Принципы работы с большими данными, парадигма MapReduce / DCA (Data-Centric Alliance) corporate blog / Habr

Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):
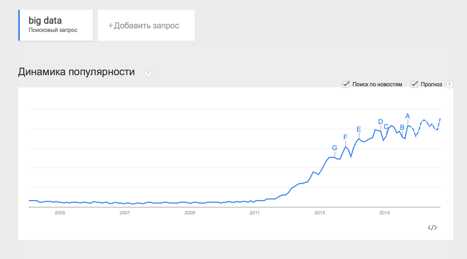
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и освятить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
И даже такие:
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):
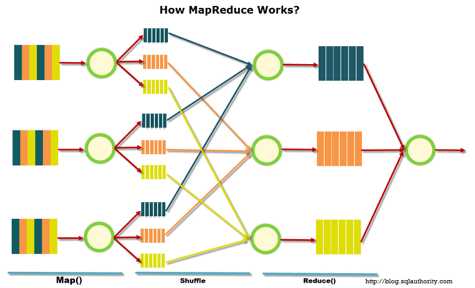
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Решение:
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
|
|
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1]), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Задача: имеется csv-лог рекламной системы вида:
<user_id>,<country>,<city>,<campaign_id>,<creative_id>,<payment></p>
11111,RU,Moscow,2,4,0.3
22222,RU,Voronezh,2,3,0.2
13413,UA,Kiev,4,11,0.7
…
Необходимо рассчитать среднюю стоимость показа рекламы по городам России.
Решение:
|
|
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Резюме
В статье мы рассмотрели несколько вводных моментов про большие данные:
· Что такое Big Data и откуда берётся;
· Каким основным принципам следуют все средства и парадигмы работы с большими данными;
· Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена.
Первая статья была больше теоретической,
В последующих статьях цикла мы рассмотрим более сложные задачи, решаемые при помощи MapReduce, расскажем об ограничениях MapReduce и о том, какими инструментами и техниками можно обходить эти ограничения.
Спасибо за внимание, готовы ответить на ваши вопросы.
Youtube-Канал автора об анализе данных
Ссылки на другие части цикла:
Часть 2: Hadoop
Часть 3: Приемы и стратегии разработки MapReduce-приложений
Часть 4: Hbase
habr.com
Big Data, методы и техники анализа больших данных
Big Data
Википедия по состоянию на середину 2018 года давала следующее определение термину Big Data:
«Большие данные (Big Data) — обозначение структурированных и неструктурированных данных огромных объёмов и значительного многообразия, эффективно обрабатываемых горизонтально масштабируемыми программными инструментами, появившимися в конце 2000-х годов и альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence».
Как видим, в этом определении присутствуют такие неопределенные термины, как «огромных», «значительного», «эффективно» и «альтернативных». Даже само название весьма субъективно. Например, 4 Терабайта (емкость современного внешнего жесткого диска для ноутбука) — это уже большие данные или еще нет? К этому определению Википедия добавляет следующее: «в широком смысле о «больших данных» говорят как о социально-экономическом феномене, связанном с появлением технологических возможностей анализировать огромные массивы данных, в некоторых проблемных областях — весь мировой объём данных, и вытекающих из этого трансформационных последствий».
Аналитики компании IBS «весь мировой объём данных» оценили такими величинами:
2003 г. — 5 эксабайтов данных (1 ЭБ = 1 млрд гигабайтов)
2008 г. — 0,18 зеттабайта (1 ЗБ = 1024 эксабайта)
2015 г. — более 6,5 зеттабайтов
2020 г. — 40–44 зеттабайта (прогноз)
2025 г. — этот объем вырастет еще в 10 раз.
В докладе также отмечается, что большую часть данных генерировать будут не обычные потребители, а предприятия
Можно пользоваться и более простым определением, вполне соответствующим устоявшемуся мнению журналистов и маркетологов.
«Большие данные — это совокупность технологий, которые призваны совершать три операции:
- Обрабатывать большие по сравнению со «стандартными» сценариями объемы данных
- Уметь работать с быстро поступающими данными в очень больших объемах. То есть данных не просто много, а их постоянно становится все больше и больше
- Уметь работать со структурированными и слабо структурированными данными параллельно и в разных аспектах»2
Считается, что эти «умения» позволяют выявить скрытые закономерности, ускользающие от ограниченного человеческого восприятия. Это дает беспрецедентные возможности оптимизации многих сфер нашей жизни: государственного управления, медицины, телекоммуникаций, финансов, транспорта, производства и так далее. Не удивительно, что журналисты и маркетологи настолько часто использовали словосочетание Big Data, что многие эксперты считают этот термин дискредитированным и предлагают от него отказаться.
Более того, в октябре 2015 года компания Gartner исключила Big Data из числа популярных трендов. Свое решение аналитики компании объяснили тем, что в состав понятия «большие данные» входит большое количество технологий, уже активно применяемым на предприятиях, они частично относятся к другим популярным сферам и тенденциям и стали повседневным рабочим инструментом.
Как бы то ни было, термин Big Data по-прежнему широко используется, подтверждением чему служит и наша статья.
Три «V» (4, 5, 7) и три принципа работы с большими данными
Определяющими характеристиками для больших данных являются, помимо их физического объёма, и другие, подчеркивающие сложность задачи обработки и анализа этих данных. Набор признаков VVV (volume, velocity, variety — физический объём, скорость прироста данных и необходимости их быстрой обработки, возможность одновременно обрабатывать данные различных типов) был выработан компанией Meta Group в 2001 году с целью указать на равную значимость управления данными по всем трём аспектам.
В дальнейшем появились интерпретации с четырьмя V (добавлялась veracity — достоверность), пятью V (viability — жизнеспособность и value — ценность), семью V (variability — переменчивость и visualization — визуализация). Но компания IDC, например, интерпретирует именно четвёртое V как value (ценность), подчеркивая экономическую целесообразность обработки больших объёмов данных в соответствующих условиях.5
Исходя из вышеприведенных определений, основные принципы работы с большими данными таковы:
- Горизонтальная масштабируемость. Это — базовый принцип обработки больших данных. Как уже говорилось, больших данных с каждым днем становится все больше. Соответственно, необходимо увеличивать количество вычислительных узлов, по которым распределяются эти данные, причем обработка должна происходить без ухудшения производительности.
- Отказоустойчивость. Этот принцип вытекает из предыдущего. Поскольку вычислительных узлов в кластере может быть много (иногда десятки тысяч) и их количество, не исключено, будет увеличиваться, возрастает и вероятность выхода машин из строя. Методы работы с большими данными должны учитывать возможность таких ситуаций и предусматривать превентивные меры.
- Локальность данных. Так как данные распределены по большому количеству вычислительных узлов, то, если они физически находятся на одном сервере, а обрабатываются на другом, расходы на передачу данных могут стать неоправданно большими. Поэтому обработку данных желательно проводить на той же машине, на которой они хранятся.
