Правильный robots.txt для WordPress — 2019
Robots.txt – текстовой файл, который сообщает поисковым роботам, какие файлы и папки следует сканировать (индексировать), а какие сканировать не нужно.
Поисковые системы, такие как Яндекс и Google сначала проверяют файл robots.txt, после этого начинают обход с помощью веб-роботов, которые занимаются архивированием и категоризацией веб сайтов.
Файл robots.txt содержит набор инструкций, которые просят бота игнорировать определенные файлы или каталоги. Это может быть сделано в целях конфиденциальности или потому что владелец сайта считает, что содержимое этих файлов и каталогов не должны появляться в выдаче поисковых систем.
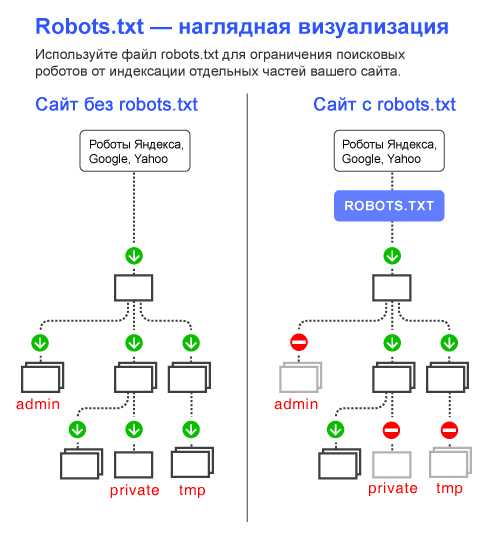
Если веб-сайт имеет более одного субдомена, каждый субдомен должен иметь свой собственный файл robots.txt. Важно отметить, что не все боты будут использовать файл robots.txt. Некоторые злонамеренные боты даже читают файл robots.txt, чтобы найти, какие файлы и каталоги Вы хотели скрыть. Кроме того, даже если файл robots.txt указывает игнорировать определенные страницы на сайте, эти страницы могут по-прежнему появляться в результатах поиска, если на них ссылаются другие просканированные страницы. Стандартный роботс тхт для вордпресс открывает весь сайт для интдекса, поэтому нам нужно закрыть не нужные разделы WordPress от индексации.
Оптимальный robots.txt
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # системная папка на хостинге, закрывается всегда Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # запрос поиска Disallow: *&s= # запрос поиска Disallow: /search/ # запрос поиска Disallow: /author/ # архив автора, если у Вас новостной блог с авторскими колонками, то можно открыть # архив автора, если у Вас новостной блог с авторскими колонками, то можно открыть Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads # Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent # не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже. Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Host прописывать больше не нужно.
Расширенный вариант (разделенные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google, # т.к. для них правила ниже Disallow: /cgi-bin # папка на хостинге Disallow: /? # все параметры запроса на главной Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет, # правило можно удалить) Disallow: *?s= # поиск Disallow: *&s= # поиск Disallow: /search/ # поиск Disallow: /author/ # архив автора Disallow: /users/ # архив авторов Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой # ссылки на статью Disallow: */feed # все фиды Disallow: */rss # rss фид Disallow: */embed # все встраивания Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете, # правило можно удалить) Disallow: /xmlrpc.php # файл WordPress API Disallow: *utm*= # ссылки с utm-метками Disallow: *openstat= # ссылки с метками openstat Allow: */uploads # открываем папку с файлами uploads User-agent: GoogleBot # правила для Google (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Allow: */uploads Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета) Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета) Allow: /wp-*.png # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д. Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д. Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS User-agent: Yandex # правила для Яндекса (комментарии не дублирую) Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать # от индексирования, а удалять параметры меток, # Google такие правила не поддерживает Clean-Param: openstat # аналогично # Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent # не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже. Sitemap: http://site.ru/sitemap.xml Sitemap: http://site.ru/sitemap.xml.gz # Host прописывать больше не нужно.
Оптимальный Robots.txt для WooCommerce
Владельцы интернет-магазинов на WordPress – WooCommerce также должны позаботиться о правильном robots.txt. Мы закроем от индексации корзину, страницу оформления заказа и ссылки на добавление товара в корзину.
User-agent: * Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: /wp/ Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: */wlwmanifest.xml Disallow: /xmlrpc.php Disallow: *utm*= Disallow: *openstat= Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Sitemap: https://site.ru/sitemap_index.xml
Вопрос/ответ
Где находится файл robots.txt в вордпресс
Обычно robots.txt располагается в корне сайта. Если его нет, то потребуется создать текстовой файл и загрузить его на сайт по FTP или панель управления на хостинге. Если Вы не смогли найти роботс тхт в корне сайта, но при переходе по ссылке вашсайт.ру/robots.txt он открывается, значит какой то из SEO плагинов сам генерирует его.
