Читайте про Дубли страниц в нашем словаре SEO терминов
Дубли страниц — различные интернет-страницы конкретного ресурса с максимально схожим или полностью идентичным контентом. Бытует мнение, что дубликаты являются совершенно безобидными. Это относится лишь к пользователям, для которых присутствие таких страниц не играет особой роли. Но в отношении продвижения и ранжирования сайтов поисковиками они способны создать негативный эффект.
Отрицательные факторы влияния дублей:
- Индексация. Дублирующийся контент заставляет ботов поисковых систем терять драгоценный краулинговый бюджет на такие страницы. При этом действительно важная информация сайта может остаться без индексации.
- Понижение процента общей уникальности контента, размещенного на портале.
- Внешние ссылки продвигаемых интернет-страниц теряют вес. Это происходит, когда посетитель делится ссылкой на страницу-дубликат.
- Неуникальный контент.

- Возможность продвижения нерелевантной интернет-страницы. Поисковик способен отображать в результатах выдачи совершенно не ту страницу, которую оптимизатор пытается продвинуть.

Страничные дубли являются частичными, либо же полными. В полных дублях контент абсолютно идентичен, в частичных – контент похож. При этом более безопасными и безобидными считаются частичные дубли, ведь они не дают сайту сильно пострадать из-за своего присутствия. Хотя постепенное понижение в ранжировании все равно может происходить. Что касается полных дубликатов, то подобные страницы зачастую обнаруживаются в интернет-магазинах (карточки и описание товаров).
Почему же появляются дубли? Например, они в состоянии автоматически генерироваться движком сайта. Либо же речь может идти о корректировке структуры портала. В этом случае старые адреса не только сохраняются, но и дополнительно получают новые адреса.
Поиск страниц-дублей на сайте
Далее будут представлены самые эффективные способы поиска дублей интернет-страниц.
Сканирование ресурса благодаря специализированным приложениям
Выявлять дубликаты можно с помощью особых программ (например, Screaming Frog Seo Spider, NetPeak Spider), которые являются платными или бесплатными. Такие приложения умеют довольно быстро сканировать ресурс, чтобы найти дубли. В этих программах возможно осуществить выгрузку списка URL-адресов. Есть возможность отсортировать результаты по тегам Description и Title. Это позволяет оперативно находить повторяющийся текстовый контент.
Вебмастер Google или Yandex
Вот как происходит поиск дублей в соответствующей консоли Google:
- открываем панель инструментов;
- нажимаем на пункт «Вид в поиске»;
- выбираем «Оптимизация HTML».
Теперь дубликаты можно увидеть в разделе «Повторяющиеся заголовки».
Ищем дубли страниц в Яндексе:
- находим пункт «Страницы в поиске», который располагается в сервисе Яндекс.Вебмастер;
- переходим в «Исключенные страницы»;
- сейчас нам нужна «Сортировка: Дубль»;
- не забываем применять действия;
- система осуществит выдачу повторяющихся страниц.
Если это необходимо, то всегда можно выгрузить готовый список для собственных нужд.
Ручной поиск
Профессиональный вебмастер способен отыскать дубли вручную. Как правило, для этих целей используется url-адрес ресурса. Он многократно вводится с помощью различных вариаций (например, добавляются какие-то знаки или символы).
Оператор «site:»
Открываем поисковую строку, чтобы ввести «site:site_name.ru». В выдаче появятся все страницы вашего ресурса, прошедшие индексацию. Такой метод дает возможность отыскать не только страницы-дубли, но и «мусорный» контент.
Удаляем дубли страниц
Нет желания постоянно заниматься выявлением дублей страниц, а также их закрытием от поисковиков? Тогда лучше раз и навсегда от них избавиться.
Файл .htaccess и 301 редирект
Если дубли появились абсолютно случайно (к примеру, был использован двойной пробел), то можно воспользоваться обычной настройкой 301 редиректа. Для этого нужно установить необходимое перенаправление при помощи файла .htaccess.
Запрет индексации страниц-дублей через robots.txt
Есть возможность закрыть некоторые интернет-страницы от роботов поисковых систем. В файле robots.txt прописываем:
User-agent: *
Disallow: /page-name
Такой способ будет максимально эффективен в отношении служебных страниц, повторяющих контент главной страницы площадки. Если же интернет-страница уже присутствует в индексе, тогда данный метод может не работать.
Указание канонической старницы
Мы можем задать каноническую страницу для последующего индексирования используя тег rel=»canonical». При этом она будет открыта для просмотра. Это очень полезно для различных фильтров, а также страниц-сортировок. Нужно лишь указать соответствующий атрибут canonical в теге <link>. Причем делается это в коде HTML текущей интернет-страницы.
Мета-тег
Есть возможность насильно запретить роботам поисковиков индексировать определенные документы при помощи тега noindex. Благодаря этому специальные боты не будут переходить по ссылкам. Сам тег располагается в блоке <meta name=»robots» content=»noindex, nofollow> или <meta name=»robots» content=»noindex, follow>
Данный вариант очень часто применяется, когда речь заходит о вкладках с пользовательскими отзывами о том или ином товаре или услуге.
Когда повторяющийся контент будет удален (или скрыт), то рекомендуется осуществить повторную проверку ресурса. Причем делать это нужно регулярно, чтобы случайно не выпасть из рейтинга поисковых систем. Важно, чтобы количество страниц с дублирующимися материалами было сведено к минимуму, либо же вообще равнялось нулю.
Поиск дублей страниц сайта | Как проверить онлайн и убрать дубли
Сколько раз делаю технический аудит какого-нибудь клиентского сайта, так обязательно нахожу дубли страниц. Это особенная проблема для больших интернет магазинов. Давайте сейчас разберемся, как эту проблему диагностировать и решить.
Дубли сайта — это страницы с идентичным или почти одинаковым контентом но разными URL.
Дублями могут быть мета-теги title и description, могут быть дубли текста или полного контента, то есть всего содержимого страницы. Наиболее часто дублями бывают страницы пагинации, карточки товаров, страницы фильтра или теги.
Причем частичное совпадение контента допустимо, например, в каких-то карточках товаров могут дублироваться характеристики или какие-то блоки на странице могут дублироваться, например, отзывы. Но если взять сайт в целом, то каждая страница на сайте должна быть уникальной.
От дублей страниц очень много бед для сайта.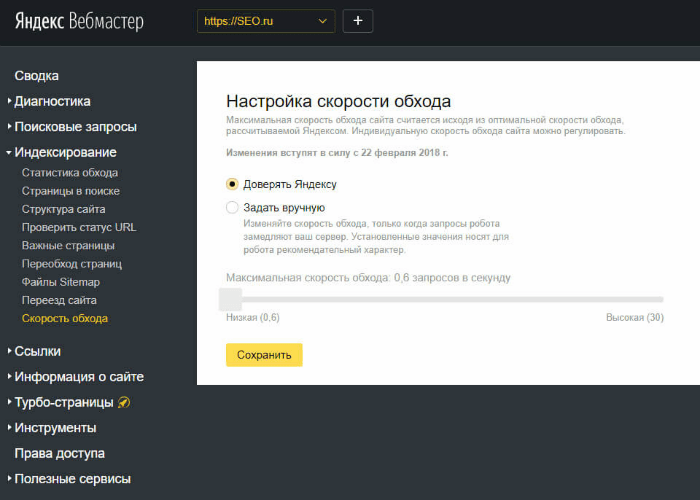
Например, яндекс идентифицирует дубли, они отображаются в яндекс вебмастере, он просто выплевывает их из выдачи.
А google наоборот их хранит и при достижении какого-то критического значения накладывает фильтр на сайт. В общем, вреда от дублей для сайта много и поэтому от них обязательно нужно избавляться.
Но для начала их нужно идентифицировать, и есть несколько способов поиска и проверки дублей страниц сайта онлайн, я разберу способы ручные и способы автоматизированные. Эти способы являются универсальными и подойдут для любого движка, будь то wordpress, битрикс, opencart, joomla и других.
Проверка дублей через яндекс вебмастер
Самый простой способ, если у вас есть яндекс вебмастер, вы можете зайти в раздел «Индексирование — страницы в поиске».
Выбрать здесь «Исключенные страницы» и посмотреть, нет ли у вас вот такой картины.
Вебмастер показывает, что это дубли, и если такое присутствует, то нужно от этого избавляться. Дальше я покажу, какие есть варианты исправить их.
Поиск через индекс поисковых систем
Следующий способ также ручной — нужно вбить в поисковую строку google такую комбинацию site:santerma.shop (после двоеточия адрес вашего сайта), и покажутся все страницы, которые есть в индексе поисковой системы.
Аналогично работает и в яндексе.
Затем вручную пройтись по сайту и посмотреть, какие есть проблемы. Например, вот видно, есть какие-то дубликаты заголовков — интернет магазин сантехники и водоподготовки САНТЕРМА.
Можно перейти и посмотреть, что это за дубликаты, заголовки у них одинаковые, получается страницы тоже могут быть одинаковые.
Это страницы пагинации, о чем я и говорил, что очень часто дублями является такие страницы. То есть сами страницы не являются дублями, но здесь дубли мета-теги, тайтл у всех этих страниц одинаковый.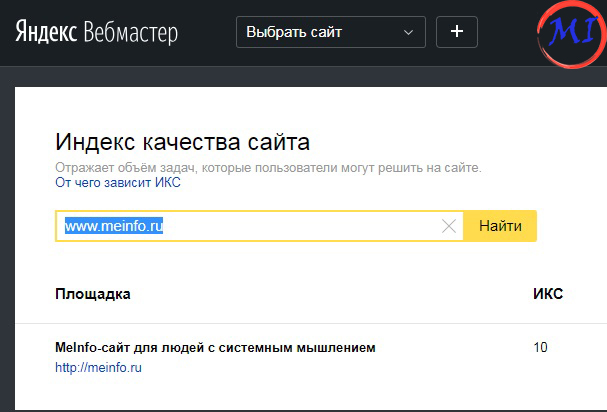
Это означает, что вот таких страниц «Интернет магазин сантехники и водоподготовки» очень много, соответственно, эту проблему тоже нужно решать, для страниц пагинации делают rel canonical.
Как проверить дубли с помощью Screaming Frog
Следующий способ, как можно проверить онлайн и найти дубли страниц на сайте, уже является автоматическим, с помощью программы Screaming frog. Загружаем адрес сайта, нажимаем «Старт», и программа начинает парсить весь сайт.
Затем переходим в раздел Page title, нажимаем сортировку, и вот опять видно, что тайтлы полностью идентичные, причем разные url, а тайтлы везде одинаковые.
Это очень грубая ошибка, ее нужно исправлять, то есть тайтл для каждой страницы должен быть уникальным.
Как найти дубли сайта онлайн с помощью Saitreport
Еще один способ, как найти дубли сайта — через сервис Saitreport. Я записывал обзор по этому сервису, посмотрите видео:
Вкратце скажу, что дубли страниц можно найти во вкладке «Контент», спускаемся вниз и здесь вот есть «Полные дубликаты», «Почти дубликаты» и «Очень похожие».
Нас интересуют вот эти полные совпадения и почти дубликаты, особенно полные совпадения, переходим сюда и видим, что достаточно много дублей.
По URL видно, что эта страницы фильтров, две полностью идентичные страницы. Самое главное, чтобы фильтр был закрыт от индексации, чтобы весь этот мусор не попал в индекс. Если это просто находится на сайте, но не в индексе, то ничего страшного нет, но если этот мусор попадет в индекс, то можно легко похерить сайт.
Проверка дублей страниц index.php и index.html
И последний способ найти дубли — проверить файлы index.php и index.html, которые могут отвечать за отображение главной страницы сайта. Часто бывает, что на сайтах эти файлы настроены неправильно.
Чтобы это проверить нужно к адресу главной страницы через слэш прописать index.php. Если все настроено правильно, то должен произойти 301 редирект (сайт перебросит с index.php на главную страницу) или должна открыться страница 404 ошибки.
Но если по адресу site. ru/index.php открывается опять главная страница, то это является дублем, то есть страница site.ru/index.php дублирует главную страницу.
ru/index.php открывается опять главная страница, то это является дублем, то есть страница site.ru/index.php дублирует главную страницу.
В этом случае нужно проверить внутренние страницы — также через слэш прописать index.php. Скорее всего опять откроются дубли внутренних страниц, иногда открывается опять главная, получаются многократные дубли через неправильную настройку этого файла.
Аналогично нужно проверить файл index.html. Как я сказал, должен произойти или 301 редирект (перебросить на главную страницу) или открыться страница 404 ошибки.
Как убрать дубли
Итак, что теперь делать с этими дублями, которые найдены? Вариантов много, и каждый вариант нужно выбирать в зависимости от ситуации, сайта, потому что один и тот же вариант может подойти одному сайту, но не подойдет другому.
Самое главное, нужно определить, насколько важны эти страницы для продвижения сайта. Есть ли на них трафик или может быть планируется, и дальше действовать в соответствии с этой важностью.
Если эта страницы не важны, то есть варианты:
- закрыть их от индексации;
- настроить на них canonical;
- совсем удалить их сайта.
Если же это страницы важные, то нужно их уникализировать:
- переписать метатеги;
- переписать заголовоки;
- переписать контент;
- сделать каждую страницу уникальный, чтобы она несла пользу посетителю и продвигалась в поиске.
Для закрепления материала, посмотрите более подробное и наглядное видео по поиску дублей:
Итак, я надеюсь, что статья была полезной для вас! Пишите ваши вопросы, комментарии, может что-то не понятно, просто пишите, если статья понравилась, я рад любой обратной связи. Поделитесь ею с друзьями в социальных сетях!
Сергей Моховиков
SEO специалист
Здравствуйте! Я специалист по продвижению сайтов в поисковых системах Яндекс и Google. Веду свой блог и канал на YouTube, где рассказываю самые эффективные технологии раскрутки сайтов, которые применяю сам в своей работе.
Вы можете заказать у меня следующие услуги:
Загрузка…листалки, версии для печати и другое; Как защитить контент.
Многие перечисленные выше доработки направлены на то, чтобы на сайте не создавались лишние страницы, точные копии существующего контента. Опасность наличия таких страниц описана в третьей главе. Они могут повлечь за собой как некорректный выбор релевантной страницы, так и наложение санкций на сайт.
Существуют два вида дублей – полные и нечеткие.
Полные дубли – это страницы, содержание которых идентично друг другу, различны только их URL.
Нечеткие дубли – это страницы, которые содержат очень большое количество одинаковой информации, но они не полностью идентичны; их URL также различны.
Источники дублей в сети различны. В одних случаях дубли появляются из-за технических недоработок web-мастеров, в других – в результате осознанного влияния оптимизатора на ответ поисковой машины.
За технические ошибки и форматы документов отвечают непосредственно владелец и разработчик сайта. Дубли текста же могут появляться, в том числе, в результате кражи контента с сайта-первоисточника. Однако борьба оптимизаторов с «нахлебниками» не имеет отношения к технической оптимизации, поэтому далее речь пойдет о недоработках на сайте, автоматически генерирующих дублированные страницы.
Чаще всего проблема решается устранением всех дублей, адреса которых будут отдавать и посетителям, и поисковой системе 404 ошибку, при этом необходимо позаботиться об устранении еще и всех образовавшихся битых ссылок.
Большинство рекомендаций по работе с дублями можно свести к следующему:
1. Закрыть от индексации в файле robots.txt все имеющиеся на сайте дубли.
2. При формировании страниц, которые являются дублями, в их мета-теги прописывать <meta name=»robots» content=»noindex,nofollow»/>. Это запретит роботу индексировать данные страницы и переходить по ссылкам с этих страниц.
Это запретит роботу индексировать данные страницы и переходить по ссылкам с этих страниц.
Внутри сайта дубли страниц могут создаваться по разным причинам. Например, дубли могут возникнуть из-за повторения контента в анонсе и на самой странице новости. Другой случай – когда «версия для печати» полностью дублирует основную страницу и т.д.
3. Использовать тег <link rel=»canonical» href=»адрес оригинала» /> на всех автоматически генерируемых страницах.
Однако каждый частный случай появления дублей страниц на сайте нужно рассматривать отдельно и применять те меры, которое будут приемлемы для этого конкретного сайта. Ниже приведены самые распространенные причины автоматической генерации дублей страниц на сайте и варианты их устранения.
«Листалки»
Если на сайте присутствует многостраничный каталог, то очень часто вторая, третья и другие его страницы могут содержать много повторяющейся информации. Это могут быть одинаковые мета-теги или текстовые блоки, которые отображаются на всех страницах каталога из-за особенностей CMS сайта.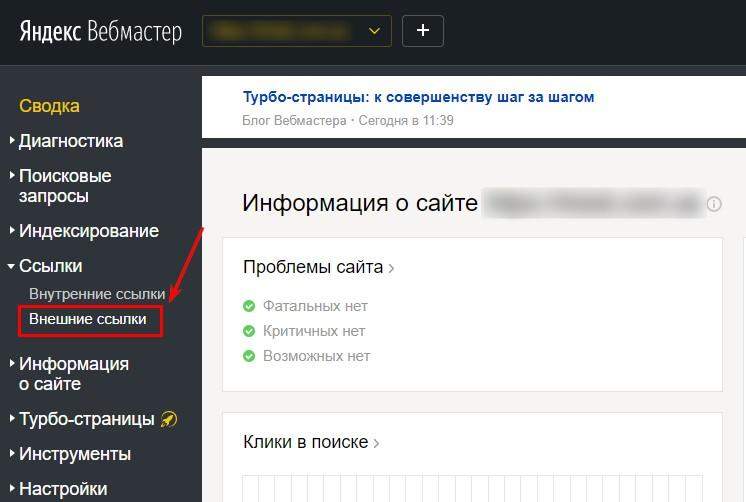 Получается, что на множестве страниц присутствует один и тот же текст, что особенно плохо, если этот текст оптимизирован для продвижения – он просто «растворяется» в множестве дублей.
Получается, что на множестве страниц присутствует один и тот же текст, что особенно плохо, если этот текст оптимизирован для продвижения – он просто «растворяется» в множестве дублей.
Чтобы не допускать дублирования контента в «листалках», можно воспользоваться следующими методами:
1. Закрыть все дублирующиеся страницы через robots.txt, мета-тег “ROBOTS” или использовать тег «rel=”canonical”».
2. Сделать так, чтобы все значимые текстовые блоки отображались только на первой странице и не дублировались на остальных. Это целесообразно, если в продвижении находится только первая страница и на ней остается весь контент, релевантный запросу. Эти работы выполняют разработчики, а вы должны указать им необходимость их выполнения.
Помимо дублей контента на страницах «листалок» также очень часто встречается проблема одинаковых мета-тегов на всех страницах каталога. В этом нет большого вреда, но их уникализация может дать дополнительные бонусы при ранжировании ресурса. Наиболее удобный вариант работы с мета-тегами – создать единый шаблон title и мета-тегов в зависимости от содержания страницы.
Наиболее удобный вариант работы с мета-тегами – создать единый шаблон title и мета-тегов в зависимости от содержания страницы.
Нередко встречается, что «листалка» содержит развернутое описание товара, и точно такой же текст фигурирует на странице с карточкой товара. За счет этого происходит дублирование контента, что может негативно сказаться на ранжировании. У поискового робота возникает диссонанс: какую страницу считать более релевантной?
Чтобы предотвратить такое дублирование, можно:
1. Закрыть страницы «листалки» в robots.txt.
2. Публиковать в «листалках» только небольшую часть из описания товара или услуги со ссылкой на полную версию описания или на карточку товара.Сортировка, фильтрация и поиск
В случае если на сайте располагаются формы сортировки, фильтрации и поиска, то, как правило, результат формируется на отдельной странице с динамическим URL. Эта страница может содержать фрагменты текстов с других страниц сайта. Если не проводить работу с множественными страницами результатов сортировки (или поиска), то они будут открыты для индексации роботами поисковых систем.
В сортировке участвует несколько категорий, фильтрация идет в разных сочетаниях, поиск двух разных слов может привести к одному результату – все это порождает очень много автоматически сгенерированных страниц. А это нарушает лицензию поисковых систем, в частности, Яндекса.
Самый простой способ бороться с такими дублями — закрывать страницы результатов от индексации в robots.txt.
Например, строчка, закрывающая результаты поиска, может принять следующий вид: Disallow: /search=*
Рекомендуется периодически анализировать URL страниц сайта, попадающих в индекс, чтобы вовремя устранять проблемы с сортировкой, фильтрацией и поиском. В качестве алгоритма анализа можем предложить следующее решение:
1. Проанализировать параметры, найденные инструментом GoogleWebmaster и указанные в разделе «Конфигурация – Параметры URL».
Как часто проверять сайт на дубли страниц?
Это зависит от объема контента, периодичности обновлений, наличия поиска.
 В среднем такую проверку рекомендуется устраивать раз в месяц.
В среднем такую проверку рекомендуется устраивать раз в месяц.2. Отобрать параметры, которые являются «незначащими», и задать в Google Webmaster команду «пропускать при индексации». Для настройки сайта под Яндекс следует указать данные параметры в robots.txt как маски для закрытия от индексации.
3. Проанализировать адреса страниц в индексе с помощью Яндекс.Вебмастер (раздел «Индексирование сайта -> Страницы в поиске»). Выявить одинаковые мета-теги (аналогичный инструмент есть и в Google Webmaster), одинаковые адреса с переставленными параметрами (например, первый «/?pr=gr&cost=big» и второй «/?cost=big&pr=gr»), количество страниц одной статьи за счет комментариев. Как только выявлены дубли, необходимо дать задание разработчику, чтобы он закрыл их от индексации.
4. Установить и устранить причину дублей, используя один из перечисленных ранее способов или их комбинацию. В идеале следует пересмотреть структуру сайта и алгоритм формирования URL.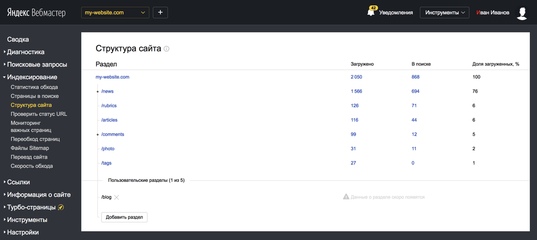
Сортировка, фильтрация и поиск являются важными навигационными элементами сайта; без них нельзя обойтись, особенно на большом сайте, т.к. это серьезно влияет на юзабилити. Но при использовании данных элементов нужно предвидеть возможные проблемы дублирования, периодически проводить проверки и своевременно устранять выявленные недочеты.
Версия для печати
Страница «Версия для печати» имеет большое значение для удобства использования сайта, поэтому ссылки на такие страницы рекомендуется ставить на всех карточках товаров, на странице контактов и в других значимых разделах сайта. Однако страница с версией для печати отличается от основной страницы только отсутствием графической составляющей, т.е. весь контент, как правило, дублируется.
Фактически проблема нечетких дублей в данном случае решается аналогично проблеме полных дублей. Можно воспользоваться атрибутом rel=canonical, мета-тегом «robots» или прописать запрет на индексацию дубля в файле robots.txt. Однако в последнем случае ссылка с оригинала будет передавать вес на страницу печати, что приведет к потере веса продвигаемой страницей. Чтобы этого избежать, ссылку «версия для печати» на странице-оригинале необходимо дополнительно закрыть тегом nofollow. В этом случае робот не будет пытаться переходить по данной ссылке и ошибок сканирования не возникнет.
Чтобы этого избежать, ссылку «версия для печати» на странице-оригинале необходимо дополнительно закрыть тегом nofollow. В этом случае робот не будет пытаться переходить по данной ссылке и ошибок сканирования не возникнет.
Также можно создать версию страницы для печати через технологии JavaScript и CSS. Это позволит избежать проблемы с дублями и оптимизирует взаимодействие сайта со сканирующим роботом. Однако к этой работе потребуется привлечь веб-разработчика.
CMS и неосознанные дубли
Некоторые системы управления сайта (CMS) автоматически создают несколько дублей каждой страницы. Например, в WordPress дубли возникают из-за повторения контента в анонсах и на самих страницах. Другая популярная CMS – Joomla – также создает множество дублей из-за того, что одна и та же страница может быть получена множеством различных способов.
