Создать robots.txt онлайн
Чтобы активировать PRO версию программы достаточно только нажать и поделиться страницей через социальные сети выше.
Robots.txt является обыкновенным текстовым файлом, располагающимся в корне вашего сайта, просмотреть и отредактировать его можно используя любой текстовый редактор. В данном файлике записаны инструкции, которыми должны руководствоваться поисковые машины (роботы). Собственно, отсюда и пошло название этого документа. Инструкции эти указывают поисковику, что подлежит индексированию, а что трогать не нужно. Наверное, каждый вебмастер хотел бы, чтобы созданный им сайт как можно быстрее был проиндексирован поисковой системой, причем чтобы этот процесс прошел правильно и без ошибок. Поэтому, нужно понимать, что без грамотно составленного файла robots.txt это маловероятно, следовательно, нужно позаботиться о его создании. Конечно же вы можете самостоятельно написать данный файл, к тому же примеров в сети очень много. Но, намного правильнее и быстрее будет воспользоваться нашим инструментомЕсть ли какие-то отличия Robots.txt для Яндекса в сравнении с файлами для других роботов?
На самом деле каждая поисковая машина использует разные методы индексирования, и вообще работают они по-разному. Каждый поисковик имеет свои методики ранжирования, присвоения сайтам определенного места в своем списке. Однако, практически все они одинаково индексируют и понимают файл Robots.txt. Практика свидетельствует, что один файл Robots.txt подходит абсолютно ко всем поисковым системам и с ним не возникает никаких проблем.Есть ли возможность проверить существующий файл Robots.txt?
Если вы сами писали данный файл, или использовали другой генератор, и сомневаетесь в его работоспособности, то можете проверить его с помощью специального сервиса на нашем сайте. Если в ходе такой проверки обнаружатся те или иные проблемы, то вы с легкостью сможете сгенерировать новый файлик воспользовавшись нашим инструментом. Специалисты всегда рекомендуют проверять самодельные файлы Robots.txt с помощью уже проверенных генераторов, чтобы избежать возможных проблем в будущем.Создание robots.txt онлайн
Запрет индексации для следующих ботов:
Для всех
Яндекс
Google
Mail.ru
Рабмлер
Бинг
Yahoo
Основной домен сайта:
Таймаут между переходами робота по страницам:
1 секунда5 секунд10 секунд60 секунд
| Запрет индексации разделов, страниц: | Пример: /contacts/ /category1/ /category2/ /page.html |
Готовый robots.txt:
Сохраните данные в файл «robots.txt» и скопируйте в конревую папку сайта.
Для чего предназначен инструмент «Генератор robots.txt»
Сервис cy-pr.com представляет вам инструмент «Генератор robots.txt», с помощью которого можно в режиме онлайн за несколько секунд создать файл robots.txt, а также установить запрет на индексацию страниц сайта определенными поисковыми системами.
Что такое robots.txt
Robots.txt – это файл, который расположен в корне сайта и в котором содержатся указания для поисковых ботов. Заходя на любой ресурс, роботы начинают с ним знакомство с файла robots.txt – своеобразной «инструкции по применению». Издатель указывает в данном файле, как роботу необходимо взаимодействовать с ресурсом. Например, здесь может содержаться запрет индексации некоторых страниц или рекомендация о соблюдении временного интервала между сохранением документов с веб-сервера.
Возможности инструмента
Веб-мастер может установить запрет на индексацию роботами поисковых систем Яндекс, Google, Mail.ru, Рамблер, Bing или Yahoo!, а также задать тайм-аут между переходами поискового робота по страницам ресурса и запретить индексацию избранных страниц сайта. Кроме этого, в специальной строке можно указать поисковым роботам путь к карте сайта (sitemap.xml).
После того, как вы заполните все поля инструмента и нажмете кнопку «Создать», система автоматически сгенерирует файл для поисковых ботов, который вы должны будете разместить в корневой зоне вашего сайта.
Обратите внимание, что файл robots.txt нельзя применять для скрытия страницы из результатов поиска, потому что на нее могут ссылаться иные ресурсы, и поисковые роботы так или иначе ее проиндексируют. Напоминаем, что для блокировки страницы в результатах поисковой выдачи используется специальный тег «noindex» или устанавливается пароль.
Стоит также отметить, что с помощью инструмента «Генератор robots.txt» вы создадите файл исключительно рекомендательного характера. Само собой, боты «прислушиваются» к указаниям, оставленным для них веб-мастерами в файле robots.txt, но иногда игнорируют их. Почему так происходит? Потому, что каждый поисковый робот имеет свои настройки, согласно которым он интерпретирует информацию, полученную из файла robots.txt.
www.cy-pr.com
Создать Robots.txt онлайн — автоматическая генерация
Автоматическая генерация robots.txt подходит лишь для базового создания файла. Для тонкой настройки нужен анализ структуры сайта и директорий, которые необходимо скрыть от поисковых систем во избежании дублей в индексе и исключения попадания в поисковую базу лишней информации.
Онлайн-генератор Robots.txt — поля заполняйте последовательно:
Откройте текстовый редактор, вставьте в него полученный результат и сохраните файл под именем robots.txt
После этого разместите файл в корневой директории вашего сайта. Файл должен быть доступен по ссылке http://ваш-сайт.com/robots.txt
Пояснения к атрибутам для файла Robots.txt
Директива «User-agent» — указывает для бота какой поисковой системы действуют расположенные ниже предписания. Файл Robots.txt можно создавать как с едиными для всех поисковых роботов указаниями, так и с отдельными предписаниями для каждого бота.