К примеру плагин Yoast SEO создает виртуальный файл, которого нет в корне сайта.
Как редактировать robots.txt с помощью Yoast SEO
- Зайдите в админ панель сайта
Админа панель находится по следующему адресу вашсайт.ру/wp-admin/
- Слева в консоли наведите на кнопку SEO и в выпадающем окне выберите “Инструменты”
Перейдите в раздел, как указано на картинке.
- Зайдите в редактор файлов
Этот инструмент позволит быстро отредактировать такие важные для вашего SEO файлы, как robots.txt и .htaccess (при его наличии).
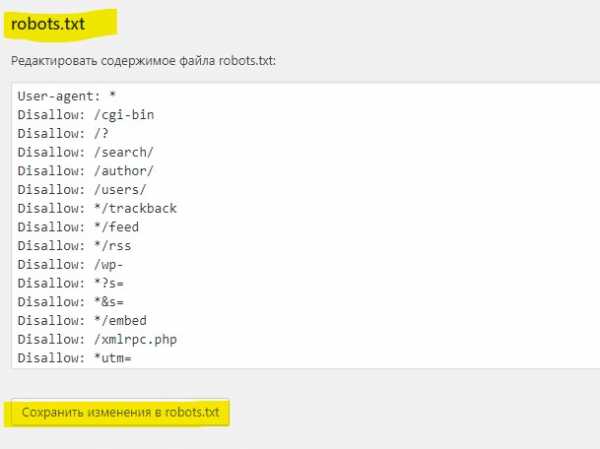
- Если файла Robots нет, нажмите на кнопку создать, либо вставьте нужный роботс и нажмите сохранить.
robots.txt для WordPress вы можете скопировать или скачать выше.
Чтобы установить плагин Yoast SEO воспользуйтесь данной статьей – ссылка.
Как проверить правильность robots.txt
У Google и Яндекс есть средства для проверки файла роботс.
Яндекс – https://webmaster.yandex.ru/tools/robotstxt/
Google – https://support.google.com/webmasters/answer/6062598?hl=ru
xn——6kcgnhys3cgg3ne.xn--p1ai
Правильный Robots.txt для WordPress 2019 — AWayne
Одной из важнейших вещей при создании и оптимизации сайта для поисковых систем считают Robots.txt. Небольшой файлик, где прописаны правила индексирования для поисковых роботов.
Если файл будет настроен неправильно, то сайт может неправильно индексироваться и терять большие доли трафика. Грамотная настройка наоборот позволяет улучшить SEO, и вывести ресурс в топы.
Сегодня мы поговорим о настройке Robots.txt для WordPress. Я покажу вам правильный вариант, который сам использую для своих проектов.
Что такое Robots.txt
Как я уже и сказал, robots.txt – текстовой файлик, где прописаны правила для поисковых систем. Стандартный robots.txt для WordPress выглядит следующим образом:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Именно в таком виде он создается плагином Yoast SEO. Некоторые считают, что этого хватит для правильной индексации. Я же считаю, что нужна более детальная проработка. А если речь идет о нестандартных проектах, то проработка нужна и подавно. Давайте разберемся в основных директивах:
| Директива | Значение | Пояснение |
| User-agent: | Yandex, Googlebot и т.д. | В этой директиве можно указать к какому конкретно роботу мы обращаемся. Обычно используются те значения, которые я указал. |
| Disallow: | Относительная ссылка | Директива запрета. Ссылки, указанные в этой директиве будут игнорироваться поисковыми системами. |
| Allow: | Относительная ссылка | Разрешающая директива. Ссылки, которые указаны с ней будут проиндексированы. |
| Sitemap: | Абсолютная ссылка | Здесь указывается ссылка на XML-карту сайта. Если в файле не указать эту директиву, то придется добавлять карту вручную (через Яндекс.Вебмастер или Search Console). |
| Crawl-delay: | Время в секундах (пример: 2.0 – 2 секунды) | Позволяет указать таймаут между посещениями поисковых роботов. Нужна в случае, если эти самые роботы создают дополнительную нагрузку на хостинг. |
| Clean-param: | Динамический параметр | Если на сайте есть параметры вида site.ru/statia?uid=32, где ?uid=32 – параметр, то с помощью этой директивы их можно скрыть. |
В принципе, ничего сложного. Дам дополнительные пояснения по директивам Clean-param (откройте вкладку).