Самая распространенная ошибка – передача лишних параметров. Этим грешат более 90% движков. Например, исходная страница site.ru/index.php?id=602, и только она должна индексироваться.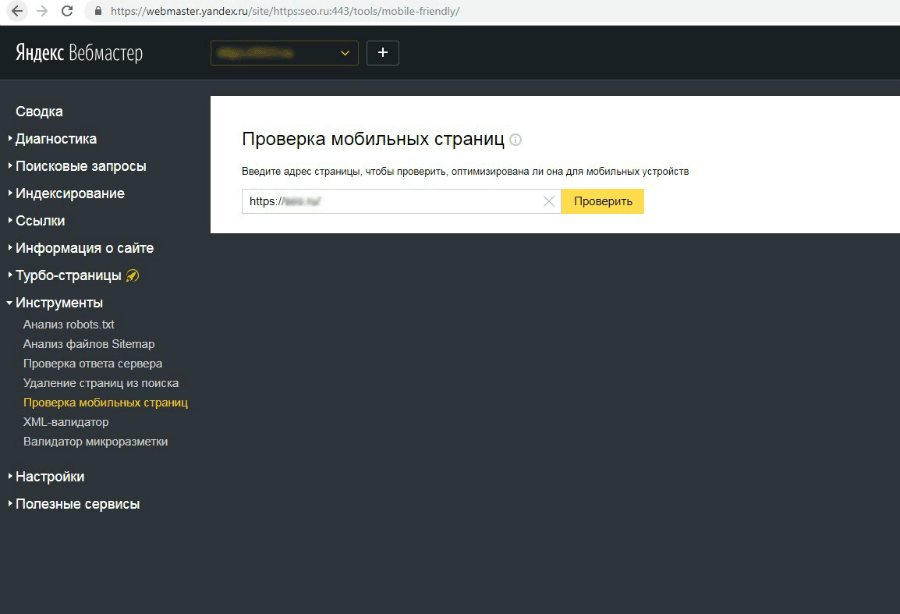 Из-за идентификатора сессий и особенностей формирования динамических страниц появляются дубли: site.ru/index.php? showid=602&fs=12&345?SessionID=98765432156789.
Из-за идентификатора сессий и особенностей формирования динамических страниц появляются дубли: site.ru/index.php? showid=602&fs=12&345?SessionID=98765432156789.
Другой случай – наличие главной страницы по разным адресам, например, http://site.ru/ и http://site.ru/index.php.
Часть дублей обычно закрывается от индексации средствами самой CMS, но оставшуюся часть придется дополнительно закрывать методами, описанными выше: настраивать robots.txt (директива сlean-param и/или запрет индексации дублей), работать с битыми ссылками, настраивать 301 редиректы.
Бывает, что проблемы с дублями начинаются при переносе сайта с одной CMS на другую. В этом случае старые параметры накладываются на страницы нового движка, что может вызвать образование большого количества дублей. Поэтому при переносе сайта первое время необходимо контролировать техническую сторону вопроса более тщательно.
Внутренние и внешние дубли
Дубли могут быть созданы не только автоматически, но и вручную вполне осознанно.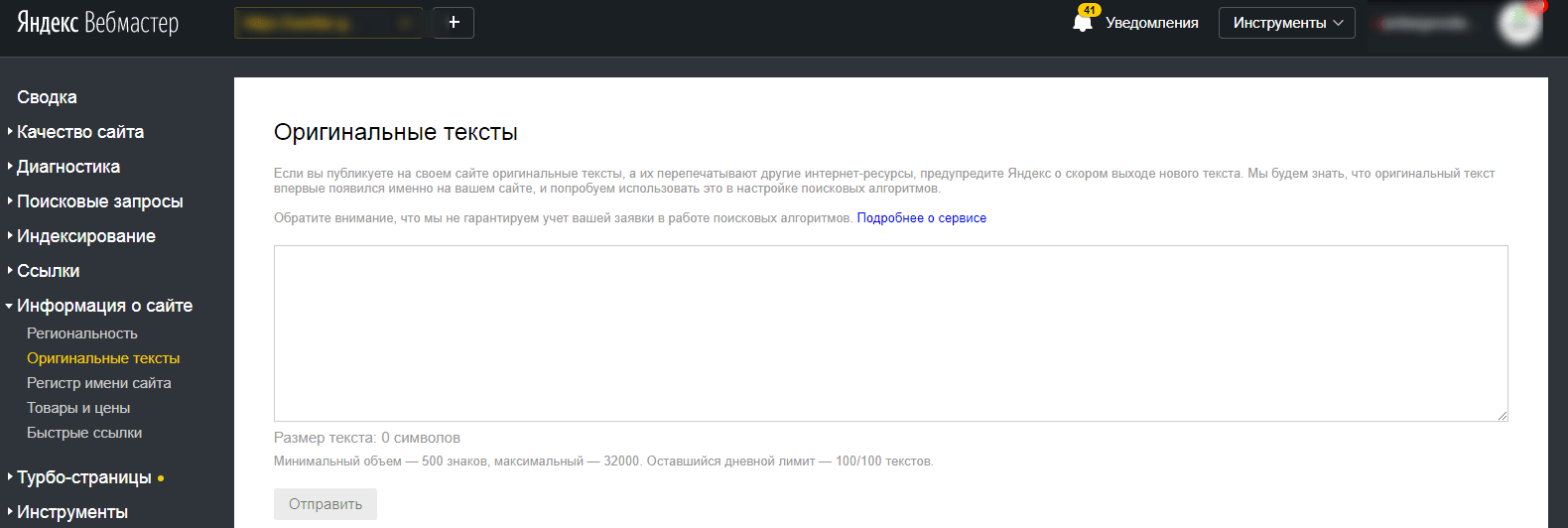 Например, на сайте есть две страницы. Первая – главная, вторая — страница «О компании», которая совпадает с главной (в свое время некогда было написать текст на эту страницу).
Например, на сайте есть две страницы. Первая – главная, вторая — страница «О компании», которая совпадает с главной (в свое время некогда было написать текст на эту страницу).
Подобная ситуация может встретиться и с каталогом однотипной продукции. Самый верный способ — сделать все страницы на сайте уникальными, но если это невозможно, необходимо прибегнуть к ранее перечисленным советам.
За внутренние дубли санкции на сайт не накладываются, но могут возникнуть сложности в передаче веса. Если же у сайта есть внешние дубли (кто-то украл контент и разместил его на своем домене), то возможна пессимизация сайта со стороны поисковых систем.
К сожалению, бывают случаи, когда уникальную информацию с сайта растаскивают по сети, и сайт из-за этого не может занять высокие позиции.
Яндекс очень серьезно относится к использованию на сайте неуникальных текстов (раздел «Яндекс.Помощь», подраздел «Советы вебмастеру»):
«Мы стараемся не индексировать или не ранжировать высоко: сайты, копирующие или переписывающие информацию с других ресурсов и не создающие оригинального контента…».
Один из способов запретить копировать текст с вашего сайта – заменить тег body на страницах сайта на тег body onco py=«return false». Другой способ – использовать специальный java-скрипт, который запретит использование правой кнопки мыши на web-странице, затрудняя копирование текста и изображений. Однако через исходный код страницы произвести копирование текста будет возможно, но при этом сохранятся все ссылки.
Такая позиция оправдывается главным принципом поисковых систем – информация в выдаче должна быть релевантной, актуальной и качественной. Неуникальный контент нельзя назвать качественным, для поисковых систем это ведет к увеличению индексных баз и повышенной нагрузке на поисковые сервера.
Как защитить контент
Поисковым системам сложно установить первоисточник, но соответствующие исследования ведутся. Например, Яндекс предложил веб-мастерам защитить контент с помощью сообщения о размещенном на сайте материале через сервис «Оригинальные тексты» в панели Яндекс. Вебмастер. Таким образом, при краже контента Яндекс будет знать, кто правонарушитель, и сайт не будет понижен в выдаче.
Вебмастер. Таким образом, при краже контента Яндекс будет знать, кто правонарушитель, и сайт не будет понижен в выдаче.
Есть еще один вариант появления дублированного контента на сайте – когда вы сами как владелец сайта позаимствовали его на других ресурсах. Такие действия уменьшают доверие поисковых систем к сайту и приводят к сложностям в продвижении. Среди сайтов, участвующих в отборе в ТОП-10, даже малейший недочет может сыграть не в пользу вашего сайта. Первая десятка должна быть разнообразной и отвечающей полностью на запрос пользователя, поэтому сайтов с двумя одинаковыми текстами в ней быть не может. Уникальность контента – это одно из главных требований, предъявляемых к сайту. Уважайте авторские права других людей!
Вернуться назад: Внутренние корректировки страниц сайтаЧитать далее: Оптимизация текста
поиск, причины появления и удаление
Краткое содержание статьи:
Техническая оптимизация сайта включает в себя множество
различных этапов.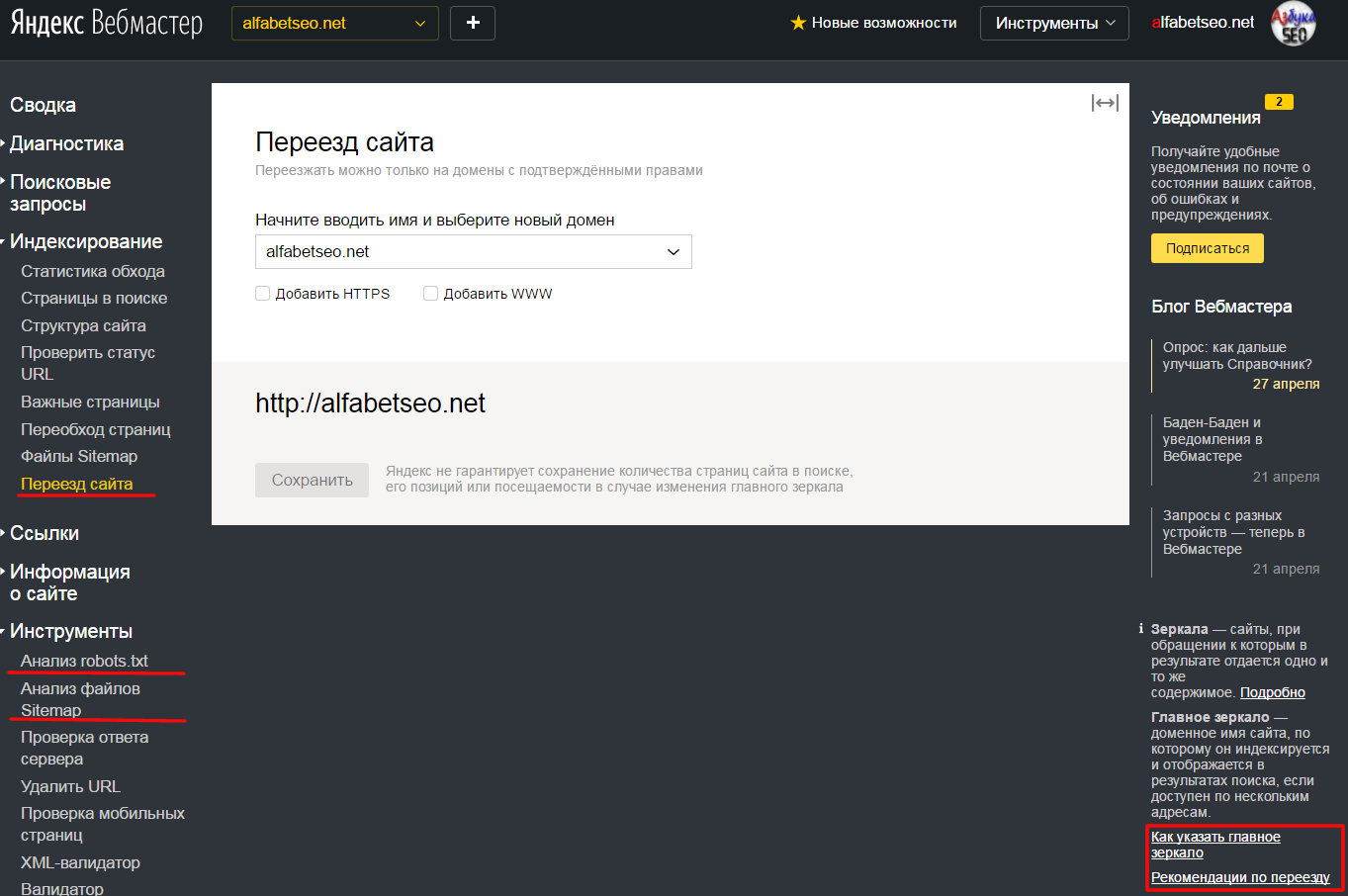 Особое место среди этих пунктов занимает отслеживание и
устранение дублей страниц. Они могут быть полными и неполными. Например, в
первом случае это зеркала главной страницы — site.ru и www.site.ru. Неполные
дубли проявляются, как одинаковые участки текстов на разных URL-адресах. Такие
копии важно найти и удалить.
Особое место среди этих пунктов занимает отслеживание и
устранение дублей страниц. Они могут быть полными и неполными. Например, в
первом случае это зеркала главной страницы — site.ru и www.site.ru. Неполные
дубли проявляются, как одинаковые участки текстов на разных URL-адресах. Такие
копии важно найти и удалить.
Опасность дублей на сайте
Поисковые системы негативно реагируют на совпадающий материал в пределах одного ресурса. Из-за их появления могут понизиться позиции сайта или появиться фильтры. Вот основные опасные моменты, которые возникают на портале, если поисковый робот обнаружит дубль страницы:
- Определение неверных релевантных URL-адресов в поисковой выдаче. Робот не может точно определить, какая страница является реальной, а где дубль. Из-за этого начинают скакать позиции, сайт опускается всё ниже.
- Неправильное
распределение ссылочного веса. Закупка внешних ссылок заканчивается тем,
что происходит путаница с URL-адресами. Появляются рекомендации пользователей
интернета на дубли, а не на основной ресурс. Робот такое поведение расценивает
плохо, отправляет сайт под фильтр.
- Контент становится неуникальным. Копии текстов и картинок — это негативное влияние на ранжирование всего портала. Поэтому нельзя вставлять одинаковую информацию на разных URL-адресах. Продвигайте страницы сайта по разным ключевым запросам.
- Поисковики Google и Яндекс могут наложить санкции на портал. Манипуляции с дублями страниц воспринимаются роботами этих систем, как способ манипуляции для попадания в верхние строчки выдачи. Не хотите фильтров — боритесь с таким контентом!
 Появляются рекомендации пользователей
интернета на дубли, а не на основной ресурс. Робот такое поведение расценивает
плохо, отправляет сайт под фильтр.
Появляются рекомендации пользователей
интернета на дубли, а не на основной ресурс. Робот такое поведение расценивает
плохо, отправляет сайт под фильтр.К сожалению, многие владельцы сайтов не знают об опасности дублей страниц. В целях экономии они используют одинаковые тексты на страницах и потом удивляются, почему их ресурс занимает нижние строчки в поисковой выдаче.
Как появляются дубли страниц на сайте?
Перед тем, как заняться их поиском, нужно понять причину их
появления. Дубли страниц на сайте чаще всего возникают по следующим причинам:
Дубли страниц на сайте чаще всего возникают по следующим причинам:
- Применение системы управления контентом. Сбой возникает, когда запись на портале может относиться к различным рубрикам или разделам. При этом их домены включены в адрес сайта самой записи. Часто такое встречается на информационных ресурсах или в блогах. Поэтому важно контролировать работу CMS.
- Ошибки в технических разделах. Часто такое можно встретить в системах управлениях Bitrix и Joomla. Происходит это при нелогичной генерации одной из функций сайта — регистрации, фильтра или внутреннего поиска. В этом случае появляются дубли, но URL страницы не учитывается.
- Человеческий фактор. С любым сайтом работают люди, которые пишут тексты и проводят оптимизацию каждой страницы. Но даже специалист может ошибиться или где-то полениться. Часто такое происходит с текстами, когда нет времени писать разный контент.
- Технические
ошибки. Если к несовершенной работе системы управления контентом добавить
человеческий фактор, то возникают странно прописанные адреса. Часто они
являются дублями каких-то страниц.
 Если к несовершенной работе системы управления контентом добавить
человеческий фактор, то возникают странно прописанные адреса. Часто они
являются дублями каких-то страниц.
Если к несовершенной работе системы управления контентом добавить
человеческий фактор, то возникают странно прописанные адреса. Часто они
являются дублями каких-то страниц.Невозможно избавиться от дубликатов на сайте, если не уметь их находить. Поэтому каждый владелец ресурса должен понимать, как это делается.
Поиск дублей
Копии на портале можно искать несколькими проверенными способами:
- использование программы XENU (Xenu Link Sleuth). Она поможет отыскать не только дубли, но и битые ссылки. Программу используют для поиска полных копий. XENU требует скачивания на свой компьютер, разработана только для операционной системы Windows. С установкой программы не должно возникнуть сложностей. Во время ввода страницы для проверки, обращайте внимание на наличие символом слеш «/» в конце.
- с помощью расширенного поиска Google. В строку поиска нужно вставить адрес главной или интересующей страницы. После этого система предложит полный список страниц, которые проиндексированы. Проанализировав его, можно отыскать копии.
 Проанализировав его, можно отыскать копии.
Проанализировав его, можно отыскать копии.- с помощью web-мастерской Google. Владельцу сайта нужно будет пройти регистрацию. Увидеть копии страниц можно в разделе «Оптимизация Html». Ещё там будет представлен список одинаковых <Title>. Но неполные дубли этим методом не отыщешь.
- за счёт seo-платформа Serpstat. Для работы придётся пройти регистрацию.Выбираем раздел «Аудит сайта», потом «Суммарный отчёт». В течение определённого времени система покажет дублей Title, Description, h2. В бесплатной версии ресурса имеются ограничения, но информации достаточно для выявления копий.
Отыскав все дубли страницы, и проанализировав причины их появления, можно смело начать их удалять. Ни в коем случае не игнорируйте эти пункты, иначе копии снова начнут возникать на портале.
Простые способы удалить дубли страниц на сайте
Копии в Title,
Description и h2
исправляются в ручном режиме. А дубли страниц устраняем этими способами:
А дубли страниц устраняем этими способами:
- Через robots.txt — это самый лёгкий вариант. Необходимо только прописать нужные директивы.
- Воспользоваться 301 редиректом. С помощью этой директивы можно перенаправить роботов поисковых систем с дубля на оригинальную страницу. 301 редирект сообщает о том, что странички больше не существует.
- Link rel=»canonical» — вариант подходит для страниц с разными URL, но одинаковыми тестами. В код имеющегося дубля необходимо внедрить следующий тег — <link=»canonical» href=»http://site.ru/cat1/page.php»>. Он указывает на страницу, которая нуждается в индексации.
Попасть под фильтры Panda и АГС может любой сайт с дублями. Поэтому от копий нужно избавляться в первую очередь. В противном случае это отразиться на ранжировании. Вы потеряете позиции в поисковой выдаче, следовательно, и потенциальные клиенты или читатели не смогут находить ваш ресурс.
Если самостоятельно отыскать и удалить дубли страниц на
сайте не получается, то обратитесь за помощью к специалистам компании Grand-SEO.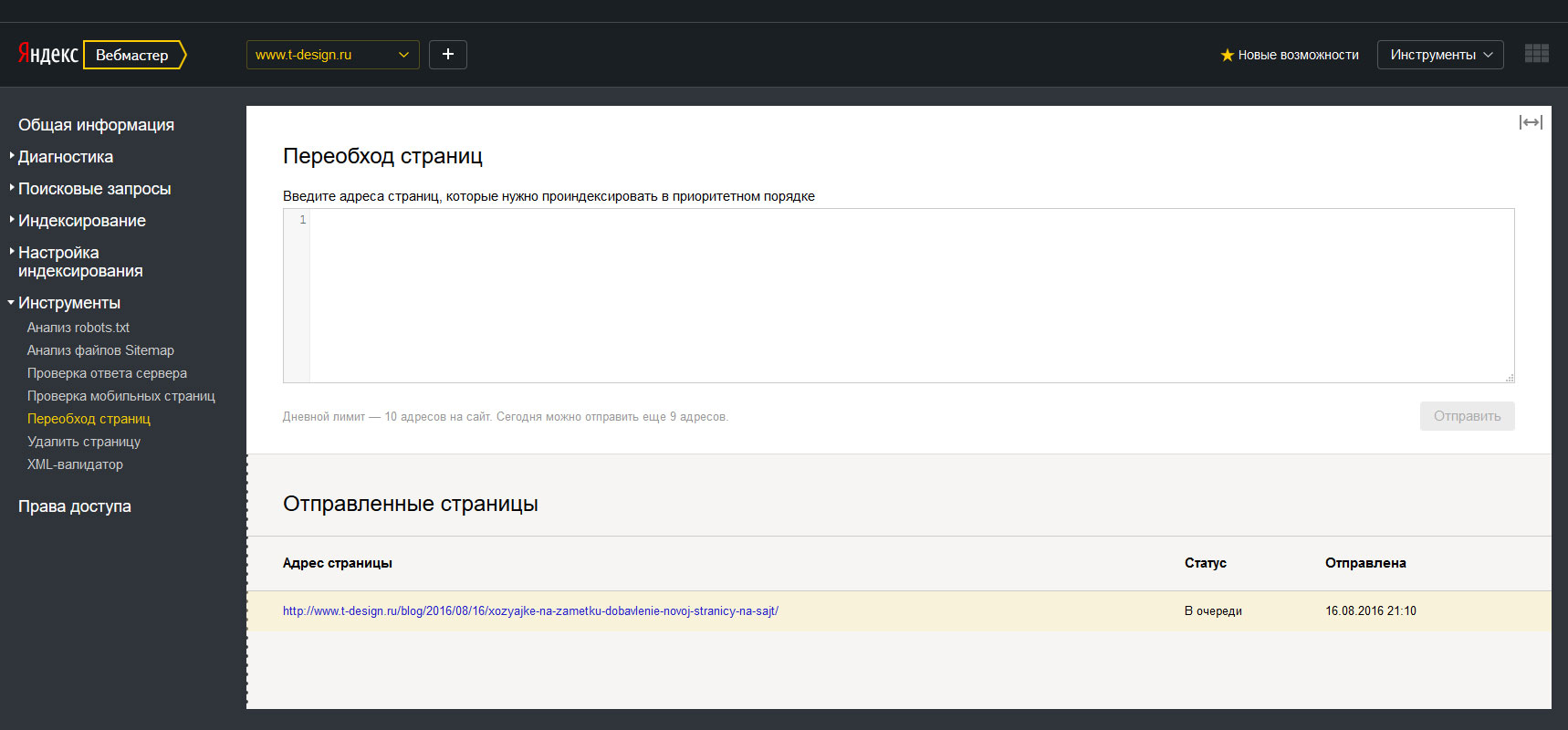
Яндекс Вебмастер (Webmaster Yandex): от А до Я
В предыдущей статье про Вебмастер Гугл я рассказал, что Вебмастер — это Ваш способ заявить поисковой системе.
Яндекс выпустил сервис в 2007 году, официально открыв его для владельцев сайтов 21 декабря.
На сегодня он оброс дополнительными функциями, выдает огромное количество информации, необходимой для SEO оптимизатора, и фактически без него невозможно провести полноценный аудит сайта.
Анализ ошибок и отчетов Вебмастера Яндекс позволяет провести достаточно глубокий аудит любого вебсайта, выявить причины падения отдельных страниц в индексе и дать ответы на многие вопросы.
ОТОБРАЖЕНИЕ САЙТА В ЯНДЕКСЕ
Все мы знаем, что в контекстной рекламе мы можем решить, как будет выглядеть наше объявление.
Также мы можем в любой момент его отредактировать.
В естественной выдаче Вы тоже можете решить, что будет отображаться и как.
В выдаче в органике отображение Вашего сайта называется Сниппет.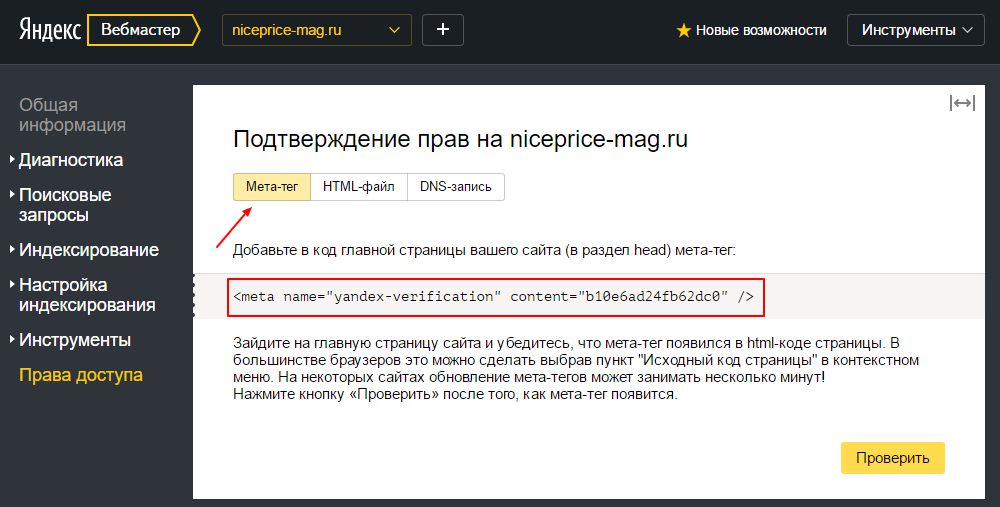
По факту у Вас нет прямой возможности редактировать.
