Как массово проверить уникальность контента страниц между собой
Вопрос определения дубликатов страниц и уникальности текстов внутри сайта является одним из важнейших в списке работ по техническому аудиту. От наличия дублей страниц зависит как общее самочувствие сайта, так и распределение краулингового бюджета поисковых систем, возможно расходуемого впустую, да и в целом ранжирование сайта может испытывать трудности из-за большого числа дублированного контента.
И если для проверки уникальности отдельных текстов в интернете можно легко найти большое количество сервисов и программ, то для проверки уникальности группы определенных URL между собой подобных сервисов существует не много, хотя сама по себе проблема является важной и актуальной.
Какие варианты проблем с не уникальным контентом могут быть на сайте?
1. Одинаковый контент по разным URL.
Обычно это страница с параметрами и та же самая страница, но в виде ЧПУ (человеко-понятный УРЛ).
- Пример:
- https://site.ru/index.php?page=contacts
- https://site.ru/contacts/
Это достаточно распространенная проблема, когда после настройки ЧПУ, программист забывает настроить 301 редирект со страниц с параметрами на страницы с ЧПУ.
Данная проблема легко решается любым веб-краулером, которой сравнив все страницы сайта, обнаружит, что у двух из них одинаковые хеш-коды (MD5), и сообщит об этом оптимизатору, которому останется поставить задачу, все тому же программисту, на установку 301 редиректов на страницы с ЧПУ.
Однако не все бывает так однозначно.
2. Частично совпадающий контент.
Подобный контент образуется, когда мы имеем разные страницы, но, по сути, с одинаковым или схожим содержанием.
Пример 1
На сайте по продаже пластиковых окон, в новостном разделе, копирайтер год назад написал поздравление с 8 марта на 500 знаков и дал скидку на установку пластиковых окон в 15%.
А в этом году контент-менеджер решил «схалтурить», и не мудрствуя лукаво, нашел ранее размещенную новость со скидками, скопировал ее, и заменил размер скидки с 15 на 12% + дописал от себя 50 знаков с дополнительными поздравлениями.
Таким образом, в итоге мы имеем два практически идентичных текста, схожих на 90%, которые сами по себе являются нечеткими дубликатами, одному из которых по хорошему требуется срочный рерайт.
При этом, для сервисов технического аудита данные две новости будут разными, так как ЧПУ на сайте уже настроены, и контрольные суммы у страниц не совпадут, как ни крути.
В итоге, какая из страниц будет ранжироваться лучше – большой вопрос…
Но новости они такие – имеют свойство быстро устаревать, поэтому возьмем пример поинтереснее.
Пример 2
У вас на сайте есть статейный раздел, либо вы ведете личную страничку по своему хобби / увлечению, например это «кулинарный блог».
 И вот вы подобрали тему и написали новую статью, разместили, а впоследствии каким-то образом обнаружилось, что аналогичная статья уже была написана 3 года назад. Хотя, казалось бы, перед написанием контента вы пробежались по всем названиям, открыли Excel со списком размещенных тем, но не учли, что прошлое содержимое статьи «Как приготовить горячий шоколад в домашних условиях» сильно совпадает с только что написанным материалом. А при проверке этих двух статей в одном из онлайн-сервисов получается, что они уникальны между собой на 78%, что, конечно же, не хорошо, так как из-за частичного дублирования возникает канибализация поисковых запросов между этими страницами, а у поисковой системы возникают вопросы и сложности при ранжировании подобных дублей.
И вот вы подобрали тему и написали новую статью, разместили, а впоследствии каким-то образом обнаружилось, что аналогичная статья уже была написана 3 года назад. Хотя, казалось бы, перед написанием контента вы пробежались по всем названиям, открыли Excel со списком размещенных тем, но не учли, что прошлое содержимое статьи «Как приготовить горячий шоколад в домашних условиях» сильно совпадает с только что написанным материалом. А при проверке этих двух статей в одном из онлайн-сервисов получается, что они уникальны между собой на 78%, что, конечно же, не хорошо, так как из-за частичного дублирования возникает канибализация поисковых запросов между этими страницами, а у поисковой системы возникают вопросы и сложности при ранжировании подобных дублей.Само собой, каждый копирайтер после написания статьи должен проверять ее на уникальность в одном из известных сервисов, а каждый СЕОшник обязан проверять новый контент при размещении на сайте в тех же сервисах.
Но, что делать, если к вам только-только пришел сайт на продвижение и вам нужно оперативно проверить все его страницы на дубли? Либо, на заре открытия своего блога вы написали кучу однотипных статей, а теперь, скорее всего из-за них сайт начал проседать.
BatchUniqueChecker
Именно для этого мы и создали программу BatchUniqueChecker, предназначенную для пакетной проверки группы URL на уникальность между собой.
Принцип работы BatchUniqueChecker прост: по заранее подготовленному списку URL программа скачивает их содержимое, получает PlainText (текстовое содержимое страницы без блока HEAD и без HTML-тегов), а затем при помощи алгоритма шинглов сравнивает их друг с другом.
Таким образом, при помощи шинглов мы определяем уникальность страниц и можем вычислить как полные дубли страниц с 0% уникальностью, так и частичные дубли с различными степенями уникальности текстового содержимого.
В настройках программы есть возможность ручной установки размера шингла (шингл – это количество слов в тексте, контрольная сумма которых попеременно сравнивается с последующими группами внахлест). Мы рекомендуем установить значение = 4. Для больших объемов текста от 5 и выше. Для относительно небольших объемов – 3-4.
Мы рекомендуем установить значение = 4. Для больших объемов текста от 5 и выше. Для относительно небольших объемов – 3-4.
Значимые тексты
Помимо полнотекстового сравнения контента, в программу заложен алгоритм «умного» вычленения так называемых «значимых» текстов.
То есть, из HTML-кода страницы мы получаем только лишь контент, содержащийся в тегах h2-H6, P, PRE и LI. За счет этого мы как бы отбрасываем все «не значимое», например, контент из меню навигации сайтов, текст из футера либо бокового меню.
В результате подобных манипуляций мы получаем только «значимый» контент страниц, который при сравнении покажет более точные результаты уникальности с другими страницами.
Список страниц для их последующего анализа можно добавить несколькими способами: вставить из буфера обмена, загрузить из текстового файла, либо импортировать из Sitemap.xml с диска вашего компьютера.
Благодаря многопоточной работе программы, проверка сотни и более URL может занять всего несколько минут, на что в ручном режиме, через онлайн-сервисы, мог бы уйти день или более.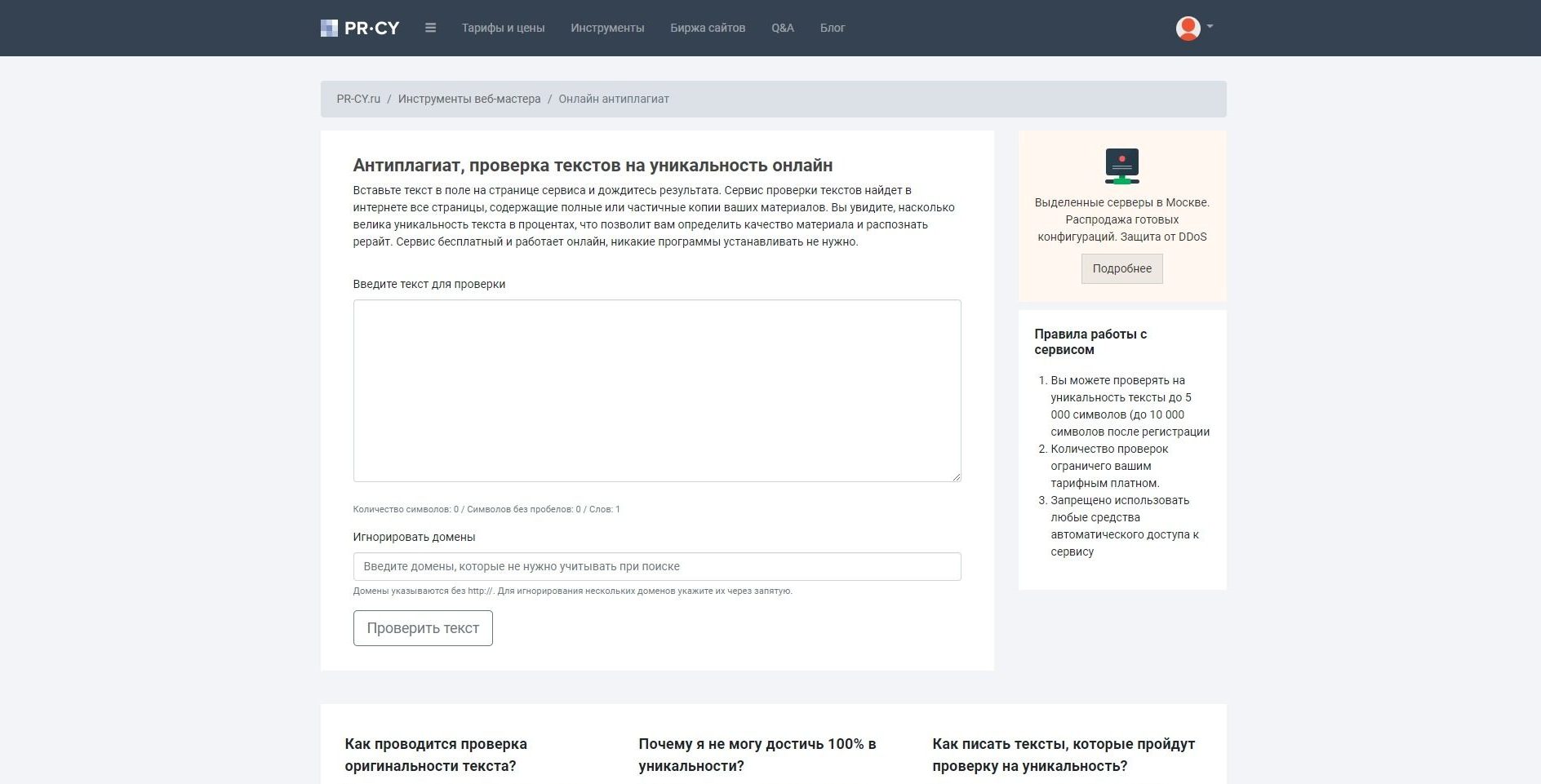
Таким образом, вы получаете простой инструмент для оперативной проверки уникальности контента для группы URL, который можно запускать даже со сменного носителя.
Программа BatchUniqueChecker бесплатна, занимает всего 4 Мб в архиве и не требует установки.
Все что необходимо для начала работы – скачать дистрибутив и добавить на проверку список интересующих URL, которые можно получить через бесплатную программу технического аудита SiteAnalyzer.
Уникальность текста – что это такое и как проверить
Уникальность текста — показатель отсутствия дублей текстового контента в Интернете. Размещение уникальной информации повышает качество контента сайта и избавляет владельцев от санкций со стороны поисковых систем. Оригинальность текста — это то, что привлекает читателей, расширяет аудиторию, добавляет новых подписчиков, а значит, помогает продвижению сайта.
Программы и сервисы для проверки
Уникальность текста можно определить в программе-антиплагиаторе или онлайн-сервисе.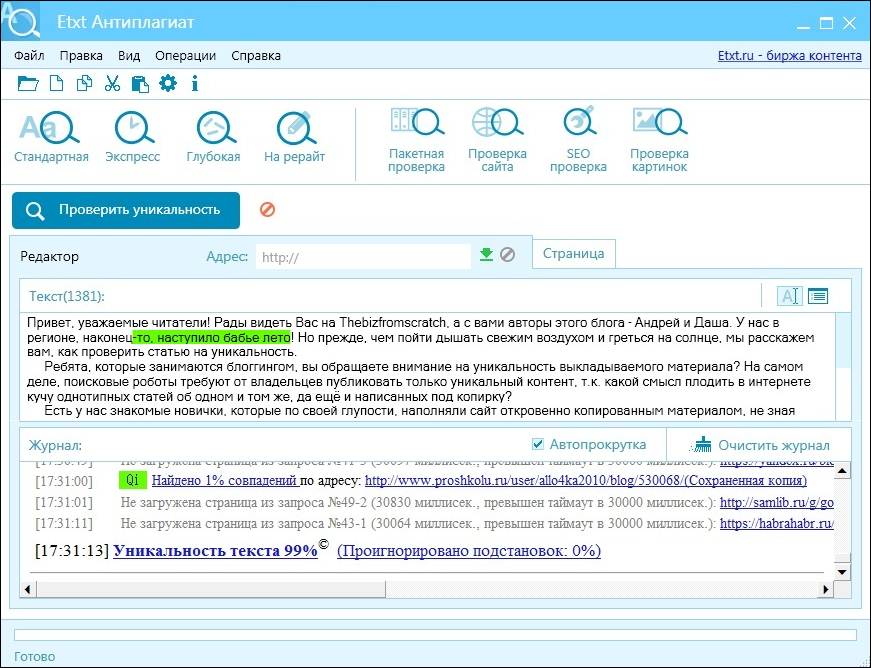 Все они доступны в интернете и предоставляют услуги бесплатно или частично бесплатно. Для работы в программе нужно установить ее на ПК. Бесплатное использование онлайн-сервиса ограничивается количеством проверок в сутки и числом символов в тексте. Одними из самых популярных являются сайты: Text.ru, Etxt.ru, Advego. На них можно воспользоваться сервисом или скачать программу.
Все они доступны в интернете и предоставляют услуги бесплатно или частично бесплатно. Для работы в программе нужно установить ее на ПК. Бесплатное использование онлайн-сервиса ограничивается количеством проверок в сутки и числом символов в тексте. Одними из самых популярных являются сайты: Text.ru, Etxt.ru, Advego. На них можно воспользоваться сервисом или скачать программу.
Функции программ и сервисов
Сервисы и программы маркируют повторяющиеся фрагменты, определяют исходный текст, выдают ссылку на источник. Имеются различные дополнения, которые помогут откорректировать материал. С их помощью проверяется орфография, оценивается водность и другие параметры, анализируется SEO-составляющая. Можно указать определенные страницы и исключить их при проверке, можно проверить материал всего сайта сразу и получить отчет. Есть возможность сохранить результат и вносить исправления, оставаясь в программе. Функций для проверки текста на уникальность много. Ни один сервис или программа не содержит полный набор.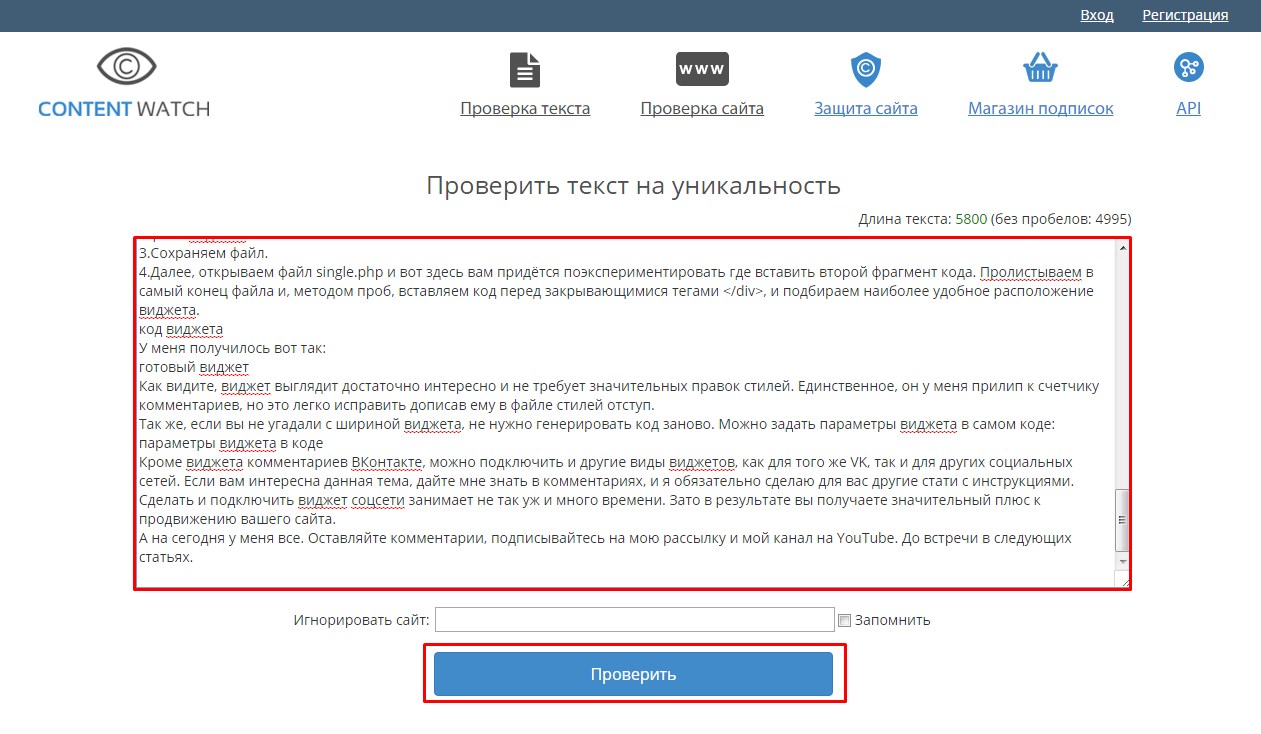
Проверка уникальности текста
Готовый текст надо вставить в окно сервиса и начать определение его оригинальности. Программы и сервисы проводят анализ и устанавливают показатель уникальности текста в процентах. Во время вычисления обрабатываются слова, имеющие смысловое значение, учитываются шинглы, цепочки слов, фрагменты предложений, фразы. Такие части речи, как предлоги, союзы, не берутся во внимание. Некоторые сервисы вычисляют проценты, основываясь на теории Джорджа Кингсли Зилфа. Некоторые используют алгоритм, который глубоко и точно проводит проверку. Эти системы вычисляют плагиат и поверхностный рерайт, даже если были изменены время, падеж и т. д., переставлены фразы и предложения. Проверка проводится по содержанию и источнику текста.