Подробнее о Clean-param
Параметры, как правило, используются на динамических сайтах. Они могут передавать поисковым системам лишнюю информацию – создавать дубли. Чтобы избежать этого, мы должны указать в Robots.txt директиву Clean-param с указанием параметра и ссылки, к которой это параметр применяется.
В нашем примере site.ru/statia?uid=32 – site.ru/statia – ссылка, а все, что после знака вопроса – параметр. Здесь это uid=32. Он динамический, и это значит, что параметр uid может принимать другие значения.
Например, uid=33, uid=34…uid=123434. В теории их может быть сколько угодно, поэтому мы должны закрыть от индексации все параметры uid. Для этого директива должна принять такой вид:
Clean-param: uid /statia # все параметры uid для statia будут закрыты
Более подробно о том, что такое Robots.txt можно узнать из Яндекс.Помощи. Или из этого видеоролика:
Базовый Robots.txt для WordPress
Совсем недавно я приобрел плагин Clearfy Pro для своих проектов. Там очень много разных функций, и одна из них – создание идеального Robots.txt. На самом деле насколько он идеален – я не знаю, вебмастера расходятся во мнениях.
Кто-то предпочитает делать более краткие версии роботса, указывая правила для всех поисковых систем сразу. Другие прописывают отдельные правила для каждого поисковика (в основном для Яндекса и Гугла).
Что из этого правильно – точно сказать не могу. Однако я предлагаю вам ознакомиться с базовой версией Robots.txt для WordPress от Clearfy Pro. Я немного подредактировал ее – указал директиву Sitemap. Удалил директиву Host.
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.php Disallow: /readme.html Disallow: /*? Disallow: /?s= Allow: /*.css Allow: /*.js Sitemap: https://site.ru/sitemap.xml
Не могу сказать, что это лучший вариант для блогов на ВП. Но во всяком случае, он лучше, чем то, что нам предлагает Yoast SEO по умолчанию.
Расширенный Robots.txt для WordPress
Теперь посмотрим на расширенную версию Robots.txt для WordPress. Наверняка вы знаете, что все сайты на WP имеют одинаковую структуру. Одинаковые названия папок, файлов и т.д. позволяют специалистам выявить наиболее приемлемый вариант роботса.
В этой статье я хочу представить вам свой вариант Robots.txt. Его я использую как для своих сайтов, так и для клиентских. Вы могли видеть такой вариант и на других сайтах, т.к. он обладает некоторой популярностью.
Итак, правильный Robots.txt для WordPress выглядит следующим образом:
User-agent: * # Для всех поисковых систем, кроме Яндекса и Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Disallow: /tag/ # Закрываем метки Disallow: /readme.html # Закрываем бесполезный мануал по установке WordPress (лежит в корне) Disallow: *?replytocom Allow: */uploads User-agent: GoogleBot # Для Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Disallow: /tag/ # Закрываем метки Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php User-agent: Yandex # Для Яндекса Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: /tag/ # Закрываем метки Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign Clean-Param: openstat Sitemap: https://site.com/sitemap_index.xml # Карта сайта, меняем site.com на нужный адрес.
Важно:
Ранее в Robots.txt использовалась директива Host. Она указывала главное зеркало сайта. Теперь это делается при помощи редиректа. Подробнее об этом можно почитать в блоге Яндекса.Комментарии (текст после #) можно удалить. Указываю Sitemap с https протоколом, т.к. большинство сайтов сейчас используют защищенное соединение. Если у вас нет SSL, то измените протокол на http.
Обратите внимание на то, что я закрываю метки (теги). Делаю это потому, что они создают большое количество дублей. Это плохо сказывается на SEO, но если вы хотите открыть метки, тогда уберите строчку disallow: /tag/ из файла.
Заключение
В общем-то, вот так выглядит правильный Robots.txt для WordPress. Смело копируйте данные в файл и пользуйтесь. Отмечу, что этот вариант подходит только для стандартных информационных сайтов.
В других ситуациях может потребоваться индивидуальная проработка. На этом все. Спасибо за внимание. Буду благодарен, если вы включите уведомления через колокольчик и подпишитесь на почтовую рассылку. Тут будет круто :).
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Настройка Robots.txt для WordPress 2019
4.6 (91.02%) Оценок: 49awayne.biz
Правильный Robots.txt для WordPress (2019) — как сделать?
