Что такое большие данные и для чего они нужны
Большие данные – направление, о котором все говорят, но мало кто хорошо в нём разбирается. Гиганты электронной коммерции, промышленные компании и информационные корпорации инвестируют в эту технологию миллиарды. Что же такое Big Data, какие перспективы они предлагают и где используются?
Что такое большие данные

Большие данные – современное технологическое направление, связанное с обработкой крупных массивов данных, которые постоянно растут. Big Data – это сама информация, методы её обработки и аналитики. Перспективы, которые может принести Big Data интересны бизнесу, маркетингу, науке и государству.
В первую очередь большие данные – это всё-таки информация. Настолько большая, что ей сложно оперировать с помощью обычных программных средств. Она бывает структурированной (обработанной), и неструктурированной (разрозненной). Вот некоторые её примеры:
• Данные с сейсмологических станций по всей Земле.
• База пользовательских аккаунтов Facebook.
• Геолокационная информация всех фотографий, выложенных за сегодня в Instagram.
• Базы данных операторов мобильной связи.
Для Big Data разрабатываются свои алгоритмы, программные инструменты и даже машины. Чтобы придумать средство обработки, постоянно растущей информации, необходимо создавать новые, инновационные решения. Именно поэтому большие данные стали отдельным направлением в технологической сфере.
VVV — признаки больших данных

Чтобы уменьшить размытость определений в сфере Big Data, разработаны признаки, которым они должны соответствовать. Все начинаются с буквы V, поэтому система носит название VVV:
• Volume – объём. Объём информации измерим.
• Velocity – скорость. Объём информации не статичен – он постоянно увеличивается, и инструменты обработки должны это учитывать.
• Variety – многообразие. Информация не обязана иметь один формат. Она может быть неструктурированной, частично или полностью структурированной.
К этим трём принципам, с развитием отрасли, добавляются дополнительные V. Например, veracity – достоверность, value – ценность или viability – жизнеспособность.
Но для понимания достаточно первых трёх: большие данные измеримые, прирастающие и неоднообразные.
Для чего необходимы большие данные

Главная цель работы с большими данными – обуздать их (проанализировать) и направить. Человечество научилось производить и извлекать огромные массивы информации, а с их управлением ещё есть проблемы.
Прямо сейчас большие данные помогают в решении таких задач:
• повышение производительности труда;
• точная реклама и оптимизация продаж;
• прогнозирование ситуаций на внутренних и глобальных рынках;
• совершенствование товаров и услуг;
• улучшение логистики;
• качественное таргетирование клиентов в любой сфере бизнеса.
Большие данные делают услуги удобнее и выгоднее как для продавцов, так и для покупателей. Предприятия могут узнать, какая продукция популярнее, как сформировать ценовую политику, когда лучшее время для продаж, как оптимизировать ресурсы на производстве, чтобы сделать его эффективнее. За счёт этого клиенты получают точное предложение «без воды».

Источник: lifehacker.ru
Где используются больше данные

• Облачные хранилища. Хранить всё на локальных компьютерах, дисках и серверах неудобно и затратно. Крупные облачные data-центры становятся надёжным способом хранения информации, доступной в любой момент.
• Блокчейн. Революционная технология, сотрясающая мир в последние годы, упрощает транзакции, делает их безопаснее, а, главное, хорошо справляется с обработкой операций между гигантским количеством контрагентов за счёт своего математического алгоритма.
• Самообслуживание. Роботизация и промышленная автоматизация снижают расходы на ведение бизнеса и уменьшают стоимость товаров или услуг.
• Искусственный интеллект и глубокое обучение. Подражание мышлению головного мозга помогает делать отзывчивые системы, эффективные в науке и бизнесе.
Big Data будет неотъемлемой частью Индустрии 4.0 и интернета вещей, когда сложные системы из огромного числа устройств работают, как единое целое. Вот простые, уже не футуристические, примеры этого:
• Автоматизированный завод сам изменяет линейку продукции, ориентируясь на анализ спроса, поставок, себестоимости и рыночной ситуации.
• Умный дом даёт рекомендации о том, как одеться по погоде и по какому маршруту быстрее всего добраться до работы утром.
• Компания анализирует производство и каналы сбыта с учётом изменений реальной обстановки на рынке.
• Дорожная безопасность повышается за счёт сбора данных о стиле вождения и нарушениях отдельных водителей, а также состояния их машин.
Кто использует большие данные

Наибольший прогресс отрасли наблюдается в США и Европе. Вот крупнейшие иностранные компании и ведомства, которые используют Big Data:
• HSBC повышает безопасность клиентов пластиковых карт. Компания утверждает, что в 10 раз улучшила распознавание мошеннических операций и в 3 раза – защиту от мошенничества в целом.
• Суперкомпьютер Watson, разработанный IBM, анализирует финансовые транзакции в режиме реального времени. Это позволяет сократить частоту ложных срабатываний системы безопасности на 50% и выявить на 15% больше мошеннических действий.
• Procter&Gamble проводит с использованием Big Data маркетинговые исследования, более точно прогнозируя желания клиентов и спрос новых продуктов.
• Министерство труда Германии добивается целевого расхода средств, анализируя большие данные при обработке заявок на пособия. Это помогает направить деньги тем, кто действительно в них нуждается (оказалось, что 20% пособий выплачивались нецелесообразно). Министерство утверждает, что инструменты Big Data сокращают затраты на €10 млрд.
Среди российских компаний стоит отметить следующие:
• Яндекс. Это корпорация, которая управляет одним из самых популярных поисковиков и делает цифровые продукты едва ли не для каждой сферы жизни. Для Яндекс Big Data – не инновация, а обязанность, продиктованная собственными нуждами. В компании работают алгоритмы таргетинга рекламы, прогноза пробок, оптимизации поисковой выдачи, музыкальных рекомендаций, фильтрации спама.
• Мегафон. Телекоммуникационный гигант обратил внимание на большие данные примерно пять лет назад. Работа над геоаналитикой привела к созданию готовых решений анализа пассажироперевозок. В этой области у Мегафон есть сотрудничество с РЖД.
• Билайн. Этот мобильный оператор анализирует массивы информации для борьбы со спамом и мошенничеством, оптимизации линейки продуктов, прогнозирования проблем у клиентов. Известно, что корпорация сотрудничает с банками – оператор помогает анонимно оценивать кредитоспособность абонентов.
