Как самостоятельно проверить контент на дублирование
112
Дублированный контент может ввести Google в заблуждение. Если он находится на разных страницах вашего или других сайтов, поисковая система Google будет прибывать в неведении того откуда начать ранжирование. Прилагайте все усилия, чтобы избежать дублирования контента. Время от времени проводите проверку с целью выявить копии.
Как бы то ни было, если вы пишите замечательный контент, вам предстоит столкнуться с его дублированием. И копии этого контента не всегда будут содержать ссылку на ваш сайт. Это еще одна причина регулярно проверять контент на дублирование. В этой статье я расскажу вам, как быстро найти дублированный контент вашего сайта.
Сервис проверки дублированного контента CopyScape
Существует множество инструментов для поиска дублированного контента. Одним из самых известных вероятно является сервис CopyScape.com. Он прост в использовании: вставьте ссылку и CopyScape уведомит вас, на каких еще страницах размещается ваш контент:
Это первый этап. Мы получим какое-то количество результатов (в моем случае 1), представленных в виде результатов поиска Google.

CopyScape красиво выделяет текст, который сервис определил, как дублированный, таким образом давая понять насколько серьезным было копирование. Кроме этого он может показать ссылки на сайты которые скопировали ваш контент. Если это всего-то 2% содержимого страницы, то заморачиваться не стоит. Если это более 40%, что составляет значительную часть страницы, я бы просто связался с ними посредством e-mail и попросил изменить скопированный текст.
«Между прочим, уважаемый коллега, если вы хотите копировать наш контент, пожалуйста, редактируйте его под свой веб-сайт. Фраза «в этой статье» в данном случае совершенно бессмысленна :P»
Кстати, мы часто сталкиваемся с тем, что описания производителей в онлайн магазинах оказываются дубликатами. Обычно, они автоматически импортируются в систему управления контентом магазина. Как правило, не только для вашего сайта. Помните об этом. Понимаю, что сделать уникальными описания для всех продуктов довольно хлопотно, но хотя бы начните с тех, которые пользуются наибольшим спросом и избавьте их от этой участи. Не откладывайте.
Пользуйтесь сервисом CopyScape, чтобы выявить контент, скопированный с вашего сайта на другие. Опять-таки, это один из многих инструментов, но в то же время бесплатный и простой в использовании. Если вы хотите несколько углубиться в тему дублированного контента и провести более глубокий анализ, CopyScape также предлагает премиум доступ.
Внутренняя проверка дублированного контента посредством «Siteliner»
Siteliner – это брат CopyScapes, который проводит поиск дублированного контента в пределах веб-сайта. Этот инструмент предназначен для поиска дублированного контента на вашем собственном сайте.
Очень типичным примером является случай, когда блог на WordPress не использует выдержки, а целиком показывает статью на своей домашней странице. Это свидетельствует о том, что пост доступен по крайней мере на двух страницах: на домашней и на той, которой находится оригинал. И помимо этого, вероятно, на страницах обзора, в разделах «категории» и «теги». Уже видим четыре версии одной и той же статьи на вашем собственном сайте.
Преимущество от использования выдержек заключается в том, что в них всегда имеется соответствующая ссылка на пост. Эта ссылка укажет Google, что оригинальный контент находится не на страницах блога/категории/тега, а в самом посте. Это в свою очередь означает, что у половины веб-сайтов в действительности имеются внутренние проблемы с дублированным контентом.
Сервис проверки дублированного контента «Siteliner» предоставит вам большое количество информации, но с ограничением в 250 страниц и 30 дней. И опять же, есть премиум-версия, но для формирования ясного представления будет достаточно и бесплатной. Просто произведите поиск, найдите страницу обзора и, пожалуйста, кликайте для получения более подробной информации. Не пугайтесь большого количества, имеющегося у вас дублированного контента, поскольку такая проверка расценивает, в качестве дублированного контента даже выдержки:
Процентные соотношение
Тогда, как Google понимает боковую панель, похоже на то, что CopyScape и Siteliner включают в свои процентные вычисления весь текст страницы. Пожалуйста помните об этом, когда вы пользуетесь одним из этих сервисов. Фактически же, процентное соотношение дублирующего контента при просмотре лишь основной его части, может быть выше. Будьте внимательны! Переживаю ли я на этот счет? Нет. Просто перейдите по одной из ссылок и проверьте на самом ли деле речь идет об отрывке. Общее количество совпавших слов – 223, но на самом деле, в основной разделе статьи к «дублированной части» относятся лишь 57 из 1086 слов. И очевидно, что отрывок ссылается на статью, так что все хорошо.