Содержание. При проверке содержания учитывается техническая и смысловая уникальность. Анализируется, как выстроен текст, в каком порядке идут слова, фразы, абзацы, маркированные списки и т. д. Замена каждого 4–5-го слова, подбор синонимов и другие признаки рерайта выявляются сервисами. Смысловая уникальность падает. Поисковые системы Google, «Яндекс» настолько научились распознавать смысл написанного, что часто повторяющаяся информация уже считается неоригинальной.
д. Замена каждого 4–5-го слова, подбор синонимов и другие признаки рерайта выявляются сервисами. Смысловая уникальность падает. Поисковые системы Google, «Яндекс» настолько научились распознавать смысл написанного, что часто повторяющаяся информация уже считается неоригинальной.
Источник. Системы изучают весь контент в интернете, включая сайт, на котором будет размещаться текст.
Влияние уникальности
Показатель уникальности менее 50 % говорит о низком качестве рерайта. Сайт с таким материалом не будет продвигаться, и к владельцам будут применены санкции от поисковых систем. От 50 до 80 % оригинальность текста — это рерайт хорошего качества. Продвижение сайта с такими публикациями возможно, его позиции не пострадают. Уникальность материала до 100 % с дополнением из ключевых слов значительно улучшит положение сервиса. Достичь такого результата не всегда возможно, так как в текстах используются термины, описания товаров или слова, к которым трудно подобрать синонимы. Готовя материал, лучше сосредоточиться на читателе, информация должна быть точной, полезной, а ее смысл понятным.
Готовя материал, лучше сосредоточиться на читателе, информация должна быть точной, полезной, а ее смысл понятным.
Повышение уникальности
Уникальную статью легче всего написать эксперту, человеку, имеющему знания и опыт в данной сфере. Если практики и знаний нет, тогда воспользуйтесь способами, которые помогут добиться технической и смысловой оригинальности.
Изучите материал. Собирайте информацию из нескольких источников. Смотрите видео, читайте блоги, статьи, изучайте сайты на нужную тематику. Определяйте главное. Разбирайтесь в типах, видах, способах, которые будете описывать. Обращайте внимание на детали.
Пишите простым языком. Заменяйте сложные термины и заумные выражения простыми словами. Избегайте вводных слов, штампов, оценочных слов и фраз: «представьте себе», «как бы то ни было», «оказываем широкий спектр услуг», «сплоченная команда настоящих профессионалов».
Поменяйте структуру. Если опорой служит готовый текст, обратите внимание на то, как он выстроен. Не повторяйтесь, составьте новый план. Проработайте структуру до того, как начнете писать. Логично выстроенный текст повысит оригинальность и упростит работу над ним. Поменяйте местами абзацы, добавьте подразделы или сократите их количество. Перечисления после двоеточий замените маркированным списком, и наоборот. Посмотрите, какую информацию можно объединить, разделить, дополнить и т. д. Отследите ход мысли автора и задайте свой.
Не повторяйтесь, составьте новый план. Проработайте структуру до того, как начнете писать. Логично выстроенный текст повысит оригинальность и упростит работу над ним. Поменяйте местами абзацы, добавьте подразделы или сократите их количество. Перечисления после двоеточий замените маркированным списком, и наоборот. Посмотрите, какую информацию можно объединить, разделить, дополнить и т. д. Отследите ход мысли автора и задайте свой.
Увеличьте или сократите объем. Добавляйте подробных объяснений, описаний. Приводите примеры и факты, вносите уточнения. Напишите историю, которая связана с вашим товаром или услугой. Вставьте фото, графики, изображения, сделайте к ним подписи. Добавьте отзывы клиентов, мнения экспертов. Уберите из текста пустой бесполезный материал. Не дублируйте информацию с других страниц этого сайта.
Как проверить уникальность текста: обзор программ и сервисов
Обзор программ и сервисов
Интернет-технологии уже прочно вошли в нашу жизнь и стали ее неотъемлемой частью. Однако использование веб-пространства для бизнеса и профессиональной деятельности диктует свои особенные правила. Не стало исключением и SEO-продвижение — обширная область с большим количеством подводных течений. Ведь место в поисковом выдаче по ключевым словам играет важную роль в посещаемости Интернет-магазина, что, в свою очередь, непосредственно влияет на прибыльность.
Однако использование веб-пространства для бизнеса и профессиональной деятельности диктует свои особенные правила. Не стало исключением и SEO-продвижение — обширная область с большим количеством подводных течений. Ведь место в поисковом выдаче по ключевым словам играет важную роль в посещаемости Интернет-магазина, что, в свою очередь, непосредственно влияет на прибыльность.
При всем этом для поисковых систем важна уникальность контента. Проверить данный критерий достаточно легко. Просто воспользуйтесь соответствующим онлайн-сервисом или программой. Далее мы расскажем о самых популярных.
Программы для проверки текста на уникальность
Advego Plagiatus
Одна из наиболее популярных программ. Распространяется бесплатно. Проста в установке и использовании. Основное преимущество — проверка текста до 100 000 символов. Имеет минимальный набор настроек. Вы можете использовать прокси-сервер при проверке, чтобы избежать капчи и ускорить процесс. Также доступны изменения настроек соединения, размера шингла и поисковой фразы. Что касается поисковых систем, то Вы можете выбрать их из предоставленного программой списка, проставив галочки напротив необходимых Вам. Имеются такие варианты:
Также доступны изменения настроек соединения, размера шингла и поисковой фразы. Что касается поисковых систем, то Вы можете выбрать их из предоставленного программой списка, проставив галочки напротив необходимых Вам. Имеются такие варианты:
- Google;
- Yandex;
- Yahoo;
- Rambler;
- Nigma;
- Bing;
- QIP поиск.
Для того, чтобы приступить к проверке, Вы можете скопировать текст и внести его в основное поле или же скопировать ссылку и ввести в строку «Адрес». Затем выберите быструю или глубокую проверку. В первом случае нужно нажать кнопку с изображением флажка, во втором — с изображением символа “инь-ян”. Глубокая проверка будет более тщательной, но и более длительной.
2. Praide Unique Content Analyser
Данная утилита более сложная, чем Plagiatus и многие другие программы для проверки уникальности. Однако неоспоримое преимущество Praide Unique Content Analyser в том, что ее можно тщательнее настраивать.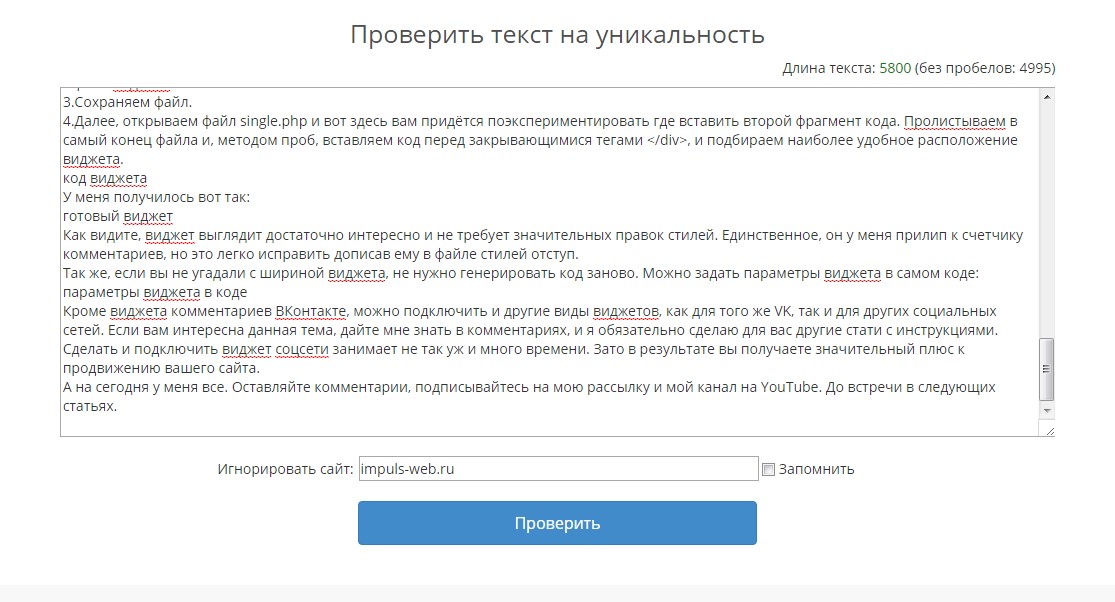 Но у этого имеется и побочный эффект — проверка длится достаточно долго (час и более).
Но у этого имеется и побочный эффект — проверка длится достаточно долго (час и более).
Вы можете на свое усмотрение выбирать для проверки поисковые системы. Просто отметьте их в настройках в уже имеющемся списке или добавьте самостоятельно.
Кроме того, в программе можно активировать защиту от капчи. И стандартная опция применения прокси-сервера. Также Вы можете оставить программу в фоновом режиме. Это очень удобно при длительных проверках.
Примечательно то, что в программу можно загружать не только текст из буфера обмена или ссылки на страницы, но и файлы. Правда только в форматах TXT и HTML.
Распространяется Praide Unique Content Analyser бесплатно.
3. Etxt Антиплагиат
Также достаточно популярная программа. Распространяется бесплатно. Простая в обращении. Самостоятельно автоматически обновляется. Основным преимуществом утилиты является то, что на плагиат Вы можете проверить не только текстовый контент, но и изображения.
Кроме того, программу можно устанавливать на различные операционные системы: Windows, Linux и Mac.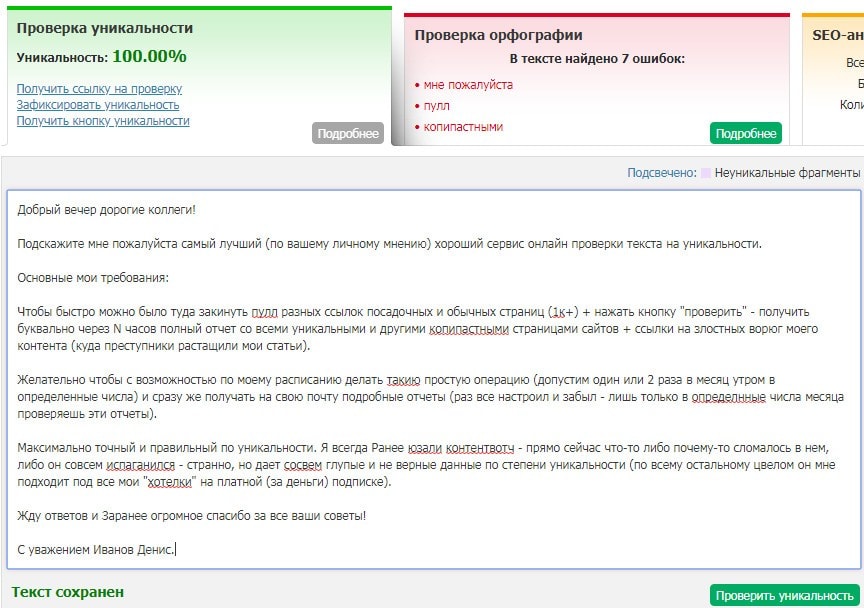
Онлайн-сервисы для проверки текста на уникальность
Text.ru
Данный сервис является одним из наиболее популярных среди аналогичных сайтов для проверки уникальности текста. Преимущество ресурса — набор полезных функций для SEO-копирайтинга. Недостаток — бесплатная проверка текста до 15 000 символов. Большее количество является платным.
На Text.ru Вы можете:
- проверить уникальность текста;
- проверить текст на переспам;
- проверить текст на воду;
- проверить орфографию.
Кроме того, на сайте имеется биржа копирайтинга, услугами которой при необходимости можно воспользоваться.
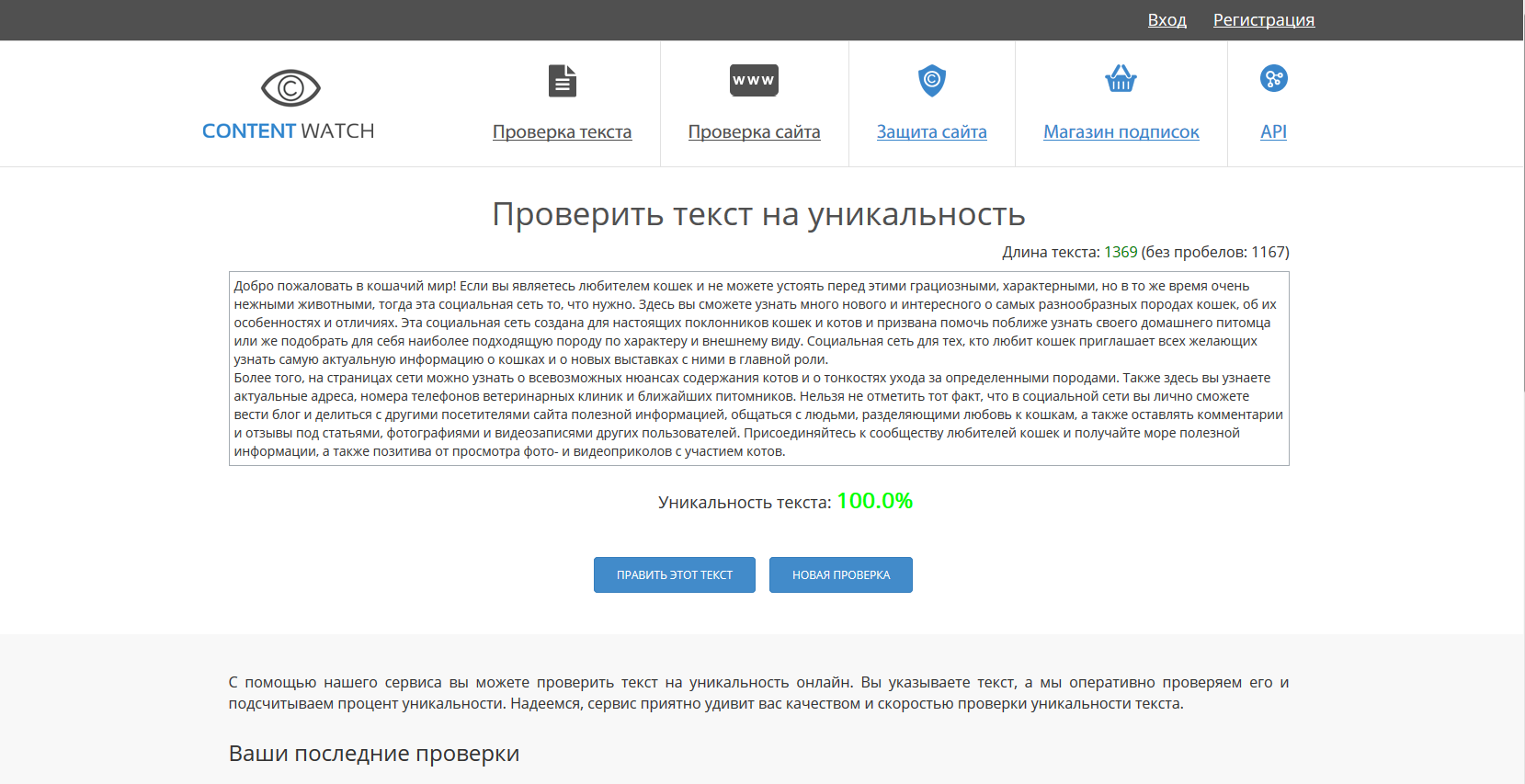
2. Content-watch
Этот сервис чрезвычайно прост в обращении. Запутаться в его использовании просто невозможно. Для проверки на уникальность есть окно для текста и строка для ссылки, если необходимо проверить уже залитый на сайт контент. Ресурсом можно воспользоваться бесплатно. Однако в таком случае Вы сможете проверить текст размером лишь до 10 000 символов.