• Сбербанк. В крупнейшем банке России супермассивы анализируются для оптимизации затрат, грамотного управления рисками, борьбы с мошенничеством, а также расчёта премий и бонусов для сотрудников. Похожие задачи с помощью Big Data решают конкуренты: Альфа-банк, ВТБ24, Тинькофф-банк, Газпромбанк.
И за границей, и в России организации в основном пользуются сторонними разработками, а не создают инструменты для Big Data сами. В этой сфере популярны технологии Oracle, Teradata, SAS, Impala, Apache, Zettaset, IBM, Vowpal.
Читайте: Что такое интернет вещей, как он работает и чем полезен
invlab.ru
Big Data: размер имеет значение
Простыми словами рассказываем, что такое большие данные, где они используются, кто и как с ними работает.
Термину Big Data более десяти лет, но вокруг него до сих пор много путаницы. Доступно рассказываем, что же такое «большие данные», откуда эти данные берутся и где используются, кто такие аналитики данных и чем они занимаются.
Три признака больших данных
Традиционно большие данные характеризуют тремя признаками (так называемым правилом VVV):
- Большой объем (Volume). Термин Big Data предполагает большой информационный объем (терабайты и петабайты информации). Важно понимать, что для решения определенного бизнес-кейса ценность обычно имеет не весь объем, а лишь незначительная часть. Однако заранее эту ценную составляющую без анализа определить невозможно.
- Большая скорость обновлений (Velocity). Данные регулярно обновляются и требуют постоянной обработки. Обновление чаще всего подразумевает рост объема.
- Многообразие (Variety). Данные могут иметь различные форматы и быть структурированы лишь частично или быть вовсе сырыми, неоднородными. Необходимо учитывать, что часть данных почти всегда недостоверна или неактуальна на момент проведения исследования.
В качестве простейшего примера можно представить таблицу с миллионами строк клиентов крупной компании. Столбцы – это характеристики пользователей (Ф.И.О., пол, дата, адрес, телефон и т. д.), один клиент – одна строка. Информация обновляется постоянно: клиенты приходят и уходят, данные корректируются.
Но таблицы – это лишь одна из простейших форм отображения информации. Обычно представление больших данных имеет куда более витиеватый и менее структурированный характер. Так, ниже показана схема базы данных проекта MediaWiki:
Большой объем предполагает особую инфраструктуру хранения данных – распределенные файловые системы. Для работы с ними используются реляционные системы управления базами данных. Это требует от аналитика уметь составлять соответствующие запросы к базам данных.
Где живут большие данные?
Инструменты Big Data используются во многих сферах жизни современного человека. Перечислим некоторые из наиболее популярных областей с примерами бизнес-задач:
- Поисковая выдача (оптимизация отображаемых ссылок с учетом сведений о пользователе, его местоположении, предыдущих поисковых запросах).
- Интернет-магазины (повышение конверсии).
- Рекомендательные системы (жанровая классификация фильмов и музыки).
- Голосовые помощники (распознавание голоса, реакция на запрос).
- Цифровые сервисы (фильтрация спама в электронной почте, индивидуальная новостная лента).
- Социальные сети (персонализированная реклама).
- Игры (внутриигровые покупки, игровое обучение).
- Финансы (принятие банком решений о кредитовании, трейдинг).
- Продажи (прогнозирование остатков на складе для снижения издержек).
- Системы безопасности (распознавание объектов с видеокамер).
- Автопилотируемый транспорт (машинное зрение).
- Медицина (диагностика заболеваний на ранних стадиях).
- Городская инфраструктура (предотвращение пробок на дорогах, предсказание пассажиропотока в общественном транспорте).
- Метеорология (прогнозирование погоды).
- Промышленное производство товаров (оптимизация конвейера, снижение рисков).
- Научные задачи (расшифровка геномов, обработка астрономических данных, космических снимков).
- Обработка информации с фискальных накопителей (прогнозирование стоимости товаров).
Для каждой из перечисленных задач можно найти примеры решений с помощью технологий, входящих в сферу Data Science и Machine Learning. Объем используемых данных определяет стратегию и точность решения.
Чем занимаются люди в Big Data?
Анализ Big Data находится на стыке трех областей:
- Computer Science/IT
- Математика и статистика
- Специальные знания анализируемой области
Поэтому аналитик данных – междисциплинарный специалист, обладающий знаниями и в математике, и в программировании, и в базах данных. Вышеперечисленные примеры задач предполагают, что человек должен быстро разбираться в новой предметной области, иметь коммуникативные навыки. Особенно важно уметь находить аналитически обоснованный и полезный для бизнеса результат. Немаловажно грамотно эти выводы визуализировать и презентовать.
Очередность действий в проводимом исследовании примерно сводится к следующему:
- Работа с базами (структурирование, логика).
- Извлечение необходимой информации (написание SQL-запросов).
- Предобработка данных.
- Преобразование данных.
- Применение статистических методов.
- Поиск паттернов.
- Визуализация данных (выявление аномалий, наглядное представление для бизнеса).
- Поиск ответа, формулировка и проверка гипотезы.
- Внедрение в процесс.
Итог работы представляет сжатый отчет с визуализацией результата либо интерактивную панель (dashboard). На такой панели обновляемые данные после обработки предстают в удобной для восприятия форме.
Ключевые навыки и инструменты аналитика
Навыки и соответствующие инструменты, применяемые аналитиками, обычно следующие:
- Извлечение данных из источников данных (MS SQL, MySQL, NoSQL, Hadoop, Spark).
- Обработка данных (Python, R, Scala, Java).
- Визуализация (Plotly, Tableau, Qlik).
- Исследование по критериям бизнес-задачи.
- Формулировка гипотез.
Выбор языка программирования диктуется имеющимися наработками и необходимой скоростью конечного решения. Язык определяет среду разработки и инструменты анализа данных.
Большинство аналитиков используют в качестве языка программирования Python. В этом случае для анализа больших обычно применяется Pandas. При работе в команде общепринятым стандартом документов для хранения и обмена гипотезами являются ipynb-блокноты, обычно обрабатываемые в Jupyter. Этот формат представления данных позволяет совмещать ячейки с программным кодом, текстовые описания, формулы и изображения.
