Как создать правильный файл robots.txt, настройка, директивы
Файл robots.txt — текстовый файл в формате .txt, ограничивающий поисковым роботам доступ к содержимому на http-сервере.
Как определение, Robots.txt — это стандарт исключений для роботов, который был принят консорциумом W3C 30 января 1994 года, и который добровольно использует большинство поисковых систем. Файл robots.txt состоит из набора инструкций для поисковых роботов, которые запрещают индексацию определенных файлов, страниц или каталогов на сайте. Рассмотрим описание robots.txt для случая, когда сайт не ограничивает доступ роботам к сайту.
Простой пример:
User-agent: * Allow: /
Здесь роботс полностью разрешает индексацию всего сайта.
Файл robots.txt необходимо загрузить в корневой каталог вашего сайта, чтобы он был доступен по адресу:
ваш_сайт.ru/robots.txt
Для размещения файла в корне сайта обычно необходим доступ через FTP.
Если файл доступен, то вы увидите содержимое в браузере.
Для чего нужен robots.txt
Сформированный файл для сайта является важным аспектом поисковой оптимизации. Зачем нужен robots.txt? Например, в SEO robots.txt нужен для того, чтобы исключать из индексации страницы, не содержащие полезного контента и многое другое. Как, что, зачем и почему исключается уже было описано в статье про запрет индексации страниц сайта, здесь не будем на этом останавливаться. Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы, например директива Host или Sitemap, но об этом ниже.
Как создать robots.txt
Поскольку это текстовый файл, нужно воспользоваться любым текстовым редактором, например Блокнотом. Как только вы открыли новый текстовый документ, вы уже начали создание robots.txt, осталось только составить его содержимое, в зависимости от ваших требований, и сохранить в виде текстового файла с названием robots в формате txt. Все просто, и создание файла не должно вызвать проблем даже у новичков. О том, как составить и что писать в роботсе на примерах покажу ниже.
Cоздать robots.txt онлайн
Вариант для ленивых: скачать в уже в готовом виде. Создание robots txt онлайн предлагает множество сервисов, выбор за вами. Главное — четко понимать, что будет запрещено и что разрешено, иначе создание файла robots.txt online может обернуться трагедией, которую потом может быть сложно исправить. Особенно, если в поиск попадет то, что должно было быть закрытым. Будьте внимательны — проверьте свой файл роботс, прежде чем выгружать его на сайт. Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Редактирование robots.txt
После того, как вам удалось создать файл robots.txt онлайн или своими руками, вы можете редактировать robots.txt. Изменить его содержимое можно как угодно, главное — соблюдать некоторые правила и синтаксис robots.txt. В процессе работы над сайтом, файл роботс может меняться, и если вы производите редактирование robots.txt, то не забывайте выгружать на сайте обновленную, актуальную версию файла со всем изменениями. Далее рассмотрим правила настройки файла, чтобы знать, как изменить файл robots.txt и «не нарубить дров».
Правильная настройка robots.txt
Правильная настройка robots.txt позволяет избежать попадания частной информации в результаты поиска крупных поисковых систем. Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита. Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Чтобы понять, как сделать правильный robots txt, для начала необходимо разобраться с общими правилами, синтаксисом и директивами файла robots.txt.
Правильный robots.txt начинается с директивы User-agent, которая указывает, к какому роботу обращены конкретные директивы.
Примеры User-agent в robots.txt:
# Указывает директивы для всех роботов одновременно User-agent: * # Указывает директивы для всех роботов Яндекса User-agent: Yandex # Указывает директивы для только основного индексирующего робота Яндекса User-agent: YandexBot # Указывает директивы для всех роботов Google User-agent: Googlebot
Учитывайте, что подобная настройка файла robots. txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
Пример robots.txt с несколькими вхождениями User-agent:
# Будет использована всеми роботами Яндекса User-agent: Yandex Disallow: /*utm_ # Будет использована всеми роботами Google User-agent: Googlebot Disallow: /*utm_ # Будет использована всеми роботами кроме роботов Яндекса и Google User-agent: * Allow: /*utm_
Директива User-agent создает лишь указание конкретному роботу, а сразу после директивы User-agent должна идти команда или команды с непосредственным указанием условия для выбранного робота. В примере выше используется запрещающая директива «Disallow», которая имеет значение «/*utm_». Таким образом, закрываем все страницы с UTM-метками. Правильная настройка robots.txt запрещает наличие пустых переводов строки между директивами «User-agent», «Disallow» и директивами следующими за «Disallow» в рамках текущего «User-agent».
Пример неправильного перевода строки в robots. txt:
txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Пример правильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Как видно из примера, указания в robots.txt поступают блоками, каждый из которых содержит указания либо для конкретного робота, либо для всех роботов «*».
Кроме того, важно соблюдать правильный порядок и сортировку команд в robots.txt при совместном использовании директив, например «Disallow» и «Allow». Директива «Allow» — разрешающая директива, является противоположностью команды robots.txt «Disallow» — запрещающей директивы.
Пример совместного использования директив в robots.txt:
User-agent: * Allow: /blog/page Disallow: /blog
Данный пример запрещает всем роботам индексацию всех страниц, начинающихся с «/blog», но разрешает индексации страниц, начинающиеся с «/blog/page».
Прошлый пример robots.txt в правильной сортировке:
User-agent: * Disallow: /blog Allow: /blog/page
Сначала запрещаем весь раздел, потом разрешаем некоторые его части.
Еще один правильный пример robots.txt с совместными директивами:
User-agent: * Allow: / Disallow: /blog Allow: /blog/page
Обратите внимание на правильную последовательность директив в данном robots.txt.
Директивы «Allow» и «Disallow» можно указывать и без параметров, в этом случае значение будет трактоваться обратно параметру «/».
Пример директивы «Disallow/Allow» без параметров:
User-agent: * Disallow: # равнозначно Allow: / Disallow: /blog Allow: /blog/page
Как составить правильный robots.txt и как пользоваться трактовкой директив — ваш выбор. Оба варианта будут правильными. Главное — не запутайтесь.
Для правильного составления robots.txt необходимо точно указывать в параметрах директив приоритеты и то, что будет запрещено для скачивания роботам. Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы
Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы
Синтаксис robots.txt
Роботы поисковых систем добровольно следуют командам robots.txt — стандарту исключений для роботов, однако не все поисковые системы трактуют синтаксис robots.txt одинаково. Файл robots.txt имеет строго определённый синтаксис, но в то же время написать robots txt не сложно, так как его структура очень проста и легко понятна.
Вот конкретные список простых правил, следуя которым, вы исключите частые ошибки robots.txt:
- Не указывайте больше одной директивы в одной строке;
- Не ставьте пробел в начало строки;
- Параметр директивы должен быть в одну строку;
- Не нужно обрамлять параметры директив в кавычки;
- Параметры директив не требуют закрывающих точки с запятой;
- Команда в robots.
 txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел];
txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел]; - Допускаются комментарии в robots.txt после знака решетки #;
- Пустой перевод строки может трактоваться как окончание директивы User-agent;
- Директива «Disallow: » (с пустым значением) равнозначна «Allow: /» — разрешить все;
- В директивах «Allow», «Disallow» указывается не более одного параметра;
- Название файла robots.txt не допускает наличие заглавных букв, ошибочное написание названия файла — Robots.txt или ROBOTS.TXT;
- Написание названия директив и параметров заглавными буквами считается плохим тоном и если по стандарту, robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файлов и директорий;
- Если параметр директивы является директорией, то перед название директории всегда ставится слеш «/», например: Disallow: /category
- Слишком большие robots.txt (более 32 Кб) считаются полностью разрешающими, равнозначными «Disallow: »;
- Недоступный по каким-либо причинам robots. txt может трактоваться как полностью разрешающий;
- Если robots.txt пустой, то он будет трактоваться как полностью разрешающий;
- В результате перечисления нескольких директив «User-agent» без пустого перевода строки, все последующие директивы «User-agent», кроме первой, могут быть проигнорированы;
- Использование любых символов национальных алфавитов в robots.txt не допускается.
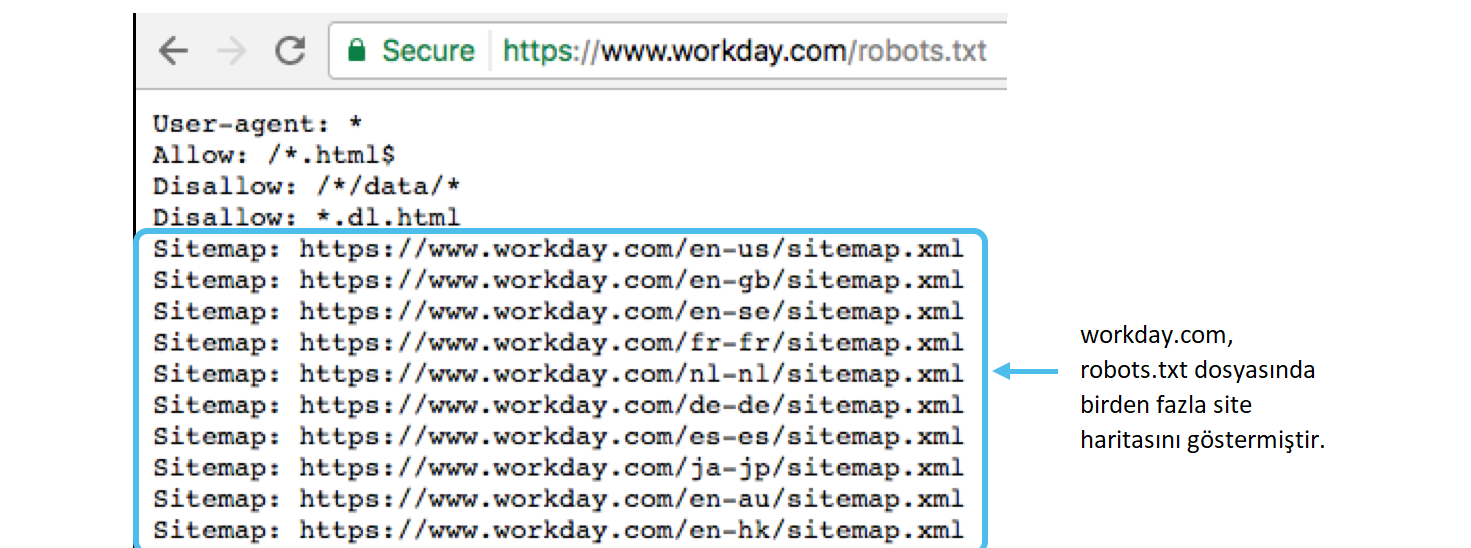 txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел];
txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел]; txt может трактоваться как полностью разрешающий;
txt может трактоваться как полностью разрешающий;Поскольку разные поисковые системы могут трактовать синтаксис robots.txt по-разному, некоторые пункты можно опустить. Так например, если прописать несколько директив «User-agent» без пустого перевода строки, все директивы «User-agent» будут восприняты корректно Яндексом, так как Яндекс выделяет записи по наличию в строке «User-agent».
В роботсе должно быть указано строго только то, что нужно, и ничего лишнего. Не думайте, как прописать в robots txt все, что только можно и чем его заполнить. Идеальный robots txt — это тот, в котором меньше строк, но больше смысла. «Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
«Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
Как проверить robots.txt
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы анализа сайта для вебмастеров, которые включают анализ robots.txt:
Проверка файла robots.txt в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
Проверка файла robots.txt в Google: https://www.google.com/webmasters/tools/siteoverview?hl=ru
Для того, чтобы проверить robots.txt онлайн необходимо загрузить robots.txt на сайт в корневую директорию. Иначе, сервис может сообщить, что не удалось загрузить robots.txt. Рекомендуется предварительно проверить robots.txt на доступность по адресу где лежит файл, например: ваш_сайт.ru/robots.txt.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.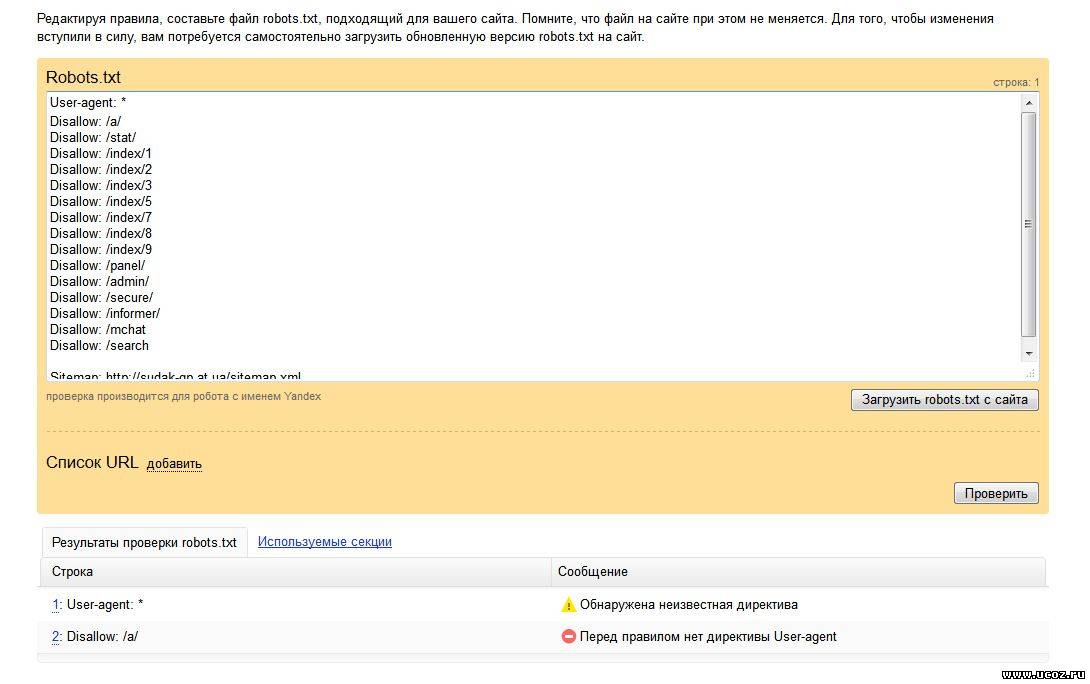 txt.
txt.
Robots.txt vs Яндекс и Google
Есть субъективное мнение, что указание отдельного блока директив «User-agent: Yandex» в robots.txt Яндекс воспринимает более позитивно, чем общий блок директив с «User-agent: *». Аналогичная ситуация robots.txt и Google. Указание отдельных директив для Яндекс и Google позволяет управлять индексацией сайта через robots.txt. Возможно, им льстит персонально обращение, тем более, что для большинства сайтов содержимое блоков robots.txt Яндекса, Гугла и для других поисковиков будет одинаково. За редким исключением, все блоки «User-agent» будут иметь стандартный для robots.txt набор директив. Так же, используя разные «User-agent» можно установить запрет индексации в robots.txt для Яндекса, но, например не для Google.
Отдельно стоит отметить, что Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта. Подробнее директиву «Host» рассмотрим ниже.
Подробнее директиву «Host» рассмотрим ниже.
Запретить индексацию: robots.txt Disallow
Disallow — запрещающая директива, которая чаще всего используется в файле robots.txt. Disallow запрещает индексацию сайта или его части, в зависимости от пути, указанного в параметре директивы Disallow.
Пример как в robots.txt запретить индексацию сайта:
User-agent: * Disallow: /
Данный пример закрывает от индексации весь сайт для всех роботов.
В параметре директивы Disallow допускается использование специальных символов * и $:
* — любое количество любых символов, например, параметру /page* удовлетворяет /page, /page1, /page-be-cool, /page/kak-skazat и т.д. Однако нет необходимости указывать * в конце каждого параметра, так как например, следующие директивы интерпретируются одинаково:
User-agent: Yandex Disallow: /page
User-agent: Yandex Disallow: /page*
$ — указывает на точное соответствие исключения значению параметра:
User-agent: Googlebot Disallow: /page$
В данном случае, директива Disallow будет запрещать /page, но не будет запрещать индексацию страницы /page1, /page-be-cool или /page/kak-skazat.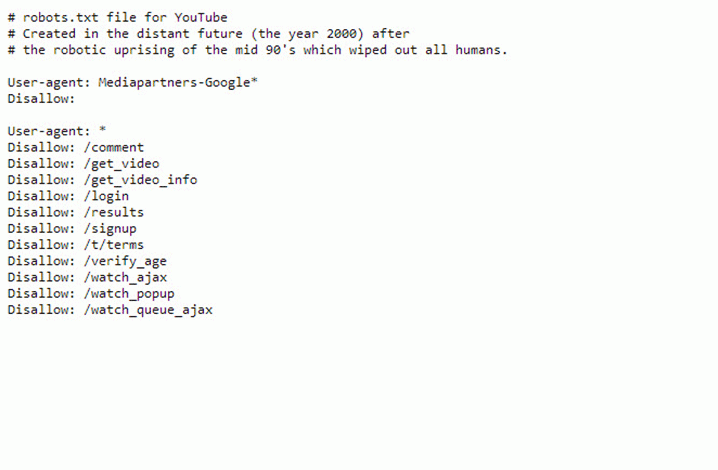
Если закрыть индексацию сайта robots.txt, в поисковые системы могут отреагировать на так ход ошибкой «Заблокировано в файле robots.txt» или «url restricted by robots.txt» (url запрещенный файлом robots.txt). Если вам нужно запретить индексацию страницы, можно воспользоваться не только robots txt, но и аналогичными html-тегами:
- <meta name=»robots» content=»noindex»/> — не индексировать содержимое страницы;
- <meta name=»robots» content=»nofollow»/> — не переходить по ссылкам на странице;
- <meta name=»robots» content=»none»/> — запрещено индексировать содержимое и переходить по ссылкам на странице;
- <meta name=»robots» content=»noindex, nofollow»/> — аналогично content=»none».
