инструкция для новичков — CheckROI
Поделитесь статьей, пожалуйста:
В статье про технический аудит сайта мы упомянули, что среди прочего SEO-специалисту важно проверить, а есть ли дубли страниц на продвигаемом им веб-ресурсе. И если они найдутся, то нужно немедленно устранить проблему. Однако там в рамках большого обзора я не хотел обрушивать на голову читателя кучу разнообразной информации, поэтому о том, что такое дубликаты страниц сайта, как их находить и удалять, мы вместе с вами детальнее рассмотрим здесь.
Почему и как дубли страниц мешают поисковому продвижению
Для начала отвечу на вопрос «Как?». Дубликаты страниц сильно затрудняют SEO, т. к. поисковые системы не могут понять, какую из веб-страниц им нужно показывать в выдаче по релевантным запросам. Поэтому чаще всего, чтобы не путаться, они понижают сайт в ранжировании или даже банят его, если проблема имеет массовый характер. После этого должно быть понятно, насколько важно сразу проверить продвигаемый ресурс на дубликаты.
Теперь давайте посмотрим, почему так получается, что дубли создают проблему? Для этого рассмотрим такой простой пример. Взгляните на следующее изображение и определите, какой из овощей наиболее точно соответствует запросу «спелый помидор»?

Хотя овощи немного отличаются размером, но все три из них подходят под категорию «спелого помидора». Поэтому сделать выбор в пользу одно из них довольно сложно.
Такая же дилемма встает перед поисковыми алгоритмами, когда они видят на сайте несколько одинаковых (полных) или почти одинаковых (частичных) копий одной и той же страницы.
Как наличие дублей сказывается на продвижении:
- Чаще всего падает релевантность основной продвигаемой страницы и, соответственно, снижаются позиции по используемым ключевым словам.
- Также могут «прыгать» позиции по ключам из-за того, что поисковик будет менять страницу для показа в поисковой выдаче.
- Если проблема не ограничивается несколькими урлами, а распространяется на весь сайт, то в таком случае Яндекс и Google могут наказать неприятным фильтром.
Понимая теперь, насколько серьезными могут быть последствия, рассмотрим виды дубликатов.
SEO-шников много, профессионалов — единицы. Научитесь технической и поведенческой оптимизации, создавайте семантические ядра и продвигайте проекты в ТОП!
Получить скидку →

