Как пользоваться Яндекс Wordstat: инструкция для начинающих
Что такое Яндекс Wordstat
Яндекс Wordstat — это бесплатный сервис подбора слов, позволяющий оценить пользовательский интерес к определенной тематике, товару или услуге. Благодаря сервису вы можете получить информацию о количестве и частоте запросов в поисковой системе Яндекс по заданной фразе.
Яндекс Wordstat можно использовать для подбора ключевых слов при запуске контекстной рекламы, анализа популярности поисковых запросов, сбора семантического ядра для SEO-продвижения сайта.
Как пользоваться Яндекс Wordstat
- Для начала работы с сервисом перейдите на страницу Яндекс Wordstat. Если вы не авторизированы в Яндексе, войдите в аккаунт или создайте новый.
В поисковой строке введите интересующие вас ключевые слова или словосочетания и нажмите «Подобрать». Все ключевые фразы можно вносить в именительном падеже, так как сервис автоматически учитывает результаты запросов в разных падежах и числах.
После ввода ключевой фразы вы увидите статистику по прогнозируемому количеству показов по выбранному запросу. Прогноз формируется на основе данных за последние 30 дней и учитывает только результаты поиска Яндекса.
2. В левой колонке интерфейса отображается общая частотность запросов, включающих указанное ключевое слово и его словоформы, а также словосочетания, которые включают первоначальную ключевую фразу.
В правой колонке указаны похожие запросы, которые вводили пользователи в поиске Яндекса. Цифры рядом с каждым запросом обозначают прогнозируемое число показов в месяц по данной ключевой фразе.
3. Вкладка «По регионам» помогает понять, насколько указанный запрос популярен в регионе или конкретном городе.
Параметр «Региональная популярность» при значении более 100% говорит о повышенном интересе к данному запросу, менее 100% — о пониженном.
4.Обратите внимание, что по умолчанию отображается статистика по всем регионам, где используется поиск Яндекса. Вы можете выбрать конкретный регион показа объявлений во вкладке «Все регионы».
Вы можете выбрать конкретный регион показа объявлений во вкладке «Все регионы».
5. Также вы можете выбрать тип устройства пользователя. Фильтр «Десктопы» учитывает запросы с компьютеров и ноутбуков, «Мобильные» — с телефонов и планшетов.
6. Яндекс Wordstat позволяет оценить динамику пользовательских запросов по выбранной ключевой фразе. Данные анализируются за последние два года, что помогает определить сезонность пользовательского интереса. Информация доступна во вкладке «История запросов».
Работа с ключевыми словами
Важно понимать, что Яндекс Wordstat не отображает точное количество показов по заданной фразе. Значение «Что искали со словом…» подразумевает общее количество запросов, в которых встречаются указанные ключевые слова.
Так, по запросу «купить мебель» мы видим 37 859 показов. Однако, это число включает в себя показы не только по словам «купить мебель», но и все показы по запросам, включающим в себя это словосочетание, например, «купить мебель недорого» или «купить детскую мебель» и т.
Для более точной формулировки ключевых фраз используйте специальные символы и операторы. Например, если вы хотите узнать точное количество запросов по заданной ключевой фразе, используйте операторы ! и ««. В таком случае будут учтены запросы, не содержащие дополнительных слов, с фиксированной формой слов (число, падеж, время).
Пользуясь операторами, вы получите более корректные данные по частоте использования интересующих вас запросов, что позволит подобрать наиболее релевантные ключевые слова.
Получите бесплатные кампании для старта
При пополнении баланса eLama на сумму от 10 000 ₽ бесплатно создадим вам кампании в Яндекс.Директе и Google Ads.
Как пользоваться Wordstat — как работать с операторами Яндекс Вордстат и статистикой поисковых запросов
В этой статье мы расскажем:
- как работать со статистикой поисковых запросов Яндекса с самых азов;
- рассмотрим на примерах основные и дополнительные операторы;
- научимся определять сезонность спроса;
- дадим полезные советы по использованию софта, облегчающего работу.


Яндекс Вордстат – это бесплатный сервис компании Yandex, призванный помочь оптимизаторам и владельцам сайтов узнать, как люди ищут товары или услуги и собрать ключевые слова для продвижения сайтов.
Помимо этого, сервис позволит:
- узнать частотность;
- определить сезонность по каждому продвигаемому запросу;
- определить спрос по конкретным регионам;
- определить долю популярности фраз по устройствам (смартфон, десктоп, планшет).
Вы сможете собрать полное семантическое ядро и разработать структуру проекта. Сделать это проще с помощью специализированного софта, но вернемся к этому позже.
Начало работы
Для доступа к статистике сначала необходимо зарегистрироваться в Яндексе.
- заведите почтовый ящик на Яндекс и авторизуйтесь;
- откройте инструмент по ссылке https://wordstat.yandex.ru/.
Готово, можно приступать к работе.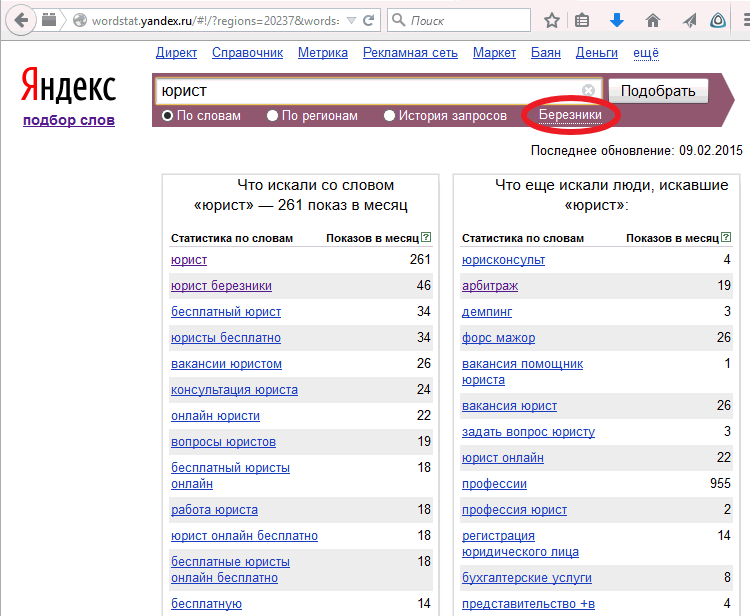
Поиск по словам
Осуществляется поиск запросов, в которых присутствует введенная фраза (в левой колонке), а также всех похожих (в правой колонке). В колонке «Показов в месяц» выводится базовая частотность за последний месяц (суммарная частотность фраз из левой колонки).
Частота по регионам
Отражает частотность запроса в отдельности по регионам, во второй и третьей колонках отражена популярность в числовом и процентном соотношении. Можно вывести списком и на карте для наглядности.
История запросов — сезонность запроса
С помощью этого инструмента можно проанализировать сезонность спроса по товару или услуге. Показывает популярность поискового запроса по месяцам или неделям. По скриншоту ниже видим, что спрос на услугу по «созданию сайтов» имеет значительный рост популярности в период с апреля по июнь.
Регион отображаемой статистики
Выбираем регион, статистика по которому нас интересует. При продвижении, скажем, по Москве – выбираем «Москва и область».
При продвижении, скажем, по Москве – выбираем «Москва и область».
Инструмент позволяет сделать выгрузку по всей России, а также СНГ, Европе, Азии, Африке, Северной и Южной Америке, Австралии и Океании.
Статистика по устройствам
Вкладки «десктоп, мобильные, только телефон, только планшеты» содержат информацию с каких конкретно устройств наиболее часто вводят поисковый запрос.
Операторы Wordstat
Операторы необходимы для уточнения формулировки запроса и точного определения частотности ключевых фраз. Если ввести интересующие слова без применения специальных символов, то получим их базовую частотность, то есть – суммарную частоту поисковых запросов пользователей Яндекс с применением данной фразы.
Пример:
Частотность всех ключей со словом «велосипед» – купить велосипед, детский велосипед, трехколесный велосипед и т.д.
Ниже предлагаем рассмотреть основные операторы.
“Кавычки”
Фразы, зафиксированные оператором “кавычки”, например «создание сайтов», отобразят частотность только данного словосочетания без хвостов, во всех возможных формах и в любом порядке.
Сбор статистики запросов определенной длины
С помощью оператора “кавычки” можно вывести на экран статистику запросов, состоящих из заданного количества слов – из 2, 3, 4 и так далее.
Например, чтобы получить список ключей из 2 слов по фразе «велосипед», введите в Wordstat следующую конструкцию – “велосипед велосипед”.
В итоге получаем ключевые слова и базовую частотность по всем запросам из двух слов с заданной фразой. Данная конструкция применима для произвольного количества слов в запросе и любых тематик.
!Восклицательный !знак
Если перед введенными фразами применить оператор «восклицательный знак», то получите частотность по всем фразам с их присутствием именно в том виде и с тем окончанием, как вы ввели.
“!Кавычки !с !восклицательным !знаком”
Если совместить использование операторов Яндекс Вордстат “кавычки” и !восклицательный !знак, сервис покажет частотность четко по заданной фразе слово в слово, без учета порядка.
Дополнительные операторы
Операторы, предназначенные для более сложной сортировки данных при работе со статистикой запросов Wordstat.
[Квадратные скобки]
С помощью данной конструкции фиксируется порядок слов в запросе.
Пример – [стол для обеда]
Абсолютно точная частота запроса с учетом порядка, состава слов и окончаний.
Для получения точной частотности, используйте конструкцию вида – «[!стол !для !обеда]».
(Или|Или)
Вводится с применением вертикального разделителя “|” между словами и заключением их в круглые скобки. Чаще всего применяется, когда необходимо сравнить статистику по двум одинаковым по смыслу запросам, но с разным написанием.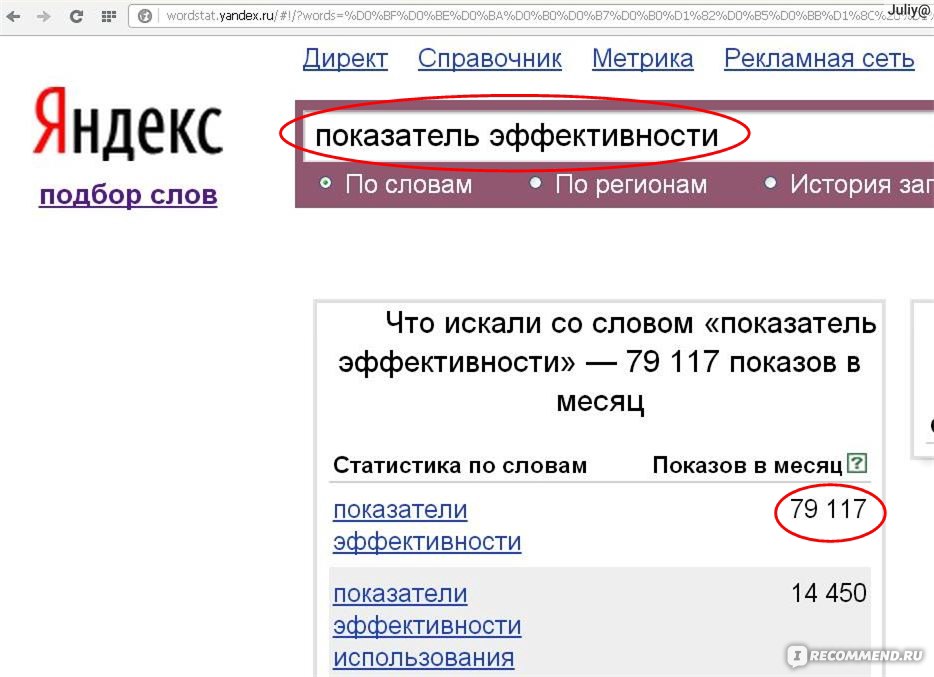
Пример –
(Iphone|айфон), (сайт|вебсайт), (раскрутка|продвижение).
Таким образом, Вордстат показывает все ключи и число их показов сразу по обеим фразам – “iphone” и “айфон”.
Оператор “+”
Если перед любым словом указать символ «плюс», то оно становится обязательным для программы. Также его использование очень полезно для выделения предлогов, так как сам Вордстат их не учитывает.
Пример #1. Вводим поисковый запрос с предлогом
Как мы видим, инструмент проигнорировал наличие предлога и мы не получили статистику в том виде, в каком хотели.
Пример #2. Указываем перед предлогом «+»
Теперь видим, что в левой колонке все запросы содержат нужное нам слово.
С помощью данной конструкции удобно готовить контент-план для публикаций в блоге. Для этого используйте вместе с основным запросом вопросительные плюс-фразы: «как, зачем, почему, своими руками» и так далее.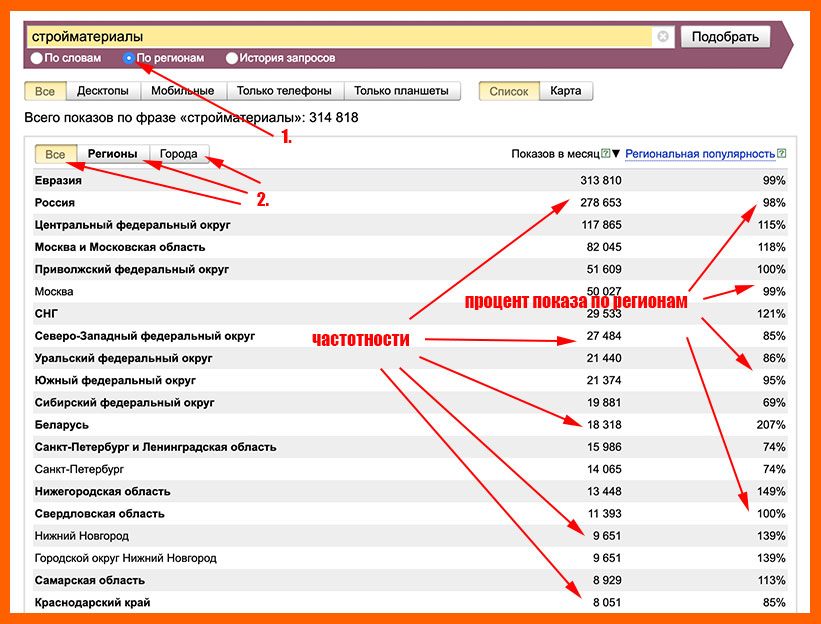
Оператор “-”
Добавление символа “минус” перед словом поможет исключить все ключи с его участием. Можно добавлять неограниченное количество минус-фраз.
