Как убрать дубли страниц сайта: пошаговая инструкция
В статье про технический аудит сайта мы упомянули, что среди прочего SEO-специалисту важно проверить, а есть ли дубли страниц на продвигаемом им веб-ресурсе. И если они найдутся, то нужно немедленно устранить проблему. Однако там в рамках большого обзора я не хотел обрушивать на голову читателя кучу разнообразной информации, поэтому о том, что такое дубликаты страниц сайта, как их находить и удалять, мы вместе с вами детальнее рассмотрим здесь.
Почему и как дубли страниц мешают поисковому продвижению
Для начала отвечу на вопрос «Как?». Дубликаты страниц сильно затрудняют SEO, т. к. поисковые системы не могут понять, какую из веб-страниц им нужно показывать в выдаче по релевантным запросам. Поэтому чаще всего, чтобы не путаться, они понижают сайт в ранжировании или даже банят его, если проблема имеет массовый характер. После этого должно быть понятно, насколько важно сразу проверить продвигаемый ресурс на дубликаты.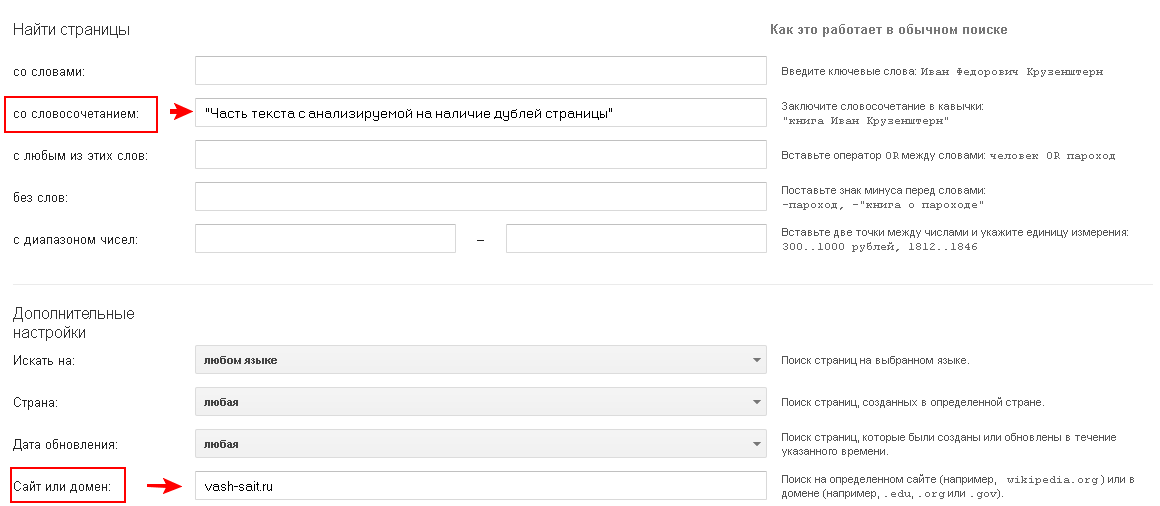
Теперь давайте посмотрим, почему так получается, что дубли создают проблему? Для этого рассмотрим такой простой пример. Взгляните на следующее изображение и определите, какой из овощей наиболее точно соответствует запросу «спелый помидор»?
Хотя овощи немного отличаются размером, но все три из них подходят под категорию «спелого помидора». Поэтому сделать выбор в пользу одно из них довольно сложно.
Такая же дилемма встает перед поисковыми алгоритмами, когда они видят на сайте несколько одинаковых (полных) или почти одинаковых (частичных) копий одной и той же страницы.
Как наличие дублей сказывается на продвижении:
- Чаще всего падает релевантность основной продвигаемой страницы и, соответственно, снижаются позиции по используемым ключевым словам.
- Также могут «прыгать» позиции по ключам из-за того, что поисковик будет менять страницу для показа в поисковой выдаче.
- Если проблема не ограничивается несколькими урлами, а распространяется на весь сайт, то в таком случае Яндекс и Google могут наказать неприятным фильтром.

Понимая теперь, насколько серьезными могут быть последствия, рассмотрим виды дубликатов.
SEO-шников много, профессионалов — единицы. Научитесь технической и поведенческой оптимизации, создавайте семантические ядра и продвигайте проекты в ТОП!
Получить скидку →
Виды дублей
Выше мы уже выяснили, что дубли бывают идентичными (полными) и частичными. Полным называют такой дубликат, когда одну и ту же веб-страницу поисковик находит по различным адресам.
Когда появляются полные дубли:
- Зачастую это происходит, если забыли указать главное зеркало, и весь сайт может показываться в поиске с www и без него, c http и с https. Чтобы устранить эту проблему, читайте здесь детальнее о том, что такое зеркало сайта.
- Кроме того, бывают ситуации, когда возникают дубли главной страницы ввиду особенностей движка или проведенной веб-разработчиком работы. Тогда, к примеру, главная может быть доступна со слешем «/» в конце и без него, с добавлением слов home, start, index. php и т. п.
- Нередко дубли возникают, когда в индекс попадают страницы с динамичными адресами, появляющиеся обычно при использовании фильтров для сортировки и сравнения товаров.
- Часть движков (WordPress, Joomla, Opencart, ModX) сами по себе генерируют дубли. К примеру, в Joomla по умолчанию часть страниц доступна к отображению с разными урлами: mysite.ru/catalog/17 и mysite.ru/catalog/17-article.html и т. п.
- Если для отслеживания сессий применяют специальные идентификаторы, то они также могут индексироваться и создавать копии.
- Иногда в индекс также попадают страницы по адресам, к которым добавлены utm-метки. Такие метки вставляют, чтобы отслеживать эффективность проводимых рекламных кампаний, и по-хорошему они не должны быть проиндексированы. Однако на практике подобные урлы часто можно видеть в поисковой выдаче.
 php и т. п.
php и т. п.Когда возникают частичные дубли
Полные дубли легко найти и устранить, а вот с частичными уже придется повозиться. Поэтому на рассмотрении их видов стоит остановиться детальнее.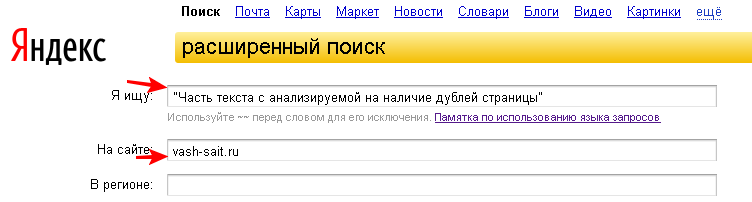
Пагинация страниц
Используя пагинацию страниц, владельцы сайтов делают навигацию для посетителей более простой, но вместе с тем создают проблему для поискового продвижения. Каждая страница пагинации – это фактически дубль зачастую с теми же мета-данными, СЕО-текстом.
К примеру, основная страница имеет вид https://mysite.ru/women/clothes, а у страницы пагинации адрес будет https://mysite.ru/women/clothes/?page=2. Адреса получаются разные, а содержимое будет почти одинаковым.
Блоки новостей, популярных статей и комментариев
Чтобы удержать пользователя на сайте, ему часто предлагают ознакомиться с наиболее интересными новостями, комментариями и статьями. Название этих объектов с частью содержимого обычно размещают по бокам или снизу от основного материала. Если эти куски будут проиндексированы, то поисковик определит, что на некоторых страницах одинаковый контент, а это очень плохо.
На скриншоте видно, как внизу главной страницы сайта размещаются три блока с последними статьями, новостями и отзывами. То есть текстовое содержимое есть в соответствующих разделах сайта, и здесь на главной оно повторяется, создавая частичные дубли.
То есть текстовое содержимое есть в соответствующих разделах сайта, и здесь на главной оно повторяется, создавая частичные дубли.
Версии страниц для печати
Некоторые веб-страницы сайта доступны в обычном варианте и в версии для печати, которая отличается от основной адресом и отсутствием значительной части строк кода, т. к. для печатаемой страницы не нужна значительная часть функционала.
Обычная страница может открываться, например, по адресу https://my-site.ru/page, а у варианта для печати адрес немного изменится и будет похож на такой: https://my-site.ru/page?print.
Сайты с технологией AJAX
На некоторых сайтах, применяемых технологию AJAX, возникают так называемые html-слепки. Сами по себе они не опасны, если нет ошибок в имплантации способа индексирования AJAX-страниц, когда поисковых ботов направляют не на основную страницу, а на html-слепок, где робот индексирует одну и ту же страницу по двум адресам:
- основному;
- адресу html-слепка.
Для нахождения таких html-слепков стоит в основном адресе заменить часть «!#» на такой код: «?_escaped_fragment_=».
Частичные дубли опасны тем, что они не вызывают значительного снижения позиций в один момент, а понемногу портят картину, усугубляя ситуацию день за днем.
Как происходит поиск дублей страниц на сайте
Существует несколько основных способов, позволяющих понять, как найти дубли страниц оптимизатору на сайте:
Вручную
Уже зная, где стоит искать дубликаты, SEO-специалист без особого труда может найти значительную часть копий, попробовав различные варианты урлов.
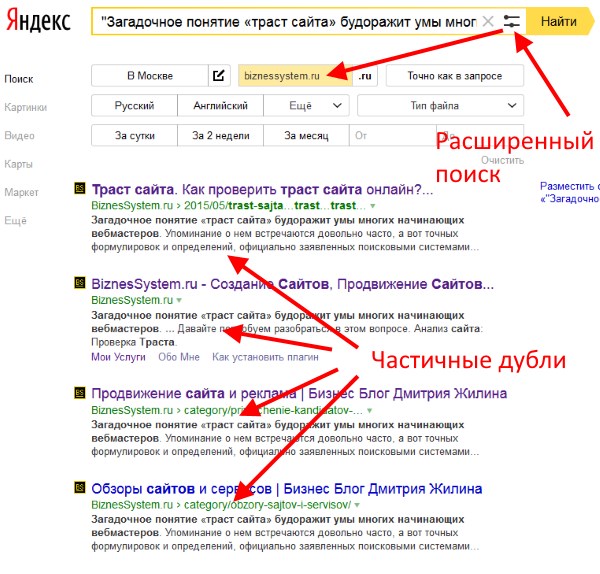
С применением команды site
Вставляем в адресную строку команду «site:», вводим после нее домен и часть текстового содержания, после чего Google сам выдаст все найденные варианты. На скриншоте ниже видно, что мы ввели первое предложение свежей статьи после команды «site:», и Google показывает, что у основной страницы с материалом есть частичный дубль на главной.
С использованием программ и онлайн-сервисов
Для поиска дублей часто применяют три популярные программы на ПК:
- Xenu – бесплатная;
- NetPeak – от $15 в месяц, но есть 14-дневный trial;
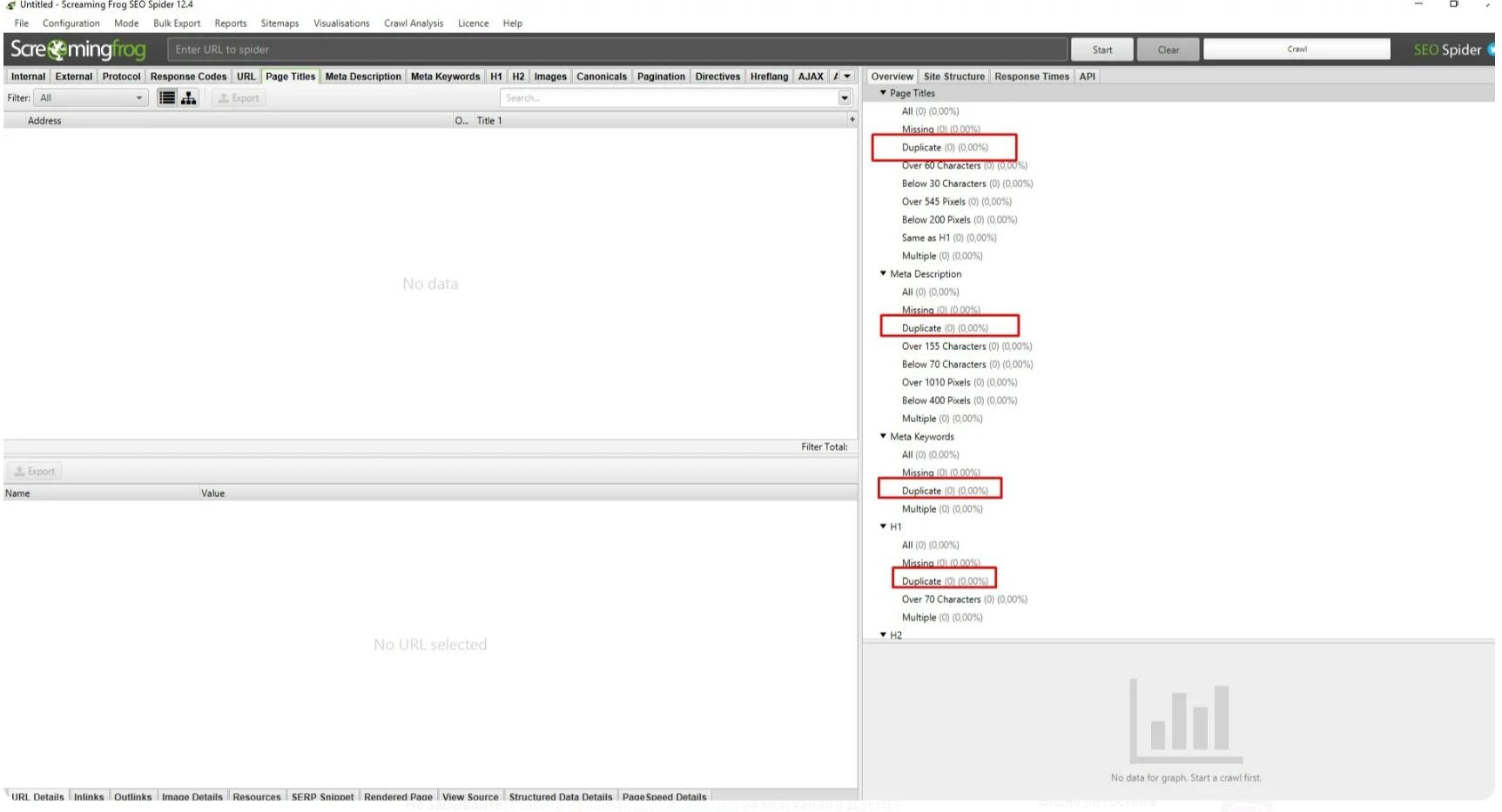
- Screaming Frog – платная (149 фунтов за год), но есть ограниченная бесплатная версия, которой хватает для большинства нужд.
Вот пример того, как ищет дубликаты программа Screaming Frog:
А вот как можно проверить дубли страниц в NetPeak:
Для онлайн-поиска дублей страниц можно использовать специальные веб-сервисы наподобие Serpstat.
Использование Google Search Console и Яндекс Вебмастер
В обновленной версии Google Search Console для поиска дублей смотрим «Предупреждения» и «Покрытие». Там поисковая система сама сообщает о проблемных, на ее взгляд, страницах, которым нужно уделить внимание.
Что касается Yandex, то здесь все намного удобнее. Для поиска дублей заходим в Яндекс Вебмастер, открыв раздел «Индексирование» – «Страницы в поиске». Опускаемся в самый низ, выбираем справа удобный формат файла – XLS или CSV, скачиваем его и открываем. В этом документе все дубликаты в строке «Статус» будут иметь обозначение DUPLICATE.
Как убрать дубли?
Чтобы удалить дубли страниц на сайте, можно использовать разные приемы в зависимости от ситуации. Давайте же с ними познакомимся:
При помощи noindex и nofollow
Самый простой способ – закрыть от индексации, используя метатег <meta name=”robots” content=”noindex,nofollow”/>, который помещают в шапку между открывающим тегом <head> и закрывающим </head>. Попав на страницу с таким метатегом, поисковые алгоритмы не станут ее индексировать и учитывать ссылки, находящиеся здесь.
