Тег noindex и атрибут nofollow: что это такое
Тег noindex введен поисковой системой Яндекс. Он предназначен для закрытия от индексации роботами ссылки или части html кода на странице. Имеет следующую структуру:
<noindex> ссылка или часть кода, которые необходимо скрыть, </noindex>
Данный тег не чувствителен к вложенности и может быть размещен в любой части кода. Поисковые машины, кроме Яндекса, воспринимают команду в качестве невалидной. Если валидность кода важна, тег оформляется следующим образом:
<!—noindex—> текст <!—/noindex—>
Функции:
Тег noindex позволяет:
- повысить релевантность страницы поисковым запросам за счет уменьшения доли второстепенной информации и увеличения плотности ключевых слов,
- скрыть дублирующийся контент, за использование которого может последовать пессимизация сайта в выдаче Яндекса,
- сохранять статический вес страниц и управлять его передачей, так как закрытие одних ссылок пропорционально увеличивает вИЦ оставшихся,
- улучшить сниппет.
 Если в ходе раскрутки сайта в его текстовое описание в выдаче попадает ненужная информация со страницы, ее закрывают от индексации,
Если в ходе раскрутки сайта в его текстовое описание в выдаче попадает ненужная информация со страницы, ее закрывают от индексации, - скрыть от роботов лишние данные (коды счетчиков, ссылки на сайты с постоянно изменяющейся информацией и т.д.).
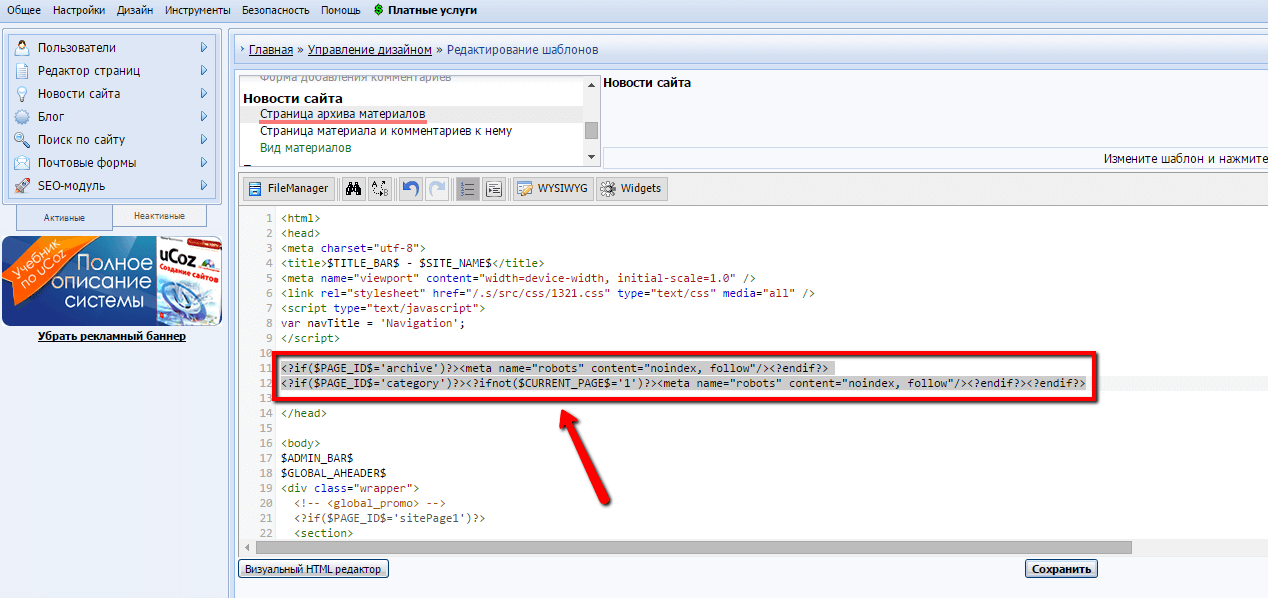 Если в ходе раскрутки сайта в его текстовое описание в выдаче попадает ненужная информация со страницы, ее закрывают от индексации,
Если в ходе раскрутки сайта в его текстовое описание в выдаче попадает ненужная информация со страницы, ее закрывают от индексации,Nofollow
Атрибут nofollow не оказывает влияния на индексацию ссылок, но сообщает поисковым роботам, что вес данного линка равен нулю. При продвижении сайта это позволяет сохранить его PR и тИЦ, которые на указанную страницу не передаются. Поисковые боты (кроме googlebot) по ссылке переходят. Атрибут поддерживают Google, Yahoo и Яндекс (с 30 апреля 2010 года). Структура написания параметра следующая: анкор ссылкиАтрибут nofollow используют для ссылок на все сайты, которым не требуется передавать TrustRank ресурса-донора. Для внутренней перелинковки прием не применяется.
Noindex и nofollow позволяют закрыть от индексацию не только отдельную ссылку, но и всю страницу (прописываются внутри нее или в файле robots. txt):
txt):
<Meta name=”robot” content=”noindex, nofollow”>
или
<html>
<head>
<meta content=”nofollow”/>
</head>
Nofollow и noindex могут использоваться совместно:
<noindex><a rel=»nofollow» href=»http://example.ru»> анкор ссылки</a></noindex>.
В таком случае поисковый робот Google ссылку проигнорирует, а Яндекса не увидит.
Другие термины на букву «N»
Совпадений не найдено
Все термины SEO-ВикипедииТеги термина
что это такое за тег для Яндекса
Noindex – это тег, с помощью которого можно управлять функцией индексации поискового робота. Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш.
Вторая, не менее важная функция тега noindex, состоит в том, чтобы блокировать индексацию отдельных страниц сайта, предназначенных для публикации пользовательского контента. К таким относятся страницы с отзывами, комментариями, сообщениями и др. В данном случае noindex позволяет избежать распространения нежелательной информации и использовать менее жесткий режим модерирования пользовательских сообщений.
Тег noindex учитывает только Яндекс. Google игнорирует его присутствие и проводит полную индексацию текстового содержания страницы. Для задействования блокировки индексации, актуальной для всех поисковиков, следует прописывать соответствующий метатег для отдельных страниц или всего сайта в файле robots.txt. Недостаток данного способа очевиден: запрет на индексацию возможен только по отношению ко всей странице, но не отдельному текстовому фрагменту.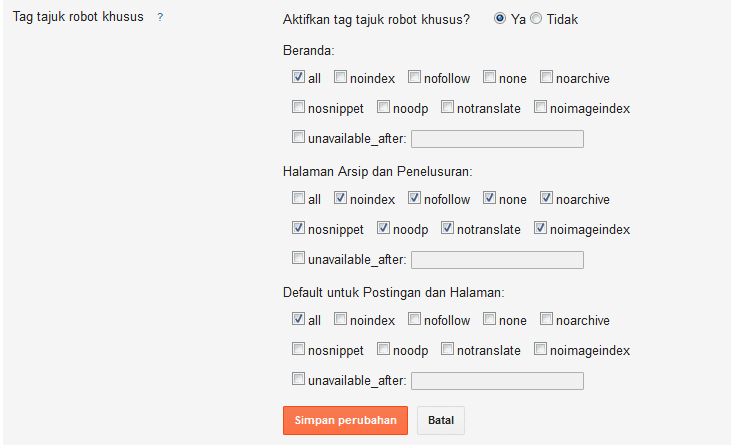
Преимущества тега noindex
- Сокрытие второстепенной информации позволяет повысить релевантность индексируемой страницы за счет возрастания относительной плотности ключевых фраз.
- С помощью noindex можно спрятать содержимое сквозных блоков, информация в которых будет дублироваться на нескольких страницах, что отразится на пессимизации сайта в поисковой выдаче Yandex.
- В некоторых случаях в сниппет может попасть нежелательная или служебная информация, которую проще всего скрыть тегом noindex.
Принцип действия
Noindex может находиться в любом месте HTML-кода вне зависимости от уровня вложенности. Для сохранения валидности кода тег следует использовать в следующем формате:
<!—noindex—>Здесь находится закрытый для индексации текст<!—/noindex—>.
Несмотря на тот факт, что noindex был изначально предложен разработчиками Yandex, использование данного инструмента может быть расценено в качестве серого метода оптимизации. Это связано с тем, что некоторые веб-мастера применяют его не по прямому назначению. В частности, от робота прячется неуникальный контент или качественный текст, не содержащий ключевых слов, рассчитанный на прочтение посетителем сайта. Одновременно поисковику предлагается насыщенный ключевыми фразами текст, тяжелый для восприятия человека.
Это связано с тем, что некоторые веб-мастера применяют его не по прямому назначению. В частности, от робота прячется неуникальный контент или качественный текст, не содержащий ключевых слов, рассчитанный на прочтение посетителем сайта. Одновременно поисковику предлагается насыщенный ключевыми фразами текст, тяжелый для восприятия человека.
