На этой странице представлены сервисы и программное обеспечение для работы с ключевыми словами.
Сервисы от поисковых систем
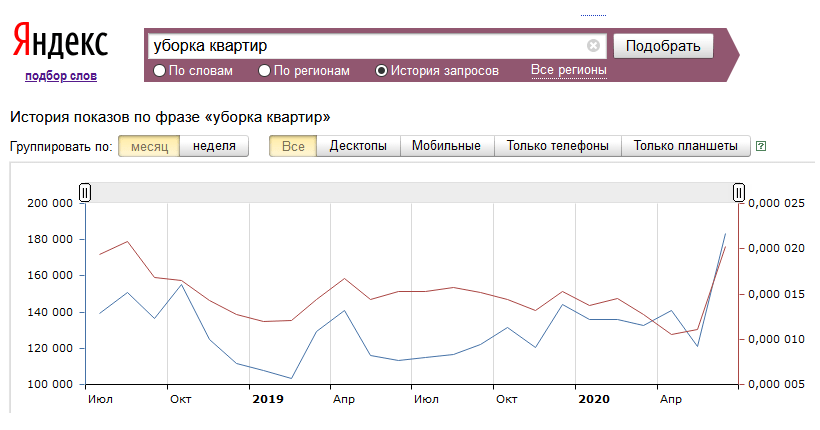
 Яндекс Вордстат, wordstat.yandex.ru — главный бесплатный сервис поисковой системы Яндекс для оценки пользовательского интереса к конкретным тематикам и для подбора ключевых слов рекламодателями. Сервис содержит подробную статистику запросов на протяжении месяца.
Яндекс Вордстат, wordstat.yandex.ru — главный бесплатный сервис поисковой системы Яндекс для оценки пользовательского интереса к конкретным тематикам и для подбора ключевых слов рекламодателями. Сервис содержит подробную статистику запросов на протяжении месяца.
 Google KeywordPlanner, ads.google.com/aw/keywordplanner/home — бесплатный инструмент AdWords по подбору различных вариантов поисковых запросов, комбинированию имеющихся списков ключевых слов, подбору оптимальных ставок и бюджетов контекстных кампаний. Сервис полезен как опытным, так и начинающим рекламодателям.
Google KeywordPlanner, ads.google.com/aw/keywordplanner/home — бесплатный инструмент AdWords по подбору различных вариантов поисковых запросов, комбинированию имеющихся списков ключевых слов, подбору оптимальных ставок и бюджетов контекстных кампаний. Сервис полезен как опытным, так и начинающим рекламодателям.
Google Trends, trends.google.ru/trends/ — публичный сервис, основанный на поиске Google, который показывает на картах и в таблицах, как часто определенный термин ищут по отношению к общему объему поисковых запросов в различных регионах мира и на различных языках.
 Mail.Ru Вордстат, webmaster.mail.ru/querystat — статистика по запросам поисковой системы Mail.Ru.
Mail.Ru Вордстат, webmaster.mail.ru/querystat — статистика по запросам поисковой системы Mail.Ru.
Сервисы для группировки ключевых слов
 СЕМЁН ЯДРЁН, semen-yadren.com — агентство семантики. В личном кабинете присутствуют бесплатные инструменты для быстрого внедрения семантического ядра на сайт. Самый большой на рынке объем выгружаемой информации после группировки(12 отчетов), включая ТЗ копирайтеру.
СЕМЁН ЯДРЁН, semen-yadren.com — агентство семантики. В личном кабинете присутствуют бесплатные инструменты для быстрого внедрения семантического ядра на сайт. Самый большой на рынке объем выгружаемой информации после группировки(12 отчетов), включая ТЗ копирайтеру.
 Just Magic, just-magic.org — система автоматизации SEO в части семантики и текстов.
Just Magic, just-magic.org — система автоматизации SEO в части семантики и текстов.
 Engine, engine.seointellect.ru — помощник оптимизатора, автоматическая кластеризация ключевых слов.
Engine, engine.seointellect.ru — помощник оптимизатора, автоматическая кластеризация ключевых слов.
 Coolakov, coolakov.ru/tools/razbivka — бесплатный сервис для автоматической группировки запросов. Разбивка запросов на группы производится на основе схожести топ10 Яндекса.
Coolakov, coolakov.ru/tools/razbivka — бесплатный сервис для автоматической группировки запросов. Разбивка запросов на группы производится на основе схожести топ10 Яндекса.
 SEMparser, semparser.ru — платный сервис по структуризации семантики для SEO и контекста.
SEMparser, semparser.ru — платный сервис по структуризации семантики для SEO и контекста.
 STOOLZ, stoolz.ru — платный сервис кластеризации запросов предназначен для быстрой автоматизированной группировки больших списков запросов на основе выдачи поисковой системы Яндекс.
STOOLZ, stoolz.ru — платный сервис кластеризации запросов предназначен для быстрой автоматизированной группировки больших списков запросов на основе выдачи поисковой системы Яндекс.
 Rush Analytics, rush-analytics.ru — сбор Яндекс.Вордстат, подсказок и автоматическая кластеризация запросов.
Rush Analytics, rush-analytics.ru — сбор Яндекс.Вордстат, подсказок и автоматическая кластеризация запросов.
Вам нужно семантическое ядро?
Но, все это для Вас слишком сложно, нет времени или опыта.
Обращайтесь в агентство семантики «Семён Ядрён».
Десктопные программы для работы с ключевыми словами
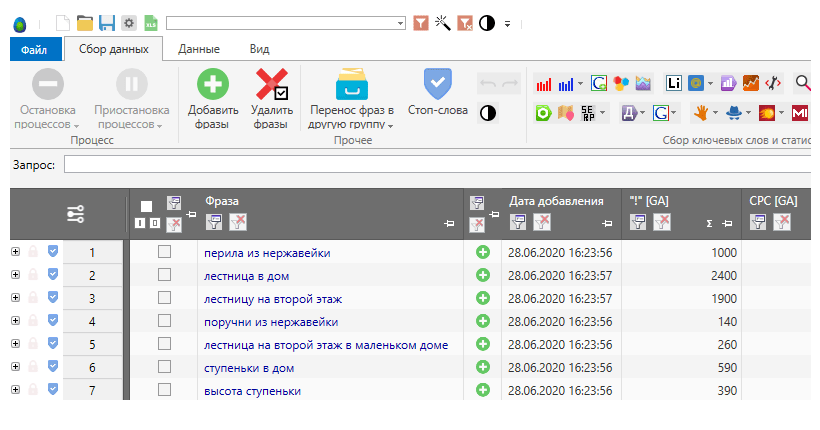
 Key Collector, key-collector.ru — лучшая программа по сбору и чистке ключевых фраз из разных источников, позволяет значительно облегчить процесс подготовки семантического ядра. Платная.
Key Collector, key-collector.ru — лучшая программа по сбору и чистке ключевых фраз из разных источников, позволяет значительно облегчить процесс подготовки семантического ядра. Платная.
 СловоЁБ, seom.info/2012/05/04/slovoeb-2-0 — младший брат Key Collector. Одна из лучших бесплатных программ для составления семантического ядра.
СловоЁБ, seom.info/2012/05/04/slovoeb-2-0 — младший брат Key Collector. Одна из лучших бесплатных программ для составления семантического ядра.
 Allsubmitter, webloganalyzer.biz/rus/allsubmitter.html — многофункциональная программа, при помощи которой можно подбирать ключевые слова из 14 источников, используется модуль «подбор ключевых слов». Платная.
Allsubmitter, webloganalyzer.biz/rus/allsubmitter.html — многофункциональная программа, при помощи которой можно подбирать ключевые слова из 14 источников, используется модуль «подбор ключевых слов». Платная.
 Магадан, magadanparser.ru — программа для удобного автоматического сбора, анализа и обработки ключевых слов Яндекс.Директа. Широкий спектр функциональных возможностей и удобный интерфейс.«LITE» — бесплатная ознакомительная редакция с символическими ограничениями функциональных возможностей.«PRO» — платная редакция, не содержащая искусственных ограничений по функционалу.
Магадан, magadanparser.ru — программа для удобного автоматического сбора, анализа и обработки ключевых слов Яндекс.Директа. Широкий спектр функциональных возможностей и удобный интерфейс.«LITE» — бесплатная ознакомительная редакция с символическими ограничениями функциональных возможностей.«PRO» — платная редакция, не содержащая искусственных ограничений по функционалу.
 Букварикс, bukvarix.com — бесплатная программа для ОЧЕНЬ быстрого подбора ключевых слов по собственной базе в 460 млн. слов и словосочетаний. Выбранные словосочетания сопровождаются такой полезной информацией, как количество показов в Яндексе, конкуренция в Google и Яндекс.Директ, а также годовой тренд поиска в Яндексе с выделением наиболее активного месяца.
Букварикс, bukvarix.com — бесплатная программа для ОЧЕНЬ быстрого подбора ключевых слов по собственной базе в 460 млн. слов и словосочетаний. Выбранные словосочетания сопровождаются такой полезной информацией, как количество показов в Яндексе, конкуренция в Google и Яндекс.Директ, а также годовой тренд поиска в Яндексе с выделением наиболее активного месяца.
Плагины, расширения для браузера
Yandex Wordstat Helper — Расширение для Mozilla Firefox и Google Chrome, позволяющее значительно ускорить сбор слов с помощью сервиса wordstat.yandex.ru.
Yandex Wordstat Assistant — Расширение для браузеров Google Chrome, Яндекс.Браузер и Opera, которое позволяет значительно ускорить ручной сбор слов с помощью сервиса подбора слов Яндекс (wordstat).
Сервисы для подбора ключевых слов
 SEMrush (СЕМраш), semrush.com — сервис для исследования конкурентов, позволяет узнать кейворды (запросы), по которым любой домен или сайт попадает в SERP или Ads.
SEMrush (СЕМраш), semrush.com — сервис для исследования конкурентов, позволяет узнать кейворды (запросы), по которым любой домен или сайт попадает в SERP или Ads.
 SpyWords (СпайВордс), spywords.ru — уникальный сервис, позволяющий узнать все секреты твоих конкурентов: их запросы в контексте и поиске, тексты объявлений и позиции, бюджеты и многое другое.
SpyWords (СпайВордс), spywords.ru — уникальный сервис, позволяющий узнать все секреты твоих конкурентов: их запросы в контексте и поиске, тексты объявлений и позиции, бюджеты и многое другое.
 Serpstat (Серпстат), serpstat.com — сервис для анализа конкурентов в поиске и подбора ключевых фраз. Сервис поможет узнать поисковые запросы конкурентов, их суммарный трафик, страницы с наибольшей видимостью.
Serpstat (Серпстат), serpstat.com — сервис для анализа конкурентов в поиске и подбора ключевых фраз. Сервис поможет узнать поисковые запросы конкурентов, их суммарный трафик, страницы с наибольшей видимостью.
 Мутаген, mutagen.ru — платно / бесплатный сервис подбора для своего или чужого сайта ключевых слов, по которым показов много, а конкуренции почти нет.
Мутаген, mutagen.ru — платно / бесплатный сервис подбора для своего или чужого сайта ключевых слов, по которым показов много, а конкуренции почти нет.
 МегаИндекс, keywords.megaindex.ru/cabinet/ — бесплатный инструмент по определению видимости сайта и подбору ключевых фраз
МегаИндекс, keywords.megaindex.ru/cabinet/ — бесплатный инструмент по определению видимости сайта и подбору ключевых фраз
 Топвизор, topvisor.ru — сервис по подбору ключевых слов для составления семантического ядра сайта из всех доступных источников: Яндекс.Директ, Google Adwords, Webmaster Bing, Webmaster Mail.
Топвизор, topvisor.ru — сервис по подбору ключевых слов для составления семантического ядра сайта из всех доступных источников: Яндекс.Директ, Google Adwords, Webmaster Bing, Webmaster Mail.
 SimilarWeb, similarweb.com — условно бесплатный сервис отображает разные параметры сайта, в том числе, по каким запросам он получает трафик из органического поиска или контекста.
SimilarWeb, similarweb.com — условно бесплатный сервис отображает разные параметры сайта, в том числе, по каким запросам он получает трафик из органического поиска или контекста.
 Кейсо — keys.so — сервис является первым сервисом анализа ключей, специализирующимся на работе с информационными сайтами, что это означает на практике: 1. Максимальный охват ключевых фраз 2. Особое внимание на частотность и валидность слово-форм 3. Минимальное количество неточных дублей ключевых фраз 4. Информация о сайтах и группах сайтов для упрощения анализа.
Кейсо — keys.so — сервис является первым сервисом анализа ключей, специализирующимся на работе с информационными сайтами, что это означает на практике: 1. Максимальный охват ключевых фраз 2. Особое внимание на частотность и валидность слово-форм 3. Минимальное количество неточных дублей ключевых фраз 4. Информация о сайтах и группах сайтов для упрощения анализа.

