Атрибут rel | htmlbook.ru
| Internet Explorer | Chrome | Opera | Safari | Firefox | Android | iOS |
| 10.50+ | 4.0+ |
Спецификация
| HTML: | 3.2 | 4.01 | 5.0 | XHTML: | 1.0 | 1.1 |
Описание
Атрибут rel определяет отношения между текущим документом и документом, на который ведет ссылка, заданная атрибутом href. Несмотря на то, что браузеры в большинстве своем не поддерживают атрибут rel, на сайтах часто можно встретить код rel=»nofollow», предназначенный для поисковых систем Google и Яндекс. Ссылки, помеченные таким образом, не передают PageRank и ТИЦ.
Синтаксис
<a rel="строка">.
..</a>
Обязательный атрибут
Нет.
Значения
Некоторые возможные значения перечислены ниже.
- answer
- Ответ на вопрос.
- chapter
- Раздел или глава текущего документа.
- co-worker
- Ссылка на страницу коллеги по работе.
- colleague
- Ссылка на страницу коллеги (не по работе).
- contact
- Ссылка на страницу с контактной информацией.
- details
- Ссылка на страницу с подробностями.
- edit
- Редактируемая версия текущего документа.
- Ссылка на страницу друга.
- question
- Вопрос.
Весь список значений можно посмотреть по адресу http://wiki.whatwg.org/wiki/RelExtensions
В HTML5 поддерживается следующие значения.
- archives
- Ссылка на архив сайта.
- author
- Ссылка на страницу об авторе на том же домене.
- bookmark
- Постоянная ссылка на раздел или запись.
- first
- Ссылка на первую страницу.
- help
- Ссылка на документ со справкой.
- Ссылка на содержание.
- last
- Ссылка на последнюю страницу.
- license
- Ссылка на страницу с лицензионным соглашением или авторскими правами.
- me
- Ссылка на страницу автора на другом домене.
- next
- Ссылка на следующую страницу или раздел.
- nofollow
- Не передавать по ссылке ТИЦ и PR.
- noreferrer
- Не передавать по ссылке HTTP-заголовки.
- prefetch
- Указывает, что надо заранее кэшировать указанный ресурс.
- prev
- Ссылка на предыдущую страницу или раздел.
- search
- Ссылка на поиск.
- sidebar
- Добавить ссылку в избранное браузера.
- tag
- Указывает, что метка (тег) имеет отношение к текущему документу.
- up
- Ссылка на родительскую страницу.

Значение по умолчанию
Нет.
Пример 1
HTML 4.01IECrOpSaFx
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>Тег А, атрибут rel</title> </head> <body> <p><a href="http://ya.ru" rel="nofollow">Наш ответ Яндексу</a></p> </body> </html>
Пример 2
HTML5IECrOpSaFx
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Добавить в избранное</title>
</head>
<body>
<p><a href="http://htmlbook.ru" rel="sidebar">Добавить в избранное</a></p>
</body>
</html>
Браузеры
Firefox поддерживает значение prefetch и sidebar.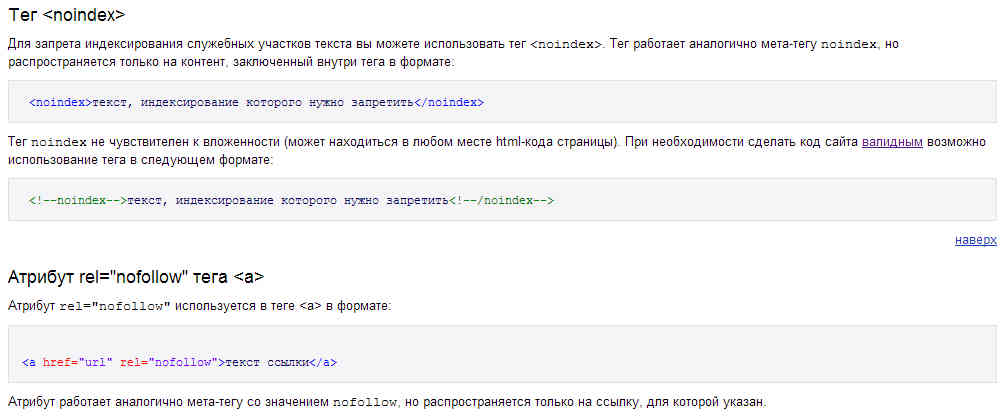 Opera поддерживает значение sidebar.
Opera поддерживает значение sidebar.
Грамотное использование nofollow и noindex / Арктическая Лаборатория
Noindex и Яндекс
Noindex – тег, введенный поисковой системой Yandex. С его помощью разработчики могут закрыть от индексации определенную часть html кода. Стоит отметить, что всемирно известный поисковик Google никак не воспринимает данный тег.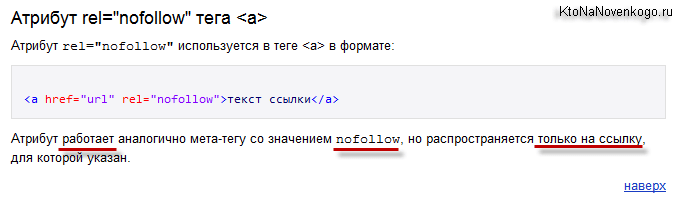
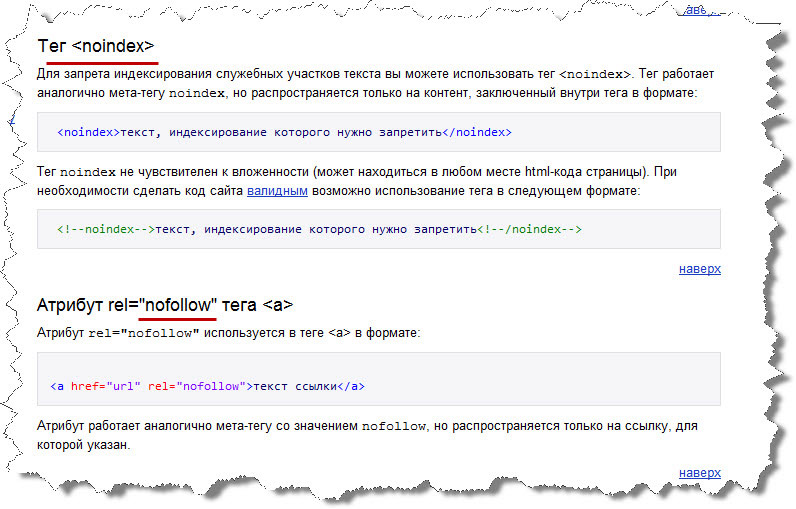
Синтаксис: <noindex>текст</noindex>
В связи с тем, что данный тег не является валидным, многие редакторы просто отказываются его воспринимать. Например, визуальный редактор wordpress просто удалит тег noindex. Для того чтобы этого не произошло, следует тегу придать валидности. В результате он будет записываться следующим образом:
<!— noindex —> <!—/ noindex —>
В такой форме тег является валидным, и его можно с легкостью прописывать в редакторе WordPress, не боясь, что он пропадет.
Не нужно путать обычный тег noindex и метатег noindex, который прописывается в самом начале страницы. Данные теги выполняют совершенно разные задачи. С помощью простого тега закрывается от индексации та часть текста, которая расположена между открывающимся и закрывающимся noindex, а метатег запрещает индексировать всю страницу полностью.
Как правило, noindex работает безотказно. Вся текстовая информация не попадает в индекс Яндекса.
Как написано в справке Яндекса, не обязательно соблюдать вложенность тегов noindex. Он сработает даже при неправильной вложенности. Главное, используя открывающийся тег, нужно не забыть поставить закрывающийся. В противном случае, весь текст, находящийся после <noindex> проиндексирован не будет.
Целесообразность использования тега noindex
Данный тег следует применять только в том случае, если есть необходимость скрыть от Яндекса определенную часть html кода.
Noindex стоит использовать, чтобы:
1. Скрыть не уникальный или часто меняющийся текст (копипаст, цитаты и так далее).
2. Не давать поисковику видеть коды всевозможных счетчиков (rambler100, liveinternet, счетчики тИЦ и PR).
3. Закрыть нецензурную речь, которую лучше вообще не употреблять.
4. Скрыть ненужные данные, находящиеся в сайдбарах (текст, баннер).
5. Не давать поисковой системе видеть rss, форму рассылок и так далее.
Не следует применять noindex в следующих ситуациях:
1. При размещении рекламных материалов от Гугл Адсенс, Яндекс Директ, Бегун.
2. Для ссылок в комментариях.
3. При размещении внутренних или внешних ссылок.
Nofollow и Google
В октябре 2005 года по инициативе компании Google был введен атрибут nofollow, который предназначался для борьбы со спамом в комментариях. Поддерживают этот атрибут MSN/Bing и Yahoo. Спустя несколько лет, а именно в 2010 году, компания Яндекс тоже стала обращать внимание на данный атрибут.
Стоит отметить, что nofollow был известен и ранее, новым стало лишь то, что он позволяет закрывать от индексации не все ссылки, находящиеся на странице, а только ненужные.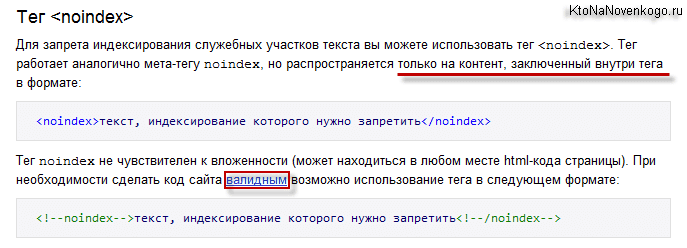
Для того, чтобы конкретная ссылка не учитывалась, следует применять атрибут rel=»nofollow».
Синтаксис: a href=»адрес» rel=»nofollow»>ссылка</a>
Например, если ссылка, находящаяся в комментариях, ведет на сайт, который не заслуживает доверия, и нет возможности предварительно модерировать оставленный комментарий, то самым верным решением будет использование атрибута rel=»nofollow». В противном случае, сайт может быть наказан, вплоть до исключения страницы из индекса.
Предотвратить индексацию всех ссылок, находящихся на странице, поможет атрибут content=»nofollow» для мета-тегаrobots.
Синтаксис: <meta name=»robots» content=»nofollow»/>.
В этом случае все ссылки, независимо от наличия у них своих атрибутов, не будут учитываться поисковыми системами.
Принцип работы атрибута nofollow
Несколько лет назад компания Google, чтобы предотвратить манипуляции с распределением веса, изменила схему определения значимости ссылок на страницах сайта. В результате, закрытая атрибутом nofollow ссылка не добавляет вес другим ссылкам, которые не спрятаны с помощью rel=»nofollow».
В результате, закрытая атрибутом nofollow ссылка не добавляет вес другим ссылкам, которые не спрятаны с помощью rel=»nofollow».
Иначе говоря, ранее, когда на странице находилось четыре ссылки и две из них были закрыты атрибутом rel=»nofollow», оставшиеся две получали весь вес страницы. Они становились более весомыми, получая по половине веса, в то время как при четырёх открытых ссылках они получали по четверти веса на каждую. На сегодняшний день, независимо от того, сколько ссылок будет закрыто атрибутом rel=»nofollow», каждая получает постоянное значение, а именно — четверть веса. В результате вес ссылки, закрытой rel=»nofollow», безвозвратно пропадает.
Стоит отметить, что, несмотря на корректную работу данного атрибута, у поисковика Bing от компании Microsoft время от времени возникают проблемы, когда закрытые ссылки попадают в индекс. При возникновении такой ситуации следует обращаться непосредственно в службу технической поддержки компании.
Ссылки nofollow и панель управления сайтом
Обратные ссылки на сайт можно увидеть в панели управления любого поисковика. Многие из них могут быть закрыты атрибутом nofollow. Они не учитываются при подсчете веса страницы. Иначе говоря, это отображение работы индексирующих алгоритмов. Оценка выполняется на более поздних этапах, поэтому к списку обратных ссылок добавляется, что он рассматривается как приблизительный.
Многие из них могут быть закрыты атрибутом nofollow. Они не учитываются при подсчете веса страницы. Иначе говоря, это отображение работы индексирующих алгоритмов. Оценка выполняется на более поздних этапах, поэтому к списку обратных ссылок добавляется, что он рассматривается как приблизительный.
Например, анализируя бэки в Yahoo, следует учитывать то, что в списке будут находиться и те ссылки, которые закрыты атрибутом «nofollow». Помимо этого, «быстроробот» от Яндекса тоже может индексировать ссылки, закрытые атрибутом nofollow. Однако после очередного апдейта данные ссылки будут удалены из списка.
Использование nofollow и noindex вместе
Оба этих тега прекрасно себя чувствуют и в том случае, если находятся в непосредственной близости друг от друга. Например:
<noindex><a href=»http://site/» rel=»nofollow»>link</a></noindex>.
Данный подход позволяет разработчикам не только удержать вес страницы, но и скрыть анкор от поисковой системы Яндекс.
В заключение следует отметить, что нет никакого смысла закрывать ссылку тегом noindex, так как поисковик не увидит только текст, а ссылка будет проиндексирована. В этом случае использование атрибута nofollow будет самым разумным подходом.
Noindex, nofollow для Google — как и когда использовать с пользой для SEO продвижения
Noindex – это директива для поисковых систем, которая запрещает отображать страницу либо часть текста в результатах поиска. Давайте рассмотрим подробнее – где и в каких случаях используется эта директива?
Mетатег “robots” со значением “noindex”
Чтобы не допустить определенную страницу к индексированию поисковыми системами используется метатег robots с добавлением значения “noindex”.