Директива «Disallow» — данная директива указывает какие каталоги и фалы запрещено индексировать поисковикам. Если вы создаете отдельные предписания для каждого поискового бота, то для каждого такого предписания создаются отдельные правила «Disallow». Этой директивой можно запретить индексировать сайт полностью (Disallow: /) или запрещать индексирование отдельных каталогов. В случае запрета индексации отдельных директорий количество предписаний «Disallow» может быть неограниченным.
Директива «Host» определяет главное зеркало сайта. Сайт может быть доступен по 2-м адресам: «с WWW» и «без WWW». Если файл Robots.txt отсутствует на сервере или в нем не заполнена запись «Host», роботы поисковых систем определяют главное зеркало для сайта по своему усмотрению, но если вы хотите сделать это самостоятельно вам следует указать это правило в директиве «Host».
Директива «Sitemap» указывает по какому пути находится файл Sitemap.xml (карта сайта). Этот файл существенно облегчает и ускоряет индексацию сайта роботами поисковых систем. Особенно важен файл Sitemap.xml для сайтов с большим количеством страниц и сложной структурой (высокий уровень вложенности).
Совет SEO-специалиста: Файл Robots.txt очень важен при продвижении сайта, т.к. он указывает поисковым системам Ваши пожелания по индексации/запрету_индексации разделов Вашего сайта. Поисковики не гарантируют соблюдение предписаний в robots.txt, но учитывают их при индексации. Для сайтов, созданных на популярных CMS, обычно есть готовые варианты файлов robots.txt, но если Вы делали доработки функционала, то может потребоваться его ручная корректировка.
mediasova.com
Создание robots.txt онлайн
Запрет индексации для следующих ботов:
Яндекс
Mail.ru
Рабмлер
Бинг
Yahoo
Основной домен сайта:
Таймаут между переходами робота по страницам:
1 секунда5 секунд10 секунд60 секунд
| Запрет индексации разделов, страниц: | Пример: /contacts/ /category1/ /category2/ /page.html |
Готовый robots.txt:
Сохраните данные в файл «robots.txt» и скопируйте в конревую папку сайта.
Для чего предназначен инструмент «Генератор robots.txt»
Сервис cy-pr.com представляет вам инструмент «Генератор robots.txt», с помощью которого можно в режиме онлайн за несколько секунд создать файл robots.txt, а также установить запрет на индексацию страниц сайта определенными поисковыми системами.
Что такое robots.txt
Robots.txt – это файл, который расположен в корне сайта и в котором содержатся указания для поисковых ботов. Заходя на любой ресурс, роботы начинают с ним знакомство с файла robots.txt – своеобразной «инструкции по применению». Издатель указывает в данном файле, как роботу необходимо взаимодействовать с ресурсом. Например, здесь может содержаться запрет индексации некоторых страниц или рекомендация о соблюдении временного интервала между сохранением документов с веб-сервера.
Возможности инструмента
Веб-мастер может установить запрет на индексацию роботами поисковых систем Яндекс, Google, Mail.ru, Рамблер, Bing или Yahoo!, а также задать тайм-аут между переходами поискового робота по страницам ресурса и запретить индексацию избранных страниц сайта. Кроме этого, в специальной строке можно указать поисковым роботам путь к карте сайта (sitemap.xml).
После того, как вы заполните все поля инструмента и нажмете кнопку «Создать», система автоматически сгенерирует файл для поисковых ботов, который вы должны будете разместить в корневой зоне вашего сайта.
Обратите внимание, что файл robots.txt нельзя применять для скрытия страницы из результатов поиска, потому что на нее могут ссылаться иные ресурсы, и поисковые роботы так или иначе ее проиндексируют. Напоминаем, что для блокировки страницы в результатах поисковой выдачи используется специальный тег «noindex» или устанавливается пароль.
Стоит также отметить, что с помощью инструмента «Генератор robots.txt» вы создадите файл исключительно рекомендательного характера. Само собой, боты «прислушиваются» к указаниям, оставленным для них веб-мастерами в файле robots.txt, но иногда игнорируют их. Почему так происходит? Потому, что каждый поисковый робот имеет свои настройки, согласно которым он интерпретирует информацию, полученную из файла robots.txt.
www.cy-pr.com
Генератор robots.txt 🔧
Запрет индексации для следующих ботов:
Для всех
Яндекс
Google
Mail.ru
Рабмлер
Бинг
Yahoo
Основной домен сайта:
Таймаут между переходами робота по страницам:
1 секунда5 секунд10 секунд60 секунд
| Запрет индексации разделов, страниц: | Пример: /contacts/ /category1/ /category2/ /page.html |
Готовый robots.txt:
Сохраните данные в файл «robots.txt» и скопируйте в конревую папку сайта.
Для чего предназначен инструмент «Генератор robots.txt»
С помощью «Генератор robots.txt» можно в режиме онлайн за несколько секунд создать файл robots.txt, а также установить запрет на индексацию страниц сайта определенными поисковыми системами.
Что такое robots.txt
Robots.txt – это файл, который расположен в корне сайта и в котором содержатся указания для поисковых ботов. Заходя на любой ресурс, роботы начинают с ним знакомство с файла robots.txt – своеобразной «инструкции по применению». Издатель указывает в данном файле, как роботу необходимо взаимодействовать с ресурсом. Например, здесь может содержаться запрет индексации некоторых страниц или рекомендация о соблюдении временного интервала между сохранением документов с веб-сервера.
Возможности инструмента
Веб-мастер может установить запрет на индексацию роботами поисковых систем Яндекс, Google, Mail.ru, Рамблер, Bing или Yahoo!, а также задать тайм-аут между переходами поискового робота по страницам ресурса и запретить индексацию избранных страниц сайта. Кроме этого, в специальной строке можно указать поисковым роботам путь к карте сайта (sitemap.xml).