Поиск дублированного контента вручную
Сервисы CopyScape и Siteliner замечательны и удобны в использовании. Тем не менее, если вы хотите оценить дублированный контент с точки зрения Google, не примените им воспользоваться.
Если есть определенная страница, которую вы хотели бы проверить, просто перейдите на нее. Скопируйте фрагмент текста, желательно из раздела, который вы считаете привлекательным для копирования. Вставьте этот фрагмент в поле поиска Google, используя двойные кавычки, как показано ниже:

«Продвижение веб-сайта статьями – один из наиболее эффективных методов продвижения на сегодняшний день».
Ограничьтесь в этой фразе 32 словами, поскольку лишь столько Google примет во внимание. В моем случае, google показывает только мои страницы где встречается такая фраза. Это три ссылки на страницу самого поста, на главную страницу сайта и на категорию где размещена статья.
Отслеживайте собственный дублированный контент
Пользуйтесь сервисом поиска дублированного контента CopyScape, чтобы выявить, какой контент был скопирован с вашего сайта, и поисковой системой Google, чтобы узнать на каких еще веб-ресурсах он всплывет. Это простые инструменты, которые служат для достижения высокой цели – предотвратить дублирование контента.
Читать подробнее: Что такое дублированный контент
starting-constructor.ru
что это такое и как их удалить
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
![]()
Дубли страниц – это идентичные друг другу страницы, находящиеся на разных URL-адресах. Копии страниц затрудняют индексацию сайтов в поисковых системах.
Что такое дубли страниц на сайте
Дубли могут возникать, когда используются разные системы наполнения контентом. Ничего страшного для пользователя, если дубликаты находятся на одном сайте. Но поисковые системы, обнаружив дублирующиеся страницы, могут наложить фильтр\понизить позиции и т. д. Поэтому дубли нужно быстро удалять и стараться не допускать их появления.
Какие существуют виды дублей
Дубли страниц на сайте бывают как полные, так и неполные.
- Неполные дубли – когда на ресурсе дублируются фрагменты контента. Так, например, и разместив части текста в одной статье из другой, мы получим частичное дублирование. Иногда такие дубли называют неполными.
- Полные дубли – это страницы, у которых есть полные копии. Они ухудшают ранжирование сайта.
Например, многие блоги содержат дублирующиеся страницы. Дубли влияют на ранжирование и сводят ценность контента на нет. Поэтому нужно избавляться от повторяющихся страниц.
Причины возникновения дублей страниц
- Использование Системы управления контентом (CMS) является наиболее распространённой причиной возникновения дублирования страниц. Например, когда одна запись на ресурсе относится сразу к нескольким рубрикам, чьи домены включены в адрес сайта самой записи. В результате получаются дубли страниц: например:
wiki.site.ru/blog1/info/
wiki.site.ru/blog2/info/ - Технические разделы. Здесь наиболее грешат Bitrix и Joomla. Например, одна из функций сайта (поиск, фильтрация, регистрация и т.д.) генерирует параметрические адреса с одинаковой информацией по отношению к ресурсу без параметров в URL. Например:
site.ru/rarticles.php
site.ru/rarticles.php?ajax=Y - Человеческий фактор. Здесь, прежде всего, имеется ввиду, что человек по своей невнимательности может продублировать одну и ту же статью в нескольких разделах сайта.
- Технические ошибки. При неправильной генерации ссылок и настройках в различных системах управления информацией случаются ошибки, которые приводят к дублированию страниц. Например, если в системе Opencart криво установить ссылку, то может произойти зацикливание:
Чем опасны дубли страниц
- Заметно усложняется оптимизация сайта в поисковых системах. В индексе поисковика может быть много дублей одной страницы. Они мешают индексировать другие страницы.
- Теряются внешние ссылки на сайт. Копии усложняют определение релевантных страниц.
- Появляются дубли в выдаче. Если дублирующий источник будет снабжаться поведенческими метриками и хорошим трафиком, то при обновлении данных она может встать в выдаче поисковой системы на место основного ресурса.
- Теряются позиции в выдаче поисковых систем. Если в основном тексте имеются нечёткие дубли, то из-за низкой уникальности статья может не попасть в SERP. Так, например часть новостей, блога, поста, и т. д. могут быть просто не замечены, так как поисковый алгоритм их принимает за дубли.
