Как правильно искать и удалять дубли страниц на сайте

13 июля Яндекс провел очередной вебинар для вебмастеров, посвященный одной из самых распространенных проблем при работе с сайтом с точки зрения поисковой оптимизации —выявлению и удалению дублей страниц и других ненужных документов. Александр Смирнов рассказал и показал, как работать со «Статистикой обхода» и архивами загруженных страниц, которые помогают находить дубли и служебные страницы. Также объяснил, как составлять robots.txt для документов такого типа.
Перед тем, как начать говорить о дублях, Александр дал определение дублирующей странице сайта:
Дубли – две или более страниц одного сайта, которые содержат идентичный или в достаточной мере похожий текстовый контент.
Довольно часто дубли – это одна и та же страница сайта, доступная по разным URL-адресам.
Причин появления дублей на сайте – множество и все они связаны с различными ошибками. Например:
Ошибки в содержимом страниц:
• некорректные относительные ссылки
• отсутствие текста
Некорректные настройки:
• HTTP-200 вместо HTTP-404
• доступность служебных страниц
Ошибки в CMS:
• особенности структуры
Большое количество возможных причин возникновения дублей обычно очень гнетет вебмастеров и они откладывают их поиск в долгий ящик, не желая тратить на это время. Делать этого не стоит, так как наличие дублей страниц на сайте зачастую приводит к различным проблемам.
01 | Опасность дублей на сайте
Проблемы, к которым приводят дубли:
• Смена релевантной страницы в результатах поиска
• Затруднение сбора статистики
Смена релевантной страницы
Например, на сайте есть бухгалтерские услуги, описание которых доступно по двум адресам:
site.ru/uslugi/buhgalterskie-uslugi/
site.ru/buhgalterskie-uslugi/
Первый адрес находится в разделе «Услуги», а второй адрес – это страничка в корне сайта. Контент обеих страниц абсолютно одинаков.
Робот не хранит в своей базе несколько идентичных документов, поэтому в поиске остается только один из них – на усмотрение робота. Кажется, что в этом нет ничего плохого, ведь страницы идентичны. Однако опытные вебмастера знают, что позиции конкретной страницы по запросам рассчитываются на основании нескольких сотен показателей, поэтому при смене страницы в поисковой выдаче, позиции могут измениться.
Именно так и произошло в случае с бухгалтерскими услугами – по конкретному запросу [услуги бухгалтерского учета] в середине июня произошло конкретное проседание позиций, чтобы было связано со сменой релевантной страницы в поисковой выдаче.

Через некоторое время релевантная страница вернулась в выдачу, однако совершенно очевидно, что даже такое небольшое изменение может повлиять на количество трафика на ресурс.
Обход дублирующих страниц
При наличии большого количества дублей на ресурсе, поисковому роботу приходится постоянно посещать большое количество страниц. Поскольку количество запросов со стороны индексирующего робота ограничено (производителем сервера или CMS сайта, вебмастером с помощью директивы Crawl-delay), он, при наличии большого количества дублирующих страниц, начинает скачивать именно их, вместо того чтобы индексировать нужные страницы сайта. В результате в поисковой выдаче могут показываться какие-то неактуальные данные и пользователи не смогут найти нужную им информацию, хоть она и размещена на сайте.
Пример из практики по обходу дублирующих страниц, из которого видно, что до конца мая робот ежедневно скачивал чуть меньше миллиона страниц интернет-магазина. После обновления ресурса и внесения изменений на сайт, робот резко начинает увеличивать нагрузку на ресурс, скачивая по несколько миллионов страниц в день:

Большая часть этих страниц – дубли, с некорректными GET-параметрами, которые появились из-за некорректной работы CMS, используемой на сайте.
Проблемы со сбором статистики в Яндекс.Вебмастере и Яндекс.Метрике
Если говорить о Вебмастере, то в разделе «Страницы в поиске» можно наблюдать вот такую картину:

При каждом обновлении поисковой базы, количество страниц в поиске остается практически неизменным, но видно, что робот при каждом обновлении добавляет и удаляет примерно одинаковое количество страниц. То есть какой-то процесс происходит, постоянно что-то удаляется и добавляется, при этом количество страниц в поиске остается неизменным. Если посмотреть статистику обхода, то мы увидим, что ежедневно робот посещает несколько тысяч новых страниц сайта, при этом эти новые страницы в поисковую выдачу не попадают. Это как раз-таки и связано с обходом роботом дублирующих страниц, которые потом в поисковую выдачу не включаются.
Если смотреть статистику посещаемости конкретной страницы в Яндекс. Метрике, то может возникнуть следующая ситуация: данная страница показывалась ранее по конкретному запросу и на нее были переходы из результатов поиска, которые почему-то прекратились в начале мая:

А произошло следующее – включилась в поисковую выдачу дублирующая страница, и пользователи с поиска начали переходить на нее, а не на нужную страницу сайта.
Казалось бы, эти три большие проблемы, вызываемые наличием дублей страниц на сайте, должны мотивировать вебмастеров к их устранению. А чтобы удалить дубли с сайта, сначала их нужно найти.
02 | Поиск дублей
— Видишь дублирующие страницы?
— Нет.
— И я нет. А они есть.
Самый простой способ искать дублирующие страницы – это с помощью раздела «Страницы в поиске» в Яндекс.Вебмастере:
Страницы в поиске -> Исключенные страницы -> Сортировка: Дубль -> Применить

В результате можно увидеть все страницы, которые исключил робот, посчитав их дублирующими.
Если таких страниц много, например, несколько десятков тысяч, можно полученную страницу выгрузить из Вебмастера и дальше использовать ее по своему усмотрению.
Второй способ
Статистика обхода -> Сортировка: 200 (ОК)

В этом разделе можно увидеть не только страницы, которые посещает робот, не только дубли, но и различные служебные страницы сайта, которые в поиске видеть бы не хотелось.
Третий способ – с применением фантазии.
Берем любую страницу сайта и добавляем к ней произвольный GET-параметр (в нашем случае это /?test=123. При помощи инструмента «Проверка ответа сервера», проверяем код ответа от данной страницы:

Если данная страница доступна и отвечает, как на скриншоте, кодом ответа 200, то это может привести к появлению дублирующих страниц на сайте. Например, если робот найдет где-то такую ссылку в интернете, он ее проиндексирует и потенциально она может стать дублирующей.
Четвертый способ – это проверка статуса URL.
В ситуации, когда нужная страница уже пропала из результатов поиска, при помощи этого инструмента можно проверить, по каким именно причинам это произошло:

В данном случае видно, что страница была исключена из поиска поскольку является дублем.
Кроме этих четырех способов можно использовать еще какие-то свои способы, например: посмотреть логи своего сервера, статистику Яндекс.Метрики, в конце концов, посмотреть поисковую выдачу, там тоже можно выявить дублирующие страницы.
03 | Устранение дублей
Все возможные дубли страниц можно разделить на две категории:
• Явные дубли (полностью идентичный контент)
• Неявные дубли (страницы с похожим содержимым)
Внутри этих двух категорий представлено большое количество видов дублей, на которых сейчас мы остановимся подробней и разберемся, как их можно устранить.
1. Страницы со слэшом в конце адреса и без
Пример:
site.ru/page
site.ru/page/
Что делаем:
— HTTP-301 перенаправление с одного вида страниц на другие с помощью .hitacces/CMS
Какие именно страницы нужно оставлять для робота решает сам вебмастер в каждом конкретном случае. Можно посмотреть на страницы своего сайта в поиске, какие из них присутствуют в нем в данный момент, и принимать решение, исходя из этих данных.
2. Один и тот же товар в нескольких категориях
Пример:
site.ru/игрушки/мяч
site.ru/мяч
Что делаем:
— Используем атрибут rel=”canonical” тега <link>
Оставлять для робота лучше те страницы, формат адресов которых наиболее удобен для посетителей сайта.
3. Страницы версий для печати
Пример:

Что делаем:
Используем запрет в файле robots.txt, который укажет роботу, что все страницы с подобными адресами индексировать нельзя —
Disallow://node_print.php*
4. Страницы с незначащими параметрами
Пример:
site.ru/page
site.ru/page?utm_sourse=adv
site.ru/page?sid=e0t421e63
Что делаем:
Прибегаем к помощи специальной директивы Clean-param в robots.txt и указываем все незначащие параметры, которые используются на сайте –
Clean-param: sis&utm_sourse
5. Страницы действий на сайте
Пример:
site.ru/page?add_basket=yes
site.ru/page?add_compare=list
site.ru/page?comment_page_1
Что делаем:
Запрет в robots.txt –
Disallow:* add_basket=* Disallow:* add_compare=* Disallow:* comment_*Или
Disallow:*?*
6. Некорректные относительные адреса
Пример:
site.ru/игрушки/мяч
site.ru/игрушки/ игрушки/ игрушки/ игрушки/мяч
Что делаем:
1. Ищем источник появления
2. Настраиваем HTTP-404 на запросы робота
7. Похожие товары
Пример:
— товары отличаются характеристиками (размером, цветом)
— похожие товары одной категории
Что делаем:
— Оставляем товар на одном URL и используем селектор (возможность выбора нужного цвета и размера)
— Добавляем на такие страницы дополнительное описание, отзывы
— Закрываем ненужное в noindex
8. Страницы с фотографиями без описания
Пример:
Страницы фотогалерей, фотобанков
Что делаем:
— Добавляем дополнительное описание, теги
— Открытие комментариев на странице
9. Страницы фильтров и сортировки
Пример:
site.ru/shop/catalog/podarki/?sort=minimum_price&size=40
site.ru/shop/catalog/filter/price-from-369-to-804/pr_material-f22-or-c5/
Что делаем:
— Определяем востребованность и полезные оставляем
— Для бесполезных прописываем запрет в robots.txt –Disallow:*sort=* Disallow:*size=* Disallow:*/filter/*
10. Страницы пагинации
Пример:
site.ru/shop/catalog/podarki/
site.ru/shop/catalog/podarki/?page_1
site.ru/shop/catalog/podarki/?page_2
Что делаем:
Используем атрибут rel=”canonical” тега <link>
04 | Выводы:
Причины возникновения и виды дублей разнообразны, поэтому различными и должны быть подходы к ним с точки зрения поисковой оптимизации. Не нужно их недооценивать. Почаще нужно заглядывать в Вебмастер и своевременно вносить соответствующие изменения на сайт.
Шпаргалка по работе с дублями:

www.searchengines.ru
Что такое дубли страниц? Как найти дубли страниц? tipsite
Всем привет! В этой статье на Tipsite.ru мы разберемся с тем, что такое дубли страниц и как найти дубли страниц.
Тема эта очень и очень важная, поскольку дубли негативно сказываются на продвижении сайта и… Хотя не буду забегать наперед, поскольку об этом подробнее поговорим по ходу данной статьи. И чтобы не ходить вокруг да около, сразу перейдем к первому вопросу.
Что такое дубли страниц?
Согласно словарям, дубль означает «повторение» или «двойной».
Значит, в нашем случае дубль страницы – это копия или повтор определенной страницы, в общем, клон. Причем одинаковым может быть либо содержимое страницы, либо ее адрес (URL).
То есть, если на вашем блоге присутствует две страницы с одинаковым содержанием, но разными адресами, то это дубль. Точно также, если есть две страницы с разным содержанием, но одинаковым адресом (URL), это тоже дубль.
Хочу заметить, что дубли страниц бывают полными и неполными (частичными). Если, к примеру, содержимое двух страниц полностью совпадает, то это полный дубль. Ну и, соответственно, когда совпадение страниц частичное, то и дубль называется неполным.
Ну вот, с терминологией разобрались, теперь можно переходит к следующему вопросу.
Чем опасны дубли страниц?
Главная опасность дублей страниц заключается в том, что они очень уж «раздражают» поисковые системы. И если Яндекс ведет себя еще более-менее сносно, то Гугл просто рвет и мечет. Наличие большого количества дублей на сайте может привести к серьезным проблемам в его продвижении.
1) Если две страницы содержат одинаковый контент (текст), то в глазах поисковиков они, естественно, не уникальны. А теперь представим, что на каком-либо сайте имеется 100 страниц и все они обзавелись дублями 😯 . Получается, все, что было нажито непосильным трудом, все пропало! Тексты, которые писал автор, для поисковиков будут неуникальными. Из-за этого сайт может значительно потерять свои позиции в поисковой выдаче.
2) Дубли «размывают» вес страницы. Каждая страница имеет свой статический вес. При наличии дублей этот вес размывается. А зачем оно нам надо? Правильно, не зачем!
3) Ссылки, которые вы проставляете при внутренней перелинковке, могут уводить не на основную страницу, а на ее дубликат, что не есть хорошо.
4) В особо тяжелых случаях поисковые роботы могут посчитать дубль страницы более релевантным (актуальным, точным) запросам пользователей, чем оригинал.
Как видите, дубли страниц – это зло, с которым нужно бороться. Они мешают продвижению сайта, а в некоторых случаях делают его невозможным.
Известны случаи, когда популярные сайты начинали терять свои позиции и трафик, а вебмастера рвали себе волосы на голове и не могли понять, в чем дело. В дальнейшем выяснялось, что проблема была в сотнях и тысячах (!) дублей. Как я уже говорил, Google очень жестко борется с дублями и задвигает сайты с ними куда-нибудь подальше. Яндекс, конечно, более лоялен в этом вопросе – обычно он просто склеивает дубли, но в любом случае, продвижению сайта это не способствует.
Откуда берутся дубли страниц?
Вопрос логичный и интересный. Как появляются эти самые дубли? А причин для этого может быть несколько.
1) Плодить дубли может движок вашего сайта (CMS). Хотя чаще всего в этом обвиняют WordPress, но та же Joomla или DLE клепают дубли ничуть не хуже. Чаще всего дубли появляются на страницах рубрик, архивов, RSS и комментариев (comments, replytocom). Одним из способов избавиться от такого мусора является создание правильного robots.txt, в котором ненужные страницы запрещаются для индексирования. Правда, в случае с Гуглом такой метод не гарантирует 100% результата.
2) Отсутствие 301-ого редиректа. Если ваш сайт доступен по такому адресу – site.ru, и по такому – www.site.ru, то это очень плохо. Для поисковых систем это два разных сайта, а с учетом того, что их содержимое совершенно одинаковое, ждать чего-то хорошего в этом случает не стоит, ведь это очевидный дубль, причем в очень больших масштабах. Основной адрес сайта (главное зеркало) должен быть один и настроить его поможет 301-й редирект.
3) Ошибки вебмастера. Конечно, вебмастер не сможет слишком нашкодить сайту и тем более он не станет это делать намеренно. Но иногда из-за невнимательности или спешки автор может прописать одинаковое название (Title) двум статьям. Бывали случаи, когда вебмастер публиковал одну и ту же статью два раза. Результат таких провалов – дубли!
Это основные причины появления дублей страниц на сайте. Возможно, есть и другие специфические варианты, но встречаются они намного реже. Ну а теперь переходим к самому интересному вопросу.
Как найти дубли страниц?
Для начала можно посмотреть общую картину с количеством проиндексированных страниц в поисковиках. В этом нам поможет очень полезное расширение для браузера – RDS Bar. Прежде всего нужно подсчитать примерное количество страниц на сайте. У меня на Tipsite.ru на данный момент должно индексироваться примерно 80 страниц. Теперь смотрим, что показывает RDS Bar.
В индексе Яндекса присутствует 83 страницы, что в пределах нормы, а вот Google проиндексировал 144 страницы. Из них 60% (примерно 86 страниц) находится в основном индексе, а вот остальные 40% (58 страниц) – это, так называемые «сопли». Такое прикольное название возникло из-за того, что кроме основного индекса у Google есть еще один – Supplemental Index, который переводится, как «дополнительный». Ну а при попытке прочитать это заграничное слово буквально, получается очень веселое название.
Итак, с общей картиной ознакомились, теперь можно переходит к более точным данным. Начнем с Google. Для этого в адресной строке браузера пишем вот такой запрос: site:tipsite.ru/& (вместо tipsite.ru подставляйте адрес своего сайта). После этого в результатах поиска мы увидим все страницы сайта без «соплей», которые находятся в основном индексе Google.
Теперь пишем немного другой запрос: site:tipsite.ru. В результатах будут показаны все проиндексированные страницы вместе с «соплями».
Переходим на последнюю страницу и нажимаем на неприметную ссылку «Показать скрытые результаты».
Снова двигаемся ближе к концу выдачи и видим, что за «сопли» попали в индекс.
В моем случае это лента RSS. Что самое интересное, эти файлы у меня закрыты от индексации в robots.txt. Сам Google этого тоже не отрицает и вместо сниппета пишет про ограничения в robots.txt, но несмотря на это в индекс, почему то, добавил.
Что касается Яндекса, то с ним все просто и ясно. Он либо индексирует страницу, либо нет и никаких «соплей» в индексе не развешивает. Да и то, что запрещено для индексации в robots.txt Яндекс трогать не будет. Чтобы просмотреть, какие страницы находятся в индексе Яндекса нужно набрать уже знакомый запрос: site:tipsite.ru.
Еще один вариант отыскать дубли страниц – это воспользоваться расширенным поиском. В Яндексе расширенный поиск доступен по адресу https://yandex.ru/search/advanced, ну а в Google вначале нужно нажать «Настройки», а там уже до расширенного поиска рукой подать.
Итак, открываем окно расширенного поиска и вписываем отрывок какой-либо статьи, а также адрес своего сайта. После этого нажимаем кнопку «Найти» и смотрим результаты.