Разрешить индексацию: robots.txt Allow
Allow — разрешающая директива и противоположность директиве Disallow. Эта директива имеет синтаксис, сходный с Disallow.
Пример, как в robots. txt запретить индексацию сайта кроме некоторых страниц:
txt запретить индексацию сайта кроме некоторых страниц:
User-agent: * Disallow: / Allow: /page
Запрещается индексировать весь сайт, кроме страниц, начинающихся с /page.
Disallow и Allow с пустым значением параметра
Пустая директива Disallow:
User-agent: * Disallow:
Не запрещать ничего или разрешить индексацию всего сайта и равнозначна:
User-agent: * Allow: /
Пустая директива Allow:
User-agent: * Allow:
Разрешить ничего или полный запрет индексации сайта, равнозначно:
User-agent: * Disallow: /
Главное зеркало сайта: robots.txt Host
Директива Host служит для указания роботу Яндекса главного зеркала Вашего сайта. Из всех популярных поисковых систем, директива Host распознаётся только роботами Яндекса. Директива Host полезна в том случае, если ваш сайт доступен по нескольким доменам, например:
mysite.ru mysite.com
Или для определения приоритета между:
mysite.
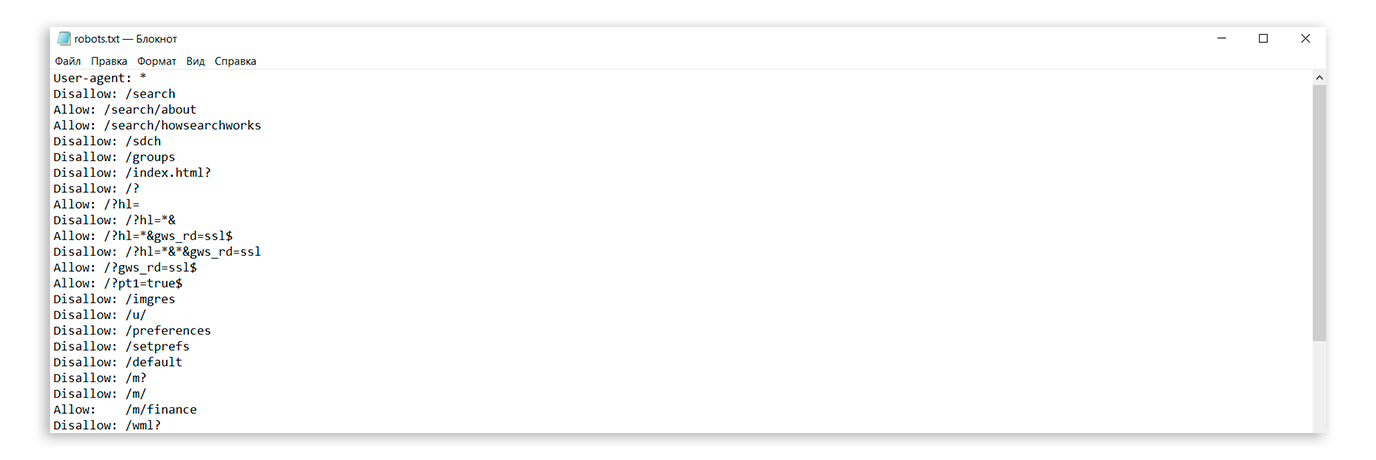 ru
www.mysite.ru
ru
www.mysite.ruРоботу Яндекса можно указать, какое зеркало является главным. Директива Host указывается в блоке директивы «User-agent: Yandex» и в качестве параметра, указывается предпочтительный адрес сайта без «http://».
Пример robots.txt с указанием главного зеркала:
User-agent: Yandex Disallow: /page Host: mysite.ru
В качестве главного зеркала указывается доменное имя mysite.ru без www. Таки образом, в результатах поиска буде указан именно такой вид адреса.
User-agent: Yandex Disallow: /page Host: www.mysite.ru
В качестве основного зеркала указывается доменное имя www.mysite.ru.
Директива Host в файле robots.txt может быть использована только один раз, если же директива Хост будет указана более одного раза, учитываться будет только первая, прочие директивы Host будут игнорироваться.
Если вы хотите указать главное зеркало для робота Google, воспользуйтесь сервисом Google Инструменты для вебмастеров.
Карта сайта: robots.
 txt sitemap
txt sitemapПри помощи директивы Sitemap, в robots.txt можно указать расположение на сайте файла карты сайта sitemap.xml.
Пример robots.txt с указанием адреса карты сайта:
User-agent: * Disallow: /page Sitemap: http://www.mysite.ru/sitemap.xml
Указание адреса карты сайта через директиву Sitemap в robots.txt позволяет поисковому роботу узнать о наличии карты сайта и начать ее индексацию.
Директива Clean-param
Директива Clean-param позволяет исключить из индексации страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL страницы. Проще говоря, будто страница доступна по разным адресам. Наша задача убрать все лишние динамические адреса, которых может быть миллион. Для этого исключаем все динамические параметры, используя в robots.txt директиву Clean-param.
Синтаксис директивы Clean-param:
Clean-param: parm1[&parm2&parm3&parm4&..
 &parmn] [Путь]
&parmn] [Путь]Рассмотрим на примере страницы со следующим URL:
www.mysite.ru/page.html?&parm1=1&parm2=2&parm3=3
Пример robots.txt Clean-param:
Clean-param: parm1&parm2&parm3 /page.html # только для page.html
или
Clean-param: parm1&parm2&parm3 / # для всех
Директива Crawl-delay
Данная инструкция позволяет снизить нагрузку на сервер, если роботы слишком часто заходят на ваш сайт. Данная директива актуальна в основном для сайтов с большим объемом страниц.
Пример robots.txt Crawl-delay:
User-agent: Yandex Disallow: /page Crawl-delay: 3
В данном случае мы «просим» роботов яндекса скачивать страницы нашего сайта не чаще, чем один раз в три секунды. Некоторые поисковые системы поддерживают формат дробных чисел в качестве параметра директивы Crawl-delay robots.txt.
Комментарии в robots.txt
Комментарий в robots.txt начинаются с символа решетки — #, действует до конца текущей строки и игнорируются роботами.
Примеры комментариев в robots.txt:
User-agent: * # Комментарий может идти от начала строки Disallow: /page # А может быть продолжением строки с директивой # Роботы # игнорируют # комментарии Host: www.mysite.ru
В заключении
Файл robots.txt — очень важный и нужный инструмент взаимодействия с поисковыми роботами и один из важнейших инструментов SEO, так как позволяет напрямую влиять на индексацию сайта. Используйте роботс правильно и с умом.
Если у вас есть вопросы — пишите в комментариях.
Рекомендуйте статью друзьям и не забывайте подписываться на блог.
Новые интересные статьи каждый день.
Автогенерация robots.txt и sitemap.xml
Файлы robots.txt и sitemap.xml – это самые важные для SEO-продвижения файлы сайта. В них содержатся команды для поисковых роботов. Благодаря им они понимают, какие страницы индексировать, а какие нет.
При создании интернет-магазина эти файлы создаются администратором сайта. Подробности читайте в документации 1С-Битрикс:
Подробности читайте в документации 1С-Битрикс:
Генератор robots.txt
Генерация файла карты сайта
Далее вам нужно сгенерировать эти же файлы для каждого региона. Обычно файлы robots.txt и sitemap.xml для различных регионов создаются, настраиваются и редактируются вручную. В Аспро: Приорити реализована возможность автоматической генерации файлов. Это принципиально новое решение задачи, которое позволит вам сэкономить время SEO-специалиста и сократить количество ошибок, которые возможны при ручном создании robots.txt и sitemap.xml под каждый регион. Рассмотрим, как работает этот функционал, и как с его помощью научиться автоматически генерировать нужные файлы.
После того, как вы создали файлы robots.txt и sitemap.xml для основного домена, инструкции из них можно продублировать в файлы, настраивающие доступ поисковых роботов к поддоменам. И здесь вам понадобится функция генерации файлов.
Чтобы воспользоваться автоматической генерацией robots. txt, перейдите в административной части сайта в Аспро: Рriority (1) → Генерация файлов (2) → robots.txt (3). Включите региональность и выберите тип «на поддоменах» для возможности перегенерации robots.txt.
txt, перейдите в административной части сайта в Аспро: Рriority (1) → Генерация файлов (2) → robots.txt (3). Включите региональность и выберите тип «на поддоменах» для возможности перегенерации robots.txt.Используйте кнопку «Пересоздать robots.txt» для копирования основного файла robots.txt в директорию /aspro_regions/robots/ для каждого поддомена. Копии основного файла для поддоменов именуются по шаблону «robots_DOMAIN.txt». В каждой из них запись директивы Host будет изменена.
Также предусмотрена возможность пересоздания файла robots.txt только для конкретного поддомена. Для редактирования файла используйте одноименные кнопки.
Чтобы использовать автогенерацию на sitemap.xml, перейдите в Рабочий стол (1) → Аспро: Рriority → Генерация файлов (2)→ sitemap.xml (3).
Внимание! Для того, чтобы использовать автогенерацию на sitemap.xml необходимо установить модуль «Поисковой оптимизации». Если у вас нет этого модуля, перейдите в Рабочий стол → Настройки (1) → Настройки продукта (2) → Модули (3).
Если у вас нет этого модуля, перейдите в Рабочий стол → Настройки (1) → Настройки продукта (2) → Модули (3).
Найдите в списке модуль «Поисковая оптимизация (seo). Статистика и инструменты для поисковой оптимизации сайта» и нажмите кнопку «Установить» напротив него.
Вернемся к генерации файлов sitemap.xml. Кнопка «Пересоздать sitemap.xml» копирует все файлы в корне сайта с маской, указанной здесь же в поле «Адрес карты сайта», в директорию /aspro_regions/sitemap/ для каждого поддомена. Копии файлов для поддоменов имеют вид «файлы_по_маске_DOMAIN.xml». В этих копиях адрес сайта заменяется на значение, указанное в поле «Адрес сайта в карте сайта».
Создать Robots.txt онлайн — автоматическая генерация
Автоматическая генерация robots.txt подходит лишь для базового создания файла. Для тонкой настройки нужен анализ структуры сайта и директорий, которые необходимо скрыть от поисковых систем во избежании дублей в индексе и исключения попадания в поисковую базу лишней информации.
Онлайн-генератор Robots.txt – поля заполняйте последовательно:
Откройте текстовый редактор, вставьте в него полученный результат и сохраните файл под именем robots.txt
После этого разместите файл в корневой директории вашего сайта. Файл должен быть доступен по ссылке http://ваш-сайт.com/robots.txt
Пояснения к атрибутам для файла Robots.txt
Директива «User-agent» — указывает для бота какой поисковой системы действуют расположенные ниже предписания. Файл Robots.txt можно создавать как с едиными для всех поисковых роботов указаниями, так и с отдельными предписаниями для каждого бота.
Директива «Disallow» — данная директива указывает какие каталоги и фалы запрещено индексировать поисковикам. Если вы создаете отдельные предписания для каждого поискового бота, то для каждого такого предписания создаются отдельные правила «Disallow». Этой директивой можно запретить индексировать сайт полностью (Disallow: /) или запрещать индексирование отдельных каталогов. В случае запрета индексации отдельных директорий количество предписаний «Disallow» может быть неограниченным.
В случае запрета индексации отдельных директорий количество предписаний «Disallow» может быть неограниченным.
Директива «Host» определяет главное зеркало сайта. Сайт может быть доступен по 2-м адресам: «с WWW» и «без WWW». Если файл Robots.txt отсутствует на сервере или в нем не заполнена запись «Host», роботы поисковых систем определяют главное зеркало для сайта по своему усмотрению, но если вы хотите сделать это самостоятельно вам следует указать это правило в директиве «Host».
Директива «Sitemap» указывает по какому пути находится файл Sitemap.xml (карта сайта). Этот файл существенно облегчает и ускоряет индексацию сайта роботами поисковых систем. Особенно важен файл Sitemap.xml для сайтов с большим количеством страниц и сложной структурой (высокий уровень вложенности).
Совет SEO-специалиста: Файл Robots.txt очень важен при продвижении сайта, т.к. он указывает поисковым системам Ваши пожелания по индексации/запрету_индексации разделов Вашего сайта. Поисковики не гарантируют соблюдение предписаний в robots.txt, но учитывают их при индексации. Для сайтов, созданных на популярных CMS, обычно есть готовые варианты файлов robots.txt, но если Вы делали доработки функционала, то может потребоваться его ручная корректировка.
Поисковики не гарантируют соблюдение предписаний в robots.txt, но учитывают их при индексации. Для сайтов, созданных на популярных CMS, обычно есть готовые варианты файлов robots.txt, но если Вы делали доработки функционала, то может потребоваться его ручная корректировка.
Как создать файл Robots.txt: настройка, проверка, индексация
В SEO мелочей не бывает. Иногда на продвижение сайта может оказать влияние всего лишь один небольшой файл — Robots.txt. Если вы хотите, чтобы ваш сайт зашел в индекс, чтобы поисковые роботы обошли нужные вам страницы, нужно прописать для них рекомендации.
«Разве это возможно?», — спросите вы. Возможно. Для этого на вашем сайте должен быть файл robots.txt. Как правильно составить файл роботс, настроить и добавить на сайт – разбираемся в этой статье.
Получайте до 18% от расходов на контекст и таргет!Рекомендуем: Click.ru – маркетплейс рекламных платформ:
- Более 2000 рекламных агентств и фрилансеров уже работают с сервисом.
- Подключиться можно самому за 1 день.
- Зарабатывайте с первого потраченного рубля, без начальных ограничений, без входного барьера.
- Выплаты на WebMoney, на карту физическому лицу, реинвестирование в рекламу.
- У вас остаются прямые доступы в рекламные кабинеты, рай для бухгалтерии по документообороту и оплатам.

Читайте также: Как проиндексировать сайт в Яндексе и Google
Что такое robots.txt и для чего нужен
Robots.txt – это обычный текстовый файл, который содержит в себе рекомендации для поисковых роботов: какие страницы нужно сканировать, а какие нет.
Важно: файл должен быть в кодировке UTF-8, иначе поисковые роботы могут его не воспринять.
Зайдет ли в индекс сайт, на котором не будет этого файла? Зайдет, но роботы могут «выхватить» те страницы, наличие которых в результатах поиска нежелательно: например, страницы входа, админпанель, личные страницы пользователей, сайты-зеркала и т. п. Все это считается «поисковым мусором»:
Если в результаты поиска попадёт личная информация, можете пострадать и вы, и сайт. Ещё один момент – без этого файла индексация сайта будет проходить дольше.
В файле Robots.txt можно задать три типа команд для поисковых пауков:
- сканирование запрещено;
- сканирование разрешено;
- сканирование разрешено частично.
Все это прописывается с помощью директив.
Как создать правильный файл Robots.txt для сайта
Файл Robots.txt можно создать просто в программе «Блокнот», которая по умолчанию есть на любом компьютере. Прописывание файла займет даже у новичка максимум полчаса времени (если знать команды).
Также можно использовать другие программы – Notepad, например. Есть и онлайн сервисы, которые могут сгенерировать файл автоматически. Например, такие как CY-PR.com или Mediasova.
Вам просто нужно указать адрес своего сайта, для каких поисковых систем нужно задать правила, главное зеркало (с www или без). Дальше сервис всё сделает сам.
Дальше сервис всё сделает сам.
Лично я предпочитаю старый «дедовский» способ – прописать файл вручную в блокноте. Есть ещё и «ленивый способ» — озадачить этим своего разработчика 🙂 Но даже в таком случае вы должны проверить, правильно ли там всё прописано. Поэтому давайте разберемся, как составить этот самый файл, и где он должен находиться.