Готовые базы ключевых слов
 MOAB, moab.pro — база ключевых слов, 3.2 млрд запросов из Яндекс.Метрики Ваших конкурентов, 1.4 млрд. запросов из Яндекс.Подсказок с обновлениями 2 раза в месяц.
MOAB, moab.pro — база ключевых слов, 3.2 млрд запросов из Яндекс.Метрики Ваших конкурентов, 1.4 млрд. запросов из Яндекс.Подсказок с обновлениями 2 раза в месяц.
 База Пастухова, pastukhov.com — база ключевых слов Яндекс и Google (русских ключей в базе: 1 млрд, английских ключей в базе: 1 млрд.).
База Пастухова, pastukhov.com — база ключевых слов Яндекс и Google (русских ключей в базе: 1 млрд, английских ключей в базе: 1 млрд.).
 KeyBooster, keybooster.ru — онлайн-база ключевых слов, ключевых слов в базе: 55 млн. Помимо значений месячной статистики показов каждого ключевого слова, база содержит информацию о связях между ключевыми словами, сезонных трендах и другую полезную информацию.
KeyBooster, keybooster.ru — онлайн-база ключевых слов, ключевых слов в базе: 55 млн. Помимо значений месячной статистики показов каждого ключевого слова, база содержит информацию о связях между ключевыми словами, сезонных трендах и другую полезную информацию.
 FastKeywords.biz — онлайн-база русских ключевых слов (ключей в полной базе: 780 млн.).
FastKeywords.biz — онлайн-база русских ключевых слов (ключей в полной базе: 780 млн.).
 Roostat.ru — база ключевых слов от сервиса Rookee (поисковых запросов в базе: 230 млн.).
Roostat.ru — база ключевых слов от сервиса Rookee (поисковых запросов в базе: 230 млн.).
Собственные системы аналитики
Собственные счетчики и системы аналитики позволяют собирать списки ключевых слов, по которым люди уже заходили на сайт.
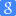 Google Analytics, marketingplatform.google.com/about/analytics/ — Сервис веб-аналитики для сайта от Google. Ресурс не покажет зашифрованные запросы Яндекса, а также скроет многие ключи, по которым люди переходили из Google, но какой-то полезный список ключевых слов все же можно получить. При связи с панелью для вебмастеров (search.google.com/search-console) можно получить больше информации по запросам. Google Analytics позволяет оценивать рентабельность инвестиций, отслеживать Flash- и видеорекламу, а также распространение контента в приложениях и социальных сетях.
Google Analytics, marketingplatform.google.com/about/analytics/ — Сервис веб-аналитики для сайта от Google. Ресурс не покажет зашифрованные запросы Яндекса, а также скроет многие ключи, по которым люди переходили из Google, но какой-то полезный список ключевых слов все же можно получить. При связи с панелью для вебмастеров (search.google.com/search-console) можно получить больше информации по запросам. Google Analytics позволяет оценивать рентабельность инвестиций, отслеживать Flash- и видеорекламу, а также распространение контента в приложениях и социальных сетях.
 Яндекс Метрика, metrika.yandex.ru — бесплатный сервис статистики переходов и ключевых слов на сайт из Яндекса, других поисковиков, Яндекс Картинок и других источников. Инструмент для оценки посещаемости сайта, анализа поведения посетителей и эффективности рекламы. Мониторинг доступности сайта.
Яндекс Метрика, metrika.yandex.ru — бесплатный сервис статистики переходов и ключевых слов на сайт из Яндекса, других поисковиков, Яндекс Картинок и других источников. Инструмент для оценки посещаемости сайта, анализа поведения посетителей и эффективности рекламы. Мониторинг доступности сайта.
 LiveInternet, liveinternet.ru, Полезно использовать вместе с другими системами аналитики, чтобы собирать как можно больше данных. Сервис статистики для сайтов, предоставляющий наиболее качественные инструменты сбора, обработки и последующего анализа данных посещаемости Интернет-ресурсов. Присутствуют инструменты обработки данных, графическое отображение результатов и удобный интерфейс.
LiveInternet, liveinternet.ru, Полезно использовать вместе с другими системами аналитики, чтобы собирать как можно больше данных. Сервис статистики для сайтов, предоставляющий наиболее качественные инструменты сбора, обработки и последующего анализа данных посещаемости Интернет-ресурсов. Присутствуют инструменты обработки данных, графическое отображение результатов и удобный интерфейс.
Для англоязычных проектов
 Spy Fu, spyfu.com — платный сервис по подбору англоязычных запросов для зарубежных проектов. Итоговая статистика имеет параметр сложности продвижения запросов.
Spy Fu, spyfu.com — платный сервис по подбору англоязычных запросов для зарубежных проектов. Итоговая статистика имеет параметр сложности продвижения запросов.
 Keyword Eye, keywordeye.com — платный ресурс для выгрузки по заданной фразе базы ключей и просмотра конкурентности заданных англоязычных ключевых слов в виде облака.
Keyword Eye, keywordeye.com — платный ресурс для выгрузки по заданной фразе базы ключей и просмотра конкурентности заданных англоязычных ключевых слов в виде облака.
 Keyword Tool, keywordtool.io — удобная и бесплатная альтернатива AdWords Planner. Больше 750 предложений для каждого ключевого слова, основанные на подсказках Google для разных языков (83 доступных языка) и регионов (192 домена Google). Присутствует возможность подбора семантики из YouTube, AppStore и Bing.
Keyword Tool, keywordtool.io — удобная и бесплатная альтернатива AdWords Planner. Больше 750 предложений для каждого ключевого слова, основанные на подсказках Google для разных языков (83 доступных языка) и регионов (192 домена Google). Присутствует возможность подбора семантики из YouTube, AppStore и Bing.
 Wordtracker, wordtracker.com — популярный платный зарубежный инструмент анализа ключевых слов.
Wordtracker, wordtracker.com — популярный платный зарубежный инструмент анализа ключевых слов.
 Neilpatel, neilpatel.com — бесплатный парсер поисковых подсказок Google. Можно задать язык и вертикаль поиска – например, спарсить семантику из поиска, изображениям, новостям, видео и т.д.
Neilpatel, neilpatel.com — бесплатный парсер поисковых подсказок Google. Можно задать язык и вертикаль поиска – например, спарсить семантику из поиска, изображениям, новостям, видео и т.д.
 Keywordshitter — keywordshitter.com — бесплатный и простой сервис по подбору англоязычных подсказок поисковых запросов.
Keywordshitter — keywordshitter.com — бесплатный и простой сервис по подбору англоязычных подсказок поисковых запросов.
 Searchmetrics.com — Searchmetrics is the pioneer and leading global provider of search analytics, digital marketing software and SEO services.
Searchmetrics.com — Searchmetrics is the pioneer and leading global provider of search analytics, digital marketing software and SEO services.
Сервисы для сбора семантического ядра
Сбор семантического ядра – неотъемлемая часть работы по продвижению сайта. Такую работу возможно осуществить вручную, если ее объемы невелики, но если речь идет о масштабном проекте, для сбора семантического ядра стоит воспользоваться специальными онлайн-сервисами. О лучших из них мы расскажем в этой статье.
Что такое семантическое ядро и для чего оно нужно?
Семантическое ядро – совокупность ключевых слов и фраз, отражающих тематику веб-ресурса. По этому набору ключевых фраз и слов и осуществляется продвижение сайта.
Осуществить сбор семантического ядра необходимо для того, чтобы роботы поисковых систем показывали пользователям по их запросу страницы именно продвигаемого сайта. Наличие семантического ядра необходимо для упорядочивания структуры сайта и для оптимизации страниц под конкретные ключевые запросы.
Помимо этого, при помощи семантического ядра можно определить, какие еще страницы и разделы имеет смысл добавить на ваш ресурс, а также подобрать темы для составления ТЗ копирайтерам.
Подробнее о том, что такое семантическое ядро и как его составить, читайте на нашем сайте:
Что такое семантическое ядро сайта
Как правильно составить семантическое ядро сайта? Практические советы и рекомендации.
Сервисы для сбора семантического ядра
Зачем использовать специальные сервисы для составления семантического ядра?
Конечно, если вы занимаетесь продвижением, например, интернет-магазина с товарами, относящимися к узкой нише, или продающего одну услугу определенного специалиста, сбор запросов вполне реально осуществить вручную. В иных случаях, связанных с гораздо большим объемом работы, на помощь в сборе семантического ядра могут прийти специальные сервисы.
Предлагаем подборку пяти полезных сео-специалистам онлайн-сервисов для сбора нового семантического ядра или расширения уже существующего на данный момент.
Сервисы, рассмотренные в этой статье, были отобраны по таким критериям, как:
- работающие только с качественными и актуальными базами
- имеющие возможность выгрузить данные в excel/гугл документы
- работающие в онлайн-режиме, не требуя инсталляции на ПК
- имеющие бесплатную версию для тестирования возможностей сервиса и изучения его функционала
Serpstat
Сервис, обладающий широким функционалом для анализа конкурентов и ключевых слов. Имеет красивый и удобный интерфейс со множеством категорий/подкатегорий, с которыми можно разобраться при помощи подробного руководства (включая обучающие видео). Также есть возможность получить индивидуальную демонстрацию работы по видеозвонку.
Возможности сервиса:
- Сравнение доменов конкурентов и выгрузка упущенных ключей. Чтобы воспользоваться этим методом, необходимо зайти в раздел анализ сайта, далее перейти в анализ доменов, оттуда в ppc-анализ и затем запустить сравнение доменов, где необходимо будет указать два-три url-адреса (к примеру, собственного ресурса и сайтов-конкурентов) и кликнуть по кнопке «сравнить». В результате сервис выдаст вам диаграмму, в которой вы сможете увидеть, как пересекаются семантические ядра.
- Есть возможность отбора и фильтрации по различным параметрам ключей, не являющихся общими и их дальнейшей выгрузки в Excel.
- Отображение заголовков и текстового содержания объявлений сайтов-конкурентов в контекстной рекламе. Эти данные можно найти в разделе «ppc-анализ», перейдя на ключевые фразы.