Виды дублей
Выше мы уже выяснили, что дубли бывают идентичными (полными) и частичными. Полным называют такой дубликат, когда одну и ту же веб-страницу поисковик находит по различным адресам.
Когда появляются полные дубли:
- Зачастую это происходит, если забыли указать главное зеркало, и весь сайт может показываться в поиске с www и без него, c http и с https. Чтобы устранить эту проблему, читайте здесь детальнее о том, что такое зеркало сайта.
- Кроме того, бывают ситуации, когда возникают дубли главной страницы ввиду особенностей движка или проведенной веб-разработчиком работы. Тогда, к примеру, главная может быть доступна со слешем «/» в конце и без него, с добавлением слов home, start, index.php и т. п.
- Нередко дубли возникают, когда в индекс попадают страницы с динамичными адресами, появляющиеся обычно при использовании фильтров для сортировки и сравнения товаров.
- Часть движков (WordPress, Joomla, Opencart, ModX) сами по себе генерируют дубли. К примеру, в Joomla по умолчанию часть страниц доступна к отображению с разными урлами: mysite.ru/catalog/17 и mysite.ru/catalog/17-article.html и т. п.
- Если для отслеживания сессий применяют специальные идентификаторы, то они также могут индексироваться и создавать копии.
- Иногда в индекс также попадают страницы по адресам, к которым добавлены utm-метки. Такие метки вставляют, чтобы отслеживать эффективность проводимых рекламных кампаний, и по-хорошему они не должны быть проиндексированы. Однако на практике подобные урлы часто можно видеть в поисковой выдаче.
Когда возникают частичные дубли
Полные дубли легко найти и устранить, а вот с частичными уже придется повозиться. Поэтому на рассмотрении их видов стоит остановиться детальнее.
Пагинация страниц
Используя пагинацию страниц, владельцы сайтов делают навигацию для посетителей более простой, но вместе с тем создают проблему для поискового продвижения. Каждая страница пагинации – это фактически дубль зачастую с теми же мета-данными, СЕО-текстом.
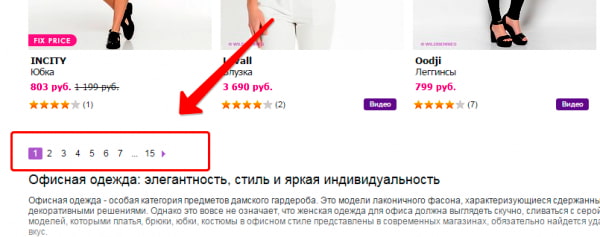
К примеру, основная страница имеет вид https://mysite.ru/women/clothes, а у страницы пагинации адрес будет https://mysite.ru/women/clothes/?page=2. Адреса получаются разные, а содержимое будет почти одинаковым.
Блоки новостей, популярных статей и комментариев
Чтобы удержать пользователя на сайте, ему часто предлагают ознакомиться с наиболее интересными новостями, комментариями и статьями. Название этих объектов с частью содержимого обычно размещают по бокам или снизу от основного материала. Если эти куски будут проиндексированы, то поисковик определит, что на некоторых страницах одинаковый контент, а это очень плохо.
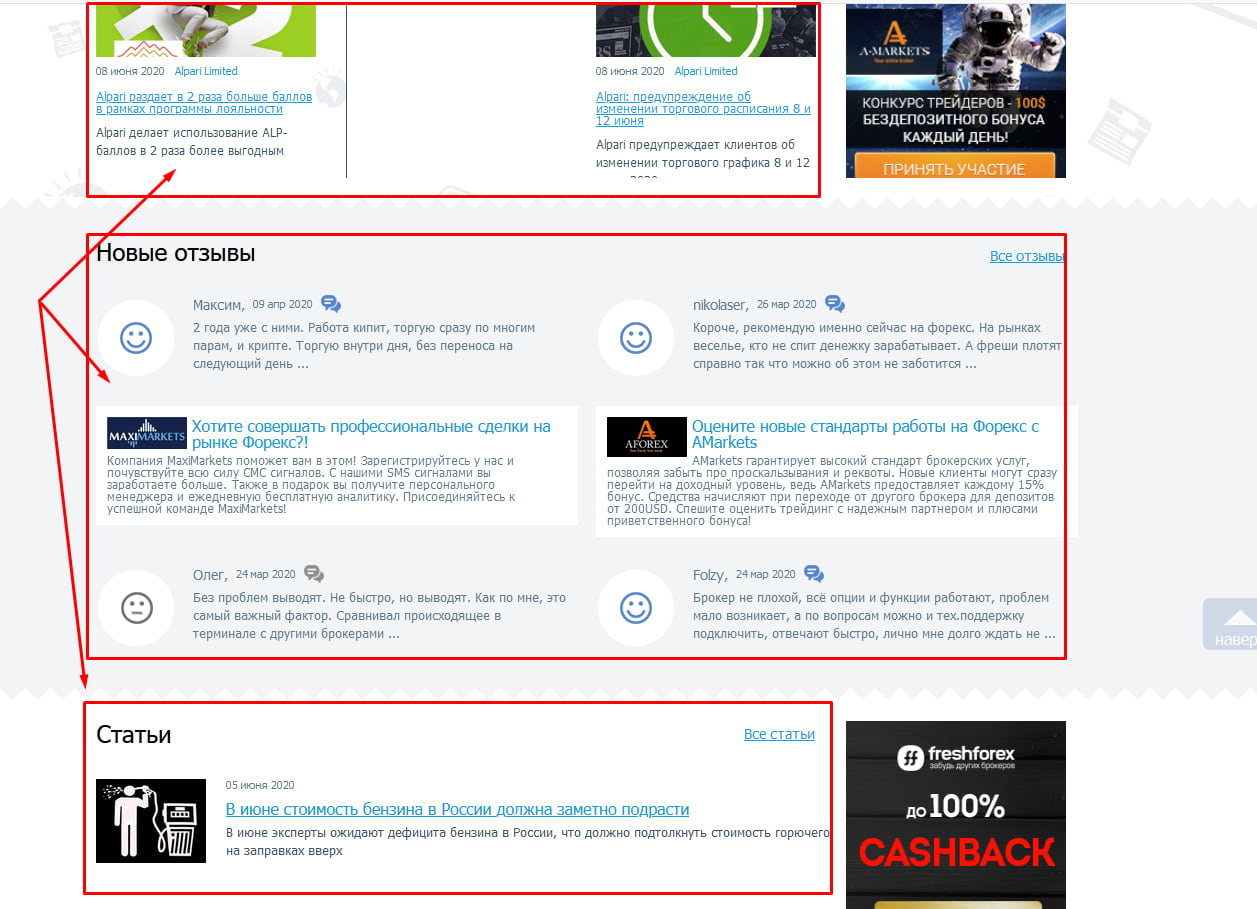
На скриншоте видно, как внизу главной страницы сайта размещаются три блока с последними статьями, новостями и отзывами. То есть текстовое содержимое есть в соответствующих разделах сайта, и здесь на главной оно повторяется, создавая частичные дубли.
Версии страниц для печати
Некоторые веб-страницы сайта доступны в обычном варианте и в версии для печати, которая отличается от основной адресом и отсутствием значительной части строк кода, т. к. для печатаемой страницы не нужна значительная часть функционала.
Обычная страница может открываться, например, по адресу https://my-site.ru/page, а у варианта для печати адрес немного изменится и будет похож на такой: https://my-site.ru/page?print.
Сайты с технологией AJAX