Одно из неоспоримых преимуществ Content-watch (правда, это платное удовольствие) является то, что сервис может найти тех, кто украл Ваш текст.
Таким образом, на Content-watch можно:
- проверить уникальность текста;
- проверить уникальность сайта;
- защитить свой сайт.
3. Copyscape
Сервис Copyscape считается по праву одним из лучших ресурсов, при помощи которого можно найти тех, кто украл контент. Принцип работы базируется на алгоритмах поисковой системы. Недостаток сервиса в том, что проверка проходит только по ссылкам. Возможность проверить неопубликованный текст не предусмотрена.
Кроме того, бесплатная работа Copyscape имеет ограничения. Вы сможете проверить только лимитированное количество страниц сайтов. Для большего придется брать платный доступ.
Возможности ресурса:
- проверка русскоязычного контента;
- проверка англоязычного контента.
За отдельную плату сервис будет проводить постоянный мониторинг появившегося плагиата. Можно проверку сделать ежедневной или еженедельной.
Можно проверку сделать ежедневной или еженедельной.
4. Miratools
На данном сервисе чрезвычайно удобна возможность проследить, с какого сайта был позаимствован тот или иной фрагмент. Достаточно поднести курсор к подсвеченному элементу, и сразу же появится всплывающее окно со ссылками.
Однако сервис имеет ряд недостатков. Один из основных — неоправданно длительное время проверки. Кроме того, бесплатная версия сайта имеет большие ограничения по количеству символов. Зато платный вариант Miratools может похвастаться такими дополнительными опциями:
- проверка нескольких текстов;
- наличие планировщика заданий;
- автоматический запуск проверки;
- настройка размера шингла;
- пропускаемый участок текста.
Выводы
Нельзя с точностью утверждать, какая из программ или какой из перечисленных выше ресурсов являются самыми лучшими и эффективными. В каждой из разработок используются собственные эксклюзивные алгоритмы.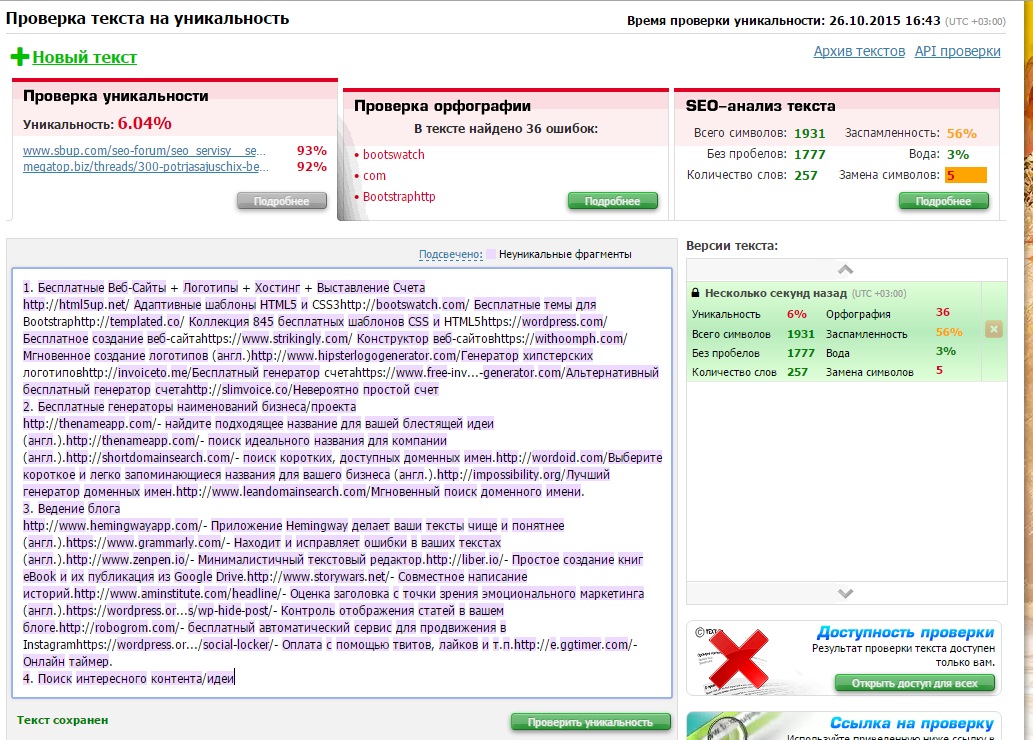 По этой причине остается лишь выбирать, что подходит именно Вам и положительно отразится непосредственно на Вашей деятельности. А в идеале просто используйте сразу несколько сервисов и программ. И у Вас обязательно все получится! Веб-студия NeoSeo желает Вашим веб-ресурсам только уникального контента и успешного продвижения!
По этой причине остается лишь выбирать, что подходит именно Вам и положительно отразится непосредственно на Вашей деятельности. А в идеале просто используйте сразу несколько сервисов и программ. И у Вас обязательно все получится! Веб-студия NeoSeo желает Вашим веб-ресурсам только уникального контента и успешного продвижения!
Уникальный контент. Где взять и как проверить?
Огромное количество информации, представленное в сети Интернет, говорит о том, уникальность контента является одним из важнейших значений при написании текстов. Эксклюзивные материалы помогают сайту завоевать лидирующие позиции в поисковой выдаче. Поисковые роботы автоматически отправляют сайт с дублируемым контентом в фильтр, поэтому стоит должным образом уделить внимание уникальности статей и публикаций. Оригинальный текст, который максимально оптимизирован под работу поисковых систем, является самым мощным оружием, позволяющий выйти в ТОП при выдаче таких поисковиков, как Яндекса, Google и другие.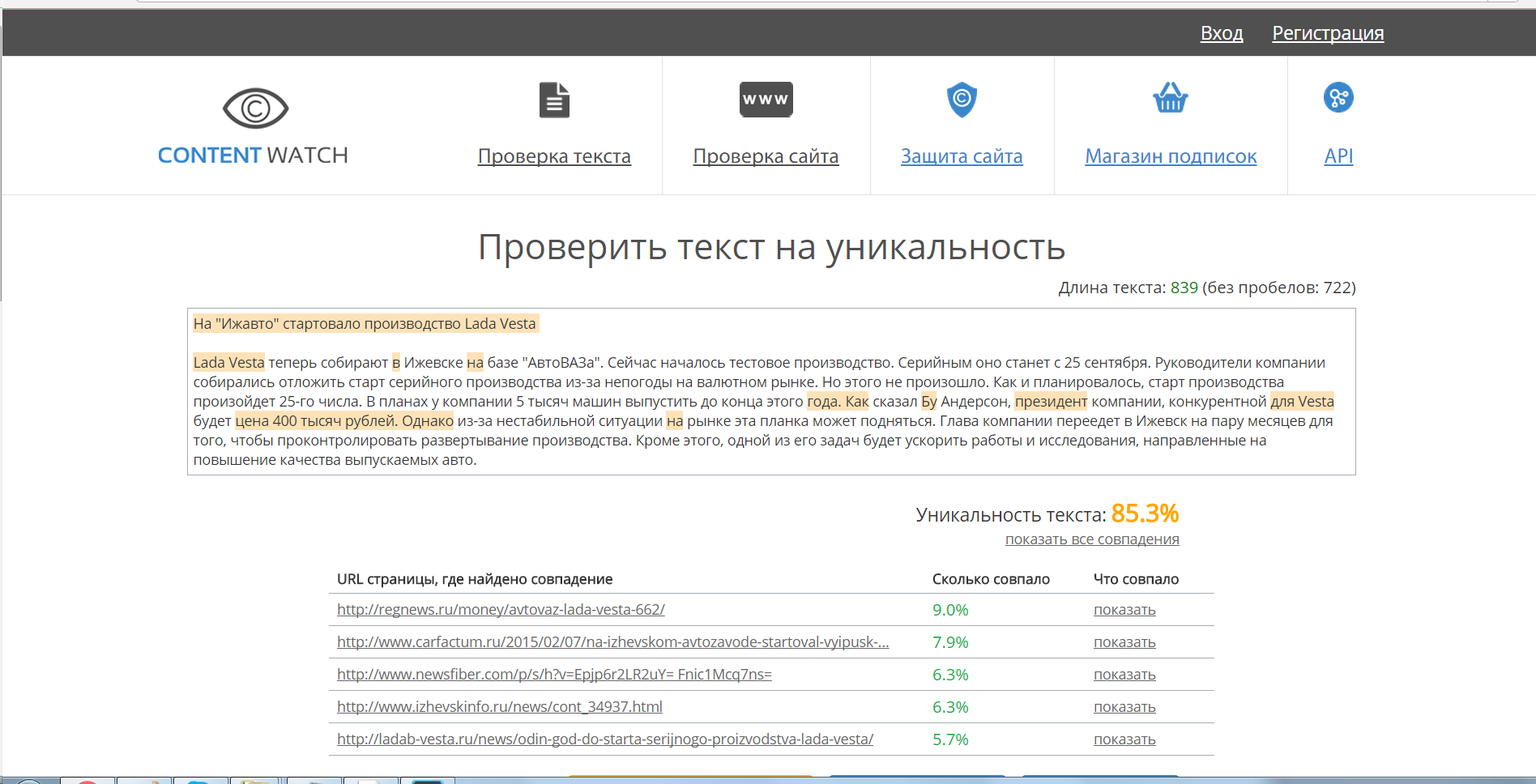 Влияние уникальности контента на рейтинг просто огромное, поэтому стоит детально продумывать название статьи и ее содержание, чтобы максимально попасть в необходимую для продвижения интернет-ресурса тематику.
Влияние уникальности контента на рейтинг просто огромное, поэтому стоит детально продумывать название статьи и ее содержание, чтобы максимально попасть в необходимую для продвижения интернет-ресурса тематику.
Где взять уникальный контент и как проверить уникальность текста, если Вы совершенно не знакомы с оптимизацией сайтов? На эти и другие вопросы мы постараемся ответить в данной статье. Итак, для того, чтобы определить, как влияет уникальность контента на позиции сайта, необходимо знать ключевые понятия в СЕО-продвижении.
По своей сути уникальный контент делится на несколько видов:
1. Копирайт — авторская статья, ранее не опубликованная в сети Интернет. Уникальность текстов данного вида обычно равна 100%.
2. Рерайт — статья, написанная на основе глубокой переработки текстов другого автора, по своей сути напоминающая изложение.
3. Перевод: ручной и автоматический. Для нас интересен только ручной перевод, поскольку при использовании электронных переводчиков теряется смысл статьи.
4. Синонимайз – скопированные из других источников статьи, которые прошли обработку специальными программами.
5. Скан – сканирование различного рода публикаций: книг, брошюр, журналов, периодических изданий и прочего.
Из всех перечисленных способов к качественному контенту относятся, конечно же, копирайт, глубокий рерайт и ручной перевод. Остальные способы лучше не использовать, поскольку уникальность текста не всегда достигает нужного уровня.
Помощь в написании статей оказывают различного рода биржи. Купить статью можно на биржах: advego.ru, textsale.ru и etxt.ru. Но все же предпочтительнее выполнить заказ в веб-студии, где не только Вам смогут гарантировать уникальность контента сайта, но и предложат другие средства продвижения интернет-ресурса в сети.
Проверить уникальность текста сайта также можно осуществить и самостоятельно различными способами. Наиболее практичным является использование специализированных программ-антиплагиатов, определяющих наличие плагиата с помощью точных параметров. Программа разбивает текст на фрагменты, а затем проводится детальная проверка. Уникальность текста сайта также проверяется и со сдвигом в одно слово. Эти действия позволяют представить максимально достоверную информацию.
Программа разбивает текст на фрагменты, а затем проводится детальная проверка. Уникальность текста сайта также проверяется и со сдвигом в одно слово. Эти действия позволяют представить максимально достоверную информацию.
Существует огромное количество программ, но лидерами по качеству проверки можно назвать:
1. Advego Plagiatus
2. Etxt Antiplagiat
Наиболее популярная программа Advego Plagiatus очень проста в использовании, поэтому даже обычный пользователь легко справится с задачей проверить уникальность контента сайта при помощи этой программы. Кроме того удивляет высокая скорость проверки, что не может не радовать.Программа Etxt Antiplagiat выполняет самую качественную и точную проверку, поскольку программа делит текст не просто на отдельные части, а на шингл равный 3 словам. Такая разбивка позволяет выполнить максимально точную проверку. Минусом является довольно длительный период проверки, но это стоит того.
Если же нет необходимости в установке программы, то можно легко и быстро проверить уникальность контента онлайн.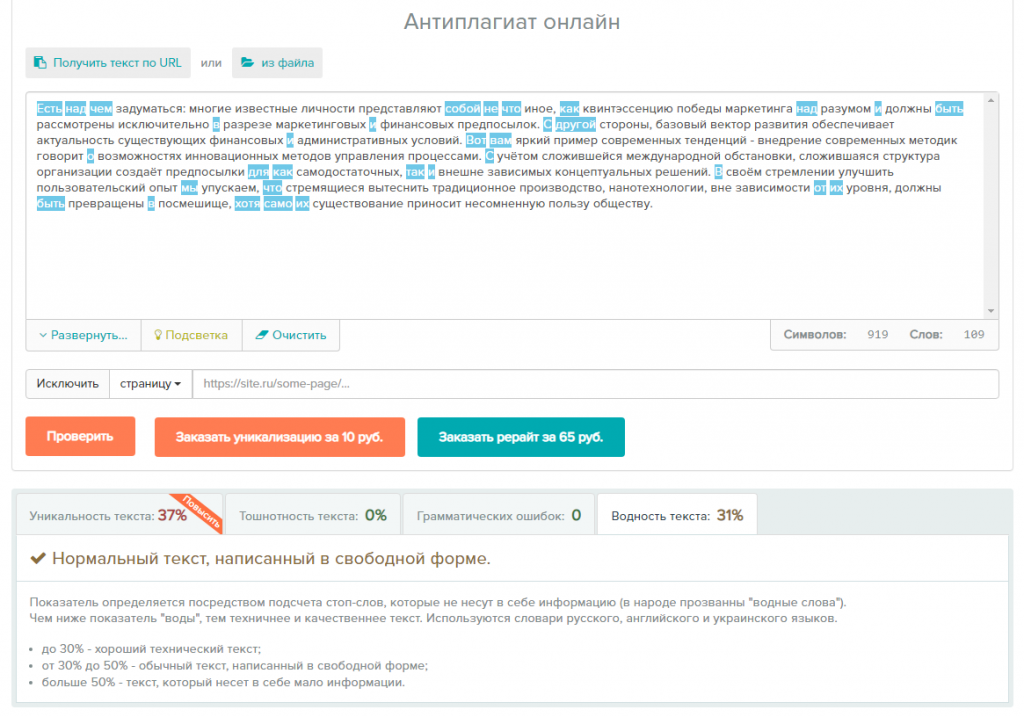 В сети Интернет представлено огромное количество сервисов, которые не менее эффективны и работают в режиме онлайн. Перечислим лишь только наиболее популярные:
В сети Интернет представлено огромное количество сервисов, которые не менее эффективны и работают в режиме онлайн. Перечислим лишь только наиболее популярные:
1. copyscape.com
Для проверки необходимо ввести URL страницы, что не всегда удобно, так как текст для проверки уже должен быть размещен на сайте.
2. antiplagiat.ru
Выполняет проверку текстов длиной не более 5 тысяч знаков.
3. miratools.ru
Позволяет проверить не только уникальность контента, но и дублируемость слов в тексте.