После того, как вы заполните все поля инструмента и нажмете кнопку «Создать», система автоматически сгенерирует файл для поисковых ботов, который вы должны будете разместить в корневой зоне вашего сайта.
Обратите внимание, что файл robots.txt нельзя применять для скрытия страницы из результатов поиска, потому что на нее могут ссылаться иные ресурсы, и поисковые роботы так или иначе ее проиндексируют. Напоминаем, что для блокировки страницы в результатах поисковой выдачи используется специальный тег «noindex» или устанавливается пароль.
Стоит также отметить, что с помощью инструмента «Генератор robots.txt» вы создадите файл исключительно рекомендательного характера. Само собой, боты «прислушиваются» к указаниям, оставленным для них веб-мастерами в файле robots.txt, но иногда игнорируют их. Почему так происходит? Потому, что каждый поисковый робот имеет свои настройки, согласно которым он интерпретирует информацию, полученную из файла robots.txt.
i-leon.ru
Как составить robots.txt самостоятельно
Как правильно составить robots.txt и зачем он нужен, как закрыть индексацию через robots.txt и бесплатно проверить robots.txt с помощью онлайн-инструментов.
Как поисковики сканируют страницу
Роботы-краулеры Яндекса и Google посещают страницы сайта, оценивают содержимое, добавляют новые ресурсы и информацию о страницах в индексную базу поисковика. Боты посещают страницы регулярно, чтобы переносить в базу обновления контента, отмечать появление новых ссылок и их доступность.
Зачем нужно сканирование:
- Собрать данные для построения индекса — информацию о новых страницах и обновлениях на старых.
- Сравнить URL в индексе и в списке для сканирования.
- Убрать из очереди дублирующиеся URL, чтобы не скачивать их дважды.
Боты смотрят не все страницы сайта. Количество ограничено краулинговым бюджетом, который складывается из количества URL, которое может просканировать бот-краулер. Бюджета на объемный сайт может не хватить. Есть риск, что краулинговый бюджет уйдет на сканирование неважных или «мусорных» страниц, а чтобы такого не произошло, веб-мастеры направляют краулеров с помощью файла robots.txt.
Боты переходят на сайт и находят в корневом каталоге файл robots.txt, анализируют доступ к страницам и переходят к карте сайта — Sitemap, чтобы сократить время сканирования, не обращаясь к закрытым ссылкам. После изучения файла боты идут на главную страницу и оттуда переходят в глубину сайта.
Какие страницы краулер просканирует быстрее:
- Находятся ближе к главной.
Чем меньше кликов с главной ведет до страницы, тем она важнее и тем вероятнее ее посетит краулер. Количество переходов от главной до текущей страницы называется Click Distance from Index (DFI). - Имеют много ссылок.
Если многие ссылаются на страницу, значит она полезная и имеет хорошую репутацию. Нормальным считается около 11-20 ссылок на страницу, перелинковка между своими материалами тоже считается. - Быстро загружаются.
Проверьте скорость загрузки инструментом, если она медленная — оптимизируйте код верхней части и уменьшите вес страницы.
Все посещения ботов-краулеров не фиксируют такие инструменты, как Google Analytics, но поведение ботов можно отследить в лог-файлах. Некоторые SEO-проблемы крупных сайтов можно решить с помощью анализа лог-файлов который также поможет увидеть проблемы со ссылками и распределение краулингового бюджета.
Посмотреть на сайт глазами поискового бота
Robots.txt для Яндекса и Google
Веб-мастеры могут управлять поведением ботов-краулеров на сайте с помощью файла robots.txt. Robots.txt — это текстовый файл для роботов поисковых систем с указаниями по индексированию. В нем написано какие страницы и файлы на сайте нельзя сканировать, что позволяет ботам уменьшить количество запросов к серверу и не тратить время на неинформативные, одинаковые и неважные страницы.
В robots.txt можно открыть или закрыть доступ ко всем файлам или отдельно прописать, какие файлы можно сканировать, а какие нет.
Требования к robots.txt:
- файл называется «robots.txt«, название написано только строчными буквами, «Robots.TXT» и другие вариации не поддерживаются;
- располагается только в корневом каталоге — https://site.com/robots.txt, в подкаталоге быть не может;
- на сайте в единственном экземпляре;
- имеет формат .txt;
- весит до 32 КБ;
- в ответ на запрос отдает HTTP-код со статусом 200 ОК;
- каждый префикс URL на отдельной строке;
- содержит только латиницу.
Если домен на кириллице, для robots.txt переведите все кириллические ссылки в Punycode с помощью любого Punycode-конвертера: «сайт.рф» — «xn--80aswg.xn--p1ai».
Robots.txt действует для HTTP, HTTPS и FTP, имеет кодировку UTF-8 или ASCII и направлен только в отношении хоста, протокола и номера порта, где находится.
Его можно добавлять к адресам с субдоменами — http://web.site.com/robots.txt или нестандартными портами — http://site.com:8181/robots.txt. Если у сайта несколько поддоменов, поместите файл в корневой каталог каждого из них.
Как исключить страницы из индексации с помощью robots.txt
В файле robots.txt можно запретить ботам индексацию некоторого контента.
Яндекс поддерживает стандарт исключений для роботов (Robots Exclusion Protocol). Веб-мастер может скрыть содержимое от индексирования ботами Яндекса, указав директиву «disallow». Тогда при очередном посещении сайта робот загрузит файл robots.txt, увидит запрет и проигнорирует страницу. Другой вариант убрать страницу из индекса — прописать в HTML-коде мета-тег «noindex» или «none».