В разделе <head> страницы размещается следующая конструкция:
<head>
<meta name="robots" content="noindex" />
…
</head>
Данный метатег распространяется на всех роботов поисковых систем.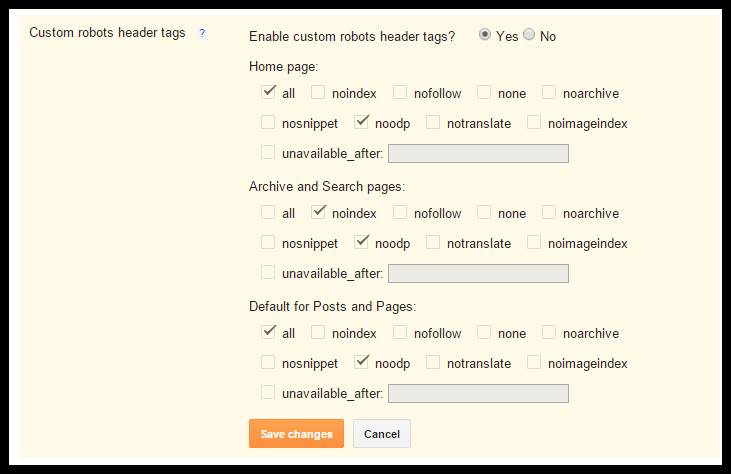 Но иногда может использоваться только для определенных роботов, в зависимости от целей. Например, можно запретить индексацию только лишь определенной поисковой системе, указав в значении для атрибута “name” название робота (например – Googlebot, для Google):
Но иногда может использоваться только для определенных роботов, в зависимости от целей. Например, можно запретить индексацию только лишь определенной поисковой системе, указав в значении для атрибута “name” название робота (например – Googlebot, для Google):
<meta name="googlebot" content="noindex" />
Пример: Вы не хотите, чтобы ваши изображения были найдены через поиск по изображениям и использованы кем-то в личных целях.
Решение: Можно запретить индексацию страницы с данными изображениями только в поиске по изображениям, используя робот Googlebot-Image:
<meta name="googlebot-image" content="noindex" />
Таким образом, страница появится в результатах обычного поиска, но её содержимое не будет индексироваться для поиска по изображениям.
Тег <noindex> – для закрытия от индексации части контента
Для того, чтобы закрыть от индексации часть текста используется тег <noindex>, который может быть помещен в любые элементы html-кода страницы:
<noindex>текст, который будет запрещен к индексированию</noindex>
Однако, данный тег будет восприниматься только поисковиком Яндекс, так как он не является стандартизированным и был введен только этой поисковой системой.
Если мы разместим текст внутрь тега, то он не будет индексироваться при сканировании роботом Яндекс и при этом будет попадать в индекс всех остальных поисковиков.
Валидность
Так как тег <noindex> не является стандартизированным, то могут возникать ошибки валидации. Чтобы код оставался валидным, рекомендуется использование тега в таком виде:
<!--noindex-->текст, который будет запрещен к индексированию<!--/noindex-->
Варианты использования meta robots noindex
Мета-тег “Robots” содержит директивы, разделенные запятыми:
- Index/Noindex задает правило индексации страницы;
- Follow/Nofollow разрешает или запрещает переходить по ссылкам со страницы. Значения по умолчанию – Index и Follow.
Существуют следующие варианты использования метатега:
| <meta name=“robots” content=“index,follow”> | Разрешено индексировать страницу и переходить по ссылкам на ней. |
| <meta name=“robots” content=“noindex,follow”> | Запрещено индексировать страницу, но можно переходить по ссылкам на ней. |
| <meta name=“robots” content=“index,nofollow”> | Разрешено индексировать страницу, но нельзя переходить по ссылкам на странице. |
| <meta name=“robots” content=“noindex,nofollow”> | Запрещено индексировать страницу и переходить по ссылкам на ней. |
Как показывает практика (см. эксперимент С. Кокшарова), Google обычно корректно воспринимает данные правила. Что касается Яндекс, то он может не всегда следовать правилу “noindex, nofollow” и переходит по ссылкам, чтобы проверить их качество (под такими директивами иногда прячутся недобросовестные сайты).
Отличия meta robots noindex от noindex в robots.txt
Есть 2 способа скрыть страницу от индексирования:
- Закрыть страницу в robots.txt с помощью Disallow.
- Добавить на страницу в <head> метатег:
<meta name="robots" content="noindex" />
Основные отличия:
- В robots. txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
- <meta name=”robots” content=”noindex, follow”> позволяет закрывать страницы точечно, а также передавать ссылочный вес.
 txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.Если необходимо закрыть определенную страницу, лучше все-же воспользоваться метатегом чтобы не перегружать robots.txt лишними строками. Кроме того, выше вероятность того, что правило сработает (по сравнению с robots.txt).
Помните, что robots.txt – это всего лишь рекомендации, то есть поисковые системы могут игнорировать его — индексировать и сканировать запрещенные URL. Поэтому, если вы хотите скрыть URL с гарантией, лучше это сделать через метатег. А если уж наверняка – то можно, например, закрыть директории паролем.
Распространенные ошибки
Страница закрыта через метатег, но все равно находится в поиске
Возможные причины:
- Страница закрыта также robots. txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
- Робот еще не успел посетить страницу (на сайте много страниц).
 txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.Решение: Чтобы закрыть страницу через метатег, необходимо, чтобы она была открыта в robots.txt. Если на сайте много страниц, а страницу нужно срочно закрыть – лучше воспользоваться панелью вебмастера.
Внедрение одновременно noindex и rel canonical на страницах (например, пагинации)
Это частая ошибка вебмастеров, ведь эти два тега противоречат друг другу. Google дает четкий ответ по этому поводу тут: https://www.seroundtable.com/noindex-canonical-google-18274.html .
Решение для страниц пагинации:
- canonical не использовать,
- на страницах пагинации прописать: <meta name=”robots” content=”noindex, follow” />, а также link rel=”prev” и link rel=”next”.
На сайте есть не закрытые метатегом служебные страницы – версии страниц «для печати», а также служебные/шаблонные страницы, которые создаются динамически.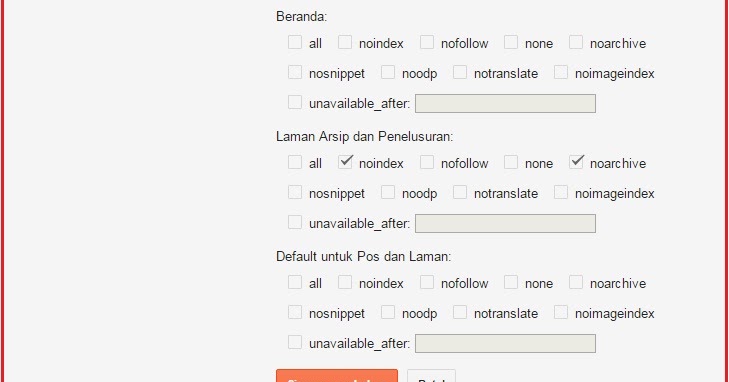 Это частая проблема, так как в индекс могут попасть сотни ненужных страниц. В дальнейшем эти «мусорные» страницы могут ранжироваться в поиске вытесняя полезные продвигаемые страницы. Закрытие через robots.txt может не решить проблему.
Это частая проблема, так как в индекс могут попасть сотни ненужных страниц. В дальнейшем эти «мусорные» страницы могут ранжироваться в поиске вытесняя полезные продвигаемые страницы. Закрытие через robots.txt может не решить проблему.
Решение: Google советует закрыть такого рода страницы через метатег <meta name="robots" content="noindex, nofollow" />.
Атрибут rel-nofollow
Значение rel=”nofollow” запрещает поисковой системе переходить по конкретной ссылке.
Пример использования: <a href="test.com" rel="nofollow">Ссылка</a>
Google утверждает: «…Как правило, переход не производится. Это означает, что по этим ссылкам Google не передает ни PageRank, ни текст ссылки…»
Однако, «как правило» предполагает, что бывают исключения. Также, например, ссылки с nofollow могут быть проиндексированы, если на страницу ссылаются другие сайты без использования nofollow, либо страница есть в Sitemap.
Как и где использовать
Рекомендуется использовать rel=”nofollow”:
- для закрытия ссылок на некачественный контент или контент, которому вы не доверяете,
- для закрытия неуникального контента,
- для закрытия платных ссылок,
- для корректной индексации (например, чтобы скрыть технические страницы и не тратить ресурсы робота на их сканирование).
Помимо этих случаев, многие оптимизаторы используют rel=”nofollow”, когда хотят, чтобы внешняя ссылка не передавала вес.
Передает ли nofollow вес
По словам Google, rel=”nofollow” не передает ссылочный вес. Однако, есть свидетельства, что Google учитывает ссылки социальных сетей Facebook, Twitter не смотря на nofollow.
Что касается Яндекс, то с 2010 года он не учитывает ссылки с nofollow и, соответственно ссылка не передает вес. Это официальная версия Яндекс. Однако, есть подтверждения экспериментов, что Яндекс учитывает анкоры таких ссылок.
Это официальная версия Яндекс. Однако, есть подтверждения экспериментов, что Яндекс учитывает анкоры таких ссылок.
Как бы там ни было, ваш ссылочный профиль должен быть разнообразным и рекомендуется разбавлять анкор-лист ссылками с rel=”nofollow”.
Распространенные ошибки
Использование rel=”nofollow” для внутренней перелинковки.
Google так делать не советует (https://www.searchengines.ru/mett_katts_ne_nofollow_int_links.html )
Использовать rel nofollow на каждый язык языковой версии чтобы «сегментировать» их, не передавая вес друг-другу.
Не нужно с помощью rel nofollow пытаться манипулировать весом. Если сайт целостный, все равно в рамках внутренней перелинковки вес будет переходить. Как уже говорилось выше – Google не приветствует rel nofollow для внутренней перелинковки. Но не забудьте об использовании hreflang.
Использовать rel nofollow для ссылок на страницы фильтра.
Рекомендуется не использовать атрибут nofollow, а реализовать фильтры с помощью JS или закрывать страницы метатегом noindex, nofollow.
Надеемся, что данная статья ответила на основные вопросы по использованию тегов noindex, nofollow. Желаем успешного продвижения!
Тег noindex и rel=»nofollow» — инструкция по применению
Тег noindex и атрибут nofollow способны помочь в оптимизации вашего сайта. Правда применять их нужно грамотно. Когда и для чего их использовать, рассмотрим в этом материале.
Подробнее о теге noindex
Даже если судить только по названию, не сложно догадаться о его назначении. Данный тег запрещает индексировать всё, что им отмечено (но это не касается ссылок и картинок — только текста).
Следует заметить, что ряд HTML-редакторов принципиально не работают с тэгом noindex — например, в WordРress он удаляется автоматически. Но в определённом виде его всё-таки можно использовать: Этот тег работает только с поисковой системой Яндекс. Тег noindex Google, не смотря на все свои возможности, не воспринимает.
Можно применять noindex и в качестве простого тега и в качестве мета-тега. Соответственно, их функции в таком случае будут разными. Обычный тег скроет от индексации только тот участок кода, который будет находиться между его открывающим и закрывающим тэгами.
Соответственно, их функции в таком случае будут разными. Обычный тег скроет от индексации только тот участок кода, который будет находиться между его открывающим и закрывающим тэгами.
Применяемый в качестве мета-тега, noindex, прописанный в файле robots.txt, запретит индексировать всю страницу целиком.
Как правило, этот тег нормально функционирует и выполняет свои непосредственные обязанности. Тем не менее в ряде случаев, скрытая им от индексирования текстовая информация, все равно обрабатывается поисковыми ботами. Это связано с самим принципом работы поисковой системы. Тег noindex Yandex воспринимает, но все равно проиндексирует целиком весь код HTML, и только после этого отфильтрует значения, согласно тегам. Так что даже проиндексированный текст, спрятанный данным тегом, скоро исчезнет из поля зрения Яндекса.
К слову — для noindex вложенное размещение необязательно. В справке поисковой системы Яндекс указано, что тег будет работать и без вложения.
Какая польза от тега noindex
Тег был разработан, чтобы поисковая система не считывала ненужные куски кода, которые не несут важной информации для поиска. Поэтому грамотно будет прописать noindex для того, чтобы не индексировать коды счетчиков, формы подписок и рассылок, баннеры и информацию из сайдбаров, часто меняющееся текстовое наполнение. Иногда тэг употребляют, чтобы спрятать копипаст, а также нецензурщину на странице. Уместно и к страницам, находящимся на реконструкции, применять функцию: запрещено элементом noindex.
Поэтому грамотно будет прописать noindex для того, чтобы не индексировать коды счетчиков, формы подписок и рассылок, баннеры и информацию из сайдбаров, часто меняющееся текстовое наполнение. Иногда тэг употребляют, чтобы спрятать копипаст, а также нецензурщину на странице. Уместно и к страницам, находящимся на реконструкции, применять функцию: запрещено элементом noindex.
Но, как уже говорилось, бессмысленно применять тег для того, чтобы скрыть внутренние и внешние ссылки, а также рекламу типа Яндекс.Директ и тому подобное.
Подробнее о nofollow
Параметр nofollow link способен скрыть ссылки от индексации. Причем, он одинаково эффективно взаимодействует и с Google, и с Яндекс. Кстати, последний научился его воспринимать относительно недавно. Так в чем разница между dofollow и nofollow — это два противоположных по своему действию параметра. Один открывает индексацию, а другой, соответственно, закрывает.
Nofollow имеет непосредственную связь с так называемым весом ссылки. Это один из тех параметров, о которых нужно знать каждому вебмастеру. Вес ссылки показывает ее значимость при продвижении ресурса. Его используют поисковые системы при ранжировании сайтов. Ресурс, на который ведёт большое количество внешних ссылок (ссылок с других сайтов), будет иметь более высокий рейтинг.
Это один из тех параметров, о которых нужно знать каждому вебмастеру. Вес ссылки показывает ее значимость при продвижении ресурса. Его используют поисковые системы при ранжировании сайтов. Ресурс, на который ведёт большое количество внешних ссылок (ссылок с других сайтов), будет иметь более высокий рейтинг.
Вес ссылки, при использовании атрибута rel nofollow, не будет передан на сайт-акцептор. То есть, как непосредственный инструмент продвижения, работать она не будет. Так же возможен вариант использования rel dofollow — для форсирования передачи веса.
