что это такое за тег для Яндекса
Noindex – это тег, с помощью которого можно управлять функцией индексации поискового робота. Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш. Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы.
Вторая, не менее важная функция тега noindex, состоит в том, чтобы блокировать индексацию отдельных страниц сайта, предназначенных для публикации пользовательского контента. К таким относятся страницы с отзывами, комментариями, сообщениями и др. В данном случае noindex позволяет избежать распространения нежелательной информации и использовать менее жесткий режим модерирования пользовательских сообщений.
Тег noindex учитывает только Яндекс. Google игнорирует его присутствие и проводит полную индексацию текстового содержания страницы. Для задействования блокировки индексации, актуальной для всех поисковиков, следует прописывать соответствующий метатег для отдельных страниц или всего сайта в файле robots.txt. Недостаток данного способа очевиден: запрет на индексацию возможен только по отношению ко всей странице, но не отдельному текстовому фрагменту.
Преимущества тега noindex
- Сокрытие второстепенной информации позволяет повысить релевантность индексируемой страницы за счет возрастания относительной плотности ключевых фраз.
- С помощью noindex можно спрятать содержимое сквозных блоков, информация в которых будет дублироваться на нескольких страницах, что отразится на пессимизации сайта в поисковой выдаче Yandex.
- В некоторых случаях в сниппет может попасть нежелательная или служебная информация, которую проще всего скрыть тегом noindex.
Принцип действия
Noindex может находиться в любом месте HTML-кода вне зависимости от уровня вложенности. Для сохранения валидности кода тег следует использовать в следующем формате:
<!—noindex—>Здесь находится закрытый для индексации текст<!—/noindex—>.
Несмотря на тот факт, что noindex был изначально предложен разработчиками Yandex, использование данного инструмента может быть расценено в качестве серого метода оптимизации. Это связано с тем, что некоторые веб-мастера применяют его не по прямому назначению. В частности, от робота прячется неуникальный контент или качественный текст, не содержащий ключевых слов, рассчитанный на прочтение посетителем сайта. Одновременно поисковику предлагается насыщенный ключевыми фразами текст, тяжелый для восприятия человека.
Для борьбы с подобными методами оптимизации Yandex анализирует текст, закрытый тегом noindex, проводя его индексацию, но впоследствии отфильтровывая скрытое содержимое. В результате изучения контента страницы поисковик может принять решение о наложении санкций на сайт, если сочтет, что его владелец использует неправомерные способы влияния на результаты поисковой выдачи.
wiki.rookee.ru
| HTML | WebReference
Поисковый робот Яндекса «ходит» по сайтам, просматривает и анализирует их содержимое, после чего сохраняет указатель на текст и изображения в поисковую базу данных Яндекса. Такой процесс называется индексированием. Часть веб-страницы можно закрыть от индексирования, поместив её внутрь элемента <noindex>. Тогда при следующем посещении веб-страницы поисковый робот проигнорирует такое содержимое и не станет добавлять его в свою базу данных. Это делается по разным причинам, к примеру, закрытые от индексации ссылки не передают ТИЦ (тематический индекс цитирования).
Важно понимать, что это нестандартный элемент и придуман Яндексом для своих целей. Браузеры никак не поддерживают <noindex> и просто выводят его содержимое как обычно.
Если вам нужно закрыть ссылку для поисковиков, добавьте к ней атрибут rel со значением nofollow:
<a href="//webref.ru" rel="nofollow">Ссылка не индексируется</a>Если требуется закрыть для поисковиков всю страницу используйте элемент <meta>, добавив его в код HTML:
<meta name="robots" content="noindex">Или добавьте в файл robots.txt следующую строку:
Disallow: /private.htmlГде private.html адрес страницы.
Закрывающий тег
Пример
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>noindex</title> </head> <body> <noindex> <p>Данный текст Яндекс не будет индексировать.</p> </noindex> </body> </html>
Браузеры
В таблице браузеров применяются следующие обозначения.
- — элемент полностью поддерживается браузером;
- — элемент браузером не воспринимается и игнорируется;
- — при работе возможно появление различных ошибок, либо элемент поддерживается с оговорками.
Число указывает версию браузреа, начиная с которой элемент поддерживается.
×Автор и редакторы
Автор: Клим Щербаков
Последнее изменение: 30.08.2018
Редакторы: Влад Мержевич
webref.ru
что это значит, в чем разница и как правильно их использовать
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Больше видео на нашем канале - изучайте интернет-маркетинг с SEMANTICA
В чем отличие между noindex и nofollow
Первое существенное отличие их в том, что первый был виден ранее для Google, а второй - только для Яндекса и Rambler. В настоящее время Яндекс также научился распознавать Ноуфоллоу, который работает только для ссылок, а Ноуиндекс - для любого кода сайта.