Для борьбы с подобными методами оптимизации Yandex анализирует текст, закрытый тегом noindex, проводя его индексацию, но впоследствии отфильтровывая скрытое содержимое. В результате изучения контента страницы поисковик может принять решение о наложении санкций на сайт, если сочтет, что его владелец использует неправомерные способы влияния на результаты поисковой выдачи.
Что это за теги Nofollow и Noindex, в чем разница и как правильно прописывать
Выясняем, как работают тег noindex и атрибут nofollow. Подробно рассмотрим сценарии использования и узнаем, как прописывать теги для роботов в зависимости от поставленных задач.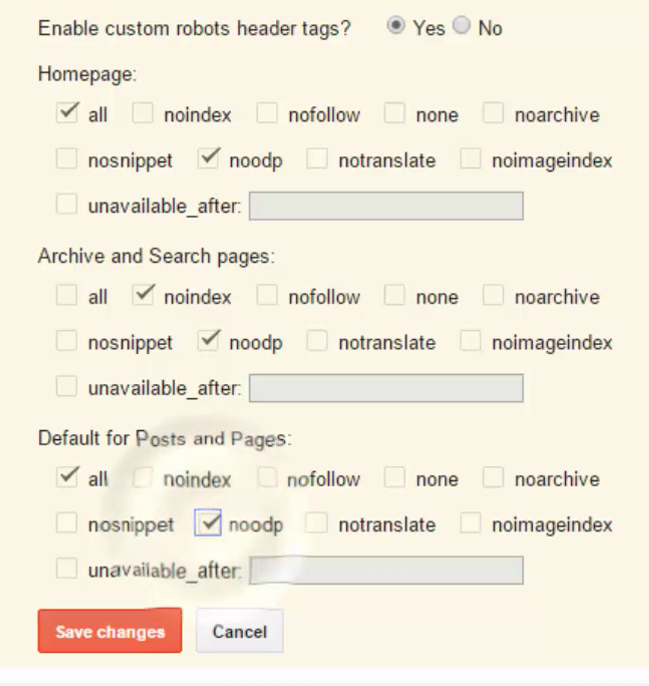
Теги и атрибуты
Их еще называют дескрипторами. Это элементы разметки, с помощью которых объектам в текстовом документе придаются определенные свойства. Эти свойства зависят от языка разметки и поставленных задач. Сделать шрифт жирным, превратить кусок текста в гиперссылку или задать ей специфичные визуальные характеристики…
Но есть теги, которые выполняют несколько иные функции. В их числе nofollow и noindex. В любых своих проявлениях они никак внешне не влияют на текст и ссылки. Посетитель сайта не заметит, если часть страницы обведут в тег или пометят атрибутом nofollow. Текст будет выглядеть без изменений.
Изменения произойдут на технической стороне. Отличия заметит поисковой робот, анализирующий и индексирующий веб-страницы.
Что такое noindex
«Ноиндекс» – тег и атрибут HTML-страницы. Можно пометить им страницу целиком, придав ей определенные свойства, либо выбрать отдельный участок кода и применить атрибут к нему.
Функция noindex заключается в «сокрытии» контента от поисковых роботов, машин, анализирующих и индексирующих веб-сайты.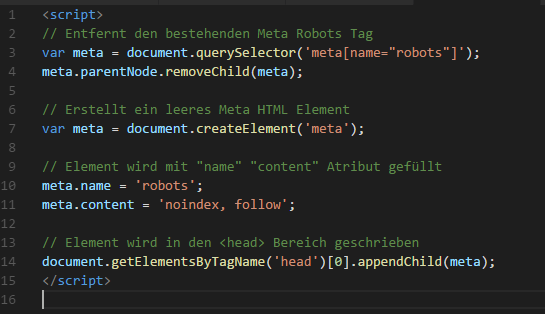 Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Они собирают базу данных для поисковых служб и предоставляют пользователям релевантные результаты поиска.
Если какая-то часть контента на странице помечена тегом noindex, то робот ее проигнорирует и в поиске она учтена не будет, что прямо повлияет на SEO-продвижение ресурса, на котором были произведены соответствующие изменения.
На самом деле, робот, конечно же, посмотрит все, что есть на сайте. Просто не будет заносить это в индексную базу.
Какой контент помечается этим тегом?
Любой. В зависимости от помеченной информации и поискового робота тег будет восприниматься по-разному.
Обычно в noindex заворачивают четыре типа текстового контента:
- Информацию с низкой уникальностью, чтобы избежать проблем с антиплагиатом.
- Коды счетчиков (типа метрики и других аналитических систем), ненужные поисковику.
- Контактные данные, номера и ссылки, которые не стоило бы показывать в поисковой выдаче.
- Постоянно меняющийся текст, индексация которого не принесет никакой пользы.

Как использовать тег?
Тег можно вставить в <head> страницы как мету (атрибутом), увеличив область его действия на всю страницу.
С таким кодом индексация страницы разрешается:
<meta name="robots" content="index"/>
А с таким индексация запрещается:
<meta name="robots" content="noindex"/>
Такое правило можно указать для конкретного робота. Например, поискового бота Google:
<meta name="googlebot" content="noindex"/>
Еще один способ — встраивание тегов в текст и оборачивание в него ссылок.
<noindex>кусок текста, который хотелось бы скрыть от индексации поисковиками</noindex>
Правда, такая разметка может нагородить ошибок из-за того, что многие поисковики не понимают тег <noindex> и считают его наличие в тексте ошибкой. Поэтому приходится исползать его вариацию <!–noindex–>. В таком виде роботы, понимающие тег, считывают его без проблем и задают нужные свойства, а непонимающие попросту игнорируют.
Независимо от типа скрываемого контента, принцип остается тем же. Поэтому, если нужно скрыть от индексации код счетчика, ничего специфичного делать не придется. Так же оборачиваем его в <noindex> и все.
Что такое nofollow
Атрибут, вставляющийся перед ссылками и запрещающий по ним переходить.
Вес страницы — это своего рода уровень авторитетности сайтов, один из факторов, учитываемых при ранжировании страниц в поисковых запросах. Чтобы не передавать вес страницы другим сайтам по размещенным на них ссылкам, данные ссылки оборачивают в тег nofollow.
Какой контент помечается этим атрибутом?
Ссылки. Но не все ссылки, а те, что могут как-то негативно повлиять на вес ресурса. Это касается автоматических ссылок, появляющихся в тех или иных участках сайта. Атрибут nofollow стоило бы приписывать любым внешним ссылкам, за которые вы не можете ручаться. Добавленные на ресурс другими пользователями через секцию комментариев или в графу профиля БИО.
Как прописывать тег?
С таким тегом индексирование страницы разрешается, но запрещается переход по всем ссылкам:
<meta name="robots" content="nofollow"/>
Как и в случае с <noindex>, правило можно задать для конкретного поискового робота:
<meta name="googlebot" content="nofollow"/>
Если мы говорим о конкретных ссылках, то переход на них можно запретить прямо внутри разметки.
<a href=“page.html” rel=“nofollow”>Гиперссылка</a>
Преимущества тега noindex и атрибута nofollow
Некоторые полезные свойства тегов мы уже обсудили выше, но на эту тему можно сказать больше.
- Теги помогают сделать информацию на сайте более релевантной за счет вычленения из нее неуникального и разного рода утилитарного контента, который никак не связан с данными для посетителей. Не только пропадает текст, понижающий общую уникальность, но и увеличивается плотность вхождения ключевых слов.
- Тегами можно спрятать информацию из сквозных блоков, которые часто воспринимаются роботами как дубликаты данных.
- Я уже упомянул выше, что за тегом <noindex> частенько прячут контактную информацию, но не пояснил зачем. Дело в поисковых сниппетах Яндекса и Google, в которые ненароком могут попасть номера телефонов и адреса, указанные на другом сайте или закрепленные за другой компанией в Яндекс.Справочнике.
- Атрибут nofollow может прятать платные ссылки. Рекламные статьи, заметки и обзоры, размещенные на странице. Поисковикам запрещают переход по ним, чтобы избежать санкций со стороны Google или Яндекса.
- Еще nofollow нужен для распределения приоритетов сканирования. Чтобы в него не попадали всякие формы регистрации и прочие технические страницы. Сканирование этой информации никакой пользы не принесет.
Выше мы использовали <noindex> и nofollow в качестве мета-атрибутов, чтобы задать свойства всей странице целиком. Посмотрим, как разрешить для роботов весь контент и все ссылки:
Посмотрим, как разрешить для роботов весь контент и все ссылки:
<meta name="robots" content="index, follow"/>
А это полный запрет на контент и ссылки:
<meta name="robots" content="noindex, nofollow"/>
Данный тег спрячет от ботов страницу целиком, но то же самое можно сделать, указав соответствующую ссылку в графе Disallow файла robots.txt, который отвечает за «исключение» страниц из индексации.
