый шаг в использовании Power Pivot — это добавление его на ленту Excel.В последние версии Microsoft Excel (13-17 дюймов) Power Pivot встроен, но вам может потребоваться его активировать.
Включите Power Pivot, щелкнув Файл -> Параметры -> Надстройки -> Microsoft Power Pivot для Excel:
Теперь Power Pivot включен, но не совсем готов к использованию. Остался еще один шаг.
Вам нужно будет указать Power Pivot, куда следует импортировать данные.Для этого щелкните вкладку Power Pivot на ленте -> Управление данными -> Получить внешние данные. В списке источников данных есть много вариантов. В этом примере будут использоваться данные из другого файла Excel, поэтому выберите вариант Microsoft Excel внизу списка. Для больших объемов данных импорт займет некоторое время.
После завершения импорта вы увидите данные в главном окне Power Pivot. Одновременно будут открыты два окна — обычное окно Excel и окно Power Pivot.Однако вам не обязательно иметь данные на открытой странице Excel.
Одновременно будут открыты два окна — обычное окно Excel и окно Power Pivot.Однако вам не обязательно иметь данные на открытой странице Excel.
Создание базовой сводной таблицы Power
Допустим, у вас есть электронная таблица со списком продаж продуктов. Каждая строка представляет собой идентификатор клиента, а столбцы — это имя, номер счета, дата, количество и цена.
Поскольку у клиентов есть несколько счетов-фактур, но только один идентификатор клиента, информация о клиенте должна повторяться несколько раз.Это не проблема, когда счетов-фактур всего несколько. Но когда счета-фактуры начнут увеличиваться до одного миллиона, будет менее эффективно использовать этот формат в базовом Excel и более эффективно будет создавать Power Pivot.
Для этого откройте новую книгу Excel. Выберите Power Pivot на ленте, затем нажмите «Управление» -> «Из других источников» и прокрутите вниз до Excel. На экране выберите файл с помощью кнопки «Обзор».
На экране выберите файл с помощью кнопки «Обзор».
После выбора файла щелкните Далее.Заголовок «Удобное имя» можно переименовать в заголовок, описывающий набор данных. В этом случае название было изменено на «Счета-фактуры». Щелкните Готово.
Успех! Список счетов был импортирован в Power Pivot Table. Отсюда вы можете создавать диаграммы сводной таблицы так же, как и с меньшими наборами данных (объяснено в следующем разделе). Опять же, причина использования Power Pivot здесь заключается в том, что данные были в другом формате (SQL, Access, Oracle) или если в файле Excel было более миллиона строк.В противном случае использование базовой функции сводной таблицы в Excel будет работать без ошибок.
Создание сводной диаграммы из сводной таблицы Power
Чтобы создать диаграмму из этой Power Pivot, щелкните значок сводной таблицы на ленте Excel и выберите «Сводная диаграмма» (выберите «Сводная таблица», если вы хотите создать обычную сводную таблицу в Excel перед созданием диаграммы).
Откроется новая рабочая тетрадь.Используйте панель инструментов полей справа, чтобы выбрать поля для таблицы. В этом примере заказ каждой компании сравнивается месяц за месяцем. Итак, имя клиента, дата и количество были выбраны и включены в сводную диаграмму.
Совет: формулы Power Pivot
Power Pivot имеет множество полезных функций и преимуществ. В дополнение к обычным функциям Excel он вводит более 75+ новых формул. Вот два важных вопроса:
= COUNTROWS: Подсчитывает количество строк в источнике данных.Если у вас есть несколько источников данных, которые связаны друг с другом по идентификатору, например по названию продукта, вы также можете подсчитать количество строк по отношению к этим идентификаторам.
= SWITCH: Switch невероятно полезен для данных, которые нужно редактировать. Например, у вас могут быть строки с номером, обозначающим определенный месяц, вместо фактического названия месяца — 1 для января, 2 для февраля, 3 для марта и т. Д. Используйте = SWITCH, чтобы изменить (переключить) все числа на фактический месяц.
Д. Используйте = SWITCH, чтобы изменить (переключить) все числа на фактический месяц.
Power Pivot автоматически использует вычисление = SUM для суммирования числовых данных, что является отличной функцией. Чтобы изменить используемый тип расчета, щелкните правой кнопкой мыши внутри сводной таблицы и выберите «Параметры поля значений» -> «Суммировать значения по вкладке». Как вы можете видеть на изображении, параметры = COUNT, = AVERAGE, = MIN, = MAX и многие другие.