Но я расскажу, какие элементы можно изменять.
Отображение сайта в выдаче обычно можно схематически изобразить так:
Заголовок — изменяется непосредственно в HTML коде Вашей страницы.
Это тот самый Title, который Вы можете редактировать в админке своего сайта.
Есть определенные рекомендации по созданию кликабельных и привлекательных Title.
- Используйте ключевые слова страницы.
- Используйте большие буквы. Это упрощает восприятие. Но не КАПЛОК.
- Старайтесь изложить в Title, о чем эта страница в 60-65 символах.
Вы можете воспользоваться специальной утилитой КАЛЬКУЛЯТОРА ЗАГОЛОВКОВ, а также ознакомиться с техникой Эверест, как при помощи Title увеличить кликабельность своих страниц в органике.
КАЛЬКУЛЯТОР TITLEОписание. Ранее — это был тег Description, но после недавних изменений в технике формирования сниппетов, теперь в описании отображается наиболее релевантный поисковому запросу фрагмент контента страницы.
Текст может выбираться из фрагментов микроразметки Open Graph и Schema.org.
Это не значит, что тег дескрипшн заполнять не нужно.
Если Вы его не заполните, Яндекс понизит Ваши позиции (об этом ниже).
Если Вам нужно сделать так, чтобы не все подставлялось в сниппет, запретите индексирование отдельных фрагментов контента в коде при помощи тега noindex.
Если нужно закрыть от индексации ссылку, поставьте для нее тег Nofollow.
По микроразметке и сниппете рекомендую ознакомиться с официальным гайдом от Яндекс.
В поисковой выдаче фрагменты описания будут подсвечены жирным шрифтом по ключевым словам для удобства выбора нужной странички.
Быстрые ссылки. Отображается обычно для сайтов с высоким уровнем доверия, а также с хорошим трафиком.
Если сайт отображается с верхнем блоке ТОП5 выдачи, под Заголовком может отображаться блок быстрых ссылок.
Какие ссылки отображать и выводить, Вы можете изменить в вебмастере.
Но Вы не можете добавить их самостоятельно — Вам придется выбирать из предложенных.
Фавикон. Современные CMS предлагают добавить его без особых трудностей.
Это — та маленькая иконка, которая отображается сразу рядом с выдачей и в браузере в вкладке.
Помните, фавикон должен быть простым и понятным стилизованным логотипом Вашей компании — его должны узнавать пользователи.
Специальные данные. Яндекс также выводит помимо быстрых ссылок и сниппета, еще и другие.
Первый — хлебные крошки.
Если Ваша страница находится на втором и третьем уровне вложенности, Яндекс отобразит в сниппете символически путь к этой странице.
Это достигается за счет микроразметки BreadCrump.
Второй элемент — это физический адрес компании.
Достигается за счет прописывания микроразметки Company, где Вы прописываете реальный адрес, телефон, время работы компании.
И третий элемент — экспериментальный — если Вы используете чат Jivosite на своем сайте.
Да, Яндекс провел эксперимент с Jivosite и сайты с этим модулем получили возможность начать чат с клиентом без посещения самого сайта.
Некоторые элементы можно контролировать и изменять непосредственно из Вебмастера.
ГЛАВА 1:
Использование Яндекс Вебмастера
В этой главе мы расскажем, как добавить свой сайт в Вебмастер Яндекса и дать доступ своим сотрудникам.
Вебмастер от российского поисковика Яндекс отличается достаточно простым интерфейсом и понятен большинству владельцев сайтов и оптимизаторов.
Для начала работы рекомендуется добавить свой сайт (для входа воспользуйтесь своей учеткой в Яндексе), карту сайта и предоставить доступ своим коллегам и партнерам.
ДОБАВЛЕНИЕ САЙТА В ВЕБМАСТЕР ЯНДЕКС
Для добавления сайта перейдите по ссылке на Webmaster.Yandex.Ru, нажмите кнопку + и напишите URL Вашего сайта (полностью, с учетом http:// или https://).
ПЕРЕЙТИ в ЯНДЕКС ВЕБМАСТЕРЗатем система предложит Вам подтвердить право на владение своим сайтом.
Через метатег.
Для этого скопируйте указанный код в окошке и отредактируйте шапку сайта, разместив его перед закрывающим тегом </head>.
Затем нажмите кнопку Проверить.
Через HTML файл.
Зайдите на Ваш FTP (или в диспетчер файлов на хостинге) и загрузите файл (клик на верхнюю ссылку с названием файла скачивает его на Ваш жесткий диск).
Проверьте, чтобы файл открывался (кликните после его установки на хостинге на нижнюю ссылку в окне вебмастера).
Затем нажмите кнопку Проверить для подтверждения владения сайтом.
Через DNS запись.
Просто зайдите в настройки DNS и добавьте запись типа TXT с указанным текстом.
Затем подождите несколько часов и подтвердите владение сайтом, нажав кнопку Проверить.
Убедитесь, что Вы выбрали правильную версию домена!
Например, если Вы выбрали домен с WWW., а подтверждаете владение сайтом без WWW, ничего не сработает.
КАК ДАТЬ ДОСТУП НА ЯНДЕКС.
 ВЕБМАСТЕР
ВЕБМАСТЕРДоступ для Яндекс.Вебмастера обязательно должен быть у Вашего SEO-оптимизатора.
Для этого перейдите в раздел Права Доступа и в окошке Делегирование праввпишите Яндекс почту Вашего оптимизатора.
При этом в разделе Метод проверки будет показано, каким образом логин получил права на сайт.
ГЛАВА 2:
Индекс Качества Сайта
Что известно о новой пузомерке Яндекса?Как ее использовать для анализа сайта?
В чем отличие от почившего ТИЦ?
В этой главе мы все узнаем подробно.
Мы знаем, что Google отказался от своего фактора PageRank (или скрыл его метод расчета, и само значение скрыл).
Совсем недавно Яндекс внедрил новый показатель качества сайта — ИКС (или Индекс Качества Сайта).
Он пришел на смену устаревшему ТИЦ (который учитывал индекс цитирования ссылками сайтами из Яндекс.Каталога).
Так как Яндекс.Каталог уже ушел на покой, ТИЦ давно нужно было заменить.
Вебмастер Яндекс отображает ИКС вместо ТИЦ.
Вы можете провероить ИКС для любого сайта по ссылке.
Сейчас ИКС рассчитывается по следующим критериям:
- Размер аудитории сайта. Чем больше трафик Вашего сайта, тем выше потенциальный ИКС. Увеличить его можно за счет привлечения трафика на свой сайт за счет контекста, Email рассылок, рефералов и соцсетей, а также оффлайн-маркетинга.
- Уровень удовлетворенности пользователей на сайте. Улучшайте время пользователя на сайте, уменьшайте показатель отказов.
- Уровень доверия пользователей к сайту. Обычно наличие роста брендового трафика — хороший знак, что Вы становитесь более известны и поисковик начинает Вас лучше ранжировать
- Уровень доверия Яндекса к Вашему сайту. Да, у Яндекса есть свой чеклист, где он оценивает Ваш сайт по собственным параметрам. Об этом далее
- Другие критерии. Влияние асессоров (сотрудников Яндекс), скрытые алгоритмы поисковика.
Мы знаем, что ИКС для зеркал передается идентичный.
Если доменные имена совпадают, ИКС основого сайта совпадает с зеркалом.
Если Ваш сайт занимается публикацией материалов (статейник или блог), Вы можете разместить код Вашего ИКС на Вашем сайте — это будет красноречивый знак о качестве Вашего ресурса для Яндекса: ссылки с сайта с высоким ИКС ценятся гораздо выше.
ГЛАВА 3:
Возможности Вебмастера Яндекс
В этой главе мы рассмотрим, как можно использовать Яндекс Вебмастер новичку, и на какие разделы обратить внимание в первую очередь.Эти данные удивят своей полезностью даже опытных специалистов.
Теперь перейдем непосредственно к функционалу, как ним пользоваться.
Раздел СВОДКА встречает Вас готовым набором виджетов и отображает ключевые новости (изменения) для Вашего сайта.
В Виджетах при помощи списков и инфографики отображаются последние изменения на сайте — проблемы, клики, обход поискового робота, новые ссылки на Вас и изменение индекса ИКС.
Из главного экрана перейти на более глубокие отчеты.
Диагностика сайта
Проверка сайта на ошибки, безопасность и нарушения (диагностика).
Ошибки делятся на несколько типов: фатальные, критичные, возможные проблемы и рекомендации.
Отчеты по ошибкам достаточно подробные и позволяют оперативно на них реагировать на нарушения.
Ошибки делятся на Фатальные, Критичные, Возможные и Рекомендации.
Фатальные ошибки Вашего сайта
Фатальные ошибки, которые Вы можете допустить:
- Сайт закрыт от индексации в файле robots.txt. Проверить его можно при помощи специальной утилиты в вебмастере (о ней — ниже).
- Есть ошибки DNS (вашего хостинга). Если Вы видите эту ошибку, сайт может выпасть из индекса на долгое время.
- Не загружается главная страница. Из-за различных сбоев хостинга или работы сайта, если поисковик не может получить документ главной страницы, то Вы можете потерять сайт из выдачи.
- На сайте обнаружены проблемы с безопасностью. Есть огромное количество ошибок и нарушений, которые может применить к Вам Яндекс.
Нарушения безопасности — очень опасные нарушения, и могут повлечь к необратимым последствиям для Вашего сайта
После восстановления сайта от нарушения может пройти от двух до четырех недель на анализ выдачи — после обхода поискового робота пересматривается текущий показатель качества сайта и отдельных страниц.
Я кратко расскажу, что может быть применено к сайту за каждое нарушение.
Общие нарушения
- Дорвей. Если Вы создали сайт, который переводит пользователей на другой сайт, то использование дорвеев — это методика черного SEO и Яндекс за это наказывает понижений позиций или удалением из индекса.
- Клоакинг. Вид нарушения, когда Вы показываете поисковику один контент, а пользователю — другой (например, перенаправляете пользователей на закрытые от индексации страницы, а в индексе находятся безвредные версии). Этим промышляют сайты по продаже порнографического и запрещенного законодательством контента и товаров.
- Партнерские программы. Если Вы предлагаете услуги и продукцию из других сайтов, при этом сам сайт не имеет никакого полезного уникального контента. Например, в Казахстане модно создавать парсинг-клоны сайтов магазина IKEA (оригинальная компания IKEA там не работает, а товар востребован), где все страницы парсятся на основе оригинального сайта.
Ссылочные нарушения
- Покупка ссылок для продвижения. Да, если Вас Яндекс заподозрит в закупке ссылок на сторонних ресурсах, Вы приедете в Минусинск (не город). От такого фильтра избавиться очень трудно — так как Вам придется снимать ссылки вручную (обращаясь к владельцам сайтов и хостинг-провайдерам с просьбой снять ссылки). Кстати это — слабое место, ведь недобросовестные конкуренты могут накупить на Вас ссылок с мусорных ресурсов, а Вы не можете никак от этого защититься. По факту алгоритм должен блокировать некачественные ссылки, но пока это лишь в теории.
- Размещение (продажа) SEO ссылок. Да, подобный процесс касается и сайтов, которые размещают SEO ссылки. Исходящие ссылки должны быть тематическими, неспамными и вести на целевой контент.
 Да, если Вас Яндекс заподозрит в закупке ссылок на сторонних ресурсах, Вы приедете в Минусинск (не город). От такого фильтра избавиться очень трудно — так как Вам придется снимать ссылки вручную (обращаясь к владельцам сайтов и хостинг-провайдерам с просьбой снять ссылки). Кстати это — слабое место, ведь недобросовестные конкуренты могут накупить на Вас ссылок с мусорных ресурсов, а Вы не можете никак от этого защититься. По факту алгоритм должен блокировать некачественные ссылки, но пока это лишь в теории.
Да, если Вас Яндекс заподозрит в закупке ссылок на сторонних ресурсах, Вы приедете в Минусинск (не город). От такого фильтра избавиться очень трудно — так как Вам придется снимать ссылки вручную (обращаясь к владельцам сайтов и хостинг-провайдерам с просьбой снять ссылки). Кстати это — слабое место, ведь недобросовестные конкуренты могут накупить на Вас ссылок с мусорных ресурсов, а Вы не можете никак от этого защититься. По факту алгоритм должен блокировать некачественные ссылки, но пока это лишь в теории.Текстовые нарушения
- SEO тексты. Да, создание текстов, которые влияют на выдачу поисковой системы, является нарушением и к Вам может быть применен фильтр. Один из них — Баден-Баден, второй — более грубый — Переоптимизация.
- Сайты с бесполезным (малополезным) контентом, с нарушениями правил рекламы и распространением спама.
- Спам поисковых запросов. Создание множества страниц, заточенных под разные повторяющиеся поисковые запросы, и перенасыщенные контентом с поисковыми запросами. Обычно Вы можете подумать, что это может коснуться тегов, разделов каталога и фильтров, но это не так: фильтр направлен на запросный спам в текстовых блоках в подвале страниц, созданных для вывода посадочной страницы под поисковые ключи.
- Скрытый текст. Использование текста, который написан нулевым шрифтом или скрыт под изображением или в скрываемом блоке, напичканный ключевыми словами, который поисковик ошибочно считает полезным. В случае нарушения выдача будет понижена.
Мошенничество и взлом
- Накрутка ПФ (поведенческого фактора). Как известно, показатель отказов — фактор ранжирования, и иногда хочется его улучшить… любой ценой. Я бы не советовал — за это нарушение Ваш сайт может надолго вылететь из поиска.
- Предложение по накрутке ПФ (мотивация пользователей накручивать Вам поведенческие факторы) наказывается тем же.
- Подключение платных услуг подписки для мобильных пользователей. Да, Яндекс, если заподозрит Вас в этом, резко даст о себе знать.,
- На сайте обнаружены нежелательные программы или файлы (кряки, зараженные файлы, украденный контент). Наличие подобных элементов может послужить сигналом для удаления страниц из индекса.
- Опасные сайты. Если Ваш сайт подвергся заражению, он будет помечен как небезопасный.
- Фишинг. В отличие от партнерок, некоторые сайты могут быть похожи на популярные порталы — практически точными копиями. Такие сайты создаются для воровства личных данных (логины, пароли, учетные данные) пользователей
- Кликджекинг — аналогично фишингу, сайты, которые позволяют украсть личные данные пользователя, не ставя его в известность
Что делать, если Яндекс ошибся?
Методы Яндекса очень точные, и он редко ошибается.
Шанс ошибки по статистике около 1%.
Но вдруг Вам повезло войти в этот процент, Вы получили подобное письмо счастья, и Ваш сайт понизился в выдаче, или совсем вылетел из нее?
Тогда перейдите по ссылке, выберите и заполните форму.
Опишите тщательно ситуацию.
И терпеливо ждите ответа.
Критичные ошибки
Есть две критичные ошибки, которые не являются фатальными, но могут сказаться на Вашем ИКС. Мы рекомендуем их исправить как можно быстрее.
- Битые ссылки. Если на сайте много внутренних ссылок, которые не работают (отдают ошибку), это усложняет навигацию. Поисковый робот выдаст страницы с ошибками и порекомендует их исправить
- Долгий ответ сервера. Если Ваш хостинг отвечает больше 3 секунд, Ваш сайт получит понижение позиций. Если Вы увидели такую ошибку, свяжитесь с Вашим провайдером услуг хостинга (выберите VPS или подключите более мощный тариф или смените его).
Возможные ошибки
Список ошибок из этой категории может повлиять на качество, релевантность и скорость индексации Ваших страниц.
- Ошибки файла Robots.txt (нет файла, или в файле обнаружены ошибки)
- Ошибки файла Sitemap.xml (нет файла, файл давно не обновлялся, не прописан в Robots или в индекс загружены ненужные страницы или в файле есть ошибки)
- Ошибки в уникальных страницах (есть дубли контента)
- Ошибки редиректов главной страницы (неверно настроен 301 редирект)
- Ошибка кода 404 Not Found (ответа на запрос на несуществующие страницы)
- Ошибки качества рекламы на сайте согласно IAB Russia.
- Ошибки в мета данных (отсутствуют теги Title и Description на страницах в индексе).

Все ошибки вполне исправимы — просто приведите в порядок файл sitemap, robots и пропишите грамотно заголовки и описания для индексируемых страниц.
Рекомендации Яндекс
Финальный список чеклиста оптимизатора уже скорее влияет на отображение и правильность индексации Вашего сайта.
Старайтесь и тут не наломать дров и не забыть про каждый пункт.
- Настройка региона для выдачи. Укажите город и страну для гео принадлежности Вашего сайта. Сайты с городами — поддоменами — для каждого поддомена для каждого города пропишите в вебмастере уникальный город (предварительно добавьте каждый в вебмастер).
- Сайт не найден в Яндекс Справочнике (или Яндекс Картах).
- Нет фавикона.
- Сайт не оптимизирован для мобильных. Сейчас — это важный фактор ранжирования в связи с ростом мобильного трафика. Если Вы увидели эту ошибку, передайте этот список Вашему программисту.
- Ошибка Яндекс Метрики. Сам счетчик должен обязательно быть установлен корректно для всех индексируемых страниц сайта.
- Неверная разметка для видео-контента. Используйте корректно разметку для видео на своем сайте. Полную инструкцию для программиста можно прочесть тут.

Держите этот чеклист перед глазами — и при помощи вебмастера Яндекс Вы всегда сделаете технический аудит без всяких трудностей!
ГЛАВА 4:
Раздел индексирования
Часто бывает ситуация, когда Ваш многостраничный сайт попадает в индекс с ошибками, или не полностью?В этом разделе Вы сможете контролировать индексацию сайта в Яндексе и ключевые слова, по которым Вы получаете показы и трафик.
В данном разделе находится инструментарий, отвечающий за статус нахождения страниц сайта в индексе Яндекса.
Индексация — автоматический процесс, и происходит за счет поискового робота, который руководствуется настроенной картой сайта и файлом robots, а также тегами разметки на Ваших страницах (index, follow и микроразметки).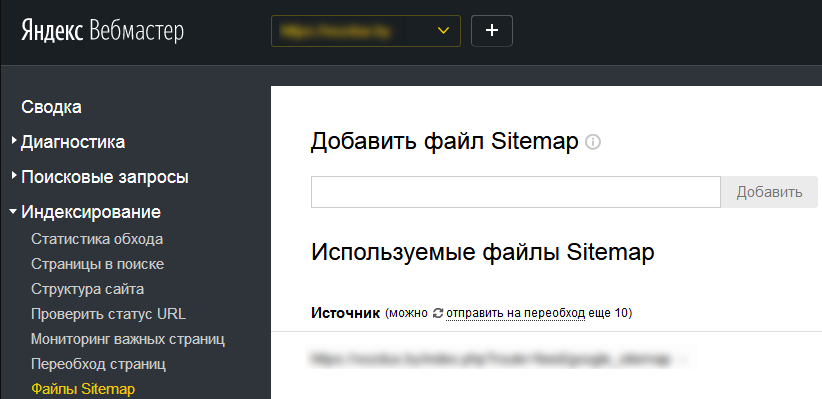
Но также в вебмастере и ручные методы запуска механизма индексации — например в случае сбоя робота, Вы можете его перенаправить вручную.
Изучим все инструменты подробно.
Статистика запросов
Простой и понятный способ посмотреть, какие поисковые запросы работают на Вашем сайте: какую позицию они занимают, как часто Ваш сайт отображается в поиске.
Оценивайте как для каждого запроса, так и для всего сайта в целом Позицию, Клики, средний CTR.
В разделе ВСЕ ЗАПРОСЫ и ГРУППЫ Вы можете собрать запросы в группы (Избранные или создать собственные), пользоваться простыми фильтрами для отображения данных.
На основе этих данных стройте стратегию продвижения
- Улучшайте контент на страниц, где есть смысл усилить позиции.
- Работайте над сниппетами (Title и Description) для запросов, где у Вас высокая позиция, но низкий CTR.
- Создавайте новый контент для тех запросов, где у Вас нет позиций и у Вас нет целевых страниц.
Статистика обхода
Данный раздел сайта помогает узнать, как поисковый робот Яндекс индексирует и обходит Ваши страницы.
Можно выявить, какие страницы робот обошел, а с какими возникли трудности из-за ошибок индексации.
Страницы в поиске
Отображает статистику индексации Вашего сайта — в динамике.
Сколько страниц было добавлено и удалено из индекса.
И по какой причине.
Например, недостаточно качественные страницы, выпавшие из индекса, отображаются в этом отчете.
Структура сайта
Данный раздел позволяет отследить иерархию по уровням загруженных страниц и процент индексации каждого подраздела.
Именно по этому отчету Яндекс может выделить наиболее важные разделы Вашего сайта для отображения сниппета “Быстрые ссылки”.
Утилита для переезда сайта (индексирование).
Позволяет безболезненно переехать с одного домена на другой без потери позиций.
Важные страницы и переобход страниц (индексирование) позволяет отслеживать до 100 важных страниц и провести приоритетный обход роботом Яндекса до 20 новых страниц.
Проверить статус URL
Позволяет оперативно проверить наличие ссылки в поисковой базе Яндекс (и код отклика – 200, 301, 403 или 404).
Отслеживайте Важные страницы
Любой SEO оптимизатор должен знать, как его страницы индексируются в поиске.
Для удобства отслеживания страниц создали специальный инструмент.
Просто добавляйте списком отслеживаемые страницы и проследите за их ответом.
Если Вы не можете определиться, Яндекс Вебмастер предлагает на выбор Вам наиболее рекомендованные страницы — которые лучше всего индексируются и привлекают трафик.
Переобход страниц
Отдельный инструмент, который позволяет проверить обход страниц поисковым роботом.
Да, если вдруг у Вас медленно проводится индексация, но нужно все же ускорить добавление в индекс новых страниц, есть ручной метод для этих целей.
В день можно попросить обойти робота в ручном приоритетном порядке.
Зачем это нужно?
Например, если Ваша страница была недоступна (отдала ответ 404 сервера), она может быть исключена из индекса.
Для повторной индексации потребуется повторно роботу обойти эту страницу, а робот Яндекса очень медлителен.
Поэтому в таком случае запускайте обход отдельных страниц вручную.
Файлы Sitemap.xml
Карта сайта — это файл, содержащий список страниц для индексации.
Это не вебстраница на сайте, на которой Вы сделали ссылки!
Это отдельный файл, который находится на Вашем FTP сайта и отвечает за время обновления каждой страницы, которую Вы хотите передать списком для поисковика.
Если у Вас нет карты сайта, создайте ее.
Для добавления карты сайта в Яндекс перейдите по ссылке.
Введите ссылку на файл карты сайта и нажмите кнопку Добавить.
Также Яндекс.Вебмастер по умолчанию может подтянуть карту сайта непосредственно из файла robots.txt.
Инструмент позволяет отследить все ошибки непосредственно в картах сайта и показывает объем ссылок, которые передаются в Яндекс для индексации.
Просто кликните на Ошибки и изучите полученный отчет со списком ссылок.
Внесите правки в файлы sitemap и попробуйте снова.
Переезд Сайта
Иногда приходится переезжать со старого домена на новый.
Например, если Вы съезжаете с WWW. домена на обычный.
Или установили HTTPS сертификат.
Для вебмастера это — разные сайты.
И нужно об этом сообщить.
Или например — переехали вообще с старого домена на новый.
Для удобства, в Яндекс Вебмастере есть соответствующий раздел.
Выберите новый домен из списка с подтвержденными правами.
При помощи галочек Вы можете добавить к домену HTTPS и WWW (по мере необходимости).
Затем нужно нажать Сохранить и дождаться изменения в индексации.
Если все сделали правильно, Яндекс произведет переезд сайта без ухудшения его позиций.
Скорость обхода
Если Вы считаете, что робот Яндекса замедляет Ваш сайт или же индексация сайта проходит достаточно медленно, Вы можете внести корректировки на скорость обхода Вашего сайта.
Мы рекомендуем этот раздел менять только в крайнем случае и выставить по умолчанию пункт “Доверять Яндексу”.