Но способы отличаются тем, что мета-тег разрешает поисковикам заходить на сайт и анализировать его содержимое. А вот если ссылка указана в robots.txt, то бот не сможет на нее зайти и провести индексирование.
Во избежание неадекватного поведения ботов, на уже проиндексированных страницах лучше использовать мета-теги, а в robots.txt заносите новые ссылки, неизвестные для Google и Яндекс.
Итоги
Теперь вы знаете, какие задачи выполняют теги noindex и nofollow. С помощью них можно строго задать поведение поисковых ботов Google и Яндекс в отношении вашего сайта и тем самым улучшить показатели SEO.
что это за тег для Яндекса
Для того чтобы сайт или отдельные его страницы попадали в выдачу поисковых машин, они должны проходить индексацию. Однако зачастую не весь текстовый контент должен индексироваться, так как на любом ресурсе могут присутствовать не несущие полезной нагрузки для SEO данные. Тег noindex позволяет скрывать ненужные фрагменты текста, в результате чего они не проходят индексацию, так как поисковик их игнорирует. Этот инструмент ввели специалисты «Яндекса», значительно упростив задачи для веб-разработчиков.
Также noindex позволяет блокировать индексацию целых страниц. Чаще всего это необходимо для того, чтобы в поисковом продвижении не участвовал пользовательский контент, например комментарии, сообщения или отзывы. Это снимает нагрузку с модераторов и позволяет без помех проводить кампании по SEO-продвижению.
На текущий момент этот тег работает только для поисковой машины «Яндекса», а Google игнорирует его и индексирует весь контент сайта, поэтому при ориентировании на него необходимо использовать файл robots. txt и соответствующие метатеги. Однако так удастся скрыть только отдельные страницы ресурса целиком, но не локальные фрагменты текста.
txt и соответствующие метатеги. Однако так удастся скрыть только отдельные страницы ресурса целиком, но не локальные фрагменты текста.
Что дает использование тега noindex?
- Обеспечивает максимальную релевантность страниц за счет исключения из индексации второстепенного текстового контента, способного изменить плотность ключевых слов и смысловое содержание в целом;
- Позволяет избежать блокировок или игнорирования ресурса, которые могут возникнуть по причине дублируемого на страницах текста. Его можно просто скрыть от поисковой машины;
- Исключает вероятность попадания в сниппеты ненужной информации – каких-либо технических, служебных данных.
Как это работает?
Каждая страница построена на основе HTML-кода с различными уровнями вложенности. Тег может быть прописан абсолютно в любом месте, и правильный формат его вставки будет таким:
<!—noindex—>Неиндексируемый контент<!—/noindex—>
Изначально этот тег был внедрен специалистами «Яндекса» для облегчения задач веб-разработчикам, но нередко он используется в качестве инструмента для так называемой «серой» оптимизации. То есть некоторые веб-мастера применяют его для сокрытия контента, который предназначен для прочтения пользователем, но при этом не содержит ключевых слов. Причем это может быть неуникальный контент или копипаст, использование которого в обычном режиме может привести к утрате позиций в поисковой выдаче и к блокировке ресурса. А для SEO на сайте оставляют оптимизированный фрагмент уникального текста, который остается видимым для робота.
То есть некоторые веб-мастера применяют его для сокрытия контента, который предназначен для прочтения пользователем, но при этом не содержит ключевых слов. Причем это может быть неуникальный контент или копипаст, использование которого в обычном режиме может привести к утрате позиций в поисковой выдаче и к блокировке ресурса. А для SEO на сайте оставляют оптимизированный фрагмент уникального текста, который остается видимым для робота.
В связи с этим «Яндекс» усовершенствовал алгоритм работы с тегом noindex, и сейчас его содержимое также проходит первичную индексацию, но впоследствии при отсутствии проблем со скрытым контентом он просто игнорируется. Если же машина сочтет, что разработчик использовал тег для «серого» продвижения, найдет признаки нерелевантности ресурса используемым запросам, то сайт будет заблокирован и не попадет в выдачу.
Noindex — Словарь— PromoPult.ru
Noindex — это инструкция для поискового робота, запрещающая индексировать определенный контент.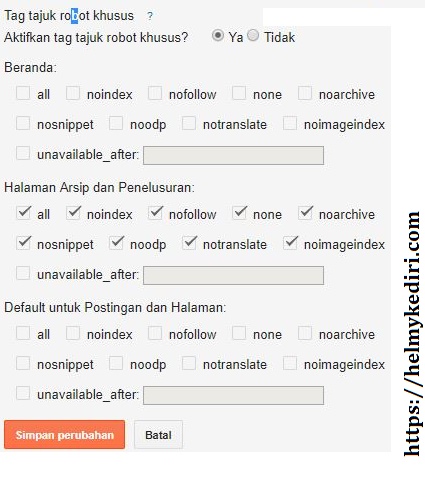
Noindex может быть HTML-тегом, атрибутом метатега robots, заголовком HTTP-ответа.
Тег Noindex для запрета индексации
Тег Noindex предназначен для блокировки индексации заданной части страницы. Можно выделить определенный отрезок контента в HTML-документе (например, счетчики статистики или сквозной блок на сайте), заключить между тегами Noindex и поисковый робот не станет помещать его в индекс. Синтаксис выглядит так:
<!--noindex-->Текст, не подлежащий индексации<!--/noindex-->
Данное правило блокировки работает только в отношении поисковой машины Яндекс — Google его игнорирует.
Атрибут Noindex для запрета индексации
Можно закрыть от индексации отдельную страницу сайта — для этого служит атрибут Noindex метатега Robots. Данное правило прописывается в директиве <head>> страницы и поддерживает и Яндекс, и Google. Синтаксис следующий:
<meta name="robots" content="noindex">
В таком виде страница будет запрещена к индексации всеми известными роботами. Однако можно указать конкретный вид робота, например Googlebot:
Однако можно указать конкретный вид робота, например Googlebot:
<meta name="googlebot" content="noindex">
HTTP-заголовок для запрета индексации
Вместо использования метатега можно возвращать заголовок X-Robots-Tag. В ответе должно быть указано значение noindex. Пример HTTP-ответа, где X-Robots-Tag запрещает индексировать страницу:
HTTP/1.1 200 OK () X-Robots-Tag: noindex ()
Отличие Noindex и Nofollow
Инструкции Noindex и Nofollow часто путают, при этом они выполняют разные функции. Атрибут Nofollow тега <а> или метатега Robots используется только в отношении ссылок на странице — для запрета перехода по ним и их учета при оценке страницы.
См. также
Noindex и nofollow в метатеге Robots и другие способы запрета индексации
Содержание статьи
Когда нужно запретить индексацию целой категории или ряда страниц, это легче сделать с помощью правильного robots.txt. Но как быть, если требуется закрыть от индексации одну страницу либо вообще часть текста на странице? Поговорим сейчас об элементах, которые призваны решать именно эту проблему.
Что такое мета тег Robots
Сначала уясним, что есть мета тег Robots, а есть файл Robots.txt, и путать их не будем. Метатег имеет отношение только к одной html странице (на которой он указан), в то время, как файл txt может содержать директивы не только к странице, но к целым каталогам.
Важный момент — для поисковика директивы метатега Роботс имеют преимущество перед директивами из robots.txt. То есть если в .txt у вас указано, что страницу можно индексировать, а в её метатеге указано, что нельзя, поисковик будет слушаться именно директиве из метатега.
При помощи мета тега Robots можно запрещать индексировать содержимое всей страницы. На страницах моего блога он выглядит так:
<meta name="robots" content="noodp"/>
Это означает, что метатег роботс не запрещает индексировать страницу. Noodp тут означает, что он запрещает Google брать в сниппеты описание для страниц из каталога DMOZ — это одна из стандартных настроек плагина Yoast SEO, которым я пользуюсь.
А вот как выглядит метатег Robots, который запрещает индексацию страницы:
<meta name =“robots” content=”noindex,nofollow”/>
Как прописать
Дедовский способ — вручную прописать для страницы. Способ подходит для сайтов на чистом HTML.
Для сайтов на CMS рекомендую использовать SEO-плагины. Я, например, для WordPress использую плагин Yoast SEO, и там под каждой записью в режиме редактирования есть такая опция:
То есть проставить нужное значение можно парой щелчков.
Как использовать noindex и nofollow в meta robots
Посмотрим на возможные значения атрибута content:
- noindex, nofollow – запрещена к индексации вся страница и переходы по ссылкам на ней; кстати, идентичной будет значение при записи: <meta name =”robots” content=”none”/>
- noindex, follow – страница не индексируется, но поисковик может переходить по ссылкам;
- index, nofollow – страница индексируется, но переход по ссылкам запрещен;
- index, follow – разрешены к индексированию как страница, так и ссылки на ней;
- noarchive – работает как в yandex, так и в google – не показывает страницу на сохраненную копию;
- noyaca – работает только в Яндексе, если сайт зарегистрирован в каталоге YACA – запрещает использовать описание в результатах поиска, которое берется из Яндекс.Каталога; выглядит так: <meta name =”robots” content=”noyaca”/>
- noodp – работает и в Яндексе, и в Google – запрещает использовать в результатах описания, которые взяты из Каталога ДМОЗ (разумеется, если сайт там зарегистрирован).