Что касается тега Noindex, то с ним работает только Яндекс. Гугл же просто проигнорирует его. Использовать его нужно в тех случаях, когда вы хотите закрыть какой-то участок страницы — текст, картинку или ссылку — от индексации. Поисковик контент распознает, но впоследствии выкидывает из индекса. Эта мера установлена для полного анализа страницы и процедуры наложения возможных санкций за нарушения.
Для чего нужен Noindex
- Закрывается ненужная/неуникальная информация, что улучшает релевантность страницы, потому что увеличивается плотность ключевых фраз, соответствие тематике, уникальность.
- Прячутся сквозные блоки и гиперссылки, наличие которых может приводить к пессимизации.
- Скрывается личная и служебная информация, если вы не хотите, чтобы она легко находилась через поиск.
Для чего нужен Nofollow
- Закрытие лишних веб-ссылок.
- Сохранение веса страницы неизменным.
- Распределение определенного веса по ссылкам.
Как использовать noindex и nofollow
Тэг Noindex для любого контента применяется так:
текст, который надо скрыть <a href=”ссылка куда-то”>, и еще</a> текст</noindex>.
Весь текст и анкор ссылки изначально индексируются, но потом удаляются из базы поисковика. Гиперссылка индексируется, и вес по ней передается.
При работе с Ноиндекс существует вероятность того, что снизится валидность кода, так как данный тэг знает только российский поисковик. Поэтому рекомендуется следующий вариант написания:
<!--Noindex--> Весь текст, который надо скрыть <!--/noindex-->.
Весь текст, который надо скрыть .
При этом другие поисковики просто его пропустят, и валидность кода останется неизменной.
Атрибут Nofollow для ссылок применяется
<a href=”веб-ссылка куда-то” rel=”nofollow”> анкор </a>
При этом анкор попадает в индекс, но поисковик по веб-ссылке не идет, вес на странице остается.
Если на странице слишком много Нофоллоу, то это может негативно сказаться на лояльности поисковиков.
Совместное использование
Для того чтобы закрыть и текстовую часть, и гиперссылку, следует придерживаться такого написания:
<!--Noindex--> Весь текст, который надо скрыть <a href=”веб-ссылка куда-то” rel=”nofollow”> анкор </a>, и еще текст <!--/noindex-->
Варианты правильного использования Noindex и Nofollow для запрета индексации документа в целом
Тег и атрибут, все время ходят “за ручку”, и часто их применяют вместе. Они могут применяться в meta name=robots документа для указания рекомендаций по его индексации и переходу по веб-ссылкам. Указание на запрет индексации необходимо, если обнаружены дубли страниц, Или в сети появилась конфиденциальная или устаревшая информация, а другим способом страницы убрать нельзя.
В случае, если вы хотите закрыть всю страницу от индексации и запретить учет располагающихся на ней ссылок, необходимо указать в метаданных страницы - следующее:
Ноуиндекс создает команду Яндексу не индексировать контент на странице, но робот ходит по ее веб-ссылкам. Поэтому дополнительный Ноуфоллоу указывает по ним на не ходить. Данное указание воспринимают как Яндекс, так и Google.
Что касается удаления документа из индекса Google, то поисковиком предусмотрен альтернативный метод: запись X-Robots-Tag: noindex, nofollow. Данное указание закрепляется в http-заголовках, не видимых в коде страницы.
Рассказываем о разнице между Nofollow и Noindex, как их правильно использовать для ссылок и скрытия контента на сайте.
Всегда следите за наличием рассмотренных в статье тегов и атрибутов в нужных местах, чтобы получать именно тот результат, которого вы ожидаете.
semantica.in
Тег noindex, валидный метатег, что значит запрещен к индексированию, настройки
Тег noindex служит для обозначения фрагментов текста, запрещенных для индексирования поисковой системой Яндекс.
Тег введен в оборот системой яндекс и используется только ей и, возможно, Рамблер.
Google его не понимает и никак не учитывает.
Первоначально, чтобы закрыть часть текста от индексации, нужно было обернуть его, как указано ниже:
<noindex>текст, закрытый от индексации</noindex>
<noindex>текст, закрытый от индексации</noindex> |
Поскольку тег не является частью утвержденных стандартов, возникают проблемы валидации страницы при ее проверке в любом сервисе проверки валидностью кода html.
