Нужно ли использовать тег NOINDEX и зачем? — Devaka SEO Блог
23.8К просмотров
В последнее время, анализируя проблемные сайты клиентов, часто сталкиваюсь с тем фактом, что многие из них активно используют тег <noindex> для скрытия части контента от Яндекса. Для тех, кто не знаком с этим тегом, привожу ссылку на документацию. Как там указано, он предназначен для запрета индексирования служебных участков текста.
Стоит заметить, что в документации указан ответ на вопрос “как использовать этот тег”, но совсем не сказано “зачем он введён”. Отчасти, это и является причиной возникновения многих вопросов от вебмастеров.
Если мы поищем в Google ответ на вопрос какая польза от тега noindex или любые рекомендации от сотрудников Яндекса по этому поводу, то ожидаемого ответа на вопросы, зачем он всё-таки был введён и в каких случаях его рекомендуется использовать, мы не получим. Сотрудники Яндекса не берут на себя ответственность в подобных рекомендациях, но при этом и не запрещают использовать noindex в своих целях.
Какие были преимущества у этого тега?
1. Можно было закрыть блок внешних ссылок от индексации (как это делает, например, студия Артемия Лебедева в легендарном смайлике).
Действительно, удобно было закрывать таким способом немодерируемые ссылки, в том числе и в комментариях. Но после введения Яндексом возможности использовать rel=nofollow, как это делают другие крупные поисковые системы, можно смело отказаться от тега noindex, если он использовался только для закрытия внешних ссылок.
2. Можно управлять сниппетом (описанием сайта) в поисковой выдаче.
Так как Яндекс не всегда умеет формировать из контента страницы хорошие сниппеты для своей выдачи, оптимизаторы нашли выход использовать <noindex>, подбирая оптимальные варианты. Кто из вас так делает? Наверняка меньшинство, так как это трудная и долгая работа. Вместо того, чтобы решить проблему на своей стороне (в алгоритмах), Яндекс предлагает решать проблему вебмастерам.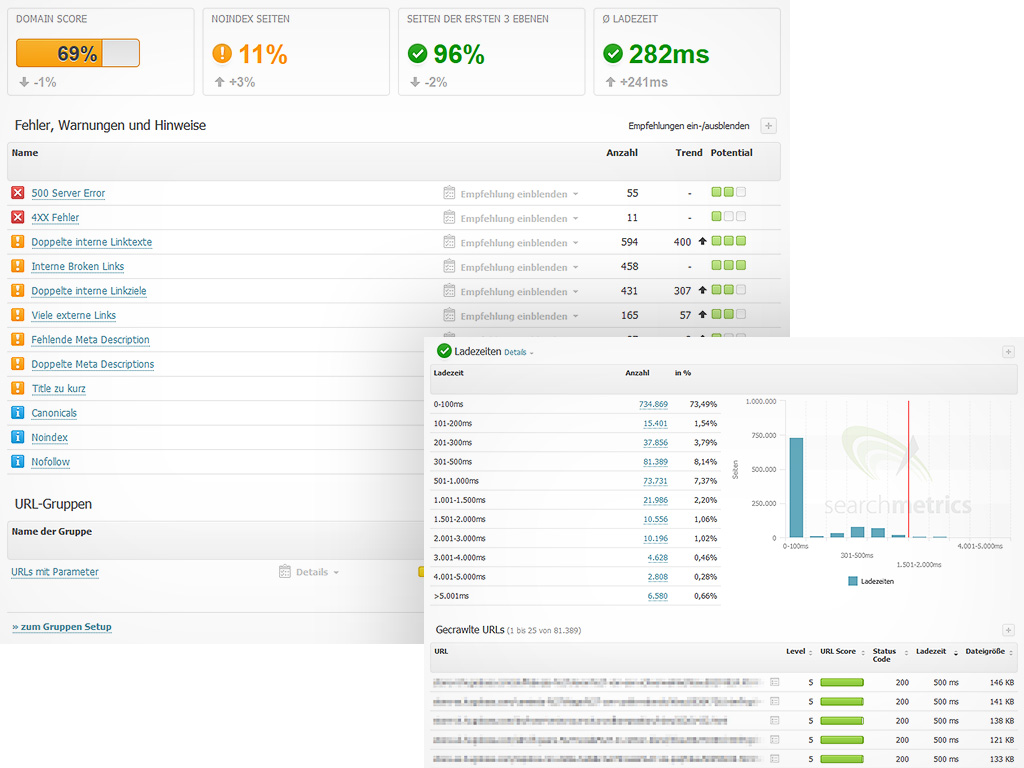 Кстати, в Google нет подобного тегу noindex функционала 😉
Кстати, в Google нет подобного тегу noindex функционала 😉
3. Для Google показывать одно, для Яндекса – другое!
Тегом <noindex> вебмастера пытались оптимизировать контент сайта и для Яндекса (от которого надо было спрятать некоторые участки кода) и для Google, используя совместно другие техники. Не это ли является явным манипулированием поисковыми алгоритмами или подменой контента, против которой так яро борятся яндексоиды? 🙂
4. Подбирать оптимальную плотность ключевых фраз.
Доходит до того, что в тексте оптимизаторы лишние фразы закрывают этим тегом, чтобы Яндекс не счел этот текст спамным. При этом, для посетителей он-таки часто остаётся спамным 🙂 Отсюда и корни большинства бед в SEO, а нужно было лишь дать оптимизаторам этот тег. С другой стороны, Яндекс всегда может узнать по таким маркерам, работал ли с текстом оптимизатор или это нормальный контент.
Кстати, Яндекс не рекомендовал использовать noindex для подбора оптимальной плотности ключевиков, это уже происки оптимизаторов (об этом яндекс и не мог подозревать при введении поддержки тега), зато он активно пессимизирует документы, где часто встречается этот тег.
5. Закрывать счетчики и баннеры.
Экономя на каждой ссылке, вебмастера закрывали в noindex и счетчики посещаемости. Прошло много лет, сейчас Яндекс прекрасно понимает, где что у вас расположено на сайте (в том числе и счетчики). Закрывать их от индексации смысла нет, лучше убрать всё неиспользуемое.
Как мы видим, <noindex> используется лишь оптимизаторами и всё, для чего используется это не попытка сделать ресурс лучше, а попытка управлять поисковым алгоритмом в свою сторону, хотя это и не всегда получается. Также все рекомендации, присутствующие в сети по использованию noindex даны оптимизаторами и ни одной от А.Садовского или И.Сегаловича.
Учитывая всё вышеперечисленное, настоятельно не рекомендуется использовать инструмент серой оптимизации noindex, особенно если он раньше не использовался на сайте и существуют дополнительные проблемы с ресурсом (фильтры, подмена релевантной страницы, и другие).
И ещё… У яндекса нет ни одной причины продолжать поддерживать тег noindex (разве что “не трогать то, что работает”). После ввода поддержки атрибута nofollow для ссылок, сложно понять мотив яндексоидов оставить noindex. Возможно, скоро его поддержка будет прекращена.
После ввода поддержки атрибута nofollow для ссылок, сложно понять мотив яндексоидов оставить noindex. Возможно, скоро его поддержка будет прекращена.