Поговорим чуть больше о noodp
Иногда Гугл может добавлять в сниппет описание из DMOZ. Именно для этого и используется атрибут noodp. Кстати, его можно использовать вместе с тегом nofollow. Выглядит это так:
<meta name=“robots” content=”noodp, nofollow”/>
Чего нужно опасаться при использовании
Из-за невнимательности (особенно у новичков) могут случаться конфликты между тегами: в таком случае главным будет положительное значение (разрешающее индексацию). Например тут:
<meta name =”robots” content=”all”/> <meta name =”robots” content=”noindex, nofollow”/>
Тут выбрано будет первое значение, так как там оно положительно.
Что такое тег Noindex
Noindex — это тег, в который вы заключаете часть кода, и этот код по идее не должен индексироваться Яндексом. Тег ноиндекс был предложен именно Яндексом, и по сей день учитывается только системами Yandex и Rambler. Вот как он выглядит:
<noindex>скрываемый текст</noindex>
Noindex – парный тег, и его необходимо закрывать.
Noindex не чувствителен к вложенности.
Целесообразность использования тега
Лично я смысла в его использовании не вижу. Потому что Google этот тег игнорирует. Да и зачем скрывать что-то? Надо делать сайты для людей!
Раньше сеошники скрывали в него часть текста, чтобы не было переспама. Но лично я предпочитаю в целях борьбы с переспамом просто снижать количество ключей в наиболее важных зонах документа.
Если же вы все-таки решили пользоваться этим тегом, то гляньте видео от ТопЭксперт:
Как пользоваться тегом Noindex
Нужно просто обернуть им тег:
<noindex>текст, который нам не нужен</noindex>
Валидный Noindex
Чтобы сделать его валидным, нужно закомментировать тег. Выглядит это так:
<!- -noindex- ->вот так все норм<!- -/noindex- ->
Для чего нужны теги, запрещающие индексацию
Как я писал выше, тег Noindex вообще ни для чего не нужен. Он себя давно изжил. А вот метатег роботс — довольно нужная вещь. Вот примеры ситуаций, когда он бывает полезен:
- На сайте есть какая-то страница, которую бы вы не хотели видеть в индексе. Например, страница с информацией для рекламодателей. А прописывать в роботсе по каким-то причинам не хотите (например, хотите скрыть её от оптимизаторов, которые лазят по чужим роботсам). Тогда вы просто парой щелчков через плагин ставите ноиндекс для этой страницы;
- Поскольку мета тег роботс имеет приоритет перед robots.txt, можно запретить индексирование какой-либо страницы, которая находится в директории, разрешенной для индексации.
Для чего нужен атрибут rel nofollow
Если метатег robots должен закрывать от индексации страницу, а тег noindex — её часть, то атрибут rel nofollow должен запрещать поисковику переходить по ссылке. Он является атрибутом тега А и выглядит так:
<a href =”http://website.ru” rel=”nofollow”>скрытая ссылка</a>
Зеленые вебмастера, которые впервые узнали о рел нофоллоу, сразу думают: «Отлично! Теперь я всем ссылкам его пропишу и вес не будет утекать никуда».
На самом деле поисковик вполне себе переходит по ссылкам с этим атрибутом и они вполне себе забирают ссылочный вес у ваших страниц. То есть смысла в этом атрибуте, как и в noindex, нет. Ссылки закрывать эффективно только через Ajax, да и это я думаю не навсегда. Но, если же вы все-таки решили сконцентрировать внимание на этой точке, которая в лучшем случае даст вам микроскопический рост, то вот еще один видос от ТопЭксперт:
Страницы с тегом
Для чего нужен элемент noindex
Тег <noindex> используется для запрета индексации служебных участков текста. Данный тег может находиться в любом участке HTML-кода страницы, учитывается он только Яндексом. Google и другие поисковые системы будут его игнорировать.
Работает этот элемент аналогично МЕТА-тегу noindex, но распространяется исключительно на текстовый контент, который размещен на странице, то есть, закрыть от индексации ссылки с его помощью не получится.
Приведем пример использования:
<noindex>служебный текст, который не нужно индексировать</noindex>
И еще один верный вариант:
<!--noindex-->служебный текст, который не нужно индексировать<!--/noindex-->
В каких случаях можно употреблять
При ответе на этот вопрос важно уточнить, что же такое индексация. Это процесс анализа информации на web-ресурсе и последующее добавление ее в индекс (базу данных поисковых систем) для формирования поисковой выдачи по релевантным запросам. Соответственно, тегом noindex мы советуем закрывать ту информацию, которая не должна участвовать в процессе ранжирования и отображаться в поисковой выдаче, но при этом не содержит ничего, за что можно получить санкции от Яндекса. Например, это может быть мобильный номер телефона, который не должен отображаться в выдаче, но нужен пользователям на страницах сайта.
Нужно учитывать еще один важный фактор — тег noindex запрещает Яндексу индексировать участок текста, но не устанавливает запрет на его чтение. То есть, применять данный элемент для сокрытия скопированных с других ресурсов текстов не получится, так как плагиат все равно будет обнаружен, и сайт подвергнется пессимизации.
Как обнаружить страницы с этим тегом на сайте
При продвижении очень важно знать, на каких страницах вашего сайта употребляется этот атрибут, поскольку часть важной информации могла быть закрыта от индексации или другие оптимизаторы использовали этот тег не по назначению.
Сервис Labrika предлагает удобный отчет по страницам с тегом <noindex>. Найти его можно в подразделе «Страницы с тегом noindex» раздела «SEO-аудит» в левом боковом меню:
В этом отчете содержится информация обо всех страницах вашего сайта, на которых находится тег <noindex>. Выглядит он следующим образом:
Для того, чтобы воспользоваться отчетом и получить актуальную на данный момент информацию, необходимо обновить SEO-аудит. Сделать это можно с помощью соответствующей кнопки прямо на странице отчета:
Разница между метатегами Noindex и Nofollow
Слышал про index, noindex, follow, nofollow… .и интересно, о чем, черт возьми, люди говорят? Ознакомьтесь с этим руководством, чтобы узнать больше!
NOINDEX
Директива noindex — часто используемое значение в метатеге, которое можно добавить в исходный HTML-код веб-страницы, чтобы предложить поисковым системам (в первую очередь Google) не включать эту конкретную страницу в свой список результатов поиска.
По умолчанию для веб-страницы установлено значение «index.”Вам следует добавить директиву на веб-страницу в разделе
Какие примеры страниц следует установить на «noindex»?
- Страницы с благодарностью. Если вы включаете на свой веб-сайт формы сбора потенциальных клиентов, такие как «Свяжитесь с нами» или «Назначьте встречу», вы, вероятно, направите пользователей из своих веб-форм на уникальные страницы с благодарностью после того, как пользователь отправит форму.Наличие уникальных страниц с благодарностью для каждой формы — это лучший способ отслеживать цели и заявки потенциальных клиентов на вашем веб-сайте, но вы не хотите, чтобы посетители попадали на ваши страницы с благодарностью, потому что они включены в индекс Google! Посетитель должен появиться на ваших страницах с благодарностью только после того, как они заполнили вашу веб-форму. Установка для ваших страниц благодарности значения «noindex» поможет предотвратить включение этих страниц в поисковую выдачу.
- Страницы только для членов — Если у вас есть раздел вашего веб-сайта, посвященный вашим сотрудникам или членам организации, но вы не хотите, чтобы эти веб-страницы были доступны для широкой публики или поисковых систем, директива «noindex» поможет уберечь эти страницы от быть найденным в поисковой выдаче.
NOFOLLOW
Директива nofollow — часто используемое значение в метатеге, которое может быть добавлено в исходный HTML-код веб-страницы, чтобы предложить поисковым системам (в первую очередь Google) не передавать равенство ссылок через какие-либо ссылки на данной веб-странице.
Ссылки являются важной частью поисковой оптимизации, хотя эксперты все время спорят о том, какую роль ссылки играют в общем рейтинге. Мы знаем, что ссылки с внешних авторитетных веб-сайтов помогут укрепить доверие к нашему собственному веб-сайту и повысить его рейтинг.Внутренние ссылки тоже полезны! Они помогают пользователям и роботу Googlebot перемещаться по вашему веб-сайту и объединять важные идеи.
По умолчанию для ссылок установлено значение «следовать». Вы можете установить ссылку на «nofollow» следующим образом: Anchor Text , если вы хотите предложить Google что гиперссылка не должна передавать ссылочной стоимости / значению SEO целевой ссылке.