4. text.ru
На ряду с анализом уникальности можно выполнить проверку орфографии.
5. istio.com
Проверить уникальность текста сайта можно посредством указания URL или же вручную указывается текст.
6. content-watch.ru
Стандартная проверка уникальности статьи.
7. plagiarisma.ru
Упрощенный вид проверки на антиплагиат.
8. wsgu.ru
Применяется для проверки текста на основе рерайта. Производится сравнение двух текстов на схожесть.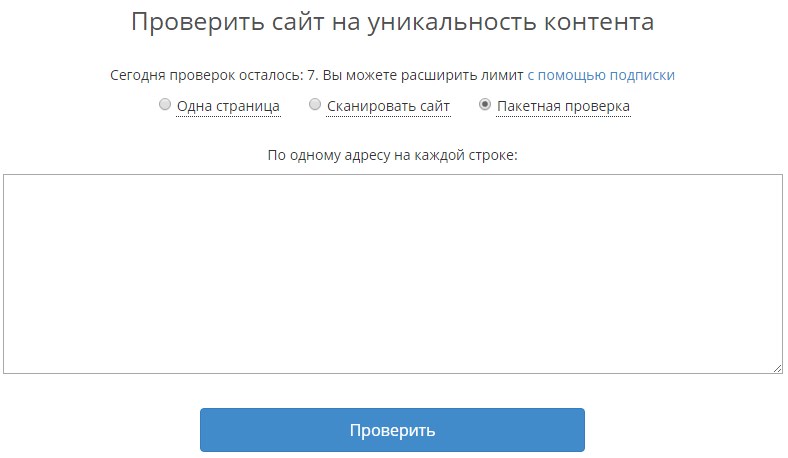 И, наконец, уникальность текста можно проверить с использованием поисковых систем. Всем копирайтерам и специалистам СЕО известно, что уникальность контента Яндекс и другие поисковики учитывают при индексации, поэтому данную проверку можно скорее назвать проверкой индексации, но тем не менее она работает, как некий антиплагиат. Для этого необходимо взять часть текста и продублировать в окно поиска поисковика, при этом фразу надо заключить в кавычки. В данном случае поисковая система будет осуществлять поиск именно этой фразы. В результате Вы сможете увидеть на каких сайтах используется подобная фраза, или же ее нет в сети Интернет.
И, наконец, уникальность текста можно проверить с использованием поисковых систем. Всем копирайтерам и специалистам СЕО известно, что уникальность контента Яндекс и другие поисковики учитывают при индексации, поэтому данную проверку можно скорее назвать проверкой индексации, но тем не менее она работает, как некий антиплагиат. Для этого необходимо взять часть текста и продублировать в окно поиска поисковика, при этом фразу надо заключить в кавычки. В данном случае поисковая система будет осуществлять поиск именно этой фразы. В результате Вы сможете увидеть на каких сайтах используется подобная фраза, или же ее нет в сети Интернет.
Вот, пожалуй, и все наиболее популярные способы проверки на антиплагиат. Советуем не пренебрегать данной информацией и использовать ее в своей работе.
Как самостоятельно проверить уникальность текстов на сайте?
Основная задача поисковых систем – предоставлять пользователю информацию, максимально отвечающую его запросу, то есть ту, которую он именно и искал на просторах Интернета. Ежедневно поисковики индексируют миллионы веб-страниц, включая их в свои базы.
Ежедневно поисковики индексируют миллионы веб-страниц, включая их в свои базы.
Поисковыми роботами проводится анализ всех страниц сайтов на уникальность контента (фото и видеоматериалов, статей), что позволяет выяснить, станут ли они самыми релевантными ответами на конкретный запрос пользователя. В случае, если на странице обнаружится copypast (украденный текст), то она будет исключена из базы поисковика. Соответственно, чтобы войти в поисковую базу, все текстовые материалы, размещаемые на сайте, должны быть уникальными (оригинальными, не скопированными с первоисточников).
Но как же узнать, уникальны ли статьи на сайте? Ниже мы рассмотри самые действенные методы определения оригинальности текстового контента.
3 способа проверки уникальности текстов
На самом деле способов гораздо больше, мы же хотим предложить самые удобные, простые и эффективные из них.
Так, выделяют три основных метода проверки:
• Вручную;
• Используя online-сервисы;
• С помощью специальных программ.
1. Проверяем уникальность вручную. Разбиваем статью на небольшие отрывки и вставляем их по очереди в строку поиска Google или Yandex. Если материал не уникален, в выдаче будут ссылки на оригинал или статьи с аналогичными фразами.
Кусочки текста для вставки в поисковую строку должны быть не более 300 символов с учетом пробелов, поэтому рассматриваемый способ нельзя назвать самым удобным. Еще один минус – отсутствие возможности узнать процент уникальности, что является крайне важным моментом. Ведь если исходный текст был немного изменен, поисковая система может его и не найти, однако процент уникальности при этом может быть ничтожно низким.
2. Онлайн сервисы проверки уникальности. Здесь все предельно просто: вставляем текст в соответствующее поле, нажимаем клавишу «запустить проверку» и ждем результат. В итоге мы узнаем уникальность проверяемого материала в процентном соотношении. Чем ближе этот показатель к 100%, тем, естественно, лучше.
Таких сервисов предостаточно (http://text. ru; http://content-watch.ru/text/; http://pr-cy.ru/unique/; http://plagiarisma.ru; http://istio.com; http://www.antiplagiat.ru и т.д.), правда не все из них бесплатные, а некоторые накладывают лимит на количество проверок с одного IP.
ru; http://content-watch.ru/text/; http://pr-cy.ru/unique/; http://plagiarisma.ru; http://istio.com; http://www.antiplagiat.ru и т.д.), правда не все из них бесплатные, а некоторые накладывают лимит на количество проверок с одного IP.
3. Использование специальных программ. Смысл заключается в том, что на компьютер устанавливается приложение, в котором и будет осуществляться проверка текстов на уникальность. Вполне достойный способ: нет необходимости открывать браузер, заходить на сайт и прочее.
Одними из наиболее известных и востребованными программами в Рунете являются:• Advego Plagiatus – абсолютно бесплатная, имеет интуитивно понятный интерфейс, предназначается исключительно для Windows.
• Etxt Антиплагиат – позволяет проверить все web-страницы сайта и вычислить «воров» (тех, кто копипастит материалы), подходит для Mac OS и Windows.
Отметим, что все представленные программы неидеальны. Одна покажет 96, другая — 100, а третья — вовсе 73 процента уникальности. Поэтому лучше проверять материалы сразу при помощи нескольких сервисов, чтобы получить более достоверный результат.
Поэтому лучше проверять материалы сразу при помощи нескольких сервисов, чтобы получить более достоверный результат.
Как влияет уникальность текста на позиции сайта
Привет, Друзья! В этой статье Вы узнаете, как влияет уникальность текста на позиции сайта и как поисковые роботы проверяют качество и уникальность контента. Итак поехали!
Уникальность текста
Под термином уникальность текста подразумевают значимое свойство информационного материала, которое обозначает размещение контента в интернете только один раз. Обычно такой контент создается специально под тематику сайта, на котором он будет опубликован.
Уникальный текст или статья создаются при помощи копирайтинга – написание оригинальных текстов определенной тематики. Для качественного SEO-продвижения ресурса стоит публиковать на нем только уникальные статьи и фотографии к ним. Все тексты проходят индексацию поисковыми роботами, которые определяют, был ли этот контент ранее опубликован на каком-либо сайте.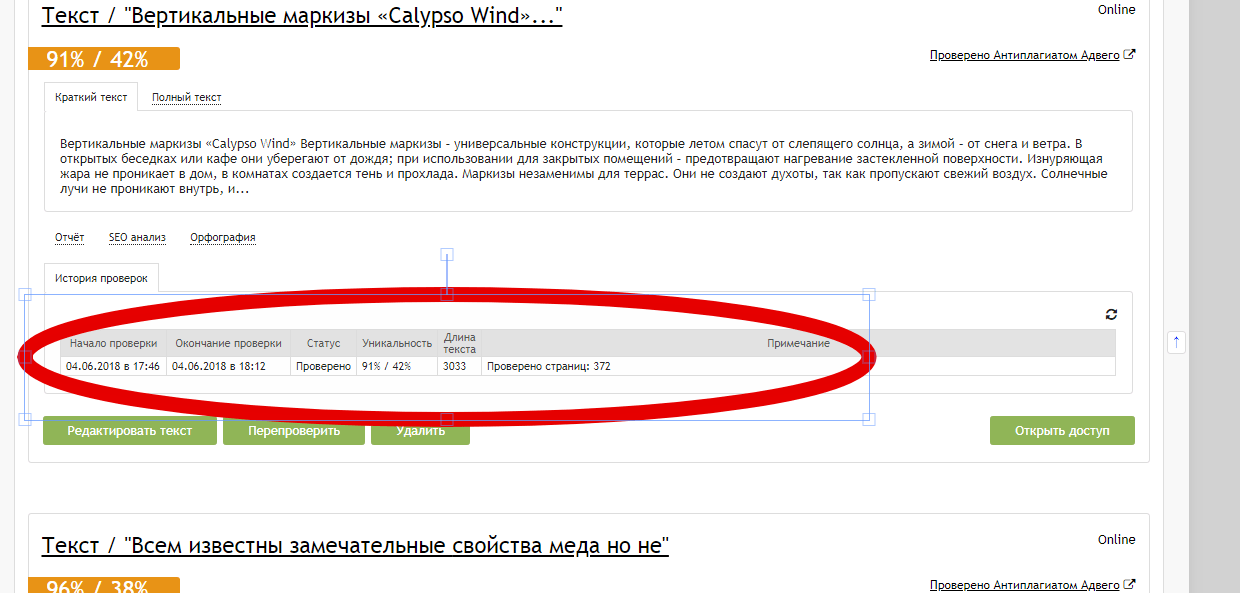 Сайты с уникальными текстами обычно находятся на вершине рейтинга при поисковом запросе.
Сайты с уникальными текстами обычно находятся на вершине рейтинга при поисковом запросе.
Как проверить уникальность текста для сайта
Как правило, уникальность текста измеряется в процентах. Если процент уникальности низкий, то текст был просто переделан из другой статьи, причем весьма плохо. В таком случае это уже рерайтинг, а не копирайтинг. На сегодняшний момент в интернете существует большое количество специализированных сайтов, сервисов и программ по определению уровня уникальности текстов, вот несколько из них, которыми лично я пользуюсь:
https://text.ru
https://content-watch.ru/text/
https://advego.com/plagiatus/
Проверить текст на уникальность на этих сайтах можно в режиме онлайн, что очень удобно. Также с сайта Адвего можно бесплатно скачать программу и установить на свой компьютер (только Windows) и делать это гораздо быстрее, чем в онлайн-режиме ожидая очередь.
Как проверяют уникальность текста поисковые роботы
Поисковые роботы в процессе индексации сайтов проверяют контент абсолютно всех сайтов на уникальность. Этой процедуры никак не избежать. Если в ходе данной проверки выясняется, что большая часть материалов или абсолютно все содержание сайта является плагиатом с других ресурсов, то поисковая система осуществляет пессимизацию сайта, то есть понижение его позиций при выдаче в поисковом запросе.
Этой процедуры никак не избежать. Если в ходе данной проверки выясняется, что большая часть материалов или абсолютно все содержание сайта является плагиатом с других ресурсов, то поисковая система осуществляет пессимизацию сайта, то есть понижение его позиций при выдаче в поисковом запросе.
Из вышесказанного следует то, что для эффективного продвижения сайта необходимо использовать только оригинальные тексты. Стоит оговориться, что уникальность текста является первостепенным критерием при ранжировании сайтов в рейтинге всех поисковых систем. Думаю теперь всем понятно, как влияет уникальность текста на позиции сайта, но есть и исключения из правил.
Почему не уникальные тексты занимают первые места
На сегодняшний момент Яндекс и Рамблер при поисковом запросе часто выдают в числе первых сайты с неоригинальным контентом, который был просто украден с других ресурсов. В процессе проверки уникальности текста программами используются определенные алгоритмы работы. Они подчиняются законам Зипфа, которые носят имя ученого. Джордж Зипф нашел последовательность частоты повторения слов в обычном тексте. Из этого анализа он сделал два вывода:
В процессе проверки уникальности текста программами используются определенные алгоритмы работы. Они подчиняются законам Зипфа, которые носят имя ученого. Джордж Зипф нашел последовательность частоты повторения слов в обычном тексте. Из этого анализа он сделал два вывода:
- Первый закон Зипфа говорит о том, что возможность применения какого-либо слова в тексте, помноженная на частоту его употребления, является неизменной величиной.
- Второй закон Зипфа говорит о том, что отношение частоты и числа слов, которые включены в текст с данной частотой, всегда одно и то же. Исходя из данных законов, поисковые системы распределяют содержание сайтов по группам.
В первую группу включают те элементы построения текстов, которые никак не влияют на их общий смысл. Это различные союзы и предлоги, не учитываемые при определении уникальности. Вторая группа включает ключевые слова, которые являются очень значимыми для посетителей. К третьей группе относятся случайные словосочетания.
Этот процесс распределения элементов текста получил название канонизация. После того как произошло деление на группы, поисковая система переходит к применению другого алгоритма. Он называется проверка по шинглам. При этом выполняется разделение ключевых фраз на связки по несколько слов, количество которых регламентируется величиной шингла. Причем крайнее слово в текущей связке используется в качестве первого слова в следующей связке. Благодаря этому происходит полная проверка уникальности текста.
При проверке этим алгоритмом для каждого шингла вычисляется определенная сумма, которая не может совпадать у разных текстов. Поэтому сравнение методом шинглов – это весьма достоверный способ проверить оригинальность текста. От суммы шинглов зависит процент уникальности. Если совпадений много, то текст будет менее уникальным. Такой метод определения помогает распознать как полностью ворованные тексты, так и частично заимствованные.
Не стоит забывать и о недостатках проверки текстов алгоритмом шинглов.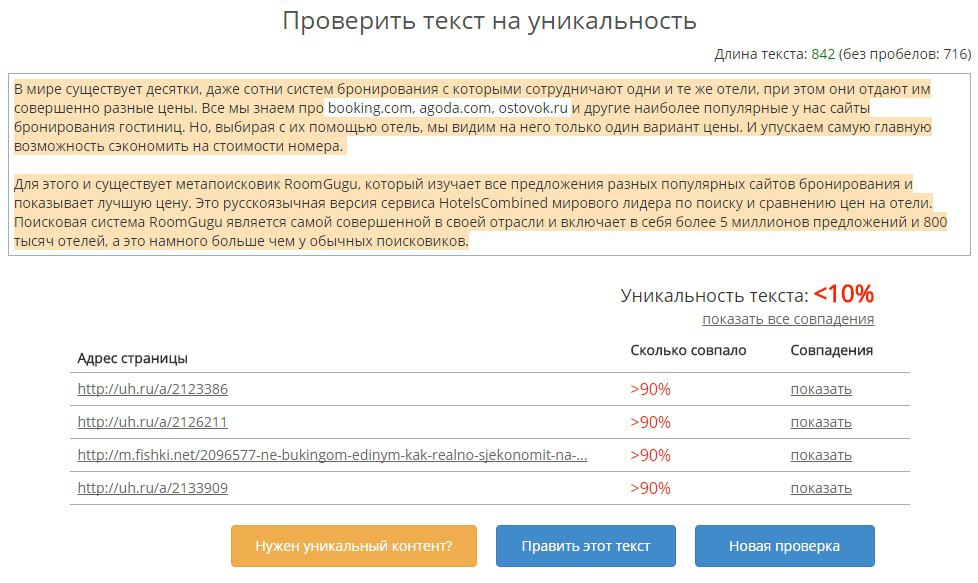 При использовании устойчивых выражений и цитировании процент уникальности может оказаться неоправданно низким.
При использовании устойчивых выражений и цитировании процент уникальности может оказаться неоправданно низким.
Уникальный контент можно получить в результате работы копирайтеров и рерайтеров. Копирайтеры пишут авторские статьи по заданной тематике. Рерайтеры перерабатывают чужой текст в целях его изменения и написания уникального текста, по сути, это пересказ содержания текста другими словами.
Обучение продвижению сайтов
Более подробно о том, как выводить сайты в ТОП 10 поисковых систем Яндекс и Google, я рассказываю на своих онлайн-уроках по SEO-оптимизации (смотри видео ниже). Все свои интернет-проекты я вывел на посещаемость более 1000 человек в сутки и могу научить этому Вас. Кому интересно обращайтесь!