Таков мой взгляд на однобокий тег noindex. А что вы думаете по этой теме?
nofollow и noindex | Закрыть ссылку от индексации
nofollow и noindex | Закрыть ссылку от индексации
nofollow и noindex – любимые персонажи разметки html-страницы, главная задача которых состоит в запрете индексирования ссылок и текстового материала веб-страницы поисковыми роботами.
nofollow и noindex – самые загадочные персонажи разметки html-страницы, главная задача которых состоит в запрете индексирования ссылок и текстового материала веб-страницы поисковыми роботами.
nofollow (Яндекс & Google)
nofollow – валидное значение в HTML для атрибута rel тега «a» (rel=»nofollow») Оно устанавливает запрет на переход по ссылке и последующее её индексирование. |
rel=»nofollow» – не переходить по ссылке
Оба главных русскоязычных поисковика (Google и Яндекс) – прекрасно знают атрибут rel=»nofollow» и, поэтому – превосходно управляются с ним. В этом, и Google, и Яндекс, наконец-то – едины. Ни один поисковый робот не пойдёт по ссылке, если у неё имеется атрибут rel=»nofollow»:
<a href=»http://example.ru» rel=»nofollow»>анкор (видимая часть ссылки)</a>
content=»nofollow» – не переходить по всем ссылкам на странице
Допускается указывать значение nofollow для атрибута content метатега <meta>.
В этом случае, от поисковой индексации будут закрыты все ссылки на веб-странице
<meta name=»robots» content=»nofollow»/>
Атрибут content является атрибутом тега <meta> (метатега). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса несколько разное:
- Увидев атрибут rel=»nofollow»
<a href=»http://example.ru» rel=»nofollow»>Анкор</a>
А, чтобы раз и навсегда закрыть от роботов Google всю веб-страницу,
достаточно добавить в её заголовок строку с метатегом: - Яндекс
- Для роботов Яндекса атрибут rel=»nofollow» имеет действие запрета только! на индексацию ссылки и переход по ней.
 Видимую текстовую часть ссылки (анкор) – роботы Яндекса всё равно проиндексируют.
Видимую текстовую часть ссылки (анкор) – роботы Яндекса всё равно проиндексируют.
Для роботов Яндекса атрибут метатега content=»nofollow» имеет действие запрета только! на индексацию ссылок на странице и переходов по них. Всю видимую текстовую часть веб-страницы – роботы Яндекса всё равно проиндексируют.
 Видимую текстовую часть ссылки (анкор) – роботы Яндекса всё равно проиндексируют.
Видимую текстовую часть ссылки (анкор) – роботы Яндекса всё равно проиндексируют.noindex – не индексировать текст
(тег и значение только для Яндекса)
Тег <noindex> не входит в спецификацию HTML-языка.
Тег <noindex> – это изобретение Яндекса, который предложил в 2008 году использовать этот тег в качестве маркера текстовой части веб-страницы для её последующего удаления из поискового индекса. Поисковая машина Google это предложение проигнорировала и Яндекс остался со своим ненаглядным тегом, один на один. Поскольку Яндекс, как поисковая система – заслужил к себе достаточно сильное доверие и уважение, то придётся уделить его любимому тегу и его значению – должное внимание.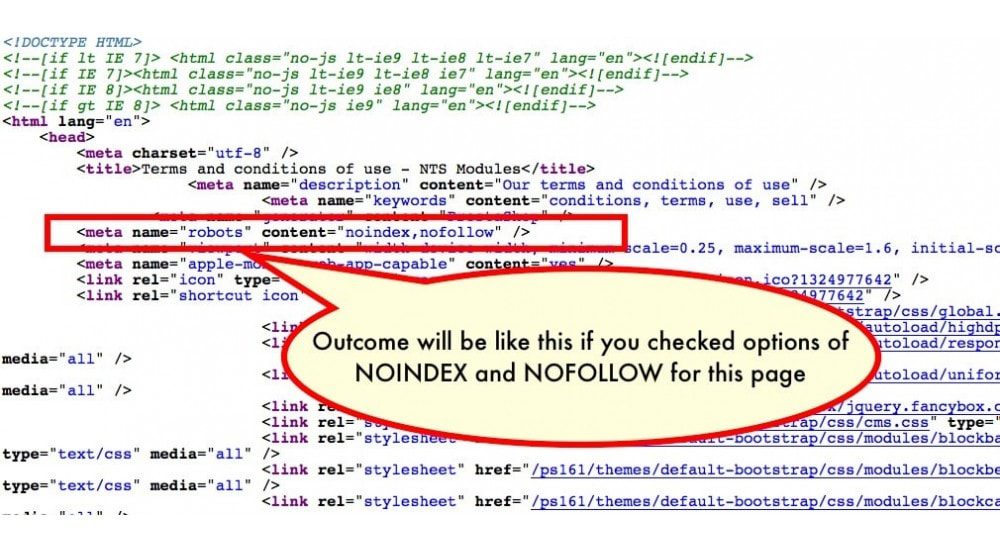
Тег <noindex> – не признанное изобретение Яндекса
Тег <noindex> используется поисковым алгоритмом Яндекса для исключения служебного текста веб-страницы поискового индекса. Тег <noindex> поддерживается всеми дочерними поисковыми системами Яндекса, вида Mail.ru, Rambler и иже с ними.
Тег noindex – парный тег, закрывающий тег – обязателен!
Учитывая не валидность своего бедного и непризнанного тега,
Яндекс соглашается на оба варианта для его написания:
Не валидный вариант – <noindex></noindex>,
и валидный вариант – <!— noindex —><!—/ noindex —>.
Хотя, во втором случае – лошади понятно, что для гипертекстовой разметки HTML, это уже никакой не тег, а так просто – html-комментарий на веб-странице.
Тег <noindex> – не индексировать кусок текста
Как утверждает справка по Яндекс-Вебмастер, тег <noindex> используется для запрета поискового индексирования служебных участков текста. Иными словами, часть текста на странице, заключённая в теги <noindex></noindex> удаляется поисковой машиной из поискового индекса Яндекса. Размеры и величина куска текста не лимитированы. Хоть всю страницу можно взять в теги <noindex></noindex>. В этом случае – останутся в индексе одни только ссылки, без текстовой части.
Иными словами, часть текста на странице, заключённая в теги <noindex></noindex> удаляется поисковой машиной из поискового индекса Яндекса. Размеры и величина куска текста не лимитированы. Хоть всю страницу можно взять в теги <noindex></noindex>. В этом случае – останутся в индексе одни только ссылки, без текстовой части.
Поскольку Яндекс подходит раздельно к индексированию непосредственно самой ссылки и её видимого текста (анкора), то для полного исключения отдельно стоящей ссылки из индекса Яндекса потребуется наличие у неё сразу двух элементов – атрибута rel=»nofollow» и тега <noindex>. Такой избирательный подход Яндекса к индексированию ссылок даёт определённую гибкость при наложении запретов.