Средняя скорость обхода равна 3 запросам в одну секунду на Ваш сайт.
ГЛАВА 5:
Раздел ссылочного анализа
Самый недооцененный раздел Яндекс Вебмастера.Но при помощи него можно решить множество задач — как сделать перелинковку, так и изучить внешний ссылочный профиль сайта.
Раздел ссылочного анализа
Ссылочный анализ для Вебмастера является не менее важным, чем раздел индексации.
Ссылки Вашего сайта являются важным фактором ранжирования.
На Вашем сайте по факту должны быть все исходящие рабочие ссылки (как на внешние источники, так и внутренние), так и у Вас должен быть хороший ссылочный профиль.
Анализ внутренних ссылок в Вебмастере
Раздел внутренних ссылок выдает список внутренних неработающих URL на Вашем сайте.
Проанализируйте Вашу карту сайта и внутренние ссылки на Вашем сайте и удалите битые нерабочие URLы.
Внешние ссылки
Как мы изучили, внешние ссылки — это важный инструмент вебмастера.
Если Вы хотите видеть, какие ссылки на Вас ставятся и с каким ИКС (индексом качества) — Вы можете изучить непосредственно в этом разделе.
Помните, что за покупку SEO ссылок на бирже Вы рискуете получить фильтр Минусинск и потерять значительно в выдаче.
Поэтому мы рекомендуем изучать Ваш ссылочный профиль и вовремя реагировать на некачественное проведение.
Помните, хорошие ссылки следует создавать только белыми методами.
Мы их расписывали в этой статье.
Также можете изучить в нашем материале, чем отличаются черные и белые методы продвижения.
Если вдруг Вы заподозрили, что Ваша SEO компания размещает на Вас некачественные ссылки, или же в этом деле были замечены Ваши конкуренты, мы рекомендуем изучить отчет по внешним ссылкам и вовремя известить SEO отдел.
Мы можем помочь проанализировать качество ссылочного профиля Вашего сайта.
Для этого заполните форму и мы свяжемся с Вами в течение дня.
ГЛАВА 6:
Изменение информации о сайте
В этом разделе мы рассмотрим, как можно изменить региональность Вашего сайта, а также сообщить об оригинальном контенте для защиты от кражи.
Предыдущие разделы отвечали за индексацию сайта и ссылки.
Это действительно важные факторы ранжирования.
Но следует знать, что важно не просто быть в индексе.
Важно быть в индексе по правильным ключевым словам.
В этом нам поможет раздел Информации о Сайте.
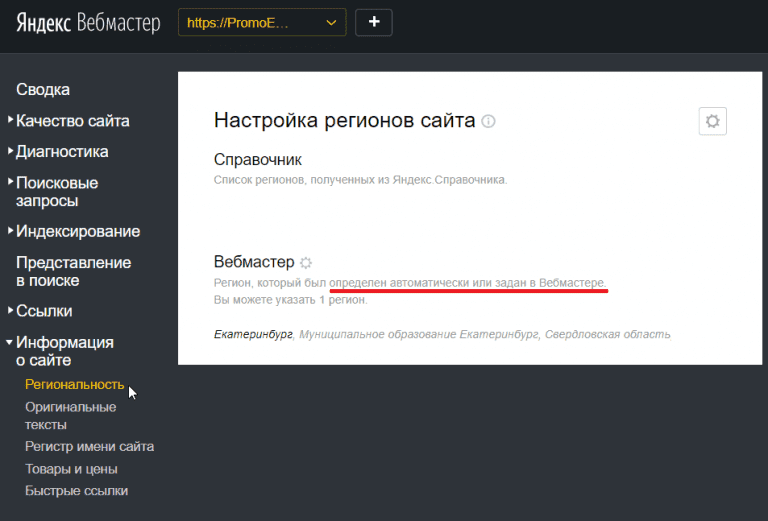
Региональность
Очень лаконичный и простой раздел.
По факту регион присваивается сайту при помощи двух инструментов — справочника и собственно — вебмастера.
В справочнике можно выбрать таргетинг вручную.
Здесь Вы можете настроить для своего сайта регион согласно Яндекс Карт.
При клике на раздел ИЗМЕНИТЬ РЕГИОНЫ Вас переадресует на Яндекс.Справочник, где будет предложено отредактировать Ваши данные на Яндекс.Картах.
Вы можете присвоить нужный город, адрес и телефон Вашей компании, а также категорию бизнеса.
Для верификации следует подождать некоторое время — в случае подтверждения Вы получите соответствующее уведомление.
В Яндекс.Вебмастере Вы можете прописать вручную регион, но для верификации потребуется указать страницу, где указаны Ваши адресные данные.
Защита от копирования оригинальных текстов
Часто бывает ситуация, когда Вы пишете тексты, но их успевают у Вас украсть?
Или же нужно успеть написать свой контент первым?
А Вы можете опубликовать контент, но в индекс попадаете медленнее конкурентов?
Раздел “Оригинальные тексты” позволяет добавить тексты до их предварительной заливки на сайт во избежание воровства (перепечатывания) Вашего уникального контента.
В день можно заливать не более 100 текстов объемом от 500 до 32 тыс. символов.
Очередность добавления контента отображается ниже.
Регистр имени сайта
Иногда хочется выделить составное имя в своем названии.
Например, если оно состоит из двух слов.
И нужно, чтобы в выдаче каждый слог был выделен разным регистром?
Перейдите в раздел Регистр Имени Сайта и пропишите его так, как Вам нужно.
И желательно опишите причину.
Это не влияет на SEO и результаты выдачи, но влияет на отображение Вашего сайта в результатах.
Есть определенные ограничения: нельзя делать 5 заглавных букв подряд, заглавные буквы аббревиатур должны подтверждаться контентом сайта, слитные слова.
Слова, разделенные дефисом, не подвергаются изменению.
В нижнем регистре всегда прописываются домены первого уровня (com.ua, org, ru) и префиксы (www., ftp.).
Товары и цены
Вы знаете, что у Яндекса есть свой инструмент для привлечения трафика для интернет-магазина — Яндекс.Маркет.
Но Вы можете улучшить свое отображение сниппетов в выдаче.
Первоначально подключите свой магазин к Яндекс.Маркету.
Ознакомьтесь с лицензионным соглашением и создайте Файл YML со списком Ваших товаров.
Он Вам дальше пригодится.
После добавления магазина в Яндекс.Маркет в вебмастере Вы сможете прописать все необходимые данные и отредактировать сниппеты.
Раздел “Товары и цены” позволяет подключить к Вашему сайту Яндекс.Маркет.
Создайте YML файл со списком выгружаемых товаров и зарегистрируйтесь в Яндекс.Маркет и отслеживайте работу Вашего магазина.
Быстрые ссылки
Мы уже рассказали, что в сниппете мы не можем повлиять на быстрые ссылки.
Но в Вебмастере есть инструмент, который позволяет выбрать из подходящих быстрых ссылок нужные.
Вы можете отключить ненужные (1) быстрые ссылки, а также отсортировать весь список по весу.
Вес ссылок распределяется благодаря внутренней перелинковке.
Распределяйте правильно вес внутренних ссылок по сайту, чтобы важные ссылки получали больше разделов.
Это обычно достигается за счет хлебных крошек, организованного каталога и удобной навигации в статьях и товарных страницах.
Если Вы выбрали нужные быстрые ссылки, Вы можете изучить, как будет выглядеть Ваш сниппет.
Турбо-страницы
Мобильные технологии шагают вперед достаточно быстро.
Одна из особенность мобильных устройств — это малые размеры, а вторая — небольшие потребности в трафике.
Так, веб-страницы для мобильных устройств должны загружаться быстро.
Причем — очень быстро.
Одна из новых технологий Яндекса — поддержка Турбо-страниц.
Все настройки турбо страниц Вы производите непосредственно в Яндекс Вебмастере — просто настройте свой RSS канал (или загружайте контент через API).
Проверка обычно занимает около двух часов.
В разделе настроек Вы можете выбрать тип отображения Ваших турбо страниц, добавить стили CSS Для персонализации, настроить меню и подключить счетчики отслеживания.
В разделе ОТЛАДКИ Вы сможете проверить отображение своего сайта в простом редакторе.
Если Вы подключены к рекламной сети Яндекса (РСЯ) или сети ADFOX, Вы можете добавить отображение рекламных блоков.
ГЛАВА 7:
Инструменты Яндекс Вебмастера
В этом разделе мы рассмотрим инструменты, которые доступны внутри интерфейса Яндекс.Вебмастер
Еще Яндекс Вебмастер, как и Гугл Вебмастер, предлагает свои утилиты.
Валидатор XML фидов
Валидатор XML фидов позволит проверить экспортные файлы XML, которые используются в сервисах Яндекс: в Яндекс.Недвижимости, Авто, Работе, Видео, Яндекс.
Отзывах, Маркете и Справочнике.
Просто выберите тип файла, укажите ссылку (или загрузите) и проверьте результат соответствия.
Незаменима для программистов — часто приходится настраивать.
Валидатор микроразметки
Валидатор микроразметки позволит проверить корректность установки микроразметки на Вашем сайте и даст рекомендации по ее настройке.
Есть удобный инструмент.
Проверка мобильных страниц.
Проверка мобильных страниц.
Позволяет проверить, оптимизирована ли конкретная посадочная страница для мобильных устройств, покажет превью мобильной версии и даст рекомендации относительно отдельных ошибок.
Утилита достаточно простая.
Вставьте ссылку и подождите несколько минут.
Готовый чеклист проверяет, прописали ли Вы Viewport для мобильных устройств, не прогружается ли горизонтальная прокрутка, отсутствуют ли Flash/Silverlight/JAVA элементы, и размер шрифта достаточно крупный, чтобы был удобен для чтения.
Также Яндекс не преминет напомнить о Турбо страницах, если Вы их не внедрили.
Удалите ссылку из индексации
Удалите ссылку из индексации.
Иногда бывает, что ссылки могли ошибочно попасть в индекс, (например — плохой программист или SEO оптимизатор открыл все страницы в Robots.txt) а на их удаление может пройти несколько месяцев.
А нужно все решить в считанные часы.
На помощь приходит простой и понятный инструмент.
Поддерживает два интерфейса.
Удаление по URL позволяет закинуть списком ссылки, которые требуется удалить вручную.
В день можно закинуть по 500 страниц.
Второй способ пригодится в более тяжелых случаях — например, для удаления из индекса целых разделов сайта.
Не забудьте внести правки затем в файл robots.txt во избежание повторного попадания в индекс.
Проверка ответа сервера
Проверка ответа сервера позволит отслеживать важные страницы, а также в ручном режиме проверить работоспособность страниц и их обход поисковым роботом.
Утилита достаточно понятная, и отображает, как поисковый робот воспринимает контент каждой страницы.
Инструмент проверки Sitemap.xml
Инструмент проверки Sitemap.xml позволит проверить качество собранного файла карты сайта.
Просто вставьте ссылку и проверьте, есть ли ошибки — попадают ли в карту закрытые от индексации страницы.
Сервис отклонения ссылок Яндекс.Вебмастер
К сожалению, сервиса, аналогичного Disavow Links, как у Гугла, у Яндекса пока не предвидится, поэтому, если конкуренты разместили на Вас много ссылок, в вебмастере Вы ничего сделать не сможете.
Есть огромное количество жалоб по этой теме в сети, и Яндекс всячески старается дорабатывать алгоритм по отслеживанию некачественных ссылок.
Как я говорил, также не стоит забывать, что в Вебмастере есть собственная техподдержка, где можно изложить претензии и написать сообщение напрямую.
ВЫВОДЫ
Яндекс Вебмастер — один из наиболее мощных инструментов для анализа ошибок Вашего сайта.
Те SEO оптимизаторы, которые не анализируют ошибки при помощи Вебмастеров, обычно затем не понимают, почему их сайты не продвигаются в ТОП и вообще почему теряют позиции в Яндекс.
Хотите проверить качество Ваших оптимизаторов?
Зайдите в вебмастер Яндекс и изучите следущие отчеты в первую очередь:
- Есть ли ошибки в разделе Диагностика. Если они были, посмотрите, когда были отправки на повторный анализ
- Нет ли никаких санкций в разделе Безопасность и нарушения?
- Какие запросы находятся в избранных? Идет ли отслеживание позиций по ним? Соответствуют ли они Вашему семантическому ядру сайта?
- Проводите ли Вы мониторинг Важных страниц сайта? Есть ли они в индексе?
- Добавлены ли карта сайта в вебмастере?
- Добавляются ли новый контент для статей в раздел Оригинальные тексты?
- Используется ли привязка к региону в справочнике и вебмастере?
- Включен ли раздел Товары и Цены для интернет-магазинов?
- Используется ли раздел Турбо-страницы для блога и новостного сайта?
- Проверьте статус URL важных страниц. Есть ли они в индексе и обходятся ли они роботом.
Этот несложный чеклист позволит Вам узнать, проводит ли Ваш SEO оптимизатор работу над сайтом и как он держит его в тонусе.
Оставляйте комментарии и делитесь своими успехами в продвижении!
Почему страницы сайта удаляются из поиска Яндекса и Google?
Не так страшен чёрт, как его малюют
– русская пословица
Иногда довольно сложно понять, что от тебя хотят поисковые системы, что именно они понимают под значением «страницы низкого качества»? Порой смотришь на страницу и откровенно не понимаешь, почему же её невзлюбил Яндекс или Google. В этой статье мы рассмотрим страницы, которые ПС удаляют из поиска, считая недостаточно качественными.
Страницы низкого качества в понимании поисковых систем
В блоге Яндекса Елена Першина даёт следующее определение страницы низкого качества: «Под понятием некачественная страница мы понимаем страницы, вероятность показа которых в поиске практически нулевая. По понятным причинам мы не рассказываем способы определения таких страниц, но это чёткий сигнал, что если вы хотите видеть эту страницу в поиске, то со страницей нужно что-то делать».
Внесём немного корректив в слова представителя Яндекса: так как алгоритмы иногда дают сбой, причём в пользу сайтов, страница может занимать ТОП, а потом бесследно пропасть из выдачи.
То есть, страницы низкого качества – это документы, которые не имеют ценности, не несут новую и полезную информацию, не дают релевантный ответ на вопрос пользователя, с точки зрения поисковых систем.
Как обнаружить удалённые низкокачественные страницы
Яндекс.Вебмастер
Проще всего найти исключённые страницы, воспользовавшись инструментом Яндекс.Вебмастер.
Переходим в раздел «Индексирование» – «Страницы в поиске».
Переходим на вкладку «Исключённые страницы» – выбираем статус «Недостаточно качественная».
Можно, не переходя с «Последних изменений», выбрать статус «Удалено: Недостаточно качественная».
Google Search Console
В отличие от Яндекса, Google не предоставляет информацию о том, какие страницы были удалены из поиска из-за качества. Даже в новой бета-версии Google Search Console, к сожалению, эта функция отсутствует.
Единственным сигналом от Google сейчас можно считать «Отправленный URL возвращает ложную ошибку 404». В таких случаях нужно проанализировать страницы, убедиться, что они существуют, а не удалены (и просто ответ сервера некорректен). Подробнее о мягкой 404 можно прочесть в нашем блоге.
Итак:
- Переходим в новую версию Google Search Console.
- В боковом меню находим «Статус» – «Индексирование отправленных URL».
- Выбираем строку «Отправленный URL возвращает ложную ошибку 404».
- Анализируем исключённые страницы.
Причины удаления страниц
Проанализировав большое количество различных сайтов и выявив закономерность у страниц, удалённых по причине низкого качества, мы пришли к следующим выводам:
1) Алгоритм Яндекса недоскональный: вместо того, чтобы отнести страницу в удалённые, например, по причине дублирования, он исключает её как низкокачественную.
2) Страницы низкого качества чаще встречаются на коммерческих сайтах – интернет-магазинах и агрегаторах, чем на информационных (за счёт автоматической генерации).
Типология удалённых страниц низкого качества
1. «Жертвы» некорректной работы алгоритма
К этой категории мы отнесём страницы, которые должны были быть удалены по другим причинам.
1.1. Дубли страниц
К страницам низкого качества довольно часто попадают дубликаты страниц.
Такие страницы довольно легко определить, если кроме URL ничего не уникализированно.
1.2. Страницы сортировки, пагинации и GET-параметры
Чаще Яндекс исключает такие страницы, как дубли, но, как показано на примере ниже, они могут быть удалены и по другой причине.
Страницы сортировки:
Страницы пагинации:
GET-параметры:
В этом примере GET-параметры определяют регион пользователя.
1.3. Неглавное зеркало
Сайт переехал на защищённый протокол. Долгое время робот Яндекса не знал, что делать со старой страницей на HTTP и, то удалял её как некачественную, то добавлял обратно в поиск. По итогу, спустя несколько месяцев, он удалил страницу как неглавное зеркало.
1.4. Страницы, закрытые в файле robots.txt
Директивы в файле robots.txt не являются прямыми указаниями для поисковых роботов, а служат больше рекомендациями. Исходя из практики, бот Яндекса больше придерживается установок, прописанных в файле, чем Google. Но не в этот раз. Как и в прошлом примере, «помучив» несколько раз страницу, он всё-таки «снизошёл» и удалил её из поиска как запрещённую в файле robots.txt.
2. Действительные недостаточно качественные страницы
В эту группу «я плох, бесполезен и никому не нужен» попадают страницы низкого качества, которые действительно являются таковыми.
2.1. Шаблонная генерация страниц
Часто шаблонное заполнение и генерация страниц влечёт за собой ошибки внутренней оптимизации: неуникальные Title, отсутствует Description, с h2 что-то не так и т. д.
Тут важно сказать, что пользователь без проблем поймёт разницу в страницах и для него они могут быть даже полезными, но он о них не узнает, так как роботы стоят на страже порядка не допустят попадания данных страниц в поиск.
Увидев Title на странице, долго не пришлось гадать, что с ней не так.
2.2. Плохое заполнение карточек товара
Создать карточку товара просто, а вот наполнить её качественным контентом, описанием товара, изображениями – не каждому под силу.
2.3. Листинг без листинга
Создавать страницы категорий/подкатегорий без товара – лишено смысла, так как:
- вряд ли такая страница попадёт в ТОП;
- вероятнее всего, показатель отказов на такой странице будет максимальный.
Об этом скажет и сам Яндекс, исключив страницу из поиска как недостаточно качественную.
2.4. Страницы с малым количеством контента
Несмотря на слова поддержки Яндекса, что важно не количество контента, а качество, его отсутствие – не очень хорошая идея.
Например, на этой странице, кроме шаблонной части и двух изображений, ничего нет.
2.5. Страницы, не предназначенные для поиска
В эту группу относятся страницы robots.txt, Sitemap, RSS-ленты.
Чуть ли не в каждом проекте можно встретить файл robots.txt, удалённый из поиска как недостаточно качественная страница.
Не стоит паниковать, робот о нём знает и помнит. Страница просто не будет отображаться в поисковой выдаче – ну а зачем она там нужна?
XML- и HTML-карты сайта также исключаются. Особенно если у вас многостраничная карта сайта – какая польза от неё в поиске?
Яндекс считает, что RSS-лентам в поиске тоже нет места.
2.6. Страницы с некорректным ответом сервера
В эту группу мы отнесём страницы, которые должны выдавать 404 ответ сервера, а вместо этого отвечают 200 ОК.
Например, это могут быть несуществующие страницы пагинации. Яндекс исключил восьмую страницу пагинации, при имеющихся семи.
Также это могут быть пустые страницы. В таком случае нужно анализировать и принимать решение: настраивать 404 ответ сервера или 301 редирект.
Google может удалить такие страницы, как SOFT 404, но об этом чуть позже.
2.7. «Нужно больше страниц»
Этим часто грешат агрегаторы и интернет-магазины, считая, что чем больше страниц, тем больше видимость и трафик. Страницы создают, не беря во внимание их качество и надобность.
Например, низкокачественными являются страницы, созданные под каждый вопрос из FAQ.
Часто бесполезные страницы создаются с помощью применения всех фильтров. Я соглашусь, что нужно думать о посетителях и удобстве пользования сайтом. Если у интернет-магазина большой ассортимент, то структура сайта должна состоять из множества категорий и подкатегорий, а также иметь различные фильтры. Но, во-первых, нужно ли создавать страницу для «Фарфоровых кукол 20 см с голубыми глазами в розовом платье с корзинкой» и, во-вторых, нужны ли такие страницы в поиске?
2.8. Технические ошибки
Яндекс не жалует страницы с pop-upом, который перекрывает текст без возможности его закрыть, или случайно созданные страницы под изображения.
Как должно быть и как реализовано на сайте:
Случайно созданная страница:
2.9. SOFT 404
Как мы уже говорили, Google прикрепляет страницам именно такой ярлык. Это могут быть пустые страницы или же страницы с очень малым количеством контента.
Влияние низкокачественных страниц на ранжирование
Сколько бы страниц ни было исключено из поиска по этой причине, на ранжировании остальных страниц сайта это никак не отразится.
Этот алгоритм удаления страниц анализирует каждую страницу отдельно, пытаясь ответить на вопрос: «Если страница будет в поиске, даст ли она релевантный ответ на вопрос пользователя?».
Как говорит Яндекс, страница может быть исключена из поиска даже в том случае, если отсутствуют запросы. Робот может вернуть её, если количество запросов, которым будет релевантна страница, увеличится.
Что же делать со страницами низкого качества
Принимать меры можно только после того, как вы определили причину исключения страницы из поиска. Без выяснения обстоятельств не стоит паниковать, сразу удалять страницы, настраивать 301 редирект.
Алгоритм действий после определения причины удаления страницы:
Дубли страниц: 301 редирект или rel=“canonical”.
Страницы сортировки, пагинации и GET-параметры: настраиваем rel=“canonical”/уникализируем страницы пагинации.
Неглавное зеркало: проверяем 301 редирект, отправляем на переиндексацию.
Страницы, закрытые в файле robots.txt: если страница не нужна в поиске, настраиваем метатег noindex.
Шаблонная генерация страниц: если страница нужна в поиске – уникализируем её, работаем над качеством.
Плохое заполнение карточек товара: добавляем описание товара, изображения и т. д.
Листинг без листинга:
- проверяем, приносили ли такие страницы трафик;
- определяем, нужны ли они пользователям;
- временно ли на них отсутствует товар или его не было и не будет.
Принимаем действия исходя из результата. Например, если страница приносила трафик и на ней временно отсутствует товар, можно вывести ленту с похожими товарами или со смежных категорий.
Страницы с малым количеством контента: определяем необходимость таких страниц в поиске, если они нужны – наполняем качественным контентом; не нужны – настраиваем метатег noindex.
Страницы, не предназначенные для поиска: тут всё просто – ничего не делаем, просто живём с этим.
Страницы с некорректным ответом сервера и SOFT 404: как бы ни логично это прозвучит, настраиваем корректный ответ сервера.
«Нужно больше страниц»: проверяем, приносили ли такие страницы трафик, определяем, нужны ли они пользователям в поиске, частотны ли запросы – принимаем действия исходя из результата.
Страницы с техническими ошибками: исправляем недочёты/если страницы не нужны – закрываем noindex/настраиваем 404 ответ сервера.
ВАЖНО: выше перечислены общие рекомендации, которые чаще всего предпринимаются в той или иной ситуации. Каждый случай нужно рассматривать в индивидуальном порядке, находить оптимальное решение проблемы.
Заключение
К сожалению, выдача поисковых систем переполнена мусором, некачественным контентом и бессмысленными сгенерированными страницами. Яндекс и Google активно борются с такими страницами, исключая их из поиска. Мы за качественный контент. Поэтому, если у вас возникли трудности, вы наблюдаете, как поисковики удаляют страницы, ссылаясь на недостаточное качество, мы можем провести технический аудит вашего сайта и написать инструкции по решению проблемы.
Подписаться на рассылкуЕще по теме:
Ксения П.
SEO-TeamLead
За два года от стажера до тимлида.
Google меня любит.
Множко катаю на сапборде.
Девиз: Либо делай качественно, либо делай качественно.
Оцените мою статью:
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.
Борьба с дублями страниц — создание и продвижение сайтов
Дубли страниц сайта, их влияние на поисковую оптимизацию. Ручные и автоматизированные способы обнаружения и устранения дублированных страниц.
Влияние дублей на продвижение сайта
Наличие дублей негативно сказывается на ранжировании сайта. Как сказано выше, поисковики видят оригинальную страницу и ее дубль как две отдельные страницы. Контент, продублированный на другой странице, перестает быть уникальным. Кроме того, теряется ссылочный вес продублированной страницы, поскольку ссылка может перенести не на целевую страницу, а на ее дубль. Это касается как внутренней перелинковки, так и внешних ссылок.
