Влияние тега noindex и атрибута «nofollow» на SEO
Здравствуйте, дорогие мои читатели. Сейчас дедушка-сеошник поделится своими мыслями по поводу использования тега <noindex> и атрибута у ссылок rel=nofollow.
Использование тега <noindex>
Пример использования данного контейнера:
<noindex>
<form id="forma" class="justbox" method="get" action="/results.html" name="forma">
... [содержание формы] ...
</form>
</noindex>
Справочник BookHtml.ru: правильная и валидная запись тега noindex
Я вижу смысл данного тега только для того, чтобы показать поисковому роботу один факт: контент, заключённый в данном теге, необходимо считать не информативным для пользователя. Таким образом, я использую тег <noindex> для форм поиска, форм подбора какой-либо услуги (например, форма бронирования столиков на главной странице сайта). Т.е. в этом теге предпочтительно заключать информацию технической направленности. И чтобы не «захламлять» информационную составляющую своего сайта с точки зрения поисковой машину, и используется данный тег.
Поисковые системы (Яндекс и Google) замечательно индексируют и контент, и ссылки, которые находятся внутри контейнера <noindex>. Не стоит бояться покупать ссылки с таких сайтов — ведь намного важнее та ссылка, с которой есть реальные живые переходы, а не только сам факт её индексации.
Атрибут «nofollow» для ссылок
Атрибут «rel» со значением «nofollow» принятно использовать для того, чтобы данная ссылка не передавала вес. Удобно проставлять этот параметр по умолчанию со всех исходящих ссылок в темах и комментариях форума или профилей пользователей. Пример использования атрибута «rel» у ссылок:
<a href="url" rel="nofollow">анкор</a>
Справочник BookHtml.ru: правильная и валидная запись тега <a>
Только что было сказано насчёт ссылок в контейнере <noindex>. Абсолютно то же правило относится и к атрибуту «nofollow». Не надо бояться закупать или проставлять ссылки с данным атрибутом — они работают.
За сим разрешите откланяться. Ваш дед-сеошник.
Задавайте вопросы.
endseo.ru
Теги noindex и nofollow в чем разница и как они работают
Привет, Друзья! На показатели сайта в первую очередь влияет количество и естественность входящих ссылок. По сути, ссылки (линки) переносят вес с сайтов-доноров на продвигаемый веб-сайта. В том случае, если постоянно ставить ссылки на другие сайты, и не дай бог другого профиля (тематики), то в этом случае общий вес сайта будет значительно снижен. Именно об этом и будет этот текст, как можно управлять индексацией поисковых систем, скрывать целые блоки текстов и ссылки от поисковых роботов. Все это можно сделать, воспользовавшись мета-тегами, которые понимают только поисковые роботы. С целью управления этим процессом и были разработаны поисковыми системами специальные теги nofollow и noindex.
Как закрыть внешние ссылки от индексации
Для того чтобы запретить к индексации текстовые фрагменты, на сайте нужно использовать тег noindex. Важно знать, что этот тег способен закрывать только текстовые блоки. Картинки, баннеры, и другие элементы запретить к индексации с помощью этого тега нельзя. Многие люди совершают большую ошибку, когда заключают в этот тег ссылку. Поисковая система без проблем считывает и индексирует ссылку. В этом случае запрещён к индексации только анкор ссылки, так как это текст. Будьте внимательны.
Тег noindex прописывается в исходный код сайта. Имеет открывающий и закрывающий тег. Текст помещается между этими тегами.
Теперь подробнее:
Этот текст поисковые системы не отдадут на индексацию. А также тег noindex может выступать в роли метатега, который расположен в начале страницы и он отличается в корне. Если на странице расположен метатег noindex, в этом случае он запрещает индексирование всей страницы. При этом не только тексты, но и все что на ней находится — ссылки, картинки, баннеры, формы и так далее, всё это будет запрещено к индексации. Лучше всего для запрета индексация целых страниц использовать специальный файл robots.txt.
Как правильно ставить тег noindex
Вначале можно прочитать, что тег noindex создан исключительно для поисковых машин. То есть этот тег не является официальным тегом языка html. Именно поэтому HTML-редакторы могут показывать, что тег написан с ошибкой. Не пугайтесь, это происходит по причине того, что они просто не понимают этот тег и не считают его валидным. Но, так или иначе, его без проблем прочитают поисковые машины.
И ещё важно знать и запомнить, на тег noindex будет реагировать только поисковая система Яндекс, так как он его и создал. Поисковая система Google не реагирует на такой тег вообще.
Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега. Для того чтобы скрыть ссылку от индексации нужно использовать другой тег — nofollow, об этом ниже.
Владельцам сайта не запрещается манипулировать тегами, можно не смотреть за их вложенностью, noindex будет работать при любом раскладе. Об этом пишет сам Яндекс. Главное, быть внимательным при работе с этими тегами, так как если вы забудете поставить закрывающий тег, схема работать не будет. В этом случае поисковая система Яндекс проиндексирует и отдаст всё что есть на странице в выдачу.
Как скрыть ссылки от индексации
В случае когда в тег ссылки добавить отдельный, дополнительный атрибут rel=»nofollow», это будет означать, что ссылка не будет проиндексирована поисковым роботом. Вот пример как это выглядит в коде HTML:
Этот параметр очень важен для тех сайтов, которые не хотят делиться весом своего ресурса с другими WEB-проектами. Но также важно запомнить, что он не оставляет этот вес и у себя, по сути, он просто сгорает и не достаётся никому.