Так, например, можно создать четыре конструкции, где:
- Ссылка индексируется полностью
- <a href=»http://example.ru»>Анкор (видимая часть ссылки)</a>
- Индексируется только анкор (видимая часть) ссылки
- <a href=»http://example. ru» rel=»nofollow»>Анкор</a>
- Индексируется только ссылка, без своего анкора
- <a href=»http://example.ru»><noindex>Анкор</noindex></a>
- Ссылка абсолютно НЕ индексируется
- <a href=»http://example.ru» rel=»nofollow»><noindex>Анкор</noindex></a>
 ru» rel=»nofollow»>Анкор</a>
ru» rel=»nofollow»>Анкор</a>Для справки: теги <noindex></noindex>, особенно их валидный вариант <!— noindex —><!—/ noindex —> – абсолютно не чувствительны к вложенности. Их можно устанавливать в любом месте HTML-кода. Главное, не забывать про закрывающий тег, а то – весь текст, до самого конца страницы – вылетит из поиска Яндекса.
Метатег noindex – не индексировать текст всей страницы
Допускается применять noindex в качестве значения для атрибута метатега content –
в этом случае устанавливается запрет на индексацию Яндексом текста всей страницы.
Атрибут content является атрибутом тега <meta> (метатег). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Абсолютно достоверно, ясно и точно, что использование noindex в качестве значения атрибута content для метатега <meta> даёт очень хороший результат и уверенно «выбивает» такую страницу из поискового индекса Яндекса.
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом в заголовке –
Яндекс совершенно не индексирует, но при этом он –
проиндексирует все ссылки на ней.
Разница в действии тега и метатега noindex
Визуально, разница в действии тега и метатега noindex заключается в том, что запрет на поисковую индексацию тега noindex распространяется только на текст внутри тегов <noindex></noindex>, тогда как запрет метатега – сразу на текст всей страницы.
Пример: <noindex>Этот текст будет не проиндексирован</noindex>
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом – Яндекс полностью не индексирует
Принципиально, разница в действии тега и метатега проявляется в различиях алгоритма по их обработке поисковой машиной Яндекса. В случае с метатегом noindex, робот просто уходит со страницы, совершенно не интересуясь её содержимым (по крайней мере – так утверждает сам Яндекс). А, вот в случае с использованием обычного тега <noindex> – робот начинает работать с контентом на странице и фильтровать его через своё «ситечко». В момент скачивания, обработки контента и его фильтрации возможны ошибки, как со стороны робота, так и со стороны сервера. Ведь ни что не идеально в этом мире.
В случае с метатегом noindex, робот просто уходит со страницы, совершенно не интересуясь её содержимым (по крайней мере – так утверждает сам Яндекс). А, вот в случае с использованием обычного тега <noindex> – робот начинает работать с контентом на странице и фильтровать его через своё «ситечко». В момент скачивания, обработки контента и его фильтрации возможны ошибки, как со стороны робота, так и со стороны сервера. Ведь ни что не идеально в этом мире.
Поэтому, кусок текста страницы, заключённого в теги <noindex></noindex> – могёт запросто попасть Яндексу «на зуб» для дальнейшей поисковой индексации. Как утверждает сам Яндекс – это временное неудобство будет сохраняться до следующего посещения робота. Чему я не очень охотно верю, потому как, некоторые мои тексты и страницы, с тегом и метатегом noindex – висели в Яндексе по нескольку месяцев.
Особенности метатега noindex
Равно, как и в случае с тегом <noindex>, действие метатега noindex позволяет гибко накладывать запреты на всю страницу. Примеры метатегов для всей страницы сдерём из Яндекс-Вебмастера:
Примеры метатегов для всей страницы сдерём из Яндекс-Вебмастера:
- не индексировать текст страницы
- <meta name=»robots» content=»noindex»/>
- не переходить по ссылкам на странице
- <meta name=»robots» content=»nofollow»/>
- не индексировать текст страницы и не переходить по ссылкам на странице
- <meta name=»robots» content=»noindex, nofollow»/>
- что, аналогично следующему:
- запрещено индексировать текст и переходить
по ссылкам на странице для роботов Яндекса - <meta name=»robots» content=»none»/>
Вот такой он, тег и значение noindex на Яндексе :):):).
Тег и метатег noindex для Google
Что-же касается поисковика Google, то он никак не реагирует на присутствие выражения noindex, ни в заголовке, ни в теле веб-страницы. Google остаётся верен своему валидному «nofollow», который он понимает и выполняет – и для отдельной ссылки, и для всей страницы сразу (в зависимости от того, как прописан запрет). После некоторого скрипения своими жерновами, Яндекс сдался и перестал продвижение своего тега и значения noindex, хотя – и не отказывается от него полностью. Если роботы Яндекса находят тег или значение noindex на странице – они исправно выполняют наложенные запреты.
После некоторого скрипения своими жерновами, Яндекс сдался и перестал продвижение своего тега и значения noindex, хотя – и не отказывается от него полностью. Если роботы Яндекса находят тег или значение noindex на странице – они исправно выполняют наложенные запреты.
Универсальный метатег (Яндекс & Google)
С учётом требований Яндекса, общий вид универсального метатега,
закрывающего полностью всю страницу от поисковой индексации,
выглядит так:
- <meta name=»robots» content=»noindex, nofollow»/>
- – запрещено индексировать текст и переходить по ссылкам на странице
для всех поисковых роботов Яндекса и Google
nofollow и noindex | Закрываемся от индексации на tehnopost.info
- nofollow (Яндекс & Google)
- rel=»nofollow» – не переходить по ссылке
- content=»nofollow» – не переходить по всем ссылкам
- Действие rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса
- noindex – не индексировать текст
(тег и значение только для Яндекса)- Тег <noindex> – не признанное изобретение Яндекса
- Тег <noindex> – не индексировать кусок текста
- Метатег noindex – не индексировать текст всей страницы
- Разница в действии тега и метатега noindex
- Особенности метатега noindex
- Тег и метатег noindex для Google
- Универсальный метатег (Яндекс & Google)
что это такое, как правильно использовать
Nofollow – это атрибут, который прописывается для определенной ссылки или всех ссылок на странице в мета-теге robots с целью запрета поисковым роботам на переход по ним.
Noindex – это атрибут, который закрывает от индексации текст на странице.
То есть, noindex отвечает за контент в документе и запрет на индексацию его, в то время как nofollow – за ссылку.
Правила применения и зачем нужен nofollow?
Чтобы понять, в каких случаях может вообще пригодиться этот атрибут, рассмотрим, как к нему относятся популярнейшие поисковые системы.