На некоторых сайтах, применяемых технологию AJAX, возникают так называемые html-слепки. Сами по себе они не опасны, если нет ошибок в имплантации способа индексирования AJAX-страниц, когда поисковых ботов направляют не на основную страницу, а на html-слепок, где робот индексирует одну и ту же страницу по двум адресам:
- основному;
- адресу html-слепка.
Для нахождения таких html-слепков стоит в основном адресе заменить часть «!#» на такой код: «?_escaped_fragment_=».
Частичные дубли опасны тем, что они не вызывают значительного снижения позиций в один момент, а понемногу портят картину, усугубляя ситуацию день за днем.
Как происходит поиск дублей страниц на сайте
Существует несколько основных способов, позволяющих понять, как найти дубли страниц оптимизатору на сайте:
Вручную
Уже зная, где стоит искать дубликаты, SEO-специалист без особого труда может найти значительную часть копий, попробовав различные варианты урлов.
С применением команды site
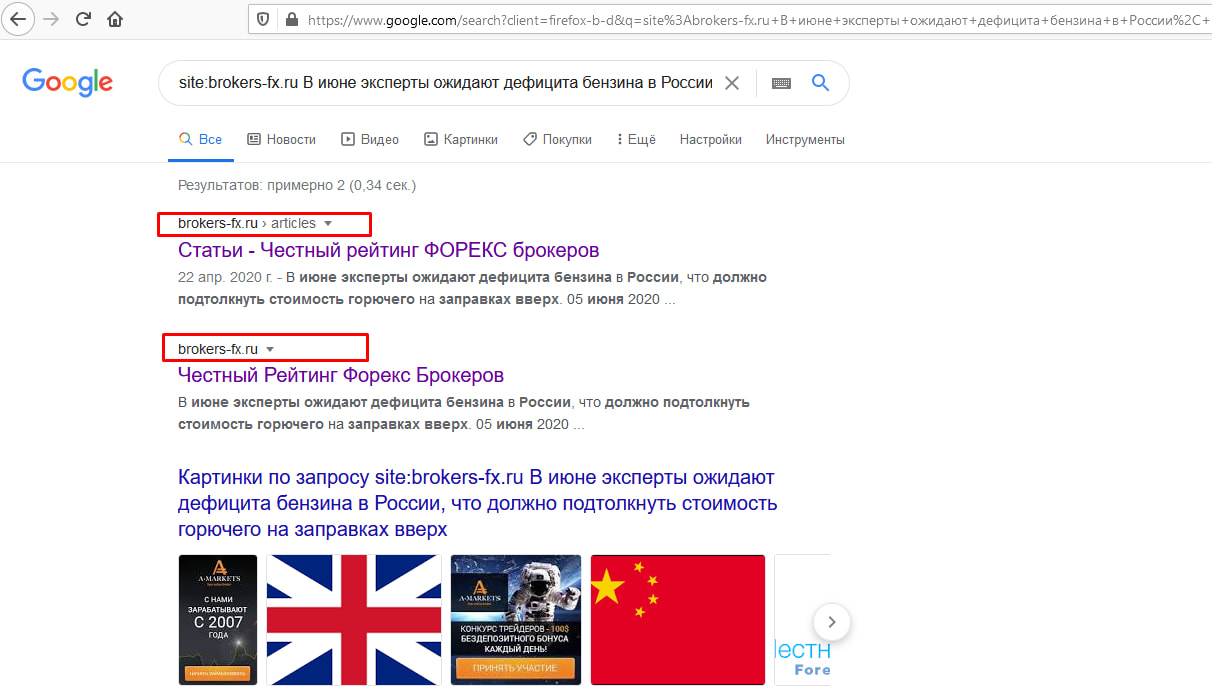
Вставляем в адресную строку команду «site:», вводим после нее домен и часть текстового содержания, после чего Google сам выдаст все найденные варианты. На скриншоте ниже видно, что мы ввели первое предложение свежей статьи после команды «site:», и Google показывает, что у основной страницы с материалом есть частичный дубль на главной.
С использованием программ и онлайн-сервисов
Для поиска дублей часто применяют три популярные программы на ПК:
- Xenu – бесплатная;
- NetPeak – от $15 в месяц, но есть 14-дневный trial;
- Screaming Frog – платная (149 фунтов за год), но есть ограниченная бесплатная версия, которой хватает для большинства нужд.
Вот пример того, как ищет дубликаты программа Screaming Frog:
А вот как можно проверить дубли страниц в NetPeak:
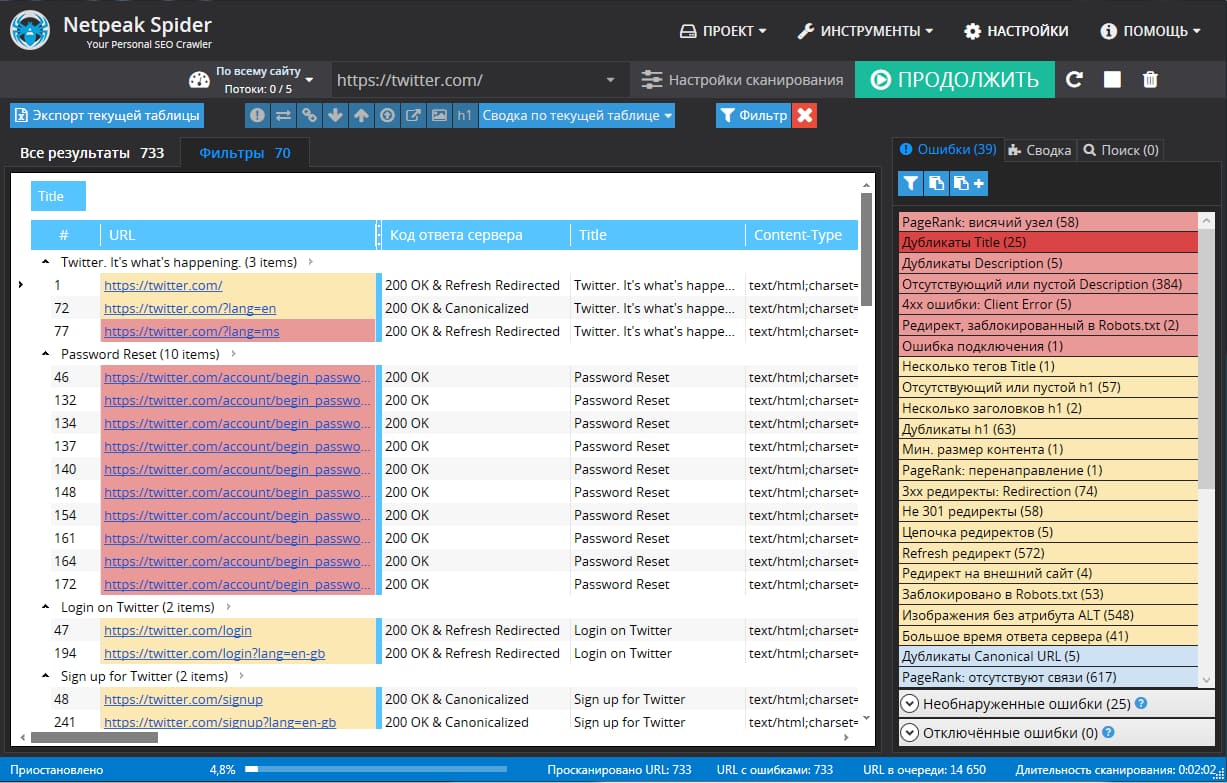
Для онлайн-поиска дублей страниц можно использовать специальные веб-сервисы наподобие Serpstat.
Использование Google Search Console и Яндекс Вебмастер
В обновленной версии Google Search Console для поиска дублей смотрим «Предупреждения» и «Покрытие». Там поисковая система сама сообщает о проблемных, на ее взгляд, страницах, которым нужно уделить внимание.
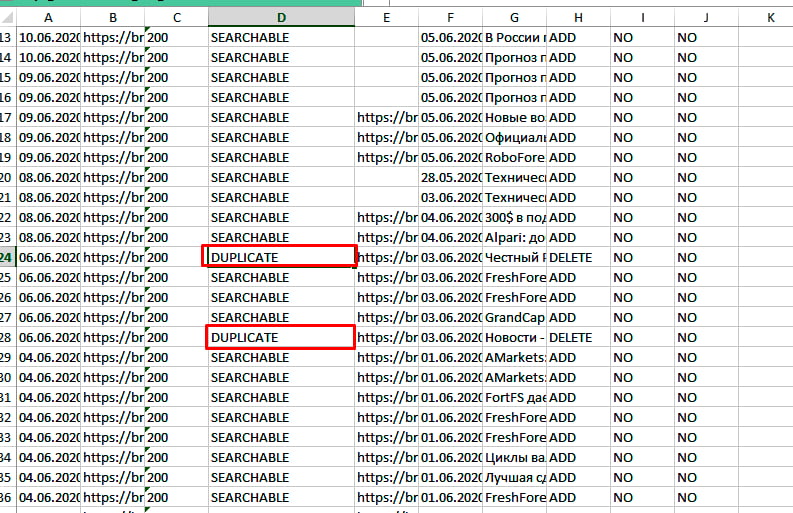
Что касается Yandex, то здесь все намного удобнее. Для поиска дублей заходим в Яндекс Вебмастер, открыв раздел «Индексирование» – «Страницы в поиске». Опускаемся в самый низ, выбираем справа удобный формат файла – XLS или CSV, скачиваем его и открываем. В этом документе все дубликаты в строке «Статус» будут иметь обозначение DUPLICATE.
Как убрать дубли?
Чтобы удалить дубли страниц на сайте, можно использовать разные приемы в зависимости от ситуации. Давайте же с ними познакомимся:
При помощи noindex и nofollow
Самый простой способ – закрыть от индексации, используя метатег <meta name=”robots” content=”noindex,nofollow”/>, который помещают в шапку между открывающим тегом <head> и закрывающим </head>. Попав на страницу с таким метатегом, поисковые алгоритмы не станут ее индексировать и учитывать ссылки, находящиеся здесь.
При добавлении метатега «noindex,nofollow» на страницу, крайне важно, чтобы для нее не была запрещена индексация через файл robots.txt.
При помощи robots.txt
Индексирование отдельных дублей можно запретить в файле robots.txt, используя директиву Disallow. В таком случае примерный вид кода, добавляемого в robots.txt, будет таким:
User-agent: *
Disallow: /dublictate.html
Host: mysite.ru
Через robots.txt удобно запрещать индексацию служебных страниц. Выглядит это следующим образом:

Этот вариант зачастую применяют, если невозможно использовать предыдущий.
При помощи canonical
Еще один удобный способ – применить метатег canonical, который говорит поисковым роботам, что они попали на страницу-дубликат, а заодно указывает, где находится основная страница. Этот метатег помещают в шапку между открывающим тегом <head> и закрывающим </head>, и выглядит он так:
<link rel=”canonical” href=”адрес основной страницы” />
Как убрать дубликаты на страницах с пагинацией
В случае присутствия на сайте многостраничного каталога, на второй и последующих страницах могут возникать частичные дубли. Смотрим, как это может быть:
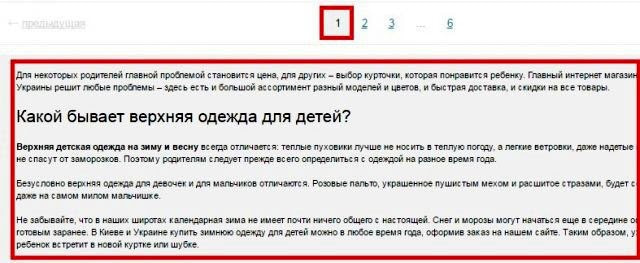
Выше на скрине 1-я страница каталога, а вот вторая:
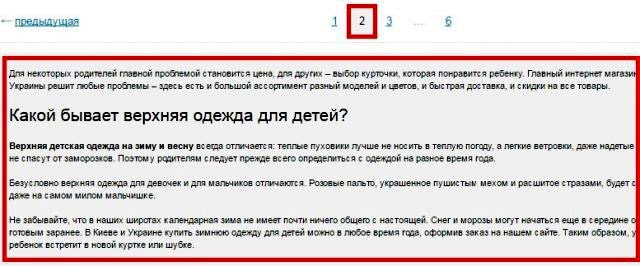 То есть на каждой странице дублируется текст и теги: Title и Description.
То есть на каждой странице дублируется текст и теги: Title и Description.
В таких случаях SEO-специалисту нужно добиться, чтобы:
- текст отображался только на 1-й странице;
- Title и Description были уникальными для каждой страницы, хотя их можно сделать шаблонными с минимальными отличиями;
- в адресах страниц пагинации должны отсутствовать динамические параметры.
Понимая теперь, что такое дубликаты страниц сайта, и как бороться с дублями, вы сможете не допустить попадания в индекс копий, которые будут препятствовать продвижению в поисковых системах. Если после прочтения статьи у вас остались вопросы, или вы хотите дополнить материал своими ценными замечаниями, то обязательно сделайте это в комментариях ниже.
Поделитесь статьей, пожалуйста:
Как найти дубли страниц на сайте
Содержание статьи
Наличие дублей страниц в индексе — это такая страшная сказка, которой seo-конторы пугают обычно владельцев бизнеса. Мол, смотрите, сколько у вашего сайта дублей в Яндексе! Честно говоря, не могу предоставить примеры, когда из-за дублей сильно падал трафик. Но это лишь потому, что эту проблему я сразу решаю на начальном этапе продвижения. Как говорится, лучше перебдеть, поэтому приступим.
Что такое дубли страниц?
Дубли страниц – это копии каких-либо страниц. Если у вас есть страница site.ru/bratok.html с текстом про братков, и точно такая же страница site.ru/norma-pacany.html с таким же текстом про братков, то вторая страница будет дублем.
Могут ли дубли плохо сказаться на продвижении сайта
Могут, если у вашего сайта проблемы с краулинговым бюджетом (если он маленький).
Краулинговый бюджет — это, если выражаться просто, то, сколько максимум страниц вашего сайта может попасть в поиск. У каждого сайта свой КБ. У кого-то это 100 страниц, у кого-то — 25000.
Если в индексе будет то одна страница, то другая, в этом случае они не будут нормально получать возраст, поведенческие и другие «подклеивающиеся» к страницам факторы ранжирования. Кроме того, пользователи могут в таком случае ставить ссылки на разные страницы, и вы упустите естественное ссылочное. Наконец, дубли страниц съедают часть вашего краулингового бюджета. А это грозит тем, что они будут занимать в индексе место других, нужных страниц, и в итоге нужные вам страницы не будут находиться в поиске.
Причины возникновения дублей
Сначала вам нужно разобраться, почему на вашем сайте появляются дубли. Это можно понять по урлу, в принципе.
- Дубли могут создавать ID-сессии. Они используются для контроля за действиями пользователя или анализа информации о вещах, которые были добавлены в корзину;
- Особенности CMS (движка). В WordPress такой херни обычно нету, а вот всякие Джумлы генерируют огромное количество дублей;
- URL с параметрами зачастую приводят к неправильной реализации структуры сайтов;
- Страницы комментариев;
- Страницы для печати;
- Разница в адресе: www – не www. Даже сейчас поисковые роботы продолжают путать домены с www, а также не www. Об этом нужно позаботиться для правильной реализации ресурса.
Способы поиска дублирующего контента
Можно искать дубли программами или онлайн-сервисами. Делается это по такому алгоритму — сначала находите все страницы сайта, а потом смотрите, где совпадают Title.
XENU
XENU – это очень олдовая программа, которая издавна используется сеошниками для сканирования сайта. Лично мне её старый интерфейс не нравится, хотя задачи свои она в принципе решает. На этом видео парень ищет дубли именно при помощи XENU:
Screaming Frog
Я лично пользуюсь либо Screaming Frog SEO Spider, либо Comparser. «Лягушка» — мощный инструмент, в котором огромное количество функций для анализа сайта.
Comparser
Comparser – это все-таки мой выбор. Он позволяет проводить сканирование не только сайта, но и выдачи. То есть ни один сканер вам не покажет дубли, которые есть в выдаче, но которых уже нет на сайте. Сделать это может только Компарсер.
Поисковая выдача
Можно также и ввести запрос вида site:vashsite.ru в выдачу поисковика и смотреть дубли по нему. Но это довольно геморройно и не дает полной информации. Не советую искать дубли таким способом.
Онлайн-сервисы
Чтобы проверить сайт на дубли, можно использовать и онлайн-сервисы.
Google Webmaster
Обычно в панели вебмастера Google, если зайти в «Вид в поиске — Оптимизация HTML», есть информация о страницах с повторяющимся метаописанием. Так можно найти часть дублей. Вот видеоинструкция:
Sitereport
Аудит сайта от сервиса Sitereport также поможет найти дубли, помимо всего прочего. Хотя дублированные страницы можно найти и более простыми/менее затратными способами.
Решение проблемы
Для нового и старого сайта решения проблемы с дублями — разные. На новом нам нужно скорее предупредить проблему, провести профилактику (и это, я считаю, самое лучшее). А на старом уже нужно лечение.
На новом сайте делаем вот что:
- Сначала нужно правильно настроить ЧПУ для всего ресурса, понимая, что любые ссылки с GET-параметрами нежелательны;
- Настроить редирект сайта с www на без www или наоборот (тут уж на ваш вкус) и выбрать главное зеркало в инструментах вебмастера Яндекс и Google;
- Настраиваем другие редиректы — со страниц без слеша на страницы со слешем или наоборот;
- Завершающий этап – это обновление карты сайта.
Отдельное направление – работа с уже имеющимся, старым сайтом:
- Сканируем сайт и все его страницы в поисковых системах;
- Выявляем дубли;
- Устраняем причину возникновения дублей;
- Проставляем 301 редирект и rel=»canonical» с дублей на основные документы;
- В обязательном порядке 301 редиректы ставятся на страницы со слешем или без него. Обязательная задача – все url должны выглядеть одинаково;
- Правим роботс — закрываем дубли, указываем директиву Host для Yandex с заданием основного зеркала;
- Ждем учета изменений в поисковиках.
Как-то так.
Как найти и удалить дубли страниц на сайте
Дубль – страница, которая полностью или частично дублирует контент другой страницы. Одна из причин потери трафика из поисковых систем – наличие дублей страниц на сайте.
Принципы определения дублей поисковыми системами
Поисковые системы (далее «ПС») имеют свои алгоритмы проверки и определения дублей страниц.
Основные параметры, которые учитывают ПС при определении дублей:
- Мета-теги;
- Заголовки h2-H6;
- Текст страницы.
Способы определения дублей страниц на сайте
Статус «Дубль» присваивается поисковым роботом соответствующей поисковой системы при сканировании страниц сайта. Воспользуйтесь Вебмастерами поисковых систем, чтобы определить наличие дублей. Или воспользуйтесь специализированными программами для ручного поиска дублей.
Способ 1: Дубли страниц в Яндекс.Вебмастер
В поисковой системе Яндекс увидеть дубли страниц можно в Яндекс.Вебмастер, в разделе Индексирование → Страницы в поиске → Исключенные страницы → Статус «Дубль».
 Дубли страниц в Яндекс.Вебмастер
Дубли страниц в Яндекс.ВебмастерСпособ 2: Дубли страниц в Google Search Console
В поисковой системе Google увидеть дубли страниц можно в Google Search Console, в разделе «Покрытие» → «Исключено».
 Дубли страниц в Google Search Console
Дубли страниц в Google Search ConsoleСпособ 3: Через программы для комплексного анализа сайтов
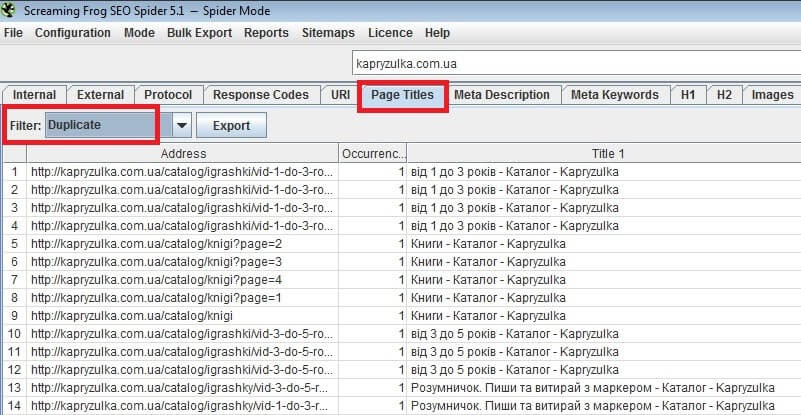
Поисковые системы не всегда корректно распознают дубли. Используя различные программы сканирования сайтов можно определить наличие дублей на сайте. Например, программа Screaming Frog позволяет это сделать.
Чтобы найти дубли с помощью Screaming Frog используйте те же самые основные параметры поиска:
-
Поиск одинаковых Title. Вкладка «Page Titles» → Filter «Duplicate»
 Список страниц с одинаковыми Title в программе Screaming Frog
Список страниц с одинаковыми Title в программе Screaming Frog -
Одинаковые заголовки h2, h3. Вкладка «h2» или «h3» → Filter «Duplicate»
Список страниц с одинаковыми h2 в программе Screaming Frog
 Список страниц с одинаковыми Title в программе Screaming Frog