Google предупреждает, что robots.txt не предусмотрен для блокировки показа страниц в результатах выдачи. Он позволяет запретить индексирование только некоторых типов контента: медиафайлов, неинформативных изображений, скриптов или стилей. Исключить страницу из выдачи Google можно с помощью пароля на сервере или элементов HTML — «noindex» или атрибута «rel» со значением «nofollow».
Если на этом или другом сайте есть ссылка на страницу, то она может оказаться в индексе, даже если к ней закрыт доступ в файле robots.txt.
Закройте доступ к странице паролем или «nofollow» , если не хотите, чтобы она попала в выдачу Google. Если этого не сделать, ссылка попадет в результаты но будет выглядеть так:
 Доступная для пользователей ссылка
Доступная для пользователей ссылкаТакой вид ссылки означает, что страница доступна пользователям, но бот не может составить описание, потому что доступ к ней заблокирован в robots.txt.
Содержимое файла robots.txt — это указания, а не команды. Большинство поисковых ботов, включая Googlebot, воспринимают файл, но некоторые системы могут его проигнорировать.
Если нет доступа к robots.txt
Если вы не имеете доступа к robots.txt и не знаете, доступна ли страница в Google или Яндекс, введите ее URL в строку поиска.
На некоторых сторонних платформах управлять файлом robots.txt нельзя. К примеру, сервис Wix автоматически создает robots.txt для каждого проекта на платформе. Вы сможете посмотреть файл, если добавите в конец домена «/robots.txt».
В файле будут элементы, которые относятся к структуре сайтов на этой платформе, к примеру «noflashhtml» и «backhtml». Они не индексируются и никак не влияют на SEO.
Если нужно удалить из выдачи какие-то из страниц ресурса на Wix, используйте «noindex».
Как составить robots.txt правильно
Файл можно составить в любом текстовом редакторе и сохранить в формате txt. В нем нужно прописать инструкцию для роботов: указание, каким роботам реагировать, и разрешение или запрет на сканирование файлов.
Инструкции отделяют друг от друга переносом строки.
Символы robots.txt
«*» — означает любую последовательность символов в файле.
«$» — ограничивает действия «*», представляет конец строки.
«/» — показывает, что закрывают для сканирования.
«/catalog/» — закрывают раздел каталога;
«/catalog» — закрывают все ссылки, которые начинаются с «/catalog».
«#» — используют для комментариев, боты игнорируют текст с этим символом.
User-agent: * Disallow: /catalog/ #запрещаем сканировать каталог
Директивы robots.txt
Директивы, которые распознают все краулеры:
User-agent
На первой строчке прописывают правило User-agent — указание того, какой робот должен реагировать на рекомендации. Если запрещающего правила нет, считается, что доступ к файлам открыт.
Для разного типа контента поисковики используют разных ботов:
- Google: основной поисковый бот называется Googlebot, есть Googlebot News для новостей, отдельно Googlebot Images, Googlebot Video и другие;
- Яндекс: основной бот называется YandexBot, есть YandexDirect для РСЯ, YandexImages, YandexCalendar, YandexNews, YandexMedia для мультимедиа, YandexMarket для Яндекс.Маркета и другие.
Для отдельных ботов можно указать свою директиву, если есть необходимость в рекомендациях по типу контента.
User-agent: * — правило для всех поисковых роботов;
User-agent: Googlebot — только для основного поискового бота Google;
User-agent: YandexBot — только для основного бота Яндекса;
User-agent: Yandex — для всех ботов Яндекса. Если любой из ботов Яндекса обнаружит эту строку, то другие правила User-agent: * учитывать не будет.
Sitemap
Указывает ссылку на карту сайта — файл со структурой сайта, в котором перечислены страницы для индексации:
User-agent: * Sitemap: http://site.com/sitemap.xml
Некоторые веб-мастеры не делают карты сайтов, это не обязательное требование, но лучше составить Sitemap — этот файл краулеры воспринимают как структуру страниц, которые не можно, а нужно индексировать.
Disallow
Правило показывает, какую информацию ботам сканировать не нужно.
Если вы еще работаете над сайтом и не хотите, чтобы он появился в незавершенном виде, можно закрыть от сканирования весь сайт:
User-agent: * Disallow: /
После окончания работы над сайтом не забудьте снять блокировку.
Разрешить всем ботам сканировать весь сайт:
User-agent: * Disallow:
Для этой цели можно оставить robots.txt пустым.
Чтобы запретить одному боту сканировать, нужно только прописать запрет с упоминанием конкретного бота. Для остальных разрешение не нужно, оно идет по умолчанию:
Пользователь-агент: BadBot Disallow: /
Чтобы разрешить одному боту сканировать сайт, нужно прописать разрешение для одного и запрет для остальных:
User-agent: Googlebot Disallow: User-agent: * Disallow: /
Запретить ботам сканировать страницу:
User-agent: * Disallow: /page.html
Запретить сканировать конкретную папку с файлами:
User-agent: * Disallow: /name/
Запретить сканировать все файлы, которые заканчиваются на «.pdf»:
User-agent: * Disallow: /*.pdf$
Запретить сканировать раздел http://site.com/about/:
User-agent: * Disallow: /about/
Запись формата «Disallow: /about» без закрывающего «/» запретит доступ и к разделу
http://site.com/about/, к файлу http://site.com/about.php и к другим ссылкам, которые начинаются с «/about».
Если нужно запретить доступ к нескольким разделам или папкам, для каждого нужна отдельная строка с Disallow:
User-agent: * Disallow: /about Disallow: /info Disallow: /album1
Allow
Директива определяет те пути, которые доступны для указанных поисковых ботов. По сути, это Disallow-наоборот — директива, разрешающая сканирование. Для роботов действует правило: что не запрещено, то разрешено, но иногда нужно разрешить доступ к какому-то файлу и закрыть остальную информацию.