Если же ссылку использовать без этого тега nofollow, то вес страницы, через эту ссылку уйдёт на другой сайт. Исходя из этого, важно понимать, что если внести этот атрибут во все ссылки, которые уходят на другие сайты, сайт потеряет в весе.
Как работает этот атрибут nofollow на примере:
Конечно, если ссылка ссылается на страницу в рамках одного сайта или блога, то проставлять это свойство бесполезно и даже вредно. Это можно использовать только в тех случаях, когда стоит задача не передавать вес отдельным страницам сайта. Например, если есть продающая страница, куда должен поступать весь трафик, имеет ссылку на внутреннюю страницу, например, ответы на вопросы, то, конечно, лучше эту ссылку поместить в атрибут nofollow.
Как использовать тег noindex и nofollow одновременно
Данные теги не конфликтуют между собой, поэтому совершенно спокойно можно использовать их одновременно на одной странице или участке текста. В этом случае и текст и ссылка не будет доступна к индексации. Но важно не забывать, что текст будет скрыт только для поисковой системы Яндекс.
Обучение продвижению сайтов
Более подробно о том, как выводить сайты в ТОП 10 поисковых систем Яндекс и Google, я рассказываю на своих онлайн-уроках по SEO-оптимизации (смотри видео ниже). Все свои интернет-проекты я вывел на посещаемость более 1000 человек в сутки и могу научить этому Вас. Кому интересно обращайтесь!
На этом сегодня всё, всем удачи и до новых встреч!
hozyindachi.ru
Метатег robots | Закрыть страницу от индексации
Метатег robots | Закрыть страницу от индексации
Статья для тех, кому лень читать справку по GoogleWebmaster и ЯндексВебмастер
|
|
Закрывание ненужных страниц веб-ресурса от поисковой индексации очень важно для его SEO-оптимизации, особенно на начальном этапе становления сайта или блога «на ноги». Такое действие способствует продвижению в SERP (СЕРП) и рекомендовано к применению для служебных страниц. К служебным страницам относятся технические и сервисные страницы, предназначенные исключительно для удобства и обслуживания уже состоявшихся клиентов. Эти страницы с неудобоваримым или дублирующим контентом, который не представляет абсолютно никакой поисковой ценности. Сюда входят – пользовательская переписка, рассылка, статистика, объявления, комментарии, личные данные, пользовательские настройки и т.д. А, также – страницы для сортировки материала (пагинация), обратной связи, правила и инструкции и т.п. |
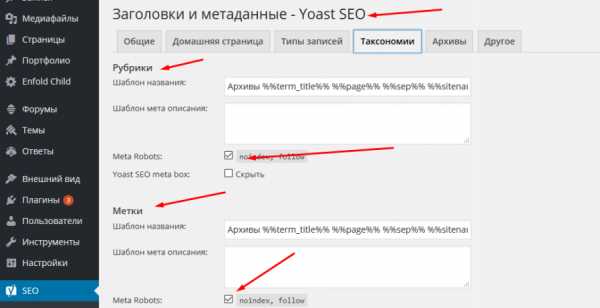
- Метатег robots
- Почему метатег robots лучше файла robots.txt
Метатег robots
Для управления поведением поисковых роботов на веб-странице, в HTML существует метатег robots и его атрибут content. закрытия веб-страницы от поисковой индексации,
nofollow и noindex – самые загадочные персонажи разметки html-страницы, главная задача которых состоит в запрете индексирования ссылок и текстового материала веб-страницы поисковыми роботами.
nofollow (Яндекс & Google)
|
nofollow – валидное значение в HTML для атрибута rel тега «a» (rel=»nofollow») |
rel=»nofollow» – не переходить по ссылке
Оба главных русскоязычных поисковика (Google и Яндекс) – прекрасно знают атрибут rel=»nofollow» и, поэтому – превосходно управляются с ним. В этом, и Google, и Яндекс, наконец-то – едины. Ни один поисковый робот не пойдёт по ссылке, если у неё имеется атрибут rel=»nofollow»:
<a href=»http://example.ru» rel=»nofollow»>анкор (видимая часть ссылки)</a>
content=»nofollow» – не переходить по всем ссылкам на странице
Допускается указывать значение nofollow для атрибута content метатега <meta>.
В этом случае, от поисковой индексации будут закрыты все ссылки на веб-странице
<meta name=»robots» content=»nofollow»/>
Атрибут content является атрибутом тега <meta> (метатега). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса несколько разное:
- Увидев атрибут
<a href=»http://example.ru» rel=»nofollow»>Анкор</a>
А, чтобы раз и навсегда закрыть от роботов Google всю веб-страницу,
<meta name=»robots» content=»nofollow»/> - Яндекс
- Для роботов Яндекса атрибут rel=»nofollow» имеет действие запрета только! на индексацию ссылки и переход по ней. Видимую текстовую часть ссылки (анкор) – роботы Яндекса всё равно проиндексируют.
Для роботов Яндекса атрибут метатега content=»nofollow» имеет действие запрета только! на индексацию ссылок на странице и переходов по них. Всю видимую текстовую часть веб-страницы – роботы Яндекса всё равно проиндексируют.
Для запрета индексации видимой текстовой части ссылки или страницы для роботов Яндекса – ещё потребуется добавить его любимый тег или значение noindex
noindex – не индексировать текст
(тег и значение только для Яндекса)
Тег <noindex> не входит в спецификацию HTML-языка.
Тег <noindex> – это изобретение Яндекса, который предложил в 2008 году использовать этот тег в качестве маркера текстовой части веб-страницы для её последующего удаления из поискового индекса. Поисковая машина Google это предложение проигнорировала и Яндекс остался со своим ненаглядным тегом, один на один. Поскольку Яндекс, как поисковая система – заслужил к себе достаточно сильное доверие и уважение, то придётся уделить его любимому тегу и его значению – должное внимание.