Список страниц с одинаковыми Title в программе Screaming Frog Список страниц с одинаковыми h2 в программе Screaming Frog
Список страниц с одинаковыми h2 в программе Screaming FrogПодобным образом можно найти дубли во вкладке Description, h3.
Способ 4: Ручной поиск – проверка типичных ошибок
Дубли сайта формируются на основании технических особенностей систем, на которых пишутся сайты.
Основные ручные проверки, которые необходимо провести:
- Доступность страницы с добавлением index.php / index.html / index.htm для каждой страницы после слеша. Например, есть страница https://site.ru, нужно проверить доступность страницы по адресам:
- https://site.ru/index.php
- https://site.ru/index.html
- https://site.ru/index.htm
- Доступность страницы по HTTP и HTTPS страницы: https://site.ru и http://site.ru. Если страница доступна по разным протоколам, то необходимо настроить 301 редирект с HTTP на HTTPS
- Доступность страницы по разным зеркалам. Адреса с «www» и без «www»:
- http://site.ru
- http://www.site.ru
- Доступность страницы с разным регистром в URL:
- http://site.ru/example/
- http://site.ru/EXAMPLE/
- Доступность одной и той же страницы по разным URL:
- http://site.ru/catalog/tovar1/
- http://site.ru/tovar1/
- Доступность страницы со слешами («/», «//», «///») и без них в конце:
- http://site.ru/example
- http://site.ru/example//
- http://site.ru///example/
- Доступность страницы-дубля через пагинацию:
- http://site.ru/catalog/
- http://site.ru/catalog/page1
Как избавиться от дублей страниц
- Установить тег canonical. Установить тег в head: link rel=»canonical» href=»ссылка на каноничную страницу»;
- Изменить контент страницы. Изменить мета-теги, заголовки h2-h6, текст, учитывая особенности контента, расположенного на странице. Используйте в случае необходимости индексирования страницы-дубля;
- Удалить страницу;
- Установить 301 редирект с дубля на оригинальную страницу. Попадая на страницу дубль, пользователь будет переадресован на нужную страницу;
- Запретить индексирование в robots.txt. Указать поисковому роботу, что добавлять в индекс такие страницы не нужно;
- Установить мета-тег noindex. Добавить в head: meta name=»robots» content=»noindex».
Влияние дублей страниц на поисковое продвижение
- Любой поисковая система имеет лимит на сканирование страниц для одного сайта. При появлении дублей, увеличивается общее количество страниц на сайте. При большом количестве страниц-дублей, поисковой робот может вовсе пропустить важные страницы;
- Изменение релевантности страницы. Поисковой робот может решить, что страница-дубль отвечает на запрос лучше, чем оригинальная страница и в поисковой выдаче будет показывать страницу-дубль;
- Потеря ссылочной массы оригинальной страницы и посетители станут попадать на страницы-дубли.
что такое, как найти и удалить с сайта
 Всем, привет! Дубли страниц на сайтах – одна из серьезных и к сожалению, весьма распространенных проблем. Из-за появления в интернете повторяющихся страниц и одинакового контента, возрастает нагрузка на сервера поисковых машин.
Всем, привет! Дубли страниц на сайтах – одна из серьезных и к сожалению, весьма распространенных проблем. Из-за появления в интернете повторяющихся страниц и одинакового контента, возрастает нагрузка на сервера поисковых машин.
Как удалить дубли страниц и что это такое
Естественно, поисковые компании не хотят платить лишних денег за обработку одной и той же информации два, а то и несколько раз. Поэтому сайты, имеющие дубли страниц и дублированный контент, в случае их обнаружения поисковыми системами (что часто и бывает) подвергаются различным санкциям.
В общем плане считается, что сайты с дублями, с точки зрения поисковых систем, являются менее информационно ценными и полезными для людей. Соответственно, снижаются перспективы успешного продвижения в ТОП10 и привлечения хорошего трафика.
Кроме того, поисковые алгоритмы все еще не абсолютно совершенны. Зачастую в результате канонической (основной) посадочной страницы поисковые роботы выбирают дубль, случайно оказавшийся первым в поле внимания.
В результате ошибочного назначения канонической страницы ресурс требует ссылочную массу, ухудшается поисковое продвижение. Потенциальные клиенты попадают из поиска не на сервисную или продающую страницу, а на дубль и это приводит к снижению качества продаж.
Большое число одинаковых страниц увеличивает потребление программно-аппаратного ресурса на сервере хостинг-провайдера, из-за чего нормальная работа сайта оказывается затруднена. В этом случае дубли могут привести к необходимости переходить на более дорогой тариф хостинговых услуг.
Неопрятности, возникающие из-за появления дублей на сайте, можно еще долго перечислять. Важно разобраться с вопросом – как найти и удалить дубли страниц практически?
Причины возникновения дублей веб-страниц
Приводит к появлению одинаковых или очень похожих веб-страниц могут как ошибки человеческого фактора, так и технические проблемы.
- Баги систем управления контентом.
- Недоработки плагинов.
- Ошибки в работе систем автоматизации SEO-оптимизации динамических сайтов.
Больше всего нареканий со стороны веб-мастеров в отношении дублирования к самой популярной в мире CMS WordPress. В частности, при использовании функции пагинации на сайтах, движок Вордпресс оформляет страниц так, что с точки зрения поисковых алгоритмов они выглядят как дубли.
Опытные блогеры и веб-разработчики время от времени публикуют статьи, в которых рассказывается, как устранить проблему создания дублирующих страниц и контента в том или ином плагине.
Однако решить проблему дублирования для абсолютно всех плагинов Вордпресс нереально – слишком много и часто создаются расширения и дополнения для этой самой распространенной системы управления сайтами. Зачастую плагины разрабатываются независимыми программистами, а исходный код дополнения не публикуется в открытом доступе.
В итоге, задачу найти и удалить дубли на сайте приходится решать вручную либо при помощи различных SEO-приложений и онлайн-сервисов.
Способы обнаружения дублей и удаления на сайта
Для масштабных интернет-ресурсов с тысячами страниц основная задача – максимально автоматизировать процесс и избавиться от ручного просмотра всех разделов ресурса в поисках повторений.
Следует учитывать и то, что для поисковых роботов-индексаторов дублями будут являться не полные клоны (реплики) веб-страниц, но повторяющиеся мета-теги Title, Description, совпадающие фрагменты текста (низкая уникальность), похожие URL-адреса. Как вы понимаете, если все эти параметры проверять вручную – на это уйдет слишком много времени, которого веб-мастерам и администраторам сайтов и так всегда не хватает.
Поэтому чтобы найти дублированные элементы используется специальное программное обеспечение.
- Онлайн-анализаторы, иногда отдельные инструменты в составе комплексных SEO-сервисов.
- Устанавливаемое на компьютер программное обеспечение. Возможны варианты поиска дублей в онлайн-режиме, с запросом данных непосредственно на сервере хостинг-провайдера либо офлайн-приложения, для которых файлы сайта необходимо предварительно скопировать на локальный диск компьютера.
Здесь можно упомянуть качественный софт от авторитетного американского SEO-блогера и цифрового антрепренера Нила Пателя (Neil Patel) приложение для анализа сайтов «Screaming Frog SEO Spider».
- Плагины для систем управления контентом. В частности, для CMS WordPress разработан плагин «Trash Duplicate».
- Профессиональные конструкторы сайтов обычно имеют встроенный SEO-модуль, с помощью которого можно провести комплексное тестирование (аудит) сайта на предмет поиска различного рода ошибок. В том числе найти и удалить дубли. Например, такой модуль для комплексного тестирования и автоматизации процесса исправления ошибок имеется в конструкторе сайтов Serif WebPlus.
- Инструменты для веб-мастеров, предоставляемый поисковыми компаниями – Яндекс.Вебмастер или Google Console (ранее сервис назывался Google Webmaster Tools).
- SEO-расширения и дополнения, плагины, устанавливаемые в веб-браузерах.
Сторонние SEO-сервисы и приложения могут только находить дублирования на сайте, но не имеют возможностей их удалять, поскольку для редактирования сайта требуются права администратора. После составления списка адресов дублей администратору предстоит вручную заняться редактированием сайта и удалением дублированный.
В этом смысле более удобны в работе устанавливаемые в CMS плагины и SEO-модули в составе инструментов конструкторов сайтов. В этих случаях поиск и уничтожение дублей может происходить «одним кликом».
Чтобы наглядно разобраться, как осуществляется проверка сайта на наличие дублей, можно рассмотреть некоторые из упомянутых в списке инструментов отдельно.
Онлайн-сервис поиска дублей, битых ссылок и прочего