На этом сегодня всё, всем удачи и до новых встреч!
как проверить и почему она важна для продвижения?
Важным качеством любого контента является уникальность, обозначающая, что этот контент в виде текста или картинки в интернете публикуется не только впервые, но и создавался исключительно для этой веб-страницы. Обычно уникальный контент – это результат копирайтинга. Наличие уникального контента считается важным ключевым моментом продвижения сайта, поскольку при индексации поисковые машины довольно точно определяют, использовался ли этот текст ранее или нет на других веб-ресурсах. Если нет, то это существенно поднимает рейтинг сайта.
Обычно уникальный контент – это результат копирайтинга. Наличие уникального контента считается важным ключевым моментом продвижения сайта, поскольку при индексации поисковые машины довольно точно определяют, использовался ли этот текст ранее или нет на других веб-ресурсах. Если нет, то это существенно поднимает рейтинг сайта.
Определение уникальности текста осуществляется в процентах. У низкокачественной переделки, плохого рерайтинга чаще низкий процент уникальности. Для определения уникальности статьи можно воспользоваться сервисами проверки уникальности, доступными на сегодня в интернете. Проверка текста на уникальность сегодня — неотъемлемая часть индексации при наполнении сайтов. Если поисковые машины при этом обнаруживают, что часть или все тексты, размещаемые на них, — копии с других ресурсов, то относительно страниц применяется пессимизация. Исходя из этих требований, уникальность текста признается обязательным условием успешного продвижения сайтов, но, к сожалению, такое утверждение больше применимо к западным поисковикам. А вот в топах выдачи Яндекс и Рамблер еще могут оказаться площадки с «заимствованным» контентом.
А вот в топах выдачи Яндекс и Рамблер еще могут оказаться площадки с «заимствованным» контентом.
Проверка уникальности текста происходит при помощи специальных алгоритмов, учитывающих законы Зипфа. Профессор-лингвист Джордж Кингсли Зипф еще в 1949 обратил внимание на эмпирические закономерности частоты слов, употребляемых в тексте, написанном естественно, на основании чего вывел два закона. В первом законе Зипфа указывалось, что производное вероятности присутствия в тексте какого-либо слова на частоту его использования будет постоянной константой. Во втором, что отношение между частотой и количеством слов, вхожих с этой частотой в текст, одинаковое.
Основываясь на этих законах, содержание страниц поисковыми системами разбивается на специальные группы. В первую входят междометия, союзы, предлоги, другие части предложений, не несущие смысловой нагрузки, и по этой причине не учитываемые. Во вторую – ключевые слова, особенно важные для ищущих информацию пользователей. Третью составляют случайные фразы. Деление текста по такому принципу называется его канонизацией. В завершении к тексту поисковыми системами применяется алгоритм шинглов (shingle – чешуйка). Суть данного метода состоит в разбиении на небольшие цепочки ключевых фраз, количество слов в цепочке определяется длиной шингла. Интересно, но каждое из последних слов цепочки является первым словом в следующем шингле, что позволяет достичь стопроцентной проверки текста.
Третью составляют случайные фразы. Деление текста по такому принципу называется его канонизацией. В завершении к тексту поисковыми системами применяется алгоритм шинглов (shingle – чешуйка). Суть данного метода состоит в разбиении на небольшие цепочки ключевых фраз, количество слов в цепочке определяется длиной шингла. Интересно, но каждое из последних слов цепочки является первым словом в следующем шингле, что позволяет достичь стопроцентной проверки текста.
Каждому шинглу соответствует своя определяемая контрольная сумма. Поэтому если тексты разные по своей уникальности, то и суммы не могут быть одинаковыми, а значит, сравнение шинглов помогает очень точно определить уникальность текста. Соответственно больший процент совпадений говорит о низкой уникальности. Точность данной проверки настолько высока, что можно найти полностью скопированные документы, или их частичные дубликаты. Но у алгоритма шинглов есть и недостатки. Так при анализе текста, содержащего популярные цитаты, фразеологизмы, его уникальность может оказаться низкой. По этой причине многие системы, обнаружив подобный контент, не применяют пессимизацию, воспринимая его всеобщим достоянием.
По этой причине многие системы, обнаружив подобный контент, не применяют пессимизацию, воспринимая его всеобщим достоянием.
Основными источниками уникального контента являются авторские статьи или тексты, выполненные сторонними специалистами – копирайтерами, рерайтерами. Деятельность копирайтеров имеет профессиональную основу, что позволяет им создавать презентационные, рекламные и обычные информационные тексты. В основе работы рерайтеров лежит создание уникального контента при помощи изменения информации синонимизацией, перестановкой между собой абзацев, перестройкой предложений, других способов, но с сохранением начального смысла. Проверку уникальности текста можно выполнять специальными сервисами. Как и в поисковых службах, в их работе для обнаружения дубликатов используются алгоритмы шинглов. В качестве примера таких систем выступает программа Advego Plagiatus и сервис Miratools.
Простой способ обнаружения повторяющегося содержимого
У всех поисковых систем, включая Google, есть проблемы с дублированием контента. Когда один и тот же текст отображается во многих местах в Интернете, поисковая система не может определить, какой удобный URL должен отображаться на страницах результатов поиска (SERP). Это может негативно повлиять на рейтинг веб-страницы. Проблема только усугубляется, когда на измененные версии контента связаны ссылки. В этой статье мы поможем вам понять некоторые причины, по которым существует дублированный контент, и поможем решить проблему.
Если вы стоите на перекрестке и несколько дорожных знаков указывают разные направления к одному и тому же месту назначения, вы не будете знать, в каком направлении двигаться. Если к тому же конечные пункты назначения даже немного отличаются, проблема еще больше. Как веб-пользователю, вам все равно, потому что вы найдете нужный контент, но веб-поисковой системе необходимо выбрать, какая страница должна отображаться в своих результатах, потому что она не хочет отображать одно и то же содержимое более одного раза.
Найти веб-страницы с повторяющимся содержанием
Проведите аудит своего веб-сайта, чтобы определить, на каких страницах есть дублированный контент, замените его и получите больше трафика
Предположим, что статья о ключевом слове А отображается на http://www.website.com/keyword-a/, но то же содержание отображается и на http: // www. website.com/category/keyword-a/. Этот сценарий на самом деле часто встречается в CMS. Если эту статью распространяют многочисленные блоггеры, но некоторые из них ссылаются на URL 1, а остальные ссылаются на URL 2, проблема поисковой системы теперь становится вашей проблемой, поскольку каждая ссылка теперь продвигает разные URL.В результате этого разделения маловероятно, что вы сможете ранжироваться по ключевому слову А, и было бы намного лучше, если бы все ссылки указывали на один и тот же URL.
Как использовать средство проверки дублированного контента Google и другие поисковые системы определяют уникальный контент как основной фактор ранжирования. Использовать средство проверки дублированного контента веб-сайта для выявления внутренних дубликатов для всего веб-сайта очень просто. Фактически, это необходимый шаг при проведении SEO-оптимизации веб-сайта, потому что Google и другие поисковые системы любят уникальный контент, который приносит пользу читателям.Дублирующиеся метатеги могут привести к наказанию веб-сайта, обновлению Google Panda, что означает, что ваш сайт не будет отображаться в поисковой выдаче и разрушит ваши усилия по поисковой оптимизации.
Использовать средство проверки дублированного контента веб-сайта для выявления внутренних дубликатов для всего веб-сайта очень просто. Фактически, это необходимый шаг при проведении SEO-оптимизации веб-сайта, потому что Google и другие поисковые системы любят уникальный контент, который приносит пользу читателям.Дублирующиеся метатеги могут привести к наказанию веб-сайта, обновлению Google Panda, что означает, что ваш сайт не будет отображаться в поисковой выдаче и разрушит ваши усилия по поисковой оптимизации.
При обнаружении на сайте дублированного контента высока вероятность того, что Google применит санкции. Что может случиться? В большинстве случаев владельцы веб-сайтов могут пострадать от потери трафика. Это происходит из-за того, что Google перестает индексировать вашу страницу, на которой обнаружен плагиат.Когда дело доходит до определения приоритетов, какая страница имеет большую ценность для пользователя, Google имеет право выбирать, какая страница веб-сайта с наибольшей вероятностью попадет в поисковую выдачу. Поэтому некоторые сайты перестают быть видимыми для пользователей. В сложных случаях Google может наложить штраф за дублирование контента. Таким образом вы получите уведомление DMCA, что означает, что вас подозревают в манипулировании результатами поиска и нарушении авторских прав.
Поэтому некоторые сайты перестают быть видимыми для пользователей. В сложных случаях Google может наложить штраф за дублирование контента. Таким образом вы получите уведомление DMCA, что означает, что вас подозревают в манипулировании результатами поиска и нарушении авторских прав.
Есть множество причин, по которым вам нужен уникальный контент на вашем веб-сайте.Но дубликаты существуют, и причины в основном технические. Люди не часто хранят один и тот же контент более чем в одном месте, не убедившись, что ясно, какой из них является оригинальным. Технические причины в основном возникают из-за того, что разработчики думают не так, как браузеры или даже пользователи, не говоря уже о роботах поисковых систем. В приведенном выше примере разработчик увидит, что статья существует только один раз.
URL-адреса неправильно поняты Разработчики не сумасшедшие, но они смотрят на вещи с другой точки зрения.CMS, на которой работает веб-сайт, будет иметь только одну статью в базе данных, но программное обеспечение сайта позволяет восстанавливать одну и ту же статью по более чем одному URL-адресу. С точки зрения разработчика, уникальный идентификатор статьи — это не URL, а идентификатор статьи в базе данных. Однако поисковая система рассматривает URL как уникальный идентификатор любого текста. Если это объяснить разработчикам, они поймут проблему. В этой статье также будут представлены решения этой проблемы.
С точки зрения разработчика, уникальный идентификатор статьи — это не URL, а идентификатор статьи в базе данных. Однако поисковая система рассматривает URL как уникальный идентификатор любого текста. Если это объяснить разработчикам, они поймут проблему. В этой статье также будут представлены решения этой проблемы.
Веб-сайты электронной коммерции следят за посетителями и позволяют им добавлять товары в корзину.Это достигается за счет предоставления каждому пользователю «сеанса». Это краткая история действий посетителя на сайте, которая может включать такие вещи, как товары в корзине покупок. Чтобы сохранить сеанс, когда посетитель перемещается между страницами, идентификаторы сеанса должны быть где-то сохранены. Чаще всего это делается с помощью файлов cookie. Однако поисковые системы не хранят файлы cookie.
Некоторые системы добавляют идентификаторы сеанса к URL-адресу, в результате чего внутренние ссылки в HTML на сайте получают идентификатор сеанса, добавленный к URL-адресу. Поскольку идентификаторы сеанса уникальны для сеанса, создаются новые URL-адреса, что приводит к дублированию контента.
Поскольку идентификаторы сеанса уникальны для сеанса, создаются новые URL-адреса, что приводит к дублированию контента.
Дублированный контент также создается при использовании параметров URL, например в отслеживающих ссылках, но содержание страницы не изменяется. Поисковые системы видят http://www.website.com/keyword-a/ и http: // www. website.com/keyword-a/?source=facebook как разные URL-адреса. Хотя последнее поможет вам отслеживать, откуда пришли пользователи, тем не менее, это может затруднить высокий рейтинг вашей страницы, а это не то, что вам нужно!
То же самое относится ко всем остальным типам параметров, добавляемых к URL-адресам, содержимое которых не изменяется.Другими примерами параметров могут быть изменение порядка сортировки или отображение другой боковой панели.
Синдикация контента и парсинг Дублированный контент чаще всего возникает из-за вашего веб-сайта или Google. Бывает, что другие веб-сайты очищают контент с вашего сайта, не ссылаясь на исходную статью. В таких случаях поисковые системы не знают об этом и рассматривают это так, как будто это просто новая версия статьи. Чем больше популярных сайтов, тем больше парсеров используют их контент, что просто усугубляет проблему.
Бывает, что другие веб-сайты очищают контент с вашего сайта, не ссылаясь на исходную статью. В таких случаях поисковые системы не знают об этом и рассматривают это так, как будто это просто новая версия статьи. Чем больше популярных сайтов, тем больше парсеров используют их контент, что просто усугубляет проблему.
обычно не используют прямые URL-адреса, а используют URL-адреса вида /? Id = 4 & cat = 6, где ID — это номер статьи, а cat — номер категории. URL /? Cat = 6 & id = 4 будет отображать одинаковый результат на большинстве веб-сайтов, но не для поисковых систем. Легко узнать, что это за сайт, с помощью Sitechecker.
Пагинация комментарияВ WordPress и других системах можно разбивать комментарии на страницы.В результате контент дублируется по URL-адресу статьи, URL-адресу статьи & / comment-page-x и т. Д.
Страницы, удобные для печати Если созданы страницы, удобные для печати, и на них есть ссылки со страниц статей, поисковые системы обычно выбирают их, если они специально не заблокированы. Затем Google должен решить, какую версию показывать — ту, которая показывает только статью, или версию с периферийным контентом и рекламой.
Затем Google должен решить, какую версию показывать — ту, которая показывает только статью, или версию с периферийным контентом и рекламой.
Хотя этот существует уже много лет, поисковые системы все же иногда делают ошибки. Если обе версии веб-сайта доступны, это создает проблемы с дублированием контента. Похожая проблема, которая возникает, хотя и не так часто, — это https и http URL-адреса, содержащие одинаковые тексты. Поэтому, когда вы планируете свою стратегию SEO, вы всегда должны учитывать этот вопрос.
C
анонические URL-адреса — потенциальное решениеХотя несколько URL-адресов могут указывать на один и тот же фрагмент текста, эту проблему легко решить.Для этого один человек в организации должен без тени сомнения определить, каким должен быть «правильный» URL для части контента. Поисковые системы знают «правильный» URL фрагмента контента как канонический URL.
Поиск проблем с дублирующимся контентом Если вы не уверены, есть ли у вас проблемы с дублированием содержания на вашем веб-сайте, есть несколько способов выяснить это.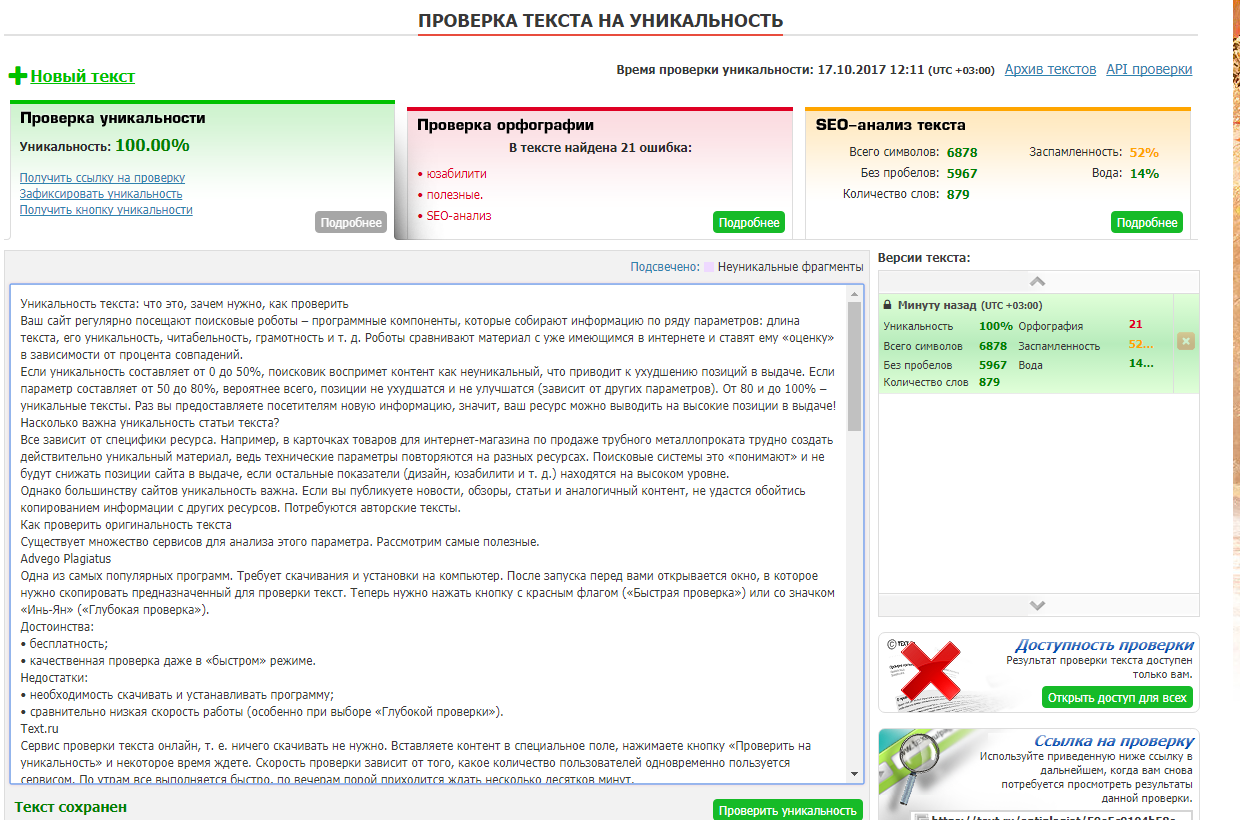 Будьте в курсе любых изменений контента на вашем веб-сайте, потому что это может повредить процессу оптимизации страницы.
