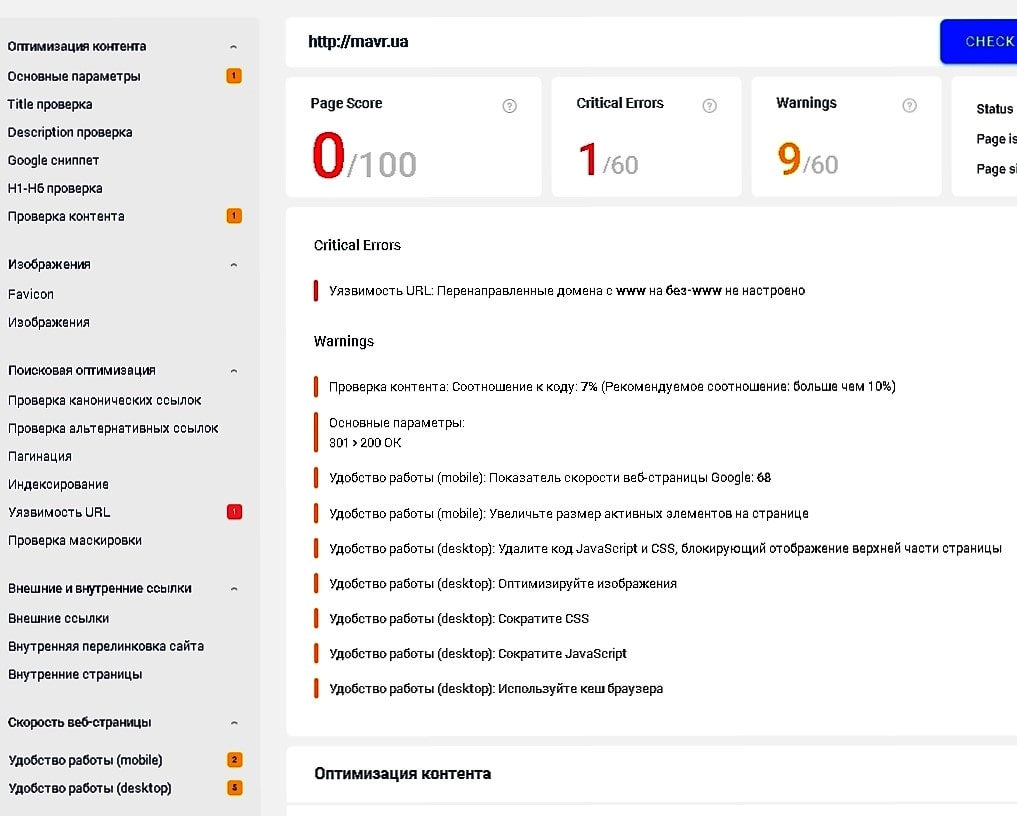
Индексация страниц пагинации: закрывать или нет?
Что такое страницы пагинации и как они выглядят
Без пагинации длинные страницы напоминали бы огромный свиток, который приходится раскручивать метр за метром в поисках нужной информации. Прежде всего, это касается интернет-магазинов, блогов, сайтов-справочников и т.д.
Чтобы представить ассортимент товаров или информационные ресурсы в наиболее удобном для пользователя виде, разработчики обращаются к следующим видам пагинации:
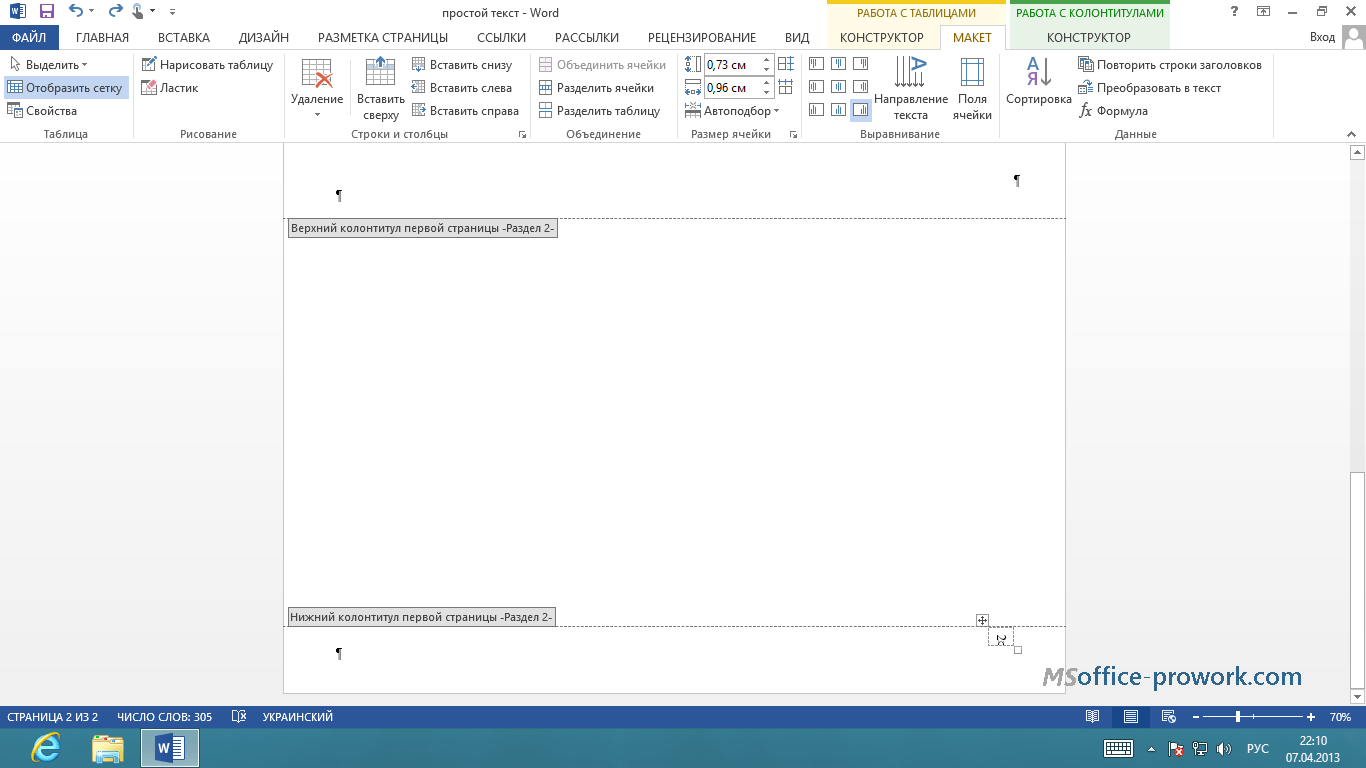
- Нумерация страниц. Массив данных делится на блоки, каждый из которых получает свой порядковый номер. Для быстрого перехода между блоками предусматриваются кнопки «Назад» и «Далее». Этот вид пагинации часто используется для каталогов интернет-магазинов.
Пагинация в формате нумерации страниц
- Алфавитный порядок. Это оптимальное решение для информационных сайтов, справочников и словарей.
Пагинация в алфавитном порядке
- Пагинация по датам.


Пагинация по датам
Возможные проблемы с индексацией пагинации
Существует ряд сложностей, которые возникают при индексации страниц с пагинацией:
- Дублирование данных. Чаще всего элементы пагинации имеют похожий или полностью идентичный контент. Нередко их метатеги title и description тоже совпадают. Поисковые боты могут идентифицировать такие страницы как дубли. Выявить наличие полностью идентичных разделов сайта можно при помощи сервисов Google Search Console и Netpeak Spider. Внутренние текстовые дубли появляются, когда контент повторяется на всех элементах пагинации. Найти их можно путем проверки текста на плагиат. Для этого используется Advego либо другие подобные сервисы.
- Ошибки в поисковой выдаче. Вместо главной страницы поисковый бот может предложить пользователю любой другой раздел сайта.
- Расход бюджета на индексацию. Зачастую поисковые роботы тратят массу времени на обход всех разделов сайта, а нужные блоки так и не попадают в поисковую выдачу.
- Чрезмерная нагрузка на сервер. Эта проблема напрямую связана с предыдущей. Во время сканирования сайта поисковый бот создает неоправданную нагрузку на сервер.
- Плохая индексация страниц с пагинацией. Эта проблема может быть связана с тем, что все страницы пагинации закрыты в robots.txt. Бот-поисковик не посещает каталог сайта и не выводит конкретные элементы в результатах поиска.
Чтобы избежать всех этих сложностей, важно корректно оптимизировать страницы пагинации в рамках общей оптимизации сайта.
Нужно ли закрывать пагинацию от индексации
Определенно, не нужно. В таком случае элементы сайта не будут индексироваться поисковыми системами. Боты Яндекса и Google просто не смогут понять, какой контент представлен на сайте, и не будут показывать его страницы по релевантным запросам пользователей.
Таким образом, чтобы пагинация не мешала продвижению, ее не нужно закрывать от индексации. Вместо этого следует правильно настроить работу сайта.
Рекомендации Яндекса
В блоге Яндекса рекомендуется указать посредством атрибута rel=»canonical» в теге <link> адрес канонической страницы. Это наиболее предпочитаемая страница в группе страниц-дублей. Именно она будет индексироваться и отображаться в результатах поиска, в то время как остальные разделы сайта будут видны для поисковых ботов, но не будут появляться в поисковой выдаче.
В целом, эксперты Яндекса советуют веб-мастерам ориентироваться прежде всего на содержимое сайта. Если отдельные страницы пагинации содержат данные, которые могут быть интересны пользователям, закрывать их от индексации не следует. Лучше сделать эти разделы доступными для поисковых роботов. Если содержимое конкретных страниц полностью дублируется в других разделах сайта, их индексирование можно прекратить посредством атрибута rel=»canonical» или через мета-тег noindex.
Если содержимое конкретных страниц полностью дублируется в других разделах сайта, их индексирование можно прекратить посредством атрибута rel=»canonical» или через мета-тег noindex.
Рекомендации Google
Представители этой поисковой системы предлагают два решения:
- Довериться алгоритмам Google и не оптимизировать страницы с пагинацией. Поисковый робот самостоятельно выберет раздел с наиболее релевантным содержимым и продемонстрирует его по соответствующему запросу пользователя.
- Создать общий раздел, в котором будет отражен весь ассортимент товаров и все возможные категории. На него можно будет ссылаться со всех элементов пагинации. Для этой страницы указать атрибут pageall. Вставлять атрибут rel=»canonical» в код всех страниц пагинации, начиная с первой, следует на страницу со всеми товарами (pageall).
Выбирая второй вариант, помните, что элемент rel=”canonical” не является обязательным, поэтому поисковая система может проигнорировать его.
Как оптимизировать страницы пагинации
Итак, обратите внимание на решения, которые актуальны в 2021 году:
- Использовать rel=»canonical» для страницы с полным ассортиментом (pageall). Если на сайте предусмотрен раздел с полным перечнем товаров или статей, можно настроить rel=»canonical» со всех страниц пагинации на него. Это наиболее простой способ показать поисковым роботам, что индексировать нужно именно эту страницу. Текстовый материал, оптимизированный под поисковые системы, следует разместить в общем разделе. Дублировать его на страницах пагинации не нужно. При этом важно, чтобы страница с полным перечнем товаров хорошо грузилась, не заставляя пользователей ждать. В противном случае они будут уходить с сайта, что негативно скажется на поведенческих показателях. Получается, если в каталоге очень много товаров, этот вариант оптимизации страниц пагинации вряд ли подойдет. Однако представители Google считают этот метод приоритетным.
- Использовать rel=»canonical” со всех элементов пагинации на стартовую страницу.

Выбирать вариант использования атрибута rel=»canonical” стоит, отталкиваясь от того, подходит ли он конкретно вашему сайту или нет. Если говорить о крупных интернет-магазинах, то, как правило, используется второй вариант.
Мы считаем, что оптимальный метод оптимизации пагинации — открыть все похожие страницы для индекса, а текстовый материал расположить только на главной. Первый раздел при этом нужно сделать доступным только по URL без указания на пагинацию. При этом важно, чтобы метатеги не дублировали друг друга.
При этом важно, чтобы метатеги не дублировали друг друга.
Оптимизации страниц пагинации следует уделять особое внимание. Если полностью закрыть эти элементы сайта от роботов, то важные разделы не будут индексироваться либо окажутся некачественными с точки зрения Яндекса и Google.
Правильная индексация страниц пагинации — Офтоп на vc.ru
Что такое пагинация
{«id»:41221,»url»:»https:\/\/vc.ru\/flood\/41221-pravilnaya-indeksaciya-stranic-paginacii»,»title»:»\u041f\u0440\u0430\u0432\u0438\u043b\u044c\u043d\u0430\u044f \u0438\u043d\u0434\u0435\u043a\u0441\u0430\u0446\u0438\u044f \u0441\u0442\u0440\u0430\u043d\u0438\u0446 \u043f\u0430\u0433\u0438\u043d\u0430\u0446\u0438\u0438″,»services»:{«facebook»:{«url»:»https:\/\/www.