Из-за этого яндекс ввел другую версию тега вида <!–noindex–>неиндексируемый текст<!–/noindex–>. При таком использовании страница нормально проходит проверку. Первый вариант также до сих пор работает, но более правильно использовать второй вариант.
Применять данный тег можно, например, чтобы закрыть счетчики, комментарии. Но нет смысла закрывать, например, меню в целях перераспределения ссылочного веса на сайте.
Передача веса закрытой ссылке
Тег закрывает от индексации только текст, заключенный в него, но не влияет на индексирование ссылок внутри этого текста и передачу веса по ним. Для закрытия ссылки нужно использовать атрибут rel=”nofollow”, как писал здесь.
Метатег noindex
Метатег в коде страницы вида:
<meta name="robots" content="noindex,nofollow"/>
<meta name="robots" content="noindex,nofollow"/> |
запрещает от индексации содержимое всей страницы (за это отвечает noindex), а также индексацию ссылок на этой страницы (за это отвечает nofollow).
Для массового проставления данного метатега, например, для архивов и других таксономий в wordpress можно использовать плагин Yoast SEO. В нем можно прописать метатеги в том числе и для отдельных страниц.
В robots.txt тег noindex не работает и не используется.
Сообщение – url запрещен к индексированию тегом noindex
В некоторых случаев вебмастер яндекс выдает сообщение, что адрес страницы, например, главной запрещен от индексации. Это значит, что на странице появился обнаружен этот метатег. Чаще всего такое бывает в двух случаях. Когда создавали сайт, то указали настройку “Попросить поисковые системы не индексировать сайт” на время разработки. Теперь нужно просто убрать эту пометку и отправить сайт в вебмастере на перепроверку. Или второй вариант – у вас стоит SEO плагин вроде Yoast Seo, в настройках которого вы указали запрет индексации, соответственно теперь его нужно убрать.
delaemsait.info
Noindex и nofollow в метатеге Robots и другие способы запрета индексации
Содержание статьи
Когда нужно запретить индексацию целой категории или ряда страниц, это легче сделать с помощью правильного robots.txt. Но как быть, если требуется закрыть от индексации одну страницу либо вообще часть текста на странице? Поговорим сейчас об элементах, которые призваны решать именно эту проблему.
Что такое мета тег Robots
Сначала уясним, что есть мета тег Robots, а есть файл Robots.txt, и путать их не будем. Метатег имеет отношение только к одной html странице (на которой он указан), в то время, как файл txt может содержать директивы не только к странице, но к целым каталогам.
Важный момент — для поисковика директивы метатега Роботс имеют преимущество перед директивами из robots.txt. То есть если в .txt у вас указано, что страницу можно индексировать, а в её метатеге указано, что нельзя, поисковик будет слушаться именно директиве из метатега.
При помощи мета тега Robots можно запрещать индексировать содержимое всей страницы. На страницах моего блога он выглядит так:
<meta name="robots" content="noodp"/>
<meta name="robots" content="noodp"/> |
Это означает, что метатег роботс не запрещает индексировать страницу. Noodp тут означает, что он запрещает Google брать в сниппеты описание для страниц из каталога DMOZ — это одна из стандартных настроек плагина Yoast SEO, которым я пользуюсь.
А вот как выглядит метатег Robots, который запрещает индексацию страницы:
<meta name =“robots” content=”noindex,nofollow”/>
<meta name =“robots” content=”noindex,nofollow”/> |
Как прописать
Дедовский способ — вручную прописать для страницы. Способ подходит для сайтов на чистом HTML.
Для сайтов на CMS рекомендую использовать SEO-плагины. Я, например, для WordPress использую плагин Yoast SEO, и там под каждой записью в режиме редактирования есть такая опция:
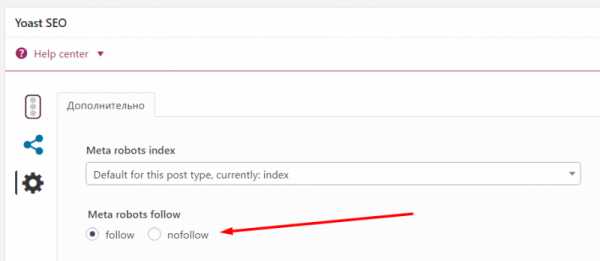
То есть проставить нужное значение можно парой щелчков.