Тег <noindex> – не признанное изобретение Яндекса
Тег <noindex> используется поисковым алгоритмом Яндекса для исключения служебного текста веб-страницы поискового индекса. Тег <noindex> поддерживается всеми дочерними поисковыми системами Яндекса, вида Mail.ru, Rambler и иже с ними.
Тег noindex – парный тег, закрывающий тег – обязателен!
Учитывая не валидность своего бедного и непризнанного тега,
Яндекс соглашается на оба варианта для его написания:
Не валидный вариант – <noindex></noindex>,
и валидный вариант – <!— noindex —><!—/ noindex —>.
Хотя, во втором случае – лошади понятно, что для гипертекстовой разметки HTML, это уже никакой не тег, а так просто – html-комментарий на веб-странице.
Тег <noindex> – не индексировать кусок текста
Как утверждает справка по Яндекс-Вебмастер, тег <noindex> используется для запрета поискового индексирования служебных участков текста. Иными словами, часть текста на странице, заключённая в теги <noindex></noindex> удаляется поисковой машиной из поискового индекса Яндекса. Размеры и величина куска текста не лимитированы. Хоть всю страницу можно взять в теги <noindex></noindex>. В этом случае – останутся в индексе одни только ссылки, без текстовой части.
Поскольку Яндекс подходит раздельно к индексированию непосредственно самой ссылки и её видимого текста (анкора), то для полного исключения отдельно стоящей ссылки из индекса Яндекса потребуется наличие у неё сразу двух элементов – атрибута
Так, например, можно создать четыре конструкции, где:
- Ссылка индексируется полностью
- <a href=»http://example.ru»>Анкор (видимая часть ссылки)</a>
- Индексируется только анкор (видимая часть) ссылки
- <a href=»http://example.ru» rel=»nofollow»>Анкор</a>
- Индексируется только ссылка, без своего анкора
- <a href=»http://example.ru»><noindex>Анкор</noindex></a>
- Ссылка абсолютно НЕ индексируется
- <a href=»http://example.ru» rel=»nofollow»><noindex>Анкор</noindex></a>
Для справки: теги <noindex></noindex>, особенно их валидный вариант <!— noindex —><!—/ noindex —> – абсолютно не чувствительны к вложенности. Их можно устанавливать в любом месте HTML-кода. Главное, не забывать про закрывающий тег, а то – весь текст, до самого конца страницы – вылетит из поиска Яндекса.
Метатег noindex – не индексировать текст всей страницы
Допускается применять noindex в качестве значения для атрибута метатега content –
в этом случае устанавливается запрет на индексацию Яндексом текста всей страницы.
Атрибут content является атрибутом тега <meta> (метатег). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Абсолютно достоверно, ясно и точно, что использование noindex в качестве значения атрибута content для метатега <meta> даёт очень хороший результат и уверенно «выбивает» такую страницу из поискового индекса Яндекса.
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом в заголовке –
Яндекс совершенно не индексирует, но при этом он –
проиндексирует все ссылки на ней.
Разница в действии тега и метатега noindex
Визуально, разница в действии тега и метатега noindex заключается в том, что запрет на поисковую индексацию тега noindex распространяется только на текст внутри тегов <noindex></noindex>, тогда как запрет метатега – сразу на текст всей страницы.
Пример: <noindex>Этот текст будет не проиндексирован</noindex>
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом – Яндекс полностью не индексирует
Принципиально, разница в действии тега и метатега проявляется в различиях алгоритма по их обработке поисковой машиной Яндекса. В случае с метатегом noindex, робот просто уходит со страницы, совершенно не интересуясь её содержимым (по крайней мере – так утверждает сам Яндекс). А, вот в случае с использованием обычного тега <noindex> – робот начинает работать с контентом на странице и фильтровать его через своё «ситечко». В момент скачивания, обработки контента и его фильтрации возможны ошибки, как со стороны робота, так и со стороны сервера. Ведь ни что не идеально в этом мире.
Поэтому, кусок текста страницы, заключённого в теги <noindex></noindex> – могёт запросто попасть Яндексу «на зуб» для дальнейшей поисковой индексации. Как утверждает сам Яндекс – это временное неудобство будет сохраняться до следующего посещения робота. Чему я не очень охотно верю, потому как, некоторые мои тексты и страницы, с тегом и метатегом noindex – висели в Яндексе по нескольку месяцев.
Особенности метатега noindex
Равно, как и в случае с тегом <noindex>, действие метатега noindex позволяет гибко накладывать запреты на всю страницу. Примеры метатегов для всей страницы сдерём из Яндекс-Вебмастера:
- не индексировать текст страницы
- <meta name=»robots» content=»noindex»/>
- не переходить по ссылкам на странице
- <meta name=»robots» content=»nofollow»/>
- не индексировать текст страницы и не переходить по ссылкам на странице
- <meta name=»robots» content=»noindex, nofollow»/>
- что, аналогично следующему:
- запрещено индексировать текст и переходить
по ссылкам на странице для роботов Яндекса - <meta name=»robots» content=»none»/>
Вот такой он, тег и значение noindex на Яндексе :):):).
Тег и метатег noindex для Google
Что-же касается поисковика Google, то он никак не реагирует на присутствие выражения noindex, ни в заголовке, ни в теле веб-страницы. Google остаётся верен своему валидному «nofollow», который он понимает и выполняет – и для отдельной ссылки, и для всей страницы сразу (в зависимости от того, как прописан запрет). После некоторого скрипения своими жерновами, Яндекс сдался и перестал продвижение своего тега и значения noindex, хотя – и не отказывается от него полностью. Если роботы Яндекса находят тег или значение noindex на странице – они исправно выполняют наложенные запреты.