Например, вы хотите создать сайт веб-студии и ваш основной запрос «Создание сайтов». Вам необходимо оценить количество коммерческих запросов и их частотность для понимания целесообразности продвижения в данной тематике.
Для этого соберите список всех минус-фраз, либо найдите в интернете (существует множество готовых списков почти под любую тематику) и введите их все по данной конструкции: создание сайтов -бесплатно -самостоятельно -обучение -курсы и так далее.
Группировка запросов с использованием различных операторов
Пример конструкции:
В данному случае, мы сгруппировали фразы «seo, сео, поисковое, поисковая система, поисковик, яндекс, google» с фразами «продвижение, раскрутка, оптимизация» и убрали ключевые слова с вхождениями «бесплатно, самостоятельно, самому, инструкция».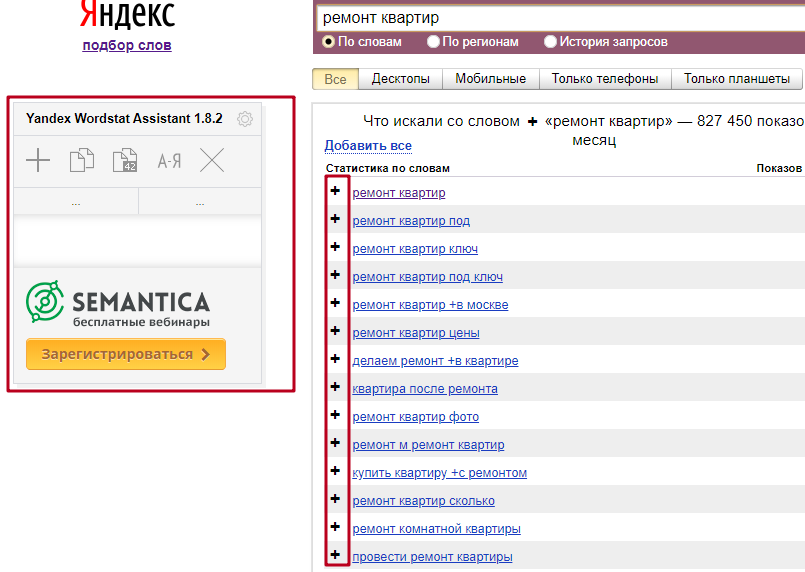
Как автоматизировать работу со статистикой Вордстат?
Сбор семантического ядра через Вордстат для крупного ресурса или интернет-магазина – очень трудоемкий процесс. Его можно автоматизировать с помощью дополнительного программного обеспечения, сильно сэкономив свое время. Существует большое количество различного ПО для подбора, расширения семантики, анализа видимости конкурентов. Ниже перечислим самые основные и популярные.
1. Yandex Wordstat Helper – бесплатное расширение для браузера Chrome, с помощью которого вы сможете добавлять выбранные запросы в отдельное поле (нажатием на «+»), а потом копировать вместе с частотами одним нажатием кнопки.
Скачать его можно здесь
2. KeyCollector — инструмент для автоматического парсинга статистики с Wordstat. Использование КейКоллектор исключает необходимость ручного сбора и копирования. Для формирования полного семантического ядра вам понадобится только список базовых запросов:
- вносите их в инструмент;
- выбираете регион сбора статистики;
-
запускаете процесс.

Программе понадобится от нескольких часов до нескольких дней, в зависимости от количества ключевых слов в вашей тематике. После окончания сбора ядра необходимо произвести чистку от ненужных фраз и кластеризацию. Но это уже тема для отдельной статьи.
2. Just Magic – содержит модуль парсинга статистики из левой колонки Wordstat с функцией поддержки всех операторов.
3. Букварикс – готовая онлайн база ключевых слов. Для моментальной выгрузки достаточно ввести базовые запросы и инструмент предоставит полный список необходимых вам фраз.
4. SpyWords – позволяет выгрузить видимость сайта конкурента в Яндекс и Google, определив по каким запросам его находят в поиске.
Итог
Надеемся, наша инструкция по Яндекс Вордстат помогла вам разобраться с сервисом. В этой статье мы рассказали о функциях и возможностях программы, а также упомянули инструменты, помогающие упростить и автоматизировать работу.
Еще мы помогаем с продвижением сайтов. Делаем полный анализ тематики вашей деятельности, составляем стратегию, оптимизируем ресурс для выхода в ТОП поисковых систем. Заполните форму ниже, мы вам перезвоним и проконсультируем.
Как пользоваться Яндекс.Вордстат: инструкция с примерами – статьи про интернет-маркетинг
Время прочтения: 15 минут
Тэги: SEO, Яндекс, интернет-маркетинг
О чем статья?
- Зачем маркетологам и бизнесу работать с запросами
- Простота и нюансы интерфейса Яндекс.Вордстат
- Работа с операторами
- Как получить данные о запросах по регионам
- Как попадать в тренды
Кому полезна эта статья?
- Digital-маркетологам, не являющимся оптимизаторами
- Руководителям отделов маркетинга
- Владельцам и директорам бизнеса
Wordstat предназначен для определения частотности запросов и подбора ключевых слов.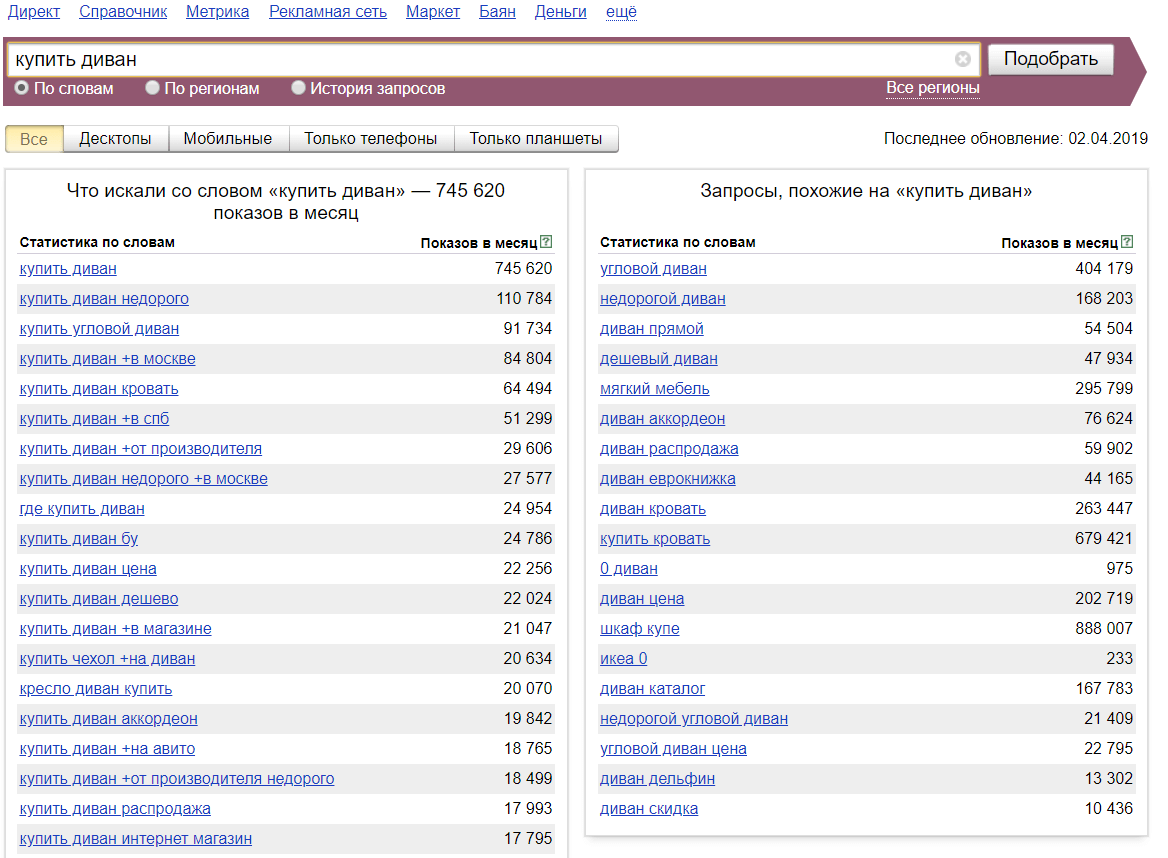 Казалось бы, сервис чисто для семантиков, зачем он кому-то еще? Тем не менее, аналитики и маркетологи работают в сервисе, чтобы оценить степень интереса пользователей, с каких устройств они чаще заходят, сезонные тренды рыночной ниши, перспективу расширения продаж в регионы.
Казалось бы, сервис чисто для семантиков, зачем он кому-то еще? Тем не менее, аналитики и маркетологи работают в сервисе, чтобы оценить степень интереса пользователей, с каких устройств они чаще заходят, сезонные тренды рыночной ниши, перспективу расширения продаж в регионы.
Руководители пользуются Вордстатом, когда хотят оценить работу своего маркетингового отдела или стороннего агентства, особенно если тот активно расходует бюджет на продвижение или контекстную рекламу. Умение перепроверить частотность запросов поможет, например, убедиться в том, что наемный специалист по рекламе ориентирован на продажи, а не просто сливает бюджет в траффик по информационным запросам. Аналогично можно проверить, что ищут потенциальные клиенты вашего бизнеса, и запланировать создание новых страниц на сайте.
Главное, что работать с Wordstat относительно проста (по сравнению с другими инструментами автоматизации SEO) и его базовое освоение не займет много времени.
Начало работы
Яндекс. Вордстат располагается по адресу https://wordstat.yandex.ru/. Для его использования нужен аккаунт в Яндексе (почта) и больше ничего. Вот так выглядит начальная страница.
Итак, у вас уже есть набор ключей, которые вы хотите проверить (а заодно с ними и вашего специалиста по контекстной рекламе или по продвижению). Или же запросов нет, но есть тема или поисковые подсказки, для которых вы хотите собрать ключи. Вводите все по очереди в поисковую строку. Учтите, что словосочетание длиннее 8 слов Вордстат не воспринимает.
В нашем примере берем ключевой запрос «контекстная реклама».
Что показывает левая колонка Яндекс.Вордстат
Здесь мы видим количество показов по данному запросу за последний месяц. Обратите внимание: верхний запрос в колонке содержит в себе все последующие (вложенные запросы).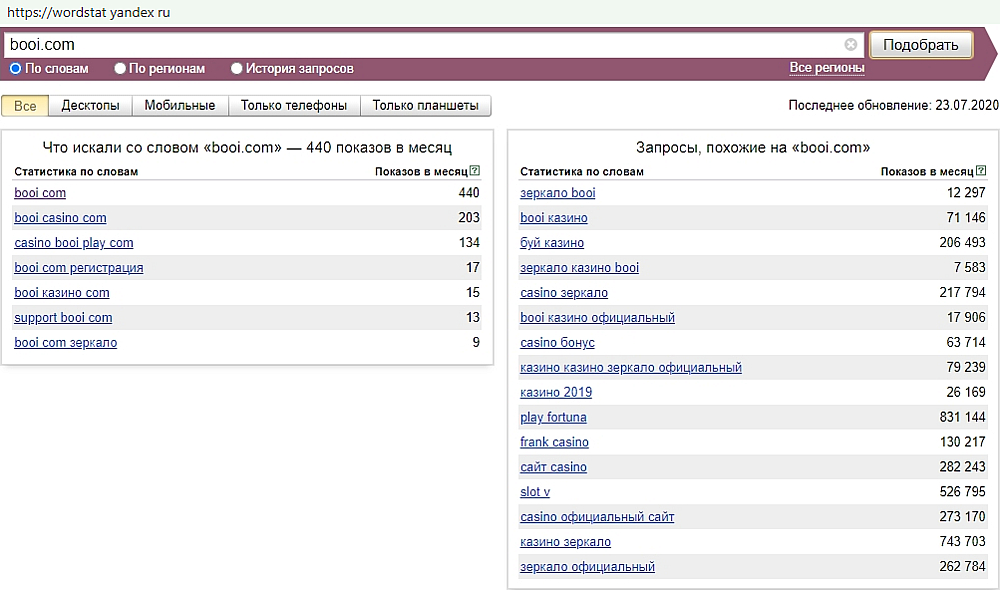 В примере запрос «контекстная реклама» искали 66 975 раз. При этом 10430 из них пользователи искали «контекстная реклама яндекс», а 4309 — «настройка контекстной рекламы». Вложенных запросом может быть несколько сотен или даже тысяч, поэтому внизу, как правило, есть постраничная навигация.
В примере запрос «контекстная реклама» искали 66 975 раз. При этом 10430 из них пользователи искали «контекстная реклама яндекс», а 4309 — «настройка контекстной рекламы». Вложенных запросом может быть несколько сотен или даже тысяч, поэтому внизу, как правило, есть постраничная навигация.
Учтите, что:
- Это не гарантированные цифры показа на следующий месяц, а статистика запросов за прошлый!
- Яндексом пользуется примерно 55% пользователей поисковых систем, а Вордстат использует данные только поиска Яндекса. Чтобы работать с ключевиками в Googlе, нужен аналогичный сервис Googlе Keyword Planner.
- Сервис дает цифры только по тем запросам, которые ищут регулярно. Если какого-то запроса в прошедшем месяце не было, в левой колонке вы его не увидите.