В моем случае дубли не были найдены.
Ну и напоследок хочу рассказать про автоматический способ поиска дублей. В этом деле нам поможет программка Xenu, которая также неплохо ищет битые ссылки, или же Google Webmaster. В пункте «Оптимизация HTML» можно увидеть повторяющиеся метаописания и заголовки, которые могут оказаться дублями страниц.
На этом данная статья подходит к завершению. Те, кто внимательно ее прочитал, теперь точно знают, что такое дубли страниц и как их найти. В следующей статье я расскажу, как бороться с дублями, то есть, как от них избавиться. Подписывайтесь на обновления Tipsite.ru, чтобы не пропустить публикацию данного поста. Благодарю вас за внимание и пока!
tipsite.ru
Все о том, как найти дубли страниц на сайте… и убрать
Все, что вы хотели найти про дубли страниц на сайте и дублирование контента. Узнайте 7 методов, чтобы проверить, найти и убрать все, что мешает развитию.
Неважно какой движок у вашего сайта: Bitrix, WordPress, Joomla, Opencart… Проверка сайта на дубли страниц может выявить эту проблему и её придется срочно решать.
Дублирование контента, равно как и дубли страниц на сайте, является большой темой в области SEO. Когда мы говорим об этом, то подразумеваем наказание от поисковых систем.
Этот потенциальный побочный эффект от дублирования контента едва ли не самый важный. Даже с учетом того, что Google по сути почти никогда не штрафует сайты за дублирование информации.
Наиболее вероятные проблемы для SEO из-за дублей:
Потраченный краулинговый бюджет.
Если дублирование контента происходит внутри веб-ресурса, гарантируется, что вы потратите часть краулингового бюджета (выделенного лимита на количество индексируемых за один заход страниц) при обходе дублей страниц поисковым роботом. Это означает, что важные страницы будут индексироваться менее часто.
Разбавление ссылочного веса.
Как для внешнего, так и для внутреннего дублирования контента разбавление ссылочного веса является самым большим недостатком для SEO. Со временем оба URL-адреса могут получить обратные ссылки. Если на них отсутствуют канонические ссылки (или 301 редирект), указывающие на исходный документ, вес от ссылок распределится между обоими URL.
Только один вариант получит место в поиске по ключевой фразе.
Когда поисковик найдет дубли страниц на сайте, то обычно он выберет только одну в ответ на конкретный поисковый запрос. И нет никакой гарантии, что это будет именно та, которую вы продвигаете.
Любые подобные сценарии можно избежать, если вы знаете, как найти дубли страниц на сайте и убрать их. В этой статье представлено 7 видов дублирования контента и решение по каждому случаю.
Стоит заметить, что дубли контента могут быть не только у вас на сайте. Ваш текст могут просто украсть. Начнем разбор с этого варианта.
1 Копирование контента
Скопированное содержание в основном является неоригинальной частью контента на сайте, который был скопирован с другого сайта без разрешения. Как я уже говорилось ранее, Google не всегда может точно определить, какая часть является оригинальной. Так что задачей владельца сайта является поиск фактов копирования контента и принятие мер, если обнаружится факт кражи контента.
Увы, это не всегда легко и просто. Но иногда может помочь маленькая хитрость.
Отслеживайте сохранение уникальности ваших документов (если у вас есть блог, желательно это контролировать) с помощью каких-либо сервисов (например, text.ru) или программ. Скопируйте текст своей статьи и запустите проверку уникальности.
Конечно, если сайт содержит сотни статей, то проверка займет много времени. Поэтому я установил на данный сайт комментарии «Hypercomments» и включил функцию фиксации цитирования. Каждый раз, как кто-то скопирует кусок текста, он появляется во вкладке цитаты. Мне сразу видно, что был скопирован весь текст такой-то статьи. Это повод проверить её уникальность через некоторое время.
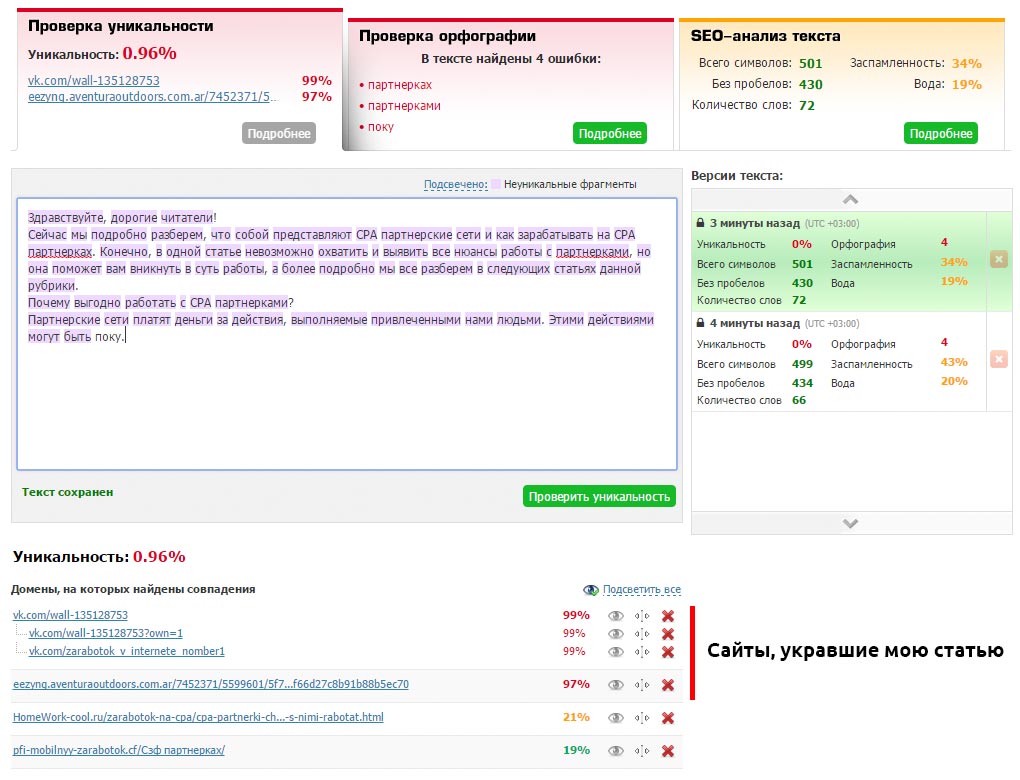
Таким образом вы найдет все сайты, которые содержат текст полностью или частично взятый с вашего сайта. В таком случае необходимо первым делом обратиться к веб-мастеру с просьбой удалить позаимствованный контент (или поставить каноническую ссылку, если это для вашего бизнеса работает и его сайт не слишком плохой в плане SEO). Если консенсус не будет достигнут, вы можете сообщить о копии в Google: отчет о нарушении авторских прав.
2 Синдикация контента
Синдикация – это переиздание содержания на другом сайте с разрешения автора оригинального произведения. И хотя она является законным способом получения вашего контента для привлечения новой аудитории, важно установить рекомендации для издателей, чтобы синдикация не превратилась в проблемы для SEO.
В идеале, издатель должен использовать канонический тег на статью, чтобы указать, что ваш сайт является первоисточником. Другой вариант заключается в применении тега noindex к синдицированному контенту.
Вариант 1: <link rel=»canonical» href=»http://site.ru/original-content» />
Вариант 2: <div rel=»noindex»>Синдицированный контент</div>
Всегда проверяйте это вручную каждый раз, когда разрешаете дублирование вашего контента на других сайтах.
3 HTTP и HTTPS протоколы
Одной из наиболее распространенных внутренних причин дублирования страниц на сайте является одновременная работа сайта по протоколам HTTP и HTTPS. Эта проблема возникает, когда перевод сайта на HTTPS реализован с нарушением инструкции, которую можно прочитать по ссылке. Две распространенные причины:
Отдельные страницы сайта на протоколе HTTPS используют относительные URL
Это часто актуально, если использовать защитный протокол только для некоторых страниц (регистрация/авторизация пользователя и корзина покупок), а для всех остальных – стандартный HTTP. Важно иметь в виду, что защищенные страницы могут иметь внутренние ссылки с относительными URL-адресами, а не абсолютными:
Абсолютный: https://www.homework-cool.ru/category/product/
Относительный: /product/
Относительные URL не содержат информацию о протоколе. Вместо этого они используют тот же самый протокол, что и родительская страница, на которой они расположены. Если поисковый бот найдет такую внутреннюю ссылку и решит следовать по ней, то перейдет по ссылке с HTTPS. Затем он может продолжить сканирование, пройдя по нескольким относительным внутренним ссылкам, а может даже просканировать весь сайт с защитным протоколом. Таким образом в индекс попадут две совершенно одинаковые версии ресурса.
В этом случае необходимо использовать абсолютные URL-адреса вместо относительных для внутренних ссылок. Если боту уже удалось найти дубли страниц на сайте, и они отобразились в панели вебмастера в Яндексе или Google, то установите 301 редирект, перенаправляя защищенные страницы на правильную версию с HTTP. Это будет лучшим решением.
Вы полностью перевели сайт на HTTPS, но HTTP версия все еще доступна
Это может произойти, если есть обратные ссылки с других сайтов, указывающие на HTTP версию, или некоторые из внутренних ссылок на вашем ресурсе по-прежнему содержат старый протокол.