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено:
User-agent: * Allow: /catalog Disallow: /
Сканировать файл «photo.html» разрешено, а всю остальную информацию в каталоге /album1/ запрещено:
User-agent: * Allow: /album1/photo.html Disallow: /album1/
Заблокировать доступ к каталогам «site.com/catalog1/» и «site.com/catalog2/» но разрешить к «catalog2/subcatalog1/»:
User-agent: * Disallow: /catalog1/ Disallow: /catalog2/ Allow: /catalog2/subcatalog1/
Бывает, что для страницы оказываются справедливыми несколько правил. Тогда робот будет отсортирует список от меньшего к большему по длине префикса URL и будет следовать последнему правилу в списке.
Директивы, которые распознают боты Яндекса:
Clean-param
Некоторые страницы дублируются с разными GET-параметрами или UTM-метками, которые не влияют на содержимое. К примеру, если в каталоге товаров использовали сортировку или разные id.
Чтобы отследить, с какого ресурса делали запрос страницы с книгой book_id=123, используют ref:
«www.site. com/some_dir/get_book.pl?ref=site_1& book_id=123″
«www.site. com/some_dir/get_book.pl?ref=site_2& book_id=123″
«www.site. com/some_dir/get_book.pl?ref=site_3& book_id=123″
Страница с книгой одна и та же, содержимое не меняется. Чтобы бот не сканировал все варианты таких страниц с разными параметрами, используют правило Clean-param:
User-agent: Yandex Disallow: Clean-param: ref/some_dir/get_book.pl
Робот Яндекса сведет все адреса страницы к одному виду:
«www.example. com/some_dir/get_book.pl? book_id=123″
Для адресов вида:
«www.example2. com/index.php? page=1&sid=2564126ebdec301c607e5df»
«www.example2. com/index.php? page=1&sid=974017dcd170d6c4a5d76ae»
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: sid/index.php
Для адресов вида
«www.example1. com/forum/showthread.php? s=681498b9648949605&t=8243″
«www.example1. com/forum/showthread.php? s=1e71c4427317a117a&t=8243″
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s/forum/showthread.php
Если переходных параметров несколько:
«www.example1.com/forum_old/showthread.php?s=681498605&t=8243&ref=1311″
«www.example1.com/forum_new/showthread.php?s=1e71c417a&t=8243&ref=9896″
robots.txt будет содержать:
User-agent: Yandex Disallow: Clean-param: s&ref/forum*/showthread.php
Host
Правило показывает, какое зеркало учитывать при индексации. URL нужно писать без «http://» и без закрывающего слэша «/».
User-agent: Yandex Disallow: /about Host: www.site.com
Сейчас эту директиву уже не используют, если в ваших robots.txt она есть, можно удалять. Вместо нее нужно на всех не главных зеркалах сайта поставить 301 редирект.
Crawl-delay
Раньше частая загрузка страниц нагружала сервер, поэтому для ботов устанавливали Crawl-delay — время ожидания робота в секундах между загрузками. Эту директиву можно не использовать, мощным серверам она не требуется.
Время ожидания — 4 секунды:
User-agent: * Allow: /album1 Disallow: / Crawl-delay: 4
Только латиница
Напомним, что все кириллические ссылки нужно перевести в Punycode с помощью любого конвертера.
Неправильно:
User-agent: Yandex Disallow: /каталог
Правильно:
User-agent: Yandex Disallow: /xn--/-8sbam6aiv3a
Пример robots.txt
Запись означает, что правило справедливо для всех роботов: запрещено сканировать ссылки из корзины, из встроенного поиска и админки, карта сайта находится по ссылке http://site.com/sitemap, ref не меняет содержание страницы get_book:
User-agent: * Disallow: /bin/ Disallow: /search/ Disallow: /admin/ Sitemap: http://site.com/sitemap Clean-param: ref/some_dir/get_book.pl
Составить robots.txt бесплатно поможет
инструмент для генерации robots.txt от PR-CY, он позволит закрыть или открыть весь сайт для ботов, указать путь к карте сайта, настроить ограничение на посещение страниц, закрыть доступ некоторым роботам и установить задержку:
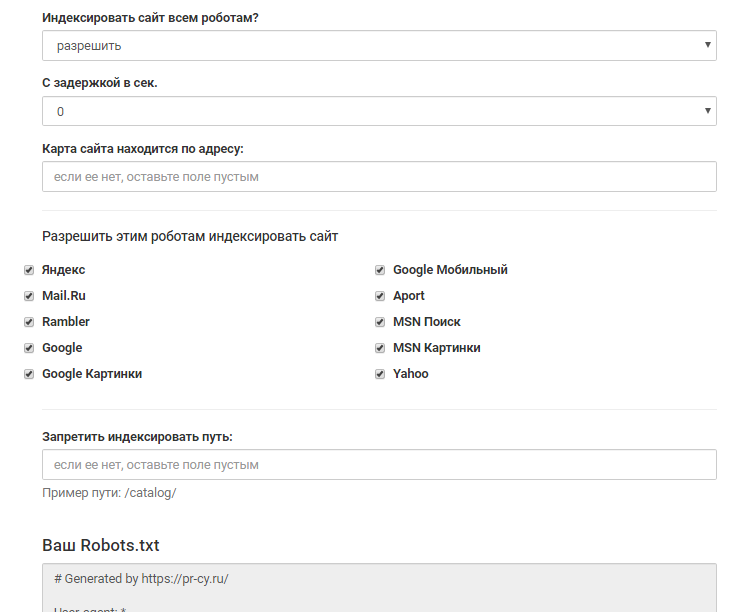 Графы инструмента для заполнения
Графы инструмента для заполненияДля проверки файла robots.txt на ошибки у поисковиков есть собственные инструменты:
Инструмент проверки файла robots.txt от Google позволит проверить, как бот видит конкретный URL. В поле нужно ввести проверяемый URL, а инструмент покажет, доступна ли ссылка.