Эти принципы отличаются от тех, которые характерны для традиционных, централизованных, вертикальных моделей хранения хорошо структурированных данных. Соответственно, для работы с большими данными разрабатывают новые подходы и технологии.
Технологии и тенденции работы с Big Data
Изначально в совокупность подходов и технологий включались средства массово-параллельной обработки неопределённо структурированных данных, такие как СУБД NoSQL, алгоритмы MapReduce и средства проекта Hadoop. В дальнейшем к технологиям больших данных стали относить и другие решения, обеспечивающие сходные по характеристикам возможности по обработке сверхбольших массивов данных, а также некоторые аппаратные средства.
- MapReduce — модель распределённых параллельных вычислений в компьютерных кластерах, представленная компанией Google. Согласно этой модели приложение разделяется на большое количество одинаковых элементарных заданий, выполняемых на узлах кластера и затем естественным образом сводимых в конечный результат.
- NoSQL (от англ. Not Only SQL, не только SQL) — общий термин для различных нереляционных баз данных и хранилищ, не обозначает какую-либо одну конкретную технологию или продукт. Обычные реляционные базы данных хорошо подходят для достаточно быстрых и однотипных запросов, а на сложных и гибко построенных запросах, характерных для больших данных, нагрузка превышает разумные пределы и использование СУБД становится неэффективным.
- Hadoop — свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. Считается одной из основополагающих технологий больших данных.
- R — язык программирования для статистической обработки данных и работы с графикой. Широко используется для анализа данных и фактически стал стандартом для статистических программ.
- Аппаратные решения. Корпорации Teradata, EMC и др. предлагают аппаратно-программные комплексы, предназначенные для обработки больших данных. Эти комплексы поставляются как готовые к установке телекоммуникационные шкафы, содержащие кластер серверов и управляющее программное обеспечение для массово-параллельной обработки. Сюда также иногда относят аппаратные решения для аналитической обработки в оперативной памяти, в частности, аппаратно-программные комплексы Hana компании SAP и комплекс Exalytics компании Oracle, несмотря на то, что такая обработка изначально не является массово-параллельной, а объёмы оперативной памяти одного узла ограничиваются несколькими терабайтами.6
Консалтинговая компания McKinsey, кроме рассматриваемых большинством аналитиков технологий NoSQL, MapReduce, Hadoop, R, включает в контекст применимости для обработки больших данных также технологии Business Intelligence и реляционные системы управления базами данных с поддержкой языка SQL.
Методы и техники анализа больших данных
Международная консалтинговая компания McKinsey, специализирующаяся на решении задач, связанных со стратегическим управлением, выделяет 11 методов и техник анализа, применимых к большим данным.
• Методы класса Data Mining (добыча данных, интеллектуальный анализ данных, глубинный анализ данных) — совокупность методов обнаружения в данных ранее неизвестных, нетривиальных, практически полезных знаний, необходимых для принятия решений. К таким методам, в частности, относятся обучение ассоциативным правилам (association rule learning), классификация (разбиение на категории), кластерный анализ, регрессионный анализ, обнаружение и анализ отклонений и др.
• Краудсорсинг — классификация и обогащение данных силами широкого, неопределённого круга лиц, выполняющих эту работу без вступления в трудовые отношения
• Смешение и интеграция данных (data fusion and integration) — набор техник, позволяющих интегрировать разнородные данные из разнообразных источников с целью проведения глубинного анализа (например, цифровая обработка сигналов, обработка естественного языка, включая тональный анализ, и др.)
• Машинное обучение, включая обучение с учителем и без учителя — использование моделей, построенных на базе статистического анализа или машинного обучения для получения комплексных прогнозов на основе базовых моделей
• Искусственные нейронные сети, сетевой анализ, оптимизация, в том числе генетические алгоритмы (genetic algorithm — эвристические алгоритмы поиска, используемые для решения задач оптимизации и моделирования путём случайного подбора, комбинирования и вариации искомых параметров с использованием механизмов, аналогичных естественному отбору в природе)
• Распознавание образов
• Прогнозная аналитика
• Имитационное моделирование (simulation) — метод, позволяющий строить модели, описывающие процессы так, как они проходили бы в действительности. Имитационное моделирование можно рассматривать как разновидность экспериментальных испытаний
• Пространственный анализ (spatial analysis) — класс методов, использующих топологическую, геометрическую и географическую информацию, извлекаемую из данных
• Статистический анализ — анализ временных рядов, A/B-тестирование (A/B testing, split testing — метод маркетингового исследования; при его использовании контрольная группа элементов сравнивается с набором тестовых групп, в которых один или несколько показателей были изменены, для того чтобы выяснить, какие из изменений улучшают целевой показатель)
• Визуализация аналитических данных — представление информации в виде рисунков, диаграмм, с использованием интерактивных возможностей и анимации как для получения результатов, так и для использования в качестве исходных данных для дальнейшего анализа. Очень важный этап анализа больших данных, позволяющий представить самые важные результаты анализа в наиболее удобном для восприятия виде.7
Большие данные в промышленности
Согласно отчету компании McKinsey «Global Institute, Big data: The next frontier for innovation, competition, and productivity», данные стали таким же важным фактором производства, как трудовые ресурсы и производственные активы. За счет использования больших данных компании могут получать ощутимые конкурентные преимущества. Технологии Big Data могут быть полезными при решении следующих задач:
- прогнозирование рыночной ситуации
- маркетинг и оптимизация продаж
- совершенствование продукции
- принятие управленческих решений
- повышение производительности труда
- эффективная логистика
- мониторинг состояния основных фондов8,9
На производственных предприятиях большие данные генерируются также вследствие внедрения технологий Промышленного интернета вещей. В ходе этого процесса основные узлы и детали станков и машин снабжаются датчиками, исполнительными устройствами, контроллерами и, иногда, недорогими процессорами, способными производить граничные (туманные) вычисления. В ходе производственного процесса осуществляется постоянный сбор данных и, возможно, их предварительная обработка (например, фильтрация). Аналитические платформы обрабатывают эти массивы информации в режиме реального времени, представляют результаты в наиболее удобном для восприятия виде и сохраняют для дальнейшего использования. На основе анализа полученных данных делаются выводы о состоянии оборудования, эффективности его работы, качестве выпускаемой продукции, необходимости внесения изменений в технологические процессы и т.д.