Вот один из примеров применения nofollow wordpress:Но при этом ссылки, которые ведут на внутренние страницы сайта, во многих случаях бесполезно закрывать атрибутом nofollow.
Как пользоваться nofollow
Тег nofollow логично будет применять, чтобы ограничить передачу веса по ссылкам, которые ведут на ненадежный для поисковых систем сайт, или любой другой ресурс, не имеющий принципиального значения для владельца сайта-донора. Тегом можно запретить передачу веса по ссылке на сайт, который не соответствует тематике вашего ресурса. Всем открытым ссылкам бот автоматически приписывает параметр dofollow. Если вас интересует, как сделать ссылку dofollow, то ответом будет — просто не закрывать её nofollow.
Тегом можно запретить передачу веса по ссылке на сайт, который не соответствует тематике вашего ресурса. Всем открытым ссылкам бот автоматически приписывает параметр dofollow. Если вас интересует, как сделать ссылку dofollow, то ответом будет — просто не закрывать её nofollow.
Также атрибут будет полезен при уменьшении количества исходящих ссылок — если страница перегружена ими. Nofollow может ограничить переливание веса на крупные ресурсы с высокими показателями ИКС.
Важно не переусердствовать — использовав на все внешние ссылки nofollow, можно автоматически снизить доверие к ней со стороны поисковых систем. Лучше оставить две-три ссылки. На вес это практически не повлияет.
Можно ли использовать nofollow noindex совместно
Эти инструменты прекрасно взаимодействуют, и их можно ставить рядом. Приведем пример:
Подобная комбинация ограничивает передачу веса ссылки, а Яндекс еще и не заметит ее анкора.
Но по сути нет смысла в том, что бы постоянно использовать вместе noindex и nofollow. Применение noindex приводит лишь к сокрытию анкора. Ссылке достаточно атрибута nofollow. Так что ставить их рядом — значит излишне перегружать код страницы.
Применение noindex приводит лишь к сокрытию анкора. Ссылке достаточно атрибута nofollow. Так что ставить их рядом — значит излишне перегружать код страницы.
Заключение
Знание подобных инструментов HTML-кода позволяет легко и уверенно вносить правки прямо в тело вашего сайта. Чем более продуманной и оптимизированной будет его структура, тем выше вы сможете подняться в поисковой выдаче и тем большую аудиторию сможете собрать. Именно такие мелочи отличают опытных специалистов от начинающих вебмастеров. Обширные знания позволяют повышать позиции ресурса, даже без внесения изменений в его наполнение, одним лишь улучшением структуры.
Вся правда о теге NOINDEX
Noindex — тег разработанный ПС Яндекс для запрета индексирования служебных участков текста. Несмотря на его предназначение большинство сеошников до сих пор используют его для закрытия не служебных, а вполне важных участков сайта таких как меню, сайдбары, футеры и т.д, а делают это как правило для того, чтобы скрыть ссылки, которые якобы забирают вес со страницы. Также часто тег <noindex></noindex> используют для скрытия от Яндекса кода счетчиков, информеров, рекламных блоков, Iframe, и это уже ближе к истине его предназначения, но работает ли такой подход?
Также часто тег <noindex></noindex> используют для скрытия от Яндекса кода счетчиков, информеров, рекламных блоков, Iframe, и это уже ближе к истине его предназначения, но работает ли такой подход?
Закрывает ли тег noindex ссылки от индексации?
Нет! Неужели всем так тяжело зайти в справку для вебмастеров и почитать что об этом говорит сам Яндекс? Там черным по белому написано что noindex — это тег для скрытия служебных участков текста, а для запрета на индексация ссылок используется атрибут rel=»nofollow» тега <a>, ровно как и в Google. Пример ниже:
<noindex>текст, индексирование которого нужно запретить</noindex>
<a href="https://seonomad.net/url" rel="nofollow">текст ссылки</a>Видит ли Яндекс участки сайта закрытые в тег noindex?
Как уже говорилось выше тег и был создан для того, чтобы указывать роботу Яндекса о том, что выделенный участок текста (кода) не стоит учитывать при индексации. Но это вовсе не значит, что Яндекс не знает и не видит то, что находится внутри тегов <noindex></noindex>.
Но это вовсе не значит, что Яндекс не знает и не видит то, что находится внутри тегов <noindex></noindex>.
То есть, если у вас имеется на сайте контент который не рекомендуется Яндексом (например тизерки с сиськами или болячками какими), то закрытие их в теги <noindex></noindex> вас от фильтра не спасут. По сути noindex это всего лишь подсказка поисковику, а не железное правило. Поэтому нежелательные для попадания участки контента все же стоит закрывать, но скрыть что либо от «глаз» поисковика не получится.
Понимает ли noindex Google?
Нет, поисковая система Google игнорирует этот тег и относится к нему как к невалидному html коду. Чтобы закрыть контент от Гугла используют такой тег:
<!--googleoff: all-->
Текст который не должен индексироваться Google
<!--googleon: all-->Но.. Это касается только тега в <body>, если это метатег в <head><meta name=»robots» content=»noindex, nofollow»> — то страница и ссылки будут закрыты для индексации и в Google, и в Яндекс (и других поисковиках). Пруф
Пруф
В этом варианте правило content=»noindex» указывает поисковикам на неиндексацию текста, а content=»nofollow» на закрытие ссылок.
Как насчет Rambler и Mail?
Также тег <noindex></noindex> вроде как понимает Rambler, но доказательств я даже искать не стал, про Mail.ru информации и фактов по даанному вопросу не найдено.
Noindex
В продолжение тематики про NoFollow и DoFollow сегодня хочу рассказать про тег NoIndex. Следует разделять, что существует мета тег NoIndex:
<meta name=»robots» content=»noindex, nofollow» />
И существует тег NoIndex:
<noindex>HTML код</noindex>
Мета тег используется для того, чтобы указать поисковому роботу, что данную страницу не следует индексировать. Но при этом разные поисковые системы по разному его интерпретируют:
Google – не индексирует страницу, не сохраняет страницу в кеш, не выдает в результатах поиска.
MSN – выдает в результатах поиска адрес сайта, показывает ссылку на кеш, но он отсутствует.
Yahoo – аналогичен MSN, отсутствует кеш, но присутствует ссылка на него, а также отображается ссылка на сайт в результатах поиска.
Yandex – не индексирует страницу.
Зачем вообще использовать подобный тег? Причин может быть несколько:
- Вы не хотите, чтобы робот внес в индекс страницы с закрытой или личной информацией;
- Вы не хотите, чтобы поисковый робот индексировал огромные страницы на вашем сайте или базы данных;
- В совокупности с NoFollow вы избегаете учета ссылок на вашей странице для расчета Page Rank и релевантности ссылаемой страницы. Детальнее тут.
Что касается тега <noindex>, то он используется для запрета индексировать определенную часть страницы. Т.е. с помощью его можно сделать следующее:
- Запретить индексировать ссылки внутри указанного блока на вашем сайте. В данном случае это аналогично использованию параметра NoFollow в ссылке.
- Запретить индексировать часть страницы, а не всю, как в случае с мета тегом.
- Запретить индексировать коды счетчиков, баннеров и т.д..
- Убрать из индексирования ненужный код, текст, рекламу, что может поднять релевантность страницы.
 В данном случае это аналогично использованию параметра NoFollow в ссылке.
В данном случае это аналогично использованию параметра NoFollow в ссылке.Но главной особенностью данного тега является то, что его понимают только Yandex и Rambler, все остальные ведущие забугорные поисковые системы (Google, Yahoo, MSN) игнорируют данный тег. А также тега <noindex> нет в стандарте W3C, поэтому страница с данным тегом не может пройти валидацию.
SEO — noindex, nofollow и канонический тег
Мне нужно кое-что объяснить по поводу моего вопроса.
Пример в моем заголовке уже добавлен
<meta name="robots" content="noindex, nofollow" />
Должен ли я снова добавить канонический тег в свой заголовок?
<link rel=”canonical” href=”http://www. example.com/product.php?item=big-fish” />
 example.com/product.php?item=big-fish” />
example.com/product.php?item=big-fish” />
Дайте мне знать 🙂
канонический тег
Обновление
мы знаем, что canonical tag в настоящее время также поддерживается google, yahoo и live search. Как насчет noindex и nofollow? yahoo и live (bing) тоже поддерживаются?
seo canonical-link nofollow noindexПоделиться Источник wow 25 июля 2009 в 04:02
9 ответов
- noIndex, noFollow и канонические Теги на странице фасета SEO
Мы поняли, что у нас есть большое количество дубликатов страниц нашего сайта eCommerce, индексированных в Google, особенно большое количество фасетных URL-адресов, таких как цветные страницы, ценовые страницы и т. д. Они уже проиндексированы, каждый из которых имеет каноническое url, указывающее…
- Установите NOINDEX, NOFOLLOW на определенные продукты
My magento store имеет следующее, чтобы позволить google / поисковым системам сканировать весь сайт.
<meta name=robots content=INDEX,FOLLOW /> Я теперь нуждаюсь в некоторых конкретных продуктах, чтобы иметь: <meta name=robots content=NOINDEX,NOFOLLOW /> чтобы google не…
 <meta name=robots content=INDEX,FOLLOW /> Я теперь нуждаюсь в некоторых конкретных продуктах, чтобы иметь: <meta name=robots content=NOINDEX,NOFOLLOW /> чтобы google не…
<meta name=robots content=INDEX,FOLLOW /> Я теперь нуждаюсь в некоторых конкретных продуктах, чтобы иметь: <meta name=robots content=NOINDEX,NOFOLLOW /> чтобы google не…
12
Google , Yahoo! и Bing (Live) поддерживают noindex и nofollow в мета-директивах.
noindex говорит поисковым системам, чтобы они не утруждали себя кэшированием вашей страницы для включения в свои результаты.
nofollow говорит им, что вы не хотите, чтобы по какой-либо ссылке на странице следовали.
Добавление тега canonical на ту же страницу не повредит, но эффекты неизвестны, если вы не поговорите с одним из поисковых инженеров.
Поделиться random 25 июля 2009 в 13:58
6
В этом нет особого смысла, не так ли? Поисковая система все равно не будет индексировать вашу страницу!
Хотя я полагаю, что если вы когда-нибудь захотите проиндексировать его в будущем, то это будет хорошей практикой, хотя только в том случае, если один и тот же контент страницы будет доступен через разные URLs.
Поделиться Jason Berry 25 июля 2009 в 04:06
4
Просто чтобы прояснить некоторые вещи раз и навсегда
Реализация этого
<meta name="robots" content="noindex, nofollow" />
не только говорит ботам не индексировать страницы, но и блокирует их передачу PageRank по всем ссылкам, найденным на странице. Но это не проблема сама по себе. Проблема в том, что такие страницы становятся тупиковыми страницами, иначе называемыми «Dangling pages» или «Nodes», которые вызывают разбавление PageRank, потому что сок будет удален из графика PR.
Тем не менее, оптимальной метой будет реализация:
<meta name="robots" content="noindex,noarchive,nosnippet,follow" />
Если эта страница дублируется, то неплохо также реализовать канонический тег, связывающий версию страницы, которую вы хотите проиндексировать. Если нет, то хотя бы на самую актуальную страницу.
Если нет, то хотя бы на самую актуальную страницу.
Использование только канонического тега не препятствует индексации. По крайней мере, не во всех случаях. Например, если страница имеет PR5, которая имеет каноническую ссылку, указывающую на идентичную страницу, которая имеет PR 1, Google может игнорировать канонический тег и индексировать страницу с PR 5.
Поэтому, чтобы избежать каких-либо заблуждений, канонический тег не является 301-м редиректом. Тем не менее, страницы с каноническим тегом все еще могут накапливать PageRank. Все зависит от того, сколько сока достигнет этой страницы.
Итак, еще одна причина, по которой имеет смысл добавить директиву «follow» meta robots в качестве последней.
По словам Мэтта Каттса, руководителя команды веб-спама Google, просто используя «noindex» или «noindex,noarchive,nosnippet» без добавления директивы «follow» в конце, может быть, что Googlebot может испортить и не перейти по ссылкам на этой странице.
Я надеюсь, что все вышесказанное поможет!
Поделиться John Britsios 28 февраля 2012 в 19:21
- Noindex, nofollow с метатегами Ruby gem не работает
Я использую мета-теги gem и пытаюсь добавить в свой вид мета-теги noindex и nofollow.
В файле представления HAML у меня есть: — noindex_meta_tag — content_for :head do — display_meta_tags noindex: true, nofollow: true В application_helper.rb году у меня есть: def noindex_meta_tag set_meta_tags… - Как добавить `nofollow, noindex` все страницы в robots.txt?
Я хочу добавить nofollow и noindex на мой сайт, пока он строится. Клиент имеет запрос я использую эти правила. Я осознаю, что <meta name=robots content=noindex,nofollow> Но у меня есть только доступ к файлу robots.txt . Кто-нибудь знает правильный формат, который я могу использовать для…
 В файле представления HAML у меня есть: — noindex_meta_tag — content_for :head do — display_meta_tags noindex: true, nofollow: true В application_helper.rb году у меня есть: def noindex_meta_tag set_meta_tags…
В файле представления HAML у меня есть: — noindex_meta_tag — content_for :head do — display_meta_tags noindex: true, nofollow: true В application_helper.rb году у меня есть: def noindex_meta_tag set_meta_tags…
3
Поскольку вы говорите искателю не индексировать и не следовать, я не понимаю, почему вы должны использовать канонический.
Вы должны использовать канонический файл только в том случае, если у вас есть один и тот же контент под разными URLs.