Универсальный метатег (Яндекс & Google)
С учётом требований Яндекса, общий вид универсального метатега,
закрывающего полностью всю страницу от поисковой индексации,
выглядит так:
- <meta name=»robots» content=»noindex, nofollow»/>
- – запрещено индексировать текст и переходить по ссылкам на странице
для всех поисковых роботов Яндекса и Google
Почему метатег robots лучше файла robots.txt
Самый простой и популярный способ закрыть веб-страницу от индексации – это указать для неё соответствующую директиву в файле robots.txt. Для этого, собственно файл robots.txt и существует. Однако, закрывать через метатег robots – гораздо надёжнее.
И, вот почему.
Алгоритмы обработки роботами метатега robots и файла robots – совершенно различные. Работу этих алгоритмов можно сравнить с действием в известном анекдоте, где бьют не «по паспорту», а – «по морде». Пусть этот пример весьма груб и примитивен, но он, как нельзя лучше – отображает поведение поискового робота на странице:
- В случае использования метатега robots, поисковик просто и прямо заходит на веб-страницу и читает её заголовок («смотрит в её морду». Если робот там находит метатег robots – он разворачивается и уходит восвояси. Вуаля! Всё предельно просто. Робот увидел запись, что здесь ловить нечего, и сразу же – «свалил». Ему проблемы не нужны. Это есть работа по факту записи прямо в заголовке страницы («по морде»).
- В случае использования файла robots.txt, поисковик, перед заходом на страницу – сверяется с этим файлом (читает «паспорт»). Это есть работа по факту записи в постороннем файле («по паспорту»). Если в файле robots.txt («паспорте») прописана соответствующая директива – робот её выполняет. Если нет, то он – сканирует страницу в общем порядке, поскольку по-умолчанию – к сканированию разрешены все страницы.
Казалось-бы, какая разница.
Тем более, что сам Яндекс рассказывает следующее:
При сканировании сайта, на основании его файла robots.txt – составляется специальный список (пул), в котором ясно и чётко указываются и излагаются директории и страницы, разрешённые к поисковому индексированию сайта.
Ну, чего ещё проще – составил списочек,
прошёлся списочком по сайту,
и всё – можно «баиньки»…
Простота развеется, как майский дым, если мы вспомним, что роботов много, что все они разные, и самое главное – что все роботы ходят по ссылкам. А сей час, представим себе стандартную ситуацию, которая случается в интернете миллионы раз на дню – поисковый робот пришёл на страницу по ссылке из другого сайта. Вот он, трудяга Сети – уже стоит у ворот (у заголовка) странички. Ну, и где теперь файл robots.txt?
У робота, пришедшего на сайт по внешней ссылке, выбор не большой. Робот может, либо лично «протопать» к файлу robots.txt и свериться с ним, либо просто скачать страницу себе в кэш и уже потом разбираться – индексировать её или нет.
Как поступит наш герой, мы не знает. Это коммерческая тайна каждой поисковой системы. Несомненно, одно. Если в заголовке страницы будет указан метатег robots – поисковик выполнит его немедля. И, если этот метатег запрещает индексирование страницы – робот уйдёт немедля и без раздумий.
Вот теперь, совершенно ясно, что прямой заход на страницу, к метатегу robots –
всегда короче и надёжнее, нежели долгий путь через закоулки файла robots.txt
Метатег robots | Закрыть страницу от индексации на tehnopost.info
- Метатег robots
- Почему метатег robots лучше файла robots.txt
tehnopost.info
Noindex, nofollow для Google — как и когда использовать с пользой для SEO продвижения
Существуют три разных понятия:
- метатег “robots” со значением”noindex”;
- тег <noindex>;
- атрибут rel=”nofollow”.
Noindex
Noindex – это директива для поисковых систем, которая запрещает отображать страницу либо часть текста в результатах поиска. Давайте рассмотрим подробнее – где и в каких случаях используется эта директива?
Mетатег “robots” со значением “noindex”
Чтобы не допустить определенную страницу к индексированию поисковыми системами используется метатег robots с добавлением значения “noindex”.
В разделе <head> страницы размещается следующая конструкция:
<head>
<meta name="robots" content="noindex" />
…
</head>
Данный метатег распространяется на всех роботов поисковых систем. Но иногда может использоваться только для определенных роботов, в зависимости от целей. Например, можно запретить индексацию только лишь определенной поисковой системе, указав в значении для атрибута “name” название робота (например – Googlebot, для Google):
<meta name="googlebot" content="noindex" />
Пример: Вы не хотите, чтобы ваши изображения были найдены через поиск по изображениям и использованы кем-то в личных целях.
Решение: Можно запретить индексацию страницы с данными изображениями только в поиске по изображениям, используя робот Googlebot-Image:
<meta name="googlebot-image" content="noindex" />
Таким образом, страница появится в результатах обычного поиска, но её содержимое не будет индексироваться для поиска по изображениям.
Тег <noindex> – для закрытия от индексации части контента
Для того, чтобы закрыть от индексации часть текста используется тег <noindex>, который может быть помещен в любые элементы html-кода страницы:
<noindex>текст, который будет запрещен к индексированию</noindex>
Однако, данный тег будет восприниматься только поисковиком Яндекс, так как он не является стандартизированным и был введен только этой поисковой системой.