Чтобы избежать разбавления ссылочного веса и траты краулингового бюджета используйте 301 редирект с HTTP и убедитесь, что все внутренние ссылки указаны с помощью относительных URL-адресов.
Чтобы быстро проверить дубли страниц на сайте из-за HTTP/HTTPS протокола, нужно проконтролировать работу настроенных редиректов.
4 Страницы с WWW и без WWW
Одна из самых старых причин для появления дублей страниц на сайте, когда доступны версии с WWW и без WWW. Как и HTTPS, эта проблема обычно решается за счет включения 301 редиректа. Также необходимо указать ваш предпочтительный домен в панели вебмастера Google.
Чтобы проверить дубли страниц на сайте из-за префикса WWW, так же редирект должен корректно работать.
5 Динамически генерируемые параметры URL
Динамически генерируемые параметры часто используются для хранения определенной информации о пользователях (например, идентификаторы сеансов) или для отображения несколько иной версии той же страницы (например, сортировка или корректировка фильтра продукции, поиск информации на сайте, оставление комментариев). Это приводит к тому, что URL-адреса выглядят следующим образом:
URL 1: https:///homework-cool.ru/position.html?newuser=true
URL 2: https:///homework-cool.ru/position.html?older=desc
Несмотря на то, что эти страницы будут содержать дубли контента (или очень похожую информацию), для поисковых роботов это повод их проиндексировать. Часто динамические параметры создают не две, а десятки различных версий страниц, которые могут привести к значительному количеству напрасно проиндексированных документов.
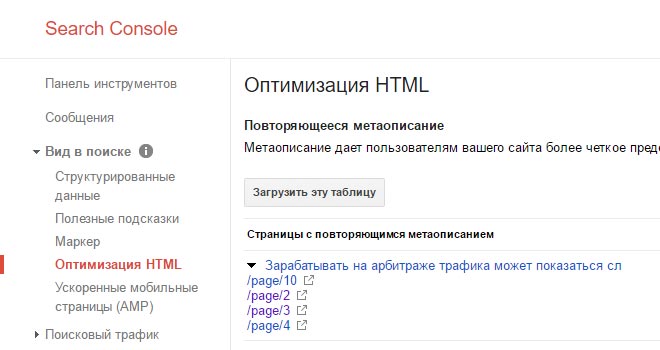
Найти дубли страниц на сайте можно с помощью панели вебмастера Google в разделе «Вид в поиске — Оптимизация HTML»
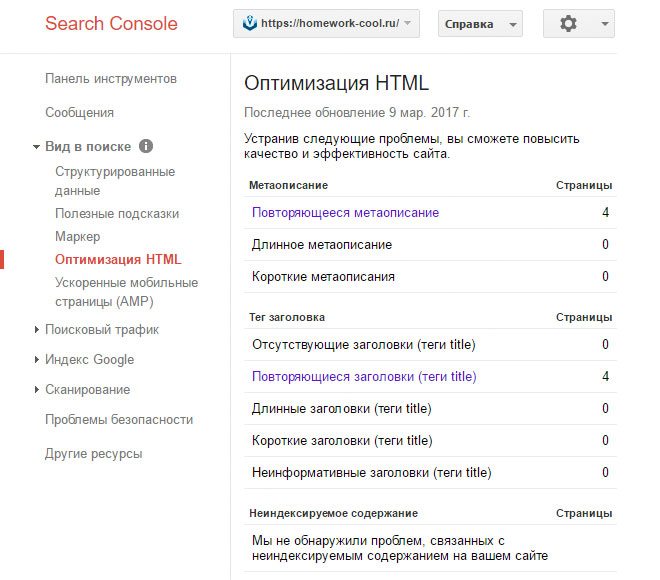
Яндекс Вебмастер покажет их в «Индексирование – Страницы в поиске»
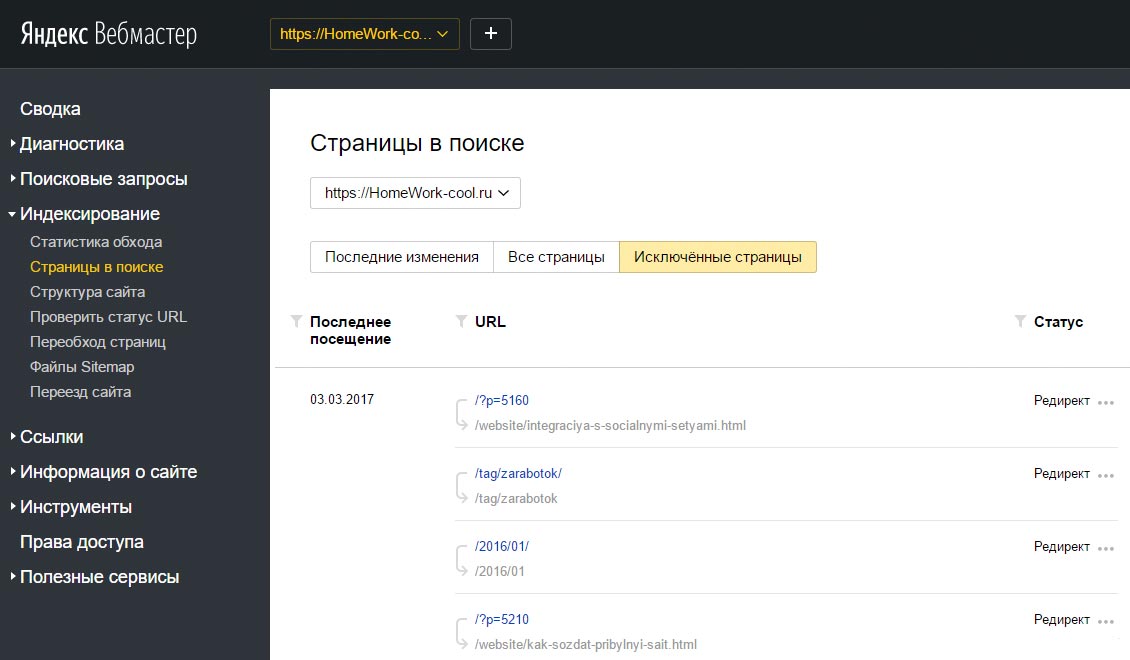
Для конкретного случая в индексе Google находятся четыре страницы пагинации с одинаковым метаописанием. А скриншот из Яндекса наглядно показывает, что на все «лишние» атрибуты в ссылках настроен редирект, включая теги.
Еще можно прямо в поисковике ввести в строку:
site:domen.ru -site:domen.ru/&
Таким образом можно найти частичные дубли страниц на сайте и малоинформативные документы, находящиеся в индексе Google.
Если вы найдете такие страницы на вашем сайте, убедитесь, что вы правильно классифицируете параметры URL в панели вебмастера Google. Таким образом вы расскажите Google, какие из параметров должны быть проигнорированы во время обхода.
6 Подобное содержание
Когда люди говорят про дублирование контента, они подразумевают совершенно идентичное содержание. Тем не менее, кусочки аналогичного содержания так же попадают под определение дублирования контента на сайте от Google:
«Если у вас есть много похожих документов, рассмотрите вопрос о расширении каждого из них или консолидации в одну страницу. Например, если у вас есть туристический сайт с отдельными страницами для двух городов, но информация на них одинакова, вы можете либо соединить страницы в одну о двух городах или добавить уникальное содержание о каждом городе»
Такие проблемы могут часто возникать с сайтами электронной коммерции. Описания для аналогичных продуктов могут отличаться только несколькими специфичными параметрами. Чтобы справиться с этим, попробуйте сделать ваши страницы продуктов разнообразными во всех областях. Помимо описания отзывы о продукте являются отличным способом для достижения этой цели.
На блогах аналогичные вопросы могут возникнуть, когда вы берете старую часть контента, добавите некоторые обновления и опубликуете это в новый пост. В этом случае использование канонической ссылки (или 301 редиректа) на оригинальный пост является лучшим решением.
7 Страницы версий для печати
Если страницы вашего сайта имеют версии для печати, доступные через отдельные URL-адреса, то Google легко найдет их и проиндексирует через внутренние ссылки. Очевидно, что содержание оригинальной статьи и её версии для печати будет идентичным – таким образом опять тратится лимит индексируемых за один заход страниц.
Если вы действительно предлагаете печатать чистые и специально отформатированные документы вашим посетителям, то лучше закрыть их от поисковых роботов с помощью тега noindex. Если все они хранятся в одном каталоге, таком как https://homework-cool.ru/news/print/, вы можете даже добавить правило Disallow для всего каталога в файле robots.txt.
Disallow: /news/print
Подведем итоги
Дублирование контента и скрытые дубли страниц на сайте могут обернуться головной болью для оптимизаторов, так как это приводит к потере ссылочного веса, трате краулингового бюджета, медленной индексации новых страниц.
Помните, что вашими лучшими инструментами для борьбы с этой проблемой являются канонические ссылки, 301 редирект и robots.txt. Не забывайте периодически проверять и обновлять контент вашего сайта с целью улучшения индексации и ранжирования в поисковых системах.
Какие случаи дублей страниц вы находили на своем сайте, какие методы используете, чтобы предотвратить их появление? Я с нетерпением жду ваших мыслей и вопросов в комментариях.
homework-cool.ru
Как найти и удалить дубли страниц на сайте?
Дубли страниц — документы, имеющие одинаковый контент, но доступные по разным адресам. Наличие таких страниц в индексе негативно сказывается на ранжировании сайта поисковыми системами.
Какой вред они могут нанести
- Снижение общей уникальности сайта.
- Затрудненное определение релевантности и веса страниц (поисковая система не может определить, какую страницу из дубликатов необходимо показывать по запросу).
- Зачастую дубли страниц имеют одинаковые мета-теги, что также негативно сказывается на ранжировании.
Как появляются дубликаты
Технические ошибки
К ним относят доступность страниц сайта:
- по www и без www;
- со слэшем на конце и без;
- с index.php и без него;
- доступность страницы при добавлении различных GET-параметров.
Особенности CMS
- страницы пагинации сайта;
- страницы сортировки, фильтрации и поиска товаров;
- передача лишних параметров в адресе страницы.
Важно! Также дубли страниц могут появляться за счет доступности первой страницы пагинации по двум адресам: http://site.ru/catalog/name/?PAGEN_1=1 и http://site.ru/catalog/name/.
Дубликаты, созданные вручную
Один из наиболее частых примеров дублирования страниц — привязка товаров к различным категориям и их доступность по двум адресам. Например: http://site.ru/catalog/velosiped/gorniy/stern-bike/ и http://site.ru/catalog/velosiped/stern-bike/.
Также страницы могут повторяться, если структура сайта изменилась, но старые страницы остались.
Поиск дублей страниц сайта
Существует большое количество методов нахождения дубликатов страниц на сайте. Ниже описаны наиболее популярные способы:
- программа Screaming Frog;
- программа Xenu;
- Google Webmaster: «Вид в поиске» -> «Оптимизация HTML»;
- Google Webmaster: «Сканирование» -> «Оптимизация HTML».
Для программы Screaming Frog и Xenu указывается адрес сайта, и после этого робот собирает информацию о нем. После того, как робот просканирует сайт, выбираем вкладку Page Title — Duplicate, и анализируем вручную список полученных страниц.