Это интересно: Как увеличить посещаемость сайта
Где должен находиться файл Robots
Готовый файл Robots.txt должен находиться в корневой папке сайта. Просто файл, без папки:
Хотите проверить, есть ли он на вашем сайте? Вбейте в адресную строку адрес: site.ru/robots.txt. Вам откроется вот такая страничка (если файл есть):
Файл состоит из нескольких блоков, отделённых отступом. В каждом блоке – рекомендации для поисковых роботов разных поисковых систем (плюс блок с общими правилами для всех), и отдельный блок со ссылками на карту сайта – Sitemap.
Внутри блока с правилами для одного поискового робота отступы делать не нужно.
Каждый блок начинается директивой User-agent.
После каждой директивы ставится знак «:» (двоеточие), пробел, после которого указывается значение (например, какую страницу закрыть от индексации).
Нужно указывать относительные адреса страниц, а не абсолютные. Относительные – это без «www.site.ru». Например, вам нужно запретить к индексации страницу www.site.ru/shop. Значит после двоеточия ставим пробел, слэш и «shop»:
Disallow: /shop.
Звездочка (*) обозначает любой набор символов.
Знак доллара ($) – конец строки.
Вы можете решить – зачем писать файл с нуля, если его можно открыть на любом сайте и просто скопировать себе?
Для каждого сайта нужно прописывать уникальные правила. Нужно учесть особенности CMS. Например, та же админпанель находится по адресу /wp-admin на движке WordPress, на другом адрес будет отличаться. То же самое с адресами отдельных страниц, с картой сайта и прочим.
Читайте также: Как найти и удалить дубли страниц на сайте
Настройка файла Robots.
 txt: индексация, главное зеркало, диррективы
txt: индексация, главное зеркало, диррективыКак вы уже видели на скриншоте, первой идет директива User-agent. Она указывает, для какого поискового робота будут идти правила ниже.
User-agent: * — правила для всех поисковых роботов, то есть любой поисковой системы (Google, Yandex, Bing, Рамблер и т.п.).
User-agent: Googlebot – указывает на правила для поискового паука Google.
User-agent: Yandex – правила для поискового робота Яндекс.
Для какого поискового робота прописывать правила первым, нет никакой разницы. Но обычно сначала пишут рекомендации для всех роботов.
Рекомендации для каждого робота, как я уже писала, отделяются отступом.
Disallow: Запрет на индексацию
Чтобы запретить индексацию сайта в целом или отдельных страниц, используется директива Disallow.
Например, вы можете полностью закрыть сайт от индексации (если ресурс находится на доработке, и вы не хотите, чтобы он попал в выдачу в таком состоянии). Для этого нужно прописать следующее:
Для этого нужно прописать следующее:
User-agent: *
Disallow: /
Таким образом всем поисковым роботам запрещено индексировать контент на сайте.
А вот так можно открыть сайт для индексации:
User-agent: *
Disallow:
Потому проверьте, стоит ли слеш после директивы Disallow, если хотите закрыть сайт. Если хотите потом его открыть – не забудьте снять правило (а такое часто случается).
Чтобы закрыть от индексации отдельные страницы, нужно указать их адрес. Я уже писала, как это делается:
User-agent: *
Disallow: /wp-admin
Таким образом на сайте закрыли от сторонних взглядов админпанель.
Что нужно закрывать от индексации в обязательном порядке:
- административную панель;
- личные страницы пользователей;
- корзины;
- результаты поиска по сайту;
- страницы входа, регистрации, авторизации.
Можно закрыть от индексации и отдельные типы файлов. Допустим, у вас на сайте есть некоторые .pdf-файлы, индексация которых нежелательна. А поисковые роботы очень легко сканируют залитые на сайт файлы. Закрыть их от индексации можно следующим образом:
Допустим, у вас на сайте есть некоторые .pdf-файлы, индексация которых нежелательна. А поисковые роботы очень легко сканируют залитые на сайт файлы. Закрыть их от индексации можно следующим образом:
User-agent: *
Disallow: /*. pdf$
Как отрыть сайт для индексации
Даже при полностью закрытом от индексации сайте можно открыть роботам путь к определённым файлам или страницам. Допустим, вы переделываете сайт, но каталог с услугами остается нетронутым. Вы можете направить поисковых роботов туда, чтобы они продолжали индексировать раздел. Для этого используется директива Allow:
User-agent: *
Allow: /uslugi
Disallow: /
Главное зеркало сайта
До 20 марта 2018 года в файле robots.txt для поискового робота Яндекс нужно было указывать главное зеркало сайта через директиву Host. Сейчас этого делать не нужно – достаточно настроить постраничный 301-редирект.
Что такое главное зеркало? Это какой адрес вашего сайта является главным – с www или без. Если не настроить редирект, то оба сайта будут проиндексированы, то есть, будут дубли всех страниц.
Если не настроить редирект, то оба сайта будут проиндексированы, то есть, будут дубли всех страниц.
Карта сайта: robots.txt sitemap
После того, как прописаны все директивы для роботов, необходимо указать путь к Sitemap. Карта сайта показывает роботам, что все URL, которые нужно проиндексировать, находятся по определённому адресу. Например:
Sitemap: site.ru/sitemap.xml
Когда робот будет обходить сайт, он будет видеть, какие изменения вносились в этот файл. В итоге новые страницы будут индексироваться быстрее.
Читайте по теме: Как сделать карту сайта
Директива Clean-param
В 2009 году Яндекс ввел новую директиву – Clean-param. С ее помощью можно описать динамические параметры, которые не влияют на содержание страниц. Чаще всего данная директива используется на форумах. Тут возникает много мусора, например id сессии, параметры сортировки. Если прописать данную директиву, поисковый робот Яндекса не будет многократно загружать информацию, которая дублируется.
Прописать эту директиву можно в любом месте файла robots.txt.
Параметры, которые роботу не нужно учитывать, перечисляются в первой части значения через знак &:
Clean-param: sid&sort /forum/viewforum.php
Эта директива позволяет избежать дублей страниц с динамическими адресами (которые содержат знак вопроса).
Директива Crawl-delay
Эта директива придёт на помощь тем, у кого слабый сервер.
Приход поискового робота – это дополнительная нагрузка на сервер. Если у вас высокая посещаемость сайта, то ресурс может попросту не выдержать и «лечь». В итоге робот получит сообщение об ошибке 5хх. Если такая ситуация будет повторяться постоянно, сайт может быть признан поисковой системой нерабочим.
Представьте, что вы работаете, и параллельно вам приходится постоянно отвечать на звонки. Ваша продуктивность в таком случае падает.
Так же и с сервером.
Вернемся к директиве. Crawl-delay позволяет задать задержку сканирования страниц сайта с целью снизить нагрузку на сервер. Другими словами, вы задаете период, через который будут загружаться страницы сайта. Указывается данный параметр в секундах, целым числом:
Другими словами, вы задаете период, через который будут загружаться страницы сайта. Указывается данный параметр в секундах, целым числом:
Crawl-delay: 2
Комментарии в robots.txt
Бывают случаи, когда вам нужно оставить в файле комментарий для других вебмастеров. Например, если ресурс передаётся в работу другой команде или если над сайтом работает целая команда.
В этом файле, как и во всех других, можно оставлять комментарии для других разработчиков.
Делается это просто – перед сообщением нужно поставить знак решетки: «#». Дальше вы можете писать свое примечание, робот не будет учитывать написанное:
User-agent: *
Disallow: /*. xls$
#закрыл прайсы от индексации
Как проверить файл robots.txt
После того, как файл написан, нужно узнать, правильно ли. Для этого вы можете использовать инструменты от Яндекс и Google.
Через Яндекс.Вебмастер robots.txt можно проверить на вкладке «Инструменты – Анализ robots. txt»:
txt»:
На открывшейся странице указываем адрес проверяемого сайта, а в поле снизу вставляем содержимое своего файла. Затем нажимаем «Проверить». Сервис проверит ваш файл и укажет на возможные ошибки:
Также можно проверить файл robots.txt через Google Search Console, если у вас подтверждены права на сайт.
Для этого в панели инструментов выбираем «Сканирование – Инструмент проверки файла robots.txt».
На странице проверки вам тоже нужно будет скопировать и вставить содержимое файла, затем указать адрес сайта:
Потом нажимаете «Проверить» — и все. Система укажет ошибки или выдаст предупреждения.
Останется только внести необходимые правки.
Если в файле присутствуют какие-то ошибки, или появятся со временем (например, после какого-то очередного изменения), инструменты для вебмастеров будут присылать вам уведомления об этом. Извещение вы увидите сразу, как войдете в консоль.
Это интересно: 20 самых распространённых ошибок, которые убивают ваш сайт
Частые ошибки в заполнении файла robots.
 txt
txtКакие же ошибки чаще всего допускают вебмастера или владельцы ресурсов?
1. Файла вообще нет. Это встречается чаще всего, и выявляется при SEO-аудите ресурса. Как правило, на тот момент уже заметно, что сайт индексируется не так быстро, как хотелось бы, или в индекс попали мусорные страницы.
2. Перечисление нескольких папок или директорий в одной инструкции. То есть вот так:
Allow: /catalog /uslugi /shop
Называется «зачем писать больше…». В таком случае робот вообще не знает, что ему можно индексировать. Каждая инструкция должна иди с новой строки, запрет или разрешение на индексацию каждой папки или страницы – это отдельная рекомендация.
3. Разные регистры. Название файла должно быть с маленькой буквы и написано маленькими буквами – никакого капса. То же самое касается и инструкций: каждая с большой буквы, все остальное – маленькими. Если вы напишете капсом, это будет считаться уже совсем другой директивой.
4. Пустой User-agent. Нужно обязательно указать, для какой поисковой системы идет набор правил. Если для всех – ставим звездочку, но никак нельзя оставлять пустое место.
5. Забыли открыть ресурс для индексации после всех работ – просто не убрали слеш после Disallow.
6. Лишние звездочки, пробелы, другие знаки. Это просто невнимательность.
Регулярно заглядывайте в инструменты для вебмастеров и вовремя исправляйте возможные ошибки в своем файле robots.txt.
Удачного вам продвижения!
Создать и настроить robots.txt в битриксе
Важно передать поисковикам актуальную информацию о страницах, которые закрыты от индексации, о главном зеркале и карте сайта (sitemap.xml). Для этого в корне сайта создается файл robots.tx и заполняется директивами.
Рассмотрим как в самом общем случае в битриксе создать файл robots.txt.
Первое, переходим на страницу Рабочий стол -> Маркетинг -> Поисковая оптимизация -> Настройка robots. txt
txt
Второе, указываем основные правила.
На первой строчке видим User-agent: * , это означает, что директивы указаны для всех роботов всех поисковых систем.
Закрываем от индексации страницу авторизации, личного кабинета и другие директории и страницы, которые не должны попасть в результаты поиска.
Для того, чтобы закрыть директорию пишем правило:
Disallow: /auth/
Третье, указываем главное зеркало сайта с помощью директивы Host. Учтите www, если главным выбран домен с www.
Четвертое, в директиве Sitemap прописываем ссылку к файлк sitemap.xml.
В целом, это все что требуется, для того, чтобы передать файл в вебмастера Яндекса и Google.
В интерфейсе cms битрикс, есть возможность работать с каждым роботом(у поисковиков есть несколько ботов(роботов), которые занимаются отдельными действиями).
Вот роботы Яндекса:
- YandexBot — основной индексирующий
- YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы
- YandexMedia — робот, индексирующий мультимедийные данные
- YandexImages — индексатор Яндекс. Картинок
- YandexBlogs поиска по блогам — робот, индексирующий посты и комментарии
- YandexNews — робот Яндекс.Новостей
- YandexMetrika — робот Яндекс.Метрики
- YandexMarket — робот Яндекс.Маркета
 Картинок
КартинокНапример, вам не нужно индексировать картинки, находящиеся в папке /include/, но вы хотите, чтобы статьи из этого раздела индексировались. Для этого, следует закрыть директивой Disallow папку /include/ для робота YandexImages.
User-agent: YandexImages
Disallow: /include/
Семен Голиков.
Создание правильного robots.txt в Битрикс
Многие сталкиваются с проблемами неправильного индексирования сайта поисковиками. В этой статье я объясню как создать правильный robots.txt для Битрикс чтобы избежать ошибок индексирования.
Что такое robots.txt и для чего он нужен?
Robots.txt — это текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем (информация Яндекса).В основном он нужен чтобы закрыть от индексации страницы и файлы, которые поисковикам индексировать и, следовательно, добавлять в поисковую выдачу не нужно.
Обычно это технические файлы и страницы, панели администрирования, кабинеты пользователя и дублирующаяся информация, например поиск вашего сайта и др.
Создание базового robots.txt для Битрикс
Частая ошибка начинающих кроется в ручном составлении этого файла. Это делать не нужно.В Битриксе уже есть модуль, отвечающий за файл robots.txt. Его можно найти на странице «Маркетинг -> Поисковая оптимизация -> Настройка robots.
 txt».
txt».На этой странице есть кнопка для создания базового набора правил под систему Битрикс. Воспользуйтесь ей, чтобы создать все стандартные правила:
Дальше в настройках генерации карты сайта укажите галочку для добавления ее в robots.txt:
После генерации карты сайта путь к ней автоматически добавится в robots.txt.
После этого у вас уже будет хороший базовый набор правил. А дальше уже следует исходить из рекомендаций SEO-специалиста и закрывать (кнопкой «Запретить файл/папку») необходимые страницы. Обычно это страницы поиска, личные кабинеты и другие.
И не забывайте, что вы можете обратиться к нам за продвижением сайта. Мы настроим все правильно и выведем ваш сайт на Битриксе на хорошие позиции.
Robots.txt для сайта: правила и примеры
Что такое robots.txt и для чего нужен?
SEO-продвижение сайта подразумевает его оптимизацию под требования поисковых систем. Главная цель – это улучшение позиций в органической выдаче поисковиков, и как следствие, привлечение целевого трафика. При этом не все страницы сайта имеют ценность для потенциальной аудитории, и, соответственно, часть из них не должна участвовать в ранжировании.
Перед процессом ранжирования, поисковики собирают информацию со страниц сайта, индексируя ее с помощью специальных роботов – краулеров. Владелец сайта имеет в своем распоряжении инструмент, который позволяет запрещать или разрешать индексацию тех или иных страниц для конкретно выбранных поисковых краулеров. Этим инструментом и выступает файл robots.txt.
Приведем перечень страниц, которые наверняка не должны участвовать в поисковом ранжировании:
- Файлы и страницы административной части сайта.
- Различные формы, например, авторизации пользователей и т.д.
- Страницы поисковых инструментов внутри сайта.
- Опции сравнения товаров в интернет-магазинах. Не путать с фильтрами в категориях товаров.
- Дубли страниц.
- Прочие служебные страницы, к примеру, личный кабинет.
Подобные страницы, если они доступны для сканирования, могут приводить к ряду проблем:
- На сканирование сайта выделяется краулинговый бюджет, определяющий количество страниц, которые поисковый робот обойдет за условный промежуток времени. Нецелевые документы, которые не решают задач сайта, будут тратить этот бюджет понапрасну. Если сайт большой, то могут возникнуть задержки в процессе индексации целевых страниц. Другими словами, новые или измененные страницы в поисковой выдаче могут появляться с задержками.
- Представим ситуацию, когда нецелевая страница попала в органическую выдачу. Перейдя на нее, пользователь с большой долей вероятности покинет ее, негативно повлияв при этом на процент отказов. Который в свою очередь, является важнейшим фактором ранжирования не только одного конкретно взятого документа, но и иногда сайта в целом. Так что одной из основных задач при комплексном SEO-продвижении является снижение количества отказов.
- В некоторых случаях в индекс могут попадать дубликаты страниц. Это приведет к тому, что поисковые алгоритмы попытаются самостоятельно определить каноническую (главную) версию документа, и часто в индексе вместо нее остается дубликат.
Правила создания robots.txt
Структура файла состоит из групп правил, адресованных поисковым роботам.
Следует понимать следующие принципы заполнения файла:
- Структура представляет собой набор разделов и непосредственно правил-директив.
- Разделы начинаются с директивы User-agent, обозначающей название поискового робота, на которого распространяется запрет/разрешение, указанное в текущей секции.
- При этом каждый из разделов является самостоятельной единицей и обрабатываются краулерами отдельно друг от друга. Другими словами, предыдущие правила переписывают последующие.
- Разделы обрабатываются сверху вниз, по порядку.
- Если в robots.txt отсутствует директива для документа, то по умолчанию его разрешено индексировать всем краулерам.
- Следует учитывать регистр букв в написании подстрок, т.е., /file.html и /FILE.HTML – разные документы.
- Для комментирования используется символ решетки (#). Им удобно пользоваться, когда требуется временно отключить определенные директивы.
- Каждый из наборов правил для определенных ботов должен разделяться пустой строкой.