При добавлении метатега «noindex,nofollow» на страницу, крайне важно, чтобы для нее не была запрещена индексация через файл robots.txt.
При помощи robots.txt
Индексирование отдельных дублей можно запретить в файле robots.txt, используя директиву Disallow. В таком случае примерный вид кода, добавляемого в robots.txt, будет таким:
В таком случае примерный вид кода, добавляемого в robots.txt, будет таким:
User-agent: *
Disallow: /dublictate.html
Host: mysite.ru
Через robots.txt удобно запрещать индексацию служебных страниц. Выглядит это следующим образом:
Этот вариант зачастую применяют, если невозможно использовать предыдущий.
При помощи canonical
Еще один удобный способ – применить метатег canonical, который говорит поисковым роботам, что они попали на страницу-дубликат, а заодно указывает, где находится основная страница. Этот метатег помещают в шапку между открывающим тегом <head> и закрывающим </head>, и выглядит он так:
<link rel=”canonical” href=”адрес основной страницы” />
Как убрать дубликаты на страницах с пагинацией
В случае присутствия на сайте многостраничного каталога, на второй и последующих страницах могут возникать частичные дубли. Смотрим, как это может быть:
Выше на скрине 1-я страница каталога, а вот вторая:
То есть на каждой странице дублируется текст и теги: Title и Description.
В таких случаях SEO-специалисту нужно добиться, чтобы:
- текст отображался только на 1-й странице;
- Title и Description были уникальными для каждой страницы, хотя их можно сделать шаблонными с минимальными отличиями;
- в адресах страниц пагинации должны отсутствовать динамические параметры.
Понимая теперь, что такое дубликаты страниц сайта, и как бороться с дублями, вы сможете не допустить попадания в индекс копий, которые будут препятствовать продвижению в поисковых системах. Если после прочтения статьи у вас остались вопросы, или вы хотите дополнить материал своими ценными замечаниями, то обязательно сделайте это в комментариях ниже.
Как найти дубли страниц на сайте и удалить | WAYTOSTART
Очень часто новички сталкиваются с проблемой потери трафика в интернете. Вроде бы все делают правильно, но поисковики все равно опускают позиции. Почему? Одной из причин являются дубли страниц. Сегодня мы поговорим о том, что такое дубли страниц на сайте, как проверить их на сайте и каким образом можно удалить.
Что такое дубли страниц?
Дубли — страницы с разными адресами, где полностью или частично совпадает контент. Любите разгадывать ребусы? Внимательно посмотрите на эту картинку и подумайте, какое из этих трех изображений наиболее соответствует запросу: «зеленая груша»? Сложно ответить, не так ли? Да, потому что все три груши одинаково зеленые, а выбрать нужно только одну, которая наиболее релевантна условиям поиска. Дилемма? В точно такой же непростой ситуации находятся и поисковики в случае обнаружения дублей. Они недоумевают, какую страницу нужно показать в поиске в ответ на запрос пользователя. Бывает, что поисковик считает главной страницей именно дубль, в результате в индекс не попадает ни одна, и сайт стремительно теряет свои позиции.
Зачем нужно удалять дубли страниц?Каждый сеошник знает, что наличие дублей очень опасно для SEO. Пользователям они не мешают получить необходимую информацию. Копия страницы сайта очень серьезно воспринимается поисковиками и может в критических ситуациях привести к наложению санкций со стороны Яндекса и Google. Поэтому важно вовремя найти все дубли страниц и обезвредить их.
Поэтому важно вовремя найти все дубли страниц и обезвредить их.
В первую очередь произойдет снижение позиций в поиске по отдельным ключевым фразам. Сначала они начнут просто скакать из — за постоянной смены привязки ключа к релевантной странице, а потом поисковик существенно понизит сайт в ранжировании. Вот с этого момента можно включать режим SOS и оперативно исправлять ситуацию.
Какими бывают дубли страниц?Специалисты поисковой оптимизации различают дубли страниц двух типов — полные или частичные.Первые — когда две или более страницы содержат одинаковый контент.Вторые — когда какая-то часть контента дублируется на нескольких страницах. Такое часто происходит, когда, например, копирайтеры берут кусок из одной статьи и вставляют его в другую.
Что такое полные дубли страниц и как они появляются?- Когда создаются адреса с «www» и без «www»: http://wts.ru/about http://www.wts.ru/about
- Адреса со слешами и без них http://wts. ru/seo///top3 http://wts.ru/seo/top3
- Адреса с HTTP и HTTPS http://wts.ru/seo https://wts.ru/seo
- Создать дубли могут и реферальные ссылки. Как правило, реферальная ссылка имеет после знака «?» хвостик, начинающийся с «ref=…». Когда поcетитель переходит по ссылке с такой меткой, ему должна открываться обычная ссылка. Но часто оптимизаторы и веб — разработчики просто забывают убрать параметр «ref=…» и получают дубли.
- Дубли страниц могут появляться в результате неправильной настройки страницы с 404 — ошибкой.
- Некоторые страницы с utm — меткой или гет — параметрами «gclid», необходимыми для отслеживания рекламного трафика, часто попадают в индекс поисковиков и тоже являются дублями. http://mysite.ru/?utm_source=yandex&amp;amp;utm_medium=cpc&amp;amp;utm_campaign=sale http://mysite.ru
- Страницы с прописными и строчными буквами в урл http://wts.ru/seo http://wts.ru/SEO
- Приписка цифр в строку URL http://wts.ru/seo123 http://wts.ru/seo123/999
 ru/seo///top3 http://wts.ru/seo/top3
ru/seo///top3 http://wts.ru/seo/top3Такая ситуация часто случается на страницах сайтов на основе cамой популярной системы управления контентом — WordPress. Как мы уже говорили выше, поисковики очень не любят наличие такой критичной ошибки как дубли страниц. За это Яндекс и Google могут применить карательные санкции — наложить на сайт фильтр или опустить в позициях. Полные дубли обнаружить гораздо проще, но вот проблем они могут принести из-за своего масштаба очень много.
Как мы уже говорили выше, поисковики очень не любят наличие такой критичной ошибки как дубли страниц. За это Яндекс и Google могут применить карательные санкции — наложить на сайт фильтр или опустить в позициях. Полные дубли обнаружить гораздо проще, но вот проблем они могут принести из-за своего масштаба очень много.
В отличие от первого варианта, в этом случае диагностировать ошибку гораздо труднее. Немало неудобств доставляет и процедура самого избавления от частичных дублей. Частичные дубли подразумевают под собой дублирования части контента на нескольких страницах.
- Очень часто можно встретить частичные дубли на страницах листинга (ссылочного блока, при помощи которого на странице отдельная часть информации из общего массива данных), фильтров, различных сортировок. В этом случае на всех страницах присутствуют куски одного и того же контента, меняется только порядок и структура их размещения.
- Частичные дубли также могут появляться в описании товаров в карточках и каталоге. Чтобы исключить такую ошибку, нужно не выводить полную информацию о товаре в каталоге, либо написать уникальный текст, который не будет перекликаться с описанием в самой карточке товара. Но оптимизаторы часто пытаются сэкономить на копирайтинге, что выливается потом в серьезные проблемы с индексацией ссылок в поиске.
- Страницы скачивания и печати могут дублироваться с основной страницей. Например: http://wts.ru/seo https://wts.ru/seo/print
 Чтобы исключить такую ошибку, нужно не выводить полную информацию о товаре в каталоге, либо написать уникальный текст, который не будет перекликаться с описанием в самой карточке товара. Но оптимизаторы часто пытаются сэкономить на копирайтинге, что выливается потом в серьезные проблемы с индексацией ссылок в поиске.
Чтобы исключить такую ошибку, нужно не выводить полную информацию о товаре в каталоге, либо написать уникальный текст, который не будет перекликаться с описанием в самой карточке товара. Но оптимизаторы часто пытаются сэкономить на копирайтинге, что выливается потом в серьезные проблемы с индексацией ссылок в поиске.В отличие от полных дублей, частичные не сразу сказываются потерями в позициях сайта, они потихоньку будут подтачивать камень водой, делая жизнь оптимизатора все невыносимее.
Как найти дубли страниц на сайте?Первый способ — при помощи оператора «site», вы просто вводите в Яндекс или Google оператора и название сайта:site:wts.ruВторой способ — специальные сервисы или парсеры, которые могут обнаружить наличие дублей на сайте. К таким программам можно отнести — ComparseR 1.0.129, Xenu, WildShark SEO Spider, британский парсер Frog Seo Spider, Majento SiteAnalayzer 1. 4.4.91, Serpstat.Многие из них бесплатные.Механизм работы парсеров очень прост: программа запускает бота на сайт, анализирует и определяет список урлов с возможными совпадениями. Таким образом поиск дублей страниц сайта не занимает много времени, достаточно просто ввести в строку параметры сайта и ждать результата. Не так давно появилась и версия программы российских разработчиков Апполон (https://apollon.guru/duplicates), которая позволяет проверить сайт на дубли страниц онлайн. В открывающееся окошко можно ввести до 5 url. После сканирования программа выдает отчет.
4.4.91, Serpstat.Многие из них бесплатные.Механизм работы парсеров очень прост: программа запускает бота на сайт, анализирует и определяет список урлов с возможными совпадениями. Таким образом поиск дублей страниц сайта не занимает много времени, достаточно просто ввести в строку параметры сайта и ждать результата. Не так давно появилась и версия программы российских разработчиков Апполон (https://apollon.guru/duplicates), которая позволяет проверить сайт на дубли страниц онлайн. В открывающееся окошко можно ввести до 5 url. После сканирования программа выдает отчет.
Третий способ — потенциальные дубли может определить инструмент для веб — мастеров Google Search Console. Для этого его нужно открыть, зайти во вкладку «Оптимизация HTML» и проанализировать все страницы, на которых повторяется описание.Четвертый способ — ручной. Опытные оптимизаторы и разработчики могут вручную просканировать дубли страниц в местах сайта, которые кажутся им проблемными.
Как удалить дубли страниц на сайте?Не обладая специальными навыками и опытом, избавиться от дублей собственными силами будет очень трудно. Нужно будет самому изучить основы веб — разработки, различные коды программирования, азы seo — оптимизации. На это могут уйти несколько месяцев, а позиции сайта будут опускаться в выдаче. Лучше обратиться к профессионалам, которые оперативно удалят дубли и сделают специальные настройки:
Нужно будет самому изучить основы веб — разработки, различные коды программирования, азы seo — оптимизации. На это могут уйти несколько месяцев, а позиции сайта будут опускаться в выдаче. Лучше обратиться к профессионалам, которые оперативно удалят дубли и сделают специальные настройки:
- Запретят индексацию дублей в специальном текстовом файле в «robots.txt»
- В файле — конфигураторе добавят 301 редирект. Этот способ является основным при искоренении ошибки. Редирект нужен для автоматической переадресации с одного урл на другой.
- Для устранения дублей при выводе на печать и скачивании добавят тег meta name=»robots» content=»noindex, nofollow»
Иногда решение проблемы может заключаться в настройке самого движка, поэтому первоочередной задачей специалистов является выявление дублей, а уже потом их оперативное устранение. Дело в том, что для создания контента могут одновременно использоваться разные движки сайта (opencart, joomla, wordpress, bitrix). Например, главная структура сайта будет сделана на опенкарт, а блог на вордпресс. Естественно, что дубли на этих двух сайтах тоже будет сильно отличаться друг от друга.
Естественно, что дубли на этих двух сайтах тоже будет сильно отличаться друг от друга.
Битыми ссылками называют такие URL, которые ведут пользователей на несуществующие страницы. Несуществующие страницы могут появляться в случае когда сайт был удален, страница поменяла адрес, случайно удалили страницу, на которую ссылаются, а также в результате сбоя при автоматическом обновлении данных. Когда робот находит в поиске такие ссылки, он переходит по ней и видит 404 ошибку, из- за чего на сайт может быть поставлен штамп низкокачественного ресурса. Что нужно сделать в этом случае?
- Удалить ссылки, которые направляют пользователей на несуществующие страницы
- Можно заполнить страницу полезным и интересным контентом
- Если обновили систему, то нужно сделать редирект 301
Что нужно усвоить из этой статьи?
- Дубли — это страницы, на которых возможно полное или частичное повторение контента.
- Основными причинами возникновения ошибки являются ошибки разработчиков и оптимизаторов, ошибки в самом движке, автоматическая генерация.
- Дубли очень негативно сказываются на SEO — индексация ухудшается, позиции в поиске понижаются, возможны санкции со стороны поисковиков.
- Обнаружить дубли могут помочь специальные сервиcы, Гугл Консоль, оператор site.
- Чтобы удалить дубли, нужно воспользоваться специальными тегами, а лучше всего доверить эту работу профессионалам.
Что такое дубли страниц?
- – Автор: Игорь (Администратор)
В рамках данной заметки, я расскажу вам что такое дубли страниц, а так же некоторые особенности. И начну с определения.
Что такое дубли страниц и чем опасны?
Дубли страниц — это схожие или идентичные страницы сайта, которые доступны по разным URL-адресам. Основная проблема таких страниц в том, что, без определенных действий, они негативно влияют на индексацию и ранжирование в поисковых системах.
Основная проблема таких страниц в том, что, без определенных действий, они негативно влияют на индексацию и ранжирование в поисковых системах.
А теперь чуть более развернуто. Суть в том, что поисковики, такие как Яндекс и Google, определяют какую конкретно страницу необходимо отображать пользователям для их поисковых запросов, исходя из ряда факторов, в том числе и текста. Это означает, что если поисковик увидит в сайте 2 одинаковые страницы по содержанию (или смыслу, но об этом чуть позже), то у него возникнет неопределенность — «какую из них индексировать (и, соответственно, отображать)». Это уже не говоря о том, что дубли страниц — это в некотором смысле спам.
Подобное приводит к следующим проблемам:
1. Часть нужных страниц может быть не проиндексировано. К примеру, один и тот же обзор отображается для адреса «site/page1» и «site/page2». Вы выстраиваете сео оптимизацию относительно «site/page1», однако поисковик вместо этого проиндексировал только «site/page2».
2. Уменьшается влияние ссылочной массы. Ссылочная масса используется поисковиками для определения важности сайта и его отдельных страниц. Если не считать искусственно созданную массу, которая направляется на конкретные заранее заданные страницы, то естественная растет исходя из того, с чем сталкиваются пользователи сайта. А откуда последние знают, что данная страница дубль и что в комментариях нужно писать другой адрес? Ниоткуда. Поэтому часть таких ссылок могут быть бесполезными.
3. Дубли страниц в SERP. Если в serp-е поисковика отображаются дубли страниц, то это плохо, как минимум, по двум причинам. Во-первых, это захламление, которое неудобно ни пользователям, ни поисковикам. А, во вторых, существуют поведенческие факторы. Это означает, что если пользователи будут более активны в копиях страниц, то поисковик может посчитать их более важными и, соответственно, отображать выше основной.
4. Снижаются позиции в поисковиках. Как уже было не сложно догадаться, дубли — это ряд проблем и «неоднозначностей». Поэтому чем их больше, тем выше вероятность, что позиции каждой из страниц будут снижены. Утрируя, если продублировать 1 страницу 1000 раз, то вряд ли хоть одна из них сможет достигнуть топа.
Как уже было не сложно догадаться, дубли — это ряд проблем и «неоднозначностей». Поэтому чем их больше, тем выше вероятность, что позиции каждой из страниц будут снижены. Утрируя, если продублировать 1 страницу 1000 раз, то вряд ли хоть одна из них сможет достигнуть топа.