Выбор инструментария для решения задачи зависит от кейса и требований заказчика к точности, надежности и скорости выполнения алгоритма решения. Также важна возможность объяснить составляющие алгоритма от этапа ввода данных до вывода результата.
Так, для задач, связанных с обработкой изображений, чаще применяются нейросетевые инструменты, такие как TensorFlow или один из десятка других фреймворков глубокого обучения. Но, к примеру, при разработке финансовых инструментов нейросетевые решения могут выглядеть «опасными», ведь проследить путь нахождения результата оказывается затруднительно.
Выбор модели анализа и ее архитектуры не менее тривиален, чем вычислительный процесс. Из-за этого в последнее время развивается направление автоматического машинного обучения. Данный подход вряд ли сократит потребность в аналитиках данных, но уменьшит число рутинных операций.
Как разобраться в Big Data?
Как можно понять из приведенного обзора, большие данные предполагают от аналитика и большой объем знаний их различных областей. Разобраться с основами поможет наш учебный план. Если захочется углубиться и попытаться последовательно охватить все аспекты вопроса, изучите roadmap Data Science:
В упомянутом репозитории вы также найдете краткие описания и ссылки к некоторым из компонентов карты.
С чего начать, если хочется попробовать прямо сейчас, но нет данных?
Опытные аналитики советуют пораньше знакомиться с Kaggle. Это популярная платформа для организации конкурсов по анализу больших объемов данных. Здесь найдутся не только соревнования с денежными призами за первые места, но и ipynb-блокноты с идеями и решениями, а также интересные датасеты (наборы данных) различного объема.
Понравилась статья? Что бы еще вы хотели узнать о Big Data?
proglib.io
что это такое, где и как использовать технологии больших данных
Определение Big data обычно расшифровывают довольно просто – это огромный объем информации, часто бессистемной, которая хранится на каком либо цифровом носителе. Однако массив данных с приставкой «Биг» настолько велик, что привычными средствами структурирования и аналитики «перелопатить» его невозможно. Поэтому под термином «биг дата» понимают ещё и технологии поиска, обработки и применения неструктурированной информации в больших объемах.

Экскурс в историю и статистику
Словосочетание «большие данные» появилось в 2008 году с легкой руки Клиффорда Линча. В спецвыпуске журнала Nature эксперт назвал взрывной рост потоков информации — big data. В него он отнес любые массивы неоднородных данных свыше 150 Гб в сутки.
Из статистических выкладок аналитических агентств в 2005 году мир оперировал 4-5 эксабайтами информации (4-5 миллиардов гигабайтов), через 5 лет объемы big data выросли до 0,19 зеттабайт (1 ЗБ = 1024 ЭБ). В 2012 году показатели возросли до 1,8 ЗБ, а в 2015 – до 7 ЗБ. Эксперты прогнозируют, что к 2020 году системы больших данных будут оперировать 42-45 зеттабайтов информации.

До 2011 года технологии больших данных рассматривались только в качестве научного анализа и практического выхода ни имели. Однако объемы данных росли по экспоненте и проблема огромных массивов неструктурированной и неоднородной информации стала актуальной уже в начале 2012 году. Всплеск интереса к big data хорошо виден в Google Trends.
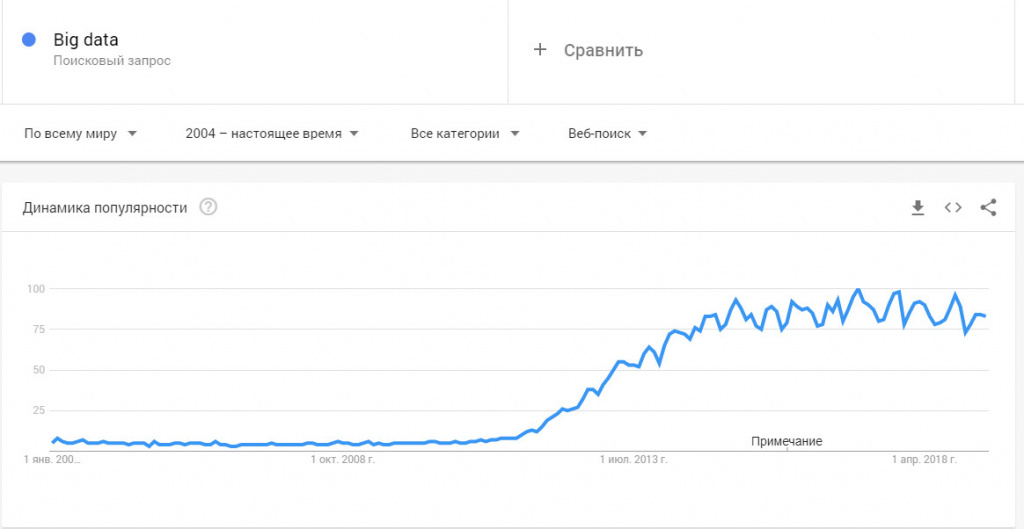
К развитию нового направления подключились мастодонты цифрового бизнеса – Microsoft, IBM, Oracle, EMC и другие. С 2014 года большие данные изучают в университетах, внедряют в прикладные науки – инженерию, физику, социологию.
Как работает технология big data?
Чтобы массив информации обозначить приставкой «биг» он должен обладать следующими признаками:

Правило VVV:
- Объем (Volume) – данные измеряются по физической величине и занимаемому пространству на цифровом носителе. К «биг» относят массивы свыше 150 Гб в сутки.
- Скорость, обновление (Velocity) – информация регулярно обновляется и для обработки в реальном времени необходимы интеллектуальные технологии больших данных.
- Разнообразие (Variety) – информация в массивах может иметь неоднородные форматы, быть структурированной частично, полностью и скапливаться бессистемно. Например, социальные сети используют большие данные в виде текстов, видео, аудио, финансовых транзакций, картинок и прочего.
В современных системах рассматриваются два дополнительных фактора:
- Изменчивость (Variability) – потоки данных могут иметь пики и спады, сезонности, периодичность. Всплески неструктурированной информации сложны в управлении, требует мощных технологий обработки.