- Между правилами для одного бота пустые строки должны отсутствовать.
Технические требования к файлу:
- Размер файла не должен превышать 500 КБ.
- Формат файла – TXT, сохраненного в кодировке UTF-8.
- Должен быть расположен в корневой директории сайта. В ином случае краулером будет зафиксировано его отсутствие.
- Доступ к файлу должен быть открытым, а при посещении возвращать код 200.
- Допускается использование одного файла в рамках одного ресурса.
- Заполняется исключительно в латинице. Если в домен входят кириллические символы, то он должен быть сконвертирован с помощью Punycode в латиницу.
Директивы
Robots.txt содержит в себе набор инструкций, распространяющихся на всех или некоторых поисковых краулеров.
Синтаксис файла включает в себя следующие символы:
- # – комментарии, та текстовая часть файла, которая не учитывается ботами.
- * – этот символ допускает любой набор символов после себя. Т.е., например, директива «Disallow: *» закрывает все директории ресурса от индексации.
- $ – перекрывает действие *, обозначает, что после этого символа следует остановиться.
Теперь разберем директивы файла robots.txt для сайта.
User-agent
Относится к обязательным директивам, с нее должна начинаться каждая группа правил. В этом поле указывается тип краулера, на которого распространяется действие группы правил.
User-agent содержит в себе название поискового робота, но если инструкция распространяется на все типы ботов, то указывается «*».
Список основных ботов, которые можно указывать в robots.txt:
- Yandex – касается всех роботов Яндекса.
- YandexBot – основной краулер Яндекса, отвечает за индексацию текстового контента.
- YandexImages – также краулер от Яндекса, который индексирует изображения.
- YandexMedia – бот Яндекса, который индексирует мультимедийный контент по типу видео.
- Google – все роботы Google.
- Googlebot – основной бот Google.
- Googlebot-Image – робот Google, целью работы которого является индексация изображений.
Одну и ту же директорию сайта можно запретить или разрешить для индексирования разным поисковым ботам.
Пример – не забываем вставлять пустую строку между правилами:
User-agent: Google Disallow: /main/ User-agent: Yandex Allow: /main/
Пример с набором нескольких директив для одного робота. Между директивами не должно быть пустых строк:
# Правильно: User-agent: Google Disallow: /files/ Disallow: /wp-admin/ # Неправильно User-agent: Google Disallow: /files/ Disallow: /wp-admin/
Как говорилось выше, файл считывается роботами сверху вниз по порядку. Все последующие инструкции для конкретно взятого робота игнорируются. Т.е., в приоритете всегда первая директива.
# Директива для робота Googlebot-Image. В ней разрешается индексация папки images: User-agent: Googlebot-Image Allow: /images/ # Директива для всех ботов, запрещающая индексацию папки images. При этом правило не будет распространяться на Googlebot-Image: User-agent: * Disallow: /images/
Disallow
Это обязательная директива – в каждой из групп правил должно содержаться Disallow или Allow. Суть ее заключается в указании документа или каталога на сайте, запрещенного для индексирования. Для документов (страниц) следует прописывать полный путь, а для каталога достаточно завершить его название символом «/» – в этом случае, все последующие директории также будут закрыты от индексации.
# Запрет на индексацию всего сайта: User-agent: * Disallow: / # Запрет индексирования конкретного раздела (директории): User-agent: * Disallow: /main/ # Запрет на индексацию всех URL-адресов, начинающихся с /main: User-agent: * Disallow: /main
Если в «Disallow» не указана директория, то правило игнорируется:
# Весь сайт доступен для индексации: User-agent: * Disallow:
Allow
Allow содержит в себе адрес документа или каталога, для которых разрешена индексация. Аналогичным образом, если указывается страница, то для нее прописывается полный URL-адрес, если это каталог, то после его названия ставится символ «/».
С помощью следующей комбинации Allow и Disallow можно строить правила исключений, например:
# Запрет на индексацию директории main, при этом ее подкаталог images доступен для сканирования: User-agent: * Disallow: /main/ # индексирование запрещено Allow: /main/ images/ # данный подкаталог доступен для индексации всеми поисковиками
Если в правилах указаны противоречащие друг другу директивы: Allow и Disallow, то Allow имеет приоритет:
# Запрет на индексацию директории main, при этом ее подкаталог images доступен для сканирования: User-agent: * Disallow: /main/ # индексирование запрещено Allow: /main/ images/ # данный подкаталог доступен для индексации всеми поисковиками
Sitemap
С помощью этой директивы можно подсказать роботам расположение файла карты сайта.
Sitemap: https://sitename.com/sitemap.xml
Допускается указание нескольких файлов карт.
Замечание: просмотр файла robots.txt доступен для всех, а с помощью карты сайта любой желающий может найти недавно опубликованные, но не проиндексированные страницы.
Clean-param
Если URL-адрес содержит в себе какие-либо динамические параметры, например, UTM-метки, но не влияющие на отображение документа, то это можно указать в директиве Clean-param.
Схема директивы: <параметр> <URL-адрес документа (страницы) для которой не учитывается параметр>:
User-agent: * Disallow: /main/ # Указывает на то, что параметры utm в URL-адресе с cat.php не обладают какой-либо значимостью. # (например, в адресе sitename.com/cat.php?utm=1 параметр utm не учитывается. Clean-param: utm cat.php
Эта директива призвана помочь алгоритмам Яндекса в определении тех страниц, URL-адреса которых должны попасть в органическую выдачу.
Также допускается указание нескольких директив «Clean-param» в одной группе правил.
Примеры robots.txt для разных CMS
Ниже представлены варианты robots.txt для некоторых CMS, их можно использовать по умолчанию, но не стоит использовать их вслепую, предварительно ознакомьтесь с основными директивами и спецсимволами.
WordPress
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.php Disallow: /readme.html Disallow: /*? Disallow: /?s= Allow: /*.css Allow: /*.js Sitemap: https://site.ru/sitemap.xml
Joomla
Robots.txt для Joomla, скрыты от индексации основные директории со служебным контентом.
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Sitemap: https://sitename.com/sitemap.xml
1С-Битрикс
User-agent: * Disallow: /cgi-bin Disallow: /bitrix/ Disallow: /local/ Disallow: /*index.php$ Disallow: /auth/ Disallow: *auth= Disallow: /personal/ Disallow: *register= Disallow: *forgot_password= Disallow: *change_password= Disallow: *login= Disallow: *logout= Disallow: */search/ Disallow: *action= Disallow: *print= Disallow: *?new=Y Disallow: *?edit= Disallow: *?preview= Disallow: *backurl= Disallow: *back_url= Disallow: *back_url_admin= Disallow: *captcha Disallow: */feed Disallow: */rss Disallow: *?FILTER*= Sitemap:
Каждый из представленных robots.txt следует дорабатывать под особенности своего проекта, это лишь примеры расширенных вариантов базовых файлов.
Проверка robots.txt
Первым делом следует проверить файл на доступность. Сделать это можно в панели Вебмастера от Яндекса: «Инструменты – Проверка ответов сервера».
Проверяем ответ сервера
Файл должен отдавать 200 код ответа.
Затем переходим по следующему пути: «Инструменты – Анализ robots.txt».
Здесь будут показаны ошибки, если они есть, а также можно удобно изучить структуру файла.
Анализ robots.txt в Яндекс.Вебмастере
Далее переходим в инструмент Google Search Console «Анализ robots.txt» и проверяем наш файл повторно.
Пример отчета
Robots.txt является важнейшим файлом при SEO-продвижении, к его созданию следует подходить основательно. Неправильная его настройка может привести к тому, что сайт перестанет индексироваться или в индекс попадут «мусорные» страницы.
Создайте файл Robots.txt | Центр поиска Google | Разработчики Google
Если вы пользуетесь услугами хостинга сайтов, например Wix или Blogger, вы может не потребоваться создавать или редактировать файл robots.txt.Начало работы
Файл robots.txt находится в корне вашего сайта. Итак, для сайта www.example.com ,
файл robots.txt находится по адресу www.example.com/robots.txt . robots.txt — это простой
текстовый файл, следующий за
Стандарт исключения роботов.Файл robots.txt состоит из одного или нескольких правил. Каждое правило блокирует (или разрешает) доступ для
данного поискового робота на указанный путь к файлу на этом веб-сайте.
Вот простой файл robots.txt с двумя правилами, описанными ниже:
# Группа 1 Пользовательский агент: Googlebot Запретить: / nogooglebot / # Группа 2 Пользовательский агент: * Позволять: / Карта сайта: http://www.example.com/sitemap.xml
Пояснение:
- Пользовательскому агенту с именем «Googlebot» не разрешено сканировать
http: // example.com / nogooglebot /или любые подкаталоги. - Всем остальным пользовательским агентам разрешено сканировать весь сайт. Это могло быть пропущено и результат будет таким же; по умолчанию пользовательские агенты могут сканировать весь сайт.
- Файл карты сайта находится по адресу
http://www.example.com/sitemap.xml.
Дополнительные примеры см. В разделе синтаксиса.
Основные принципы robots.txt
Вот несколько основных рекомендаций для файлов robots.txt. Мы рекомендуем вам прочитать полный синтаксис файлов robots.txt, поскольку Синтаксис robots.txt имеет некоторые тонкие особенности, которые вам следует понять.
Формат и расположение
Вы можете использовать практически любой текстовый редактор для создания файла robots.txt. Текстовый редактор должен уметь для создания стандартных текстовых файлов UTF-8. Не используйте текстовый процессор; текстовые процессоры часто экономят файлы в проприетарном формате и могут добавлять неожиданные символы, такие как фигурные кавычки, которые может вызвать проблемы для сканеров.
Используйте тестер robots.txt для написания или редактирования файлов robots.txt для вашего сайта. Этот инструмент позволяет вам проверить синтаксис и поведение против вашего сайта.Правила формата и расположения:
- Файл должен называться robots.txt.
- На вашем сайте может быть только один файл robots.txt.
- Файл robots.txt должен находиться в корне хоста веб-сайта, чтобы
который применяется. Например, для управления сканированием всех URL-адресов ниже
http: // www.example.com/, файл robots.txt должен находиться по адресуhttp://www.example.com/robots.txt. Это не может быть помещено в подкаталог (например,http://example.com/pages/robots.txt). Если ты не знаете, как получить доступ к корню вашего веб-сайта или вам нужны разрешения для этого, обратитесь к своему веб-сайту провайдер хостинг-услуг. Если вы не можете получить доступ к корню вашего сайта, используйте альтернативную блокировку метод, такой как метатеги. - Роботы.txt может применяться к субдоменам (например,
http: // website .example.com / robots.txt) или на нестандартных порты (например,http://example.com: 8181 /robots.txt).
Синтаксис
- Файл robots.txt должен быть текстовым файлом в кодировке UTF-8 (включая ASCII). Использование другого персонажа наборы невозможно.
- Файл robots.txt состоит из одной или нескольких групп .
- Каждая группа состоит из нескольких правил или директив (инструкции), по одной директиве на строку.
- Группа предоставляет следующую информацию:
- Кому относится группа (пользовательский агент )
- К каким каталогам или файлам может обращаться агент
- К каким каталогам или файлам агент не может получить доступ
- Группы обрабатываются сверху вниз, и пользовательский агент может соответствовать только одному набору правил, который это первое, наиболее конкретное правило, соответствующее данному пользовательскому агенту.
- Предположение по умолчанию состоит в том, что пользовательский агент может сканировать любую страницу или каталог.
не заблокирован правилом
Disallow:. - Правила чувствительны к регистру . Например,
Disallow: /file.aspприменяется кhttp://www.example.com/file.asp, но неhttp://www.example.com/FILE.asp. - Комментарии — это любое содержимое после отметки
#.
В файлах robots.txt используются следующие директивы:
-
Пользовательский агент:[ Обязательно, по одному или нескольким на группу ] директива определяет имя автоматического клиента, известного как сканер поисковой системы, который правило применяется к. Это первая строка для любой группы правил. Имена пользовательских агентов Google: перечисленные в Список пользовательских агентов Google. Использование звездочки (*), как в примере ниже, будет соответствовать всем поисковым роботам. , за исключением различных поисковых роботов AdsBot , которые должны иметь явное имя. Примеры:# Пример 1. Заблокировать только Googlebot Пользовательский агент: Googlebot Запретить: / # Пример 2. Блокировка роботов Googlebot и Adsbot Пользовательский агент: Googlebot Пользовательский агент: AdsBot-Google Запретить: / # Пример 3. Блокировка всех сканеров, кроме AdsBot Пользовательский агент: * Disallow: /
-
Disallow:[ Как минимум один или несколькоDisallowилиРазрешитьзаписей в правиле ] Каталог или страница относительно корневого домена, что вы не хотите, чтобы пользовательский агент сканировал.Если правило относится к странице, это должно быть полное имя страницы, как показано в браузере; если он относится к каталогу, он должен заканчиваться на Марка/. -
Разрешить:[ Как минимум один или несколькоЗапретитьилиРазрешитьзаписей в правиле ] Каталог или страница относительно корневого домена, которые могут сканироваться только что упомянутым пользовательским агентом. Это используется для отменыDisallow Директива, разрешающая сканирование подкаталога или страницы в запрещенном каталог.Для одной страницы полное имя страницы, отображаемое в браузере, должно быть указано. В случае каталога правило должно заканчиваться отметкой/. -
Карта сайта:[ Необязательно, ноль или более на файл ] расположение карты сайта для этого веб-сайта. URL-адрес карты сайта должен быть полным URL-адресом; Google не предполагает и не проверяет альтернативы http / https / www.non-www. Файлы Sitemap — хороший способ указать, какой контент Google должен сканировать , а не какой контент может или не может сканировать .Узнайте больше о файлах Sitemap. Пример:Карта сайта: https://example.com/sitemap.xml Карта сайта: http://www.example.com/sitemap.xml
Все директивы, кроме карты сайта , поддерживают подстановочный знак * для пути
префикс, суффикс или целая строка.
Строки, не соответствующие ни одной из этих директив, игнорируются.
Другой пример файла
Файл robots.txt состоит из одной или нескольких групп, каждая из которых начинается с User-agent строка, указывающая цель групп.Вот файл с двумя
группы; встроенные комментарии объясняют каждую группу:
# Заблокировать googlebot из example.com/directory1 / ... и example.com/directory2 / ... # но разрешить доступ к directory2 / subdirectory1 / ... # Все остальные каталоги на сайте разрешены по умолчанию. Пользовательский агент: googlebot Запретить: / directory1 / Запретить: / каталог2 / Разрешить: / каталог2 / подкаталог1 / # Блокировать весь сайт от другого сканера. Пользовательский агент: anothercrawler Disallow: /
Полный синтаксис robots.txt
Вы можете найти полные robots.txt здесь. Пожалуйста, прочтите полную документацию, так как в синтаксисе robots.txt есть несколько сложных частей, которые важно учиться.
Полезные правила robots.txt
Вот несколько общих полезных правил robots.txt:
| Правило | Образец |
|---|---|
| Запретить сканирование всего веб-сайта. Имейте в виду, что в некоторых ситуаций URL-адреса с веб-сайта все еще могут быть проиндексированы, даже если они не были поползли.Это не соответствует различные сканеры AdsBot, который должен быть назван явно. | Пользовательский агент: * Disallow: / |
| Запретить сканирование каталога и его содержимого , следуя имя каталога с косой чертой. Помните, что вам не следует использовать robots.txt для блокировки доступ к частному контенту: вместо этого используйте правильную аутентификацию.URL-адреса, запрещенные Файл robots.txt может быть проиндексирован без сканирования, а файл robots.txt могут быть просмотрены кем угодно, потенциально раскрывая местонахождение вашего личного контента. | Пользовательский агент: * Запретить: / календарь / Disallow: / junk /. |
| Разрешить доступ одному искателю | User-agent: Googlebot-news Позволять: / Пользовательский агент: * Disallow: / |
| Разрешить доступ всем, кроме одного поискового робота | Пользовательский агент: Ненужный бот Запретить: / Пользовательский агент: * Разрешить: / |
Запретить сканирование отдельной веб-страницы , указав страницу после слэш: | Пользовательский агент: * Запретить: / частный_файл.HTML |
Заблокировать определенное изображение из Картинок Google: | Пользовательский агент: Googlebot-Image Запретить: /images/dogs.jpg |
Заблокировать все изображения на вашем сайте из Картинок Google: | Пользовательский агент: Googlebot-Image Disallow: / |
Запретить сканирование файлов определенного типа (например, | Пользовательский агент: Googlebot Disallow: /*.gif$ |
Запретить сканирование всего сайта, но показывать рекламу AdSense на этих страницах ,
и запретить использование всех поисковых роботов, кроме | Пользовательский агент: * Запретить: / Пользовательский агент: Mediapartners-Google Разрешить: / |
Чтобы сопоставить URL-адреса, которые заканчиваются определенной строкой , используйте $ . Для
Например, пример кода блокирует любые URL-адреса, заканчивающиеся на .xls : | Пользовательский агент: Googlebot Запретить: /*.xls$ |
Роботы.txt Введение и руководство | Центр поиска Google
Что такое файл robots.txt?