Что показывает правая колонка Яндекс.Вордстат
Вернемся к рисунку с поиском и посмотрим на содержимое правой колонки.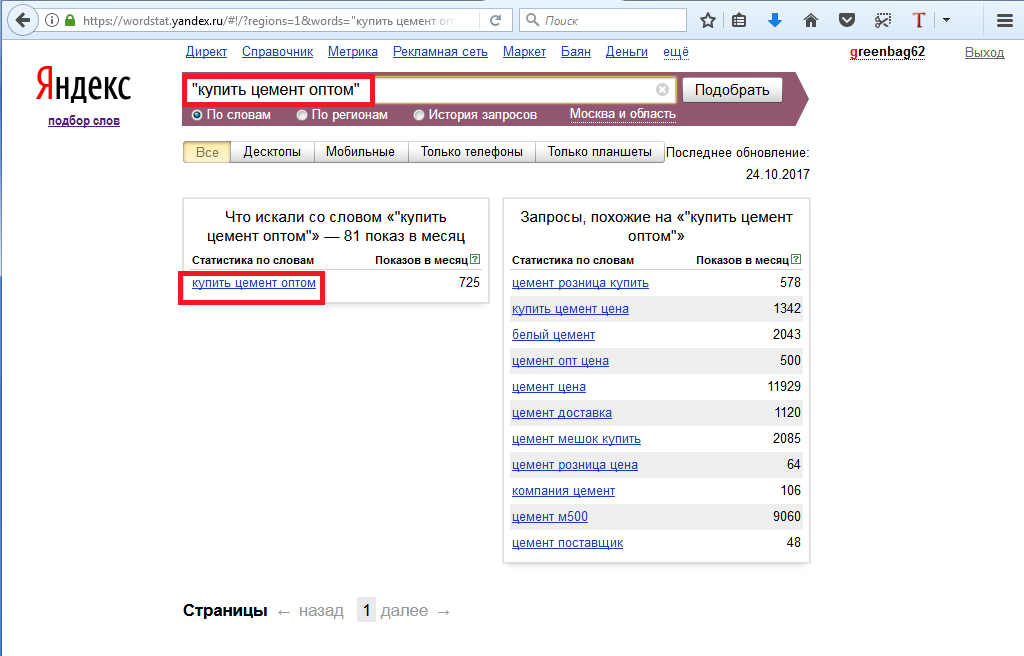
Здесь алгоритм Вордстата собрал запросы, похожие на наш. Не вложенные, как в левой колонке, а похожие по смыслу. Это позволяет нам расширить количество ключей за счет словосочетаний, синонимичных по смыслу, но использующих другие слова.
Учтите, что: при оценке правой колонки, предложенной нейросетью, следует включать критическое мышление. Потому что чем сложнее по смыслу то, что вы ищете, тем труднее роботу правильно оценить, что, собственно, имеется в виду.
«Неглиже» — женская легкая ночная рубашка. Вордстат (как и многие люди) не очень представляет, что это такое, и предлагает в правой колонке более общие запросы. По сути «неглиже» действительно входит в понятие «женское нижнее белье». И тут уже задача маркетолога оценить, нужно вам продвигаться по более распространенному запросу «белье девушка нижний» или необходимо остаться в более узкой нише «неглиже».
Запросы для бизнеса
Слова «купить, заказать, цена, стоимость» и т.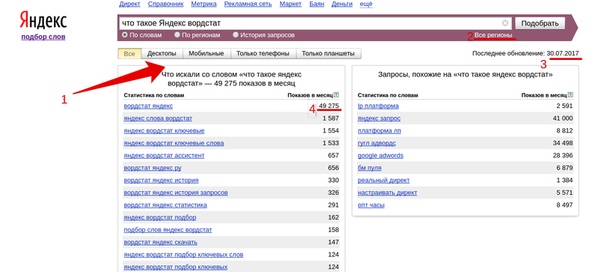 п., указывающие на желание что-то приобрести, делают запрос коммерческим. Запросы без этих слов считаются информационными: возможно, человек когда-нибудь и купит данную вещь, но пока он хочет только узнать о ней.
п., указывающие на желание что-то приобрести, делают запрос коммерческим. Запросы без этих слов считаются информационными: возможно, человек когда-нибудь и купит данную вещь, но пока он хочет только узнать о ней.
Как правило, для бизнеса важнее коммерческие запросы, так как они чаще конвертируются в продажи. Они часто оказываются вложенными у информационных.
Яркий пример: по информационному запросу 6 из первых 10 вложенных — коммерческие.
При этом нужно отсекать запросы со словами, которые делают ключ бесполезным для конверсии. Это слова типа «бесплатно», «своими руками», «сделать самому» и т.п.
Если те, кто ищет просто «стол на дачу», вполне могут его купить, то те, кто ищет его со словами «своими руками» и «сделать», явно не намерены ничего покупать. Запросы со словами «дешево», «недорого» тоже могут не давать конверсию, если вы не торгуете реально дешевыми столами.
Чтобы сразу избавиться от неподходящих запросов, используйте операторы Вордстата.
Работа с операторами в Яндекс.Вордстате
Операторы — это символы типа «+», «-» и им подобных знаков. Они задают условия для поиска.
- «+» перед словом требует обязательно учитывать это слово при поиске. При поиске на русском языке многие предлоги, союзы, частицы игнорируются, а их отсутствие может стать критичным для смысла запроса.
Пример запроса «участок с домом».
Обратите внимание, что Вордстат сам предлагает варианты запросов как с предлогом «с», так и без него. При этом в запросах без предлога смысл — «на участке уже есть дом» — размывается: здесь и «участок под дом», и «участок под строительство дома».
Если мы используем знак «+» сразу в поиске, Вордстат покажет более целевые ключи.
- «-» перед словом удаляет его из поиска. Очень полезный оператор, который позволяет отсеять те ключи, которые нам не нужны. Например, если мы продаем или покупаем сланцы (пляжную обувь), то нас не интересуют пользователи, которые ищут город Сланцы, расписание автобусов и погоду в нем или полезные ископаемые сланцы.
 Например, если мы продаем или покупаем сланцы (пляжную обувь), то нас не интересуют пользователи, которые ищут город Сланцы, расписание автобусов и погоду в нем или полезные ископаемые сланцы.
Например, если мы продаем или покупаем сланцы (пляжную обувь), то нас не интересуют пользователи, которые ищут город Сланцы, расписание автобусов и погоду в нем или полезные ископаемые сланцы.
Чтобы не отсеивать эти запросы вручную, просто используем оператор «-» сразу в поиске. Ненужные ключи вводите через пробел без запятой.
Если по-прежнему остались «мусорные» запросы, нужно добавить их в строку поиска. На сужение аудитории также хорошо работают специфические для бизнеса термины. Сравните разницу в запросе на просто «носки» и специализированные «носки для батута».
- «!» требует искать запрос дословно. Это важно, например, если вы хотите привести на сайт оптовиков, которые буду закупать «чехлы для смартфонов», а не обычных людей, которым нужен один-единственный «чехол для смартфона».
По умолчанию Вордстат покажет все словоформы.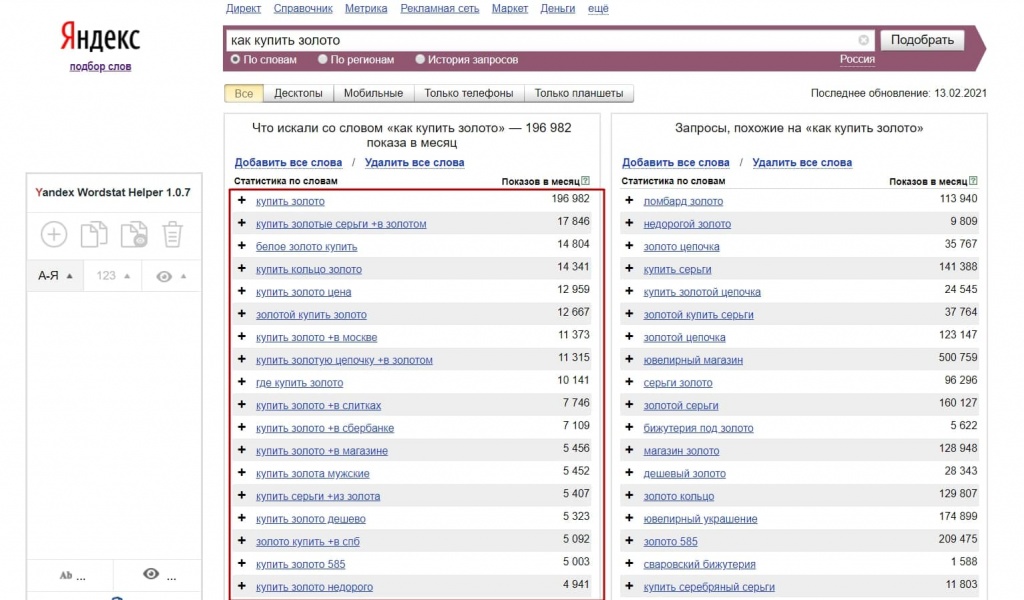
А с оператором «!» можно увидеть, сколько на самом деле пользователей горит желанием покупать чехлы для смартфонов в количестве больше 1.
- «» — если взять запрос в кавычки, вы получите данные только по нему, без дополнительных слов (хвостов). По умолчанию Вордстат прибавляет к вашему запросу уточняющие слова.
А если взять запрос в кавычки, в левой колонке вы получите данные только по тем словам, которые задали. Раскладка клавиатуры при вводе кавычек неважна.
Теперь вы видите точку роста — сколько возможных посетителей вы можете привлечь, если ваш сайт выйдет в топ по этому запросу. Кстати, чем более похожи цифры без кавычек и с ними — тем качественнее сформулирована ключевая фраза.
- [] – если взять запрос в квадратные скобки, то его порядок слов при поиске не будет меняться. Это обычно важно для тематик грузоперевозок, продажи билетов на транспорт, логистики, туризма — тех, где важно расположение конечных пунктов.

Здесь, как вы видите, показываются рейсы и туда, и обратно.
А при фиксированном порядке слов потенциальных пользователей оказывается примерно в 2 раза меньше. Это важно для получения целевого трафика по ключевой фразе, чтобы не платить деньги за приход на страницу и тех, кто летит в заданном направлении, и тех, кому нужно наоборот.
Работа с фильтрами: по регионам
Вернемся к поисковой строке работы с Вордстат. До сих пор мы использовали подбор запросов с опцией «по словам», а рядом есть еще «по регионам».
Этот фильтр полезен, если вы продаете свои товары/услуги только в определенном регионе. Или, наоборот, хотите оценить перспективу распространения бренда по стране.
Данные по региональной популярности в процентах нужно читать следующим образом. 100% — норма, то есть регион ничем не выделяется в показах по данному запросу. Региональная популярность выше 100% показывает, что интерес к запросу повышен, есть смысл выходить на рынок данного региона. Цифра меньше 100% означает пониженный интерес в данном регионе. Планируя развитие бизнеса, необходимо также учитывать количество населения региона как общее число потенциальных покупателей.
Региональная популярность выше 100% показывает, что интерес к запросу повышен, есть смысл выходить на рынок данного региона. Цифра меньше 100% означает пониженный интерес в данном регионе. Планируя развитие бизнеса, необходимо также учитывать количество населения региона как общее число потенциальных покупателей.
Вкладка «Все» отражает данные по регионам (странам, областям, краям) и городам, «Регионы» — без городов, «Города» — только по городам (включает городские округа и городские образования).
Работа с фильтрами: по типам устройств
Вернемся опять в начало и оценим количество обращений пользователей с различных устройств.
На примере видно, что есть некоторое различие между тем, что ищут люди с настольных компьютеров (вероятно, офисные работники) и те, кто предпочитает входить в интернет с мобильного устройства. Этим стоит воспользоваться при настройке показов рекламных объявлений.
Также данные по мобильным устройствам могут существенно отличаться от реальных. В России распространены смартфоны и планшеты на Android, где имеется встроенная поисковая строка Google, а Вордстат с ним не работает.
Как находить тренды?
Мы уже упомянули, что Wordstat оценивать частотность запросов за последний месяц, причем не в режиме реального времени, а с задержкой примерно недели на две. Но, как правило, бизнес сам знает нужные сезонные тренды. Например, понятно, что к летнему сезону растут продажи купальников и товаров для дачи, а к зимнему — теплых курток. В Яндекс.Вордстате есть вкладка «история запросов», которая позволяет как оценить вашу гипотезу, так и проанализировать тренды прошлых лет.
Здесь вы можете увидеть ожидаемый рост продаж пляжной обуви в начале лета. Данные по месяцам или по неделям позволят более точно прогнозировать рекламную кампанию.
Анализ Вордстата может показать рост новых запросов в связи с выходом на рынок новых товаров и создание моды на них.
Например, попыт — резиновую версию полиэтиленовой пленки «с пупырышками», которыми многие любят хлопать — год назад не искал никто просто потому, что ее не было на рынке. А в последние 2 месяца запросы пошли вверх и составляют уже достойное количество.
Однако следует учитывать, что мода непостоянна, и долгосрочным такой тренд, скорее всего, не будет. Это подтверждает история запросов на покупку сквишей — резиновых игрушек для сдавливания, предшественников попыта в категории релакс-игрушек.
На таком спросе можно подняться, но, очевидно, ненадолго.
Расширения для работы с Вордстатом
Собирать большие объемы данных в ручном режиме и тем более работать с ними – нерациональный подход. Прежде чем осваивать более сложные инструменты, можно попробовать браузерные расширения, облегчающие обработку массивов слов.
Yandex Wordstat Helper
Нарядный виджет доступен по адресу arcticlab.ru/yandex-wordstat-helper/. Предназначен для Mozilla Firefox, Google Chrome и Яндекс.Браузер. Он позволяет все проверяемые ключи добавлять в перечень и сразу по этому списку видеть некоторые данные. Правда, не полные. Расширение покажет количество внесенных ключей и базовую частотность, а также позволит отсортировать запросы по алфавиту, частотности или времени добавления в список
Yandex Wordstat Assistant
Дополнение для браузеров Google Chrome, Яндекс.Браузер, Opera, Mozilla Firefox можно бесплатно взять на страничке разработчика semantica.in/tools/yandex-wordstat-assistant. Оно выполняет все те же функции, что и вышеописанное дополнение, только сортировку, по мнению специалистов, делать чуть менее удобно.
Конечно, эти дополнения не позволяют полностью автоматизировать процесс, и подходят только при небольших объемах работы или для проверочных действий.
Выводы
- Сервис дает лишь прогноз на основании статистики за месяц и предлагает довольно много нецелевых запросов. Эти недостатки можно компенсировать, сравнивая данные с разных вкладок и используя операторы.
- Яндекс.Wordstat оперирует данными Яндекса, соответственно, это лучший выбор для продвижения и рекламы в Яндексе.
- Вордстат особенно полезен тем, кто работает с коммерческими запросами и собирает ключи для контекстной рекламы.
- Сервис дает владельцу бизнеса возможность проверить работу своих маркетологов, оценить популярность запросов, ширину ниши, региональные перспективы. Анализируя данные Вордстата можно подкрепить гипотезы о трендах и найти точки роста для бизнеса.