Если мы разместим текст внутрь тега, то он не будет индексироваться при сканировании роботом Яндекс и при этом будет попадать в индекс всех остальных поисковиков.
Валидность
Так как тег <noindex> не является стандартизированным, то могут возникать ошибки валидации. Чтобы код оставался валидным, рекомендуется использование тега в таком виде:
<!--noindex-->текст, который будет запрещен к индексированию<!--/noindex-->
Варианты использования meta robots noindex
Мета-тег “Robots” содержит директивы, разделенные запятыми:
- Index/Noindex задает правило индексации страницы;
- Follow/Nofollow разрешает или запрещает переходить по ссылкам со страницы. Значения по умолчанию – Index и Follow.
Существуют следующие варианты использования метатега:
| <meta name=“robots” content=“index,follow”> | Разрешено индексировать страницу и переходить по ссылкам на ней. |
| <meta name=“robots” content=“noindex,follow”> | Запрещено индексировать страницу, но можно переходить по ссылкам на ней. |
| <meta name=“robots” content=“index,nofollow”> | Разрешено индексировать страницу, но нельзя переходить по ссылкам на странице. |
| <meta name=“robots” content=“noindex,nofollow”> | Запрещено индексировать страницу и переходить по ссылкам на ней. |
Как показывает практика (см. эксперимент С. Кокшарова), Google обычно корректно воспринимает данные правила. Что касается Яндекс, то он может не всегда следовать правилу “noindex, nofollow” и переходит по ссылкам, чтобы проверить их качество (под такими директивами иногда прячутся недобросовестные сайты).
Отличия meta robots noindex от noindex в robots.txt
Есть 2 способа скрыть страницу от индексирования:
- Закрыть страницу в robots.txt с помощью Disallow.
- Добавить на страницу в <head> метатег:
<meta name="robots" content="noindex" />
Основные отличия:
- В robots.txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
- <meta name=”robots” content=”noindex, follow”> позволяет закрывать страницы точечно, а также передавать ссылочный вес.
Если необходимо закрыть определенную страницу, лучше все-же воспользоваться метатегом чтобы не перегружать robots.txt лишними строками. Кроме того, выше вероятность того, что правило сработает (по сравнению с robots.txt).
Помните, что robots.txt – это всего лишь рекомендации, то есть поисковые системы могут игнорировать его — индексировать и сканировать запрещенные URL. Поэтому, если вы хотите скрыть URL с гарантией, лучше это сделать через метатег. А если уж наверняка – то можно, например, закрыть директории паролем.
Распространенные ошибки
Страница закрыта через метатег, но все равно находится в поиске
Возможные причины:
- Страница закрыта также robots.txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
- Робот еще не успел посетить страницу (на сайте много страниц).
Решение: Чтобы закрыть страницу через метатег, необходимо, чтобы она была открыта в robots.txt. Если на сайте много страниц, а страницу нужно срочно закрыть – лучше воспользоваться панелью вебмастера.
Внедрение одновременно noindex и rel canonical на страницах (например, пагинации)
Это частая ошибка вебмастеров, ведь эти два тега противоречат друг другу. Google дает четкий ответ по этому поводу тут: https://www.seroundtable.com/noindex-canonical-google-18274.html .
Решение для страниц пагинации:
- canonical не использовать,
- на страницах пагинации прописать: <meta name=”robots” content=”noindex, follow” />, а также link rel=”prev” и link rel=”next”.
На сайте есть не закрытые метатегом служебные страницы – версии страниц «для печати», а также служебные/шаблонные страницы, которые создаются динамически. Это частая проблема, так как в индекс могут попасть сотни ненужных страниц. В дальнейшем эти «мусорные» страницы могут ранжироваться в поиске вытесняя полезные продвигаемые страницы. Закрытие через robots.txt может не решить проблему.
Решение: Google советует закрыть такого рода страницы через метатег <meta name="robots" content="noindex, nofollow" />.
Атрибут rel-nofollow
Значение rel=”nofollow” запрещает поисковой системе переходить по конкретной ссылке.
Пример использования: <a href="test.com" rel="nofollow">Ссылка</a>
Google утверждает: «…Как правило, переход не производится. Это означает, что по этим ссылкам Google не передает ни PageRank, ни текст ссылки…»
Однако, «как правило» предполагает, что бывают исключения. Также, например, ссылки с nofollow могут быть проиндексированы, если на страницу ссылаются другие сайты без использования nofollow, либо страница есть в Sitemap.
Как и где использовать
Рекомендуется использовать rel=”nofollow”:
- для закрытия ссылок на некачественный контент или контент, которому вы не доверяете,
- для закрытия неуникального контента,
- для закрытия платных ссылок,
- для корректной индексации (например, чтобы скрыть технические страницы и не тратить ресурсы робота на их сканирование).
Помимо этих случаев, многие оптимизаторы используют rel=”nofollow”, когда хотят, чтобы внешняя ссылка не передавала вес.
Передает ли nofollow вес
По словам Google, rel=”nofollow” не передает ссылочный вес. Однако, есть свидетельства, что Google учитывает ссылки социальных сетей Facebook, Twitter не смотря на nofollow.
Что касается Яндекс, то с 2010 года он не учитывает ссылки с nofollow и, соответственно ссылка не передает вес. Это официальная версия Яндекс. Однако, есть подтверждения экспериментов, что Яндекс учитывает анкоры таких ссылок.
Как бы там ни было, ваш ссылочный профиль должен быть разнообразным и рекомендуется разбавлять анкор-лист ссылками с rel=”nofollow”.
Распространенные ошибки
Использование rel=”nofollow” для внутренней перелинковки.