Инструмент проверки от Яндекса покажет, правильно ли заполнен файл. Нужно указать сайт, для которого создан robots.txt, и перенести его содержимое в поле.
Файл robots.txt не подходит для блокировки доступа к приватным файлам, но направляет краулеров к карте сайта и дает рекомендации для быстрого сканирования важных материалов ресурса.
pr-cy.ru
Как создать правильный файл robots.txt, настройка, директивы

Файл robots.txt — текстовый файл в формате .txt, ограничивающий поисковым роботам доступ к содержимому на http-сервере. Как определение, Robots.txt — это стандарт исключений для роботов, который был принят консорциумом W3C 30 января 1994 года, и который добровольно использует большинство поисковых систем. Файл robots.txt состоит из набора инструкций для поисковых роботов, которые запрещают индексацию определенных файлов, страниц или каталогов на сайте. Рассмотрим описание robots.txt для случая, когда сайт не ограничивает доступ роботам к сайту.
Простой пример robots.txt:
User-agent: * Allow: /
Здесь роботс полностью разрешает индексацию всего сайта.
Файл robots.txt необходимо загрузить в корневой каталог вашего сайта, чтобы он был доступен по адресу:
ваш_сайт.ru/robots.txt
Для размещения файла robots.txt в корне сайта обычно необходим доступ через FTP. Однако, некоторые системы управления (CMS) дают возможность создать robots.txt непосредственно из панели управления сайтом или через встроенный FTP-менеджер.
Если файл доступен, то вы увидите содержимое robots.txt в браузере.
Для чего нужен robots.txt
Roots.txt для сайта является важным аспектом поисковой оптимизации. Зачем нужен robots.txt? Например, в SEO robots.txt нужен для того, чтобы исключать из индексации страницы, не содержащие полезного контента и многое другое. Как, что, зачем и почему исключается уже было описано в статье про запрет индексации страниц сайта, здесь не будем на этом останавливаться. Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование robots.txt подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы robots.txt, например директива Host или Sitemap, но об этом ниже.
Как создать robots.txt
Поскольку robots.txt — это текстовый файл, и чтобы создать файл robots.txt, можно воспользоваться любым текстовым редактором, например Блокнотом. Как только вы открыли новый текстовый документ, вы уже начали создание robots.txt, осталось только составить его содержимое, в зависимости от ваших требований, и сохранить в виде текстового файла с названием robots в формате txt. Все просто, и создание файла robots.txt не должно вызвать проблем даже у новичков. О том, как составить robots.txt и что писать в роботсе на примерах покажу ниже.
Cоздать robots.txt онлайн
Вариант для ленивых — создать роботс онлайн и скачать файл robots.txt уже в готовом виде. Создание robots txt онлайн предлагает множество сервисов, выбор за вами. Главное — четко понимать, что будет запрещено и что разрешено, иначе создание файла robots.txt online может обернуться трагедией, которую потом может быть сложно исправить. Особенно, если в поиск попадет то, что должно было быть закрытым. Будьте внимательны — проверьте свой файл роботс, прежде чем выгружать его на сайт. Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Редактирование robots.txt
После того, как вам удалось создать файл robots.txt онлайн или своими руками, вы можете редактировать robots.txt. Изменить его содержимое можно как угодно, главное — соблюдать некоторые правила и синтаксис robots.txt. В процессе работы над сайтом, файл роботс может меняться, и если вы производите редактирование robots.txt, то не забывайте выгружать на сайте обновленную, актуальную версию файла со всем изменениями. Далее рассмотрим правила настройки файла, чтобы знать, как изменить файл robots.txt и «не нарубить дров».
Правильная настройка robots.txt
Правильная настройка robots.txt позволяет избежать попадания частной информации в результаты поиска крупных поисковых систем. Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Чтобы понять, как сделать правильный robots txt, для начала необходимо разобраться с общими правилами, синтаксисом и директивами файла robots.txt.
Правильный robots.txt начинается с директивы User-agent, которая указывает, к какому роботу обращены конкретные директивы.
Примеры User-agent в robots.txt:
# Указывает директивы для всех роботов одновременно User-agent: * # Указывает директивы для всех роботов Яндекса User-agent: Yandex # Указывает директивы для только основного индексирующего робота Яндекса User-agent: YandexBot # Указывает директивы для всех роботов Google User-agent: Googlebot
Учитывайте, что подобная настройка файла robots.txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
Пример robots.txt с несколькими вхождениями User-agent:
# Будет использована всеми роботами Яндекса User-agent: Yandex Disallow: /*utm_ # Будет использована всеми роботами Google User-agent: Googlebot Disallow: /*utm_ # Будет использована всеми роботами кроме роботов Яндекса и Google User-agent: * Allow: /*utm_
Директива User-agent создает лишь указание конкретному роботу, а сразу после директивы User-agent должна идти команда или команды с непосредственным указанием условия для выбранного робота. В примере выше используется запрещающая директива «Disallow», которая имеет значение «/*utm_». Таким образом, закрываем все страницы с UTM-метками. Правильная настройка robots.txt запрещает наличие пустых переводов строки между директивами «User-agent», «Disallow» и директивами следующими за «Disallow» в рамках текущего «User-agent».
Пример неправильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Пример правильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Как видно из примера, указания в robots.txt поступают блоками, каждый из которых содержит указания либо для конкретного робота, либо для всех роботов «*».
