Как расширить семантическое ядро — SEO на vc.ru
О сборе семантического ядра, кластеризации, структуризации написано уже очень много и подробно. Разжёвывать ещё раз эту тему мы не будем. Мы поговорим о том, что делать, если семантическое ядро уже собрано и кластеризовано и мы решили его актуализировать или добавить смежную тематику. Как дособрать и с каких источников тоже написано много прекрасных статей, в том числе здесь на vc. Но как конкретно распределить дособранные ключевые фразы по имеющимся группам, ответа нигде нет. Постараемся в этой статье заполнить этот пробел.
{«id»:160018,»url»:»https:\/\/vc.ru\/seo\/160018-kak-rasshirit-semanticheskoe-yadro»,»title»:»\u041a\u0430\u043a \u0440\u0430\u0441\u0448\u0438\u0440\u0438\u0442\u044c \u0441\u0435\u043c\u0430\u043d\u0442\u0438\u0447\u0435\u0441\u043a\u043e\u0435 \u044f\u0434\u0440\u043e»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/seo\/160018-kak-rasshirit-semanticheskoe-yadro»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/seo\/160018-kak-rasshirit-semanticheskoe-yadro&title=\u041a\u0430\u043a \u0440\u0430\u0441\u0448\u0438\u0440\u0438\u0442\u044c \u0441\u0435\u043c\u0430\u043d\u0442\u0438\u0447\u0435\u0441\u043a\u043e\u0435 \u044f\u0434\u0440\u043e»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/seo\/160018-kak-rasshirit-semanticheskoe-yadro&text=\u041a\u0430\u043a \u0440\u0430\u0441\u0448\u0438\u0440\u0438\u0442\u044c \u0441\u0435\u043c\u0430\u043d\u0442\u0438\u0447\u0435\u0441\u043a\u043e\u0435 \u044f\u0434\u0440\u043e»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.
2344 просмотров
На первый взгляд всё просто – пересобрали wordstat и другие источники и всё. Но при более глубоком рассмотрении оказывается, что уже составлена структура с группами. Группы ранее были кластеризованы и вручную доработаны. А на часть групп уже написаны тексты и опубликованы страницы. Рассмотрим несколько способов, как это сделать максимально быстро и продуктивно.
Расширение семантики отдельно по каждой группе
Рассмотрим ситуацию, когда у Вас уже готова структура с рассортированными фразами в Key Collector
Мы можем принять каждую фразу в группе за маркер и собрать по фразы из всех возможных источников — расширить группу, собирая «хвосты».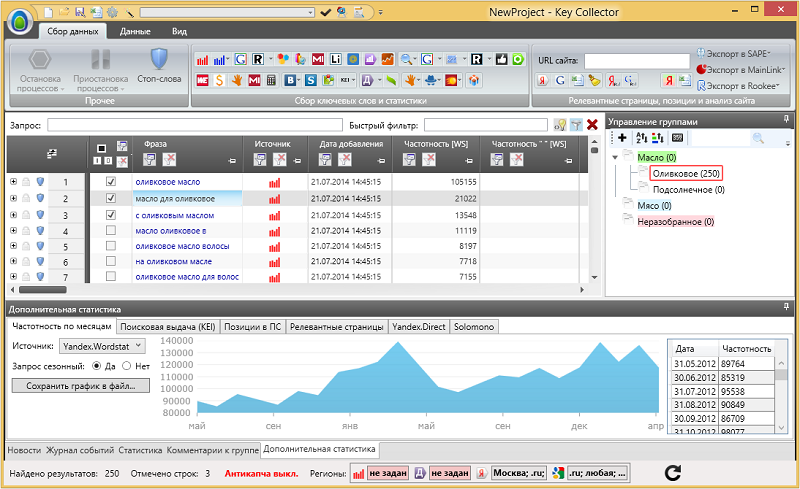
- Новая фраза может быть с другим интентом и её логично было бы переместить в другую группу. На большом проекте проверить каждую фразу очень сложно.
- Второй недостаток – мы не расширим группу фразами с тем же интентом, у которых маркеры являются синонимами нашим фразам. Например, если наша группа содержит все фразы с маркером «водонагреватель ariston», то фразы с маркером «бойлер аристон» не попадут туда.
- Мы можем расширить, собрать хвосты. А найти фразы с меньшим количеством слов не получится. Например, если у нас в группе самая короткая фраза «циклонный фильтр-насадка для пылесоса», то фраза «циклонный фильтр для пылесоса» в группу не попадёт.
Расширение семантики целиком с ручным распределением фраз по группам
Этот способ позволяет дособрать ключевые слова гораздо более широко. Берём все возможные маркеры, которые использовали при первоначальном сборе, добавляем новые, собираем ключевые фразы со всех возможных источников, чистим и распределяем вручную по имеющимся группам. В результате получаем максимально расширенную семантику, однако данный метод тоже имеет свои недостатки:
- Колоссальные трудозатраты. Могут уйти недели времени на разгруппировку среднего по размерам ядра по имеющимся группам.
- На средних и больших ядрах почти невозможно уйти от ошибок, если вы не супер-специалист в той тематике, ядро на которую расширяете.

Автоматический метод расширения семантического ядра
Готовая структура семантического ядра в KeyAssort
Но и не беда, если структура семантического ядра сформирована в Кей Коллекторе, тогда мы просто импортируем готовый проект *.kc4 с сохранением структуры в правую часть KeyAssort:
Импорт проекта Key Collector в KeyAssort
Обратите внимание! В статье рассматриваются Key Collector 4 и KeyAssort 2. В более ранних версиях программ каких-то функций может не быть.
Далее вновь собранное ядро в виде списка фраз с параметрами мы импортируем в левую часть KeyAssort и отмечаем все фразы слева цветом, чтобы потом отыскать их справа и проверить, насколько точно мы выбрали режим группировки.
Подготовка к расширению семантики в KeyAssort
Собираем данные выдачи, в том числе пересобираем у фраз справа, чтобы кластеризация прошла по актуальным топам. Мы использовали сервис XMLRiver, где быстро и просто собирается актуальная «живая» выдача.
После этого в настройках программы отмечаем функцию «Расширение семантики». При включенной функции фразы слева будут объединены с группами справа, ориентируясь на выдачу, а фразы, которые не нашли связей с группами справа, будут кластеризованы в обычном режиме в левой части программы.
Функция «Расширение семантики» в KeyAssort
Процесс занимает считанные минуты на среднем по размеру ядре. После завершения процесса, отфильтровываем группы, которые были расширены новыми фразами и проверяем качество.
Выбор расширенных групп с помощью фильтра по цвету
В случае неудовлетворительного результата мы можем вернуть последнее действие и повторить с другим режимом группировки.
Далее переносим новые группы, полученные слева, в соответствующие категории справа. Их тоже можно будет предварительно отметить другим цветом и впоследствии отфильтровать для дальнейшего создания новых страниц на сайте.
Их тоже можно будет предварительно отметить другим цветом и впоследствии отфильтровать для дальнейшего создания новых страниц на сайте.
Итак, с данным методом пересобирать семантику можно хоть каждый месяц. Ни один сезонный запрос не будет упущен.
Если эта статья была полезна или интересна, сохраняйте ее и делитесь с друзьями и коллегами. Также оставляйте комментарии, нам очень важен фидбек!
Делаем правильно кластеризацию семантического ядра
Важным этапом продвижения сайта является сбор семантического ядра и кластеризация ключевых поисковых запросов. Ошибки при группировке будут стоить драгоценного времени, денег и других проблем. В этой статье я хочу рассказать главные принципы и правила группировки, а также показать примеры сервисов и программ.
Кластеризация ключевых фраз
Я выделяю 2 основных момента при группировке:
- запросы должны подходить друг к другу по логическому смыслу
- запросы должны показывать одинаковую выдачу в Яндексе
С логическим смыслом все понятно — нельзя поместить на одну страницу ключи “купить телефон” и “покраска авто в Омске”. Так или иначе запросы должны подходить друг к другу по смыслу. Если у нас страница про отделка потолков в квартире, то все запросы должны быть про отделку потолков.
Вот с проверкой по выдаче все не так однозначно. В целом суть следующая — вводим запросы в Яндекс в режиме “инкогнито”, выбираем регион продвижения и смотрим, насколько пересекается выдача.
Допустим, есть 2 запроса “отделка потолков в квартире” и “отделка потолков в ванной”, нужно понять, подойдут ли эти ключи на одну страницу или нет.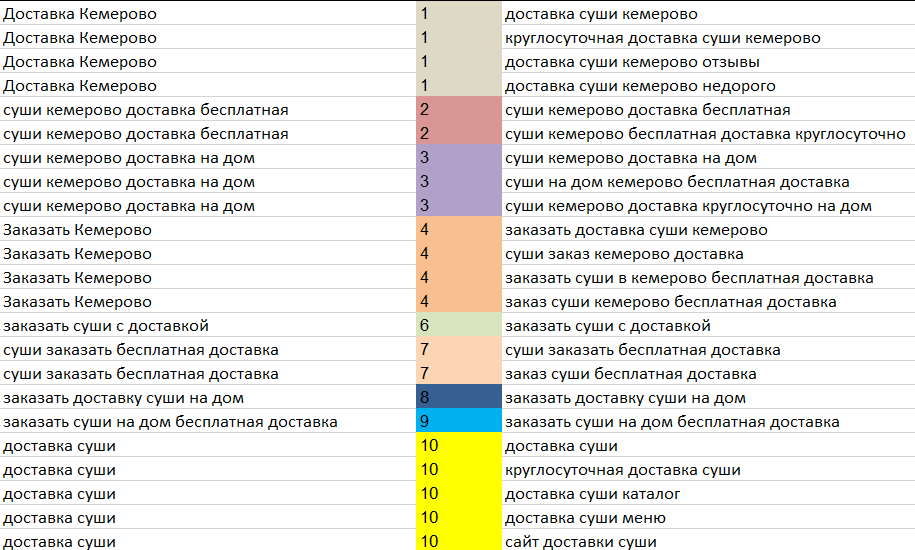 Открываем 2 окна в Яндексе и вводим эти запросы.
Открываем 2 окна в Яндексе и вводим эти запросы.
Сразу видно, что в первом случае четко говорится про отделку потолков в квартире, а во втором — в ванной. Значит, запросы ведут на разные страницы и объединять их нельзя.
А вот еще один пример: фразы “купить батареи отопления” и “купить радиаторы отопления”. Вроде кажется, что запросы разные, но посмотрим выдачу.
Как видим, выдача одинаковая — и там и там присутствуют и батареи и радиаторы. Поэтому эти 2 запроса можно смело помещать на одну страницу.
Программы и сервисы для кластеризации ключевых слов
Кластеризация семантического ядра в Excel делается достаточно просто — загоняете все запросы в программу и начинаете группировать руками. Сам принцип группировки используете, как я написал выше. То есть сначала группируем по смыслу, потом проверяем выдачу Яндекса.
Но, кстати, бывает так, что выдача “мутная” по двум или более запросам, не понятно, куда их поместить вместе или врозь. Это означает, что конкуренция здесь маленькая и выдача четко не сформирована, значит, не будет ошибкой или поместить запросы вместе или на разные страницы, как вам будет удобнее.
Вот пример кластеризации семантического ядра в программе Excel.
Этот способ я сам часто использую, если тематика не сложная и ни много ключевых слов, 100-200 ключей вполне подойдет.
Посмотрите видео, как кластеризовать ядро в программе Эксель.
Можно еще как альтернативу excel использовать бесплатный онлайн сервис ручной кластеризации kg.ppc-panel.ru.
Автоматическая кластеризация
Если семантическое ядро очень большое, то я пользуюсь сервисом автоматической кластеризации поисковых запросов promopult.ru. Это ОЧЕНЬ дешевый сервис по сравнению с аналогами.
Единственным его минусом является не совсем точная группировка, так как все равно нужно в итоге пересматривать кластеризацию.
Хотя, я думаю, что нет НИ ОДНОГО сервиса, который бы делал 100% правильную группировку. Даже конторы, которые занимаются только сбором и кластеризацией семантики, все равно проверяют и правят вручную конечный результат.
Вот краткий обзор по настройке проекта.
Сервис посчитает, сколько стоит кластеризация ядра и предложит запустить проект. Это вариант платной кластеризации, которым я пользуюсь, он меня вполне устраивает.
А вот подробное видео, как пользоваться инструментом:
Кластеризация в Just-magic
Тоже хороший способ кластеризации, который я иногда использую. Он более точный, чем сервис PromoPult, но более дорогой. Вот посмотрите видео, как делать кластеризацию в этом сервисе.
Кластеризация запросов в key collector
Этот способ тоже достаточно широко используется, но как и везде, дорабатывать все равно нужно вручную.
Загружаете семантическое ядро в программу, выбираете регион продвижения.
Далее по шагам:
- Выбираете вкладку “Данные”
- Раздел “Анализ групп”
- Группировка по поисковой выдаче
- Сила по SERP — 6
- Нажимаете “Вычислить группировку”
- И экспортируете готовый файл в Excel
Получается вот такая штука на выходе.
Но я повторюсь, что при кластеризации запросов в кей коллектор, все равно результат нужно чистить вручную, так как НИ ОДИН сервис или программа не делает 100% правильной группировки ключевых слов.
Заключение
Итак, еще раз общий вывод, как можно делать кластеризацию:
- Вручную в программе Excel
- Использовать автоматические сервисы (я пользуюсь promopult и just-magic)
- В программе Key Collector
P. S. Если вам понравилась статья или она была полезной для вас, то поделитесь ею с друзьями в соц. сетях, а также пишите ваши вопросы или замечания в комментариях.
S. Если вам понравилась статья или она была полезной для вас, то поделитесь ею с друзьями в соц. сетях, а также пишите ваши вопросы или замечания в комментариях.
Сергей Моховиков
SEO специалист
Здравствуйте! Я специалист по продвижению сайтов в поисковых системах Яндекс и Google. Веду свой блог и канал на YouTube, где рассказываю самые эффективные технологии раскрутки сайтов, которые применяю сам в своей работе.
Вы можете заказать у меня следующие услуги:
Загрузка…Особенности различных методов кластеризации поисковых запросов
Кластеризация – это процесс группировки и распределения поисковых запросов по посадочным страницам. Также часто называется «разбивкой». Позволяет определить, какие запросы можно продвигать на одной странице, а под какие потребуется создание отдельной, оптимизированной посадочной страницы, более точно удовлетворяющей интенту (поисковой потребности) пользователя.
Кластеризация является важнейшим этапом построения эффективной для SEO-продвижения структуры сайта, значительно влияет на успешность привлечения поискового трафика по всем направлениям, соответствующим тематике сайта.
Упрощенно, под проработкой структуры проекта можно понимать:
- сбор и чистку семантического ярда;
- распределение запросов по посадочным страницам;
- корректировку структуры сайта: разделение/объединение/создание новых посадочных страниц под неохваченный спрос;
- ручную оптимизацию страниц с использованием информации о запросах, соответствующих рассматриваемым страницам.
Сам процесс может быть в той или иной степени автоматизирован, но в большинстве случаев требует ручного труда оптимизатора.
В статье намеренно не рассматриваются подробно сами сервисы и программы для группировки запросов, а только приводятся примеры использования тех или иных сервисов для различных видов разбивки.
Виды кластеризации
По семантической схожести (по словоформе)
Вид распределения запросов по группам, при котором используется схожесть слов в группах.
Популярные инструменты: Excel (при помощи фильтров), надстройка SEO Excel, Key Collector в режиме «Анализ групп».
Плюсы: выполняется быстро, высокая степень автоматизации.
Минусы: в автоматизированном виде – не учитывает синонимы, а также степень коммерциализации запросов.
Примеры
При использовании группировки по семантической близости синонимичные запросы, которые возможно продвигать на одной странице, попадут в разные семантические группы.
| Группа | Запросы |
|---|---|
| ушм |
Ушм Купить ушм Ушм цены |
| болгарка |
Болгарка Купить болгарку Болгарки цены |
Также при использовании данного метода разбивки запросы информационного и коммерческого характера могут попадать в одну группу, а продвигаться – лишь на отдельных страницах.
| Группа | Запросы |
|---|---|
| Кондиционеры |
Купить кондиционер Цены на кондиционеры Кондиционер для спальни Лучшие кондиционеры 2020 |
Пример гиперболизирован, однако с учетом того, что помимо запросов с явным (коммерческим или информационным) интентом, существует масса запросов с неявным интентом, корректная разбивка данным способом существенно осложняется.
По ТОПу
Наиболее популярный способ распределения ключевых слов. Работает при помощи выгрузки списков URL страниц из топа и поиска количества совпадений – общих URL для разных запросов.
Лишен проблем, описанных в примерах предыдущего способа. На тех же запросах с силой группировки 2 и указанием региона «Москва» получаются следующие кластеры:
Кластеризация данным методом, зачастую подразумевает:
- Указание региона для парсинга ТОПа.
- Указание силы группировки: минимального количества общих URL для разных запросов, необходимого для объединения запросов в одну группу.
- Опционально: выбор метода группировки.
Методы
Soft кластеризация подразумевает группировку запросов в случае, если в группе каждый из запросов связан как минимум с одним другим запросом группы.
Medium кластеризация означает, что для создания группы каждый из запросов должен быть связан с одним, главным («маркерным») запросом группы.
Hard кластеризация означает наличие связи между всеми запросами группы.
Нужно понимать, что «наличие связи» выявляется с учетом силы группировки. То есть при силе группировки 2 и методе Hard у всех запросов, попавших в одну группу, будут выявляться как минимум два общих URL в каждом ТОПе.
Схематично методы группировки можно изобразить следующим образом.
Популярные инструменты: инструмент Just Magic, Rush Analitycs, Coolakov, Key Collector с использованием выгрузки ТОПов поисковых систем.
Плюсы: выполняется быстро, высокая степень автоматизации.
Минусы: играя с настройками по типу и силе группировки, мы рискуем.
- либо создать лишнюю страницу (более слабую по ассортименту/контенту, а также по скорости накопления данных о ПФ), разбив подробнее,
- либо не попасть в интент точного запроса пользователя, заведомо «вывалив» на него не точно соответствующий ассортимент/информацию, а более широкий спектр товаров/услуг/информации.
По интенту (по смыслу)
Глубоко погрузившись в тематику и детально анализируя потребности пользователей на выдаче, мы приходим к идеальному, казалось бы, способу кластеризации запросов – по их смыслу.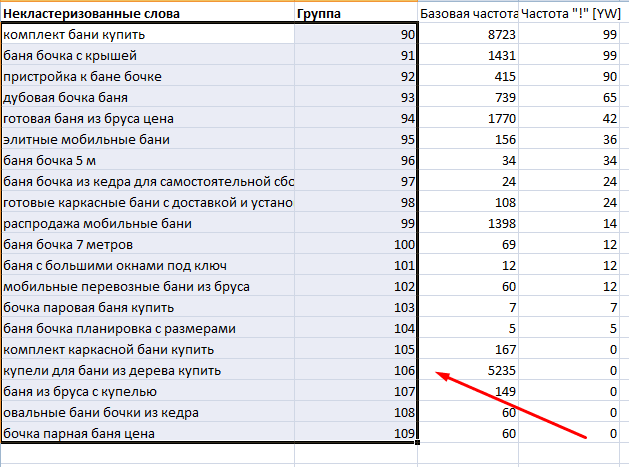
Плюсы: при глубоком погружении в тематику – безошибочное соответствие потребностям пользователя.
Минусы: настолько медленно и трудозатратно, что можно рассматривать полную кластеризацию по интенту лишь для микросайтов с малым объемом семантического ядра.
По ТОПу с объединением по интенту
Изначально воспользовавшись методом автоматической кластеризации по ТОПу (выбрав метод и силу группировки в соответствии с конкуренцией в тематике и особенностями проекта), автоматически созданные группы затем объединяются вручную в более крупные кластеры запросов по общему смыслу.
Руководствуясь потребностями пользователя на выдаче, можно для отдельных групп запросов снизить силу группировки, формируя более полные кластеры и создавая под них общие, более «сильные» по оптимизации и полные по контенту страницы.
Плюсы: автоматизированный первичный этап (по ТОПу), детальная группировка по интенту.
Минусы: отсутствуют.
Полноту контента следует воспринимать не только для информационных ресурсов в контексте полноты статьи, но и для коммерческих ресурсов: общие, полные листинги, либо страницы услуг, охватывающие максимально количество связанных пользовательских интентов.
По ТОПу с разбивкой по интенту. «Сверхкластеризация»
Здесь мы поступаем аналогично предыдущему методу. Изначально мы используем автоматическую кластеризацию по ТОПу с использованием любых сервисов и базовых настроек, которые соответствуют состоянию проекта и конкуренции. Затем сформированные группы дополнительно разбиваем вручную на отдельные, более соответствующие точному спросу кластеры с созданием наиболее оптимизированных, детальных посадочных страниц.