- Значение данных (Value) – информация может иметь разную сложность для восприятия и переработки, что затрудняет работу интеллектуальным системам. Например, массив сообщений из соцсетей – это один уровень данных, а транзакционные операции – другой. Задача машин определить степень важности поступающей информации, чтобы быстро структурировать.
Принцип работы технологии big data основан на максимальном информировании пользователя о каком-либо предмете или явлении. Задача такого ознакомления с данными – помочь взвесить все «за» и «против», чтобы принять верное решение. В интеллектуальных машинах на основе массива информации строится модель будущего, а дальше имитируются различные варианты и отслеживаются результаты.
Современные аналитические агентства запускают миллионы подобных симуляций, когда тестируют идею, предположение или решают проблему. Процесс автоматизирован.
К источникам big data относят:
- интернет – блоги, соцсети, сайты, СМИ и различные форумы;
- корпоративную информацию – архивы, транзакции, базы данных;
- показания считывающих устройств – метеорологические приборы, датчики сотовой связи и другие.
Принципы работы с массивами данных включают три основных фактора:
- Расширяемость системы. Под ней понимают обычно горизонтальную масштабируемость носителей информации. То есть выросли объемы входящих данных – увеличились мощность и количество серверов для их хранения.
- Устойчивость к отказу. Повышать количество цифровых носителей, интеллектуальных машин соразмерно объемам данных можно до бесконечности. Но это не означает, что часть машин не будет выходить из строя, устаревать. Поэтому одним из факторов стабильной работы с большими данными является отказоустойчивость серверов.
- Локализация. Отдельные массивы информации хранятся и обрабатываются в пределах одного выделенного сервера, чтобы экономить время, ресурсы, расходы на передачу данных.
Для чего используют?
Чем больше мы знаем о конкретном предмете или явлении, тем точнее постигаем суть и можем прогнозировать будущее. Снимая и обрабатывая потоки данных с датчиков, интернета, транзакционных операций, компании могут довольно точно предсказать спрос на продукцию, а службы чрезвычайных ситуаций предотвратить техногенные катастрофы. Приведем несколько примеров вне сферы бизнеса и маркетинга, как используются технологии больших данных:
- Здравоохранение. Больше знаний о болезнях, больше вариантов лечения, больше информации о лекарственных препаратах – всё это позволяет бороться с такими болезнями, которые 40-50 лет назад считались неизлечимыми.
- Предупреждение природных и техногенных катастроф. Максимально точный прогноз в этой сфере спасает тысячи жизней людей. Задача интеллектуальных машин собрать и обработать множество показаний датчиков и на их основе помочь людям определить дату и место возможного катаклизма.
- Правоохранительные органы. Большие данные используются для прогнозирования всплеска криминала в разных странах и принятия сдерживающих мер, там, где этого требует ситуация.
Методики анализа и обработки

К основным способам анализа больших массивов информации относят следующие:
- Глубинный анализ, классификация данных. Эти методики пришли из технологий работы с обычной структурированной информацией в небольших массивах. Однако в новых условиях используются усовершенствованные математические алгоритмы, основанные на достижениях в цифровой сфере.
- Краудсорсинг. В основе этой технологии возможность получать и обрабатывать потоки в миллиарды байт из множества источников. Конечное число «поставщиков» не ограничивается ничем. Разве только мощностью системы.
- Сплит-тестирование. Из массива выбираются несколько элементов, которые сравниваются между собой поочередно «до» и «после» изменения. А\В тесты помогают определить, какие факторы оказывают наибольшее влияние на элементы. Например, с помощью сплит-тестирования можно провести огромное количество итераций постепенно приближаясь к достоверному результату.
- Прогнозирование. Аналитики стараются заранее задать системе те или иные параметры и в дальнейшей проверять поведение объекта на основе поступления больших массивов информации.
- Машинное обучение. Искусственный интеллект в перспективе способен поглощать и обрабатывать большие объемы несистематизированных данных, впоследствии используя их для самостоятельного обучения.
- Анализ сетевой активности. Методики big data используются для исследования соцсетей, взаимоотношений между владельцами аккаунтов, групп, сообществами. На основе этого создаются целевые аудитории по интересам, геолокации, возрасту и прочим метрикам.
Большие данные в бизнесе и маркетинге
Стратегии развития бизнеса, маркетинговые мероприятия, реклама основаны на анализе и работе с имеющимися данными. Большие массивы позволяют «перелопатить» гигантские объемы данных и соответственно максимально точно скорректировать направление развития бренда, продукта, услуги.
Например, аукцион RTB в контекстной рекламе работают с big data, что позволяет эффективно рекламировать коммерческие предложения выделенной целевой аудитории, а не всем подряд.
Какие выгоды для бизнеса:
- Создание проектов, которые с высокой вероятностью станут востребованными у пользователей, покупателей.
- Изучение и анализ требований клиентов с существующим сервисом компании. На основе выкладки корректируется работа обслуживающего персонала.
- Выявление лояльности и неудовлетворенности клиентской базы за счет анализа разнообразной информации из блогов, соцсетей и других источников.
- Привлечение и удержание целевой аудитории благодаря аналитической работе с большими массивами информации.
Технологии используют в прогнозировании популярности продуктов, например, с помощью сервиса Google Trends и Яндекс. Вордстат (для России и СНГ).

Методики big data используют все крупные компании – IBM, Google, Facebook и финансовые корпорации – VISA, Master Card, а также министерства разных стран мира. Например, в Германии сократили выдачу пособий по безработице, высчитав, что часть граждан получают их без оснований. Так удалось вернуть в бюджет около 15 млрд. евро.
Недавний скандал с Facebook из-за утечки данных пользователей говорит о том, что объемы неструктурированной информации растут и даже мастодонты цифровой эры не всегда могут обеспечить их полную конфиденциальность.

Например, Master Card используют большие данные для предотвращения мошеннических операций со счетами клиентов. Так удается ежегодно спасти от кражи более 3 млрд. долларов США.
В игровой сфере big data позволяет проанализировать поведение игроков, выявить предпочтения активной аудитории и на основе этого прогнозировать уровень интереса к игре.

Сегодня бизнес знает о своих клиентах больше, чем мы сами знаем о себе – поэтому рекламные кампании Coca-Cola и других корпораций имеют оглушительный успех.