Файл robots.txt сообщает сканерам поисковых систем, какие страницы или файлы он может или
не могу запросить с вашего сайта. Это используется в основном для того, чтобы не перегружать ваш сайт
Запросы; это не механизм для защиты веб-страницы от Google. Чтобы веб-страница не попала в Google, вы должны использовать директив noindex ,
или защитите свою страницу паролем.
Для чего используется файл robots.txt?
Файл robots.txt используется в основном для управления трафиком сканера на ваш сайт, а обычно для хранения файла вне Google, в зависимости от типа файла:
| Тип файла | Управление движением | Скрыть от Google | Описание |
|---|---|---|---|
| Веб-страница | Для веб-страниц (HTML, PDF или другие форматы, не относящиеся к мультимедиа, которые может читать Google), файл robots.txt можно использовать для управления сканирующим трафиком, если вы считаете, что ваш сервер будет перегружен запросами от поискового робота Google, или чтобы избежать сканирования неважных или похожих страниц на вашем сайте. Вы не должны использовать файл robots.txt как средство, чтобы скрыть свои веб-страницы от результатов поиска Google. Это потому, что, если другие страницы указывают на вашу страницу с описательным текстом, ваша страница все равно может быть проиндексирована без посещения страницы. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или директиву Если ваша веб-страница заблокирована файлом robots.txt , она все равно может отображаться в результатах поиска, но результат поиска не будет иметь описания и будет выглядеть примерно так. Файлы изображений, видеофайлы, PDF-файлы и другие файлы, отличные от HTML, будут исключены. Если вы видите этот результат поиска для своей страницы и хотите его исправить, удалите запись robots.txt, блокирующую страницу. Если вы хотите полностью скрыть страницу от поиска, воспользуйтесь другим методом. | ||
| Медиа-файл | Используйте robots.txt для управления трафиком сканирования, а также для предотвращения появления файлов изображений, видео и аудио в результатах поиска Google. (Обратите внимание, что это не помешает другим страницам или пользователям ссылаться на ваш файл изображения / видео / аудио.) | ||
| Файл ресурсов | Вы можете использовать файл robots.txt для блокировки файлов ресурсов, таких как неважные изображения, скрипты или файлы стилей, , если вы считаете, что страницы, загруженные без этих ресурсов, не пострадают от потери .Однако, если отсутствие этих ресурсов затрудняет понимание страницы поисковым роботом Google, вы не должны блокировать их, иначе Google не справится с анализом страниц, зависящих от этих ресурсов. |
Я пользуюсь услугами хостинга сайтов
Если вы используете службу хостинга веб-сайтов, такую как Wix, Drupal или Blogger, вам может не потребоваться (или у вас будет возможность) напрямую редактировать файл robots.txt. Вместо этого ваш провайдер может открыть страницу настроек поиска или какой-либо другой механизм, чтобы сообщить поисковым системам, сканировать ли вашу страницу или нет.
Чтобы узнать, просканировала ли ваша страница Google, найдите URL-адрес страницы в Google.
Если вы хотите скрыть (или показать) свою страницу от поисковых систем, добавьте (или удалите) любую страницу входа в систему. требования, которые могут существовать, и поиск инструкций по изменению вашей страницы видимость в поисковых системах на вашем хостинге, например: wix скрыть страницу от поисковых систем
Ознакомьтесь с ограничениями файла robots.txt
Прежде чем создавать или редактировать файл robots.txt, вы должны знать ограничения этого метода блокировки URL. Иногда вам может потребоваться рассмотреть другие механизмы, чтобы гарантировать, что ваши URL-адреса не будут найдены в Интернете.
- Директивы Robots.txt могут поддерживаться не всеми поисковыми системами.
Инструкции в файлах robots.txt не могут обеспечить поведение сканера на вашем сайте; гусеничный робот должен им подчиняться. В то время как робот Googlebot и другие известные поисковые роботы подчиняются инструкциям в файле robots.txt, другие поисковые роботы могут этого не делать.Поэтому, если вы хотите защитить информацию от веб-сканеров, лучше использовать другие методы блокировки, такие как защита паролем личных файлов на вашем сервере. - Разные поисковые роботы по-разному интерпретируют синтаксис
Хотя респектабельные поисковые роботы следуют директивам в файле robots.txt, каждый поисковый робот может интерпретировать директивы по-разному. Вы должны знать правильный синтаксис для обращения к разным поисковым роботам, поскольку некоторые из них могут не понимать определенные инструкции. - Роботизированная страница все еще может быть проиндексирована, если на нее есть ссылки с других сайтов
Хотя Google не будет сканировать и индексировать контент, заблокированный файлом robots.txt, мы все равно можем найти и проиндексировать запрещенный URL, если на него есть ссылка с другого места в сети. В результате URL-адрес и, возможно, другая общедоступная информация, такая как текст привязки в ссылках на страницу, все еще может отображаться в результатах поиска Google. Чтобы правильно предотвратить появление вашего URL в результатах поиска Google, вы должны защитить паролем файлы на своем сервере или использовать метатегnoindexили заголовок ответа (или полностью удалить страницу).
Тестирование страницы на наличие блоков robots.txt
Вы можете проверить, заблокирована ли страница или ресурс правилом robots.txt.
Для проверки директив noindex используйте инструмент проверки URL.
Как создать идеальный файл Robots.txt для SEO
Все любят «хаки».”
Я не исключение — мне нравится находить способы сделать свою жизнь лучше и проще.
Вот почему техника, о которой я расскажу вам сегодня, — одна из моих самых любимых. Это законный SEO-прием, которым вы можете сразу начать пользоваться.
Это способ улучшить ваше SEO за счет использования естественной части каждого веб-сайта, о которой редко говорят. Реализовать тоже несложно.
Это файл robots.txt (также называемый протоколом исключения роботов или стандартом).
Этот крошечный текстовый файл есть на каждом веб-сайте в Интернете, но большинство людей даже не знают о нем.
Он разработан для работы с поисковыми системами, но, что удивительно, это источник сока SEO, который только и ждет, чтобы его разблокировали.
Я видел, как клиент за клиентом отклонялись назад, пытаясь улучшить свое SEO. Когда я говорю им, что они могут редактировать небольшой текстовый файл, они мне почти не верят.
Однако существует множество несложных или трудоемких методов улучшения SEO, и это один из них.
Для использования всех возможностей robots.txt не требуется никакого технического опыта. Если вы можете найти исходный код для своего веб-сайта, вы можете использовать его.
Итак, когда вы будете готовы, следуйте за мной, и я покажу вам, как именно изменить файл robots.txt, чтобы он понравился поисковым системам.
Почему важен файл robots.txtВо-первых, давайте посмотрим, почему файл robots.txt вообще так важен.
Роботы.txt, также известный как протокол или стандарт исключения роботов, представляет собой текстовый файл, который сообщает веб-роботам (чаще всего поисковым системам), какие страницы вашего сайта сканировать.
Он также сообщает веб-роботам, какие страницы , а не сканировать.
Допустим, поисковая система собирается посетить сайт. Перед посещением целевой страницы он проверяет robots.txt на наличие инструкций.
Существуют разные типы файлов robots.txt, поэтому давайте рассмотрим несколько различных примеров того, как они выглядят.
Допустим, поисковая система находит этот пример файла robots.txt:
Это базовый скелет файла robots.txt.
Звездочка после «user-agent» означает, что файл robots.txt применяется ко всем веб-роботам, посещающим сайт.
Косая черта после «Запретить» указывает роботу не посещать никакие страницы сайта.
Вы можете спросить, зачем кому-то мешать веб-роботам посещать свой сайт.
В конце концов, одна из основных целей SEO — заставить поисковые системы легко сканировать ваш сайт, чтобы повысить ваш рейтинг.
Вот где заключается секрет этого SEO-взлома.
У вас наверняка много страниц на сайте? Даже если вы так не думаете, пойдите и проверьте. Вы можете быть удивлены.
Если поисковая система просканирует ваш сайт, она просканирует каждую из ваших страниц.
А если у вас много страниц, боту поисковой системы потребуется некоторое время, чтобы их просканировать, что может отрицательно повлиять на ваш рейтинг.
Это потому, что у робота Googlebot (робота поисковой системы Google) есть «краулинговый бюджет.”
Это делится на две части. Первый — это ограничение скорости сканирования. Вот как Google объясняет это:
Вторая часть — требование сканирования:
По сути, краулинговый бюджет — это «количество URL-адресов, которые робот Googlebot может и хочет просканировать».
Вы хотите помочь роботу Googlebot оптимально расходовать бюджет сканирования для вашего сайта. Другими словами, он должен сканировать ваши самые ценные страницы.
Есть определенные факторы, которые, по мнению Google, «негативно повлияют на сканирование и индексирование сайта.”
Вот эти факторы:
Итак, вернемся к robots.txt.
Если вы создадите правильную страницу robots.txt, вы можете указать роботам поисковых систем (и особенно роботу Googlebot) избегать определенных страниц.
Подумайте о последствиях. Если вы укажете роботам поисковых систем сканировать только ваш самый полезный контент, они будут сканировать и индексировать ваш сайт только на основе этого контента.
По словам Google:
«Вы не хотите, чтобы ваш сервер был перегружен поисковым роботом Google или тратил бюджет на сканирование неважных или похожих страниц вашего сайта.”
Правильно используя robots.txt, вы можете указать роботам поисковых систем разумно расходовать свой краулинговый бюджет. Именно это делает файл robots.txt таким полезным в контексте SEO.
Заинтригованы силой robots.txt?
Так и должно быть! Поговорим о том, как его найти и использовать.
Поиск файла robots.txtЕсли вы просто хотите быстро просмотреть свой файл robots.txt, есть очень простой способ просмотреть его.
Фактически, этот метод будет работать для любого сайта .Так что вы можете заглянуть в файлы других сайтов и увидеть, что они делают.
Все, что вам нужно сделать, это ввести основной URL-адрес сайта в строку поиска вашего браузера (например, neilpatel.com, quicksprout.com и т. Д.). Затем добавьте в конец /robots.txt.
Произойдет одна из трех ситуаций:
1) Вы найдете файл robots.txt.
2) Вы найдете пустой файл.
Например, у Disney не хватает файла robots.txt:
3) Вы получите 404.
Метод возвращает 404 для robots.txt:
Найдите секунду и просмотрите файл robots.txt своего собственного сайта.
Если вы обнаружите пустой файл или ошибку 404, вы захотите это исправить.
Если вы найдете действительный файл, вероятно, для него установлены настройки по умолчанию, которые были созданы при создании вашего сайта.
Мне особенно нравится этот метод просмотра файлов robots.txt других сайтов. После того, как вы изучите все тонкости robots.txt, это может стать полезным упражнением.
Теперь давайте посмотрим, как на самом деле изменить файл robots.txt.
Поиск файла robots.txtВаши следующие шаги будут зависеть от того, есть ли у вас файл robots.txt. (Проверьте, делаете ли вы это, используя метод, описанный выше.)
Если у вас нет файла robots.txt, вам придется создать его с нуля. Откройте текстовый редактор, например Блокнот (Windows) или TextEdit (Mac).
Используйте для этого только текстовый редактор .Если вы используете такие программы, как Microsoft Word, программа может вставлять дополнительный код в текст.
Editpad.org — отличный бесплатный вариант, и вы увидите, что я использую в этой статье.
Вернуться в robots.txt. Если у вас есть файл robots.txt, вам нужно найти его в корневом каталоге вашего сайта.
Если вы не привыкли ковыряться в исходном коде, то найти редактируемую версию файла robots.txt может быть немного сложно.
Обычно вы можете найти свой корневой каталог, перейдя на веб-сайт своей учетной записи хостинга, войдя в систему и перейдя в раздел управления файлами или FTP вашего сайта.
Вы должны увидеть что-то вроде этого:
Найдите файл robots.txt и откройте его для редактирования. Удалите весь текст, но сохраните файл.
Примечание. Если вы используете WordPress, вы можете увидеть файл robots.txt при переходе на yoursite.com/robots.txt, но вы не сможете найти его в своих файлах.
Это связано с тем, что WordPress создает виртуальный файл robots.txt, если в корневом каталоге нет файла robots.txt.
Если это произойдет с вами, вам нужно будет создать новый файл robots.txt файл.
Создание файла robots.txtВы можете создать новый файл robots.txt, используя любой текстовый редактор по вашему выбору. (Помните, используйте только текстовый редактор.)
Если у вас уже есть файл robots.txt, убедитесь, что вы удалили текст (но не файл).
Во-первых, вам нужно познакомиться с некоторым синтаксисом, используемым в файле robots.txt.
У Google есть хорошее объяснение некоторых основных терминов robots.txt:
Я покажу вам, как настроить простого робота.txt, а затем мы рассмотрим, как настроить его для SEO.
Начните с установки термина пользовательского агента. Мы собираемся настроить его так, чтобы он применялся ко всем веб-роботам.
Сделайте это, поставив звездочку после термина пользовательского агента, например:
Затем введите «Disallow:», но после этого ничего не вводите.
Поскольку после запрета ничего нет, веб-роботы будут направлены на сканирование всего вашего сайта. Прямо сейчас все на вашем сайте — это честная игра.
На данный момент ваш файл robots.txt должен выглядеть так:
Я знаю, что это выглядит очень просто, но эти две строчки уже многое делают.
Вы также можете создать ссылку на свою карту сайта XML, но это не обязательно. Если хотите, вот что нужно набрать:
Вы не поверите, но именно так выглядит базовый файл robots.txt.
Теперь давайте перейдем на новый уровень и превратим этот маленький файл в средство повышения SEO.
Оптимизирующие роботы.txt для SEO
Как вы оптимизируете robots.txt, все зависит от содержания вашего сайта. Есть много способов использовать robots.txt в ваших интересах.
Я рассмотрю некоторые из наиболее распространенных способов его использования.
(Имейте в виду, что вам следует , а не , использовать robots.txt для блокировки страниц от поисковых систем . Это большой запрет)
Одно из лучших применений файла robots.txt — увеличить бюджеты сканирования поисковых систем, запретив им сканировать те части вашего сайта, которые не отображаются для публики.
Например, если вы посетите файл robots.txt для этого сайта (neilpatel.com), вы увидите, что он запрещает страницу входа (wp-admin).
Поскольку эта страница используется только для входа в серверную часть сайта, роботам поисковых систем не имеет смысла тратить время на ее сканирование.
(Если у вас WordPress, вы можете использовать ту же самую запрещающую строку.)
Вы можете использовать аналогичную директиву (или команду), чтобы запретить ботам сканировать определенные страницы.После запрета введите часть URL-адреса после .com. Поместите это между двумя косыми чертами.
Итак, если вы хотите запретить боту сканировать вашу страницу http://yoursite.com/page/, введите следующее:
Вам может быть интересно, какие типы страниц исключить из индексации. Вот несколько распространенных сценариев, в которых это может произойти:
Умышленное дублирование контента. Хотя дублированный контент — это в большинстве случаев плохо, в некоторых случаях это необходимо и приемлемо.
Например, если у вас есть версия страницы для печати, технически у вас дублированное содержимое. В этом случае вы можете сказать ботам, чтобы они не сканировали одну из этих версий (обычно это версия для печати).
Это также удобно, если вы тестируете страницы с одинаковым содержанием, но с разным дизайном.
Спасибо страниц. Страница благодарности — одна из любимых страниц маркетологов, потому что она означает нового потенциального клиента.
… Верно?
Как оказалось, некоторые страницы благодарности доступны через Google .Это означает, что люди могут получить доступ к этим страницам без прохождения процесса захвата лидов, и это плохие новости.
Блокируя страницы с благодарностью, вы можете быть уверены, что их видят только квалифицированные лиды.
Допустим, ваша страница с благодарностью находится по адресу https://yoursite.com/thank-you/. В вашем файле robots.txt блокировка этой страницы будет выглядеть так:
Поскольку не существует универсальных правил для запрещенных страниц, ваш файл robots.txt будет уникальным для вашего сайта.Используйте здесь свое суждение.
Вам следует знать еще две директивы: noindex и nofollow .
Вы знаете эту директиву запрета, которую мы использовали? Фактически это не препятствует индексации страницы.
Итак, теоретически вы можете запретить страницу, но она все равно может оказаться в индексе.
Как правило, вы этого не хотите.
Вот почему вам нужна директива noindex. Он работает с директивой disallow, чтобы роботы не посещали или , индексируя определенные страницы.
Если у вас есть страницы, которые вы не хотите индексировать (например, эти драгоценные страницы с благодарностью), вы можете использовать директиву disallow и noindex:
Теперь эта страница не будет отображаться в поисковой выдаче.