- Яндекс. Когда на вашем ресурсе содержатся разделы, предназначенные специально для обсуждения записей, написания комментариев к статьям или форум, важно следить за тем, какие исходящие ссылки оставляют в них посетители. Желательно модерировать каждый комментарий. Благодаря этому владелец сайта сможет предотвратить размещение различных вредоносных ссылок от спамеров. Хотя поисковик и не учитывает их, спам сильно влияет на репутацию веб-ресурса и к нему может быть применен фильтр. В связи с этим следует проверять все комментарии, и если есть какие-то сомнения относительно качества размещаемой ссылки, пропишите для них атрибут rel=”nofollow”. Сейчас, в измененном руководстве Яндекс, данный текст был удален и осталось только правило применения rel=»nofollow» Руководство Яндекс о nofollow
- Google. Если у вашего сайта есть раздел, где пользователи могут комментировать записи, есть большой риск, что в комментариях появятся ссылки на вредоносные страницы. Спамеры «любят» сайты с комментариями без модерации. Атрибут nofollow для спам-ссылок спасет ваш ресурс и сохранит его чистую репутацию в глазах поисковой системы. Если же вы доверяете сайту, на который ссылается посетитель или вы сами ссылаетесь, то нет необходимости прописывать nofollow. Руководство Google о nofollow
 Сейчас, в измененном руководстве Яндекс, данный текст был удален и осталось только правило применения rel=»nofollow» Руководство Яндекс о nofollow
Сейчас, в измененном руководстве Яндекс, данный текст был удален и осталось только правило применения rel=»nofollow» Руководство Яндекс о nofollowЭти сообщения взяты с официальных сайтов поисковиков. Как видите, в Яндекс и Google написаны аналогичные вещи: значение nofollow нужно использовать в тех случаях, когда вы хотите сообщить ботам о недоверии в отношении сайта, на который ведет ссылка.
Только в Яндекс упор делается, что ссылка с rel=»nofollow» не будет индексироваться поисковой системой, а в Google говорится о том, что робот не будет переходить по такой ссылке.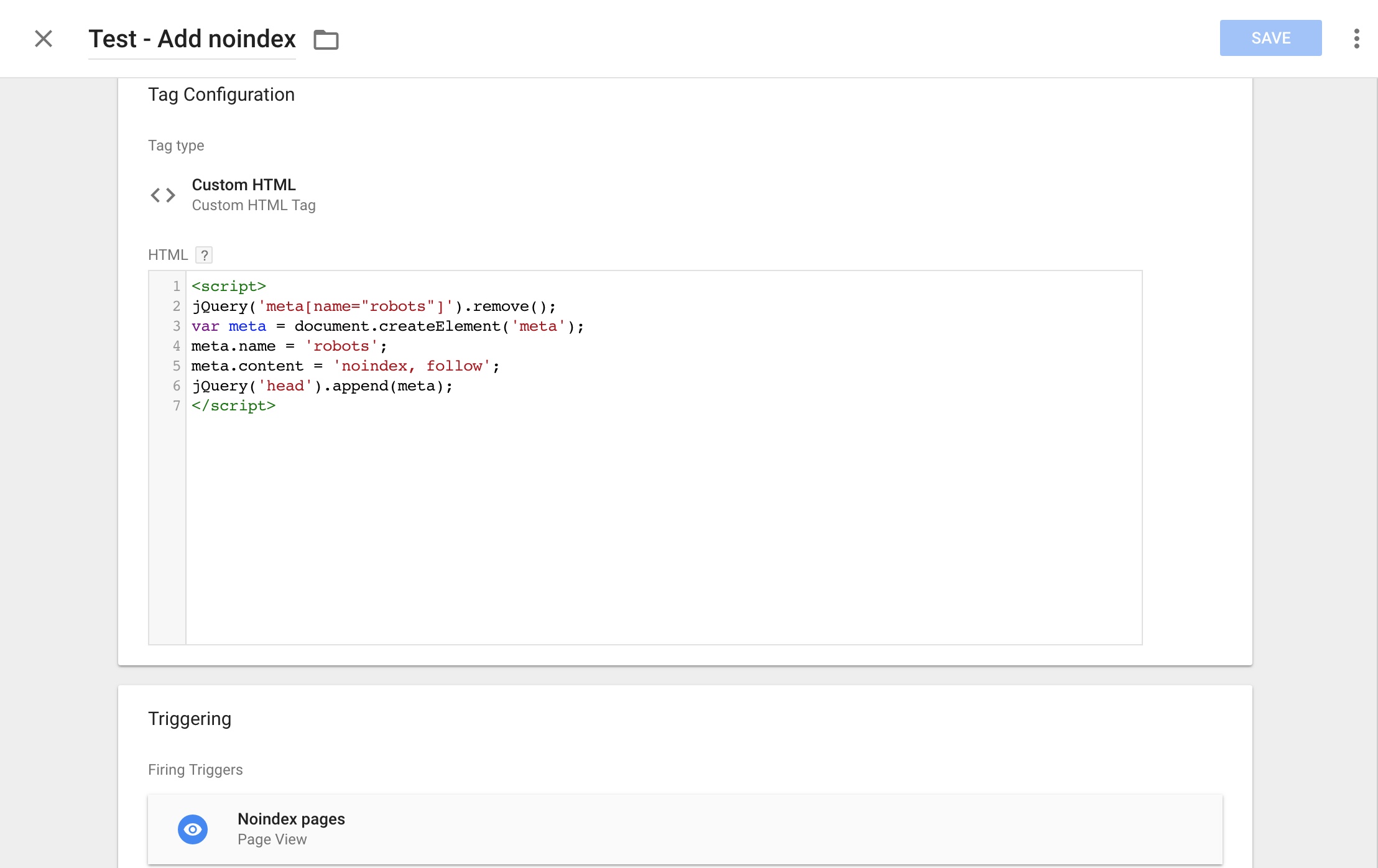
Рассмотрим более конкретный пример, когда для ссылки требуется прописать запрещающий атрибут:
Материал сомнительного качества. Если вам не нравится содержание страницы, на которую посетитель оставляет ссылку в комментарии, и вы не желаете жертвовать репутацией своего сайта, прописывайте в теги данной ссылки значение rel=”nofollow”. Спамеры, заметив на вашем ресурсе тенденцию, когда к непроверенным ссылкам добавляется блокирующий атрибут, вскоре прекратят попытки навредить сайту. Если же вы видите, что пользователь оставляет ссылку на качественный материал, вручную или автоматически nofollow можно удалить.
Как правильно прописать nofollow?
Это сейчас nofollow позволяет управлять каждой ссылкой отдельно, но когда-то данное значение можно было задействовать только в мета-теге, который закрывал от поисковой системы абсолютно все ссылки на странице. И для запрета перехода по отдельным ссылкам вебмастерам приходилось блокировать их URL в robots. txt.
txt.
Robots Nofollow
Эти мета-теги так и остались по сей день. Если вы хотите закрыть от индексации все ссылки, содержащиеся на определенной странице, то на этой странице нужно прописать такой код:
<meta name=”robots” content=”nofollow” />Важно не путать данный тег с двумя нижеприведенными кодами, content=»none» и content=”noindex, nofollow” блокируют доступ ботов ко всей странице, а не только к ее ссылкам. Поэтому, если вы хотите чтобы страницы индексировались, то ни в коем случае не прописывайте для них два вот этих тега:
<meta name=”robots” content=”none” /><meta name =”robots” content=”noindex, nofollow” />Rel=»Nofollow»
Выше мы рассмотрели варианты, как запретить переход поисковых роботов по всем ссылкам на страницах. Но еще можно назначить запрет на переход к конкретной ссылке.