Перспективы развития
В 2019 году важность понимания и главное работы с массивами информации возросла в 4-5 раз по сравнению с началом десятилетия. С массовостью пришла интеграция big data в сферы малого и среднего бизнеса, стартапы:
- Облачные хранилища. Технологии хранения и работы с данными в онлайн-пространстве позволяет решить массу проблем малого и среднего бизнеса: дешевле купить облако, чем содержать дата-центр, персонал может работать удаленно, не нужен офис.
- Глубокое обучение, искусственный интеллект. Аналитические машины имитируют человеческий мозг, то есть используются искусственные нейронные сети. Обучение происходит самостоятельно на основе больших массивов информации.
- Dark Data – сбор и хранение не оцифрованных данных о компании, которые не имеют значимой роли для развития бизнеса, однако они нужны в техническом и законодательном планах.
- Блокчейн. Упрощение интернет-транзакций, снижение затрат на проведение этих операций.
- Системы самообслуживания – с 2016 года внедряются специальные платформы для малого и среднего бизнеса, где можно самостоятельно хранить и систематизировать данные.
Резюме
Мы изучили, что такое big data? Рассмотрели, как работает эта технология, для чего используются массивы информации. Познакомились с принципами и методиками работы с большими данными.
Рекомендуем к прочтению книгу Рика Смолана и Дженнифер Эрвитт «The Human Face of Big Data», а также труд «Introduction to Data Mining» Майкла Стейнбаха, Випин Кумар и Панг-Нинг Тан.
www.calltouch.ru
Что такое Big Data? – ответы на главные вопросы
Появление больших данных в публичном пространстве было связано с тем, что эти данные затронули практически всех людей, а не только научное сообщество, где подобные задачи решаются давно. В публичную сферу технологии Big Data вышли, когда речь стала идти о вполне конкретном числе — числе жителей планеты. 7 миллиардов, собирающихся в социальных сетях и других проектах, которые агрегируют людей. YouTube, Facebook, ВКонтакте, где количество людей измеряется миллиардами, а количество операций, которые они совершают одновременно, огромно. Поток данных в этом случае — это пользовательские действия. Например, данные того же хостинга YouTube, которые переливаются по сети в обе стороны. Под обработкой понимается не только интерпретация, но и возможность правильно обработать каждое из этих действий, то есть поместить его в нужное место и сделать так, чтобы эти данные каждому пользователю были доступны быстро, поскольку социальные сети не терпят ожидания.
Многое из того, что касается больших данных, подходов, которые используются для их анализа, на самом деле существует довольно давно. Например, обработка изображений с камер наблюдения, когда мы говорим не об одной картинке, а о потоке данных. Или навигация роботов. Все это существует десятки лет, просто сейчас задачи по обработке данных затронули гораздо большее количество людей и идей.
Многие разработчики привыкли работать со статическими объектами и мыслить категориями состояний. В больших данных парадигма другая. Ты должен уметь работать с непрекращающимся потоком данных, и это интересная задача. Она затрагивает все больше и больше областей.
В нашей жизни все больше аппаратных средств и программ начинают генерировать большое количество данных — например, «интернет вещей».
Вещи уже сейчас генерируют огромные потоки информации. Полицейская система «Поток» отправляет со всех камер информацию и позволяет находить машины по этим данным. Все больше входят в моду фитнес-браслеты, GPS-трекеры и другие вещи, обслуживающие задачи человека и бизнеса.
Департамент информатизации Москвы набирает большое количество аналитиков данных, потому что статистики по людям накапливается очень много и она многокритериальная (то есть о каждом человеке, о каждой группе людей собрана статистика по очень большому количеству критериев). В этих данных надо находить закономерности и тенденции. Для таких задач необходимы математики с IT-образованием. Потому что в конечном итоге данные хранятся в структурированных СУБД, и надо уметь к ним обращаться и получать информацию.
Раньше мы не рассматривали большие данные как задачу по той простой причине, что не было места для их хранения и не было сетей для их передачи. Когда эти возможности появились, данные тут же заполнили собой весь предоставленный им объем. Но как бы ни расширяли пропускную способность и способность к хранению данных, всегда найдутся источники, допустим, физические эксперименты, эксперименты по моделированию обтекаемости крыла, которые будут продуцировать информации больше, чем мы можем передать. По закону Мура, производительность современных параллельных вычислительных систем стабильно возрастает, растут и скорости сетей передачи данных. Однако данные нужно уметь быстро сохранять и извлекать с носителя (жесткого диска и других видов памяти), и это еще одна задача в обработке больших данных.
postnauka.ru
История больших данных (Big Data) – часть 1
Недостаточно только получить знания; надо найти им приложение. И. Гёте
По следам из хлебных крошек
На понимание технологий и подходов к хранению, обработке и анализу информации, ныне известных как Big Data, сегодня мы решили взглянуть сквозь призму времени. Возможно, кому-то данный подход покажется слегка наивным, но мы уверены: ничто не ново под луной и аналоги проблем, которые стоят перед современным человеком в данной области, можно с лёгкостью найти на всех этапах развития цивилизации, а мы, подобно Гензель и Гретель, попытаемся оставить след из хлебных крошек, который выведет нас из темного леса истории к светлым лугам познания.
Всю свою историю человечество осознанно или нет сталкивалось и решало проблемы хранения и обработки информации. Ещё 10-20 тысяч лет назад прародители современного человека использовали кости для записи остатков собранных запасов – предположительно, чтобы вести торговую активность и иметь прогнозируемый остаток на нужды собственно пропитания. Это всего лишь теория, но, если она верна – это первый пример получения и анализа информации в нашей истории.
Первые библиотеки Вавилона в 2000-х годах до нашей эры, позднее – библиотеки в Александрии – всё это пример того, как люди в тот или иной момент сталкивались с вопросами хранения большого объема информации и ее консолидации для удобства использования. Проблемы тогда, правда, сводились в основном к тому, чтобы не потерять всю накопленную мудрость при следующем вражеском набеге, как это произошло в Александрии при вторжении римлян, когда большая часть библиотеки была утрачена.
Про какой-либо серьезный анализ в привычном нам контексте в то время говорить не приходилось вплоть до середины XVII века, когда Джон Грант, известный своими работами в области демографической статистики, кроме прочего выпустил труд, описывавший теорию, в которой использование аналитики смертности позволяло предупреждать о начале эпидемии бубонной чумы.