основные правила, операторы – советы от BDBD
Яндекс.WordStat – сервис, позволяющий просмотреть статистику количества запросов в поисковую систему Яндекс по заданной ключевой фразе за последний месяц, а также за последние 2 года.
В данной статье разберемся какие возможности есть у данного инструмента и как им правильно пользоваться.
Для эффективной работы со статистикой запросов Яндекс.WordStat необходимо использовать операторы, которые позволяют уточнить запрос и получить необходимый результат.
К примеру, по слову стилист вордстат будет показывать суммарную статистику по ключевикам: парикмахер стилист, как стать стилистом, курсы стилистов и др.
Общая статистика бывает малоинформативна, и вот тогда на помощь приходят дополнительные операторы.
Операторы Wordstat
Получить дополнительную статистику можно с помощью таких операторов, как «восклицательный знак», «кавычки» и «квадратные скобки». Они необходимы для уточнения и фиксации ключевых слов.
«Восклицательный знак» – позволяет зафиксировать словоформу (т.е. учитывать только заданное окончание), но не фиксирует порядок слов.
Например, запрос !мягкая !игрушка – при таком вводе будут показаны только фразы с точным вхождением мягкая игрушка и игрушка мягкая, а фразы вроде купить мягкую игрушку, мягкой игрушкой, как пользоваться игрушкой мягкой и пр. учитываться не будут.
«Кавычки» – позволяет отрезать хвосты у фразы и показать спрос только на заданную фразу без дополнительных слов, но в разных словоформах и в любом порядке.
Например, запрос «мягкая игрушка» — при таком вводе будет показан суммарный спрос на такие запросы как: мягкая игрушка, мягкой игрушкой, игрушка мягкая и пр.
«Квадратные скобки» — позволяет зафиксировать порядок ключевых слов.
Например, запрос [мягкая игрушка] – при таком вводе будет показан суммарный спрос на запросы: купить мягкая игрушка, мягкая игрушка цена, мягкая игрушка, мягкой игрушкой, купить мягкую игрушку и пр.
«Восклицательный знак», «кавычки» и «квадратные скобки» — совместное использование
Если требуется узнать «чистый» спрос, т.е. сколько раз пользователи спрашивали заданную фразу в точном написании, без перестановок, изменения словоформ и хвостов, то требуется использовать все операторы вместе:
Например, «[!мягкая !игрушка]»
*Обратите внимание на порядок операторов
Вспомогательные операторы
Если использовать вспомогательные операторы, то ваши возможности относительно работы с Яндекс.WordStat значительно расширяются.
-
«Минус» – используется, когда нужно исключить из статистики определенный ряд слов;
Например, ремонт bmw -руководство компания занимается ремонтом BMW и нужно узнать сколько людей ищут именно услуги ремонта, а не самостоятельное решение проблемы:
-
«Плюс» – используется, когда нужно получить статистику со стоп-словами, включая частицы, предлоги, союзы;
Например, ремонт bmw +на
-
«Или» – задаётся символом «|» и скобками, используется для подбора семантики, для сравнения нескольких слов или смещения фраз в статистической выдаче;
Например, ремонт (bmw | бмв)
-
«Группировка» – используется, когда нужно сгруппировать несколько операторов для получения узконаправленной статистики.
Например, ремонт (bmw | бмв) (двигателей | турбины)
Дополнительные функции Яндекс.Wordstat
История запроса. Данная опция позволяет получить статистику относительно проявляемого интереса пользователей к тому или иному товару/запросу/услуге, т.е. узнать сезонность.
Важно: в истории запросов нельзя использовать операторы, о которых говорилось ранее.
Например, запрос ремонт bmw, судя по графику июль и октябрь являются пиковыми месяцами, это стоит учитывать при работе над проектом.
По регионам. Очень полезная опция, так как позволяет разделить географические результаты. Можно получить точные сведения относительно популярности того или иного запроса в конкретном регионе – Москве, Сочи, Санкт-Петербурге и др.
По устройствам. Можно просмаривать статистику по отдельным устройствам: десктопы, мобильные, только телефоны и только планшеты
Важно: при использовании Вордстата обязательно необходимо выбирать регион, т.к. по умолчанию показывается суммарный спрос по всем регионам.
Яндекс.WordStat очень полезен для специалистов, и позволяет получить точную статистику при умелой работе с сервисом.
Специалисты используют все опции, указанные в этой статье; при правильном применении дополнительные операторы
значительно упрощают работу и сокращают время на формировании семантического ядра.
Полное руководство по работе с Яндекс.Wordstat
Разбираемся, что представляет собой Яндекс.Вордстат и как им правильно пользоваться. Цели статьи – узнать предназначение сервиса, выяснить, как работают операторы, и понять, как добывать из Wordstat только полезные данные.
Что такое Яндекс.Вордстат
Речь идет о сервисе компании Яндекс, предоставляющем доступ к статистическим данным из одноименной поисковой службы. Wordstat показывает, что ищут люди в сети.
- Сервис отображает популярность выбранного запроса (он указывается в поисковой строке Wordstat).
- Дает четкое понимание сезонности выбранных запросов.
- Показывает географию спроса на те или иные услуги.
- Показывает техническое оснащение пользователей, выполняющих запрос в сети.
- Отображает долгосрочные тренды в интернете.
- Помогает лучше понимать целевую аудиторию.
Эти данные дают возможность настроить рекламную кампанию, ориентируясь на количество запросов.
Для работы с Яндекс.Вордстат нужен аккаунт в Яндексе (профиль в Метрике или Директе необязателен).
Зачем обучаться работе с Wordstat?
Яндекс.Вордстат – это удобный инструмент, который почему-то игнорируют многие предприниматели, хотя как раз таки им он может заметно помочь.
- Если вы бизнесмен, то изучение Wordstat поможет лучше понять работу вашего SEO-специалиста и общее направление продвижения бренда. Это еще одна степень контроля, которая точно не помешает при работе с людьми по найму.
- Если вы маркетолог, разбирающийся в теме, то можете проследить количество специфичных запросов (с какой-то узконаправленной терминологией, например) и построить семантическое ядро (вкупе со всей рекламной кампанией) на их базе, избавившись по пути от кучи конкурентов.
Ну а для всех остальных Яндекс.Вордстат остается удобным способом отслеживать статистику запросов. Главное, делать это с умом. А для этого нужно хорошо понимать принципы работы Wordstat.
Как работать с Яндекс.Вордстат?
Интерфейс Wordstat не отличается сложностью. В нем можно разобраться самостоятельно, но есть ряд нюансов.
- С ходу трудно сказать, как вообще пользоваться сервисом. На главной странице нет никаких явных подсказок. Такая неочевидность повышает порог вхождения для новичков в SEO.
- Для наиболее эффективного взаимодействия с сервисом придется выучить поисковые операторы. У них тоже есть свои особенности, и далее мы их подробно рассмотрим.
- Умение управлять инструментом не делает из человека специалиста в области работы с информацией. А умение обрабатывать данные в нашем случае критически важно (важнее умения искать ее).
По ходу статьи мы «устраним» все сложности, мешающие работе с Яндекс.Вордстатом, и рассмотрим другие детали, связанные с работой сервиса и помогающие отыскать подходящую нишу, оценить ее популярность и шансы на успех при попытке монетизировать выбранное направление.
Знакомимся с интерфейсом
Первое, что увидит пользователь, посетив сайт Яндекс.Вордстата, – поисковую строку с небольшим набором настроек и кнопку «Подобрать». Это все, с чем нам придется работать. Здесь же отображается краткая справка по работе с сервисом и в общих чертах описывается логика отображаемых данных.
Первое, что нужно сделать, – ввести фразу, которую вы хотите использовать в качестве ключевого запроса для поисковых служб. Например «электрогитара» или «андроид смартфон». После этого на экране отобразится список запросов и их вариаций в левой колонке, а также схожие ключевые фразы в правой колонке.
Первый запрос в левой колонке содержит в себе все последующие. То есть расширенные ключевые слова под основным – это не дополнительные запросы, а вложенные. Это значит, что «семиструнная электрогитара» с 416 показами включает в себя «семиструнная гитара купить» с 91 показом из вышеназванных 416.
Не нужно складывать «ключи» друг с другом, так как получится некорректный расчет. Сами показатели условны. Это не точная статистика, а лишь прогноз на количество показов по выбранному ключевому слову.
В правой колонке отображаются отдельные запросы. Они независимы друг от друга и показывают количество вхождений только для самих себя. Без вложенных «ключей».
Изучаем поисковые операторы
Запросы в Яндекс.Вордстате можно дополнительно настроить с помощью специальных символов. Их ставят перед словом или фразой для выполнения какого-то условия. Соответственно, у каждого символа есть свое предназначение и выполняемое условие.
- + – этот символ обязывает систему Wordstat учитывать слово при поиске. По умолчанию некоторые слова русского языка игнорируются. Это касается предлогов и следующих союзов: в, на, от, для, как, из, и, от.
- ! – этот символ запрещает Яндекс.Вордстату корректировать словоформу. То есть поиск будет учитывать исключительно ключевые слова с выбранным окончанием, числом, родом и т.п. Его рекомендуют использовать оптовикам, чтобы точно учитывать запросы на покупку большого количества товаров.
- «» – кавычки выводят статистику по выделенному слову или фразе в отдельное окно, чтобы можно было оценить количество запросов без вложенных «ключей». То есть увидеть запрос «купить электрогитару» без «купить электрогитару Ibanez» и других вариаций, которые учитываются в первом значении левого столбца Яндекс.Вордстата.
- [] – этим символом можно зафиксировать используемый в запросе порядок слов. Этим пользуются туристические фирмы и авиакомпании, чтобы предлагать клиентам билеты в точных (а не в похожих) направлениях.
- ( | ) – в скобки можно занести 2 или больше похожих слов. К примеру, если вы продаете товары сразу из двух стран, можно занести их в скобки и посмотреть статистику сразу по двум категориям запросов.
Удаление ненужных слов из запросов (оператор «минус»)
Еще один оператор выделим в отдельную категорию. Он позволяет более адекватно оценивать перспективность выбранной ниши за счет исключения из ключевой фразы всех лишних составляющих, способных повлиять на результат.
Допустим, вы хотите разыскать клиентов по запросу «электрогитара», так как занимаетесь их продажей. Но по такому запросу ищут не только гитары для покупки. Сюда входят:
- обучающие видео и другие формы уроков игры на гитаре;
- популярные выступления на этом инструменте;
- табулатуры, аккорды и ноты для исполнения популярных гитарных композиций;
- странные запросы в духе «электрогитары скачать»;
- поиск Б/У-товаров, что в случае с официальным магазином моментально делает запрос нерелевантным.
Куча «мусора», а нам нужны более конкретные запросы. Поэтому при поиске важно не только включить все необходимые «ключи» в нужной форме, но и исключить все лишние, чтобы не быть обманутым завышенными показателями.
Собираем данные по регионам
Эта опция важна для локального бизнеса. Нужно ориентироваться на клиентов из конкретного региона, поэтому брать статистику запросов по всей стране нет смысла, если продавать свои услуги вы собираетесь только в условном Саранске.
Чтобы увидеть количество запросов в отсортированном по зонам виде, нужно кликнуть по соответствующему фильтру рядом с поисковой строкой.
Процентное соотношение в этом интерфейсе говорит о среднестатистической популярности ключевой фразы. За 100% берется среднее количество выбранных поисковых запросов в регионе. Если это значение выше 100%, значит, популярность «ключа» выше среднего. Если меньше, то наоборот. Но помимо процентного соотношения важно ориентироваться на общее число потенциальных покупателей и население региона.
Для онлайн-магазинов и информационных ресурсов региональный фильтр не так важен. Первые могут продавать товары по всей стране и ориентироваться на общее число поисковых запросов. Вторые могут создавать полезные материалы для людей из соседних регионов, повышая популярность собственного бренда по стране.
Выясняем, как угодить в тренды
Это важный момент, потому что Wordstat не показывает актуальную информацию. Чтобы хоть как-то состыковаться с последними тенденциями, нужно брать в расчет статистику запросов за несколько лет. И это касается только регулярного повышения популярности запросов. Например, повышенный спрос на цветы и разного рода подарки перед 8 марта и в саму дату. Событие произойдет, а в Яндекс.Вордстате информация появится только через пару недель.
Поэтому ориентироваться стоит только на регулярные тренды. В их числе праздники (повышенный спрос на подарки определенной тематики), распространенные сезонные активности (отпуск зимой и летом), постоянное актуальные запросы (аренда жилья) и т.п. А еще стоит обратить внимание на поисковые подсказки. Можно открыть тот же Яндекс и ввести туда «ключ». Вместе с «ключом» появится целый список дополнительных запросов. По ним можно сориентироваться и понять, что сейчас популярно, а что не особо.
Не стоит забывать, что умение прогнозировать и создавать страницы под естественные запросы клиентов куда важнее, чем пытаться «взлететь» на неперспективном тренде, который создает много шума в информационном поле, но однозначно исчезнет в ближайшем будущем.
Разница между коммерческими и информационными запросами
Хотелось бы затронуть эту тему в отдельном блоке. Существует принципиальная разница между запросами: «Android смартфон» и «Android смартфон купить». Да, ни один из них не гарантирует продажи, но у второго шансов на конверсию больше.
Такие запросы, как второй, называются коммерческими. Они включают в себя слова, связанные с покупкой товара. То есть такие, как: купить, сколько стоит, цена, с доставкой и т.п. А еще к коммерческим запросам относят ключевые фразы с названиями населенных пунктов. К примеру:
- «Купить Android смартфон с доставкой»,
- «Сколько стоит Android смартфон в Нижневартовске».
Запрос в духе «Телевизор» считается информационным. В нем не прослеживается интенция что-либо купить, но поисковики часто отображают на первых позициях именно магазины с соответствующим товаром. Поэтому работать с такими ключевыми фразами нужно осторожно. Если же в запросе есть фразы типа «своими руками», то она моментально делает «ключ» бесполезным – по нему точно ничего не удастся продать.
Возможные проблемы при работе с Яндекс.Вордстат
У системы есть недостатки. С чем придется вам столкнуться:
- Зачастую даже половина найденных показов на деле не приносит пользы, потому что содержит вложенные запросы. Если не отсечь лишнее, то статистика будет некорректной.