5. При большом количестве дубликатов возможны фильтры. Поисковикам не нравятся дубли, поэтому чем их больше в сайте, тем больше вероятность возникновения фильтров. При чем речь не только о конкретных страницах «под копирку», фильтр может касаться всего сайта в целом. Утрируя, если на сайте из 5 страниц сделать 1000 дубликатов одной из них, то с большой вероятностью такой сайт вообще не будет отображаться.
Тем не менее, стоит понимать, что поисковики прекрасно понимают, что полностью избавиться от дублей не всегда возможно, поэтому многое зависит от того, как они возникли и каково их количество. Например, несколько копий в сайте с тысячами обзоров вряд ли вызовет особые проблемы. Однако, это и не означает, что с дублями не нужно бороться.
Примечание: Кстати, так же советую ознакомиться с обзором — Парадокс дублированного контента (скопированного) на сайте.
Какие бывают виды дублей?
Полные дубли страниц — это ситуации, когда по разным URL-адресам отображается одна и та же страница. При чем чаще всего речь о контенте, так как менюшки и прочие элементы могут частично или незначительно меняться. Например, разные «хлебные крошки», или фоновая картинка, или реклама.
Частичные дубли страниц (неполные)
Смысловые копии страниц — это ситуации, когда чисто технически текст в страницах различается, но смысл у них один и тот же.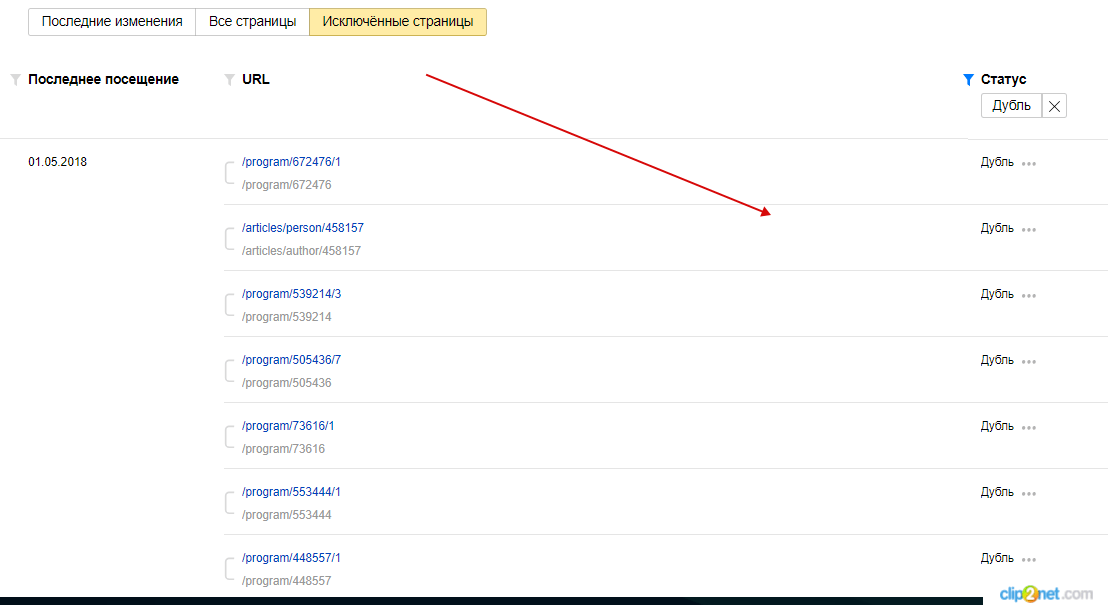
Чаще всего обращают внимание только на первый вид, но в реальности важны все три. Утрируя, 1000 обзоров о том как продвигать сайт низкочастотными запросами, написанные разными авторами, но расположенными в одном сайте по разным URL-адресам, принесут больше вреда, чем пользы.
Примечание: Кстати, поэтому-то в форумах часто не дают создавать разные ветки для обсуждения одних и тех же вопросов. Не говоря уже о том, что контент как бы «расползается».
Причины возникновения дублей страниц
Вообще, существует много возможных причин возникновения дублей, но рассмотрим самые частые из них:
1. Сайт с www и без www. Чисто технически это дубль не только отдельной страницы, но и вообще всего сайта, так как никто не запрещает в сайте с www отображать иной контент, чем в сайте без www. Иными словами, «www.site/page1» и «site/page1» это дубли.
Примечание: Обзоры как решить проблему с www.
2. Сайт с https и без.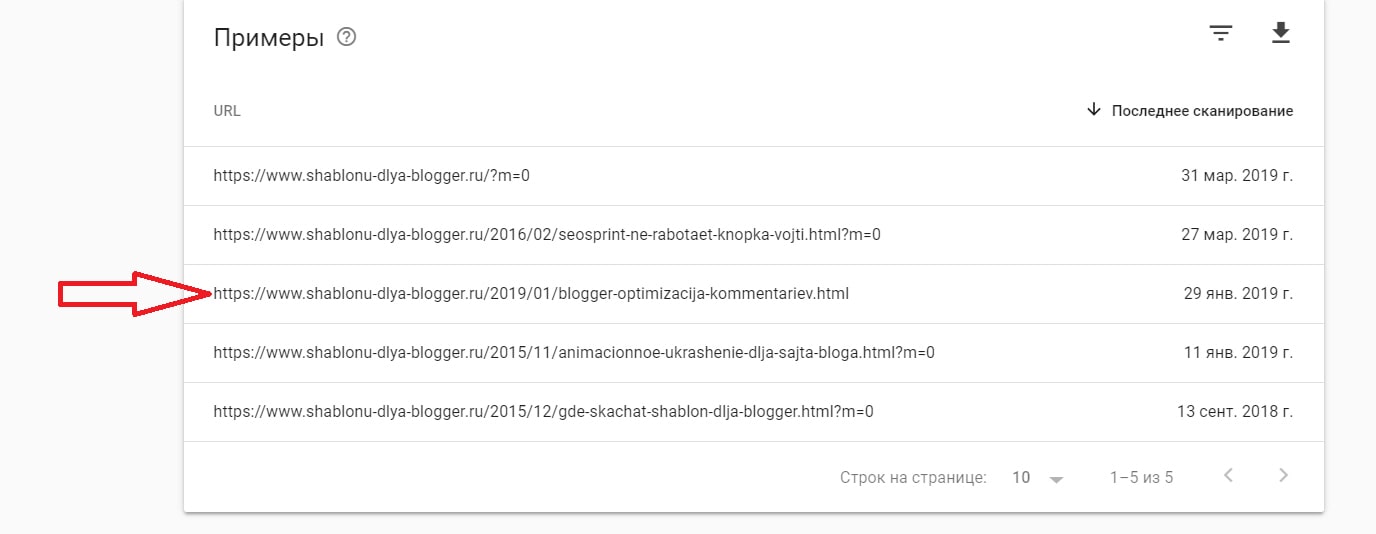 Аналогично предыдущему, никто не мешает сайту отображать разный контент в зависимости от используемого протокола.
Аналогично предыдущему, никто не мешает сайту отображать разный контент в зависимости от используемого протокола.
Примечание: Обзоры как решить проблему с https.
3. Ручные копии. Банально, но нередко бывает в больших сайтах, когда одна и та же тема освещается в нескольких обзорах. Поэтому прежде, чем размещать что-либо, стоит проверять наличие уже существующего контента.
4. Особенности CMS. Например, бывает так, что CMS подразумевает дублирование контента. Утрируя, если обзор page1 находится в категории cat1 и cat2, то возможно появление дублей вида «site/cat1/page1» и «site/cat2/page1».
5. Параметры в URL. Вообще, чисто технически параметры в URL-адресе формируют разные страницы. Например, «site/?page=123» и «site/?page=2543» это разные страницы. В чем важность? Дело в том, что это необходимо учитывать при использовании реферальных ссылок или utm меток, так как они создают из одного адреса несколько.
Так же это касается и технических аспектов. Например, если у вас автоматически формируются ссылки с различными параметрами в стиле «site/page1?from_url=menu» («с какого адреса пришли») для одних и тех же страниц, то, по сути, каждая такая ссылка формирует дубль страницы.
6. Ошибки в сайте. Как говорится, ошибки бывают.
7. Главная страница сайта. Нередкая ситуация, когда главная страница сайта доступна по нескольким разным URL-адресам. В стиле «site», «site/index.php», «site/index.html» и т.п. Поэтому это так же стоит проверять.
8. Со слешом и без слеша в конце адреса. Суть в URL вида «site/page1» и «site/page1/». Чисто технически это два разных адреса, ведь никто не мешает в коде сайта проверять наличие слеша в адресе.
9. Разный регистр. Многие пользователи Windows могли привыкнуть, что регистр никак не влияет. Однако, в случае с сайтами регистр важен. Например, ссылки «site/page» и «site/PAGE» — это два разных адреса.
Как найти дубли страниц на сайте?
Вообще, подход очень сильно зависит от того, большой ли у вас сайт или маленький, и от того, необходимо ли проверить конкретные страницы или же весь сайт. Поэтому далее приведу несколько методов, а там уже подбирайте в зависимости от задач.
1. Ручной поиск. В данном случае речь идет о двух вещах. Во-первых, можно воспользоваться встроенным поисков в самом сайте. А, во-вторых, можно использовать поисковые системы, добавив к ним «site:[ЗДЕСЬ_ВАШ_САЙТ]» (позволяет отображать только страницы вашего сайта).
Отдельно отмечу, что эти два метода различаются и об этом необходимо помнить. Дело в том, что поисковые системы могут не проиндексировать все страницы сайта. Некоторые из них могут выпадать из результатов поиска, из-за тех же дублей или еще каких причин.
2. Онлайн сервисы для поиска дублей страниц. Не указываю конкретных сайтов, так как они периодически то появляются, то исчезают. При чем далеко не у каждого из них существует бесплатный вариант, а если существует, то он может быть сильно ограничен по возможностям. Поэтому тут лучше самим в поиске пробежаться по актуальным сервисам.
При чем далеко не у каждого из них существует бесплатный вариант, а если существует, то он может быть сильно ограничен по возможностям. Поэтому тут лучше самим в поиске пробежаться по актуальным сервисам.
3. Специальные программы. Например, программа Xenu из обзора программ для проверки ссылок. Вообще, она не совсем для этого предназначена, но ее так же можно использовать для поиска дублей. Дело в том, что она позволяет находить повторяющиеся заголовки (title) и описание (description). Полезно для поиска полных дубликатов.
4. Проверка отдельных случаев. Например, с тем же www или https. Это вполне несложно сделать вручную. Кроме того, не будет лишним посмотреть основные возможности сайта. Например, создать обзор, разместить его в нескольких категориях и посмотреть возникнут ли дубли страниц.
5. Анализ ссылочной массы. Существует немало разных онлайн сервисов (названия так же не указываю, так как их список от года к году разный — проще самим посмотреть в поисковиках), которые позволяют отображать обратные ссылки. Не говоря уже о том, что и сами панели поисковиков могут это делать. Например, панель Яндекса позволяет просматривать обратные ссылки. Соответственно, собрав такую информацию, можно узнать какие URL-адреса используются и нет ли в них таких, которые вы не предусматривали.
Не говоря уже о том, что и сами панели поисковиков могут это делать. Например, панель Яндекса позволяет просматривать обратные ссылки. Соответственно, собрав такую информацию, можно узнать какие URL-адреса используются и нет ли в них таких, которые вы не предусматривали.
Как убрать дубли страниц?
Существует четыре основных метода:
1. Использование rel=»canonical». Суть в том, что если в тэге head разместить специальный тег с указанием основного адреса страницы, то тогда у поисковиков не возникнет особых проблем, так как их боты будут видеть «это оригинальная страница или копия», а так же «по какому адресу расположена оригинальная страница».
<link rel="canonical" href="http://site/cat1/page.php" />
В таком случае внешние ссылки на дубли страниц, как и сами страницы, должны нормально восприниматься поисковиками и передавать вес в основную. Однако, как говорится, механизм поисковиков известен только самим поисковикам.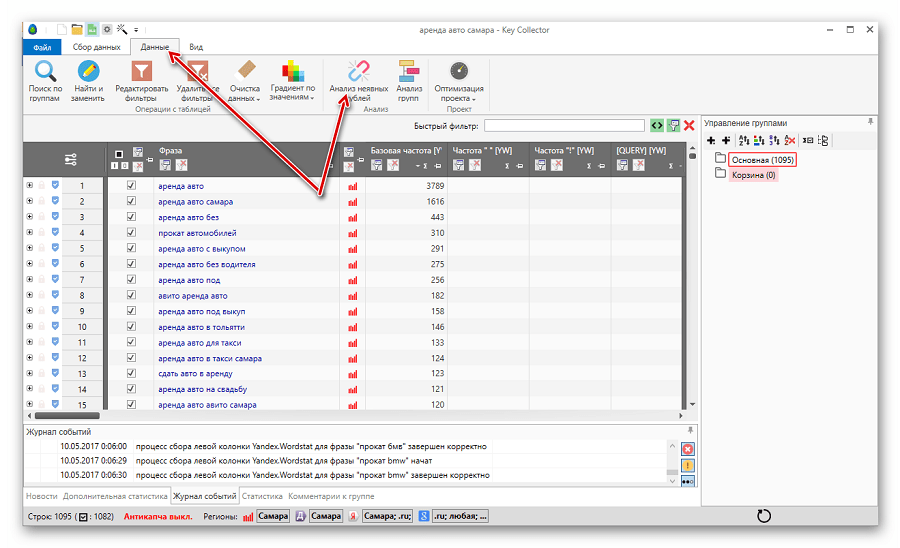 И это необходимо учитывать.
И это необходимо учитывать.
2. Использовать robots.txt. Если вы точно знаете, что некие разделы или части сайта созданы только лишь для удобства пользователей и не должны индексироваться поисковиками, то их можно исключить через robots.txt.
Минус данного метода в том, что внешние ссылки на непроиндексированные страницы могут игнорироваться или восприниматься с меньшим эффектом, не говоря уже о том, что такие варианты не всегда можно составить для всех случаев.
3. Noindex, Nofollow. Можно исключать из индекса дубли страниц с помощью мета-тегов с noindex. Однако, минус такой же, как и у robots.txt — вопрос внешних ссылок и передачи их веса.
4. 301 редирект. Редирект это переадресация страниц, поэтому в данном случае со стороны поисковика это выглядит как физическое избавление от дублей страниц (это уже не говоря о том, что самих копий в природе может не существовать). Плюсы данного метода в: перенос веса внешних ссылок, пользователи используют только один вариант страницы (даже те, которые перешли по другой ссылке, их же ведь перенаправит). Минусы в: редирект это время, не для каждого сайта подходит такой метод, копии страниц становятся недоступными.
Минусы в: редирект это время, не для каждого сайта подходит такой метод, копии страниц становятся недоступными.
Вообще, приоритетными являются 1-й и 4-й, так как у них меньше негативный эффект на сео. Однако, ситуации бывают разными, поэтому стоит знать о каждом из них. Так же настоятельно советуется не сильно усложнять сайт использованием комбинаций методов. Иначе вполне возможно, что будут возникать проблемные ситуации. Например, пересечение страниц robots и canonical. Файл robots.txt является первичным, поэтому поисковик попросту не будет учитывать canonical (хотя всякое бывает, например, поисковик может игнорировать robots, но это скорее исключение).
Понравилась заметка? Тогда время подписываться в социальных сетях и делать репосты!
☕ Хотите выразить благодарность автору? Поделитесь с друзьями!
- Что такое ЧПУ в сео?
- Дроп домен: что такое, зачем нужны, плюсы и минусы
Добавить комментарий / отзыв
Поиск дубликатов страниц на сайте
Иногда на сайте появляются страницы с идентичным или похожим содержанием. При этом адреса у этих страниц разные. Такие страницы называются дубликатами.
При этом адреса у этих страниц разные. Такие страницы называются дубликатами.
Дубликаты негативно влияют на индексацию сайта, поэтому важно вовремя их найти и устранить.