В интернете можно найти много публикаций на тему, как составить лучший (или даже самый лучший) файл robots.txt для WordPress. При этом в ряде таких популярных статей многие правила не объясняются и, как мне кажется, вряд ли понимаются самими авторами. Единственный обзор, который я нашел и который действительно заслуживает внимания, — это статья в блоге wp-kama. Однако и там я нашел не совсем корректные рекомендации. Понятно, что на каждом сайте будут свои нюансы при составлении файла robots.txt. Но существует ряд общих моментов для совершенно разных сайтов, которые можно взять за основу. Robots.txt, опубликованный в этой статье, можно будет просто копировать и вставлять на новый сайт и далее дорабатывать в соответствии со своими нюансами.
Более подробно о составлении robots.txt и значении всех его директив я писал здесь. Ниже я не буду подробно останавливаться на значении каждого правила. Ограничусь тем, что кратко прокомментирую что для чего необходимо.
Правильный Robots.txt для WordPress
Действительно самый лучший robots.txt, который я видел на данный момент, это роботс, предложенный в блоге wp-kama. Ряд директив и комментариев я возьму из его образца + внесу свои корректировки. Корректировки коснутся нескольких правил, почему так напишу ниже. Кроме того, напишем индивидуальные правила для всех роботов, для Яндекса и для Google.
Ниже привожу короткий и расширенный вариант. Короткий не включает отдельные блоки для Google и Яндекса. Расширенный уже менее актуален, т.к. теперь нет принципиальных особенностей между двумя крупными поисковиками: обеим системам нужно индексировать файлы скриптов и изображений, обе не поддерживают директиву Host. Тем не менее, если в этом мире снова что-то изменится, либо вам потребуется все-таки как-то по-отдельному управлять индексацией файлов на сайте Яндексом и Гугл, сохраню в этой статье и второй вариант.
Еще раз обращаю внимание, что это базовый файл robots.txt. В каждом конкретном случае нужно смотреть реальный сайт и по-необходимости вносить корректировки. Поручайте это дело опытным специалистам!
Короткий вариант (оптимальный)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ruРасширенный вариант (отдельные правила для Google и Яндекса)
User-agent: * # общие правила для роботов, кроме Яндекса и Google,
# т.к. для них правила ниже
Disallow: /cgi-bin # папка на хостинге
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: /wp/ # если есть подкаталог /wp/, где установлена CMS (если нет,
# правило можно удалить)
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search/ # поиск
Disallow: /author/ # архив автора
Disallow: /users/ # архив авторов
Disallow: */trackback # трекбеки, уведомления в комментариях о появлении открытой
# ссылки на статью
Disallow: */feed # все фиды
Disallow: */rss # rss фид
Disallow: */embed # все встраивания
Disallow: */wlwmanifest.xml # xml-файл манифеста Windows Live Writer (если не используете,
# правило можно удалить)
Disallow: /xmlrpc.php # файл WordPress API
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Allow: */uploads # открываем папку с файлами uploads
User-agent: GoogleBot # правила для Google (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Disallow: *utm*=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js # открываем js-скрипты внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # открываем css-файлы внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
Allow: /wp-admin/admin-ajax.php # используется плагинами, чтобы не блокировать JS и CSS
User-agent: Yandex # правила для Яндекса (комментарии не дублирую)
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: /wp/
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: */wlwmanifest.xml
Disallow: /xmlrpc.php
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
Clean-Param: utm_source&utm_medium&utm_campaign # Яндекс рекомендует не закрывать
# от индексирования, а удалять параметры меток,
# Google такие правила не поддерживает
Clean-Param: openstat # аналогично
# Укажите один или несколько файлов Sitemap (дублировать для каждого User-agent
# не нужно). Google XML Sitemap создает 2 карты сайта, как в примере ниже.
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap.xml.gz
# Укажите главное зеркало сайта, как в примере ниже (с WWW / без WWW, если HTTPS
# то пишем протокол, если нужно указать порт, указываем). Команда стала необязательной. Ранее Host понимал
# Яндекс и Mail.RU. Теперь все основные поисковые системы команду Host не учитывают.
Host: www.site.ruВ примере я не добавляю правило Crawl-Delay, т.к. в большинстве случаев эта директива не нужна. Однако если у вас крупный нагруженный ресурс, то использование этой директивы поможет снизить нагрузку на сайт со стороны роботов Яндекса, Mail.Ru, Bing, Yahoo и других (Google не учитывает). Подробнее про это читайте в статье Robots.txt.