- Яндекс.Вордстат не дает актуальной информации, только статистику за последние 30 дней.
- Система не воспринимает «ключи», состоящие из более чем 8 слов.
- Пользователи часто вводят запросы, используя синонимы. Поэтому они могут искать один и тот же товар или услугу, но используя десяток разных слов и их форм.
- Яндексом пользуется около половины жителей страны, поэтому реальная статистика может отличаться вдвое. С мобильными устройствами ситуациями аналогичная. В России преобладает Андроид с предустановленными сервисами Google.
Пример использования Wordstat
Вернемся к примеру с теми же гитарами. Можно создать 200 с лишним лендингов под все услуги вашего магазина. Берем запрос «электрогитара» и идем по списку:
- «Купить электрогитару» (каталог+описываем преимущества магазина),
- «Настройка электрогитары» (полезный пост в блоге и ссылка на магазин),
- «Лучшие электрогитары» (можно сделать топ с ссылками на инструменты в нашем магазине).
И таких вариаций много. Все популярные запросы можно проследить в Яндекс.Вордстат и использовать для развития проекта, ориентируясь на темы, которые интересуют пользователей.
Дополнительное программное обеспечение
Чтобы упростить работу с Яндекс.Вордстат, можно использовать сторонние дополнения для браузеров. Рассмотрим два наиболее популярных.
Ассистент Яндекс.Вордстат
Это небольшое расширение, позволяющее собирать подходящие запросы в отдельную группу с последующим ее использованием в других приложениях. После установки Ассистента на сайте Яндекс.Вордстат появляется кнопка «+» рядом с каждым «ключом». Нажатие по нему добавляет текст запроса и частоту его использования в панель Ассистента.
Скачать
Yandex.Wordstat Helper
Расширение для браузеров Firefox и Google Chrome, выполняющее схожую с Ассистентом функцию, но немного быстрее. Интерфейс почти не отличается. Преимущество расширения – наличие большего количества категорий, по которым можно сортировать объекты, добавленные в интерфейс расширения.
Скачать
Вместо заключения
Итак, работая с Wordstat, делаем следующее:
- В первую очередь обращаем внимание на коммерческие запросы со словами «купить».
- Учитываем регион поиска и особенности целевой аудитории.
- Пользуйтесь «минусами» при анализе любых ключевых фраз.
- Сужайте аудиторию за счет использования специфичных терминов.
Описанной информации хватит, чтобы собрать данные из Яндекс.Вордстат и скорректировать SEO-параметры для более эффективного продвижения ресурса.
обзор возможностей. Для маркетологов и SEO-оптимизаторов
Продвижение сайта без специальных сервисов — малоэффективное занятие. Когда же речь идет о сборе семантики — без помощи дополнительных инструментов просто не обойтись. Существует довольно много сервисов для работы с поисковыми запросами, но если спросить у любого SEO-специалиста, какой инструмент для него наиболее значим, большая часть наверняка ответит — Яндекс.Вордстат.
Для чего нужен Яндекс.Вордстат
Каждая страница сайта должна создаваться с учетом спроса. Проверить, интересуются ли люди тем или иным поисковым запросом помогают специальные анализаторы. Яндекс.Вордстат — один из таких инструментов. Это бесплатный сервис, с помощью которого проверяют популярность того или иного пользовательского запроса в поисковой системе Яндекс. На основе этих данных можно:
- Создать семантическое ядро для сайта.
- Оптимизировать статью под ключевые запросы.
- Собрать анкоры для максимально эффективного (и безопасного) ссылочного продвижения.
- Спрогнозировать, сколько трафика сможет в перспективе получать сайт.
- Оптимизировать рекламную кампанию в Директе.
- Проверить сезонность спроса.
Как видно, возможностей немало. Помимо функциональности Вордстат ценят за простоту использования, точные данные (это официальный сервис Яндекса) и, конечно же, то, что он полностью бесплатный. Далее мы подробно поговорим о том, какими возможностями обладает этот инструмент.
Вам также может быть интересно: Как работать с ключами, чтобы попасть в топ поисковой выдачи?
Как пользоваться Вордстатом
Чтобы начать использовать сервис, достаточно авторизоваться в Яндексе и перейти на страницу Wordstat. Введя интересующий вас запрос и нажав кнопку «Подобрать», инструмент предоставит следующую статистику.
- Общее количество запросов с указанной фразой.
- Расширенные запросы, т.е. все формулировки, включающие заданную вами фразу.
- Похожие запросы по теме.
Цифры показывают, сколько раз в месяц интересуются каждой фразой, т. е. указывают на ее частотность.
По умолчанию Вордстат отображает долю запросов со всех устройств. При необходимости статистику можно сегментировать: посмотреть, как интересуется фразой отдельно мобильная и отдельно десктопная аудитория. Также доступна фильтрация по устройствам: смартфонам и планшетам.
Это очень удобная опция, которая помогает оценить процент мобильного трафика в тематической нише и принять стратегические решения по оптимизации. Например, если вы видите, что в вашей теме ощутимо преобладает мобильный трафик, но у вашего сайта нет надлежащей мобильной адаптации — это повод принять меры.
Читайте по теме: Как понять, что вы недооценили мобильный трафик и успеть исправить ситуацию
Статистика показов по регионам
По умолчанию статистика запросов в Вордстате собирается со всего поиска. Если вы хотите узнать, как ищут запрос в конкретном регионе, необходимо задать соответствующие настройки в отдельной вкладке.
Перейдя во вкладку «По регионам», можно сравнить, насколько популярен запрос в разных регионах в процентном соотношении. Эта информация помогает в принятии стратегических бизнес-решений. Например, проанализировав региональную популярность запроса, можно предварительно спрогнозировать в каких городах услуга будет пользоваться большим спросом, а в каких меньшим. Конечно, для более точного прогноза придется учесть и дополнительные факторы: конкуренцию на местном рынке, средний доход в регионе и пр.
История запросов и прогнозирование сезонного трафика
В «Истории запросов» можно посмотреть, как меняется интерес аудитории к тематике на протяжении года. Если спрос имеет сезонный характер, это будет четко видно на графике.
Что значит абсолютное и относительное значение?
Статистика отображается в виде двух графиков.
Абсолютный показатель отражает, сколько раз пользователи водили указанный запрос. Это основной график, к которому нужно привязываться при анализе сезонности.
Относительный показатель — это отношение показов по указанному запросу к общему числу показов в сети.
Оба графика должны плюс-минус повторять друг друга. Выраженное расхождение может говорить о том, что с запросом происходят неестественные процессы. Возможно, имеет место его накрутка или, несмотря на сезонный спад, по каким-либо причинам интерес к теме остается высоким (при таких сценариях красный график будет выше синего). Когда фактический спрос ниже ожидаемых значений, красная линия сильно проседает вниз.
Как на практике использовать сезонную статистику?
Графики из истории запросов помогают в эффективном планировании продаж. Из них можно извлечь много пользы даже для бизнеса с очевидной сезонностью. Например, мы знаем, что продажа лыж — это сугубо сезонная история, но в Вордстате видно, что интересоваться этой тематикой начинают намного раньше, чем стартует сезон. Эту информацию можно использовать для стратегического бизнес-планирования, например, для первого запуска рекламной компании.
Существует много товаров и услуг, для которых сезонность спроса не столь очевидна. Например, мало кто задумывался над тем, что продажа палок для селфи также подчиняется определенным циклам — Яндекс.Вордстат наглядно показывает, каким именно.
Понимая, что ваша тематика имеет ярко выраженную сезонность, вы будете готовы к тому, что в определенные месяцы поисковый трафик будет сильно проседать. В этот период целесообразно заниматься подготовкой сайта к новому сезону продаж, а не переживать на счет того, куда делся трафик.
Вам также может быть интересно: На сайте упала или перестала расти посещаемость. Что делать?
Понимание сезонных колебаний важно учитывать при составлении семантического ядра. Если по запросам нет частотности, возможно, сейчас период тематического простоя, и они появятся в выдаче позже. Проверив историю запросов, вы проясните эту ситуацию.
Статистика из истории запросов также способна помочь в контент-планировании. Как это работает на практике? Например, мы подготавливаем контент для блога туристического магазина. У нас есть тема про спальные мешки. Вбиваем в Вордстат высокочастотный запрос, и видим, что, как и предполагалось, тема имеет выраженную сезонность. Статью лучше написать на спаде. Пока этой темой никто не интересуется, материал успеет проиндексироваться, «отстояться» в поиске и будет нормально ранжироваться, когда пойдет волна пользовательских запросов.
Операторы в Яндекс.Вордстат. Уточняем данные по статистике
Вордстат собирает статистику по широкому спектру запросов. В выдачу попадает много нерелевантных ключей, а также тех, которые не несут нужного смысла. Для более точного поиска и отсеивания ненужных запросов используют операторы — это специальные знаки, уточняющие параметры подбора слов.
Оператор «»Кавычки позволяют собирать статистику только по указанному слову или фразе. Например, если ввести уже упомянутый запрос «спальный мешок» — получим статистику 57 164 показов в месяц. Но в это число включены вариации запроса с дополнительными словами: «спальный мешок купить», «спальный мешок цена» и т.д.
Если они вам не нужны, берем запрос в кавычки и получаем статистику только по исходной формулировке.
Просто фразу «спальный мешок» в поиск вбивают куда реже — Вордстат выдает 3 063 показа в месяц.
Оператор !
Данный оператор фиксирует форму слова в точном вхождении: без изменения падежа, числа, времени. Например, нам нужно узнать частотность запроса «доставка грузов в Москву» строго в таком вхождении, т.к. другие словоформы изменят смысл фразы.
Вот что Вордстат выдает без оператора:
Используя восклицательный знак, мы получим статистику с точным вхождением слов.
Этот оператор очень полезен при поиске анкоров для ссылок.
Оператор +Вордстат по умолчанию игнорирует предлоги и союзы, считая их стоп-словами. В некоторых запросах эти части речи имеют принципиальное значение, т.к. без них смысл фразы становится совершенно иным. Оператор + дает указание учитывать все отмеченные предлоги и союзы.
Сравните результаты выдачи с ним и без него:
Без учета предлога Вордстат предлагает нерелевантные запросы.
Задав команду учитывать предлог — получаем статистику по нужному запросу.
Оператор —Логика работы этого оператора обратная: он убирает из выборки нежелательные слова.
Например, если компания изготавливает только шкафы, то все ключи, связанные с мягкой мебелью или «своими руками» будут засорять статистику. Их убирают при помощи знака минус.
Оператор (|)Оператор перебора используют для проверки серии похожих запросов.
Например, у нас есть три запроса:
- купить беговые лыжи;
- купить лыжи для конькового хода;
- купить охотничьи лыжи.
Мы можем вводить каждый запрос отдельно, но куда удобнее все сделать в один заход. Для этого группируем слова следующим образом: «купить (беговые|для конькового хода|охотничьи) лыжи».
Таким образом, используя оператор (|) можно не вводить один за другим похожие запросы, а сразу получать сводную статистику. Это очень помогает при сборе семантического ядра, когда нужно собрать частотность по большому количеству похожих запросов.
Оператор [ ]Данный оператор фиксирует порядок слов в запросе.
Например: билет из [из Новосибирска в Москву]. Благодаря квадратным скобкам Вордстат не будет предлагать ключи, связанные с направлением Москва-Новосибирск.
Другой пример: запрос [лечение при осложнениях] бронхита. Оператор фиксирует порядок слов и в выдаче не будет запросов осложнения при лечении бронхита, которые придают фразе совершенной иной смысл.
Совет! Для еще более быстрого и точного сбора запросов некоторые операторы сочетают друг с другом. Например, операторы «» и ! работают в комбинации. При этом команды «» и (|) не сочетаются.
Отдельно отметим, что операторы поддерживаются только при поиске по словам. При просмотре истории запросов они не работают.
Как пользоваться Яндекс.Вордстат: инструкция по применению
Yandex.Wordstat – бесплатный сервис Яндекса для определения пользовательского интереса к определенным категориям товаров, услуг, тематик. Его используют маркетологи, копирайтеры, SEO-специалисты, владельцы бизнеса. Сервис считает все запросы, которые оставляют пользователи со всех устройств из всех регионов, и показывает их количество.
С помощью Yandex.Wordstat можно быстро определить, чего хочет ваша аудитория, и найти вопросы, которые ее больше всего волнует. После определения таких потребностей, охватывать интересы аудитории гораздо проще.
Ниже мы расскажем, как получить доступ к сервису, как правильно пользоваться Вордстатом, и как упростить работу по сбору статистики.
Как начать использовать Wordstat
Чтобы получить доступ, нужно зарегистрировать почту Яндекса и перейти на страницу https://wordstat.yandex.ru/. При первом введении слова в поле запросов, Яндекс предложит войти в аккаунт. Если его нет, нужно зарегистрироваться.
Обзор функционала
Поиск по словам
Это функция, которая показывает все ключи с включением конкретных слов. Чтобы было понятнее, будем искать запросы с включением слова «Велосипед»:
Левая колонка показывает запросы с вхождением указанного слова. Правая – похожие или тематические.
Выдачу ключей можно сортировать по используемым аудиторией устройствам.
Выбираем телефон, планшет или десктоп, сервис сразу же подстраивается и показывает, сколько запросов оставлено с тех или иных устройств.
Региональная привязка пользователей
Так можно посмотреть, сколько релевантных запросов введено в разных регионах:
История запросов
В Вордстате можно пользоваться динамикой роста количества запросов. Функция полезна для определения сезонности разных товаров и услуг:
На графике видно, что интерес к велосипедам из нашего примера имеет выраженную сезонную окраску, их начинают активнее искать в марте, интерес сохраняется до сентября, но с июля востребованность начинает падать:
География
По умолчанию сервис показывает запросы из всех регионов. Если хотите увидеть выдачу с конкретной географической привязкой и более точно подобрать статистику ключевых запросов, нужно поставить пару галочек. Допустим, вам интересна Республика Крым, за исключением Бахчисарского района, Керчи и Судака:
Количество запросов изменилось. Бывает так, что конкретные товары или услуги востребованы и популярны в одном регионе, а в другом – пользователи вообще не проявляют к ним интереса. Не забывайте пользоваться этой настройкой, чтобы не потерять бюджеты на продвижении неактуальных для региона товаров и услуг.