Как использовать noindex и nofollow в meta robots
Посмотрим на возможные значения атрибута content:
- noindex, nofollow – запрещена к индексации вся страница и переходы по ссылкам на ней; кстати, идентичной будет значение при записи: <meta name =”robots” content=”none”/>
- noindex, follow – страница не индексируется, но поисковик может переходить по ссылкам;
- index, nofollow – страница индексируется, но переход по ссылкам запрещен;
- index, follow – разрешены к индексированию как страница, так и ссылки на ней;
- noarchive – работает как в yandex, так и в google – не показывает страницу на сохраненную копию;
- noyaca – работает только в Яндексе, если сайт зарегистрирован в каталоге YACA – запрещает использовать описание в результатах поиска, которое берется из Яндекс.Каталога; выглядит так: <meta name =”robots” content=”noyaca”/>
- noodp – работает и в Яндексе, и в Google – запрещает использовать в результатах описания, которые взяты из Каталога ДМОЗ (разумеется, если сайт там зарегистрирован).
Поговорим чуть больше о noodp
Иногда Гугл может добавлять в сниппет описание из DMOZ. Именно для этого и используется атрибут noodp. Кстати, его можно использовать вместе с тегом nofollow. Выглядит это так:
<meta name=“robots” content=”noodp, nofollow”/>
<meta name=“robots” content=”noodp, nofollow”/> |
Чего нужно опасаться при использовании
Из-за невнимательности (особенно у новичков) могут случаться конфликты между тегами: в таком случае главным будет положительное значение (разрешающее индексацию). Например тут:
<meta name =”robots” content=”all”/> <meta name =”robots” content=”noindex, nofollow”/>
<meta name =”robots” content=”all”/> <meta name =”robots” content=”noindex, nofollow”/> |
Тут выбрано будет первое значение, так как там оно положительно.
Что такое тег Noindex
Noindex — это тег, в который вы заключаете часть кода, и этот код по идее не должен индексироваться Яндексом. Тег ноиндекс был предложен именно Яндексом, и по сей день учитывается только системами Yandex и Rambler. Вот как он выглядит:
<noindex>скрываемый текст</noindex>
<noindex>скрываемый текст</noindex> |
Noindex – парный тег, и его необходимо закрывать.
Noindex не чувствителен к вложенности.
Целесообразность использования тега
Лично я смысла в его использовании не вижу. Потому что Google этот тег игнорирует. Да и зачем скрывать что-то? Надо делать сайты для людей!
Раньше сеошники скрывали в него часть текста, чтобы не было переспама. Но лично я предпочитаю в целях борьбы с переспамом просто снижать количество ключей в наиболее важных зонах документа.
Если же вы все-таки решили пользоваться этим тегом, то гляньте видео от ТопЭксперт:
Как пользоваться тегом Noindex
Нужно просто обернуть им тег:
<noindex>текст, который нам не нужен</noindex>
<noindex>текст, который нам не нужен</noindex> |
Валидный Noindex
Чтобы сделать его валидным, нужно закомментировать тег. Выглядит это так:
<!- -noindex- ->вот так все норм<!- -/noindex- ->
<!- -noindex- ->вот так все норм<!- -/noindex- -> |
Для чего нужны теги, запрещающие индексацию
Как я писал выше, тег Noindex вообще ни для чего не нужен. Он себя давно изжил. А вот метатег роботс — довольно нужная вещь. Вот примеры ситуаций, когда он бывает полезен:
- На сайте есть какая-то страница, которую бы вы не хотели видеть в индексе. Например, страница с информацией для рекламодателей. А прописывать в роботсе по каким-то причинам не хотите (например, хотите скрыть её от оптимизаторов, которые лазят по чужим роботсам). Тогда вы просто парой щелчков через плагин ставите ноиндекс для этой страницы;
- Поскольку мета тег роботс имеет приоритет перед robots.txt, можно запретить индексирование какой-либо страницы, которая находится в директории, разрешенной для индексации.
Для чего нужен атрибут rel nofollow
Если метатег robots должен закрывать от индексации страницу, а тег noindex — её часть, то атрибут rel nofollow должен запрещать поисковику переходить по ссылке. Он является атрибутом тега А и выглядит так:
<a href =”http://website.ru” <strong>rel=”nofollow”</strong>>скрытая ссылка</a>
<a href =”http://website.ru” <strong>rel=”nofollow”</strong>>скрытая ссылка</a> |
Зеленые вебмастера, которые впервые узнали о рел нофоллоу, сразу думают: «Отлично! Теперь я всем ссылкам его пропишу и вес не будет утекать никуда».