Чтобы запретить для индексации и переход робота по ссылке, к ней надо прописать атрибут rel=”nofollow”, в коде это выглядит так:
<a href=”URL” rel=”nofollow”>анкор гиперссылки</a>Утекает ли вес ссылки через nofollow?
Хотя Google в своих заявлениях позиционирует применение атрибута nofollow как переход по ссылке. И это подтвердило обращение бывшего главы компании по борьбе с поисковым спамом, Мэтта Катса. Он заявил, что «Google может учитывать ссылки из социальных сетей, даже несмотря на nofollow».
И это подтвердило обращение бывшего главы компании по борьбе с поисковым спамом, Мэтта Катса. Он заявил, что «Google может учитывать ссылки из социальных сетей, даже несмотря на nofollow».
А вот с Яндексом вопрос не явный. Он четко пишет в своей документации, что данный атрибут запрещает индексацию таких ссылок.
А если мы перейдем в описание атрибута robots nofollow, то здесь уже видим запрет на переход, и не слово про индексацию.
Но, раньше можно было это проверить, если применить в поиске такую конструкцию url: ваш урл << inlink:(“анкор ссылки”), и Яндекс нам отображал только те страницы, где содержится наш искомый анкор ссылки. Сейчас же этот метод не работает, поисковая система Яндекс запретила использовать такую конструкцию в поиске. Поэтому можно с большей долью вероятностью сказать, что Яндекс может учитывать такие ссылки, потому что они появляются в Яндекс Вебмастер.
Видно, например, что Яндекс учитывает ссылки с Твиттера, даже если они отдаются через редирект и закрыты nofollow.
В целом можно сказать, что применение данного атрибута для поисковых роботов не всегда является запретом, если особенно сайт авторитетный.
Стоит ли закрывать внутренние ссылки в nofollow?
В прошлом, seo оптимизаторы сильно злоупотребляли rel=»nofollow» тем самым манипулирую передаваемым весом внутри сайта. Поэтому поисковая система Google заявила, что все внутренние ссылки отмеченные rel=»nofollow» будут отдавать вес вникуда https://www.mattcutts.com/blog/pagerank-sculpting/.
То есть со страницы где стоит такая ссылка будет уходить вес, но на страницу на которую стоит ссылка он не будет передаваться, получается он будет обнуляться.
Об этом в видео говорит бывший руководитель поиска в Google. Видео на английском, поэтому включите русские субтитры.
Атрибут noindex: что это и чем отличается от nofollow?
Многие начинающие вебмастера ломают голову, не понимая, чем noindex отличается от nofollow.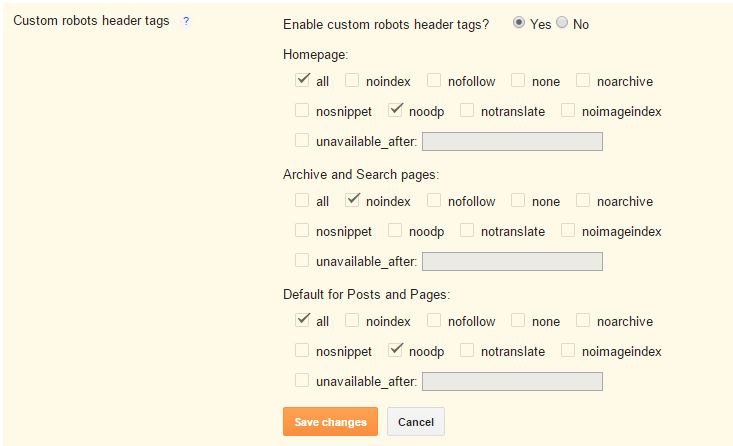 Все просто:
Все просто:
- nofollow — применяется к ссылкам
- noindex — применяется к тексту
Если вы хотите запретить текст на всей странице сайта для индексации, но при этом учитывать ссылки, на странице нужно прописать следующий код:
<meta name=”robots” content=”noindex, follow: />Если вы хотите закрыть часть текста, то в Google нет такого атрибута, но в Яндексе это возможно. Тег noindex был внедрен поисковиком Яндекс, так как раньше он не понимал nofollow, а ненужные ссылки нужно было как-то закрывать от роботов.
Но в 2010 году поисковая система начала работать с атрибутом rel=”nofollow”, при этом noindex не исчез, а остался отвечать за скрытие текста. Теперь, если вы хотите закрыть от индексации текст или например анкор ссылки, пропишите команду:
<noindex><a href=”url”>анкор ссылки</a></noindex>
Сама ссылка будет открыта для перехода роботами поисковых систем, не учтется только ее текст (анкор). Так же можно закрывать не только анкоры ссылок, но и контент.
Так же можно закрывать не только анкоры ссылок, но и контент.
Например это удобно было, когда Яндекс ввел новый алгоритм Баден-Баден, который накладывал санкции за seo тексты. Стоило закрыть портянки текста в noindex, и можно было выйти из под этого фильтра, причем не потерять позиции в Google, так как поисковая система Google не учитывает тег <noindex></noindex>.
Выводы
Nofollow отвечает за переход поисковых систем по этим ссылкам, как на всей странице, так и для определенной ссылки. Ранее noindex тоже выполнял аналогичную функцию, но только по отношению к Яндексу, который со временем начал понимать nofollow, в результате чего значением noindex начали закрывать от индексации контент на странице.
Владелец сайта должен грамотно использовать атрибут nofollow и понимать, в каких именно случаях это делать:
- Когда ссылка ведет на веб-ресурсы с некачественным контентом.
- Когда вы размещаете на странице коммерческий контент.
По атрибуту nofollow ссылка может индексироваться и передавать свой вес, если она стоит на качественный ресурс.
Главная задача использования nofollow — помочь указать приоритетные для сканирования ссылки, разделить продающие статьи от информационных, а также защитить сайт от спама, который, если не контролировать, может привести к снижению ранжирования или куда хуже, вылету ресурса из индекса.
Для всех других ситуаций можете смело применять dofollow ссылки, открытые для поисковых роботов. Репутация сайта ничуть не ухудшится, а даже улучшится, если вы будете оставлять ссылки на полезные для вашей целевой аудитории страницы. И никакой вес ваши документы не потеряют, а наоборот даже могут приобрести за счет обратного PageRank.
Страницы с тегом
Для чего нужен элемент noindex
Тег <noindex> используется для запрета индексации служебных участков текста. Данный тег может находиться в любом участке HTML-кода страницы, учитывается он только Яндексом. Google и другие поисковые системы будут его игнорировать.
Работает этот элемент аналогично МЕТА-тегу noindex, но распространяется исключительно на текстовый контент, который размещен на странице, то есть, закрыть от индексации ссылки с его помощью не получится.
Приведем пример использования:
<noindex>служебный текст, который не нужно индексировать</noindex>
И еще один верный вариант:
<!--noindex-->служебный текст, который не нужно индексировать<!--/noindex-->
В каких случаях можно употреблять
При ответе на этот вопрос важно уточнить, что же такое индексация. Это процесс анализа информации на web-ресурсе и последующее добавление ее в индекс (базу данных поисковых систем) для формирования поисковой выдачи по релевантным запросам. Соответственно, тегом noindex мы советуем закрывать ту информацию, которая не должна участвовать в процессе ранжирования и отображаться в поисковой выдаче, но при этом не содержит ничего, за что можно получить санкции от Яндекса. Например, это может быть мобильный номер телефона, который не должен отображаться в выдаче, но нужен пользователям на страницах сайта.