Стоимость использования:
Бесплатный тариф предлагает не более 30-ти запросов за день и отчет, состоящий из десяти результатов. Платное использование сервиса составляет 19 usd/месяц, но за подписку на год вам сделают скидку в размере 20%.
Rush Analytics
Сервис по сбору семантического ядра от Rush Agency, способный за два-три часа собрать семантическое ядро без использования прокси и анти-капчи. Интерфейс сервиса интуитивно понятный, при этом пользователям доступны руководства в видео-формате и демонстрация работы в режиме online.
Особенности сервиса:
- Сбор поисковых подсказок Яндекса и Google на всех языках мира с отсеиванием из них ненужных
- Парсинг с Яндекс.Вордстата до 40 страниц, показывая частотность по всем вхождениям ключей
- Очистка уже имеющегося семантического ядра от ключевых слов низкого качества
- Помощь в очистке нового семантического ядра
Стоимость использования:
При регистрации все сервисе вам будет доступно 200 бесплатных действий; за подписку необходимо будет заплатить от 999р./месяц.
JustMagic
Профессиональная сео-платформа с широким функционалом, при помощи которой можно составить семантическое ядро для сайта.
Возможности платформы:
- Выдача маркетинговых запросов с учетом статистики Яндекс.Метрики
- Сбор данных из Wordstat по всем регионам (первые 40 страниц)
- Расширение и кластеризация семантического ядра по собственным базам платформы
- Парсинг поисковых подсказок по конкернтому региону
- Удаление дублей и пустых запросов
- Проверка уже существующего семантического ядра