4704 просмотров
Пагинация (pagination, пейджинг, листинг) происходит от слов «page» и «navigation» и в буквальном смысле означает «постраничную навигацию».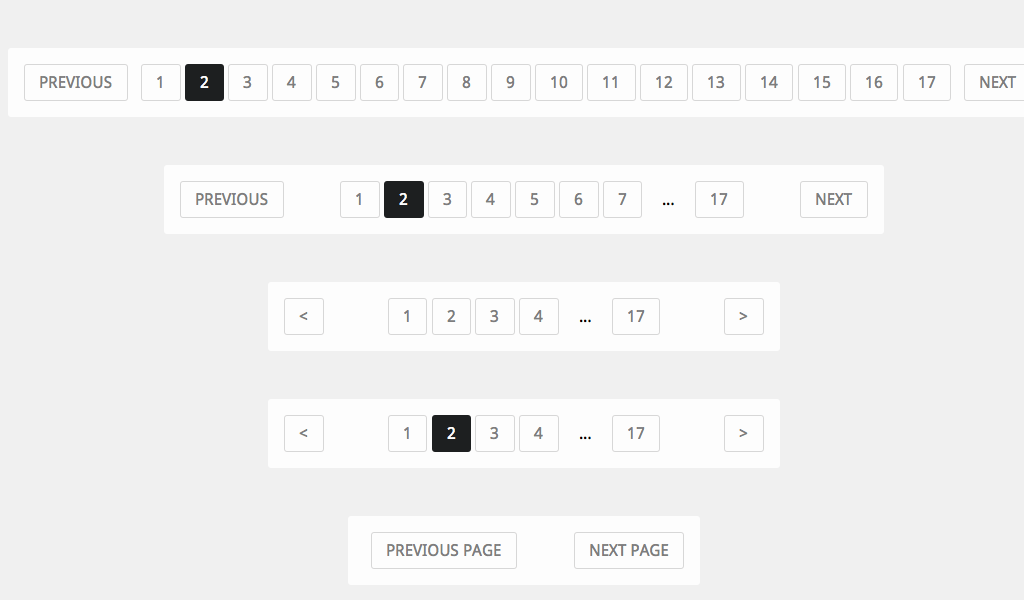 Вывод массива данных (например товаров в категории интернет-магазина) с разбиением на несколько страниц.
Вывод массива данных (например товаров в категории интернет-магазина) с разбиением на несколько страниц.
Если показывать все товары на одной странице, то при большом количестве их загрузка может занять много времени и замедлить работу браузера. Поэтому задача пагинации — представление ассортимента товаров в наиболее удобном для пользователя виде.
Нужно ли закрывать ее от индексации
Однозначно — не нужно. Но для того чтобы пагинация не вредила продвижению сайта, необходимо выполнить определенные настройки.
К сожалению, на момент написания заметки ни в одной CMS данный функционал не реализован полноценно, что заставляет проводить доработки и вносить правки в логику работы. Если этого не сделать, то
Если этого не сделать, то
страницы-пагинации будут дублировать контент, заголовки и мета-теги первой страницы, а поисковые системы, как известно, негативно относятся к дублям на сайте.
{«url»:»https:\/\/booster.osnova.io\/a\/relevant?site=vc»,»place»:»between_entry_blocks»,»site»:»vc»,»settings»:{«modes»:{«externalLink»:{«buttonLabels»:[«\u0423\u0437\u043d\u0430\u0442\u044c»,»\u0427\u0438\u0442\u0430\u0442\u044c»,»\u041d\u0430\u0447\u0430\u0442\u044c»,»\u0417\u0430\u043a\u0430\u0437\u0430\u0442\u044c»,»\u041a\u0443\u043f\u0438\u0442\u044c»,»\u041f\u043e\u043b\u0443\u0447\u0438\u0442\u044c»,»\u0421\u043a\u0430\u0447\u0430\u0442\u044c»,»\u041f\u0435\u0440\u0435\u0439\u0442\u0438″]}},»deviceList»:{«desktop»:»\u0414\u0435\u0441\u043a\u0442\u043e\u043f»,»smartphone»:»\u0421\u043c\u0430\u0440\u0442\u0444\u043e\u043d\u044b»,»tablet»:»\u041f\u043b\u0430\u043d\u0448\u0435\u0442\u044b»}},»isModerator»:false}
Отношение к пагинации у Яндекса и Google
В своем блоге Яндекс советует использовать атрибут rel=»canonical» тега <link>, в котором в качестве канонического адреса необходимо указывать первую страницу. В поиске будет участвовать только она одна, но остальные страницы будут посещаться поисковым роботом, с которых он перейдет на страницы товаров.
В поиске будет участвовать только она одна, но остальные страницы будут посещаться поисковым роботом, с которых он перейдет на страницы товаров.
- Ничего не делать и положиться на алгоритм Google — он сам выберет страницу с наиболее релевантным содержимым.
- В атрибуте rel=»canonical» в качестве канонической указать страницу «Показать все», на которой выводились бы все товары категории.
- Указать логическую связь между страницами пагинации с помощью атрибутов rel=»next» и rel=»prev» для тега <link>.
Первый вариант отметаем сразу, так как в Яндексе будет полный беспорядок.
Второй вариант имеет право на жизнь, что подтверждается представителем Яндекса в одном из обсуждений «Клуба о поиске Яндекса». Но если на вашем сайте в категории огромное количество товаров, которые будут выведены на одной странице, это может создать сложности для индексации и верного восприятия содержимого страницы. К тому же, таким образом вы даете понять поисковикам, что именно эту страницу необходимо ранжировать, а значит в поиске будет появляться именно она, и при переходе на нее пользователи будут долго ждать полной загрузки. Получается, что пагинация не будет выполнять своей функции. Поэтому такой способ применим только для небольших каталогов.
Третий вариант отлично работает для Google, но, к сожалению, данные атрибуты не воспринимаются Яндексом, и без дополнительных настроек будет неразбериха, как и при первом варианте.
Как правильно реализовать индексацию пагинации
Чтобы найти компромисс между рекомендациями Яндекса и Google, мы в своей работе придерживаемся следующих правил:
- Страницы пагинации открыты для индексации (исключение составляют страницы вида пагинация+сортировка и пагинация+фильтрация, если для фильтрации не предусмотрен корректно реализованный функционал смарт-фильтра).
- Текст с описанием категории выводится только на первой странице. На второй, третьей и так далее страницах он не выводится (не скрывается в display:none, а именно не выводится). Это актуально для интернет-магазинов и неактуально, например, для раздела статей или новостей — в этом случае у разделов не бывает описаний, а в качестве контента выступают превью статей/новостей.
- Первая страница должна быть доступна только по адресу без префикса пагинации. Например, в Bitrix пагинация по умолчанию строится с помощью GET-параметров, которые имеют вид PAGEN_1=N, где N — номер страницы пагинации. Допустим, первая страница категории имеет вид /catalog/category/, вторая — /catalog/category/?PAGEN_1=2, третья — /catalog/category/?PAGEN_1=3 и так далее. В этом случае важно, чтобы первая страница НЕ была доступна по адресу /catalog/category/?PAGEN_1=1 (это можно настроить с помощью 301-редиректов и правильного построения ссылок в навигационной цепочке).
- Мета-теги и заголовок Title не должны дублироваться. Например, если для первой страницы задан оптимизированный title, то для страниц пагинации его можно строить по шаблону «%name% — страница N», где %name% — название категории, а N — номер страницы пагинации.
- Используем атрибуты rel=»next» и rel=»prev» тега <link> — для Google это будет плюсом, для Яндекса вреда не принесет.


Можно заметить, что мы не во всем следуем официальным рекомендациям поисковиков, и вот почему:
- Указание в качестве канонической страницы вида «Показать все» для больших каталогов неприемлемо, как описывалось выше.
- Указание в качестве канонической первой страницы категории создаст трудности для Google — это не вписывается ни в одну рекомендацию и может создать проблемы при индексации и верном восприятии сайта.
- Задание уникальных мета-тегов и заголовков в совокупности с различными выводимыми товарами делает страницы пагинации уже не дубликатами — на каждой из них свой контент. По этой же причине связывать их через rel=»canonical» становится нелогично.
- Благодаря оптимизированным мета-тегам, заголовкам и описанию, в поиске приоритет всегда будет отдаваться первой странице категории. Однако если возникнет ситуация, что в выдаче Яндекса ее место займет какая-либо страница пагинации, это можно расценивать как сигнал о переоптимизации страницы, что упрощает обнаружение данного фильтра.
 Однако если возникнет ситуация, что в выдаче Яндекса ее место займет какая-либо страница пагинации, это можно расценивать как сигнал о переоптимизации страницы, что упрощает обнаружение данного фильтра.
Однако если возникнет ситуация, что в выдаче Яндекса ее место займет какая-либо страница пагинации, это можно расценивать как сигнал о переоптимизации страницы, что упрощает обнаружение данного фильтра.Такой подход позволяет избежать всех проблем, связанных с индексацией страниц пагинации.
Ждите новые заметки в блоге или ищите на нашем сайте.
Правильная SEO оптимизация страниц пагинации
Всем привет! Есть в SEO, как кажутся, элементарные и очевидные вещи, но если немного разобраться в них, возникает много вопросов и нюансов, которые беспокоят владельцев проектов. Сегодня я хочу поговорить про страницы пагинации (или еще их называют страницами листинга). Хочется написать развернутый урок: что, зачем и почему, чтобы все разъяснить, как удалось это сделать с уроком про переход на https.
Хочется написать развернутый урок: что, зачем и почему, чтобы все разъяснить, как удалось это сделать с уроком про переход на https.
Я уже рассказывал на своем блоге, как сделать пагинацию в WordPress (там же и рассказывал, что такое постраничная навигация). Теперь пришло время показать, что нужно с ними делать с точки зрения SEO. Многих беспокоят следующие вопросы:
- стоит ли их закрывать индексацию пагинации в robots.txt;
- может стоит закрыть их с помощью meta name=”robots”;
- или лучше использовать rel=canonical;
- а может вообще их оставить открытыми для индексации;
- ну и другие вопросы.
Итак, поехали!
Оглавление:
- Страницы пагинации
- Индексация пагинации
- Дублирование в пагинации
- Как оформить страницы пагинации
- Вывод – как же в итоге поступить правильно?
Страницы пагинации
Страницы пагинации – это страницы, которые создаются, когда список постов или товаров разбиваются на несколько страниц. Вот пример постраничной навигации на моем блоге, эти ссылки ведут на страницы пагинации:
Вот пример постраничной навигации на моем блоге, эти ссылки ведут на страницы пагинации:
Как вы уже поняли постраничная навигация может быть на страницах, где размещено большое количество:
- карточек товаров;
- информационных постов;
- обсуждения на форумах.
Индексация пагинации
Лучше страницы пагинации не запрещать от индексирования, чтобы роботы доходили до как можно большего количества товаров/постов (особенно важно, когда у вас очень много товаров). Но опять же, несмотря на то, что страницы открыты для индексирования, я бы рекомендовал сделать так, чтобы они не участвовали в основном поиске. Я противник низкокачественных страниц в индексе и считаю, что в поиске должны быть только нужные страницы, и важность подобных страниц будет выше, нежели будет полно низкосортного контента. Как же тогда быть?
Вся сложность заключается в том, что у двух наиболее крупных поисковиков на нашем рынке (Яндекс и Google) разные требования. Давайте разберем их.
Давайте разберем их.
Требования Яндекса
Яндекс рекомендует ставить rel=canonical со второй, третьей и последующих страниц на первую (взял отсюда https://yandex.ru/blog/platon/2878):
Причем в данном случае проблем с индексацией товаров или постов не будет, так как rel=canonical не запрещает ходить роботам по страницам, но в индексе будет только основная страница в обоих поисковиках.
Требования Google
Гугл же рекомендует использовать теги rel=”prev” и rel=”next”, чтобы указать логическую последовательность между URL (вот тут https://support.google.com/webmasters/answer/1663744?hl=ru&ref_topic=4617741):
И в тоже время, Google рекомендует rel=canonical ставить саму на себя (в той же справке по ссылке выше):
То есть Гугл не рекомендует, как это делает Яндекс, ставить каноникал на первую страницу, также он говорит, что это неправильно. Но по опыту замечено, что, если ставить rel=canonical на первую страницу, ничего критичного не происходит, сайты хорошо чувствуют себя в обоих поисковых системах.
И да, есть такой момент: Яндексу все равно на теги rel=prev и rel=next, он не понимает их и просто игнорирует.
А что же говорят SEOшники?
Мнений на эту тему очень много, приведу парочку.
Кто-то говорит, что каждую страницу пагинации нужно подтачивать под разные запросы. К примеру, первую страницу под “Купить ноутбук”, вторую под “Купить ноутбук недорого”, третью под “Купить ноутбук в интернет-магазине” и так далее. Не делайте так. Поисковики не настолько тупые, может быть это еще и работало лет 5-8 назад, но сейчас однозначно так не стоит делать.
А кто-то говорит запретить в robots.txt или использовать тег meta name=”robots” content=”noindex,follow”. Я раньше тоже так делал, но это не совсем правильно, так как поведенческие факторы со страниц пагинации не будут передаваться. Да и Яндекс также говорит:
Я не продвигаю страницы категорий на блоге (а зря, я рассказывал про пользу правильной SEO-оптимизацию категорий), все руки не доходят, как-нибудь доберусь обязательно, уберу “noindex, follow”. Тем, кто продвигает категории, рекомендую использовать инструкцию выше.
Тем, кто продвигает категории, рекомендую использовать инструкцию выше.