- Повышается вероятность попадания основного сайта под фильтр поисковых систем. Поисковики Google и Яндекс ведут борьбу с неуникальной информацией, на сайт могут наложить санкции.
Как найти дубли страниц
Чтобы удалить дубли страниц, их сначала надо найти. Существует три способа нахождения копий на сайте.
- Нахождение дублей на сайте с помощью расширенного поиска Google. Укажите в расширенном поиске адрес главной страницы. Система выдаст общий список проиндексированных страниц. А если указать адрес конкретной страницы, то поисковик покажет весь перечень проиндексированных дублей. В отличие от Google, в Яндексе копии страниц сразу видны.
Например, такой вид имеет расширенный поиск Google:
На сайте может быть много страниц. Разбейте их на категории — карточки товара, статьи, блога, новости и ускорьте аналитический процесс. - Программа XENU (Xenu Link Sleuth) позволяет провести аудит сайта и найти дубли. Чтобы получить аудит и произвести фильтрацию по заголовку требуется в специальную строку ввести URL сайта. Программа поможет найти полные совпадения. Однако через данную программу невозможно найти неполные дубли.
- Обнаружение дублей при помощи web – мастерской Google. Зарегистрируйтесь, и тогда в мастерской, разделе «Оптимизация Html», будет виден список страниц с повторяющимся контентом, тегами <Title>. По таблице можно легко найти чёткие дубли. Недостаток такого метода заключается в невозможности нахождения неполных дублей.
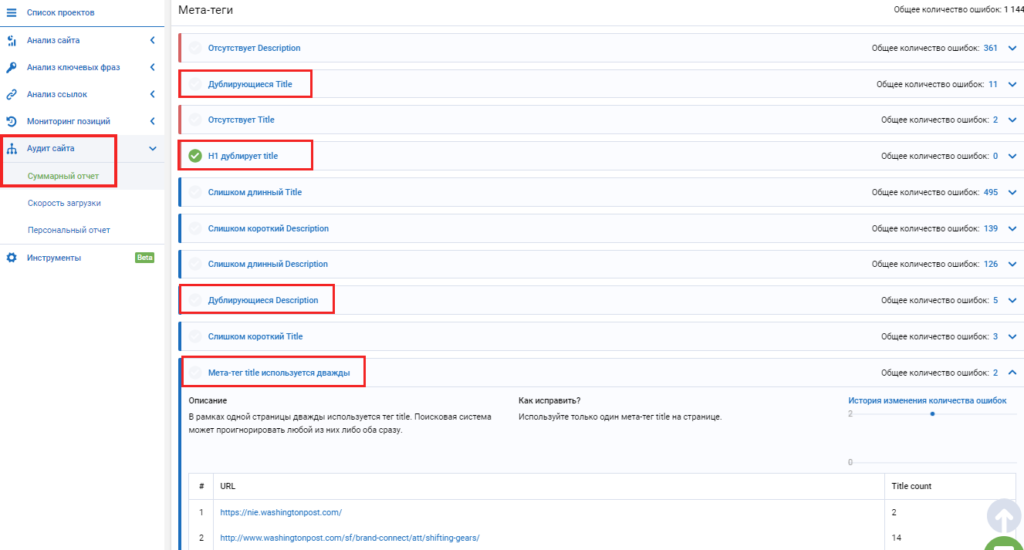
- Онлайн seo-платформа Serpstat проводит технический seo-аудит сайта по 55+ ошибок. Среди них есть блок для анализа дублируемого контента на сайте. Так сервис найдет дублирующиеся Title, Description, h2 на двух и больше страницах. Также видит случаи, когда h2 дублирует Title, на одной странице по ошибке прописаны два мета-тега Title и больше одного заголовка Н1.
Чтобы сделать технический аудит в Serpstat, нужно зарегистрироваться в сервисе и создать проект для аудита сайта.

Как убрать дубли страниц
От дублей нужно избавляться. Необходимо понять причины возникновения и не допускать распространение копий страниц.
- Можно воспользоваться встроенными функциями поисковой системы. В Google используйте атрибут в виде rel=»canonical». В код каждого дубля внедряется тег в виде <link=»canonical» href=»http://site.ru/cat1/page.php»>, который указывает на главную страницу, которую нужно индексировать.
- Запретить индексацию страниц можно в файле robots.txt. Однако таким путём не получится полностью устранить дубли в поисковике. Ведь для каждой отдельной страницы правила индексации не провпишешь, это сработает только для групп страниц.