Поделиться Nathan 25 июля 2009 в 04:09
3
Страницы, включенные в файл Robots.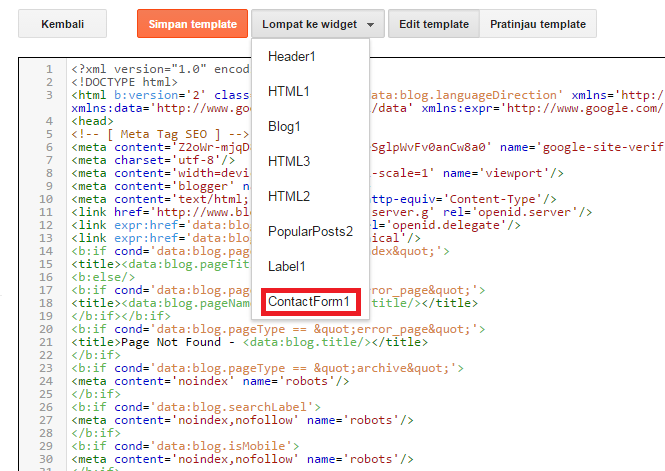 txt, заставляют поисковые системы NOT сканировать эти страницы. Однако страницы в файле Robots.txt все еще могут накапливаться PageRank и могут быть проиндексированы в результатах поиска, говорит Мэтт Каттс.
txt, заставляют поисковые системы NOT сканировать эти страницы. Однако страницы в файле Robots.txt все еще могут накапливаться PageRank и могут быть проиндексированы в результатах поиска, говорит Мэтт Каттс.
Тег NoIndex означает, что поисковые системы могут сканировать страницу и давать ей PageRank, однако поисковые системы не должны индексировать страницу, и она не будет отображаться в результатах поиска. Опять же, страница с тегом NoIndex может накапливать PageRank, потому что ссылки все еще следуют наружу со страницы NoIndex.
Страница с тегом NoFollow сообщает поисковым системам, что да, эту страницу можно обойти, но не показывайте ее вообще в индексе Google и не переходите по исходящим ссылкам, и никакой PageRank не течет с этой страницы.
Поделиться Sam 23 сентября 2011 в 08:22
1
Тег ‘canonical’ нужен только в том случае, если существует несколько способов обращения к странице. Например, если ‘http://www.example.com/products/big-fish’ и ‘http://www.example.com/product.php?item=big-fish’ указывают на одну и ту же страницу (т. е. один-это псевдоним для другого), используйте ‘canonical’.
Например, если ‘http://www.example.com/products/big-fish’ и ‘http://www.example.com/product.php?item=big-fish’ указывают на одну и ту же страницу (т. е. один-это псевдоним для другого), используйте ‘canonical’.
Поделиться Kevin Lacquement 25 июля 2009 в 04:08
Поделиться Sebastian Schuon 19 октября 2011 в 07:29
0
Подводя итог книге Art of SEO by Eric Enge & Co, а также гуглящим статьям и форумам, я предлагаю следующее. Кроме того, в основном мы предполагаем, что ваш сайт использует канонические ссылки, чтобы избежать проблемы дубликатов страниц, а все остальные страницы URLs с параметрами cgi считаются нежелательными страницами с точки зрения поисковой системы (хотя и полностью функциональными и доступными для посетителей).
Канонические URL страницы — PRODUCT, INFO, ARTICLES разрешают все, кроме неканонических ссылок (нежелательных страниц).
Делая это, мы не даем им никакого сока и никаких рейтинговых бонусов. Другие страницы также не выигрывают от этого. Но мы держим рейтинг нежелательных страниц ниже, а полезные страницы выше в результатах поиска.< a href=»mysite.com/catalogue/product.php?id=123″ rel=»NoFollow» >
Дублированные страницы — PRODUCT, PRINT поисковая система считывает код страницы, идентифицирует каноническую ссылку в самом начале, рассматривает ее как эквивалент полезной страницы и исключает из индекса как нежелательную. SE робот прочитал страницу, поэтому он все еще может просматривать ссылки. Поэтому мы запрещаем переходить по ссылкам на другие нежелательные страницы с неканоническими URLs. Чтобы сделать эту страницу более эквивалентной своей канонической цели, мы опускаем другие запрещающие параметры (достаточно канонического тега).
< ссылка rel=»canonical» href=»mysite.com/catalogue/my-product/» >
< a href=»mysite.com/catalogue/product.php?id=123″ rel=»NoFollow» >
Технические страницы — REGISTRATION, BASKET, ORDER запрещают роботам читать все эти страницы, чтобы даже не добраться до каких-либо тегов в коде страницы.
Но все же посетители могут перейти на эти страницы, и роботы найдут ссылку на вашу нежелательную страницу на своем сайте. Поэтому нам дополнительно нужны все запрещающие теги, чтобы игнорировать эту страницу поисковыми системами и не переходить по ссылкам на нежелательные страницы.Disallow:/catalogue/product.* # В файле robots.txt.
< мета имя=содержимое «robots»=»параметр noindex,легкая, быстрая, социальная,nocache,nosnippet» />
< a href=»mysite.com/catalogue/product.php?id=123″ rel=»NoFollow» >
 Делая это, мы не даем им никакого сока и никаких рейтинговых бонусов. Другие страницы также не выигрывают от этого. Но мы держим рейтинг нежелательных страниц ниже, а полезные страницы выше в результатах поиска.
Делая это, мы не даем им никакого сока и никаких рейтинговых бонусов. Другие страницы также не выигрывают от этого. Но мы держим рейтинг нежелательных страниц ниже, а полезные страницы выше в результатах поиска. Но все же посетители могут перейти на эти страницы, и роботы найдут ссылку на вашу нежелательную страницу на своем сайте. Поэтому нам дополнительно нужны все запрещающие теги, чтобы игнорировать эту страницу поисковыми системами и не переходить по ссылкам на нежелательные страницы.
Но все же посетители могут перейти на эти страницы, и роботы найдут ссылку на вашу нежелательную страницу на своем сайте. Поэтому нам дополнительно нужны все запрещающие теги, чтобы игнорировать эту страницу поисковыми системами и не переходить по ссылкам на нежелательные страницы.Поделиться Zon 28 августа 2014 в 15:00
Поделиться doctorlai 14 июля 2016 в 20:53
Похожие вопросы:
Noindex, nofollow-достаточно ли поместить их в ответ HTTP?
Я думаю, что название этого вопроса говорит все это — при разработке и развертывании бета-версий, я должен поставить X-Robots-Tag: noindex, nofollow в ответе HTTP, или <meta name=robots.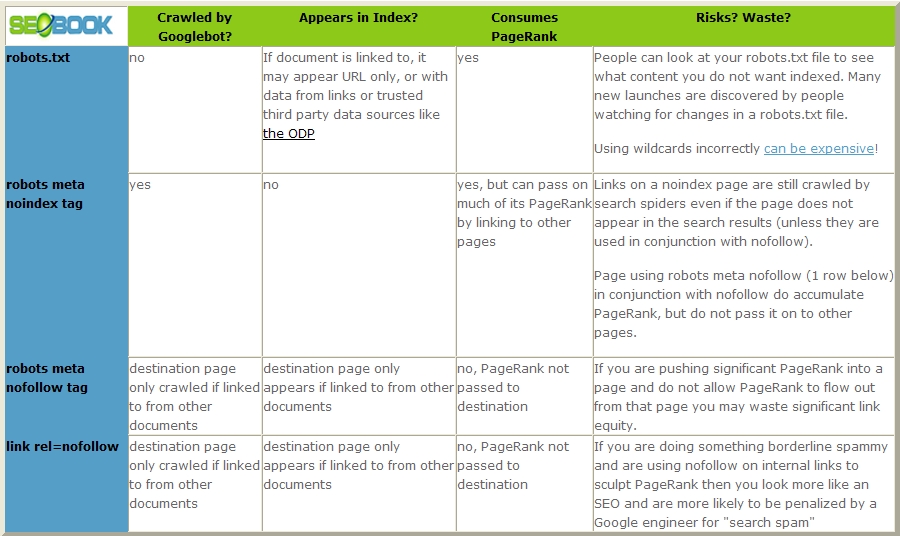 ..
..
noindex, nofollow для всей установки WordPress в подкаталоге?
Итак, у меня есть WordPress, работающий в корневом каталоге моего веб-пространства; я установлю другой экземпляр WordPress в подкаталоге того же сервера через пару дней для тестирования. Итак, вот в…
Как сделать разработку сайта Noindex Nofollow, но производство без
У меня есть сайт разработки joomla 3.3 и производственный сайт. Я делаю все разработки на сайте разработки, и каждый раз, когда разработка подталкивается к производству,мне нужно убедиться, что я…
noIndex, noFollow и канонические Теги на странице фасета SEO
Мы поняли, что у нас есть большое количество дубликатов страниц нашего сайта eCommerce, индексированных в Google, особенно большое количество фасетных URL-адресов, таких как цветные страницы,…
Установите NOINDEX, NOFOLLOW на определенные продукты
My magento store имеет следующее, чтобы позволить google / поисковым системам сканировать весь сайт. <meta name=robots content=INDEX,FOLLOW /> Я теперь нуждаюсь в некоторых конкретных…
<meta name=robots content=INDEX,FOLLOW /> Я теперь нуждаюсь в некоторых конкретных…
Noindex, nofollow с метатегами Ruby gem не работает
Я использую мета-теги gem и пытаюсь добавить в свой вид мета-теги noindex и nofollow. В файле представления HAML у меня есть: — noindex_meta_tag — content_for :head do — display_meta_tags noindex:…
Как добавить `nofollow, noindex` все страницы в robots.txt?
Я хочу добавить nofollow и noindex на мой сайт, пока он строится. Клиент имеет запрос я использую эти правила. Я осознаю, что <meta name=robots content=noindex,nofollow> Но у меня есть только…
Установите target=“_blank” и ref= «nofollow, noindex, noreferrer» для всех ссылок
Там, кажется, есть способ, как установить внешние ссылки на no-follow по умолчанию, чтобы избежать потери важных ссылок сок через do-follow ссылки на внешние сайты было бы очень хорошо и сделать…
Как добавить nofollow и noindex в код php?
Это мой код, как я могу добавить nofollow и noindex по социальным ссылкам? <?= wp_nav_menu([ ‘menu’ => ‘social_links’, ‘menu_class’ => ‘social-links’, ‘container’ => false, ‘echo’ =>. ..
..
Prestashop-noindex, nofollow в Мультисторе
У меня есть магазин на PrestaShop с функцией Мультистора. Я хочу добавить noindex, nofollow в один из моих магазинов. У меня есть основной магазин: например. www.shop.com и второй магазин, например….
noindex vs. nofollow — Справочный центр Siteimprove
Модуль Siteimprove SEO уведомляет пользователей о страницах, исключенных с помощью noindex / nofollow. Эта статья предназначена для объяснения разницы между метатегами noindex и nofollow, когда их использовать и как эти теги влияют на веб-индексирование и страницы результатов поисковой системы (SERP).
Как noindex, так и nofollow являются частью протокола исключения роботов (REP) , стандарта для управления индексированием веб-страниц на вашем сайте.Давайте рассмотрим несколько примеров noindex и nofollow и то, как они контролируют доступ и индексацию вашего веб-сайта Google и другими поисковыми системами.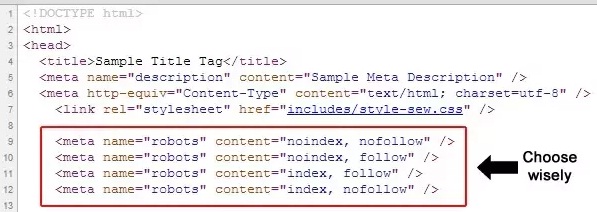
Что такое noindex и когда его использовать?
Обычно, когда робот Googlebot находит страницу, он читает все ссылки на этой странице, а затем выбирает эти страницы и индексирует их. Это основной процесс, с помощью которого робот Googlebot «сканирует» Интернет. Это полезно, поскольку позволяет Google включать все страницы вашего сайта, если они связаны друг с другом.Что делать, если вы не хотите, чтобы некоторые страницы вашего сайта отображались в индексе Google? Здесь применяется метатег noindex.
Когда вы добавляете метатег «noindex» к веб-странице, он сообщает поисковой системе, что она не может добавить страницу в свой поисковый индекс, даже если поисковая система может сканировать страницу.
, пример Noindex
статей в разделе «Последние новости» CNN могут появиться только на несколько часов, прежде чем они будут обновлены и перенесены в раздел «Статьи». В этом случае CNN захочет проиндексировать полные статьи, а не раздел последних новостей с короткой частью полной статьи.
Таким образом, вы можете добавить тег noindex к статьям, находящимся в настоящее время в разделе «Последние новости», и удалить этот тег, как только статья больше не будет актуальной.
Чтобы превратить обычные ссылки в ссылки noindex, добавьте «noindex» в HTML-код:
Текст ссылки
Что такое nofollow и когда его использовать?
Nofollow — это атрибут HTML, который предписывает большинству поисковых систем воздерживаться от перехода по ссылке и тем самым передавать значение на страницу, на которую ведет ссылка.Некоторые эксперты по SEO интерпретируют это как способ сообщить поисковым системам, что вы не доверяете или не можете поручиться за содержание ссылки, на которую ведет ссылка. Короче говоря, если вы хотите, чтобы поисковая машина проиндексировала вашу веб-страницу в поиске, но вы, , не хотите, чтобы переходила по ссылкам на этой странице; добавьте на свою страницу тег nofollow.
Чтобы превратить обычные ссылки в ссылки nofollow, добавьте «nofollow» в HTML-код *:
Текст ссылки
* Вы можете добавить код вручную, но многие CMS автоматически вставляют его при необходимости.Обратитесь к своему веб-мастеру за советом.
Пример Nofollow
Когда пользователи ищут в Google фразы, связанные с новостями, CNN хочет, чтобы разделы их статей (со статьями) занимали первое место в поисковой выдаче, потому что статьи являются наиболее ценным активом CNN.
Не имеет смысла располагать их раздел авторизации вверху.
Таким образом, чтобы сообщить Google, что статьи важнее входа в систему, CNN добавит тег nofollow к своей ссылке для входа.