Дублирование в пагинации
Кстати, если Яндекс считает, что страницы пагинации – это дубли, то Google так не считает, ему главное указать rel=prev и rel=next. Если вы используете тег rel=canonical на основную страницу, то в индексе будет только она. Если же использовать только rel=prev и rel=next, страницы пагинации будут попадать в индекс поисковых систем.
Теги prev и next показывают роботу, что страницы связаны в логической последовательности, как бы это одна большая страница. Именно поэтому одновременно использовать rel prev/next и rel canonical на основную страницу – неправильно. То есть, если вы хотите указать и каноникал, и prev/next, тогда каноникал указываем только на саму страницу (саму на себя).
Как оформить страницы пагинации
Текст описания рубрики/категории нужно выводить только на первой странице, на остальных страницах пагинации не выводим. Это чтобы не было сильного дублирования, да и текста в первую очередь все равно выводятся для роботов. И пользователи, уже перешедшие на вторую и др. страницы, уже не заинтересованы в текстах + улучшение юзабилити.
И пользователи, уже перешедшие на вторую и др. страницы, уже не заинтересованы в текстах + улучшение юзабилити.
Также рекомендую, чтобы Title страниц пагинации генерировался. У меня плагин Yoast SEO просто дописывает “Страница Х из Y” и настраивается, если что это тут:
Если у вас интернет-магазин, можно добавить ссылку на страницу “Все товары” данной категории. Это позволит просмотреть страницу сразу, без переходов на другие страницы. В этом случае rel=canonical поисковики рекомендуют ставить rel=canonical на эту страницу со всеми товарами без пагинации. Но здесь нужно быть аккуратным, потому что если выводить много товаров/постов, то страница подгружается дольше, а поисковики любят как можно более быстрые сайты.
И еще, если мы находимся на второй или любой другой странице, ссылка на первую страницу должна идти сразу на основную, а не на /page/1, вот пример:
Повторюсь, закрывать от индексации страницы пагинации не нужно. Опять же скриншот комментария “Платона” и ссылку на него уже приводил выше.
Кто-то делает бесконечный скроллинг (товары/посты подгружаются по мере пролистывания страницы вниз). Если вы делаете это, снова нужно быть аккуратным. Либо кто-то выводит кнопки “Показать еще”:
Бесконечный скроллинг и прочие javascript/ajax использовать можно, но чтобы не было проблем, я бы рекомендовал сделать так, чтобы все элементы индексировались и отдавались роботу. И все же, я бы продублировал бесконечный скроллинг цифрами 1,2,3,4, так как некоторым пользователям так удобнее. Вот пример:
Также, когда страниц очень много, можно сделать разбивку по 10 страниц для того, чтобы индексирующему роботу “бегать” по страницам было легче, да и страницы будут располагаться в меньшем количестве кликов. То есть выводим примерно так:
1, 2, 3 … 10, 20, 30, 40, 50, 60, 70…79.
И, конечно, выводить всю пагинацию (ссылки на все страницы) не нужно – это слишком много ненужных внутренних ссылок, да и с эстетической точки зрения смотрится не очень.
Вывод – как же в итоге поступить правильно?
На мой взгляд есть 3 варианта наиболее правильных развития событий:
- Если вам важен Яндекс или интересны оба поисковика (практически для всех проектов под Россию), то делаем каноникал на первую страницу.
- Если интересует только Гугл (например, ваш сайт находится в странах СНГ, где в некоторых из них трафика в Яндексе практически нет, или зарубежные проекты), то делаем rel canonical саму на себя и прописываем prev/next.
- Если у вас есть страница, где выводятся все товары, можно указать рел каноникал на нее, использовать rel=prev и rel=next. Тогда будет правильно для обоих поисковых систем. Но в таком случае, напомню, минусы тоже есть: если у вас имеются категории, где выводятся больше количество товаров, то это замедлит скорость загрузки сайта, а это влияет на ранжирование.
Во всех случаях запрета на индексирование не требуется (ни в robots.txt, ни в meta name=”robots”). Не забываем, что текст размещаем только на 1-ой странице, чтобы не было дублей с большим количеством совпадений. Вы можете проследить за изменения страниц в индексе в панели вебмастеров Яндекса и Google.
Если делать подобные шаги для оптимизации сайта, результат не заставит себя ждать. Вот свежий пример из последних наших работ (это суммарный трафик с поисковых систем, начали работать в октябре 2017-го года, кликните, чтобы увеличить):
Вот свежий пример из последних наших работ (это суммарный трафик с поисковых систем, начали работать в октябре 2017-го года, кликните, чтобы увеличить):
Ребята, кто успел попасть на предзапись моего SEO-марафона, я почти всем ответил на вопросы, осталось еще чуть-чуть, вопросов пришло очень много, разгребаю. 🙂 Если вдруг вы не успели записаться на предзапись марафона, ждите новостей на блоге (подпишитесь на рассылку по почте, чтобы не пропустить старт продаж), в феврале стартуем!
Ну и вопрос: а что вы делаете со страницами пагинации на своих проектах?
Yoast SEO. Как закрыть страницы пагинации и добавить ключевые слова
27 октября 2020 в 12:40 SEOплагине Yoast с версии 6.3 теперь нет вкладки Другое, а значит нет возможности закрыть страницы пагинации и нет возможности добавлять ключевые слова. У многих с этим возникли проблемы, хотя не понимаю зачем вообще такой функционал нужен. Поисковики и без него прекрасно все индексируют и никаких дублей нет. По крайней мере, по моим наблюдениям…
По крайней мере, по моим наблюдениям…
Весь код необходимо добавлять в файл functions.php через дочернюю тему или например пустой плагин. Прежде чем, вносить какие либо изменения, сделайте бекап сайта.
Как закрыть от индексации страницы пагинации?
Тут все просто, проверяем что это страница пагинации и подсовываем ей метатег robots
/* * Закрытие страниц пагинации от индексирования */ add_action( ‘wp_head’, ‘art_noindex_paged’, 2 ); function art_noindex_paged() {
if ( is_paged() ) { echo ‘<meta name=»robots» content=»noindex,nofollow»>’;
} } |
Вот и все. До кучи, можно еще выключить канонические ссылки и теги rel=”prev” и rel=”next”, чтобы поисковые системы не вводить в заблуждение.
/** * Закрытие страниц пагинации от индексирования */ add_action( ‘wpseo_head’, ‘art_noindex_paged’, 0 ); function art_noindex_paged() {
if ( is_paged() ) { add_filter( ‘wpseo_canonical’, ‘__return_false’ ); // отключаем канонические ссылки add_filter( ‘wpseo_disable_adjacent_rel_links’, ‘__return_true’ );// отключаем теги prev|next echo ‘<meta name=»robots» content=»noindex,nofollow»>’;
} } |
Надо ли закрывать от индексации страницы пагинации?
Вопрос на миллион! Точно никто не говорит, сколько людей столько и мнений. Но есть докуметация поисковиков.
Но есть докуметация поисковиков.
Гугл
Гугл — молоток, все прекрасно понимает. Умеет определять теги rel="prev" и rel="next", что как раз и позволяет не закрывать от индексации страницы пагинации.
В статье про обновление Yoast 6.3 есть ссылки на источники почитайте, многое станет понятнее
Яндекс
Тук как обычно, точно ничего не говорят. Вроде и rel="canonical" понимают, но только как рекомендации. Погуглил немного. Есть два подхода
- Закрывать страницы пагинации — однозначно и обязательно
- Закрывать не надо. Но требуется:
- чтобы в теге
rel="canonical"сслыки вели на главную - делать разные заголовки и описание в
titleиdescriptionдля каждой страницы пагинации
- чтобы в теге
Разные заголовки и описание можно добавить через настройки Yoast используя специальные переменные. Идем SEO → Заголовки и метаданные → Таксономии и добавляем нужные переменные. Должно быть так
Должно быть так
Тогда в исходном коде будет так, при условии что у вас заполнено описание для рубрик
Результат уникализации заголовков и описаний страниц пагинацииЧто из этого получается и что верно, не знаю. Но судя по наблюдениям Гугл спокойно хавает страницы пагинации и никаких дублей нет, как будет вести себя Яндек не понятно, но вроде тоже пока дублей нет.
How to add “noindex, nofollow” on paginated content yoast
Закрывать или нет страницы пагинации на статейных сайтах?
Часто на информационных сайтах на страницах категорий можно встретить метатег «robots noindex, follow». То есть эти страницы закрывают от индексации. Но действительно ли это стоит делать, или лучше страницы рубрик/категорий держать открытыми для индексации? Давайте разберемся.
Рубрики и теговые страница на сайтах статейниках
Скажем сразу, метатег «noindex, follow» закрывает от индексации страницу, но разрешает учет ссылок, которые с нее ведут. То есть дает рекомендацию поисковой системе учитывать эти ссылки.
На информационных сайтах рубрики, как правило, не продвигаются. И не потому, что это технически невозможно, а просто там нет такой семантики, которая лучше бы продвигалась именно на них. Как правило, больше 90% семантики раскидывается по конкретным статьям, и продвигать отдельно рубрики особого смысла нет.
То же самое можно сказать и о страницах пагинации: они не собирают на себя трафик, поэтому нет смысла акцентироваться на них. Но что с ними делать?
Закрывать или не закрывать?
Страницы рубрик и пагинации ни на информационных сайтах, ни на коммерческих закрывать от индексации через robots, или через robots.txt, или через тег robots не рекомендуется. Лучше либо повесить на них «canonical», который будет вести на первую страницу, либо вообще ничем не закрывать, а уникализировать эти странички. То есть написать для них условно уникальные titles, descriptions — просто добавить в дополнение к тому, какой у первой, слова «страница 1, страница 2, страница 3, страница 4» и т.д..
Лучше либо повесить на них «canonical», который будет вести на первую страницу, либо вообще ничем не закрывать, а уникализировать эти странички. То есть написать для них условно уникальные titles, descriptions — просто добавить в дополнение к тому, какой у первой, слова «страница 1, страница 2, страница 3, страница 4» и т.д..
И так как там набор статей будет другой, то велика вероятность, что эта страничка ни к чему не подклеится и будет нормально оставаться в индексе. Правда и трафик на себя собирать не будет, поэтому пользы особой вы от этого не получите. Единственное, для того, чтобы ссылки учитывались, лучше, чтобы страница не была никак закрыта. То есть она должна быть открыта и для индексации тоже, а не только так, когда мы говорим «ты ее не индексируй, а ссылки с нее учти». Поэтому, если нам нужно, чтобы ссылки со страницы нормально учитывались, нужно делать эту страницу такой, чтобы она нормально индексировалась.
Читайте про Страницы пагинации в нашем словаре SEO терминов
Страницами пагинации называют определенные страницы каталога, где присутствует список статей или товаров, которые не поместились на самых первых страницах раздела и категории. Как правило, это вторая, третья и остальные страницы, кроме первой. Почти всегда располагается в нижней области интернет-ресурса, хотя можно размещать и сверху.
Как правило, это вторая, третья и остальные страницы, кроме первой. Почти всегда располагается в нижней области интернет-ресурса, хотя можно размещать и сверху.
Правила настройки пагинации
На многих страницах пагинации происходит частичное дублирование текстового контента. Это же относится и к мета-тегам. Но такое решение не только существенно ухудшает показатели внутренней оптимизации, но и негативно влияет на релевантность главных посадочных интернет-страниц в отношении пользовательских запросов через поисковики. Конечно же, подобные площадки будут намного хуже ранжироваться в выдаче поиска.
При этом существует и другая серьезная проблема, которую не всегда учитывают. Поисковые роботы посещают ресурс, а затем анализируют его. Но количество и глубина просматриваемых страниц могут иметь ограничения, зависящие не только от частоты обновления материалов, но и траста. При этом наличие частичных дублей снижает вероятность индексирования необходимых страниц, так как бот впустую тратит драгоценные переходы.
Но сейчас грамотно оптимизировать подобные страницы можно разными способами. При этом каждый подход имеет положительные и отрицательные стороны, а также определенную сложность внедрения.
Неактуальные методы оптимизации страниц пагинации
Скрытие страниц пагинации при помощи robots.txt
Нет необходимости редактировать код интернет-ресурса, что делает данный способ быстровыполнимым. Благодаря маске директивы в robots.txt есть возможность быстро закрыть нумерованные страницы. Но конкретная директива напрямую связана с вариантом реализации подобных страниц площадки.
Данный метод действительно позволяет избавиться от дублирующихся страниц нумерации, которые относятся к индексу поисковиков. Вот только придется достаточно долго ждать, когда из индекса все-таки исчезнут страницы, попавшие туда ранее. Робот (поисковая система) увидит директиву с запретом в данном файле, а потом просто проигнорирует такую страницу. Могут возникнуть неприятности с индексированием товарных страниц пагинации, располагающихся в файле robots.txt.
Могут возникнуть неприятности с индексированием товарных страниц пагинации, располагающихся в файле robots.txt.
Использование <meta name=»robots» content=»noindex, follow»>
Как и в предыдущем методе страницы пагинации будут запрещены для индексации. Но есть отличия:
-
Робот сможет беспрепятственно переходить по страницам пагинации и индексировать все ссылки на них, что решает проблему индексации карточек товаров.
-
Попавшие в индекс страницы пагинации при переобходе будут удалены из индекса.
Но у этого метода тоже есть свои минусы:
-
Теряются ссылочные свойства
-
Не подходит для больших статей, разбитых на страницы, т.к. часть важного контента закрыта от поисковых роботов.