На самом деле поисковик вполне себе переходит по ссылкам с этим атрибутом и они вполне себе забирают ссылочный вес у ваших страниц. То есть смысла в этом атрибуте, как и в noindex, нет. Ссылки закрывать эффективно только через Ajax, да и это я думаю не навсегда. Но, если же вы все-таки решили сконцентрировать внимание на этой точке, которая в лучшем случае даст вам микроскопический рост, то вот еще один видос от ТопЭксперт:
znet.ru
Noindex - это... Что такое Noindex?
noindex — имя не входящего в официальную спецификацию тега языка гипертекстовой разметки веб-страниц HTML, предназначенного для включения в него частей веб-страниц, не предлагаемых к индексации поисковыми системами.
Тег предложен российской компанией «Яндекс» в качестве альтернативы атрибуту nofollow и в настоящее время только им и распознаётся[1].
Данный тег предназначен для поисковых систем: он указывает им на то, что часть страницы, находящуюся между <noindex> и </noindex>, не следует никаким образом учитывать при индексировании данной страницы.
При использовании этого метода часть страницы, где он применяется, становится неэффективной для поисковой оптимизации.
С мая 2010 года «Яндекс» также стал учитывать микроформат nofollow[2].
Мета-тег noindex
Существует также мета-тег en:Noindex с тем же именем и с похожим предназначением. Отличие от «российского» — несколько другое использование, а также область действия (на всю страницу)[3].
Пример тега noindex:
<body> ... <noindex><a href="http://www.example.com">Попытка рекламы</a></noindex>
Пример мета-тега noindex:
<html> <head> <meta name="robots" content="noindex" /> <title>Don't index this page</title> </head>
Noindex и Википедия
Стоит отметить, что в отличие от nofollow, Википедия не «обертывает» внешние ссылки тегами noindex, что раньше могло давать почву для спама вики-статей внешними ссылками, добавляемыми «поисковыми оптимизаторами» и владельцами некоторых сайтов для собственной «раскрутки» "под Яндекс". Однако с мая 2010 и это стало бесполезным занятием.
Совместимость
Поскольку тег noindex не входит в официальную спецификацию языка HTML, то большинство HTML-валидаторов считает его ошибкой. Потому для того, чтобы сделать код с noindex валидным рекомендуется использовать тот факт, что noindex не чувствителен к вложенности и это позволяет использовать следующую конструкцию[1]:
<!--noindex-->Текст или код, который нужно исключить из индексации<!--/noindex-->
Подсветка Noindex
Подсветка seo тега noindex на сайтах в браузере Firefox [4] реализована в плагине RDS bar.
Примечания
dic.academic.ru
Полное руководство по Robots.txt и метатегу Noindex
Файл Robots.txt и мета-тег Noindex важны для SEO-продвижения. Они информируют Google, какие именно страницы необходимо сканировать, а какие – индексировать (отображать в результатах поиска).
С помощью этих средств можно ограничить содержимое сайта, доступное для индексации.
Robots.txt – это файл, который указывает поисковым роботам (например, Googlebot и Bingbot), какие страницы сайта не должны сканироваться.
Файл robots.txt сообщает роботам системам, какие страницы могут быть просканированы. Но не может контролировать их поведение и скорость сканирования сайта. Этот файл, по сути, представляет собой набор инструкций для поисковых роботов о том, к каким частям сайта доступ ограничен.
Но не все поисковые системы выполняют директивы файла robots.txt. Если у вас остались вопросы насчет robots.txt, ознакомьтесь с часто задаваемыми вопросами о роботах.
По умолчанию файл robots.txt выглядит следующим образом:
Можно создать свой собственный файл robots.txt в любом редакторе, который поддерживает формат .txt. С его помощью можно заблокировать второстепенные веб-страницы сайта. Файл robots.txt – это способ сэкономить лимиты, которые могут пойти на сканирование других разделов сайта.
User-Agent: определяет поискового робота, для которого будут применяться ограничения в сканировании URL-адресов. Например, Googlebot, Bingbot, Ask, Yahoo.
Disallow: определяет адреса страниц, которые запрещены для сканирования.
Allow: только Googlebot придерживается этой директивы. Она разрешает анализировать страницу, несмотря на то, что сканирование родительской веб-страницы запрещено.
Sitemap: указывает путь к файлу sitemap сайта.
В файле robots.txt символ (*) используется для обозначения любой последовательности символов.