Примечание: Сканер Siteimprove не учитывает «noindex» или «nofollow» при определении содержания для сканирования.Сканируем на основе настроек сканирования.
Что это такое и как их использовать?
Три слова, приведенные выше, могут звучать как SEO gobbledegook, но это слова, которые стоит знать, поскольку понимание того, как их использовать, означает, что вы можете управлять роботом Googlebot. Это весело.
Это весело.
Итак, начнем с основ: есть три способа контролировать, какие части вашего сайта будут сканироваться поисковыми системами:
- Noindex: указывает поисковым системам не включать ваши страницы в результаты поиска.
- Disallow: говорит им не сканировать ваши страницы.
- Nofollow: говорит им не переходить по ссылкам на вашей странице.
Что такое метатег Noindex?
Тег noindex указывает поисковым системам не включать страницу в результаты поиска.
Наиболее распространенный метод запрета индексации страницы — это добавление тега в заголовок HTML или в заголовки ответов. Чтобы поисковые системы могли видеть эту информацию, страница не должна быть заблокирована (запрещена) в файле robots.txt файл. Если страница заблокирована с помощью вашего файла robots.txt, Google никогда не увидит тег noindex, и страница может по-прежнему отображаться в результатах поиска.
Чтобы поисковые системы не индексировали вашу страницу, просто добавьте в раздел следующее:
Вторая часть тега содержимого указывает, что необходимо переходить по всем ссылкам на этой странице, которые мы обсудим ниже.
В качестве альтернативы тег noindex можно использовать в теге X-Robots-Tag в заголовке HTTP:
X-Robots-Tag: noindex
Дополнительную информацию см. В сообщении разработчиков Google о спецификациях метатега Robots и HTTP-заголовка X-Robots-Tag.
Как я могу использовать Noindex в файле Robots.txt?
Тег noindex в файле robots.txt также сообщает поисковым системам не включать страницу в результаты поиска, но это более быстрый и простой способ не индексировать сразу много страниц, особенно если у вас есть доступ к вашему robots.txt файл. Например, вы не можете индексировать любые URL-адреса в определенной папке.
Вот пример директивы noindex, которую можно поместить в файл robots.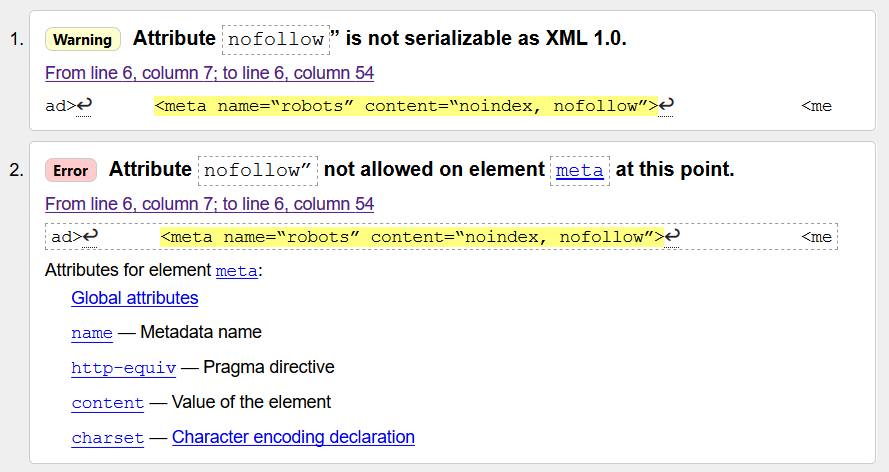 txt:
txt:
Noindex: / robots-txt-noindexed-page /
Однако Google не рекомендует использовать этот метод: Джон Мюллер заявил, что «не следует полагаться на него».
Что такое запретная директива?
Запрещение страницы означает, что вы даете поисковым системам указание не сканировать ее, что должно быть выполнено в файле robots.txt вашего сайта. Это полезно, если у вас много страниц или файлов, которые бесполезны для читателей или поискового трафика, поскольку это означает, что поисковые системы не будут тратить время на сканирование этих страниц.
Чтобы добавить запрет, просто добавьте в файл robots.txt следующую строку:
Запретить: / your-page-url /
Если на странице есть внешние ссылки или канонические теги, указывающие на нее, ее все равно можно проиндексировать и ранжировать, поэтому важно сочетать запрет с тегом noindex, как описано ниже.
Предупреждение: запрещая страницу, вы фактически удаляете ее со своего сайта.
Запрещенные страницы не могут передавать PageRank где-либо еще — поэтому любые ссылки на этих страницах фактически бесполезны с точки зрения SEO, а запрет на включение страниц, которые должны быть включены, может иметь катастрофические последствия для вашего трафика, поэтому будьте особенно осторожны при написании запрещающих директив.
Как объединить Noindex и Disallow?
Noindex (страница) + Disallow: Disallow не может сочетаться с noindex на странице, потому что страница заблокирована, и поэтому поисковые системы не будут сканировать ее, чтобы знать, что они не должны оставлять страницу вне индекс.
Noindex (robots.txt) + Disallow : предотвращает появление страниц в индексе, а также предотвращает сканирование страниц. Однако помните, что через эту страницу не может пройти PageRank.
Чтобы объединить запрет с индексом noindex в файле robots.txt, просто добавьте обе директивы в файл robots.txt:
Запрещено: / example-page-1/
Запрещено: / example-page-2/
Noindex: / example-page-1/
Noindex: / example-page-2/
Что такое тег Nofollow?
Тег nofollow в ссылке указывает поисковым системам не использовать ссылку для определения важности связанных страниц (PageRank) или обнаружения дополнительных URL-адресов на том же сайте.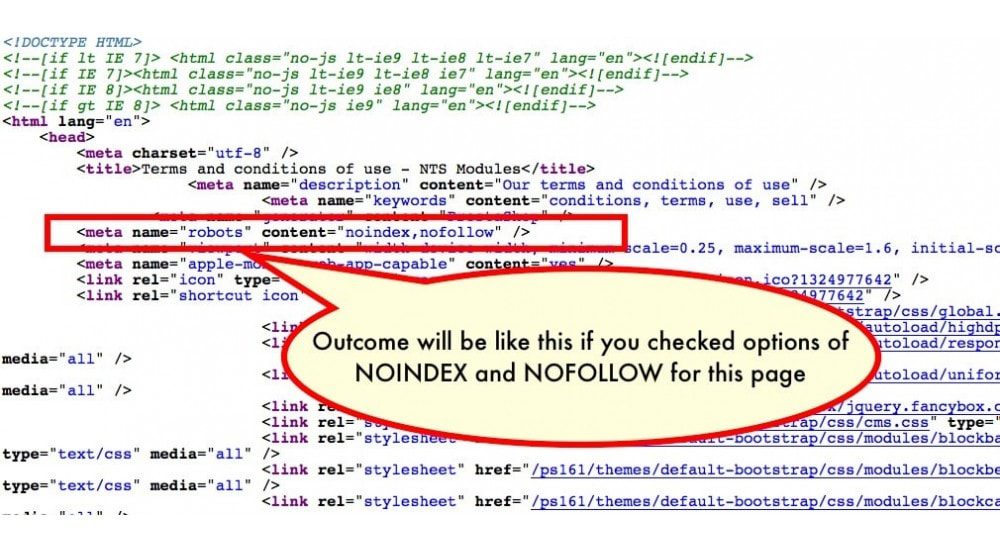
Обычно nofollows использует ссылки в комментариях и другом контенте, который вы не контролируете, платные ссылки, встраиваемые элементы, такие как виджеты или инфографику, ссылки в гостевых сообщениях или что-нибудь не по теме, на которое вы все еще хотите связывать людей.
Исторически сложилось так, что оптимизаторы поисковых систем также избирательно исключали переход по ссылкам, чтобы направлять внутренний PageRank на более важные страницы.
Теги Nofollow могут быть добавлены в одном из двух мест:
- страницы (чтобы nofollow все ссылки на этой странице):
- Код ссылки (для nofollow отдельной ссылки): пример страницы
nofollow не предотвратит полное сканирование связанной страницы; он просто предотвращает сканирование по этой конкретной ссылке. Наши и другие тесты показали, что Google не будет сканировать URL-адрес, который он находит в ссылке nofollowed.
Google заявляет, что если другой сайт ссылается на ту же страницу без использования тега nofollow или страница отображается в файле Sitemap, эта страница может по-прежнему отображаться в результатах поиска. Точно так же, если это URL, о котором уже знают поисковые системы, добавление ссылки nofollow не удалит его из индекса.
В сентябре 2019 года Google объявил об обновлении своей директивы nofollow и представил два новых атрибута ссылки, а именно:
- rel = «sponsored» — Атрибут sponsored следует использовать для идентификации ссылок, предназначенных для рекламных целей, при наличии соглашений о спонсорстве и компенсации.
- rel = «ugc» — В качестве атрибута для пользовательского контента это значение рекомендуется для ссылок на сайтах пользовательского контента, например для сообщений на форумах и комментариев в блогах.
Кроме того, все ссылки, помеченные как nofollow, sponsored или ugc, теперь обрабатываются как подсказки относительно того, какие ссылки следует учитывать при поиске и сканировании, а не просто как сигнал, как ранее использовалось для nofollow. Вы можете узнать больше об этом обновлении в нашем посте, который также охватывает их влияние, а также мнения экспертов.
Вы можете узнать больше об этом обновлении в нашем посте, который также охватывает их влияние, а также мнения экспертов.
Что такое Noindex Nofollow?
Как упоминалось выше, добавление тега nofollow к странице не препятствует ее полному сканированию.Поэтому, чтобы предотвратить индексирование, вам также нужно не индексировать страницу. Это позволит Google по-прежнему сканировать страницу, но она не будет отображаться в индексе. Страницы, которые вы, вероятно, захотите включить в noindex; страницы администратора / входа, внутренние результаты поиска и страницы регистрации. Чтобы Google полностью прекратил сканирование страницы, вы также должны запретить это (см. Выше).
Другие директивы: Canonical Tags, Pagination и Hreflang
Есть и другие способы сообщить Google и другим поисковым системам, как обрабатывать URL-адреса:
- Канонические теги сообщают поисковым системам, какую страницу из группы похожих страниц следует проиндексировать. Канонизированные (т.е. вторичные страницы, которые направляют поисковые системы к первичной версии) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на свои настольные.
- Разбивка на страницы группирует несколько страниц вместе, чтобы поисковые системы знали, что они являются частью набора. Поисковые системы должны отдавать приоритет первой странице каждого набора при ранжировании страниц, но все страницы в наборе останутся в индексе.
- Hreflang сообщает поисковым системам, какие международные версии одного и того же контента предназначены для какого региона, чтобы они могли определить приоритетность правильной версии для каждой аудитории.Все эти версии останутся в индексе.
 Канонизированные (т.е. вторичные страницы, которые направляют поисковые системы к первичной версии) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на свои настольные.
Канонизированные (т.е. вторичные страницы, которые направляют поисковые системы к первичной версии) не включаются в индекс. Если у вас есть отдельные мобильные и настольные сайты, вы должны канонизировать свои мобильные URL-адреса на свои настольные.Сколько времени вам следует потратить на сокращение краулингового бюджета?
Вы можете услышать много разговоров на форумах SEO о том, насколько важны эффективность сканирования и бюджет сканирования для SEO, и, хотя обычной практикой является запрещение и noindex большие группы страниц, которые не имеют преимуществ для поисковых систем или читателей (например, back -end кода, который используется только для работы сайта или некоторых типов дублированного контента), решение о том, скрывать ли много отдельных страниц, вероятно, не лучший вариант использования времени и усилий..png)
Google любит индексировать как можно больше URL-адресов, поэтому, если нет особой причины скрыть страницу от поисковых систем, обычно можно оставить решение на усмотрение Google. В любом случае, даже если вы скроете страницы от поисковых систем, Google все равно будет проверять, изменились ли эти URL-адреса. Это особенно актуально, если есть ссылки, указывающие на эту страницу; даже если Google забыл об URL-адресе, он может снова обнаружить его в следующий раз, когда на него будет найдена ссылка.
Тестирование с помощью Search Console, DeepCrawl и Robotto
Тестовые роботы.txt с помощью Search Console
Тестер robots.txt в Search Console (в разделе «Сканирование») — популярный и в значительной степени эффективный способ проверить новую версию файла на наличие ошибок до того, как он будет опубликован, или протестировать конкретный URL, чтобы убедиться, что он заблокирован:
Однако этот инструмент не работает точно так же, как Google, с некоторыми небольшими различиями в конфликтующих правилах разрешения / запрета, которые имеют одинаковую длину.
Инструмент тестирования robots.txt сообщает, что они разрешены, однако Google сказал: «Если результат не определен, robots.txt могут разрешить или запретить сканирование. По этой причине не рекомендуется полагаться на то, что какой-либо из результатов будет использоваться повсеместно ».
Подробнее см. В этом обсуждении на справочном форуме в Центре веб-мастеров.
Найти все неиндексируемые страницы с помощью DeepCrawl
Запустите универсальное сканирование без каких-либо ограничений (но с применением условий robots.txt), чтобы DeepCrawl мог вернуть все ваши URL-адреса и показать вам все индексируемые / неиндексируемые страницы.
Если у вас есть параметры URL, которые были заблокированы для робота Google с помощью Search Console, вы можете имитировать эту настройку для сканирования, используя поле «Удалить параметры» в разделе Расширенные настройки> Перезапись URL .