Стоимость использования:
Платформа предлагает бесплатную версию с лимитов в 100 действий; за использование платной нужно будет оформить подписку на месяц стоимостью 1000р.
PixelPlus
Сервис с набором инструментов для сбора семантического ядра от компании с идентичным названием.
Возможности сервиса:
- Проверка запросов по геозависимости, локализации и коммерциализации
- Выдача подсказок из Ютуб
- Показ частоты запросов Яндекс.Вордстат на телефонах и планшетах
- Еще более 50-ти инструментов, более тридцати из которых доступны в бесплатной версии.
![]()
Стоимость использования:
В бесплатном тарифе доступно 200 действий; стоимость подписки составляет 1990р./месяц.
Планировщик ключевых слов Google
Инструмент для сбора семантического ядра, подходящий не только для ru-сегмента, но и для любых регионов, работающих с google.adsense.
Функции сервиса:
- Возможность подбора синонимичных фраз
- Возможность задать минус-слова списками
- Работа с объемной базой поисковых запросов от Гугл
- Выгрузка полученной информации в CSV и Google-таблицы
Стоимость использования:
В сервисе можно работать с бесплатного аккаунта – при этом частотность будет не точной, что не позволит ориентироваться на полученные результаты при продвижении ресурса. Для полноценной работы необходимо использовать платный аккаунт.
Яндекс Wordstat
Базовый, один из самых наиболее известных и простых в использовании сервисов для сбора семантического ядра.
Функции сервиса:
- Подбор ключей по словам и словоформам, а также по геолокации
- Подбор ключей с частотностью запросов
- Возможность выбрать устройство, с которого производится поиск информации пользователями – телефон, планшет, ПК
- Показ историю и динамику запросов за два года
- Показ похожих запросов
- Работа с морфологическими словоформами
В сервисе также имеются дополнительные расширения:
Яндекс Wordstat Helper (для сортировки ключей и удаления дублей) и Яндекс Wordstat Assistant (для синхронизации полученных данных в таблицу с возможностью добавления/удаления ключевых слов и фраз).
Стоимость использования:
Использование сервиса является бесплатным.
Следующим этапом работы является кластеризация семантического ядра.
Инструменты для сбора семантического ядра позволяют собрать сотни и тысячи ключевых слов. Но в этом списке неизбежно будут повторяющиеся запросы, лишние символы, пробелы, фразы с нулевой частотностью и т. д. Весь этот «мусор» надо почистить.
На примере интернет-магазина электроники по шагам показываем, как с помощью инструментов Click.ru собрать пул запросов для контекста и привести его в юзабельный вид.
1. Собираем пул запросов
Для сбора семантического ядра сайта в Click.ru есть бесплатный инструмент «Медиапланирование».
Как с ним работать:
1. Зарегистрируйтесь в Click.ru. Кликните «Создать аккаунт». В открывшемся окне выберите рекламную систему и назовите аккаунт.
2. Добавьте кампанию. Назовите ее, выберите места показа объявлений, укажите URL, геотаргетинг.
3. Система предложит подобрать слова или добавить свои. Кликните «Подобрать слова» — медиапланер подберет ключевые слова на основе контента рекламируемого сайта.
4. Добавьте подобранные слова в медиаплан. В нашем примере система собрала 623 ключевых слова. Для добавления их в медиаплан установите галочку в шапке таблицы и кликните «Добавить в медиаплан».
5. Расширьте семантическое ядро словами, по которым продвигаются ваши конкуренты. Для этого в разделе «Автоматический подбор слов» выберите «Слова конкурентов».
Система предложит до 5 конкурентов и соберет по ним слова. Проверьте, совпадает ли ассортимент предложенных сайтов-конкурентов с вашим. Если нет, удалите предложенные сайты и задайте URL конкурентов самостоятельно (до 10 площадок за раз).
Системе потребуется несколько минут на сбор слов. После этого кликните «Показать слова конкурентов».
В примере система собрала 2849 слов. Для их просмотра пролистайте таблицу вниз и нажмите «Показать все».
Просмотрите список собранных слов. Не все они будут релевантными, поскольку даже у ближайших конкурентов может не совпадать товарный ассортимент. Избавиться от лишних слов можно двумя способами:
- Удалить их сразу вручную
- Почистить уже в самом конце — после группировки (тогда словам можно будет удалять «пачками», а не по одному).
Если слов много, лучше выбрать второй вариант.
Итак, теперь нам нужно выгрузить собранные ключи. Для этого добавим их в медиаплан. Для добавления всех слов из таблицы в медиаплан установите галочку в шапке таблицы — система автоматически поставит галочки напротив каждой фразы. Далее кликните «Добавить в медиаплан».
Выгрузите добавленные в медиаплан слова в XLS–файл.
С помощью двух подборщиков (по контенту сайта и по словам конкурентов) получилось собрать и добавить в медиаплан 3492 слова. Теперь все это нужно очистить.
2. Удаляем дублирующиеся запросы, спецсимволы, пробелы, пустые строки
Вручную найти дубли в списке, состоящем из 1000 и более слов, сложно. Для этого подойдет бесплатный нормализатор ключевых слов.
Что он умеет:
- Удалять дубликаты слов в точном вхождении. Например, если инструмент обнаружит в списке две ключевые фразы «купить samsung galaxy s10», то одну из них он удалит.
- Удалять дубли с учетом морфологии и перестановки слов. Например, если система обнаружит две фразы «купить samsung galaxy s10» и «samsung galaxy s10 купить», то вторая фраза будет считаться дублем и будет удалена.
- Удалять спецсимволы в начале и конце слова. В собранных запросах (особенно если это делается с помощью сторонних сервисов) могут попадаться спецсимволы: вопросительные знаки, плюсы и минусы. Например, нормализатор нашел в списке слов фразу с плюсом: «samsung galaxy s10 + купить». Он просто удалит плюс и лишние пробелы, а сам запрос останется без изменений.
- Удаляет лишние пробелы. Если в начале, середине или в конце ключевой фразы есть лишние пробелы, то инструмент обнаружит их и удалит.
- Удаляет табуляцию и пустые строки. Инструмент удаляет отступы в начале и конце строки. Если в таблице есть пустые строки, то они тоже удаляются.
- Преобразовывает слова в нижний регистр. Если в списке есть спарсенные заголовки, прописанные в верхнем регистре, то система их переводит в нижний регистр.
- Заменяет ё на е. Если вы не используете букву «ё», то установите галочку напротив опции «Заменить ё на е».
Особенности инструмента:
- Бесплатное использование.
- Проверка осуществляется онлайн. Не надо устанавливать софт или держать страницу открытой.
- Неограниченное количество слов в списке.
- Выполненные задачи хранятся в аккаунте Click.ru неограниченное количество времени.
- Не надо вводить капчу.
Как использовать инструмент
Перейдите на страницу инструмента и добавьте слова.
Выберите, какие действия необходимо выполнить с ядром, и нажмите «Выполнить».
Системе понадобится пара минут, чтобы выполнить заданные действия. Отчет доступен для загрузки в виде XLSX-файла.
Для загрузки отчета в «Списке задач» нажмите на кнопку «Скачать XLSX».
Отчет состоит из двух страниц:
- очищенный от дублей список слов;
- исходные настройки (исходный список слов и настройки необходимых действий с ядром).
Фрагмент отчета:
В примере исходный список состоял из 3492 запросов. После чистки их количество сократилось до 2828 слов, то есть дубликаты занимали 19% ядра.
3. Удаляем слова с нулевой частотностью
Для целей контекстной рекламы слова с околонулевой частотностью не представляют интереса, поскольку по ним не будет показов. Такие слова лучше сразу удалить.
Для проверки частотности большого массива ключей в Click.ru есть парсер Wordstat. Он собирает частотности из левой колонки Wordstat. Он парсит частотность в любом регионе Яндекса и учитывает тип соответствия ключевых слов.
Как пользоваться инструментом
Перейдите на страницу инструмента. Добавьте запросы.
Выберите регион, по которому инструмент будет парсить частотности.
Укажите параметры сбора частотности. Инструмент собирает частотности по запросам в широком соответствии, фиксирует количество слов и морфологию, фиксирует порядок слов.
Подробнее о возможностях парсера Wordstat читайте в статье: «Как быстро уточнить частотность в Wordstat»
Для запуска задачи нажмите кнопку «Запустить проверку». Время сбора зависит от количества запросов, регионов и типов соответствия.
Отчет доступен в списке задач в формате XLSX.
В отчете указывается частотность запросов в разных типах соответствия. Удалите слова с нулевой и околонулевой частотностью.
Важно! Будьте внимательны с ключевыми словами, связанными с сезонными товарами/услугами. В Вордстате статистика собирается за последний месяц, поэтому если сейчас в вашей нише спад, частотность будет низкой. Детально об анализе частотности в Вордстате мы писали здесь. Также вам может помочь сервис Google Trends. Как с ним работать, тоже рассказывали.
После удаления «нулевок» можно приступать к группировке слов.
4. Разбиваем собранные слова на группы и завершаем очистку ядра
Для группировки ключевиков используйте кластеризатор. Инструмент группирует слова на основе сравнения ТОПов поисковой выдачи в заданном регионе. Инструмент обычно используют SEO-специалисты для разбивки ключей по страницам. Но также он хорошо подходит для целей контекстной рекламы.
Как пользоваться инструментом
Перейдите на страницу инструмента. Для удобства навигации в отчетах укажите адрес сайта и назовите проект.
Загрузите запросы файлом или списком. В списке должно быть не менее 20 запросов.
Выберите способ кластеризации. Доступно два варианта: сравнение ТОПов и профессиональная настройка. В настройках укажите поисковую систему, диапазон точности, количество слов в кластере (для профессиональной настройки). Нажмите на кнопку «Запустить кластеризацию».
Подробнее о настройке и возможностях кластеризатора Click.ru читайте в статье «Как сгруппировать ключевые запросы с помощью кластеризации?»
Скачайте отчет в списке задач.
В отчете запросы для объявлений сгруппированы по кластерам на основе результатов поисковой выдачи. Просмотрите отчет и удалите кластеры с нерелевантными запросами. Это намного удобней делать именно сейчас, а не по одному слову на этапе подбора.
В результате вы получите сгруппированную и очищенную от мусора семантику, готовую к применению.
Не хватает слов для семантики — расширьте список
Бывает, что после очистки список слов сильно сокращается. В таком случае используйте инструменты для расширения семантики:
Подробно о расширении ядра в узкой нише читайте в статье «Как расширить англоязычную семантику для поисковой рекламы в узкой нише».
Еще один вариант пополнения семантики — парсинг ключевых слов, по которым запущена реклама конкурентов с помощью бесплатного парсера. Подробно о нем — по ссылке.
от сбора ключевых слов до кластеризации
Очень важно, чтобы семантическое ядро состояло из релевантной семантики, которая пользуется спросом в интернете и отвечает на поисковые запросы целевой аудитории (ЦА).
Тщательная работа по созданию семантического ядра — основа успешного SEO, так как поисковые системы все чаще ориентированы на контент. В 2011 году компания Google стала активно двигаться в сторону искусственного интеллекта (ИИ), были разработаны уникальные алгоритмы семантического анализа:
“Чтобы подобрать страницы, содержащие релевантные сведения, прежде всего необходимо проанализировать значение слов в запросе. Мы разрабатываем языковые модели, позволяющие определять, какие сочетания слов следует искать в индексе. Для этого выполняется ряд действий – от интерпретации орфографических ошибок, до определения типа введенного запроса на основе результатов последних исследvj,ований в области понимания естественного языка…
…Затем мы подбираем страницы, содержащие информацию, которая соответствует запросу. Обычно, когда пользователь вводит запрос, наши алгоритмы ищут в индексе подходящие страницы, а также определяют, как часто ключевые слова встречаются на странице и в каких ее разделах (например, в заголовке или основном тексте).
Наши алгоритмы не только сопоставляют ключевые слова, но и определяют, насколько полная информация содержится в предполагаемых результатах поиска. Например, пользователя, указавшего запрос «собаки», вряд ли интересует страница, в которой сотни раз повторяется это слово. Мы стараемся убедиться в том, что та или иная страница содержит сведения по запросу, а не просто дублирует его. Так, алгоритмы Поиска определят, представлен ли на страницах нужный контент, например изображения собак, видео с их участием или список пород. Наконец, пользователю в первую очередь будут показаны страницы на том же языке, на котором введен запрос.
Мы разрабатываем алгоритмы, позволяющие оценивать релевантность страниц, чтобы наиболее подходящие из них по
Что такое SC?
Прежде чем мы полностью поймем, что это такое, мы столкнемся с некоторыми трудностями, с которыми может столкнуться ваш бизнес, если вы сразу не подумаете о сборе семантического ядра:
- Не будет дешевого трафика.
- Продвижение сайта будет очень сложным.
- Трудности во внутренней оптимизации.