Google так делать не советует (https://www.searchengines.ru/mett_katts_ne_nofollow_int_links.html )
Использовать rel nofollow на каждый язык языковой версии чтобы «сегментировать» их, не передавая вес друг-другу.
Не нужно с помощью rel nofollow пытаться манипулировать весом. Если сайт целостный, все равно в рамках внутренней перелинковки вес будет переходить. Как уже говорилось выше – Google не приветствует rel nofollow для внутренней перелинковки. Но не забудьте об использовании hreflang.
Использовать rel nofollow для ссылок на страницы фильтра.
Рекомендуется не использовать атрибут nofollow, а реализовать фильтры с помощью JS или закрывать страницы метатегом noindex, nofollow.
Надеемся, что данная статья ответила на основные вопросы по использованию тегов noindex, nofollow. Желаем успешного продвижения!
proposition.com.ua
Nofollow-ссылки. Нужно ли их использовать в SEO?
Споры о том, нужны ли nofollow ссылки для SEO — бесконечны. Главный тезис спора
Если nofollow ссылки не передают ссылочный вес, а значит не влияют на продвижение сайта, зачем их добывать?
Если вы согласны с этим мнением, то сегодня ваш мир изменится 😉
Но обо всем по порядку …
Что такое nofollow-ссылки?
Техническое определение:
Nofollow — это значение атрибута rel для HTML-тега «a» (rel="nofollow").
Пример:
<a href="http://site.com/" rel="nofollow">текст ссылки</a>
Зачем
С какой целью вообще используется атрибут nofollow? Зачем им присваивать этот тег?
Причины:
- не передавать вес всем внешним сайтам, а сохранить его;
- закрывать в nofollow ссылки на сайты, в качестве которых вы не уверены;
- закрывать внутренние страницы или разделы сайта, чтобы перераспределить веса;
- указать поисковому роботу неприоритетные страницы, например, «Вход», «Регистрации» и т.д.
- применение nofollow на уровне страницы используя конструкцию
<meta name="robots" content="nofollow" />позволяет закрыть от индексации поисковыми роботами нежелательных, либо низкокачественных страниц; - строить более естественный ссылочный профиль. Обычные пользователи, когда ставят ссылки не думают как они реализованы редирект, nofollow, если в вашем ссылочном профиле будут преобладать dofollow ссылки это будет весьма странно.
Есть и другие варианты применения nofollow, это самые распространенные.
Как понять, что ссылка nofollow?
Выбирая площадки для получения ссылок, нужно уметь определять dofollow, nofollow, redirect ссылки.
Самый простой способ это найти внешнюю ссылку и посмотреть ее в коде.
Открываем контекстное меню:
Жмем Inspect и смотрим, что в коде:
Видим тег rel="nofollow noopener", по факту это тоже самое что и тег nofollow, именно nofollow noopener начал использоваться в последних версиях WordPress, по этому вы будете видеть его также часто.
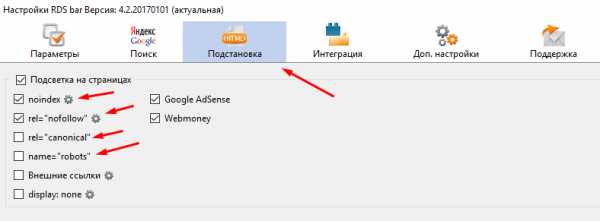
Еще один вариант, это использовать расширение для браузера RDS Bar, либо другие аналогичные.
Выставьте в настройках подсветку nofollow ссылок:

Заходя на сайты с этим тегом, вы будете видеть зачеркнутые ссылки:
Но есть проблема, что в RDS Bar сейчас не подсвечивается rel="nofollow noopener", учитывая, что сайты на CMS WordPress это 30% интернета, то придется перепроверять руками в коде.
Установили себе уже RDS Bar?
Сейчас переходим к интересному, к тому как поисковые системы воспринимают nofollow.
Вы ведь этого ждали? 😉
Ноуфоллоу в Гугл
Вот что нам говорит справка Google:
Обратите внимание:
То есть, в своей официальной справке Google заявляет, что
nofollow не во всех случаях является запретом для передачи веса по ссылке
Update! Хорошее дополнение сделал . Сам по себе факт того, что в Search Console Гугла в отчетах «Ссылки на ваш сайт» можно найти немалое множество и nofollow ссылок, и той же Quora, должно заставить задуматься:

Алексей Трудов сделал исследование по учету nofollow ссылок для Яндекса, результат предсказуем — поисковой робот Яндекса переходит по ссылке и учитывает.
Интересно. Что думают эксперты на западе по этому поводу, чтобы не тратить ваше время, приведу пару ссылок:
Все сводится к тому, что nofollow во многих случаях не является ограничением для поисковых систем.
Надеюсь, мы разобрались, что nofollow работают во многих случаях? 😉
Теперь давайте разберем какую еще пользу могут приносить ссылки, кроме веса для SEO.
Зачем нужны ссылки бизнесу?
Вне зависимости от того, передают nofollow, redirect, span ссылки какой-то вес или нет, главное, что они выполняют свою основную функцию — переводят пользователя с одной страницы на другую.
Повышение узнаваемости
Это значит, что люди будут попадать на ваш сайт, проводить на нем время, касаться вашего бизнеса.
Если у вас качественный продукт, удобный сайт, то вы получите хорошие поведенческие факторы страниц, что непременно повлияет на SEO. Вы получите брендовый и прямой трафик, который имеет большое значение для поисковых систем.