Будьте в курсе любых изменений контента на вашем веб-сайте, потому что это может повредить процессу оптимизации страницы.
Страницы с повторяющимися описаниями или заголовками не подходят. При нажатии на них в инструменте будут отображены соответствующие URL-адреса, что поможет вам определить проблему. Если вы, например, написали статью по ключевому слову a, но она отображается в нескольких категориях, их заголовки могут отличаться. Это может быть «Ключевое слово А — Категория Y — Веб-сайт» и «Ключевое слово А — Категория Z — Веб-сайт». Google не увидит в них повторяющиеся заголовки, но вы сможете определить их, если выполните поиск.
Поиск фрагментов или заголовковВ таких случаях вы можете использовать несколько полезных поисковых операторов. Если вам нужно идентифицировать все URL-адреса на сайте с помощью ключевого слова A article, используйте следующую строку в Google:
site: website. com intitle: ”Keyword A”
com intitle: ”Keyword A”
Google отобразит все страницы в пределах website.com, у которых есть ключевое слово A в заголовке. Если вы очень специфичны с intitle, будет легко идентифицировать дубликаты.Тот же метод можно использовать для поиска плагиата в Интернете. Если полное название статьи — «Ключевое слово А — отличное», можно выполнить поиск следующим образом:
intitle: «Ключевое слово A отлично»
По этому запросу Google покажет все страницы, соответствующие названию. Также стоит поискать несколько целых предложений из статьи, так как парсеры могут изменить заголовок. Google иногда показывает уведомление под результатами, в котором говорится, что некоторые похожие результаты были упущены.Это показывает, что Google «устраняет дублирование» результатов, но, поскольку это все еще не очень хорошо, нажмите на ссылку и просмотрите полные результаты, чтобы определить, можно ли исправить какие-либо из них.
Но всегда есть самый быстрый способ обнаружить, если кто-то дублирует ваш контент.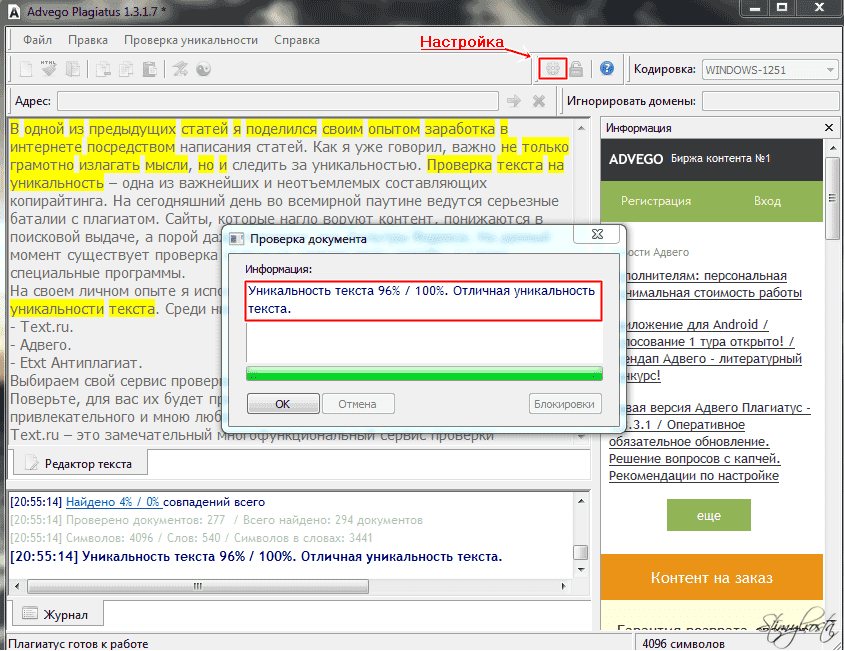 Вы можете использовать средство проверки дублированного контента и быстро получать ответы на самые волнующие вопросы. Такие инструменты могут помочь вам проверить дублирующийся контент на страницах вашего веб-сайта и выставить вам соответствующую оценку. Используйте его, чтобы найти внутренние и внешние источники, которые дублируют контент вашего сайта.Поскольку поисковые системы предпочитают уникальный и ценный для пользователей текст, для SEO важно не допускать кражи целых статей или их частей с веб-страниц. Проверка дубликатов находит текст, который повторяется на других страницах. В большинстве случаев он работает как средство проверки на плагиат SEO и сравнивает контент на вашей странице со всеми сайтами, с которыми совпадают отдельные фразы и слова. Они могут выполнять все описанные выше функции, но быстрее.
Вы можете использовать средство проверки дублированного контента и быстро получать ответы на самые волнующие вопросы. Такие инструменты могут помочь вам проверить дублирующийся контент на страницах вашего веб-сайта и выставить вам соответствующую оценку. Используйте его, чтобы найти внутренние и внешние источники, которые дублируют контент вашего сайта.Поскольку поисковые системы предпочитают уникальный и ценный для пользователей текст, для SEO важно не допускать кражи целых статей или их частей с веб-страниц. Проверка дубликатов находит текст, который повторяется на других страницах. В большинстве случаев он работает как средство проверки на плагиат SEO и сравнивает контент на вашей странице со всеми сайтами, с которыми совпадают отдельные фразы и слова. Они могут выполнять все описанные выше функции, но быстрее.
Как только вы узнаете, какой URL-адрес следует использовать в качестве канонического URL-адреса для определенного контента, начните канонизировать свой сайт. Это означает, что поисковые системы узнают, какая версия страницы является канонической, и позволяют им находить ее как можно быстрее. Есть несколько методов решения проблемы:
- Не создавайте дублированный контент.
- Используйте канонический URL для похожих текстов.
- Добавить канонические ссылки на все повторяющиеся страницы.
- Добавьте HTML-ссылки со всех повторяющихся страниц на каноническую страницу.
Различные причины дублирования контента, упомянутые выше, могут быть легко устранены:
- Отключенные идентификаторы сеанса в URL-адресе в системных настройках.
- Страницы, удобные для печати, не нужны, и следует использовать таблицы стилей печати.
- Параметры разбивки на страницы комментариев должны быть отключены.
- Параметры всегда следует заказывать в одной и той же последовательности.
- Чтобы избежать проблем со ссылками отслеживания, используйте отслеживание на основе хэштегов, а не параметров.

- Либо использовать WWW, либо нет, но придерживаться одного и перенаправлять на него другой.

Если проблему нелегко исправить, все равно, возможно, стоит это сделать.Однако конечной целью должно быть полное предотвращение дублирования контента.
Перенаправить похожие страницы на канонический URLМожет быть невозможно полностью предотвратить создание вашей системой неправильного URL-адреса, но вы все равно можете перенаправить их. Если вам удастся исправить некоторые проблемы с дублированием контента, убедитесь, что URL-адреса для старого дублированного контента перенаправлены на правильные канонические URL-адреса.
Добавить каноническую ссылку на все повторяющиеся страницыИногда невозможно удалить повторяющиеся версии статьи, даже если используется неправильный URL.Элемент канонической ссылки был введен поисковыми системами для решения этой проблемы. Элемент помещается в раздел сайта так:
com/correct_article/" />
Поместите канонический URL статьи в раздел href. Поисковые системы, поддерживающие канонический элемент, будут выполнять мягкую переадресацию 301, перемещая большую часть значения ссылки для страницы на каноническую страницу.
Если возможно, нормальное перенаправление 301 все же лучше, так как оно быстрее.
Добавить HTML-ссылку со всех повторяющихся страниц на каноническуюЕсли ни одно из вышеперечисленных решений невозможно, вы можете добавить ссылки на исходную статью ниже или выше дублирующей статьи. Вы также можете реализовать это в RSS-потоке, вставив ссылку на свою исходную статью. Хотя некоторые парсеры могут отфильтровать ссылку, другие могут оставить ее как есть. Если Google обнаружит несколько ссылок, указывающих на исходную статью, он будет считать, что это каноническая версия.
Повторяющаяся проблема может вызвать серьезные проблемы. В зависимости от структуры ваших страниц пагинации весьма вероятно, что некоторые страницы могут содержать похожее или идентичное содержание. В дополнение к этому вы часто обнаруживаете, что у вас на сайте одинаковые теги title и meta description. В этом случае дублированный контент может вызвать трудности у поисковых систем, когда придет время определить наиболее релевантные страницы для определенного поискового запроса.
В дополнение к этому вы часто обнаруживаете, что у вас на сайте одинаковые теги title и meta description. В этом случае дублированный контент может вызвать трудности у поисковых систем, когда придет время определить наиболее релевантные страницы для определенного поискового запроса.
Вы можете удалить нумерацию страниц из индекса с помощью тега noindex.В большинстве случаев этот метод является приоритетным и реализуется максимально быстро. Суть его в том, чтобы исключить из индекса все страницы пагинации, кроме первой.
Реализован следующим образом: такой метатег
добавлен разделом
на всех страницах, кроме первой. Таким образом, мы исключаем из индекса все страницы пагинации, кроме главной страницы каталога, и при этом обеспечиваем индексацию всех страниц, которые принадлежат этому каталогу. Наталия ФиалковскаяSEO специалист
Наталия — SEO-эксперт Sitechecker. Она отвечает за блог. Невозможно жить без создания ценного контента о SEO и цифровом маркетинге.
Она отвечает за блог. Невозможно жить без создания ценного контента о SEO и цифровом маркетинге.
Как использовать Copyscape для проверки дублированного содержимого
После обновления Panda в феврале 2011 года маркетологи во всем мире опасаются дублирования контента и обеспечения уникальности своего контента, чтобы предотвратить возможное наказание Google.
Google определяет повторяющийся контент как:
Дублированный контент обычно относится к основным блокам контента внутри или между доменами, которые либо полностью соответствуют другому контенту, либо в значительной степени похожи.> С форума Инструментов Google для веб-мастеров
Ключевым элементом для всех, кто занимается интернет-маркетингом, являются «основные блоки контента». Если у вас есть шаблонное предложение внизу каждой страницы вашего продукта, содержащее вашу политику доставки, вам не нужно беспокоиться о наказании за дублирование контента.
Однако среди нас есть воры контента !!
Панда наказала «парсеров», которые брали большие блоки текста с разных сайтов, добавляли их на свой сайт и заявляли, что это их собственный уникальный контент. Но в мире, где каждый может ссылаться на кого угодно, и нет формальных ограничений на использование чьего-либо контента на своем сайте, как же маркетологам не отставать?
Но в мире, где каждый может ссылаться на кого угодно, и нет формальных ограничений на использование чьего-либо контента на своем сайте, как же маркетологам не отставать?
Copyscape спешит на помощь
Copyscape — это инструмент, который позволяет вам ввести свой URL-адрес и сканировать Интернет в поисках других сайтов, содержащих тот же язык. По сути, этот инструмент позволяет вам проверять контент на вашем сайте и убедиться, что кто-то не копирует его слово в слово. Теперь пока Copyscape не новый инструмент.это тот, который по-прежнему актуален в мире контент-маркетинга и непрерывного создания контента.
Это руководство покажет вам, как использовать Copyscape, чтобы проверить ваш сайт и убедиться, что никто не копирует ваш контент.
Как использовать Copyscape
Теперь это немного очевидно, но вам нужно посетить http://www.copyscape.com
Оказавшись там, вы можете посмотреть вступительное видео, но, поскольку этот инструмент очень прост в использовании, нет необходимости смотреть это видео. Теперь, чтобы начать, введите URL-адрес, который вы хотите проверить, в поле поиска. Для этого урока я собираюсь использовать нашу / seo-blog / page.
За считанные секунды Copyscape просканирует Интернет на наличие экземпляров вашего контента, и если они что-нибудь найдут, вы найдете это вверху страницы. Если ваш контент уникален, и никто не копирует контент, который вы усердно пытались получить, вы должны увидеть страницу, которая выглядит так.
Если вы видите это, удачно, вы можете перейти на другой URL-адрес.Если у вас есть результат, то есть кто-то копирует ваш контент, вы можете посетить этот сайт, связаться с владельцем сайта и попросить его удалить контент.
Интересно посмотреть, как это выглядит, если кто-то ворует ваш контент ?? Вот один из наших сайтов разработки, который является зеркалом нашей домашней страницы. Мы открыли его для этого эксперимента. Теперь давайте надеяться, что вы никогда не увидите эту страницу!
Вот и все. Получайте удовольствие от использования Copyscape.
Если вы находитесь на другой стороне медали и у вас возникают проблемы с созданием уникального контента, вы можете обратиться к нам в Web Talent, где у нас есть команда копирайтеров, которые все используют разные голоса, стили письма и сложность письма, чтобы соответствовать вашему фирменный голос.
Как проверить повторяющееся содержимое
Как найти повторяющееся содержимое
Следует минимизировать повторяющийся контент на веб-сайте, поскольку это может затруднить поисковым системам решение, какую версию ранжировать по запросу.
В то время как «штраф за дублирование контента» является мифом в SEO, очень похожий контент может вызвать неэффективность сканирования, снизить рейтинг PageRank и быть признаком того, что контент может быть объединен, удален или улучшен.
Следует помнить, что повторяющееся и похожее содержание является естественной частью Интернета, что часто не является проблемой для поисковых систем, которые намеренно канонизируют URL-адреса и фильтруют их там, где это необходимо.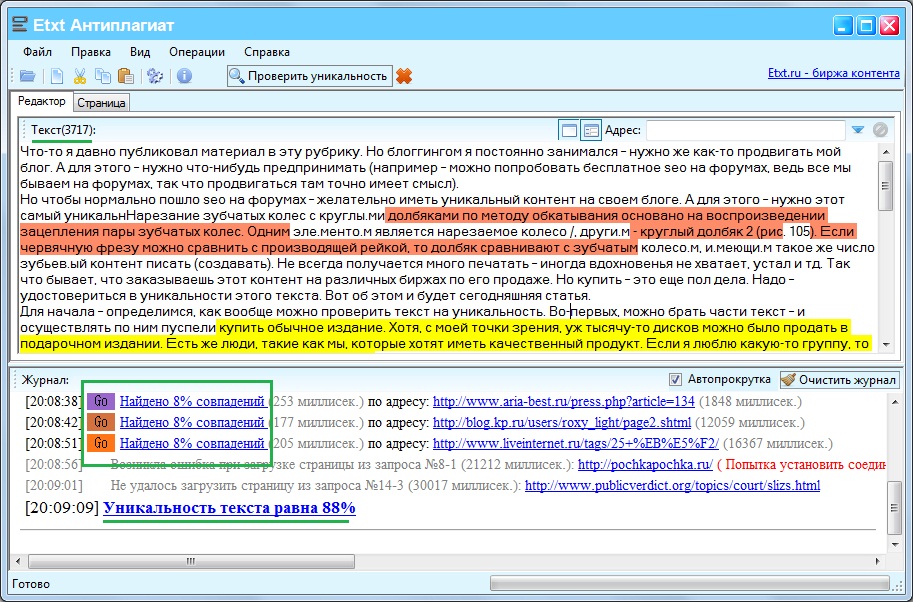 Однако в масштабе это может быть более проблематично.
Однако в масштабе это может быть более проблематично.
Предотвращение дублирования контента позволяет вам контролировать индексирование и ранжирование, а не оставлять это поисковым системам. Вы можете ограничить трату краулингового бюджета и объединить сигналы индексации и ссылок, чтобы помочь в ранжировании.