Нужно учитывать еще один важный фактор — тег noindex запрещает Яндексу индексировать участок текста, но не устанавливает запрет на его чтение.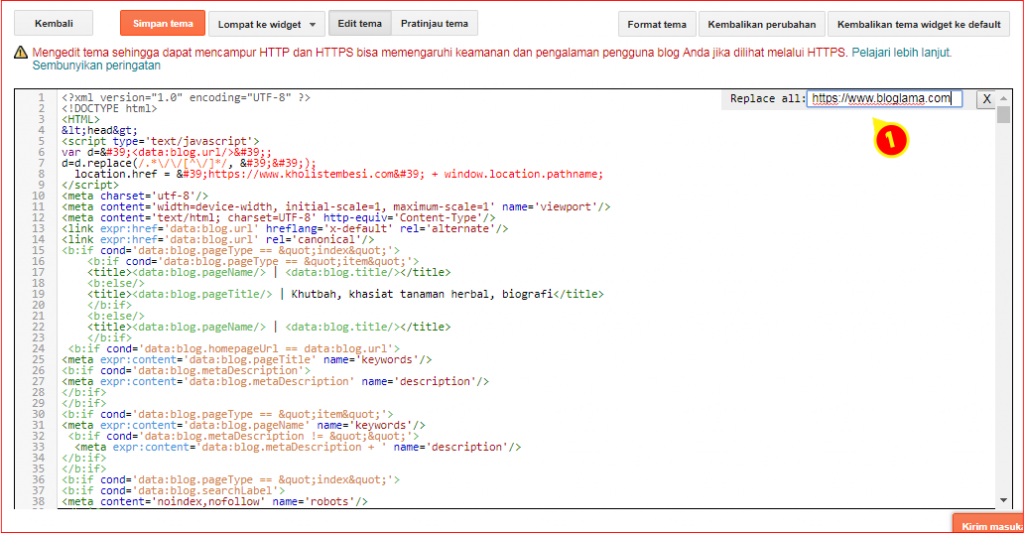 То есть, применять данный элемент для сокрытия скопированных с других ресурсов текстов не получится, так как плагиат все равно будет обнаружен, и сайт подвергнется пессимизации.
То есть, применять данный элемент для сокрытия скопированных с других ресурсов текстов не получится, так как плагиат все равно будет обнаружен, и сайт подвергнется пессимизации.
Как обнаружить страницы с этим тегом на сайте
При продвижении очень важно знать, на каких страницах вашего сайта употребляется этот атрибут, поскольку часть важной информации могла быть закрыта от индексации или другие оптимизаторы использовали этот тег не по назначению.
Сервис Labrika предлагает удобный отчет по страницам с тегом <noindex>. Найти его можно в подразделе «Страницы с тегом noindex» раздела «SEO-аудит» в левом боковом меню:
В этом отчете содержится информация обо всех страницах вашего сайта, на которых находится тег <noindex>. Выглядит он следующим образом:
Для того, чтобы воспользоваться отчетом и получить актуальную на данный момент информацию, необходимо обновить SEO-аудит. Сделать это можно с помощью соответствующей кнопки прямо на странице отчета:
Noindex определение | Что такое Noindex термины
Что такое noindex
Noindex – тэг, который запрещает роботу индексировать часть страницы. Если вы продвигаете свой сайт в Google, используйте robots. Кроме всего прочего, он способен обработать всю веб-страницу.
Если вы продвигаете свой сайт в Google, используйте robots. Кроме всего прочего, он способен обработать всю веб-страницу.
Тег noindex Яндекс ввел по собственной инициативе, которую до сегодняшнего дня разделяет лишь Рамблер. Поэтому при использовании тега noindex, Google не будет обращать на него внимания.
Также noindex и его постоянный спутник nofollow могут использоваться совершенно в ином виде – как значения атрибута content в составе мета-тега robots.
Noindex – это тег, с помощью которого можно управлять функцией индексации поискового робота. Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш.
Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы. alt= Что такое noindex термин определение
Noindex определение
Вторая, не менее важная функция тега noindex, состоит в том, чтобы блокировать индексацию отдельных страниц сайта, предназначенных для публикации пользовательского контента. К таким относятся страницы с отзывами, комментариями, сообщениями и др.
К таким относятся страницы с отзывами, комментариями, сообщениями и др.
Noindex термин
Тег noindex учитывает только Яндекс. Google игнорирует его присутствие и проводит полную индексацию текстового содержания страницы. Для задействования блокировки индексации, актуальной для всех поисковиков, следует прописывать соответствующий метатег для отдельных страниц или всего сайта в файле robots.txt.
Стань эффективным интернет-маркетологом — запишись к нам на курсы! Школа Интернет Маркетинга Онлайн.
Google прекращает поддержку директивы noindex в robots.txt — SEO на vc.ru
После 1.09.2019 года, поисковый гигант прекратит следовать директивам, которые не поддерживаются и не опубликованы в robots exclusion protocol. Изменения были анонсированы в блоге компании (https://webmasters. googleblog.com/2019/07/a-note-on-unsupported-rules-in-robotstxt.html). Это значит, что Google не будет учитывать файлы robots с записанной внутри директивой “noindex”.
googleblog.com/2019/07/a-note-on-unsupported-rules-in-robotstxt.html). Это значит, что Google не будет учитывать файлы robots с записанной внутри директивой “noindex”.