Чем плохи дубли и как они влияют на позиции сайта
- Ошибочное определение релевантной страницы.
Из двух страниц с одинаковым содержанием поисковик в результаты выдачи выбирает одну, которая, по его мнению, максимально соответствует запросу. Иногда такой страницей становится дубликат, то есть не та страница, продвижение которой планировалось. Как результат, релевантной становится дубликат, а оригинал, который создавался для продвижения, теряет в релевантности. - В результате этого ссылки, привязанные к оригиналу, теряют в позициях.
- Потеря естественных ссылок.
Когда пользователи ссылаются на дубликат страницы, это снижает эффективность продвижения. - Теряется уникальность текста на основной странице.
Если текст, размещенный на странице, встречается где-то еще, он перестает быть уникальным. А за неуникальный текст поисковики снижают позиции сайта. - Ухудшение индексации.
Если поисковый робот регулярно обнаруживает на сайте дубликаты, он занижает позиции сайта и увеличивает интервал сканирования.
В итоге из-за дубликатов снижаются позиции сайта, доверие к нему со стороны поисковиков падает.
- Виды дубликатов:
- Полный. Возникает, когда одна страница размещена по нескольким адресам, т.е у двух или нескольких страниц полностью идентичный контент.
- Частичный. Появляется, когда у двух или нескольких страниц дублируется только часть контента.
- Неправильная настройка фильтра в каталоге
- Страницы пагинации. Когда переход на следующую страницу происходит не перезагрузкой существующей, а добавлением к ней нового контента. Например, переход со страницы на страницу в каталоге товаров.
- Наличие у страницы версии для печати.
- Анонсы публикаций. Когда часть текста публикации используется как анонс. В итоге и у публикации и у страницы с анонсом появляется блок идентичного текста.
- Комментарии, отзывы, спецификация товара. Например, при выборе вкладки характеристик товара в интернет-магазине URL изменяется, но основной контент страницы остается прежним.
- Недостаточное наполнение страницы. Когда у страницы настолько мало текста, что навигационного текста и служебных надписей больше, чем самого контента.
Полные дубликаты страниц
Полные дубликаты страниц появляются по причинам, связанным с особенностями CMS, или из-за ошибок веб-разработчика. Самые распространенные причины появления полных дублей:
1 Не выбрано главное зеркало сайта, вследствие чего главная страница становится доступна по адресу с www и без.
2 Дубли страниц с разными протоколами http и https.
Например, http://site.ru и https://site.ru
3 К адресу страницы добавились index, index/, index.php, index.php/, index.html, index.html/.
Например, http://site.ru/index.html — дубль страницы http://site.ru
4 Нарушена иерархия url, изменена исходная структура сайта.
Например, если страница товара создана сначала в одном отделе каталога, а потом перенесена в другой. Из-за этого на сайте появляется две страницы с одинаковым содержанием, но c разными url.
5 Добавление слеша в url.
Например, http://mysite.ru/page и http://mysite.ru/page/
6 Реферальная ссылка.
Рекламная ссылка на страницу использует параметр «?ref=…». По правилам с рекламного url должен быть настроен редирект на url без этого параметра, но иногда этого не делают, и появляется страница-дубль.
7 Индексация страниц с utm-меткам и параметрами «gclid».
Ссылки с такими метками не должны индексироваться, но иногда это случается, и дубликат с utm меткой попадает в индекс.
Частичные дубликаты страниц
Не так страшны для индексации, но с течением времени всё же негативно влияют на репутацию сайта. Такой тип дублей сложнее обнаружить.
- Самые распространенные причины возникновения:
Как найти дубликаты
Существуют специальные сервисы для поиска дубликатов страниц на сайте, это и онлайн-инструменты и программы. Но можно ли найти дубли вручную?
Да, и вот несколько способов:
1. Поиск среди всех проиндексированных страниц в выдаче.
В поисковой строке браузера нужно перед url сайта добавить «site:». Поисковик выдаст список всех страниц в индексе.
2. Инструменты Search Console и Вебмастер.
В Search Console нужно зайти в раздел «Вид в поиске» и выбрать вкладку «Оптимизация HTML». Там можно увидеть мета-теги title и description у страниц и по ним выявить дубликаты.
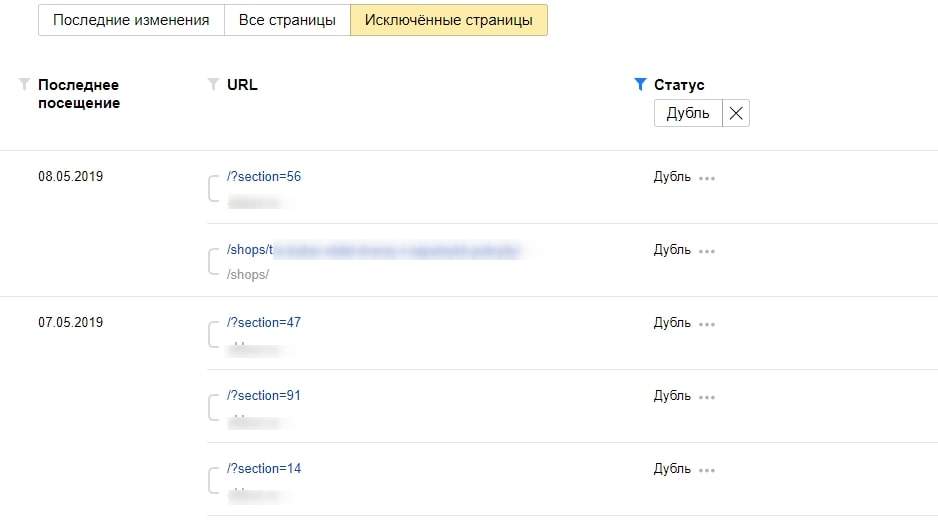
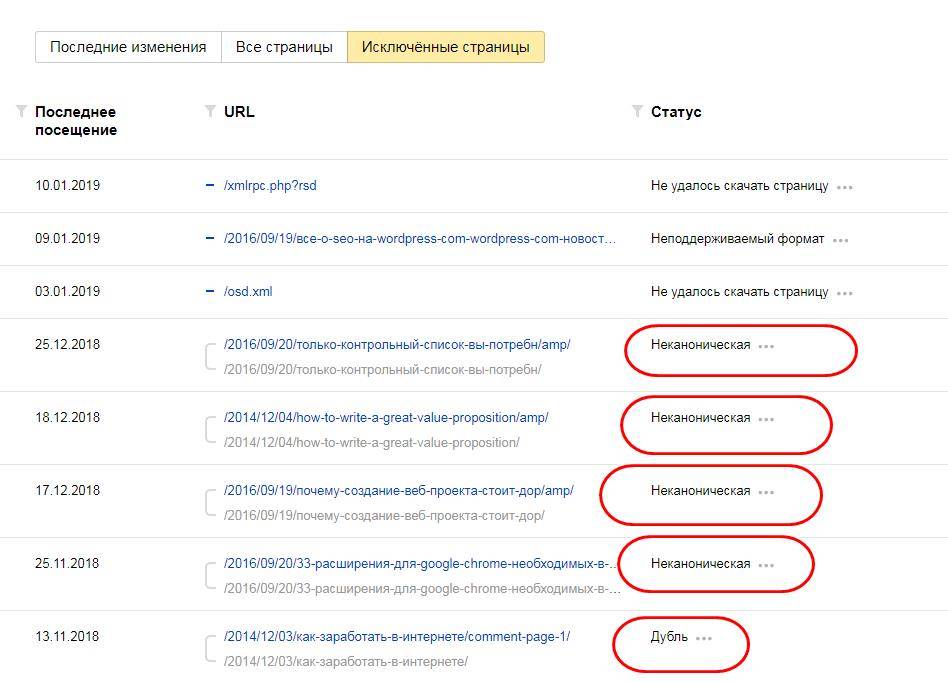
В Вебмастере нужно зайти в раздел «Индексирование» и перейти во вкладку «Страницы в поиске». Затем выбрать пункт «Исключенные страницы». На этой странице будет отображаться список исключенных из поиска страниц. В столбе «Статус» будет указана причина исключения. Среди них нужно искать «Дубль».
3. Ручной поиск на сайте (способ для опытных вебмастеров).
Что делать с дублями страниц?
После того, как дублирующие страницы обнаружены, нужно от них избавиться. Есть несколько способов:
- Удалить дублирующие страницы.
- Прописать запрет на индексацию дублей в robots.txt.
- Настроить редирект с дубля на оригинал.
- В коде страниц-дублей прописать в специальном теге ссылку на канонический url оригинала.
- В коде страниц дублей добавить мета-тег , чтобы запретить их индексацию.
Необходимо регулярно проводить мониторинг дубликатов, особенно если это большой сайт со множеством страниц. Например, форум или интернет-магазин. Даже частичные дубликаты негативно влияют на ранжирование сайта.
Нужен настоящий SEO-сайт и интернет-реклама? Пишите, звоните:
Наша почта:
Единая справочная: 8 (843) 2-588-132
WhatsApp: +7 (960) 048 81 32
Оставить заявку
Дубли страниц без rel canonical, как быстро найти
С точки зрения SEO, дубли страниц без rel canonical являются очень опасными. Поисковые системы воспринимают их критично, что приводит к потере ранжирования, а иногда к наложению фильтра. Чтобы избежать подобной ситуации, необходимо своевременно находить и удалять дубли.
Поисковые системы воспринимают их критично, что приводит к потере ранжирования, а иногда к наложению фильтра. Чтобы избежать подобной ситуации, необходимо своевременно находить и удалять дубли.Возникновение этой дилеммы приводит к разным негативным последствиям:
- Снижение релевантности главной страницы и позиций ключевых слов.
- Из-за интенсивного изменения релевантных привязок происходят «скачки» позиций ключевых слов.
- Общее снижение в ранжировании целого сайта или отдельной URL страницы.
Какие бывают дубли и как от них избавиться
По своему строению дубли бывают двух типов, следовательно, поиск и борьба с ними немного отличаются:- Полный дубль – это когда одна страница размещается по двум или более адресам.
-
Частичный дубль – это когда часть контента повторяется в ряде страниц. В этой ситуации страница не будет являться полным оригиналом.
 В этой ситуации страница не будет являться полным оригиналом.
В этой ситуации страница не будет являться полным оригиналом.Быстрый поиск дублей
Благодаря sonar.network можно оперативно узнать расположение дублей и удалить их в несколько кликов. Для этого не нужно устанавливать подозрительные программы и тратить массу времени, все происходит в режиме онлайн:- Вам нужно зарегистрироваться на сайте;
- Выбрать подходящий тариф и начать им пользоваться.
Анализ сайта занимает малое количество времени, 30-40 минут. После этого вам подробно высветятся дубли и способы их удаления.
 Большинство клиентов исправляют данные ошибки в первый день пользования.
Большинство клиентов исправляют данные ошибки в первый день пользования.Преимущества
Технический аудит сайта проходит в автоматическом режиме. Вам не нужно что-то скачивать или устанавливать на компьютер. Система сама готовит и отправляет вам отчет на облако. К другим фактическим преимуществам относится следующее:- Круглосуточная техническая поддержка пользователей оперативно и четко отвечает на вопросы связанные с системой.
- Ошибки сконструированы по типам: они формируются по степени важности.
- Актуальная стоимость, недорогие тарифные пакеты.
- Также вы получаете возможность осуществить seo анализ страницы, провести аналитику сайта онлайн и анализ качества сайта.
Для того чтобы проанализировать сайт не нужно тратить много времени. Сервис sonar.network, благодаря которому можно провести анализ сайта быстро и качественно. Для глубокой проверки seo сайта необходим только адрес веб-страницы, который вводится в специальную строку.
 По истечении короткого времени, вы получаете автоматизированный и быстрый анализ сайта, который поможет справиться с любой проблемой, связанной с кодом.
По истечении короткого времени, вы получаете автоматизированный и быстрый анализ сайта, который поможет справиться с любой проблемой, связанной с кодом.Внутренние дубли страниц сайта: последствия, поиск, удаление
Привет, друзья! Сейчас оптимизация сайта под поисковые системы это по большому счету систематический труд по его развитию, нежели применение каких-то секретных действий и технологий. Одним из таких систематических мероприятий является удаление из выдачи поисковиков дублей контента. Вот об этом действии и пойдет речь в сегодняшнем материале.
В первую очередь, нужно ответить на вопрос, почему дубли страниц негативно сказываются на его продвижении. На это есть несколько причин:
- Размывается внутренний ссылочный вес. Это происходит в том случае, когда в структуре сайта некорректные линки ссылаются на дубли страниц вместо того, чтобы увеличивать «значимость» продвигаемых документов.
- Смена релевантных страниц. Например, вы продвигаете карточку товара, текст которой полностью дублируется в категории. Поисковая система раздел может посчитать более релевантным. Итого получится, что вместо того, чтобы пользователь сразу попадал на товар, он направляется в общую категорию, где продвигаемый продукт может просто потеряться среди других. Потенциальный клиент может превратиться в уходящего посетителя.
- Уникальный контент, который представлен только в одном месте, ценнее того, который дублируется во множестве веб-документов.
 Поисковая система раздел может посчитать более релевантным. Итого получится, что вместо того, чтобы пользователь сразу попадал на товар, он направляется в общую категорию, где продвигаемый продукт может просто потеряться среди других. Потенциальный клиент может превратиться в уходящего посетителя.
Поисковая система раздел может посчитать более релевантным. Итого получится, что вместо того, чтобы пользователь сразу попадал на товар, он направляется в общую категорию, где продвигаемый продукт может просто потеряться среди других. Потенциальный клиент может превратиться в уходящего посетителя.В основном дубли появляются из-за особенностей систем управления контентом (CMS), либо из-за действий вебмастера, который копирует тексты или создает практически идентичные документы. Они бывают полными или частичными (здесь я не беру в расчет момент, когда тексты копируются на другие сайты). Полные — это когда контент полностью идентичен под другим URL, частичные — когда частично.
На мой взгляд, если один и тот же кусок контента частично дублируется в нескольких документах на сайте в пределах 10-15%, то ничего страшного. Если же больше 50%, то с этим уже нужно что-то делать.
Соотношение «реальных» страниц с количеством проиндексированных
Иногда встречаю фразы типа:
Яндекс плохо индексирует блог. В индексе всего лишь 50 страниц. А вот Google хорошо. У него 1250 страниц.
На первый взгляд какая-то проблема с индексацией в отечественном поисковике, но после уточняющего вопроса о количестве опубликованных постов, все становится на свои места. Оказывается у автора в блоге всего лишь 30 записей. Это говорит о том, что с Яндексом все в порядке, а вот в Гугле большое количество дублей. В связи с этим нужно сначала соотнести количество «реальных» страниц на сайте, которые могут быть полезны пользователю и (или) поисковику, а также не запрещены к индексации, с количеством проиндексированных. Как это сделать?
И снова пример на основе блога. Сейчас количество проиндексированных документов выглядит следующим образом.
Google занес в индекс в 2 раза больше страниц. Кто прав? Начинаю считать примерное количество нормальных страниц на сайте.
- 1011 постов;
- 20 категорий;
- главная;
- 8 пунктов меню;
- 120 страниц пагинации (навигация внизу на главной и в категориях)
Еще штук 30 различных файлов, которые я загружал (здесь же, например, флэш баннеры). Итого получаем, что нормальных страниц в блоге около 1200. Яндекс ближе всего оказался к истине. Эти дополнительные 150 документов я так и не смог найти (в этом поисковике можно просматривать только 1000 результатов выдачи).
Google, несмотря на то, что показывает цифру в 2730, в SERP выдает только 700-800. Зато в опущенных результатах находятся подобные вещи.
Даоса уже давно на блоге нет, а документы с feed на конце запрещены в robots.txt. Предполагаю, что добрая половина от цифры 2730 это и есть фиды и ссылки daos.