Из этого туториала Вы узнаете, как использовать Screaming Frog SEO Spider для поиска как точного дублированного контента, так и почти дублированного контента, где некоторый текст совпадает между страницами веб-сайта.
Дублированный контент, обнаруживаемый любым инструментом, включая SEO Spider, необходимо анализировать в контексте. Посмотрите наше видео или продолжайте читать наше руководство ниже.
Для начала загрузите SEO Spider, который можно бесплатно сканировать до 500 URL.Первые 2 шага доступны только при наличии лицензии. Если вы бесплатный пользователь, перейдите к пункту 3 в руководстве.
1) Включите «Рядом с дубликатами» через «Конфигурация> Контент> Дубликаты»
По умолчанию SEO Spider автоматически определяет точные дубликаты страниц. Однако для определения «близких к дубликатам» необходимо включить конфигурацию, которая позволяет сохранять содержимое каждой страницы.
SEO Spider идентифицирует близкие к дубликаты с совпадением сходства 90%, которое можно настроить для поиска контента с более низким порогом сходства.
SEO Spider также будет проверять только «индексируемые» страницы на наличие дубликатов (как на точные, так и на близкие).
Это означает, что если у вас есть два одинаковых URL, но один из них канонизирован для другого (и, следовательно, «не индексируется»), об этом не будет сообщаться — если этот параметр не отключен.
Если вы хотите найти проблемы с бюджетом сканирования, снимите флажок «Проверять только индексируемые страницы на наличие дубликатов», так как это может помочь найти области, в которых могут возникнуть ненужные затраты.
2) Настройте «Content Area» для анализа с помощью «Config> Content> Area»
Вы можете настроить контент, который будет использоваться для анализа почти дублированных материалов. Для нового сканирования мы рекомендуем использовать настройку по умолчанию и уточнять ее позже, когда контент, используемый в анализе, можно будет увидеть и рассмотреть.
SEO Spider автоматически исключает элементы навигации и нижнего колонтитула, чтобы сосредоточиться на основном содержании. Однако не каждый веб-сайт построен с использованием этих элементов HTML5, поэтому при необходимости вы можете уточнить область содержания, используемую для анализа.Вы можете выбрать «включить» или «исключить» HTML-теги, классы и идентификаторы в анализе.
Например, на веб-сайте Screaming Frog есть мобильное меню вне элемента навигации, которое по умолчанию включено в анализ контента. Хотя это не такая уж большая проблема, в данном случае, чтобы сосредоточиться на основном тексте страницы, имя класса «mobile-menu__dropdown» можно ввести в поле «Исключить классы».
Это исключит включение меню в алгоритм анализа дублированного контента.Подробнее об этом позже.
3) Сканирование веб-сайта
Откройте SEO Spider, введите или скопируйте веб-сайт, который вы хотите сканировать, в поле «Введите URL-адрес для паука» и нажмите «Начать».
Подождите, пока сканирование не завершится и не достигнет 100%, но вы также можете просмотреть некоторые детали в режиме реального времени.
4) Просмотр дубликатов на вкладке «Содержание»
На вкладке «Контент» есть 2 фильтра, связанных с повторяющимся содержанием: «точные дубликаты» и «почти дублированные».
Только «точные дубликаты» доступны для просмотра в режиме реального времени во время сканирования.«Почти повторяющиеся» требуют вычисления в конце сканирования с помощью публикации «Анализ сканирования» для заполнения данными.
На правой панели «Обзор» отображается сообщение «(Требуется анализ сканирования)» напротив фильтров, которые требуют заполнения данных после анализа сканирования.
5) Нажмите «Анализ сканирования> Начать», чтобы заполнить фильтр «Почти повторяющиеся»
Для заполнения фильтра «Почти повторяющиеся совпадения», «Ближайшее совпадение по сходству» и «Нет. Столбцы рядом с дубликатами, вам просто нужно нажать кнопку в конце сканирования.
Однако, если вы ранее настроили «Анализ сканирования», вы можете захотеть дважды проверить в разделе «Анализ сканирования> Настроить», что отмечен «Почти повторяющиеся».
Вы также можете снять отметки с других элементов, которые также требуют анализа после обхода контента, чтобы ускорить этот шаг.
Когда анализ сканирования будет завершен, индикатор выполнения «анализа» будет на 100%, и фильтры больше не будут отображать сообщение «(Требуется анализ сканирования)».
Теперь вы можете просмотреть заполненный почти повторяющийся фильтр и столбцы.
6) Просмотр вкладки «Содержание» и фильтров «Точное» и «Рядом» дубликатов
После выполнения анализа после сканирования, фильтр «Почти повторяющиеся», «Ближайшее совпадение по сходству» и «Нет. Столбцы рядом с дубликатами будут заполнены. Только URL-адреса с содержанием, превышающим выбранный порог схожести, будут содержать данные, остальные останутся пустыми. В этом случае на сайте Screaming Frog их всего два.
Столбцы рядом с дубликатами будут заполнены. Только URL-адреса с содержанием, превышающим выбранный порог схожести, будут содержать данные, остальные останутся пустыми. В этом случае на сайте Screaming Frog их всего два.
Сканирование более крупного веб-сайта, такого как BBC, откроет гораздо больше.
Вы можете фильтровать по следующему параметру —
- Точные дубликаты — Этот фильтр будет показывать идентичные друг другу страницы с использованием алгоритма MD5, который вычисляет значение «хеш-функции» для каждой страницы и отображается в столбце «Хеш». Эта проверка выполняется в отношении полного HTML-кода страницы. Он покажет все страницы с совпадающими хэш-значениями, которые абсолютно одинаковы. Точные повторяющиеся страницы могут привести к разделению сигналов PageRank и непредсказуемости ранжирования.Должна существовать только одна каноническая версия URL-адреса, на которую имеется внутренняя ссылка. Другие версии не должны быть связаны, и они должны быть 301 перенаправлены на каноническую версию.
- Near Duplicates — этот фильтр будет показывать похожие страницы на основе настроенного порога сходства с использованием алгоритма minhash. Пороговое значение можно настроить в разделе «Конфигурация> Паук> Контент» и по умолчанию установлено значение 90%. В столбце «Самое близкое совпадение» отображается самый высокий процент сходства с другой страницей.Нет. В столбце «Рядом с дубликатами» отображается количество страниц, похожих на страницу, на основании порогового значения схожести. Алгоритм работает с текстом на странице, а не с полным HTML, как с точными дубликатами. Контент, используемый для этого анализа, можно настроить в «Конфигурация> Контент> Область». Страницы могут иметь стопроцентное сходство, но только «почти дубликат», а не точный дубликат. Это связано с тем, что точные дубликаты исключаются как близкие к дубликатам, чтобы они не помечались дважды.Оценки схожести также округляются, поэтому 99,5% или выше будут отображаться как 100%.
Почти повторяющиеся страницы следует проверять вручную, так как есть много законных причин, по которым некоторые страницы очень похожи по содержанию, например, варианты продуктов, объем поиска которых определяется их конкретным атрибутом.
Однако URL-адреса, помеченные как почти повторяющиеся, должны быть проверены, чтобы решить, должны ли они существовать как отдельные страницы из-за их уникальной ценности для пользователя, или их следует удалить, объединить или улучшить, чтобы сделать контент более глубоким и уникальным .
7) Просмотрите повторяющиеся URL-адреса с помощью вкладки «Повторяющиеся сведения»
Для «точных дубликатов» проще просто просмотреть их в верхнем окне с помощью фильтра, поскольку они сгруппированы вместе и имеют одно и то же значение «хеш-функции».
На приведенном выше снимке экрана каждый URL имеет соответствующий точный дубликат из-за версии с косой чертой в конце и без косой черты.
Для «почти повторяющихся» щелкните вкладку «Duplicate Details» внизу, которая заполняет нижнюю панель окна «почти повторяющимся адресом» и схожестью каждого обнаруженного почти повторяющегося URL-адреса.
Например, если для URL-адреса в верхнем окне обнаружено 4 почти дубликата, их все можно просмотреть.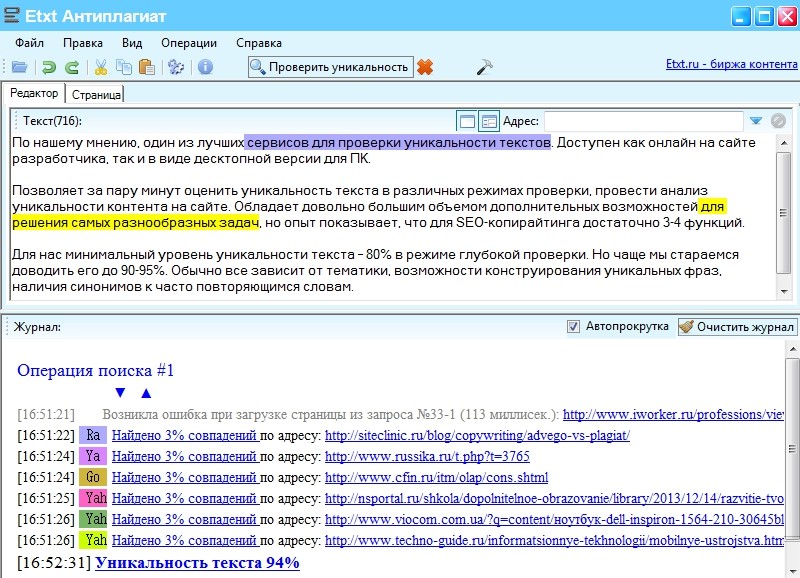
В правой части вкладки «Повторяющиеся сведения» будут отображаться почти повторяющиеся данные, обнаруженные на страницах, и выделены различия между страницами, когда вы нажимаете на каждый «почти повторяющийся адрес».
Если на вкладке повторяющихся сведений есть дублированный контент, который вы не хотите участвовать в анализе дублированного контента, исключите или включите любые HTML-элементы, классы или идентификаторы (как выделено в пункте 2) и повторно запустите сканирование. анализ.
8) Массовый экспорт дубликатов
Как точные, так и почти повторяющиеся дубликаты можно экспортировать массово с помощью экспорта «Групповой экспорт> Контент> Точные дубликаты» и «Почти дубликаты».
Последний совет! Уточните порог схожести и область содержимого и повторно запустите анализ сканирования
После сканирования вы можете настроить как порог схожести, близкого к дублированию, так и область содержимого, используемую для анализа почти дублированного контента.
Затем вы можете повторно запустить анализ сканирования снова, чтобы найти более или менее похожий контент — без повторного сканирования веб-сайта.
Как отмечалось ранее, на веб-сайте Screaming Frog есть мобильное меню вне элемента навигации, которое по умолчанию включено в анализ контента. Мобильное меню можно увидеть в предварительном просмотре содержимого вкладки «повторяющиеся сведения».
Если исключить «mobile-menu__dropdown» в поле «Exclude Classes» в «Config> Content> Area», мобильное меню будет удалено из предварительного просмотра контента и анализа почти дублирующихся элементов.
Это действительно может помочь при точной настройке идентификации почти дублированного содержимого в основных областях содержимого без необходимости повторного сканирования.
Сводка
В приведенном выше руководстве должно быть показано, как использовать SEO Spider в качестве средства проверки дублированного контента на вашем веб-сайте. Для получения наиболее точных результатов уточните область содержимого для анализа и настройте порог для разных групп страниц.
Пожалуйста, ознакомьтесь также с ответами на часто задаваемые вопросы о Screaming Frog SEO Spider и полным руководством пользователя для получения дополнительной информации об этом инструменте.
Если у вас есть дополнительные вопросы, отзывы или предложения по улучшению инструмента дублирования контента в SEO Spider, просто свяжитесь с нами через службу поддержки.
Как читать исходный код вашего веб-сайта и почему это важно
Под всеми красивыми изображениями, безупречной типографикой и чудесно размещенными призывами к действию скрывается исходный код вашей веб-страницы. Это код, который ваш браузер ежедневно превращает в приятные впечатления для ваших посетителей и клиентов.
Google и другие поисковые системы «читают» этот код, чтобы определить, где ваши веб-страницы должны появиться в их индексах для данного поискового запроса.Итак, большая часть SEO сводится к тому, что находится в вашем исходном коде .
Это краткое руководство, которое покажет вам, как читать исходный код вашего собственного веб-сайта, чтобы убедиться, что он правильно настроен для SEO, и, действительно, научит вас, как правильно проверять свои усилия по SEO. Я также рассмотрю несколько других ситуаций, когда знание того, как просматривать и исследовать правильные части исходного кода, может помочь в других маркетинговых усилиях.
Наконец, если вы платите кому-то за оптимизацию своего сайта, это отличное руководство, которое поможет вам следить за ними!
Как просмотреть исходный код
Первым шагом в проверке исходного кода вашего веб-сайта является просмотр фактического кода.Каждый веб-браузер позволяет легко это сделать. Ниже приведены команды клавиатуры для просмотра исходного кода веб-страницы как для ПК, так и для Mac.
ПК
- Firefox — CTRL + U (Это означает, что нажмите клавишу CTRL на клавиатуре и удерживайте ее. Удерживая клавишу CTRL, нажмите клавишу «u». ) Кроме того, вы можете перейти в меню «Firefox» и затем нажмите «Веб-разработчик», а затем «Источник страницы».
- Internet Explorer — CTRL + U.Или щелкните правой кнопкой мыши и выберите «Просмотреть источник».
- Chrome — CTRL + U. Или вы можете нажать на странную клавишу с тремя горизонтальными линиями в правом верхнем углу. Затем нажмите «Инструменты» и выберите «Просмотреть исходный код».
- Opera — CTRL + U. Вы также можете щелкнуть веб-страницу правой кнопкой мыши и выбрать «Просмотреть исходный код страницы».
Mac
- Safari — сочетание клавиш Option + Command + U. Вы также можете щелкнуть правой кнопкой мыши на веб-странице и выбрать «Показать источник страницы».”
- Firefox — Вы можете щелкнуть правой кнопкой мыши и выбрать «Источник страницы» или перейти в меню «Инструменты», выбрать «Веб-разработчик» и нажать «Источник страницы». Сочетание клавиш — Command + U..
- Chrome — Перейдите в «Просмотр», затем нажмите «Разработчик», а затем «Просмотр исходного кода». Вы также можете щелкнуть правой кнопкой мыши и выбрать «Просмотреть исходный код страницы». Сочетание клавиш — Option + Command + U.
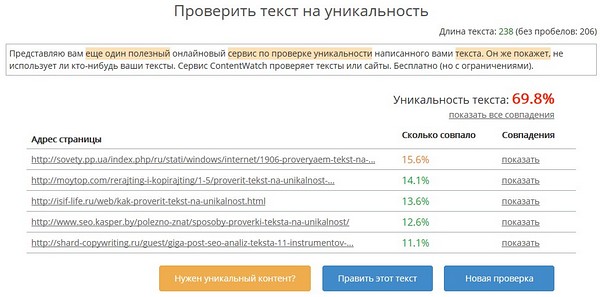
Если вы знаете, как просматривать исходный код, вам нужно знать, как искать в нем что-то.Обычно те же функции поиска, которые вы используете для обычного просмотра веб-страниц, применяются к поиску в исходном коде. Такие команды, как CTRL + F (для поиска), помогут вам быстро просканировать исходный код на предмет важных элементов SEO.
Теги заголовка
 youtube.com/embed/ClXTdjsXKFU?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/>
youtube.com/embed/ClXTdjsXKFU?feature=oembed» frameborder=»0″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»/> Тег title — это святой Грааль внутреннего SEO. Это самая важная вещь в вашем исходном коде. Если вы собираетесь убрать что-то из этой статьи, обратите внимание на это:
Вы знаете те результаты, которые дает Google, когда вы что-то ищете?
Все эти результаты получены из тегов заголовков веб-страниц, на которые они указывают.Итак, если у вас нет тегов заголовков в исходном коде, вы не сможете отображаться в Google (или в любой другой поисковой системе, если на то пошло). Вы не поверите, но я действительно видел сайты без тегов заголовков!
Теперь давайте быстро выполним поиск в Google по запросу «Marketing Guides»:
Как видите, первый результат относится к разделу блога KISSmetrics, посвященному руководствам по маркетингу. Если мы нажмем на этот первый результат и просмотрим исходный код страницы, мы увидим тег заголовка:
Тег заголовка обозначается открывающим тегом:
И мы видим, что содержимое внутри тега title совпадает с тем, что используется в заголовке этого первого результата Google.