Плюсы: автоматизированный первичный этап (по ТОПу), детальная группировка по интенту.
Минусы: отсутствуют.
Применяя «Сверхкластеризацию», мы получаем идеально соответствующие спросу кластеры, несмотря на то, что в текущем ТОПе таковых не представлено.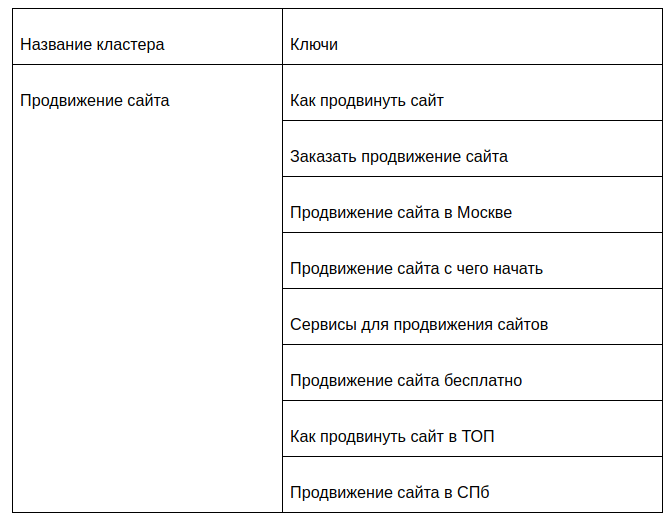 Этот метод позволяет молодым сайтам со слабой оптимизацией конкурировать даже с лидерами тематики за счет более точного ответа на запрос пользователя.
Этот метод позволяет молодым сайтам со слабой оптимизацией конкурировать даже с лидерами тематики за счет более точного ответа на запрос пользователя.
При этом для оценки необходимости дополнительной разбивки можно ориентироваться на соседние, схожие по смыслу кластеры, и по аналогии «доразбить» то, что объединено по ТОПу.
Лучший метод кластеризации
С точки зрения нашего многолетнего опыта наилучшими вариантами являются:
- кластеризация по ТОПу с последующим объединением по интенту;
- кластеризация по ТОПу с последующей разбивкой по интенту.
Автоматизация первого этапа (кластеризация по ТОПу, с использованием одного из сервисов или программных решений) позволяет ускорить процесс на больших массивах данных, выполняя роль первичной группировки. Дальнейший ручной этап помогает сформировать наиболее конкурентоспособные группы и создать соответствующую структуру сайта.
В большинстве случаев эти два подхода – объединение и разбивка – по сути не делятся на отдельные операции. На ручном этапе SEO-специалист принимает решение о необходимости объединения или разнесения запросов по страницам с учетом особенностей конкретного проекта и конкуренции в тематике.
Ссылка на публикацию
что это такое, зачем ее делать
Яндекс.Директ, Яндекс Маркет, Google Adwords, Google Merchant, Ремаркетинг
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Кластеризация семантического ядра — это разделение множества разнородных запросов на группы по смыслу.
 youtube.com/embed/_EpuxLQpBX4″ frameborder=»0″ allowfullscreen=»allowfullscreen»/>
youtube.com/embed/_EpuxLQpBX4″ frameborder=»0″ allowfullscreen=»allowfullscreen»/>Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Чтобы лучше понять, что такое кластеризация семантического ядра, можно представить подготовку белья перед стиркой. Чтобы стирка прошла быстро и продуктивно, вещи разделяют на несколько групп по цветам. А опытные хозяйки проводят сортировку белья с более подробной детализацией. В каждой цветовой группе найдутся вещи, которые нуждаются в особом температурном режиме. Их выделяют в отдельные группы. Нечто подобное происходит и при кластеризации ключевых слов. Это процесс, который превращает сотни и тысячи пользовательских запросов в упорядоченную структуру.
В идеале кластеризация ключей должна осуществляться на базе перечня свойств объектов, которые характеризуют данные ключи, а также контекста их применения. Однако на данный момент не существует открытых баз, хранящих такие сведения. По этой причине группировка ключевых слов проводится на основе поисковой выдачи.
Этапы кластеризации:
- Получение выборки объектов для группировки.
- Задание перечня критериев оценки объектов в выборке.
- Определение степени сходства между анализируемыми объектами.
- Проведение кластерного анализа для формирования групп объектов.
- Представление результатов кластеризации.
Зачем нужно проводить кластеризацию СЯ
С помощью грамотных инструментов можно в минимальные сроки и группировать большие семантические ядра. Если в прошлом на создание ядра уходили целые месяцы, то сейчас эта работа занимает всего пару часов. Одним из преимуществ кластеризации является распределение поисковых запросов по страницам таким образом, чтобы их продвижение происходило одновременно.
Кластеризация семантического ядра позволяет получить:
- Существенную экономию времени за счет сокращения рутинной работы.
- Информационный гид по темам, популярным среди пользователей.
- План продвижения.
- Представление структуры разрабатываемого сайта.
- Объективную оценку популярности продукцию в указанной нише.
- Перечень ключей для оптимизации ресурса.
- Осуществление корректной переадресации веб-страниц.
- Создание большого хвоста поисковых запросов.

Что происходит, если не проводить кластеризацию
Если пренебречь разбиением семантического ядра сайта на кластеры, то его владелец не получит полной картины продвижения своего ресурса. Подобный результат можно получить и вследствие неправильного распределения поисковых фраз.
Вот перечень проблем, которые возникнут после некорректной группировки ключей:
- Теряется позиция в ТОПе поисковой выдачи;
- Происходит каннибализация и, как следствие, в индексах поисковиков возникает множество дублей;
- Происходит дезориентация поведенческих факторов, мешающая продвижению ресурса;
- Расходуются большие средства на создание «лишнего» контента.
Устранение и предупреждение подобных проблем — это главный ответ на вопрос: «зачем делать кластеризацию ся».
Алгоритмы кластеризации
SEO-специалисты выделяют два типа классификации алгоритмов кластеризации:
Иерархические и плоские
Иерархические алгоритмы (еще их называют алгоритмами-таксонами) формируют не одно разделение множества на пересекающиеся кластеры, а многоуровневую структуру вложенных разбиений. В результате формируется дерево кластеров. В качестве его корня выступает общая выборка, а в качестве листьев — самые мелкие группы.
Плоские алгоритмы формируют одно разделение объектов на группы.
Четкие и нечеткие
Четкие алгоритмы связывают каждый элемент выборки с номером кластера. Нечеткие алгоритмы связывают каждый элемент выборки с комбинацией вещественных значений, отражающих меру принадлежности элемента к кластерам. Таким образом каждый элемент выборки относится к каждой группе с определенной долей вероятности.
Как провести кластеризацию запросов вручную
Для ручной кластеризации семантического ядра сайта достаточно самостоятельно проанализировать ключевики и разделить их на группы. Эту работу можно облегчить с помощью инструментов Excel, LibreOffice, OpenOffice. Эти приложения позволяют работать с таблицами данных, выполнять сортировку и фильтрование по определенным параметрам.
Представленные инструменты имеют ряд достоинств:
- Универсальность — производят группировку с учетом множества разных критериев;
- Высокая точность обработки;
- LibreOffice, OpenOffice — бесплатные.
В числе их недостатков:
- Необходимость периодических бекапов;
- Низкая скорость обработки;
- Лицензионный Excel — платный.
Ручная кластеризация семантического ядра сайта более сложная и длительная по сравнению с автоматизированной. Зато можно лично проконтролировать весь процесс. Если этому уделить должное внимание, то результат качественно превзойдет автоматическую кластеризацию ся.
Автоматизированная кластеризация ся
Разделение семантического ядра на группы происходит автоматически.
Вебмастеру достаточно оценить полученные результаты. Единственным минусом такого подхода является периодически возникающее несоответствие машинной логики представлениям пользователя.
Обойти эту проблему может полуавтоматический способ группировки поисковых запросов. Для этого специалисту необходимо самостоятельно подобрать группы по полученным запросам. А автоматизированная система сама разделит запросы по указанным пользователем группам. Такой подход позволяет существенно минимизировать ошибки машинного алгоритма.
Как провести кластеризацию запросов с помощью Key Collector
Одним из лучших приложений для проведения кластеризации считается Key Collector. Программа позволяет быстро получить ключи, на основании которых будет сформировано семантическое ядро. Система может оценить конкурентность, эффективность и стоимость ключей, а также проанализировать ресурс на соответствие его контента полученному ядру.
Схема работы Key Collector достаточно проста. Чтобы разделить все полученные запросы, необходимо воспользоваться опцией «Анализ групп». При этом системе нужно указать режим кластеризации («по отдельным словам», «по составу фраз», «по поисковой выдаче», «по составу фраз и поисковой выдаче»). Режим «по отдельным словам» группирует поисковые запросы, у которых присутствует совпадение даже по одному слову. Режим «по составу фраз» ориентируется на строение ключевых фраз. Это наиболее подходящий способ разбиения большого количества запросов. Режим «по поисковой выдаче» группирует ключевые фразы по количеству совпавших ссылок в результатах поиска. Режим «по составу фраз и поисковой выдаче» сочетает в себе два предыдущих критерия.
Далее системой производится группировка запросов.
Пример кластеризации семантического ядра в системе Key Collector:
Чтобы оценить группы, которые получились, их можно выгрузить в табличный редактор (например в Excel).
Кластеризация запросов: 20 сервисов + как сделать
Кластеризация семантического ядра – это разделение всех собранных запросов на группы для последующего определения целевых посадочных страниц и их продвижения.
Это крайне важный этап работы с семантикой, который может как улучшить, так и ухудшить ранжирование сайта по запросам в поисковиках. А все работы по сайту зависят от того, как будут распределены ключевые фразы по сайту.
Лучшие сервисы кластеризации
Если Вы уже все про кластеризацию знаете, то вот Вам сразу сервисы. Мы разделили их на категории – сервисы с одной функцией кластеризации и площадки с комплексом SEO инструментов. Практически в каждом есть бесплатный период, поэтому Вы сможете протестировать сервис и выбрать наиболее удобный для себя.
Кроме сервисов на рынке есть программы с различными функциями по работе с семантическим ядром – Key-collector и KeyAssort. Чтобы пользоваться, Вы платите уже не за запрос, либо месяц, а покупаете лицензию.
– Только кластеризация
| Сервис | Бесплатный доступ | Стоимость | Метод группировки | Поисковая система | Можно задавать регионы | Сила группировки |
| Сoolakov | Нет | 0,2 руб/запрос | Не регулируется | – Яндекс. | Да | от 2 до 10 |
| Stoolz | 1 500 запросов | 0,1 руб/запрос | – Hard. | – Яндекс. | Да | от 2 до 10 |
– С другими SEO инструментами
| Сервис | Бесплатный доступ | Стоимость | Метод группировки | Поисковая система | Можно задавать регионы | Сила группировки |
| SERanking | 14 дней | от 0,12 руб/слово | – Soft; – Hard. | – Яндекс; – Google. | Да | от 1 до 9 |
| PromoPult | Есть | Рассчитывается индивидуально | – Hard. | – Яндекс; – Google. | Да | от 1 до 10 |
| Serpstat | Есть | от 5 275 руб/мес | – Soft; – Hard. | – Яндекс; – Google. | Да | – Weak; – Medium; – Strong. |
| Rush-analytics | Есть | от 500 руб/мес | – Soft; – Hard. | – Яндекс; – Google. | Да | от 3 до 8 |
| Megaindex | Бесплатный тариф | от 1 490 руб/мес | Не регулируется | – Яндекс; – Google. | Да | от 3 до 10 |
| Keys.so | Нет | от 1 500 руб/мес | Не регулируется | – Яндекс; – Google. | Нет | от 10 до 100% |
| Topvisor | 200 запросов | от 0,09 руб/слово | – Soft; – Hard; – Moderate. | – Яндекс; – Google. | Да | от 1 до 9 |
| Just-magic | Бесплатный тариф | 1 000 руб/мес | – Hard.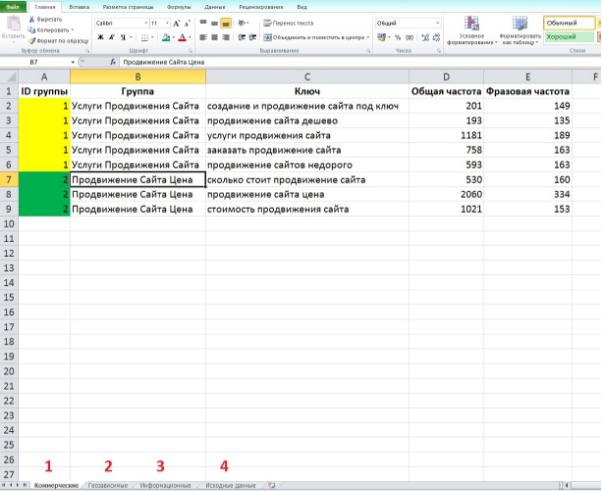 | – Яндекс; – Google. | Да | Не регулируется |
| Seoquick | Нет | Рассчитывается индивидуально | Не регулируется | Не регулируется | Нет | Не регулируется |
| Semparser | 50 запросов | от 0,18 руб/запрос | Не регулируется | – Яндекс; – Google. | Да | от 1 до 10 |
| Engine.seointellect | Нет | 0,2 руб/запрос | – Soft; – Hard; – Balance. | – Яндекс. | Да | Не регулируется |
| Semantist | Нет | 2 000 руб/10 000 запросов | Не регулируется | – Яндекс. | Да | от 1 до 10 |
| Arsenkin | Бесплатный тариф | от 549 руб/мес | – Soft; – Hard. | – Яндекс. | Да | от 2 до 10 |
| Majento | Нет | Бесплатно | – Soft; – Hard. | – Яндекс. | Нет | Не регулируется |
| Be1 | Нет | Бесплатно | Не регулируется | – Яндекс. | Да | Не регулируется |
как сделать кластеризацию в сервисе
Все перечисленные сервисы в принципе работают одинаково, просто в них разные возможности – где-то больше настроек, где-то меньше. Мы рассмотрим кластеризацию запросов семантического ядра на примере сервиса SERanking.
Шаг 1. Настройка
После регистрации найдите вкладку “Кластеризация” в разделе “Инструменты”. В окне настройки первое, что нужно сделать – это ввести название отчета. Далее указать поисковую систему, по которой будут анализироваться ТОПы. Это может быть Google или Яндекс.
Онлайн сервис кластеризации позволяет выбрать регион, город или индекс и язык интерфейса Google выбранной страны. Ниже устанавливается уровень точности. Он задает, сколько нужно общих URL в выдаче для того, чтобы объединить ключи в одну группу.
То есть чем больше степень группировки, тем большее количество групп с меньшим количеством запросов будет создано в результате кластеризации.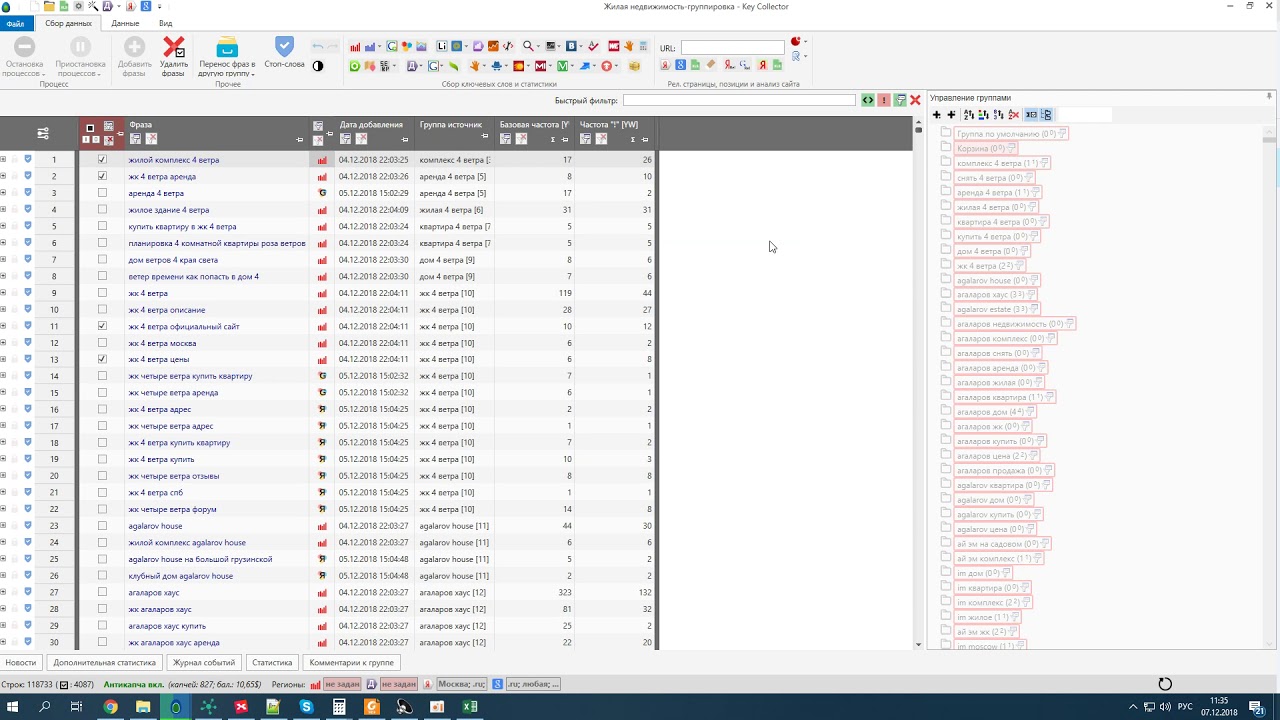 Оптимально 2-3.
Оптимально 2-3.
Шаг 2. Выбор метода
Далее необходимо выбрать метод кластеризации, их в данном сервисе два. Если Вы не знаете о них, то ниже в теории я расписала их и еще один метод, который можно встретить в других сервисах.
По методу Soft сервис находит совпадения в выдаче каждого запроса и самого частотного, при этом в пределах одной группы может не быть общих URL.
По методу Hard – ключи будут сравниваться между собой и объединяться в группу, только если будут найдены общие URL у всех в ТОПе. За дополнительную плату (0.05 руб за ключевое слово) можно провести проверку частотности.
Методы кластеризацииШаг 3. Добавление запросов
Далее следует добавить в систему ключевые фразы, которые необходимо кластеризовать. Это можно сделать вручную или импортировать из файла. Но оба способа одновременно использовать нельзя.
Для ручного ввода предусмотрена специальная область, каждую фразу нужно вносить с новой строки. Если будете загружать из файла, оставьте его пустым – тогда внизу появится поле для импорта.
Добавление запросовШаг 4. Получение результатов
Они отобразятся в виде таблицы. В ней указано общее количество добавленных запросов, число групп, которые получились и точность кластеризации.
РезультатыГалочкой можно отметить отдельные кнопки для выгрузки результатов. Данные экспортируются в форматах .xls и .csv с помощью соответствующей кнопки.
Выборка для выгрузкиЕсли нужны подробные результаты группировки, разверните любую группу, нажав на маленьких треугольник рядом с ней.
Подробности группыПри клике на название группы, можно просмотреть все запросы, которые попали в одну группу, частотности, если собирались и количество совпадений URL и ТОП-10 сайтов по конкретному запросу. А также выделенные слова из сниппета по запросу.
Топ сайтовВажно. Выжимайте из бизнеса максимум с помощью нашей методички формата “фишечная стратегия”. В ней самый сок из сотен тренингов и книг по маркетингу и продажам. А также концентрат успешных действий. По ссылке скидка 50% в течение 4 часов, кликайте -> “Реальный маркетинг: 165 фишек + 33 основы“
А также концентрат успешных действий. По ссылке скидка 50% в течение 4 часов, кликайте -> “Реальный маркетинг: 165 фишек + 33 основы“
как сделать кластеризацию вручную
Способ подойдет, если ключевых запросов у Вас не много. Удобнее всего делать кластеризацию вручную в MS Excel. Для примера – создадим кластеры для интернет-магазина винтажной одежды.
Шаг 1. Создайте таблицу в Excel и загрузите в неё ключевые запросы и их частотность.
Таблица с ключевыми запросамиВыделите для себя основные запросы с максимальной частотой.
Запросы с максимальной частотойШаг 2. В колонке с ключевыми запросами с помощью фильтра или сами найдите однокоренные слова, слова-синонимы и слова-интенты.
Фильтр запросовПолучившийся списокШаг 3. Из получившихся групп запросов сформируйте кластеры.