По мнению некоторых веб-мастеров, небольшое количество страниц-дублей в целом не нанесет серьезного вреда сайту, но если их число близится к 40-50% от общего объема сайта, неизбежны серьезные трудности в продвижении.
Причины появления дублейЧаще всего, дубли появляются как следствие некорректных настроек отдельных CMS. Внутренние скрипты движка начинают работать неверно и генерируют копии страниц сайта.
Известно также явление нечетких дублей – страниц, контент которых идентичен только частично. Такие дубли возникают, чаще всего, по вине самого веб-мастера. Это явление характерно для интернет-магазинов, где страницы карточек товаров строятся по одному шаблону, и в конечном итоге различаются между собой лишь несколькими строками текста.
Методы поиска дублированных страниц
Есть несколько способов обнаружения страниц-дублей. Можно обратиться к поисковикам: для этого в Google или «Яндекс» следует ввести в строку поиска команду вида «site:sitename.ru», где sitename.ru – домен Вашего сайта. Поисковик выдаст все проиндексированные страницы сайта, и Вашей задачей будет обнаружить дублированные.
Существует и другой не менее простой способ: поиск по фрагментам текста. Чтобы искать таким способом, нужно добавить в строку поиска небольшой фрагмент текста с Вашего сайта, 10-15 символов. Если в выдаче по искомому тексту будет две или несколько страниц Вашего сайта, обнаружить дубли не составит труда.
Однако, эти способы подходят для сайтов, состоящих из небольшого количества страниц. Если на сайте несколько сотен или даже тысяч страниц, то поиск дублей вручную и оптимизация сайта в целом становится невыполнимыми задачами. Для таких целей есть специальные программы, например, одна из наиболее распространенных — Xenu`s Link Sleuth.
Кроме того, существуют специальные инструменты для проверки состояния индексации в панелях Google Webmaster Tools и «Яндекс.Вебмастер». Ими также модно воспользоваться с целью обнаружения дублей.
Методы устранения дублированных страниц
Устранить ненужные страницы можно также несколькими способами. Для каждого конкретного случая подходит свой метод, но чаще всего, при оптимизации сайта, они применяются в комплексе:
- удаление дублей вручную – подходит, если все ненужные были обнаружены также вручную;
- склеивание страниц с помощью редиректа 301 – подходит, если дубли различаются только отсутствием и наличием «www» в URL;
- применение тега «canonical» — подходит в случае возникновения нечетких дублей (например, упомянутая выше ситуация с карточками товаров в интернет-магазине) и реализуется посредством введения кода вида «link rel=»canonical» href=»http://sitename.ru/stranica-kopiya»/» в пределы блока head страниц-дублей;
- правильная настройка файла robots.txt – с помощью директивы “Disallow” можно запретить дублированные страницы для индексации поисковиками.
Заключение
Возникновение страниц-дублей может стать серьезным препятствием в деле оптимизации сайта и вывода его в топ-позиции, поэтому данную проблему необходимо решать на начальной стадии ее возникновения.
повторяющихся страниц — Вебмастер. Справка
Страницы считаются дубликатами , если они доступны по разным URL-адресам, но имеют одинаковое содержание. В этом случае робот-индексатор группирует такие страницы как дубликаты. В результатах поиска отображается только одна из страниц — та, которую выберет робот.
Примечание. Дубликаты — это страницы на одном сайте. Например, страницы в региональных субдоменах с одинаковым содержанием не считаются дубликатами.
Дубликаты страниц появляются по разным причинам:
Естественный.Например, если страница с описанием товара доступна в нескольких категориях интернет-магазина).
Относится к функциям сайта или его CMS.
- Перейдите на страницу «Страницы в поиске» в Яндекс.Вебмастере и выберите в таблице Все страницы.
- Скачиваем архив — выбираем формат файла внизу страницы. В файле дублирующиеся страницы имеют статус DUPLICATE. Узнать больше о статусах
Примечание. Дублирующаяся страница может быть либо обычной страницей сайта, либо ее быстрой версией, например страницей AMP.
Чтобы в результатах поиска появлялась нужная страница, укажите ее для робота Яндекс. Это можно сделать несколькими способами в зависимости от типа URL.
- URL-адрес страницы, включая путь к странице, отличается.
Пример для обычного сайта:
http://example.com/page1/ и http://example.com/page2/В данном случае:
Пример для сайта со страницами AMP:
http: // example.com / page / и http://example.com/AMP/page/В этом случае добавьте директиву Disallow в файл robots.txt, чтобы предотвратить дублирование индексации страниц.
- URL-адрес отображает URL-адрес главной страницы сайта.
https://example.com и https://example.com/index.phpВ данном случае:
- URL-адрес присутствует или отсутствует /
http: // example .com / page / и http://example.com/pageВ этом случае настройте перенаправление 301 с одной повторяющейся страницы на другую.В этом случае цель перенаправления будет включена в результаты поиска.
- Параметры GET отличаются URL.
http://example.com/page/, http://example.com/page?id=1 и http://example.com/page?id=2В данном случае:
- URL-теги (UTM, от и т. Д.) Различаются
http://example.com/page?utm_source=link&utm_medium=cpc&utm_campaign=new и http://example.com/page?utm_source=instagram&utm_medium= cpcВ этом случае добавьте директиву Clean-param в файл robots.txt, чтобы робот игнорировал параметры в URL.
- URL-адрес содержит параметры страницы AMP
http://example.com/page/ и http://example.com/page?AMPВ этом случае добавьте директиву Clean-param в файл robots.txt, чтобы робот игнорировал параметры в URL.
Робот узнает об изменениях при следующем посещении вашего сайта. Как только это произойдет, страница, которую не следует включать в поиск, будет исключена из него в течение трех недель.Если на сайте много страниц, это может занять больше времени.
Проверить вступление изменений в силу можно в разделе «Страницы в поиске» Яндекс.Вебмастера.
Инструменты Яндекса для веб-мастеров — преимущества и поддержка — SEOrigin.net
Yandex Webmaster Tools — это официальный бесплатный веб-сервис поисковой системы Яндекса, который позволяет владельцам сайтов отслеживать их эффективность в поиске Яндекса. Кроме того, в Яндексе для веб-мастеров есть множество утилит, которые могут улучшить видимость сайта в поиске.Первая версия Yandex Webmaster Tools была выпущена в 2007 году. Несмотря на схожесть многих функций Yandex Webmaster Tools и Google Search Console, это два инструмента, которые были разработаны независимо друг от друга.
Как получить доступ к инструментам Яндекс для веб-мастеров?
Для доступа к Яндекс. Инструментам для веб-мастеров необходимо зарегистрировать аккаунт. Все сервисы Яндекса, такие как Яндекс Инструменты для веб-мастеров, Почта, Карты, Яндекс Метрика, привязаны к одной учетной записи, как и Google. После регистрации аккаунта перейдите на https: // webmaster.yandex.com/ и добавьте свой первый сайт.
Как добавить сайт в Яндекс для веб-мастеров?
Процесс добавления сайта в Яндекс Инструменты для веб-мастеров состоит из двух простых шагов и не отличается от процесса добавления сайта в Google Search Console.
Добавить сайт в Яндекс Инструменты для веб-мастеров:
На верхней панели нажмите кнопку со значком плюса, а в форме ниже укажите URL вашего сайта:
После добавления сайта вам нужно будет его подтвердить.
Проверить сайт в Яндексе для веб-мастеров:
Существует четыре способа подтверждения своего веб-сайта:
- Проверка путем добавления метатега
- Проверка путем загрузки файла HTML в корневую папку сайта
- Проверка путем добавления записи DNS
- Проверка с помощью WHOIS — это худший вариант из-за популярности Whois Privacy Protection.
Верификация в Яндексе для веб-мастеров с помощью метатега:
Скопируйте метатег и добавьте его в раздел
вашего сайта.Если ваш сайт работает на WordPress, то в плагине Yoast SEO есть встроенное поле для проверки сайта в Яндексе для веб-мастеров. Откройте вкладку Yoast → Общие → Инструменты для веб-мастеров и вставьте содержимое проверочного метатега в поле Яндекс для веб-мастеров.
После добавления метатега на ваш сайт нажмите кнопку «Проверить».
Верификация в Яндексе для веб-мастеров с помощью HTML-файла:
Загрузите HTML-файл и загрузите его в корневую папку своего сайта и нажмите кнопку «Проверить».
Верификация в Яндексе для веб-мастеров с помощью записи DNS:
Чтобы использовать этот метод проверки, вам необходимо зайти в настройки DNS вашего домена и добавить запись TXT, указав данные, полученные в Яндексе для веб-мастеров, в поле значения.
После добавления записи DNS нажмите кнопку «Проверить».
Если проверка прошла успешно, вы можете приступить к работе с Яндексом для веб-мастеров. Имейте в виду, что не все данные появятся сразу, Яндексу требуется некоторое время (обычно пара дней), чтобы собрать и отобразить всю информацию.
Обзор инструментов Яндекса для веб-мастеров:
Сводка — это дашборд, где вы можете увидеть сводную информацию о вашем сайте.
- Проблемы с сайтом
- Статистика сканирования.
- Число кликов в результатах поиска
- Показатель индекса качества сайта (SQI).
- Входящие ссылки.
Яндекс для веб-мастеров: Качество сайта.
В этом разделе представлена информация о метриках качества сайта, присвоенных Яндексом.
Индекс качества сайта Яндекса (SQI)
Индекс качества сайта Яндекса — это показатель популярности сайта.В алгоритме расчета участвуют следующие параметры: размер аудитории сайта, поведенческие факторы, авторитет домена и т. Д. Эта метрика регулярно обновляется.
Значки Яндекс для веб-мастеров
Значки присваиваются веб-сайтам по мере достижения ими определенных целей. Значки появляются в результатах поиска, тем самым положительно влияя на CTR в поисковой выдаче.
На данный момент имеется 4 значка:
- Популярный сайт — выдается сайтам с высокой посещаемостью и постоянной аудиторией
- Выбор пользователя — выдается сайтам с высоким уровнем вовлеченности пользователей и лояльности аудитории
- Безопасное соединение — выдается, если сайт работает по протоколу HTTPS
- Turbo Pages — выдается для использования технологии Turbo Pages (некий аналог технологии AMP)
Яндекс для веб-мастеров: Устранение неполадок
В этом разделе отображается информация о проблемах сайта:
- Диагностика сайта — отображает информацию о проблемах с индексацией, проблемах оптимизации на странице.В этом разделе также даются рекомендации по улучшению сайта.
- Безопасность и нарушения — Информация о проблемах безопасности и штрафах Яндекса
Инструменты Яндекса для веб-мастеров: поисковые запросы
В этом разделе представлена информация о поисковых запросах. Здесь вы можете увидеть общую статистику по кликам и показам, а также данные о кликах и показах для определенных страниц и разделов сайта.
Тенденции:
Раздел «Тенденции» позволяет сравнить ваш сайт с другими аналогичными сайтами.
Рекомендуемые запросы
В этом разделе вы можете запросить дополнительные ключевые слова, под которые можно оптимизировать ваш сайт.
Яндекс для веб-мастеров: раздел индексирования
Этот раздел содержит статистику индексации, а также инструменты для ее улучшения.
Статистика сканирования
В этом разделе вы можете увидеть статистику сканирования Яндекс-ботов. Функциональные возможности в целом идентичны разделу «Статистика сканирования» в устаревших инструментах Google Search Console.
страниц с возможностью поиска
Здесь вы можете увидеть все страницы, проиндексированные Яндексом. Этот раздел почти идентичен разделу Покрытие в Google Search Console.
Структура сайта
В этом разделе вы можете увидеть структуру сайта, как ее видит робот Яндекс. Страницы организованы в кластеры URL.
Проверить статус URL
Здесь вы можете проверить статус страницы, доступна ли она для бота Яндекса, запрещена ли индексация и т. Д.Отправленные URL-адреса можно пометить как важные и добавить в Мониторинг важных страниц.
Мониторинг важных страниц.
Это очень полезная функция, которая позволяет вам добавлять самые важные страницы вашего веб-сайта для непрерывного мониторинга и получать уведомления, если что-то пойдет не так.
Переиндексировать страницы
Здесь вы можете запросить переиндексирование страниц. Эта функция идентична функции индексирования запросов в инструменте проверки URL-адресов в консоли поиска Google, с той лишь разницей, что вы можете добавить список из нескольких URL-адресов (дневной лимит составляет 110 URL-адресов.)
Файлы Sitemap
Раздел для добавления файлов Sitemap.xml для ускорения индексации сайта. Аналогично разделу Sitemap в консоли поиска Google.
Переместить объект
Этот раздел необходим, если вы решили перенести сайт в другой домен (или другую версию домена — WWW / не WWW и HTTP / HTTPS). Аналогично изменению адреса в консоли поиска Google.
Настройки скорости сканирования
Здесь вы можете настроить скорость сканирования вашего сайта.Функциональность идентична настройкам в Google Search Console.
Яндекс. Инструменты для веб-мастеров: отображение в поиске
В этом разделе показано, как сайт выглядит в результатах поиска. Вы можете увидеть, отображается ли сайт в специальных результатах (аналогично избранным сниппетам в Google), а также какие данные отображаются во фрагменте (значки, дополнительные ссылки, рейтинг, адреса и т. Д.).
Яндекс Инструменты для веб-мастеров: ссылки
В этом разделе содержится информация о ссылках: входящих и исходящих.В разделе Внутренние ссылки вы можете увидеть все ваши обратные ссылки, обнаруженные Яндекс Ботом, а также битые обратные ссылки.
Яндекс. Инструменты для веб-мастеров: информация о сайте
В этом разделе вы можете установить регистр букв для отображения названия вашего сайта в результатах поиска, установить региональный таргетинг, настроить дополнительные ссылки.
Инструменты Яндекса для веб-мастеров: Дополнительные инструменты
- Анализатор Robots.txt — позволяет проверить и подтвердить ваш файл robots.txt. Подобно роботам Google.txt Tester Tool
- Валидатор Sitemap.xml позволяет проверить ваш sitemap.xml. Вы можете загрузить XML-файл, указать URL-адрес или просто вставить содержимое файла sitemap.xml.
- Server Response Checker — позволяет проверять коды HTTP-ответов URL-адресов для различных ботов Яндекса.
- Удалить страницы из поиска — позволяет исключать страницы или кластеры URL-адресов из результатов поиска. Идентичен инструменту удаления URL-адресов в Google Search Console
- Аудит страниц на совместимость с мобильными устройствами — проверьте, правильно ли отображается страница на мобильных устройствах.
- Валидатор структурированных данных — позволяет проверять различные типы структурированной разметки. Проверка доступна для следующих структурированных разметок: микроданные, schema.org, микроформаты, OpenGraph и RDF
В целом Яндекс. Инструменты для веб-мастеров содержат большое количество инструментов, которые могут быть полезны, даже если вы не занимаетесь поисковой оптимизацией для Яндекс. Если вы использовали Яндекс Вебмастер, поделитесь своим мнением в разделе «Отзывы» ниже.
Sitecore SEO: Google, Яндекс и Bing
Хотя Bing и Яндекс могут показаться незначительными в цифрах, они входят в пятерку самых популярных поисковых систем на планете, а Яндекс — на первом месте.1 в России. Они не только доминируют в мире поисковых систем, но и создали новый канал в современном маркетинге — поисковую оптимизацию (SEO).
Google, Яндекс и Bing — крупнейшие поисковые системы в настоящее время. У Google колоссальная доля рынка 91,89%, за ней следуют Bing с 2,79% и Яндекс с 0,54% .
С их постоянно развивающимися алгоритмическими изменениями и обновлениями поисковая оптимизация становится более сложной, чем когда-либо. Упрощение SEO имеет решающее значение для успеха на этом канале.В этой статье рассказывается, что вам нужно сделать, чтобы добиться максимальной производительности Sitecore SEO от вашего сайта Sitecore.
Как попасть в индекс в Google, Яндекс и Bing
Первое и самое важное, что необходимо сделать перед оптимизацией, — это проиндексировать ваш сайт Sitecore поисковыми системами. Есть множество способов подойти к этому, но лучший из них — самый простой.
Подключение вашего сайта Sitecore к консоли поиска Google
Google Search Console — это набор инструментов и ресурсов, которые помогают владельцам веб-сайтов и специалистам по поисковой оптимизации отслеживать и обслуживать веб-сайты.
Некоторые из основных функций включают предоставление информации о внешнем виде поиска, производительности трафика, технических обновлениях, статусе сканирования и данных, обратных ссылках и ссылочных URL-адресах и многое другое.
- Зарегистрируйтесь в Google Search Console аккаунт
- Нажмите Добавьте свойство и в поле URL-адреса добавления сайта
- Выберите HTML-тег в качестве метода проверки
- Скопируйте метатег и вставьте его в раздел вашего сайта
- Как только это будет сделано, нажмите Проверить в окне консоли поиска Google
Источник: Google
Подключение вашего сайта Sitecore к Bing
После подключения вашего сайта к Google Search Console подключиться к Bing Webmaster довольно просто.Это можно сделать двумя способами. Первый — вручную, а второй — для проверки вашего сайта путем импорта аутентификации из Google Search Console.
- Откройте учетную запись Bing для веб-мастеров
- На главной панели инструментов нажмите кнопку в правом верхнем углу с надписью Пропустить проверку, импортировав свой сайт из консоли поиска Google
Источник: Bing
Подключение вашего сайта Sitecore к Яндексу
Для бизнеса, у которого есть российский сайт, обязательно присутствие на Яндексе.Это потому, что Яндекс — поисковая система №1, которую выбирают люди в России.
- Создать аккаунт на Яндексе
- Перейдите на домашнюю страницу, найдите карточку веб-мастера и нажмите Добавить домен
- Введите имя вашего домена и нажмите Добавить
Подтвердите, что вы являетесь владельцем сайта:
- Файл HTML : создайте файл HTML с указанным уникальным именем и содержанием и поместите его в корневой каталог вашего сайта
- Мета-тег: Добавьте специальный метатег в HTML-код на главной странице сайта (в элементе head)
- Если у вас уже есть основной домен, нажмите Сделать основным .После этого ваш новый домен станет основным доменом, а старый домен будет переведен в псевдоним домена .
Узнайте о других способах подключения домена к Яндекс.
Источник: Яндекс
Подключение ваших XML-карт сайта к Google, Яндекс и Bing
После подключения и проверки вашего веб-сайта следующим шагом будет загрузка вашей XML-карты сайта во все инструменты для веб-мастеров (Яндекс, Bing и Google Search Console).
XML-карта сайта содержит список всех (включенных) страниц вашего веб-сайта.Хорошо структурированная иерархия / карта сайта в формате xml ведет поисковые системы ко всем вашим важным страницам.
Карту сайта обычно можно найти, добавив /sitemap.xml к URL-адресу вашего веб-сайта. Например: www.nameofyourwebsite.com/sitemap.xml. Если у вас нет карты сайта, попросите своего партнера по технологиям создать ее для вас.
Подключение XML-карты сайта Sitecore к Google Search Console
- На панели инструментов Google Search Console перейдите к левой панели. В разделе Индекс нажмите Файлы Sitemap
- Введите URL-адрес вашей карты сайта в поле Добавить новую карту сайта .URL-адрес обычно /sitemap.xml, но убедитесь, что перед отправкой
- После отправки, в зависимости от размера вашего сайта, в отчете ниже статус будет зеленым.
Подключение XML-карты сайта Sitecore к Bing
- На панели инструментов Bing Webmasters перейдите к левой панели. В разделе Настроить личный сайт щелкните Файлы Sitemap
- Нажмите новый Перейти к карте сайта ссылка
- Нажмите Отправить карту сайта и отправьте URL-адрес, по которому находится ваша карта сайта
Подключение XML-карты сайта Sitecore к Яндексу
- В панели управления Яндекс Вебмастера перейдите на левую панель.В разделе Индексирование щелкните Файлы Sitemap
- Нажмите новый Перейти к карте сайта ссылка
- Введите URL-адрес карты сайта в поле Добавить новую карту сайта
- Нажмите Отправить
Когда веб-сайт проверен и карта сайта успешно отправлена, как вы оптимизируете свой сайт Sitecore для Google, Яндекс и Bing для улучшения SEO? Это может быть очень детализировано, но три наиболее важные и часто используемые категории оптимизации:
- Техническое SEO
- Внутреннее SEO (контент)
- Off-page SEO (профили с обратными ссылками)
Техническое SEO
Более 95% оптимизаций, сделанных для одной поисковой системы, обычно одинаковы для других поисковых систем.
Если вы правильно понимаете технические требования Google к SEO, вы в значительной степени правильно поняли и Bing, и Яндекс, хотя есть некоторые очень отличительные особенности, которые требуют большего внимания, чем другие.
Убедитесь, что ваш веб-сайт оптимизирован для мобильных устройств
Как следует из названия, мобильный контент предназначен для оптимизации ваших технических, дизайнерских и контентных основ для мобильных пользователей, а также для удобства использования мобильных устройств.
Ниже приведены 26 рекомендаций, которые помогут улучшить индексацию вашего сайта Sitecore на мобильных устройствах.
- Используйте одни и те же метатеги robots на мобильном и настольном сайте
- Не ленитесь загружать основной контент при взаимодействии с пользователем
- Разрешить Google сканировать все ресурсы
- Убедитесь, что содержимое одинаково на настольных компьютерах и мобильных устройствах
- Используйте те же четкие и содержательные заголовки
- Убедитесь, что на вашем мобильном устройстве и на компьютере используются одинаковые структурированные данные.
- Используйте правильные URL-адреса в структурированных данных
- Если вы используете Data Highlighter, обучите его на своем мобильном сайте
- Поместите одинаковые метаданные в обе версии вашего сайта (метатеги, метаописания и т. Д.)
- Обеспечивает высокое качество изображения
- Использовать поддерживаемый формат для изображений
- Не используйте URL-адреса, которые меняются каждый раз при загрузке страницы
- Убедитесь, что на мобильном сайте есть тот же замещающий текст для изображений, что и на сайте для настольных компьютеров.
- Убедитесь, что качество содержимого мобильной страницы такое же хорошее, как и страница для ПК.
- Не используйте URL-адреса, которые меняются каждый раз при загрузке страницы для ваших видео
- Использовать поддерживаемый формат для видео
- Использовать те же структурированные видеоданные
- Поместите видео в удобное для поиска место на странице при просмотре на мобильном устройстве
- Убедитесь, что статус страницы ошибки одинаков как на настольном, так и на мобильном сайте.
- Убедитесь, что в вашей мобильной версии нет URL-адресов фрагментов.Например, страницы, начинающиеся с #, эти страницы не будут проиндексированы .
- Убедитесь, что у настольных версий, обслуживающих разный контент, есть эквивалентные мобильные версии.
- Проверьте обе версии вашего сайта в консоли поиска (только если у вашего сайта есть собственный URL)
- Проверить hreflang ссылок на отдельные URL
- Убедитесь, что ваш мобильный сайт имеет достаточную емкость для обработки повышенной скорости сканирования.
- Убедитесь, что ваши директивы robots.txt работают так, как вы предполагаете, для обеих версий (если у вас есть сайт для мобильных устройств)
- Используйте правильные атрибуты rel = canonical и rel = alternate для отдельных URL-адресов
Вы также можете использовать тест Google Mobile Friendly, чтобы узнать, насколько эффективен ваш сайт на мобильных устройствах.
Узнайте больше о передовых методах работы с мобильными устройствами.
Понимание основ JavaScript SEO
Все специалисты по SEO и маркетологи должны привыкнуть к некоторым техническим особенностям SEO с использованием JavaScript. JavaScript — важная часть набора инструментов веб-разработки, поскольку он предоставляет множество функций, которые превращают веб-разработку в мощную платформу приложений.
Создание веб-приложений на базе JavaScript, которые можно обнаружить с помощью поисковых систем, может помочь новым пользователям и повторно привлечь существующих пользователей в процессе поиска контента, предоставляемого вашим веб-сайтом.
Понимание того, как AMP выглядит в результатах поиска и работает
В отличие от JavaScript SEO, Accelerated Mobile Pages намного проще, но в равной степени является неотъемлемой частью технического контента и планов SEO.
AMP — это более простые страницы вашего текущего веб-сайта, которые могут быть обслужены пользователями намного быстрее. Это улучшает работу в Интернете для мобильных посетителей, особенно при медленном подключении к Интернету. Google Search и все другие поисковые системы индексируют AMP.