Благодаря мониторингу информации в режиме реального времени персонал предприятия может:
- сокращать количество простоев
- повышать производительность оборудования
- уменьшать расходы на эксплуатацию оборудования
- предотвращать несчастные случаи
Последний пункт особенно важен. Например, операторы, работающие на предприятиях нефтехимической промышленности, получают в среднем около 1500 аварийных сообщений в день, то есть более одного сообщения в минуту. Это приводит к повышенной усталости операторов, которым приходится постоянно принимать мгновенные решения о том, как реагировать на тот или иной сигнал. Но аналитическая платформа может отфильтровать второстепенную информацию, и тогда операторы получают возможность сосредоточиться в первую очередь на критических ситуациях. Это позволяет им более эффективно выявлять и предотвращать аварии и, возможно, несчастные случаи. В результате повышаются уровни надежности производства, промышленной безопасности, готовности технологического оборудования, соответствия нормативным требованиям.10
Кроме того, по результатам анализа больших данных можно рассчитывать сроки окупаемости оборудования, перспективы изменения технологических режимов, сокращения или перераспределения обслуживающего персонала — т.е. принимать стратегические решения относительно дальнейшего развития предприятия.11
Ссылки:
1. https://rb.ru/howto/chto-takoe-big-data/
2. https://postnauka.ru/faq/46974
3. https://www.datacenterknowledge.com/archives/2015/03/30/big-data-bubble-set-burst
4. http://www.tadviser.ru/index.php/Статья:Большие_данные(Big_Data)
5. https://ru.wikipedia.org/wiki/Большие_данные
6. https://intellect.ml/big-data-6821
7. http://sewiki.ru/index.php?title=Большие_данные&oldid=3075
8.http://www.mckinsey.com/insights/business_technology/big_data_the_next_frontier_for_innovation
9. http://engjournal.ru/articles/1228/1228.pdf
10. https://www.crn.ru/news/detail.php?ID=117807
11. http://www.ogcs.com.ua/index.php/articles/121-big-data-v-promyshlennosti-innovatsii-k-kotorym-pridetsya-privykat
www.it.ua
Основы Big data – Weril
Конспект вебинара HonorCup E=DC2 для сдачи HCNA Storage.
Big data – вся совокупность огромных объемов данных (структуированных и неструктуированных), которые не могут быть обработаны для получения воспринимаемых человеком результатов в рамках текущих программно-аппаратных средств.
Big data is a term for data sets that are so large or complex that traditional data processing application software is inadequate to deal with them.
Во многом понятие big data – маркетинговый булшит: многие процессы связанные сейчас с большими данными были и до этого (БД крупных контент провайдеров, биллинг крупных провайдеров связи и проч – распределенные системы хранения). Да и Hadoop появился в 2005, Google File System в 2000, а термин big data в 2008.
Зачем надо
Проблема в том, что объем данных растет, причем особенно растет объем неструктуированных данных и сейчас их более ¾ от общего количества. По информации от gartner (исслед./консал. компания):
- 5 экзабайт (10^18 байт) до 2003 года было сгенерировано и сохранено данных
- 5 экзабайт в 2011 году генерировались за два дня
- 5 экзабайт в 2013 году генерировались за 10 минут
- к 2010 году объем глобальных данных преодолел 1 зетабайт (10^21 байт)
- к 2020 году общее количество сгенерированных данных будет 40 зетабайт (рост в 40 раз за 10 лет)

Факторы роста:
- Мобильные телефоны
- Рост коммуникаций (соцсети, мессенжеры, etc)
- Рост каналов передачи данных
- Изменение структуры данных
- Рост качества фото/видео и результирующий рост их объема

И в тоже время, текущие реляционные БД не способны справится с растущим объемом данных.
Предпосылки проблемы
Источники данных различны и они генерируются пользователями в повседневной жизни. Помимо пользователей данные генерируются и устройствами и этих устройств становится все больше (умные часы/холодильники/чайники, не говоря про IT оборудование/системы).
Без развития ИТ технологий появление новых устройств и контент услуг из-за повышающегося объема был бы невозможен. Поэтому развитие ИТ технологий сыграло большую роль в появлении проблематики Big Data – развитие обеспечило платформу для роста потребностей через планомерное повышение производительности, максимального объема, уменьшение стоимости, появление cloud технологий, технологий noSQL и newSQL.

Работа с данными
Эволюция работы с данными или повышение ценности данных:
- Отчеты вида что произошло
- Excel/OLAP позволили отвечать на вопрос почему это произошло
- Мониторинг позволил знать, что происходит сейчас
- Анализ/предсказание/оптимизация позволили смотреть в будущее (предсказание эпидемий по запросам симптомов в google)
Процедура обработки big data по сути не отличается от обработки обычных данных: сбор данных, хранение, управление, аналитика данных. Источники/средства/методы сбора данных зависят в основном от источника.
Структуированные и неструктуированные данные
Три типа данных по пригодности их для автоматизированной работы с данными (обработки/аналитики/оценки ценности/извлечения информации):
- Под структуированными (structured data) данными подразумеваются данные, пригодные для этих операций (записи в базах данных, таблицах).
- Неструктуированные (unstructured data) данные требуют новых баз и инструментов для возможности этих операций над ними (фото, аудио, видео, текстовые документы, веб-страницы).
- Различают так же полуструктуированные данные (semi-structured data), данные могут быть частично автоматизировано обработаны (текстовые документы, веб-страницы, логи).
С big data постоянно приходится работать двум типам IT-компаний:
- контент провайдеры
- телеком провайдеры
Уровень структуированности проходящих через них данных у обоих типов компаний довольно плох.

Характеристики
Под big data попадают данные со следующими характеристиками (четыре V big data):
- Volume (объем) – огромный объем
- Variety (вариативность) – огромное количество типов данных
- Velocity (скорость) – растет скорость объема, причем неструктуированные данные растут быстрее структуированных
- Value (ценность) – невозможно оценить ценность данных и она может отличаться
К тому же, зачастую, такие данные записаны один раз и в них вносятся редкие модификации, но им требуется долговременное хранение (фотки с отпуска).

Технологии
Object-based storage
К двум существующим вариантам хранения добавляется новый тип OBS (не путать OBS и NoSQL Object database – это разные вещи):
- Блоковое (iSCSI, FC) – блоки данных передаются к системе хранения напрямую. Высокая скорость и низкие задержки, но высокая стоимость, относительно плохая масштабируемость (не подходит для big data) и проблемы с передачей данных между разными SAN сетями. Сценарии использования: базы данных Enterprise (Oracle, MSSQL).
- Файловое (NFS, CIFS, POSIX) – создание файловой системы на основе блочного хранилища, передаются сами файлы. Легкое управление, простая работа с приложениями, простая передача данных между разными сетями. Средняя масштабируемость с рядом ограничений. Сценарии: file sharing, интеграция приложений в Enterprise.
- OBS – Object-based storage (HTTP, REST, S3) или распределенная файловая система (в русской wiki) – при использовании OBS создается слой объектного управления на основе блоковых систем хранения. По сути, OBS – это распределенная файловая система. Почти неограниченное масштабирование за счет использования объектов (уникальный ключ, файл данных, метаданные, пользовательские метаданные) и функции саморегуляции объектов. Использование стандартных Internet протоколов для передачи данных (по аналогии с файловыми системами) позволяет обеспечить простое взаимодействие разных систем между собой. Сценарии: бекапы, архивация данных в Enterprise. Используется контент провайдерами гигантами для хранения неструктуированных данных (фото в facebook, песни Spotify, файлы в Dropbox, Amazon S3, Microsoft Azure).
Object storage systems allow retention of massive amounts of unstructured data. Object storage is used for purposes such as storing photos on Facebook, songs on Spotify, or files in online collaboration services, such as Dropbox.