Ошибочные рекомендации других блогеров для Robots.txt на WordPress
- Использовать правила только для User-agent: *
Для многих поисковых систем не требуется индексация JS и CSS для улучшения ранжирования, кроме того, для менее значимых роботов вы можете настроить большее значение Crawl-Delay и снизить за их счет нагрузку на ваш сайт. - Прописывание Sitemap после каждого User-agent
Это делать не нужно. Один sitemap должен быть указан один раз в любом месте файла robots.txt - Закрыть папки wp-content, wp-includes, cache, plugins, themes
Это устаревшие требования. Однако подобные советы я находил даже в статье с пафосным названием «Самые правильный robots для WordPress 2018»! Для Яндекса и Google лучше будет их вообще не закрывать. Или закрывать «по умному», как это описано выше. - Закрывать страницы тегов и категорий
Если ваш сайт действительно имеет такую структуру, что на этих страницах контент дублируется и в них нет особой ценности, то лучше закрыть. Однако нередко продвижение ресурса осуществляется в том числе за счет страниц категорий и тегирования. В этом случае можно потерять часть трафика - Закрывать от индексации страницы пагинации /page/
Это делать не нужно. Для таких страниц настраивается тег rel=»canonical», таким образом, такие страницы тоже посещаются роботом и на них учитываются расположенные товары/статьи, а также учитывается внутренняя ссылочная масса. - Прописать Crawl-Delay
Модное правило. Однако его нужно указывать только тогда, когда действительно есть необходимость ограничить посещение роботами вашего сайта. Если сайт небольшой и посещения не создают значительной нагрузки на сервер, то ограничивать время «чтобы было» будет не самой разумной затеей. - Ляпы
Некоторые правила я могу отнести только к категории «блогер не подумал». Например:Disallow: /20— по такому правилу не только закроете все архивы, но и заодно все статьи о 20 способах или 200 советах, как сделать мир лучше 🙂
Спорные рекомендации других блогеров для Robots.txt на WordPress
- Комментарии
Некоторые ребята советуют закрывать от индексирования комментарииDisallow: /commentsиDisallow: */comment-*. - Открыть папку uploads только для Googlebot-Image и YandexImages
User-agent: Googlebot-ImageСовет достаточно сомнительный, т.к. для ранжирования страницы необходима информация о том, какие изображения и файлы размещены на ней.
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
Спасибо за ваше внимание! Если у вас возникнут вопросы или предложения, пишите в комментариях!
Оцените статью
Загрузка…Друзья, буду благодарен за ваши вопросы, дополнения и рекомендации по теме статьи. Пишите ниже в комментариях.
Буду благодарен, если поставите оценку статье.
seogio.ru
Плагин wordpress robots.txt установка и настройка – ТОП
Здравствуйте !
Сегодня я покажу вам и расскажу как пользоваться файлом robots.txt. Что это такое ? файл robots.txt позволит вам скрывать от индексации некоторые разделы или отдельные страницы вашего сайта, чтобы они не попадали в поиск Google и Yandex. Для чего это нужно ? поисковые системы индексируют всё содержимое вашего сайта без разбора, поэтому если вы хотите скрыть какую-либо конфиденциальную информацию,
например личные данные ваших пользователей, переписка, счета и т.д., то вам нужно будет самостоятельно добавить адреса страниц с данными в файл robots.txt. Что ещё можно сделать с помощью файла robots.txt ? если у вашего сайта есть зеркала, то в их файлах robots.txt можно указать на главный сайт, чтобы индексировался только он.
Видео о файле robots.txt
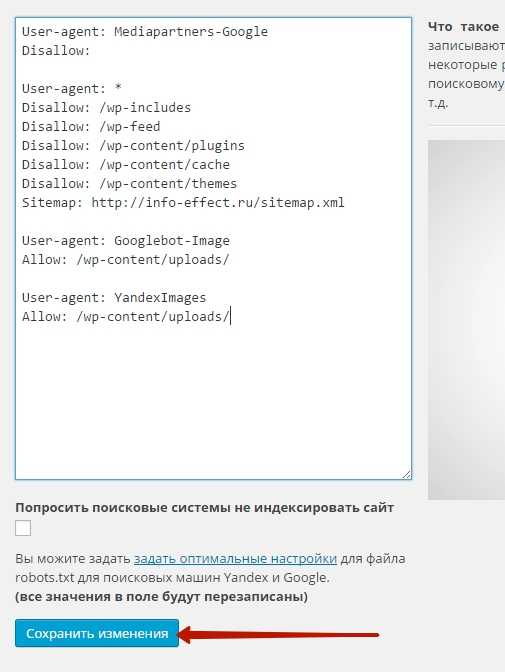
Настраивать файл robots.txt мы будем с помощью плагина – DL Robots.txt. Установить данный плагин вы сможете прямо из своей админ-панели wordpress. Перейдите по вкладке: Плагины – Добавить новый, введите название плагина в форму поиска, нажмите Enter, установите и активируйте открывшийся плагин.