Какие примеры ссылок следует установить на «nofollow»?
- Ссылки в комментариях блога — Если вы потратили время на то, чтобы написать ценный пост для своего веб-сайта, вы не хотите, чтобы конкурент или спамер по ссылкам мог добавить бесполезный комментарий к вашему сообщению в блоге со ссылкой на свой собственный веб-сайт, на котором написано что-то вроде «Отличный блог.Я также написал блог на эту горячую тему »и включил обратную ссылку на его / ее веб-страницу, чтобы он / она извлекли выгоду из ссылки, которую этот человек только что добавил с вашего веб-сайта на свой собственный. Если для этой ссылки установлено значение «nofollow», спамер по ссылкам может сказать это заранее и может не беспокоиться о добавлении комментария «Отличный блог» к вашему сообщению в блоге, зная, что от этого не будет никакой выгоды для SEO.
- Платные ссылки. Еще одна тактика SEO, завоевавшая популярность в SEO-сообществе черных шляп, — это массовая покупка ссылок в Интернете.Владельцы веб-сайтов со страницей спонсоров на своем сайте могут включить логотипы и ссылки на свои веб-сайты спонсоров мероприятия, но использовать метатег «nofollow» для каждой ссылки на странице спонсора, чтобы указать Google, что они не могут поручиться за каждую. веб-сайт организации, на который делается ссылка. Имейте в виду, что хотя ссылки «nofollow» не предназначены для повышения SEO для связанного контента, ссылки по-прежнему ценны для взаимодействия с пользователем и для привлечения трафика.
ЗАКЛЮЧЕНИЕ
Надеюсь, это руководство дало вам лучшее понимание noindex vs.nofollow и когда каждый из них может быть полезен. Напоминаем:
- «noindex» предлагает поисковым системам (в первую очередь Google) не индексировать определенную веб-страницу.
- «nofollow» предлагает поисковым системам (в первую очередь Google) не передавать ссылочную массу через ссылки на веб-странице.
Обязательно проконсультируйтесь с квалифицированным агентством цифрового маркетинга при применении директив noindex и nofollow к своему веб-сайту. Если сделать это неправильно, эти маленькие теги могут нанести большой ущерб вашему органическому трафику.
Познакомьтесь с Кэти Хельгесен
Кэти Хельгесен, директор по SEO в Launch Digital Marketing, имеет более чем 15-летний опыт работы в области цифрового маркетинга, SEO и аналитики. Ей нравится кататься на американских горках, читать, смеяться, спать и проводить время со своим мужем, 3 детьми и 2 собаками. Просмотреть все сообщения Кэти Хельгесен → Индексирование поиска блоковс помощью noindex
Вы можете запретить отображение страницы в поиске Google, указав noindex метатег в HTML-коде страницы или путем возврата заголовка noindex в HTTP
отклик.Когда робот Googlebot в следующий раз просканирует эту страницу и увидит тег или заголовок, он сбросит
эта страница полностью из результатов поиска Google, независимо от того, ссылаются ли на нее другие сайты.
noindex вступила в силу, страница не должен блокировать файлом robots.txt, иначе это должно быть
доступный для краулера. Если страница заблокирована
robots.txt или он не может получить доступ к странице, поисковый робот никогда не увидит noindex , и страница по-прежнему может отображаться в результатах поиска, например
если на него ссылаются другие страницы. Использование noindex полезно, если у вас нет root-доступа к вашему серверу, поскольку он
позволяет вам контролировать доступ к вашему сайту на постраничной основе.
Реализация
noindex Есть два способа реализовать noindex : как метатег и как HTTP-ответ.
заголовок. У них такой же эффект; выберите способ, который удобнее для вашего сайта.
Чтобы запретить большинству поисковых роботов индексировать страницу вашего сайта, поместите
следующий метатег в раздел вашей страницы:
Чтобы запретить только поисковым роботам Google индексировать страницу:
Вы должны знать, что некоторые веб-сканеры поисковых систем могут интерпретировать noindex иначе.В результате возможно, что ваша страница может
по-прежнему появляются в результатах других поисковых систем.
Узнайте больше о метатеге noindex .
Вместо метатега вы также можете вернуть заголовок X-Robots-Tag со значением
либо noindex , либо none в вашем ответе. Вот пример
HTTP-ответ с X-Robots-Tag , инструктирующим сканеры не индексировать страницу:
HTTP / 1.1 200 ОК (…) X-Robots-Тег: noindex (…)
Узнайте больше о заголовке ответа noindex .
Помогите нам определить ваши метатеги
Нам необходимо просканировать вашу страницу, чтобы увидеть метатеги и заголовки HTTP. Если страница все еще появляется в результатах, вероятно, потому, что мы не сканировали страницу с тех пор, как вы добавили тег. Вы можете запросить у Google повторное сканирование страницы с помощью Инструмент проверки URL.Другая причина также может заключаться в том, что файл robots.txt блокирует URL-адрес из сети Google. сканеры, поэтому они не видят тег. Чтобы разблокировать свою страницу от Google, вы должны отредактировать свой файл robots.txt. Вы можете редактировать и тестировать свой robots.txt, используя robots.txt Тестер инструмент.
Что такое теги NoIndex и как они влияют на SEO?
Директивы «Нет индекса» предписывают поисковым системам исключить страницу из индекса, что делает ее непригодной для отображения в результатах поиска.
«Noindex» мета-роботы Теги
Самый распространенный способ запретить поисковым системам индексировать страницу — это включить тег Meta Robots в тег
HTML-страницы с помощью директивы noindex, как показано ниже:Примерно в 2007 году основные поисковые системы начали реализовывать поддержку директив noindex в тегах Meta Robots. Теги Meta Robots могут также включать другие директивы, такие как директива «follow» или «nofollow», которая предписывает поисковым системам сканировать или не сканировать ссылки, найденные на текущей странице.
Обычно веб-мастера используют директиву noindex для предотвращения индексации контента, не предназначенного для поисковых систем.
Некоторые распространенные варианты использования директив noindex:
- Страницы, содержащие конфиденциальную информацию
- Корзина покупок или страницы оформления заказа на веб-сайте электронной коммерции
- Альтернативные версии страниц для активных A / B или сплит-тестов
- «Промежуточные» (или незавершенные) версии страниц, еще не готовые для публичного использования
Кроме того, поисковые системы поддерживают директиву noindex, доставляемую через заголовки HTTP-ответа для данной страницы.Хотя этот подход менее распространен и его труднее определить с помощью обычных инструментов SEO, иногда инженерам или веб-мастерам проще включить его в зависимости от конфигурации их сервера.
Имя и значение для заголовка ответа «noindex» следующие:
X-Robots-Tag: noindex
Лучшие практики SEO для директив noindex
1. Избегайте использования «noindex» на ценных страницах.
Случайное включение тега или директивы noindex на ценную страницу может привести к тому, что эта страница будет удалена из индексов поисковой системы и перестанет получать весь органический трафик.
Например, если новая версия веб-сайта запущена, но теги «noindex», которые были включены для предотвращения индексации поисковыми системами новых версий страниц до того, как они были готовы, остаются на месте, новая версия веб-сайта может немедленно перестать получать трафик. из поиска
2. Поймите, что «noindex» в конечном итоге рассматривается как «nofollow»
Веб-мастера часто используют теги Meta Robots или заголовки ответов, чтобы сигнализировать поисковым системам, что текущая страница не должна индексироваться, но ссылки на странице должны сканироваться, как со следующим тегом Meta Robots:
Обычно используется для страниц с разбивкой на страницы.Например, «noindex, follow» может применяться к спискам архивов блога, чтобы сами страницы архива не появлялись в результатах поиска, но позволяли поисковым системам сканировать, индексировать и оценивать сами сообщения блога.
Однако этот подход может работать не так, как предполагалось, поскольку Google объяснил, что их системы в конечном итоге обрабатывают директиву «noindex, follow» как «noindex, nofollow» — другими словами, они в конечном итоге перестанут сканировать ссылки на любой странице с директива noindex.Это может помешать вообще проиндексировать страницы назначения ссылок или снизить их PageRank или авторитет, снизив их рейтинг по релевантным ключевым словам.
3. Избегайте использования правил «noindex» в файлах Robots.txt
Хотя никогда официально не поддерживался, поисковые системы какое-то время соблюдали директивы noindex в правилах robots.txt. Поскольку правила robots.txt с подстановочными знаками могут применяться ко многим страницам одновременно без каких-либо изменений, требуемых на самих страницах, многие веб-мастера предпочли этот метод.Google не рекомендует использовать файлы robots.txt для установки директив noindex и устаревшего кода, который поддерживал эти правила в сентябре 2019 года.
Какие страницы на вашем сайте использовать noindex или nofollow? • Yoast
Михил ХеймансМихиэль был одним из наших первых сотрудников и раньше был партнером Yoast. Начните оптимизацию своего сайта с его статей!