Наконец, есть директива nofollow. Фактически это то же самое, что и ссылка nofollow. Короче говоря, он сообщает веб-роботам, чтобы они не сканировали ссылки на странице.
Но директива nofollow будет реализована немного иначе, потому что на самом деле она не является частью robots.txt файл.
Однако директива nofollow все еще инструктирует веб-роботов, так что это та же концепция. Единственная разница в том, где это происходит.
Найдите исходный код страницы, которую хотите изменить, и убедитесь, что вы находитесь между тегами .
Затем вставьте эту строку:
Так должно получиться так:
Убедитесь, что вы не помещаете эту строку между другими тегами — только тегами
.Это еще один хороший вариант для страниц с благодарностью, поскольку веб-роботы не будут сканировать ссылки на какие-либо лид-магниты или другой эксклюзивный контент.
Если вы хотите добавить директивы noindex и nofollow, используйте эту строку кода:
Это даст веб-роботам сразу обе директивы.
Проверяем всеНаконец, проверьте файл robots.txt, чтобы убедиться, что все в порядке и работает правильно.
Google предоставляет бесплатный тестер robots.txt как часть инструментов для веб-мастеров.
Сначала войдите в свою учетную запись для веб-мастеров, нажав «Войти» в правом верхнем углу.
Выберите свой ресурс (например, веб-сайт) и нажмите «Сканировать» на левой боковой панели.
Вы увидите «robots.txt Tester». Щелкните по нему.
Если в поле уже есть какой-либо код, удалите его и замените новым файлом robots.txt.
Щелкните «Тест» в правой нижней части экрана.
Если текст «Тест» изменится на «Разрешено», это означает, что ваш robots.txt действителен.
Вот еще немного информации об инструменте, чтобы вы могли подробно узнать, что все означает.
Наконец, загрузите файл robots.txt в корневой каталог (или сохраните его там, если он у вас уже есть). Теперь у вас есть мощный файл, и ваша видимость в результатах поиска должна повыситься.
ЗаключениеМне всегда нравится делиться малоизвестными «хитростями» SEO, которые могут дать вам реальное преимущество во многих отношениях.
Правильно настроив файл robots.txt, вы не просто улучшите свой собственный SEO. Вы также помогаете своим посетителям.
Если роботы поисковых систем могут разумно расходовать свои бюджеты сканирования, они будут организовывать и отображать ваш контент в поисковой выдаче наилучшим образом, а это означает, что вы будете более заметны.
Также не требуется много усилий для настройки файла robots.txt. В основном это однократная настройка, и при необходимости вы можете вносить небольшие изменения.
Независимо от того, запускаете ли вы свой первый или пятый сайт, с помощью robots.txt может иметь большое значение. Я рекомендую попробовать, если вы не делали этого раньше.
Каков ваш опыт создания файлов robots.txt?
Узнайте, как мое агентство может привлечь огромное количество трафика на ваш веб-сайт
- SEO — разблокируйте огромное количество SEO-трафика. Смотрите реальные результаты.
- Контент-маркетинг — наша команда создает эпический контент, которым будут делиться, получать ссылки и привлекать трафик.
- Paid Media — эффективные платные стратегии с четкой окупаемостью.
Заказать звонок
Файл Robots.txt [Примеры 2021] — Moz
Что такое файл robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы проинструктировать веб-роботов (обычно роботов поисковых систем), как сканировать страницы на своем веб-сайте. Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям. REP также включает в себя такие директивы, как мета-роботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «следовать» или «nofollow»).
На практике файлы robots.txt указывают, могут ли определенные пользовательские агенты (программное обеспечение для веб-сканирования) сканировать части веб-сайта. Эти инструкции сканирования определяются как «запрещающие» или «разрешающие» поведение определенных (или всех) пользовательских агентов.
Базовый формат:User-agent: [user-agent name] Disallow: [URL-строка не должна сканироваться]
Вместе эти две строки считаются полным файлом robots.txt, хотя один файл robots может содержат несколько строк пользовательских агентов и директив (т.е., запрещает, разрешает, задержки сканирования и т. д.).
В файле robots.txt каждый набор директив пользовательского агента отображается как дискретный набор , разделенных разрывом строки:
В файле robots.txt с несколькими директивами пользовательского агента, каждое запрещающее или разрешающее правило только применяется к агенту (ам) пользователя, указанному в этом конкретном наборе, разделенном разрывом строки. Если файл содержит правило, которое применяется более чем к одному пользовательскому агенту, поисковый робот только обратит внимание (и будет следовать директивам в) наиболее конкретной группе инструкций .
Вот пример:
Msnbot, discobot и Slurp вызываются специально, поэтому эти пользовательские агенты только обратят внимание на директивы в своих разделах файла robots.txt. Все остальные пользовательские агенты будут следовать директивам в группе user-agent: *.
Пример robots.txt:
Вот несколько примеров использования robots.txt для сайта www.example.com:
URL файла Robots.txt: www.example.com/robots.txt Блокировка всех поисковых роботов для доступа ко всему содержимомуUser-agent: * Disallow: /
Использование этого синтаксиса в файле robots.txt укажет всем поисковым роботам не сканировать никакие страницы www.example .com, включая домашнюю страницу.
Разрешение всем поисковым роботам доступа ко всему контентуUser-agent: * Disallow:
Использование этого синтаксиса в файле robots.txt указывает поисковым роботам сканировать все страницы на www.example.com, включая домашнюю страницу.
Блокировка определенного поискового робота из определенной папкиUser-agent: Googlebot Disallow: / example-subfolder /
Этот синтаксис предписывает только поисковому роботу Google (имя агента пользователя Googlebot) не сканировать страницы, которые содержать строку URL www.example.com/example-subfolder/.
Блокировка определенного поискового робота с определенной веб-страницыПользовательский агент: Bingbot Disallow: /example-subfolder/blocked-page.html
Этот синтаксис сообщает только поисковому роботу Bing (имя агента пользователя Bing) избегать сканирование конкретной страницы www.example.com/example-subfolder/blocked-page.html.
Как работает robots.txt?
У поисковых систем есть две основные задачи:
- Сканирование Интернета для обнаружения контента;
- Индексирование этого контента, чтобы его могли обслуживать искатели, ищущие информацию.
Чтобы сканировать сайты, поисковые системы переходят по ссылкам с одного сайта на другой — в конечном итоге просматривая многие миллиарды ссылок и веб-сайтов. Такое ползание иногда называют «пауками».”
После перехода на веб-сайт, но перед его сканированием поисковый робот будет искать файл robots.txt. Если он найдет его, сканер сначала прочитает этот файл, прежде чем продолжить просмотр страницы. Поскольку файл robots.txt содержит информацию о , как должна сканировать поисковая система, найденная там информация будет указывать на дальнейшие действия сканера на этом конкретном сайте. Если файл robots.txt не содержит , а не содержат директив, запрещающих действия пользовательского агента (или если на сайте нет файла robots.txt), он продолжит сканирование другой информации на сайте.
Другой быстрый файл robots.txt, который необходимо знать:
(более подробно обсуждается ниже)
Чтобы его можно было найти, файл robots.txt должен быть помещен в каталог верхнего уровня веб-сайта.
Robots.txt чувствителен к регистру: файл должен иметь имя «robots.txt» (не Robots.txt, robots.TXT и т. Д.).
Некоторые пользовательские агенты (роботы) могут игнорировать ваш robots.txt файл. Это особенно характерно для более гнусных поисковых роботов, таких как вредоносные роботы или парсеры адресов электронной почты.
Файл /robots.txt является общедоступным: просто добавьте /robots.txt в конец любого корневого домена, чтобы увидеть директивы этого веб-сайта (если на этом сайте есть файл robots.txt!). Это означает, что любой может видеть, какие страницы вы хотите или не хотите сканировать, поэтому не используйте их для сокрытия личной информации пользователя.
Каждый субдомен в корневом домене использует отдельных роботов.txt файлы. Это означает, что и blog.example.com, и example.com должны иметь свои собственные файлы robots.txt (по адресу blog.example.com/robots.txt и example.com/robots.txt).
Обычно рекомендуется указывать расположение любых карт сайта, связанных с этим доменом, в нижней части файла robots.txt. Вот пример:
Технический синтаксис robots.txt
Синтаксис robots.txt можно рассматривать как «язык» файлов robots.txt. Есть пять общих терминов, которые вы, вероятно, встретите в файле robots.К ним относятся:
User-agent: Конкретный поисковый робот, которому вы даете инструкции для сканирования (обычно это поисковая система). Список большинства пользовательских агентов можно найти здесь.
Disallow: Команда, используемая для указания агенту пользователя не сканировать определенный URL. Для каждого URL разрешена только одна строка «Disallow:».
Разрешить (применимо только для робота Googlebot): команда, сообщающая роботу Googlebot, что он может получить доступ к странице или подпапке, даже если его родительская страница или подпапка могут быть запрещены.
Crawl-delay: Сколько секунд сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что робот Googlebot не подтверждает эту команду, но скорость сканирования можно установить в консоли поиска Google.
Карта сайта: Используется для вызова местоположения любых XML-файлов Sitemap, связанных с этим URL. Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
Сопоставление с шаблоном
Когда дело доходит до фактических URL-адресов для блокировки или разрешения, robots.txt могут быть довольно сложными, поскольку они позволяют использовать сопоставление с шаблоном для охвата диапазона возможных вариантов URL. И Google, и Bing соблюдают два регулярных выражения, которые можно использовать для идентификации страниц или подпапок, которые SEO хочет исключить. Эти два символа — звездочка (*) и знак доллара ($).
- * — это подстановочный знак, который представляет любую последовательность символов.
- $ соответствует концу URL-адреса
. Google предлагает здесь большой список возможных синтаксисов и примеров сопоставления с образцом.
Где находится файл robots.txt на сайте?
Когда бы они ни заходили на сайт, поисковые системы и другие роботы, сканирующие Интернет (например, сканер Facebook Facebot), знают, что нужно искать файл robots.txt. Но они будут искать этот файл в только в одном конкретном месте : в основном каталоге (обычно это корневой домен или домашняя страница). Если пользовательский агент посещает www.example.com/robots.txt и не находит там файла роботов, он будет считать, что на сайте его нет, и продолжит сканирование всего на странице (и, возможно, даже на всем сайте. ).Даже если бы страница robots.txt действительно существовала , скажем, по адресу example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не была бы обнаружена пользовательскими агентами и, следовательно, сайт обрабатываться так, как если бы в нем вообще не было файла robots.
Чтобы гарантировать, что ваш файл robots.txt найден, всегда включает его в свой основной каталог или корневой домен.
Зачем нужен robots.txt?
Файлы Robots.txt управляют доступом поискового робота к определенным областям вашего сайта.Хотя это может быть очень опасным, если вы случайно запретите роботу Google сканировать весь ваш сайт (!!), в некоторых ситуациях файл robots.txt может оказаться очень полезным.
Некоторые распространенные варианты использования включают:
- Предотвращение появления дублированного контента в результатах поиска (обратите внимание, что мета-роботы часто являются лучшим выбором для этого)
- Сохранение конфиденциальности целых разделов веб-сайта (например, промежуточного сайта вашей группы инженеров)
- Предотвращение показа страниц результатов внутреннего поиска в общедоступной поисковой выдаче
- Указание местоположения карты (карт) сайта
- Предотвращение индексации определенных файлов на вашем веб-сайте поисковыми системами (изображений, PDF-файлов и т. Д.))
- Указание задержки сканирования для предотвращения перегрузки ваших серверов, когда сканеры загружают сразу несколько частей контента
Если на вашем сайте нет областей, к которым вы хотите контролировать доступ агента пользователя, вы не можете вообще нужен файл robots.txt.
Проверка наличия файла robots.txt
Не уверены, есть ли у вас файл robots.txt? Просто введите свой корневой домен, а затем добавьте /robots.txt в конец URL-адреса. Например, файл роботов Moz находится по адресу moz.ru / robots.txt.
Если страница .txt не отображается, значит, у вас нет (активной) страницы robots.txt.
Как создать файл robots.txt
Если вы обнаружили, что у вас нет файла robots.txt или вы хотите изменить свой, создание его — простой процесс. В этой статье от Google рассматривается процесс создания файла robots.txt, и этот инструмент позволяет вам проверить, правильно ли настроен ваш файл.
Хотите попрактиковаться в создании файлов роботов? В этом сообщении блога рассматриваются некоторые интерактивные примеры.
Лучшие практики SEO
Убедитесь, что вы не блокируете какой-либо контент или разделы своего веб-сайта, которые нужно просканировать.
Ссылки на страницах, заблокированных файлом robots.txt, переходить не будут. Это означает 1.) Если на них также не ссылаются другие страницы, доступные для поисковых систем (т. Е. Страницы, не заблокированные через robots.txt, мета-роботы или иным образом), связанные ресурсы не будут сканироваться и индексироваться. 2.) Никакой ссылочный капитал не может быть передан с заблокированной страницы на место назначения ссылки.Если у вас есть страницы, на которые вы хотите передать средства, используйте другой механизм блокировки, отличный от robots.txt.
Не используйте robots.txt для предотвращения появления конфиденциальных данных (например, личной информации пользователя) в результатах поисковой выдачи. Поскольку другие страницы могут напрямую ссылаться на страницу, содержащую личную информацию (таким образом, в обход директив robots.txt в вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или метадирективу noindex.
Некоторые поисковые системы имеют несколько пользовательских агентов. Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений. Большинство пользовательских агентов из одной и той же поисковой системы следуют одним и тем же правилам, поэтому нет необходимости указывать директивы для каждого из нескольких сканеров поисковой системы, но возможность делать это позволяет вам точно настроить способ сканирования содержания вашего сайта.
Поисковая машина кэширует содержимое robots.txt, но обычно обновляет кэшированное содержимое не реже одного раза в день.Если вы изменили файл и хотите обновить его быстрее, чем это происходит, вы можете отправить свой URL-адрес robots.txt в Google.
Robots.txt vs meta robots vs x-robots
Так много роботов! В чем разница между этими тремя типами инструкций для роботов? Во-первых, robots.txt — это фактический текстовый файл, тогда как meta и x-robots — это метадирективы. Помимо того, чем они являются на самом деле, все три выполняют разные функции. Robots.txt определяет поведение сканирования сайта или всего каталога, тогда как мета и x-роботы могут определять поведение индексации на уровне отдельной страницы (или элемента страницы).
Продолжайте учиться
Приложите свои навыки к работе
Moz Pro может определить, блокирует ли ваш файл robots.txt доступ к вашему веб-сайту. Попробовать >>
Как добавить файл Robots.txt
Как добавить файл robots.txt на свой сайт
Текстовый файл robots или файл robots.txt (часто ошибочно называемый файлом robot.txt) необходим для каждого веб-сайта. Добавление файла robots.txt в корневую папку вашего сайта — очень простой процесс, и наличие этого файла фактически является «признаком качества» для поисковых систем.Давайте посмотрим на параметры файла robots.txt, доступные для вашего сайта.
Что такое текстовый файл роботов?
Файл robots.txt — это просто файл в формате ASCII или обычный текстовый файл, который сообщает поисковым системам, где им не разрешено заходить на сайт — также известный как Стандарт для исключения роботов. Любые файлы или папки, перечисленные в этом документе, не будут сканироваться и индексироваться пауками поисковых систем. Наличие даже пустого файла robots.txt показывает, что вы признаете, что поисковые системы разрешены на вашем сайте и что они могут иметь свободный доступ к нему.Мы рекомендуем добавить текстовый файл роботов к вашему основному домену и всем субдоменам на вашем сайте.
Параметры форматирования Robots.txt
Создание robots.txt — простой процесс. Выполните следующие простые шаги:
- Откройте Блокнот, Microsoft Word или любой текстовый редактор и сохраните файл как «robots», все в нижнем регистре, не забудьте выбрать .txt в качестве расширения типа файла (в Word выберите «Обычный текст»).
- Затем добавьте в файл следующие две строки текста:
Пользовательский агент: *
Disallow:
«Пользовательский агент» — это другое слово для роботов или пауков поисковых систем.Звездочка (*) означает, что эта строка относится ко всем паукам. Здесь нет файла или папки, перечисленных в строке Disallow, что означает, что любой каталог на вашем сайте может быть доступен. Это базовый текстовый файл для роботов.
- Одной из опций robots.txt является также блокировка «пауков» поисковых систем со всего вашего сайта. Для этого добавьте в файл эти две строчки:
Пользовательский агент: *
Disallow: /
- Если вы хотите заблокировать доступ пауков к определенным областям вашего сайта, ваш robots.txt может выглядеть примерно так:
User-agent: *
Disallow: / database /
Disallow: / scripts /
Эти три строки говорят всем роботам, что им не разрешен доступ к чему-либо в каталогах или подкаталогах базы данных и сценариев. Помните, что в строке Disallow можно использовать только один файл или папку. Вы можете добавить столько строк Disallow, сколько вам нужно.