Необходимо понимать, что грамотное SEO-продвижение обеспечит постоянный приток посетителей в интернет-магазин, при этом цена трафика будет регулярно снижаться, а конверсия, наоборот, возрастать.Поэтому составление семантического ядра — это тот фактор, который ни в коем случае не следует упускать из виду на начальном этапе создания сайта и контента.
Теперь точно! Семантическое ядро - это механизм, похожий на сердечно-сосудистую систему, а именно те запросы, по которым вас можно найти в поисковых системах.
Например, вы продаете блюда для ресторанов. Как пользователь будет искать ваш продукт? «Куплю посуду для ресторанов», «Посуда для ресторанов цена», «Куплю набор посуды для ресторанов и кафе ул.Петербург »и т. Д. SY для такого магазина будет простой таблицей, в которой с одной стороны будет список всех возможных ключевых опций, а скорее количество раз, когда этот запрос был введен всеми пользователями. В этом вопросе желательно учитывать именно то место, где вы ведете бизнес.

Какая польза от семантики для торговой онлайн-платформы?
- Это ядро оптимизации. Делайте все правильно с самого начала, потому что исправление ошибок позже может быть дорогим.
- Благодаря его составлению можно составить гармоничный и структурированный каталог товаров и услуг, понятный потенциальным покупателям.
- Пользователям будет легко перейти именно к вашему ресурсу, а не к конкурентам.
- Упрощает продвижение. В будущем будет не только легче приобрести покупателя, но и намного дешевле; крупных рекламных вложений не потребуется.
А теперь, на примере конкретного магазина, мы рассмотрим, как правильно собирать ключевые запросы и применять их на практике.

Инструменты для создания ядра
Как пользователи могут найти конкретный продукт в Интернете?
- Если мы ищем посуду для кафе или ресторана, то поиск возможен по определенному типу или номеру модели. Например — стакан для виски, нож для резки, сковорода для гриля и многое другое.
- Категории, тип продукта, серийное производство или общие наименования.
- Объединение двух предыдущих принципов.
- Поиск по темам — «что», «как ..», «почему ..», и в конце концов совершить покупку.
Если вы новичок в этой проблеме и все еще пытаетесь сделать все самостоятельно, не привлекая сторонних специалистов, то вы вполне можете использовать следующие инструменты:
- Wordstat.yandex.ru. Этот инструмент позволит вам узнать, насколько популярен конкретный запрос в данный момент времени, по геолокации. Использовать это приятно и очень просто. Достаточно ввести предложенный ключ, и сразу вы увидите статистику по частоте за последний месяц.Подходит для сбора малогабаритной семантики в ручном режиме.
- СловоЕб, Словодер и Магадан Лайт. Сервисы в автоматическом режиме отрабатывают весь процесс, но в процессе разработки они могут оказаться более непонятными, чем предыдущий. Для пользователей, которые уже работали с Wordstat и выжали из него все, они могут быть полезны в качестве нового шага.
- KeyCollector. Платформа для денег, подходящая для профессионалов, потому что это не легко учиться.Хорошо для сбора больших ядер.

Как лучше всего начать?
Позвольте мне отметить тот факт, что СЦ для разделов с каталогом и страниц с карточками продуктов будет совершенно другим.
Начните с тщательного расчета и продумывания схемы каталогов, чтобы вы могли ее оптимизировать. Если он понятен и удобен для пользователей, он автоматически поднимет вас в результатах поиска, изучит факторы, влияющие на поведение клиентов, и выберет компетентное ядро.
- Готовый шаблон. На просторах сети достаточно подходящих «шаблонов» для подготовки каталога. Они пригодятся для составления небольшого сайта СЦ.
- Заполнение таблицы. Ядром для компиляции станет ассортимент сайтов интернет-трейдинга. Но сначала позаботьтесь о семантике всех разделов. Сделайте это в первую очередь, и вы всегда можете вернуться к карточкам продуктов и улучшить их позже. Самый простой способ создать каталог — это проанализировать ТОП конкурентов и немного изменить, другими словами, сделать копию.Кроме того, эффективный метод будет компилироваться на основе ваших собственных взглядов и предпочтений. Тем не менее, здесь вы должны быть более чем на 100% уверены в своих собственных вкусах и интуиции, иначе будет сложно все исправить позже, а тем более.
- Мы отбираем запросы. Во-первых, мы обозначаем концепцию релевантного запроса для новичков в рядах сеошников. Что это означает? Это самая основа для оптимизации всех ваших ресурсов и привлечения посетителей. Релевантность определить не сложно — посмотрите, сколько человек задали тот или иной вопрос в поиске и по количеству все станет ясно.Чем выше число, тем более актуален запрос. Мы уже говорили об инструменте wordstat.yandex.ru выше, вначале этого будет вполне достаточно. Это даст конкретику запросам по всем категориям и даже выведет ресурс в ТОП и введет больше разделов.

Теперь давайте немного поговорим об оптимизации всех страниц сайта. Первый шаг — «подогнать» теги title и description.
Для тега «Заголовок» необходимо выбрать наиболее популярные запросы. В результатах поиска эти теги видны сразу — это самая «жирная» первая строка, которая ведет на сайт. Многие SEO-специалисты не уходят далеко и не изобретают велосипед, а заимствуют его у конкурентов из ведущих списков. Метод вполне приемлемый и даже очень эффективный.
Описание — краткое описание предоставляемых продуктов или услуг. Идет сразу после предыдущего тега.
Есть еще один важный «товарищ».Они называют его h2. В данном случае это название категории или самого продукта. По умолчанию он должен содержать основной ключ, и все имена страниц вписываются в него.
Что касается описания категорий, то здесь есть алгоритм. Используйте не более полутора тысяч символов, при этом вхождение ключей не должно превышать двух вхождений прямых ключей и двух частичных. ВНИМАНИЕ!
Никогда не дублируйте страницы на сайте интернет-магазина! Представьте, что вы делаете ОДНУ категорию, но на сумму более двухсот товаров и только печатаете на самом деле 20.Что случается? Получается целых девять повторений! А теперь, пожалуйста, получите подпись — около десяти страниц с одинаковыми тегами, хотя доставка товара будет другой. Есть ли способ избежать этого? Воспользуйтесь Rel Canonical, который, как настоящая страница, поможет PS в определении действительно главной страницы.

В заключение возьмем несколько советов от профи:
- Помните! Сначала мы собираем SN для самого каталога, то есть его категорий и разделов, и только потом мы начинаем работу с описанием товара.
- Не забывайте, что название продукта может быть введено пользователем не только на русском или украинском, но и на английском языке. То есть «старая мода» и «старая мода» (речь идет о стаканах для ароматного виски) дадут разные результаты. И вы рассматриваете все варианты!
- Поставщики, конечно, ху-ребята, но доверять им с точки зрения разделения на группы товаров не стоит. Их цены не самый надежный источник. Любой долго обдуманный бизнесмен скажет вам, что там дьявол сломает ногу.Но тебе это не нужно? Исходя из ваших собственных пожеланий, а лучше поставьте себя на место покупателя — тогда будет «лед».
- Не тратьте деньги на дорогостоящее программное обеспечение. Попробуйте сначала бесплатные услуги. Вы понимаете, что для вас это не уровень? Тогда иди вперед!
- Не все владельцы интернет-магазинов считают необходимым обратить внимание на семантику. Теперь все «очень умные». Будьте выше этого, а значит и выгоднее. Сначала подумайте о семантике.
- Даже если вы давно развиваете интернет-предпринимательство и только сейчас читаете, что существует концепция, о которой мы говорили выше, не беспокойтесь. Как в песне — «не паникуйте, потому что мы не в Титанике!». Сначала проверьте все ваши запросы. Возможно, изначально вам повезло на интуитивном уровне, и сайт был правильно оптимизирован в этом отношении.

К какому выводу мы пришли? Составление семантического ядра для интернет-магазина является важной и эффективной частью продвижения.Начинающий ты или профи — не играет роли. Позаботься об этом и получи огромные доходы!
Что такое семантическое ядро?
Это понятие означает группы слов и фраз, которые могут наиболее точно описать не только товары и услуги, представленные на сайте, но и деятельность в целом, а также привести целевого посетителя на сайт. Проще говоря, это набор тех слов, с помощью которых каждый человек может понять, о чем ваш портал.
Благодаря специальным сервисам вы можете видеть статистику частоты определенных запросов, вводимых пользователями в поисковых системах.

Как составить СБ?
Составление может быть выполнено как самостоятельно, так и с помощью подрядчика. Вы можете сделать это вручную, но это займет много времени. Оптимально использовать специальные инструменты, а некоторые из них работают абсолютно бесплатно.
Список услуг и приложений для сбора:
- Google Analytics, Яндекс.Метрика, LiveInternet следует использовать, если у вас уже есть давно работающий сайт и посетители его. Данные собираются из проприетарных аналитических систем;
- Яндекс.Wordstat;
- Mutagen, KeyBooster, RooStat — платные сервисы с готовыми базами данных;
- Prodvigator, TopVisor, SimilarWeb, Alexa — инструменты для анализа конкурентов на платной основе;
- Все знают Slovoeb, Magadan и KeyCollector;
- Яндекс плагины для сбора семантики.
Мы разберемся с основными видами поисковых запросов.

Семантическая
Существует такая интересная концепция — намерение.Мысль в вашей голове может иметь совершенно разные значения. Например, знаменитый чехол с золотым кольцом. Вы вводите два слова в строке, понимая для себя, что вам нужен тур или информация о местности, и система предоставляет вам ювелирные магазины или наоборот.
Поэтому при сборе семантики вам нужно выбрать те ключи, которые полностью раскрывают вашу тему. Очень легко определить цель с небольшим AX самостоятельно — введите запрос и посмотрите, что он вам дает.Для больших объемов лучше использовать специальные программы.