- Можно воспользоваться 301 редиректом. Так, роботы будут перенаправляться с дубля на оригинальный источник. При этом ответ сервера 301 будет говорить им, что такая страница более не существует.
Дубли влияют на ранжирование. Если вовремя их не убрать, то существует высокая вероятность попадания сайта под фильтры Panda и АГС.
semantica.in
Ищем дубли при помощи нового Яндекс Вебмастера
Совсем недавно Яндекс запустил бета тестирование обновленного сервиса для вебмастеров.
В Яндекс Вебмастер были добавлены новые отчеты, существенно улучшена визуализация данных, изменился интерфейс и многое другое.
Нововведений достаточно много, но сегодня хотелось бы остановиться на отчете «Статистика индексирования», и как с его помощью можно обнаружить дубли и мусорные страницы.
На многих сайтах есть неинформативные страницы, которые сканируют поисковые системы, но не добавляют в свой индекс, т.к. понимают что они появились в результате технических ошибок. Работа seo специалиста как раз таки заключается в том, чтобы устранить все проблемы в сканировании и индексировании ресурса.
Если мы устраним десятки, а то и сотни мусорных страниц, на сканирование которых тратят время поисковые системы, мы сможем увеличить частоту сканирования и индексирования полезных страниц сайта, а следовательно и улучшить ранжирование ресурса в поисковых системах.
На странице отчета «Статистика индексирования» мы сможем узнать:
- Какие страницы сайта сканирует робот;
- Какие страницы робот исключил из поиска;
- Какие страницы проиндексированы и находятся в индексе поисковой системы Яндекс.
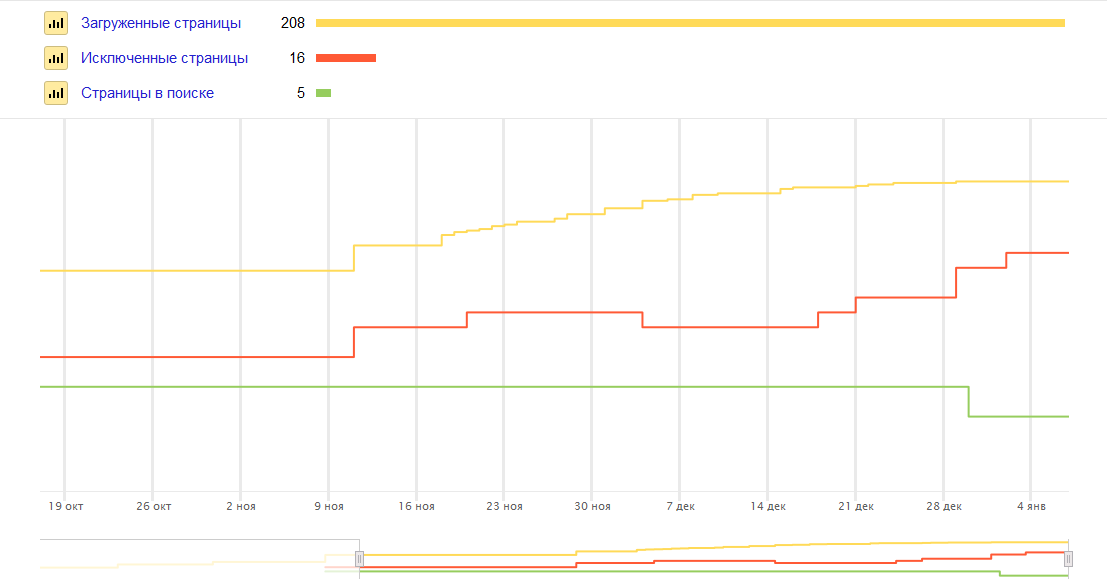
Для поиска дубликатов и мусорных страниц достаточно проанализировать полный список загруженных Яндексом url-адресов.
В сервисе есть возможность выгрузить архив со всеми url-адресами, которые были просканированы роботом Яндекса. Для загрузки нужно перейти по ссылке :

В итоге мы получаем файл в формате .tsv, открыть который можно через Excel, Libre Office или простым блокнотом.

Файл также содержит следующие данные :
- Коды ответа сервера.
- Дату последнего сканирования в формате Unix time, преобразовать можно, задав в консоли запрос вида date -r .
- Проиндексированность страниц.
- В столбце «Double» находятся ссылки на дубликаты страницы, если они есть.