Структура технологии хранения OBS.
- OSD – Object storage device – хранилище данных.
- MDS – MetaData server, по сути name сервер. По имени файла находит OSD и дает ее ссылку Client. Хранит связующую информацию между файлами и OSD.
- Client – обращается к MDS для логического доступа к данным OSD по полученному от MDS адресу.

Сравнение доступа к данным в файловой и OBS моделях.
- В файловой системе традиционных систем хранения используется дерево-каталог (иерархическая структура). Если много файлов и файловая структура многоуровневая, нагрузка на корневой каталог высока, что влияет на производительность.
- В случае ODS используется плоская, децентрализованная структура, что хорошо сказывается на производительности при больших объемах данных.

Если свести к одному, то вот основные преимущества OBS:
- Плоская архитектура
weril.me
Big Data — что такое системы больших данных? Развитие технологий Big Data
Содержание статьи:
Большие данные — определение
Под термином «большие данные» буквально понимают огромный объем хранящейся на каком-либо носителе информации. Причем данный объем настолько велик, что обрабатывать его с помощью привычных программных или аппаратных средств нецелесообразно, а в некоторых случаях и вовсе невозможно.
Big Data – это не только сами данные, но и технологии их обработки и использования, методы поиска необходимой информации в больших массивах. Проблема больших данных по-прежнему остается открытой и жизненно важной для любых систем, десятилетиями накапливающих самую разнообразную информацию.
С данным термином связывают выражение «Volume, Velocity, Variety» – принципы, на которых строится работа с большими данными. Это непосредственно объем информации, быстродействие ее обработки и разнообразие сведений, хранящихся в массиве. В последнее время к трем базовым принципам стали добавлять еще один – Value, что обозначает ценность информации. То есть, она должна быть полезной и нужной в теоретическом или практическом плане, что оправдывало бы затраты на ее хранение и обработку.
Источники больших данных

В качестве примера типичного источника больших данных можно привести социальные сети – каждый профиль или публичная страница представляет собой одну маленькую каплю в никак не структурированном океане информации. Причем независимо от количества хранящихся в том или ином профиле сведений взаимодействие с каждым из пользователей должно быть максимально быстрым.
Большие данные непрерывно накапливаются практически в любой сфере человеческой жизни. Сюда входит любая отрасль, связанная либо с человеческими взаимодействиями, либо с вычислениями. Это и социальные медиа, и медицина, и банковская сфера, а также системы устройств, получающие многочисленные результаты ежедневных вычислений. Например, астрономические наблюдения, метеорологические сведения и информация с устройств зондирования Земли.
Big Data на российском рынке наружной рекламы
Информация со всевозможных систем слежения в режиме реального времени также поступает на сервера той или иной компании. Телевидение и радиовещание, базы звонков операторов сотовой связи – взаимодействие каждого конкретного человека с ними минимально, но в совокупности вся эта информация становится большими данными.
Технологии больших данных стали неотъемлемыми от научно-исследовательской деятельности и коммерции. Более того, они начинают захватывать и сферу государственного управления – и везде требуется внедрение все более эффективных систем хранения и манипулирования информацией.
История появления и развития Big Data

Впервые термин «большие данные» появился в прессе в 2008 году, когда редактор журнала Nature Клиффорд Линч выпустил статью на тему развития будущего науки с помощью технологий работы с большим количеством данных. До 2009 года данный термин рассматривался только с точки зрения научного анализа, но после выхода еще нескольких статей пресса стала широко использовать понятие Big Data – и продолжает использовать его в настоящее время.
В 2010 году стали появляться первые попытки решить нарастающую проблему больших данных. Были выпущены программные продукты, действие которых было направлено на то, чтобы минимизировать риски при использовании огромных информационных массивов.
К 2011 году большими данными заинтересовались такие крупные компании, как Microsoft, Oracle, EMC и IBM – они стали первыми использовать наработки Big data в своих стратегиях развития, причем довольно успешно.
ВУЗы начали проводить изучение больших данных в качестве отдельного предмета уже в 2013 году – теперь проблемами в этой сфере занимаются не только науки о данных, но и инженерия вкупе с вычислительными предметами.
Техники и методы анализа и обработки больших данных

К основным методам анализа и обработки данных можно отнести следующие:
- Методы класса или глубинный анализ (Data Mining).
Данные методы достаточно многочисленны, но их объединяет одно: используемый математический инструментарий в совокупности с достижениями из сферы информационных технологий.
- Краудсорсинг.
Данная методика позволяет получать данные одновременно из нескольких источников, причем количество последних практически не ограничено.
- А/В-тестирование.
Из всего объема данных выбирается контрольная совокупность элементов, которую поочередно сравнивают с другими подобными совокупностями, где был изменен один из элементов. Проведение подобных тестов помогает определить, колебания какого из параметров оказывают наибольшее влияние на контрольную совокупность. Благодаря объемам Big Data можно проводить огромное число итераций, с каждой из них приближаясь к максимально достоверному результату.
- Прогнозная аналитика.
Специалисты в данной области стараются заранее предугадать и распланировать то, как будет вести себя подконтрольный объект, чтобы принять наиболее выгодное в этой ситуации решение.
- Машинное обучение (искусственный интеллект).
Основывается на эмпирическом анализе информации и последующем построении алгоритмов самообучения систем.
- Сетевой анализ.
Наиболее распространенный метод для исследования социальных сетей – после получения статистических данных анализируются созданные в сетке узлы, то есть взаимодействия между отдельными пользователями и их сообществами.
Перспективы и тенденции развития Big data
В 2017 году, когда большие данные перестали быть чем-то новым и неизведанным, их важность не только не уменьшилась, а еще более возросла. Теперь эксперты делают ставки на то, что анализ больших объемов данных станет доступным не только для организаций-гигантов, но и для представителей малого и среднего бизнеса. Такой подход планируется реализовать с помощью следующих составляющих:
- Облачные хранилища.
Хранение и обработка данных становятся более быстрыми и экономичными – по сравнению с расходами на содержание собственного дата-центра и возможное расширение персонала аренда облака представляется гораздо более дешевой альтернативой.
- Использование Dark Data.
Так называемые «темные данные» – вся неоцифрованная информация о компании, которая не играет ключевой роли при непосредственном ее использовании, но может послужить причиной для перехода на новый формат хранения сведений.
- Искусственный интеллект и Deep Learning.
Технология обучения машинного интеллекта, подражающая структуре и работе человеческого мозга, как нельзя лучше подходит для обработки большого объема постоянно меняющейся информации. В этом случае машина сделает все то же самое, что должен был бы сделать человек, но при этом вероятность ошибки значительно снижается.
Эта технология позволяет ускорить и упростить многочисленные интернет-транзакции, в том числе международные. Еще один плюс Блокчейна в том, что благодаря ему снижаются затраты на проведение транзакций.
- Самообслуживание и снижение цен.