Повышение скорости страницы
Иногда поисковые системы могут быть довольно снисходительными, когда дело доходит до того, что некоторые мелкие технические элементы не совсем правильны, но скорость страницы не входит в их число.Самым важным ожиданием от поисковой системы, будь то Google, Bing или Яндекс, является то, что все они требуют, чтобы ваш веб-сайт и отдельные страницы имели хорошую скорость загрузки.
Все поисковые системы недавно сделали скорость страницы обязательным фактором ранжирования. Инструмент Google Page Speed Tool — отличный способ узнать, насколько эффективно загружается страница вашего сайта Sitecore.
Содержимое HTTPS и смешанное содержимое
HTTPS стал фактором ранжирования в 2014 году для Google и в 2015/2016 для других поисковых систем.
Предполагается, что более 80% веб-сайтов во всех поисковых системах поддерживают протокол HTTPS. Вот почему важно проверять распространенные проблемы HTTPS в рамках ежемесячного аудита, поскольку новые объекты и вновь созданный контент не всегда могут быть безопасными. Например, проблемы смешанного содержимого обычно возникают, когда защищенный контент (ресурсы и страницы HTTPS) смешивается с незащищенными страницами (ресурсы и страницы HTTP). Это ослабляет воспринимаемую безопасность.
Канонические проблемы и проблемы с hreflang
Канонический тег или rel = canonical информирует поисковые системы о том, что конкретный URL-адрес является главной копией страницы.Другими словами, это предпочтительный URL для индексации.
Использование канонического тега предотвращает проблемы идентификации, с которыми сталкиваются сканеры, посещающие веб-страницу, и предотвращает индексацию дублированного контента. Он сообщает поисковым системам, какую версию URL вы хотите проиндексировать и таким образом отображать в поисковых системах.
Некоторые передовые практики:
- Канонические теги могут ссылаться на себя
- Убедитесь, что вы канонизируете свою домашнюю страницу.
- Проверьте динамические канонические теги (не пытайтесь написать скрипт для заполнения ваших канонических тегов, это может пойти не так и потенциально проиндексировать 100 неправильных страниц)
- Включите поле Canonical URL в редактор содержимого всех ваших страниц Sitecore
Если на вашем сайте Sitecore включено международное управление версиями, то применение атрибута hreflang оптимизирует ваше SEO.
Применение тега hreflang сообщает поисковым системам, какую версию контента показывать в зависимости от языка и региона посетителя. hreflang также предотвращает проблемы с дублированием содержимого. Имея идентификатор страны / языка в URL-адресе (например, страница www / yourdomain.com / en-gb / ) в сочетании с атрибутами hreflang для региональных / языковых вариантов, эта английская версия страницы будет отображаться в поисковой выдаче для пользователь в Великобритании.
Внутренние ссылки и «ссылочный сок»
Внутренние ссылки могут быть частью более сложной технической экосистемы, но также являются частью оптимизации контента.
Внутренние ссылки помогают поисковым системам лучше сканировать сайт. Думайте об этом как о строках, которые связывают все статьи и страницы друг с другом. Сканеры используют эти строки для поиска контента и его индексации. Чем больше строк связано со всеми частями сайта, тем лучше индексация. Это также называется «ссылочным весом».
Очень важно, чтобы вы включали релевантные ссылки на другие части веб-сайта на каждой странице или в каждой статье. Но постарайтесь не переусердствовать, поскольку контент должен хорошо (и естественно) читаться посетителям.
Статьи в блогах — лучшее место для связи с другими частями вашего сайта.
Чтобы лучше понять, как работают внутренние ссылки, просмотрите отчеты профилей ссылок в Google Search Console, Яндексе и Bing.
Увеличьте свой краулинговый бюджет
Бюджет сканирования — это количество страниц, которые поисковые системы просматривают за определенный период времени. Это не фактор ранжирования, но он помогает чаще приглашать роботов к вашему поиску.
Чтобы понять, как это работает, просмотрите разделы в своих веб-мастерах, которые говорят: Статистика сканирования или Статус сканирования .
Если вы видите, что графики краулингового бюджета высоки, это означает, что ваш сайт нуждается в хорошей очистке с точки зрения SEO. Так что же такое хорошая чистка?
- Удалите дублирующийся контент, , чтобы не тратить краулинговый бюджет
- Ограничить индексацию страниц без значения SEO . Страницы со старым контентом, которые не работают должным образом или имеют больше проблем, которые посещают, или, что еще лучше, перенаправляют их
- Добавить параметры URL в Google Search Console .По умолчанию Google сканирует все страницы, представленные на веб-сайте, но иногда важно добавить ограничения для параметров URL, чтобы ограничить индексирование таких страниц, как страницы BackToResults или динамические страницы, найденные с помощью расширенных фильтров на вашем сайте
- Исправить цепочки переадресации. Цепочка перенаправления — это цепочка перенаправлений, которая может быть собрана в течение периода перенаправления одних и тех же страниц на другие страницы, не зная, перенаправлялись ли они ранее. Избегайте этого, потому что поисковый робот постоянно индексирует те же самые страницы
SEO на странице
Оптимизация на странице — это практика оптимизации отдельных веб-страниц для повышения их рейтинга в поисковых системах и увеличения посещаемости.В отличие от технического SEO, оптимизация на странице в основном связана с контентом и связанным с ним HTML.
Ниже приведены некоторые методы, которые помогут вашему Sitecore на странице SEO:
Публикуйте высококачественный контент
Качество может иметь большое значение для многих маркетологов. Обычно это приводит к слишком большому количеству контента, слишком маленькому контенту, нерелевантному контенту или контенту, который поглощается ключевыми словами. Ниже приведены несколько советов по улучшению SEO на странице Sitecore:
- Исходное содержимое: Не копировать и не переписывать существующее содержимое и постарайтесь использовать на странице как можно больше исходных ресурсов
- Добавьте канонические теги : убедитесь, что у каждой статьи или сообщения есть канонический URL.
- Значение : публикация содержимого, предоставляющего значение
- Исследование : Напишите хорошо проработанный контент
- Деталь: Изготовление более длинных и подробных статей
Заголовки страниц и метаописания
Это основная форма SEO и фундаментальный фактор ранжирования.Вот несколько советов:
- Каждая страница должна иметь уникальный заголовок и соответствовать тому, что страница пытается сказать
- Добавьте ключевые слова в начало заголовков страниц
- Пишите короткие и описательные заголовки. Пользователи обычно нажимают на короткие точные заголовки
- Не всегда обязательно указывать название вашего домена
- Убедитесь, что в заголовке указано ограничение на количество символов в поисковой системе.
Мета-описание — это описание страницы в нескольких словах, которое часто можно увидеть прямо на странице результатов поисковой системы.Это возможность превратить холодного пользователя в читателя. Вот несколько способов оптимизации метаописаний:
- Найдите время, чтобы написать оригинальные метаописания и сохранить уникальность тегов
- Убедитесь, что вы также добавили в него целевые ключевые слова.
- Не превышайте ограничение по количеству слов в мета-описании, которое есть в поисковых системах.
Оптимизировать содержимое страницы
Оптимизация общего форматирования контента и самого контента является ключевым моментом, поскольку сканеры всех поисковых систем следуют текстовому формату HTML.Так что убедитесь:
- Все теги заголовков верны (h2, h3, h4 и т. Д.)
- Попробуйте включить ключевые слова в заголовки
- Используйте в тексте хорошо изученные ключевые слова с высокой посещаемостью.
- Используйте ключевые слова LSI (слова, которые имеют прямое или косвенное отношение к вашей теме)
- Сохраняйте изображения высокого качества
- Убедитесь, что изображения имеют замещающий текст и другие атрибуты, такие как «Название».
- Добавить разметку схемы или структурированные данные
- Добавьте Facebook Open Graph для лучшего обмена в социальных сетях
- Избегайте длинных абзацев.Сделайте статью удобочитаемой и разбейте на кусочки информацию
Оптимизировать URL-адрес
Это может быть самый простой из всех методов оптимизации на странице, но в большинстве статей это неверно из-за динамически генерируемых URL-адресов. По возможности избегайте этого и пишите простые, точные и релевантные структуры URL-адресов с соответствующими ключевыми словами.
Внутренняя ссылка
Как уже упоминалось, внутренние ссылки помогают поисковым системам лучше сканировать веб-сайт, поскольку они используют ссылки для перемещения по сайту.
Внешние ссылки
Наличие внешних ссылок из вашей статьи на другой надежный источник или публикацию повышает надежность статьи. Это положительный фактор SEO. Каждый раз, когда вы цитируете или используете контент с другого веб-сайта, упомяните источник и сделайте ссылку на статью.
SEO вне страницы
Off-page SEO — это оптимизация вашего собственного сайта. Он получает рейтинг SEO по сравнению с другими внешними веб-сайтами в виде обратных ссылок. Google недавно подтвердил, что обратные ссылки являются одним из трех наиболее важных факторов ранжирования.Обратные ссылки должны быть в верхней части списка для всех маркетологов.
Как получить обратные ссылки:
- Начать гостевой блог с авторитетными блогами и издателями
- Переверните обратные ссылки ваших конкурентов и внесите вклад в их источники обратных ссылок
- Упоминайте ключевых влиятельных лиц отрасли в своих сообщениях в блоге
- Публикуйте загружаемый контент и руководства со ссылками на ваш основной веб-сайт.
- Публикация статей или контента в качестве приглашенных пользователей на сайтах пользователей и в социальных сетях
- Станьте лидером отрасли, публикуя контент других участников на своем сайте в обмен на публикацию вашего контента на их сайте.
Оптимизация для Google похожа на оптимизацию для всех других поисковых систем, поскольку они являются наиболее сложной и доминирующей поисковой системой на рынке.Выполнение шагов, описанных в этой статье, улучшит SEO Sitecore для Google, Яндекс и Bing.
Наша команда по цифровому опыту помогла многим клиентам как начать работу с SEO на сайтах Sitecore, так и решить более сложные задачи SEO. Чтобы получить дополнительную информацию о том, как SEO-аудит может помочь вашему сайту, свяжитесь с нами.
Фатальных ошибок дорвея Яндекс вебмастера. Избавляемся от фатальной ошибки в Яндекс
Поисковая оптимизация — это большая работа над множеством различных факторов.Дизайн, техническая составляющая, контент. Даже, казалось бы, незначительные детали очень важны для продвижения. Мы уже рассказывали о самых распространенных ошибках в дизайне сайтов. Сегодня мы разберем 9 фатальных SEO-ошибок, которые могут «угробить» любой сайт.
- Фильтры и санкции поисковых систем
Хотя бы раз в неделю рекомендую заглядывать к вебмастерам Яндекс и Гугл на предмет санкций. В Яндексе это можно сделать в разделе Диагностика → Безопасность и нарушения … В Google — Поисковый трафик → Ручное действие .
Как показывает наша практика, чаще всего владельцы сайтов даже не знают о наложенных ограничениях. Недавний пример из нашей работы:
Большое количество чужих текстов на сайте и открытых исходящих ссылок. Результат на скриншоте.
Пока не будут сняты все ограничения, в продвижении нет смысла. Исправляем все ошибки, информируем поисковик и ждем снятия санкций.
- Содержание
Мы постоянно говорим о том, насколько важны тексты.Контент — причина, по которой пользователи посещают сайты. Неуникальный и неинтересный контент никому не нужен. Поисковые системы недооценивают такие ресурсы в результатах поиска, и клиенты устали читать одни и те же тексты шаблонов на сотнях сайтов. Доказательство того, какой контент можно летать с хорошей позиции.
Перед размещением на text.ru проверьте уникальность текстов.
Как писать тексты, на каких страницах и вообще о содержании, в нашем блоге много написано. Вот симпатичная подборка статей от нашего копирайтера Дарьи.
- Теги заголовка и описания, заголовки h2-h4
Основа SEO продвижения — это правильные ключевые слова. Это очень важный фактор при оценке релевантности вашего сайта поисковому запросу.
Чаще всего встречаются две ошибки. Полное отсутствие ключевых слов в тегах:
Тег Title должен быть заполнен как связное предложение с включенными ключевыми словами.
Или спам с ключами в заголовках:
Важно найти золотую середину.Теги должны быть полезны не только поисковым роботам, но и обычным людям. Не забывайте быть информативным. Как правильно писать заголовок, описание и заголовки h2, наш копирайтер Екатерина хорошо объясняет в своей статье.
- Переход на https
С января 2017 года браузер Google Chrome (начиная с версии 56) начал отмечать все HTTP-сайты, содержащие любые формы, передающие личные данные пользователей (электронная почта, пароли, данные кредитных карт и т. Д.), Как «небезопасные».Кроме того, наличие сертификата SSL — небольшое повышение в рейтинге Google.
Все интернет-магазины должны сначала перейти на протокол https. В этом случае очень важно соблюдать правильный алгоритм действий.
Самая распространенная ошибка — просто настроить 301 редирект со старой версии http на https после покупки сертификата SSL. Владельцы веб-сайтов забывают о файле robots.txt, директиве Host и настройке веб-мастеров. Сайт с http выпадает из индекса, новый сайт по https еще не проиндексирован.Все позиции моментально влетают в трубу.
В нашем блоге есть подробные инструкции, как правильно перевести сайт с http на https. Если возникнут вопросы, напишите нам, обязательно поможем.
- Файл Robots.txt
Текстовый файл, размещенный на сайте и предназначенный для роботов поисковых систем. В этом файле вы должны указать параметры индексации вашего сайта для поисковых роботов.
Иногда вообще отсутствует файл robots.txt.
Свежий пример из нашей работы.Интернет-магазин станков, работа выполнялась в рамках сервиса поисковой оптимизации. Сайт был полностью открыт для индексации поисковыми роботами и вообще не имел файла robots.txt.
Настроили для него роботов, сейчас все в порядке:
Что именно мы сделали?
Админ-панель сайта, служебные страницы 404 и 403, страница поиска, корзина закрыты из индексации. Указал URL карты сайта, настроил директиву Host.
Вместе с остальной работой по оптимизации это помогло достичь следующих результатов:
Еще одна серьезная ошибка — сайт полностью закрыт от индексации. За это отвечают директивы Disallow и Allow, которые запрещают или разрешают индексирование разделов, отдельных страниц сайта или файлов соответственно. В поисковых системах есть специальные инструменты для проверки файла: Яндекс и Гугл.
Убедитесь, что на вашем сайте есть файл robots.txt и заполнен правильно. Все служебные страницы, страницы поиска и фильтрации должны быть закрыты от индексации. Дубликаты, страницы регистрации, авторизации. Корзина покупок и страница оформления заказа для интернет-магазинов. …
- Дублированный контент (повторяющиеся страницы)
Дублированный контент или просто дубликаты — это страницы вашего сайта, которые полностью (устранение дубликатов) или частично (нечеткие дубликаты) совпадают друг с другом, но каждая из них имеет свой собственный URL.
На одной странице может быть один или несколько дубликатов:
Поисковые роботы негативно относятся к дублированному контенту и могут занижать свои позиции в поисковой выдаче из-за отсутствия уникальности, а значит, полезности для клиента.Нет смысла читать одно и то же на разных страницах сайта.
Соответствующая страница может измениться. Робот может выбрать выдачу дубликата страницы, если он считает, что ее содержимое более соответствует запросу. Сайт потеряет позиции и упадет в результатах поиска. В 90% случаев продвижению мешают дубликаты, и после их устранения позиции сайта улучшаются.
Как найти и удалить дубликаты на сайте, мы расскажем в этой статье.
- Зеркала сайта
Зеркала — это сайты, которые являются полными копиями друг друга, доступными по разным адресам.Важно через 301 редирект проклеить все зеркала сайта.
Показатели TCI, вес внешних ссылок не должен распространяться, но они будут распространяться, потому что поисковые системы считают сайты, расположенные по разным адресам, разными ресурсами. Подмена релевантной страницы в результатах поиска, возможно дублирование контента. 100% тормозит рост сайта в поисковой выдаче.
Сайт не должен открываться по разным адресам, с www и без www, только site.ru и site.ru/index.php, http и https и др .:
Контрольный список для проверки:
- Сайт должен быть доступен только по одному протоколу http или https.
- Выбирается главное зеркало сайта, с www или без www, указанное в Вебмастере.
- Настроил 301 редирект со всех зеркал.
- Главная страница сайта доступна по одному адресу, без /index.php, /index.html и т. Д.
- Адаптивная верстка (версия сайта для мобильных устройств)
100% must-have для всех сайтов в 2017 году.Сегодня рост мобильного трафика опережает рост компьютерного. Количество пользователей, использующих смартфоны для совершения покупок в мире, растет с каждым днем. Алгоритмы поисковых систем учитывают адаптируемость при ранжировании сайта в результатах мобильного поиска.
Google использует алгоритм Google для мобильных устройств с 2015 года.
- Скорость загрузки сайта
Здесь все просто. Пользователи не любят медленные сайты. Поисковые системы также предпочитают быстрые, хорошо оптимизированные сайты.Вы можете проверить скорость загрузки вашего сайта с помощью инструмента Google. Красный — медленный, важно срочно увеличить скорость, желтый — нормально, но можно оптимизировать, зеленый — отлично.
Рассмотрим на конкретном примере
Напомним, в начале статьи мы упоминали интернет-магазин станков. Что мы исправили из фатальных ошибок:
Мы написали хороший продающий, уникальный текст на главной странице сайта.
Исправлены теги title и description, заголовки h2.
Создал и настроил файл robots.txt. Сайт теперь правильно индексируется поисковыми системами. До этого, как уже было сказано выше, этого файла на сайте вообще не было.
- Наличие отклеенных зеркал
Зеркала наклеены. Сайт был доступен по двум адресам с www и без него.
- Неверный ответ сервера на несуществующие страницы
Создал отдельную страницу 404 и настроил правильный ответ сервера для несуществующих страниц.
До завершения работы несуществующие страницы через редирект 302 перенаправляли пользователя на главную страницу сайта.
Результаты:
Положительная динамика роста трафика с поисковых систем:
Трафик от Google увеличился вдвое:
Результат через 3 месяца:
+8 запросов от Яндекса, +6 Google входит в топ-5
+19 запросов от Яндекса, +9 Google входит в топ-10
+25 запросов от Яндекса, +11 Google входит в топ-20
+14 запросов от Яндекса, +4 Google в топ-50
Хотите того же? Проверьте, существуют ли эти ошибки на вашем сайте.Если у вас нет времени и желания разобраться, закажите у нас поисковое продвижение, мы будем рады помочь.
Не так давно Яндекс изменил алгоритмы определения полезных и бесполезных сайтов. Все малопригодные сайты, по его мнению, он помечает фатальной ошибкой.
Сообщение об ошибке выглядит так:
Сайт может угрожать безопасности пользователя, либо на нем были обнаружены нарушения правил поисковой системы. Эта проблема негативно сказывается на позициях сайта в поисковой выдаче.
При более подробной навигации можно увидеть следующее:
Все это звучит как приговор и не надо радоваться:
Что делать?
Понять, в чем причина, довольно сложно, поскольку ошибка имеет общий вид и включает в себя всевозможные частные и случайные нарушения.
На Яндексе есть ссылки на инструкции, что делать. Есть общие черты и разные причины:
Малоценный контент
Некачественные сайты
Нет смысла писать поддержку Яндекс.Они отвечают, но типичными сообщениями. И когда все же получается человеческий ответ, это не воодушевляет и часто звучит так (своими словами, пересказ слов поддержки):
Все это хорошо, но иногда это полнейшая чушь и вот почему. Для сайта можно создать как минимум тысячу полезных страниц, но если у него есть технические недоработки, все это пойдет насмарку. Потому что, если сайт нормальный и не предназначен для рассылки спама, причиной могут быть технические проблемы с сайтом.Но они ответят вам так, что вы не поймете. Поэтому лучше сосредоточиться на технических проблемах, которые часто вызваны движком, и тщательно перепроверить свой сайт.
Удаление мобильных перенаправлений
Потом смотрим файл .htaccess, на других сайтов быть не должно.
Сюда входит предотвращение любых мобильных перенаправлений, в том числе на ваши собственные сайты. Яндекс может понизить рейтинг выдачи для такого редиректа, вставив фатальную ошибку, приняв ее за вредоносный скрипт.. * (\\ BCrMo \\ b | CriOS | Android. * Chrome \\ / [. 0-9] * \\ s (Mobile)?
| \\ bDolfin \\ b | Opera. * Mini | Opera. * Mobi | Android. * Opera | Mobile. * OPR \\ / + | Coast \\ / + | Skyfire | Mobile \\ sSafari \\ / [. 0-9] * \ sEdge | IEMobile | MSIEMobile | fennec | firefox. * Maemo |
(Mobile | Tablet). * Firefox | Firefox. * Mobile | FxiOS | bolt | teashark | Blazer | Version. * Mobile. * Safari |
Safari. * Mobile | MobileSafari | Tizen | UC. * Браузер | UCWEB | baiduboxapp | baidubrowser |
DiigoBrowser | Puffin | \\ bMercury \\ b | Obigo | NF-Browser | NokiaBrowser | OviBrowser | OneBrowser | TwonkyBeamBrowser | SEMC.* Браузер |
FlyFlow | Minimo | NetFront | Новарра-Вижн | MQQBrowser | MicroMessenger |
Android. * PaleMoon | Мобильный. * PaleMoon | Android | ежевика |
\ bBB10 \ b | обод \ стабильный \ сос | PalmOS | авантго | блейзер | Элейн |
хиптоп | пальма | щипчик | xiino | Symbian | SymbOS | Series60 |
Series40 | SYB- + | \\ bS60 \\ b | Windows \ sCE. * (КПП | Смартфон | Мобильный
| (3) x (3)) | Окно \\ sMobile | Windows \ sPhone \ s + | WCE; | Windows \ sPhone \ s10.0 | Windows \ sPhone \ s8.1 |
Windows \ sPhone \ s8.0 | Windows \ sPhone \ sOS | XBLWP7 |
ZuneWP7 | Винда \ sNT \ s6 \. \\; \\ SARM \\; | \\ biPhone. * Мобильный | \\ biPod | \\ biPad |
Apple-iPhone7C2 | MeeGo | Maemo | J2ME \\ / | \\ bMIDP \\ b | \\ bCLDC \\ b | webOS |
hpwOS | \\ bBada \\ b | BREW). *
Яндекс может не понравиться. Лучше этого избежать.
Если вы не видите ошибок на сайте, нет редиректов и вирусов, обратите внимание на количество рекламы.Яндексу может не понравиться то, что на одном пространстве экрана видны несколько рекламных блоков. Некоторые рекламные блоки следует уменьшить.
Неверный файл robots.txt
Это чуть ли не основная причина большинства проблем. Очень важно забанить все ненужные страницы на сайте. Для этого и делаем.
После того, как все исправили. Из того, что казалось нуждающимся в исправлении, мы отправляем сайт на проверку. И ждем месяц в надежде, что это недоразумение.
Можно и без этой кнопки.Если конкретно ошибки, из-за которых Яндекс поставил бан, были исправлены, сайт может выйти из-под санкций почти через несколько дней после исправления.
С сентября 2017 года количество уведомлений в панели Яндекс Вебмастера о фатальной ошибке резко увеличилось, и часто санкциям подвергаются сайты, не имеющие отношения к фильтру теории заговора поиска. Что это … откуда у атамана деньги и как избавиться от фильтра? Начнем с погружения в суть проблемы:
Обнаружены нарушения или проблемы безопасности
Основная причина санкций
В последние годы Платон Щукин и Ко.не раз устраивали для веб-мастеров Варфоломеевскую ночь. Все началось с борьбы со ссылками и со временем переросло в нечто большее, требующее погружения в основы бизнеса.
Яндекс — коммерческая компания, и акционеры хотят в лучшем случае получить прибыль, в худшем — увидеть инновации со стороны менеджмента. Лучшее было тесно переплетено с худшим, и под лозунгом борьбы за качество результатов поиска Яндекс стал забирать 80% прибыли у создателей сайтов.Поскольку коммерческие проекты богаче, мы начали с них, убедительно без применения насилия убедительно объяснив, что Директ полезен для бизнеса.
Ссылки на 90% ушли в небытие, коммерция, низко склонив голову, ушла в Директ и пришло время информационных сайтов. Массово вывести их на контекстную рекламу не получится, но дыры в бюджете надо закрывать, если не прибылью, то активностью (читайте выше). Массовое появление фатальной ошибки в панели свидетельствует об очистке результатов поиска.Какая здесь прибыль? Все просто — отсекаются сайтов с малым и средним трафиком, их заменяют некорректные порталы типа fb. ru, которые кушают со стола яндекса и сами его кормят .