Пагинация с тегом rel = «canonical» на начальную страницу
Чуть ли не самое распространенное решение для борьбы с дублирующимися страницами пагинации в поисковом индексе. Причем такой метод действительно является эффективным. Но он существенно затрудняет индексирование товаров, которые находятся на страницах пагинации.
Причем такой метод действительно является эффективным. Но он существенно затрудняет индексирование товаров, которые находятся на страницах пагинации.
В органическом поиске этот метод плохо влияет на ранжирование. Причины такие же, как в предыдущем методе.
А с недавних пор Гугл причислил настройку ссылок канонического типа, располагающихся на самой начальной странице категории, к наиболее частым ошибкам. В Google заявляют, что каноникал используется для дублированного контента, в то время как страницы пагинации дублями не являются.
При этом в Яндексе этот способ является рекомендованным.
Теги Prev/Next
Ранее использование этих указаний было идеальным способом для Google. Но в 2019 году поисковик заявил об отказе от их использования. Яндекс не учитывал их и ранее.
Прогрессивные способы оптимизации страниц пагинации
Создание цельной страницы без пагинации
Как говорится нет пагинации – нет проблем. Для обоих поисковиков это будет лучшим способом, имеющим ряд преимуществ:
Для обоих поисковиков это будет лучшим способом, имеющим ряд преимуществ:
-
Пользователя удобнее смотреть весь контент сразу, чем переключаться между страницами.
-
Сохраняются все свойства и не возникает проблем с индексацией.
-
Улучшение ранжирования. Поисковики любят, когда страница решает максимальное количество проблем пользователей, за что могут поднять ее в выдаче.
Но, как и везде, существует несколько минусов:
-
Скорость загрузки для большого количества контента может значительно упасть, что ухудшит поведенческие факторы (увеличит количество отказов), и таким образом негативно скажется на ранжировании.
-
Чтобы решить проблему скорости загрузки необходимо настроить отображение страницы по частям с динамической подгрузкой контента по мере скролинга.
При этом поисковым роботам при сканировании контент должен быть доступен целиком. для реализации понадобится помощь квалифицированного программиста.
 При этом поисковым роботам при сканировании контент должен быть доступен целиком. для реализации понадобится помощь квалифицированного программиста.
При этом поисковым роботам при сканировании контент должен быть доступен целиком. для реализации понадобится помощь квалифицированного программиста.
Оставить все как есть
Как ни странно, но это вполне работает, и даже рекомендуется Гуглом, как нормальное решение проблемы. Поисковый гигант мотивирует это верой в свои алгоритмы, которые по их словам могут сами разобраться в данной ситуации.
Но есть одно НО. Часто некоторые страницы признаются дублями и вылетают из индекса.
Поэтому чтобы способ стал не просто нормальным, а хорошим необходимо внести некоторые доработки. Для любого типа сайта нужно уникализировать мета-теги. Проще всего это сделать добавив в title и description страниц пагинации номера страниц (например, «стр.- 4»).
Вторым важным моментом являются дубли контента на странице. Это актуально для интернет-магазинов, в которых текст повторяется на каждой странице. Необходимо оставить его только на той странице, которую вы хотите видеть в индексе (обычно первая).
Необходимо оставить его только на той странице, которую вы хотите видеть в индексе (обычно первая).
Что выбрать?
При выборе способа лучше отталкиваться от вашей конкретной ситуации и приоритетной поисковой системы. Прогрессивные методы подойдут для обоих поисковиков, но сложны в реализации при отсутствии навыков, поэтому потребуют привлечения хорошей компании по продвижению сайтов.Как избавиться от дублей страниц в Bitrix
Наличие дублирующих страниц – частая проблема, с которой приходится сталкиваться оптимизаторам. Наличие таких страниц на сайте ведёт к «замусориванию» индекса, трате краулингового бюджета на ненужные страницы, появлению на выдаче дублей вместо продвигаемых страниц. Всё это в конечном итоге ведёт к ухудшению ранжирования сайта.
Среди разных CMS в моём личном рейтинге 1С-Битрикс не занимает первого места по количеству типичных проблем с дублями. Например, от Joomla можно ожидать куда большего числа проблем с разными типами дублей. Но и 1С-Битрикс не лишена своих особенностей. Наиболее часто сложности возникают с фильтром, товарами и страницами пагинации.
Но и 1С-Битрикс не лишена своих особенностей. Наиболее часто сложности возникают с фильтром, товарами и страницами пагинации.
Но сперва расскажу про те случаи возникновения дублей, которые характерны для всех типов сайтов и CMS.
Чтобы проверить их наличие, следует проверить доступность главной страницы по следующим адресам:
https://www.oridis.ru/index.php
https://www.oridis.ru/home.php
https://www.oridis.ru/index.html
https://www.oridis.ru/home.html
https://www.oridis.ru/index.htm
https://www.oridis.ru/home.htm
(наиболее распространённые варианты)
Корректным ответом сервера при открытии подобных страниц будет 404 или 301.
Если же страница возвращает 200 ОК, это говорит нам о наличии дубля.
Быстро и удобно проверить главную страницу на наличие дублей можно при помощи данного сервиса:
https://apollon.guru/duplicates/
Перед началом продвижения обязательно следует определиться с тем, какой адрес сайта считать главным зеркалом – с www или без него.
Оба варианта имеют свои плюсы и минусы. Вариант без www короче. При длинном доменном имени добавление ещё четырёх символов не всегда выглядит красиво. А к плюсам варианта с www можно отнести, что при написании адреса сайта с www в некоторых редакторах адрес автоматически становится гиперссылкой.
Форма отправки письма Outlook
На нашем сайте основным зеркалом выбрана версия www.oridis.ru
Теперь для проверки корректности настройки следует проверить, что страницы без префикса www перенаправляют на страницы с www в адресе.
Пример:
https://oridis.ru/seo/
В данном случае страница перенаправляет на www-версию. Проблем нет.
Код ответа страницы можно проверить при помощи инспектора браузера либо при помощи онлайн-сервиса, например:
https://bertal.ru/index.php?a7054246/https://oridis.ru/seo/#h
О том, как правильно настроить редирект, можно узнать в материале https://www.oridis.ru/articles/301-redirect.html
Прекрасный способ отыскать дубли и другие «мусорные» страницы – это посмотреть проиндексированные страницы в поисковых системах:
https://yandex. ru/search/?text=host%3Awww.oridis.ru&lr=213&clid=2186620
ru/search/?text=host%3Awww.oridis.ru&lr=213&clid=2186620
Часто там можно обнаружить совершенно удивительные страницы, о которых даже сложно было предположить.
В индекс попадают и страницы с метками (например, UTM). Чтобы исключить такие страницы можно использовать директиву Clean-param:
https://yandex.ru/support/webmaster/robot-workings/clean-param.html
Именно таким способом пользуется OZON.RU:
https://www.ozon.ru/robots.txt
Другой альтернативный метод борьбы с дублями GET-параметров – это закрывать их в robots.txt через директиву Disallow. Google не воспринимает директиву Clean-param, зато директиву Disallow прекрасно понимает как Google, так и Яндекс.
Крупный интернет-магазин Эльдорадо (работающий, кстати, на Битрикс), использует Disallow для закрытия ненужных GET-параметров:
https://www.eldorado.ru/robots.txt
Если вы хотите закрыть от индексации все страницы с GET-параметрами, то достаточно прописать строчку:
Disallow: /*?
Далее перейдём к более специфичным особенностям 1С-Битрикс.
В Битрикс подобные страницы, как правильно имеют вид:
https://site.ru/catalog/inventar/?PAGEN_1=7
Что же с ними делать? Как избавиться от подобных страниц в индексе? И нужно ли это делать в принципе?
Читаем рекомендации поисковых систем.
Яндекс:
Если в какой-либо категории на вашем сайте находится большое количество товаров, могут появиться страницы пагинации (порядковой нумерации страниц), на которых собраны все товары данной категории. Если на такие страницы нет трафика из поисковых систем и их контент во многом идентичен, то советую настраивать атрибут rel=»canonical» тега <link> на подобных страницах и делать страницы второй, третьей и дальнейшей нумерации неканоническими, а в качестве канонического (главного) адреса указывать первую страницу каталога, только она будет участвовать в результатах поиска.
https://yandex.ru/blog/platon/2878
Т.е. Яндекс рекомендует ставить нам canonical на пагинаторные страницы, ведущие на основную категорию.
Сами рекомендации датированы 2015-м годом. Обращался в техподдержку Яндекса, чтобы узнать не потеряли ли актуальность данные рекомендации. Техподдержка актуальность рекомендаций подтвердила.
Google ранее советовал настраивать link rel next/prev для пагинаторных страниц. Но на данный момент от данной рекомендации он отказался:
Spring cleaning!
— Google Search Central (@googlesearchc) March 21, 2019
As we evaluated our indexing signals, we decided to retire rel=prev/next.
Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search. Know and do what's best for *your* users! #springiscoming pic.twitter.com/hCODPoKgKp
Google также сообщает, что использование canonical на пагинаторных страницах со ссылкой на основную категорию (первую страницу) является ошибкой:
https://webmasters.googleblog.com/2013/04/5-common-mistakes-with-relcanonical.html
Таким образом получается, что рекомендации Яндекс и Google противоречат друг другу.
Что делать в этой ситуации – каждый должен решить для себя.
Например, я обычно проставляю canonical на основную категорию, следуя рекомендациям Яндекса. Причина такого решения заключается в том, что продвижение мы в основном ведём под Рунет, где доля Яндекса пока ещё больше Google. Если же вы продвигаетесь в иностранном сегменте интернета, где царствует Google, старайтесь ориентироваться на актуальные рекомендации этой поисковой системы.
Если же вы продвигаетесь в иностранном сегменте интернета, где царствует Google, старайтесь ориентироваться на актуальные рекомендации этой поисковой системы.
При работе с интернет-магазином на 1С-Битрикс можно часто столкнуться со страницами с /filter/clear/apply/ в адресе.
Один из вариантов решения – прописать каноникал на основную категорию.
Т.е. страница:
https://site.ru/catalog/aksessuary/podsumki-i-patrontashi/filter/clear/apply/
должна содержать canonical, ведущий на:
https://site.ru/catalog/aksessuary/podsumki-i-patrontashi/
Решение можно считать правильным (по крайней мере, с точки зрения Яндекса). Однако такой подход требует определённых трудозатрат программиста на написание нужного функционала.
К тому же каноникал не является панацеей и строгой рекомендацией для поисковых систем (в отличии, например, от файла robots.txt). Канонические страницы вполне могут попадать в индекс, если поисковая система сочтёт это нужным:
https://webmaster. yandex.ru/blog/nekanonicheskie-stranitsy-v-poiske
Наименее трудозатратный и наиболее простой способ быстро решить данную проблему – это прописать соответствующие директивы в файле robots.txt.
Например, можно полностью закрыть все страницы с «filter»:
Disallow: /*filter
Часто встречаю подобный вариант написания директив:
Disallow: /*filter*
Однако, нет никакой необходимости ставить звёздочку на конце строчки. Дело в том, что по умолчанию в конце записи, если не указан спецсимвол «$», всегда подразумевается звёздочка.
Из коробки 1C-Битрикс не содержит файла robots.txt. Чтобы его создать необходимо перейти в административную панель и выбрать:
Маркетинг > Поисковая оптимизация > Настройка robots.txt
Далее можно выбрать «Стартовый набор» и нажать кнопку «Сохранить».
В результате создастся файл robots.txt. Его содержимое может иметь следующий вид:
User-Agent: *
Disallow: */index.php
Disallow: /bitrix/
Disallow: /*show_include_exec_time=
Disallow: /*show_page_exec_time=
Disallow: /*show_sql_stat=
Disallow: /*bitrix_include_areas=
Disallow: /*clear_cache=
Disallow: /*clear_cache_session=
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*ORDER_BY
Disallow: /*PAGEN
Disallow: /*?print=
Disallow: /*&print=
Disallow: /*print_course=
Disallow: /*?action=
Disallow: /*&action=
Disallow: /*register=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*login=
Disallow: /*logout=
Disallow: /*auth=
Disallow: /*backurl=
Disallow: /*back_url=
Disallow: /*BACKURL=
Disallow: /*BACK_URL=
Disallow: /*back_url_admin=
Disallow: /*?utm_source=
Disallow: /*?bxajaxid=
Disallow: /*&bxajaxid=
Disallow: /*?view_result=
Disallow: /*&view_result=
Allow: /bitrix/components/
Allow: /bitrix/cache/
Allow: /bitrix/js/
Allow: /bitrix/templates/
Allow: /bitrix/panel/
Host: www. 1097lab.bitrixlabs.ru
1097lab.bitrixlabs.ru
Закрыты от индексации основные технические разделы и страницы. Отрыты – пути к CSS и JS-файлам. Если этого не сделать, поисковые системы могут воспринимать сайт некорректно. Например, сервис Google Mobile-Friendly Tools не сможет увидеть корректный дизайн и сайт может не пройти проверку на мобильность.
Также стоит отметить, что строчка Host лишняя и её можно смело удалять (особенно, если у вас настроены редиректы). Яндекс отменил данную директиву, но Битрикс продолжает по-прежнему генерировать файл robots.txt вместе с ней.
Распространённая трудность не только с сайтами на Битрикс, но и с любыми другими интернет-магазинами.