Совет: Power Pivot и SharePoint
Многие организации используют Microsoft Sharepoint.Панели мониторинга, графики и сводные диаграммы Power Pivot можно публиковать прямо в Sharepoint для быстрого просмотра любым сотрудником вашей организации. Чтобы использовать это, установите подключаемый модуль «Power Pivot для SharePoint» на сайте Sharepoint вашей компании.
Power Pivots может показаться расширенной функцией Excel, но ими легко пользоваться, если вы понимаете, как получить доступ к функции и импортировать набор данных.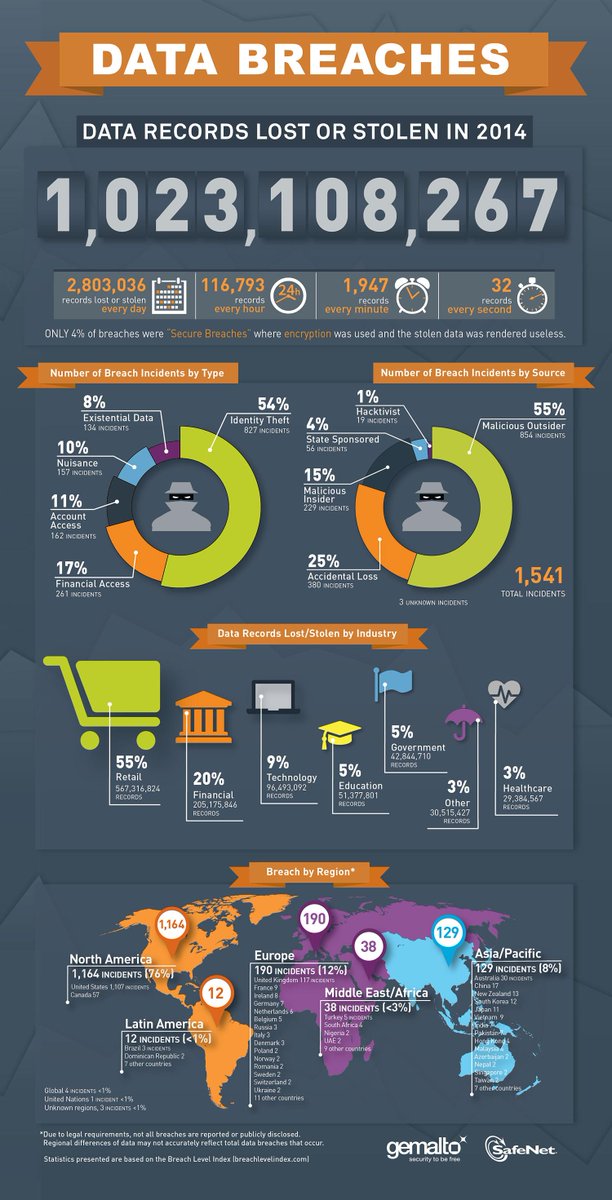 После ввода данных вы можете запустить сводную таблицу или сводную диаграмму из набора данных, как и обычную таблицу данных.Power Pivot — один из самых быстрых способов предоставить вам простую информацию о больших объемах данных, которые в противном случае могут привести к сбою Excel или, как минимум, свести вас с ума. Поэтому, если вы обнаружите, что в электронной таблице миллионы строк, найдите и используйте Power Pivot.
После ввода данных вы можете запустить сводную таблицу или сводную диаграмму из набора данных, как и обычную таблицу данных.Power Pivot — один из самых быстрых способов предоставить вам простую информацию о больших объемах данных, которые в противном случае могут привести к сбою Excel или, как минимум, свести вас с ума. Поэтому, если вы обнаружите, что в электронной таблице миллионы строк, найдите и используйте Power Pivot.
Если вы еще не освоили сводные таблицы, мы предлагаем вам начать с них, прежде чем переходить к Power Pivot. Познакомьтесь с сводными таблицами ЗДЕСЬ, посмотрите часовой веб-семинар по сводным таблицам ЗДЕСЬ
Более подробное руководство по Power Pivot можно найти здесь:
Наконец, чтобы загрузить 100 наиболее полезных советов по Excel, щелкните ЗДЕСЬ
больших объемов данных — перевод на китайский — примеры английский
Эти примеры могут содержать грубые слова на основании вашего поиска.
Эти примеры могут содержать разговорные слова, основанные на вашем поиске.