Кроме того, важно соблюдать правильный порядок и сортировку команд в robots.txt при совместном использовании директив, например «Disallow» и «Allow». Директива «Allow» — разрешающая директива, является противоположностью команды robots.txt «Disallow» — запрещающей директивы.
Пример совместного использования директив в robots.txt:
User-agent: * Allow: /blog/page Disallow: /blog
Данный пример запрещает всем роботам индексацию всех страниц, начинающихся с «/blog», но разрешает индексации страниц, начинающиеся с «/blog/page».
Прошлый пример robots.txt в правильной сортировке:
User-agent: * Disallow: /blog Allow: /blog/page
Сначала запрещаем весь раздел, потом разрешаем некоторые его части.
Еще один правильный пример robots.txt с совместными директивами:
User-agent: * Allow: / Disallow: /blog Allow: /blog/page
Обратите внимание на правильную последовательность директив в данном robots.txt.
Директивы «Allow» и «Disallow» можно указывать и без параметров, в этом случае значение будет трактоваться обратно параметру «/».
Пример директивы «Disallow/Allow» без параметров:
User-agent: * Disallow: # равнозначно Allow: / Disallow: /blog Allow: /blog/page
Как составить правильный robots.txt и как пользоваться трактовкой директив — ваш выбор. Оба варианта будут правильными. Главное — не запутайтесь.
Для правильного составления robots.txt необходимо точно указывать в параметрах директив приоритеты и то, что будет запрещено для скачивания роботам. Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками.
Синтаксис robots.txt
Роботы поисковых систем добровольно следуют командам robots.txt — стандарту исключений для роботов, однако не все поисковые системы трактуют синтаксис robots.txt одинаково. Файл robots.txt имеет строго определённый синтаксис, но в то же время написать robots txt не сложно, так как его структура очень проста и легко понятна.
Вот конкретные список простых правил, следуя которым, вы исключите частые ошибки robots.txt:
- Каждая директива начинается с новой строки;
- Не указывайте больше одной директивы в одной строке;
- Не ставьте пробел в начало строки;
- Параметр директивы должен быть в одну строку;
- Не нужно обрамлять параметры директив в кавычки;
- Параметры директив не требуют закрывающих точки с запятой;
- Команда в robots.txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел];
- Допускаются комментарии в robots.txt после знака решетки #;
- Пустой перевод строки может трактоваться как окончание директивы User-agent;
- Директива «Disallow: » (с пустым значением) равнозначна «Allow: /» — разрешить все;
- В директивах «Allow», «Disallow» указывается не более одного параметра;
- Название файла robots.txt не допускает наличие заглавных букв, ошибочное написание названия файла — Robots.txt или ROBOTS.TXT;
- Написание названия директив и параметров заглавными буквами считается плохим тоном и если по стандарту, robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файлов и директорий;
- Если параметр директивы является директорией, то перед название директории всегда ставится слеш «/», например: Disallow: /category
- Слишком большие robots.txt (более 32 Кб) считаются полностью разрешающими, равнозначными «Disallow: »;
- Недоступный по каким-либо причинам robots.txt может трактоваться как полностью разрешающий;
- Если robots.txt пустой, то он будет трактоваться как полностью разрешающий;
- В результате перечисления нескольких директив «User-agent» без пустого перевода строки, все последующие директивы «User-agent», кроме первой, могут быть проигнорированы;
- Использование любых символов национальных алфавитов в robots.txt не допускается.
Поскольку разные поисковые системы могут трактовать синтаксис robots.txt по-разному, некоторые пункты можно опустить. Так например, если прописать несколько директив «User-agent» без пустого перевода строки, все директивы «User-agent» будут восприняты корректно Яндексом, так как Яндекс выделяет записи по наличию в строке «User-agent».
В роботсе должно быть указано строго только то, что нужно, и ничего лишнего. Не думайте, как прописать в robots txt все, что только можно и чем его заполнить. Идеальный robots txt — это тот, в котором меньше строк, но больше смысла. «Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
Как проверить robots.txt
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка файла robots.txt в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
Для того, чтобы проверить robots.txt онлайн необходимо загрузить robots.txt на сайт в корневую директорию. Иначе, сервис может сообщить, что не удалось загрузить robots.txt. Рекомендуется предварительно проверить robots.txt на доступность по адресу где лежит файл, например: ваш_сайт.ru/robots.txt.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Robots.txt vs Яндекс и Google
Есть субъективное мнение, что указание отдельного блока директив «User-agent: Yandex» в robots.txt Яндекс воспринимает более позитивно, чем общий блок директив с «User-agent: *». Аналогичная ситуация robots.txt и Google. Указание отдельных директив для Яндекс и Google позволяет управлять индексацией сайта через robots.txt. Возможно, им льстит персонально обращение, тем более, что для большинства сайтов содержимое блоков robots.txt Яндекса, Гугла и для других поисковиков будет одинаково. За редким исключением, все блоки «User-agent» будут иметь стандартный для robots.txt набор директив. Так же, используя разные «User-agent» можно установить запрет индексации в robots.txt для Яндекса, но, например не для Google.
Отдельно стоит отметить, что Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта. Подробнее директиву «Host» рассмотрим ниже.
Запретить индексацию: robots.txt Disallow
Disallow — запрещающая директива, которая чаще всего используется в файле robots.txt. Disallow запрещает индексацию сайта или его части, в зависимости от пути, указанного в параметре директивы Disallow.
Пример как в robots.txt запретить индексацию сайта:
User-agent: * Disallow: /
Данный пример закрывает от индексации весь сайт для всех роботов.