- Не забудьте добавить удобный для поисковых систем XML-файл карты сайта в текстовый файл robots.Это гарантирует, что «пауки» найдут вашу карту сайта и легко проиндексируют все страницы вашего сайта. Используйте этот синтаксис:
Карта сайта: http://www.mydomain.com/sitemap.xml
- По завершении сохраните и загрузите файл robots.txt в корневой каталог вашего сайта. Например, если ваш домен www.mydomain.com, вы разместите файл по адресу www.mydomain.com/robots.txt.
- После того, как файл будет размещен, проверьте файл robots.txt на наличие ошибок.
Search Guru может помочь реализовать этот и другие технические элементы SEO.Свяжитесь с нами сегодня чтобы начать!
Создайте лучший с помощью этого руководства на 2021 год
Robots.txt вкратце
Файл robots.txt содержит директивы для поисковых систем. Вы можете использовать его, чтобы запретить поисковым системам сканировать определенные части вашего веб-сайта и давать поисковым системам полезные советы о том, как они могут лучше всего сканировать ваш веб-сайт. Файл robots.txt играет большую роль в SEO.
При внедрении robots.txt помните о следующих передовых методах:
- Будьте осторожны при внесении изменений в роботов.txt: этот файл может сделать большую часть вашего сайта недоступной для поисковых систем.
- Файл robots.txt должен находиться в корне вашего веб-сайта (например,
http://www.example.com/robots.txt). - Файл robots.txt действителен только для всего домена, в котором он находится, включая протокол (
httpилиhttps). - Разные поисковые системы по-разному интерпретируют директивы. По умолчанию всегда побеждает первая соответствующая директива.Но с Google и Bing побеждает специфика.
- По возможности избегайте использования директивы задержки сканирования для поисковых систем.
Что такое файл robots.txt?
Файл robots.txt сообщает поисковым системам, каковы правила взаимодействия с вашим сайтом. Большая часть SEO — это отправка правильных сигналов поисковым системам, а файл robots.txt — один из способов сообщить поисковым системам о ваших предпочтениях сканирования.
В 2019 году мы заметили некоторые изменения, связанные с роботами.txt: Google предложила расширение для протокола исключения роботов и открыла исходный код для своего парсера robots.txt.
TL; DR
- Интерпретатор Google robots.txt довольно гибкий и на удивление снисходительный.
- В случае возникновения путаницы в директивах Google перестраховывается и предполагает, что разделы должны быть ограничены, а не неограничены.
Поисковые системы регулярно проверяют роботов сайта.txt, чтобы узнать, есть ли какие-либо инструкции по сканированию веб-сайта. Мы называем эти инструкции директивами .
Если файл robots.txt отсутствует или соответствующие директивы отсутствуют, поисковые системы будут сканировать весь веб-сайт.
Хотя все основные поисковые системы уважают файл robots.txt, поисковые системы могут игнорировать (части) вашего файла robots.txt. Хотя директивы в файле robots.txt являются сильным сигналом для поисковых систем, важно помнить о файле robots.txt представляет собой набор необязательных директив для поисковых систем, а не мандат.
robots.txt — самый конфиденциальный файл во вселенной SEO. Один персонаж может сломать весь сайт.
Терминология вокруг файла robots.txt
Файл robots.txt является реализацией стандарта исключения роботов , также называемого протоколом исключения роботов .
Зачем вам нужен файл robots.txt?
Роботы.txt играет важную роль с точки зрения SEO. Он сообщает поисковым системам, как им лучше всего сканировать ваш сайт.
Используя файл robots.txt, вы можете запретить поисковым системам доступ к определенным частям вашего веб-сайта , предотвратить дублирование контента и дать поисковым системам полезные советы о том, как они могут сканировать ваш веб-сайт более эффективно .
Будьте осторожны, , когда вносите изменения в свой robots.txt: этот файл может сделать большие части вашего веб-сайта недоступными для поисковых систем.
Robots.txt часто слишком часто используется для уменьшения дублирования контента, тем самым убивая внутренние ссылки, поэтому будьте с ними очень осторожны. Мой совет — всегда использовать его только для файлов или страниц, которые поисковые системы никогда не должны видеть или которые могут существенно повлиять на сканирование, будучи допущенными к ним. Типичные примеры: области входа в систему, которые генерируют много разных URL-адресов, тестовые области или где может существовать многогранная навигация. И обязательно следите за своим файлом robots.txt на предмет любых проблем или изменений.
Подавляющее большинство проблем, которые я вижу с роботами.txt делятся на три сегмента:
- Неправильная обработка подстановочных знаков. Довольно часто можно увидеть заблокированные части сайта, которые должны были быть заблокированы. Иногда, если вы не будете осторожны, директивы также могут конфликтовать друг с другом.
- Кто-то, например разработчик, неожиданно внес изменение (часто при добавлении нового кода) и случайно изменил robots.txt без вашего ведома.
- Включение директив, не относящихся к robots.txt файл. Robots.txt является веб-стандартом и имеет некоторые ограничения. Я часто вижу, как разработчики создают директивы, которые просто не работают (по крайней мере, для подавляющего большинства поисковых роботов). Иногда это безобидно, иногда не очень.
Пример
Давайте рассмотрим пример, чтобы проиллюстрировать это:
У вас есть веб-сайт электронной коммерции, и посетители могут использовать фильтр для быстрого поиска по вашим товарам. Этот фильтр генерирует страницы, которые в основном показывают то же содержание, что и другие страницы.Это отлично работает для пользователей, но сбивает с толку поисковые системы, поскольку создает дублированный контент.
Вы не хотите, чтобы поисковые системы индексировали эти отфильтрованные страницы и тратили свое драгоценное время на эти URL с отфильтрованным содержимым. Поэтому вам следует установить правила Disallow , чтобы поисковые системы не получали доступ к этим отфильтрованным страницам продуктов.
Предотвращение дублирования контента также можно выполнить с помощью канонического URL-адреса или метатега robots, однако они не адресуются, позволяя поисковым системам сканировать только те страницы, которые имеют значение.
Использование канонического URL или метатега robots не помешает поисковым системам сканировать эти страницы. Это только предотвратит отображение этих страниц в результатах поиска поисковыми системами. Поскольку поисковые системы имеют ограниченное время для сканирования веб-сайта, это время следует потратить на страницы, которые вы хотите отображать в поисковых системах.
Ваш robots.txt работает против вас?
Неправильно настроенный файл robots.txt может сдерживать эффективность SEO. Сразу же проверьте, так ли это на вашем сайте!
Это очень простой инструмент, но файл robots.txt может вызвать множество проблем, если он неправильно настроен, особенно для крупных веб-сайтов. Очень легко сделать ошибки, например заблокировать весь сайт после развертывания нового дизайна или CMS или не заблокировать разделы сайта, которые должны быть приватными. Для крупных веб-сайтов очень важно обеспечить эффективное сканирование Google, и хорошо структурированный файл robots.txt является важным инструментом в этом процессе.
Вам нужно потратить время, чтобы понять, какие разделы вашего сайта лучше всего держать подальше от Google, чтобы они тратили как можно больше своих ресурсов на сканирование страниц, которые вам действительно интересны.
Как выглядит файл robots.txt?
Пример того, как может выглядеть простой файл robots.txt для веб-сайта WordPress:
Агент пользователя: *
Disallow: / wp-admin / Давайте объясним анатомию файла robots.txt на основе приведенного выше примера:
- User-agent:
user-agentуказывает, для каких поисковых систем предназначены следующие директивы. -
*: это означает, что директивы предназначены для всех поисковых систем. -
Disallow: это директива, указывающая, какой контент недоступен для пользовательского агента -
/ wp-admin /: это путь
Вкратце: этот файл robots.txt сообщает всем поисковым системам, чтобы они не заходили в каталог / wp-admin / .
Давайте более подробно проанализируем различные компоненты файлов robots.txt:
User-agent в robots.txt
Каждая поисковая система должна идентифицировать себя с помощью пользовательского агента . Роботы Google идентифицируются как Googlebot , например, роботы Yahoo — как Slurp , а робот Bing — как BingBot и так далее.
Запись пользовательского агента определяет начало группы директив. Все директивы между первым пользовательским агентом и следующей пользовательской записью обрабатываются как директивы для первого пользовательского агента .
могут применяться к определенным пользовательским агентам, но они также могут применяться ко всем пользовательским агентам. В этом случае используется подстановочный знак: User-agent: * .
Директива Disallow в robots.txt
Вы можете запретить поисковым системам получать доступ к определенным файлам, страницам или разделам вашего веб-сайта. Это делается с помощью директивы Disallow . За директивой Disallow следует путь , к которому не следует обращаться. Если путь не определен, директива игнорируется.
Пример
Агент пользователя: *
Disallow: / wp-admin / В этом примере всем поисковым системам предлагается не обращаться к каталогу / wp-admin / .
Директива Allow в robots.txt
Директива Allow используется для противодействия директиве Disallow . Директива Allow поддерживается Google и Bing. Используя вместе директивы Allow и Disallow , вы можете указать поисковым системам, что они могут получить доступ к определенному файлу или странице в каталоге, который иначе запрещен.За директивой Allow следует путь , к которому можно получить доступ. Если путь не определен, директива игнорируется.
Пример
Агент пользователя: *
Разрешить: /media/terms-and-conditions.pdf
Disallow: / media / В приведенном выше примере всем поисковым системам не разрешен доступ к каталогу / media / , за исключением файла /media/terms-and-conditions.pdf .
Важно: при одновременном использовании директив Allow и Disallow не используйте подстановочные знаки, поскольку это может привести к конфликту директив.
Пример конфликтующих директив
Агент пользователя: *
Разрешить: / каталог
Disallow: * .html Поисковые системы не будут знать, что делать с URL-адресом http://www.domain.com/directory.html . Для них неясно, разрешен ли им доступ. Когда директивы не ясны для Google, они будут использовать наименее ограничительную директиву, что в данном случае означает, что они фактически получат доступ к http://www.domain.com/directory.html .
Правила запрета в файле robots.txt сайта невероятно эффективны, поэтому с ними следует обращаться осторожно. Для некоторых сайтов предотвращение сканирования определенных URL-адресов поисковыми системами имеет решающее значение для обеспечения возможности сканирования и индексации нужных страниц, но неправильное использование правил запрета может серьезно повредить SEO сайта.
Отдельная строка для каждой директивы
Каждая директива должна быть на отдельной строке, иначе поисковые системы могут запутаться при парсинге robots.txt файл.
Пример неверного файла robots.txt
Предотвратить появление файла robots.txt, подобного этому:
Пользовательский агент: * Disallow: / directory-1 / Disallow: / directory-2 / Disallow: / directory-3/ Robots.txt - одна из тех функций, которые я чаще всего вижу реализованными неправильно, поэтому он не блокирует то, что они хотели заблокировать, или блокирует больше, чем они ожидали, и оказывает негативное влияние на их веб-сайт. Robots.txt - очень мощный инструмент, но слишком часто он неправильно настраивается.
Использование подстановочного знака *
Подстановочный знак можно использовать не только для определения пользовательского агента , но и для сопоставления URL-адресов. Подстановочный знак поддерживается Google, Bing, Yahoo и Ask.
Пример
Агент пользователя: *
Запретить: *? В приведенном выше примере всем поисковым системам не разрешен доступ к URL-адресам, которые содержат вопросительный знак (? ).
Разработчики или владельцы сайтов часто думают, что могут использовать всевозможные регулярные выражения в файле robots.txt, тогда как на самом деле допустимо только очень ограниченное количество сопоставлений с образцом - например, подстановочные знаки (
*). Кажется, время от времени возникает путаница между файлами .htaccess и robots.txt.
Использование конца URL $
Чтобы указать конец URL-адреса, вы можете использовать знак доллара ( $ ) в конце пути .
Пример
Агент пользователя: *
Disallow: * .php $ В приведенном выше примере поисковым системам не разрешен доступ ко всем URL-адресам, которые заканчиваются на.php. URL-адреса с параметрами, например https://example.com/page.php?lang=en не будет запрещен, поскольку URL-адрес не заканчивается после .php .
Добавьте карту сайта в robots.txt
Несмотря на то, что файл robots.txt был изобретен, чтобы указывать поисковым системам, какие страницы не сканировать , файл robots.txt также можно использовать для направления поисковым системам на карту сайта XML. Это поддерживается Google, Bing, Yahoo и Ask.
На карту сайта XML следует ссылаться как на абсолютный URL.URL-адрес , а не должен находиться на том же хосте, что и файл robots.txt.
Ссылка на XML-карту сайта в файле robots.txt - одна из лучших практик, которую мы советуем вам всегда делать, даже если вы уже отправили свою XML-карту сайта в Google Search Console или Bing Webmaster Tools. Помните, что существует больше поисковых систем.
Обратите внимание, что можно ссылаться на несколько карт сайта XML в файле robots.txt.
Примеры
Несколько файлов Sitemap XML, определенных в файле robots.txt файл:
Агент пользователя: *
Запретить: / wp-admin /
Карта сайта: https://www.example.com/sitemap1.xml
Карта сайта: https://www.example.com/sitemap2.xml В приведенном выше примере говорится, что все поисковые системы не должны обращаться к каталогу / wp-admin / и что есть две карты сайта XML, которые можно найти по адресу https://www.example.com/sitemap1.xml и https://www.example.com/sitemap2.xml .
Одна карта сайта XML, определенная в файле robots.txt:
Агент пользователя: *
Запретить: / wp-admin /
Карта сайта: https: // www.example.com/sitemap_index.xml В приведенном выше примере говорится, что все поисковые системы не должны обращаться к каталогу / wp-admin / , а карту сайта XML можно найти по адресу https://www.example.com/sitemap_index .xml .
Часто задаваемые вопросы
Комментарии
Комментарии предшествуют # и могут быть помещены в начало строки или после директивы в той же строке. Все, что находится после # , будет проигнорировано.Эти комментарии предназначены только для людей.
Пример 1
# Не разрешать доступ к каталогу / wp-admin / для всех роботов.
Пользовательский агент: *
Disallow: / wp-admin / Пример 2
User-agent: * # Применимо ко всем роботам
Disallow: / wp-admin / # Не разрешать доступ к каталогу / wp-admin /. В приведенных выше примерах передается одно и то же сообщение.
Задержка сканирования в robots.txt
Директива Crawl-delay - это неофициальная директива, используемая для предотвращения перегрузки серверов слишком большим количеством запросов.Если поисковые системы могут перегружать сервер, добавление Crawl-delay в ваш файл robots.txt является лишь временным решением. Дело в том, что ваш сайт работает в плохой среде хостинга и / или ваш сайт неправильно настроен, и вы должны исправить это как можно скорее.
. Способ обработки поисковыми системами Crawl-delay отличается. Ниже мы объясним, как с этим справляются основные поисковые системы.
Часто задаваемые вопросы
Задержка сканирования и Google
Сканер Google, робот Google, не поддерживает директиву Crawl-delay , поэтому не беспокойтесь об определении задержки сканирования Google.
Однако Google поддерживает определение скорости сканирования (или «скорости запросов», если хотите) в консоли поиска Google.
Установка скорости сканирования в GSC
- Войдите в старую Google Search Console (откроется в новой вкладке).
- Выберите веб-сайт, для которого нужно определить скорость сканирования.
- Есть только один параметр, который вы можете настроить:
Скорость сканирования, с ползунком, где вы можете установить предпочтительную скорость сканирования. По умолчанию для скорости сканирования установлено значение «Разрешить Google оптимизировать мой сайт (рекомендуется)».
Вот как это выглядит в Google Search Console:
Задержка сканирования и Bing, Yahoo и Яндекс
Bing, Yahoo и Яндекс поддерживают директиву Crawl-delay для ограничения сканирования веб-сайта. Однако их интерпретация задержки сканирования немного отличается, поэтому обязательно проверьте их документацию:
Директива Crawl-delay должна быть размещена сразу после директив Disallow или Allow .
Пример:
Пользовательский агент: BingBot
Disallow: / private /
Задержка сканирования: 10 Задержка сканирования и Baidu
Baidu не поддерживает директиву crawl-delay , однако можно зарегистрировать учетную запись Baidu Webmaster Tools, в которой вы можете контролировать частоту сканирования, аналогично Google Search Console.
Когда использовать файл robots.txt?
Мы рекомендуем всегда использовать файл robots.txt.В его наличии нет абсолютно никакого вреда, и это отличное место, чтобы передать директивы поисковым системам о том, как они могут лучше всего сканировать ваш сайт.