В 2017 году планируется внедрить «платформы самообслуживания» – это бесплатные площадки, где представители малого и среднего бизнеса смогут самостоятельно оценить хранящиеся у них данные и систематизировать их.
Большие данные в маркетинге и бизнесе

Все маркетинговые стратегии так или иначе основаны на манипулировании информацией и анализе уже имеющихся данных. Именно поэтому использование больших данных может предугадать и дать возможность скорректировать дальнейшее развитие компании.
Методы машинного обучения для бизнеса
К примеру, RTB-аукцион, созданный на основе больших данных, позволяет использовать рекламу более эффективно – определенный товар будет показываться только той группе пользователей, которая заинтересована в его приобретении.
Чем выгодно применение технологий больших данных в маркетинге и бизнесе?
- С их помощью можно гораздо быстрее создавать новые проекты, которые с большой вероятностью станут востребованными среди покупателей.
- Они помогают соотнести требования клиента с существующим или проектируемым сервисом и таким образом подкорректировать их.
- Методы больших данных позволяют оценить степень текущей удовлетворенности всех пользователей и каждого в отдельности.
- Повышение лояльности клиентов обеспечивается за счет методов обработки больших данных.
- Привлечение целевой аудитории в интернете становится более простым благодаря возможности контролировать огромные массивы данных.
Например, один из самых популярных сервисов для прогнозирования вероятной популярности того или иного продукта – Google.trends. Он широко используется маркетологами и аналитиками, позволяя им получить статистику использования данного продукта в прошлом и прогноз на будущий сезон. Это позволяет руководителям компаний более эффективно провести распределение рекламного бюджета, определить, в какую область лучше всего вложить деньги.
Примеры использования Big Data
Активное внедрение технологий Big Data на рынок и в современную жизнь началось как раз после того, как ими стали пользоваться всемирно известные компании, имеющие клиентов практически в каждой точке земного шара.
Это такие социальные гиганты, как Facebook и Google, IBM., а также финансовые структуры вроде Master Card, VISA и Bank of America.
К примеру, IBM применяет методы больших данных к проводимым денежным транзакциям. С их помощью было выявлено на 15% больше мошеннических транзакций, что позволило увеличить сумму защищенных средств на 60%. Также были решены проблемы с ложными срабатываниями системы – их число сократилось более, чем наполовину.
Компания VISA аналогично использовала Big Data, отслеживая мошеннические попытки произвести ту или иную операцию. Благодаря этому ежегодно они спасают от утечки более 2 млрд долларов США.
Министерство труда Германии сумело сократить расходы на 10 млрд евро, внедрив систему больших данных в работу по выдаче пособий по безработице. При этом было выявлено, что пятая часть граждан данные пособия получает безосновательно.
Big Data не обошли стороной и игровую индустрию. Так, разработчики World of Tanks провели исследование информации обо всех игроках и сравнили имеющиеся показатели их активности. Это помогло спрогнозировать возможный будущий отток игроков – опираясь на сделанные предположения, представители организации смогли более эффективно взаимодействовать с пользователями.
К числу известных организаций, использующих большие данные, можно также отнести HSBC, Nasdaq, Coca-Cola, Starbucks и AT&T.
Проблемы Big Data

Самой большой проблемой больших данных являются затраты на их обработку. Сюда можно включить как дорогостоящее оборудование, так и расходы на заработную плату квалифицированным специалистам, способным обслуживать огромные массивы информации. Очевидно, что оборудование придется регулярно обновлять, чтобы оно не теряло минимальной работоспособности при увеличении объема данных.
Вторая проблема опять же связана с большим количеством информации, которую необходимо обрабатывать. Если, например, исследование дает не 2-3, а многочисленное количество результатов, очень сложно остаться объективным и выделить из общего потока данных только те, которые окажут реальное влияние на состояние какого-либо явления.
Проблема конфиденциальности Big Data. В связи с тем, что большинство сервисов по обслуживанию клиентов переходят на онлайн-использование данных, очень легко стать очередной мишенью для киберпреступников. Даже простое хранение личной информации без совершения каких-либо интернет-транзакций может быть чревато нежелательными для клиентов облачных хранилищ последствиями.
Проблема потери информации. Меры предосторожности требуют не ограничиваться простым однократным резервированием данных, а делать хотя бы 2-3 резервных копии хранилища. Однако с увеличением объема растут сложности с резервированием – и IT-специалисты пытаются найти оптимальное решение данной проблемы.
Рынок технологий больших данных в России и мире
По данным на 2014 год 40% объема рынка больших данных составляют сервисные услуги. Немного уступает (38%) данному показателю выручка от использования Big Data в компьютерном оборудовании. Оставшиеся 22% приходятся на долю программного обеспечения.
Наиболее полезные в мировом сегменте продукты для решения проблем Big Data, согласно статистическим данным, – аналитические платформы In-memory и NoSQL . 15 и 12 процентов рынка соответственно занимают аналитическое ПО Log-file и платформы Columnar. А вот Hadoop/MapReduce на практике справляются с проблемами больших данных не слишком эффективно.
Результаты внедрения технологий больших данных:
- рост качества клиентского сервиса;
- оптимизация интеграции в цепи поставок;
- оптимизация планирования организации;
- ускорение взаимодействия с клиентами;
- повышение эффективности обработки запросов клиентов;
- снижение затрат на сервис;
- оптимизация обработки клиентских заявок.
Лучшие книги по Big Data
«The Human Face of Big Data», Рик Смолан и Дженнифер Эрвитт
Подойдет для первоначального изучения технологий обработки больших данных – легко и понятно вводит в курс дела. Дает понять, как обилие информации повлияло на повседневную жизнь и все ее сферы: науку, бизнес, медицину и т. д. Содержит многочисленные иллюстрации, поэтому воспринимается без особых усилий.
«Introduction to Data Mining», Панг-Нинг Тан, Майкл Стейнбах и Випин Кумар
Также полезная для новичков книга по Big Data, объясняющая работу с большими данными по принципу «от простого к сложному». Освещает многие немаловажные на начальном этапе моменты: подготовку к обработке, визуализацию, OLAP, а также некоторые методы анализа и классификации данных.
«Python Machine Learning», Себастьян Рашка
Практическое руководство по использованию больших данных и работе с ними с применением языка программирования Python. Подходит как студентам инженерных специальностей, так и специалистам, которые хотят углубить свои знания.
«Hadoop for Dummies», Дирк Дерус, Пол С. Зикопулос, Роман Б. Мельник
Hadoop – это проект, созданный специально для работы с распределенными программами, организующими выполнение действий на тысячах узлов одновременно. Знакомство с ним поможет более детально разобраться в практическом применении больших данных.
promdevelop.ru
Биг-дата что это такое? Простыми словами о Big-Data технологии
Термин «Биг-Дата», возможно, сегодня уже узнаваем, но вокруг него все еще довольно много путаницы относительно того, что же он означает на самом деле. По правде говоря, концепция постоянно развивается и пересматривается, поскольку она остается движущей силой многих продолжающихся волн цифрового преобразования, включая искусственный интеллект, науку о данных и Интернет вещей. Но что же представляет собой технология Big-Data и как она меняет наш мир? Давайте попробуем разобраться объяснить суть технологии Биг-Даты и что она означает простыми словами.