В 1865 году профессор Ричард Миллер Девинс (Richard Millar Devens) впервые ввел в обиход термин Business Intelligence, использовав его в своей книге Cyclopedia of Commercial and Business Anecdotes, где кроме прочего рассказал Генри Фернезе, который пришёл к успеху благодаря структурированию и анализу информации о деловой активности.
С увеличением количества данных, которые люди стали использовать в различных сферах своей деятельности, возникало все больше проблем с их обработкой и анализом. Так, перед переписью 1880 года американское бюро, занимавшееся переписью населения, столкнулось с трудностью и объявило, что с современными подходами к работе с данными произвести подсчет они смогут лишь за 8 лет, а при следующей переписи в 1890 году, ввиду увеличения численности населения и постоянной миграции, дать точные результаты удастся не раньше чем через 10 лет, когда они уже полностью устареют. Получалась ситуация, когда к моменту следующего сбора данных не будут еще полностью проанализированы результаты прошлой переписи, что полностью обесценивает эту информацию и ставит само существование бюро под сомнение.
На помощь пришел инженер по имени Герман Холлерит (Herman Hollerith), который в 1881 году создал устройство (табулятор), которое, оперируя перфокартами, сокращало 10-летний труд до 3 месяцев. Воодушевленный успехом Холлерит создал компанию TMC, специализирующуюся на создании табулирующих машин. Позже ее купила компания C-T-R, которая в 1924 году была переименована в IBM.
Дальнейший рост информации и проблемы, встававшие перед нашими предшественниками, всегда сводились в равной степени к вопросам хранения и скорости обработки этих данных.
Во время Второй мировой войны необходимость в быстром анализе данных послужила созданию ряда компьютеров, позволяющих дешифровать сообщения неприятеля. Так, в 1943 году британские ученые создали машину Colossus, которая ускорила расшифровку сообщений с нескольких недель до нескольких часов. Как таковой личной памяти у «Колосса» не было, поэтому данные подавались через перфорированное колесо. Трудно представить сейчас, сколько жизней спас этот, по нашим меркам, допотопный компьютер с производительностью около 6 мегагерц и как изменился бы ход истории, если не существовало бы проблем со скоростью обработки информации.
Но скорость анализа не единственный вопрос, которым были озадачены наши предшественники в середине XX века. В 1944 году библиотекарь Фремонт Райдер (Fremont Rider) выпустил труд The Scholar and the Future of the Research Library, в котором он проанализировал, что с существующим ростом выпускаемых работ библиотеки должны удваивать свою вместительность каждые 16 лет. Это приведет к тому, что, к примеру, Йельская библиотека к 2040 году должна будет состоять из 6000 миль (около 10000 км) полок.
Дальше – больше. Начиная с 1950-х годов, наряду с все увеличивающейся потребностью в хранении и обработке информации, начался бурный рост технологий ее хранения, начали появляться центры обработки данных. Люди из разных отраслей деятельности стали приходить к пониманию, что их преимущества так или иначе будут зависеть от умения хранить и анализировать информацию, а также от скорости этого анализа и полученной от него ценностью.
С началом эры Интернета, переходом на центральные хранилища данных и с лавинообразным ростом количества веб-контента (для сравнения: в 1995 году в мире существовало 23 500 веб-сайтов, а уже через год – больше 250 000) встал вопрос поиска по многообразию существующего контента. Несмотря на существование уже нескольких созданных к тому времени поисковых систем (к слову, Yahoo не имела своей вплоть до 2002 года, а использовала сторонние разработки), первой действительно приближенной к современным была система AltaVista. Ее уникальность была в том, что она использовала лингвистический алгоритм, разбивая поисковую фразу на слова и проводя поиск по существующим индексам для ранжирования результата. За два года количество запросов в день изменилось с 300 000 до 80 миллионов.
Все, о чем мы рассказали выше, – примеры вопросов, связанных с хранением и обработкой информации. Эту цепочку можно продолжать до бесконечности, но сам термин Big Data пришёл к нам лишь на стыке тысячелетий и кроме подходов, которые были заложены в его основу, явил миру всю совокупность проблем, с которыми сталкивался человек с начала своей истории работы с информацией.
Магия литеры V
Перед тем как вплотную подойти к вопросу о Больших Данных, технологиях и областях применения, необходимо сделать ремарку и подготовить почву для обсуждения самого вопроса.
6 февраля 2001 года Дуг Лейни (Doug Laney) из Meta Group (входит в состав Gartner) издал документ, описывающий основные проблемные зоны, связанные с повышенными требованиями к центральным хранилищам данных на фоне бурного роста e-commerce, а также делающий прогноз на изменение стратегии IT-компаний в отношении подходов к построению архитектуры решений, связанных с хранением и обработкой информации.
Было выделено три важнейших направления, на которых стоит сосредоточиться для решения вопросов управления данными: Volume, Velocity и Variety. Позже эти понятия стали основой для описательной модели Больших Данных под названием 3V (VVV).
Нужно учесть, что эти аспекты обсуждались без отсылки к понятию Больших Данных, концепцию которых начали применять чуть позже, но эти параметры как никакие другие описали основные принципы того, что мы с вами называем Big Data.
Volume
Важность правильного подхода к вопросам увеличения объемов данных заложена в самом понятии Big Data. Но как определить этот порог, который отличает обычное хранилище от Больших Данных? Ответ прост – никак. Big Data – это не список статичных значений, при достижении которых определяется принадлежность решения, а целый набор методик и технологий получения, хранения и обработки информации, несмотря на наличие или отсутствие в ней структурированности.
Давайте рассмотрим этот момент на примере компании Facebook, так как индустрию социальных сетей уже невозможно представить в отрыве от использования технологий Big Data. Каждые 60 секунд происходит загрузка более 130 000 фотографий и добавляется либо обновляется около 1 000 000 записей, не говоря о присоединении новых пользователей к уже существующим двум миллиардам, а также происходит коммуникация между ними и добавление медиаконтента. Большой объем данных? Несомненно. Но давайте представим, что Facebook ограничился бы исключительно получением, хранением и предоставлением этой информации по запросу. Такой подход нельзя было бы отнести к понятию Big Data. Это был бы просто огромный массив данных.