{«id»:76431,»url»:»https:\/\/vc.ru\/seo\/76431-google-prekrashchaet-podderzhku-direktivy-noindex-v-robots-txt»,»title»:»Google \u043f\u0440\u0435\u043a\u0440\u0430\u0449\u0430\u0435\u0442 \u043f\u043e\u0434\u0434\u0435\u0440\u0436\u043a\u0443 \u0434\u0438\u0440\u0435\u043a\u0442\u0438\u0432\u044b noindex \u0432 robots.txt»,»services»:{«facebook»:{«url»:»https:\/\/www.facebook.com\/sharer\/sharer.php?u=https:\/\/vc.ru\/seo\/76431-google-prekrashchaet-podderzhku-direktivy-noindex-v-robots-txt»,»short_name»:»FB»,»title»:»Facebook»,»width»:600,»height»:450},»vkontakte»:{«url»:»https:\/\/vk.com\/share.php?url=https:\/\/vc.ru\/seo\/76431-google-prekrashchaet-podderzhku-direktivy-noindex-v-robots-txt&title=Google \u043f\u0440\u0435\u043a\u0440\u0430\u0449\u0430\u0435\u0442 \u043f\u043e\u0434\u0434\u0435\u0440\u0436\u043a\u0443 \u0434\u0438\u0440\u0435\u043a\u0442\u0438\u0432\u044b noindex \u0432 robots.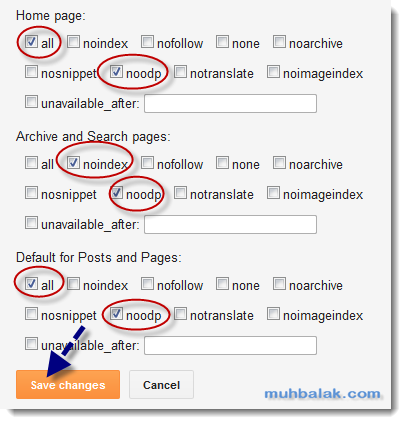 txt»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/seo\/76431-google-prekrashchaet-podderzhku-direktivy-noindex-v-robots-txt&text=Google \u043f\u0440\u0435\u043a\u0440\u0430\u0449\u0430\u0435\u0442 \u043f\u043e\u0434\u0434\u0435\u0440\u0436\u043a\u0443 \u0434\u0438\u0440\u0435\u043a\u0442\u0438\u0432\u044b noindex \u0432 robots.txt»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/seo\/76431-google-prekrashchaet-podderzhku-direktivy-noindex-v-robots-txt&text=Google \u043f\u0440\u0435\u043a\u0440\u0430\u0449\u0430\u0435\u0442 \u043f\u043e\u0434\u0434\u0435\u0440\u0436\u043a\u0443 \u0434\u0438\u0440\u0435\u043a\u0442\u0438\u0432\u044b noindex \u0432 robots.txt»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.
txt»,»short_name»:»VK»,»title»:»\u0412\u041a\u043e\u043d\u0442\u0430\u043a\u0442\u0435″,»width»:600,»height»:450},»twitter»:{«url»:»https:\/\/twitter.com\/intent\/tweet?url=https:\/\/vc.ru\/seo\/76431-google-prekrashchaet-podderzhku-direktivy-noindex-v-robots-txt&text=Google \u043f\u0440\u0435\u043a\u0440\u0430\u0449\u0430\u0435\u0442 \u043f\u043e\u0434\u0434\u0435\u0440\u0436\u043a\u0443 \u0434\u0438\u0440\u0435\u043a\u0442\u0438\u0432\u044b noindex \u0432 robots.txt»,»short_name»:»TW»,»title»:»Twitter»,»width»:600,»height»:450},»telegram»:{«url»:»tg:\/\/msg_url?url=https:\/\/vc.ru\/seo\/76431-google-prekrashchaet-podderzhku-direktivy-noindex-v-robots-txt&text=Google \u043f\u0440\u0435\u043a\u0440\u0430\u0449\u0430\u0435\u0442 \u043f\u043e\u0434\u0434\u0435\u0440\u0436\u043a\u0443 \u0434\u0438\u0440\u0435\u043a\u0442\u0438\u0432\u044b noindex \u0432 robots.txt»,»short_name»:»TG»,»title»:»Telegram»,»width»:600,»height»:450},»odnoklassniki»:{«url»:»http:\/\/connect.ok.ru\/dk?st.cmd=WidgetSharePreview&service=odnoklassniki&st.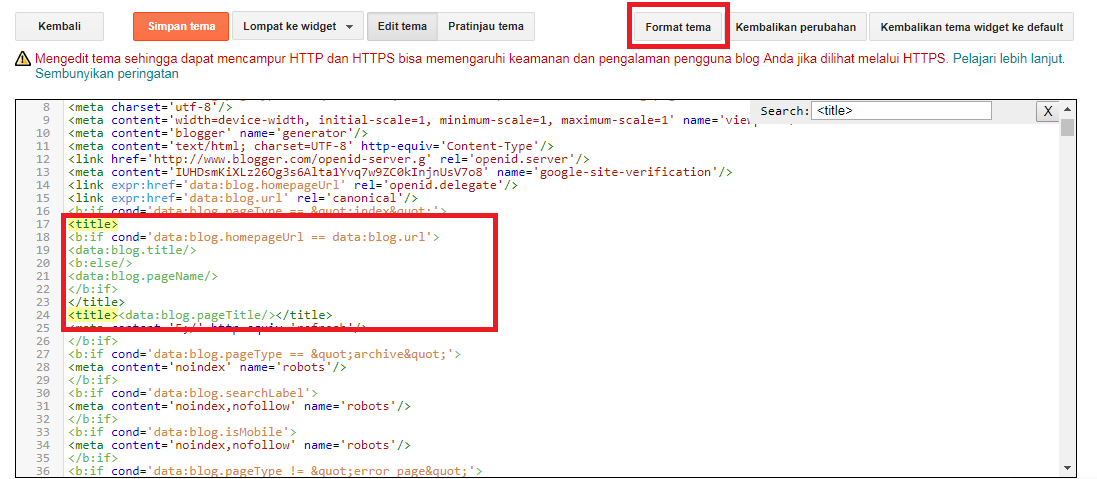 shareUrl=https:\/\/vc.ru\/seo\/76431-google-prekrashchaet-podderzhku-direktivy-noindex-v-robots-txt»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=Google \u043f\u0440\u0435\u043a\u0440\u0430\u0449\u0430\u0435\u0442 \u043f\u043e\u0434\u0434\u0435\u0440\u0436\u043a\u0443 \u0434\u0438\u0440\u0435\u043a\u0442\u0438\u0432\u044b noindex \u0432 robots.txt&body=https:\/\/vc.ru\/seo\/76431-google-prekrashchaet-podderzhku-direktivy-noindex-v-robots-txt»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
shareUrl=https:\/\/vc.ru\/seo\/76431-google-prekrashchaet-podderzhku-direktivy-noindex-v-robots-txt»,»short_name»:»OK»,»title»:»\u041e\u0434\u043d\u043e\u043a\u043b\u0430\u0441\u0441\u043d\u0438\u043a\u0438″,»width»:600,»height»:450},»email»:{«url»:»mailto:?subject=Google \u043f\u0440\u0435\u043a\u0440\u0430\u0449\u0430\u0435\u0442 \u043f\u043e\u0434\u0434\u0435\u0440\u0436\u043a\u0443 \u0434\u0438\u0440\u0435\u043a\u0442\u0438\u0432\u044b noindex \u0432 robots.txt&body=https:\/\/vc.ru\/seo\/76431-google-prekrashchaet-podderzhku-direktivy-noindex-v-robots-txt»,»short_name»:»Email»,»title»:»\u041e\u0442\u043f\u0440\u0430\u0432\u0438\u0442\u044c \u043d\u0430 \u043f\u043e\u0447\u0442\u0443″,»width»:600,»height»:450}},»isFavorited»:false}
1317 просмотров
Что произошло? В течение многих лет файл robots позволял ограничивать доступ к некоторым (или всем) страницам сайта для разного рода роботов, парсеров, пауков или скраулеров. Крупные поисковики следовали этим правилам, но не всегда были понятны принципы их обработки, поскольку отсутствовал официальный стандарт. Теперь же компания Google решила официально утвердить протокол REP для возможностей его расширения в будущем и предотвращения разных толкований одной записи. Основные изменения:
Крупные поисковики следовали этим правилам, но не всегда были понятны принципы их обработки, поскольку отсутствовал официальный стандарт. Теперь же компания Google решила официально утвердить протокол REP для возможностей его расширения в будущем и предотвращения разных толкований одной записи. Основные изменения:
- Директивы теперь используются для любого протокола: кроме HTTP/HTTPS, они распространяются на FTP и прочие;
- Поисковые пауки обязательно сканируют первые 512Кб файла robots.txt. Если файл большой, то дальше они могут его не сканировать..