Операторы для уточнения информации
Простого поиска запросов часто недостаточно. Причина – статистика спроса неточная. Чтобы уточнить количество ключей и найти/исключить схожие по тематике, мы расскажем, как в Яндекс Вордстат пользоваться специальными операторами.
Кавычки
Заключая слово в кавычки, вы получаете статистику по конкретному запросу с возможными ошибками. Для примера возьмем фразу «купить велосипед». Регион подбора оставим прежним. Смотрите, как меняется выдача с кавычками и без:
| Без кавычек | С кавычками |
При этом правая колонка остается без изменений.
Восклицательный знак
Этот оператор фиксирует окончания слов, оставляя только точную словоформу. Обычно при таком формировании запроса к Вордстату меняется число показов. Смотрите:
| Без оператора | С восклицательными знаками |
Эти операторы можно использовать вместе, тогда вы получите выдачу с точными окончаниями по конкретному запросу:
Исчезли измененные окончания и изменилось количество показов. Вот так выглядела выдача до применения восклицательных знаков:
Плюс и минус
Полезные операторы, когда для анализа из выдачи нужно исключить часть запросов. Например, убрать региональную привязку к одному или нескольким регионам. Смотрите, как ими пользоваться:
Было до добавления операторов:
Стало после добавления:
Таким же образом можно поступить с любыми частями запросов, например, характеризующих велосипед: -женский, -детский, -мужской, -спортивный. Или убрать коммерческие и оставить только информационные: -цена, -купить.
Оператор плюс работает прямо наоборот. Он добавляет ключи в выдачу статистики запросов и сужает ее. Допустим, мы хотим продавать БУ-велосипеды в Крыму, и нам нужно узнать, актуально ли это вообще. Добавляем к запросу +бу и +крым, получаем выдачу:
Вспомогательные сервисы
Работу с вордстатом можно упростить, для этого есть специальные расширения/плагины для браузеров и сторонние приложения.
Плагины:
Yandex Wordstat Helper – сервис помогает быстро формировать списки ключевых запросов и сортировать их. С ним проще выстраивать списки ключей, например, для разных услуг или географических привязок.
Еще один плагин с аналогичными функциями – Yandex Wordstat Assistant.
Приложения
Лидер в этом сегменте – key-collector.ru . Это мощный десктопный инструмент для парсинга ключей из Вордстата. Не нужно вручную собирать, программа расширяет пул запросов, исходя из вашего маленького списка. Вам нужно только определить основные ниши и указать приложению, что искать.
У программы есть пара недостатков:
Есть бесплатный аналог с более узким функционалом – «Словоёб» (уж простите, такое название, создатели были очень креативными).
Для ведения нескольких или крупных проектов, такие приложения просто незаменимы. Потратьте полчаса на настройку один раз, и вы сэкономите десятки часов при постоянном использовании программ в продвижении проектов и анализе спроса.
Еще обратите внимание на дополнительный источник ключей – это «Букварикс». Эта программа подскажет, как еще можно смотреть статистику запросов в Яндексе. Она похожа на Wordstat, но информация по запросам разнится из-за разных алгоритмов сбора.
Если вы хотите научиться использовать эти приложения, собирать правильную семантику и продвигать сложные проекты тогда вам сюда:
→ 10 лучших курсов по SEO
А если планируете настраивать контекстную рекламу, то вам подойдёт вот эта подборка курсов:
→ ТОП-11 курсов по контекстной рекламе в Яндекс.Директ и Google AdWords
Статья помогла? Поблагодарите в комментариях. Если есть замечания, оставляйте их там же, мы обязательно исправимся. Чтобы получать полезную информацию о продвижении, программировании и дизайне, подписывайтесь на наш канал в Телеграм.
Поделитесь материалом в соцсетях — обсудите его с друзьями и коллегами!Узнайте, как установить и запустить анализ содержимого WordStat и интеллектуальный анализ текста для Stata
WordStat для Stata дает вам возможность анализировать любые строковые переменные / текстовые данные, содержащиеся в числовых и категориальных файлах, которые вы анализируете в Stata. WordStat сочетает в себе обработку естественного языка, анализ содержимого и статистические методы для быстрого извлечения тем, закономерностей и взаимосвязей в больших объемах текста.Он может обрабатывать миллионы слов за секунды и сравнивать извлеченные темы с любыми другими числовыми, категориальными переменными или переменными даты в файле Stata.
WordStat for Stata — это то же программное обеспечение с теми же возможностями, что и версия, работающая с QDA Miner или SimStat. Единственное отличие состоит в том, что при установке WordStat для Stata устанавливается расширение для Stata, которое позволяет запускать WordStat в качестве модуля анализа содержимого и импортировать файлы с помощью мастера преобразования документов. Следовательно, вы всегда должны устанавливать Stata перед установкой WordStat для Stata.
После установки Stata и WordStat для Stata откройте Stata. Откройте файл, который хотите проанализировать. Перейдите к кнопке Пользователи на панели инструментов. Щелкните WordStat в раскрывающемся меню и выберите Анализ содержимого.
После того, как вы нажмете «Анализ содержимого», появится экран ниже, предлагающий вам выбрать строковую переменную, которую вы хотите проанализировать.
Щелкните OK, и вы готовы использовать различные функции WordStat для анализа содержимого.Вы можете увидеть все возможности WordStat, перейдя на наш веб-сайт или просмотрев наши обучающие видеоролики. В этом блоге мы покажем вам, как запустить WordStat для Stata для анализа файлов, импортированных в Stata. Если вы хотите проанализировать файлы и напрямую импортировать их в WordStat для Stata, вы можете сделать это с помощью мастера преобразования документов. В этом видео показано, как это работает. Обучающее видео по мастеру преобразования документов.
Если у вас есть дополнительные вопросы, вы можете написать нам на * защищенный адрес электронной почты *
WordStat для Stata — инструмент анализа содержимого и интеллектуального анализа текста
Stata — это полный интегрированный пакет статистического программного обеспечения, созданный StataCorp LP (www.stata.com). Он обеспечивает широкий спектр статистического анализа, управления данными и графики. В последних версиях Stata добавлено много новых функций, включая тип данных с длинной строкой, позволяющий хранить вместе с числовыми и категориальными данными документы до 2 миллиардов символов. Таким образом, можно создать статистическую базу данных с выдержками из журналов, стенограммами новостей, патентами, отчетами об инцидентах, отзывами клиентов, интервью и т. Д.
WordStat для Stata был создан, чтобы позволить пользователям Stata 13 и Stata 16, работающим под Windows, применять методы текстовой аналитики к любым строковым переменным, хранящимся в файле данных Stata.WordStat сочетает в себе обработку естественного языка, анализ содержимого и статистические методы для быстрого извлечения тем, закономерностей и взаимосвязей в больших объемах текста. Он может обрабатывать миллионы слов за секунды и сравнивать извлеченные темы с любыми другими числовыми, категориальными переменными или переменными даты в файле Stata.
Для чего это используется?
WordStat может использоваться всеми, кому нужно быстро извлекать и анализировать информацию, хранящуюся в текстовых переменных Stata. Может использоваться для:
• Прямой импорт текстовых и количественных данных из социальных сетей, платформ онлайн-опросов, инструментов управления ссылками
• Контент-анализ открытых ответов, интервью или стенограммы фокус-групп
• Бизнес-аналитика и анализ конкурентных веб-сайтов
• Извлечение информации и обнаружение знаний из отчетов об инцидентах, жалоб клиентов
• Анализ содержания новостей или научной литературы (наукометрические или библиометрические исследования)
• Автоматическая пометка и классификация документов
• Выявление мошенничества, установление авторства, патентный анализ
• Разработка и проверка таксономии
• И т.(некоторые примеры исследований с использованием WordStat см. на странице «Исследования»).
WordStat (образовательный) — Science Plus Group bv
WordStat — это гибкое и простое в использовании программное обеспечение для анализа текста — нужны ли вам инструменты интеллектуального анализа текста для быстрого извлечения тем и тенденций или тщательное и точное измерение с помощью современных инструментов количественного анализа контента. Полная интеграция WordStat с SimStat — нашим инструментом статистического анализа данных — QDA Miner — нашим программным обеспечением для качественного анализа данных — и Stata — комплексным статистическим программным обеспечением от StataCorp, дает вам беспрецедентную гибкость для анализа текста и соотнесения его содержания со структурированной информацией, включая числовую. и категориальные данные.
ДЛЯ ЧЕГО ИСПОЛЬЗУЕТСЯ?
WordStat может использоваться всеми, кому нужно быстро извлекать и анализировать информацию из больших объемов документов. Наше программное обеспечение для контент-анализа и интеллектуального анализа текста используется для:
• Контент-анализ открытых ответов, интервью или стенограммы фокус-группы
• Бизнес-аналитика и анализ конкурентных веб-сайтов
• Извлечение информации и обнаружение знаний из отчетов об инцидентах, жалоб клиентов
• Контент-анализ освещения новостей или научной литературы
• Автоматическая пометка и классификация документов
• Выявление мошенничества, указание авторства, патентный анализ
• Разработка и проверка таксономии
Выпущен WordStat 9!
Он предлагает множество новых функций, включая возможность обработки китайского, японского, корейского, тайского и других «новых» языков.
Также имеются расширенные возможности предварительной и последующей обработки с помощью R и Python.
Другие функции включают:
- Перекрестная таблица с панелями диаграмм и фильтрацией
- Интерактивная матрица совместной встречаемости
- Пакетная обработка тематических моделей
- Создание облака слов при поиске ключевых слов и результатах KWIC
- Другие правила приближения
- Более эффективное использование подстановочных знаков и словарного взаимодействия
- Новые возможности очистки данных
- Новые диаграммы с областями с накоплением
- Улучшенная пузырьковая диаграмма
- Буфер анализа связи
(PDF) Обзор программного обеспечения: WordStat 5.0
в разные годы или все вместе. В других случаях может не быть переменных, которые могут разбить текстовые данные
на несколько корпусов и, таким образом, могут анализировать только один корпус.
ПРОГРАММА)
Поскольку я использовал WordStat только в сочетании с SimStat, я остановлюсь только на этой опции. В порядке использования WordStat
сначала необходимо преобразовать корпус или корпус в базу данных WordStat
с помощью мастера преобразования документов, служебной программы, которая поставляется с пакетом WordStat
.Этот процесс преобразования работает с файлами Word, RTF, PDF, ASCII и Excel. Затем необходимо открыть новую базу данных
в SimStat, где нужно определить зависимые и независимые переменные, которые будут изучены. Если аналитик желает добавить другие независимые переменные, это также можно сделать здесь. После определения всех переменных
необходимо выбрать «Анализ содержимого» в меню «Статистика», чтобы запустить
WordStat. Экран WordStat состоит из шести вкладок, которые я рассмотрю в порядке их появления
: «Словари», «Параметры», «Частоты», «Перекрестная таблица», «Ключевое слово в контексте» и « Характеристика
Извлечение ».
Словари. На этой вкладке исследователь настраивает инструменты анализа. Как упоминалось выше
, WordStat основан на словарном подходе. Основной словарь называется «словарь категоризации
». Этот словарь сравнивается с корпусом или корпусом, загруженным в
WordStat. Словарь категоризации может использоваться для анализа содержания, если он содержит слова содержания
определенной области, или для лингвистического анализа, когда он содержит, например, местоимения, даунтонеры,
выражений нечеткости, слова отрицания или любое другое интересующее языковое явление. это может быть
, записанное в виде словаря.Записи в словаре категоризации могут состоять из
отдельных слов или многословных выражений. Вместо окончаний слов можно использовать звездочки, так что словарная статья
охватывает все родственные словоформы (например, стратегия * соответствует стратегии, стратегии, стратегии и стратегу),
, что критически важно для того, чтобы охватить все слова, которые предназначен для захвата, но также
несет опасность того, что в счетчик частоты будут включены слова, которые не предназначены для включения.
В дополнение к словарю категоризации аналитик может разработать список исключений, который содержит все
слов или многословных выражений, которые затем не будут включены в конкретный анализ. Это позволяет
исключать многословные выражения, содержащие слово, которое само по себе является словарной статьей, но
имеет другое значение в сочетании с другими словами. Например, при проверке превосходной степени
WordStat — Alfasoft
Высокотехнологичное программное обеспечение для анализа контента и анализа текста с непревзойденными возможностями обработки и анализа,
WordStat * — это гибкое и простое в использовании программное обеспечение для анализа текста — нужны ли вам инструменты интеллектуального анализа текста для быстрого извлечения тем и тенденций или тщательное и точное измерение с помощью современных инструментов количественного анализа контента. WordStat Полная интеграция с SimStat — нашим инструментом статистического анализа данных — и QDA Miner — нашим программным обеспечением для качественного анализа данных — дает вам беспрецедентную гибкость для анализа текста и соотнесения его содержания со структурированной информацией, включая числовые и категориальные данные.
* Требуется QDA Miner или Simstat для запуска
Для чего это используется?