Сформированные кластерыподробнее о кластеризации
Если не уверены в своих знаниях по кластеризации сематического ядра сайта или хотите их освежить, то читайте до конца. И первая мысль – чтобы правильно сгруппировать запросы, важно разобраться с понятием поискового интента.
Интент – та потребность, с которой пользователь пришел на сайт: что именно ищет человек, вбивая данный запрос в поисковик.
Один запрос может одновременно иметь несколько интентов, то есть пользователи могут иметь в виду абсолютно разные вещи, набирая одинаковый запрос в поиск. Например, “такси” – это непосредственно служба такси и фильм.
При правильной кластеризации все запросы, посаженные на одну страницу для продвижения, должны отвечать одному и тому же интенту пользователя.
1. Виды группировки
Здесь поговорим о том, как можно группировать запросы, какой вариант и для каких тематик подойдет, а также расскажу о недостатках каждого из видов.
– Логическое разбиение
Просмотр запросов и предположение, что искал пользователь. Подходит для низко конкурентных тематик или если это совершенно новая тема.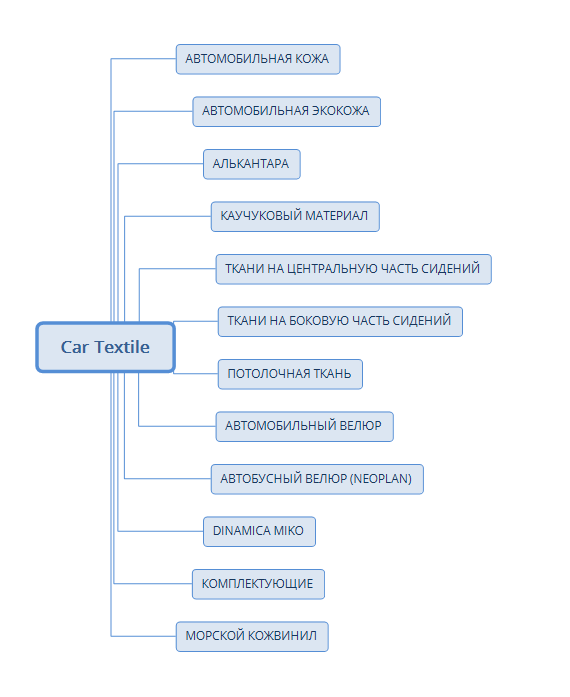 Соответственно, состав выдачи будет постоянно меняться и далеко не факт, что результаты в ней будут релевантны.
Соответственно, состав выдачи будет постоянно меняться и далеко не факт, что результаты в ней будут релевантны.
Или в случае, если в семантическом ядре много низкочастотных запросов. Конкуренция низкая, у поисковиков мало данных о поведении пользователей – и качество выдачи низкое.
В остальных случаях группировать запросы с точки зрения логики – не рационально, так как слишком высока вероятность ошибки и много времени понадобится на работу, особенно если ядро запросов большое.
– Группировка по семантической схожести
Запросы объединяются в одну группу, когда у них есть пересечение общих фраз. Например: “телефон купить”, “телефон обзор”, “телефон бу”. Телефон – общее слово, поэтому ключевые слова объединяются в одну группу.
Этот вид группировки часто приводит к ошибкам, так как на одну страницу могут сесть одновременно коммерческие и информационные запросы, чего делать не стоит – выдача по ним разная.
Также в этом случае не учитывается интент пользователя. Если страница не будет ему соответствовать, и пользователь увидит не ту информацию, что хотел найти – он закроет сайт и вернется в выдачу. Такие действия снижают конверсию и поведенческие факторы.
– Группировка по ТОПам
Более совершенный вид, так как разделение запросов на группы происходит через анализ ТОП-10 поисковой системы, через оценку схожести поисковой выдачи.
Если в выдаче для двух разных запросов находятся общие документы, можно предположить, что их можно объединить. Чем больше пересечений, тем выше вероятность, что ключи можно продвинуть на одной странице. Если общих URL-ов нет, то скорее всего запросы нужно сажать на разные страницы.
2. Методы
Выше в инструкции мы уже говорили о методах группировки, но сейчас рассмотрим их подробнее. Различают следующие методы группировки семантики:
1. Soft. Запросы сравниваются с главным ключевым словом (с большей частотностью), но не сопоставляются между собой. Если найдено заданное настройками число одинаковых результатов в выдаче, то запросы попадают в один кластер.
Группы могут получиться слишком обширные, нужно обязательно корректировать результат вручную, чтобы получить данные, с которыми можно работать. Метод больше подходит для информационных проектов и тематик с невысокой конкуренцией, где точность группировки не так важна.
2. Hard. Запросы сравниваются и с главным ключевым словом, и между собой. Из них те, по которым не найдено заданного количества одинаковых URL-ов в поиске, выпадают из группы.
Это более точный метод, используется для сложных и высококонкурентных тематик. Количество совпадений определяется показателем “сила кластеризации”. Им задается минимальное число совпадений в выдаче у фраз, чтобы они объединялись в одну группу.
3. Moderate или Middle. Это компромисс между Soft и Hard. Берется один самый частотный запрос, а все остальные сравниваются с ним по количеству общих URL-ов. В то же время инструмент сравнивает все ключевые слова друг с другом.
Если количество общих урл превышает заданный порог или равно ему, то запрос добавляют в группу. По итогу в кластере все запросы будут попарно связаны друг с другом, но в разных парах URL могут отличаться.
3. Способы
Группировка может делаться вручную и с применением специальных программ.
- Ручная. Занимает много времени, невозможна на крупных проектах, велика вероятность человеческого фактора;
- Сервисы. Позволяют работать с большим объемом данных, но не всегда выдают качественный результат.
Поэтому целесообразно использовать оба способа в комплексе: сначала делите запросы на группы автоматически, потом проверяйте полученные результаты вручную. Прежде чем пользоваться инструментом, разберитесь, по какому методу он работает, поскольку среди них встречаются те, что сравнивают схожесть только по словоформам, а не выдаче, например, Mc-Castle.ru или программа МегаЛемма.
Важно. Если Вы настраиваете контекстную рекламу или только собираетесь это сделать, то обязательно используйте сервис Click. Он поможет сделать правильные настройки и сэкономит бюджет. К тому же в нем есть плюшки, которые помогут увеличить конверсию и привлечь больше клиентов. Кликайте и изучайте сервис -> Click
4. Ошибки
Теперь перейдем к самым часто совершаемым ошибкам при кластеризации запросов, а также расскажу, к чему они могут привести.
- Смешивать коммерческие и информационные запросы;
- Объединили несколько интентов на одной странице;
- Запросы не соответствуют тематике сайта;
- Семантическое ядро без синонимов ключевых слов и фраз;
- Ключевые слова содержат ошибки;
- Маленькое сем. ядро без низкочастотных запросов;
- Слишком много ключей в одном кластере;
- Дубли, нулевые, ошибки в словах, спецсимволы в семантике.
Из-за таких ошибок охват собранной семантики низкий, тип содержания страницы не соответствует поисковому запросу, либо сразу несколько страниц сайта отвечают на запрос пользователя. Соответственно все это приводит к размытию релевантности и ухудшению поведенческих факторов.
НАС УЖЕ БОЛЕЕ 32 000 чел.
ВКЛЮЧАЙТЕСЬ
коротко о главном
Группировка необходима, чтобы наилучшим образом с позиции поисковых систем распределить запросы по посадочным страницам. Это один из важнейших этапов построения семантического ядра, ибо в случае ошибок все дальнейшие работы по оптимизации придется переделывать.
Ни один сервис кластеризации, платный или бесплатный, не гарантирует идеальный результат. Полученные кластеры нужно анализировать, пробовать разные варианты точности кластеризации. Но из всех площадок мы советуем эти:
И запомните, кластеризацию нельзя сделать один раз и навсегда. Выдача со временем меняется, где раньше был коммерческий запрос, через пару месяцев может оказаться информационный. Поэтому периодически пересматривайте семантику, удаляйте запросы, которые больше не актуальны, добавляйте новые и вносите необходимые правки на сайт.
По теме:
Массово проверить частоту запросов: 20 сервисов + как сделать
ТОП-70 СЕО-инструментов (по категориям) + рейтинг от эксперта
Кластеризация запросов семантического ядра.
 Группировка запросов.
Группировка запросов.После подбора всех возможных ключевых запросов нужно определиться с тем, на каких страницах сайта они будут размещены. Для этого ключевые слова и фразы необходимо разбить на группы по определенным признакам. Этот процесс и называется кластеризацией семантического ядра. В некоторых источниках малопонятный новичку термин «кластеризация» заменяется более понятным – «группировка».
Для чего нужна кластеризация поисковых запросов
Давайте разберемся, почему же так важно распределить и собрать поисковые запросы по группам.
Во-первых, с помощью кластеров можно четко разграничить информационные запросы (какие шины лучше для зимы) и коммерческие (купить зимние шины недорого в киеве). Страница, на которой размещены оба этих запроса, не будет продвигаться успешно. Поэтому стоит отказаться от соблазна нафаршировать страницы как можно большим количеством ключевых запросов. Гораздо лучше будет информационные запросы размещать на информационных страницах, а коммерческие – на страницах, которые продают товар.
Во-вторых, правильная разбивка ключевиков важна для последующего написания контента. Грамотно отсортированные ключевые запросы можно поместить в одну статью, получив гораздо лучший результат, чем от написания десяти статей с неразумно расставленными ключами. Для планирования бюджета на продвижение сайта и работу копирайтера это очень важно.
Что вы получите в результате грамотно проведенной кластеризации ключевых запросов
- Четкое понимание того, какая структура будет у сайта, над которым вы работаете
- Темы и контент, которые интересны пользователям
- Вы будете регулярно собирать статистику поисковых систем и знать все о текущем спросе на определенный товар или услугу
- Сможете написать контент-план для создания и выкладки материалов на сайт
- Организовать правильную перелинковку на сайте, чтобы на каждой странице была ссылка на другую страницу сайта.
Группировка поисковых запросов является способом максимально привлечь траффик из всех поисковых систем.
Кластеризацию ключевых запросов делают по смыслу. Существуют информационные запросы и коммерческие. Если информационные служат для того, чтобы получить максимум знаний о товаре или услуге, то коммерческие – это исключительно вопросы о том как купить, где достать, насколько лучше и тому подобнее. Ориентируясь по этим запросам поиска, вы создадите контент, полностью соответствующий целям сайта.
К примеру, возьмем сайт интернет-магазина, у которого есть раздел статей, разделы товаров и новостной блок.
- Для главной страницы сайта нужно отобрать самые высокочастотные и конкурентные ключи. Они и станут основой семантического ядра при продвижении сайта. Для главной страницы нашего магазина подойдут ключи «зимние шины киев», «шины с доставкой в киеве» и т.п.
- Группы товаров и услуг. Для этих категорий идет сбор слов и фраз, которые соответствуют общим определениям товаров или услуг, без четкой конкретики. К примеру, «зимние шины», «шины с протектором»
- Конкретные услуги, товары, сервис. Здесь мы еще больше детализируем ключевые слова, размещая в эту категорию запросы типа «шины на ауди», «резина на грузовик».
- Блок статей. Сюда мы относим все ключевые запросы информационного характера. По ним впоследствии будут написаны статьи. Это очень важная группа, так как дает возможность максимально расширить охват запросов. С помощью исключительно категорий товаров и конкретных услуг это было бы невозможно сделать. К статьям относятся запросы типа «какая зимняя резина лучше», «как поставить зимние шины самостоятельно» и т.д. Руководствуясь такими фразами, можно набрасывать костяк статей.
- Новости. Как правило, небольшая группа seo-запросов, которая будет способствовать дополнительному притоку посетителей на сайт. В эту категорию хорошо вписываются достаточно редкие ключи, которые не подходят ни в одну другую. Пример: хороший ключ – «давление в шинах зимой». Люди, которые интересуются данной темой, являются потенциальными клиентами для интернет-магазина покрышек, описанного в нашем примере.
Запросы нужно дробить на кластеры как можно тщательнее. Даже если под отдельные из них на вашем сайте страниц не существует, их нужно либо создать, либо вписать ключи в блоки статей. Выделив отдельную страницу под какую-либо группу запросов, шансы получить лояльность поисковиков и потенциальных клиентов возрастают просто на глазах.
Группировка семантического ядра. Методы и сервисы
Группировка ключей бывает ручная, полуавтоматическая и автоматическая. У каждого из этих методов есть как сторонники, так и противники. Рассмотрим их подробнее
- Ручная кластеризация – поиск, который пугает начинающих. Ведь сотни, а иногда тысячи запросов нужно обработать вручную, просмотрев каждый и распределив его по группам. Подходит для новых и создающихся сайтов, структура которых еще не выстроена. К плюсам этого способа относится то, что каждый ключ вы еще раз просмотрите и окинете свежим взглядом. Точность работы при этом возрастает по сравнению с автоматическим методом. Минусы – человеческий фактор, при котором «замыливается глаз», снижается внимание в процессе обработки запросов, большая трата времени на работу. Для лучшего понимания процесса рекомендуется все же провести группировку вручную, даже если это займет несколько дней.
- Полуавтоматическая. Данный метод совмещает плюсы как ручного, так и автоматического способа. Скорость и возможность проверить каждый кластер собственноручно – вот его главные достоинства. При этом группировка ключей по запросу доверяется программе, а результат тщательно проверяется лично.
- Автоматический сбор данных. Как выглядит процесс сбора – весь огромный список ключей просто загоняется в одну из программ для группировки. Она делает все сама буквально за считанные минуты. Скорость – вот основное преимущество метода. Однако программа, какой бы современной она ни была, не может сравниться с человеком по способности группировки ключевых слов.
Мы рекомендуем, особенно поначалу, даже созданные автоматически группировки проверять лично. Это значительно снизит риск ошибок.
Это значительно снизит риск ошибок.
Виды кластеризации
В зависимости от алгоритма обработки запросов поисковых систем, выделяют три вида кластеризации.
Soft – при этой группировке определяют самое популярное и часто применяемое ключевое слово (фразу), после чего все остальные ключевики сравниваются с ним по количеству результатов выдачи поисковой системы. На основании частоты совпадений, запросы и комбинируются по категориям. При этом все элементы запроса обязательно связаны с главным ключевым словом, но могут не зависеть друг от друга. Например, ключ «купить зимние шины» — главный, а к нему можно подвязать ключевые запросы «купить зимние шины киев», «купить зимние шины с доставкой»
Moderate – этот вид кластеризации выполняется посредством обработки совпадений ключевых слов с учетом степени группировки. Здесь все запросы будут «связаны» попарно, но для разных пар URL–адреса могут быть разными.
Hard – в этом случае проверятся не только выдача на основании одного запроса, но и сравнивается пересечение между словами из запросов. К примеру, запросы «какие шины купить на зиму» и «купить шины в киеве недорого». Если при проверке выдачи эти запросы пересекаются три раза, то эти запросы объединяются
Какие программы используются для кластеризации поисковых запросов
Ручная кластеризация удобнее всего проводится в простых программах Excel, LibreOffice, OpenOffice. Это медленно, но зато надежно.
1. Открываем файл с загруженными ключевыми запросами. Теперь воспользуемся инструментом «Фильтр», который находится в правом верхнем углу таблиц.
Нужно выделить ячейку с запросом и нажать на значок фильтра. Далее выбираем текстовый фильтр. И в него вводим слово или часть слово, запрос с которым нужно отнести к отдельной группе.
В данном случае, мы отделили запросы с зимними шинами от всех остальных запросов в системе
Таким образом нужно группировать все имеющиеся запросы.
Подобным образом работают и LibreOffice, OpenOffice
Для автоматической кластеризации также существуют удобные и достаточно простые программы, в которых просто разобраться новичку.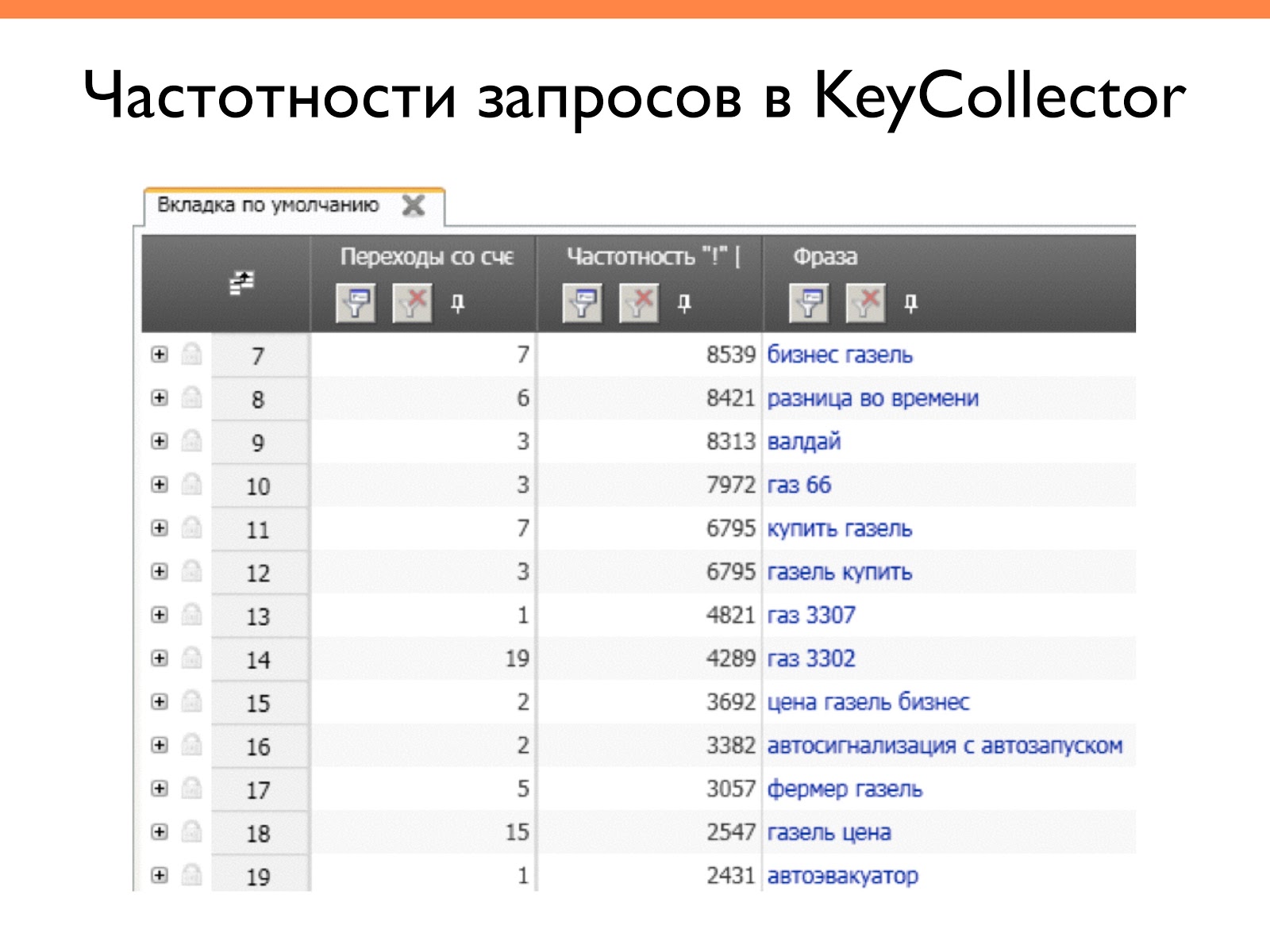
coolakov.ru
Здесь находится онлайн кластеризатор, который работает бесплатно и может обработать до 500 запросов. Интерфейс программы интуитивно прост и понятен
При нажатии на кнопку мы получаем вполне вменяемый список групп.
Mc-Castle.ru — Кластеризатор
Онлайн программа, которая группирует семантику исключительно по словоформе. Достаточно простая и подойдет для тех, кому не хочется возиться с сервисом вручную
kg.ppc-panel.ru
Простой онлайн-сервис. Нужно загрузить список запросов, отфильтровать, разбить на группы. Работает быстро, понятен интуитивно. Никакой регистрации не нужно, скачивать очередную программу на свой компьютер тоже. Однако в этой программе есть и минусы: нельзя сохранять проекты непосредственно в нем. Если у вас вдруг перебои со светом, или заглючило саму программу, то данные просто пропадут. Для того, чтобы потренироваться и понять суть группировки запросов, подойдет отлично.
Key Collector
Эта программа прочно обосновалась на рабочем столе тех, кто решил заняться сео-продвижением. Группировка ключевых слов – это лишь малая часть умений программы. Из минусов программы необходимость разбираться в интерфейсе, невозможность редактировать получившиеся группы в программе – нужно только скачивать в файл, и править там. Плюс нужно заводить аккаунты, при помощи которых будет проводиться сбор и анализ данных.