Как искать дубли страниц?
От последствий и причин перехожу к методам поиска дублей на сайте.
1) Полный анализ проиндексированных документов. Способ сводится к тому, чтобы просмотреть все страницы, которые включены в индекс. Для этого нужно ввести запрос site:vash-domen.ru и просмотреть все результаты (для Яндекса не более 1000, у Google — непонятно).
Для этого нужно ввести запрос site:vash-domen.ru и просмотреть все результаты (для Яндекса не более 1000, у Google — непонятно).
Чаще всего нужно анализировать URL’ы и искать среди них нетипичные. Например, у вас стоит ЧПУ, а в выдаче встретился URL с каким-нибудь таким окончанием me&catid2012220&offsetsort=price. Скорее всего, подобный документ нужно запретить к индексации.
2) Проверка внутренних ссылок, создающих дублированные страницы. Мне встречались CMS, которые создавали дубли документов внутренними ссылками, то есть ссылались не на основной материал, а на дубликат. Например, представьте, если в WordPress в анонсе поста заголовок ссылался на страницу записи (http://myblog.ru/moya-zapis/), а ссылка «Читать далее» на какую-нибудь страницу типа http://myblog.ru/moya-zapis/content/. Подобные вещи нужно либо удалять, либо превращать в адекватные (можно в принципе и продублировать линк, если он стоит на картинке или добавить якорь #).
Подобные ссылки можно смотреть самому или воспользоваться специальным софтом. Программа Xenu умеет обходить все линки на сайте, ища битые (нерабочие). Она на английском, но пользоваться ею несложно.
Сначала нужно скачать Xenu (кнопка Download) и установить ее на компьютер. Далее запустить, нажать File -> Check URL. Затем введите в первое поле адрес своего ресурса http://vashdomen.ru/ и нажмите «ОК». Программа начнет ходить по ссылкам и фиксировать рабочие, нерабочие, внутренние, внешние, заголовки, description и так далее.
Xenu выдаст результаты в зависимости от объема ресурса. Мой блог программа анализировала 29 минут
.После завершения утилита предложит создать карту для сайта и сразу залить ее по ftp. Это можно не делать. Нужно сохранить результаты. File -> Export to TAB separated file. Это позволит сохранить все данные в текстовый файлик. Далее его содержимое можно скопировать в Excel, чтобы легче было производить анализ. Можно также отсортировать URL’ы по алфавиту.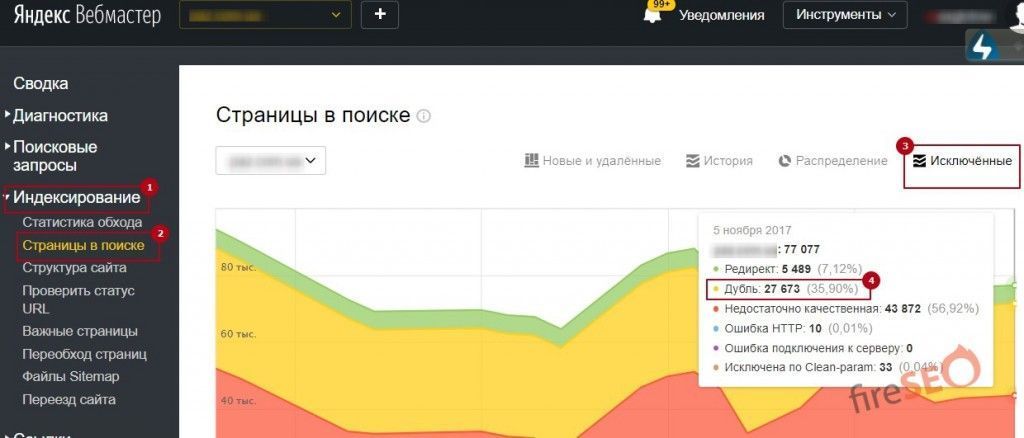
Я например, увидел, что в rel=’shortlink’ есть урлы вида ?p=43242, но они все имеют 301-редирект на соответствующие материалы с ЧПУ.
3) Поиск по кусочкам текста. Одна из самых стандартных процедур. Она заключается в том, что берется кусок текста из структурной единицы (например, предложение с 7-12 словами) и ищется в кавычках в Яндексе или Google в поиске по сайту.
Запрос имеет следующий вид site:vashdomen.ru «кусок-текста». Я вставил одно предложение из кейса по созданию и распределению семантического ядра. Яндекс нашел 3 документа, которые его содержат. Это собственно сама запись и 2 ее анонса: на главной и в категории. Дублирующие анонсы небольшие, поэтому бояться нечего. Если взять, например, какое-нибудь нижнее предложение из того же материала, то найдется только страница самого поста, так как искомый кусок текста в анонсы не попадает
.Что я подразумеваю под структурной единицей? Все просто — это главная, категории, меню, карточка товара (пост, статьи и так далее). Желательно подобным образом проверить не менее 10 документов из каждой структурной единицы.
Желательно подобным образом проверить не менее 10 документов из каждой структурной единицы.
4) Использование языков запросов. Аналогично 3-му пункту. Только поиск производится в заголовках (тег title) и в URL документах ресурса. Как правило, у дублирующих друг друга страниц эти элементы очень схожи. Примеры поиска:
а) Для Яндекса — site:vashdomen.ru title:(продвижение сайтов)
Этот запрос будет искать вхождение «продвижение сайтов» в теге title. Альтернатива для Google — site:vashdomen.ru intitle:продвижение сайтов.
б) Для Яндекса и Гугла — site:sosnovskij.ru inurl:prodvizhenie
Этот запрос будет искать прямое вхождение «prodvizhenie» в URL документов.
Как убирать дубли?
Есть несколько способов удаления дублей сайта из поисковой выдачи. Для некоторых случаев может подойти какой-то один, для других — комплекс из всех пунктов.
1) Meta name=»robots». Самый эффективный метод для документов, для которых не подходят пункты 2-4. Подробнее можно прочитать в этом эксперименте.
Подробнее можно прочитать в этом эксперименте.
2) Ручное удаление. Если вручную была создана дублирующая статья (запись, карточка) или html-страничка, то ее также нужно вручную удалить.
3) 301-редирект. Стандартная процедура для склеивания полностью идентичных документов (например, доступность с www и без www).
4) Атрибут rel=»canonical». Этот атрибут сейчас понимает и Google, и Яндекс. Он призван давать поисковому роботу информацию о предпочитаемой странице среди множества схожих по содержанию документов. Например, в интернет-магазине в категории чемоданов есть несколько сортировок: по цене, дате добавления, популярности и так далее. Поисковая система может проиндексировать данные сортировки. Так вот, чтобы среди подобных документов алгоритм ПС выбрал главную страницу категории в качестве канонической (грубо говоря, самой релевантной), нужно указать rel=»canonical» для всех подобных, которые копируют ее.
Например, есть URL’ы:
— http://internet-magazin-chemodanov. ru/chernye-chemodany
ru/chernye-chemodany
— http://internet-magazin-chemodanov.ru/chernye-chemodany&sort=price
— http://internet-magazin-chemodanov.ru/chernye-chemodany&sort=date
— http://internet-magazin-chemodanov.ru/chernye-chemodany&sort=popular
На 3-х последних урлах в пределах тега head нужно вставить следующий код:
В таком случае поисковики предпочтут первую страницу в качестве самой релевантной. В современных движках (например, WordPress) данный атрибут уже включен в структуру создания документов.
5) robots.txt. Этот файл запретит поисковому роботу индексировать определенное содержание ресурса. В первую очередь, нужно поискать стандартный robots.txt для вашей системы управления сайтом («robots.txt для …» — вместо троеточия название вашей CMS). Как правило, он уже должен оградить ресурс от индексирования основных документов, которые дублируют содержание.
Для частных ситуаций нужно уметь пользоваться директивой disallow и спецсимволами «*» и «$» (не стоит забывать и про host). Подробно об этом можно почитать в помощи Яндекса. Если брать ситуацию с чемоданами, то robots.txt мог выглядеть так:
User-agent: *
Disallow: /*sort=
Только тут нужно быть уверенным, что кусок «sort=» не используется при построении URL’ов у нормальных страниц с полезным содержанием. Иначе и они будут запрещены к индексации.
Возникали ли у вас проблемы с поиском дублей и их удалением? Как справились с задачей? Поделитесь своим опытом. С нетерпением жду ваши комментарии
.Дубли страниц на сайте
Что такое дубли страниц?
Дубли страниц на сайте — это грубая SEO-ошибка, которая характеризуется тем, что контент одной страницы полностью идентичен содержанию другой. Таким образом, они в точности копируют друг друга, но при этом доступны по разным URL-адресам.
Самые частые причины возникновения дублей:
Не сделан редирект страниц, имеющих адреса с www и без www. В этом случае каждая страница сайта будет дублироваться, так как остается доступной по двум адресам, например:
http://www.site.ru/page и http://site.ru/pageСтраницы сайта доступны по адресу со слэшем и без слэша:
http://site.ru/page/ и http://site.ru/pageТакже URL страницы может быть с .php и .html на конце либо без расширения. Как правило, это связано с особенностями cms (административной панели сайта):
http://site.ru/page.html и http://site.ru/page; http://site.ru/page.php и http://site.ru/page- Отдельно стоит выделить неполные дубли страниц. В этом случае контент на двух разных страницах не будет идентичным на 100%. Сходство и дублирование может появляться по причине того, что некоторые блоки на сайте являются сквозными — например, это может быть блок о доставке, который отображается на страницах всех товаров.
- Некоторые карточки со схожими товарами содержат идентичное описание, что также может рассматриваться как грубая ошибка.
- Постраничная пагинация каталога с товарами. В этом случае текст и МЕТА-теги на всех страницах одной категории могут быть одинаковыми.
Как дубли влияют на ранжирование?
Дубли негативно влияют на ранжирование вашего сайта — за наличие дубликатов страниц интернет-ресурс может с большой степенью вероятности подвергнуться пессимизации со стороны поисковых систем.
- Яндекс и Google очень трепетно относятся к уникальности контента на web-ресурсах. В случае, если данные на страницах дублируются, они признаются неуникальными. За это на сайт могут быть наложены санкции.
- Наличие большого количества дублей страниц сильно усложняет процесс индексации сайта и запутывает поисковых роботов.
- Затрудняется продвижение посадочных страниц, так как поисковая система не может выбрать релевантную страницу из двух одинаковых.
- Теряется «вес» страниц, поскольку распределяется между двумя одинаковыми документами.
Подробно описывается негативное влияние дублей и методы борьбы с ними в статье Google «Консолидация повторяющихся URL»
Яндекс, в свою очередь, предлагает на эту тему видеоурок «Поисковая оптимизация сайта: ищем дубли страниц», где разъясняется терминология и способы решения проблемы.
Как обнаружить дубли у себя на сайте?
С этим могут возникнуть трудности не только у обладателей больших web-ресурсов, но и у владельцев совсем небольших сайтов, так как некоторые дубли, возникающие из-за особенностей и ошибок CMS, очень сложно обнаружить. Быстро и без лишних трудозатрат найти дубли страниц можно с помощью сервиса Labrika. Для этого нужно посмотреть соответствующий отчет. Находится он в подразделе «Похожие страницы» раздела «SEO-аудит» в левом боковом меню:
В отчете вы можете увидеть следующую информацию:
- Страница сайта, которая имеет дубль.
- Дубль этой страницы
- Процент схожести страниц. Благодаря этому проценту вы сможете определить, является ли дубль страницы полным.
Получив данные из отчета, вы сможете сэкономить время и сразу начать устранять эти ошибки.
Как устранить дубли на сайте?
В первую очередь, необходимо установить характер дубля и уже после этого выбирать способ его устранения.
- Если дублей на сайте небольшое количество и их происхождение связано с ошибками CMS (допустим, страница доступна по адресам http://site.ru/category/tovar и http://site.ru/tovar), то самым простым методом решения проблемы будет следующий. Дубль необходимо запретить для индексации поисковых систем в robots.txt (также см. информацию о robots.txt от Google). Затем воспользоваться формой удаления URL из индекса в Яндекс.Вебмастер — https://webmaster.yandex.ru/tools/del-url/ и инструментом аналогичного назначения в Google Webmaster — https://www.google.com/webmasters/tools/url-removal. Подробнее про использование инструмента от Google вы можете прочитать здесь.
- Если появление дубликатов носит системный характер и связано с такими ошибками, как, например, несклеенный домен (страница доступна по адресу с www и без www), то в таком случае необходимо выбрать главное зеркало (например, адрес сайта без www), воспользоваться командой 301 redirect (перенаправление со страниц с www на страницы без них), которая прописывается в специальном файле htaccess.
- В случае, если вы имеете дело с постраничной пагинацией товаров одной категории, Яндекс советует использовать атрибут rel=»canonical». Более подробно о применении этого атрибута на страницах с пагинацией вы можете прочитать в статье Блога Яндекс «Несколько советов интернет-магазинам по настройкам индексирования».
Проверка дублированного контента — 5 лучших онлайн-инструментов для проверки дублированного контента
Контент-маркетинг, SEO,
Вы, как владелец / менеджер веб-сайта, знаете, что веб-сайты должны содержать оригинальный контент. Таким образом, вы всегда должны стремиться к тому, чтобы страницы вашего веб-сайта не содержали плагиата. Google и другие поисковые системы могут наказать ваш сайт за содержание плагиата, а вы этого не хотите. Этот штраф лишит вас цели создания веб-сайта.
Есть еще одна возможность, и это то, что другой сайт публикует ваш контент без вашего разрешения. Да, этим занимаются недобросовестные интернет-маркетологи. Они видят, что ваш сайт хорошо ранжируется и получает хороший трафик. Они попытаются настигнуть вас, используя ваш контент против вас. Они могут даже превзойти вас в поисковых системах.
Что такое определение дублированного контента?
Справочный центр Google Search Console гласит: «Под дублированием контента понимаются основные блоки контента внутри или между доменами.Они либо полностью соответствуют другому контенту, либо в значительной степени похожи ».
Следует ожидать дублирования контента (как это сделано выше) из другого источника или сайтов электронной коммерции, которые предоставляют общие описания продуктов от поставщиков о продуктах.
Это вызывает беспокойство, когда на нескольких страницах веб-сайтов размещается похожий контент. Это влияет на рейтинг сайта и может привести к его исчезновению из результатов поиска.
Поисковые системы не отображают несколько страниц с похожим содержанием; они отображают веб-сайт, страницы которого лучше всего соответствуют запросу зрителя.Во-вторых, если входящие ссылки указывают на несколько страниц, содержащих дублированный контент на нескольких сайтах, сила входящей ссылки снижается.
Есть много вариантов, когда дело доходит до поиска онлайн-проверки на плагиат. Вы можете попробовать их, так как некоторые из них бесплатны, а другие предлагают бесплатную пробную версию.
5 лучших инструментов, которые помогут вам найти дублированный контент на веб-сайтах
Самый простой способ найти дублированный контент — использовать онлайн-средство проверки на плагиат. В Интернете доступно несколько бесплатных приложений для проверки на плагиат, и вы должны выбрать лучшую из доступных на рынке приложений для проверки на плагиат.
Лучшая бесплатная программа проверки на плагиат, которую вы найдете при проверке дублированного контента или контента на плагиат в Интернете:
Duplichecker
Самая популярная онлайн-программа проверки на плагиат, указанная по запросу Google, — duplichecker.com. Он прост в использовании и бесплатен. Он предоставляет три варианта проверки на плагиат; вы можете скопировать / вставить текст или загрузить файл, а в-третьих, ввести URL-адрес веб-страницы для проверки.
Он выполняет глубокий поиск и предоставляет подробный отчет о плагиате.При обнаружении плагиата отображается процент, уникальный процент и связанный с ним значимый процент. Контент для проверки отображается в левом столбце, а сайты с аналогичным контентом отображаются в правом столбце. Вы также можете распечатать отчет о результатах.