Региональный
Определите, важно ли ваше местоположение для пользователя. Отсюда содержание запроса будет «танцевать».
- В зависимости от географии — товар нужен только в определенном месте. Пример: «купить шезлонг Москва»;
- Независимо от местоположения — региональная принадлежность не имеет большого значения.
Для информационных запросов, например, местоположение не имеет значения вообще.Если пользователь ищет рецепт борща, то какая разница, его готовили в Уфе или Лондоне? Исключением может быть поиск по адресу или номеру телефона организации или филиала.
Региональность учитывается только тогда, когда вы ведете работу только в определенном регионе. Это типично для коммерческих запросов в большей степени. Допустим, вы являетесь владельцем службы сбора мусора в Харькове. Здесь ясно, что работать с донецкой аудиторией, по крайней мере, неразумно.

Степень популярности
- Высокая частота — включает короткие запросы, такие как «одежда», «газонокосилка», «реклама» и т. Д.
- Средняя частота — двухсложная с уточнением, для Например, «мобильный телефон», «ювелирные изделия», «верхняя одежда».
- Низкочастотный — такие запросы помогают сузить поиск, точнее и быстрее отображают на нужной странице нужную страницу — «LG LCD TV», «мобильный телефон xiaomi».
- С ультранизкими частотами — максимально точно и продуктивно. Например, «xiaomi mi 8 mobile phone» и так далее.
При высокой частоте запросов их очень мало. Большинство страниц интернет-магазинов предназначены для низкочастотных запросов.
Типичный
- Информативный — под этот тип запроса, как правило, пишутся статьи, обзоры и блоги. Для интернет-магазинов сайты не очень популярны.
- По навигации — этот тип ведет конкретно на сайт.Например, пользователь ищет вашу организацию или бренд, поэтому он просто вводит название в строку поиска и попадает на сайт.
- По категориям и товарам — приводит в каталог или на карточку желаемого товара.
- Коммерческие или транзакционные — содержат слова «купить», «заказ», «стоимость», «недорого» и так далее.
Для новостных порталов наиболее важны информационные, для коммерческих.
Пользователи, которых вы привлекаете с помощью таких запросов, чаще покупают продукт или читают письменную публикацию на интересную для них тему.

Бесплатная коллекция семантического ядра для портала
Каким бы ни был список запросов, вы можете их собрать. Имея в своем арсенале только браузер, так как инструменты статистики не требуют оплаты этой услуги. Вы можете использовать плагины, чтобы ускорить и упростить задачу.
Давайте рассмотрим шаг за шагом, как это сделать.
Мы сразу рассмотрим самый трудоемкий вариант — сбор NW для торгового ресурса. Представьте, что вам нужно собирать семантику для магазина одежды в Харькове.
Для этого мы будем использовать Яндекс.Вордстат и Словоеб — это самые популярные бесплатные сервисы.
Первым шагом является определение категорий товаров. Распределите продукты по марке, типу и типу. В нашем случае это может быть женская, мужская, детская одежда, будь то зима в другое время года, обувь, аксессуары, размерная сетка.
Анализ структуры конкурентов. Как ни странно, но этот метод очень полезен. Иногда действительно лучше немного скопировать представление каталога от лидеров поисковой системы для вашей темы.Посмотрите, какие ключи можно использовать для заголовков страниц и фильтров. Установите плагин для Яндекса. В Wordstat вы можете собрать десять самых важных фраз и скопировать их в буфер обмена. Старайтесь не принимать запросы, не подходящие по типу, например, информационные, слова иностранных брендов.
Метод подходит для небольшого сайта, для других вариантов мы используем «Словоеб». Здесь необходимо будет дать имя создаваемому проекту и выбрать для него регион. В одном столбце вы увидите запросы, а в другом их частота, согласно статистике.
Программа работает полностью автоматически и даст более сотни результатов. А теперь самое интересное. Есть много запросов, но они должны быть проверены и отсортированы вручную. Что поделаешь, робот, он тоже робот в Африке. Среди выдачи будет много неуместных, например, некоммерческих ключей.
Семантика необходима для того, чтобы четко распределить содержимое портала. Это касается не только интернет-магазинов, но и информационных ресурсов, новостных сайтов, блогов.Таким образом, пользователь сможет соблюдать логику при построении сайта, ему будет удобно и интересно пользоваться.

Группировка запросов
Собранная масса ключей должна быть впоследствии разделена на кластеры. Это так называемые группы по схожим запросам. Здесь в самом начале запросы делятся на информационные и коммерческие, также выделяются группы для посадок.
Это коммерческие, как правило, кластеризованные относительно структуры сайта. Опять же, если ядро мало, вы можете справиться с этим вручную. Если он состоит из нескольких тысяч слов, вам нужно использовать специальные программы.
Сама по себе кластеризация очень полезна, поскольку позволяет решать две важные задачи: группировать по смыслу
- в зависимости от того, что пользователь будет делать и чего он хочет;
- Проверка совместимости запросов, позволяет продвигать их на одной странице.
Ключевые группы делятся на категории, разделы и т. Д.Для любого ресурса должна появиться понятная и понятная структура для пользователя. Например, для интернет-магазина это может выглядеть следующим образом:
- Главная страница-категории-раздел-дополнительная карта-подраздел-группа-продукт.
- Для информационного портала схема примерно такая же, только для статей и публикаций.
Примером высококачественной кластеризации будет случай, когда в одном наборе слов пересекаются несколько коротких замыканий, похожих по теме и семантическому содержанию.
Таким образом, если вы наблюдаете за структурой, вы заметите, что область поиска начинает сужаться и становится более точной.