Затем вы можете использовать следующие отчеты, чтобы убедиться, что сайт настроен так, как вы ожидали при первом сканировании, а затем объединить их со встроенными журналами изменений при последующих сканированиях.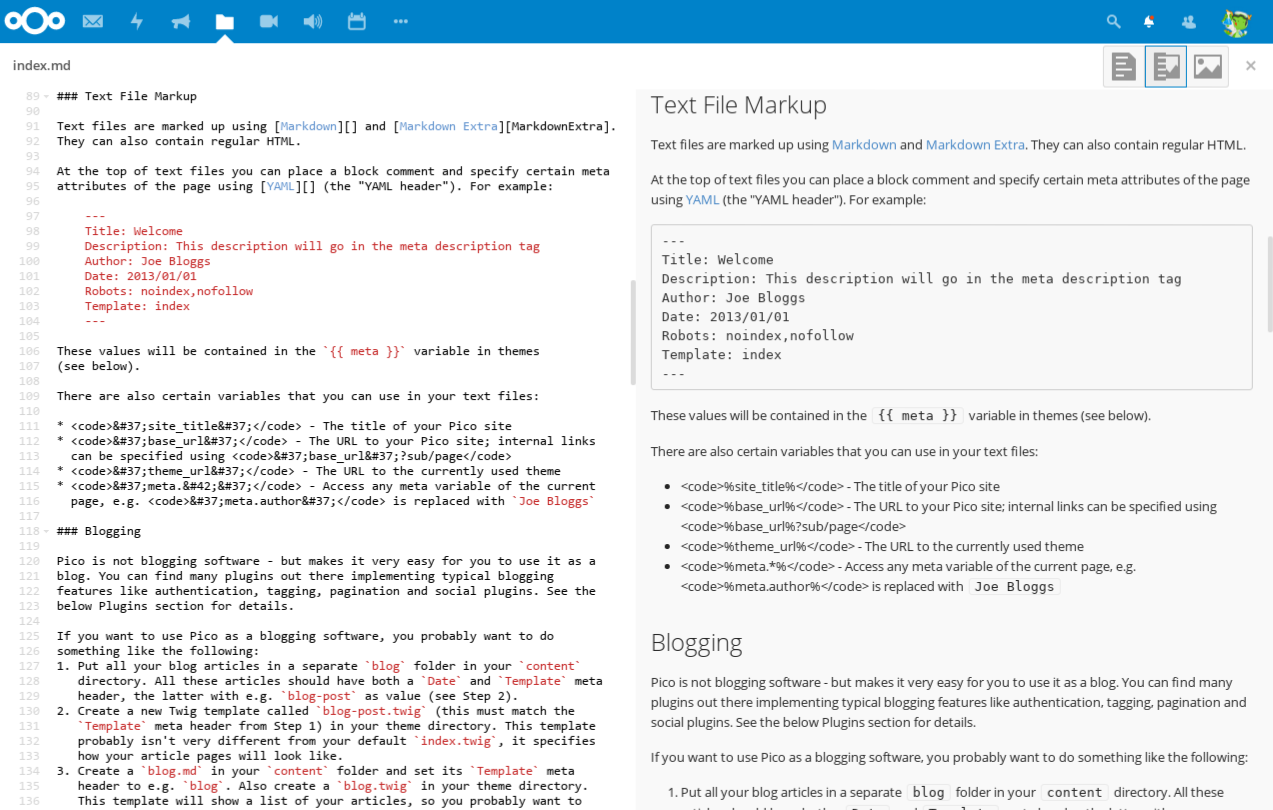
Индексация> Страницы Noindex
В этом отчете будут показаны все страницы, содержащие тег noindex в метаинформации, HTTP-заголовке или файле robots.txt файл.
Индексация> Запрещенные страницы
Этот отчет содержит все URL-адреса, сканирование которых невозможно из-за запрещающего правила в файле robots.txt. На панели управления вашего отчета есть цифры для обоих этих отчетов:
Используйте наши интуитивно понятные отчеты в каждом из наших отчетов, чтобы проверить определенные папки и выявить шаблоны в URL-адресах, которые вы иначе могли бы пропустить:
Протестируйте новый файл robots.txt с помощью DeepCrawl
Используйте роботов DeepCrawl.txt Функция перезаписи в дополнительных настройках для замены живого файла на пользовательский.
Затем при следующем запуске сканирования вы можете использовать тестовую версию вместо активной.
В отчетах о добавленных и удаленных запрещенных URL-адресах будет показано, какие именно URL-адреса были затронуты измененным файлом robots. txt, что упростит оценку.
txt, что упростит оценку.
Для получения дополнительной информации прочтите наше руководство по управлению изменениями robots.txt с помощью DeepCrawl.
Хотите больше такого?
Мы надеемся, что вы нашли этот пост полезным для получения дополнительной информации о noindex, nofollow и disallow для управления сканированием вашего сайта.
Вы можете узнать больше об этих темах в нашей Технической библиотеке SEO или, если вы хотите узнать, как проводить технический SEO-аудит, прочтите наше руководство.
Кроме того, если вы заинтересованы в том, чтобы быть в курсе последних обновлений Google и рекомендациями по передовому опыту, почему бы не заглянуть в наши электронные письма?
Зайди меня!
Автор
Сэм Марсден
Сэм Марсден — менеджер по поисковой оптимизации и контенту DeepCrawl.Сэм регулярно выступает на маркетинговых конференциях, таких как SMX и BrightonSEO, и является автором отраслевых публикаций, таких как Search Engine Journal и State of Digital.
Теги
Управление роботами
Разница между метатегами Noindex и Nofollow
Слышал про index, noindex, follow, nofollow… .и интересно, о чем, черт возьми, люди говорят? Прочтите это руководство, чтобы узнать больше!
NOINDEX
Директива noindex — это часто используемое значение в метатеге, которое может быть добавлено в исходный HTML-код веб-страницы, чтобы предложить поисковым системам (в первую очередь Google) не включать эту конкретную страницу в свой список результатов поиска.
По умолчанию веб-страница настроена на «индексирование». Вам следует добавить директиву на веб-страницу в разделе
Какие примеры страниц следует установить на «noindex»?
- Страницы с благодарностью. Если вы включаете на свой веб-сайт формы сбора потенциальных клиентов, такие как «Свяжитесь с нами» или «Назначьте встречу», вы, вероятно, направите пользователей из своих веб-форм на уникальные страницы с благодарностью после того, как пользователь отправит форму. Наличие уникальных страниц с благодарностью для каждой формы — это лучший способ отслеживать цели и заявки потенциальных клиентов на вашем веб-сайте, но вы не хотите, чтобы посетители попадали на ваши страницы с благодарностью, потому что они включены в индекс Google! Посетитель должен появиться на ваших страницах с благодарностью только после того, как они заполнили вашу веб-форму. Установка для ваших страниц благодарности значения «noindex» поможет предотвратить включение этих страниц в поисковую выдачу.
- страниц только для участников — если у вас есть раздел вашего веб-сайта, посвященный вашим сотрудникам или членам организации, но вы не хотите, чтобы эти веб-страницы были доступны широкой публике или поисковым системам, директива noindex поможет защитить эти страницы от быть найденным в поисковой выдаче.
 Наличие уникальных страниц с благодарностью для каждой формы — это лучший способ отслеживать цели и заявки потенциальных клиентов на вашем веб-сайте, но вы не хотите, чтобы посетители попадали на ваши страницы с благодарностью, потому что они включены в индекс Google! Посетитель должен появиться на ваших страницах с благодарностью только после того, как они заполнили вашу веб-форму. Установка для ваших страниц благодарности значения «noindex» поможет предотвратить включение этих страниц в поисковую выдачу.
Наличие уникальных страниц с благодарностью для каждой формы — это лучший способ отслеживать цели и заявки потенциальных клиентов на вашем веб-сайте, но вы не хотите, чтобы посетители попадали на ваши страницы с благодарностью, потому что они включены в индекс Google! Посетитель должен появиться на ваших страницах с благодарностью только после того, как они заполнили вашу веб-форму. Установка для ваших страниц благодарности значения «noindex» поможет предотвратить включение этих страниц в поисковую выдачу.NOFOLLOW
Директива nofollow — это часто используемое значение в метатеге, которое может быть добавлено в исходный HTML-код веб-страницы, чтобы предложить поисковым системам (в первую очередь Google) не передавать равенство ссылок через какие-либо ссылки на данной веб-странице.
Ссылки — важная часть поисковой оптимизации, хотя эксперты все время спорят о том, какую роль ссылки играют в общем рейтинге. Мы знаем, что ссылки с внешних авторитетных веб-сайтов помогут укрепить доверие к нашему собственному веб-сайту и повысить его рейтинг.Внутренние ссылки тоже полезны! Они помогают пользователям и роботу Google перемещаться по вашему веб-сайту и объединять важные идеи.
По умолчанию ссылки настроены на «подписку». Вы можете установить ссылку на «nofollow» следующим образом: Anchor Text , если вы хотите предложить Google что гиперссылка не должна передавать ссылочной стоимости / ценности SEO целевой ссылке.
Какие примеры ссылок следует установить на «nofollow»?
- Ссылки в комментариях блога — Если вы потратили время на то, чтобы написать ценный пост в блоге для своего веб-сайта, вы не хотите, чтобы конкурент или спамер по ссылкам мог добавить бесполезный комментарий к вашему сообщению в блоге со ссылкой на свой собственный веб-сайт, на котором написано что-то вроде «Отличный блог. Я также написал блог на эту горячую тему »и включил обратную ссылку на его / ее веб-страницу, чтобы он / она извлекли выгоду из ссылки, которую этот человек только что добавил с вашего веб-сайта на свою. Если для этой ссылки установлено значение «nofollow», спамер по ссылкам может сообщить об этом заранее и может не беспокоиться о добавлении комментария «Отличный блог» к вашему сообщению в блоге, зная, что это не принесет пользы для SEO.
- Платные ссылки. Еще одна тактика SEO, завоевавшая популярность в сообществе SEO-специалистов по поисковой оптимизации, — это массовая покупка ссылок в Интернете.Владельцы веб-сайтов со страницей спонсоров на своем сайте могут выбрать включение логотипов и ссылок на свои веб-сайты спонсоров мероприятия, но использовать метатег «nofollow» для каждой ссылки на странице спонсора, чтобы указать Google, что они не могут поручиться за каждую. веб-сайт организации, на который делается ссылка. Имейте в виду, что, хотя ссылки «nofollow» не предназначены для повышения SEO связанного контента, они по-прежнему ценны для взаимодействия с пользователем и привлечения трафика.
 Я также написал блог на эту горячую тему »и включил обратную ссылку на его / ее веб-страницу, чтобы он / она извлекли выгоду из ссылки, которую этот человек только что добавил с вашего веб-сайта на свою. Если для этой ссылки установлено значение «nofollow», спамер по ссылкам может сообщить об этом заранее и может не беспокоиться о добавлении комментария «Отличный блог» к вашему сообщению в блоге, зная, что это не принесет пользы для SEO.
Я также написал блог на эту горячую тему »и включил обратную ссылку на его / ее веб-страницу, чтобы он / она извлекли выгоду из ссылки, которую этот человек только что добавил с вашего веб-сайта на свою. Если для этой ссылки установлено значение «nofollow», спамер по ссылкам может сообщить об этом заранее и может не беспокоиться о добавлении комментария «Отличный блог» к вашему сообщению в блоге, зная, что это не принесет пользы для SEO.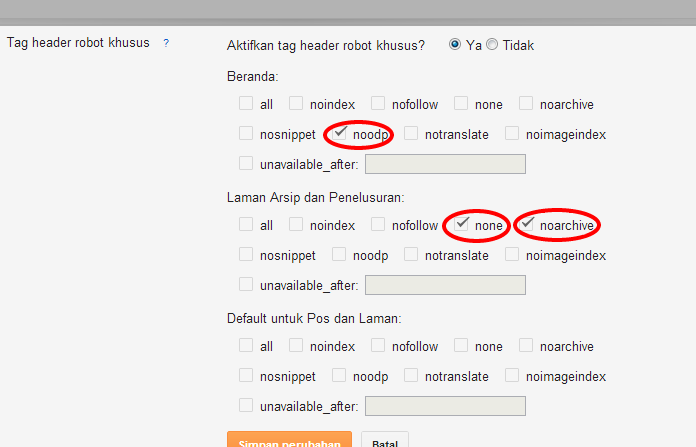
ЗАКЛЮЧЕНИЕ
Надеюсь, это руководство дало вам лучшее понимание noindex vs.nofollow и когда каждый из них может быть полезен. Напоминаем:
- «noindex» предлагает поисковым системам (в первую очередь Google) не индексировать определенную веб-страницу.
- «nofollow» предлагает поисковым системам (в первую очередь Google) не передавать ссылочную массу через ссылки на веб-странице.
Обязательно проконсультируйтесь с квалифицированным агентством цифрового маркетинга при применении директив noindex и nofollow к своему веб-сайту. Если все сделано неправильно, эти маленькие теги могут нанести большой ущерб вашему органическому трафику.
Познакомьтесь с Кэти Хельгесен
Кэти Хельгесен, директор по SEO в Launch Digital Marketing, имеет более чем 15-летний опыт работы в области цифрового маркетинга, SEO и аналитики. Она любит кататься на американских горках, читать, смеяться, спать и проводить время со своим мужем, 3 детьми и 2 собаками. Просмотреть все сообщения Кэти Хельгесен →
Просмотреть все сообщения Кэти Хельгесен →Что такое теги NoIndex и как они влияют на SEO?
Директивы «Без индекса» предписывают поисковым системам исключить страницу из индекса, что делает ее непригодной для отображения в результатах поиска.
«Noindex» Мета-роботы Теги
Самый распространенный способ запретить поисковым системам индексировать страницу — это включить тег Meta Robots в тег
HTML-страницы с помощью директивы noindex, как показано ниже:Примерно в 2007 году основные поисковые системы начали внедрять поддержку директив noindex в тегах Meta Robots. Теги Meta Robots могут также включать другие директивы, такие как директива «follow» или «nofollow», которая предписывает поисковым системам сканировать или не сканировать ссылки, найденные на текущей странице.