Поэтому расскажу, как решить этот вопрос в общем случае. Существует как минимум два подхода для устранения таких дублей.
Сперва приведу примеры. Итак, у нас есть один и тот же товар, который относится к нескольким категориям:
http://site.ru/catalog/phones/honor-10/
http://site.ru/catalog/electronics/honor-10/
Решение №1
Отказаться от вложенных адресов и формировать адреса товаров независимо от категории:
http://site. ru/detail/honor-10/
http://site.ru/detail/xiaomi-mi-9/
Решение №2
Пользоваться canonical. Для этого один из адресов товара выбираем каноническим и проставляем link rel=»canonical» на страницах с повторяющимися предложениями.
Здесь на помощь приходят различные программы-краулеры. Мой личный фаворит — Netpeak Spider. Другой способ, о котором я уже писал выше – изучение индекса поисковых системах.
И конечно же вы всегда можете обратиться к нам. Поможем устранить дубли, исправить технические ошибки и сделаем ваш сайт удобным и привлекательным для пользователей.
Ямщиков Сергей, интернет-маркетолог
Вот как это исправить
Цель rel = prev / next — указать страницы в серии, разбитые на страницы. Изначально Google использовал разметку для обмена сигналами с группой страниц, разбитых на страницы, при этом все еще меняя местами, чтобы отображать наиболее релевантную страницу в результатах поиска. Типичные варианты использования включают разделение контента на несколько частей и создание нескольких страниц для списков продуктов, обсуждений на форумах и списков блогов.
Давайте посмотрим, как может выглядеть реальный код для трехстраничной серии.
Первая страница:
Это первая страница, поэтому на ней нужно ссылаться только на следующую страницу.
Генеральная уборка!По мере того, как мы оценивали наши сигналы индексации, мы решили исключить rel = prev / next.
Исследования показывают, что пользователям нравится одностраничный контент, стремитесь к этому, когда это возможно, но и многостраничный контент также подходит для поиска Google. Знайте и делайте то, что лучше всего для * ваших * пользователей! #springiscoming pic.twitter.com/hCODPoKgKp— Google Webmasters (@googlewmc) 21 марта 2019 г.Это изменение действительно не повлияло на SEO. В случае дублирования контента наличие нескольких одинаковых блоков текста не повредит вашему сайту и не будет наказуемо. Google по-прежнему будет пытаться найти лучшую версию этого контента для показа.
Итак, вопрос в том, почему это изменение? И что с этим делать?
Из этого поста вы узнаете:
Давайте начнем с самого начала.
Почему Google убрал поддержку rel = prev / next?
До того, как Google бросил бомбу, что они больше не используют rel = prev / next, одна из официальных рекомендаций по разбивке на страницы заключалась в том, чтобы ничего не делать и дать им понять это.
Ничего не делать. Контент с разбивкой на страницы очень распространен, и Google хорошо справляется с задачей, возвращая пользователям наиболее релевантные результаты, независимо от того, разделен ли контент на несколько страниц.
Зная это, наиболее вероятная причина, по которой они перестали использовать rel = prev / next, заключается в том, что они просто стали лучше разбираться в этом и почувствовали, что им больше не нужны дополнительные подсказки.
У Google есть несколько опций, помимо rel = prev / next, которые они могут использовать для идентификации страниц в серии.По большей части веб-сайты соответствуют их реализации страниц с разбивкой на страницы, и Google может смотреть на такие вещи, как:


- Заголовки
- Заголовки страниц (тот же заголовок или с добавленным номером страницы)
- Ссылки на странице (внутренние ссылки на другие страницы в наборе)
Также возможно, что рекомендации по разбивке на страницы приводили к неудовлетворительному опыту пользователей, поскольку сайты разделяли свой контент на несколько страниц. В большинстве случаев это делалось для просмотра страниц и доходов от рекламы, но это раздражало пользователей и мешало людям находить то, что они искали.Вот два примера того, что я имею в виду.
В большинстве случаев это делалось для просмотра страниц и доходов от рекламы, но это раздражало пользователей и мешало людям находить то, что они искали.Вот два примера того, что я имею в виду.
Откуда оптимизаторы могли знать, что rel = prev / next не работает?
Когда Google объявил, что не поддерживает rel = prev / next в течение многих лет, один из первых вопросов, который я получил от многих специалистов по поисковой оптимизации, заключался в том, как мы, технические специалисты по поисковой оптимизации, могли этого не знать?
Простой ответ — не было способа сказать. Если бы Google не сказал нам, мы бы не узнали.
Если бы пагинация работала, то Google объединял бы сигналы для набора страниц.Хотя они обычно показывали первую страницу в наборе, они также меняли местами, какая страница была показана, если в результатах поиска была более релевантная страница из набора. Если бы разбивка на страницы не работала, что ж, то же самое произошло бы, потому что так работает поиск — Google возвращает наиболее релевантную страницу для запроса.
Следует ли оптимизаторам поисковых систем удалять rel = prev / next?
№
Если вы уже реализовали rel = prev / next на своем веб-сайте, не удаляйте его. Google был не единственным источником, использовавшим эту информацию.Он по-прежнему рекомендован W3C и используется для веб-доступности и соответствия ADA. Некоторые браузеры также используют его для предварительной выборки. Кроме того, другие поисковые системы, такие как Bing, по-прежнему используют разметку.
Мы используем rel prev / next (как и большинство других разметок) в качестве подсказок для поиска страниц и понимания структуры сайта. На данный момент мы не объединяем страницы в индекс на их основе и не используем предыдущую / следующую в модели ранжирования. https://t.co/ZwbSZkn3Jf— Frédéric Dubut (@CoperniX) 21 марта 2019 г.
Допустимые реализации нумерации страниц
В большинстве конфигураций, использующих rel = prev / next, также используются канонические теги, ссылающиеся на себя. Для этой настройки вообще ничего не меняйте. Обращайтесь со страницами, как с любой другой индексируемой страницей на вашем сайте, и убедитесь, что у вас есть внутренние ссылки на другие страницы в наборе нумерации страниц.
Для этой настройки вообще ничего не меняйте. Обращайтесь со страницами, как с любой другой индексируемой страницей на вашем сайте, и убедитесь, что у вас есть внутренние ссылки на другие страницы в наборе нумерации страниц.
Вы также можете канонизировать страницы с разбивкой на страницы, чтобы они указывали на страницу для просмотра всего, на которой отображается все содержимое. Таким образом, контент по-прежнему может быть разбит на страницы для пользователей, но проиндексированная версия будет содержать весь контент.
Как люди вредят своим сайтам
Вот как выглядит типичная настройка, при которой каждая страница сканируется и обнаруживается:
Но есть несколько распространенных ошибок, которые люди допускают при разбиении на страницы, которые наносят вред их сайту.Это:
- Канонизация на первую страницу
- Страницы без индексации
- Ссылки без отслеживания
- Блокировка сканирования
Давайте подробнее рассмотрим каждую из этих проблем и способы их проверки на вашем сайте.
Ошибка 1. Канонизация до первой страницы
В лучшем случае Google игнорирует канонический тег. Если канонические теги соблюдаются, вы в конечном итоге отключите пути сканирования ко многим страницам и потеряете содержание.Это затрудняет поисковым системам поиск и индексирование ценного контента, а также ограничивает поток PageRank по всему вашему сайту.
Как проверить наличие этой ошибки на вашем веб-сайте
Просканируйте свой сайт с помощью аудита сайта Ahrefs, затем перейдите в проводник страниц и примените этот набор фильтров:
Если есть какие-либо совпадающие URL-адреса, взгляните на канонический URL. Страницы в серии нумерации страниц, которые канонизируются на первую страницу, должны быть изменены.
Ошибка 2: Нет индексации страниц
Добавление noindex к страницам приведет к удалению страниц из индекса.Эти страницы больше не имеют права на ранжирование, и PageRank не будет передаваться.
Хотя ссылки на странице изначально могут сканироваться, это может измениться со временем. Аналитик Google Webmaster Trends Джон Мюллер упомянул, что страницы noindex в какой-то момент будут обрабатываться как nofollow, но неизвестно, сколько времени это займет. Когда об этом спросили другого аналитика тенденций для веб-мастеров Гэри Иллиса, он, похоже, подумал, что они все равно будут сканироваться. Не зная полностью, как это работает, лучше проявить осторожность и не индексировать эти страницы, если у вас нет альтернативного пути сканирования.
Аналитик Google Webmaster Trends Джон Мюллер упомянул, что страницы noindex в какой-то момент будут обрабатываться как nofollow, но неизвестно, сколько времени это займет. Когда об этом спросили другого аналитика тенденций для веб-мастеров Гэри Иллиса, он, похоже, подумал, что они все равно будут сканироваться. Не зная полностью, как это работает, лучше проявить осторожность и не индексировать эти страницы, если у вас нет альтернативного пути сканирования.
Как проверить наличие этой ошибки на вашем веб-сайте
Просканируйте свой сайт с помощью аудита сайта Ahrefs, затем перейдите в проводник страниц и примените этот набор фильтров:
Если есть какие-либо совпадающие URL-адреса, удалите директиву noindex из метатег robots или HTTP-заголовок X ‑ Robots-Tag на странице или URL.
Ошибка 3: Ссылки Nofollow
Внутренние ссылки на другие страницы, разбитые на страницы, никогда не должны быть помечены как nofollow. Nofollow теперь является подсказкой для Google, и в лучшем случае они игнорируют то, что вы отмечаете как nofollow. Что происходит, так это то, что вы можете отключить сканирование и передачу таких сигналов, как PageRank, через свой сайт, и снова можете потерять страницы.
Что происходит, так это то, что вы можете отключить сканирование и передачу таких сигналов, как PageRank, через свой сайт, и снова можете потерять страницы.
Как проверить наличие этой ошибки на своем веб-сайте
Просканируйте свой сайт с помощью аудита сайта Ahrefs, затем перейдите в проводник страниц и примените этот набор фильтров:
Если есть какие-либо совпадающие URL-адреса, нажмите на номер «Нет. столбца inlinks nofollow ».
Появится наложение, показывающее, где на вашем сайте найти эти nofollow-ссылки.
Удалите атрибуты nofollow из этих конкретных ссылок или удалите директиву nofollow из метатега robots или HTTP-заголовка X ‑ Robots-Tag на странице или URL.
Ошибка 4: Блокировка от сканирования
Блокировка страниц от сканирования снова затруднит поиск контента на веб-сайте, приведет к тому, что страницы станут сиротами, а также прервет поток PageRank через ваш сайт.
Как проверить наличие этой ошибки на вашем сайте
Проверьте свой robots. txt для директив, запрещающих поисковым системам сканировать страницы, разбитые на страницы. Вот как это может выглядеть:
txt для директив, запрещающих поисковым системам сканировать страницы, разбитые на страницы. Вот как это может выглядеть:
User-agent: * Запретить: / блог / страница /
Удалите эти директивы из файла robots.txt.
Заключительные мысли
Если вы уже реализовали rel = prev / next для разбивки на страницы, оставьте это в покое. Нет причин менять его, и вы, скорее всего, принесете больше вреда, чем пользы.
Если вы хотите изменить разбиение на страницы, потому что считаете, что эти страницы с разбивкой на страницы имеют низкое качество или не представляют большой ценности, рассмотрите возможность группировки страниц таким образом, чтобы это было полезно для пользователей, а также предоставило альтернативный путь сканирования для поисковых систем.Например, если вы хотите использовать категории для группировки нескольких сообщений в блогах, то это, вероятно, более полезно для пользователей, чем набор страниц с разбивкой на страницы, содержащих сообщения по многим темам. Эти страницы категорий, содержащие сообщения по одной теме, могут отображаться в поисковой выдаче по соответствующим терминам категории.
Эти страницы категорий, содержащие сообщения по одной теме, могут отображаться в поисковой выдаче по соответствующим терминам категории.
Если вы собираетесь использовать категории в качестве пути сканирования и навигации, вам также необходимо убедиться, что ваши категории связаны с вашей домашней страницей. Для этого может потребоваться редизайн веб-сайта, поэтому я не рекомендую это делать, если вы все равно не собираетесь менять дизайн своего сайта.Даже с помощью этого метода вы все равно можете использовать некоторую форму разбивки на страницы для категорий, если у вас много сообщений в каждой из них, поэтому это также усложняет настройку.
Если вы еще не реализовали rel = prev / next и хотите знать, стоит ли вам это делать, то это трудный вызов. Я бы сказал, что это в основном зависит от усилий, необходимых для добавления сейчас, по сравнению с воздействием. Помните, что эта разметка по-прежнему используется другими поисковыми системами, некоторыми браузерами и для обеспечения доступности, поэтому, возможно, она стоит затраченных усилий.
На всякий случай, если кому-то понадобится ссылка на исходную документацию, которая была удалена, пожалуйста.
Есть вопросы о rel = prev / next или pagination? Напишите мне в Twitter.
лучших практик для ссылок rel = «next» и rel = «prev»
Важное примечание о поддержке компанией Google rel next / prev
21 марта 2019 года Джон Мюллер из Google написал в Твиттере:
Google утверждает, что выяснил, как лучше всего работать с сериями страниц, разбитых на страницы, и поэтому прекратил использовать атрибуты ссылки rel = "next" и rel = "prev" .
Это объявление застало врасплох всю индустрию SEO. В ContentKing мы внимательно следим за развитием пагинации и будем обновлять эту статью по мере развития истории.