Примеры найденных ошибок на сайтах благодаря данным о загруженных страницах роботами Яндекса :
Сайт asteria.ua :
Были обнаружены следующие страницы:
http://asteria.ua/special/razdel/104.html
http://asteria.ua/uslugi/razdel/77.html
http://asteria.ua/kompaniya/razdel/27.html
http://asteria.ua/partneri/razdel/4.html
Это полные дубликаты страниц сайта, они не проиндексированы, но регулярно сканируются Яндексом, следовательно их нужно как можно скорее устранить.
Ещё несколько страниц дубликатов:
http://asteria.ua/index.php?get=easytostart.html
http://asteria.ua/index.php?get=vkluchenie.html
http://asteria.ua/index.php?get=uslugi.html
http://asteria.ua/index.php?get=kontakti.html
http://asteria.ua/index.php?get=shtraf_uvelichili.html
Эти страницы, на момент анализа, перенаправляли пользователей на корректный url-адрес с ЧПУ, но отдавали код 200, а не 301.
Сайт novebti.ua :
Были найдены дубликаты главной страницы сайта :
http://novebti.ua/?razdel=uslugi_view&content=41
http://novebti.ua/?razdel=uslugi_view&content=1
http://novebti.ua/?razdel=uslugi_view&content=26
http://novebti.ua/?razdel=reviews
С этих страниц нужно написать link rel=»canonical» на главную страницу сайта.
А также дубликаты других страниц сайта :
http://novebti.ua/index.php?do=contacts
http://novebti.ua/index.php?do=uslugi/razrabotka_gradostroitelnogo_rascheta
Страницы пагинации и тегов:
http://novebti.ua/faq?ask=true?p=35
http://novebti.ua/article?tag=%CD%EE%E2%EE%F1%F2%E8%20%EA%EE%EC%EF%E0%ED%E8%E8
http://novebti.ua/faq?ask=true?p=40
http://novebti.ua/faq?p=47
Страницы такого типа лучше всего закрывать при помощи мета тега robots=»noindex, follow».
Сайт asiamshop.com.ua :
Было обнаружено множество страниц вида:
http://asiamshop.com.ua/component/jcomments/captcha/32798
http://asiamshop.com.ua/component/jcomments/captcha/42306
Таких страниц много десятков, они генерируются модулем комментирования jcomments, такие страницы нужно закрыть от сканирования, так как они не несут никакой ценности.Так как у этих страниц нет возможности прописать мета тег robots, то лучше их закрыть при помощи файла Robots.txt.
Алина Глазырина
главный редактор блога Inweb
Вывод:
Основное преимущество сервиса состоит в том, что мы анализируем базу url-адресов поисковой системы, а не парсера страниц сайта, который не сможет найти url-адреса на которые нет внутренних ссылок.
Используя инструмент «Статистика индексирования» в новом Яндекс Вебмастере можно в течение 30 минут проанализировать страницы, которые посещает робот, обнаружить проблемы и продумать варианты их решения.
Если вы нашли ошибку, выделите участок текста и нажмите Ctrl + Enter или воспользуйтесь ссылкой, чтобы сообщить нам.
inweb.ua
Дублирование контента – к чему оно может привести
Имеет ли значение дублирование контента на сайте
Ранее мы уже рассказывали о такой проблеме, как дубликаты страниц сайта. Тогда речь шла о возможности существования полностью одинаковых страниц с разными адресами и влиянии этого на продвижение веб-ресурсов.
Теперь же, давайте рассмотрим другую ситуацию – частичное дублирование контента на разных страничках в пределах сайта.
Наверняка не все знают, что это является проблемой. Ведь в большей части теории по SEO упоминается лишь о том, что не должно быть прецедентов дублирования контента, который уже размещен на каком-нибудь другом сайте.
На самом деле нужно следить за уникальностью не только в интернете в общем, но и внутри Вашего веб-ресурса.
Почему дублирование контента на сайте это плохо?
- Ухудшение индексации. Учитывая то, что роботам поисковиков приходится тратить определенные ресурсы на индексацию страничек, замечая повторяющий контент в пределах одного и того же веб-ресурса, они начинают реже возвращаться на него для повторения этой процедуры.
В конце концов, если подобная проблема будет повторяться все чаще, индексация сайта может вообще прекратиться. К тому же это негативно сказывается на мнении поисковиков о нем и, как результат, вполне может стать причиной понижения позиций.
- Возможность попасть под фильтры поисковых систем значительно увеличивается, если имеется дублирование контента на сайте, даже если в остальном используется исключительно белое SEO.