Keyword Assistant
Позволяет обработать огромные списки, включающие в себя несколько тысяч слов, пять тысяч слов программа будет обрабатывать около получаса. Группирует запросы по ключевым словам и словосочетаниям.
Схема работы несложная. Создается новый проект, для которого загружается файл с уже готовым списком ключевых слов. Файл для экспорта можно получить в том же Key Collector. Загруженные в программу запросы делятся на исходные, сгруппированные и черный список. Переносить запросы из одного списка в другой можно нажатием горячих клавиш. На сайте с программой находится очень понятное и простое видео, которое подробно объясняет алгоритмы работы.
Итак, мы разобрались в вопросе, что такое кластеризация ключевых слов и для чего она делается. Далеко не все программы для группировки можно рассмотреть в одной статье. Существует большое количество платных или условно бесплатных программ с разным уровнем сложности, с помощью которых собираются, анализируются и группируются запросы.
Кластеризация запросов семантического ядра сайта – важный и ответственный этап работы, от которого зависит не только структура сайта. От того, как будет размещен контент, насколько он будет востребованным и интересным для посетителей, зависит успех сайта.
Для того, чтобы вникнуть в тему кластеризации, начинать лучше именно с ручной проработки, хотя такой способ является долгим и не всегда вызывает энтузиазм. Потренироваться стоит на разных сервисах с тем, чтобы выбрать наиболее подходящий для себя.
Путем использования разных сервисов вы сможете проверить правильность выполненной группировки и максимально исправить все недочеты до того, как семантическое ядро будет внедрено на сайт. Ведь собрать множество ключей – еще не гарантия продвижения сайта в ТОП. Нужно грамотно разместить запросы по страницам сайта. Именно это позволит сделать фундамент для будущего успешного продвижения.
Подпишись на новости
Семантическое ядро: Кластеризация (Группировка) ключевых слов
Методов по поиску ключей на самом деле много.Вы можете воспользоваться следующими механизмами:
- Собрать ключевые слова при помощи SERPSTAT — сняв позиции, поисковые подсказки и слова, по которым тоже ранжируется сайт. Выкачать все удобными списками в Excel и объединить воедино.
- Провести аналогичные действия в AHREFS — собрав ключевые слова, подсказки, релевантные слова и спарсив все ключи у конкурентов.
- Собрать ключевые слова в выдаче при помощи нашей утилиты. В прошлой статье мы сделали обзор, как можно найти ключевые слова.
- Воспользоваться планировщиком ключевых слов и скачать подсказки от AdWords.
- Воспользоваться сторонними сервисами по ключевым словам — keywordtool.io или ubersuggest.com.
- Запустить KeyCollector и спарсить поисковые подсказки из WORDSTAT Яндекса, Google.
Способов много, но все они сходятся к одной проблеме.
Как распределить ключевые слова по страницам?
Ведь просто сваленные в кучу слова все же объединяются в единые группы, по которым можно создать ограниченное количество страниц.
Из личного опыта могу сказать, что ни на одних SEO-курсах и платных семинарах не проходят детально эту тему.
И вообще не останавливаются на проблематике кластеризации.
Даже опытные сеошники, которые не один год потратили в SEO делают эту работу не правильно.
В последствие продвигаются не релевантные страницы, которые не дают результаты.
Полгода уходят впустую и только потом ищут причины.
Сегодня мы расскажем Вам все этапы кластеризации, чтобы Вы не потеряли эти полгода на продвижение сайта.
ГЛАВА 1:
О кластеризации
В этом блоке мы рассмотрим саму процедуру кластеризации, а также коснемся важных методов:- метод по выдаче;
- ручной метод.
И оценим их преимущества и недостатки.
В интернете Вы найдете много обзоров, как относятся к кластеризации семантического ядра те или иные SEO-блогеры.
Например, Сергей Салтыков справедливо считает, что для подбора ключевых слов нужно учитывать много факторов, таких как трудность ключей и их конкуренция.
При этом отмечает, что семантическое ядро для контент-менеджера и итоговое СЯ для сайта будут отличаться, а для контекста вообще нет смысла кластеризовать семантическое ядро.
Не соглашусь, так как для контекста умение группировать запросы по смыслу имеет наибольшее значение.
Вы должны учесть как отдельные фразы, так и точные вхождения тех или иных запросов за счет правильно кластеризованной семантики.
СПОСОБ ПЕРВЫЙ. ПО ВЫДАЧЕ
Вы знаете, что самый простой способ сделать кластеризацию — довериться поисковой системе и просто оценить выдачу.
Этот метод основан на простом и незамысловатом процессе:
- Берем список ключевых слов.
- Закидываем одно из них в поисковую систему.
- Смотрим, что получилось в ТОП-10.
- Записываем выдачу по каждому ключу.
- Затем сравниваем процент совпадений.
Когда страницы совпадают между собой, это значит, что выбранные ключи родственные друг другу.
Такой тип группировки называется SERP-кластеризацией или кластеризацией по выдаче.
Ее активно пиарят многие SEO-блогеры, специалисты и интернет-издания, но при этом мало кто ею пользуется.
Например, услуга по кластеризации отсутствует в AHREFS (удивительно, почему) и не очень хорошо работает в SERPSTAT.
Почему не очень хорошо?
Потому что допускает иногда очень грубые ошибки, запихивая в кластер не совсем однородные слова, а также формирует очень много двусловных кластеров — без адекватной структуры.
Готовую семантику затем достаточно сложно “обрабатывать” копирайтеру.
Надеемся, что кластеризатор SERPSTAT станет лучше.
Подобная услуга есть только у web-сервисов, которые не очень распространены в мире.
В чем же подвох?
Вы не поверите, но он есть.
И он очевиден.
При помощи этого метода семантика, собранная два месяца назад и кластеризованная в то же время, может отличаться кардинально от тех же ключей, но кластеризованных сегодня.
Представьте себе такого SEО-специалиста, который каждые три месяца ключи в семантике перераспределяет туда-сюда, никак это не мотивируя.
Да, именно этот очевидный недостаток влияет на кластеризацию при помощи ряда платных сервисов.
Мы раньше часто пользовались Topvisor, Rush analytics и пришли к печальному выводу, что у таких сервисов есть три недостатка:
- готовая кластеризация может отличаться спустя время из-за смены сайтов в выдаче;
- их готовые семантические ядра нужно постоянно дорабатывать;
- они дорогие.
Конечно, если Вы собираете семантику для собственного ресурса, Вам понравится такой помощник.
Но когда Вы регулярно ее обновляете и дорабатываете, а также ведете много других проектов, все недостатки будут видны налицо.
Ну и отдавать 5$ за то, чтобы кластеризовать 1000 слов, только поначалу кажется недорого.
Например, я для нового сайта собирал ключи (где нужно было продумать существующие страницы и прописать новые).
Для кластеризации и чистки я перебрал 80 000 запросов, собранных из разных источников.
Каким способом я их кластеризовал, расскажу в этой статье ниже.
Но если бы я купил кластеризацию у вышеперечисленных ребят, то разорился бы на 400$ на ровном месте.
Еще немаловажная причина того, почему не стоит платить сторонним сервисам за кластеризацию — это непонятность алгоритмов.
Например, в одном из сервисов есть такие виды кластеризации, как Soft, Moderate и Hard.
Понятно, что для разных объемов семантики рекомендуется использовать все методы, но какой именно выбрать вам — ни одна система не подскажет.
Более того, отсутствие возможностей “настройки” до мелочей делает сервисы достаточно неполноценными: например, когда очевидные синонимы все равно попадают в разные кластеры.
Еще в Вашу семантику может затесаться пул “не Ваших” запросов, которые надо бы почистить.
Но Вы забыли это сделать и закинули все в платный сервис.
ШИК — теперь и за семантику заплатили, и еще руками чистить…
СПОСОБ ВТОРОЙ. ВРУЧНУЮ
Окей, Вы решили не платить жадным сервисам, у Вас нет ничего, кроме Excel, Вашей усидчивости и времени.
Вы можете сделать все вручную.
Спросите как?
Просто!
Берем банальное приложение по картам ума (mind-mapping) и начинаем умственно чертить, чем будет заниматься наш сайт.
Для этого берем и выписываем все услуги и товары, которые мы планируем продавать.
Составляем полноценный список.
Начнем со структуры. Мы выделим те страницы, которые надо будет создать обязательно.
Главная страница — должна отвечать основному виду деятельности Вашей компании.
И основной запрос — это вид деятельности Вашего бизнеса.
SEO-студия, интернет-магазин одежды или парикмахерская в Москве — здесь и прописываем наши основные ключи.
Страницы ПРОДУКЦИИ (товаров или услуг) — в этом блоке будут товары и услуги компании, объединенные в различные категории.
На эти группы страниц будет приходиться 99% Вашей продвигаемой семантики.
Из них выделяются такие типы:
Страницы категорий верхнего уровня
Здесь находятся крупные группы товаров и услуг, которые являются фундаментально отличающимися друг от друга.
Так, например если Вы интернет-магазин техники, то Вы не будете смешивать в один блок фото и видеоаппаратуру со смартфонами и планшетами.
Правда в единый блок сможете объединить фото и видеоаппаратуру.
Данный список собирается исключительно во время мозгового штурма и после анализа конкурентов.
Страницы подкатегорий или посадочные страницы
По факту это могут быть уже внутренние подстраницы и подкатегории.
И тут результаты кластеризации должны показать себя с разных сторон.
Каждая страница должна вмещать в себя трафиковые ключи, объединенные одной логикой.
Товарные страницы или страницы услуг
На эти страницы обычно семантика подбирается реже.
Исключение — когда оптимизируются названия услуг под более высокочастотные ключевые слова.
Страницы блога
Все информационные запросы, ключи-вопросы не стоит выбрасывать.
Также все околоцелевые запросы соберите в единый пул и рассортируйте по смысловым рубрикам.
Это будут категории нашего блога.
Затем их надо будет кластеризовать.
На что следует обратить внимание при сборе ключевых слов вручную?
Совет 1. Важно использовать базы ключевых слов, собранные при помощи хороших сервисов.
Если Вы генерируете ключевые слова самостоятельно, не забывайте проверять частотность фраз как в широком, так и во фразовом соответствии.
Мы рекомендуем парсить ключевые слова при помощи следующих сервисов:
- Яндекс Wordstat;
- SERPSTAT;
- Ahrefs;
- Semrush;
- Планировщик ключевых слов.
Совет 2. Рекомендуем изучать структуру конкурентов на поиск синонимов.
Искать синонимы можно при помощи простых методов:
- SERPSTAT и Ahrefs имеют свой механизм поиска релевантных ключей.
- Поисковая выдача. Введите основной ключ и изучите сниппеты или страницы. Там можно найти сразу несколько вариантов ключевых слов.
- Яндекс Wordstat — отличный способ по поиску синонимов.
Вы можете воспользоваться скриптом для автоматизации (согласно мануалу Сергея Кокшарова).
Недостаток ручного метода — он отнимает огромное количество времени!
На сбор семантики пусть даже в том же Key Collector вручную может уйти от 10 до 50 часов даже для посредственного сайта!
Ведь Вам придется по факту перегруппировывать ключевые слова по смыслу, разносить их по группам.
Причем делать часто повторяющиеся действия “на глаз”, не используя эмпирический машинный подход нигде, кроме как в задаче принципов фильтрации!
ГЛАВА 2:
Инструкция по кластеризации
В этом блоке мы будем уже конкретно и пошагово расписывать инструкцию:- как подобрать ключевые слова;
- как присвоить им правильные группы;
- как их распределить по посадочным страницам.
И все сопроводим скринами и гайдами.
Итак, Вы все же приступили к процессу кластеризации ключевых слов.
Скачали все файлы с ключевиками.
Примерно прикинули структуру сайта (оценили, чем будете заниматься).
И у Вас стоит задача разбить их по группам максимально релевантно.
Мы создали удобный инструмент по быстрой кластеризации ключевых слов, который умеет быстро и оперативно распределять ключевые слова по группам.
КЛАСТЕРИЗАТОР КЛЮЧЕВЫХ СЛОВПросто импортируйте ключевые слова в колонку списка слов.
Краткий гайд по полям, которые есть в нашем кластеризаторе.
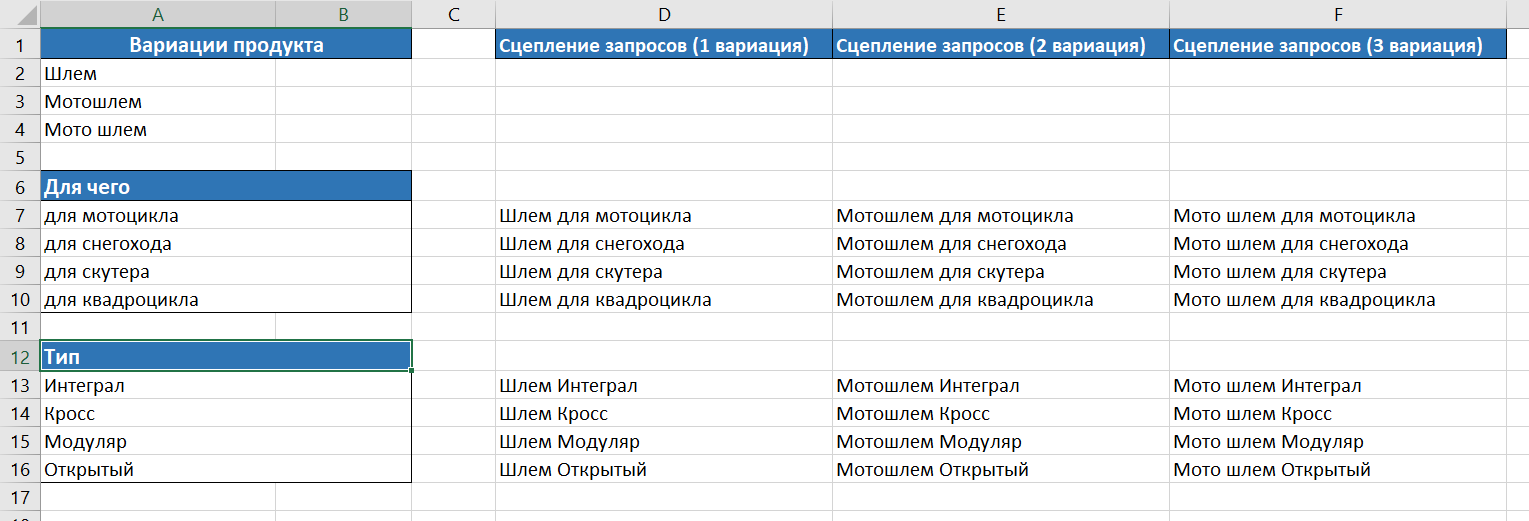
Считать как одно слово
Часто в семантике могут встречаться неразрывные словосочетания.
Например, iPhone 7, iPhone 6S, iPhone 6 — по факту это разные словосочетания, и если их не сцепить, в кластеризации в одну группу могут попадать все варианты.
А этого быть не должно.
Аналогично Вы можете вспомнить любые названия марок автомобилей, которые могут быть записаны через пробел (например A4 и A 4).
Для удобства пропишите все значения через запятую.
Минус-слова
Часто в скачанной семантике Вы можете найти огромное количество слов, которые хотелось бы до кластеризации удалить, но у Вас на это нет времени и сил.
Такое бывает, когда Вы скачаете выгрузки из SERPSTAT или AHREFS или соберете ключевые слова через тот же WORDSTAT Яндекса.
В итоге в выдаче могут появиться слова, которые явно Вам не нужны и годятся для других видов бизнеса.
Их наличие может сильно подпортить результат кластеризации.
Мы встроили простой механизм, который явно оценят сборщики семантики для контекстной рекламы — а именно механизм удаления минус-слов из скачанных списков.
Просто вставьте минус-слова через запятую в окошко.
Кстати, мы внедрили функционал поддержки точной словоформы — просто пропишите слово с восклицательным знаком (вот !Так) — и система будет удалять слова только в данной словоформе.
Это полезно, если Вам нужно, например, удалить слово !бесплатно, но оставить бесплатная (например доставка).
Список игнорируемых слов
Бывает, что в кластеризации предлоги и местоимения, а также отдельные слова встречаются очень часто, но Вам не нужно под них создавать отдельную страницу в кластеризации.
Например, эти две группы по факту — одинаковые и слово WEB не должно вообще никак фигурировать в нашей кластеризации.
Такие слова нужно просто игнорировать и не обращать на них внимание.
Для этого мы в нашем кластеризаторе добавили соответствующее поле — Список игнорируемых слов.
Слова будут проигнорированы и не учтены в алгоритме кластеризации.
В систему по умолчанию уже вшиты предлоги на русском и английском языках.
Список обязательных слов
Яркий пример, когда Вы можете утонуть в количестве слов — это когда спарсите позиции конкурентов, ассортимент которых гораздо шире Вашего.
И окажется, что среди кластера может быть огромное количество слов, не связанных с Вашей тематикой.
В нашем примере нам нужно все, что касается SEO-продвижения, и только.
Поэтому возьмем только слова, связанные с этой тематикой и оставим их, а остальное проигнорируем.
В нашем кластеризаторе мы реализовали такой функционал — просто заполните колонку «Списка обязательных слов».
Поддерживается ввод через запятую как слов, так и фраз.
Синонимы
Наиболее частая ошибка в кластеризаторах — неумение понимать и группировать синонимы.
Key Collector при группировке по словам не понимает синонимы априори, и Вы вынуждены потом руками склеивать разделенные кластеры.
SERPSTAT в кластеризации плодит много однословных кластеров, которые наоборот стоит склеить воедино.
Но часто системы не знают, что нужно сцепить в один кластер, а что должно быть в разных.
Некоторые принципы кластеризации вполне уникальны и требуют особенного подхода, поэтому мы добавили функционал синонимов.
Просто пропишите в одну строку все синонимы, разделив их запятыми.
Для добавления нового синонима нажмите кнопку “+” и добавьте новые группы синонимов.
Вы можете добавить все синонимы сразу в проект или делать это уже по мере работы с сайтом.
Учет геозависимости
Часто бывает, что нужно разделить обширную семантику по городам.
Иногда Вы можете собрать огромный пул так называемых “всероссийских” или “всеукраинских” ключей — где есть все ключевые слова + какой-то город.
И при корявой кластеризации в одну группу могут попасть сразу два или три разных города.
С точки зрения корректности семантического ядра и для настройки контекстной семантики — это не рекомендуется: по факту тот, кто ищет пиццерию в москве и пиццерию в зеленограде — это разные клиенты, и условия доставки могут разительно отличаться.
Для этого в функционале нашего кластеризатора поддерживается огромная база населенных пунктов стран СНГ и Европы.
Также мы ввели опциональный алгоритм, который не позволяет одинаковым населенным пунктам попадать в одну группу.
По умолчанию эта функция включена.
Расширенная кластеризация по коротким запросам
Часто бывает, что узкая кластеризация игнорирует вполне короткие и высокочастотные запросы — они обычно остаются за бортом и не участвуют в готовом семантическом ядре.
Их приходится уже перебирать руками и оставлять вручную.
Мы создали простую опцию, которая проверяет несортированные более короткие фразы на максимальное соответствие частотной группе и добавляет фразу в нее.
Данный функционал мы добавили недавно и он предназначен не для всех (скорее всего — для настройщиков контекстной рекламы и опытных SEO-специалистов).
По умолчанию он отключен.
Включить его легко: просто установите галочку на это поле:
Сила кластеризации
Как и в любом кластеризаторе, у нас есть разные уровни группировки ключевых слов.
Принцип разделения основан на поиске совпадения разного количества ключей в одной группе.
Система находит слова и формирует их по принципу совпадений в кластерах:
В данном примере группировка проводится по двум словам.
Всего в кластеризаторе существует 4 вида кластеризации:
- ВЧ — кластеризация по высокочастотным группам или так называемая мягкая кластеризация (Soft). Например, для сбора семантического ядра пригодится первичный уровень кластеризации. Данный метод ищет совпадения по двум словам в одном кластере.
- СЧ — кластеризация по среднечастотным группам или средняя кластеризация (Moderate). Формируются более узкие группы, которые пригодятся для составления ТЗ копирайтеру на внешние статьи, которые Вы будете публиковать на внешних площадках или в блог. Формирует кластеры по трем словам в группе.
- НЧ — кластеризация по низкочастотным группам или жесткая кластеризация (Hard). Пригодится для сбора узких групп. Применима для очень объемных СЯ и отбора информационных ключей. Формирует кластеры по 4 словам в одной группе.
- МЧ — разбивка семантики по многословным запросам или по микрочастотным группам. Применимо для информационных сайтов с огромной высокочастотной семантикой. Разбивает слова по 5 совпадениям в группе.