С помощью инструмента «Оптимизация HTML» можно выявить страницы с одинаковыми description и title. Для этого в панели Google Webmaster надо выбрать необходимый сайт, открыть раздел «Вид в поиске» и выбрать «Оптимизация HTML».

C помощью инструмента «Параметры URL» можно задать параметры, которые необходимо индексировать в адресах страниц.

Для этого надо выбрать параметр, кликнуть на ссылку «Изменить» и выбрать, какие URL, содержащие данный параметр, необходимо сканировать.
Также, найти все индексируемые дубли одной страницы можно с помощью запроса к поиску Яндекса. Для этого в поиске Яндекса необходимо ввести запрос вида site:domen.ru «фраза с анализируемой страницы», после чего проанализировать вручную все полученные результаты.

Как правильно удалить дубли
Чтобы сайт открывался лишь по одному адресу, например «http://www.site.ru/catalog/catalog-name/», а не по «http://site.ru/catalog/catalog-name/index.php», необходимо корректно настроить 301 редиректы в файле htaccess:
- со страниц без www, на www;
- со страниц без слэша на конце, на «/»;
- со страниц с index.php на страницы со слэшем.
Если вам необходимо удалить дубликаты, созданные из-за особенностей системы управления сайтом, надо правильно настроить файл robots.txt, скрыв от индексации страницы с различными GET-параметрами.
Для того чтобы удалить дублирующие страницы, созданные вручную, нужно проанализировать следующую информацию:
- их наличие в индексе;
- поисковый трафик;
- наличие внешних ссылок;
- наличие внутренних ссылок.
Если неприоритетный документ не находится в индексе, то его можно удалять с сайта.
Если же страницы находятся в поисковой базе, то необходимо оценить, сколько поискового трафика они дают, сколько внешних и внутренних ссылок на них проставлено. После этого остается выбрать наиболее полезную.
После этого необходимо настроить 301-редирект со старой страницы на актуальную и поправить внутренние ссылки на релевантные.
blog.arealidea.ru
Как избавиться от дублей страниц
![]() Всем привет! В прошлой статье мы затронули важную тему — поиск дублей страниц сайта. Как показали комментарии и несколько пришедших мне на почту писем, эта тема актуальна. Дублированный контент на наших блогах, технические огрехи CMS и различные косяки шаблонов не дают нашим ресурсам полной свободы в поисковых системах. Поэтому нам приходится с ними серьезно бороться. В этой статье мы узнаем как можно убрать дубли страниц любого сайта, примеры этого руководства покажут как от них можно избавиться простым способом. От нас просто требуется использовать полученные знания и следить за последующими изменениями в индексах поисковиков.
Всем привет! В прошлой статье мы затронули важную тему — поиск дублей страниц сайта. Как показали комментарии и несколько пришедших мне на почту писем, эта тема актуальна. Дублированный контент на наших блогах, технические огрехи CMS и различные косяки шаблонов не дают нашим ресурсам полной свободы в поисковых системах. Поэтому нам приходится с ними серьезно бороться. В этой статье мы узнаем как можно убрать дубли страниц любого сайта, примеры этого руководства покажут как от них можно избавиться простым способом. От нас просто требуется использовать полученные знания и следить за последующими изменениями в индексах поисковиков.
Моя история борьбы с дублями
Перед тем, как мы займемся рассмотрением способов устранения дубликатов, я расскажу свою историю борьбы с дублями.
Два года назад (25 мая 2012 года) я получил в свое распоряжение учебный блог на курсах se0-специалиста. Он мне был дан для того, чтобы во время учебы практиковать полученные знания. В итоге за два месяца практики я успел наплодить пару страниц, десяток постов, кучу меток и вагон дублей. К этому составу в индекс Google в последующие полгода, когда учебный блог стал моим личным сайтом, прибавились и другие дубликаты. Это получилось по вине replytocom из-за растущего число комментариев. А вот в базе данных Яндекса количество проиндексированных страниц росло постепенно.
В начале 2013 года я заметил конкретное проседание позиций моего блога в Гугле. Тогда то я и задумался, почему так происходит. В итоге докопался до того, что обнаружил большое число дублей в этом поисковике. Конечно, я стал искать варианты их устранения. Но мои поиски информации ни к чему не привели — толковых мануалов в сети по удалению дублей страниц я не обнаружил. Но зато смог увидеть одну заметку на одном блоге о том, как можно с помощью файла robots.txt удалить дубликаты из индекса.
Первым делом я написал кучу запрещающих директив для Яндекса и Гугла по запрету сканирования определенных дублированных страниц. Потом, в середине лета 2013 года использовал один метод удаления дублей из индекса Goоgle (о нем Вы узнаете в этой статье). К тому времени в индексе этой поисковой системы накопилось более 6 000 дублей! И это имея на своем блоге всего пятерку страниц и более 120-ти постов…

После того, как я реализовал свой метод удаления дублей, число их стало стремительно уменьшаться. В начале этого года я использовал еще один вариант удаления дубликатов для ускорения процесса (о нем Вы тоже узнаете). И сейчас на моем блоге число страниц в индексе Гугла приближается к идеальному — на сегодняшний день в базе данных находится около 600 страниц. Это в 10 раз меньше, чем было раньше!
Как убрать дубли страниц — основные методы
Существует несколько различных способов борьбы с дублями. Одни варианты позволяют запретить появление новых дубликатов, другие могут избавиться от старых. Конечно, самый лучший вариант — это ручной. Но для его реализации нужно отлично разбираться в CMS своего сайта и знать работу алгоритмов поисковой системы. Но и другие методы тоже хороши и не требуют специализированных знаний. О них мы сейчас и поговорим.
301 редирект
Данный способ считается самым эффективным, но и самым требовательным к знанию программирования. Дело в том, что здесь прописываются нужные правила в файле .htaccess (находиться в корне директории сайта). И если они прописываются с ошибкой, то можно не только не решить поставленную задачу удаления дублей, но и вообще убрать весь сайт из Интернета.
Как же решается задачка удаления дублей с помощью 301-го редиректа? В основу его лежит понятие переадресации поисковых роботов с одной страницы (с дубля) на другую (оригинальную). То есть робот приходит на дубликат какой-то страницы и и с помощью редиректа появляется на нужном нам оригинальном документе сайта. Его то он и начинает изучать, пропуская дубль вне поля своего зрения.

Со временем после прописки всех вариантов этого редиректа, склеиваются одинаковые страницы и дубли со временем выпадает с индекса. Поэтому этот вариант отлично чистит уже проиндексированные ранее дубли страниц. Если Вы решите воспользоваться этим методом, то обязательно перед пропиской правил в файле .htaccess, изучите синтаксис создания редиректов. Например, рекомендую для изучения руководство по 301-му редиректу от Саши Алаева.
Создание канонической страницы
Данный способ используется для указания поисковой системе того документа из всего множества его дублей, который должен быть в основном индексе. То есть такая страница считается оригинальной и участвует в поисковой выдаче.
Для ее создания необходимо на всех страницах дублей прописать код с урлом оригинального документа:
<link rel= «canonical» href= «http://www.site.ru/original-page.html»>
Конечно, прописывать все это вручную тяжковато. Для этого существуют различные плагины. Например, для своего блога, который работает на движке ВордПресс, я указал этот код с помощью плагина «All in One SEO Pack». Делается это очень просто — ставиться соответствующая галочка в настройках плагина:

К сожалению, вариант с канонической страницей не удаляет дубли страниц, а только предотвращает их дальнейшее появление. Для того, чтобы избавиться от уже проиндексированных дубликатов, можно использовать следующий способ.
Директива Disallow в robots.txt
Файл robots.txt является инструкцией для поисковых систем, в которой им даются указания, как нужно индексировать наш сайт. Без этого файла поисковый робот может дотянуться практически до всех документов нашего ресурса. Но такая вольность поискового паука нам не нужна — не все страницы мы желаем видеть в индексе. Особенно это кассается дублей, которые появляются благодаря не соврешнеству шаблона сайта или наших ошибок.
Вот поэтому то и создан такой файл, в котором прописываются различные директивы запрета и допуска индексации поисковым системам. Запретить сканирование дублей страниц можно с помощью директивы Disallow:

При создании директивы тоже нужно правильно составлять запрет. Ведь если ошибиться при заполнении правил, то на выходе может получиться совсем не та блокировка страниц. Тем самым мы можем ограничить доступ к нужным страницам и дать просочиться другим дублям. Но все же здесь ошибки не так страшны, как при составлении правил редиректа в .htaccess.
Запрет на индексацию с помощью Disallow действует для всех роботов. Но не для всех эти запреты позволяют поисковой системе убирать из индекса запрещенные страницы. Например, Яндекс со временем удаляет блокированные в robots.txt дубли страниц.
А вот Google не будет очищать свой индекс от ненужного хлама, который указал веб-мастер. К тому же директива Disallow не является гарантом этой блокировки. Если на запрещенные в инструкции страницы идут внешние ссылки, то они со временем появятся в базе данных Гугла.
Избавляемся от дублей, проиндексированных в Яндексе и Google
Итак, с различными методами разобрались, пришло время узнать пошаговый план удаления дубликатов в Яндексе и Гугле. Перед тем, как проводить зачистку, необходимо найти все дубли страниц — об этом я писал в прошлой статье. Нужно перед глазами видеть, какие элементы адресов страниц отражены в дублях. Например, если это страницы с древовидными комментариями или с пагинацией, то мы фиксируем содержащие в их адресах слова «replytocom» и «page»:

Замечу, что для случая с replytocom можно взять не это словосочетание, а просто вопросительный знак. Ведь он всегда присутствует в адресе страниц древовидных комментариев. Но тогда нужно помнить о том, что уже в урлах оригинальных новых страниц не должно быть символа «?», иначе и эти станицы уйдут под запрет.
Чистим Яндекс
Для удаления дублей в Яндексе создаем правила блокировки дубликатов с помощью директивы Disallow. Для этого совершаем следующие действия:
- Открываем в Яндекс Вебмастере специальный инструмент «Анализ robot.txt».
- Вносим в поле директив новые правила блокировки дублей страниц.
- В поле «список URL» вносим примеры адресов дубликатов по новым директивам.
- Нажимаем кнопку «Проверить» и анализируем полученные результаты.

Если мы все верно сделали, то данный инструмент покажет о наличии блокировки по новым правилам. В специальном поле «Результаты проверки URL» мы должны увидеть красную надпись о запрете:

После проверки мы должны отправить созданные директивы по дублям в настоящий файл robots.txt и переписать его в директории нашего сайта. А далее нам просто нужно подождать, пока Яндекс автоматически не выгребет из своего индекса наши дубли.
Чистим Google
 С Гуглом не все так просто. Запретные директивы в robots.txt не удаляют дубли в индексе этой поисковой системы. Поэтому нам придется все делать своими силами. Благо для этого есть отличный сервис Google вебмастер. А конкретно нас интересует его инструмент «Параметры URL».
С Гуглом не все так просто. Запретные директивы в robots.txt не удаляют дубли в индексе этой поисковой системы. Поэтому нам придется все делать своими силами. Благо для этого есть отличный сервис Google вебмастер. А конкретно нас интересует его инструмент «Параметры URL».
Именно благодаря этому инструменту, Google позволяет владельцу сайта сообщить поисковику сведения о том, как ему нужно обрабатывать те или иные параметры в урле. Нас интересует возможность показать Гуглу те параметры адресов, страницы которых являются дублями. И именно их мы хотим удалить из индекса. Вот что нам нужно для этого сделать (для примера добавим параметр на удаление дублей с replytocom):
- Открываем в сервисе Гугла инструмент «Параметры URL» из раздела меню «Сканирование».
- Нажимаем кнопку «Добавление параметра», заполняем форму и сохраняем новый параметр:

В итоге у нас получается прописанное правило для пересмотра Гуглом своего индекса на наличие дублированных страниц. Таким образом дальше мы прописываем следующие параметры для других дубликатов, от которых хотим избавиться. Например, вот так выглядит часть моего списка с прописанными правилами для Гугла, чтобы он подкорректировал свой индекс:

На этом наша работа по чистке Гугла завершена, а мой пост подошел к концу. Надеюсь, эта статья принесет Вам практическую пользу и позволит Вам избавиться от дублей страниц Ваших ресурсов.
С уважением, Ваш Максим Довженко
P.S. Друзья, если нужно сделать видео по этой теме, то напишите мне в комментарии к этой статье.
maksimdovzhenko.ru
Поиск дублей страниц и их устранение
Дубли страниц могут присутствовать на любых сайтах, независимо от того сколько им лет и из скольких страниц они состоят. Для обычного посетителя они не представляют абсолютно никаких неудобств, такие страницы содержат необходимую ему информацию, а больше ему ничего и не нужно.
Если же посмотреть на URL адреса таких страниц, то можно заметить, что они отличаются. Поэтому поисковые системы и воспринимают их как абсолютно разные страницы, со всеми вытекающими отсюда негативными последствиями. В этой статье мы рассмотрим, как производить поиск дублей страниц, какие инструменты и методы их поиска существуют и как от них избавиться.
Наличие дублей страниц может негативно сказаться на ранжировании этих же страниц в поисковых системах.
Потому как эти страницы являются по сути одинаковыми, то теряется их уникальность, а это уже большой минус. Поисковая система не может понять какая из них более релевантная и какую из них нужно ранжировать выше. Поэтому высокие позиции в поисковой выдаче таким страницам занять очень тяжело.
Тот ссылочный вес который планировалось передать данной странице может просто напросто «размыться», а может даже оказаться на той странице, которой, изначально его никто не собирался передавать.
Среди некоторых SEO специалистов бытует мнение, что небольшое количество страниц, не оказывает негативного воздействия, но наличие на сайте 40 — 50 % страниц которые дублируются может создать некоторые трудности.
Из своего опыта могу сказать, что при появлении дубля той или иной страницы в индексе Яндекса значительно снижаются позиции данной страницы по продвигаемому запросу. Именно поэтому я считаю, что эта проблема очень актуальна и сколько бы дублей страниц у вас не было нужно регулярно проверять сайт на дубли страниц и устранять их.
Разновидности и причины появления дублей страниц
В целом можно выделить 2 разновидности дублей страниц это полные дубли (четкие) и неполные (нечеткие).
Полные дубли — это страницы с абсолютно одинаковым содержимым но с разными URL адресами. URL адреса могут отличаться расширением.
Например:
http://webmastermix.ru/uroki-i-stati.html http://webmastermix.ru/uroki-i-stati.htm http://webmastermix.ru/uroki-i-stati.php
Или иметь различные индентификаторы сесий и параметры.
Например:
http://webmastermix.ru/uroki-i-stati.html?start=5
Причины появления:
1. В большинстве случаев полные дубли появляются из за различных технических недоработок CMS, на которых создаются сайты. Причем такие недоработки встречаются как у популярных так и менее популярных движков. Способы устранения таких дублей будут зависеть от вида CMS, используемых плагинов и расширений и для каждого сайта их необходимо рассматривать в отдельности.
2. Следующей причиной появления четких дублей может быть произведенный редизайн, смененная структура сайта или смена используемого движка сайта на новый. Получается, что страницы поменяли свои адреса, но и по старым URL адресам могут выдаваться определенные страницы, но совсем не те, что были по ним доступны ранее.
3. Еще одной причиной возникновения четких копий может быть не внимательность веб-мастера, контент менеджера или администратора ресурса.
Примером могут быть дубли главной страницы вида:
http://webmastermix.ru/ http://webmastermix.ru/index.html http://webmastermix.ru/default.html
Нечеткие дубли — это страницы содержимое кторых очень похоже или содержит большие части текста из других страниц.
Такие страницы возникают в следующих случаях:
1. Самый распространенный вариант, когда основное содержимое страницы сайта настолько мало, что содержимое его сквозных частей, таких как футер, хедер и боковые колонки, превышает его. В качестве примера можно привести страницы галереи, карточки товаров в интернет магазине имеющие описание в 1 — 2 предложения.
2. Страницы на которых полностью или только частично повторяются определенные части текста в любых последовательностях. Примером таких страниц могут быть страницы рубрик, где текст анонса статьи присутствует как на странице рубрики или нескольких рубрик, так и в полной версии статьи. Еще в качестве примера можно привести страницы с результатами поиска по сайту, а так же страницы различных фильтров поиска, например товаров в интернет магазинах.
Методы определения и поиска дублей страниц
Разновидности и причины появления дублей мы рассмотрели, теперь рассмотрим как найти дубли страниц и какие способы для этого существуют.
Поиск по фрагментам текста
Такая проверка очень проста и сводится к тому, чтобы вы скопировали небольшую часть текста страницы, вставили ее в поисковую строку и произвести поиск по своему сайту. Для этого можно взять 10 — 15 первых слов текста страницы, которую необходимо проверить. Слишком большой текст не берите, потому как в поисковиках есть определенное ограничение по символам, которые можно вводить для поиска.
Для поисковой системы Яндекс, зайдите в расширенный поиск, в поле «Я ищу» укажите текст, а в поле «На сайте» адрес вашего сайта и произведите поиск.
После этого визуально просмотрите результаты поиска и найдите те страницы на которых точно повторяется этот текст. Я нашел 2 таких страницы:
В данном случае у меня нашлись нечеткие дубли двух категорий на которых расположен один и тот же анонс материала. Как вы видите саму страницу с данным материалом, тоже показало, но полного повторения данного текста на ней нет. Все потому, что я всегда пишу специальный текст который и является анонсом к статье и не использую в качестве анонса введение к статье.
Такой же поиск можно произвести и в Google. Для этого текст который нужно проверить вставьте в кавычках и через пробел укажите область поиска: site:vash-sait.ru
Естественно если сайт состоит из большого числа страниц, то проверить их все будет очень сложно и долго по времени. Чтобы ускорить весь этот процесс можно воспользоваться специальной программой, которая известна многим оптимизаторам — это Xenu’s Link Sleuth.
Проверка дублей при помощи программы Xenu’s Link Sleuth
Скачать программу можно на сайте разработчика: http://home.snafu.de/tilman/xenulink.html#Download
Установите и запустите программу. После этого перейдите в пункт меню File >> Check URL, введите адрес вашего сайта и нажмите кнопку «ОК».
После этого программа начнет ходить по ссылкам вашего сайт и находить все указанные на его страницах ссылки, не зависимо от того рабочие они или нет. Кроме этого она определит тип документов, его заголовки, description и еще много всего. В зависимости от размера сайта, программа может работать продолжительное время, у меня были случаи до 30 — 40 минут. После окончания работы перед вами будет список всех ссылок вашего сайта.
Дубли можно искать двумя способами по найденным URL адресам страниц и по найденным заголовкам страниц.
Чтобы искать по URL адресам кликните по табулятору «Address» и отсортируйте все найденные адреса по алфавиту. Найдите в списке ссылки именно своего сайта и визуально просматривая их найдите, те которые выглядят иначе, чем обычные адреса сайта. Если на сайте используется ЧПУ, можно искать URL адреса содержащие и отличающиеся наличием и отсутствием идентификаторов и параметров.
На приведенном скриншоте я выделил страницы, которые в принципе могут быть дублями страницы: http://webmastermix.ru/web-design.html. Но именно вот эти страницы закрыты от индексации у меня на сайте.
Чтобы искать страницы по заголовку, нужно кликнуть по табулятору «Title» и отсортировать заголовки по алфавиту. Теперь задача найти одинаковые заголовки. Потому как страницы с четкими дублями, о которых шла речь выше, будут иметь одинаковые заголовки.
Недостатком применения данной программы является то, что она показывает все предполагаемые дубли не зависимо от того, есть они в индексе поисковиков или нет. Поэтому каждый раз необходимо проверять на предмет индексации найденные страницы. Но есть еще один способ проверить дубли страниц и он позволяет проверять и видеть только те страницы, которые находятся в индексе той или иной поисковой системы.
Анализ всех проиндексированных страниц
Данный метод основан на том, чтобы просмотреть все старницы определенного сайта которые есть в индексе той или иной поисковой системы. Чтобы увидеть все страницы вашего сайта необходимо в поисковой строке Яндекса указать: host:vash-sait.ru | host:www.vash-sait.ru или Google указать: site:vash-sait.ru | site:www.webmastermix.ru
Полученную выдачу необходимо исследовать на предмет наличия всяких не типичных ссылок. Опять же если на сайте используется ЧПУ, то можно искать такие ссылки которые заканчиваются различными идентификаторами сессий и параметрами.
Но такой способ тоже имеет свои недостатки, потому как все представленные страницы не будут упорядочены, чтобы их упорядочить по URL или заголовку можно применить языки запросов.
Использование языков запросов для анализа проиндексированных страниц
Поиск дублей осуществляется так же как и в прошлом примере, но здесь мы можем вывести проиндексированные статьи по содержимому определенных слов или словосочетаний в Title или URL адресе страницы. Выше я уже упоминал, что именно заголовок и URL является одинаковым у полных дублей.
Что бы произвести поиск по содержимому заголовка, необходимо в поисковой строке указать следующее:
Для Яндекса: site:vash-sait.ru title:(уроки html)
Для Google: site:vash-sait.ru intitle:уроки html
— где «уроки html» полный Title определенной страницы или отдельные слова из Title определенной страницы.
Так же можно производить поиск в URL адресах страниц сайта. Для этого в поисковой строке необходимо прописать, как для Яндекса так и для Google следующее: site:vash-sait.ru inurl:lessons-joomla
— в данном случае будут выведены все URL в которых присутствует — lessons-joomla.
Избавляемся от дублей страниц
Способы избавления от дублей страниц зависят от того, что это за страницы и каким образом они попали в индекс поисковой системы. Есть ряд мероприятий применив которые можно избавиться от дублей страниц. В некоторых случаях достаточно будет применить одно из них в других же понадобится комплекс мероприятий. В целом можно произвести следующее мероприятия:
1. Если та страница которая является дублем была создана вами вручную, то также в ручную вы можете ее удалить.
2. При помощи файла Robots.txt можно управлять индексацией всего сайта. Для запрета индексации определенных страниц или каталогов используется директива: «Disallow». Таким способом хорошо избавляться от дублей тех страниц, которые лежат в определенной директории сайта.
Например, чтобы закрыть от индексации страницы тегов URL которых содержит: /tag/, нужно в фале robots.txt указать следующее:
Еще таким способом хорошо избавляться от дублей адреса которых содержат идентификатор сессии и в них используется знак «?». Чтобы запретить индексацию все страниц в адресах которых содержится вопросительный знак «?», достаточно в фале robots.txt прописать следующее:
3. Использование 301 редиректа. При помощи редиректа 301 можно производить автоматическую переадресацию посетителей сайта и роботов поисковых систем с одной страницы сайта на другую. Данный редирект дает понять роботам поисковых систем, что данная страница навсегда перенесена на другой адрес и больше по данному адресу не доступна.
В результате поисковыми системами производится склеивание страниц доступных по двум или более адресам, в страницу доступную только по одному адресу указанному при настройке 301 редиректа. Подробнее о 301 редиректе читайте в статье: «Как настроить 301 редирект в htaccess и в скриптах — более 18 примеров использования».
4. Использование атрибута rel=»canonical». Данный атрибут, употребленный на определенных страницах сайта, которые имеют одинаковое или очень мало отличимое содержимое дает понять какую страницу считать основной из множества похожих документов. понимают данный атрибут ПС Яндекс и Google.
Чтобы его задать необходимо в HTML код страницы между тегами <head>…</head> поместить следующее:
<link href="http://webmastermix.ru/seo-optimization.html" rel="canonical" />
— где http://webmastermix.ru/seo-optimization.html является канонической ссылкой и если у данной страницы будут присутствовать дубли вида:
http://webmastermix.ru/seo-optimization.html?start=5 http://webmastermix.ru/seo-optimization.html?start=6 http://webmastermix.ru/seo-optimization.html?start=7
Но на всех этих страницах будет указан атрибут rel=»canonical», пример которого приведен выше, то за основную страницу будет считаться именно страница с адресом: http://webmastermix.ru/seo-optimization.html
Во многих популярных CMS, например WordPress или Joomla данный атрибут генерируется сразу при создании страниц.
Самые распространенные причины автоматического появления дублей и избавление от них
Страницы пагинации
В рубриках и категориях сайта выводить большое количество материалов на одной странице не удобно. Поэтому как правило их выводят в виде многостраничных каталогов, где каждая страница имеет свой адрес, но содержимое этих страниц может дублироваться.
Чаще всего дублируются мета теги описаний и анонсы статей. Особенно плохо когда анонсы статей или описания товаров большие по объему и берутся непосредственно из начальной части статьи. Т. е. они будут фигурировать и на страницах пагинации и в полной версии статьи.
Избавиться от такого типа дублей можно одним из следующих способов:
1. Запретить индексацию страниц в файле Robots.txt — для Яндекса данный метод работает отлично, но вот Google может игнорировать robots.txt и все равно индексировать такие страницы, как от этого избавится читайте ниже, где будет идти речь о страницах с результатами поиска и фильтров.
2. Использовать атрибут rel=»canonical», в котором указать основной адрес для всех этих страниц — в некоторых CMS он используется по умолчанию.
3. Что касается частичных дублей, то анонсы статей необходимо делать уникальными, а не брать текст из вводной части статьи.
Страницы поиска и применения фильтров
Поиск присутствует на любом сайте и поэтому страницы с результатами поиска, на которых так же частично дублируется контент, могут легко попасть в индекс ПС.
Фильтры, как правило используются когда нужно отсортировать материалы или товары в интернет магазине по определенным параметрам.
Страницы результатов поиска и сортировки имеют динамических URL и создаются автоматически. Все это может порождать большое количество копий.
Избавится от таких клонов можно одним из следующих способов:
1. Закрыть от и индексации в robots.txt. Можно закрыть все страницы сайта содержащие определенные параметры. Как вариант можно закрыть все страницы, адреса которых содержат вопросительный знак «?». Как это сделать мы рассматривали выше. Этого будет вполне достаточно для ПС Яндекс, но может оказаться мало для Google и он продолжит их индексировать. Поэтому переходим к следующему способу.
2. Использование инструментов Google Webmaster. Если в панели Google Webmaster перейти в пункт «Сканирование» >> «Параметры URL» и кликнуть по ссылке «Настройка параметров URL». Перед вами появится ряд параметров, которые присутствуют в адресах страниц вашего сайта.
И здесь у вас есть возможно запретить для индексации адреса тех страниц сайта, которые содержат определенный параметр. Для этого, на против нужного вам параметра кликните по ссылке «Изменить». Затем в выпадающем списке выбираете пункт «Нет, параметр не влияет на содержание страницы». Кликнув по «Показать примеры URL» откроются все ссылки которые содержат этот параметр и будут запрещены к индексации.
Как только удостоверились, что это именно те страницы которые вы хотели закрыть, нажимаете на кнопку «Сохранить».
Дубли возникающие из-за различных технических особенностей CMS
Ввиду некоторых технических особенностей формирования URL адреса каждой страницы все CMS могут автоматически создавать различные дубли. Например в Joomla это происходит из-за того, что одна и та же страница может быть получена несколькими способами. Если включены ЧПУ, такие страницы сразу видно. Потому, что если у вас есть страница с URL: http://ваш-сайт.ru/stranica.html, а помимо ее присутствует еще и страница: http://ваш-сайт.ru/stranica.html?view=featured, то она является копией первой страницы.
Способы борьбы:
1. Часть таких копий убирается средствами самой CMS, а те что остаются можно убрать одним или несколькими из предложенных выше способов.
2. Кроме этого в некоторых случаях придется использовать 301 редирект, чтобы склеить одни страницы с другими — все зависит от CMS.
Рекомендуем ознакомиться:
- Подробности
Опубликовано: 12 Ноябрь 2013
Обновлено: 30 Ноябрь 2013
Просмотров: 16985
webmastermix.ru
Как найти дубли страниц на сайте и удалить
Что такое дубли страниц?
Дубли — страницы с разными адресами, где полностью или частично совпадает контент. Любите разгадывать ребусы? Внимательно посмотрите на эту картинку и подумайте, какое из этих трех изображений наиболее соответствует запросу: «зеленая груша»? Сложно ответить, не так ли? Да, потому что все три груши одинаково зеленые, а выбрать нужно только одну, которая наиболее релевантна условиям поиска. Дилемма? В точно такой же непростой ситуации находятся и поисковики в случае обнаружения дублей. Они недоумевают, какую страницу нужно показать в поиске в ответ на запрос пользователя. Бывает, что поисковик считает главной страницей именно дубль, в результате в индекс не попадает ни одна, и сайт стремительно теряет свои позиции.