Некоторые страницы вашего сайта служат определенной цели, но эта цель не заключается в ранжировании в поисковых системах и даже не в привлечении трафика на ваш сайт.Эти страницы должны быть там, как клей для других страниц, или просто потому, что правила требуют, чтобы они были доступны на вашем веб-сайте. Если вы регулярно читаете наш блог, вы знаете, как noindex или nofollow могут помочь вам справиться с этими страницами. Однако, если вы новичок в этих условиях, продолжайте читать и позвольте мне объяснить, что они из себя представляют и к каким страницам они могут применяться!
Что такое noindex nofollow?
noindex означает, что веб-страница не должна индексироваться поисковыми системами и, следовательно, не должна отображаться на страницах результатов поиска. nofollow означает, что пауки поисковых систем не должны переходить по ссылкам на этой странице. Вы можете добавить эти значения в свой метатег robots. Мета-тег robots — это фрагмент кода в разделе заголовка веб-страницы. Он сообщает поисковым системам, как сканировать и индексировать ли страницу.
Наше полное руководство по метатегу robots — отличное чтение, если вы хотите немного глубже погрузиться в эту тему.
Вкратце:
- В большинстве случаев метатег robots выглядит следующим образом:
- VALUE1 и VALUE2 установлены на индекс
, по умолчанию используется, что означает данная страница может быть проиндексирована поисковыми системами, и по ссылкам на этой странице можно переходить для сканирования страниц, на которые они ссылаются. - VALUE1 и VALUE2 могут иметь значение
noindex, nofollowили другую комбинацию, например,index, nofollow.
Но пусть вас не пугает этот код. Yoast SEO поможет вам! Если вы хотите узнать, как noindex пост в WordPress супер-простым способом, вам следует прочитать этот пост: Как noindexировать пост в WordPress: простой способ.
Но когда какое значение использовать?
Страницы для установки в noindex
Авторские архивы в блоге одного автора
Если вы единственный, кто пишет для своего блога, страницы ваших авторов, вероятно, на 90% совпадают с домашней страницей вашего блога.Это бесполезно для Google и может рассматриваться как дублированный контент. Чтобы предотвратить такое дублирование контента, вы можете полностью отключить авторский архив. Вот как легко включить или отключить его с помощью Yoast SEO. Если по какой-то причине вы хотите сохранить его на своем сайте, но не в результатах поиска, вы можете noindex его. К счастью, с Yoast SEO это тоже не сложно; просто проверьте, как нельзя индексировать архив автора.
Определенные (настраиваемые) типы сообщений
Иногда плагин или веб-разработчик добавляют пользовательский тип сообщения, который вы не хотите индексировать.Например, в Yoast мы используем персонализированные страницы для наших продуктов, поскольку мы не являемся типичным интернет-магазином, продающим физические продукты. Таким образом, нам не нужно изображение продукта, фильтры, такие как размеры и технические характеристики, на вкладке рядом с описанием. Поэтому мы не индексируем обычные страницы продуктов, которые выводит WooCommerce, и используем наши собственные страницы. Действительно, у нас noindex тип сообщения о продукте.
Соответственно, мы видели решения для электронной коммерции, которые также добавляли такие характеристики, как размеры и вес, в качестве настраиваемого типа сообщений.Эти страницы считаются некачественным контентом. Вы поймете, что эти страницы не нужны ни посетителям, ни Google, поэтому их тоже нужно держать подальше от страниц результатов поиска.
Страницы благодарности
Эта страница служит только для того, чтобы поблагодарить вашего клиента / подписчика на новостную рассылку / впервые комментирующего. Эти страницы, как правило, представляют собой страницы с тонким контентом, с возможностью дополнительных продаж и социальных сетей, но они не представляют ценности для тех, кто использует Google для поиска полезной информации. Следовательно, этих страниц не должно быть на страницах результатов поиска.
Страницы администратора и входа в систему
Большинство страниц входа не должны находиться в Google. Но это так. Не допускайте попадания своего в индекс, добавив к нему noindex . Исключение составляют страницы входа в систему, которые обслуживают сообщество, например Dropbox или аналогичные службы. Просто спросите себя, стали бы вы гуглить одну из своих страниц входа в систему, если бы вы не работали в своей компании. В противном случае можно с уверенностью сказать, что Google не нужно индексировать эти страницы входа. К счастью, если вы используете WordPress, вы в безопасности, поскольку CMS автоматически не индексирует страницу входа на ваш сайт.
Результаты внутреннего поиска
Результаты внутреннего поиска — это в значительной степени последние страницы, на которые Google хотел бы отправлять своих посетителей. Если вы хотите испортить поиск, вы ссылаетесь на другие страницы поиска вместо фактического результата. Но ссылки на странице результатов поиска по-прежнему очень ценны, вы определенно хотите, чтобы Google следил за ними. Таким образом, необходимо переходить по всем ссылкам, а мета-настройка роботов должна быть:
Yoast SEO следит за тем, чтобы для ваших внутренних поисковых страниц по умолчанию было установлено значение noindex.Это одна из скрытых функций Yoast SEO. Это не редактируемый параметр, потому что это просто то, как это должно быть сделано в соответствии с рекомендациями Google, и мы полностью с ними согласны.
Только для разработчиков: если вы действительно хотите изменить это, это можно сделать с помощью одного из наших фильтров. Пример можно найти здесь.
Страницы для установки на nofollow
Для всех примеров, упомянутых выше, нет необходимости nofollow для всех ссылок на этих страницах.Вы не хотите, чтобы они отображались в результатах поиска, но вы хотите, чтобы Google переходил по ссылкам на странице. Теперь, когда следует , вы добавляете nofollow в метатег роботов?
Если вы установите для страницы значение nofollow с метатегом robots, ни одна из ссылок на этой странице не будет переходить. Google придумал nofollow, чтобы иметь возможность различать ссылки на ненадежный контент (или, позже, оплаченный, например, рекламу). На обычном веб-сайте, вероятно, очень мало страниц, на которых вы бы хотели, чтобы Google не переходил по любой ссылке .
Пример: если у вас есть страница со списком книг по SEO с избытком партнерских ссылок Amazon, они могут быть полезны для вашего сайта для ваших пользователей. Но я бы дал nofollow всю страницу, если на странице нет ничего важного. Однако вы могли бы проиндексировать его. Просто убедитесь, что вы правильно скрываете свои ссылки.
Одинарные ссылки Nofollow
Если у вас есть сообщение или страница с несколькими ссылками, вы можете помочь поисковым системам квалифицировать их.В настоящее время вы можете nofollow для одной ссылки или даже установить для нее спонсируемый или пользовательский контент. Добавление правильных атрибутов rel к вашей ссылке позволяет вам это сделать. Например, ссылка на рекламу будет выглядеть так: пример ссылки . С Yoast SEO настроить эти атрибуты rel очень просто, как вы можете видеть в этом видео:
Заключение
Как мы видели, независимо от того, используется ли noindex страница или nofollow ссылка, сводится к двум вопросам: хотите ли вы, чтобы эта страница отображалась на страницах результатов поиска и , если поисковые системы переходят по ссылкам на эта страница? Например, для страниц с благодарностями или страниц входа в систему ответ на первый вопрос — «нет».Для страницы с множеством партнерских ссылок ответ на второй вопрос — «нет». Помните о примерах из этого поста, и у вас больше не будет проблем с поиском ответов для вашего собственного сайта!
PS. Вы noindex пост или страницу, хотя не хотели? Не беспокойтесь, вы легко можете исправить случайную ошибку noindex !
Подробнее: Как не индексировать сообщение »
Google делится информацией о том, как метатег Noindex может вызывать проблемы
Джон Мюллер из Google ответил на вопрос об использовании метатега noindex на страницах товаров, которых временно нет в наличии.Джон ответил на вопрос и поделился своим мнением о том, как такое использование может немного сбить с толку Google и вызвать больше проблем.
Мета-тег роботов
Мета-тег роботов — это способ указать поисковым системам не индексировать веб-страницу. Под «индексированием» веб-страницы это означает включение в список веб-страниц, которые будут отображаться на страницах результатов поиска (также известных как поисковая выдача).
«Директива » — это код, которому поисковые системы обязаны подчиняться.
Метатег robots noindex сообщает поисковым системам, что страницу не следует включать в индекс.Страница, которая исключена из индекса, означает, что страница исключена из отображения в поисковой выдаче.
Вопрос о страницах товаров, которых нет в наличии
Вопрос, на который ответил Джон Мюллер, был задан издателем, который добавлял метатег noindex к страницам товаров, на которых товары отсутствовали.
Реклама
Читать ниже
Таким образом Google может исключить страницу с товаром, которого нет в наличии, из результатов поиска Google.
Затем издатель обновил метатег noindex до команды «index», когда продукт вернулся на склад.Изменив директиву noindex на директиву index, издатель приказал Google продолжить и начать показывать страницу в результатах поиска.