- Дублирование контента на разных страницах сайта может привести к попаданию в выдачу совершенно не той страницы, которая релевантна продвигаемому запросу. Вследствие этого, зашедшие на нее пользователи, могут значительно подпортить поведенческие факторы, что опять же несомненно не очень хорошо скажется на рейтинге веб-сайта.
Где чаще всего встречается дублирование контента на сайте
- Анонсы статей, который размещены на других страницах. Чаще всего вместо создания краткого описания статьи используются первые пару абзацев статьи и картинка из статьи.
- Дублирование названия и описания категории/рубрики/раздела на все следующие страницы пагинации (порядковой нумерации страниц).
- Одинаковые описания товаров. Является частой проблемой интернет-магазинов, у которых тысячи позиций для продажи и под схожие товары используется одинаковый текст.
Кроме того, при разных вариантах сортировки одних и тех же товаров генерируются страницы с разными URL, которые будут содержать тот же самый контент, но в разном порядке.
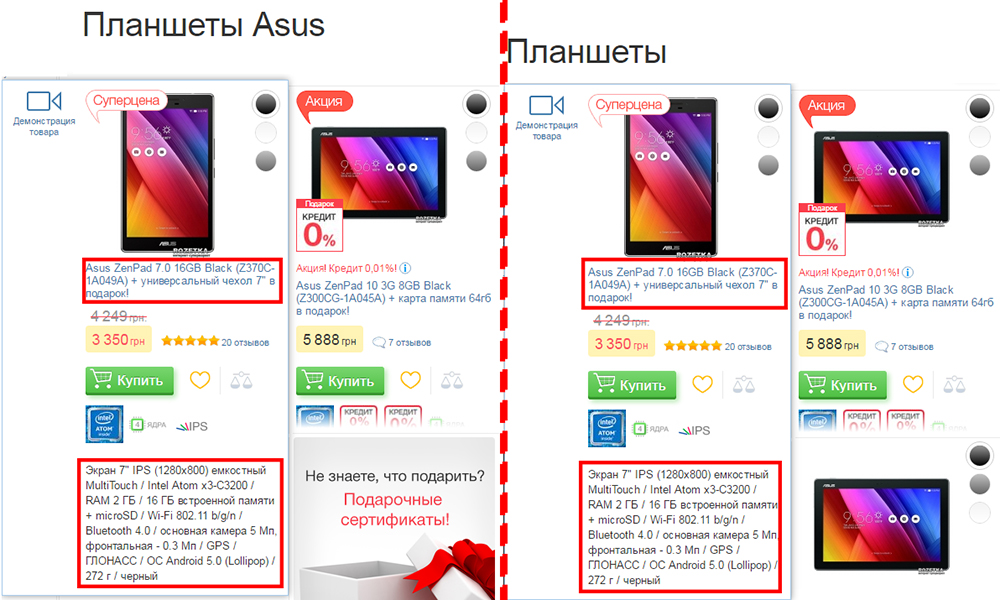
- Одинаковые подкатегории в разных категориях, товары (а следовательно и описания) в разных категориях также стоит рассматривать, как дублирование страниц сайта. Например, один и тот же планшет фирмы Asus будет отображаться в двух разных категориях «Планшеты» и «Планшеты Asus».
- Отзывы также не должны дублироваться на разных страницах.

Как определить дубль контента на сайте
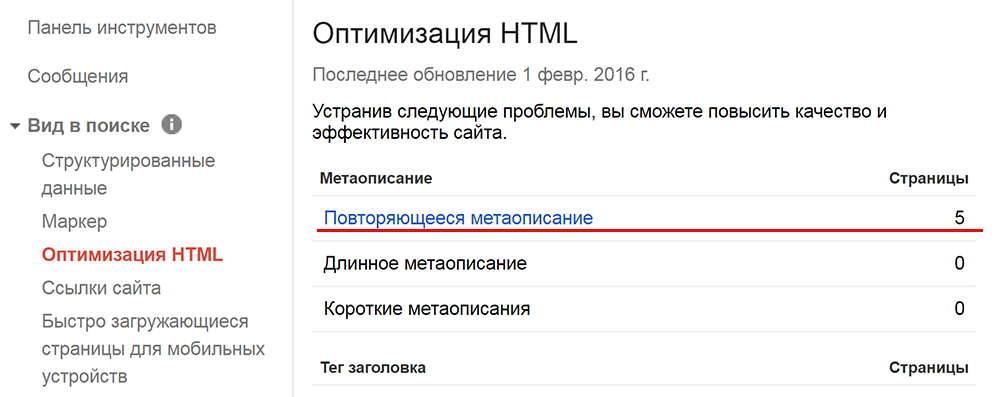
a) Панели для вебмастеров от Яндекс и Google подскажут, если имеется дублирование контента на сайте.
b) Поиск в индексе поисковых системах. Воспользуйтесь оператором site: для Google или host: — для Яндекса, после которых укажите адрес сайта и в кавычках фрагмент текста для поиска совпадений по нему.