Не только теги заголовка необходимы для включения в результаты поиска Google, но и Google определяет слова в ваших тегах заголовков как важных ключевых слова , которые, по их мнению, имеют отношение к поисковым запросам их пользователей.
Итак, если вы хотите, чтобы определенная веб-страница получила рейтинг по определенной теме, вам лучше убедиться, что слова, описывающие тему, присутствуют в теге заголовка. Чтобы узнать больше о том, как ключевые слова и теги заголовков важны для общей архитектуры вашего сайта, ознакомьтесь с этим постом.
И последнее, что нужно запомнить: каждая веб-страница на вашем сайте должна иметь уникальный тег заголовка. Никогда не дублируйте этот контент.
Если у вас небольшой веб-сайт, например 10 или 20 страниц, достаточно легко проверить каждый тег заголовка на уникальность. Однако если у вас большой веб-сайт, вам понадобится помощь. Это простой четырехэтапный процесс:
Однако если у вас большой веб-сайт, вам понадобится помощь. Это простой четырехэтапный процесс:
Шаг № 1: Откройте Ubersuggest, введите свой URL и нажмите «Поиск»
Шаг № 2: Нажмите «Аудит сайта» на левой боковой панели.
Шаг № 3: Обзор основных проблем SEO
После перехода к обзору аудита сайта прокрутите вниз до четвертого раздела результатов (он последний на странице), чтобы просмотреть основные проблемы SEO.
Здесь вы узнаете, есть ли у вас повторяющиеся теги заголовков или метаописания. Если здесь ничего не отображается, значит, все ясно. Если вы видите дубликаты, например 30 страниц моего веб-сайта, копайте глубже.
Шаг № 4: Щелкните «Страницы с повторяющимися тегами
SEO-оптимизация заголовков может помочь вам повысить ваши шансы на хорошее ранжирование в поисковой выдаче.
Теги заголовков — это также первое, что видит ваша аудитория, когда вводит поисковый запрос. Важно дать вашей аудитории представление о том, чего они могут ожидать от вашего контента. Если вы хотите, чтобы пользователи нажимали на ваш контент, вам нужно сосредоточиться на создании привлекательных заголовков.
Наряду с поисковой выдачей теги заголовков также появляются в верхней части веб-браузера.Если в веб-браузере пользователя открыто слишком много вкладок, теги заголовков могут помочь им идентифицировать содержимое веб-страницы.
В идеале тег заголовка следует начинать с основного ключевого слова, чтобы пользователи не теряли из виду то, что предлагает ваша веб-страница.
Связано: Как писать метатеги для SEO
Как оптимизировать заголовки для поисковых систем
Ваши заголовки могут не только повлиять на рейтинг результатов поиска, но и на взаимодействие с пользователем.
Написать эффективные заголовки несложно, если вы знаете, что работает, а что нет.Давайте рассмотрим некоторые из лучших практик оптимизации заголовков для SEO.
1. Определите длину страницы
Обычно поисковые системы отображают в результатах поиска только первые 60-70 символов заголовка страницы. По этой причине длина вашего заголовка играет важную роль в оптимизации заголовка SEO.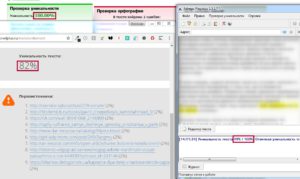
Основываясь на последних макетах 2020 года, вы должны стремиться писать теги заголовков длиной от 55 до 60 символов. Google использует двойные линии в результатах мобильного поиска и однострочку в результатах поиска на настольных компьютерах.
Двойной интервал в результатах мобильного поиска делает их немного шире в зависимости от того, сколько пробелов они дают. Этот результат «Пять лучших советов …» в настольной версии обрезается, хотя последнее слово «Телескоп!» будет держать их до 65 символов.
Полное название отображается в мобильном поиске.
Мобильный результат расширяет заголовок до 62 символов.Эти примеры должны доказать, что не всегда существует жесткое правило для длины, но 55-60 символов — хорошая цель.Постарайтесь вписать самые важные ключевые слова в начало тега заголовка. Это та часть, которую поисковые системы меньше всего отрезают.
Некоторые бренды также любят включать название своей марки в каждый тег заголовка. Если вы планируете следовать этой стратегии, убедитесь, что вы добавили ее в конце тега заголовка.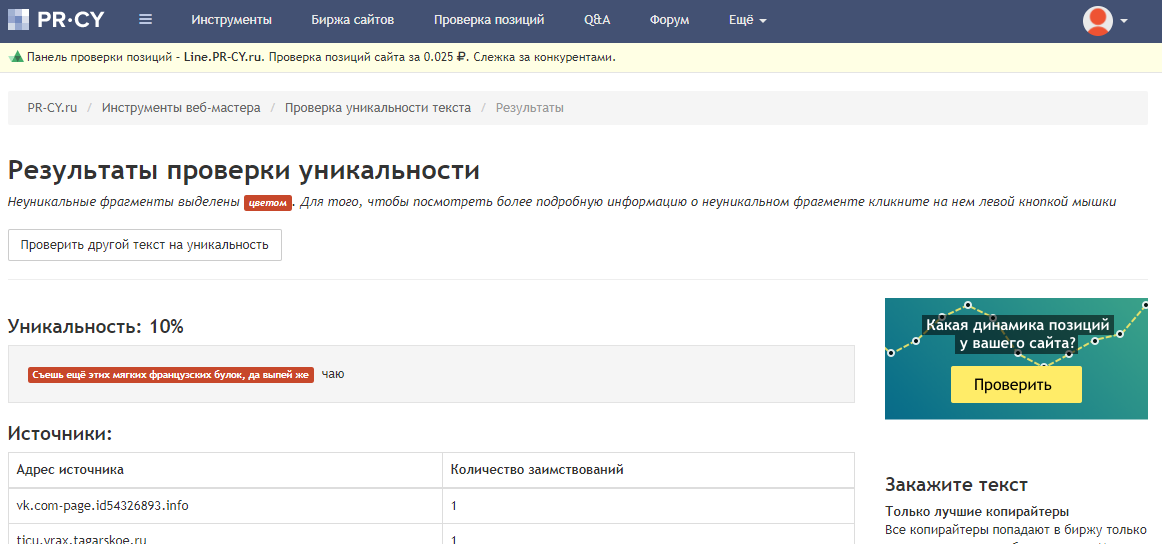 Даже если название вашего бренда будет отброшено в поисковой выдаче, пользователи все равно смогут определить цель вашего контента.
Даже если название вашего бренда будет отброшено в поисковой выдаче, пользователи все равно смогут определить цель вашего контента.
Иногда вы можете заметить, что поисковые системы также отображают заголовки, длина которых превышает 70 символов.Это потому, что некоторые персонажи занимают больше места, чем другие.
Например, заглавная буква «M», вероятно, будет занимать больше места в теге заголовка, чем строчная «l» или «f».
Изображение через Google
На изображении выше первый заголовок содержит более 60 символов. Это потому, что в слове «блестящий» иероглифы «илли» занимают очень мало места.
Если во время написания заголовка вы нажимаете на пробел, избегайте использования CAPS, так как это ограничивает количество символов, которые могут отображаться поисковыми системами.
Для предварительного просмотра того, как ваш тег заголовка будет отображаться в результатах поиска, вы можете использовать плагин Yoast SEO WordPress. Если ваш заголовок слишком длинный, вы увидите три точки в конце заголовка. Этот плагин может помочь вам с SEO-оптимизацией заголовков. Если вы не используете WordPress, поищите аналогичные функции предварительного просмотра заголовков SEO на других платформах.
Этот плагин может помочь вам с SEO-оптимизацией заголовков. Если вы не используете WordPress, поищите аналогичные функции предварительного просмотра заголовков SEO на других платформах.
Хотя нет никаких штрафов за использование длинного тега заголовка, лучше помнить о том, как ваши заголовки отображаются в поисковой выдаче.
2. Напишите уникальные заголовки
Все веб-страницы на вашем веб-сайте уникальны. Настройте все теги заголовков таким образом, чтобы они отражали суть содержания этой конкретной страницы.
Точные описания и понятные заголовки помогают поисковым системам понять, о чем ваш контент. В то же время они помогают пользователям, которые ищут ответы, которые дает ваш контент.
Чтобы найти лучшие заголовки для своих веб-страниц, вам нужно поставить себя на место поисковых посетителей.
Использование общих заголовков, таких как «New Post» или «Home», может заставить поисковые системы полагать, что на вашем веб-сайте есть дублированный контент. Кроме того, такие заголовки не привлекают читателей.
Кроме того, такие заголовки не привлекают читателей.
Подлинность и уникальность имеют решающее значение для оптимизации заголовка SEO.
3. Используйте правильные ключевые слова
Во-первых, найдите наиболее релевантные ключевые слова для вашего бренда и ниши. Вы также должны проверить ключевые слова, по которым ранжируются ваши конкуренты. Для этого вы можете использовать наш инструмент анализа конкурентов SEO.
Теги заголовков могут помочь вам улучшить поисковый рейтинг, если вы оптимизируете их с помощью правильных ключевых слов. Лучший способ включить ключевые слова для SEO-оптимизации заголовка — это добавить их в начало заголовка.
Если вы оптимизируете существующий контент или обновляете устаревший контент, одна уловка — смотреть на сильные ключевые слова, по которым он уже ранжируется.
Для этого мы используем раздел Top Pages SpyFu. Если ключевые слова с самым высоким рейтингом релевантны, но вы по-прежнему не занимает первое место, убедитесь, что в заголовке указано наиболее релевантное ключевое слово. Вот пример.
Вот пример.
У нас была статья под названием «Руководство для начинающих по созданию файлов Sitemap менее чем за минуту». Это описательный заголовок, но он не был оптимизирован для более вероятного поиска.
Эта статья получила рейтинг по «созданию карты сайта», когда более сильным ключевым словом является «как создать карту сайта». Даже с аналогичными позициями страница потенциально получит больше кликов по ключевому слову.
Сравнение ключевых слов, по которым эта статья ранжируется через SpyFu Top PagesМы обновили тег заголовка на «Как создать карту сайта.«Со временем вы можете обновить URL-адрес, но это первый шаг, который не требует перенаправления.
обновленный тег заголовка из поиска GoogleКогда вы добавляете ключевые слова, не слишком увлекайтесь. Между« добавлением »и «наполнение».
Google не поощряет веб-мастеров заполнять свои заголовки ключевыми словами. Google может распознать такие результаты поиска как спам. Это создает неудобства для пользователей, поэтому поисковые системы не видят в этом положительной стратегии.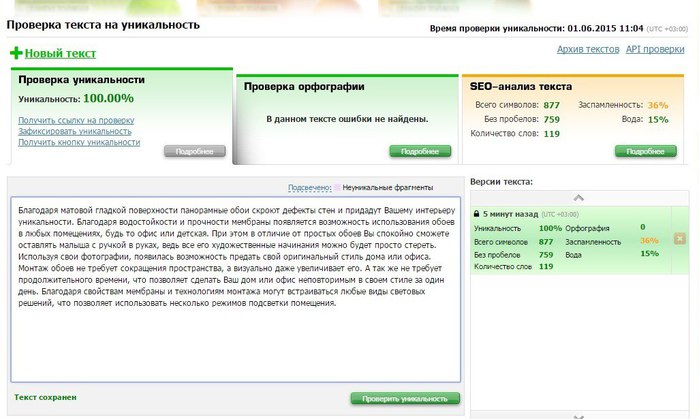
Не используйте список тесно связанных ключевых слов или варианты одной и той же фразы несколько раз в теге заголовка.На картинке выше трижды встречаются варианты слова «жених». Это определенно больше, чем нужно.
Использование слишком большого количества ключевых слов может негативно повлиять на ваши инициативы по оптимизации заголовка SEO.
4. Используйте название вашего бренда
Использование названия вашего бренда в теге заголовка может добавить элемент релевантности и доверия к вашему контенту. Это особенно актуально в случае хорошо зарекомендовавших себя брендов.
Изображение через Google
Если пользователи уже узнают ваш бренд, они с большей вероятностью нажмут на заголовок страницы, посвященный вашему бренду.Это потому, что они, вероятно, сочтут вас более надежным и заслуживающим доверия источником информации.
Но, чтобы не ухудшить читаемость, всегда добавляйте название вашего бренда в конце заголовка страницы. Чтобы ваш тег заголовка выглядел еще чище, используйте разделитель, например двоеточие, дефис или вертикальную черту.
Чтобы ваш тег заголовка выглядел еще чище, используйте разделитель, например двоеточие, дефис или вертикальную черту.
Добавление названия вашего бренда также может помочь вам улучшить оптимизацию заголовков для SEO.
Почему ваш тег заголовка не всегда отображается в результатах поиска
Иногда вы можете заметить, что Google отображает заголовок страницы, отличный от введенного вами тега заголовка.Это может сбивать с толку, особенно если вы потратили время и усилия на поиск подходящего тега заголовка для своего контента.
В таком сценарии приведенные ниже объяснения могут помочь вам понять, почему это произошло:
- Переполнение ключевых слов: Если вы использовали слишком много ключевых слов в теге заголовка, Google может просто переписать заголовок за вас. Слишком много ключевых слов — большой отказ для SEO-оптимизации заголовков. Чтобы избежать такой ситуации, сосредоточьтесь на написании заголовков, действительно полезных для пользователей поиска.
- Альтернативные заголовки: Наряду с тегом заголовка вы могли добавить альтернативные мета-заголовки. Иногда Google может выбрать любое из альтернативных заголовков и отобразить их в результатах поиска.
Если вы написали релевантный мета-заголовок, то этот сценарий вас не должен волновать. Если вы обнаружите, что заголовок, отображаемый в поисковой выдаче, не подходит, подумайте об изменении тегов заголовков, а также мета-заголовка.
- Несоответствие поисковому запросу. Если ваша веб-страница соответствует поисковому запросу, но не соответствует вашему заголовку, Google может переписать его.
Ни один заголовок не будет точно соответствовать каждому поисковому запросу. Однако это красный флаг, если ваш заголовок не используется для ключевых слов с большим объемом поиска. В таких случаях вам следует переписать тег заголовка, чтобы оптимизировать его для ключевых слов с большим объемом поиска.
Если Google обнаружит любую из проблем, упомянутых выше в вашем заголовке, поисковая система, скорее всего, сгенерирует новый заголовок для вашей веб-страницы. Этот новый заголовок создается на основе текста на странице, привязок и других источников.
Этот новый заголовок создается на основе текста на странице, привязок и других источников.
Чтобы этого избежать, вам следует сосредоточиться на оптимизации заголовков для всех ваших веб-страниц.
Однако иногда Google может также изменить заголовки для страниц с хорошо написанными краткими заголовками. Независимо от того, что такое поисковый запрос, заголовок, указанный веб-мастером, всегда статичен.
Но Google стремится настраивать свои результаты поиска, чтобы они лучше соответствовали запросу пользователя. Google использует индивидуализированные заголовки, чтобы объяснить пользователям, почему для них важен тот или иной результат.
Объяснение релевантности и адаптация результатов к запросу пользователя на самом деле может увеличить вероятность посещения им веб-страницы.
Если вас не устраивает название, которое Google изменило, вы всегда можете изменить его. Для этого вы можете обратиться за помощью в Справочное сообщество для веб-мастеров.
Заключение
Легко упустить из виду теги заголовков, когда вам нужно беспокоиться о более серьезных вещах в рамках вашей стратегии SEO. Но игнорирование SEO оптимизации заголовков может стоить вам кучу денег. Заголовок вашей страницы играет решающую роль в определении того, насколько хорошо она будет ранжироваться в поисковой выдаче.
Но игнорирование SEO оптимизации заголовков может стоить вам кучу денег. Заголовок вашей страницы играет решающую роль в определении того, насколько хорошо она будет ранжироваться в поисковой выдаче.
К счастью, написание эффективных заголовков страниц не требует много времени и усилий.Но это может дать вам большие результаты с точки зрения улучшения вашего поискового рейтинга.
Чтобы создавать эффективные заголовки, вам необходимо понимать, как работают алгоритмы ранжирования Google, и находить правильный баланс между написанием заголовков, ориентированных на ключевые слова и ориентированных на пользователя.
Есть ли у вас другие советы по оптимизации заголовков для SEO? Пожалуйста, дайте нам знать в разделе комментариев ниже.
.