Это вопрос:
«Мы часто обновляем наших мета-роботов, index и noindex. А в прошлом месяце мы внедрили последнюю модификацию на страницах продуктов, которые появились на складе за последние семь дней, и пометили их как «индекс», но мы не заметили никакого влияния на отправленные URL, помеченные как noindex. Я вручную проверил некоторые URL-адреса последних модификаций.
Google, кажется, никогда не следит за ними ».
Переключение мета-тега индекса роботов между noindex и index, похоже, не помогло издателю.
Джон Мюллер рассказал, как Google обрабатывает метатег noindex.
Объявление
Продолжить чтение ниже
«В целом, я думаю, что это колебание между индексированными и неиндексированными данными может немного сбить нас с толку.
Потому что, если мы видим страницу, которая не индексировалась в течение более длительного периода времени, мы будем считать, что это что-то вроде страницы 404, и нам не нужно ее сканировать так часто.
Так что, вероятно, происходит то, что мы рассматриваем эти страницы как noindex и решаем больше не сканировать их так часто, независимо от того, что вы отправляете в файл карты сайта.
Так что это то, где … колебания меты noindex здесь контрпродуктивны, если вы действительно хотите, чтобы эти страницы время от времени индексировались ».
Как Google обрабатывает теги Noindex
Интересно, что способ, которым Google обрабатывает метатеги noindex роботов, аналогичен тому, как они обрабатывают код ответа 404.
Тег noindex для роботов — это мощный инструмент, и его лучше всего использовать на страницах, которые издатель никогда не хочет индексировать.
Согласно странице разработчика метатега роботов Google:
«Мета-тег robots позволяет использовать детальный подход к конкретной странице для управления тем, как отдельная страница должна быть проиндексирована и предоставлена пользователям в результатах поиска Google».
На той же странице Google говорится о метатеге noindex:
«… дает указание поисковым системам не показывать страницу в результатах поиска.”
В нем ничего не говорится о том, как Google обрабатывает это, как ответ 404 страница не найдена, что заставит Google посещать страницу реже, если вообще.
Как обращаться со страницами товаров, отсутствующих на складе
Есть несколько передовых методов работы с веб-страницами, которых нет в наличии.
Страницы категорий
На страницах категорий, на которых перечислены товары, которые есть в наличии и которых нет в наличии, а также на страницах поиска на веб-сайтах рекомендуется по умолчанию сначала отображать товары, имеющиеся в наличии.
Затем покажите товары, которых нет в наличии, внизу страниц поиска и страниц категорий.
Снимок экрана страницы поиска в розничном магазине, на которой показаны последние товары, отсутствующие в наличии
Покупатели также учитываются
Лучшим способом обработки страниц товаров, отсутствующих в наличии, является отображение раздела «Покупатели также учитываются» в верхней части страницы. страницы товара.
Реклама
Продолжить чтение ниже
Таким образом вы можете показать посетителю сайта аналогичные имеющиеся в наличии товары, которые могут его заинтересовать.
Уведомление о наличии на складе
Еще одна передовая практика — отобразить заметную кнопку «Предупреждение о наличии на складе», чтобы потребители могли выбрать получение уведомления, когда товар снова появится на складе.
Снимок экрана кнопки регистрации электронного оповещения о наличии на складе
Структурированные данные «нет на складе»
Свойство структурированных данных «предложение» продукта имеет тип ItemAvailability , который можно использовать для сообщения поисковым системам о наличии товара. или нет в наличии.
Реклама
Продолжить чтение ниже
Тип ItemAvailability указан Google как рекомендуемый тип, но не является обязательным.
Снимок экрана с структурированными данными об отсутствии на складе
Если структурированные данные ItemAvailability помечены как недоступные, поисковые системы могут не показывать эту веб-страницу в результатах поиска, но продолжать ее индексировать. Неясно, не ранжируют ли эти страницы поисковые системы, но, судя по неофициальным данным, именно так поисковые системы обрабатывают данные.
Реклама
Продолжить чтение ниже
Посмотреть, как Джон Мюллер Обсудить метатег Noindex роботов
Как сказать Google не индексировать страницу в поиске
Индексирование как можно большего количества страниц на вашем веб-сайте может быть очень трудным. заманчиво для маркетологов, которые пытаются повысить авторитет своей поисковой системы.
Но, хотя это правда, что публикация большего количества страниц, релевантных для определенного ключевого слова (при условии, что они также высокого качества) улучшит ваш рейтинг по этому ключевому слову, иногда на самом деле больше пользы от сохранения определенных страниц на вашем веб-сайте из из индекс поисковой системы.
… Сказать что ?!
Оставайтесь с нами, ребята. В этом посте вы узнаете, почему вы можете захотеть удалить определенные веб-страницы из SERPS (страниц результатов поисковой системы), и как именно это сделать.
Почему вы хотите исключить определенные веб-страницы из результатов поискаВ ряде случаев вам может потребоваться исключить веб-страницу или ее часть из сканирования и индексации поисковой системой.
Для маркетологов одной из распространенных причин является предотвращение индексации дублированного контента (когда поисковыми системами индексируется несколько версий страницы, как в версии вашего контента для печати).
Еще один хороший пример? Страница благодарности (т.е. страница, на которую посетитель попадает после конверсии на одной из ваших целевых страниц). Обычно здесь посетитель получает доступ к тому предложению, которое обещала целевая страница, например, к ссылке на электронную книгу в формате PDF.
Вот как выглядит страница с благодарностью за нашу электронную книгу с советами по SEO, например:
Вы хотите, чтобы любой, кто попал на ваши страницы благодарности, попал туда, потому что они уже заполнили форму на целевой странице — , а не , потому что они нашли вашу страницу благодарности в поиске.
Почему нет? Потому что любой, кто найдет вашу страницу благодарности в поиске, может получить прямой доступ к вашим предложениям по привлечению потенциальных клиентов — без необходимости предоставлять вам свою информацию для прохождения через форму для сбора потенциальных клиентов. Любой маркетолог, понимающий ценность целевых страниц, понимает, насколько важно сначала привлечь этих посетителей в качестве потенциальных клиентов, прежде чем они смогут получить доступ к вашим предложениям.
Итог: Если ваши страницы благодарности легко обнаружить с помощью простого поиска в Google, возможно, вы оставляете на столе ценных потенциальных клиентов.
Что еще хуже, вы можете даже обнаружить, что некоторые из ваших страниц с самым высоким рейтингом для некоторых из ваших длиннохвостых ключевых слов могут быть вашими страницами благодарности — что означает, что вы можете приглашать сотни потенциальных клиентов в обход ваших форм для захвата лидов. Это довольно веская причина, по которой вы захотите удалить некоторые из своих веб-страниц из поисковой выдачи.
Итак, как вы делаете «деиндексирование» определенных страниц из поисковых систем? Вот два способа сделать это.
2 способа деиндексировать веб-страницу из поисковых системВариант №1: Добавить Robots.txt на свой сайт.
Используйте, если: вам нужен больший контроль над тем, что вы деиндексируете, и у вас есть необходимые технические ресурсы.
Один из способов удалить страницу из результатов поиска — добавить на сайт файл robots.txt. Преимущество использования этого метода заключается в том, что вы можете получить больший контроль над тем, что вы разрешаете индексировать ботам. Результат? Вы можете заранее исключить нежелательный контент из результатов поиска.
В файле robots.txt вы можете указать, хотите ли вы блокировать ботов с одной страницы, со всего каталога или даже с одного изображения или файла.Также есть возможность запретить сканирование вашего сайта, но при этом разрешить работу объявлений Google AdSense, если они у вас есть.
При этом из двух доступных вам вариантов этот требует самого технического кунг-фу. Чтобы узнать, как создать файл robots.txt, прочтите эту статью из Инструментов Google для веб-мастеров.
Клиенты HubSpot: Здесь вы можете узнать, как установить файл robots.txt на свой веб-сайт, а также узнать, как настроить содержимое роботов.txt здесь.
Если вам не нужен полный контроль над файлом robots.txt и вы ищете более простое и менее техническое решение, тогда этот второй вариант для вас.
Вариант № 2: Добавьте метатег «noindex» и / или метатег «nofollow».
Используйте, если: вам нужно более простое решение для деиндексации всей веб-страницы и / или деиндексации ссылок на всей веб-странице.
Использование метатега для предотвращения появления страницы в поисковой выдаче и / или в ссылках на странице — это просто и эффективно.Для этого требуется совсем немного технических ноу-хау — на самом деле, это просто копирование / вставка, если вы используете правильную систему управления контентом.
Теги, которые позволяют делать это, называются «noindex» и «nofollow». Прежде чем я перейду к тому, как добавлять эти теги, давайте определим их и проведем различие. В конце концов, это две совершенно разные директивы, и их можно использовать как по отдельности, так и вместе друг с другом.