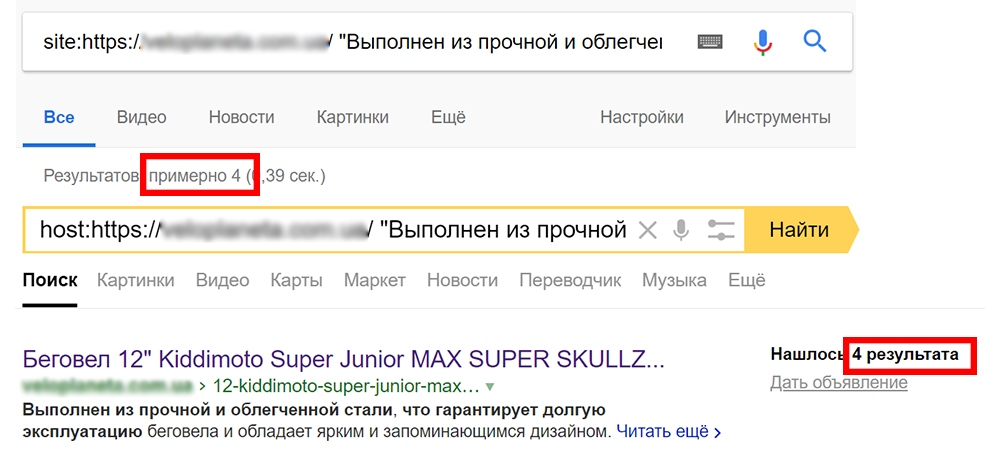
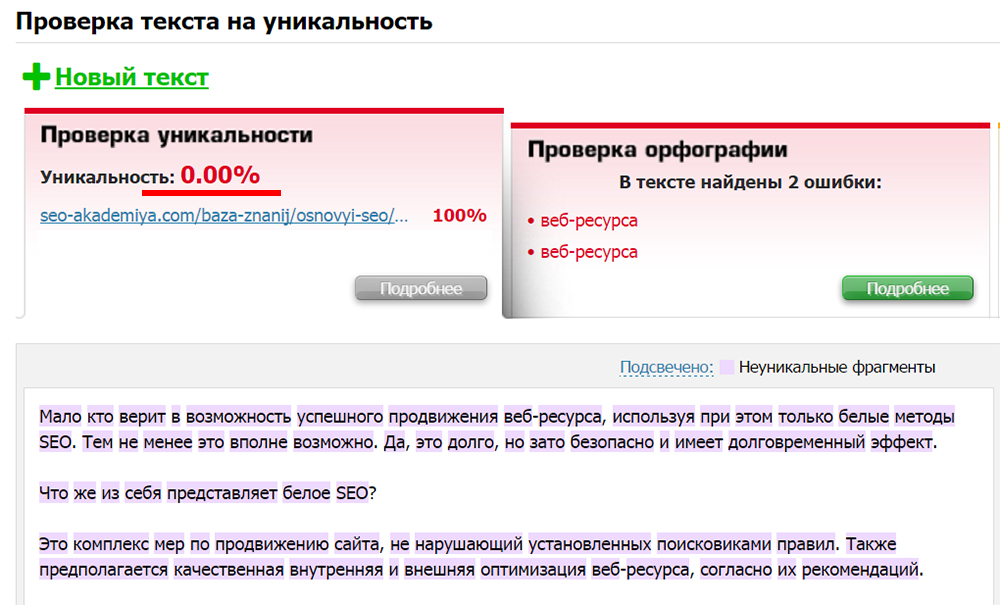
c) Различные сервисы и программы для проверки текста и картинок на уникальность знают, как определить дубль контента. В большинстве случаев помогут найти страницы, на которых проверяемый контент размещен полностью или частично.