Подводя итог вышесказанному
Сбор СК является основой для продвижения любого веб-ресурса. Неважно, какой формат вы предоставляете, участвуете в активных продажах или ведете блог с рецептами, пользователи должны легко и быстро найти ваш портал. Чем выше соответствие ключевым запросам, тем выше вероятность попадания в ТОП результатов поиска.Тщательно подходите к оптимизации страницы, чтобы не зависать в задних рядах, а быть прямо на первых страницах.
Вы можете сделать коллекцию самостоятельно, мы уже говорили об этом. Но стоит помнить, что успех сайта зависит от качества ядра. Сделанные ошибки впоследствии будет сложнее исправить. Поэтому, если вы не уверены, что можете все делать правильно, не рискуйте и обратитесь к профессионалам.
Мы надеемся, что эта статья была полезна не только для начинающих, но и для специалистов по SEO.Желаем вам высоких должностей и трафика! Далее вы найдете много полезной и интересной информации!
.Основы
Прежде чем строить семантическое ядро, задайте себе несколько вопросов.
Кто ваша целевая аудитория?
Вы должны четко понимать, кто ваши пользователи. Например, ваше приложение — это игра, в которой пользователи должны выбирать наряды для кукол. Скорее всего, ваша основная аудитория — это девушки в возрасте до 12 лет. Старшие девочки или мальчики вряд ли заинтересованы в этом. Попробуйте определить свой клиентский сегмент, прежде чем начать создавать семантическое ядро.
Какую ценность приносит ваше приложение пользователям?
О чем ваше приложение? Какова его цель? Зачем пользователю устанавливать его? Ответы на эти вопросы — ваши первые релевантные ключевые слова.
Как ваше приложение отличается от конкурентов?
Попробуйте сформулировать, что делает ваше приложение особенным. Ваши идеи — это средне- или низкочастотные поисковые запросы, которые клиенты могут использовать. Они могут быть не самыми популярными, но здесь есть скрытая ценность. Пока ваши конкуренты сосредотачиваются на наиболее часто используемых ключевых словах, вы можете достичь лучших позиций, применяя менее популярные, но целенаправленные запросы.
Кто ваши конкуренты?
На этом этапе не полагайтесь только на имена, которые приходят вам на ум. Проведите хорошее исследование и выясните, кто ваши прямые и косвенные конкуренты. После проверки каждого из них составьте список ключевых слов, которые они используют чаще всего. Вы можете «одолжить» некоторые из них и генерировать свои собственные идеи.
Какой основной рынок для вашего приложения?
Вы можете быть удивлены, но ключевые слова, используемые в британском и австралийском App Store, могут хорошо подойти и для российского рынка.Как вы можете использовать это? Даже если ваша основная клиентская база находится в России, вы можете добавить ключевые слова, которые не соответствуют русской версии (из-за ограничений на символы) для магазинов приложений в Великобритании и Австралии. Более подробная информация о дополнительных локалях и индексации в Google Play будет доступна в одной из следующих статей.
Возможно, вы уже ответили на все выделенные вопросы раньше. Скорее всего, вы сделали это еще до того, как приложение было создано. Даже лучше! Эта информация необходима для создания семантического ядра и выбора правильных ключевых слов.
Как выбрать ключевые слова
Выбор ключевых слов является основой создания семантического ядра, поэтому важно выбрать наиболее подходящие для дальнейшего продвижения. Давайте вернемся к нашему примеру — приложению Travel Ques. Это легко понять, просто прочитав название приложения, которое относится к путешествиям и квестам. Это означает, что мы должны сконцентрировать наши усилия ASO на людях, которые любят путешествовать и ищут интересные и активные способы провести время за границей.
В этом случае соответствующие запросы: «путешествия», «гид», «советы» и т. Д.Кроме того, стоит отметить аналогичные запросы, то есть слова, которые непосредственно не описывают основные функции приложения, но все же имеют потенциал для привлечения трафика. Для туристических квестов это могут быть следующие ключевые слова: «музеи», «туры», «достопримечательности». Анализируемое приложение не является туристическим агентством, однако его клиентами могут стать люди, которые планируют поездку. Актуальность запроса очень субъективна, поэтому, чем больше альтернатив вы проверяете, тем выше шансы на создание качественного семантического ядра.
Если у вас закончились идеи, используйте следующие методы для поиска релевантных ключевых слов:
- спросите текущих и потенциальных клиентов, как они нашли ваше приложение, какие слова и фразы они использовали. Короткий опрос среди ваших друзей и коллег также может дать вам много полезной информации;
- проверить названия и описания приложений конкурентов. Это очень важный шаг, уделить этому достаточно времени;
- используют аналитические и статистические инструменты, ориентированные на мобильные рынки: App Annie, Mobile Action, Sensor Tower и т. Д.Там вы можете найти некоторые ключевые слова, которые используют ваши конкуренты, чтобы получить высокие результаты в результатах поиска;
- , если ваше приложение уже в магазине, изучите комментарии пользователей;
- попробуйте инструменты для исследования ключевых слов: Google Keyword Planner, Google Trends, Yandex.Wordstat. Последнее очень полезно, если ваш основной рынок — Россия. Однако не обращайте особого внимания на значения частоты. По опыту мы знаем, что он сильно отличается между сетью и мобильностью;
- используют синонимы и словари языков, если вам нужно выбрать ключевые слова для зарубежных рынков.Мультитран, например, хороший инструмент, чтобы попробовать.
Ориентировочная частота
Как уже упоминалось выше, App Store и Google Play не предоставляют общедоступных данных о частоте поисковых запросов. Однако это не значит, что мы не можем это оценить.
Основным инструментом для этого является список поисковых предложений. Когда вы начинаете вводить запрос в строке поиска, список автоматически генерируется магазином. Самые популярные ключевые слова и ключевые фразы размещены сверху. Если запросы, которые вы планируете использовать, там не отображаются, скорее всего, они не будут привлекать трафик к вашему приложению.
Существует еще один инструмент для магазина приложений — Search Ads, недавно представленный Apple для улучшения видимости приложения в поиске. Используя его, становится возможным дать приблизительные оценки того, сколько трафика могут генерировать разные ключевые слова. В настоящее время инструмент доступен только для рынка США. Если ваше приложение ориентировано на США, у вас есть преимущество. Таким образом, получите доступ к поисковой рекламе как можно скорее!
Это очень трудоемкая задача, чтобы собрать предложения поиска вручную, проверяя каждый запрос на планшете или смартфоне.AppFollow упрощает этот процесс. Этот инструмент может программно генерировать список предложений для вашего приложения, если вы подписаны на Премиум план. На основе этого примера мы проиллюстрируем, как оценить частоту и построить семантическое ядро.
подсказки и поиск
Сбор подсказок является наиболее подходящим способом построения семантического ядра.
Если вы еще не там, зарегистрируйтесь на AppFollow.io . В верхней панели выберите «ASO Tools», затем «Suggest & Search».Вы увидите следующую страницу:
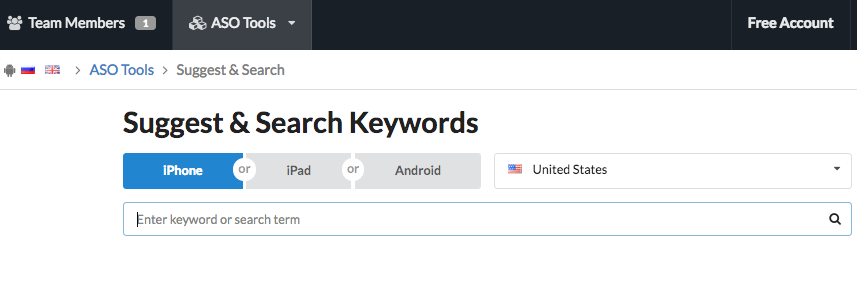
Выберите необходимое устройство: iPhone / iPad или Android . В поле за ним введите ключевые слова, которые вас интересуют. Выберите нужный язык в списке справа.
В результате вы увидите список предложений в левой колонке. Если вы сравните его со списком на вашем смартфоне, вы найдете их идентичными. В правом столбце вы можете увидеть результаты поиска по введенному ключевому слову в выбранной стране. Мы вернемся к этой части позже в статье.
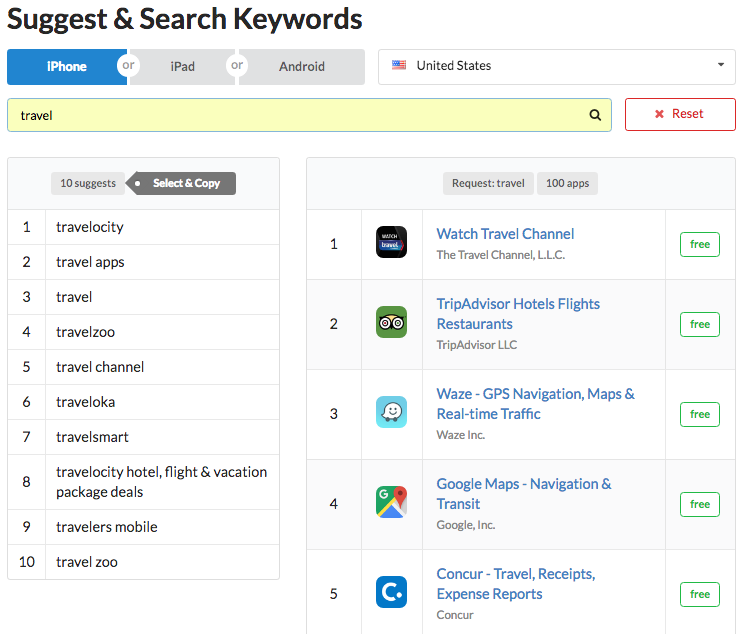