Формальная причина фатальной ошибки
Алгоритмы ранжированияЯши учитывают тысячи различных факторов, поэтому за дверью всегда находится таракан, которого хозяину сайта не удалось сбить тапком. Боты снуют по сайтам и если у ресурса нет крыши в виде высокой посещаемости и Директ рекламы, то ресурс получает фатальную ошибку.
Помните: «Был бы человек, но была бы статья»? Яндекс использует пословицу на все 100%, добавляя к ней только «чужую» причуду.
Итак, фатальная ошибка возникает в 90% случаев по причине:
- Google реклама в первом окне,
- Большой% страниц с малым объемом информации,
- Жизненная карма вебмастера,
- Just.
Если вы видели на панели:
Снижены позиции сайта в поисковой выдаче
Потом на вашу улицу пришел грустный клоун.
Признаки санкций — падение трафика на 40-80% и откат позиций на 20-30 мест по глубине выдачи.
Лечимся
Трудно лечиться, если врач поставил вам диагноз на лету, но жизнь требует биения сердца, поэтому нужно постараться избавиться от смертельного исхода Яши. Вот список действий, которые могут помочь с санкциями:
- Удаление рекламы с первого экрана,
- Удаление или запрещение небольших страниц (малоиспользуемых),
- Форматирование больших, но адаптированных страниц,
- Здоровый сон.
В 2 случаях из 5 ошибка пропадает при повторной отправке сайта на проверку без каких-либо жестов. В другом случае помогает удаление рекламы. В конце октября 2017 года не могу сказать, что это поможет в оставшихся 2 случаях, возможно, Яндекс сам поймет, что если так рубить дрова, то скоро придется жить среди пней и откатывать санкции, возвращая надежду издателю.
Еще советую не грустить, если допустишь фатальную ошибку, ведь жизнь намного шире, чем потеря трети трафика и клеймо санкционера на лбу.
В июле в акции участвовал новый сайт, созданный на WordPress. Пока сайт проходил аудит, все проиндексированные страницы были исключены из поиска Яндекса. Почему? Ответ был найден в панели веб-мастеров Яндекса. Посмотрите на восклицательный знак в красном треугольнике.
Как оказалось, произошла одна фатальная ошибка, из-за которой весь сайт был исключен из поиска. Для Яндекса сайт показался дорвеем.
Проблема оказалась в том, что Яндекс считал сайт дорвеем.Почему? Ведь на сайте не было внешних ссылок. Загрузились страницы, которые надо загрузить.
Оказывается, Яндекс считает сайт дорвеем не только при перенаправлении на другие сайты. Но даже когда внутри самого сайта слишком много перенаправлений. Откуда пришли перенаправления? Ответ также был найден в панели веб-мастеров Яндекса.
Как оказалось, WordPress генерирует повторяющиеся страницы и перенаправляет с них на страницы с ЧПУ
После исправления ошибок это будет отдельный пост, была нажата кнопка Я ИСПРАВИЛ ВСЕ.Эту кнопку можно будет снова нажать только через 30 дней. Поэтому советую внимательно проверить свой сайт, который считался дорвеем, исправить все ошибки и только после этого смело отправлять ресурс на проверку.
10 августа в панели вебмастера появилась информация об отсутствии критических ошибок. Те. сайт больше не считается дорвеем.
Ну и приятный бонус — сайт появился в поиске по некоторым запросам.
Сегодня мы подробно разберем раздел фатальных ошибок, которые не только мешают индексации сайта в поисковых системах — из-за наличия этих ошибок сайт может просто не отображаться в результатах поиска.
Итак, список фатальных ошибок Яндекс Вебмастера состоит из следующих пунктов:
1. Сайт закрыт для индексации в файле robots.txt
Robots.txt — ключевой файл, объясняющий роботам поисковых систем, где на сайт они могут заходить а куда нет. Если robots.txt полностью блокирует возможность посещения сайта роботами Яндекса, то о дальнейшей работе практически можно забыть. Поисковые системы просто не увидят никаких изменений на сайте. Поэтому очень важно, чтобы файл robots.txt не только позволяют роботам поисковых систем посещать сайт, но и направляют их по сайту так, как это необходимо для правильной оптимизации.
2. Не удалось подключиться к серверу из-за ошибки DNS.
Ошибки DNS обычно возникают либо на стороне сервера, либо из-за неправильной конфигурации домена и согласованности хостинга пользователем. Из-за ошибок DNS поисковая система не понимает, какой домен связан с вашим сайтом, и просто не показывает этот домен в результатах поиска.
3. Главная страница сайта выдает ошибку
Когда поисковая система отправляет запрос сайту о своем существовании, он должен получить один из кодов ответа, который соответствует знаниям поисковой системы. Наиболее распространенные коды:
200 — страница существует и отображается
301 — страница перенаправляет всех на другую страницу
404 — страница не существует
500 — проблема на стороне сервера
Важно, чтобы сайт выдавал именно код 200, когда сделать запрос.Только так Яндекс поймет, что с сайтом все в порядке и выставит его в поисковый рейтинг.
4. Обнаружены нарушения или проблемы безопасности
Яндекс внимательно следит за тем, чтобы посещение сайтов из результатов поиска было безопасным для компьютеров пользователей. Поэтому при наличии малейших угроз со стороны сайта поисковый робот сначала размещает предупреждение о возможных проблемах рядом с сайтом в выводе, и если проблема не будет устранена через некоторое время, он просто удалит ресурс из результаты поиска.Поэтому очень важно следить как за состоянием ресурса, так и за его безопасностью. Необходимо вовремя менять пароли и проверять сайт антивирусом.
9 самых больших различий между Яндексом и Google SEO
- Региональность
- Оптимизация для Яндекса занимает больше времени
- Манипулирование поведением пользователей
- Трафик обратных ссылок
- Возраст доменов равен авторитету
- Содержимое страницы имеет большее значение
- Меньше внимания к определенным Факторы ранжирования
- Факторы коммерческого ранжирования
- Меньше инструментов для веб-мастеров, но более отзывчивая поддержка
- Заключение
Легко забыть, что существуют поисковые системы, отличные от Google, но если ваша целевая аудитория живет в таких странах, как Китай, Южная Корея или России, вам не хватает большей части своей аудитории, если вы не показываетесь в их предпочтительных поисковых системах.
В России Яндекс — самая большая поисковая система. Более 57% российских интернет-пользователей полагаются на Яндекс как на свою главную поисковую систему, и в настоящее время он занимает первое место в рейтинге российских интернет-ресурсов. Яндекс также широко используется в соседних странах, таких как Беларусь, Казахстан и Турция.
И хотя большинство основных правил продвижения сайтов в Google применимы к Яндексу, я составил этот список из девяти конкретных различий между этими платформами.Помните об этих советах, если вы хотите освоить поисковую оптимизацию Яндекса и выйти на совершенно новый рынок.
Реклама
Читать ниже
1. Региональность
Одно из ключевых различий между Google и Яндексом заключается в том, что Яндекс уделяет первоочередное внимание геотаргетингу. Хотя локальное SEO и настройка пользователей, безусловно, играют роль на страницах результатов поисковой системы (SERP) Google, большинство пользователей будут видеть те же результаты, что и другие пользователи из своей страны. С Яндексом все не так.
В Яндексе все запросы делятся на геозависимые и геонезависимые. Для геозависимого поиска отображаются только веб-сайты из определенного региона, а это означает, что люди из разных городов будут видеть совершенно разные результаты поиска.
Положительным моментом такого пристального внимания к региональности является то, что продвигать местный бизнес очень легко. Обратной стороной является то, что труднее продвигать веб-сайты компаний, работающих в нескольких регионах.
Чтобы ваш сайт по-прежнему можно было найти, блог Яндекс для веб-мастеров предлагает следующие советы:
- Опубликуйте на сайте название, адрес, почтовый индекс, номер телефона и код города.
- Публикуйте одинаковую информацию для всех региональных филиалов вашего бизнеса.
- Сделайте каждую страницу вашего сайта доступной для робота Яндекса независимо от его IP-адреса.
Реклама
Продолжить чтение ниже
При проведении поисковой оптимизации на Яндексе чрезвычайно важно знать свой регион, прежде чем вводить какие-либо ключевые слова, и чтобы вы получали обратные ссылки от предприятий в каждом регионе.
Если вы знаете свой целевой регион, вот как вы можете продвигать свой сайт:
- Укажите регион в Яндексе для веб-мастеров.
- Разместите свой сайт в Яндекс Справ.
- Включите ваш регион в тег h2, тело и (если возможно) URL вашего контента.
- Включите свой регион в метатег и фрагмент вашего контента.
2. Оптимизация для Яндекса требует больше времени
Специалисты по SEO, оптимизирующие как для Google, так и для Яндекса, с которыми я разговаривал, единогласно считают, что оптимизация Яндекса медленнее.
Робот Googlebot постоянно сканирует и индексирует новые страницы. Это означает, что когда вы публикуете новые URL-адреса, добавляете значительную часть индексируемого контента с его собственным URL-адресом на свой веб-сайт или проверяете основные службы проверки связи, вы можете увидеть увеличение трафика в течение 24 часов после внесения изменения.
Между тем, индекс Яндекса, похоже, пересчитывается гораздо медленнее. При оптимизации для Яндекса убедитесь, что вы (и ваш работодатель) выделяете больше времени, чтобы увидеть результаты определенных действий по оптимизации — как на странице, так и вне ее.
Конечно, когда дело касается и Яндекса, и Google, требуется время, прежде чем вы сможете начать измерять истинное влияние вашей SEO-кампании. Убедитесь, что вы не остановились слишком рано.
3. Манипулирование поведением пользователей
SEO-эксперты годами спорили о том, является ли поведение пользователя важным фактором ранжирования.Это определенно кажется — было показано, что реальные эксперименты влияют на результаты SERP, и Google откровенно заявил, что «реакции пользователей на определенные результаты поиска или списки результатов поиска могут быть измерены, чтобы результаты, на которые пользователи часто нажимают, будут более высокий рейтинг ».
Однако с Яндексом споров не возникает — поведение пользователей является ОГРОМНЫМ фактором ранжирования и играет гораздо большую роль, чем другие сигналы, такие как построение ссылок. Веб-сайты, которые побуждают пользователей оставаться на сайте как можно дольше, всегда будут иметь более высокий рейтинг, чем их конкуренты.
В результате некоторые SEO-специалисты Яндекса начали манипулировать показателями поведения пользователей с помощью тактики «черной шляпы», особенно с помощью спама в комментариях. Еще в 2011 году Яндекс опубликовал две статьи (здесь и здесь) в своем блоге для веб-мастеров, предупреждая веб-мастеров об опасностях манипулирования поведением пользователей в целях SEO, но этот метод продолжает оставаться широко распространенным методом, несмотря на риск серьезных штрафов.
Реклама
Продолжить чтение ниже
Если вы хотите привлечь пользователей с помощью Яндекс, самая безопасная стратегия — это та же стратегия, которую вы использовали бы для Google, — создание качественного контента, который понравится вашей аудитории.Как говорится в статье Яндекс о странице, «насколько полезен и удобен продукт, важнее, чем то, сколько денег мы можем на нем заработать».
Чтобы отслеживать поведение пользователей на вашем сайте, Яндекс рекомендует регулярно анализировать журналы вашего веб-сервера. Обратите особое внимание на:
- Источники трафика: Определите, какие источники привлекают больше всего посетителей на ваш сайт.
- Поисковые запросы — Проанализируйте, какие запросы приводят посетителей на ваш сайт.
- Целевые страницы — Измеряйте конверсии на таких страницах, как тележки для покупок и формы.
- Технические характеристики платформы — Выясните, какие платформы используют пользователи, чтобы найти вас и оптимизировать для лучшего взаимодействия с сайтом.
4. Трафик обратных ссылок
В 2013 году Александр Садовский, руководитель службы веб-поиска Яндекс, объявил, что ссылки больше не будут фактором ранжирования для коммерческих запросов. Вместо этого Яндекс удвоил акцент на поведении пользователей.
Хотя это изменение, введенное в 2014 году, не убило наращивание ссылок, оно определенно изменило правила игры.В настоящее время в Яндексе SEO распространено мнение, что ссылки, демонстрирующие реальный трафик, более полезны, чем тысячи ссылок, на которые никогда не нажимают, потому что они демонстрируют интерес пользователей.
Реклама
Продолжить чтение ниже
По словам Дмитрия Севальнева, руководителя отдела SEO московского агентства цифрового маркетинга pixelplus.ru, Яндекс учитывает множество факторов, связанных с поведением пользователей, в том числе:
- Объем, доли , и поведение неорганического поискового трафика.
- Наличие и количество обратных ссылок, которые реально приносят трафик.
Однако Дмитрий предупреждает, что эти цифры являются вторичными факторами, которые просто влияют на более важные показатели поведения пользователей. Увеличение трафика по обратным ссылкам не обязательно означает обратные ссылки по качеству.
В конце концов, методы оптимизации для Яндекса аналогичны тем, которые вы используете для Google:
- Сосредоточьтесь на качестве ссылок, а не на количестве.
- Получайте релевантные обратные ссылки с сайтов, относящихся к вашей нише.
- Используйте ссылки, чтобы укрепить свой авторитет и доверие.
Реклама
Продолжить чтение ниже
Помните, что сами по себе обратные ссылки не являются решающим фактором ранжирования. Они начнут играть свою роль только тогда, когда количество сеансов от рефералов будет действительно значительным.
5. Возраст домена равен авторитету
Возраст домена играет более важную роль для ранжирования веб-сайтов в Яндексе, чем в Google. Получение рейтинга для новых сайтов может быть сложной задачей и отнимать много времени.Сайтам с очень небольшим количеством страниц приходится особенно тяжело.
К счастью, вы можете проверить, что Яндекс считает датой создания той или иной страницы, проверив данные кеша в Яндекс. Вы можете сделать это с помощью Website Auditor (отказ от ответственности: мой инструмент).
Website Auditor покажет вам, сколько страниц вашего домена проиндексировано Яндексом и когда они были проиндексированы.
6. Содержимое страницы имеет значение Еще
Google может заботиться о свежем и качественном содержании, но Яндекс одержим.На самом деле, по словам Мэтью Вудворда, некоторые нарушения (например, размещение слишком большого количества ключевых слов на одной странице) «более опасны [в Яндексе], чем в Google».
Реклама
Продолжить чтение ниже
Тем не менее, универсального рецепта успеха не существует, а частота обновления контента во многом зависит от характера бизнеса. Моя общая рекомендация — добавлять свежий контент так часто, как это имеет смысл для вашего сайта.
Тем не менее, имейте в виду, что за дублирование контента предусмотрены серьезные штрафы — даже технические ошибки могут привести к более серьезным негативным последствиям для рейтинга Яндекса, чем вы могли бы понести в рейтинге Google.
Например, сайты электронной коммерции, на которых есть отдельные страницы для продуктов с незначительными различиями (например, по размеру, цвету и т. Д.), Могут столкнуться с угрозой столкнуться с фильтром дублированного контента Яндекса.
Среди других распространенных ошибок:
- Межстраничная навигация с использованием JavaScript или Flash — робот Яндекса будет следовать только обычным тегам HTML, поэтому убедитесь, что вы включаете обычные текстовые ссылки на свой веб-сайт, даже если вы используете другой тип навигации.
- Слишком много автопереадресаций — По возможности избегайте использования переадресации.
- Адрес страницы — присвойте каждой странице уникальный постоянный адрес без идентификаторов сеанса.
- Маскировка — это черная шляпа SEO, при которой вы показываете роботу Яндекса один контент, а вашим посетителям — другой. Это может привести к штрафу за рейтинг.
- Изображения вместо текста — Робот Яндекса не может сканировать изображения, поэтому, если вы хотите, чтобы ваш контент ранжировался, убедитесь, что он доступен в тексте.
- Soft 404 — Когда пользователи пытаются получить доступ к несуществующей странице, не перенаправляйте их на страницу-заглушку, которая возвращает код 200 вместо сообщения 404.
- Ошибки движка сайта — Любые ошибки в скрипте вашего сайта могут повлиять на индексацию сайта и, возможно, поставить его под угрозу. Убедитесь, что все программное обеспечение вашего сайта постоянно работает правильно.
7. Меньше внимания к определенным факторам ранжирования
В большинстве недавних обновлений Google основное внимание уделялось нескольким конкретным изменениям, особенно таким показателям, как скорость сайта и удобство использования для мобильных устройств. Естественно, специалисты по SEO переориентировали свое внимание на эти области.
Реклама
Продолжить чтение ниже
Что ж, при оптимизации под Яндекс не нужно так сильно беспокоиться об этих сигналах.
По словам Майка Шакина, эксперта по поисковой оптимизации, который преуспевает в продвижении веб-сайтов как для русскоязычных, так и для англоязычных рынков,
«Яндекс меньше заботится о факторах, о которых Google беспокоился последние пару лет, таких как социальные сигналы, скорость сайта, удобство для мобильных устройств и разметка схемы. Не помешает и об этом — создавать адаптивные веб-сайты, оптимизировать скорость загрузки страниц и следить за всеми последними тенденциями, — но важно понимать, что в настоящее время они, похоже, не играют непосредственной роли в рейтинге.”
Конечно, там, где эти факторы ранжирования влияют на поведение пользователей, вам, безусловно, следует оптимизировать свой веб-сайт с учетом предпочтений посетителей.
8. Факторы коммерческого ранжирования
Яндекс недавно добавил новый сигнал ранжирования под названием «коммерческая релевантность», чтобы предоставлять более точные и качественные результаты по запросам с коммерческими намерениями. Таким образом, хотя Яндекс действительно уделяет меньше внимания перечисленным выше факторам ранжирования, эти факторы связаны с другими сигналами:
Реклама
Читать ниже
Релевантность, надежность, удобство использования, пользовательский опыт, дизайн и качество обслуживания — влияют на ваш рейтинг.
Чтобы учесть эти факторы ранжирования, убедитесь, что все описания ваших продуктов уникальны, подробны и точны. Включение актуальной региональной информации, получение обратных ссылок от доверенных органов и обращение к большему количеству пользователей также будут играть важную роль в вашей коммерческой значимости.
9. Меньше инструментов для веб-мастеров, но более оперативная поддержка
Чтобы добавить свой веб-сайт в Инструменты для веб-мастеров Яндекса:
- Войдите в свой Инструменты для веб-мастеров Яндекса или Создайте бесплатную учетную запись .
- Нажмите Добавить сайт
- Введите имя своего домена и нажмите Добавить .
- Подтвердите свой веб-сайт, используя один из трех вариантов (я рекомендую встроить метатег).
- Установите все необходимые плагины (я настоятельно рекомендую WordPress SEO, если вы используете WordPress).
- Нажмите Проверить на панели инструментов Яндекс.
- Нажмите Параметры индексирования > Файлы Sitemap . Добавьте файл карты сайта и нажмите Добавить .
После добавления файла карты сайта повторите попытку через несколько дней, чтобы убедиться, что Яндекс сканирует ваш сайт правильно. Теперь вы должны увидеть, сколько страниц вы отправили и сколько проиндексировал Яндекс.
Хотя Инструменты Google для веб-мастеров более сложны, чем Инструменты Яндекса для веб-мастеров, Яндекс обладает преимуществом небольшой и отзывчивой группы поддержки. Если ваш веб-сайт попадает под фильтр или штраф, у вас больше шансов получить быстрый ответ.
Реклама
Продолжить чтение ниже
Заключение
Если вы хотите начать свой бизнес и привлечь русскоязычную аудиторию, вам подойдет Яндекс, а не Google.Как видите, следует помнить о некоторых особенностях, но в целом принципы оптимизации кажутся универсальными.
Компаниям, стремящимся расширить свой охват на международном уровне, было бы неплохо оптимизировать свой контент для поисковых систем за пределами Google, особенно в странах, где другие платформы более популярны. Если вы уделяете первоочередное внимание качественному контенту и удобству для пользователей, вы обязательно добьетесь успеха за границей.
Источники изображений
Показанное изображение: Изображение Олега Барысевича
Скриншот Олега Барысевича.Снято в июле 2016 года.
Поддерживает ли Яндекс канонический тег?
Краткий ответ: Да, с некоторыми отличиями.
Как и Google, Яндекс поддерживает канонический тег и использует его примерно так же.
Вы можете использовать канонический код для устранения потенциального дублирования в индексе Яндекса, но вместо обычной практики добавления саморегулирующихся канонических тегов на все страницы Яндекс может рассматривать это как сбивающие с толку и выделять сообщения об ошибках, которые примерно переведены на английский язык:
Код документа страницы содержит тег с rel = ”canonical”, который ссылается на URL-адрес страницы, который был проиндексирован роботом.Rel = «canonical» обычно используется на повторяющихся страницах веб-сайта, и в этом случае исправлять нечего, поскольку нет дублирования.
Если страницы не являются дубликатами и должны индексироваться роботом, вам необходимо удалить атрибут rel = ”canonical” из их исходного кода.
Если ваш веб-сайт является международным и вы внедрили общесайтовые канонические теги со ссылками на себя в соответствии с передовой практикой Google, в вашей альтернативной русскоязычной версии может быть полезно запустить другую базу кода и обработать возможное дублирование в Google Россия в альтернативном варианте. путь — таким образом вы сможете познакомиться с лучшими практиками как крупнейшей поисковой системы России, так и Google.
Реализация тега не отличается от стандартной реализации, к которой мы привыкли с Google:
Яндекс не принимает во внимание канонический тег и выделяет ошибки, если:
- Канонический URL недоступен для робота — он перенаправляет на другую страницу или закрывается от индексации. Это означает, что его нельзя включить в поиск. В этом случае неканонический URL-адрес может быть включен в поиск вместо канонического URL-адреса при условии, что робот может получить к нему доступ.
- Канонический URL-адрес указывает на другой домен или субдомен.
- Указано несколько канонических URL-адресов.
- Указана цепочка канонических URL-адресов. Например, для example.ru/1 каноническим URL будет example.ru/2. В то же время example.ru/2 имеет канонический URL example.ru/3.
Однако Яндекс не поддерживает междоменный канонический.
Правильная работа с дублирующимися страницами. Борьба с дублированием страниц. Найти повторяющиеся страницы
Здравствуйте! В прошлой статье мы затронули важную тему — поиск повторяющихся страниц сайта.Как показали комментарии и несколько писем, пришедших мне на почту, эта тема актуальна. Дублированный контент в наших блогах, технические недоработки CMS и различные косяки шаблонов не дают нашим ресурсам полной свободы в поисковых системахох. Поэтому мы должны серьезно с ними бороться. В этой статье мы узнаем, как можно удалить повторяющиеся страницы любого сайта, примеры этого руководства покажут вам, как от них избавиться. простым способом … От нас просто требуется использовать полученные знания и отслеживать последующие изменения в индексах поисковых систем.
Моя история работы с дублями
Прежде чем мы рассмотрим способы устранения дубликатов, я расскажу вам свою историю работы с дубликатами.
Два года назад (25 мая 2012 г.) я получил в руки учебный блог для курса специалиста по SEO. Он был дан мне для того, чтобы практиковать полученные знания во время учебы. В результате за два месяца практики мне удалось создать пару страниц, дюжину постов, кучу тегов и целую череду дубликатов. К этому составу в индексе Google в течение следующих шести месяцев, когда учебный блог стал моим личным сайтом, были добавлены другие дубликаты.Это произошло по вине replytocom из-за растущего количества комментариев. Но в базе данных Яндекса количество проиндексированных страниц росло постепенно.
В начале 2013 года я заметил конкретное падение позиций моего блога в Google. Тогда я задумался, почему это происходит. В результате я докопался до того, что обнаружил в этой поисковой системе большое количество дубликатов. Конечно, я стал искать варианты их устранения. Но мои поиски информации ни к чему не привели — толковых мануалов в сети по удалению дублирующихся страниц не нашел.Но мне удалось увидеть одну заметку в одном блоге о том, как можно удалить дубликаты из индекса с помощью файла robots.txt.
Прежде всего, я написал кучу запрещающих директив для Яндекс и Google, чтобы запретить сканирование определенных страниц-дубликатов. Затем, в середине лета 2013 года, я применил один метод удаления дубликатов из индекса Google (о нем вы узнаете из этой статьи). К тому времени в индексе этой поисковой системы скопилось более 6000 дубликатов! И это всего с пятью страницами и более чем 120 сообщениями в моем блоге…
После того, как я реализовал свой метод удаления дубликатов, их количество начало стремительно уменьшаться. Ранее в этом году я использовал другой вариант удаления дубликатов, чтобы ускорить процесс (вы также узнаете об этом). И сейчас в моем блоге количество страниц в индексе Google близко к идеальному — сегодня в базе около 600 страниц. Это в 10 раз меньше, чем было раньше!