Удивительный рост Биг-Даты
Все началось со «взрыва» в объеме данных, которые мы создали с самого начала цифровой эпохи. Это во многом связано с развитием компьютеров, Интернета и технологий, способных «выхватывать» данные из окружающего нас мира. Данные сами по себе не являются новым изобретением. Еще до эпохи компьютеров и баз данных мы использовали бумажные записи транзакций, клиентские записи и архивные файлы, которые и являются данными. Компьютеры, в особенности электронные таблицы и базы данных, позволили нам легко и просто хранить и упорядочивать данные в больших масштабах. Внезапно информация стала доступной при помощи одного щелчка мыши.
Тем не менее, мы прошли долгий путь от первоначальных таблиц и баз данных. Сегодня через каждые два дня мы создаем столько данных, сколько мы получили с самого начала вплоть до 2000 года. Правильно, через каждые два дня. И объем данных, которые мы создаем, продолжает стремительно расти; к 2020 году объем доступной цифровой информации возрастет примерно с 5 зеттабайтов до 20 зеттабайтов.
В настоящее время почти каждое действие, которое мы предпринимаем, оставляет свой след. Мы генерируем данные всякий раз, когда выходим в Интернет, когда переносим наши смартфоны, оборудованные поисковым модулем, когда разговариваем с нашими знакомыми через социальные сети или чаты и т.д. К тому же, количество данных, сгенерированных машинным способом, также быстро растет. Данные генерируются и распространяются, когда наши «умные» домашние устройства обмениваются данными друг с другом или со своими домашними серверами. Промышленное оборудование на заводах и фабриках все чаще оснащается датчиками, которые аккумулируют и передают данные.
Термин «Big-Data» относится к сбору всех этих данных и нашей способности использовать их в своих интересах в широком спектре областей, включая бизнес.
Как работает технология Big-Data?
Биг Дата работает по принципу: чем больше вы знаете о том или ином предмете или явлении, тем более достоверно вы сможете достичь нового понимания и предсказать, что произойдет в будущем. В ходе сравнения большего количества точек данных возникают взаимосвязи, которые ранее были скрыты, и эти взаимосвязи позволяют нам учиться и принимать более взвешенные решения. Чаще всего это делается с помощью процесса, который включает в себя построение моделей на основе данных, которые мы можем собрать, и дальнейший запуск имитации, в ходе которой каждый раз настраиваются значения точек данных и отслеживается то, как они влияют на наши результаты. Этот процесс автоматизирован — современные технологии аналитики будут запускать миллионы этих симуляций, настраивая все возможные переменные до тех пор, пока не найдут модель — или идею — которые помогут решить проблему, над которой они работают.
 Бил Гейтс висит над бумажным содержимым одного компакт диска
Бил Гейтс висит над бумажным содержимым одного компакт дискаДо недавнего времени данные были ограничены электронными таблицами или базами данных — и все было очень упорядочено и аккуратно. Все то, что нельзя было легко организовать в строки и столбцы, расценивалось как слишком сложное для работы и игнорировалось. Однако прогресс в области хранения и аналитики означает, что мы можем фиксировать, хранить и обрабатывать большое количество данных различного типа. В результате «данные» на сегодняшний день могут означать что угодно, начиная базами данных, и заканчивая фотографиями, видео, звукозаписями, письменными текстами и данными датчиков.
Чтобы понять все эти беспорядочные данные, проекты, имеющие в основе Биг Дату, зачастую используют ультрасовременную аналитику с привлечением искусственного интеллекта и компьютерного обучения. Обучая вычислительные машины определять, что же представляют собой конкретные данные — например, посредством распознавания образов или обработки естественного языка – мы можем научить их определять модели гораздо быстрее и достовернее, чем мы сами.
Сейчас лучшее время для старта карьеры в области Data Science. В школе данных SkillFactory стартует онлайн-курс, позволяющий освоить профессию Data Scientist с нуля.
Как используется Биг-Дата?
Этот постоянно увеличивающийся поток информации о данных датчиков, текстовых, голосовых, фото- и видеоданных означает, что теперь мы можем использовать данные теми способами, которые невозможно было представить еще несколько лет назад. Это привносит революционные изменения в мир бизнеса едва ли не в каждой отрасли. Сегодня компании могут с невероятной точностью предсказать, какие конкретные категории клиентов захотят сделать приобретение, и когда. Биг Дата также помогает компаниям выполнять свою деятельность намного эффективнее.
Даже вне сферы бизнеса проекты, связанные с Big-Data, уже помогают изменить наш мир различными путями:
- Улучшая здравоохранение — медицина, управляемая данными, способна анализировать огромное количество медицинской информации и изображений для моделей, которые могут помочь обнаружить заболевание на ранней стадии и разработать новые лекарства.
- Прогнозируя и реагируя на природные и техногенные катастрофы. Данные датчиков можно проанализировать, чтобы предсказать, где могут произойти землетрясения, а модели поведения человека дают подсказки, которые помогают организациям оказывать помощь выжившим. Технология Биг Даты также используется для отслеживания и защиты потока беженцев из зон военных действий по всему миру.
- Предотвращая преступность. Полицейские силы все чаще используют стратегии, основанные на данных, которые включают их собственную разведывательную информацию и информацию из открытого доступа для более эффективного использования ресурсов и принятия сдерживающих мер там, где это необходимо.
Лучшие книги о технологии Big-Data

Проблемы с Big-Data
Биг Дата дает нам беспрецедентные идеи и возможности, но также поднимает проблемы и вопросы, которые необходимо решить:
- Конфиденциальность данных – Big-Data, которую мы сегодня генерируем, содержит много информации о нашей личной жизни, на конфиденциальность которой мы имеем полное право. Все чаще и чаще нас просят найти баланс между количеством персональных данных, которые мы раскрываем, и удобством, которое предлагают приложения и услуги, основанные на использовании Биг Даты.
- Защита данных — даже если мы решаем, что нас устраивает то, что у кого-то есть наши данные для определенной цели, можем ли мы доверять ему сохранность и безопасность наших данных?
- Дискриминация данных — когда вся информация будет известна, станет ли приемлемой дискриминация людей на основе данных из их личной жизни? Мы уже используем оценки кредитоспособности, чтобы решить, кто может брать деньги, и страхование тоже в значительной степени зависит от данных. Нам стоит ожидать, что нас будут анализировать и оценивать более подробно, однако следует позаботиться о том, чтобы это не усложняло жизнь тех людей, которые располагают меньшими ресурсами и ограниченным доступом к информации.
Выполнение этих задач является важной составляющей Биг Даты, и их необходимо решать организациям, которые хотят использовать такие данные. Неспособность осуществить это может сделать бизнес уязвимым, причем не только с точки зрения его репутации, но также с юридической и финансовой стороны.