Файл robots.txt может быть полезен для предотвращения сканирования и индексации определенных областей или документов на вашем сайте. Примерами являются, например, промежуточный сайт или PDF-файлы. Тщательно спланируйте, что нужно проиндексировать поисковыми системами, и помните, что контент, недоступный через robots.txt, может по-прежнему быть найден поисковыми роботами, если на него есть ссылки из других областей веб-сайта.
Лучшие практики robots.txt
Лучшие практики robots.txt подразделяются на следующие категории:
Расположение и имя файла
Файл robots.txt всегда должен находиться в корне веб-сайта (в каталоге верхнего уровня хоста) и иметь имя файла robots.txt , например: https: //www.example .com / robots.txt . Обратите внимание, что URL-адрес файла robots.txt, как и любой другой URL-адрес, чувствителен к регистру.
Если файл robots.txt не может быть найден в расположении по умолчанию, поисковые системы сочтут, что директивы отсутствуют, и уйдут на ваш сайт.
Порядок старшинства
Важно отметить, что поисковые системы по-разному обрабатывают файлы robots.txt. По умолчанию первая соответствующая директива всегда побеждает .
Однако с Google и Bing специфичность побеждает . Например: директива Allow имеет преимущество перед директивой Disallow , если ее длина символа больше.
Пример
Агент пользователя: *
Разрешить: / about / company /
Запретить: / about / В приведенном выше примере всем поисковым системам, включая Google и Bing, не разрешен доступ к каталогу / about / , за исключением подкаталога / about / company / .
Пример
Агент пользователя: *
Disallow: / about /
Разрешить: / about / company / В приведенном выше примере всем поисковым системам , кроме Google и Bing , запрещен доступ к каталогу / about / .Сюда входит каталог / about / company / .
Google и Bing имеют доступ к , поскольку директива Allow длиннее , чем директива Disallow .
Только одна группа директив на робота
Вы можете определить только одну группу директив для каждой поисковой системы. Наличие нескольких групп директив для одной поисковой системы сбивает их с толку.
Будьте как можно более конкретными
Директива Disallow также срабатывает при частичных совпадениях.Будьте как можно более конкретными при определении директивы Disallow , чтобы предотвратить непреднамеренное запрещение доступа к файлам.
Пример:
Агент пользователя: *
Disallow: / directory В приведенном выше примере поисковым системам запрещен доступ к:
-
/ каталог -
/ каталог / -
/ имя-каталога-1 -
/ имя-каталога.html -
/ имя-каталога.php -
/ имя-каталога.pdf
Директивы для всех роботов, а также директивы для конкретного робота
Для робота действует только одна группа директив. В случае, если директивы, предназначенные для всех роботов, сопровождаются директивами для конкретного робота, будут приняты во внимание только эти конкретные директивы. Чтобы конкретный робот также выполнял директивы для всех роботов, вам необходимо повторить эти директивы для конкретного робота.
Давайте посмотрим на пример, который прояснит это:
Пример
Агент пользователя: *
Disallow: / secret /
Запретить: / test /
Запретить: / еще не запущено /
Пользовательский агент: googlebot
Disallow: / not-loaded-yet / В приведенном выше примере всем поисковым системам , кроме Google , запрещен доступ к / secret / , / test / и / not-loaded-yet / . Google только не разрешен доступ к / not-launch-until / , но разрешен доступ к / secret / и / test / .
Если вы не хотите, чтобы робот googlebot имел доступ к / secret / и / not-loaded-yet / , вам необходимо повторить эти директивы для googlebot , в частности:
Агент пользователя: *
Disallow: / secret /
Запретить: / test /
Запретить: / еще не запущено /
Пользовательский агент: googlebot
Disallow: / secret /
Запретить: / not-launch-yet / Обратите внимание, что ваш файл robots.txt общедоступен. Запрет на использование разделов веб-сайта может быть использован злоумышленниками как вектор атаки.
Robots.txt может быть опасным. Вы не только указываете поисковым системам, куда не хотите, чтобы они смотрели, но и сообщаете людям, где скрываете свои грязные секреты.
Файл robots.txt для каждого (под) домена
Директивы Robots.txt применяются только к (под) домену, в котором размещен файл.
Примеры
http://example.com/robots.txt действительно для http://example.com , но не для http: // www.example.com или https://example.com .
Рекомендуется, чтобы в вашем (под) домене был доступен только один файл robots.txt.
Если у вас есть несколько файлов robots.txt, убедитесь, что они возвращают HTTP-статус 404 или 301 перенаправляют их в канонический файл robots.txt.
Противоречивые рекомендации: robots.txt и Google Search Console
Если ваш файл robots.txt конфликтует с настройками, определенными в Google Search Console, Google часто предпочитает использовать настройки, определенные в Google Search Console, вместо директив, определенных в robots.txt файл.
Следите за своим файлом robots.txt
Важно следить за изменениями в файле robots.txt. В ContentKing мы видим множество проблем, из-за которых неправильные директивы и внезапные изменения в файле robots.txt вызывают серьезные проблемы с поисковой оптимизацией.
Это особенно актуально при запуске новых функций или нового веб-сайта, который был подготовлен в тестовой среде, поскольку они часто содержат следующий файл robots.txt:
Агент пользователя: *
Disallow: / Мы построили роботов.txt, отслеживание изменений и оповещение по этой причине.
Как узнать об изменении файла robots.txt?
Мы видим это постоянно: файлы robots.txt меняются без ведома команды цифрового маркетинга. Не будь таким человеком. Начните отслеживать свой файл robots.txt, теперь получайте оповещения при его изменении!
Не используйте noindex в своем robots.txt
В течение многих лет Google уже открыто рекомендовал не использовать неофициальную директиву noindex (открывается в новой вкладке).Однако с 1 сентября 2019 года Google полностью прекратил его поддержку (открывается в новой вкладке).
Неофициальная директива noindex никогда не работала в Bing, что подтверждено Фредериком Дубутом в этом твите (открывается в новой вкладке):
Лучший способ сообщить поисковым системам, что страницы не следует индексировать, - это использовать метатеги robots или X-Robots-Tag.
Часто задаваемые вопросы
Запретить спецификацию UTF-8 в файле robots.txt
BOM обозначает метку порядка байтов , невидимый символ в начале файла, используемый для обозначения кодировки Unicode текстового файла.
В то время как Google заявляет (открывается в новой вкладке), они игнорируют необязательную отметку порядка байтов Unicode в начале файла robots.txt, мы рекомендуем предотвратить "UTF-8 BOM", потому что мы видели, что это вызывает проблемы с интерпретацией файла robots.txt поисковыми системами.
Несмотря на то, что Google заявляет, что может с этим справиться, вот две причины, чтобы предотвратить спецификацию UTF-8:
- Вы не хотите, чтобы у вас была двусмысленность в ваших предпочтениях при сканировании в поисковые системы.
- Существуют и другие поисковые системы, которые могут быть не такими снисходительными, как утверждает Google.
Примеры robots.txt
В этой главе мы рассмотрим широкий спектр примеров файлов robots.txt:
Разрешить всем роботам доступ ко всему
Есть несколько способов сообщить поисковым системам, что они могут получить доступ ко всем файлам:
Или файл robots.txt пустой, или файл robots.txt вообще отсутствует.
Запретить всем роботам доступ ко всему
Пример robots.txt ниже сообщает всем поисковым системам, что им нельзя обращаться ко всему сайту:
Агент пользователя: *
Disallow: / Обратите внимание, что только ОДИН дополнительный символ может иметь решающее значение.
У всех ботов Google нет доступа
Пользовательский агент: googlebot
Disallow: / Обратите внимание, что запрет на использование робота Googlebot распространяется на всех роботов Googlebot. Сюда входят роботы Google, которые ищут, например, новости ( googlebot-news ) и изображения ( googlebot-images ).
Все боты Google, кроме новостей Googlebot, не имеют доступа
Пользовательский агент: googlebot
Запретить: /
Пользовательский агент: googlebot-news
Disallow: У Googlebot и Slurp нет доступа
Агент пользователя: Slurp
Пользовательский агент: googlebot
Disallow: / У всех роботов нет доступа к двум каталогам
Агент пользователя: *
Запретить: / admin /
Disallow: / private / У всех роботов нет доступа к одному конкретному файлу
Агент пользователя: *
Запретить: / каталог / some-pdf.pdf Робот Googlebot не имеет доступа к / admin /, а Slurp не имеет доступа к / private /
. Пользовательский агент: googlebot
Запретить: / admin /
Пользовательский агент: Slurp
Disallow: / private / Часто задаваемые вопросы
Файл robots.txt для WordPress
Приведенный ниже файл robots.txt специально оптимизирован для WordPress, при условии:
- Вы не хотите, чтобы ваш раздел администратора сканировался.
- Вы не хотите, чтобы ваши страницы результатов внутреннего поиска сканировались.
- Вы не хотите, чтобы ваши страницы тегов и авторов сканировались.
- Вы не хотите, чтобы ваша страница 404 сканировалась.
Агент пользователя: *
Запретить: / wp-admin / # заблокировать доступ к разделу администратора
Запретить: /wp-login.php # заблокировать доступ в админку
Запретить: / search / # заблокировать доступ к страницам результатов внутреннего поиска
Запретить: *? S = * # заблокировать доступ к страницам результатов внутреннего поиска
Disallow: *? P = * # заблокировать доступ к страницам, для которых постоянные ссылки не работают
Disallow: * & p = * # заблокировать доступ к страницам, для которых постоянные ссылки не работают
Запретить: * & preview = * # заблокировать доступ к страницам предварительного просмотра
Запретить: / tag / # заблокировать доступ к страницам тегов
Запретить: / author / # заблокировать доступ к страницам авторов
Запретить: / 404-ошибка / # заблокировать доступ к странице 404
Карта сайта: https: // www.example.com/sitemap_index.xml Обратите внимание, что этот файл robots.txt будет работать в большинстве случаев, но вы должны всегда настраивать его и тестировать, чтобы убедиться, что он применим к вашей конкретной ситуации.
Файл robots.txt для Magento
Приведенный ниже файл robots.txt специально оптимизирован для Magento и сделает внутренние результаты поиска, страницы входа, идентификаторы сеансов и отфильтрованные наборы результатов, которые содержат цена , цвет , материал и размер критерии недоступны для поисковых роботов. .
Агент пользователя: *
Запретить: / catalogsearch /
Запретить: / search /
Запретить: / клиент / аккаунт / логин /
Запретить: / *? SID =
Запретить: / *? PHPSESSID =
Disallow: / *? Price =
Disallow: / * & price =
Запретить: / *? Color =
Запретить: / * & color =
Disallow: / *? Material =
Запретить: / * & материал =
Запретить: / *? Size =
Запретить: / * & size =
Карта сайта: https://www.example.com/sitemap_index.xml Обратите внимание, что этот файл robots.txt будет работать для большинства магазинов Magento, но вы должны всегда настраивать его и проверять, чтобы убедиться, что он применим к ваша точная ситуация.
Полезные ресурсы
Я бы всегда старался блокировать результаты внутреннего поиска в robots.txt на любом сайте, потому что эти типы поисковых URL-адресов представляют собой бесконечные и бесконечные пробелы. Робот Googlebot может попасть в ловушку поискового робота.
Каковы ограничения файла robots.txt?
Файл robots.txt содержит директивы
Несмотря на то, что robots.txt пользуется большим уважением в поисковых системах, он все же является директивой, а не предписанием.
Страницы по-прежнему отображаются в результатах поиска
Страницы, которые недоступны для поисковых систем из-за файла robots.txt, но имеют ссылки на них, могут по-прежнему отображаться в результатах поиска, если на них есть ссылки со страницы, которая просматривается. Пример того, как это выглядит:
Наконечник для профессионалов
Эти URL-адреса можно удалить из Google с помощью инструмента удаления URL-адресов Google Search Console. Обратите внимание, что эти URL-адреса будут только временно «скрыты». Чтобы они не попадали на страницы результатов Google, вам необходимо отправлять запрос на скрытие URL-адресов каждые 180 дней.
Используйте robots.txt, чтобы заблокировать нежелательные и, вероятно, вредоносные обратные ссылки на партнерские программы. Не используйте robots.txt для предотвращения индексации контента поисковыми системами, поскольку это неизбежно приведет к сбою. Вместо этого при необходимости примените директиву noindex для роботов.
Файл robots.txt кешируется до 24 часов
Google указал, что файл robots.txt обычно кэшируется на срок до 24 часов. Это важно учитывать при внесении изменений в файл robots.txt файл.
Непонятно, как другие поисковые системы справляются с кэшированием robots.txt, но в целом лучше избегать кеширования файла robots.txt, чтобы поисковые системы не занимали больше времени, чем необходимо, чтобы иметь возможность улавливать изменения.
Размер файла robots.txt
Для файлов robots.txt Google в настоящее время поддерживает ограничение на размер файла в 500 кибибайт (512 килобайт). Любое содержимое после максимального размера файла может игнорироваться.
Неясно, есть ли у других поисковых систем максимальный размер файла для роботов.txt файлы.
Часто задаваемые вопросы о robots.txt
🤖 Как выглядит пример файла robots.txt?
Вот пример содержимого robots.txt: User-agent: * Disallow:. Это говорит всем сканерам, что они могут получить доступ ко всему.
⛔ Что делает Disallow all в robots.txt?
Когда вы устанавливаете robots.txt на «Запретить все», вы, по сути, говорите всем сканерам держаться подальше. Никакие сканеры, в том числе Google, не имеют доступа к вашему сайту.Это означает, что они не смогут сканировать, индексировать и оценивать ваш сайт. Это приведет к резкому падению органического трафика.
✅ Что делает Allow all в robots.txt?
Когда вы устанавливаете robots.txt на «Разрешить все», вы сообщаете каждому сканеру, что он может получить доступ к каждому URL-адресу на сайте. Правил приема просто нет. Обратите внимание, что это эквивалентно пустому файлу robots.txt или отсутствию файла robots.txt вообще.
🤔 Насколько важен robots.txt для SEO?
В общем, роботы.txt очень важен для SEO. Для более крупных веб-сайтов файл robots.txt необходим, чтобы дать поисковым системам очень четкие инструкции о том, к какому контенту нельзя обращаться.
Дополнительная литература
Полезные ресурсы
Часто задаваемые вопросы о robots.txt
Инструмент для создания текста роботовСравнить функциональные возможности
Когда вы используете генератор файлов robots.txt, чтобы увидеть параллельное сравнение того, как ваш сайт в настоящее время обрабатывает поисковых роботов, с тем, как предлагаемые новые роботы.txt, введите или вставьте URL-адрес домена вашего сайта или страницу вашего сайта в текстовое поле, а затем нажмите Сравнить .
Когда поисковые системы сканируют сайт, они сначала ищут файл robots.txt в корне домена. В случае обнаружения они читают список директив файла, чтобы узнать, какие каталоги и файлы, если таковые имеются, заблокированы для сканирования. Этот файл можно создать с помощью генератора файлов robots.txt. Когда вы используете генератор robots.txt, Google и другие поисковые системы могут определить, какие страницы вашего сайта следует исключить.Другими словами, файл, созданный генератором robots.txt, похож на противоположность карты сайта, которая указывает, какие страницы нужно включить.
Генератор robots.txt
Вы можете легко создать новый или отредактировать существующий файл robots.txt для своего сайта с помощью генератора robots.txt. Чтобы загрузить существующий файл и предварительно заполнить инструмент генератора файлов robots.txt, введите или вставьте URL-адрес корневого домена в верхнее текстовое поле и нажмите Загрузить . Используйте инструмент генератора robots.txt для создания директив с директивами Allow или Disallow ( Разрешить, по умолчанию, нажмите, чтобы изменить) для пользовательских агентов (используйте * для всех или нажмите, чтобы выбрать только один) для указанного контента на вашем сайте.Щелкните Добавить директиву , чтобы добавить новую директиву в список. Чтобы изменить существующую директиву, щелкните Удалить директиву , а затем создайте новую.
Создание настраиваемых директив пользовательского агента
В нашем генераторе robots.txt можно указать Google и несколько других поисковых систем в соответствии с вашими критериями. Чтобы указать альтернативные директивы для одного сканера, щелкните поле списка User Agent (по умолчанию отображается *), чтобы выбрать бота. Когда вы нажимаете Добавить директиву , настраиваемый раздел добавляется в список со всеми универсальными директивами, включенными в новую настраиваемую директиву.Чтобы изменить общую директиву Disallow на директиву Allow для настраиваемого пользовательского агента, создайте новую директиву Allow для конкретного пользовательского агента для содержимого. Соответствующая директива Disallow удалена для настраиваемого пользовательского агента.
Чтобы узнать больше о директивах robots.txt, см. Полное руководство по блокировке вашего контента в поиске.
Вы также можете добавить ссылку на свой XML-файл Sitemap. Введите или вставьте полный URL-адрес XML-файла Sitemap в текстовое поле XML Sitemap .Щелкните Обновить , чтобы добавить эту команду в список файлов robots.