Группировка и фильтры
Иногда трудно во всех результатах кластеризации путешествовать и искать нужные строки.
Приходится постоянно вылавливать нужные кластеры.
Мы добавили функционал, аналогичный фильтрам в Excel и в Google Таблицах.
Просто нажмите на слово ГРУППА и в диалоговом окне очистите лишние группы и отметьте нужные.
Система быстро отфильтрует результат.
Затем отметьте нужные группы и нажмите Сохранить выделенное — система сохранит результаты кластеризации в виде отдельных файлов.
Пригодится для тех, кто перебирает огромные пулы ключей для контекстной рекламы и ищет отдельные группы ключевых слов.
Также будет полезно для SEO-специалиста для составления ТЗ копирайтеру сразу по нескольким страницам.
Импортирование, сохранение проекта
Так как наш функционал достаточно непростой и много возможностей можно настроить для каждого проекта отдельно, мы сохранили простую схему по работе с проектным файлом.
Вы можете сохранить проект кластеризации, просто нажав на кнопку СОХРАНИТЬ.
В готовом Excel файле можно сразу добавить ключевые слова, частоты, конкуренцию и стоимости кликов (например, спарсив информацию из SERPSTAT, AHREFS, Wordstat Яндекс и Планировщика ключевых слов).
В этом же файле можно заполнить все поля сразу: синонимы, минус-слова, обязательные и игнорируемые слова.
Затем легко его можно загрузить — нажав на соответствующую кнопку:
Также мы сделали поддержку импорта выгрузок из SERPSTAT, Ahrefs и тех же Планировщика ключевых слов и KeyCollector: при импорте система понимает следующие колонки:
- ключевые фразы;
- частоту;
- стоимость клика;
- конкуренцию.
Готовые результаты сохраняются при импортировании и переносятся в результаты кластеризации.
ГЛАВА 3:
Создаем семантическое ядро
Этот блок будет полезен для SEO-специалиста, который планирует собранную семантику адаптировать для собственного сайта.Мы научим, как:
- Собрать семантику в понятный файл.
- Найти релевантные страницы для кластеров.
- Подобрать правильно Title для ваших страниц.
Итак, мы уже получили готовую семантику в виде структурированного списка ключевых слов.
Сохраняем результат.
Его можно использовать сразу как есть, но иногда нужно сделать визуально симпатичный Excel файлик.
Собираем семантическое ядро в Excel файл
Учимся делать готовое ядро уже в Excel.
Откроем скачанный файл и скопируем колонки на отдельный лист.
Выберем Данные — Удалить Дубликаты — и отметим нужную колонку.
В результате у нас останутся только группы.
Посчитайте вес каждой группы, просуммировав трафик по каждой из них.
Воспользуйтесь формулой =СУММЕСЛИ()
Затем пересмотрите группы и присвойте каждой из них свою категорию.
Это нужно сделать вдумчиво и при помощи простых фильтров в Excel.
Подставить группу в список ключей можно при помощи формулы =ВПР().
После этого вероятно у Вас останутся слова, скластеризованные не по выбранной категории.
Вы увидите, что в них попали слова из разных категорий.
Не беда.
Выделите те группы, которым не присвоилась категория.
И снова закиньте в наш кластеризатор.
Только теперь по очереди прописывайте Ваши обязательные слова в ячейку СПИСОК ОБЯЗАТЕЛЬНЫХ СЛОВ.
По очереди сделайте так для каждой категории.
Затем воспользуйтесь формулой СЦЕПИТЬ и создайте уникальное название для Вашего нового кластера.
Посчитайте его вес при помощи простой формулы.
Затем поочередно отсортируйте списки сначала по ключевым словам (1), потом по кластерам (2) и затем по категориям (3).
Может оказаться, что на главную у Вас не получилось выделить ключи по причине маленького трафика предполагаемых запросов.
Не беда.
Выберите их вручную и вынесите вверх таблицы.
Воспользуйтесь функцией ПРОМЕЖУТОЧНЫЕ ИТОГИ и разделите визуально кластеры:
Затем внести несколько визуальных изменений и вуаля — семантическое ядро готово в виде читабельного Excel файла!
Его уже можно смело давать на работу копирайтеру и составлять мета.
Ищем релевантную страницу
Если же мы ищем релевантные страницы для кластеров, рекомендуем воспользоваться простой функцией.
На момент написания этой статьи мы внедряем функционал поиска релевантных страниц для нашего кластеризатора.
Сама функция достаточно проста.
Забейте в поисковую строку простой оператор site:ВАШ САЙТ и ключевое слово.
Первая страница, которая будет показана, и является релевантной.
Дальше дело техники — сохранить страничку для кластера и проверять следующий.
Если у нас получился повтор, значит нужно причесать контент, чтобы семантика на разных статьях была более релевантной каждому кластеру.
Пишем грамотно Тайтл для кластера
Для каждого кластера следует грамотно прописать Тайтл.
По поводу того, как нужно писать Тайтл для страниц, можете посмотреть наше видео по технике Эверест.
Составляем Тайтл правильно.
- Берем наиболее высокочастотную фразу.
- Ставим ее в начало предложения.
- Можем поставить точку или двоеточие.
- Стараемся добавить через запятую 2-3 слова дополнительно — при этом следим за длиной Тайтла. Рекомендуемая длина 55 символов — старайтесь не доходить до 62. CTR у 55 обычно выше.
- Постарайтесь добавить цифры и скобки.
Помните, что Тайтл — это как подпись на ценнике, где поисковую выдачу воспринимайте как витрину: Вы должны максимально емко попасть в те ключевые слова, которые находятся в Вашем кластере!
ВЫВОДЫ
Кластеризатор ключевых слов — это просто еще один качественный инструмент, который мы создали для экономии времени SEO-специалистов.
Именно экономия времени заставила нас потратить много часов на допиливание и доработку его алгоритмов.
Выводы можно сделать следующие.
- Кластеризация по выдаче — очень ненадежна и часто дает неверные результаты.
- Кластеризация — рутинный процесс, поэтому сервисы по кластеризации не должны стоить дорого. Вы можете сегментировать и разбивать по несколько раз один и тот же пул ключей.
- Кластеризация должна работать быстро. Тот же KeyCollector или Excel могут отнять десятки часов, на что в нашей утилите Вы потратите десяток минут.
- Кластеризация — тонкий процесс: Вы должны вносить ряд изменений в ее настройку — учитывать синонимы, игнорировать ненужные фразы. Наш кластеризатор имеет обширную базу ключевых слов, которые будут полезны при сборе.
- Часто кластеризаторы игнорируют фразы, которые нельзя разрывать. Это может привести к задержке сбора ключей на много часов.
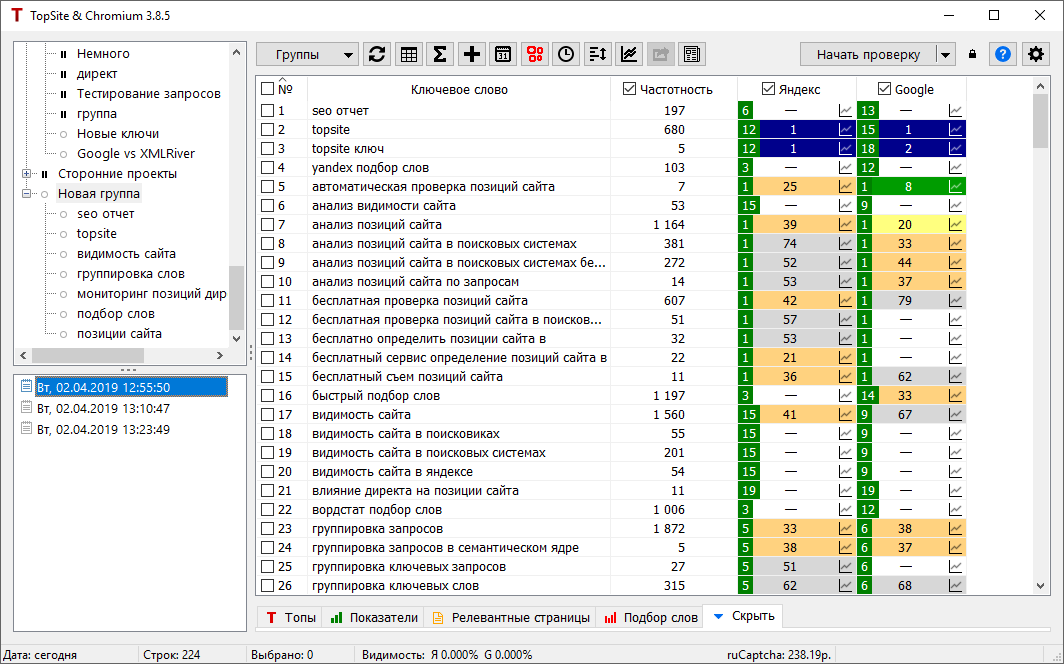
Введение в Key Collector — самый обсуждаемый инструмент SEO в России | by Jyldyz SEO
Одна вещь, которая делает мой опыт работы SEO-специалистом гораздо более увлекательным, — это работа по двум направлениям: российскому (Яндекс) и американскому (Google). Я не скажу, какая из этих двух мне больше всего нравится, лучше я познакомлю вас с программным обеспечением, которое отлично работает для обеих поисковых систем — Key Collector.
Key Collector — важный инструмент, когда дело доходит до создания семантического ядра для веб-сайтов, контекстной рекламы, расширенного анализа результатов поиска и организации ключевых слов.В этой статье я расскажу вам о наиболее важных функциях Key Collector, которые я использую ежедневно. Итак, приступим!
Это один из важнейших шагов в построении семантического ядра. Key Collector может мгновенно и одновременно собирать статистику частоты для каждого ключевого слова на основе данных из Google AdWords Keyword Planner Tool, Yandex Wordstat, Rambler Adstat.
Google AdWords Keyword Planner ToolРусский аналог Keyword Planner Tool — Яндекс wordstatДля сбора статистики выполните следующие действия:
- Создайте новый проект в Key Collector
- Выберите регионы, подходящие для вашего бизнеса
- Добавьте ключевые слова, соответствующие вашей нише в раздел «Добавить фразы»
- Выберите «G» (Google) или Rambler в качестве предпочтительной поисковой системы (ов).Яндекс доступен только в русскоязычной версии Key Collector
- Начать сбор статистики по количеству запросов по ключевым словам
Совет: для сбора полного списка ключевых фраз используйте функцию «Поисковые предложения» . Он собирает слова, подсказанные поисковыми прогнозами от Google, Yahoo, Bing и YouTube. Хорошая новость в том, что уже добавленные ключевые слова и фразы будут проигнорированы, следовательно, в таблице не будет дубликатов.Использование этой функции значительно расширяет диапазон ключевых слов для семантического ядра за счет набора ключевых слов, которые в большинстве случаев недоступны в инструменте планирования ключевых слов Google AdWords.
Key Collector — значок для поиска предложений на панели инструментовВсе, что вам нужно сделать, это выбрать значок на панели инструментов и вставить ключевые слова или фразы. После того, как вы выберете поисковую систему и регион, программа добавит дополнительные ключевые слова за считанные секунды.
Сборщик ключей позволяет избавиться от слов на основе нескольких факторов с помощью фильтра.Вы можете отредактировать условия, чтобы отфильтровать:
- Нерелевантные фразы
- Ключевые слова с низким объемом поиска, CPC, конкуренцией и т. Д.
- Дубликаты
В отличие от настроек фильтрации таблиц Excel, система фильтрации Key Collector выполняет не требуют крови, пота и слез для доведения своего смыслового ядра до совершенства. Он не только предоставляет полный набор инструментов, но и все условия фильтрации можно сохранить для дальнейшего использования в проектах.
На основании полученных данных можно очистить таблицу от тех фраз, частота которых равна нулю, а также от дубликатов. Если нет необходимости работать на сайте с низкочастотными фразами, то вы можете удалить все фразы, объем поиска которых меньше 10, 20 или 30. Фильтрация также применяется после сбора связанных поисковых запросов, которые будут рассмотрены в следующий абзац.
После того, как все ненужные фразы будут отфильтрованы, вы можете расширить список ключевых слов, отсортировав их по группам, чтобы создать базу данных связанных поисковых запросов.Этот шаг называется «синтаксическим анализом», и он значительно увеличивает количество похожих ключевых слов для каждой группы из выбранной поисковой системы.
Для сбора связанных поисковых запросов:
- Щелкните значок «G» (Google) в верхней папке
- Добавьте выбранные фразы
- Сортировка фраз по группам
- Начать сбор связанных поисковых запросов и статистики
Например, на скриншоте выше видно, что автор отсортировал ключевые слова по таким группам, как молоко, шоколад, макаронные изделия.После процесса «синтаксического анализа» программа собрала 680 связанных поисковых запросов для группы «молоко» с полной статистикой объема поиска по каждому запросу. Дополнительно рекомендуется применять расширенную систему фильтрации для каждой группы.
Это виноватое удовольствие любого SEO-специалиста. Функция предназначена для автоматической пометки всех неявных дубликатов, частота которых меньше в выбранной поисковой системе. Например, между двумя фразами, такими как «снять квартиру рядом» и «снять квартиру поблизости в аренду», программа выбирает ту, у которой больше запросов.
Чтобы найти и удалить неявные дубликаты:
- Щелкните вкладку «Данные» в заголовке
- Щелкните «Найти неявные дубликаты»
- Настройте параметры интеллектуального анализа
- Щелкните «Выполнить интеллектуальный анализ»
- Щелкните « Удалить отмеченные элементы »
Если вы хотите проверить позиции сайта в поисковых системах или узнать, какие страницы выдаются по конкретным запросам — Google SERP — идеальный инструмент для вас.Он позволяет определить позицию сайта по заданной ключевой фразе.
Необходимо выполнить простые шаги:
- Добавьте ключевые слова, по которым вы хотите сканировать позиции веб-сайта для
- Введите URL-адрес веб-сайта, который вы анализируете
- Выберите желаемую поисковую систему
- Укажите регион
- Проверьте позиции веб-сайт
Имейте в виду, Key Collector — это сложная машина, и представленный материал охватывает только базовые подходы к построению семантического ядра.Что касается цен, то стоимость подписки на 1 год составляет всего 29 долларов, что является выгодной сделкой с учетом множества предоставляемых функций.
Независимо от того, являетесь ли вы любителем или опытным SEO-специалистом, мы настоятельно рекомендуем вам попробовать удивительные инструменты Key Collector. Если вам нужна помощь, мы с нетерпением ждем ваших комментариев или вопросов в разделе комментариев. Удачи!
Методы семантического ядра сайта
Семантическое ядро сайта — это список всех слов по теме проекта, который служит основой для создания общей структуры и отдельных страниц сайта.Грамотное составление семантического ядра поможет сайту попасть в ТОП выдачи поисковых систем.
Контент
1. Что такое семантическое ядро
2. Как построить семантическое ядро
2.1. Как построить семантическое ядро из ключевых слов конкурентов
2.2. Как создать семантическое ядро сайта по похожим ключевым словам и поисковым предложениям
2.3. Использование ключевых слов, используемых конкурентами в контекстной рекламе
3. Кластеризация семантического ядра
4. Как заказать семантическое ядро
5.Пример семантического ядра
Вывод
Для успешного продвижения любого сайта необходимо семантическое ядро - полный список всех ключевых слов, относящихся к тематике ресурса, разбитых на группы которые похожи по смыслу. Семантика используется не только при создании и оптимизации сайта, но и при запуске рекламной кампании. Собирайте семантику вручную и с помощью различных сервисов. Ключевые слова (ключи) подбираются путем анализа товаров и услуг, представленных на сайте, а также семантического ядра конкурентов.Основное внимание уделяется статистике использования поисковых запросов с учетом их сезонности. Основная задача — создать на сайте страницы по всем запросам, максимально отвечающие потребностям целевой аудитории. Создание семантического ядра делится на следующие этапы: сбор ключевых слов, подробно описывающих содержание сайта с учетом его тематики и назначения; кластеризация собранных ключей по разделам и подразделам проекта оптимизация всех страниц по группам собранных ключевых слов.Для интернет-магазинов и сервисных сайтов при выборе ключевых слов их следует разделять на коммерческие и некоммерческие. В первую группу входят все фразы, которые используют посетители, которые с наибольшей вероятностью станут клиентами компании. Как правило, используются слова «купить», «заказать», «цена», «стоимость» и другие. Некоммерческие запросы — это слова, которые пользователи вводят для получения определенной информации. Такие запросы не всегда приводят на сайт целевую аудиторию, однако среди таких посетителей могут быть и потенциальные клиенты.Еще одним важным критерием группировки ключевых слов является их частота:
- Высокая частота — это основа семантики: слова, которые наиболее кратко описывают сферу деятельности компании. Чаще всего они используются при поиске сайтов по данной тематике, поэтому имеют самую высокую конкуренцию на рынке.
- Mid-range — клавиши, которые немного менее популярны, но остаются достаточно востребованными.
- Низкочастотный — такие ключи обычно состоят из нескольких слов и используются реже, чем предыдущие категории.Главное преимущество — более простое продвижение в ТОП и возможность привлечь на ресурс «теплую» целевую аудиторию, которая точно знает, что ей нужно.
Закажите бесплатную консультацию по телефону
Как построить семантическое ядро.
Существуют такие методы сбора семантического ядра онлайн:
1 Сбор семантического ядра в сервисах поисковых систем.
2 Использование семантического ядра конкурента.
3 Сборник похожих ключевых фраз и поисковых подсказок.
4 Применение ключевых слов, используемых конкурентами в контекстной рекламе.
Основные программы для сбора семантического ядра:
1. Serpstat.
2. Яндекс.Wordstat.
3. Планировщик ключевых слов Google.
4. Инструмент подсказки ключевых слов.
5.SpyWords.
6. Коллекционер ключей.
Наши услуги по оптимизации и наглядности вашего веб-сайта
Как проводить исследование ключевых слов: полное руководство для начинающих
Поисковые запросы по ключевым словам являются неотъемлемой частью SEO.Даже в то время, когда используются продвинутые поисковые алгоритмы, такие как Google Hummingbird, ключевые слова определяют тему веб-сайта для поисковых роботов. Ниже мы подробно обсудим, как проводить исследование ключевых слов, и поговорим об инструментах, которые помогут вам с этой задачей. Вы можете узнать больше об алгоритмах в статьях Google BERT Update и Google Algorithms, которые влияют на SEO.
Ключевые слова как инструмент поисковой оптимизации
Прежде чем ответить на вопрос о том, как работает исследование ключевых слов, давайте разберемся с концепциями.
Ключевые слова могут помочь повлиять на рейтинг сайта. Они делают это, сообщая поисковым системам, какие запросы будут влиять на рейтинг страницы. Ключевые слова образуют смысловое ядро. Для получения дополнительной информации см. Что такое SERP в 2020 году?
Семантическое ядро состоит из слов и фраз, которые определяют профиль сайта и его специализацию. Более подробную информацию по теме можно найти в разделе Что такое семантический поиск? Для составления ключевых слов обычно анализируются сайты конкурентов и определяются типичные поисковые запросы с помощью специальных программных инструментов.О том, как провести полный анализ конкурентов и получить все необходимые данные, читайте в статье SEO Competitive Analysis.
В следующих параграфах мы более подробно остановимся на этом.
Базовое исследование запросов — обязательный этап создания семантического ядра
Базовые запросы или запросы маркеров — это запросы пользователей, которые точно соответствуют теме вашего сайта. Например, если речь идет об интернет-магазине автомобильных запчастей и аксессуаров, будут запросы типа: «автомобильные шины», «крыло для BMW x6» и т. Д.В общем, просто изучите, какие фразы ваша целевая аудитория будет вводить в поисковик, и запишите их.
Второй шаг — собрать вторичные или немаркерные запросы. Это те же самые основные поисковые запросы или их синонимы с дополнительными уточняющими словами (обычно от одного до трех слов). Эти поисковые запросы создаются при добавлении таких слов, как «купить», «купить в Нью-Йорке», «цена», «купить подержанный». Если вы даже приблизительно не понимаете, что может подпадать под эту категорию поиска, воспользуйтесь такими инструментами поиска, как Google AdWords.О них поговорим позже.
Также может быть полезно изучение содержания популярных сайтов схожей тематики. В описаниях продуктов или статьях вы определенно можете найти хотя бы пару ранее не замеченных запросов. Для получения информации о том, как правильно анализировать ваш контент, см. Аудит контента веб-сайта.
Ключевые слова везде
И, наконец, в качестве дополнительной меры, чтобы подтвердить свои предположения, вы можете ввести интересные поисковые запросы в Google и посмотреть, что показывает категория «Люди также спрашивают».Дополнительную информацию по теме можно найти в статье «Люди тоже спрашивают».