Чтобы попасть на страницу настроек плагина, перейдите по вкладке: DL Robots.txt. Данная вкладка появится у вас в меню админ-панели wordpress, после того как вы установите и активируете плагин.
На странице настройки файла robots.txt, вы можете прочитать и посмотреть видео о том, что такое файл robots.txt. Так же здесь можно проверить файл, нажав на вкладку – Robots.txt, если файл откроется в браузере значит всё нормально.

Если на вашем сайте нет файла robots.txt, значит сейчас мы добавим его в специальное окно, которое находится на странице настроек плагина. Итак, конечно же создавать файл robots.txt необходимо исходя из предпочтений каждого отдельного сайта, но я вам предложу готовый вид файла, который подойдёт любому сайту на wordpress. В случае чего вы сможете с лёгкостью добавить в файл свои дополнения.
Вот как выглядит файл robots.txt для моего сайта.

Сейчас я объясню вам, что всё это значит.
В общем, если не вдаваться в подробности, то я запретил поисковикам индексировать: темы и плагины wordpress, кэш сайта, то есть дубликаты страниц, feed – это rss лента с записями. Теперь объясню зачем это делать, этим самым мы облегчаем работу поискового робота, чтобы он не индексировал лишний груз сайта, темы, плагины, кэш, фид, всё это можно не индексировать, в поиске вся эта информация просто не нужна.
Так же в файле указано – разрешить поисковикам индексировать все загруженные медиафайлы на вашем сайте. Такой файл robots.txt подойдёт любому сайту на wordpress.
Смотрите, к примеру вы хотите не индексировать ещё какую-либо отдельную страницу или запись на вашем сайте, тогда файл будет выглядеть следующим образом:

Поняли да, то есть добавляете только название страницы из её ссылки и впереди ставите флэш /, а для записи, название записи.html и впереди флэш /.
Итак, скачать готовый файл robots.txt можно – Здесь ! Только Внимание ! ! ! укажите свой адрес сайта вместо моего.
После того как вы скачаете файл, у вас будет два варианта:
- Загрузить файл в свою корневую директорию на хостинге. (в этом случае плагин можно не устанавливать)
- Скопировать содержание файла и вставить в специальное окно на странице настройки плагина DL Robots.txt
На этом у меня всё, если у вас остались вопросы по данной статье, то обязательно напишите мне в Обратную связь, либо оставьте комментарий к данной записи. Я всем отвечу ! Кстати, а вы проверяли файл robots.txt в Яндекс вебмастер ?
Удачи вам и до новых встреч !
Поделиться ссылкой:
https://info-effect.ru/info-effect.ru
Файл robot.txt | WordPress.org
Спасибо за ответы, только у меня вопросов прибавилось((( Я НЕ специалист к сожалению((
Мой робот я сделала давно, тогда почему-то сайт долго индексировался и мне с яндекс вебмастера предложили закрыть лишнее, чтобы робот быстрей обходил, ну я и закрыла (в интернете день читала про все — так видимо и не поняла)
Я очень уважаю ваше мнение, но чем больше я смотрю файлов и сайтов, тем больше у меня вопросов ибо в каждом что-то разное — то стоит в конце /, то не стоит и прочие значки вот по ссылке, что прислал SeVlad я вообще ничего не поняла, так как это плюс еще очередной вариант на мою и без того запутанную чайниковую голову
Yui мне лучше совсем убрать то что Вы написали или добавить разрешение allow для моей темы Нирвана (у меня закачано еще три темы — хотела сменить дизайн посмотреть, чтобы не перегружать обходящего робота) Я ОЧЕНЬ боюсь испортить или открыть больше, чем нужно.
Могли бы вы подправить, исправить, проверить мой робот тхт или написать новый , чтобы он был правильным и в тоже время не замедлял обход сайта роботами гугла и яндекса.