Лидогенерация
Если вы размещаете ссылки на релевантных страницах, то вы получите переходы аудитории, которой интересен ваш продукт и если он качественный, то однозначно получите лиды и заказы.
Ссылки порождают ссылки
Ссылки размещенные в социальных сетях могут не дать вам ожидаемый SEO-эффект, но могут спровоцировать инфоповод и принести ссылки с других площадок.
Не самый приятный кейс, но…
Федор Овчинников (CEO dodopizza) опубиковал пост:
который спровоцировал большое количество публикаций в СМИ:
- https://secretmag.ru/news/fyodor-ovchinnikov-rasskazal-o-doprose-iz-za-narkotikov-v-dodo-pizza-30-01-2018.htm
- https://vc.ru/32524-osnovatel-dodo-piccy-rasskazal-o-nastoychivyh-vyzovah-na-dopros-iz-za-odnoy-moskovskoy-piccerii
- http://www.bbc.com/russian/news-42985879
- https://www.novayagazeta.ru/articles/2018/02/08/75435-ugolovnoe-delo-idet-po-stsenariyu
И так далее. Сотни публикаций.
Если вы способны сгенерировать такой инфоповод, какая разница как будут реализованы ссылки?
Где взять лучшие nofollow-ссылки?
Лучшая ссылка = трафиковая. Если по ссылке переходит релевантная аудитория — это полезная ссылка.
Видео-хостинги
Youtube — самый популярный видео-хостинг в мире и вы думаете, что Гугл не учитывает ссылки, которые стоят под популярными видео?
Или vimeo:

Рекомендации от видео-блогеров могут дать большой объем трафика с очень хорошими поведенческими:

Социальные сети
Twitter, flickr.com, tumblr.com и десятки других социальных сетей позволяют поставить ссылку и получить аудиторию:
The @Tesla Model 3 is a love letter to the road (by @etherington) https://t.co/Nd9KXftYbJ pic.twitter.com/qmfymUiaZa
— TechCrunch (@TechCrunch) March 8, 2018
Форумы
Многие лидирующие форумы закрывают свои ссылки в nofollow или noindex, но это абсолютно не повод не работать с ними.
Например, форум Винского (крупнейший туристический форум с аудиторией 5-10 миллионов в месяц):
Но если вы хотите dofollow-ссылку, то конечно же исключайте его из своего списка подходящих площадок 😀
Q/A
- reddit.com
- quora.com
- otvet.mail.ru
Это платформы с миллиардным месячным трафиком и у них также ссылки в nofollow, а у quora ссылки реализованы через span. Но я не думаю, что поисковые системы не учитывают эти ссылки. Это не логично.
Пример ссылки quora.com:
И таких платформ сотни и тысячи, которые вы исключаете из-за SEO мифов.
Хотите получать максимум от ссылок? Регистрируйтесь в нашей системе крауд-маркетинга http://service.referr.ru/register/. Поможем построить эффективный ссылочный профиль.
http://qr.ae/TU17hj
referr.ru
Использование тега noindex и атрибута nofollow. Отличие noindex и nofollow.
Правильное использование тега noindex и атрибута nofollow – самый первый шаг в грамотной оптимизации. Ведь noindex и nofollow играют огромную роль при передаче веса с одной страницы сайта на другую. Тег noindex используется для запрета индексации какой-то части html-кода страницы. Тег noindex не является валидным, поэтому некоторые html-редакторы отказываются его воспринимать. Ноиндекс воспринимается исключительно поисковиком Яндексом, а Гугл на него никак не реагирует.
Не стоит путать обычный тег <noindex> с мета-тегом noindex, прописываемым вначале страницы, их задачи разные. Простой тег запрещает для индексации только ту часть кода страницы, которая находится между открывающимся <noindex> и закрывающимся </noindex> тегами. Что же касается мета-тега, то он запрещает индексировать всю страницу (запрет прописывается в файле robots.txt) – такую страницу Яндекс вообще не индексирует.
Тег работает безотказно: вся текстовая информация внутри него не попадает в индекс яндекса. Однако некоторые оптимизаторы утверждают, что порой текст внутри ноиндекс индексируются – увы, такое действительно бывает. Дело в том, что Яндекс все же изначально индексирует весь html-код, даже тот, что внутри тега, но потом проводит фильтрацию. В начале служебного фрагмента поставьте — <noindex>, а в конце — </noindex>, и Яндекс не будет индексировать данный участок текста. Тег noindex не чувствителен к вложенности.
Используя открывающийся тег (<noindex>), не забудьте поставить закрывающийся — (</noindex>), иначе весь текст, следующий после <noindex> не будет проиндексирован.
Поскольку тег noindex не входит в официальную спецификацию языка HTML, то большинство HTML-валидаторов считает его ошибкой. Потому для того, чтобы сделать код с noindex валидным, рекомендуется использовать следующую конструкцию:
<!–noindex–>Текст или код, который нужно исключить из индексации<!–/noindex–>
Немалая часть оптимизаторов очень часто высказывают мнения, насчет того, что Яндекс не обращает внимания на этот тег. Обычно аргументируется это тем, что текст, закрытый в ноиндекс, есть в сохраненной копии страницы в Яндексе, следовательно, поисковик видит его. Другая же часть оптимизаторов считает, что это просто на просто очередной миф, и ноиндекс есть ноиндекс, т.е. Яша не видит текст (ссылку) заключенный в него.
seoklub.ru
4 случая использования noindex и nofollow · Блог Системы PromoPult
Noindex и nofollow — похожие по форме, но разные по смыслу элементы. Их часто путают, и как их только не называют: тегами, метатегами, атрибутами. Сегодня мы расставим все точки над «i» и расскажем, чем отличается noindex от nofollow и в каких случаях их целесообразно использовать.