Стоит отметить, что если вы проверяете предложения для Android, Google Play настраивает их в соответствии с вашим IP-адресом. Это означает, что если вы находитесь в России и вам нужны предложения для США, вам нужно изменить свой IP на американский. В этом вам могут помочь бесплатные инструменты VPN. В противном случае вы увидите данные поиска для страны, в которой вы находитесь в данный момент.
Все запросы, которые имеют разумную частоту, появятся в подсказках. Они показаны в порядке убывания.Ключевое слово или ключевая фраза на первом месте имеют самую высокую частоту, а нижние — самую низкую.
Google Sheets
AppFollow предлагает простой и удобный способ экспорта предложений — через надстройку Google Sheets , доступную для всех пользователей Документов Google.
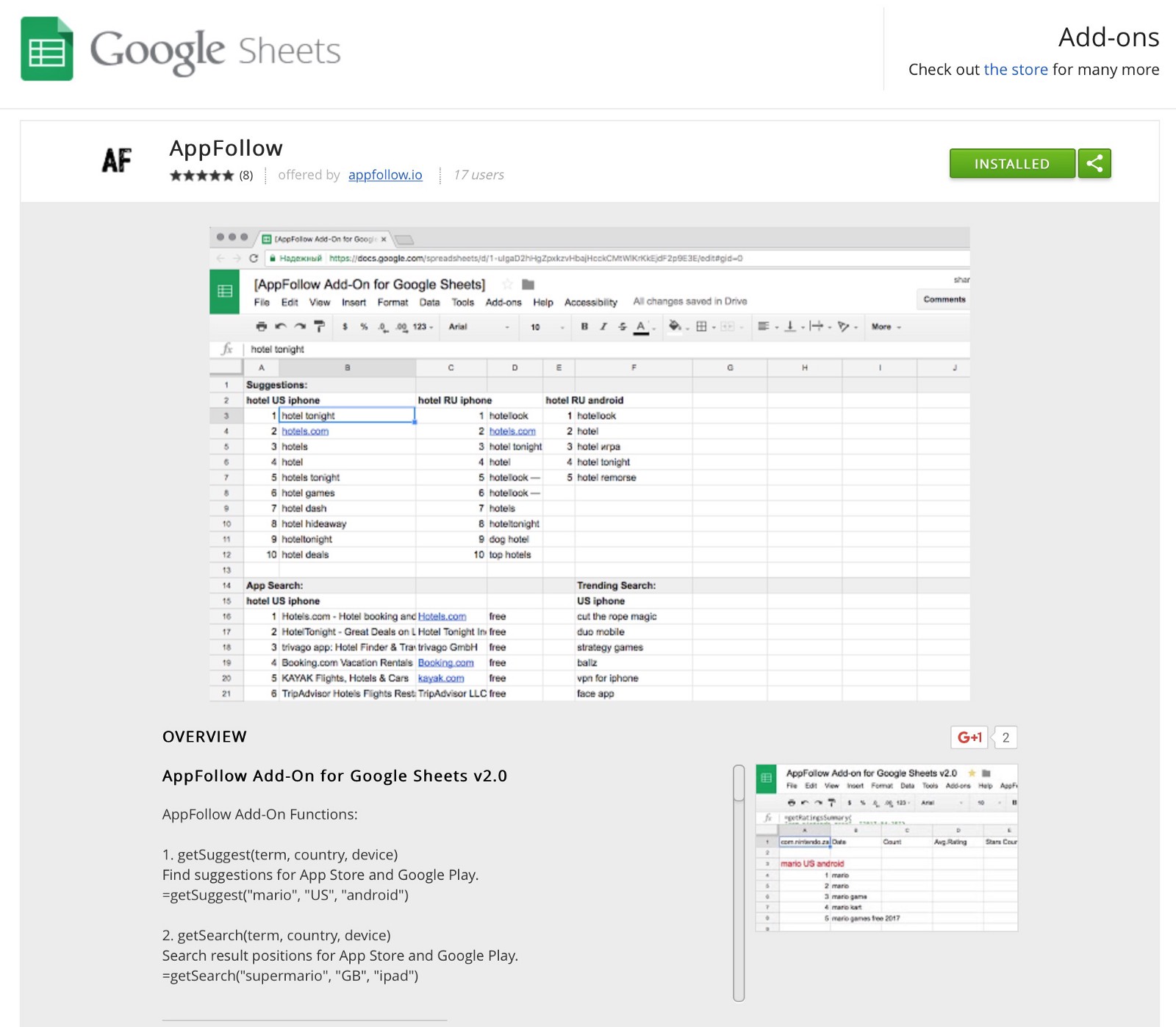 AddFollow Add-On для Google Sheets
AddFollow Add-On для Google SheetsЧтобы увидеть список предложений, добавьте следующую формулу в любую ячейку: = getSuggest («request»). Вместо «запроса» введите интересующее вас ключевое слово или фразу. Не забудьте добавить кавычки.
Выберите наиболее важные
Как описано выше, вы можете собирать предложения либо с помощью ручного поиска, либо с помощью AppFollow и Google Sheets. В конце у вас будет таблица с различными списками предложений под каждым поисковым запросом. Важно отметить, к какому рынку или локали относятся эти списки. Примерно это должно выглядеть примерно так:
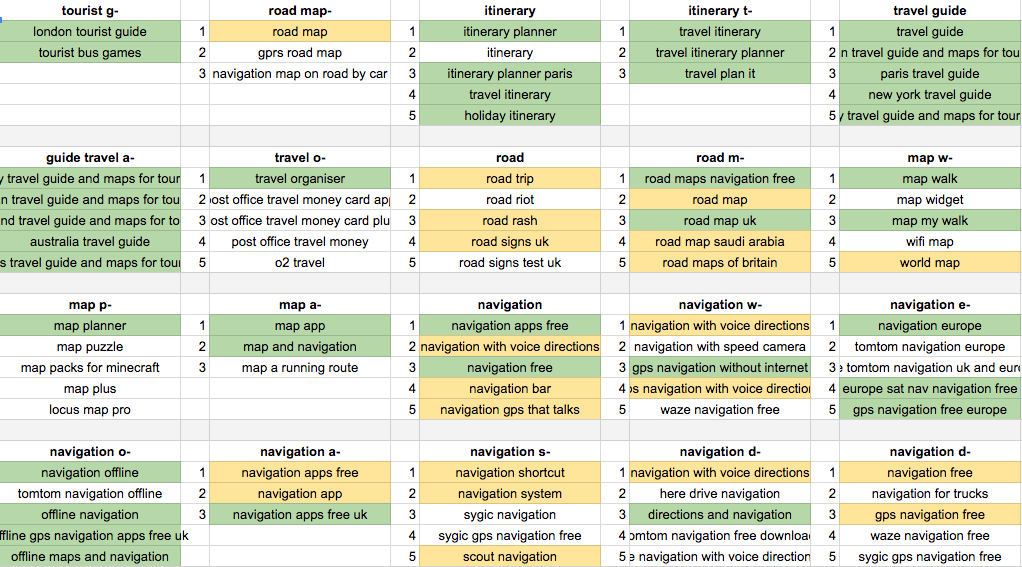
Как только вы соберете подсказки для каждого ключевого слова, отметьте их разными цветами. В нашем примере наиболее релевантные предложения выделены синим, а менее релевантные — желтым.
Не принимать во внимание названия с «-» , «:» или «&». Эти подсказки являются названиями приложений.
Вуаля! Ваше семантическое ядро готово. Следующим шагом является анализ наиболее релевантных и менее релевантных ключевых слов. Это будет основой для названия приложения и ключевых слов на странице приложения в App Store и Google Play. Тем не менее, это тема отдельной статьи, которую мы опубликуем в будущем.
P.S.
Уважаемые читатели, если эта статья была для вас полезна, пожалуйста? или порекомендовать это.Мы считаем, что это полезно для многих разработчиков приложений.
Не стесняйтесь задавать вопросы, высказывать свое мнение или комментировать неясные шаги.
.семантических технологий по сравнению
Введение
Семантические технологии относятся не к одной технологии, а скорее к боковому разнообразию инструментов и технологий, которые имеют отношение к смыслу. Некоторые фокусируются на структуре, некоторые на тексте, а некоторые на интеллекте. Понимание того, какие подкатегории существуют, может помочь вам определить, когда использовать каждую из них.
Семантическая паутина против семантических технологий
Введение
То, что семантические веб-технологии и семантические технологии, начинающиеся с семантических, часто являются источником путаницы.
Этот короткий урок проясняет связь между технологиями семантического веба и семантическими технологиями.
Сегодняшний урок
se-man-tic (прил.): Из или в значении языка.
Мы начнем с определения того, что именно мы подразумеваем под семантическими технологиями и технологиями семантического веба. Затем мы рассмотрим, как они связаны друг с другом.
Семантические технологии
Термин «семантические технологии» представляет собой довольно разнообразное семейство технологий, которые существуют в течение длительного времени и стремятся помочь извлечь смысл из информации.Некоторые примеры семантических технологий включают обработку естественного языка (NLP), интеллектуальный анализ данных, искусственный интеллект (AI), тегирование категорий и семантический поиск.
Вы можете думать о цели семантических технологий как о разделении сигнала от шума. Некоторые примеры существующих семантических технологий, используемых сегодня:
- Естественно-языковая обработка (НЛП). Технологии НЛП пытаются обрабатывать неструктурированный текстовый контент и извлекать имена, даты, организации, события и т. Д.о которых говорится в тексте.
- Интеллектуальный анализ данных. Технологии интеллектуального анализа данных используют алгоритмы сопоставления с образцом для выявления тенденций и корреляций в больших наборах данных. Интеллектуальный анализ данных можно использовать, например, для выявления подозрительного и потенциально мошеннического поведения в торговле в больших базах данных финансовых транзакций.
- Искусственный интеллект или экспертные системы. Технологии ИИ или экспертных систем используют сложные модели рассуждений для автоматического ответа на сложные вопросы.Эти системы часто включают в себя алгоритмы машинного обучения, которые со временем могут улучшить возможности системы по принятию решений.
- Классификация. Технологии классификации используют эвристику и правила, чтобы пометить данные категориями, чтобы помочь с поиском и анализом информации.
- Семантический поиск. Технологии семантического поиска позволяют людям находить информацию по концепции, а не по ключевому слову или ключевой фразе. С помощью семантического поиска люди могут легко различить поиск Джона Ф.Кеннеди, аэропорт, и Джон Ф. Кеннеди, президент.
Многие другие современные технологии можно назвать семантическими технологиями. Хотя все эти технологии имеют общую общую цель — помочь разобраться с большими или сложными наборами данных, не предоставляя каких-либо заранее определенных знаний о данных, — они не разделяют намного больше, чем это. Они реализованы с использованием множества различных языков программирования, производят данные (сигналы) во многих различных форматах, полагаются на очень разные базовые формализмы и редко работают вместе, не вкладывая значительных усилий в разработку интеграции.
Семантическая паутина
Технологии семантической сети— независимо от того, какое точное имя используется для их обозначения — представляют собой семейство очень специфических технологических стандартов Консорциума World Wide Web (W3C), которые предназначены для описания и сопоставления данных в Интернете и внутри предприятий. Эти стандарты включают в себя:
- гибкая модель данных (RDF),
- языков схем и онтологий для описания концепций и отношений (RDFS и OWL),
- язык запросов (SPARQL),
- язык правил (RIF),
- язык для разметки данных на веб-страницах (RDFa),
- и больше.
Совместная работа
Так что же конкретно представляет собой связь между семантическими технологиями и технологиями семантического веба?
Короче говоря:
- Технологии семантической паутины — это набор технологий, которые особенно хорошо подходят для реализации алгоритмов и решений семантической технологии.
- В совокупности технологии Semantic Web представляют собой набор инструментов; как таковые, они могут быть использованы для реализации широкого спектра алгоритмов, решений и приложений.Тем не менее, они особенно подходят для реализации семантических технологий. Рассмотрим следующие примеры:
- Классификация данных может быть выполнена очень эффективно путем описания информации с использованием языков схемы и онтологии, которые являются частью набора технологий семантической паутины.
- Семантический поиск требует способа концептуального описания данных и способа поиска по этим понятиям. Стек технологий Semantic Web удовлетворяет обоим этим условиям. Инструменты
- НЛП могут определять непредвиденные отношения между объектами в исходных документах.Гибкая модель данных на основе графов, являющаяся одним из основных стандартов семантической сети, является идеальным способом сбора всей информации, полученной с помощью технологии NLP, без необходимости отбрасывать какие-либо данные.
Заключение
Семантические технологии — это алгоритмы и решения, которые привносят структуру и смысл в информацию. Технологии семантического веба — это те, которые придерживаются определенного набора стандартов открытых технологий W3C, которые призваны упростить реализацию не только семантических технологических решений, но и других видов решений.
,