Сводные таблицы — это интерактивный метод быстрого суммирования больших объемов данных .
透视 表 是 一种 可以 快速 汇总 大量 数据 的 交互式 方法。Сеть — лучший способ передать больших объемов данных .
Способен обрабатывать больших объемов данных , стабильно и безопасно.
Некоторым приложениям часто требуется читать и записывать больших объемов данных на диск, что часто является самым медленным шагом в вычислениях.
有些 应用 程序 通常 会 需要 从 磁盘 中 读写 大量 的 数据 , 这 通常 中 速度 慢 的 一个 步骤。Один анализирует больших объемов данных , чтобы получить значимое понимание.
就是 从 大 数据 里 分析 提取 有用 的 信息。Системы управления базами данных появились в 1960-х годах для решения проблемы точного и быстрого хранения и извлечения больших объемов данных .
数据库 管理 系统 在 上 世纪 60 年代 出现 , 以 准确 地 存取 和 检索 大量 数据 。База данных предназначена для простой организации, хранения и извлечения больших объемов данных .
数据库 是 为了 更 容易 地 组织 、 存储 和 检索 大量 数据 。Когда большому многопользовательскому кластеру требуется доступ к очень большим объемам данных , планирование задач становится проблемой.
当 大型 多 用户 集群 需要 访问 大量 数据 时 , 任务 调度 就 成为 一个 挑战。Офисам, возможно, придется рассмотреть облачные вычисления вместо того, чтобы пытаться переместить больших объемов данных на свои собственные серверы.
国家 统计局 可能 需要 考虑 云 计算 , 而 不是 试图 把 大量 数据 迁移 到 的 服务器 上。Встроенное хранилище больших объемов данных требует использования большой твердотельной массовой памяти.
板载 大量 数据 存储 需要 使用 大型 固态 大 容量 存储器。Немногие пользователи думают, что CCRC может обрабатывать больших объемов данных , что возможно, но не рекомендуется.
很少 用户 认为 CCRC 可以 处理 大量 数据 , 这 是 可能 的 , 但 不 推荐。Масштабируемая избыточная инфраструктура базы данных, способная обрабатывать больших объемов данных на регулярной основе, включая архитектуру для внешнего хранилища
规模 可变 的 多余 数据库 基础 设施 能够 定期 处理 大量 数据 , 包括 院 外 储存 结构Аналогичным образом операторы частного сектора, обрабатывающие больших объемов данных , эффективно использовали компьютерные системы уже более 20 лет.
同样 , 处理 大量 数据 的 私营 营业 人 有效 利用 计算机 系统 至今 也 有 20 的 历史。Он представил предлагаемые им временные лицензии на изображения и объяснил свой подход к краудсорсинговому картированию для анализа больших объемов данных .
它 介绍 了 它所 提供 的 临时 成像 许可 并 对其 在 用于 分析 大量 数据 的 众 包 制图 做法 进行 了 解释。Поскольку эти сети быстро передают больших объемов данных , они идеально подходят для использования с такими устройствами, как цифровые видеокамеры или внешние жесткие диски.
由于 这些 网络 传输 大量 数据 的 速度 较快 , 因此 非常 适用 于 数字 摄像机 或 外接 硬盘 等 设备。Запрос возвратил больших объемов данных , и отображение вашей формы может занять некоторое время. Вы хотите продолжить?
查询 返回 大量 数据 , 显示 表单 可能 需要 一些 时间。 是否 继续?В то время как больших объемов данных доступны в отдельных странах, эти данные распределены между различными учреждениями и труднодоступны.
尽管 在 各国 存在 大量 数据 , 但是 这些 资料 分散 在 不同 的 机构 里 , 不易 得到。«Должны быть достаточно простые элементы управления, чтобы позаботиться обо всем», — сказала г-жа Диксон, добавив, что некоторые браузеры автоматически собирают больших объемов данных , если пользователь не сказал им этого не делать.
Dixon 建议 «应该 有 足够 简单 的 控制 选项 , 能够 处理 每 一个 单独 的 方面» , 她 补充 说 一些 浏览 器 自动 的 收集 大量 的 数据 , 除非 用户 明确 的Потенциал источников больших данных заключается в своевременной — а иногда и в реальном времени — доступности больших объемов данных , которые обычно генерируются с минимальными затратами.
大 数据 源 的 潜力 在于 及时 、 甚至 实时 提供 是以 最低 成本 生成 的 大量 数据 。 .