User-agent: *
Allow: /wp-content/uploads
Allow: /wp-content/themes/nirvana/css
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-content/cache
Disallow: /wp-login.php
Disallow: */attachment_id=*
Disallow: */trackback
Disallow: */feed/
Disallow: /?p=*
Disallow: *?s=
Disallow: /xmlrpc.php
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /wp-content/cache
Disallow: /wp-login.php
Disallow: *?replytocom=*
Disallow: */attachment_id=*
Disallow: */trackback
Disallow: */tag/*
Disallow: */feed/
Disallow: /?p=*
Disallow: *?s=
Disallow: /xmlrpc.php
Host: мойсайт.ru
Sitemap: http://мойсайт.ru/sitemap.xml
Sitemap: http://мойсайт.ru/sitemap.xml
Обязательно здесь ставить вторую строчку с gz в конце,
Грубо говоря — удаляете всё и следите за индексацией (метрика/вебмастер) и если если там появятся нежелательное — закрываете
Как я потом узнаю чем закрыть и что именно (куча значков то вначале, то в конце, то * то все вместе
Поэтому и спросила, что необходимо написать.
Тот пример который я приложила изобилует всякими функциями поэтому я и запуталась, а в моем случае многое закрыто, особенно этот css, который гугл так обожает
Заранее Спасибо за вашу помощь.Пустья покажусь бестолковой, но мне очень нужно, а может быть я даже что-то пойму на вашем примере.
ru.wordpress.org
Как сделать robots.txt для WordPress.Создаем правильный robots.txt для сайта на WordPress
Приветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет.
Фактически, с помощью этого служебного файла можно указать, какие разделы будут индексироваться в поисковых системах, а какие нет.
Создание файла robots.txt
1. Создайте обычный текстовый файл с названием robots в формате .txt.
2. Добавьте в него следующую информацию :
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= Host: site.com Sitemap: http://site.com/sitemap.xml
3. Замените в в текстовом файле строчку site.com на адрес Вашего сайта.
4. Сохраните изменения и загрузите файл robots.txt (с помощью FTP) в корневую папку Вашего сайта.
5. Готово.
Для просмотра и скачки примера, нажмите кнопку ниже и сохраните файл (Ctrl + S на клавиатуре).
Скачать пример файла robots.txtРазбираемся в файле robots.txt (директивы)
Давайте теперь более детально разберем, что именно и зачем мы добавили в файл robots.txt.
User-agent — директива, которая используется для указания названия поискового робота. С помощью этой директивы можно запретить или разрешить поисковым роботам посещать Ваш сайт. Примеры:
Запрещаем роботу Яндекса просматривать папку с кэшем:
User-agent: Yandex Disallow: /wp-content/cache
Разрешаем роботу Bing просматривать папку themes (с темами сайта):
User-agent: bingbot Allow: /wp-content/themes
Allow и Disallow — разрешающая и запрещающая директива. Примеры:
Разрешим боту Яндекса просматривать папку wp-admin:
User-agent: Yandex Allow: /wp-admin
Запретим всем ботам просматривать папку wp-content:
User-agent: * Disallow: /wp-content
В нашем robots.txt мы не используем директиву Allow, так как всё, что не запрещено боту с помощью Disallow — по умолчанию будет разрешено.
Host — директива, с помощью которой нужно указать главное зеркало сайта, которое и будет индексироваться роботом.
Sitemap — используя эту директиву, нужно указать путь к карте сайта. Напомню, что карта сайта является очень важным инструментом при продвижении сайта! Обязательно указывайте её в этой директиве!
Если остались какие-то вопросы — задавайте их в комментарий. Если же информации в этом уроке для Вас оказалось недостаточно, рекомендую почитать подробнее о всех директивах и способах их использования перейдя по этой ссылке.
Приветствую, друзья! В этом уроке мы поговорим о создании файла robots.txt, который показывает роботам поисковых систем, какие разделы Вашего сайта нужно посещать, а какие нет. Фактически, с помощью этого служебного файла можно указать, какие разделы будут индексироваться в поисковых системах, а какие нет. Создание файла robots.txt 1. Создайте обычный текстовый файл с названием robots в формате .txt. 2. Добавьте в него следующую информацию : User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-content/cache Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */trackback Disallow: */feed Disallow: /cgi-bin Disallow: /tmp/ Disallow: *?s= User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-comments Disallow: /wp-content/plugins Disallow: /wp-content/themes…
Создание и настройка robots.txt
Рейтинг: 4.49 ( 31 голосов ) 100wp-lessons.com
Делаем правильный файл Robots.txt для WordPress
Приветствую вас, друзья. Сегодня я покажу как сделать правильный файл Robots.txt для WordPress блога. Файл Robots является ключевым элементом внутренней оптимизации сайта, так как выступает в роли гида-проводника для поисковых систем, посещающих ваш ресурс – показывает, что нужно включать в поисковый индекс, а что нет.