Важно отметить, что вам не нужно удалять атрибуты rel = "next" и rel = "prev" ссылки . Несмотря на то, что Google не использует его для целей «индексирования», остается неясным, используют ли они его в других частях своих систем, например, для поиска ссылок.
Причины для сохранения атрибутов ссылки rel = "next" и rel = "prev" :
- Это не причиняет никакого вреда , его удаление будет стоить вам драгоценного времени и денег, которые лучше потратить в другом месте.
- Это все еще полезно для целей доступности.
- Некоторые браузеры используют его для предварительной загрузки.
- С тех пор, как Google придумал, как лучше всего обрабатывать страницы с разбивкой на страницы самостоятельно, просмотрев ссылки на страницах.Это означает, что ваша внутренняя структура ссылок играет еще большую роль в SEO, поэтому сосредоточьтесь на этом, чтобы убедиться, что Google правильно настроил вашу разбивку на страницы.
- Другие поисковые системы, такие как Bing, все еще используют его для понимания взаимосвязей страниц и обнаружения страниц:
Pagination — «» Процесс разделения документа на отдельные страницы, электронные или печатные. »согласно Википедии (открывается в новой вкладке).
»согласно Википедии (открывается в новой вкладке).
Когда дело доходит до веб-сайтов, разбиение на страницы, например, используется для разделения страниц продуктов и страниц категорий блога.Важно помочь поисковым системам понять взаимосвязь между серией страниц с разбивкой на страницы, чтобы предотвратить проблемы с дублированием контента из-за их сходства.
Чего можно ожидать от этой статьи
В этой статье мы собираемся изучить, как реализовать атрибуты ссылок rel = "next" и rel = "prev" , включая рекомендации, распространенные ошибки и то, что делают эксперты, когда дело касается разбивки на страницы в SEO.
Каковы атрибуты нумерации страниц rel = «next» и rel = «prev»?
Атрибуты ссылки rel = "next" и rel = "prev" используются для обозначения отношений между последовательностью страниц и поисковыми системами.
Часто они неправильно называются тегами rel = "next" и rel = "prev" пагинации и считаются метатегами — но это не так. Для краткости мы назовем атрибуты
Для краткости мы назовем атрибуты rel = "next" и rel = "prev" , атрибуты пагинации , .
Атрибуты разбивки на страницы помещаются в раздел ваших HTML-страниц и выглядят следующим образом:
Люди добавляют ссылку
rel = "next"илиrel = "prev"всодержимого, а не в, чтобы объявить связь. Скорее всего, это потому, что они, например, путают это с rel = nofollow, но это неверно.
Когда мне следует использовать атрибуты разбивки на страницы?
Очень распространенный вариант использования атрибутов разбивки на страницы — это страницы категорий на веб-сайтах электронной коммерции.Обычно страницы категорий содержат много разных продуктов и поэтому разделены на несколько страниц, на каждой из которых отображается подмножество категории.
Обратной стороной этого является то, что эти страницы выглядят очень похожими, что приводит к форме дублирования контента. Делая отношения между сериями страниц понятными для поисковых систем с помощью атрибутов разбивки на страницы, вы даете поисковым системам контекст и предотвращаете дублирование контента.
Разбивка на страницы — одна из тех вещей, которые могут действительно негативно повлиять на ваш краулинговый бюджет и видимость вашего контента, особенно если вы используете что-то вроде бесконечной прокрутки или имеете большой объем заархивированного контента.
Как реализовать атрибуты пагинации
Пример
У вас есть последовательность из трех страниц, вот как выглядит определение разбивки на страницы и канонический URL:
Страница 1 ссылается на следующую страницу:
 example.com/topic/page/2" />
example.com/topic/page/2" />
Page 2 ссылается на первую страницу и следующую страницу:
Страница 3 содержит только ссылку на предыдущую страницу (и определение канонического URL ), так как это последний в последовательности:
Лучшие практики для атрибутов разбивки на страницы
Следуйте приведенным ниже рекомендациям, чтобы разбивка на страницы работала на вас.
Канонический URL со ссылкой на себя
Реализация атрибутов разбивки на страницы Каждая страница в последовательности страниц должна иметь канонический URL-адрес, указывающий на себя.
Итак, на странице 2 последовательности ваш раздел может выглядеть так:
Если вы веб-мастер, специалист по поисковой оптимизации или владелец бизнеса, вам, вероятно, когда-то приходилось сталкиваться с разбиением на страницы. Хотя разбиение на страницы несложно, они могут показаться сложными, если вы не знаете, как и когда их использовать. Самая распространенная ошибка, которую я вижу, — это директива
rel = "canonical"для результатов с разбивкой на страницы, указывающих на страницу 1. Эта устаревшая тактика применялась в прошлом, когда пользователи пытались перенаправить равенство ссылок на этот URL. Несмотря на то, что Google подтвердил, что эта тактика не рекомендуется, она остается распространенной ошибкой.
 Не обманывайте Google, полагая, что у вас есть только одна страница результатов, и убедитесь, что вы правильно используете канонические и нумерацию страниц.
Не обманывайте Google, полагая, что у вас есть только одна страница результатов, и убедитесь, что вы правильно используете канонические и нумерацию страниц.Не нарушайте последовательность
Не нарушайте последовательность страниц. Если вы это сделаете, поисковые системы часто будут игнорировать разбиение на страницы и просто индексировать и возвращать все страницы, что может привести к проблемам с дублированием контента.
Простой пример того, как нарушить последовательность страниц: забываем ссылку rel = "prev" со страницы 2 на первую страницу.
Избегайте ссылки на редирект
Избегайте использования атрибутов разбивки на страницы и канонических ссылок URL-адресов, которые, в свою очередь, перенаправляют на другие страницы. Это сбивает с толку поисковые системы.
Правильно ли настроена нумерация страниц на вашем сайте?
Неправильная настройка страниц с разбивкой на страницы может сдерживать эффективность SEO. Проверьте, правильно ли они настроены на вашем сайте!
Проверьте, правильно ли они настроены на вашем сайте!
Использовать абсолютные URL-адреса
Несмотря на то, что это не противоречит спецификации тега ссылки, по общему мнению, относительные URL-адреса не следует использовать при определении атрибутов пагинации .Относительные URL-адреса с большей вероятностью будут неправильно интерпретированы поисковыми системами. Та же самая передовая практика применяется к другим видам использования тега ссылки: канонический URL, атрибут hreflang и мобильный атрибут.
Когда дело доходит до разбивки на страницы, жизненно важно обеспечить соответствие платформы передовым практикам разбиения на страницы, чтобы обеспечить четкие инструкции для поисковых систем. По моему опыту, на многих платформах есть стандартная стартовая страница, но есть и дополнительная страница, которая загружает те же результаты. Это само по себе вызывает дублирование, канонические проблемы и проблемы с разбивкой на страницы, если Google может проиндексировать все страницы.
 Чтобы помочь правильно реализовать разбиение на страницы, у меня есть контрольный список с лучшими практиками, такими как упомянутые в статье, который позволяет мне пройти и правильно оценить разработку или выполнить проверки, чтобы увидеть, где может произойти потенциальное падение ямы.
Чтобы помочь правильно реализовать разбиение на страницы, у меня есть контрольный список с лучшими практиками, такими как упомянутые в статье, который позволяет мне пройти и правильно оценить разработку или выполнить проверки, чтобы увидеть, где может произойти потенциальное падение ямы.Не индексируйте страницы с разбивкой на страницы
Не добавляйте директиву noindex robots на страницы с разбивкой на страницы. Почему нет?
Есть две причины:
- Если страницы долгое время не индексировались, через некоторое время Google перестанет их сканировать и, следовательно, перестанет переходить по ссылкам.
- Если вы применили атрибуты
rel = "next"иrel = "prev", поисковые системы поймут взаимосвязь между страницами и часто будут отображать только страницы с разбивкой на страницы, если вы специально ищете контент, который только на тех страницах.
Не используйте nofollow ссылки на страницы с разбивкой на страницы
Атрибут ссылки nofollow в первую очередь используется, чтобы сообщить поисковым системам две вещи:
- Не переходите по этой ссылке (да)
- Я не обязательно доверяю этой странице. Я не верю.
 Я не верю.
Я не верю.Имея это в виду, использовать nofollow по ссылкам на страницы с разбивкой на страницы очень неразумно. Он не дает поисковым системам сканировать страницы с разбивкой на страницы и находить новый контент. Вдобавок вы теряете и авторитет ссылок.
Не включайте страницы с разбивкой на страницы в карту сайта XML
Не включайте страницы с разбивкой на страницы в XML-карту сайта, даже если они индексируются. Мы твердо убеждены, что в XML-карту сайта следует включать только те страницы, по которым вы хотите ранжироваться.В большинстве случаев страницы с разбивкой на страницы не попадают в эту категорию.
Исключением из этого правила является случай, когда вы не реализуете атрибуты rel = "next" и rel = "prev" , а вместо этого выбираете разбиение на страницы со страницей «Просмотреть все». Просмотреть все страницы следует включить в вашу карту сайта XML.
Распространенные ошибки при реализации атрибутов нумерации страниц
Распространенные ошибки, которые делают люди при реализации атрибутов нумерации страниц:
- Без ссылки на себя канонический: Канонизация на первую страницу в последовательности вместо наличия канонического URL-адреса с обратной ссылкой.
- Применение разбивки на страницы для страниц без разбивки на страницы: Реализация атрибутов разбивки на страницы для страниц без разбивки на страницы, таких как, например, статьи блога. Статья в блоге A имеет атрибут
rel = "next"для статьи B в блоге, статья B имеет атрибутrel = "prev",для статьи A иrel = "next"для статьи C и т. Д. Это неправильно, и по какой-то причине многие темы WordPress используют это. - Добавление отношений к ссылкам: Реализация атрибутов нумерации страниц для ссылок в основном содержимом вместо их определения в
head-section.Это не поддерживается поисковыми системами. - Добавление директив роботов noindex к страницам с разбивкой на страницы: Люди часто применяют директиву noindex к страницам с разбивкой на страницы, помимо использования атрибутов разбиения на страницы. Это неверно.

Google определил в сообщении в блоге, что наиболее распространенная ошибка, которую они видят при разбивке на страницы, заключается в том, что люди указывают элемент канонической ссылки на первую страницу в серии страниц.
 В идеале канонические элементы ссылки должны быть самодостаточными.Разбивка на страницы распределяет PageRank по серии страниц и в идеале может привести людей к наиболее релевантной странице для их запроса на любой из страниц, разбитых на страницы, поэтому наличие канонического элемента ссылки, указывающего на первую страницу серии страниц, действительно ошибка. Лучшей страницей для Google, чтобы показать кого-то с разбитой на страницы страницы в серии страниц, в идеале может быть любая из этих страниц с разбивкой на страницы. Вот почему люди должны включать разметку нумерации страниц.
В идеале канонические элементы ссылки должны быть самодостаточными.Разбивка на страницы распределяет PageRank по серии страниц и в идеале может привести людей к наиболее релевантной странице для их запроса на любой из страниц, разбитых на страницы, поэтому наличие канонического элемента ссылки, указывающего на первую страницу серии страниц, действительно ошибка. Лучшей страницей для Google, чтобы показать кого-то с разбитой на страницы страницы в серии страниц, в идеале может быть любая из этих страниц с разбивкой на страницы. Вот почему люди должны включать разметку нумерации страниц.Часто задаваемые вопросы о разбивке на страницы в SEO
- Почему поисковые системы игнорируют мои атрибуты пагинации?
- Могу ли я также использовать rel = «previous» вместо rel = «prev»?
- Будут ли мои страницы с разбивкой на страницы индексироваться поисковыми системами?
- Могу ли я определить атрибуты rel = «next» и rel = «prev» через заголовок HTTP?
- Могу ли я определить атрибуты rel = «next» и rel = «prev» через карту сайта XML?
- Должен ли я включать свои страницы с разбивкой на страницы в мою карту сайта XML?
1.
 Почему поисковые системы игнорируют мои атрибуты нумерации страниц?
Почему поисковые системы игнорируют мои атрибуты нумерации страниц? Атрибуты rel = "next" и rel = "prev" являются сигналами, а не директивами. Поисковые системы не обязаны фактически следовать вашему определению атрибутов нумерации страниц, но обычно они это делают.
2. Могу ли я также использовать rel = «previous» вместо rel = «prev»?
Да, оба работают, но для краткости мы предпочитаем rel = "prev" .
3. Будут ли мои страницы с разбивкой на страницы индексироваться поисковыми системами?
Да, но обычно они не отображаются на страницах результатов поисковой системы, поскольку в большинстве случаев поисковые системы возвращают первую страницу в последовательности.Однако в случаях, когда на одной из страниц, разбитых на страницы, есть уникальное содержание, эта страница также может отображаться в результатах поиска.
4. Могу ли я определить атрибуты
rel = "next" и rel = "prev" через заголовок HTTP? Хотя в этой статье 2011 года на форуме Google для веб-мастеров (открывается в новой вкладке) говорится, что это так, она обычно не используется.
Мы связались с Джоном Мюллером (открывается в новой вкладке) по этому поводу и обновим эту статью, когда получим ответ.
5. Могу ли я определить атрибуты
rel = "next" и rel = "prev" через карту сайта XML?Нет, в данный момент это невозможно.