WordStat может использоваться всеми, кому нужно быстро извлекать и анализировать информацию из больших объемов документов.Наше программное обеспечение для контент-анализа и интеллектуального анализа текста используется для:
• Контент-анализ открытых ответов, интервью или стенограммы фокус-группы
• Бизнес-аналитика и анализ конкурентных веб-сайтов
• Извлечение информации и обнаружение знаний из отчетов об инцидентах, жалоб клиентов
• Контент-анализ освещения новостей или научной литературы
• Автоматически маркировка и классификация документов
• Выявление мошенничества, указание авторства, патентный анализ
• Разработка и проверка таксономии
Ключевые и уникальные особенности
| Мощное программное обеспечение для анализа контента и интеллектуального анализа текста для обработки больших объемов неструктурированной информации.WordStat может обрабатывать до 20 миллионов слов в минуту и определять все ссылки на определенные пользователем концепции с помощью словарей категоризации. |
| Интегрированные инструменты исследовательского анализа текста и визуализации , такие как кластеризация, многомерное масштабирование, графики близости и многое другое, для быстрого извлечения тем и автоматического определения шаблонов. |
| Связывает неструктурированный текст со структурированными данными , такими как даты, числа или категориальные данные, для определения временных тенденций или различий между подгруппами или для оценки взаимосвязи с рейтингами или другими видами категориальных или числовых данных. |
| Используйте существующие или создайте собственные словари иерархического анализа контента или таксономии , состоящие из слов, шаблонов слов, фраз, а также правил близости (таких как NEAR, AFTER, BEFORE) для достижения точного измерения понятий. |
| Поистине уникальная компьютерная поддержка для создания словарей с инструментами для извлечения общих фраз и технических терминов, а также для быстрого определения в вашей текстовой коллекции орфографических ошибок, синонимов, антонимов и связанных слов. |
| Доступ в один клик к ключевым словам в контексте и инструментам поиска ключевых слов для легкой идентификации и кодирования релевантных текстовых сегментов, проверки словарей контент-анализа, устранения неоднозначности слов или для перехода к исходным документам. |
| Полная интеграция с современным инструментом качественного кодирования (QDA Miner), позволяет при необходимости более точно исследовать данные или более глубоко анализировать определенные документы или извлеченные текстовые сегменты. |
| Машинное обучение для автоматической классификации документов с использованием алгоритмов Наивного Байеса и K-ближайших соседей с инструментами автоматического выбора и проверки признаков. Затем классификационные модели могут быть сохранены на диске и повторно применены к новым данным. |
| Easy импорт баз данных, электронных таблиц и документов (включая PDF и HTML), а также экспорт результатов анализа текста в распространенные отраслевые форматы файлов (Excel, SPSS, ASCII, HTML, XML, MS Word) и графики (PNG , BMP и JPEG). |
Следующие шаги
В настоящее время мы не можем выставить этот товар на продажу. Пожалуйста, свяжитесь с нами для получения дополнительной информации.
Однако мы можем предоставить вам всю необходимую поддержку программного обеспечения и советы, чтобы выбрать правильный продукт, поэтому, пожалуйста, позвоните в местный офис для получения совета или предложения.
Продукты Alfasoft
В настоящее время мы не можем предложить следующие линейки продуктов, хотя в настоящее время мы прилагаем все усилия, чтобы увеличить количество продуктов, которые мы можем предложить в будущем.Свяжитесь с нами, чтобы обсудить альтернативные продукты, которые мы можем вам предложить.
WordStat 5.0 — ИНФОРМАЦИЯ
Информация о продукте
WordStat можно приобрести на веб-сайте Provalis Research (www.provalisresearch.com). Полнофункциональная пробная версия WordStat (30 дней) доступна на той же веб-странице. Чтобы протестировать все функции программного обеспечения, вам необходимо загрузить пробную версию SimStat.На этой веб-странице есть ссылки на ряд исследований, проведенных с использованием WordStat. Цена
:
Retail
Academic
WordStat с Simstat 2.5
955 $
$ 475
WordStat с QDA Miner 1.0
$ 1095
$$ 555
WordStat
WordStat с Simstat 1.0
WordStat с Simstat 2.5 и MVSP
1195 долларов США
645 долларов США
WordStat с Simstat 2.5 и MVSP & QDA Miner 1.0
$ 1,625
$ 885
Несколько лет назад я был свидетелем доктора социальных наук. студент пытается определить, имитировала ли политическая кампания Лейбористской партии на выборах 1997 года в Великобритании кампанию Клинтона на президентских выборах в США годом ранее. Она подсчитала частоту и совпадение таких слов, как «сострадание» и «харизма», для описания качеств лидерства во всей предвыборной телевизионной рекламе как для Блэра, так и для Клинтон. Меня поразила строгость анализа такого огромного количества текстовых данных.
Контент-анализ, согласно Холсти (1969), представляет собой «любую технику, позволяющую делать выводы путем объективного и систематического определения определенных характеристик сообщения».
Уместен ли контент-анализ для O.R. профессионалов, которые больше знакомы с традиционными аналитическими методами, такими как моделирование или линейное программирование? Ответ — да, поскольку большая часть информации, которой располагает компания, — это текстовые данные в форме сообщений электронной почты, документов, отчетов и т. Д. Обычно такая текстовая информация неструктурирована.Следовательно, извлечение значимой информации для принятия решений из данных такого рода может быть довольно трудоемким и трудным. Изучение таких неиспользованных текстовых данных могло бы дополнить существующие O.R. инструменты для улучшения работы.
Многие известные компании используют инструменты анализа текста, такие как WordStat, для оценки того, как их продукты воспринимаются публикой или клиентами. WordStat анализирует базы данных отзывов клиентов и сообщений электронной почты, отправленных клиентам или в службу технической поддержки, просматривая слова, которые тесно связаны с их продуктами.Компании также пытаются идентифицировать различные типы клиентов, их потребительские привычки, их потребности, их жалобы и т. Д. Другой пример использования контент-анализа появился в статье Соди и Сон (2005) в августовском номере журнала OR / MS Today за 2005 год. Авторы провели базовый контент-анализ, чтобы выяснить, какие навыки работодатели хотят от O.R. выпускники. Анализ дает полезную информацию о ключевых навыках, которые работодатели хотят получить от O.R. выпускников и дает вид количественной продукции О.Р. люди привыкли к продюсированию.
Контент-анализ — это новая территория для O.R. профессионалов, но мы можем получить помощь с помощью такого инструмента, как WordStat 5.0 от Provalis Research. WordStat — это дополнительный модуль для пакета статистического анализа SimStat, который предоставляет статистическую базу данных O.R. профессионалам было бы вполне комфортно. По словам Провалиса, WordStat специально разработан для изучения текстовой информации, такой как ответы на открытые вопросы, интервью, заголовки, журнальные статьи, электронные сообщения и т. Д.В этом обзоре я сосредоточусь на изучении основных функций и возможностей этого программного обеспечения.
Обзор функций
WordStat может выполнять анализ текстовых полей в различных форматах, а также больших документов. Он может обрабатывать тексты, приводящие слова к канонической форме (например, «Собаки» и «Собака» в «Собака»).
WordStat может выполнять одномерный частотный анализ (количество и количество ключевых слов) и представляет результаты в матричной форме (рисунок 7). Средство поиска фраз помогает пользователям определять повторяющиеся фразы и их количество.
WordStat может выполнять двумерное сравнение между любым текстовым полем (например, персональной рекламой в учебнике в следующем разделе) и любыми номинальными и порядковыми переменными (такими как пол или возрастная группа респондентов). В WordStat есть множество показателей ассоциации для оценки взаимосвязи между появлением ключевого слова и номинальными / порядковыми переменными, например разница между появлением ключевых слов в личных объявлениях, размещаемых мужчинами и женщинами.
Ключевое слово в контексте (KWIC) — это полезная функция в WordStat, которая позволяет увидеть вхождение либо определенного слова, либо всех слов, относящихся к категории, в реальном тексте, организованном в виде таблицы.Это удобно, когда нужно оценить согласованность (или несогласованность) значений, связанных со словом (рис. 1).
Рисунок 1. Функция ключевого слова в контексте (KWIC) удобна при оценке согласованности значений, связанных со словом.
В дополнение к перечисленным выше функциям WordStat предоставляет различные другие функции, такие как автоматическая классификация текста, анализ случая или сходства документов и т. Д. Подробнее об этих и других функциях см. На сайте www.provalisresearch.com/wordstat/WordstatFeatures.html.
Мини-учебник
В этом мини-руководстве я следую краткому обзору, включенному в руководство по WordStat 5.0, на примере некоторых функций WordStat. Объем этого руководства ограничен основными функциями, такими как одномерный анализ и изучение отношений между некоторыми ключевыми словами и другими категориальными переменными. В этом примере анализируется персональная реклама. Мы проводим контент-анализ 68 личных объявлений, опубликованных в газете о культуре в Монреале, чтобы выяснить, есть ли какая-либо связь между словами, использованными в рекламе, и полом и возрастом человека, разместившего рекламу.Тогда мы сможем выяснить, верны ли такие стереотипы, как «мальчики заботятся только о внешности». Данные хранятся в файле данных, в данном случае с тремя полями: текст самого объявления и две категориальные переменные (пол и возрастная группа человека, размещающего объявление; последние два могут быть трудно вывести из само объявление и, следовательно, кодируются вручную).
Шаг 1: Создание файла данных. Чтобы создать файл данных, вы можете использовать базовую программу SimStat и вводить данные, как и другие статистические пакеты.Я обнаружил, что использовать SimStat для ввода данных и манипуляции с ними немного затруднительно из-за его довольно другого интерфейса ввода данных. Однако WordStat (через SimStat) может напрямую импортировать файлы данных различных типов, такие как MS Access, MS Excel и dBase. Кроме того, он имеет ряд инструментов, помогающих импортировать данные из текстовых или текстовых файлов.
Поле для текстовой информации можно просто скопировать и вставить в электронную таблицу или базу данных по вашему выбору и импортировать в SimStat.Категориальные и другие переменные, связанные с текстовой информацией, такие как пол и возрастная группа, очевидно, должны быть закодированы пользователем. Например, для файла данных нашего анализа объявлений о вакансиях [2] мы использовали MS Access для создания набора данных путем копирования и вставки объявлений о вакансиях с Monster.com из Интернета и файлов HTML, предоставленных OR / MS Today. Мы вручную закодировали отрасль и другие области для дальнейшего анализа.
В этом руководстве я использую образец файла данных (SEEKING.DBF), который поставляется вместе с программным обеспечением.Открыв файл, вы увидите три переменные: номинальную переменную GENDER (1 = мужчины, 2 = женщины), порядковую переменную AGEGROUP (1 = 18-24, 2 = 25-29, 3 = 30-39, 4 = 40+) и текстовой переменной AD_TEXT (рисунок 2). Переменная AD_TEXT содержит текст 68 реальных личных объявлений, скопированных и вставленных из газет; эта переменная находится в центре нашего анализа. Две другие переменные — GENDER и AGEGROUP — были вручную закодированы при просмотре личных объявлений.
Рисунок 2: Три переменные из файла выборки данных: номинальная, порядковая и текстовая.
Шаг 2: Выберите переменные. После открытия файла SEEKING.DBF в SimStat перейдите в меню СТАТИСТИКА и выполните команду ВЫБРАТЬ X-Y. Здесь нам нужно переместить переменные в соответствующие места. Давайте сначала переместим переменную AD_TEXT в список DEPENDENT. Затем две другие категориальные переменные (GENDER и AGEGROUP) необходимо поместить в поле списка INDEPENDENT (рисунок 2). Обратите внимание, что это похоже на то, что можно было бы сделать, если бы выполнялся дисперсионный анализ с количественными данными.Также обратите внимание, что до сих пор мы использовали SimStat, который представляет собой статистический пакет.
Шаг 3. Запустите WordStat. Перейдите в меню СТАТИСТИКА и выполните команду АНАЛИЗ СОДЕРЖАНИЯ. Появится новое окно с шестью вкладками, и теперь мы готовы провести анализ контента.
Шаг 4: Выберите подходящие словари. Основа использования WordStat — это «словарь». Словарь — это спецификация слов и фраз в различных именованных категориях, которая позволяет WordStat либо исключать определенные слова из анализа, либо, что более важно, создавать счетчики для каждой «категории», когда слово или фраза из этой категории обнаруживаются в записывать.
WordStat позволяет пользователям выбирать, просматривать и редактировать словари, используемые для анализа конкретного содержимого. В этом руководстве мы исключаем: 1) предварительную обработку для пользовательского преобразования текста и 2) «лемматизацию», процесс, с помощью которого различные формы слов сокращаются до более ограниченного числа канонических форм, например, преобразование множественного числа в единственное число. Третий параметр, «исключение», — это словарь, содержащий слова, которые необходимо удалить в процессе анализа. Например, слова с небольшими семантическими значениями, такие как местоимения, артикли и союзы, автоматически удаляются в соответствии с правилами, установленными в словаре исключения.С другой стороны, «категоризация» позволяет указать слова, словосочетания и фразы, которые будут включены в анализ (рис. 3).
Рисунок 3: «Категоризация» определяет слова, шаблоны слов и словосочетания, которые должны быть включены в анализ.
Все эти словари можно редактировать в программе или с помощью любого инструмента для редактирования текста (например, Блокнота). В этом руководстве мы выбираем словарь исключений по умолчанию (DEFAULT.EXC) и специальный словарь категоризации (SEEKING.CAT), который содержит слова и фразы, которые часто появляются в личной рекламе. Ключевые слова могут быть расположены в иерархическом порядке, чтобы пользователи могли иметь разные уровни анализа (рисунок 4). Категория первого уровня включает основные атрибуты, которые могут быть интересны партнерам. Например, в категории «внешний вид» можно найти различные слова, описывающие внешний вид.
Рисунок 4: Ключевые слова могут быть расположены в иерархическом порядке для разных уровней анализа.
Вы можете загрузить большое количество готовых словарей с веб-страницы (http: // www.provalisresearch.com/wordstat/RID.html), в зависимости от интересующей темы. Большинство О. пользователи захотят создавать свои собственные словари из необработанных данных с помощью WordStat. Для этого урока был дан словарь категории SEEKING.CAT. Предположим, что у нас этого не было, поэтому нам пришлось бы создать свой собственный словарь для этого анализа. В этом случае мы могли бы создать словарь категоризации, запустив частотный анализ слов и поиск фраз в WordStat, чтобы определить наиболее часто используемые.На основе результатов мы можем составить собственный словарь категорий, выбрав наиболее часто встречающиеся слова и фазы (рис. 5 и 6). Однако эти две функции действительно извлекают нерелевантные слова и фразы, такие как «ОСТАВИТЬ СООБЩЕНИЕ»; нам нужно пройтись по спискам, чтобы выделить эти слова и фразы.
Рисунок 5 (вверху) и Рисунок 6 (внизу): пользователи могут создавать свой собственный словарь категорий, выбирая наиболее часто встречающиеся слова и этапы.
После того, как вы выбрали или создали соответствующий словарь, вы можете выбрать дополнительные параметры.В этом уроке мы отключили все параметры.