Почему разнообразие ключевых слов важно для привлечения органического трафика?
Несмотря на то, что SEO-специалисты выступают за качество, а не за количество, очень важно, чтобы ключевые слова были разными. Процедура поиска по ключевым словам подразумевает разделение семантического ядра на кластеры или группы запросов по схожим нишам и направлениям.
Благодаря этому можно правильно распределять ключевые слова по страницам сайта.Например, информационный поиск лучше подходит для страниц блога, а коммерческий поиск лучше для целевых страниц товаров или категорий).
Как часто вам нужно проводить исследования?
Обычно самая глобальная работа по составлению семантического ядра проводится в самом начале продвижения сайта. Однако со временем ядро может пополняться новыми запросами, которые могут содержать тенденции.
Например, когда был представлен iPhone XS, в мире технического оснащения был резонанс.Все сайты по продаже смартфонов начали создавать огромное количество отзывов об этой новинке. Конечно, это отразилось на семантическом ядре торговых площадок — оно пополнилось как минимум одним новым ключевым словом — iPhone XS
.Поэтому однозначного ответа на частоту ревизии семантического ядра нет. Это нужно делать сразу, как только какая-то новая тенденция затронула вашу нишу.
Как составлять ключевые слова: типы настраиваемых запросов
А теперь пора выяснить, как найти лучшие ключевые слова для SEO.По сути, вам нужно знать, какие типы запросов поступают в поисковые системы от пользователей.
Оттуда вы можете использовать их как часть различных фраз, чтобы уменьшить их частоту и повысить релевантность страниц сайта.
Есть пять типов ключевых слов:
- Коммерческие : это широкая категория различных ключевых слов, которые обеспечивают большой процент органического трафика. Для веб-сайта туристического агентства ключевое слово «путеводитель» будет бесполезным.Однако, если вы предоставите некоторую информацию о туризме, это слово будет более подходящим. Чтобы понять, попадает ли ваше потенциальное ключевое слово в эту категорию, просто введите его в поиск и посмотрите, какие сайты по этой теме отображаются в поисковой выдаче. Если их бизнес-ниша идентична вашей, значит, все в порядке, и вы можете смело использовать это ключевое слово. Для получения дополнительной информации по этой теме прочтите статью Что такое поисковая выдача.
- Transactional : это еще один тип ключевого слова, который также идеально подходит для использования на коммерческих сайтах.Ключевые слова транзакции описывают целевые действия для тех пользователей, которые намереваются купить продукт или услугу. Они идеальны в тех случаях, когда человек уже искал информацию, сумел принять положительное решение и наконец приступил к процессу покупки. Такие ключевые слова всегда содержат «купить», «продать», «подписаться» и т. Д.
- Информативный : этот тип ключевых слов используется для привлечения пользователей, которые ищут информацию. Например, чтобы сравнить продукты с похожими моделями, чтобы узнать их характеристики, мы можем говорить не только о продукте, но и об общих образовательных запросах, таких как «Достопримечательности Нью-Джерси».Часто такие ключевые слова содержат вспомогательные слова, такие как «нравится», «против», «сравнивать» и т. Д.
- Навигационный : это еще один вид ключевых слов, которые напрямую относятся к определенному бренду, компании или известному сайту. В этом случае пользователи обращаются к поисковику с конкретным запросом и упоминают название сайта. Такие ключевые слова обычно полезны, когда бренд хорошо известен и популярен.
- Локальный : И, наконец, у нас есть локальные ключевые слова. Это ключевые слова, которые ориентированы на конкретное место.Чаще всего они содержат название определенного географического местоположения, например «купи обувь в Орегоне». Для получения дополнительной информации по теме см. Местный контрольный список SEO 2020.
6 шагов по ключевым словам
А теперь рассмотрим шесть последовательных шагов, которые объяснят, как найти ключевые слова для SEO.
Шаг первый: проведите терминологическое исследование
Если вы прекрасно понимаете нишу, в которой продвигаете сайт, вы уже сделали первый шаг. Вам необходимо провести масштабное терминологическое исследование ключевых слов SEO.В любой нише, будь то косметика, автомобили или ракетостроение, есть ряд брендов, определенные ключевые термины и поисковые запросы, которые чаще всего возникают среди вовлеченных в нее интернет-пользователей. Поэтому вам придется изучить терминологию, чтобы досконально разобраться в специфике того или иного вида бизнеса.
Например, если вы планируете продвигать косметический веб-сайт, введите следующие запросы: «Самые популярные косметические бренды», «Популярные косметические ингредиенты», «Типы средств по уходу за кожей», «Процедуры по уходу за кожей», «Уход за кожей» и т. Д.поможет вам в этом.
Шаг второй: начните с высокочастотных ключевых слов
Этот шаг называется базовым исследованием ключевых слов. Следовательно, вам нужно будет определить наиболее часто встречающиеся ключевые слова. Обычно они содержат от одного до трех слов. Если мы продолжим тему косметического сайта, то наиболее часто встречающимися ключевыми словами будут такие варианты, как «помада на покупку», «L’Oreal», «маска для волос» и т. Д.
Конечно, когда речь идет о сборе семантического ядра для очень большого сайта с большим ассортиментом товаров, таких запросов могут быть тысячи.В этом случае имеет смысл выбрать основные поисковые запросы, начиная с наиболее важных категорий для продвижения (наиболее маржинальных и актуальных для сезонного спроса).
Шаг третий: отслеживание конкурентов по ключевым словам
Следуя SEO-исследованию наиболее и наименее популярных ключевых слов, вы узнаете, какие ключевые слова используют ваши конкуренты. Для этого вы можете использовать один из программных инструментов, о котором мы расскажем ниже.
Шаг четвертый: рассмотрите геолокацию
Также при составлении семантического ядра важно ориентироваться на локации, в которых проживает ваша целевая аудитория.В конце концов, те же статьи о солнцезащитном креме будут намного популярнее в более теплых местах с большим количеством солнца.
Шаг пятый: создание запросов Longtail и LSI
После сбора основных ключевых слов вы должны сформулировать средне- и низкочастотный поиск. К ним относятся поиск с длинным хвостом и поиск LSI (латентное семантическое индексирование). И LSI, и длиннохвостый очень хорошо влияют на контекстный (семантический) поиск, что особенно важно с момента вступления в силу алгоритма поиска Google Hummingbird на основе искусственного интеллекта (подробнее читайте в статье Ключевые слова LSI).Поговорим о них подробнее.
LSI — косвенные ключевые слова. Это ключевые слова, которые контекстуально связаны с основным составом вашего семантического ядра, но имеют другую словоформу. Обычно это синонимы, геозависимые слова или другие слова, относящиеся к тому же предмету.
Самый простой способ найти их — использовать специальные сервисы (их список представлен в следующем абзаце), но вы также можете попробовать ручной выбор, если вы знакомы с тематикой продвигаемого веб-сайта.Вы можете установить флажки PAA (Люди также спрашивают) и SRT (Поиск по теме), чтобы узнать возможные варианты LSI без использования стороннего программного обеспечения.
Например, если ваше семантическое ядро содержит ключевое слово Android, фразу Google Play можно отнести к LSI.
Что еще можно сказать о длиннохвостых запросах? Фактически, мы неоднократно упоминали о них выше: это поиск по маркерам с квалифицирующими префиксами. Самый простой способ найти их — ввести один из основных поисковых запросов в Google и просмотреть все варианты автозаполнения.
Например, при вводе запроса «скинни в джинсах женщины» вы увидите следующие длиннохвостые ключевые слова:
На их основе уже можно составлять целые кластеры ключевых слов, о которых пойдет речь на следующем шаге.
Шаг шестой: Кластер
Как только ключевые слова, потенциально полезные для вашего сайта, найдены, стоит начать кластеризацию запросов (группировку). Это необходимо для того, чтобы не складывать все ключевые слова вместе и не создавать мегаобзоры.Таким образом, вы можете добавить максимальное количество ключевых слов, а также распределить слова из группы по отдельным целевым страницам.
Кроме того, кластеризация позволяет сузить специфику определенных веб-страниц, поскольку объединение запросов в группы происходит по темам и словоформам. Такой подход повышает актуальность.
Как сгруппировать? Очень просто. Для этого вы берете любое высокочастотное ключевое слово и добавляете к нему хвосты, чтобы сформировать средне- и низкочастотные ключевые слова. Эти хвосты обычно представляют собой слова, описывающие местоположение, действие (например, покупку), цвет, время года и другие определяющие характеристики.Мы подробно объяснили, как это сделать, на предыдущем шаге.
И чтобы не гадать, какие слова можно использовать в качестве ключевых слов, мы предлагаем узнать больше об инструментах автоматического поиска. Они помогут провести максимально информированное исследование ключевых слов.
Популярные инструменты поиска по ключевым словам
Рассмотрим десять самых популярных программных решений для поиска по ключевым словам.
Google Adwords
Google AdWords, пожалуй, самый популярный инструмент поиска по ключевым словам и группировки.Несмотря на это, SEO-специалисты это не очень любят. Это потому, что планировщик очень навязчиво предлагает запустить рекламу. Несмотря на то, что это его основная задача, Google AdWords также очень хорошо ищет ключевые слова. Кроме того, нет возможности просматривать ежемесячную частоту поиска по ключевым словам.
Все недостатки полностью окупаются тем, что вы можете найти ключевые слова, которые не покажет ни один другой инструмент. Вы также можете научиться обходить предложение о запуске кампании, не платя Google ни цента.
Вы можете узнать больше о том, как Google AdWords работает как инструмент подсказки ключевых слов, из этого видео на Youtube.
Google Тренды
Это еще один достойный инструмент подсказки ключевых слов Google. Использование данных из поисковой системы определяет частоту поиска определенных терминов в зависимости от местоположения пользователей, их языка и определенного периода времени.
В целом это очень полезное решение для тех, кто постоянно ломает голову над обновлением семантического ядра.Чтобы узнать, как использовать этот инструмент и сделать SEO более эффективным, см. Как использовать Google Trends для SEO.
Исследование ключевых слов Semrush
SEMrush — еще одно приложение для поиска по ключевым словам, которое предоставит вам бесплатную 30-дневную пробную версию.
Включает полный набор инструментов для цифрового маркетинга и инструмент для поиска по ключевым словам. Это также очень мощное решение вместе с Google Adwords. Справедливости ради отметим, что он намного удобнее, и вы не найдете агрессивных предложений по запуску платных рекламных кампаний.
Ответ
AnswerThePublic — это надстройка для вашего браузера Chrome или Firefox. С его помощью вы можете постоянно отслеживать такие показатели, как ежемесячный объем поиска и CPC. Вы также получите подробные данные о конкуренции ключевых слов на нескольких сайтах.
Все это появится по нажатию всего одной кнопки. Один щелчок — и любые страницы конкурирующих сайтов покажут вам используемые ключевые слова.
Инструмент исследования ключевых слов SpyFu
Инструмент подсказки ключевых словSpyFu предлагает колоссальный список полезных данных по очень большому количеству ключевых слов.
Чтобы начать работу, вам нужно будет ввести одно ключевое слово в строку поиска. После вы получите целый список релевантных фраз. Выберите любой из них для своего сайта, ориентируясь на частоту и тематику вашего бизнеса.
Убер-совет
Ubersuggest — еще один инструмент поиска по ключевым словам, который дает вам представление о стратегиях, которые эффективно работают для ваших конкурентов. Это решение тоже абсолютно бесплатное.
Нужны дополнительные варианты ключевых слов? С помощью этого инструмента вы получите все, от основных ключевых слов до длинных фраз.Вы также увидите объем, конкуренцию и даже сезонные тенденции для каждого выбранного вами ключевого слова. Кроме того, чтобы упростить работу с ключевыми словами, Ubersuggest создает список ключевых слов, который основан не только на стратегии SEO для поиска ключевых слов, заимствованных у ваших конкурентов, но и на том, что люди вводят в поиске Google.
SEO книга
Это еще один отличный бесплатный инструмент для подсказки ключевых слов. Среди его основных функций — охват поиска по ключевым словам, параметрам поиска (локализация пользователя, период и т. Д.), оценочная стоимость поиска (цена предложения, умноженная на ежемесячный объем поиска), данные по рынкам Великобритании и США и быстрый экспорт 1000 ключевых слов с наибольшим весом.
WordStream
Это бесплатный инструмент, который использует последние данные поиска Google для создания наиболее точных и релевантных ключевых слов. Вместо случайного составления ключевых фраз, основанных исключительно на автоматических предложениях Google, вы можете использовать простой и интуитивно понятный WordStream, не выходя за рамки своего бюджета на SEO.
Серпстат
Этот инструмент подсказки ключевых слов использует уникальный древовидный алгоритм.Он проверяет положение страниц вашего сайта в результатах поиска и помогает их оптимизировать, используя правильно подобранные ключевые слова. Кроме того, с его помощью вы можете определить связанные ключевые слова, условия поиска и фразы, которые семантически связаны с запрошенным ключевым словом.
И, наконец, с помощью настраиваемых фильтров вы можете задать собственные параметры, чтобы получить набор оптимальных ключевых слов для вашего региона.
Чего не делать с ключевыми словами: Anti Trends 2020
Следуя рекомендациям по проведению исследования ключевых слов, мы решили дать список манипуляций, которые не стоит делать.Существуют плохие методы SEO, при которых игнорируются все усилия по поиску ключевых слов. Вот они:
- Подчеркивание только одного типа ключевого слова, либо только высокочастотных ключевых слов, либо только низкочастотных ключевых слов : Иногда новички в области SEO слепо следуют рекомендациям и стараются избегать высокочастотного поиска. Это негативно сказывается на позиционировании сайта в поисковой выдаче и препятствует его продвижению. Поэтому высокочастотные ключи должны присутствовать хотя бы один раз на каждой целевой странице.Когда игнорируются ключевые слова с небольшим процентом поисковых запросов пользователей, бывает и наоборот. Из-за этого теряются ценные идеи по созданию контента, а объем потенциального органического трафика снижается. Из этого следует вывод, что при продвижении сайта стоит использовать всевозможные ключевые слова, не упуская из виду источники потенциального трафика.
- Создание контента ради использования самих ключевых слов : Многие копирайтеры, даже в наше время, любят спамить ключевыми словами, создавая совершенно неинформативные и плохо читаемые текстовые холсты.Сделайте основной акцент на качестве и полезности контента, а не на том факте, что он содержит слишком много ключевых слов.
- Передача ответственности за поиск программных инструментов : Считается, что такие инструменты, как Google Adwords, способны выполнять всю грязную работу SEO-специалистов, включая работу, связанную с поиском по ключевым словам. Конечно, это очень полезные инструменты, но пренебрегать ручным анализом ключевых слов точно не стоит. Дело в том, что пока нет ни одного машинного алгоритма, который мог бы работать на одном уровне с человеком при отслеживании отраслевых тенденций и интересов целевой аудитории.
- Слишком большой набор ключевых фраз : Иногда программные инструменты для поиска по ключевым словам довольно сложны и требуют много времени при использовании. Если вы новичок и только запускаете свой сайт, имеет смысл следить за конкурентами и ключевыми словами, которые они используют на своем сайте.
Теперь вы знаете, как искать ключевые слова для SEO. Поиск по ключевым словам требует комплексного подхода и требует подробного анализа. В противном случае вы вряд ли сможете достичь оптимальных позиций в результатах поиска, если вместо этого не воспользуетесь черным SEO, о котором вы можете узнать больше в White Hat VS Gray Hat VS Black Hat SEO.
Расскажите нам в комментариях ниже о своем опыте поиска по ключевым словам. Насколько это было продуктивно? Вы использовали программные средства, описанные в статье? Как быстро вам удалось повысить позиции вашего сайта в поисковой выдаче?
Как автоматизировать сбор и очистку семантики от дубликатов и мусора
Инструменты сбора семантического ядрапозволяют собирать сотни и тысячи ключевых слов. Но в этом списке неизбежно будут повторяющиеся запросы, лишние символы, пробелы, фразы с нулевой частотой и т. Д.Весь этот «мусор» нужно убирать.
На примере интернет-магазина электроники мы шаг за шагом покажем, как использовать инструменты Click.ru, чтобы собрать пул запросов для контекста и привести его в удобную для использования форму.
1. Собираем пул запросов
Click.ru имеет бесплатный инструмент для сбора семантического ядра сайта. «Медиа-планирование».
Как с ним работать:
1. Зарегистрируйтесь на Click.ru. Щелкните Создать учетную запись. В открывшемся окне выберите рекламную систему и назовите аккаунт.
2. Добавьте кампанию. Назовите его, выберите места, где будут появляться ваши объявления, укажите URL, геотаргетинг.
3. Система предложит вам выбрать слова или добавить свои. Нажмите «Выбрать слова» — медиапланировщик выберет ключевые слова на основе содержания рекламируемого сайта.
4. Добавьте совпадающие слова в медиаплан. В нашем примере система собрала 623 ключевых слова. Чтобы добавить их в медиаплан, установите флажок в заголовке таблицы и нажмите «Добавить в медиаплан».
5. Расширьте семантическое ядро словами, которые продвигают ваши конкуренты. Для этого в «Автоматический подбор слов» выберите «Слова конкурентов».
Система предложит до 5 участников и соберет о них слова. Проверьте, совпадает ли диапазон предлагаемых сайтов-конкурентов с вашим. Если нет, удалите предложенные сайты и установите URL конкурентов самостоятельно (до 10 сайтов одновременно).
Системе потребуется несколько минут для сбора слов. После этого нажмите «Показать слова конкурентов».
В примере система собрала 2849 слов. Для их просмотра прокрутите таблицу вниз и нажмите «Показать все».
Просмотрите список собранных слов. Не все из них будут актуальными, потому что даже у ближайших конкурентов может не быть такого же ассортимента. Есть два способа избавиться от лишних слов:
- Удалить их сразу вручную
- Чистить уже в самом конце — после группировки (тогда слова можно удалять «связками», а не по одному).
Если слов много, лучше выбрать второй вариант.
Итак, теперь нам нужно выгрузить собранные ключи. Для этого добавьте их в медиаплан. Чтобы добавить все слова из таблицы в медиаплан, установите флажок в заголовке таблицы — система автоматически установит флажки рядом с каждой фразой. Затем нажмите «Добавить в медиаплан».
Загрузите слова, добавленные в медиаплан, в файл .xls.
С помощью двух сборщиков (по содержанию сайта и по заявлению конкурентов) удалось собрать и добавить в медиаплан 3492 слова.Теперь все это нужно очистить.
2. Удаляем повторяющиеся запросы, спецсимволы, пробелы, пустые строки
Вручную найти дубликаты в списке из 1000 или более слов сложно. Для этого нужен бесплатный нормализатор ключевых слов.
Что он умеет:
- Удалить повторяющиеся слова в точном вхождении . Например, если инструмент обнаружит в списке две ключевые фразы «купите samsung galaxy s10», он удалит одну из них.
- Удалить дубликаты на основе морфологии и перестановки слов .Например, если система обнаружит две фразы «купить samsung galaxy s10» и «купить samsung galaxy s10 buy», то вторая фраза будет считаться дубликатом и будет удалена.
- Удалить специальные символы в начале и конце слова . В собранных запросах (особенно если это делается с помощью сторонних сервисов) могут появляться специальные символы: вопросительные знаки, плюсы и минусы. Например, нормализатор нашел в списке слов фразу с плюсом: «samsung galaxy s10 + buy.”Он просто удалит плюс и лишние пробелы, а сам запрос останется без изменений.
- Удаляет лишние пробелы . Если в начале, середине или конце ключевой фразы есть лишние пробелы, инструмент их обнаружит и удалит.
- Удаляет табуляторы и пустые строки . Инструмент убирает отступ в начале и конце строки. Если в таблице есть пустые строки, они также удаляются.
- Преобразует слова в нижний регистр .Если список содержит проанализированные заголовки, написанные в верхнем регистре, то система переводит их в нижний регистр.
- Заменяет e на e. Если вы не используете букву «е», установите флажок рядом с опцией «Заменить е на е».
Характеристики инструмента:
- Бесплатное использование.
- Проверка выполняется онлайн. Не нужно устанавливать программное обеспечение или держать страницу открытой.
- Неограниченное количество слов в списке.
- Выполненные задачи хранятся в аккаунте Click.ru неограниченное время.
- Не нужно вводить капчу.
Как пользоваться инструментом
Перейдите на страницу инструмента и добавьте слова.
Выберите, какие действия нужно выполнить с ядром, и нажмите «Выполнить».
Системе потребуется несколько минут для выполнения указанных действий. Отчет доступен для скачивания в виде файла .xlsx.
Чтобы загрузить отчет в «Списке задач», нажмите кнопку «Загрузить XLSX».