Интерфейс сервиса www.siteliner.com на английском, поэтому для удобства воспользуемся Google-переводчиком. Все очень просто:
- Вставляем тестируемый домен в поле поиска и нажимаем кнопку «Go».
- Ждем пока закончится процесс сканирования и анализа.
- Получаем результат теста.
Результаты исследования оформлены в виде таблицы.

В таблице указано количество сходных страниц, процент сходства, URL-адреса дублей. Полученные данные можно импортировать в различные форматы документов и скачать на компьютер для дальнейшего подробного рассмотрения.
Дается вывод относительно текущего состояния ресурса:

Состояние неплохое – если в среднем по всемирной сети сайты имеют около 14% дублирования, то наш испытуемый ресурс – всего 5%.

Кликнув по ссылке на станицу можно изучить подробности, что именно и где повторяется.

Сервис условно-бесплатный, без подписки доступно для анализа 250 веб-страниц. Для расширения возможностей необходимо зарегистрироваться и оплатить тариф Siteliner Premium.
Дополнительно сервис находит битые (неработающие, ведущие на несуществующие страницы) гиперссылки. Веб-страницы и контент, запрещенные к индексации при помощи тега Noindex и указанные в файле Robots.txt при сканировании пропускаются.

Trash Duplicate and 301 Redirect для WordPress
SEO-дополнение для движка WordPress, с помощью которого можно автоматизировать следующие задачи:
- Поиск дублей страниц и контента.
- Пакетное удаление дублирований одним кликом.
- Автоматическая расстановка редиректов 301. Удаление нежелательных переадресаций.
Для установки этого плагина требуется подписка на Бизнес-тариф сервисов Вордпресс. В реальности, пресловутая «бесплатность» здесь очень ограничена и создаваемые за 5 минут сайты на WordPress годятся разве что для персонального блога с нулевой посещаемостью.
Если вы хотите по-настоящему заниматься цифровым бизнесом на сайте Powered by WordPress, в любом случае придется инвестировать в профессиональные темы[/mask_link], плагины, и прочие возможности.
Чтобы установить плагин Trash Duplicate нужно перейти в раздел «Plagins Manage».

Ввести в строку поиска название расширения и кликнуть по значку для запуска процесса инсталляции.

После установки запускается сканирование и по результатам формируется список.
")
Теперь можно отметить галочками нежелательные или ошибочные публикации и сразу все удалить.
Поиск и удаление дублей в Яндекс.Вебмастере
В раздел «Статистика индексации» можно посмотреть отчет о страницах, которые были по каким-то причинам исключены из поиска. В одном из столбцов таблицы указана причина отказа от включения веб-страницы в базу поисковой системы.

Часть страниц обозначена как «неканонические», а часть прямо отмечена как «дубли».
Теперь дублированные посты можно либо удалить, либо установить на них редиректы. В разделе «Инструменты» имеется возможность указать URL нежелательных публикаций и пакетом их удалить из поиска. Следует понимать, что на сайте эти страницы останутся, просто перестанут индексироваться и участвовать в поиске по запросам.

Альтернативно можно указать для поисковых роботов канонические страницы при помощи атрибута rel=»canonical». Вот как эта процедура описана в Помощи к Яндекс.Вебмастеру:

Исследуемый сайт у нас как раз на WordPress и выше мы рассмотрели, как найти и удалить дубли страниц онлайн при помощи инструментов, предоставленных поисковой системой.
Заключение
Как видите, возможностей и способов найти и удалить дубли страниц онлайн на сайте в WordPress существует много. Конкретный выбор инструментов зависит от особенностей интернет-ресурса и предпочтений веб-мастера.
Наиболее удобные возможности для выявления и удаления дублей страниц, имеются в функционале профессиональных конструкторов сайтов, где действительно можно решить проблему дублей «одним кликом».
А на этом я буду закруглятся. А вы как ищите и удаляете дубли страниц у себя на сайте? Напишите своё решение проблемы в комментариях. И конечно, если хотите быть профессиональным веб-мастером, обязательно подпишитесь на обновление моего блога. До встречи, друзья.
Как найти и удалить дубли страниц на сайте — Офтоп на vc.ru
Дубли страниц — документы, имеющие одинаковый контент, но доступные по разным адресам. Наличие таких страниц в индексе негативно сказывается на ранжировании сайта поисковыми системами.
Какой вред они могут нанести
- Снижение общей уникальности сайта.
- Затрудненное определение релевантности и веса страниц (поисковая система не может определить, какую страницу из дубликатов необходимо показывать по запросу).
- Зачастую дубли страниц имеют одинаковые мета-теги, что также негативно сказывается на ранжировании.
Как появляются дубликаты
Технические ошибки
К ним относят доступность страниц сайта:
- по www и без www;
- со слэшем на конце и без;
- с index.php и без него;
- доступность страницы при добавлении различных GET-параметров.
Особенности CMS
- страницы пагинации сайта;
- страницы сортировки, фильтрации и поиска товаров;
- передача лишних параметров в адресе страницы.
Важно! Также дубли страниц могут появляться за счет доступности первой страницы пагинации по двум адресам: http://site.ru/catalog/name/?PAGEN_1=1 и http://site.ru/catalog/name/.
Дубликаты, созданные вручную
Один из наиболее частых примеров дублирования страниц — привязка товаров к различным категориям и их доступность по двум адресам. Например: http://site.ru/catalog/velosiped/gorniy/stern-bike/ и http://site.ru/catalog/velosiped/stern-bike/.
Также страницы могут повторяться, если структура сайта изменилась, но старые страницы остались.
Поиск дублей страниц сайта
Существует большое количество методов нахождения дубликатов стра
Как проверить дублированный контент: обзор и инструменты
Вы, наверное, знаете, что ваш сайт всегда должен содержать оригинальный контент. Если ваш сайт содержит дублированный контент, это огромная ошибка, которая может нанести ущерб вашему рейтингу сайта и вашей репутации. Плагиат или выдача чужой работы за свою без разрешения недопустимы как в Интернете, так и в автономном режиме. За дублированный контент вы можете быть оштрафованы Google, понизив рейтинг вашей страницы или полностью исключив вашу веб-страницу из результатов поиска.Это вообще противоречит цели публикации контента.
Другая возможность, которую вы должны учитывать, заключается в том, что другие могут дублировать контент на вашем сайте и пытаться использовать его без вашего разрешения. Эти недобросовестные маркетологи могут откровенно использовать контент, созданный вами на их веб-сайтах, даже не спрашивая вас и не сообщая вам об этом, и в конечном итоге они могут превзойти вас в рейтинге поисковых систем.
Как определяется повторяющийся контент?
Дублированный контент — это контент, который появляется более чем в одном месте в Интернете, то есть на разных веб-сайтах.Если вы публикуете свой собственный контент более чем в одном месте, у вас будет дублированный контент. Если вы копируете чужой контент на свой сайт или они публикуют ваш контент на своем сайте, это дублированный контент.
Поисковым системам может быть трудно определить, какой контент более релевантен запросу в поисковой системе, когда контент слишком похож. Цель поисковых систем — предоставить пользователям наилучшие возможные результаты при поиске определенного термина. Google и другие поисковые системы могут исключить повторяющийся контент из своих поисковых запросов.
Некоторые причины дублирования содержимого
Во многих случаях использование дублированного содержимого не является преднамеренным или преднамеренным для злонамеренных действий. Google обращается к дублированному контенту как к блокам текста, которые идентичны или существенно похожи внутри или между доменами. Примеры не вредоносного дублированного контента включают описания товаров в магазине и версии веб-страниц только для печати.
Умышленное дублирование контента — другое дело. Когда один и тот же контент используется в нескольких доменах в попытке увеличить трафик или манипулировать рейтингом в поисковых системах, это может расстраивать людей, которые пытаются искать информацию и в конечном итоге получают один и тот же контент в нескольких местах.Вот почему поисковые системы делают все возможное, чтобы воспрепятствовать этой практике.
Бесплатные инструменты для проверки дублированного контента
При написании контента вы можете непреднамеренно сделать его слишком похожим на уже опубликованный контент. Всегда полезно дважды проверять все, что вы пишете, с помощью средств проверки на плагиат, чтобы убедиться, что ваш контент рассматривается как уникальный. Некоторые из этих инструментов доступны бесплатно.
Вот несколько хороших бесплатных инструментов, которые можно использовать для проверки дублированного контента:
Copyscape — этот инструмент может быстро проверить контент, который вы написали, относительно уже опубликованного контента за считанные секунды.Инструмент сравнения выделит контент, который отображается как повторяющийся, и сообщит вам, какой процент вашего контента соответствует уже опубликованному контенту.
Plagspotter — этот инструмент может определять повторяющиеся страницы контента в Интернете. Это отличный инструмент для поиска плагиатов, укравших ваш контент. Это также позволяет вам еженедельно автоматически отслеживать ваши URL-адреса для выявления дублирующегося контента.
Duplichecker — Этот инструмент быстро проверяет оригинальность контента, который вы планируете разместить на своем сайте.Зарегистрированные пользователи могут выполнять до 50 поисков в день.
Siteliner — это отличный инструмент, который может проверять весь ваш сайт один раз в месяц на наличие дублированного контента. Он также может проверять неработающие ссылки и определять страницы, наиболее заметные для поисковых систем.
Smallseotools — доступны различные инструменты SEO, в том числе средство проверки на плагиат, которое идентифицирует фрагменты идентичного контента.
И если вы хотите копнуть глубже, эти ссылки также предлагают больше инструментов по доступной цене.
Премиум-инструменты для проверки на плагиат
Премиум-программы для проверки на плагиат имеют возможность проверять дублированный контент с помощью передовых алгоритмов. Они дают вам уверенность в том, что ваша работа не будет приписана тому, кто ее не писал.
Премиум-инструменты для борьбы с плагиатом обычно предлагают отчеты, которые могут подтвердить подлинность. Будущие выводы о том, что ваша работа не является оригинальной, могут противоречить этим отчетам, которые можно сохранить в формате PDF.
Примеры дополнительных инструментов для проверки дублированного контента:
Grammarly — их премиальный инструмент предлагает как средство проверки на плагиат, так и проверку грамматики, выбора слов и структуры предложения.
Plagium — Предлагает бесплатный быстрый поиск или расширенный глубокий поиск.
Plagiarismcheck.org — обнаруживает точные совпадения и перефразированный текст.
Ваш контент был очищен?
Содержание вашего веб-сайта должно быть полностью оригинальным, и указанные выше инструменты могут помочь вам убедиться, что вы случайно не сделали свой контент слишком похожим на контент, который появляется на чужом веб-сайте.
Другая причина постоянно проверять дублирующийся контент — это веб-сайты, которые намеренно крадут контент из чужого блога, чтобы использовать его самостоятельно. Обычно это делается с помощью автоматизированного программного обеспечения. Если у вас есть привычка проверять контент на своем собственном сайте, вы можете обнаружить, что часть его была очищена. Как можно ловить парсеры контента? Что делать, если вы обнаружите, что ваш контент дословно опубликован на чужом сайте?
Способы обнаружения парсеров контента
Регулярное использование премиальных инструментов для борьбы с плагиатом может помочь вам найти контент, который вы написали на чужом сайте.Есть еще несколько способов отловить скопированный контент.
Обратные ссылки в WordPress могут отображаться в спаме, если вы используете Askimet. Если в вашем контенте всегда есть ссылки на некоторые из ваших постов, вы сможете найти парсеры контента таким образом.
Воспользуйтесь инструментами для веб-мастеров и проверьте ссылки на свой сайт. Когда у вас есть большое количество ссылок с определенного сайта, вы можете обнаружить, что часть вашего контента была скопирована на их. Единственный способ быть уверенным — это посетить их сайт и проверить, какие страницы ссылаются на ваш сайт.Вы можете найти свой собственный контент на их сайте.
Используйте оповещения Google, чтобы получать уведомления, если какие-либо заголовки ваших сообщений появляются в сети после того, как ваш контент уже был опубликован.
Чем больше вы зарекомендуете себя в качестве авторитета в своей нише, тем больше вы можете обнаружить, что те, кто еще не установил свой собственный голос или авторитет, хотят заимствовать ваш. Это позволяет им предоставлять авторитетную информацию в своем блоге, не прилагая усилий для создания качественного контента.
Что делать со скреперами содержимого
Очистка содержимого неэтична. Как только вы обнаружите, что ваш контент был очищен, у вас есть несколько вариантов того, что вам следует делать.
Свяжитесь с владельцем веб-сайта, на котором опубликовано ваше содержимое, и сообщите ему, что вы нашли свое содержимое на его сайте. Владелец сайта может не знать, что на его сайт был добавлен украденный контент, поэтому дайте ему возможность сомневаться. Вы можете связаться с ними через их контактную форму или через любую из социальных сетей, в которых они участвуют.
Если это качественный сайт, дайте им возможность поддерживать контент в актуальном состоянии, указав вас как автора и ссылку на ваш сайт. Другой вариант — предложить написать исправленную статью в обмен на ссылку. Если это некачественный сайт, сообщите им, что вы хотите, чтобы ваш контент был немедленно удален.
Если нет очевидного способа связаться с владельцем веб-сайта, выполните поиск Whois. Это, вероятно, позволит вам узнать, кто они, если только он не зарегистрирован в частном порядке. Если вы все еще не можете узнать, кто является владельцем сайта, вы сможете узнать, кто его размещает, с помощью бесплатного инструмента Whoishostingthis.com. Свяжитесь с хостинговой компанией и сообщите им, что владелец веб-сайта публикует контент, защищенный авторским правом. Компании, предоставляющие услуги веб-хостинга, серьезно относятся к подобным жалобам и своевременно предлагают помощь.
Защита контента с помощью DMCA
Вы обладаете авторскими правами на любой исходный контент, который вы публикуете на своем сайте. Один из способов защитить себя — разместить на своем сайте значок DMCA. DMCA гласит, что они будут удалять бесплатно, если ваш контент будет украден, будучи защищенным одним из их значков.
DMCA помогает сдерживать воров и предлагает инструменты, которые помогут вам найти неавторизованные копии вашего контента на чужом сайте. Они быстро удалят плагиат, включая изображения и видео.
Заключительные мысли о повторяющемся содержании
Люди, которые выходят в Интернет для получения информации, ожидают найти оригинальный и полезный контент, и именно это они должны быть в состоянии найти. По возможности следует избегать дублирования контента. Контент должен быть хорошо написан и уникален, чтобы у читателей был лучший опыт работы в сети.
Изучите инструменты и технологии, необходимые для решения задач завтрашнего дня, с дипломом Professional в области цифрового маркетинга . Загрузите брошюру сегодня!
.Duplicate Page — плагин для WordPress
Дублирующих сообщений, страниц и настраиваемых сообщений легко с помощью одного щелчка. Вы можете дублировать свои страницы, сообщения и настраиваемые сообщения одним щелчком мыши, и они будут сохранены как выбранные вами параметры (черновик, частный, общедоступный, ожидающий).
Ключевые особенности в Duplicate Page Pro Editions
- Роли пользователей: Разрешить ролям пользователей получать доступ к дублирующейся странице.
- Типы сообщений: Фильтр для отображения ссылки на повторяющуюся страницу в типах сообщений.
- Расположение ссылки клонирования: Вариант отображения ссылки клонирования.
- Статус: Возможность выбора статуса повторяющихся сообщений.
- Перенаправление: Возможность перенаправления после нажатия на ссылку клонирования.
- Заголовок ссылки клонирования: Возможность изменить заголовок повторяющейся ссылки публикации.
- Префикс сообщения: Возможность добавления префикса сообщения.
- Пост-суффикс: Возможность добавления пост-суффикса.
- Editor : и многие другие фильтры и функции.
Купить Pro версии с различными функциями и поддержкой.
Свяжитесь с нами для поддержки пользователей только версии Pro.
Обновление до версии Pro
Как использовать
- Плагин первой активации.
- Перейти Выберите в меню настроек дубликата страницы на вкладке «Настройки» и настройках сохранения.
- Затем создайте новое сообщение / страницу или используйте старую.
- После щелчка по этой ссылке дубликат сообщения / страницы будет создан и сохранен как черновик, публикация, ожидающий, частный в зависимости от настроек.
Минимальные требования для дубликата страницы
- WordPress 3.3+
- PHP 5.x
- MySQL 5.x
- Загрузите папку
с дублирующейся страницейв каталог/ wp-content / plugins /. - Активируйте плагин с помощью меню «Плагины» в WordPress.
Я пробовал его с темой The7, и он не дублирует содержимое дублируемой страницы.Он просто запускает пустую страницу. Бесполезно …
Хорошая работа, плагин работает отлично.
Спасибо за это — отлично работает.
Работает хорошо, но не дублирует все. Он не дублирует автора или дату публикации. Возможно, сделайте их настраиваемыми.
Отлично работает. Очень простой и легкий в использовании, и он делает свое дело. Я сэкономил много часов дополнительной работы. Спасибо. Эухенио
Спасибо ребятам за этот плагин, я довольно часто им пользуюсь.
Посмотреть все 137 отзывов«Дубликат страницы» — программное обеспечение с открытым исходным кодом. Следующие люди внесли свой вклад в этот плагин.
авторов4.2 (26 марта 2020 г.)
- Проблема со строкой фиксированного перевода
4.1 (20 февраля 2020 г.)
4.0 (20 сентября 2019)
- Исправлена проблема дублирования пули
3.9 (6 августа 2019)
- Исправлены некоторые проблемы совместимости
3.8 (18 июля 2019)
- Исправлены проблемы совместимости с редактором GT3
3,7 (18 июля 2019 г.)
- Исправлены проблемы совместимости с другими редакторами
3.6 (16 июля 2019 г.)
- Исправления безопасности, внесенные в wordpress
3,5 (2 апреля 2019 г.)
- Совместимость с Гутенбергом и расширенными настраиваемыми полями
3,4 (1 апреля 2019 г.)
- Securi исправляет проблемы безопасности
3.3 (14 марта 2019)
- Совместимость с WordPress 5.1.1
3.2 (25 декабря 2018)
3.1 (5 декабря 2018)
3.0 (3 декабря 2018)
2.9 (16 ноября 2018 г.)
2.8 (20 октября 2018 г.)
- Совместимость с php 7.3 и wordpress 5.0
2.7 (28 июля 2018)
- удален бесполезный код AdSense
2.6 (24 марта 2018)
- Добавлено всплывающее окно регистрации и мелкие исправления.
2,5 (5 февраля 2018 г.)
- Устранение проблем с переводом.
2,4 (29 ноября 2017 г.)
- Дубликат страницы добавляет исходное имя сообщения исправлена.
2.3 (27 апреля 2017)
2.2 (28 января 2017)
2.1 (25 августа 2016)
- Новое текстовое поле добавлено на страницу настроек для суффикса дублирующегося заголовка сообщения, чтобы убрать путаницу с текущей дублирующейся страницей.
1.4 (18 июня 2016 г.)
1.3 (23 мая 2016 г.)
1.2 (05 мая, 2016)
- Добавлено меню настроек повторяющейся страницы.
1.1 (4 мая 2016 г.)
.Найти дубликаты в списке резервирования