6. Следует ли мне включать страницы с разбивкой на страницы в мою карту сайта XML?
Нет. Мы твердо уверены, что в XML-карту сайта следует включать только те страницы, по которым вы хотите ранжироваться. В большинстве случаев страницы с разбивкой на страницы не попадают в эту категорию.
Исключением из этого правила является случай, когда вы не реализуете атрибуты rel = "next" и rel = "prev" , а вместо этого выбираете разбиение на страницы со страницей «Просмотреть все».Просмотреть все страницы должны быть включены в вашу карту сайта XML.
Ресурсы
- Рекомендации Google (открывается в новой вкладке)
Титульный лист и разбивка на страницы — Руководство по стилю Чикаго — 17-е издание
Титульный лист и разбивка на страницы — Руководство по стилю Чикаго — 17-е издание — Руководства по исследованиям в библиотеке колледжа Камосан Перейти к основному содержанию Похоже, вы используете Internet Explorer 11 или старше. Этот веб-сайт лучше всего работает с современными браузерами, такими как последние версии Chrome, Firefox, Safari и Edge.Если вы продолжите работу в этом браузере, вы можете увидеть неожиданные результаты.
Этот веб-сайт лучше всего работает с современными браузерами, такими как последние версии Chrome, Firefox, Safari и Edge.Если вы продолжите работу в этом браузере, вы можете увидеть неожиданные результаты.
Титульный лист
Чикагский стиль цитирования требует, чтобы авторы исследовательских работ включали титульный лист. В качестве альтернативы авторы могут указать название на первой странице текста статьи; однако большинство инструкторов, использующих чикагский стиль, запрашивают полный титульный лист.Если вы не уверены, какой формат использовать, посоветуйтесь со своим инструктором.
На титульном листе необходимо указать:
- Заголовок вашей статьи (по центру и размещен примерно на одной трети длины страницы)
- Ваше имя как автор статьи (по центру, после заголовка в несколько строк)
- Название курса (по центру, под вашим именем)
- Имя преподавателя курса (по центру, под названием курса)
- Дата (по центру под именем инструктора)
Purdue OWL создала образец бумаги в стиле Чикаго, который может быть полезным для просмотра. Глядя на этот образец титульной страницы , вы можете заметить, что имя преподавателя не было , включая . Точное форматирование титульных страниц исследовательских работ в стиле Чикаго может отличаться. Если сомневаетесь, посоветуйтесь со своим профессором!
Глядя на этот образец титульной страницы , вы можете заметить, что имя преподавателя не было , включая . Точное форматирование титульных страниц исследовательских работ в стиле Чикаго может отличаться. Если сомневаетесь, посоветуйтесь со своим профессором!
Образец титульной страницы
ИССЛЕДОВАНИЕ ЭТИКИ В АРХЕОЛОГИЧЕСКОЙ ПРАКТИКЕ
INVISIBLETAB
Грег Харрингтон
Антропология 240: археологический метод и теория
Профессор Канвалджит Гилл
21 октября 2018 г.
Пагинация
Заголовки и номера страниц
В стиле Чикаго:
- Титульный лист не включает заголовок или номер страницы (см. Образец исследовательской работы).
- Вторая страница (первая страница текста) включает заголовок с вашей фамилией и номером страницы (начиная с цифры один).
- Последующие страницы включают заголовки с вашей фамилией и порядковыми номерами.

Чтобы вставить свое имя и номера страниц с помощью MS Word 2007:
- Щелкните вкладку «Вставка» на панели инструментов.
- В разделе «Верхний и нижний колонтитулы» нажмите «Номер страницы».
- В раскрывающемся меню выберите «Вверху страницы».«
- Переместите указатель мыши вниз, чтобы выбрать «Обычный номер 3».
- Вверху страницы появится панель заголовка с курсором в правой части страницы перед числом 1.
- Введите свою фамилию.
- Используйте пробел, чтобы вставить один пробел между своим именем и числом 1.
- Чтобы ваша титульная страница не имела номера страницы, установите флажок «Другая первая страница» (номер страницы исчезнет с первой страницы).
- Щелкните «Закрыть верхний и нижний колонтитулы».«
- В разделе «Верхний и нижний колонтитулы» нажмите «Номер страницы».
- В раскрывающемся меню выберите «Форматировать номера страниц . …»
- В разделе «Нумерация страниц» нажмите кнопку «Начать с». Должна появиться цифра 1 — измените ее на цифру 0 и выберите «ОК». Это гарантирует, что первая страница вашего текста будет начинаться с номера 1.
- Щелкните раскрывающееся меню «Заголовок» и выберите «Изменить заголовок».
- В разделе «Параметры» выберите поле «Другая первая страница».; Это сделает заголовок / номер невидимым на титульной странице и начнется с вашей первой страницы текста.
- Для завершения нажмите кнопку «Закрыть верхний и нижний колонтитулы».
 …»
…»Разбиение на страницы в филиале | Документация по CMS филиала
Обзор
Почти каждое приложение использует разбиение на страницы, чтобы ограничить количество элементов, отображаемых на странице.Например, на странице категории блога есть разбиение на страницы, чтобы ограничить количество сообщений, отображаемых одновременно на странице.
Вы можете использовать данные нумерации страниц для создания простых ссылок «Далее» и «Назад» или вы можете отображать стандартную навигацию по страницам, как то, что вы видите на страницах результатов поиска Google.
Стили пагинации
Вы можете использовать 4 различных стиля нумерации страниц. Обычно это можно установить на странице общих настроек в разделе настроек приложения.
Все
Возвращает каждую страницу. Это полезно для элементов управления разбивкой на страницы раскрывающегося меню с относительно небольшим количеством страниц. В этих случаях вы хотите, чтобы все страницы были доступны пользователю сразу.
Elastic
Стиль прокрутки, похожий на Google, который расширяется и сужается по мере того, как пользователь прокручивает страницы.
Переход
По мере прокрутки пользователей номер страницы продвигается до конца заданного диапазона, а затем снова начинается с начала нового диапазона.
Sliding
Стиль прокрутки Yahoo!, при котором номер текущей страницы размещается в центре диапазона страниц или как можно ближе. Это стиль по умолчанию.
Теги пагинации
| Тег | Описание |
|---|---|
| {{pagination.current}} | Номер страницы просматриваемой страницы с разбивкой на страницы. Тип: Целое число |
| {{pagination.currentItemCount}} | Количество элементов на текущей странице. Тип: Целое число |
| {{pagination.first}} | Номер первой страницы. Тип: Целое число |
| {{pagination.firstItemNumber}} | Абсолютный номер первого элемента на текущей странице. Тип: Целое число |
{{pagination.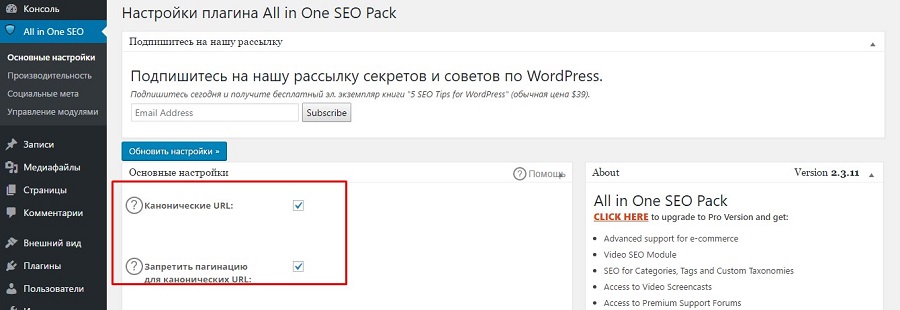 firstPageInRange}} firstPageInRange}} | Номер первой страницы в диапазоне, возвращаемом стилем прокрутки. Тип: Целое число |
| {{pagination.firstUrl}} | URL номера первой страницы. Тип: Целое число |
| {{pagination.itemCountPerPage}} | Количество элементов, доступных на каждой странице. Тип: Целое число |
| {{pagination.last}} | Номер последней страницы. Тип: Целое число |
| {{pagination.lastItemNumber}} | Абсолютный номер последнего элемента на текущей странице. Тип: Целое число |
| {{pagination.lastPageInRange}} | Номер последней страницы диапазона, возвращаемого стилем прокрутки. Тип: Целое число |
{{pagination. lastUrl}} lastUrl}} | URL последней страницы. Тип: Строка |
| {{pagination.next}} | Номер следующей страницы в диапазоне. Тип: Целое число |
| {{pagination.nextRangeUrl}} | URL-адрес следующего диапазона страниц. Тип: Строка Это полезно только в том случае, если количество элементов, отображаемых в элементе управления разбивкой на страницы (диапазон страниц), меньше общего количества страниц. Например: Лучше всего использовать со стилем нумерации страниц с прыжками. |
| {{pagination.nextUrl}} | URL следующей страницы в диапазоне. Тип: Строка |
| {{pagination.pageCount}} | Общее количество страниц. Тип: Целое число |
| {{pagination.pagesInRange}} | Список страниц для текущего диапазона на основе стиля прокрутки страницы. Тип: Массив |
| {{pagination.previous}} | Номер предыдущей страницы в диапазоне. |
| {{pagination.previousRangeUrl}} | URL-адрес предыдущего диапазона страниц. Тип: Строка Это полезно только в том случае, если количество элементов, отображаемых в элементе управления разбивкой на страницы (диапазон страниц), меньше общего количества страниц. Например: |
| {{pagination.previousUrl}} | URL-адрес предыдущей страницы в диапазоне. |
| {{pagination.totalItemCount}} | Общее количество товаров. Тип: Целое число |
| {{pagination.viewAll}} | Показывает ли при разбивке на страницы все элементы. Тип: Boolean |
| {{pagination.viewAllUrl}} | URL-адрес для просмотра всех элементов на одной странице. Тип: Строка |

{{pagination.
 pagesInRange}} Подробности
pagesInRange}} ПодробностиПеребирайте значения Pages In Range для вывода номеров отдельных страниц.
Пример:
{% для страницы при разбивке на страницы.pagesInRange%}
{% if page.number! = pagination.current%}
{{page. number}}
{% else%}
{{page.number}}
{% endif%}
{% endfor%} / loop}
| Тег | Описание |
|---|---|
| {{page.number}} | Номер страницы для отдельной страницы. Тип: Целое число |
| {{page.url}} | URL-адрес отдельной страницы. Тип: Целое число |
Разбиение на страницы · Bootstrap
Документация и примеры для отображения разбивки на страницы, чтобы указать, что на нескольких страницах существует серия связанного контента.
Обзор
Мы используем большой блок связанных ссылок для нашей разбивки на страницы, что делает ссылки трудными для пропуска и легко масштабируемыми, обеспечивая при этом большие области попадания.Разбивка на страницы построена с помощью элементов списка HTML, поэтому программы чтения с экрана могут объявить количество доступных ссылок. Используйте оборачивающий элемент , чтобы идентифицировать его как раздел навигации для программ чтения с экрана и других вспомогательных технологий.
Кроме того, поскольку страницы, вероятно, имеют более одного такого раздела навигации, рекомендуется предоставить описательный aria-label для , чтобы отразить его назначение. Например, если компонент разбивки на страницы используется для навигации между набором результатов поиска, подходящей меткой может быть aria-label = "Search results pages" .
Работа с иконками
Хотите использовать значок или символ вместо текста для некоторых ссылок на страницы? Обязательно обеспечьте надлежащую поддержку программы чтения с экрана с атрибутами aria и .. sr-only
sr-only
Отключенное и активное состояния
Ссылки пагинации настраиваются для разных обстоятельств.Используйте .disabled для ссылок, которые кажутся неактивными, и .active для обозначения текущей страницы.
Хотя класс .disabled использует события-указателя : нет – попробуйте , чтобы отключить функциональность ссылок для s, это свойство CSS еще не стандартизировано и не учитывает навигацию с клавиатуры. Таким образом, вы всегда должны добавлять
Таким образом, вы всегда должны добавлять tabindex = "- 1" для отключенных ссылок и использовать собственный JavaScript, чтобы полностью отключить их функциональность.
При желании вы можете поменять местами активные или отключенные привязки для или опустить привязку в случае стрелок «назад / вперед», чтобы удалить функциональность щелчка и предотвратить фокусировку клавиатуры при сохранении заданных стилей.
Размер
Хотите больше или меньше нумерации страниц? Складываем . или 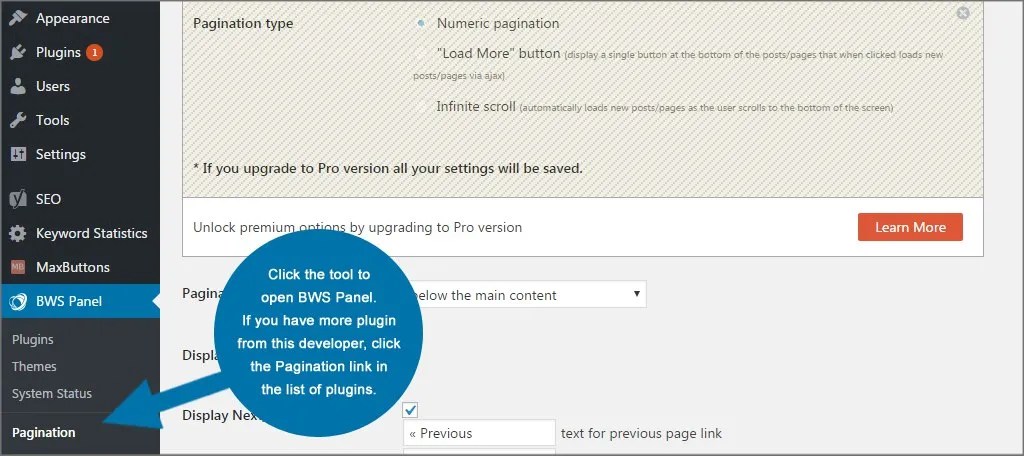 pagination-lg
pagination-lg .pagination-sm для дополнительных размеров.