В параметре директивы Disallow допускается использование специальных символов * и $:
* — любое количество любых символов, например, параметру /page* удовлетворяет /page, /page1, /page-be-cool, /page/kak-skazat и т.д. Однако нет необходимости указывать * в конце каждого параметра, так как например, следующие директивы интерпретируются одинаково:
User-agent: Yandex Disallow: /page
User-agent: Yandex Disallow: /page*
$ — указывает на точное соответствие исключения значению параметра:
User-agent: Googlebot Disallow: /page$
В данном случае, директива Disallow будет запрещать /page, но не будет запрещать индексацию страницы /page1, /page-be-cool или /page/kak-skazat.
Если закрыть индексацию сайта robots.txt, в поисковые системы могут отреагировать на так ход ошибкой «Заблокировано в файле robots.txt» или «url restricted by robots.txt» (url запрещенный файлом robots.txt). Если вам нужно запретить индексацию страницы, можно воспользоваться не только robots txt, но и аналогичными html-тегами:
- <meta name=»robots» content=»noindex»/> — не индексировать содержимое страницы;
- <meta name=»robots» content=»nofollow»/> — не переходить по ссылкам на странице;
- <meta name=»robots» content=»none»/> — запрещено индексировать содержимое и переходить по ссылкам на странице;
- <meta name=»robots» content=»noindex, nofollow»/> — аналогично content=»none».
Разрешить индексацию: robots.txt Allow
Allow — разрешающая директива и противоположность директиве Disallow. Эта директива имеет синтаксис, сходный с Disallow.
Пример, как в robots.txt запретить индексацию сайта кроме некоторых страниц:
User-agent: * Disallow: / Allow: /page
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /page.
Disallow и Allow с пустым значением параметра
Пустая директива Disallow:
User-agent: * Disallow:
Не запрещать ничего или разрешить индексацию всего сайта и равнозначна:
User-agent: * Allow: /
Пустая директива Allow:
User-agent: * Allow:
Разрешить ничего или полный запрет индексации сайта, равнозначно:
User-agent: * Disallow: /
Главное зеркало сайта: robots.txt Host
Директива Host служит для указания роботу Яндекса главного зеркала Вашего сайта. Из всех популярных поисковых систем, директива Host распознаётся только роботами Яндекса. Директива Host полезна в том случае, если ваш сайт доступен по нескольким доменам, например:
mysite.ru mysite.com
Или для определения приоритета между:
mysite.ru www.mysite.ru
Роботу Яндекса можно указать, какое зеркало является главным. Директива Host указывается в блоке директивы «User-agent: Yandex» и в качестве параметра, указывается предпочтительный адрес сайта без «http://».
Пример robots.txt с указанием главного зеркала:
User-agent: Yandex Disallow: /page Host: mysite.ru
В качестве главного зеркала указывается доменное имя mysite.ru без www. Таки образом, в результатах поиска буде указан именно такой вид адреса.
User-agent: Yandex Disallow: /page Host: www.mysite.ru
В качестве основного зеркала указывается доменное имя www.mysite.ru.
Директива Host в файле robots.txt может быть использована только один раз, если же директива Хост будет указана более одного раза, учитываться будет только первая, прочие директивы Host будут игнорироваться.
Если вы хотите указать главное зеркало для робота Google, воспользуйтесь сервисом Google Инструменты для вебмастеров.
Карта сайта: robots.txt sitemap
При помощи директивы Sitemap, в robots.txt можно указать расположение на сайте файла карты сайта sitemap.xml.
Пример robots.txt с указанием адреса карты сайта:
User-agent: * Disallow: /page Sitemap: http://www.mysite.ru/sitemap.xml
Указание адреса карты сайта через директиву Sitemap в robots.txt позволяет поисковому роботу узнать о наличии карты сайта и начать ее индексацию.
Директива Clean-param
Директива Clean-param позволяет исключить из индексации страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL страницы. Проще говоря, будто страница доступна по разным адресам. Наша задача убрать все лишние динамические адреса, которых может быть миллион. Для этого исключаем все динамические параметры, используя в robots.txt директиву Clean-param.
Синтаксис директивы Clean-param:
Clean-param: parm1[&parm2&parm3&parm4&..&parmn] [Путь]
Рассмотрим на примере страницы со следующим URL:
www.mysite.ru/page.html?&parm1=1&parm2=2&parm3=3
Пример robots.txt Clean-param:
Clean-param: parm1&parm2&parm3 /page.html # только для page.html
или
Clean-param: parm1&parm2&parm3 / # для всех
Директива Crawl-delay
Данная инструкция позволяет снизить нагрузку на сервер, если роботы слишком часто заходят на ваш сайт. Данная директива актуальна в основном для сайтов с большим объемом страниц.
Пример robots.txt Crawl-delay:
User-agent: Yandex Disallow: /page Crawl-delay: 3
В данном случае мы «просим» роботов яндекса скачивать страницы нашего сайта не чаще, чем один раз в три секунды. Некоторые поисковые системы поддерживают формат дробных чисел в качестве параметра директивы Crawl-delay robots.txt.
Комментарии в robots.txt
Комментарий в robots.txt начинаются с символа решетки — #, действует до конца текущей строки и игнорируются роботами.
Примеры комментариев в robots.txt:
User-agent: * # Комментарий может идти от начала строки Disallow: /page # А может быть продолжением строки с директивой # Роботы # игнорируют # комментарии Host: www.mysite.ru
В заключении
Файл robots.txt — очень важный и нужный инструмент взаимодействия с поисковыми роботами и один из важнейших инструментов SEO, так как позволяет напрямую влиять на индексацию сайта. Используйте роботс правильно и с умом.
Если у вас есть вопросы — пишите в комментариях.
Рекомендуйте статью друзьям и не забывайте подписываться на блог.
Новые интересные статьи каждый день.
convertmonster.ru