Что такое тег noindex?
Когда вы добавляете метатег «noindex» к веб-странице, он сообщает поисковой системе, что даже если она может сканировать страницу, она не может добавить страницу в свой поисковый индекс.
Таким образом, любая страница с директивой noindex будет , а не попадет в поисковый индекс поисковой системы и, следовательно, не может отображаться на страницах результатов поисковой системы.
Что такое тег nofollow?
Когда вы добавляете на веб-страницу метатег «nofollow», запрещает поисковым системам сканировать ссылки на этой странице. Это также означает, что любой рейтинг, который страница имеет в поисковой выдаче, будет передан , а не страницам, на которые она ссылается.
Таким образом, на любой странице с директивой nofollow все ссылки будут игнорироваться Google и другими поисковыми системами.
Когда бы вы использовали «noindex» и «nofollow» по отдельности или вместе?
Как я сказал ранее, вы можете добавить директиву noindex либо отдельно, либо вместе с директивой nofollow. Вы также можете добавить директиву nofollow отдельно.
Добавьте только тег «noindex»: , если вы, , не хотите, чтобы поисковая система индексировала вашу веб-страницу в поиске, но вы, , хотите, чтобы переходила по ссылкам на этой странице, тем самым давая рейтинг на другие страницы, на которые ссылается ваша страница.
Платные целевые страницы — отличный тому пример. Вы не хотите, чтобы поисковые системы индексировали в поиске целевые страницы, за просмотр которых люди должны платить, но вы можете захотеть, чтобы страницы, на которые они ссылаются, извлекали выгоду из его авторитета.
Добавьте только тег «nofollow»: , когда вы хотите, чтобы поисковая система проиндексировала вашу веб-страницу в поиске, но вы, , не хотите, чтобы переходила по ссылкам на этой странице.
Не так много примеров, когда вы добавляете тег «nofollow» на всю страницу без добавления тега «noindex».Когда вы выясняете, что делать на данной странице, больше вопрос в том, добавлять ли ваш тег «noindex» с тегом «nofollow» или без него.
Добавьте теги «noindex» и «nofollow»: , если вы, , не хотите, чтобы поисковые системы индексировали веб-страницу в поиске, и вы не хотите, чтобы они переходили по ссылкам на этой странице.
Страницы с благодарностью — отличный пример такого рода ситуаций. Вы не хотите, чтобы поисковые системы индексировали вашу страницу с благодарностью, и вы также не хотите, чтобы они перешли по ссылке на ваше предложение и начали индексировать содержание этого предложения.
Как добавить метатег «noindex» и / или «nofollow»
Шаг 1: Скопируйте один из следующих тегов.
Для «noindex»:
Для nofollow:
Для noindex и nofollow:
Шаг 2: Добавьте тег в раздел
HTML-кода вашей страницы, a.к.а. заголовок страницы.Если вы являетесь клиентом HubSpot, это очень просто — щелкните здесь или прокрутите вниз, чтобы увидеть инструкции, предназначенные для пользователей HubSpot.
Если вы , а не клиент HubSpot, , вам придется вручную вставить этот тег в код на своей веб-странице. Не волнуйтесь — это довольно просто. Вот как это сделать.
Сначала откройте исходный код веб-страницы, которую вы пытаетесь деиндексировать. Затем вставьте полный тег в новую строку в разделе
HTML-кода вашей страницы, известном как заголовок страницы.Скриншоты ниже помогут вам в этом.Тег
обозначает начало вашего заголовка:Вот метатег для «noindex» и «nofollow», вставленный в заголовок:
И тег означает конец заголовка:
Бум! Это оно. Этот тег указывает поисковой системе развернуться и уйти, оставив страницу вне результатов поиска.
Клиенты HubSpot: Добавить метатеги noindex и nofollow стало еще проще.Все, что вам нужно сделать, это открыть инструмент HubSpot на странице, на которую вы хотите добавить эти теги, и выбрать вкладку «Настройки».
Затем прокрутите вниз до Advanced Options и нажмите «Edit Head HTML». В появившемся окне вставьте соответствующий фрагмент кода. В приведенном ниже примере я добавил теги «noindex» и «nofollow», поскольку это страница с благодарностью.
Нажми «Сохранить», и ты золотой.
Ta Da!
Вы только что волшебным образом удалили свою страницу из результатов поиска.Теперь вы можете снова начать собирать больше потерянных потенциальных клиентов.
Имейте в виду, что вы не увидите результаты мгновенно. Ваши изменения не вступят в силу до тех пор, пока поисковая система не просканирует вашу страницу в следующий раз. В зависимости от того, как часто вы обычно публикуете новые страницы на своем веб-сайте, на самом деле это может занять несколько недель. Чем чаще вы публикуете контент, тем чаще поисковые системы будут сканировать ваш сайт. Лучший способ отслеживать, как часто Google посещает ваш веб-сайт, — это просматривать статистику сканирования в Инструментах Google для веб-мастеров.
Итог: если вы заметили, что ваша страница все еще отображается в результатах поиска Google даже с тегом «noindex», вероятно, это потому, что Google не сканировал ваш сайт с тех пор, как вы добавили этот тег. Вы можете запросить у Google повторное сканирование вашей страницы с помощью инструмента Fetch as Google.
Также обратите внимание, что веб-сканеры некоторых поисковых систем могут интерпретировать эти директивы иначе, чем Google, поэтому возможно, что ваша страница все еще может отображаться в результатах других поисковых систем.Но для Google это будет работать нормально — как только он просканирует ваш сайт. Если вы хотите узнать, как поисковые системы сканируют, индексируют и обслуживают контент, пройдите наш курс по SEO.
Тем не менее, вы сможете спать немного легче, зная, что в конечном итоге вы сделали свой веб-сайт лучшим местом для маркетинга.
Какие еще советы вы можете дать по деиндексации веб-страниц и когда это будет полезно для маркетологов? Поделитесь своими мыслями в комментариях.
Что такое Noindex и как он работает?
В то время как тег noindex сообщает боту или сканеру не добавлять страницу в индекс результатов поиска, директива disallow предписывает поисковым системам вообще не сканировать страницу.Это должно быть сделано через файл robots.txt и иногда используется вместе с noindex.
Хотя тег disallow — полезный инструмент, важно соблюдать особую осторожность при использовании директивы disallow. Запрещая страницу, вы, по сути, удаляете ее со своего сайта в отношении поиска, а также лишаете ее возможности передавать PageRank — значение, присвоенное веб-странице поисковой системой, которая позволяет ей появляться в результатах поиска. Случайное отклонение неправильной страницы — например, страницы, которая привлекает трафик на ваш сайт — может иметь катастрофические последствия для трафика и вашей тактики SEO.
Почему я должен запретить страницу?
Запрет страниц, которые не имеют ценности для читателя или SEO, может ускорить сканирование и индексирование вашего сайта ботами. Примером может служить функция поиска на сайте электронной коммерции. Хотя функция поиска обеспечивает ценность для пользователя, различные страницы, которые она извлекает, не обязательно являются страницами, которые повышают ценность вашего сайта для SEO.
Объединение Noindex и Disallow
Если есть внешние ссылки или канонические теги — теги, которые сообщают ботам, какую страницу из группы похожих страниц следует проиндексировать — указывающие на страницу, которая была запрещена, ее все равно можно проиндексировать и ранжировать, даже если она не может быть просканирована.Это означает, что он все еще может отображаться в поисковой выдаче.
Чтобы применить обе директивы, добавьте их обе в файл robot.txt. Например:
- Запретить: /example-folder/example-page.html
- Noindex: /example-folder/example-page.html
Что такое метатег Nofollow?
Тег nofollow используется для указания поисковым системам не оценивать достоинства ссылок (или конкретной ссылки), существующих на странице. Мета-директивы Nofollow также указывают ботам не открывать больше URL-адресов на сайте, устанавливая для всех ссылок значение «nofollow» — по умолчанию все ссылки на странице настроены на переход.Вы можете добавить тег nofollow к отдельным ссылкам или скрыть их с помощью метатега robots в заголовке HTML страницы. Ссылки Nofollow можно использовать в качестве тактики SEO, чтобы иметь возможность ссылаться на страницы, которые они хотят предоставить читателю, без связывания ботом или поисковым роботом этой страницы со своей собственной.
Например, одиночная ссылка nofollowed может выглядеть так:
< a href = ”https://example.com/” rel = ”nofollow”>
В то время как метатег nofollow в заголовке будет выглядеть так:
< meta name = «robots» content = «nofollow»>
Когда мне следует использовать ссылки Nofollow?
ТегиNofollow полезны, когда они применяются к ссылкам, которые вы не можете напрямую контролировать, например, ссылкам в разделах комментариев, неорганическим или нерелевантным платным ссылкам, гостевым сообщениям, ссылкам на что-то не по теме на веб-сайте или странице, или к встраиваемым таким в виде виджета или инфографики.