1. Метатеги
Прежде всего, noindex и nofollow (наряду с index и follow) — это указания для роботов в метатегах директивы <head>. Их понимают все без исключения поисковики. Указания index или noindex разрешают или запрещают роботу индексировать содержимое страницы, а follow и nofollow — переходить по ссылкам на странице.
Возможны такие варианты:
<meta name="robots" content="index, follow"/> — в этом случае разрешена индексация страницы и ссылок. <meta name="robots" content="noindex, follow"/> — запрещена индексация содержимого страницы, но разрешен переход по ссылкам. <meta name="robots" content="index, nofollow"/> — разрешена индексация, но запрещен переход по ссылкам. <meta name="robots" content="noindex, nofollow"/> — запрещается и индексация, и переход по ссылкам.
От индексации следует закрывать служебные страницы (админка, логи сервера) а также дублированный контент (страницы архивов, тегов, результаты поиска по сайту, пагинацию).
Если вы хотите оставить указания только для какого-то конкретного робота, то нужно просто указать его идентификатор в метатеге, например:
<meta name="googlebot" content="noindex, follow"/>
Если не задать указания для робота, то он по умолчанию принимает значения index и follow.
В SEO-модуле PromoPult на втором шаге создания проекта “Страницы” можно провести быстрый анализ страниц на предмет того, есть ли запреты на индексацию в метатегах. Проверка происходит за секунды и совершенно бесплатно.
2. Цитаты, копипаст и другой текст
Для того чтобы закрыть не всю страницу, а только ее часть от индексации, а именно служебные участки текста, используется тег <noindex>. Причем это «ноу-хау» Яндекса. Google тег не понимает и считает его невалидным. Синтаксис выглядит так:
<noindex>текст, который следует скрыть от индексации</noindex>
Проблема в том, что при такой конструкции во время валидации кода будут ошибки. Если вы хотите сделать код валидным, используйте такой синтаксис:
<!--noindex-->текст, который следует скрыть от индексации<!--/noindex-->
Скрывать от индексации есть смысл:
- дословные цитаты других авторов;
- выдержки из законодательства;
- регулярно повторяющийся одинаковый текст;
- служебный текст.
По поводу тега <noindex> есть заблуждение. Считается, что текст, помещенный в него, Яндекс вообще не учитывает. Это не так. Яндекс читает его и принимает во внимание при определении релевантности страницы и ее уникальности, просто он не добавляет его в индексную базу.
3. Ссылки
Изначально nofollow использовали только в метатеге на уровне страницы. Но со временем возникла острая необходимость закрывать не все ссылки на странице от индексации, а только некоторые из них. Так появился атрибут rel=»nofollow» тега . Он относится только к ссылке, для которой указан. Синтаксис выглядит так:
<a href="index.php" rel="nofollow">Перейти</a>
Некоторые пытаются закрывать ссылки от индексации таким образом:
<nofollow><a href="index.php">Перейти</a></nofollow>
Это неверно. Запомните, что тега <noindex> не существует — только атрибут rel или метатег со значением nofollow.
Более распространенная ошибка — попытка закрыть ссылку от индексации с помощью тега <noindex>. В этом случае будет закрыт только анкор, и только для Яндекса. По ссылке же роботы смогут переходить.
Закрывают ссылки атрибутом nofollow в таких случаях:
- Ненадежный контент (если вы не можете или не желаете поручиться за содержание страниц, на которые ведут ссылки, то лучше скрыть их от роботов. Например, атрибутом nofollow часто закрывают ссылки из комментариев в блогах или сообщений на форумах).
- Платные ссылки (если вы размещаете рекламные статьи, новости, обзоры, то закрытие ссылок атрибутом nofollow убережет вас от возможных санкций со стороны поисковых систем. Хотя, конечно, далеко не каждый рекламодатель захочет получать именно такую ссылку, поэтому этот подход практикуют лишь топовые площадки, и то не все).
- Приоритезация сканирования (роботам ни к чему переходить, например, по ссылкам на форму регистрации или личный кабинет. Использование атрибута nofollow позволит направить роботов в нужном русле и не тратить их время на бесполезное сканирование).
- Много внешних ссылок (если со страницы идет много внешних dofollow ссылок, то лучше закрыть некоторые из них. В противном случае страница будет терять вес).
- Перераспределение веса (с помощью nofollow можно перераспределить вес между внутренними страницами сайта. Но для этого нужно хорошо понимать, что именно и как делать, чтобы не получилось, что некоторые страницы будут просто выпадать из общей логики перелинковки).
4. Счетчики и блоки подписки
На страницах сайта зачастую расположено много служебных элементов, которые нет смысла индексировать. Их закрывают с помощью тега <noindex>. Прежде всего, это счетчики (Liveinternet, Яндекс.Метрика и т. п.), различные информеры, блоки оформления подписки и т. п. А вот блоки рекламы (Яндекс.Директ, Google Adsense и проч.) закрывать не нужно.
Совет напоследок
Некоторые оптимизаторы в погоне за сохранением драгоценного веса закрывают с помощью noindex и nofollow все, что только можно, не оставляя ни одной внешней ссылки. Это ошибка. Есть ли она на вашем сайте? Можно узнать, заказав аудит у “Персонального менеджера” PromoPult. Дело в том, что ссылки на авторитетные ресурсы поднимают рейтинг вашего сайта в глазах поисковиков. Не бойтесь ссылаться — это вполне нормально, если вы указываете источники данных и полезные ресурсы.
blog.promopult.ru