Содержание:
Само название файла robots.txt подсказываем нам, что он предназначен для роботов, а не для людей. В статье о том, как работают поисковые системы, я описывал алгоритм их работы, если не читали, рекомендую ознакомиться.
Зачем нужен файл robots.txt
Представьте себе, что ваш сайт – это дом. В каждом доме есть разные служебные помещения, типа котельной, кладовки, погреба, в некоторых комнатах есть потаенные уголки (сейф). Все эти тайные пространства гостям видеть не нужно, они предназначены только для хозяев.
Аналогичным образом, каждый сайт имеет свои служебные помещения (разделы), а поисковые роботы – это гости. Так вот, задача правильного robots.txt – закрыть на ключик все служебные разделы сайта и пригласить поисковые системы только в те блоки, которые созданы для внешнего мира.
Примерами таких служебных зон являются – админка сайта, папки с темами оформления, скриптами и т.д.
Вторая функция этого файла – это избавление поисковой выдачи от дублированного контента. Если говорить о WordPress, то, часто, мы можем по разным URL находить одни и те же статьи или их части. Допустим, анонсы статей в разделах с архивами и рубриках идентичны друг другу (только комбинации разные), а страница автора обычного блога на 100% копирует весь контент.
Поисковики интернета могут просто запутаться во всем многообразии таких страниц и неверно понять – что нужно показывать в поисковой выдаче. Закрыв одни разделы, и открыв другие, мы дадим однозначную рекомендацию роботам по правильной индексации сайта, и в поиске окажутся те страницы, которые мы задумывали для пользователей.
Если у вас нет правильно настроенного файла Robots.txt, то возможны 2 варианта:
1. В выдачу попадет каша из всевозможных страниц с сомнительной релевантностью и низкой уникальностью.
2. Поисковик посчитает кашей весь ваш сайт и наложит на него санкции, удалив из выдачи весь сайт или отдельные его части.
Есть у него еще пара функций, о них я расскажу по ходу.
Принцип работы файла robots
Работа файла строится всего на 3-х элементах:
- Выбор поискового робота
- Запрет на индексацию разделов
- Разрешение индексации разделов
1. Как указать поискового робота
С помощью директивы User-agent прописывается имя робота, для которого будут действовать следующие за ней правила. Она используется вот в таком формате:
User-agent: * # для всех роботов
User-agent: имя робота # для конкретного робота
После символа «#» пишутся комментарии, в обработке они не участвуют.
Таким образом, для разных поисковых систем и роботов могут быть заданы разные правила.
Основные роботы, на которые стоит ориентироваться – это yandex и googlebot, они представляют соответствующие поисковики.
2. Как запретить индексацию в Robots.txt
Запрет индексации осуществляется в помощью директивы Disallow. После нее прописывается раздел или элемент сайта, который не должен попадать в поиск. Указывать можно как конкретные папки и документы, так и разделы с определенными признаками.
Если после этой директивы не указать ничего, то робот посчитает, что запретов нет.
Disallow: #запретов нет
Для запрета файлов указываем путь относительного домена.
Disallow: /zapretniy.php #запрет к индексации файла zapretniy.php
Запрет разделов осуществляется аналогичным образом.
Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta
Если нам нужно запретить разные разделы и страницы, содержащие одинаковые признаки, то используем символ «*». Звездочка означает, что на ее месте могут быть любые символы (любые разделы, любой степени вложенности).
Disallow: */*test #будут закрыты все страницы, в адресе которых содержится test
Обратите внимание, что на конце правила звездочка не ставится, считается, что она там есть всегда. Отменить ее можно с помощью знака «$»
Disallow: */*test$ #запрет к индексации всех страниц, оканчивающихся на test
Выражения можно комбинировать, например:
Disallow: /test/*.pdf$ #закрывает все pdf файлы в разделе /test/ и его подразделах.
3. Как разрешить индексацию в Robots.txt
По-умолчанию, все разделы сайта открыты для поисковых роботов. Директива, разрешающая индексацию нужна в тех случаях, когда вам необходимо открыть какой-либо кусочек из блока закрытого директивой disallow.
Для открытия служит директива Allow. К ней применяются те же самые атрибуты. Пример работы может выглядеть вот так:
User-agent: * # для всех роботов Disallow: /razdel-sajta #запрет к индексации всех страниц, начинающихся с /razdel-sajta Allow: *.pdf$ #разрешает индексировать pdf файлы, даже в разделе /razdel-sajta
Теорию мы изучили, переходим к практике.
Как создать и проверить Robots.txt
Проверить, что содержит ваш файл на данный момент можно в сервисе Янде
biznessystem.ru