Smallseotools (Проверка на плагиат)
Следующая лучшая программа проверки на плагиат — smallseotools.com/plagiarism-checker. Причина включения его в список второй после duplichecker.com программы проверки на плагиат заключается в том, что она предлагает два варианта проверки содержимого: копирование / вставка содержимого или ввод URL-адреса веб-страницы для проверки.У него есть третий вариант — исключенный URL. Если вы хотите, чтобы он пропускал URL-адрес при поиске плагиата, вы можете это сделать.
В отчете о результатах отображается плагиат, уникальный процент и результат по предложению. Предложения, которые были обнаружены как плагиат, отмечены красным флажком, и есть кнопка сравнения. Щелкните по нему, и он отобразит сайт, содержащий такое же предложение. Вы также можете распечатать отчет.
Детектор плагиата
Третьим лучшим бесплатным онлайн-средством проверки плагиата является детектор плагиата.сеть. Это также дает вам возможность копировать / вставлять текст, исключать URL-адрес и проверять по URL-адресу. Представленные результаты имеют показатели уникальности и процента плагиата. Введенный текст отображается в левом столбце, а предложения с контентом с плагиатом выделяются красным цветом. В правом столбце отображаются источники плагиата. Вы можете скачать отчет.
CopyScape
Четвертое бесплатное приложение для проверки на плагиат — copyscape.com. Он выполняет поиск только путем ввода URL-адреса.Он не предлагает копировать / вставлять текст или исключать варианты URL. Это очень удобно для менеджеров веб-сайтов, которые хотят проверить, есть ли в их URL-адресах контент, похожий на контент на других веб-сайтах. В отчете о результатах отображается контент и веб-сайты с похожим контентом. Щелкните любой из URL-адресов, и подробный отчет с предложениями, выделенными красным цветом для скопированного содержимого, отобразится на другой вкладке в вашем браузере.
Siteliner
Последняя бесплатная онлайн-программа для проверки плагиата, которая будет указана здесь, — это siteliner.com. Как и Copyscape, он предлагает проверку на плагиат только по URL. Вы вводите URL-адрес, который хотите проверить, и он просканирует все страницы URL-адреса и проверит на плагиат.
В отчете отображаются результаты «ваших основных проблем» и «ваших страниц». Под вашими страницами отображается дублированный контент, результаты сравнения с результатами других сайтов. Щелкните дублированный контент, и на новой вкладке отобразятся сайты, содержащие дублированный контент, и процентное соотношение.
Заключение
Вам следует выполнять обычную проверку на наличие дублированного контента, если вы хотите быть уверенным, что ваш контент не будет украден, скопирован или дублирован.
Большинство проблем дублирования, существующих на веб-сайте, можно исправить. По вопросам внешнего дублирования вы можете связаться с сайтами, которые используют ваш контент без вашего разрешения. Вы также можете зарегистрироваться и получить значок DMCA. Они будут взимать с вас плату за каждый удаленный сайт, на котором скопирован ваш контент. Размещение этого значка на вашем веб-сайте отпугнет скребков и копировальных устройств.
Проверка дублированного содержимого для SEO — Проверка на плагиат
Homekeyboard_arrow_rightBus Businesskeyboard_arrow_rightПроверка повторяющегося содержимого для агентств SEO
Дублированный контент может быть описан как абзац, который в точности совпадает или очень похож на контент, представленный на одной или нескольких страницах веб-сайта.Во многих случаях дублированный контент приравнивается к плагиату. Копирование контента с веб-сайтов без разрешения является правонарушением.
Сравните более шестидесяти триллионов страниц в Интернете с помощью нашего инструмента. Сюда входят сайты, защищенные паролем, секретные журналы и частные архивы. Все письменные работы надлежащим образом сохранены и защищены Copyleaks. Поисковая оптимизация дублированного контента поможет вам определить, где ваш контент используется в Интернете. С дубликатом Copyleaks, средством SEO-проверки контента, вы можете предотвратить создание случайно повторно используемого контента.
ОБНАРУЖИТЬ ПЛАГИАТ ЗА СЕКУНДЫ
Отсканируйте свой текст для быстрого сканирования на плагиат прямо сейчас!
Начните сегодня бесплатно с 20 бесплатными сканированиями в месяц!
SCANorUpload File
Как использовать средство проверки дублированного содержимого
Используйте уникальное содержимое для поддержания высокого уровня поисковой системы. Однако ручная проверка дублированного контента не является возможным решением. Наша программа проверки дубликатов предназначена для проведения всестороннего сканирования для обнаружения копий. Инструмент проверки дублированного содержимого Copyleaks кратко проверяет содержимое, чтобы проверить наличие копий содержимого в Интернете.Вам просто нужно загрузить контент, который вы хотите просканировать, и получить результаты, чтобы исправить проблемы с дублированным контентом.
Почему важно предотвращать дублирование содержимого?
Проблема, вызванная дублированием контента в Интернете, заключается в уменьшении трафика. Дублированный контент также ведет к манипулированию рейтингом в поисковых системах. Поисковая система использует определенный алгоритм, с помощью которого они фильтруют исходный контент. Теперь, если на любых двух веб-сайтах есть похожие, то автоматически один из них потеряет доверие.За это будет отвечать алгоритм. Однако результат будет весьма вредным, так как снизит рейтинг одного из двух сайтов. Copyleaks гарантирует, что такого не случится, и разрушит вашу репутацию, карьеру и бизнес. Следовательно, они используют сложные технологии для регулярного поиска миллиардов различных страниц контента.
Как использовать эти результаты?
Это уместно, для начала, проблемы с внутренним дублированием контента. Используйте следующие методы, чтобы избавиться от идентичного содержимого:
- Удалите повторяющееся текстовое содержимое с веб-страниц / сообщений в блогах.
- Перенаправляйте страницы на основной веб-сайт, чтобы устранить проблему наличия нескольких версий.
- Избегайте использования очищенного содержимого.
- Исправить неработающие внутренние ссылки.
- Не использовать индекс и метатеги Follow.
Особенности средства проверки дублированного контента
книга Сообщения в блоге Вас могут заинтересовать:
Как проверить дублированный контент
В двух словах, дублированный контент — это идентичный контент, к которому можно получить доступ по двум или более различным URL-адресам.Дублирование может произойти: Во-первых, на вашем собственном веб-сайте. Во-вторых, при междоменном дублировании происходит копирование вашего контента другим веб-сайтом.
Как проверить повторяющееся содержимое
CopyScape проверка дублированного содержимого
Есть много инструментов для поиска дублированного контента. Одним из наиболее известных средств проверки дублированного контента, вероятно, является CopyScape.com. Этот инструмент работает довольно легко: вставьте ссылку в поле на главной странице, и CopyScape вернет ряд результатов, которые немного похожи на страницы результатов поиска Google.
Используйте средство проверки дублированного содержимого CopyScape, чтобы найти скопированный контент с вашего веб-сайта на других веб-сайтах. Опять же, это один из многих инструментов, но этот бесплатный и простой в использовании. Однако имейте в виду, что вы не получите неограниченное количество сканирований для одного веб-сайта. Если вы хотите глубже погрузиться в повторяющийся контент, CopyScape также предлагает премиум-версию для получения дополнительных сведений.
Используя CopyScape, мы часто обнаруживаем, что описания производителей, используемые в интернет-магазинах, дублируются. Обычно они автоматически импортируются в систему управления контентом магазина.Причем не только для вашего сайта . Помните об этом. Мы понимаем, что писать уникальные описания для каждого продукта довольно сложно. Однако разве ваши самые продаваемые продукты, по крайней мере, не заслуживают того же? Так что начните сейчас и возьмите это оттуда!
Внутренняя проверка дублированного содержимого Siteliner
Siteliner — брат CopyScape, который выполняет поиск внутренних дублированных материалов. Таким образом, эта программа проверки дублированного контента найдет дублированный контент на вашем собственном сайте .
Внутренняя проверка дублированного содержимого
Внутренний Дублированный контент, как это происходит, спросите вы? Что ж, очень распространенный пример этого — когда блог WordPress не использует выдержки, а показывает всю запись блога на главной странице блога. Это означает, что сообщение в блоге доступно как минимум на двух страницах: на домашней странице и в самом сообщении. И, вероятно, он также есть на страницах обзора категорий и тегов. Это уже четыре версии одной и той же статьи на вашем собственном сайте.
Использование отрывков (вместо показа всего сообщения) имеет то преимущество, что отрывок всегда имеет правильную ссылку на сообщение.Эта ссылка сообщит Google, что исходный контент находится не на этой странице блога / категории / тега, а в самом сообщении. Мы часто рекомендуем использовать отрывки.
Siteliner
Проверка дублированного контента Siteliner покажет вам множество вещей, но ограничено 250 страницами и один раз в 30 дней. Опять же, есть премиум-версия, но бесплатная уже произведет на вас хорошее впечатление. Просто выполните поиск, и вы окажетесь на странице обзора. В левом верхнем углу вы увидите процент внутреннего дублированного содержания.Не паникуйте, когда увидите большие числа, так как при этой проверке дублированного содержания также учитываются выдержки из дублированного содержания: просто нажмите одну из ссылок и проверьте, действительно ли это выдержка. Очевидно, что это ссылка на сообщение, так что, если это так, вы защищены.
Дополнительные советы: инструменты для дублирования содержимого
Хотя Google понимает, что такое боковая панель, CopyScape и Siteliner, похоже, включают весь текст на странице в свои процентные вычисления. Это означает, что фактический процент дублированного контента при просмотре основного контента страницы может быть выше.Помните об этом, когда будете использовать одну из этих проверок дублированного контента. Просто хедз-ап!
Проверка вручную
CopyScape и Siteliner — удобные и удобные средства проверки дублированного контента. Однако, если вы хотите увидеть, что дублируется в соответствии с Google, вы также можете просто использовать сам Google.
Если у вас есть определенная страница, которую вы хотите проверить, просто перейдите на эту страницу. Скопируйте фрагмент текста, желательно из раздела, который, по вашему мнению, может быть привлекательным для копирования другими.Давайте возьмем отрывок из нашей статьи о распространенных ошибках SEO: « Если заголовок вашей страницы слишком длинный (в настоящее время от 400 до 600 пикселей), он будет обрезан в Google. Вы не хотите, чтобы потенциальные посетители не могли прочитать полный заголовок в поисковой выдаче. ”(обратите внимание, что Google учитывает только первые 32 слова). Вставьте точный фрагмент в Google между двойными кавычками, например:
По данным Google, этот поисковый запрос возвращает «около 208 результатов», что намного превышает 10 результатов, возвращенных CopyScape.
Заключение
Люди ожидают найти уникальный и полезный контент, и это то, что они должны уметь найти. Следует по возможности избегать дублирования контента. Контент должен быть хорошо продуманным и уникальным, чтобы читатели могли лучше всего работать в Интернете.
13 лучших бесплатных инструментов для проверки дублированного контента в Интернете (обновленный список)
Google определяет Дублированный контент как «Дублированный контент обычно относится к основным блокам контента внутри или между доменами, которые либо полностью соответствуют другому контенту , либо в значительной степени похожи.В основном это не обман по происхождению ».
Дублированный контент или плагиат — злейший враг любого блога. Google ненавидит дублированный контент, и это может стоить вам падения рейтинга в поисковых системах, или Google может даже удалить ваш веб-сайт или блог, если на нем много дублированного контента.
В этом посте я поделился некоторыми из лучших онлайн-инструментов для проверки дублированного контента, к которым вы можете получить доступ совершенно бесплатно.
Google Duplicate Content Checker SEO Инструменты для вашего веб-сайта 1.Копия:Первым в списке стоит Copyscape, один из моих любимых и наиболее точных инструментов проверки дублированного контента Google, доступных в Интернете для бесплатного использования. Это один из старейших и самых популярных инструментов для проверки плагиата.
Copyscape предоставляет бесплатную услугу, которая позволяет легко искать плагиат в Интернете и выявлять случаи кражи контента. Просто введите URL-адрес исходного содержимого, а Copyscape сделает все остальное. Хотя инструмент бесплатный, но его ежедневное использование ограничено некоторыми поисковыми запросами для каждого пользователя.
Он также предлагает профессиональные услуги для более сложных задач. Если у вас большой объем контента, вы можете подписаться на премиум-сервисы Copyscape, а затем интегрировать их API в свою CMS для легкой идентификации дублированного контента.
Дополнительная литература: Как бесплатно проверить повторяющийся контент на веб-сайте в Интернете
Средство проверки дублированного содержимого, например Copyscape 2. Siteliner:Мне очень нравится этот инструмент, так как с проверкой дублированного контента он также предоставляет полный анализ веб-сайта один раз в месяц.Siteliner — это бесплатный сервис от Copyscape, который позволяет вам исследовать свой веб-сайт и выявлять ключевые проблемы, влияющие на качество и рейтинг в поисковых системах.
Siteliner может проверять дублированный контент, неработающие ссылки, мощность страницы и создает полный отчет после сканирования и анализа вашего сайта, который раскрывает полезную информацию, которая в конечном итоге может помочь вам в улучшении вашего сайта или блога.
Хотя бесплатная услуга Siteliner ограничена ежемесячным анализом до 250 страниц, этого более чем достаточно для веб-сайтов небольшого или даже среднего размера.
3. Грамматика:Grammarly предоставляет лучшую бесплатную программу проверки и корректора на плагиат. Grammarly — это автоматический корректор и средство проверки на плагиат, которое гарантирует, что все, что вы набираете, легко читается, эффективно и без ошибок.
Это один из лучших инструментов, который вы можете использовать. Grammarly также предлагает бесплатные расширения для Chrome, Safari и Firefox. Программа Grammarly для проверки на плагиат перекрестно проверяет ваш текст на более чем 8 миллиардов веб-страниц, обнаруживая плагиат отрывков и выделяя разделы, которые ранее были опубликованы в других местах.
Дополнительная литература: Обзор Cloudways 2019: Лучшая управляемая платформа облачного хостинга
4. Маленькие инструменты SEO:Это еще один инструмент для проверки дублированного контента от Small SEO Tools, который предоставляет множество полезных инструментов для поисковой оптимизации. Мне нравится этот инструмент, поскольку он выявляет повторяющийся контент в большинстве случаев, даже если этот контент пропускается Copyscape и Grammarly.
Чтобы использовать там инструмент проверки плагиата, просто скопируйте контент, который вы хотите проверить, и вставьте его в поле на их веб-сайте, затем нажмите большую красную кнопку с надписью «Проверить плагиат!» а затем он просканирует весь документ, и вы получите результаты примерно через две минуты … но у них есть ограничение в 2000 слов на поиск, поэтому, если у вас есть документ, содержащий более 2000 слов, вы можете выполнить поиск, разделив документ .
Вы также можете загрузить документ прямо со своего компьютера или загрузить из Dropbox или Google Drive. Они даже предоставляют плагин WP для проверки плагиата, который вы можете использовать для прямого сканирования всех ваших сообщений и страниц на вашем сайте WordPress.
Внутренние инструменты проверки дублированного содержимого 5. Duplichecker:Четвертым в списке стоит Duplichecker, который также является бесплатным средством проверки дублированного контента Google. Он дает два варианта: вы можете либо вставить контент и проверить его на наличие дублированного контента, либо вы можете загрузить текстовый файл.
Duplichecker бесплатен для всех и работает со 100% точностью. Каждая проверка на плагиат сравнивает ваш текст с каждой опубликованной веб-страницей в Интернете, и DupliChecker никак не может ускользнуть. Если совпадений нет, будьте уверены, что ваш текст не содержит плагиата.
Дополнительная литература: Обзор SEMrush 2019: лучший комплексный набор маркетинговых инструментов
6. Плагиат:Plagiarisma еще лучше, поскольку дает вам три варианта проверки на наличие плагиата.Вы можете загрузить любой текст, HTML, файл документа, выполнить поиск по URL-адресу или просто вставить содержимое для проверки.