Шаг 5. Выполните частотный анализ личных объявлений. Наконец, мы готовы проанализировать самые важные атрибуты Мистера или Мисс «Perfect» по персональным объявлениям. Щелкаем на третьей вкладке (Частоты), чтобы определить количество категорий слов или частотный анализ. Мы обнаружили, что слова из категории «внешний вид» являются наиболее часто упоминаемыми критериями в личных объявлениях. Действительно, 41 из 68 объявлений содержат слова, относящиеся к внешнему виду (рис. 7).Обратите внимание, что категория «внешний вид» содержит различные слова, такие как «красивый» и «мускулистый» (рис. 4). Категория «финансы», напротив, появилась меньше всего. Вы можете отобразить другие слова, не включенные в словарь категории, изменив параметр отображения.
Рисунок 7: Категория «Внешний вид» была популярна при частотном анализе личных объявлений.
Шаг 6: Изучение взаимосвязи между включенными категориями и полом автора.Пока что частотный анализ объявлений, которые мы только что сделали, показывает частоту слов независимо от пола. Также может быть очень интересно посмотреть, есть ли разница в предпочтениях между мужчинами и женщинами по сравнению с идеальными партнерами. Мы переходим на четвертую вкладку «Меню кросс-таблицы», и WordStat выполняет два отдельных частотных анализа для мужчин и женщин и предоставляет красивую таблицу (рис. 8). Результаты показывают, что наиболее важными критериями для мужчин являются «внешний вид», тогда как женщины больше всего ценят «общение» и «семью».В том же меню мы также можем оценить силу этих отношений, выбрав различные меры ассоциации, такие как хи-квадрат или статистику R Пирсона.
Рисунок 8: «Меню кросс-таблицы» предоставляет, среди прочего, красивую таблицу.
На «странице кросс-таблицы» можно выполнять различные другие задачи, например анализ корреспонденции. Вы также можете создавать «тепловые карты», которые помогают прояснить отношения между словами и категориями (рис. 9).
Рисунок 9: «Тепловые карты» помогают прояснить отношения между словами и категориями.
Мой опыт работы с WordStat
Когда мой соавтор Мохан Содхи и я изначально планировали статью «Чего работодатели отрасли хотят от выпускников OR / MS — предварительные результаты анализа объявлений о вакансиях» [2], мы были поражены огромное количество текстовой информации (более 650 объявлений о вакансиях). Наш первоначальный план состоял в том, чтобы просматривать объявления одну за другой и вручную кодировать каждую. Срок написания статьи составлял от трех до пяти месяцев. Когда мы обнаружили WordStat в Интернете, мы были взволнованы потенциалом этой методологии и ее функций, позволяющих исследовать огромное количество объявлений о вакансиях за небольшой промежуток времени.
Мы загрузили демонстрационную версию и познакомились с программным обеспечением, не пользуясь печатным руководством. Благодаря простому интерфейсу и понятному онлайн-руководству WordStat был относительно простым в использовании. Кроме того, WordStat оказался довольно универсальным с точки зрения импорта данных из популярных приложений и простого экспорта результатов в различные форматы. Мы смогли без проблем импортировать данные в формате MS Access, содержащем более 650 объявлений о вакансиях, за несколько секунд.
Две функции, которые нам особенно понравились, — это «частотный анализ для одного слова» и «экстрактор фраз». Поскольку у нас не было словаря категорий для «дисциплины», «степени», «умения» и «характера работы», нам пришлось создать собственный словарь категорий. Хотя нам пришлось перебрать более тысячи ключевых слов и фраз, автоматически определяемых этими функциями, чтобы выделить нерелевантные слова и фразы, эти две функции помогли нам быстрее и точнее определить релевантные ключевые слова и фразы.При написании статьи мы повторили описанный выше процесс, добавляя со временем больше рекламы. Поэтому нам приходилось обновлять наш словарь категорий несколько раз, и редактирование словаря категорий в WordStat не было сложным.
Мы нашли «ключевое слово в контексте» (KWIC) полезным, когда мы пытались выяснить релевантность определенных терминов. Например, мы обнаружили, что поисковая система Monster по нашей фразе «исследование операций» (в кавычках) также возвращала объявления, в которых слова «операции» и «исследования» были разделены знаком препинания.Итак, мы использовали функцию KWIC, чтобы просмотреть отдельные объявления, чтобы выявить «операции, исследования». WordStat автоматически выполнил поиск по всем объявлениям, содержащим «операции, исследования» и выделенным разными цветами, чтобы мы могли легко обнаружить и удалить рекламу с помощью «операций, исследований».
Скорость обработки записей была достаточно высокой. Спецификация компьютера, который я использую, — Intel Celeron 2.4 с 512 RAM. На частотный анализ слов потребовалось примерно три секунды и одна минута на выделение ключевой фразы из более чем 650 рекламных объявлений.
WordStat помог нам быстро и тщательно проанализировать обширную текстовую информацию. Однако манипулирование данными в базовой статистической программе SimStat было довольно сложно и обременительно по сравнению с MS Excel и MS Access, из которых данные можно импортировать напрямую.
Во время написания этого обзора я обнаружил, что различные научные и отраслевые статьи сообщают о результатах, полученных с помощью WordStat. Меня поразило, насколько творчески пользователи WordStat применяют это программное обеспечение в различных ситуациях.Например, Пеладо и Стовалл проанализировали базу данных пилотных отчетов о рисках столкновений, широко известных как отчеты TCAS (отчет системы предотвращения столкновений). Используя WordStat, они смогли определить конкретные риски в разных аэропортах, час дня, когда произошли эти ошибки, фазу полета, на которой возникли эти риски столкновения, а также некоторые свойства этих инцидентов столкновения (время событий, множественность событий, пилотные действия и др.) [1].
С помощью WordStat можно проанализировать буквально любую текстовую информацию с помощью словарей по вашему выбору.Представьте себе возможность анализировать огромное количество документов, отчетов, электронных писем, баз данных и других текстовых полей полевых операций, которые не были задействованы, потому что они были слишком громоздкими или трудоемкими для анализа вручную. В O.R. В классных комнатах внедрение инструмента анализа контента, такого как WordStat, может помочь учащимся узнать о расширении числовой статистики на текст для сбора информации.
В целом WordStat — это простое в использовании, доступное по цене и многофункциональное программное обеспечение, обеспечивающее O.R. профессионалы, владеющие еще одной аналитической техникой.
Постскрипт: Для справки, д.т.н. Студент пришел к выводу, что большая часть кампании Блэра была сопоставлена с кампанией Клинтона, и доказательства, представленные контент-анализом, были довольно убедительными.
Комментарии поставщика
Примечание редактора: политика OR / MS Today заключается в том, чтобы предоставить разработчикам рецензируемого программного обеспечения возможность уточнить и / или прокомментировать обзорную статью. Ниже приведены комментарии Нормана Пеладо, президента Provalis Research.
Рецензент предоставил отличное введение в основные функции WordStat. Его описание того, как они создали свой собственный словарь категоризации для анализа объявлений о вакансиях, дает точное представление о самой первой задаче, с которой сталкивается новый пользователь при работе с WordStat. Создание таксономий или словарей категоризации часто является важным условием для обоснованного анализа и обоснованных выводов, и WordStat предлагает множество инструментов, помогающих пользователю в решении такой задачи.
Рецензент упомянул возможность легко назначать слова или фразы из списков.Дополнительные функции включают редактор словарей с перетаскиванием и различные лексические ресурсы, которые могут предлагать дополнительные элементы для добавления к существующим категориям контента. Возможность смотреть на то, как слова и фразы сочетаются друг с другом, используя иерархическую кластеризацию, многомерное масштабирование или графики близости, представляет собой еще один способ идентифицировать темы в коллекции документов или выполнять задачи по обнаружению знаний.
Как и все инструменты расширенного анализа, которые могут быть упомянуты только в этом кратком введении, я рекомендую читателям ознакомиться с некоторыми опубликованными исследованиями, доступными на нашем веб-сайте, или загрузить электронную версию руководств или полнофункциональные демонстрации WordStat. и Simstat.
Статистическое программное обеспечение предназначено для обработки числовых данных и может быть не самым подходящим инструментом для работы с коллекциями документов. Мы полностью понимаем, что рецензенту трудно ввести эти объявления непосредственно в Simstat. Это одна из причин, по которой мы реализовали процедуры импорта для различных форматов файлов баз данных и электронных таблиц и создали мастер преобразования документов для импорта различных типов документов. Это также одна из причин, почему в прошлом году мы выпустили новое приложение под названием QDA Miner, которое можно использовать вместо Simstat в качестве базового модуля для WordStat.Это программное обеспечение использует тот же формат файлов, что и наша статистическая программа, но оно было разработано для обеспечения более удобных для пользователя функций управления документами. Он также представляет новый набор инструментов, заимствованных из социальных наук. Компьютерный качественный анализ основан на ручном и полуавтоматическом кодировании текстовых сегментов и на поиске текста.
WordStat, Simstat и QDA Miner — настольные приложения. Тем не менее, Provalis Research планирует выпустить до конца года комплект разработчика программного обеспечения (SDK), который можно будет использовать с многочисленными языками программирования и средами программирования баз данных.Такая библиотека позволит интегрировать технологии категоризации и классификации WordStat в корпоративные системы управления документами и поддержки принятия решений.
Бьюнг-Гак Сон ([email protected]) — научный сотрудник бизнес-школы Касс при Лондонском городском университете, недавно защитивший докторскую диссертацию. в управлении цепочкой поставок.
Ссылки
— Холсти, О.Р., 1969, «Анализ содержания социальных и гуманитарных наук», Ридинг, Массачусетс: Addison-Wesley.
— М.Содхи и Б. Сон, 2005 г., «Чего работодатели отрасли хотят от выпускников операционных / MS», OR / MS Today (август 2005 г.), Vol. 32, № 4, стр. 32-38.
— Пеладо, Н. и Совалл, С., 2005, «Применение анализа текстов статистического анализа содержания Provalis Research Corp. в отчетах о безопасности полетов», Глобальная информационная сеть по авиации.
8 лучших доступных систем текстовой аналитики
Системы текстовой аналитики призваны помочь вам получить высококачественную информацию из вводимого текста. По оценкам, около 80% информации , имеющей отношение к бизнесу, поступает из каких-то неструктурированных данных , большая часть которых является текстом — подумайте о таких вещах, как электронные письма, отчеты и даже сообщения в социальных сетях.
Внутри этих неструктурированных данных скрыто массивов ценной информации , но без технологических инструментов, позволяющих каким-либо образом организовать данные, их может быть очень сложно найти.
Вот здесь и приходит на помощь текстовая аналитика. Эти программы помогают анализировать текстовые данные и сортировать их, чтобы вы могли понять данные. Систем текстовой аналитики очень много, но не все они равноценны. Многие из них предлагают различные функции и возможности.Другие предоставляют мощные инструменты, но требуют сложного обучения. И еще много хороших программ, но они могут не совсем соответствовать потребностям вашего бизнеса.
Вот почему мы выбрали 8 лучших систем текстовой аналитики, которые могут помочь вам получить необходимую информацию из неструктурированных данных .
SASSAS — это программный инструмент, который призван помочь вам получить практическую информацию из неструктурированных данных, особенно онлайн-контента , от книг до форм комментариев.Поскольку это программное обеспечение также позволяет управлять процессом машинного обучения , вы можете сузить круг автоматически создаваемых тем и правил. Вы также можете увидеть, как правила меняются со временем, и, таким образом, улучшить свой подход для достижения лучших результатов.
WordStat QDA MinerQDA Miner имеет ряд возможностей для анализа качественных данных. Для анализа текста программа использует дополнительный модуль WordStat. Модуль предназначен для контент-анализа, анализа текста и тональности .Его можно использовать для анализа веб-сайтов и социальных сетей, а также для бизнес-аналитики. Есть несколько инструментов визуализации , которые помогут вам лучше интерпретировать результаты программы. Анализ соответствия WordStat помогает программе определять концепции и категории, которые присутствуют в вашем тексте.
Пакет Microsoft Cognitive ServicesCognitive Services предлагает надежный набор инструментов искусственного интеллекта , которые помогут вам создавать интеллектуальные приложения с естественным и контекстным взаимодействием.В отличие от программы строго текстовой аналитики, Cognitive Services включает элементы текстовой аналитики в том, как она анализирует речь и язык. Одной из них является интеллектуальная служба Language Understanding , которая разработана, чтобы помочь ботам и приложениям понимать человеческий ввод и общаться с людьми на естественном языке .
Rocket Enterprise Search и текстовая аналитикаБезопасность — важная проблема для компаний, работающих с большими объемами данных, и инструмент Rocket учитывает это в своем решении для текстовой аналитики.Еще одна особенность — удобство использования , поэтому команды могут быстро и легко находить нужную информацию. Если вы работаете с командами с ограниченным технологическим опытом , этот инструмент может быть очень полезным.
Voyant ToolsЭто приложение может быть использовано кем угодно в качестве инструмента анализа текста для веб-сайтов , хотя оно, как правило, популярно среди исследователей в области цифровых гуманитарных наук. Хотя Voyant Tools не является системой глубокой текстовой аналитики, у него простой интерфейс и возможности для выполнения множества аналитических задач.За секунд он может проанализировать веб-сайт и создать визуализацию данных в тексте.
УотсонВы можете помнить Watson как компьютер, который победил Jeopardy! звезда Кен Дженнингс, поэтому неудивительно, что компьютерная система IBM также имеет первоклассную систему текстовой аналитики . Он называется Watson Natural Language Understanding и использует когнитивные технологии для анализа текста, в том числе для оценки настроений и эмоций .
Открытый КалеOpen Calais — это облачный инструмент, который помогает вам тегировать содержимое . Сильной стороной этого инструмента является распознавание взаимосвязей между различными объектами в неструктурированных данных и их соответствующая организация. Хотя он не может выполнять сложный анализ настроений, он может помочь вам справиться с неструктурированными данными и превратить их в хорошо организованную базу знаний .
Folksonomy Бисмарта Программное обеспечение интеллектуальной фолксономииBismart использует интеллектуальные теги , чтобы просеивать ваши архивы неструктурированных данных и находить конкретную информацию.Это означает, что вам больше не нужно проходить долгий и утомительный процесс определения тегов и категорий. Вы можете по-разному настроить программу под разные нужды. Вы также можете реструктурировать его в реальном времени для различных целей. Это быстрый , удобный и различных вариантов , что делает его идеальным для совместных проектов .
Хотите узнать, как мы можем преобразовать ваши большие данные в ценность? Свяжитесь с нами , и наши специалисты помогут вам найти правильное решение для ваших нужд.