Отчет состоит из двух страниц:
- список слов, очищенных от дубликатов;
- начальные настройки (начальный список слов и настроек необходимых действий с ядром).
Фрагмент отчета:
В этом примере исходный список состоял из 3492 запросов. После очистки их количество сократилось до 2828 слов, то есть дубликаты занимали 19% ядра.
3. Удалить слова с нулевой частотой
Для целей контекстной рекламы слова с почти нулевой частотой не представляют интереса, так как для них не будет показов. Такие слова лучше сразу убрать.
Чтобы проверить частоту использования большого массива ключей, щелкните.ru есть парсер wordstat. Он собирает частоты из левого столбца Wordstat. Он анализирует частоту в любом регионе Яндекса и учитывает тип соответствия ключевых слов.
Как пользоваться инструментом
Перейти на страницу инструмента. Добавьте запросы.
Выберите регион, в котором инструмент будет анализировать частоты.
Укажите параметры сбора частоты. Инструмент собирает частоты по запросам в широкой переписке, фиксирует количество слов и морфологию, фиксирует порядок слов.
Подробнее о возможностях парсера Wordstat читайте в статье: «Как быстро определить частоту в Wordstat»
Чтобы запустить задачу, нажмите кнопку «Запустить сканирование». Время сбора зависит от количества запросов, регионов и типов соответствия.
Отчет доступен в списке задач в формате XLSX.
В отчете указывается частота запросов при различных типах соответствия. Удалите слова с нулевой и близкой к нулю частотами.
Важно! Будьте осторожны с ключевыми словами, связанными с сезонными товарами / услугами. В Wordstat статистика собирается за последний месяц, поэтому, если сейчас в вашей нише будет спад, частота будет низкой. Подробно о частотном анализе в Wordstat мы писали здесь. Google Trends также может помочь. Также рассказали, как с ним работать.
После удаления «нулей» можно переходить к группировке слов.
4. Разбейте собранные слова на группы и завершите очистку ядра.
Для группировки ключевых слов используйте кластеризацию.Инструмент группирует слова на основе сравнения ТОП результатов поиска в заданном регионе. Инструмент обычно используется SEO-специалистами для взлома ключей на страницах. Но он также хорошо подходит для контекстной рекламы.
Как пользоваться инструментом
Перейти на страницу инструмента. Для удобства навигации в отчетах укажите адрес сайта и назовите проект.
Запросы на загрузку с файлом или списком. В списке должно быть не менее 20 запросов.
Выберите метод кластеризации.Доступны два варианта: сравнение ТОПов и профессиональные настройки. В настройках укажите поисковую систему, диапазон точности, количество слов в кластере (для профессиональных настроек). Нажмите кнопку «Начать кластеризацию».
Подробнее о настройке и возможностях кластеризации Click.ru читайте в статье «Как сгруппировать ключевые запросы с помощью кластеризации?»
Загрузить отчет в списке задач.
В отчете запросы объявлений сгруппированы в кластеры по результатам поиска.Просмотрите отчет и удалите кластеры с нерелевантными запросами. Намного удобнее делать это прямо сейчас, а не по одному слову во время выделения.
В результате вы получаете сгруппированную семантику без мусора, готовую к использованию.
Недостаточно слов для семантики — развернуть список
Бывает, что после очистки список слов сильно сокращается. В этом случае используйте инструменты для расширения семантики:
Подробнее о расширении ядра в узкой нише читайте в статье «Как расширить англоязычную семантику для поисковой рекламы в узкой нише.”
Еще один вариант пополнения семантики — парсинг ключевых слов, запустивший рекламу конкурентов с помощью бесплатного парсера. Подробности о нем — по ссылке.
Кластеризация ключевых запросов. Кластеризация семантического ядра и поисковых запросов
Кластеризация запросов сортирует (разбивает) список семантического ядра (SJ) на группы сходства, что позволяет дополнительно оптимизировать под них страницы сайта.
Как кластеризованы запросы?
Инструмент анализирует выдачу Яндекс по каждому запросу и сравнивает ее с выдачей остальных запросов из списка.Если в ТОП-10 по разным запросам попадают одинаковые релевантные страницы, то эти запросы определяются как похожие и помещаются в одну группу. Это означает, что под них можно оптимизировать одну страницу.
Порог кластеризации запросов — это количество совпадающих релевантных страниц в результатах поиска для различных запросов. Проще говоря, если вы вводите два запроса в Яндекс и в ТОП-10 есть две одинаковые страницы (две из десяти), то при установке «порога кластеризации 2» эти два запроса будут помещены в одну группу.
Минусы ручной группировки запросов
Группировка ключевых запросов, также известная как разбивка, выполняется специалистами по оптимизации сразу после сбора AO.
- При большом количестве запросов сложно вручную определить их сходство между собой, приходится либо вводить каждый запрос в поиск, либо полагаться на интуицию / опыт, которые могут сыграть злую шутку с продвижением, а не дают желаемый результат.
- Высокая стоимость, которая образовалась из-за длительности процесса.Хорошая разбивка семантики с 500 встроенными запросами занимает в среднем 4..16 часов. Надо каждый запрос вычесть, определить его группу (наличие которой нужно иметь в виду), при необходимости перепроверить поиском или сервисами … бррр.
Плюсы автоматической группировки запросов
- Скорость пробоя примерно равна скорости звука. Система проверит выдачу каждого из запросов, сравнит их и даст возможность вручную исправить возможные незначительные исключения, после чего результат можно будет загрузить в файл CSV (Excel).
- Точность результата достигается за счет исключения человеческого фактора. Человек может отвлекаться и терять мысли, забывать, неправильно понимать или просто быть не в состоянии правильно сломаться; с программой таких сложностей не наблюдается.
- Инструмент предоставляется совершенно бесплатно; не требует ежемесячной заработной платы, отпусков, больничных; У него тоже нет графика работы: он работает 24/7.
Пагинация — очень важный процесс в продвижении, он ставит цели по оптимизации каждой страницы проекта и всего сайта в целом.
Сегодня мы поговорим о таком важном процессе подготовки к созданию контента для сайта, как кластеризация семантического ядра. Это группировка ключевых запросов от ядра в группы, так что каждая группа имеет свою страницу. После сбора ключевых слов для проекта они представляют собой список без какой-либо структуры или иерархии. В списке запросы очень похожи друг на друга и существенно различаются по смыслу.
Кластеризация позволяет группировать запросы для максимального соответствия одной странице.Кластеризация осуществляется как вручную, так и автоматически с использованием множества сервисов, существующих в Интернете. Давайте рассмотрим все приемы, которые можно применить, распределяя и группируя запросы на страницах сайта.
Содержание статьи:Кластеризация запросов ядра сайта вручную
Несмотря на то, что это довольно трудоемко и занимает много времени, это наиболее качественный вариант группировки. Подходит для небольших проектов, когда количество ключей не слишком велико.Если ключей несколько тысяч, лучше провести автоматическую кластеризацию, а затем изменить результаты вручную.
Делается просто. Ключи собраны в отдельные группы по смыслу. Чтобы было понятнее, приведу пример. Здесь собраны ключевые слова для информационного проекта по детским болезням. Необходимо разбить все смысловое ядро на группы по конкретным заболеваниям, чтобы писать о них и о методах лечения конкретные статьи.
Выбирая из массы ключей, собранных по запросу «Грудное вскармливание» те, которые содержат слово «тремор», мы соберем кластер ключей, в который будут входить все запросы, связанные с тремором у младенцев.Именно их нужно использовать при написании статьи о заболевании.
В ручной группировке вам поможет обычный Excel или Google Таблицы, позволяющие сортировать, фильтровать и выделять в них нужные строки и слова. Существуют также бесплатные сервисы, упрощающие группировку вручную. Это, например, сервис Keyword Assistant, который позволяет в несколько кликов выбрать нужные ключи из общего списка и разместить их в группе.
Автоматическая кластеризация запросов — онлайн-сервис
Автоматическая кластеризация выполняется по определенным алгоритмам.Она делает то же самое, что и мужчина. Из плюсов стоит выделить скорость работы в тысячи раз быстрее ручной, а также анализ ключевых слов и их позиций в поисковой выдаче.
Из минусов — полное отсутствие логического мышления в алгоритмах, из-за чего часто встречается некорректное включение запросов в группы. Также явно релевантные запросы не могут быть включены в одну группу. Например, запросы «Как одеть ребенка при низкой температуре наружного воздуха» и «Температура 39 для ребенка» относятся к разным группам, но алгоритмы часто объединяют их в одну.
В любом случае, после автоматической кластеризации семантическое ядро нужно модифицировать вручную, чтобы привести его к идеальному виду. От качества группировки напрямую зависит дальнейшая оптимизация сайта.
Для автоматической работы рекомендую сервис Rush analytics , который является мощным инструментом в помощь оптимизатору. Достаточно добавить все ключевые запросы, и программа максимально быстро их сгруппирует. Единственный минус в том, что услуга довольно дорогая и если вам нужно разовое использование, лучше найти оптимизатор с подпиской.За сотню-два рубля добавит ключи для пробега в сервисе.
Также актуальны следующие ресурсы: Seo intellect, KeyAssistant.
Особенности семантики кластеризации коммерческих сайтов
Если с запросами на информационные проекты все понятно. Здесь стоп-слова — это все коммерческие фразы со словом купить, заказать и т.д., то с рекламой не все так просто. Стоит немного внимания уделить тому, как лучше сгруппировать ключи, например, для интернет-магазина.
Например, в магазине электроники продаются телевизоры. Есть масса запросов со словом TV, и нам нужно их сгруппировать. Все запросы, относящиеся к коммерческим, такие как «Купить телевизор Samsung», «Купить телевизор диагональю 43», мы распределяем по нашим кластерам: по марке, диагонали или другим свойствам.
Но мы сортируем информационные запросы типа «Как выбрать хороший телевизор» или «Какой телевизор хороший в 2017 году» отдельно и предоставляем раздел блога в структуре сайта, где мы будем рассказывать пользователям о выборе или преимуществах того или иного объекта недвижимости. техники.Таким образом, мы можем привлечь больше трафика с помощью информационных запросов.
Как видите, кластеризовать семантическое ядро несложно, просто требуется много времени. Но это один из столпов подготовки к запуску проекта.
- Прочтите статьи по теме:
Даем на счет 200 лимитов попробовать!
Кластеризация ключевых слов — это автоматическое распределение запросов по группам на основе выдачи поисковыми системами.
Алгоритм кластеризации Rush Analytics будет собирать ТОП-10 URL-адресов поиска Яндекс или Google для каждого из ваших ключевых слов, сравнивать результаты по каждому ключевому слову и группировать запросы точно, как они будут успешно продвигаться в поисковых системах и насколько это будет удобно и Логично создавать страницы на сайте.
Rush Analytics можно кластеризовать двумя способами: мягким и жестким.
После обработки запросов вы получите практически готовую и правильно сформированную с точки зрения поисковых систем структуру сайта.А на основе данных о частоте для каждой группы ключевых слов вы легко можете принять решение о создании дополнительных страниц на сайте.
Посмотрите видеоурок по функциональности кластеризации.
Часто задаваемые вопросы о кластеризации: наши часто задаваемые вопросы
Кластеризация — это группировка ключевых слов, основанная на сравнении результатов поисковых систем. Алгоритм соберет ТОП10 URL по вашим ключевым словам, сравнит результаты по каждому ключевому слову и сгруппирует запросы ровно , насколько они будут успешно продвигаться в поисковых системах, и насколько удобно и логично будет создавать страницы на сайте
Вам необходимо загрузить список ключевых слов и их частоту (любую) в Rush Analytics или пометить ключевые слова как основные (маркерные запросы) и все остальные.
Для использования комбинированного алгоритма кластеризации вам потребуются как частота, так и разметка маркеров. Об этом читайте ниже.
Точность кластеризации указывает, сколько общих URL-адресов должно быть в результатах поиска для двух запросов, чтобы мы объединяли эти запросы в группу.
Другими словами, чем выше точность кластеризации (группировки), тем больше похожих фраз попадет в одну группу (кластер).
Для большинства топиков хватит точности = 5.
A: Каждая тема имеет свой необходимый и достаточный порог схожести результатов для получения качественного семантического ядра.Например, при продвижении интернет-магазинов будет большой проблемой, если при кластеризации запросов ключевые слова «мультиварка Redmond RX500» и «мультиварка Redmond RX500-1» попадут в один кластер — потому что это разные продукты и они должны быть продвигаются к разным карточкам товаров. Здесь рекомендуем использовать точность = 5
Если трафик на сайт в основном российский и с Яндекса, оптимально кластеризовать по Яндекс, выбрав регион, по которому движется сайт.
Вы можете использовать обе поисковые системы, а затем сравнить результаты. Часто результаты поисковых систем очень похожи.
Если продвигать сайт на другие рынки, кластеризация теперь доступна для всех регионов и языков мира по данным Google.
Скоро добавим функционал выбора страны и города для кластеризации при выдаче Google.com. Если вам интересен этот функционал — голосуйте в нашем сообществе и он появится намного быстрее — ссылка для голосования
Да, можно.А иногда даже нужно.
Когда два кластера можно объединить в один?
Часто такие ключевые слова, как «купить мультиварки редмонд» и «цена мультиварок редмонд» могут попадать в разные кластеры из-за низкого качества результатов поиска в Яндекс и Google по этим запросам.
В этом случае нужно объединить эти кластеры в один и продвинуть на страницу мультиварки redmond . Это совершенно нормальная ситуация.
Когда невозможно объединить два кластера в один?
Когда в одном кластере информационные запросы, а в другом коммерческий.Например, кластеры «купить мультиварки Редмонда» и «Обзор мультиварки Редмонда» нельзя объединить, потому что эти запросы должны принципиально перемещаться на разные страницы.
Сомневаюсь, объединять два кластера или нет, что делать?
Мы подробно рассказываем, что делать в этом случае, в этом руководстве.
Потому что слова из вкладки Некластеризованные не нашли пары для кластера. К сожалению, не все ключевые слова можно сгруппировать, потому что не все они взаимосвязаны.
Мы руководствуемся в первую очередь тем, как ключевые слова будут продвигаться (ранжироваться) и группироваться на основе схожести результатов поиска.
Например: запросы «мобильный телефон» и «мобильные телефоны» следует продвигать на разные страницы, потому что один запрос является информационным, а второй — коммерческим, и они никогда не будут продвигать одну страницу.
Что делать с некластеризованными запросами?
Если вы найдете ключевые слова, которые представляют для вас ценность в списке некластеризованных слов, вы можете вручную добавить их в существующие группы (они могут не быть прикреплены из-за плохих результатов) или вы можете создать отдельные страницы на сайте для этих слова.
Перед кластеризацией все фразы, содержащие стоп-слова, будут исключены из списка. Те. Ключевые слова мусора не будут использоваться при кластеризации и будут отброшены даже до сравнения запросов.
Мы рекомендуем использовать эту опцию, если вы загружаете грязный список ключевых слов в проект кластеризации. Функционал помогает сэкономить бюджет на кластеризацию и решает проблему ручной, утомительной очистки стоп-слов в Excel. Предлагаем использовать готовые списки стоп-слов для гео-запросов и различной тематики, либо составить собственный список стоп-слов.
Пошаговый алгоритм работы с сервисом:
- Создайте проект. Для создания проекта перейдите на вкладку кластеризации и нажмите «Создать новый проект»
- Шаг первый: поисковая система и регион .
Здесь необходимо ввести название проекта (обязательное поле). Вы можете ввести любое имя, часто удобно вводить название сайта, чтобы в дальнейшем было легко найти нужный проект.Далее указываем поисковик, по которому будет производиться группировка.Вы можете выбрать Яндекс или Google.
Для Google на данный момент доступны все регионы и языки мира. - Шаг второй: настройки сбора
Все о наших алгоритмах кластеризации
Метод кластеризации :- Мягкая кластеризация: в этом методе кластеризации алгоритм определяет центральные (маркерные) запросы и сравнивает с ними все остальные запросы. Алгоритм идеально подходит для кластеризации ключевых слов для проектов по трафику: интернет-магазинов, информационных сайтов, сервисных сайтов с небольшой конкуренцией.
- Жесткая кластеризация: запросов группируются только при наличии общего набора URL-адресов для всех запросов. При таком типе кластеризации группируется меньше ключевых слов, но с очень высокой точностью. Идеально подходит для конкурентных высокочастотных запросов.
У нас есть 3 алгоритма кластеризации:
- Кластеризация ручных маркеров
- Wordstat Кластеризация
- Комбинированный алгоритм кластеризации (маркеры рук + Wordstat)
Они работают по одному и тому же основному принципу — сравнивают схожесть ТОПов поисковых систем, но предназначены для решения нескольких разных задач.
Алгоритм маркера руки:
Этот алгоритм наиболее эффективен, когда у вас есть готовая и достаточно разветвленная структура сайта (каталога), и вы заранее знаете все маркеры и вам просто нужно понимать, по каким запросам вы собираетесь продвигать существующие страниц, а задача по расширению структуры сайта не стоит. В этом случае вы берете свои маркеры (названия категорий / страниц), собираете с них подсказки, отмечаете маркеры как 1, собранное облако как 0 и отправляете их на кластеризацию.На выходе вы получите готовую семантику для своих категорий, а слова, не привязанные к вашей структуре, останутся некластеризованными.
Формат загрузки данных: ключевое слово | marker (1/0) — скачать образец входного файлаАлгоритм кластеризации Wordstat
Этот алгоритм, скорее всего, решает проблему, противоположную алгоритму ручного маркера: вы все еще не знаете структуру своего сайта и не можете выбрать маркеры — вы просто собрали Wordstat, подсказки и частоту из подсказок.Теперь вам нужно структурировать эту семантику, чтобы получать группы запросов для страниц будущего сайта или будущих категорий существующего сайта. В этом случае алгоритм кластеризации Wordstat подойдет, он работает следующим образом.
Весь список ключевых слов сортируется в порядке убывания частоты, алгоритм пытается связать все возможные слова из списка с самим частотным словом и формирует кластер, затем все повторяется итеративно для ключевых слов со следующей частотой.
Не беспокойтесь, что ключевые слова могут быть прикреплены к неправильному кластеру во время первого прохода алгоритма — мы используем алгоритмы машинного обучения, построенные на двоичных деревьях, чтобы предотвратить это 🙂
Формат загрузки данных: ключевое слово | частота (любая) — скачать пример входного файлаКомбинированный алгоритм (ручные маркеры + Wordstat) — объединяет подходы двух предыдущих методов.
Этот алгоритм подходит для задачи одновременного подбора ключевых слов для существующей структуры сайта и его расширения.Работает это следующим образом: сначала мы стараемся привязать все возможные запросы к вашим запросам маркеров и сформировать готовую структуру, привязанную к вашим маркерам. Далее все запросы, не привязанные к маркерам, сортируются в порядке убывания частоты и группируются между собой. В результате вы получаете:
а) Готовую семантику для существующих категорий сайтов
б) Расширяющую семантику для вашего сайта.
Настоятельно рекомендуем использовать комбинированный алгоритм. — он дает лучший результат.
Формат загрузки данных: ключевое слово | | маркер (1/0) | частота — скачать образец входного файлаВсе, что вам нужно знать о точности кластеризации
Точность — чем выше точность кластеризации (группировки), тем больше похожих фраз попадет в одну группу (кластер).
Другими словами, эта опция отвечает за то, сколько общих URL-адресов необходимо в ТОП10 поисковой системы, чтобы ключевые слова попали в один кластер.Каждая тема имеет свой необходимый и достаточный порог схожести результатов для получения качественного семантического ядра. Например, при продвижении интернет-магазинов будет большой проблемой, если при кластеризации запросов ключевые слова «Мультиварка Redmond RX500» и «Мультиварка Redmond RX500-1» попадут в один кластер — потому что это разные продукты и они необходимо продвигать на разные карточки товаров.Здесь мы рекомендуем использовать точность = 5
Для инфотем, например, для сайтов скидок или рецептов, такая точность не нужна — здесь задача получить максимальное количество кластерных кластеров для написания статей. Для таких сайтов мы рекомендуем точность 3 или 4. А для сайтов очень конкурентной тематики, где борьба за ТОП в основном основана на конкурентных RF-запросах, мы рекомендуем использовать повышенную точность кластеризации 6 или 7, и создавать отдельные страницы для неконкурентоспособных -кластеризованные запросы.Рекомендуется выбрать варианты 3-6 и по результатам посмотреть, какая кластеризация будет иметь достаточную полноту и точность для вашей семантики. Чем выше значение точности, тем меньше группы.
Другие настройки кластеризации
Не кластеризовать, если частота меньше — эта опция позволяет не кластеризовать ключевые слова с частотой меньше указанной. Это избавит вас от ручной очистки малопопулярных запросов — такие слова будут помещены во вкладку «Не кластеризовано».Определение релевантных URL-адресов для кластеров существующего сайта
Вам просто нужно ввести имя нужного домена, и наши алгоритмы попытаются определить соответствующие URL-адреса для результирующих кластеров.