Обычно веб-мастера используют директиву noindex для предотвращения индексации контента, не предназначенного для поисковых систем.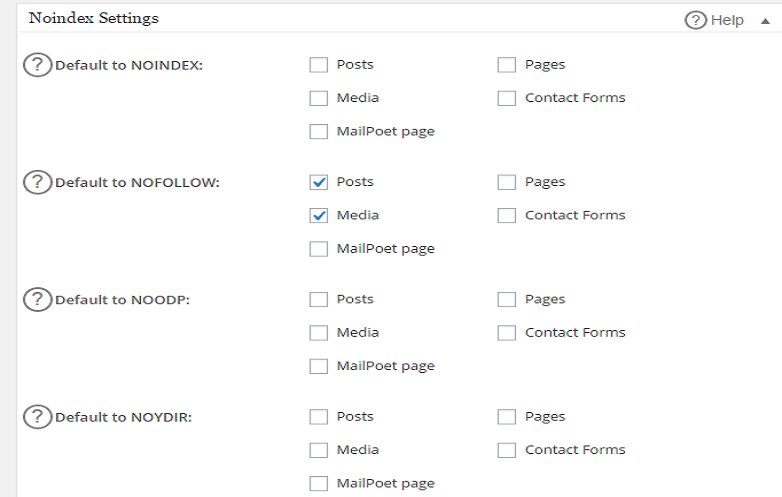
Некоторые распространенные варианты использования директив noindex:
- Страницы, содержащие конфиденциальную информацию
- Корзина покупок или страницы оформления заказа на веб-сайте электронной коммерции
- Альтернативные версии страниц для активных A / B или сплит-тестов
- «Промежуточные» (или незавершенные) версии страниц, еще не готовые для публичного использования
Кроме того, поисковые системы поддерживают директиву noindex, передаваемую через заголовки HTTP-ответа для данной страницы.Хотя этот подход менее распространен и его труднее определить с помощью обычных инструментов SEO, иногда инженерам или веб-мастерам проще включить его в зависимости от конфигурации их сервера.
Имя и значение для заголовка ответа «noindex» следующие:
X-Robots-Tag: noindex
Лучшие практики SEO для директив noindex
1. Избегайте использования «noindex» на ценных страницах.
Случайное включение тега или директивы noindex на ценную страницу может привести к тому, что эта страница будет удалена из индексов поисковой системы и перестанет получать весь органический трафик.
Например, если новая версия веб-сайта запущена, но теги «noindex», которые были включены, чтобы не дать поисковым системам индексировать новые версии страниц до того, как они были готовы, остались на месте, новая версия веб-сайта может немедленно перестать получать трафик. из поиска
2. Поймите, что «noindex» в конечном итоге рассматривается как «nofollow»
Веб-мастера часто использовали теги Meta Robots или заголовки ответов, чтобы сигнализировать поисковым системам, что текущая страница не должна индексироваться, но ссылки на странице должны сканироваться, как со следующим тегом Meta Robots:
Обычно используется для страниц с разбивкой на страницы.Например, «noindex, follow» может применяться к спискам архивов блога, чтобы сами страницы архива не появлялись в результатах поиска, но позволяли поисковым системам сканировать, индексировать и оценивать сами сообщения блога.
Однако этот подход может работать не так, как предполагалось, поскольку Google объяснил, что их системы в конечном итоге обрабатывают директиву «noindex, follow» как «noindex, nofollow» — другими словами, они в конечном итоге перестанут сканировать ссылки на любой странице с директива noindex.Это может помешать вообще проиндексировать страницы назначения ссылок или снизить их PageRank или авторитет, снизив их рейтинг по релевантным ключевым словам.
3. Избегайте использования правил «noindex» в файлах Robots.txt
Хотя никогда официально не поддерживался, поисковые системы какое-то время соблюдали директивы noindex в правилах robots.txt. Поскольку правила robots.txt с подстановочными знаками могут применяться ко многим страницам одновременно без внесения каких-либо изменений в сами страницы, многие веб-мастера предпочли этот метод.Google не рекомендует использовать файлы robots.txt для установки директив noindex и устаревшего кода, который поддерживал эти правила в сентябре 2019 года.
Как сказать Google не индексировать страницу в поиске
Индексирование как можно большего количества страниц вашего веб-сайта может быть очень заманчивым для маркетологов, которые пытаются повысить авторитет своей поисковой системы.
Но, хотя это правда, что публикация большего количества страниц, релевантных для определенного ключевого слова (при условии, что они также высокого качества) улучшит ваш рейтинг по этому ключевому слову, иногда на самом деле больше пользы от сохранения определенных страниц на вашем веб-сайте из из индекс поисковой системы.
… Сказать что ?!
Оставайтесь с нами, ребята. В этом посте вы узнаете, почему вы можете захотеть удалить определенные веб-страницы из SERPS (страниц результатов поисковой системы), и как именно это сделать.
Почему вы хотите исключить определенные веб-страницы из результатов поиска Есть несколько случаев, когда вам может потребоваться исключить веб-страницу или ее часть из сканирования и индексации поисковой системой.
Для маркетологов одной из распространенных причин является предотвращение индексации дублированного контента (когда поисковыми системами проиндексировано несколько версий страницы, как в версии для печати).
Еще один хороший пример? Страница благодарности (то есть страница, на которую посетитель попадает после конверсии на одной из ваших целевых страниц). Обычно здесь посетитель получает доступ к тому предложению, которое обещала целевая страница, например, к ссылке на электронную книгу в формате PDF.
Вот как выглядит страница с благодарностью за нашу электронную книгу с советами по SEO, например:
Вы хотите, чтобы каждый, кто попал на ваши страницы с благодарностью, попал туда, потому что они уже заполнили форму на целевой странице — , а не , потому что они нашли вашу страницу с благодарностью в поиске.
Почему нет? Потому что любой, кто найдет вашу страницу благодарности в поиске, может получить прямой доступ к вашим предложениям по привлечению потенциальных клиентов — без необходимости предоставлять вам свою информацию для прохождения через форму для сбора потенциальных клиентов. Любой маркетолог, понимающий ценность целевых страниц, понимает, насколько важно сначала привлечь этих посетителей в качестве потенциальных клиентов, прежде чем они смогут получить доступ к вашим предложениям.
Любой маркетолог, понимающий ценность целевых страниц, понимает, насколько важно сначала привлечь этих посетителей в качестве потенциальных клиентов, прежде чем они смогут получить доступ к вашим предложениям.
Итог: Если ваши страницы благодарности легко обнаружить с помощью простого поиска в Google, возможно, вы оставляете на столе ценных потенциальных клиентов.
Что еще хуже, вы можете даже обнаружить, что некоторые из ваших страниц с самым высоким рейтингом для некоторых из ваших длиннохвостых ключевых слов могут быть вашими страницами благодарности — а это значит, что вы можете приглашать сотни потенциальных клиентов, чтобы обойти ваши формы для захвата лидов. Это довольно веская причина, по которой вы захотите удалить некоторые свои веб-страницы из поисковой выдачи.
Итак, что делать с «деиндексированием» определенных страниц из поисковых систем? Вот два способа сделать это.
2 способа деиндексировать веб-страницу из поисковых системВариант №1: Добавить роботов.
 txt на свой сайт.
txt на свой сайт.Используйте, если: вам нужен больший контроль над тем, что вы деиндексируете, и у вас есть необходимые технические ресурсы.
Один из способов удалить страницу из результатов поиска — добавить на сайт файл robots.txt. Преимущество использования этого метода заключается в том, что вы можете получить больший контроль над тем, что вы разрешаете индексировать ботам. Результат? Вы можете заранее исключить нежелательный контент из результатов поиска.
В файле robots.txt вы можете указать, хотите ли вы блокировать ботов с одной страницы, со всего каталога или даже с одного изображения или файла.Существует также возможность запретить сканирование вашего сайта, но при этом разрешить работу объявлений Google AdSense, если они у вас есть.
При этом из двух доступных вам вариантов этот требует самого технического кунг-фу. Чтобы узнать, как создать файл robots.txt, прочитайте эту статью из Инструментов Google для веб-мастеров.
Клиенты HubSpot: Здесь вы можете узнать, как установить файл robots. txt на свой веб-сайт, а также узнать, как настроить содержимое роботов.txt здесь.
txt на свой веб-сайт, а также узнать, как настроить содержимое роботов.txt здесь.
Если вам не нужен полный контроль над файлом robots.txt и вы ищете более простое и менее техническое решение, тогда этот второй вариант для вас.
Вариант № 2: Добавьте метатег «noindex» и / или метатег «nofollow».
Используйте, если: вам нужно более простое решение для деиндексации всей веб-страницы и / или деиндексации ссылок на всей веб-странице.
Использование метатега для предотвращения появления страницы в поисковой выдаче и / или в ссылках на странице — это просто и эффективно.Для этого требуется совсем немного технических знаний — на самом деле, это просто копирование / вставка, если вы используете правильную систему управления контентом.
Теги, которые позволяют делать это, называются «noindex» и «nofollow». Прежде чем я перейду к тому, как добавить эти теги, давайте определим их и проведем различие. В конце концов, это две совершенно разные директивы, и их можно использовать как по отдельности, так и вместе друг с другом.
Что такое тег noindex?
Когда вы добавляете метатег «noindex» к веб-странице, он сообщает поисковой системе, что даже если она может сканировать страницу, она не может добавить страницу в свой поисковый индекс.
Таким образом, любая страница с директивой noindex будет , а не попадет в поисковый индекс поисковой системы и, следовательно, не может отображаться на страницах результатов поисковой системы.
Что такое тег «nofollow»?
Когда вы добавляете метатег «nofollow» к веб-странице, запрещает поисковым системам сканировать ссылок на этой странице. Это также означает, что любой рейтинг, который страница имеет в выдаче, будет , а не , будет передан на страницы, на которые она ссылается.
Таким образом, на любой странице с директивой nofollow все ссылки будут игнорироваться Google и другими поисковыми системами.
Когда бы вы использовали «noindex» и «nofollow» по отдельности или вместе?
Как я уже сказал, вы можете добавить директиву noindex либо отдельно, либо вместе с директивой nofollow. Вы также можете добавить директиву nofollow отдельно.
Вы также можете добавить директиву nofollow отдельно.
Добавьте только тег «noindex»: , если вы, , не хотите, чтобы поисковая система индексировала вашу веб-страницу в поиске, но вы, , хотите, чтобы переходила по ссылкам на этой странице, тем самым давая рейтинг на другие страницы, на которые ссылается ваша страница.
Платные целевые страницы — отличный тому пример. Вы не хотите, чтобы поисковые системы индексировали целевые страницы в поиске, за просмотр которых люди должны платить, но вы можете захотеть, чтобы страницы, на которые они ссылаются, извлекали выгоду из его авторитета.
Добавьте только тег «nofollow»: , когда вы хотите, чтобы поисковая система проиндексировала вашу веб-страницу в поиске, но вы, , не хотите, чтобы переходила по ссылкам на этой странице.
Не так много примеров, когда вы добавляете тег «nofollow» на всю страницу без добавления тега «noindex».Когда вы выясняете, что делать на данной странице, больше вопрос в том, добавлять ли ваш тег «noindex» с тегом «nofollow» или без него.
Добавьте теги «noindex» и «nofollow»: , если вы, , не хотите, чтобы поисковые системы индексировали веб-страницу в поиске, и вы не хотите, чтобы они переходили по ссылкам на этой странице.
Страницы с благодарностями — отличный пример такого рода ситуаций. Вы не хотите, чтобы поисковые системы индексировали вашу страницу с благодарностью, и вы также не хотите, чтобы они перешли по ссылке на ваше предложение и начали индексировать содержание этого предложения.
Как добавить метатег «noindex» и / или «nofollow»
Шаг 1: Скопируйте один из следующих тегов.
Для «noindex»:
Для «nofollow»:
Для noindex и nofollow:
Шаг 2: Добавьте тег в раздел
HTML-кода вашей страницы, a.k.a. заголовок страницы.
Если вы являетесь клиентом HubSpot, это очень просто — щелкните здесь или прокрутите вниз, чтобы просмотреть инструкции, предназначенные для пользователей HubSpot.
Если вы , а не клиент HubSpot, , вам придется вручную вставить этот тег в код на своей веб-странице. Не волнуйтесь — это довольно просто. Вот как ты это делаешь.
Сначала откройте исходный код веб-страницы, которую вы пытаетесь деиндексировать. Затем вставьте полный тег в новую строку в разделе
HTML-кода вашей страницы, известном как заголовок страницы.Скриншоты ниже помогут вам в этом.Тег
обозначает начало вашего заголовка:Вот метатег для «noindex» и «nofollow», вставленный в заголовок:
И тег означает конец заголовка:
Бум! Это оно. Этот тег указывает поисковой системе развернуться и уйти, оставив страницу вне результатов поиска.
Клиенты HubSpot: Добавить метатеги noindex и nofollow стало еще проще.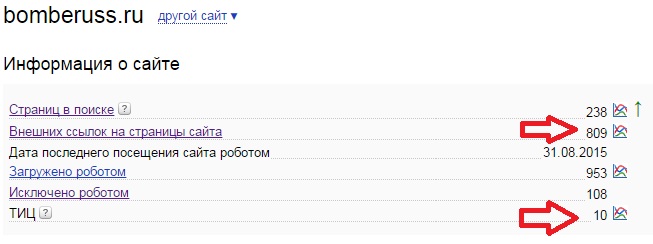 Все, что вам нужно сделать, это открыть инструмент HubSpot на странице, на которую вы хотите добавить эти теги, и выбрать вкладку «Настройки».
Все, что вам нужно сделать, это открыть инструмент HubSpot на странице, на которую вы хотите добавить эти теги, и выбрать вкладку «Настройки».
Затем прокрутите вниз до Advanced Options и нажмите «Edit Head HTML». В появившемся окне вставьте соответствующий фрагмент кода. В приведенном ниже примере я добавил теги «noindex» и «nofollow», поскольку это страница с благодарностью.
Нажмите «Сохранить», и вы золотые.
Ta Da!
Вы только что волшебным образом удалили свою страницу из результатов поиска.Теперь вы можете снова начать собирать больше потерянных потенциальных клиентов.