Информация сама по себе – не сила, иначе самыми могущественными людьми были бы библиотекари. Б. Стерлинг
Еще одно существенное уточнение. Когда вы оперируете такими объёмами информации, очень важно быть готовым к оперативному горизонтальному масштабированию всей совокупной системы ввиду потенциального роста входящих данных.
Давайте продолжим разбираться в этом вопросе еще глубже и перейдем к следующему параметру.
Velocity
Скорость обработки. В условиях постоянного прироста данных необходима возможность их обработки с той скоростью, которую требуют цели проекта, в контексте которого данный параметр обсуждается. Давайте представим себе, что все шахты нашей необъятной родины снабжены сотнями датчиков. Они анализируют тысячи параметров экосистемы конкретной шахты, которые затем поступают на хаб, передающий весь поток в центральный ЦОД, где выполняется обработка и анализ полученной информации.
Данные эти разнообразны и среди прочих включают в себя уровень содержания вредных веществ, сейсмические показания и прочую информацию, способную указать на вероятность обрушения, утечку газа или иные катастрофические последствия, возможные в конкретно взятой шахте. А теперь представьте себе, что поступившие данные в силу тех или иных причин были обработаны за 2 часа вместо, скажем, 10 минут и результатом обработки была информация о высоком риске обрушения, которое случилось во время анализа этой информации и поэтому превентивные меры не были приняты.
Пример, возможно, надуманный, но хорошо отражает суть Velocity, от которой зачастую зависит еще один параметр, который добавила компания IDC в эту цепочку из трех V, – Value, или ценность информации. В нашем примере эта ценность была равна нулю, так как потеряла свою актуальность раньше, чем ею смогли воспользоваться за период Validity этой информации, который говорит о сроке ее полезного действия. В другом контексте параметр Value следует рассматривать как стоимость данных, то есть помогли ли они получить готовые для анализа данные после обработки или оказались нам бесполезны.
Можно придти к выводу, что скорость обработки данных, как и хранилища, должна легко наращиваться при необходимости, что также заложено в некоторые технологии Больших Данных, позволяющие обрабатывать информацию децентрализованно. Это дает возможность масштабировать решения более гибко.
Так мы узнали еще одну сферу, где применение Big Data более чем оправданно, – это IOT, или интернет вещей, который уже давно перерос из бытовой сферы умных домов в нечто большее.
Variety
Все примеры работы с информацией из нашего исторического вступления сводились к работе с так или иначе структурированными данными. Но что делать, если информация приходит в неструктурированном виде и ее нельзя разложить «по полочкам»? Уже в 1998 году инвестиционный банк «Мерилл Линч» заявил, что до 90% всей потенциально полезной информации не структурировано.
Допустим, вы решили анализировать систему электронных сообщений в своей компании (естественно, с согласия своих работников). Данные, которые можно назвать структурированными, – это наименование отправителя, получателя, даты отправки, получения и прочая информация, которую можно явно определить в заранее согласованную ячейку базы данных. На этом этапе проблем не возникает, и если вы решили собирать информацию о количестве писем, частоте отправки или, скажем, среднем размере письма, у вас это легко получится. Но что делать с вложениями или текстом письма? Какую информацию можно получить, просто распределяя их в поля text или attaches, если, к примеру, вы хотите узнать, пишут ли ваши сотрудники стихи в переписке, используют ли корпоративную почту в личных целях? Без интеллектуального анализа данных разобраться в этом вопросе невозможно.
Кроме приведенного примера, неструктурированными можно считать любые данные, которые нельзя связать с уже имеющейся моделью. Поэтому одна из задач, которая ставится перед использованием Big Data (в большей степени, нежели хранение информации), – получая на входе большой массив разнотипных данных, оперативно выстроить между ними связи и на выходе отдать данные, доступные для структурированного или полуструктурированного анализа.
Давайте подытожим все, о чем мы сегодня поговорили, и попробуем сформулировать в двух словах, что мы знаем о Big Data.
Во-первых, не всегда большой объем данных говорит о системе, что она решает вопросы Больших Данных.
Во-вторых, важно поддерживать необходимую скорость обработки поступающих данных, иначе можно потерять их ценность и передать на дальнейший анализ уже невалидные данные или в качестве результата предоставить неактуальную информацию.
В-третьих, важно уметь находить связи между любыми данными, вне зависимости от уровня их структурированности, и уметь получать результат, который можно однозначно анализировать для решения той или иной задачи.
В-четвертых, система должна быть хорошо масштабируемой на уровне логики, иначе мы рискуем получить недостоверные данные ввиду потери одного из магических V, потери которого неизбежны при наличии бОльшего потока информации, нежели мы можем обработать.
Получается, что Big Data – это горизонтально масштабируемая система, использующая набор методик и технологий, позволяющих обрабатывать структурированную и неструктурированную информацию и строить связи, необходимые для получения однозначно интерпретируемых человеком данных, не успевших потерять актуальность, и несущая ценность преследуемых им целей.
Многие могут что-то добавить, ведь определений Big Data существует, возможно, не меньше, нежели компаний, ее использующих. Но этого определения нам будет достаточно для перехода ко второй части статьи, где мы рассмотрим примеры и области применения, а также поговорим о технологиях, которые используются в Big Data.
NetApp, IncNetApp – лидер на рынке систем хранения данных и решений для хранения, управления и анализа информации как в локальных, так и в гибридных облачных средах. Мы предоставляем компаниям возможность управлять своими данными и обмениваться ими в локальных, частных и общедоступных облаках.
www.netapp.ru
www.computerra.ru
Что представляют собой большие объемы данных? | Решения для больших объемов данных | VMware
Препятствия для успешной обработки больших объемов данных
Компании часто сталкиваются с препятствиями при реализации проектов, связанных с большими объемами данных. В числе этих препятствий бюджетные ограничения, отсутствие необходимых ИТ-навыков и риски привязки к платформе.
Бюджетные ограничения
Согласно исследованию Deloitte, бюджетные ограничения и высокие расходы являются основными факторами, из-за которых многие компании не развертывают решения для обработки больших объемов данных. Доказать целесообразность инвестиций в новую ИТ-инфраструктуру для обработки больших объемов данных бывает сложно, особенно если у компании нет готового экономического обоснования.