Поиск инструмента
Дубликаты в списке
Инструмент для дедупликации списка. Двойники или дубликаты — это повторяющаяся избыточная информация, представленная дважды (или более) в списке, обычно бесполезная.
Результаты
Дубликаты в списке — dCode
Тег (и): Обработка данных
Поделиться

dCode и вы
dCode является бесплатным, а его инструменты являются ценным подспорьем в играх, математике, геокэшинге, головоломках и задачах, которые нужно решать каждый день!
Предложение? обратная связь? Жук ? идея ? Запись в dCode !
Инструмент для дедупликации списка.Двойники или дубликаты — это повторяющаяся избыточная информация, представленная дважды (или более) в списке, обычно бесполезная.
Ответы на вопросы
Как убрать дубли в списке?
Укажите / скопируйте и вставьте элементы в поле списка. dCode определяет, является ли список списком терминов (по одному в строке) или списком слов (с разделителем), и находит повторяющиеся элементы более одного раза, чтобы не дублировать .
Пример: A, B, C, D, A, B, C, A, B, A можно дедуплицировать как A, B, C, D
Будьте осторожны, чтобы принять во внимание некоторые параметры
Вариант 1 : игнорировать диакритические знаки, в этом случае слова с акцентами, такие как item и ìtém, являются дубликатами , иначе нет.
Вариант 2: игнорировать прописные и строчные буквы, в этом случае элемент и ЭЛЕМЕНТ дублируют , иначе нет.
Как посчитать двойники в списке?
Перечисляя элементы, детектор dCode подсчитывает количество появлений каждого, список может быть отсортирован для обнаружения наиболее повторяющихся.
Задайте новый вопросИсходный код
dCode сохраняет за собой право собственности на исходный код онлайн-инструмента «Дубликаты в списке». За исключением явной лицензии с открытым исходным кодом (обозначенной CC / Creative Commons / free), любой алгоритм, апплет или фрагмент (конвертер, решатель, шифрование / дешифрование, кодирование / декодирование, шифрование / дешифрование, переводчик) или любая функция (преобразование, решение, дешифрование / encrypt, decipher / cipher, decode / encode, translate), написанные на любом информатическом языке (PHP, Java, C #, Python, Javascript, Matlab и т. д.)) доступ к данным, скриптам или API не будет бесплатным, то же самое касается загрузки Дубликатов в списке для автономного использования на ПК, планшете, iPhone или Android!
Нужна помощь?
Пожалуйста, заходите в наше сообщество в Discord для получения помощи!
Вопросы / комментарии
Сводка
Инструменты аналогичные
Поддержка
Форум / Справка
Рекламные объявления
Ключевые слова
дубликат, двойной, дублирование, избыточность, повторение, повторение, список, удаление, удаление, обнаружение, обнаружение, поиск, поиск
Ссылки
Источник: https: // www.dcode.fr/duplicates-detector
© 2020 dCode — Лучший «инструментарий» для решения любых игр / загадок / геокешинга / CTF. .Поиск дубликатов файлов — strchr.com
Вот интересная задача программирования: написать программу, которая находит все одинаковые файлы на вашем жестком диске. Файлы считаются идентичными , если они имеют одинаковое содержимое; их имена могут быть разными или нет. (По этому определению все файлы нулевой длины идентичны.)
Изучение возможных решений
Очевидно, что вы не можете сравнить каждый файл со всеми другими файлами на жестком диске за разумное время.Итак, должно быть реализовано своего рода хеширование: программа будет вычислять хеш для каждого файла и запоминать имя файла в хеш-таблице. После сканирования дерева папок программа может побайтно сравнить файлы с равными хэшами и найти, какие из них действительно идентичны (или просто предположить, что файлы идентичны, если хеш-функция предоставляет почти уникальных значений. ). Хеш-таблица — это решение O (N), которое для этой задачи быстрее, чем отсортированный список.
Какую хеш-функцию использовать? Возможная идея — хеширование содержимого файла с помощью функции MD5 или CRC.Однако для этого необходимо прочитать все файлы на диске (несколько гигабайт данных).
Лучшее решение
Идеальная хеш-функция могла бы читать только записи файлов в каталоге без открытия файлов и чтения их содержимого. К сожалению, популярные файловые системы не хранят CRC файлов (такие форматы архивов, как ZIP или RAR, так что вы можете искать дубликаты, не распаковывая файлы).
Давайте взглянем на запись каталога (например, структуру WIN32_FIND_DATA) и посмотрим, что можно использовать для сравнения файлов.Здесь у вас есть имя файла, дата модификации / создания, атрибуты и размер файла. Очевидно, одинаковые файлы имеют одинаковый размер.
Программа может сканировать каталоги и помещать файлы одинакового размера в одну и ту же запись хеш-таблицы. Затем он сравнивает найденные файлы (пропуская записи хеш-таблицы, содержащие только 1 файл). Для всех файлов одинакового размера рассчитывается хеш SHA-512. Файлы считаются идентичными, если их хэши SHA-512 равны. Как правило, программе требуется прочитать только несколько файлов и вычислить их хеш-коды SHA-512, поскольку файлы с разными размерами пропускаются.
# Найти файлы одинакового размера
samesize = {}
для пути, _, имен файлов в os.walk (DIRECTORY, onerror = raise_err):
для имени файла в именах файлов:
fullname = join (путь, имя файла)
samesize.setdefault (getsize (полное имя), []). append (полное имя)
# Вычислить хэши SHA-512 для этих файлов
для имен файлов в samesize.values ():
если len (имена файлов)> 1:
хеши = {}
для имени файла в именах файлов:
hashes.setdefault (hash_file (имя файла), []). append (имя файла)
# Распечатать файлы с одинаковым значением хэша
для идентичных файлов в хэшах.ценности():
если len (идентичные файлы)> 1:
print ('\ n'.join (одинаковые файлы) +' \ n ')
Загрузить полный код Python 3.0
Улучшения
- При поиске по всему NTFS-диску вы можете сканировать MFT вместо каталогов, как это делают NDFF и TFind. MFT работает более или менее непрерывно, в то время как каталоги разбросаны по диску, поэтому поиск в них занимает больше времени.
- Безусловно, программа будет быстрее, если переопределить ее на C.
Заключение
С помощью такой программы поиска дубликатов вы можете освободить свой диск от ненужных файлов. Такие утилиты включены в Total Commander и различные инструменты очистки диска.
Процесс проектирования, используемый в этой статье, можно применить ко многим проблемам: изучить возможные решения, сформулировать идеальное решение и посмотреть, насколько вы к нему близки. Проанализируйте проблему на низком уровне (в этом случае посмотрите записи каталога и таблицу MFT).
.