Зачем нужно удалять дубли страниц?
Каждый сеошник знает, что наличие дублей очень опасно для SEO. Пользователям они не мешают получить необходимую информацию. Копия страницы сайта очень серьезно воспринимается поисковиками и может в критических ситуациях привести к наложению санкций со стороны Яндекса и Google. Поэтому важно вовремя найти все дубли страниц и обезвредить их.
Как дубли страниц влияют на яндекс?
В первую очередь произойдет снижение позиций в поиске по отдельным ключевым фразам. Сначала они начнут просто скакать из — за постоянной смены привязки ключа к релевантной странице, а потом поисковик существенно понизит сайт в ранжировании. Вот с этого момента можно включать режим SOS и оперативно исправлять ситуацию.
Какими бывают дубли страниц?
Специалисты поисковой оптимизации различают дубли страниц двух типов — полные или частичные.
Первые — когда две или более страницы содержат одинаковый контент.
Вторые — когда какая-то часть контента дублируется на нескольких страницах. Такое часто происходит, когда, например, копирайтеры берут кусок из одной статьи и вставляют его в другую.
Что такое полные дубли страниц и как они появляются?
-
Когда создаются адреса с «www» и без «www»:
http://wts.ru/about
http://www.wts.ru/about -
Адреса со слешами и без них
http://wts.ru/seo///top3
http://wts.ru/seo/top3 -
Адреса с HTTP и HTTPS
http://wts.ru/seo
https://wts.ru/seo -
Создать дубли могут и реферальные ссылки. Как правило, реферальная ссылка имеет после знака «?» хвостик, начинающийся с «ref=…». Когда поcетитель переходит по ссылке с такой меткой, ему должна открываться обычная ссылка. Но часто оптимизаторы и веб — разработчики просто забывают убрать параметр «ref=…» и получают дубли.
-
Дубли страниц могут появляться в результате неправильной настройки страницы с 404 — ошибкой.
-
Некоторые страницы с utm — меткой или гет — параметрами «gclid», необходимыми для отслеживания рекламного трафика, часто попадают в индекс поисковиков и тоже являются дублями.
http://mysite.ru/?utm_source=yandex&amp;amp;utm_medium=cpc&amp;amp;utm_campaign=sale
http://mysite.ru -
Страницы с прописными и строчными буквами в урл
http://wts.ru/seo
http://wts.ru/SEO -
Приписка цифр в строку URL
http://wts.ru/seo123
http://wts.ru/seo123/999
Такая ситуация часто случается на страницах сайтов на основе cамой популярной системы управления контентом — WordPress.
Как мы уже говорили выше, поисковики очень не любят наличие такой критичной ошибки как дубли страниц. За это Яндекс и Google могут применить карательные санкции — наложить на сайт фильтр или опустить в позициях. Полные дубли обнаружить гораздо проще, но вот проблем они могут принести из-за своего масштаба очень много.
Откуда берутся частичные дубликаты страниц?
В отличие от первого варианта, в этом случае диагностировать ошибку гораздо труднее. Немало неудобств доставляет и процедура самого избавления от частичных дублей. Частичные дубли подразумевают под собой дублирования части контента на нескольких страницах.
- Очень часто можно встретить частичные дубли на страницах листинга (ссылочного блока, при помощи которого на странице отдельная часть информации из общего массива данных), фильтров, различных сортировок. В этом случае на всех страницах присутствуют куски одного и того же контента, меняется только порядок и структура их размещения.
-
Частичные дубли также могут появляться в описании товаров в карточках и каталоге. Чтобы исключить такую ошибку, нужно не выводить полную информацию о товаре в каталоге, либо написать уникальный текст, который не будет перекликаться с описанием в самой карточке товара. Но оптимизаторы часто пытаются сэкономить на копирайтинге, что выливается потом в серьезные проблемы с индексацией ссылок в поиске.
-
Страницы скачивания и печати могут дублироваться с основной страницей.
Например:
http://wts.ru/seo
https://wts.ru/seo/print
В отличие от полных дублей, частичные не сразу сказываются потерями в позициях сайта, они потихоньку будут подтачивать камень водой, делая жизнь оптимизатора все невыносимее.
Как найти дубли страниц на сайте?
Первый способ — при помощи оператора «site», вы просто вводите в Яндекс или Google оператора и название сайта:
site:wts.ru
Второй способ — специальные сервисы или парсеры, которые могут обнаружить наличие дублей на сайте. К таким программам можно отнести — ComparseR 1.0.129, Xenu, WildShark SEO Spider, британский парсер Frog Seo Spider, Majento SiteAnalayzer 1.4.4.91, Serpstat.Многие из них бесплатные.
Механизм работы парсеров очень прост: программа запускает бота на сайт, анализирует и определяет список урлов с возможными совпадениями. Таким образом поиск дублей страниц сайта не занимает много времени, достаточно просто ввести в строку параметры сайта и ждать результата. Не так давно появилась и версия программы российских разработчиков Апполон (https://apollon.guru/duplicates), которая позволяет проверить сайт на дубли страниц онлайн. В открывающееся окошко можно ввести до 5 url. После сканирования программа выдает отчет.

Третий способ — потенциальные дубли может определить инструмент для веб — мастеров Google Search Console. Для этого его нужно открыть, зайти во вкладку «Оптимизация HTML» и проанализировать все страницы, на которых повторяется описание.
Четвертый способ — ручной. Опытные оптимизаторы и разработчики могут вручную просканировать дубли страниц в местах сайта, которые кажутся им проблемными.
Как удалить дубли страниц на сайте?
Не обладая специальными навыками и опытом, избавиться от дублей собственными силами будет очень трудно. Нужно будет самому изучить основы веб — разработки, различные коды программирования, азы seo — оптимизации. На это могут уйти несколько месяцев, а позиции сайта будут опускаться в выдаче. Лучше обратиться к профессионалам, которые оперативно удалят дубли и сделают специальные настройки:
- Запретят индексацию дублей в специальном текстовом файле в «robots.txt»
- В файле — конфигураторе добавят 301 редирект. Этот способ является основным при искоренении ошибки. Редирект нужен для автоматической переадресации с одного урл на другой.
- Для устранения дублей при выводе на печать и скачивании добавят тег meta name=»robots» content=»noindex, nofollow»
Иногда решение проблемы может заключаться в настройке самого движка, поэтому первоочередной задачей специалистов является выявление дублей, а уже потом их оперативное устранение. Дело в том, что для создания контента могут одновременно использоваться разные движки сайта (opencart, joomla, wordpress, bitrix). Например, главная структура сайта будет сделана на опенкарт, а блог на вордпресс. Естественно, что дубли на этих двух сайтах тоже будет сильно отличаться друг от друга.
Что такое битые ссылки?
Битыми ссылками называют такие URL, которые ведут пользователей на несуществующие страницы. Несуществующие страницы могут появляться в случае когда сайт был удален, страница поменяла адрес, случайно удалили страницу, на которую ссылаются, а также в результате сбоя при автоматическом обновлении данных. Когда робот находит в поиске такие ссылки, он переходит по ней и видит 404 ошибку, из- за чего на сайт может быть поставлен штамп низкокачественного ресурса. Что нужно сделать в этом случае?
- Удалить ссылки, которые направляют пользователей на несуществующие страницы
- Можно заполнить страницу полезным и интересным контентом
- Если обновили систему, то нужно сделать редирект 301
Что нужно усвоить из этой статьи?
- Дубли — это страницы, на которых возможно полное или частичное повторение контента.
- Основными причинами возникновения ошибки являются ошибки разработчиков и оптимизаторов, ошибки в самом движке, автоматическая генерация.
- Дубли очень негативно сказываются на SEO — индексация ухудшается, позиции в поиске понижаются, возможны санкции со стороны поисковиков.
- Обнаружить дубли могут помочь специальные сервиcы, Гугл Консоль, оператор site.
- Чтобы удалить дубли, нужно воспользоваться специальными тегами, а лучше всего доверить эту работу профессионалам.
waytostart.ru