Опция работает следующим образом: если по основному (маркерному) запросу ваш сайт уже находится в ТОП10, мы покажем этот URL и выделим его зеленым цветом. В противном случае мы выберем URL для запроса маркера с помощью оператора site :.ВАЖНО: Релевантные URL-адреса выбираются для маркерных (основных) запросов кластера и назначаются всему кластеру (всем ключевым словам кластера).
- Шаг третий: «Ключевые слова и цена» .
Загружаем файл с запросами.
Поддерживаемые форматы: xls, xlsx. Формат ввода данных: запрос; маркер или частота. Для кластеризации с использованием метода Wordstat + Формат данных ручных маркеров: запрос; маркер; частота.Введите стоп-слова
Перед кластеризацией фразы, содержащие стоп-слова, будут исключены из списка. Функционал помогает сэкономить бюджет на кластеризацию и решает проблему ручной очистки стоп-слов.Эта функция особенно полезна при кластеризации «грязного», не очищенного ранее списка ключевых слов.Предлагаем использовать готовые списки стоп-слов для гео-запросов и различной тематики, либо создать собственный список стоп-слов. И не забудьте про «Экспертные параметры» — по умолчанию используется символьное соответствие — т.е. частичный ввод удалит все слово / фразу, если вам нужно точное совпадение со стоп-словом — выберите фразовое соответствие .
- Push «Создать новый проект» — все, ваш проект отправлен на кластеризацию!
Rush Analytics на данный момент имеет 5 статусов:
Очередь — данные еще не собраны, проект ожидает своей очереди для сбора данных
Сбор данных — счетчик показывает, сколько ключевых слов обработано
Кластер — данные проекта имеют уже собраны, система рассчитывает все необходимые метрики, чтобы предоставить вам результат.
На паузе — вы можете вручную поставить проект на паузу, если вы не уверены, что хотите его собрать.Или сам проект может быть приостановлен, потому что у вас закончились деньги на балансе.
Готов — проект готов — вы можете увидеть результаты в веб-интерфейсе или загрузить в формате XLSX
Выходной файл кластеризации — Описание столбца
Результат кластеризации в формате XLSX следующий:
- Запросы, выделенные серым цветом — запросы маркеров — указываются вручную или определяются системой
- Имя кластера — берется имя запроса маркера
- Размер кластера — количество ключевых слов в группе
- Частота ключевого слова — частота, которую вы задаете на шаге Ключевые слова.В зависимости от того, какую частоту вы использовали — базовую, в кавычках или с восклицательным знаком, результаты кластеризации могут незначительно отличаться
- Общая частота кластера — сумма частот всех ключевых слов в кластере
- TOP соответствует — количество общих URL в результатах поиска по данному запросу с выдачей справочного (маркерного) запроса
- Подсветка — Выделения из поисковых систем, собранные по вашему ключевому слову
- Подсветка кластера — Подсветка без дубликатов, по всем словам этого кластера
- Верхний URL — URL-адрес наиболее заметного конкурента во всех запросах кластера.Здесь мы оцениваем частоту появления URL-адресов конкурентов в поисковой выдаче для каждого запроса и положение каждого URL-адреса конкурентов в поисковой выдаче .
- Соответствующий URL — найден релевантный URL для кластера, если была выбрана опция «Определить релевантные URL».
Опция работает следующим образом: если по основному (маркерному) запросу ваш сайт уже находится в ТОП10, мы будем показать этот URL и выделить его зеленым цветом. В противном случае мы выбираем URL для запроса маркера с помощью оператора сайта:
Кластеризация ключевых слов — Это автоматическое распределение запросов по тематическим кластерам (группам) на основе схожести результатов поиска Яндекс или Google.Кластеризация проводится для решения следующих задач:
- Чтобы понять, какие запросы нужно продвигать вместе и на одной странице, а какие отдельно
- Превратить огромное количество запросов семантического ядра из «беспорядка» в понятную и логичную структуру
- Чтобы сразу связать целые группы запросов с существующими страницами на сайте и сделать продвижение максимально эффективным
Этот способ группировки запросов появился на рынке совсем недавно, но уже успел завоевать большую популярность.Какие преимущества у этого метода?
Преимущества верхней кластеризации
- Однозначное определение запросов, которые должны продвигаться на одну страницу, и наоборот — запросов, которые никогда не продвигаются на одну страницу, несмотря на их схожесть
- Учет синонимов и переформулировок — при группировке по методу топов запросы «рабочая одежда», «одежда рабочая», «рабочая одежда» будут учтены и прикреплены правильно без потери
- Огромная скорость группировки запросов семантического ядра.В отличие от ручного синтаксического анализа или синтаксического анализа с использованием шаблонов в Excell, кластеризация методом верхнего уровня занимает минуты, а не часы, дни или недели
Недостатки кластеризации верхнего уровня
- При низком качестве доставки по запросу или по всей теме (много неактуальных ответов, много форумов, наличие дорвеев и т. Д.) Качество кластеризации пропорционально снижается
- Сложность реализации этого метода группировки: нужен сложный многоступенчатый алгоритм, нужно собрать много данных с выхода
Кластеризация запросов в Rush Analytics
Создавая модуль кластеризации в Rush Analytics, мы постарались сделать его максимально гибким и удобным, чтобы наше решение подходило для любой задачи и любой тематики, а именно:
- Высокая скорость сбора и группировки запросов.Кластеризация семантического ядра, в зависимости от его размера, займет от нескольких секунд до нескольких минут
- Настраиваемая точность группировки — в зависимости от качества вывода по вашей теме и других факторов вы можете выбрать подходящую точность кластеризации — от 3 до 8
- Три алгоритма кластеризации:
A) По Wordstat — наиболее частыми запросами становятся вершины кластера (запросы, к которым будут привязаны остальные). Отлично подходит для информационных тем.
Б) По маркерам — вы сами выбираете маркерные запросы, которые станут вершинами кластера. Отлично подходит для магазинов с преобладающим спросом на товары.
C) Гибридный алгоритм — маркеры указываются вручную, производится группировка запросов. Для запросов, для которых не удалось выполнить привязку с помощью первого метода, автоматически выбираются вершины кластеров с помощью Wordstat и выполняется повторная кластеризация. Этот метод позволяет добиться максимальной точности и полноты.Подходит для любых проектов.
- Простой и понятный интерфейс, понятный как новичкам, так и опытным профессионалам.
- Отзывчивая служба поддержки. Если у вас есть какие-либо технические проблемы или вам просто нужна помощь по любому вопросу кластеризации, сбора советов или Wordstat, наша служба поддержки будет рада вам помочь.
Группировка ключевых слов (или, по-другому, кластеризация запросов) — это разделение ключевых слов на однородные группы по определенным критериям.Создан для повышения релевантности между ключевыми словами и рекламными объявлениями. В результате улучшается качество рекламных кампаний и снижается стоимость клика по объявлению.
При подготовке рекламных кампаний группировка ключевых слов занимает много времени. Некоторые эксперты используют подход «1 ключевое слово — 1 группа объявлений», который избавляет от необходимости группировать и экономит время. Но пользоваться им не всегда удобно, особенно при большом количестве низкочастотных ключевых слов. Если у вас есть кластерные ключевые слова, то есть разбивка на семантические группы, то структура рекламной кампании становится более понятной и простой для анализа.
Группировка ключевых слов и поисковые запросы с помощью инструмента PPCПоследнее изменение группировки ключевых слов: 24 марта 2017 г. на сайте
Семантическое ядро: зачем оно нужно, из чего состоит и как его собрать
Семантическое ядро - набор слов и ключевых фраз, которые будут использоваться для продвижения сайта в поисковых системах. Другими словами, это слова, по которым пользователи будут находить сайт в результатах поиска.
Зачем вам семантическое ядро?Сбор семантического ядра — один из первых этапов работы над сайтом, потому что на основе выбранных ключевых слов специалисты будут:
- Распространите их на определенных страницах, для чего может потребоваться изменить всю структуру сайта, добавить новые страницы и т. Д.
- Создайте контент для этих ключевых слов.
- Составляйте заголовки и описания страниц.
Следовательно, нужно как можно раньше начинать работу над семантическим ядром. Ключевые запросы можно подбирать как для всего сайта, так и для его отдельных частей, в зависимости от целей продвижения.
Из чего состоит семантическое ядро Семантическое ядро формируется из релевантных ключевых слов сайта. Ключевые слова — это слова или фразы, которые пользователи Интернета вводят в строку поиска при поиске нужной информации.
Ключевые слова или запросы можно классифицировать по-разному в зависимости от их характеристик:
- По частоте, т.е. в зависимости от того, как часто пользователи вводят слово или фразу в строку поиска. Здесь принято выделять высокочастотные, среднечастотные и низкочастотные слова и словосочетания. Причем для каждой темы будут свои диапазоны, например, для «пластиковые окна» и «музыкальная школа» определение высокочастотного запроса будет совершенно другим.При составлении семантического ядра важно использовать ключевые запросы разной частоты. Желательно не забывать про средне- и низкочастотные специфические запросы, которые четко укажут на намерение пользователя, например, «купить байк bmx в туле». Если вы выберете только высокочастотные запросы, продвижение будет сложным и дорогостоящим из-за высокой конкуренции, более того, общий характер запросов, не отражающий конкретное намерение пользователя, может привести к неадекватному трафику на сайт, например , запрос пользователя «велосипед bmx» ничего не говорит о цели его поиска.
- Ключевые запросы также имеют следующие характеристики: геозависимые (есть ссылка на конкретный регион) и негеозависимые (без региональной ссылки), информационные (отражают желание пользователя найти информацию), транзакционные (указать намерение пользователя что-то купить), бренд (содержать название бренда). Для коммерческих сайтов в первую очередь необходимо выбрать транзакционные запросы, для новостных порталов — информационные.
Формирование семантического ядра начинается с выбора базовых запросов, которые в основном являются высокочастотными.Затем этот основной список расширяется, чтобы включить ключевые слова среднего и низкого диапазона.
Если вы хотите составить основной список запросов самостоятельно и вручную, вам просто нужно записать слова и фразы, которые:
- Соответствуйте теме вашего сайта. Для каждого раздела необходимо записать слова и словосочетания с названиями основных товаров, услуг, характеристиками товаров и т. Д.
- Просмотрите сайты конкурентов, а также запишите основные ключевые слова, которые там используются.
Также для составления списка основных ключевых слов можно использовать специализированные сервисы для сбора семантики, о которых будет сказано ниже.
Расширение семантического ядраСледующим шагом будет расширение семантического ядра. Каждую фразу из базового списка необходимо как можно больше дополнить и перефразировать, чтобы получить как можно больше среднечастотных и низкочастотных запросов. И на данном этапе самый простой и быстрый способ — не делать это вручную, а воспользоваться специальными сервисами.
Яндекс.WordstatБесплатный сервис Яндекс.Wordstat доступен всем пользователям, зарегистрированным в Яндекс. Воспользоваться сервисом не так уж и сложно: достаточно ввести желаемое ключевое слово или фразу в строку поиска.
Сервис предложит список ключевых слов, соответствующих запросу:
- «Что искали по слову« … »–n совпадений в месяц» — количество поисков пользователей Яндекс с этим словом. Для расчета система использует данные за последние 30 дней.
- В левом столбце представлена статистика показов ключевых слов, содержащих запрос, и прогнозируемых показов для них.
- В правом столбце отображаются запросы, подобные заданному пользователем, и прогнозируемые им показы.
- Вкладка «История запросов» показывает динамику интереса пользователей к определенной теме за последние два года — здесь вы можете увидеть ежемесячный или еженедельный фрагмент статистики показов для данного запроса.
Бесплатный инструмент от Google находится в сервисе Google Advertising и позволяет выбирать ключевые слова и оценивать предполагаемую эффективность списков слов.Для использования инструмента требуется учетная запись Google.
Что можно делать с Планировщиком ключевых слов:
- Выберите ключевые слова, релевантные тематике сайта или целевой страницы, а также товарам и услугам, которые предлагаются на сайте.
- Просмотр данных о количестве запросов вариантов ключевых слов за определенный диапазон дат.
- Отфильтруйте результаты по тексту ключевого слова, среднему количеству поисковых запросов в месяц, минимальной и максимальной ставке для показа вверху страницы, проценту показов, полученных в обычных результатах поиска, проценту полученных показов объявлений.
- Просмотр статистики и прогнозов трафика.
- Просмотр данных визуализации в динамике количества поисковых запросов, платформ и локаций.
Платная программа Key Collector в первую очередь предназначена для сбора семантического ядра.
Особенности набора семантик, которые предлагает сервис:
- Key Collector не использует готовые базы данных и не генерирует ключевые фразы.Сервис основан на сборе данных непосредственно из исходных сервисов.
- В программе используются как русскоязычные, так и зарубежные исходные сервисы: статистика Яндекс.Wordstat, Google AdWords, Яндекс.Метрика, Google Analytics, LiveInternet, Roostat; поисковые подсказки Яндекс, Гугл, Рамблер, Нигма, Yahoo, Почта, Яндекс.Директ; Похожие запросы от поисковых систем Яндекс, Гугл, Почта.
- Вы можете выбрать регион и установить глубину поиска, чтобы отрезать ненужные фразы.
- Помимо слов, которые нашла служба, вы можете добавить свои.
- Все ключевые слова можно оценивать по разным характеристикам: например, популярность, уровень конкуренции, сезонность, геозависимость и т. Д.
- Результаты можно экспортировать в формат Microsoft Excel или CSV.
Многофункциональная платформа для SEO-специалистов Serpstat предлагает несколько отчетов, которые помогут с выбором семантического ядра.
В разделе «Анализ ключевых слов» вы можете:
- Выберите органические ключевые фразы для семантического ядра сайта или отдельных категорий и страниц.
- Найдите конкурентов из своей ниши.
- Узнайте, какие вопросы задает целевая аудитория в поиске.
- Проанализировать страницу на соответствие поисковым запросам.
Сообщает, что предлагает услуга:
- Отчет о выборе фразы, в котором вы можете найти поисковые запросы из выбранной базы данных. Ключевые фразы можно сортировать по частоте запросов Google AdWords, цене за клик, количеству результатов поиска по ключевым словам, уровню конкуренции, количеству слов в ключевом слове, наличию дополнительных элементов в результатах поиска, наличию топонимов, ключевым словам с ошибками, присутствию или отсутствие конкретных ключевых слов, количество слов в ключевом слове.
- Отчет «Подобные фразы», где вы можете увидеть все поисковые запросы, семантически связанные с искомой ключевой фразой.
- Отчет «Подсказки поиска» показывает дополнительные ключевые фразы, которые поисковая система предлагает пользователю видеть, когда он что-то ищет в поиске. Фразы для этого отчета собираются из результатов поиска в реальном времени.
Еще один сервис, который может помочь с составлением семантического ядра.SEMrush предлагает SEO-специалистам сразу несколько инструментов.
Отчет об исследовании ключевых слов:
- Позволяет выбрать подходящие ключевые слова и просмотреть следующую информацию по каждому из них: цена за клик, количество запросов, количество результатов, динамика запросов за последние 12 месяцев и примеры объявлений для поискового запроса. .
- Вы также можете увидеть, на каких крупных сайтах используются определенные ключевые слова.
- Данные доступны как для настольных, так и для мобильных устройств.
- SEMrush в настоящее время предлагает 26 баз для следующих регионов: США (Google и Bing), Великобритания, Канада, Австралия, Россия, Германия, Франция, Испания, Италия, Израиль, Бельгия, Нидерланды, Дания, Финляндия, Ирландия, Норвегия, Польша. , Швеция, Швейцария, Сингапур, Турция, Бразилия, Аргентина, Мексика и Гонконг.
Инструмент Keyword Magic:
- Предлагает пользователям доступ к базе данных из 14 миллиардов ключевых слов.
- Ключевые слова отсортированы по группам по тематике поискового запроса.
- Ключевые слова могут быть отфильтрованы по количеству поисковых запросов, сложности ключевых слов, плотности конкуренции, исходным страницам в результатах поиска, данным на CPC.
Функционал сервиса, который поможет со сбором семантического ядра:
- Автоматический сбор Яндекс.Wordstat.
- Возможность собирать подсказки с поисковых систем Яндекс, Гугл и YouTube, используя многоуровневую структуру запросов. При этом автозаполнение и «фантомные подсказки» автоматически устраняются программными фильтрами.
- Автоматическая кластеризация ключевых слов на основе ТОП-10 результатов поиска.
В сервисе SpyWords вы можете найти следующий функционал для выбора семантики:
- Умный выбор запросов, основанный на следующем принципе: сервис рекомендует запросы не на основе семантического сходства, а на основе истории использования запросов ключевыми игроками в определенной теме.
- Анализ конкурентов, который также позволяет узнать информацию о контекстных кампаниях и позициях в органическом поиске: запросы в поиске и контексте, позиции и тексты объявлений и т. Д.
- Инструмент «Битва доменов», с помощью которого вы можете сравнить сайты-конкуренты и выяснить, с какими ключевыми словами они пересекаются.
При составлении семантического ядра многие специалисты допускают следующие ошибки:
- Семантическое ядро слишком мало и содержит только высокочастотные запросы.Поэтому не забывайте о его расширении и услугах, с помощью которых это можно сделать.
- Семантическое ядро содержит только одну формулировку названия товара или услуги, забыли о синонимах и альтернативных словосочетаниях. В этом случае вы можете обратиться к подсказкам поиска или сразу к сервисам, которые выбирают семантику на их основе.
- В семантическое ядро вошли все запросы подряд, в том числе не соответствующие содержанию сайта. Многие службы сбора семантики позволяют исключить определенные слова при поиске ключей и не пренебрегают этой функцией.
- Использование искусственных запросов (например, название раздела + «покупка»), которые в реальности пользователи никогда не введут в строку поиска.
- Используйте только одну базу для сбора семантики.
- Нежелание анализировать сайты конкурентов по ключевым словам.
После того, как семантическое ядро собрано, проанализировано и «вычищено», необходимо соотнести полученные группы ключевых фраз со страницами сайта (существующими и теми, которые необходимо будет создать), и перейти к следующим этапам продвижения сайтов: создание контента, работа с метатегами и т. д.d.
Салат-латук Справочное руководство
{
"name": "io.netty.util.internal.shaded.org.jctools.queues.BaseMpscLinkedArrayQueueColdProducerFields",
"fields": [{"name": "продюсерLimit", "allowUnsafeAccess": true}]
},
{
"name": "io.netty.util.internal.shaded.org.jctools.queues.BaseMpscLinkedArrayQueueConsumerFields",
"fields": [{"name": "consumerIndex", "allowUnsafeAccess": true}]
},
{
"name": "io.netty.util.internal.shaded.org.jctools.queues.BaseMpscLinkedArrayQueueProducerFields",
"fields": [{"name": "продюсераIndex", "allowUnsafeAccess": true}]
},
{
"имя": "io.netty.util.internal.shaded.org.jctools.queues.MpscArrayQueueConsumerIndexField ",
"fields": [{"name": "consumerIndex", "allowUnsafeAccess": true}]
},
{
"name": "io.netty.util.internal.shaded.org.jctools.queues.MpscArrayQueueProducerIndexField",
"fields": [{"name": "продюсераIndex", "allowUnsafeAccess": true}]
},
{
"name": "io.netty.util.internal.shaded.org.jctools.queues.MpscArrayQueueProducerLimitField",
"fields": [{"name": "продюсерLimit", "allowUnsafeAccess": true}]
},
{
"имя": "java.nio.Buffer ",
"fields": [{"name": "address", "allowUnsafeAccess": true}]
},
{
"name": "java.nio.DirectByteBuffer",
"fields": [{"name": "cleaner", "allowUnsafeAccess": true}],
"методы": [{"name": "", "parameterTypes": ["long", "int"]}]
},
{
"name": "io.netty.buffer.AbstractReferenceCountedByteBuf",
"fields": [{"name": "refCnt", "allowUnsafeAccess": true}]
},
{
"name": "io.netty.buffer.AbstractByteBufAllocator",
"allPublicMethods": правда,
"allDeclaredFields": правда,
"allDeclaredMethods": правда,
"allDeclaredConstructors": true
},
{
"имя": "io.netty.buffer.PooledByteBufAllocator ",
"allPublicMethods": правда,
"allDeclaredFields": правда,
"allDeclaredMethods": правда,
"allDeclaredConstructors": true
},
{
"name": "io.netty.channel.ChannelDuplexHandler",
"allPublicMethods": правда,
"allDeclaredConstructors": true
},
{
"name": "io.