Глядя в будущее
Данные меняют наш мир и нашу жизнь небывалыми темпами. Если Big-Data способна на все это сегодня — просто представьте, на что она будет способна завтра. Объем доступных нам данных только увеличится, а технология аналитики станет еще более продвинутой.
Для бизнеса способность применять Биг Дату будет становиться все более решающей в ближайшие годы. Только те компании, которые рассматривают данные как стратегический актив, выживут и будут процветать. Те же, кто игнорирует эту революцию, рискуют остаться позади.
clubshuttle.ru
Big Data: характеристики, классификация, полезность, примеры
Что такое Big Data (дословно — большие данные)? Обратимся сначала к оксфордскому словарю:
Данные — величины, знаки или символы, которыми оперирует компьютер и которые могут храниться и передаваться в форме электрических сигналов, записываться на магнитные, оптические или механические носители.
Термин Big Data используется для описания большого и растущего экспоненциально со временем набора данных. Для обработки такого количества данных не обойтись без машинного обучения.
Преимущества, которые предоставляет Big Data:
- Сбор данных из разных источников.
- Улучшение бизнес-процессов через аналитику в реальном времени.
- Хранение огромного объема данных.
- Инсайты. Big Data более проницательна к скрытой информации при помощи структурированных и полуструктурированных данных.
- Большие данные помогают уменьшать риск и принимать умные решения благодаря подходящей риск-аналитике
Примеры Big Data
Нью-Йоркская Фондовая Биржа ежедневно генерирует 1 терабайт данных о торгах за прошедшую сессию.
Социальные медиа: статистика показывает, что в базы данных Facebook ежедневно загружается 500 терабайт новых данных, генерируются в основном из-за загрузок фото и видео на серверы социальной сети, обмена сообщениями, комментариями под постами и так далее.
Реактивный двигатель генерирует 10 терабайт данных каждые 30 минут во время полета. Так как ежедневно совершаются тысячи перелетов, то объем данных достигает петабайты.
Классификация Big Data
Формы больших данных:
- Структурированная
- Неструктурированная
- Полуструктурированная
Структурированная форма
Данные, которые могут храниться, быть доступными и обработанными в форме с фиксированным форматом называются структурированными. За продолжительное время компьютерные науки достигли больших успехов в совершенствовании техник для работы с этим типом данных (где формат известен заранее) и научились извлекать пользу. Однако уже сегодня наблюдаются проблемы, связанные с ростом объемов до размеров, измеряемых в диапазоне нескольких зеттабайтов.
1 зеттабайт соответствует миллиарду терабайт
Глядя на эти числа, нетрудно убедиться в правдивости термина Big Data и трудностях сопряженных с обработкой и хранением таких данных.
Данные, хранящиеся в реляционной базе — структурированы и имеют вид ,например, таблицы сотрудников компании
Неструктурированная форма
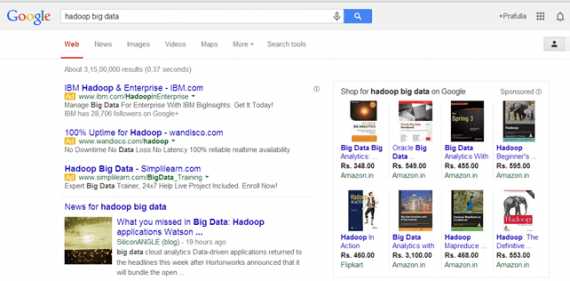
Данные неизвестной структуры классифицируются как неструктурированные. В дополнении к большим размерам, такая форма характеризуется рядом сложностей для обработки и извлечении полезной информации. Типичный пример неструктурированных данных — гетерогенный источник, содержащий комбинацию простых текстовых файлов, картинок и видео. Сегодня организации имеют доступ к большому объему сырых или неструктурированных данных, но не знают как извлечь из них пользу.
Примером такой категории Big Data является результат Гугл поиска:
Полуструктурированная форма
Эта категория содержит обе описанные выше, поэтому полуструктурированные данные обладают некоторой формой, но в действительности не определяются с помощью таблиц в реляционных базах. Пример этой категории — персональные данные, представленные в XML файле.
<rec><name>Prashant Rao</name><sex>Male</sex><age>35</age></rec> <rec><name>Seema R.</name><sex>Female</sex><age>41</age></rec> <rec><name>Satish Mane</name><sex>Male</sex><age>29</age></rec> <rec><name>Subrato Roy</name><sex>Male</sex><age>26</age></rec> <rec><name>Jeremiah J.</name><sex>Male</sex><age>35</age></rec>
Характеристики Big Data
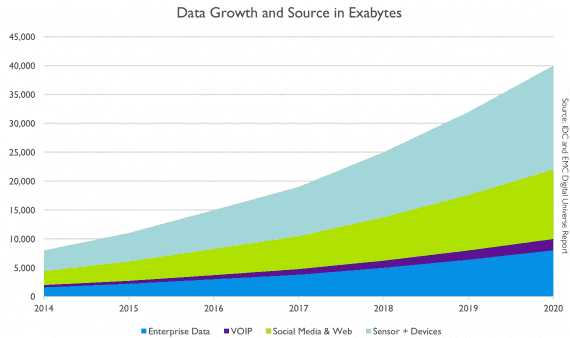
Рост Big Data со временем:
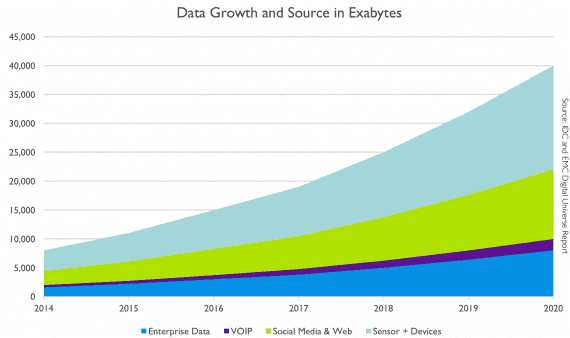
Синим цветом представлены структурированные данные (Enterprise data), которые сохраняются в реляционных базах. Другими цветами — неструктурированные данные из разных источников (IP-телефония, девайсы и сенсоры, социальные сети и веб-приложения).
В соответствии с Gartner, большие данные различаются по объему, скорости генерации, разнообразию и изменчивости. Рассмотрим эти характеристики подробнее.
- Объем. Сам по себе термин Big Data связан с большим размером. Размер данных — важнейший показатель при определении возможной извлекаемой ценности. Ежедневно 6 миллионов людей используют цифровые медиа, что по предварительным оценкам генерирует 2.5 квинтиллиона байт данных. Поэтому объем — первая для рассмотрения характеристика.
- Разнообразие — следующий аспект. Он ссылается на гетерогенные источники и природу данных, которые могут быть как структурированными, так и неструктурированными. Раньше электронные таблицы и базы данных были единственными источниками информации, рассматриваемыми в большинстве приложений. Сегодня же данные в форме электронных писем, фото, видео, PDF файлов, аудио тоже рассматриваются в аналитических приложениях. Такое разнообразие неструктурированных данных приводит к проблемам в хранении, добыче и анализе: 27% компаний не уверены, что работают с подходящими данными.