ИТ-навыки
Обработка рабочих нагрузок, связанных с большими объемами данных, значительно отличается от обработки стандартных рабочих нагрузок корпоративных приложений. Рабочие нагрузки, связанные с большими объемами данных, обрабатываются параллельно, а не последовательно. Как правило, ИТ-отделы отдают наивысший приоритет важным рабочим нагрузкам, а выполнение менее приоритетных задач планируется в пакетном режиме в ночное время или осуществляется при наличии свободных ресурсов. При анализе больших объемов данных необходимо выполнять многочисленные сценарии использования в режиме реального времени, чтобы обеспечить оперативный анализ и реагирование. Это вынуждает ИТ-отделы изменять политики ЦОД и изучать новые средства для создания, администрирования и мониторинга новых рабочих нагрузок.
Привязка к платформе
Компаниям необходимо выбирать для своих приложений и данных подходящую инфраструктуру. На приобретение оборудования требуется время. Переход в облако — хороший способ проверки концепции, однако он создает риск привязки к платформе и возникновения проблем безопасности, а также требует значительных расходов в масштабе всей системы. Компаниям также приходится выбирать, какой дистрибутив Hadoop использовать, так как Cloudera, Hortonworks, MAPR и Pivotal предлагают эффективные, но при этом несовместимые архитектуры. Так как принятые решения часто бывает трудно корректировать в дальнейшем, многие компании откладывают внедрение технологий обработки больших объемов данных.
www.vmware.com
20 ошеломляющих фактов, которые должен знать каждый / PalitrumLab corporate blog / Habr
За 5 лет непонятный термин Big Data быстро наполнился смыслом и бессмысленностью, также как и «Интернет» 20 лет назад. Поскольку люди быстрее и проще понимают концентрированную и сравнительную информацию, то мы посчитали полезным перевод статьи с собранной фактографией «о размерах бедствия». К будущему надо готовиться. Заранее.=======
Big Data — это больше, чем временное помешательство. Мы находимся на этапе революции, которая затронет каждый бизнес и каждого человека на планете.
Тем не менее, огромное количество людей и специалистов до сих пор относятся к концепции Big Ddata как к чему-то не особенно важному, что можно игнорировать, в то время как на самом деле их привычный уклад очень скоро переедет паровой каток, имя которому — Big Data.
Не верите? Представляю к ознакомлению 20 статистических фактов, которые должны убедить любого в том, что Big Data стоит пристального внимания:
1. Объёмы данных стремительно растут, за последние 2 года было сгенерировано больше данных, чем за всю прошлую историю человечества.
2. Сейчас скорость роста кол-ва данных ещё выше и к 2020 году будет создаваться 1.7 мегабайт новых данных ежесекундно на каждого человека, живущего на этой планете.
3. К 2020 году наша цифровая вселенная из накопленных данных вырастет в 10 раз — с 4.4 зеттабайт до 44 зеттабайт (44 триллиона гигабайт).
4. Мы создаём новые данные каждую секунду. К примеру, человечество генерирует 40,000 поисковых запросов каждую секунду (только в Google), что составит 3.5 запроса в день на каждого пользователя интернета и 1.2 триллиона запросов в год.
5. В августе 2015 года, более 1 миллиарда человек воспользовались Facebook-ом за сутки.
6. Пользователи Facebook в среднем каждую минуту отправляют 30 миллионов сообщений и просматривают 3 миллиона видеозаписей.
7. Мы наблюдаем быстрый рост объёмов видео и фото, более 300 часов видео-файлов каждую минуту загружаются на один лишь YouTube.
8. В 2015 году, люди сделают около 1 триллиона фотографий и миллиарды из них будут выложены в сеть. К 2017 году, около 80% всех фотографий будут сделаны со смартфонов.
9. В этом году, около 1.4 миллиарда смартфонов найдут своих обладателей, и у каждого из них есть специальные сенсоры, способные собирать самые разнообразные данные о владельце, и это не учитывая всех тех данных, что создают сами пользователи.
10. К 2020 году в мире будет свыше 6.1 миллиарда пользователей смартфонов (обогнав по количеству пользователей стационарных телефонов).
11. В течение следующих 5 лет, в мире будет 50 миллиардов «умных» аппаратов и все они будут собирать, анализировать и передавать данные.
12. К 2020 году, как минимум треть всех данных будут накапливаться в «облаках». А, значит, будут доступны для анализа.
13. Распределённые вычисления – давно уже часть существующей реальности. Google изначально использует их в повседневной работе: 1,000 компьютеров задействовано в ответе на каждый отдельный поисковый запрос, на обработку которого уходит всего 0.2 секунды.
14. По прогнозам, рынок Hadoop будет расти со скоростью 58% в год и превысит 1 миллиард долларов к 2020.
15. Исходя из прогнозов можно сделать вывод, что с помощью лучшей интеграции Big Data, можно экономить более 300 миллиардов долларов в год на здравоохранении — по $1.000 экономии на жителя США.
16. Белый Дом уже инвестировал свыше 200 миллионов долларов в Big Data — проекты.
17. Для среднестатистической компании, всего 10%-ое увеличение в доступности данных приведёт к увеличению их чистой прибыли более чем на 65 миллионов долларов.
18. Продавцы, использующие все возможности Big Data, могут увеличить свою операционную маржу до 60%.
19. 73% всех организаций уже вложились или планируют вложиться в Big Data к 2016 году
20. И один из моих любимых фактов: В настоящий момент, мы используем менее чем 0.5% всех возможных данных — просто представьте потенциал развития в этом направлении!
Мой прогноз? При той скорости, при которой растут объёмы данных и, вместе с ними, наши возможности к их анализу, бизнесы всех размеров будут использовать ту или иную форму для анализа данных в ближайшие 5 лет.
Вопрос уже не в актуальности Big Data; вопрос в том, готовы ли _вы_ к ним?
Перевод статьи Big Data: 20 Mind-Boggling Facts Everyone Must Read
=================
P.S. Автор статьи немного выдохся где-то к 15му факту, последняя часть уже не выглядит столь масштабной. Так что у читателей есть возможность дополнить интересными на ваш взгляд фактами, полезными для сообщества.
habr.com