Выравнивание
Измените выравнивание компонентов разбивки на страницы с помощью утилит flexbox.
Foundation для сайтов 6 документов
Разбиение на страницы — это тип навигации, позволяющий пользователям переходить по страницам результатов поиска, продуктов или других связанных элементов.
Основы
Список разбивки на страницы — это просто
.pagination и серией пар . Добавьте класс .current к .disabled , чтобы добавить отключенные стили к ссылке.
Обратите внимание, что список вложен в с атрибутами aria-label = "Pagination" . Это объясняет назначение компонента вспомогательным технологиям.
Дополнительный текст, предназначенный только для чтения с экрана, также следует добавить к элементу разбивки на страницы. В приведенном ниже примере пользователи, читающие страницу, будут видеть только «Следующая» и «Предыдущая», а программы чтения с экрана будут читать ее как «Следующая страница» и «Предыдущая страница». Кроме того, текст для текущей страницы будет читаться как «Вы находитесь на первой странице».
Посмотреть эту часть в видео
По центру
Элементы в списке с разбивкой на страницы — это display: inline-block , что упрощает их центрирование. Используйте наш встроенный класс
Используйте наш встроенный класс .text-center или добавьте text-align: center в свой CSS.
Посмотреть эту часть в видео
Ссылка Sass
Переменные
Стили по умолчанию для этого компонента можно настроить с помощью этих переменных Sass в файле настроек вашего проекта.
| Имя | Тип | Значение по умолчанию | Описание |
|---|---|---|---|
$ pagination-font-size | Число | rem-calc (14) | Размер шрифта элементов нумерации страниц. |
$ pagination-margin-bottom | Число | $ глобальная маржа | Нижнее поле по умолчанию для объекта разбивки на страницы. |
$ pagination-item-color | Цвет | $ черный | Цвет текста элементов нумерации страниц. |
$ pagination-item-padding | Число | rem-calc (3 10) | Заполнение внутри элементов нумерации страниц. |
$ pagination-item-spacing | Число | rem-calc (1) | Правое поле для разделения элементов нумерации страниц. |
$ pagination-radius | Число | $ global-radius | Радиус по умолчанию для элементов нумерации страниц. |
$ pagination-item-background-hover | Цвет | $ светло-серый | Цвет фона элементов нумерации страниц при наведении курсора. |
$ pagination-item-background-current | Цвет | $ основной цвет | Цвет фона элемента нумерации страниц для текущей страницы. |
$ pagination-item-color-current | Цвет | $ белый | Цвет текста элемента нумерации страниц для текущей страницы. |
$ pagination-item-color-disabled | Цвет | $ средне-серый | Цвет текста отключенного элемента нумерации страниц. |
$ pagination-ellipsis-color | Цвет | $ черный | Цвет многоточия в меню нумерации страниц. |
$ pagination-mobile-items | логический | ложный | Если |
$ pagination-mobile-current-item | логический | ложный | Если |
$ pagination-стрелки | логический | правда | Если |
$ pagination-arrow-previous | Строка | '\ 00AB' | Содержимое предыдущей стрелки, когда |
$ pagination-arrow-next | Строка | '\ 00BB' | Содержимое для следующей стрелки, когда |


Смеси
Мы используем эти миксины для создания окончательного вывода CSS этого компонента.Вы можете использовать миксины самостоятельно, чтобы построить свою собственную структуру классов из наших компонентов.
-контейнер для пагинации
@include pagination-container; Добавляет стили для контейнера нумерации страниц. Примените это к
Примените это к
pagination-item-current
@include pagination-item-current; Добавляет стили для текущего элемента нумерации страниц.Примените это к .
pagination-item-disabled
@include pagination-item-disabled; Добавляет стили для отключенного элемента нумерации страниц. Примените это к .
многоточие на страницы
@include многоточие на страницы; Добавляет стили для многоточия для использования в списке нумерации страниц.
списков коллекции Paginate | Webflow University
Paginate Collection списки и управление их внешним видом на страницах.
В этом видео используется старый интерфейс. Скоро выйдет обновленная версия!
В этом видео используется старый интерфейс. Скоро выйдет обновленная версия!
Скоро выйдет обновленная версия!
В этом видео используется старый интерфейс. Скоро выйдет обновленная версия!
Вы можете разбить список коллекции на страницы и указать, сколько элементов вы хотите отображать на каждой странице списка коллекции. Это дает много преимуществ как для создания коллекций, так и для производительности ваших страниц.С разбивкой на страницы вы сможете:
- Отображать более 100 элементов коллекции из вашей коллекции в одном списке коллекций
- Отображать меньше элементов коллекции на странице, чтобы страница работала лучше и загружалась быстрее
- Создавайте настраиваемые динамические ползунки для последние поступления, последние сообщения в блогах, продукты со скидкой и т. д.
В этом уроке
- Размещение списка коллекций
- Понимание анатомии обертки нумерации страниц
- Настройка параметров разбивки на страницы
- Поделитесь URL-адресом списка коллекций страница
- Добавьте вторую оболочку пагинации в тот же список коллекций
- Узнайте о разбивке на страницы и SEO
- Устранение известных проблем и ответы на часто задаваемые вопросы
- Создайте настраиваемую пагинацию с пронумерованными страницами
Разбейте список коллекции
на разбивку на страницы выбранный список коллекций, перейдите на панель настроек элемента и отметьте 9000 7 Пагинировать элементы . При желании вы можете изменить количество элементов, отображаемых на странице.
При желании вы можете изменить количество элементов, отображаемых на странице.
Этот флажок позволяет включать или отключать разбиение на страницы в выбранном списке коллекции. Отключение и повторное включение разбивки на страницы восстановит предыдущие настройки и стили компонентов.
Индикатор количества страницЭта текстовая строка, доступная только для чтения, указывает, сколько страниц списка собрания будет создано на основе указанного значения элементов / страницы.
Элементов на страницу (ползунок / ввод числа) Этот элемент управления позволяет указать, сколько элементов отображать на каждой странице списка коллекции. Минимальное количество, которое вы можете указать, — 1, максимальное — 100. Настройка мгновенно влияет на список коллекции на холсте и обновляет индикатор количества страниц в настройках.
Минимальное количество, которое вы можете указать, — 1, максимальное — 100. Настройка мгновенно влияет на список коллекции на холсте и обновляет индикатор количества страниц в настройках.
После включения разбивки на страницы в списке коллекции в оболочку списка коллекции будет добавлен новый компонент разбивки на страницы. Вы можете увидеть это в любое время в навигаторе. Этот компонент включает два блока ссылок: предыдущую и следующую кнопки.
Обертка разбивки на страницы и ее дочерние элементы добавляются в оболочку списка коллекции. На холсте вы увидите кнопку следующий , если в вашем списке коллекций больше элементов, чем количество из элементов на странице , которое вы указали в настройках списка коллекций.Чтобы увидеть кнопки предыдущий и следующий , переключитесь на другую страницу из настроек разбивки на страницы или щелкнув следующий в режиме предварительного просмотра.
Настроить параметры разбивки на страницы
Когда на холсте выбрана оболочка разбиения на страницы, вы можете увидеть параметров разбивки на страницы на панели параметров элементов .Вы также можете получить доступ к настройкам прямо на холсте, нажав клавишу ВВОД или дважды щелкнув оболочку пагинации.
Страница Этот параметр разбивки на страницы позволяет вам перейти на определенную страницу списка коллекции с помощью раскрывающегося списка или переключиться на предыдущую или следующую страницу с помощью стрелок . Это полезно для получения доступа к предыдущей и следующей кнопкам, когда вы хотите стилизовать и настроить эти кнопки. Он также позволяет предварительно просматривать страницы списка коллекций прямо на холсте.
Вы также можете предварительно просмотреть страницы списка коллекции и протестировать кнопки разбивки на страницы в режиме предварительного просмотра.
Показать количество страницЭтот параметр позволяет отображать текущие и общие страницы в списке вашей коллекции. Он добавляет новый текстовый блок в вашу оболочку разбиения на страницы, которую вы можете перемещать внутри оболочки и стиля, как и любой другой текстовый блок.
Поделиться URL-адресом страницы со списком коллекций
Страницы со списком собраний имеют уникальные URL-адреса, которые позволяют посетителям вашего сайта делиться прямой ссылкой на эту страницу.Так, например, если вы случайно наткнулись на фотографию и информацию друга на странице авторов блога, и случается, что их имя появляется на странице 3 списка авторов, вы сможете поделиться этой конкретной страницей с их, скопировав URL-адрес из адресной строки.
Эти уникальные URL-адреса имеют уникальный идентификатор списка коллекции и номер страницы, добавленные в конце URL-адреса страницы, например: website. com/blog/ ? Ef2f5b9e_page = 2
com/blog/ ? Ef2f5b9e_page = 2 Настроить и стилизовать кнопки разбивки на страницы
Вы можете стилизовать кнопки нумерации страниц так же, как и для любой другой кнопки.Вы можете изменить цвет значка, применив цвет шрифта к значку или блоку ссылки кнопки. Вы также можете заменить значок любым другим изображением на панели ресурсов. Чтобы сохранить размер и положение значка по умолчанию, вы можете установить ширину или высоту изображения на 20 пикселей и добавить правое или левое поле в 4 пикселя, чтобы создать зазор между значком и текстом.
Примеры пользовательских кнопок разбиения на страницыДобавить вторую оболочку разбиения на страницы в тот же список коллекции
Вы можете продублировать оболочку разбиения на страницы и переместить ее в любое место внутри оболочки списка коллекции, если она остается прямым потомком оболочки списка коллекции.
Для списков коллекций с большим количеством элементов на страницу полезно добавить вторую разбивку на страницы вверху списка коллекции. Вы можете перетащить повторяющийся список разбивки на страницы в навигаторе для большей точности.
Вы можете перетащить повторяющийся список разбивки на страницы в навигаторе для большей точности.
Поскольку разбитое на страницы содержание очень распространено в сети, поисковые системы, такие как Google, индексируют страницы с разбивкой на страницы и возвращают наиболее релевантные результаты поисковикам.
Расширенная настройка SEO
Опять же, вам не нужно ничего делать для индексации страниц, разбитых на страницы, поисковые системы позаботятся об этом за вас.Однако при желании вы можете помочь поисковым системам , указав свой постраничный контент.
Ресурсы
Устранение известных проблем и ответы на часто задаваемые вопросы
Я не могу добавить более 100 элементов на страницу списка коллекции
По умолчанию в списке коллекций может отображаться максимум 100 элементов одновременно. Это ограничение существует из соображений производительности и для минимальной скорости загрузки страницы. Чтобы отобразить более 100 элементов в списке коллекции, включите разбиение на страницы.Это позволит вам отображать все элементы вашей коллекции на нескольких страницах. Однако, опять же, из соображений производительности каждая страница списка коллекции может отображать не более 100 элементов.
Чтобы отобразить более 100 элементов в списке коллекции, включите разбиение на страницы.Это позволит вам отображать все элементы вашей коллекции на нескольких страницах. Однако, опять же, из соображений производительности каждая страница списка коллекции может отображать не более 100 элементов.
Кнопки разбивки на страницы не отображаются в двух случаях:
- , когда в вашем списке коллекции только один элемент
- , когда элементов на странице больше, чем общее количество элементы в списке коллекции.
Исправление для 1 — убедитесь, что у вас есть как минимум два элемента в вашем списке коллекции.
Исправление для 2 — установите меньшее число в поле элементов / страница
Индексируется только первая страница пагинации, потому что это тот, который показан без каких-либо строк запроса.
Поддержка результатов поиска Список появится в ближайшем будущем.
Могу ли я остановить перезагрузку страницы и ее перемещение в верхнюю часть страницы при навигации по списку сбора с разбивкой на страницы?Вы можете сделать это с помощью специального кода.Ознакомьтесь с этим руководством о том, как создать плавную разбивку на страницы.
Создание настраиваемой разбивки на страницы с пронумерованными страницами
Текущая версия разбивки на страницы состоит всего из двух кнопок: «предыдущая» и «следующая». В будущем появится возможность добавлять индивидуальные номера страниц и ссылки. На данный момент есть обходной путь с использованием ползунков и нескольких списков коллекций:
- Добавьте ползунок Элемент
- Выберите стрелки и установите для них отображение не w
- Установите для цвет фона прозрачный на панели стилей (S )
- Установите навигатор слайдов на числовые метки в Параметры элемента (D)
- Перетащите список коллекции на слайд 1 и подключите его к коллекции
- Создайте и стилизуйте свою список коллекции
- Необязательно: установите порядок сортировки
- Ограничьте коллекцию отображением только 3 элементов
- Скопируйте список коллекции
- Выберите слайд 2 и вставьте список
- Установите , начало с до 4
Слайд 1 будет отобразить пункты 1, 2 и 3.