Как удалить повторяющиеся страницы — основные методы
Есть несколько способов работать с дублями.Некоторые параметры позволяют предотвратить появление новых дубликатов, другие — избавиться от старых. Конечно, самый лучший вариант — ручной. Но для его реализации нужно хорошо разбираться в CMS своего сайта и знать, как работают алгоритмы поисковой системы. Но и другие методы тоже хороши и не требуют специальных знаний. О них и поговорим сейчас.
Этот метод считается наиболее эффективным, но также и наиболее требовательным к знаниям программирования. Дело в том, что необходимые правила написаны здесь в формате.htaccess (находится в корне каталога сайта). А если они регистрируются с ошибкой, то можно не только не решить задачу по удалению дубликатов, но и вообще удалить весь сайт из интернета.
Как решается задача удаления дубликатов с помощью 301 редиректа? В его основе лежит концепция перенаправления поисковых роботов с одной страницы (с дубликата) на другую (исходную). То есть робот заходит на дубликат какой-то страницы и с помощью редиректа оказывается на исходном документе нужного нам сайта.Затем он начинает изучать его, не попадая в поле зрения.
Со временем, после регистрации всех вариантов этого редиректа, идентичные страницы склеиваются, а дубликаты со временем выпадают из индекса. Таким образом, эта опция отлично очищает уже проиндексированные повторяющиеся страницы. Если вы решили использовать этот метод, обязательно изучите синтаксис для создания редиректов, прежде чем регистрировать правила в файле .htaccess. К примеру, рекомендую к изучению 301 редирект Саши Алаева.
Создание канонической страницы
Этот метод используется для указания поисковой системе того документа из всего набора его дубликатов, который должен быть в основном индексе. То есть такая страница считается оригинальной и участвует в поисковой выдаче.
Для его создания необходимо написать код с URL-адресом исходного документа на всех повторяющихся страницах:
Конечно, вручную все это прописать сложновато. Для этого существуют различные плагины.Например, для своего блога, который работает на движке WordPress, я указал этот код с помощью плагина «All in One SEO Pack». Делается это очень просто — в настройках плагина ставим галочку:
К сожалению, опция канонической страницы не удаляет повторяющиеся страницы, а только предотвращает их повторное появление. Чтобы избавиться от уже проиндексированных дубликатов, вы можете использовать следующий метод.
Директива Disallow в robots.txt
Файл robots.txt — это руководство для поисковых систем, в котором объясняется, как индексировать наш сайт.Без этого файла поисковый робот сможет добраться практически до всех документов нашего ресурса. Но нам не нужна такая свобода поискового паука — мы не хотим видеть все страницы в индексе. Особенно это актуально для дубликатов, которые появляются из-за несовершенства шаблона сайта или наших ошибок.
Поэтому создан такой файл, в котором прописаны различные директивы о запрете и разрешении индексации поисковиками. Вы можете отключить сканирование повторяющихся страниц с помощью директивы Disallow:
При создании директивы также нужно правильно оформить бан.Ведь если вы ошиблись при заполнении правил, то на выходе может не быть такой же блокировки страниц. Таким образом, мы можем ограничить доступ к желаемым страницам и позволить другим дублям просачиваться. Но все же ошибки здесь не так страшны, как при составлении правил редиректа в .htaccess.
Запрет индексации с помощью Disallow распространяется на всех роботов. Но не для всех эти запреты позволяют поисковой системе удалять заблокированные страницы из индекса. Например, Яндекс со временем удаляет повторяющиеся страницы, заблокированные в robots.текст.
Но Google не будет очищать свой индекс от ненужного мусора, указанного веб-мастером. Кроме того, директива Disallow не является гарантией такой блокировки. Если есть внешние ссылки на страницы, запрещенные в инструкции, то они со временем появятся в базе Google .
Избавление от дубликатов, проиндексированных в Яндекс и Гугл
Итак, разобравшись с различными методами, пора выяснить пошаговый план удаления дубликатов в Яндексе и Гугле.Перед чисткой нужно найти все повторяющиеся страницы — об этом я писал в прошлой статье. Вам нужно увидеть на своих глазах, какие элементы адресов страниц отражаются в дубликатах. Например, если это страницы с древовидными комментариями или с разбивкой на страницы, то мы исправляем слова «replytocom» и «page», содержащие в своих адресах:
Обратите внимание, что в случае с replytocom можно брать не эту фразу, а просто вопросительный знак. Ведь он всегда присутствует в адресах страниц древовидных комментариев.Но тогда нужно помнить, что уже в url-адресах исходных новых страниц не должно быть символа «?» Символ, иначе эти страницы будут забанены.
Чистим Яндекс
Для удаления дубликатов в Яндексе создайте правила блокировки дубликатов с помощью директивы Disallow. Для этого выполняем следующие действия:
- Открываем в Яндекс Вебмастере специальный инструмент «Анализ robot.txt».
- Мы вводим новые правила для блокировки повторяющихся страниц в поле директивы.
- В поле «список URL-адресов» вводим примеры повторяющихся адресов для новых директив.
- Нажмите кнопку «Проверить» и проанализируйте результаты.
Если мы все сделали правильно, то этот инструмент покажет, что есть блокировка по новым правилам. В специальном поле «Результаты проверки URL» мы должны увидеть красную запрещающую надпись:
После проверки мы должны отправить сгенерированные дублирующие директивы реальным роботам.txt и переписываем его в директорию нашего сайта. А дальше нам просто нужно дождаться, пока Яндекс автоматически извлечет наши дубликаты из своего индекса.
Очистка Google
С Google не все так просто. Запрещенные директивы в robots.txt не удаляют дубликаты в индексе этой поисковой системы. Поэтому придется делать все самостоятельно. К счастью, для этого есть отличный сервис Google для веб-мастеров. В частности, нас интересует его инструмент параметров URL.
Именно благодаря этому инструменту Google позволяет владельцу сайта сообщать поисковой системе информацию о том, как ему нужно обрабатывать определенные параметры в URL-адресе. Нас интересует возможность показывать Google те параметры адреса, страницы которых дублируются. И это то, что мы хотим удалить из индекса. Вот что нам нужно для этого сделать (например, добавим параметр для удаления дубликатов из replytocom):
- Откройте инструмент «Параметры URL» в сервисе Google из раздела меню «Сканирование».
- Нажмите кнопку «Добавить параметр», заполните форму и сохраните новый параметр:
В результате мы получаем письменное правило для Google пересматривать свой индекс на предмет дублирования страниц. Таким образом, далее мы записываем следующие параметры для других дубликатов, от которых хотим избавиться. Например, так выглядит часть моего списка с установленными правилами для Google, чтобы он исправлял свой индекс:
На этом наша работа по очистке Google завершена, и мой пост подошел к концу.Надеюсь, эта статья будет вам полезна и позволит избавиться от повторяющихся страниц ваших ресурсов.
С уважением, Довженко Максим
П.С. Друзья, если вам нужно снять видео на эту тему, то напишите мне в комментариях к этой статье.
Борьба с дублированием страниц
Владелец может даже не подозревать, что некоторые страницы на его сайте имеют копии — это чаще всего так. Страницы открываются, с их содержанием все в порядке, но если вы только обратите внимание, то заметите, что при одинаковом содержании адреса разные.Что это значит? Для живых пользователей абсолютно ничего, поскольку им интересна информация на страницах, но бездушные поисковики воспринимают такое явление совершенно по-другому — для них это совершенно разные страницы с одинаковым содержанием.
Вредны ли повторяющиеся страницы? Итак, если рядовой пользователь даже не может заметить наличие дубликатов на вашем сайте, то поисковые системы сразу это определят. Какой реакции от них ожидать? Поскольку копии по сути рассматриваются как разные страницы, содержимое на них перестает быть уникальным.И это уже негативно сказывается на рейтинге.
Также есть повторяющиеся размытия, которые оптимизатор пытался сосредоточить на целевой странице. Из-за дубликатов его может вообще не быть на той странице, на которую хотели его перенести. То есть эффект внутренней перелинковки и внешних ссылок может уменьшиться во много раз.
В подавляющем большинстве случаев виноваты дубликаты — чистые копии создаются из-за неправильных настроек и недостаточного внимания со стороны оптимизатора.В этом виноваты многие CMS, например Joomla. Универсальный рецепт решения проблемы найти сложно, но можно попробовать использовать один из плагинов для удаления копий.
Появление нечетких дубликатов, содержание которых не полностью идентично, обычно происходит по вине веб-мастера. Такие страницы часто встречаются на сайтах интернет-магазинов, где страницы с карточками товаров отличаются всего несколькими предложениями с описанием, а весь остальной контент, состоящий из сквозных блоков и других элементов, такой же.
Многие специалисты утверждают, что небольшое количество дубликатов не повредит сайту, но если их больше 40-50%, то ресурс может столкнуться с серьезными трудностями при продвижении. В любом случае, даже если копий немного, стоит их исправить, так что вы гарантированно избавитесь от проблем с дубликатами.
Поиск копий страниц Есть несколько способов найти повторяющиеся страницы, но сначала вам нужно зайти в несколько поисковых систем и посмотреть, как они видят ваш сайт — вам просто нужно сравнить количество страниц в индексе каждой.Сделать это довольно просто, не прибегая к дополнительным средствам: в «Яндексе» или Google достаточно ввести host: yoursite.ru в строку поиска и посмотреть количество результатов.
Если после такой простой проверки номер будет сильно отличаться, в 10-20 раз, то это с некоторой долей вероятности может указывать на наличие дубликатов в одном из них. Скопированные страницы могут не быть виноваты в такой разнице, но тем не менее она дает повод для дальнейшего более тщательного поиска.Если сайт небольшой, то вы можете вручную подсчитать количество реальных страниц, а затем сравнить с показателями поисковых систем.
Вы можете искать повторяющиеся страницы по URL в результатах поиска. Если у них должен быть ЧПУ, то страницы с URL-адресами непонятных символов, типа «index.php? S = 0f6b2903d», сразу будут выбиты из общего списка.
Другой способ определения наличия дубликатов с помощью поисковых систем — поиск фрагментов текста.Процедура такой проверки проста: нужно ввести в строку поиска текстовый фрагмент из 10-15 слов с каждой страницы, а затем проанализировать результат. Если в результатах поиска две или более страниц, то есть копии, но если результат только один, то на этой странице нет дубликатов, и вам не о чем беспокоиться.
Логично, что если сайт состоит из большого количества страниц, то такая проверка может превратиться в невозможную рутину для оптимизатора. Чтобы минимизировать затрачиваемое время, можно использовать специальные программы.Одним из таких инструментов, с которым, вероятно, будут знакомы опытные профессионалы, является программа Xenu’s Link Sleuth.
Чтобы проверить сайт, вам необходимо открыть новый проект, выбрав «Проверить URL» в меню «Файл», ввести адрес и щелкнуть «ОК». После этого программа начнет обработку всех URL-адресов сайтов. По окончании проверки нужно экспортировать полученные данные в любой удобный редактор и начать поиск дубликатов.
Помимо вышеперечисленных методов, инструментарий Яндекс.Панели инструментов для веб-мастеров и Google для веб-мастеров содержат инструменты для проверки индексации страниц, которые можно использовать для поиска дубликатов.
Методы решения проблем После того, как все дубликаты будут обнаружены, вам нужно будет их устранить. Это также можно сделать несколькими способами, но для каждого конкретного случая вам понадобится свой собственный метод, возможно, вам придется использовать их все.
- Скопированные страницы можно удалить вручную, но этот способ, скорее всего, подходит только для тех дубликатов, которые были созданы.вручную по неосторожности веб-мастера.
- Редирект 301 отлично подходит для склейки копий страниц с URL-адресами, которые имеют или не имеют www.
- Решение проблемы с дублями с каноническим тегом можно применить к нечетким копиям. Например, для категорий товаров в интернет-магазине, у которых есть дубликаты, различающиеся сортировкой по разным параметрам. Также канонический подходит для печатных версий страниц и других подобных случаев. Используется он довольно просто — для всех копий указывается атрибут rel = «canonical», а для главной страницы, которая наиболее актуальна, его нет.Код должен выглядеть примерно так: ссылка rel = «canonical» href = «http://yoursite.ru/stranica-kopiya» /, и находиться внутри тега head.
- Настройка файла robots.txt может помочь вам бороться с дублированием. Директива Disallow заблокирует доступ к дубликатам для поисковых роботов. Вы можете узнать больше о синтаксисе этого файла в нашем списке рассылки.
Довольно часто копии страниц существуют на одном сайте, и его владелец может даже не знать об этом. Когда вы их открываете, все отображается правильно, но если вы взглянете на адрес сайта, то можете заметить, что разные адреса могут соответствовать одному и тому же контенту.
Что это значит? Для обычных пользователей в Москве ничего, потому что они пришли на ваш сайт не для того, чтобы посмотреть заголовки страниц, а потому, что их интересовал контент. Но этого нельзя сказать о поисковых системах, так как они воспринимают такое положение дел в совершенно ином свете — они видят разные друг от друга страницы с одинаковым содержанием.
Если обычные пользователи могут не заметить дублирующиеся страницы на сайте, это наверняка не ускользнет от внимания поисковых систем.К чему это может привести? Поисковые роботы будут идентифицировать копии как разные страницы, в результате они больше не будут воспринимать свой контент как уникальный. Если вас интересует раскрутка сайтов, знайте, что это обязательно скажется на рейтинге. Кроме того, наличие дубликатов снизит вес ссылки, который появился в результате значительных усилий оптимизатора, который попытался выделить целевую страницу. Дублирование страниц может привести к выделению совершенно другой части сайта. А это может значительно снизить эффективность внешних и внутренних ссылок.
Могут ли быть вредными повторяющиеся страницы?
Часто виновником появления дубликатов является CMS, неверные настройки которой или невнимание со стороны оптимизатора могут привести к генерации четких копий. Системы управления сайтом, такие как Joomla, часто делают это. Сразу отметим, что универсального инструмента для борьбы с этим явлением просто нет, но вы можете установить один из плагинов, предназначенных для поиска и удаления копий. Однако могут появиться нечеткие дубли, содержание которых не полностью совпадает.Чаще всего это происходит из-за недостатков веб-мастеров. Часто такие страницы можно встретить в интернет-магазинах, где карточки товаров различаются лишь несколькими предложениями описания, а остальной контент, состоящий из разных элементов и сквозных блоков, остается таким же. Часто специалисты сходятся во мнении, что определенное количество дубликатов не помешает работе сайта, но если их будет около половины и более, то продвижение ресурса вызовет множество проблем. Но даже в тех случаях, когда на сайте несколько копий, лучше их найти и устранить — так вы наверняка избавитесь от дубликатов на своем ресурсе.
Найти повторяющиеся страницы
Есть несколько способов найти повторяющиеся страницы. Но до самого поиска хорошо бы посмотреть на свой сайт глазами поисковых систем: каким они его себе представляют. Для этого просто сравните количество ваших страниц со страницами в их индексе. Чтобы его увидеть, достаточно набрать в поисковой строке Google или Яндекс фразу host: yoursite.ru, затем оценить результаты.
Если такая простая проверка дает разные данные, которые могут отличаться в 10 и более раз, то есть основания полагать, что ваш электронный ресурс содержит дубликаты.Хотя это не всегда относится к повторяющимся страницам, эта проверка послужит хорошей основой для их поиска. Если ваш сайт имеет небольшой размер, то вы можете самостоятельно посчитать количество реальных страниц, а затем сравнить результат с показателями поисковых систем. Вы также можете искать дубликаты, используя URL-адреса, которые предлагаются в результатах поиска. Если вы используете ЧПУ, то страницы с непонятными символами в URL-адресах, например, index.php? C = 0f6b3953d, сразу же привлекут ваше внимание.
Другой метод определения наличия дубликатов — поиск фрагментов текста. Чтобы выполнить такую проверку, вам нужно ввести текст из нескольких слов каждой страницы в строку поиска, а затем просто проанализировать результат. В случаях, когда в результаты поиска попадают две и более страницы, становится очевидно, что копии есть. Если в результатах поиска всего одна страница, то у нее нет дубликатов. Конечно, этот метод проверки подходит только для небольшого сайта, состоящего из нескольких страниц.Когда на сайте их сотни, его оптимизатор может использовать специальные программы, например Xenu`s Link Sleuth.
Для проверки сайта откройте новый проект и перейдите в меню «Файл», найдите там «Проверить URL», введите адрес интересующего вас сайта и нажмите «ОК». Программа начнет обрабатывать все URL для указанного ресурса. Когда работа будет завершена, полученную информацию нужно будет открыть в любом удобном редакторе и поискать дубликаты. На этом методы поиска повторяющихся страниц не заканчиваются: в панели инструментов Google Webmaster и Яндекс.Вебмастер, вы можете увидеть инструменты, позволяющие проверять индексацию страниц. С их помощью также можно найти дубликаты.
К решению проблемы
Когда вы найдете все дубликаты, вам будет поставлена задача их устранить. Есть несколько способов решить эту проблему и разные способы устранения повторяющихся страниц.
Склейку скопированных страниц можно произвести с помощью редиректа 301. Это эффективно в случаях, когда URL-адреса отличаются отсутствием или присутствием www.Вы можете удалить копии страниц в ручном режиме, но этот метод успешен только для тех дубликатов, которые были созданы вручную.
Для решения проблемы дубликатов можно использовать канонический тег, который используется для нечетких копий. Таким образом, его можно использовать в интернет-магазине для категорий товаров, у которых есть дубликаты и которые отличаются только сортировкой по разным параметрам. Кроме того, канонический тег подходит для использования на печатных страницах и в подобных случаях. Использовать его совсем несложно — для каждого экземпляра устанавливается атрибут в виде rel = «канонический», для продвигаемой страницы с наиболее актуальными характеристиками этот атрибут не указывается.Примерный код просмотра: ссылка rel = «canonical» href = «http://site.ru/stranica-kopiya» /. Он должен располагаться в районе головной метки.
Правильно настроенный файл robots.txt также поможет вам справиться с дублированием. С помощью директивы Disallow вы можете заблокировать доступ поисковых роботов ко всем повторяющимся страницам.
Даже профессиональная разработка сайта не поможет вывести его в ТОП, если на ресурсе есть повторяющиеся страницы. Сегодня копирование страниц — одна из самых распространенных ошибок, от которых страдают новички.Большое их количество на вашем сайте создаст значительные трудности с выводом в ТОП, а то и вовсе сделает невозможным.
Дублирующие страницы сайта, их влияние на поисковую оптимизацию … Ручные и автоматизированные способы обнаружения и устранения повторяющихся страниц.
Влияние дубликатов на продвижение сайтаНаличие дубликатов негативно влияет на рейтинг сайта. Как указано выше, поисковые системы видят исходную страницу и ее дубликат как две отдельные страницы.Контент, дублированный на другой странице, больше не уникален. Кроме того, теряется ссылочный вес продублированной страницы, так как ссылку можно перенести не на лендинг, а на ее дубликат. Это касается как внутренних, так и внешних ссылок.
По мнению некоторых веб-мастеров, небольшое количество дублирующихся страниц в целом не нанесет серьезного вреда сайту, но если их количество приближается к 40-50% от общего объема сайта, серьезные трудности в продвижении неизбежны.
Причины появления дубликатовЧаще всего дубликаты появляются в результате неправильной настройки отдельной CMS.Внутренние скрипты движка начинают некорректно работать и генерировать копии страниц сайта.
Известно также явление нечетких дубликатов — страниц, содержание которых идентично только частично. Такие дубликаты возникают, чаще всего, по вине самого издателя. Это явление характерно для интернет-магазинов, где страницы карточек товаров построены по одному шаблону и в конечном итоге отличаются друг от друга всего несколькими строками текста.
Методы поиска повторяющихся страницЕсть несколько способов обнаружить повторяющиеся страницы.Вы можете обратиться к поисковым системам: для этого в Google или Яндексе введите в строке поиска команду вида «site: sitename.ru», где sitename.ru — домен вашего сайта. Поисковая система отобразит все проиндексированные страницы сайта, и ваша задача будет заключаться в поиске повторяющихся.
Есть еще один не менее простой способ: поиск по фрагментам текста. Чтобы искать таким образом, вам нужно добавить небольшой фрагмент текста с вашего сайта, 10-15 символов в строку поиска. Если в результатах поиска две и более страницы вашего сайта, найти дубликаты не составит труда.
Однако эти методы подходят для сайтов с небольшим количеством страниц. Если на сайте несколько сотен и даже тысяч страниц, то ручной поиск дубликатов и оптимизация сайта в целом становится невыполнимой задачей. Для таких целей существуют специальные программы, например, одна из самых распространенных — Xenu`s Link Sleuth.
Кроме того, есть специальные инструменты для проверки статуса индексации в панелях google Webmaster Tools и Яндекс.Вебмастер. Их также модно использовать для обнаружения дубликатов.
Способы устранения дубликатов страницВы также можете удалить ненужные страницы несколькими способами. Для каждого конкретного случая подойдет свой метод, но чаще всего при оптимизации сайта они используются в комбинации:
- удаление дубликатов вручную — подходит, если все ненужные также были обнаружены вручную;
- склейка страниц с редиректом 301 — подходит, если дубликаты отличаются только отсутствием и наличием «www» в URL;
- использование тега «канонический» подходит в случае нечетких дубликатов (например, вышеупомянутая ситуация с карточками товаров в интернет-магазине) и реализуется вводом кода типа «ссылка отн =« канонический »href = «http: // sitename.ru / stranica-kopiya «/» в главном блоке повторяющихся страниц;
- правильная конфигурация файла robots.txt — с помощью директивы «Disallow» вы можете предотвратить индексацию повторяющихся страниц поисковыми системами.
Заключение
Появление дублирующихся страниц может стать серьезным препятствием для оптимизации сайта и вывода его на первые позиции, поэтому эту проблему необходимо решать на начальном этапе ее появления.
Поводом для написания статьи стал очередной панический звонок бухгалтера перед сдачей отчетов по НДС.В прошлом квартале потратил много времени на устранение повторяющихся контрагентов. И снова они такие же и новые. Откуда?
Я решил потратить время и заняться причиной, а не следствием. Ситуация наиболее актуальна, когда автоматические загрузки настраиваются через планы обмена из управляющей программы (в моем случае UT 10.3) в бухгалтерию предприятия (в моем случае 2.0).
Несколько лет назад были установлены эти конфигурации и автоматический обмен между ними.Столкнулся с проблемой оригинальности ведения справочника контрагентов отделом продаж, который по тем или иным причинам стал создавать дублирующих контрагентов (с одинаковым ИНН / КПП / Именем) (один и тот же контрагент рассредоточился по разным группам). Бухгалтерия выразила «фи», и решила — нам все равно, что у них там, объедините карточки при загрузке в одну. Пришлось вмешаться в процесс передачи предметов по правилам обмена. Мы убрали поиск по внутреннему идентификатору для контрагентов, и оставили поиск по ИНН + КПП + Имя.Однако и здесь всплыли подводные камни в виде тех, кто любит переименовывать имена подрядчиков (в результате дубликаты создаются в БП по самим правилам). Мы все собрались, обсудили, решили, убедились, что в UT у нас нет дубликатов, удалили их, вернулись к стандартным правилам.
Это было только после «прочесывания» дубли в UT и в BP — внутренние идентификаторы у многих контрагентов были разными. А поскольку стандартные правила обмена ищут объекты исключительно по внутреннему идентификатору, то дубликат нового контрагента прибыл со следующей порцией документов в БП (в случае, если эти идентификаторы были другими).Но универсальный обмен xML-данными не был бы универсальным, если бы эту проблему невозможно было обойти. Поскольку id существующего объекта штатный означает, что его нельзя изменить, то обойти эту ситуацию можно с помощью специального регистра информации «Соответствие объектов обмену», который доступен во всех типовых конфигурациях от 1С.
Во избежание появления новых дубликатов алгоритм очистки дубликатов следующий:
1. В БП с помощью обработки «Найти и заменить повторяющиеся элементы» (типично, ее можно взять из конфигурации Trade Management или на ITS-диске, либо выбрать наиболее подходящий из множества вариантов на Infostart сам) нахожу дубль, определяю нужный элемент, нажимаю выполнить замену.
2. Получаю внутренний идентификатор единственного (после замены) объекта нашего дубля (я специально для этого набросал простую обработку, чтобы внутренний идентификатор автоматически копировался в буфер обмена).
3. Открываю в UT реестр «Соответствие объектов для обмена», делаю выбор по собственной ссылке.
.