Имейте в виду, что вы не увидите результаты мгновенно. Ваши изменения не вступят в силу до тех пор, пока поисковая система не просканирует вашу страницу в следующий раз. В зависимости от того, как часто вы обычно публикуете новые страницы на своем веб-сайте, на самом деле это может занять несколько недель. Чем чаще вы публикуете контент, тем чаще поисковые системы будут сканировать ваш сайт. Лучший способ отслеживать, как часто Google посещает ваш веб-сайт, — это просматривать статистику сканирования в Инструментах Google для веб-мастеров.
Лучший способ отслеживать, как часто Google посещает ваш веб-сайт, — это просматривать статистику сканирования в Инструментах Google для веб-мастеров.
Итог: если вы заметили, что ваша страница все еще отображается в результатах поиска Google даже с тегом «noindex», вероятно, это потому, что Google не сканировал ваш сайт с тех пор, как вы добавили этот тег. Вы можете запросить у Google повторное сканирование вашей страницы с помощью инструмента Fetch as Google.
Также обратите внимание, что веб-сканеры некоторых поисковых систем могут интерпретировать эти директивы иначе, чем Google, поэтому возможно, что ваша страница все еще может отображаться в результатах других поисковых систем.Но для Google он будет работать нормально — как только он просканирует ваш сайт. Если вы хотите узнать, как поисковые системы сканируют, индексируют и обслуживают контент, пройдите наш курс по SEO.
Тем не менее, вы сможете спать немного легче, зная, что в конечном итоге вы сделали свой веб-сайт лучшим местом для маркетинга.
Какие еще советы вы можете дать по деиндексации веб-страниц и когда это будет полезно для маркетологов? Поделитесь своими мыслями в комментариях.
noindex, nofollow, noarchive, noodp & noydir
Метатег для роботов контролирует сканирование и индексацию вашей веб-страницы или публикации «пауками».В этом посте мы подробно рассмотрим все типы тегов. Мы можем использовать более одного метатега на веб-странице, но это не очень хорошая практика, потому что это может вызвать конфликты. Следовательно, это должно происходить только один раз на веб-странице.
Мета-тег роботов по умолчанию
Если вы не укажете какой-либо метатег на веб-странице, то по умолчанию Spider будет сканировать и индексировать вашу веб-страницу. можно сказать, что по умолчанию он учитывает метатег ниже.
Мета-роботы noindex
Предотвращает индексацию страницы.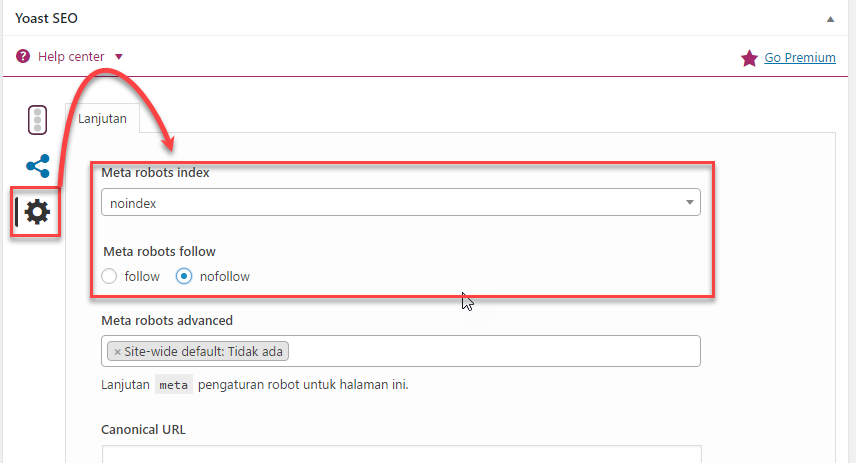 Это означает, что если вы укажете ниже метатег для страницы, эта страница не будет отображаться в результатах поиска. Например: вы не хотите, чтобы страницы с вашими авторами появлялись в результатах поиска, поэтому для предотвращения этого вы можете использовать метатег роботов ниже на страницах авторов.
Это означает, что если вы укажете ниже метатег для страницы, эта страница не будет отображаться в результатах поиска. Например: вы не хотите, чтобы страницы с вашими авторами появлялись в результатах поиска, поэтому для предотвращения этого вы можете использовать метатег роботов ниже на страницах авторов.
Мета-роботы nofollow
Этот метатег запрещает паукам переходить по любой ссылке на странице. Если вы новичок, это может вас сбить с толку.Позвольте мне объяснить вам подробно. Каждый раз, когда паук (бот Google) находит ссылку (внутреннюю или внешнюю) на странице, он попадает на эту веб-страницу для сканирования и индексации, чтобы заставить паука не переходить по какой-либо ссылке на странице, мы можем использовать этот тег. Чтобы лучше понять это, вы можете обратиться к моему посту Dofollow vs nofollow.
Мета-роботы noarchive
Вы должны были видеть в результатах поиска, что всякий раз, когда вы наводите курсор на какой-либо результат, он показывает снимок этой страницы в правой части поиска Google ( см.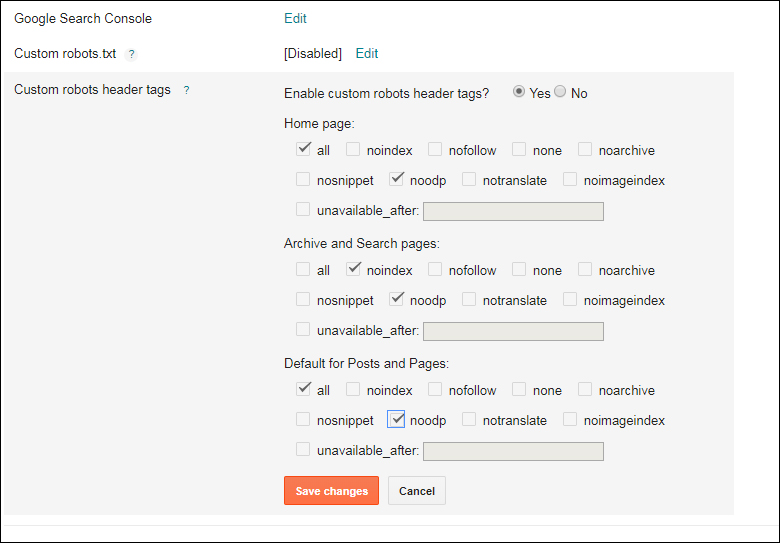 Снимок экрана ниже !! ).Это мы называем кэшированной копией веб-страницы. Чтобы предотвратить кеширование страницы, мы можем указать тег ниже.
Снимок экрана ниже !! ).Это мы называем кэшированной копией веб-страницы. Чтобы предотвратить кеширование страницы, мы можем указать тег ниже.
Мета-роботы noodp
Запрещает поисковой системе (Google, Yahoo и MSN) отображать собственное описание, взятое из его каталога, вместо вашего метаописания. Использование тега ниже гарантирует, что поисковая система будет отображать ваше метаописание под результатами поиска, и было бы полезно улучшить ваш CTR.
Мета-роботы нойдир
Это то же самое, что и вышеупомянутый тег NOODP, с той лишь разницей, что он применим только для Yahoo.
Лучшая практика для использования noodp и noydir: Вы можете использовать следующий тег для всех своих веб-страниц —
ИЛИ (над тегом и под двумя тегами — оба одинаковые)
Что делать, если на странице более одного мета-тега роботов
Мы должны использовать его только один раз на странице и это лучшая практика, но иногда из-за комбинации SEO-дружественных тем и SEO-плагинов у нас может быть несколько экземпляров таких тегов. Поэтому для таких случаев давайте обсудим, как это интерпретируют пауки (или краулеры).
Поэтому для таких случаев давайте обсудим, как это интерпретируют пауки (или краулеры).
CASE 1: Нет конфликтующих значений в метатеге robots.
Приведенные выше два тега будут взяты так же, как:
CASE 2: Значение конфликтов присутствует в метатеге robots.
Первый экземпляр:
Второй экземпляр:
В этом случае оба значения конфликтуют, поскольку одно сообщает noindex, а другое заставляет паука индексировать страницу. В таких случаях краулеры рассматривают первый случай конфликта.
Таким образом, бот поисковой системы будет принимать его как , потому что noindex encountres раньше, чем индекс один.
Как заблокировать конкретного бота поисковой системы
Указывая мета-имя как «robots», вы фактически блокируете всех роботов поисковых систем. Однако, если вы хотите заблокировать определенного бота поисковой системы, вы можете указать имя бота вместо «роботы»
Имя BOT:
Google: GOOGLEBOT
Yahoo: SLURP
MSN: MSNBOT
СПРОСИТЬ: TEOMA
Итак, если вы хотите сделать свою страницу nofollow только для бота Google, вы можете использовать тег ниже.
Примечание. В мета-имени я дал «Googlebot» вместо «robots», чтобы сделать его применимым только для бота поисковой системы Google.
Номер ссылки
Мета-тег роботов: блог Google для веб-мастеров
<Кредит изображения>
Canonical, NoIndex, NoFollow & Robots.txt
Каждую неделю мы получаем вопросы о том, какие метатеги следует использовать на сайте для достижения результата X. Во многих случаях люди пытаются решать относительно простые задачи слишком сложными методами. Когда дело доходит до SEO, лучшее сообщение, которое вы можете отправить поисковым системам, — самое простое.
Во многих случаях люди пытаются решать относительно простые задачи слишком сложными методами. Когда дело доходит до SEO, лучшее сообщение, которое вы можете отправить поисковым системам, — самое простое.
Вот простая разбивка по назначению каждого тега, включая примеры того, когда и как их следует использовать.
rel = «canonical»
Вероятно, наиболее неправильно понимаемый метатег, rel = «canonical», кажется, всплывает повсюду — и редко там, где должен!
Предполагаемая цель: Сообщать поисковым системам об исходном источнике контента, когда существует 2 или более копий этого контента.
Наилучшее использование: Чтобы отдать должное первоисточнику контента, когда вы повторно публикуете этот контент на другой странице того же сайта или на другом сайте.
Распространенное неправильное использование: Реализация канонических тегов на страницах, которые выглядят одинаково, но на самом деле не дублируют контент, например страницы со списками с разбивкой на страницы или подробное содержимое с вкладками. rel = «canonical» следует использовать только в том случае, если содержимое практически идентично.
rel = «canonical» следует использовать только в том случае, если содержимое практически идентично.
Noindex
Тег noindex на самом деле является сообщением ботам с просьбой не включать страницу в индекс.Обратите внимание, что неиндексированные страницы будут сканироваться.
Предполагаемая цель: Попросить поисковые системы исключить определенную страницу (или набор страниц) из результатов поиска.
Наилучшее использование: Для удаления страниц, которые вы не хотите включать в результаты поисковой системы, таких как продвижение, срок действия которого истек. Noindex также можно использовать для исключения ваших низкоэффективных или «слишком похожих, но конкурирующих» страниц из поисковой выдачи. Примечание: неправильное выполнение этого действия может иметь катастрофические последствия для сайта; всегда сначала консультируйтесь с надежным экспертом по SEO.
Распространенное неправильное использование: Использование noindex для скрытия личных документов.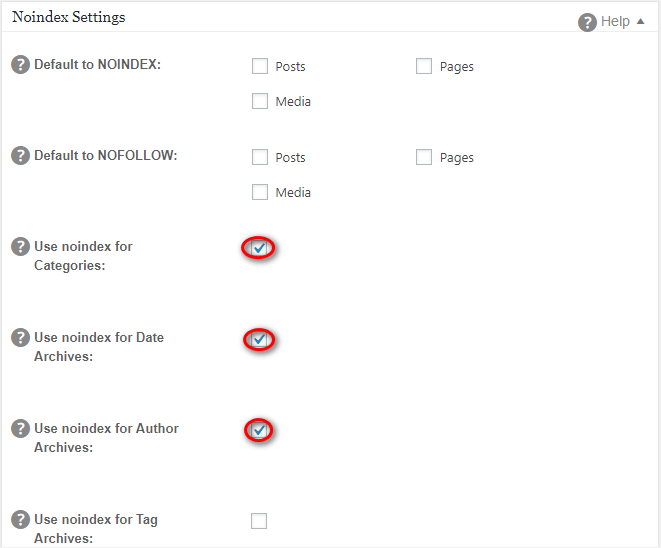 Google уважает запросы noindex, но не все роботы поисковых систем так почетны.
Google уважает запросы noindex, но не все роботы поисковых систем так почетны.
Robots.txt
Robots.txt на самом деле не является метатегом, но он часто всплывает при их обсуждении! Файл robots.txt сообщает Google не сканировать определенные страницы (или разделы сайта), но разрешает индексацию этих страниц.
Назначение: Чтобы роботы поисковых систем не тратили время зря на сканирование страниц низкой важности.
Наилучшее использование: Не используйте. Большинству сайтов он не нужен. Если вам нужен файл robots.txt, используйте его, чтобы попросить сканеров не тратить свое время, посвященное вашему сайту, на страницах или разделах, которые не имеют большого значения.
Распространенное неправильное использование: Использование robots.txt вместо noindex для исключения результатов из поисковой выдачи. Кроме того, использование robots.txt для сокрытия личных документов — поисковые системы часто по-прежнему включают URL-адреса этих страниц в результаты поиска.
Nofollow
Тег nofollow не позволяет поисковым системам «переходить» по ссылке и, следовательно, читать содержимое или передавать информацию о содержании ссылки и тексте привязки.Исторически это означало, что ссылочный вес останется на вашей странице, но обновления, сделанные в последние годы, означают, что вместо этого уменьшается количество ссылок.
Предполагаемая цель: Запрашивать поисковые системы не переходить по определенной ссылке или всем ссылкам на данной странице.
Лучшее использование: Для пометки платной рекламы или ссылок на контент, который вы не контролируете. Его также можно использовать, чтобы попросить поисковые системы не переходить по ссылкам на страницы с низким приоритетом на сайте, такие как страницы входа в панель управления или страницы с разбивкой на страницы.
Распространенное неправильное использование: Использование nofollow для значительного моделирования внутренних ссылок вместо создания логической структуры навигации для сайта.