Директива для всех типов поисковых роботов:
User-agent:*
Также символ * можно использовать, чтобы запретить все URL-адреса кроме родительской страницы.
User-agent:*
Disallow: /authors/*
Disallow: /categories/*
Это означает, что все URL-адреса дочерних страниц авторов и страниц категорий заблокированы за исключением главных страниц этих разделов.
Ниже приведен пример правильного файла robots.txt:
User-agent:* Disallow: /testing-page/ Disallow: /account/ Disallow: /checkout/ Disallow: /cart/ Disallow: /products/page/* Disallow: /wp/wp-admin/ Allow: /wp/wp-admin/admin-ajax.php Sitemap: yourdomainhere.com/sitemap.xml
После того, как отредактируете файл robots.txt, разместите его в корневой директории сайта. Благодаря этому поисковый робот увидит файл robots.txt сразу после захода на сайт.
Noindex – это метатег, который запрещает поисковым системам индексировать страницу.
Существует три способа добавления Noindex на страницы:
Разместите приведенный ниже код в раздел <head> страницы:
<meta name=”robots” content=”noindex”>
Он сообщает всем типам поисковых роботов об условиях индексации страницы. Если нужно запретить индексацию страницы только для определенного робота, поместите его название в значение атрибута name.
Чтобы запретить индексацию страницы для Googlebot:
<meta name=”googlebot” content=”noindex”>
Чтобы запретить индексацию страницы для Bingbot:
<meta name=”bingbot” content=”noindex”>
Также можно разрешить или запретить роботам переход по ссылкам, размещенным на странице.
Чтобы разрешить переход по ссылкам на странице:
<meta name=”robots” content=”noindex,follow”>
Чтобы запретить поисковым роботам сканировать ссылки на странице:
<meta name=”robots” content=”noindex,nofollow”>
x-robots-tag позволяет управлять индексацией страницы через HTTP-заголовок. Этот тег также указывает поисковым системам не отображать определенные типы файлов в результатах поиска. Например, изображения и другие медиа-файлы.
Для этого у вас должен быть доступ к файлу .htaccess. Директивы в метатеге «robots» также применимы к x-robots-tag.
Плагин YoastSEO в WordPress автоматически генерирует приведенный выше код. Для этого на странице записи перейдите в интерфейсе YoastSEO в настройки публикации, щелкнув по значку шестеренки. Затем в опции «Разрешить поисковым системам показывать эту публикацию в результатах поиска?» выберите «Нет».
Также можно задать тег noindex для страниц категорий. Для этого зайдите в плагин Yoast, в «Вид поиска». Если в разделе «Показать категории в результатах поиска» выбрать «Нет», тег noindex будет размещен на всех страницах категорий.
- Чтобы проиндексированная страница была удалена из результатов поиска, убедитесь, что она не заблокирована в файле robots.txt. И только потом добавляйте тег noindex. Иначе Googlebot не сможет увидеть тег на странице. Если заблокировать страницу без тега noindex, она все равно будет отображаться в результатах поиска:
- Добавление директивы sitemap в файл robots.txt технически не требуется, но считается хорошей практикой.
- После обновления файла robots.txt рекомендуется проверить, не заблокированы ли важные страницы. Это можно сделать с помощью txt Tester в Google Search Console.
- Используйте инструмент проверки URL-адреса в Google Search Console, чтобы увидеть статус индексации страницы.
- Также можно проверить, проиндексировал ли Google ненужные страницы. Это можно сделать с помощью отчета в Google Search Console. Еще одной альтернативой может быть использование оператора «site». Это команда Google, которая отображает все страницы сайта, доступные в результатах поиска.
В последнее время в SEO-сообществе было много недоразумений по поводу использования noindex в robots.txt. Но представители Google много раз говорили, что поисковая система не поддерживают данный метатег. И все же многие люди настаивают на том, что он все еще работает. Но лучше избегать его использования.
Заблокированные через robots.txt страницы, не могут быть проиндексированы, даже если кто-то на них ссылается.
Чтобы быть уверенным, что страница без контента случайно не появится в результатах поиска, Джон Мюллер рекомендует размещать на этих веб-страницах noindex даже после того, как вы заблокировали их в robots.txt.
Использование файла robots.txt улучшает не только SEO, но и пользовательский опыт. Для этого реализуйте приведенные выше практики.
Данная публикация представляет собой перевод статьи «The Complete Guide to Robots.txt and Noindex Meta Tag» , подготовленной дружной командой проекта Интернет-технологии.ру
www.internet-technologies.ru