Он обнаруживает нарушение авторских прав в вашем эссе, исследовательской работе, курсовой работе или диссертации и поддерживает Google, Yahoo, Scholar и Books. Plagiarisma поддерживает более 190 языков.
7. Plagium:Его можно использовать как альтернативу Copyscape, а также он имеет множество дополнительных функций. Вы можете проверить статьи, содержащие не более 25 000 символов.
Они также предлагают премиальные функции, такие как быстрый поиск для поиска плагиата за 0,04 доллара за страницу, глубокий поиск для углубленной проверки на плагиат за 0,08 доллара за страницу и сравнение файлов для сравнения загруженных файлов за 0,005 доллара за страницу.
Дополнительная литература: Инструменты подсказки ключевых слов YouTube: поиск по количеству запросов, цене за клик, тегам и прочему
8. Проверка на плагиат:Этот сайт был основан в 2006 году и предоставляет бесплатные услуги по обнаружению плагиата в Интернете.Вы можете вставить свой контент в окно поиска или просто проверить всю веб-страницу на плагиат.
Он также дает вам возможность создать оповещение Google напрямую, если вы хотите, чтобы Google отправлял вам электронное письмо, когда новые экземпляры вашей работы публикуются в Интернете.
9. Plagspotter:Это еще один онлайн-инструмент Google для проверки дублированного контента, и вы можете использовать его, введя URL-адрес веб-страницы, чтобы найти его копии в Интернете.
Plagspotter также имеет функцию пакетного поиска, с помощью которой вы можете проверить весь свой сайт на плагиат.Он позволяет автоматически отслеживать выбранные вами URL-адреса на предмет дублирования контента, сканируя ваш контент ежедневно или еженедельно, обнаруживая плагиат и уведомляя вас по электронной почте о% дублирования.
10. ThePensters:Еще один бесплатный детектор плагиата от ThePensters — отличный инструмент, который вы можете использовать для проверки дублирования в ваших заданиях или даже в сообщениях в блогах. Поддерживаются два языка: английский и испанский, и вы можете ввести максимум 1000 слов в поле для поиска любого повторяющегося контента.
Незарегистрированные пользователи могут использовать инструмент не более 5 раз в месяц, а зарегистрированные пользователи могут использовать его неограниченное количество раз. Этим эффективным инструментом могут пользоваться как блогеры, так и студенты.
Дополнительная литература: Как заработать деньги, ведя блог на WordPress Бесплатно: 30 способов
11. WorldEssays:Если вы хотите бесплатно проверить свои тексты, вот хороший вариант для сканирования ваших писем — Бесплатная проверка на плагиат от WorldEssays.com. Вы можете вставить текст для анализа с максимальным количеством символов 1000.
12. DMCA:Вы можете защитить содержимое своего веб-сайта с помощью Закона США «Об авторском праве в цифровую эпоху» (DMCA), а также предоставляет инструмент для проверки дублированного содержимого. Он также предоставляет сканер веб-сайтов и детектив веб-сайтов
DMCA имеет два плана:
Basic Protection , который является бесплатным и предназначен для небольших личных веб-сайтов и владельцев веб-сайтов, которым требуется решение, которое эффективно предотвращает кражу контента.
Pro Protection за 10 долларов в месяц, предназначен для профессиональных веб-сайтов и предприятий, которым требуется лучшая защита для защиты своей собственности.
13. Webconfs:Этот инструмент позволяет определить процент сходства между двумя страницами. Вам нужно ввести URL-адреса двух страниц, и он сделает все остальное.
Что ж, я поделился почти всеми замечательными инструментами, которые использовал для проверки дублированного контента, и они также будут полезны для вас.
Все поисковые системы очень стараются улучшить работу своих пользователей, поэтому они воспринимают плагиат как прямую угрозу их опыту.Вот почему мы настоятельно рекомендуем вам, если вы не хотите, чтобы поисковые системы наказывали вас за проверку существующего контента и любого контента, который вы планируете публиковать в будущем, на предмет дублирования. Я также регулярно использую эти инструменты для проверки моего сайта на наличие дублированного контента.
Если вы принимаете гостевые сообщения на своем веб-сайте или в блоге, вам обязательно стоит попробовать эти инструменты, поскольку много раз блоггеры пытаются предоставить дублированный контент во имя гостевой публикации только для того, чтобы получить обратную ссылку, которая может нанести вред вашему сайту.
Теперь дайте мне знать, какой инструмент вам понравился больше всего и почему, оставив небольшой комментарий ниже!
Как бесплатно проверить повторяющийся контент на веб-сайте в Интернете
Дублированный контент — это контент, который появляется в Интернете более чем в одном месте. Когда существует несколько версий контента, как это называет Google, «в значительной степени похожие» в нескольких местах, поисковым системам может быть очень сложно решить, какая версия является исходной и более релевантной для конкретного поискового запроса.
Дублированный контент может серьезно навредить вашему сайту. Google ненавидит дублированный или плагиат контента, и иногда это может повлиять на SEO вашего сайта и рейтинг в поисковых системах, или Google может даже удалить ваш сайт, если он содержит большую часть дублированного контента.
Google определяет повторяющийся контент как:
Дублированный контент обычно относится к основным блокам контента внутри или между доменами, которые либо полностью соответствуют другому контенту, либо в значительной степени похожи. По большей части это не обманчивое происхождение.
Что в итоге? Хотя технически вы можете не получить штраф, но все же дублированный контент может серьезно повредить вашему сайту, и вам следует быть более осторожными с дублированным контентом, если ваш сайт новый и не имеет большого авторитета.
В этом посте я покажу вам, как вы можете бесплатно проверить наличие внутреннего дублированного контента на своем веб-сайте с помощью простых онлайн-инструментов.
Хотите узнать самое лучшее? Я упомянул два метода: один для проверки отдельных сообщений и страниц на предмет дублирования контента, а другой — для полной проверки веб-сайта / блога, которая предоставит вам полный отчет о дублированном контенте.
Вы также можете прочитать этот пост для всех инструментов проверки дублированного контента Google:
12 бесплатных онлайн-инструментов Google Duplicate Content Checker
1. Copyscape:Самым популярным в Интернате и моим любимым инструментом для проверки дублированного контента является Copyscape. Он предоставляет вам бесплатную программу проверки на плагиат для поиска копий ваших веб-страниц в Интернете, проверки оригинальности копирования и вставки, пакетного поиска, частного индекса и отслеживания случаев всего одним щелчком мыши.
Становится лучше:
Copyscape предоставляет бесплатную услугу, которая позволяет легко искать плагиат в Интернете и выявлять случаи кражи контента. Просто введите URL-адрес исходного содержимого, а Copyscape сделает все остальное. Хотя инструмент бесплатный, но его ежедневное использование ограничено некоторыми поисковыми запросами для каждого пользователя.
Он также предлагает профессиональные услуги для более сложных задач. Если у вас большой объем контента, вы можете подписаться на премиум-сервисы Copyscape, а затем интегрировать их API в свою CMS для легкой идентификации дублированного контента.
Теперь: Давайте разберемся в процессе:
Шаг № 1: Сначала перейдите в Copyscape.
Шаг № 2: Вставьте URL-адрес веб-страницы, на которой вы хотите проверить повторяющееся содержимое, в данное поле.
Например: если вы хотите проверить копии этого URL http://backlinko.com/youtube-ranking-factors. Просто вставьте его в поле поиска и нажмите Enter.
Вы получите результаты в течение нескольких секунд, а Copyscape предоставит вам первые десять результатов в бесплатном плане.В большинстве случаев первых десяти результатов будет достаточно, и они скажут вам, есть ли у контента дубликаты в Интернете или нет.
Затем просто нажмите на отдельные ссылки, и он покажет вам, сколько именно слов на странице скопировано с URL-адресом этой страницы.
Copyscape действительно очень прост в использовании и очень точен, заняв первое место по результатам независимых тестов. Миллионы владельцев веб-сайтов доверяют Copyscape для проверки оригинальности своего нового контента, предотвращения дублирования контента и поиска копий существующего контента в Интернете.
Посмотрите это видео о Copyscape, если вам нужна дополнительная информация.
Как проверить дублированный контент веб-сайта: онлайн-инструмент Google Duplicate Content Checker 2. Siteliner:Мне очень нравится Siteliner, так как с функцией проверки дублированного контента он также предоставляет полный анализ веб-сайта один раз в месяц. Это бесплатная услуга Copyscape, которая позволяет вам исследовать свой веб-сайт и выявлять ключевые проблемы, влияющие на его качество и рейтинг в поисковых системах.
Siteliner может проверять дублированный контент, мощность страниц, неработающие ссылки и генерирует полный отчет после сканирования и анализа вашего сайта, который раскрывает полезную информацию, которая в конечном итоге может помочь вам в улучшении вашего сайта или блога.
Теперь: Давайте разберемся в процессе.
Шаг № 1: Сначала перейдите на Siteliner.
Шаг № 2: Вставьте URL-адрес веб-сайта, на котором вы хотите проверить повторяющееся содержимое.Здесь помните, что Siteliner выполнит полное сканирование веб-сайта, поэтому потребуется некоторое время, и вставит URL-адрес домашней страницы веб-сайта, а не какой-либо конкретной страницы публикации.
Шаг № 3: Просто нажмите Enter, и сканирование будет выполнено полностью. Вам будет представлен полный отчет.
Это дает вам возможность проверять дублированный контент, уникальный и общий контент, который есть на веб-сайте.
Щелкните здесь, чтобы просмотреть полный список сообщений или страниц с повторяющимся содержанием.
Этот список даст вам количество точно совпадающих слов, процентное соотношение и страниц со степенью страницы. Вы можете скачать отчет по сайту в формате PDF и карту сайта в формате XML. Это также дает вам возможность легко проверять неработающие ссылки.
Бесплатная услуга Siteliner ограничена ежемесячным анализом сайтов объемом до 250 страниц. Служба Siteliner Premium позволяет анализировать веб-сайты объемом до 25 000 страниц без ограничений по частоте выполнения анализа. Вы также можете просмотреть свои предыдущие результаты.
Хотя бесплатная услуга Siteliner ограничена ежемесячным анализом до 250 страниц, этого более чем достаточно для веб-сайтов небольшого или даже среднего размера.
Внутренние инструменты проверки дублированного содержимого:Итак, это два бесплатных онлайн-инструмента для проверки дублированного контента, которые вы можете использовать бесплатно и легко справиться с плагиатом. Если вы хотите попробовать и другие инструменты, обратитесь к этой публикации, в которой я поделился 12 лучшими бесплатными инструментами для проверки дублированного контента Google.
12 бесплатных онлайн-инструментов Google Duplicate Content Checker
Если вам понравился этот пост, поделитесь им и дайте мне знать, какой инструмент вам больше всего понравился для проверки дублированного контента и почему, оставив быстрый комментарий ниже!
5 лучших инструментов, которые помогут вам найти повторяющийся контент на веб-сайте
Вы знаете, когда ваш сайт станет успешным и займет первое место в поисковой выдаче? Успех любого сайта зависит от качественного, информативного и оригинального контента.Как владелец веб-сайта вы обязаны следить за тем, чтобы на вашем сайте не было плагиата. Если вы не знаете, позвольте мне сказать вам, что Google и другие поисковые системы могут наказать ваш сайт за дублирование или копирование контента. Как вы выходите из этой проблемы? Как проверить повторяющийся контент и удалить их? Я собираюсь обсудить некоторые инструменты, которые помогут вам найти дублированный контент на вашем сайте.
Хотите знать, что это за инструменты? Прочтите ниже 5 лучших инструментов, которые помогут вам найти дублированный контент на вашем сайте.
5 лучших инструментов помогут вам обнаружить дублирующийся контент на вашем сайте 1. Grammarly Online Проверка плагиатаGrammarly — известное имя в мире цифрового маркетинга. Я оставил его на первом номере, потому что он очень востребован. Grammarly — лучший инструмент для всех маркетологов, писателей, веб-мастеров и специалистов по поисковой оптимизации, позволяющий быстро проверить, является ли статья оригинальной или скопированной из другого источника. Если вы оператор веб-сайта и хотите проверить, не копируют ли ваши авторы контента контент из других источников, то Grammarly идеально вам подойдет.Кроме того, это многофункциональный инструмент для всех веб-мастеров. Вы можете использовать инструмент, чтобы проверить оригинальность контента. Вы также можете проверить написание статьи.
2. DuplicheckerВторой инструмент в нашем списке — Duplichecker. Это также лучшая онлайн-программа проверки плагиата, упомянутая запросом Google. Этот инструмент хорош тем, что он бесплатный и простой в использовании. Он предлагает три варианта проверки на плагиат:
- Вы можете скопировать / вставить текст
- Загрузить файл
- Введите URL-адрес веб-страницы для проверки
Этот инструмент поможет вам в глубоком изучении статьи и предоставит подробный отчет о плагиате.Если ваш контент содержит повторяющиеся слова или строки, они будут отображаться в уникальном процентном соотношении. Вы также можете распечатать результат.
3. Детектор плагиатаДетектор плагиата — третий лучший инструмент в списке инструментов проверки дублированного контента. Этот инструмент также бесплатный и точный. Вы можете найти его на plagiarismdetector.net. Здесь у вас есть возможность скопировать и вставить текст, исключить URL-адрес и проверить по URL-адресу. В левом столбце вы увидите введенный текст, и если есть плагиат предложения, он будет отображаться красным цветом.Детектор плагиата — лучший инструмент для ученых, студентов, писателей и учителей. Поэтому вы можете использовать этот инструмент, чтобы сделать свой контент аутентичным и уберечь свой веб-сайт от панелизации со стороны Google.
4. CopyscapeЧетвертый инструмент в списке — Copyscape. Это одна из самых старых и популярных шашек с плагиатом. Как найти здесь дублированный контент? Вам просто нужен URL-адрес для дублирования контента. Кроме того, это быстрый и дешевый инструмент. Copyscape — лучший инструмент для веб-мастеров, чтобы проанализировать, содержит ли их сайт дублированный контент или нет.Поэтому при добавлении любого URL-адреса вы получите подробный отчет, в котором скопированный контент отображается красным цветом. Кроме того, вы также можете купить подписку на инструмент за символическую плату, чтобы проверить плагиат.
5. QuetextПоследним и последним инструментом проверки дубликатов является Quetext. Это также бесплатный инструмент для проверки плагиата. Вы также увидите платную опцию проверки большего количества слов. Инструмент просканирует ваш веб-сайт, научные статьи и книги на предмет дубликатов. Здесь вы получите ссылки на источники, которые помогут вам указать на первоисточники, если ваш автор не упомянул или не добавил их.Здесь профессиональный план начинается с 9,99 долларов в месяц и предлагает неограниченное количество поисков. Бесплатный план ограничен 3 запросами и 500 словами на поиск. Однако в профессиональном плане вы получаете 25 000 слов за один поиск. Таким образом, вы можете загружать файлы для проверки дублированного содержимого.
Заключительные словаРебята, вам нужно понять одну вещь: если ваш сайт содержит дублирующееся содержимое, то вскоре ваш сайт станет плагиатом Google. Поэтому для вас и вашего сайта будет хорошо, если вы воспользуетесь средствами проверки дублированного контента для решения этой проблемы.Выше я поделился 5 лучшими инструментами для проверки дубликатов. Вы можете выбрать тот, который вам больше всего подходит для удовлетворения ваших требований.
Для получения более информативных статей свяжитесь с нами , а пока продолжайте читать и делитесь.
Как определить повторяющиеся страницы архива, пошаговое руководство
В этой статье я описываю метод определения элементов повторяющегося содержимого для улучшения качества и направленности ваших страниц с листингом. Это необходимо для повышения рейтинга в Google, в результате чего потенциальные клиенты быстро находят то, что им нужно, и увеличивают продажи.Этот процесс включает пустых и некачественных таксономий , таких как страницы со списком продуктов, категории блогов и теги.