- Скорость генерации. То, насколько быстро данные накапливаются и обрабатываются для удовлетворения требований, определяет потенциал. Скорость определяет быстроту притока информации из источников — бизнес процессов, логов приложений, сайтов социальных сетей и медиа, сенсоров, мобильных устройств. Поток данных огромен и непрерывен во времени.
- Изменчивость описывает непостоянство данных в некоторые моменты времени, которое усложняет обработку и управление. Так, например, большая часть данных неструктурирована по своей природе.
Big Data аналитика: в чем польза больших данных
Продвижение товаров и услуг: доступ к данным из поисковиков и сайтов, таких как Facebook и Twitter, позволяет предприятиям точнее разрабатывать маркетинговые стратегии.
Улучшение сервиса для покупателей: традиционные системы обратной связи с покупателями заменяются на новые, в которых Big Data и обработка естественного языка применяется для чтения и оценки отзыва покупателя.
Расчет риска, связанного с выпуском нового продукта или услуги.
Операционная эффективность: большие данные структурируют, чтобы быстрее извлекать нужную информацию и оперативно выдавать точный результат. Такое объединение технологий Big Data и хранилищ помогает организациям оптимизировать работу с редко используемой информацией.
Интересные статьи:
neurohive.io
Книга «Основы Data Science и Big Data. Python и наука о данных»
 Data Science — это совокупность понятий и методов, позволяющих придать смысл и понятный вид огромным объемам данных.
Data Science — это совокупность понятий и методов, позволяющих придать смысл и понятный вид огромным объемам данных.Каждая из глав этой книги посвящена одному из самых интересных аспектов анализа и обработки данных. Вы начнете с теоретических основ, затем перейдете к алгоритмам машинного обучения, работе с огромными массивами данных, NoSQL, потоковым данным, глубокому анализу текстов и визуализации информации. В многочисленных практических примерах использованы сценарии Python.
Обработка и анализ данных — одна из самых горячих областей IT, где постоянно требуются разработчики, которым по плечу проекты любого уровня, от социальных сетей до обучаемых систем. Надеемся, книга станет отправной точкой для вашего путешествия в увлекательный мир Data Science.
Анализировать данные умеют все люди. Способность нашего мозга видеть взаимосвязи, приходить к выводам на основании фактов и учиться на опыте — вот что делает человека человеком. Выживание человека в большей степени, чем любого другого биологического вида на планете, зависит от мозга; человечество сделало максимальную ставку на эту особенность, чтобы занять свое место в природе. Пока эта стратегия работает, и вряд ли мы захотим ее поменять в ближайшем будущем.
Однако в том, что касается тривиальной обработки чисел, возможности нашего мозга ограниченны. Он не справляется с объемом данных, который мы в состоянии воспринять за один раз, и с нашей любознательностью. По этой причине мы доверяем машинам часть своей работы: выявление закономерностей, формирование связей и получение ответов на многочисленные вопросы.
Стремление к знаниям заложено в наших генах. Применение компьютеров для выполнения части работы в наши гены не заложено, но без них не обойтись.
Структура книги
В главах 1 и 2 приводятся общие теоретические основы, необходимые для понимания других глав книги:
— Глава 1 знакомит читателя с data science и большими данными. Она завершается практическим примером Hadoop.
— Глава 2 посвящена процессу data science. В ней описаны шаги, присутствующие почти в каждом проекте data science.
В главах 3–5 описано применение принципов машинного обучения к наборам данных постепенно увеличивающихся размеров:
— В главе 3 рассматриваются относительно небольшие данные, легко помещающиеся в памяти среднего компьютера.
— В главе 4 задача усложняется: в ней рассматриваются «большие данные», которые могут храниться на вашем компьютере, но не помещаются в памяти, вследствие чего обработка таких данных без вычислительного кластера создает проблемы.
— В главе 5 мы наконец-то добираемся до настоящих больших данных, с которыми невозможно работать без многих компьютеров.
В главах 6–9 рассматриваются некоторые интересные вопросы data science, более или менее независимые друг от друга:
— В главе 6 рассматривается архитектура NoSQL и ее отличие от реляционных баз данных.
— В главе 7 data science применяется к потоковым данным. Здесь основная проблема связана не с размером, а со скоростью генерирования данных и потерей актуальности старых данных.
— Глава 8 посвящена глубокому анализу текста. Не все данные существуют в числовой форме. Глубокий анализ и аналитика текста начинают играть важную роль в текстовых форматах: электронной почте, блогах, контенте веб-сайтов и т. д.
— В главе 9 основное внимание уделяется последней части процесса data science (визуализации данных и построению прототипа приложения), для чего мы рассмотрим ряд полезных инструментов HTML5.
В приложениях А–Г рассматриваются процедуры установки и настройки систем Elasticsearch, Neo4j и MySQL, упоминаемых в главах книги, а также Anaconda — программного пакета Python, чрезвычайно полезного в data science.
Для кого написана эта книга
Эта книга знакомит читателя с областью data science. Опытные специалисты data science поймут, что по некоторым темам материал изложен в лучшем случае поверхностно. Другим читателям сообщим, что для извлечения максимальной пользы из книги потребуются некоторые предварительные условия: чтобы браться за практические примеры, желательно обладать хотя бы минимальными познаниями в SQL, Python, HTML5 и статистике или машинном обучении.
Об авторах
Дэви Силен — опытный предприниматель, автор книг и профессор. Вместе с Арно и Мо он является совладельцем Optimately и Maiton — двух компаний data science, базирующихся в Бельгии и Великобритании соответственно, а также одним из совладельцев еще одной компании data science в Сомалиленде. Все эти компании специализируются на стратегической обработке «больших данных»; многие крупные компании время от времени обращаются к ним за консультациями. Дэви является внештатным преподавателем школы менеджмента IESEG в Лилле (Франция), где он преподает и участвует в исследованиях в области теории «больших данных».
Мохамед Али — предприниматель и консультант в области data science. Вместе с Арно и Мо он является совладельцем Optimately и Maiton — двух компаний data science, базирующихся в Бельгии и Великобритании соответственно. Его увлечения лежат в двух областях: data science и экологически рациональные проекты. Последнее направление воплотилось в создании третьей компании, базирующейся в Сомалиленде.
Арно Мейсман — целеустремленный предприниматель и специалист data science. Вместе с Дэви и Мо он является совладельцем Optimately и Maiton — двух компаний data science, базирующихся в Бельгии и Великобритании соответственно, а также одним из совладельцев еще одной компании data science в Сомалиленде. Все эти компании специализируются на стратегической обработке «больших данных»; многие крупные компании время от времени обращаются к ним за консультациями. Арно — специалист data science с широким кругом интересов, от розничной торговли до игровой аналитики. Он полагает, что информация, полученная в результате обработки данных, в сочетании с некоторым воображением, поможет нам улучшить этот мир.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — Data Science
habr.com