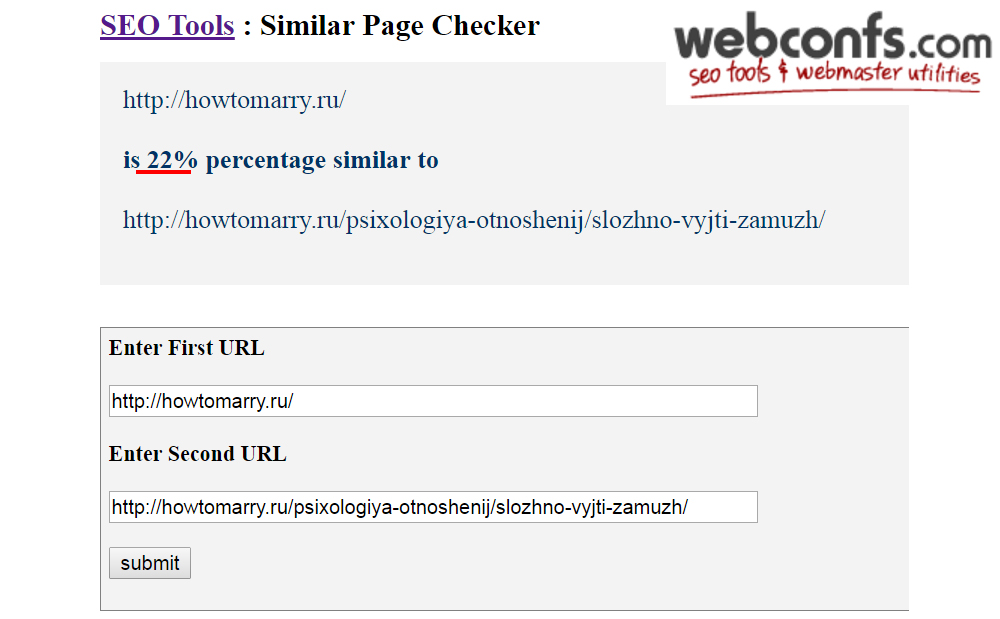
d) Онлайн-сервисы для проверки схожести страниц. Подойдут в случае, если возникает сомнение в уникальности двух конкретных страниц Вашего веб-ресурса.
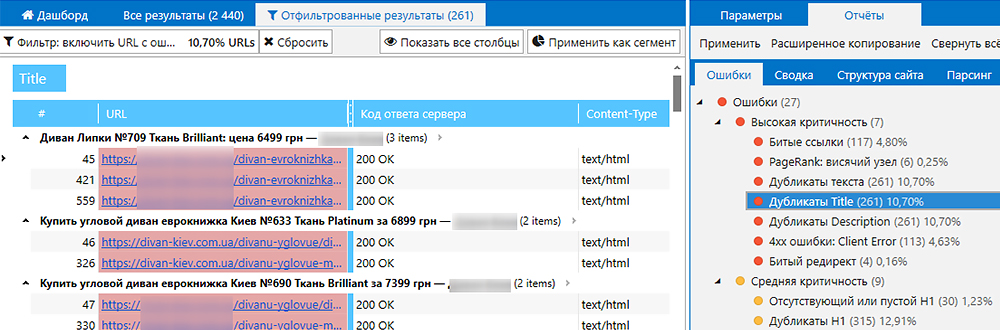
e) С помощью программ для анализа сайта. Например, воспользовавшись программой Netpeak Spider, Вы можете найти дубли Title, Description, заголовков h2, текста и полные дубли страниц.
Как устранить дублирование контента на сайте
Первым делом после выявления дублирования контента следует устранить повторы там, где это возможно:
- если это картинки и части текста в разных статьях, нужно их заменить или уникализировать;
- в случае с отзывами убрать повторяющиеся блоки и сделать их отдельными для каждой страницы;
- закрыть от индексации дублирующийся текст, используя тег <noindex> (поможет лишь в случае с Яндексом).
- для решения проблем с дублями в различных способах отображения страниц пользоваться следующими способами:
Что мы имеем в итоге?
Получается, что дублирование контента на сайте является очень серьезной проблемой, которую возможно устранить только после череды тщательных проверок всего сайта целиком.
Учитывая причины, по которым появляются повторы, нужно выбирать подходящие для каждого случая способы их устранения.
Ну а чтобы не нужно было ничего устранять, задайтесь целью размещать на страницах своего сайта только уникальный контент (даже если это интернет-магазин с десятками тысяч страниц).
Удачи Вам в применении только что обретенных знаний!
seo-akademiya.com