Предприятия электронной коммерции часто имеют несколько продуктов, категорий и подкатегорий, многие из которых не добавляют ценности. Желательно иметь меньшее количество целевых страниц, которые ранжируются по релевантному запросу, тем самым позволяя потенциальным клиентам находить ваши продукты и доверять вам как надежному продавцу. Ниже приведен пример магазина, в котором страница категории содержит только один продукт вместо ряда товаров для гигиены полости рта.
У ищущих клиентов ограниченный выбор, и они, вероятно, будут искать в другом месте.
https://www.argos.co.uk/browse/health-and-beauty/dental-care/teeth-whitening/c:29234/
То же самое относится и к веб-сайтам блогов с драматическими результатами. Издатель может создавать много статей в месяц с разными интересами. Однако малоценных страниц с ограниченным содержанием будут бороться за ранжирование по запросам, которые ищут потенциальные аудитории, и, следовательно, не будут привлекать потенциальных клиентов.Ниже приведен пример всего с двумя сообщениями. Что еще хуже, одним и тем же статьям присвоено множество таксономий, что может привести к дублированию.
https://contentmarketinginstitute.com/tertiary-category/branded-content/
Как видите, и страница со списком электронной коммерции, и страница архива содержат мало контента, и это никому не помогает. Эти примеры показывают, почему вам следует просмотреть свой сайт и убедиться, что у вас нет ничего похожего.
Простое дублирование
Если у вас есть интернет-бизнес или веб-сайт блога, создание дублирующих или малоценных страниц несложно; это особенно верно, если ваш сайт не проверяется часто.Поэтому, публикуя пост или продукт на своем сайте, я рекомендую этот простой контрольный список ниже:
- Сколько категорий вы назначили своей новой публикации / продукту?
- Сколько тегов вы добавили в свой пост / товар?
- Вы проверяли написание тегов? Соблюдали ли вы их согласованность, используя единственное / множественное число, дефис в нескольких словах и т.д.
- Обучаете ли вы своих редакторов и менеджеров по электронной коммерции?
- У вас есть надежная таксономическая стратегия?
- Вы провели тщательное исследование ключевых слов?
Многие проверенные мной веб-сайты этого не сделали.Вот почему в этой статье я описываю метод, который поможет вам найти архив или страницы со списком с небольшим содержанием или без него, будь то сообщения или продукты, и определить, какие действия необходимо предпринять для решения этой проблемы.
Дубликаты могут быть легко созданы автоматически
Действительно легко бессознательно генерировать повторяющиеся и некачественные страницы, особенно на платформах для ведения блогов, таких как WordPress, где назначение категории или тега для публикации осуществляется одним щелчком мыши. Я обычно нахожу автоматически сгенерированные дубликаты при аудите веб-сайтов.Оставленные в покое, они могут быть вредными.
Сообщение в блоге с несколькими похожими тегами, а также категориями, автоматически создает архив для каждого из них. Автоматически сгенерированные страницы также появляются, когда количество контента велико или сайту несколько лет.
Последствия незапланированного дублирования таксономии включают:
- Создание архивов с одинаковым содержанием и, как следствие, дублирование страниц
- Отсутствие оптимизации веб-страниц
- Страницы с небольшим содержанием
- Из-за плохого взаимодействия с пользователем
- Выдавать потенциальные проблемы каннибализации контента
- Принуждение Google (и других поисковых систем) к выбору страниц на других веб-сайтах
В результате на меньше органического трафика, превращающегося в лидов и потенциальных продаж.
Публикуя новый контент, вы должны организовать свой сайт так, чтобы предоставлять максимально возможную информацию по теме. Каждая страница, которую вы создаете или генерируете автоматически, должна иметь свою уникальную цель.
Есть несколько способов сделать это, что выходит за рамки данной статьи. Полезные примеры включают тематические кластеры, архитектуру веб-сайта, архитектуру сайта, внутренние ссылки, создание разрозненных структур, проблемы архитектуры и другие.
Что это на самом деле означает?
На примере блога цифрового маркетинга с акцентом на 3 широко используемых тега: «Цифровой маркетинг», «Google Реклама» и «Социальные сети».
Ниже приведен пример того, что вы можете найти на панели управления тегами:
Цифровой маркетинг
domain.com/tag/digitalmarketing
domain.com/tag/digital-marketing
Google Реклама
domain.com/tag/googleads
domain.com/tag/google-ads
domain.com/tag/adwords
domain.com/tag/ad-words
domain.com/tag/googleadwords
domain.com/tag/google-adwords
Социальные сети
domain.com/tag/social
domain.com / tag / socialmedia
domain.com/tag/social-media
domain.com/tag/socialmediamarketing
domain.com/tag/social-media-marketing
Каждая страница тегов содержит мало контента, получает низкий уровень трафика, не представляет большой ценности для ваших читателей и создает проблемы с каннибализацией контента.
Аудит с учетом вашей стратегии
Нередко веб-сайт с 1000 публикациями содержит несколько тысяч страниц таксономии.
В зависимости от масштаба вашего веб-сайта вам следует учитывать возможные проблемы с бюджетом сканирования.Ваша цель — убедиться, что Google имеет четкое представление о каждой странице, не заставляя свои алгоритмы выбирать между несколькими страницами. Стратегия содержания имеет важное значение, и ваш веб-сайт должен быть организован с новыми сообщениями, созданными после тщательного исследования ключевых слов.
При проведении аудита вашего веб-сайта отправной точкой являются вопросы, перечисленные ниже:
- Поддерживаются ли архивы с помощью исследования ключевых слов?
- Какова их цель?
- Страницы архива настраиваются или содержат только список заголовков?
Помните, что переименование, объединение или удаление страниц таксономии может повлиять на структуру сайта.Это также может повлиять на контент и технические элементы и привести к неработающим страницам или внутренним перенаправлениям.
С технической точки зрения изменение способа присвоения постов таксономиям уменьшает количество URL-адресов и генерирует битые страницы из-за уменьшения последовательности нумерации страниц — этого следует избегать.
Итак, как вы работаете со своими таксономиями? Стоит ли 301 перенаправить их? Следует ли удалить их из индекса Google? Что насчет краулингового бюджета?
С точки зрения содержания и бизнеса , представляют ли страницы архива какую-либо ценность? Получают ли они обратные ссылки? Они генерируют конверсии или трафик? Связан ли дублированный контент по всему сайту, который вы обнаружили с помощью SEO-аудита, в основном с архивными страницами? Эти вопросы следует учитывать при принятии решения, потому что каждое действие может повлиять на другие элементы.
Несмотря на то, что я твердо верю в сокращение содержания, каждый выбор должен быть частью более широкой стратегии.
Шаги, которые нужно предпринять
Как вы определяете малоценные архивные страницы, предоставляете важную информацию лицам, принимающим решения, и предпринимаете действия?
SEMrush обнаруживает повторяющиеся страницы, что является первым шагом в этом процессе.
Инструмент SEMrush Site Audit
Для более глубокого исследования вы можете собрать больше данных, определив общие шаблоны, отпечатки пальцев и элементы HTML, которые могут улучшить ваше понимание проблемы.
Я советую использовать язык под названием XPath , который помогает выбирать значения, переменные и расположение определенных элементов в документе XML. Если вы не знакомы с этим языком, я рекомендую прочитать руководство по XPath от Builtvisible для SEO, чтобы узнать, как он может быть полезен в различных контекстах.
Затем используйте инструмент, который сканирует ваш сайт и извлекает выбранные элементы. Мне больше всего нравится инструмент для очистки веб-страниц от Screaming Frog.
Давайте теперь посмотрим, как мы можем идентифицировать эти элементы, настроить Screaming Frog и извлечь информацию, необходимую для принятия правильных решений.
1) Определите общие элементы
Для начала найдите отпечатки пальцев и извлеките их.
Эти элементы представляют собой HTML-теги, ресурсы и другие шаблоны, которые позволяют распознавать отпечатки пальцев в определенных областях каждой проверяемой страницы. Это позволяет собирать эти элементы и находить аномалии или общие закономерности, которые можно улучшить.
Включить и исключить URL-адреса
Поскольку вы не хотите перегружаться данными, сканируйте только те URL-адреса, которые соответствуют страницам, содержащим идентифицированные вами отпечатки пальцев.Это определяет структуру страницы и определяет, что сканировать, а что нет.
Папки, слова и другие шаблоны являются общими элементами, которые должны быть включены в . Ниже я привел несколько примеров:
domain.com/ элемент / страница
domain.com/ тег / сообщение
domain.com/ категория / продукт
domain.com/ product-category / product
Исключение также является ключевым аспектом сканирования. В этом примере последовательности нумерации страниц не представляют интереса .Фактически, если архив разбит на страницы, минимальное количество сообщений (или продуктов) уже достигнуто. И вы также не хотите сканировать весь свой веб-сайт, так как он может потреблять ресурсы, занимать время и собирать слишком много данных.
Исключаемые страницы могут включать шаблоны вроде:
/ page /
? Page
, что означает, что в архиве несколько страниц.
h2 или тег заголовка
Это элементы, которые идентифицируют название (или заголовок) таксономии и должны быть уникальными в последовательности нумерации страниц.
Выполняя аудит, вы должны постараться исправить любые другие потенциальные проблемы, на которые вы наткнетесь. Итак, если вы не можете найти заголовок h2, это проблема, которую вы можете быстро исправить, поскольку h2 должен определять основное ключевое слово / тему страницы.
Названия статей / Названия продуктов
Заголовок сообщений (или название продуктов) является основным уникальным элементом, который идентифицирует объявление в архиве. Обратите внимание на этот компонент, чтобы составить список отпечатков пальцев.
Количество статей на странице
Этот элемент подсчитывает количество статей (или продуктов), содержащихся на странице архива. Это ключевой аспект работы, потому что он дает вам простой обзор категорий, которые необходимо проанализировать, поскольку в них отсутствует контент или продукты.
2) Найти и перевести отпечатки HTML в запросах XPath
Затем вы должны терпеливо изучить вышеупомянутые элементы и обратить внимание на исходный код HTML.
Вы можете использовать Google Chrome DevTools или очистить подобное расширение Chrome.Как упоминалось ранее, руководство SEO по XPath поможет вам выявить все элементы, а также эта шпаргалка.
Google Chrome DevTools
Очистите аналогичный хромированный удлинитель
Примеры:
Чтобы преобразовать теорию в практику, я проверил для вас три веб-сайта, идентифицировал вышеупомянутые отпечатки пальцев, выбрал элементы в исходном коде HTML и превратил их в запросы XPath.
С помощью этих примеров вы сможете увидеть, не хватает ли на странице категории контента, только с несколькими назначенными сообщениями (Content Marketing Institute и SEMrush blog), и если страницы со списком продуктов содержат мало продуктов (Argos).
После того, как вы посмотрите на каждый элемент и его запрос XPath, вы можете настроить Screaming Frog. Ниже приведены элементы для трех примеров:
Институт контент-маркетинга — https://contentmarketinginstitute.com
Тег заголовка: / html / head / title
Тег h3 со ссылкой: // h3 / a
Количество статей на странице: count (/ / div [@ class = ‘posted’])
Включенные URL-адреса blog / category: https://contentmarketinginstitute.com/.*category/.*
Исключенные URL / страница /: https://contentmarketinginstitute.com/.*/page/.*
Argos UK — https://www.argos.co.uk (Здоровье и красота)
h2 tag: // h2 [@ class = ‘search-title__term’]
Идентификатор класса, соответствующий статье: // * [@ class = ‘ac-product-name ac-product-card__name’]
Количество продуктов на странице: count (// div [@ class = ‘ac-product-name ac-product-card__name’])
Я просматриваю включенных URL / health-and-beauty /: https: // www.argos.co.uk/browse/health-and-beauty/.*
Исключенные URL-адреса / страница: X: . * / page. *
SEMrush blog — https://www.semrush.com/blog/
h2 tag: // h2
h3 tag со ссылкой: // h3 / a
Количество статей на странице: count ( // div [@ class = ‘s-col-12 b-blog__snippet__head’])
Включенные URL-адреса блог / категория: https://www.semrush.com/blog/category/.*
Исключенных URL-адресов / страница /: https://www.semrush.com/blog/.* \? стр. *
3) Настроить Кричащую лягушку
Пришло время настроить Screaming Frog.
Перейдите к Configuration > Custom > Extraction и настройте элементы XPath.
Добавьте Включить и Исключить шаблоны путей .
4) Просканируйте ваш сайт
На этом настройка завершена. Запустите сканирование с любой страницы, которая связывает шаблон URL в конфигурации «Включить».Если на вашей домашней странице нет доступа к категории блога или странице списка продуктов, выберите альтернативную отправную точку или саму страницу таксономии.
5) Анализируйте извлечение
После завершения сканирования перейдите на вкладку Custom в Screaming Frog и выберите фильтр « Extraction ». Вы увидите просканированные URL, заголовок / h2 таксономии, а также заголовки сообщений или названия продуктов.
В конце строки вы найдете количество статей (или продуктов), включенных на ту же страницу.
Экспортируйте файл, чтобы облегчить анализ сканирования в , чтобы найти повторяющиеся таксономии, небольшое содержание, похожие URL-адреса и т. Д.
6) Определите элементы, требующие действий
Как только весь анализ будет завершен, завершите процесс в соответствии со своей стратегией.
Поскольку каждый проект уникален со своими переменными, целями и ресурсами, я не могу выделить универсальный подход.
Я перечислил несколько вопросов ниже, чтобы помочь в достижении вашего трафика и бизнес-целей, а также определить ключевые элементы:
- Вы нашли больше таксономий, чем сообщений?
- Вы узнали, что в категориях очень ограниченное количество сообщений или нет сообщений?
- Можете ли вы определить эти страницы как повторяющееся содержимое?
- Есть ли у таксономий похожие названия?
- Есть ли у архивных страниц похожие имена, версии в единственном / множественном числе, дефисы / без дефисов?
- Можно ли объединить эти таксономии?
- Полезны ли страницы со списком или вы можете удалить их все?
- Полезны ли эти страницы для определения структуры сайта?
- Следует ли вам изменить URL / заголовок в соответствии с исследованием ключевых слов?
- Ранжируются ли страницы по какому-либо релевантному запросу?
- Можете ли вы оптимизировать страницы со списком, чтобы повысить ценность и повысить конверсию и рейтинг?
- Подключите Screaming Frog к Google Analytics и Google Search Console, получают ли эти страницы трафик? Из каких источников?
- Подключите Screaming Frog к Majestic, Ahrefs или Moz, получают ли эти страницы соответствующие обратные ссылки?
- Полезны ли страницы для привлечения конверсий?
- Стоит ли добавлять больше продуктов или контента на успешные страницы с листингами?
- Стоит ли добавлять больше товаров на страницы со списком товаров?
- Сколько продуктов «скоро» и «нет в наличии» вы можете найти?
- Можете ли вы найти продукты с небольшими отзывами или без них и реализовать соответствующую стратегию?
- Можете ли вы продемонстрировать, почему и как изменения могут помочь в достижении ваших бизнес-целей?
Выводы
SEO-аудит — это первый шаг для любого бизнеса, чтобы убедиться, что ваш сайт соответствует вашим бизнес-целям.
Выявление и удаление дублированного контента имеет важное значение для ранжирования ключевых слов, повышения качества веб-сайта и превращения недавно привлеченного трафика в продажи и потенциальных клиентов.
Список литературы
Руководство SEO по XPath
Полное руководство по пользовательскому извлечению Screaming Frog с помощью XPath и Regex
Шпаргалка по Xpath
Синтаксис XPath
Пользовательское извлечение в Screaming Frog: XPath и CSSPath
Сбор данных и извлечение данных из Интернета с помощью инструмента SEO Spider