- Все записи в файле кешируются сроком до 24 часов. Это сделано, чтобы не загружать сервер запросами, а также, чтобы SEO-специалист мог обновлять файл по мере необходимости и в удобные сроки. Срок кеширования можно задавать, используя директиву Cache-Control.
- Если файл по какой-то причине перестал сканироваться — правила продолжают работать. Согласно новой спецификации, в течение продолжительного времени используется последняя кэшированная копия.

Также, были пересмотрены правила для файла robots.txt. Теперь поисковой машиной Google не учитываются директивы, которые не указаны в стандарте. Первой записью, которая не попала в документ, стала директива noindex.
Каковы же альтернативы? Google такие варианты, которые, вероятно, уже использовались в любом случае:
{«url»:»https:\/\/booster.osnova.io\/a\/relevant?site=vc»,»place»:»between_entry_blocks»,»site»:»vc»,»settings»:{«modes»:{«externalLink»:{«buttonLabels»:[«\u0423\u0437\u043d\u0430\u0442\u044c»,»\u0427\u0438\u0442\u0430\u0442\u044c»,»\u041d\u0430\u0447\u0430\u0442\u044c»,»\u0417\u0430\u043a\u0430\u0437\u0430\u0442\u044c»,»\u041a\u0443\u043f\u0438\u0442\u044c»,»\u041f\u043e\u043b\u0443\u0447\u0438\u0442\u044c»,»\u0421\u043a\u0430\u0447\u0430\u0442\u044c»,»\u041f\u0435\u0440\u0435\u0439\u0442\u0438″]}},»deviceList»:{«desktop»:»\u0414\u0435\u0441\u043a\u0442\u043e\u043f»,»smartphone»:»\u0421\u043c\u0430\u0440\u0442\u0444\u043e\u043d\u044b»,»tablet»:»\u041f\u043b\u0430\u043d\u0448\u0435\u0442\u044b»}},»isModerator»:false}
1) noindex в метатегах. Данная директива, поддерживаемая в HTTP-ответах/HTML-коде — самый эффективный способ, чтобы удалить ссылки из индекса, если парсинг разрешен.
Данная директива, поддерживаемая в HTTP-ответах/HTML-коде — самый эффективный способ, чтобы удалить ссылки из индекса, если парсинг разрешен.
2) 404 и 410 коды ответов. Оба HTTP-ответа означают, что по данному URL отсутствует страница, и приведут к удалению страниц с такой ошибкой из поискового индекса если они будут или были просканированы.
3) Защита паролем. Если разметка не указывает на подписку или платный контент (https://developers.google.com/search/docs/data-types/paywalled-content), то сокрытая за формой авторизации страница со временем удалится из индекса Google.
4) Disallow в robots. txt. Поисковики индексируют известные им страницы. Поэтому, блокирование доступа к странице для краулеров означает, что контент никогда не будет проиндексирован. В то же время, поисковик также может индексировать URL-адрес, основываясь на переходах с других страниц (внутренних или внешних), не видя при этом непосредственно контент. Так что, при использовании директивы disallow рекомендую сделать страницы, закрытые ею, менее видимыми в целом.
txt. Поисковики индексируют известные им страницы. Поэтому, блокирование доступа к странице для краулеров означает, что контент никогда не будет проиндексирован. В то же время, поисковик также может индексировать URL-адрес, основываясь на переходах с других страниц (внутренних или внешних), не видя при этом непосредственно контент. Так что, при использовании директивы disallow рекомендую сделать страницы, закрытые ею, менее видимыми в целом.
5) Инструмент удаления URL в Google Search Console (https://support.google.com/webmasters/answer/1663419). С его помощью можно легко и быстро (но временно) убрать страницы из результатов поиска.
Новый стандарт. За день до этой новости, Google анонсировал, что компания также работает над разработкой стандарта, основанного на robots exclusion protocol, что является первым существенным изменением в данном направлении. Также, компания выложила исходный код парсера robots.txt в открытый доступ одновременно с новостью о разработке стандарта.
Также, компания выложила исходный код парсера robots.txt в открытый доступ одновременно с новостью о разработке стандарта.
Почему Google вводит эти изменения сейчас? Поисковый гигант искал возможности для этих изменений в течение нескольких лет и со стандартизацией протокола он наконец-то может двигаться вперед. В Google сказали, что «провели анализ по использованию разных директив в файле robots» и теперь сфокусированы на удалении основных неподдерживаемых директив – crawl-delay, nofollow, noindex.
«Поскольку эти правила никогда официально не разъяснялись компанией, их использование может плохо влиять на сканирование Googlebot’а. Также, такие ошибки плохо влияют на присутствие сайтов в поисковой выдаче»
Стоит ли переживать? Самое главное на данный момент – избавиться от директивы noindex в файле robots. txt. Если же без нее никак, то стоит воспользоваться одной из перечисленных выше альтернатив до 1 сентября. Также, обратите внимание на использование nofollow или crawl-delay команд и если они есть, то переделайте также их с использованием поддерживаемых директив. Поисковый гигант дал достаточно времени для того, чтобы все ознакомились с вносимыми изменениями и поменяли свои файлы robots.txt, поэтому нет поводов для беспокойства.
txt. Если же без нее никак, то стоит воспользоваться одной из перечисленных выше альтернатив до 1 сентября. Также, обратите внимание на использование nofollow или crawl-delay команд и если они есть, то переделайте также их с использованием поддерживаемых директив. Поисковый гигант дал достаточно времени для того, чтобы все ознакомились с вносимыми изменениями и поменяли свои файлы robots.txt, поэтому нет поводов для беспокойства.
Тем не менее, все равно интересно как коллеги решают данную проблему. Со статическими сайтами все понятно, там и в хедере можно написать все нужные метатеги. Но для SPA-сайтов было гораздо удобнее закрывать страницы по определенной маске (например https://ntile.app/some_id/*) или же скрывать целые разделы (например, https://ntile.app/taynaya-komnata-5d2ec134e12fd4000146d3ec-5d2ec134e12fd4000146d3ee, изначально созданный не для индексации, а для тестов по переспаму). С кодами ответов в заголовках много мороки получается. Да и скрывать всё за формой авторизации несколько усложняет разработку.
С кодами ответов в заголовках много мороки получается. Да и скрывать всё за формой авторизации несколько усложняет разработку.
Подскажите, кто как решает такого рода проблемы?
— HTML | MDN
HTML элемент <meta> представляет такие метаданные, которые не могут быть представлены другими HTML-метатегами, такими как <base>, <link>, <script>, <style> или <title>.
| Категории контента | Мета данные. Если задан itemprop атрибут: flow content, phrasing content. |
|---|---|
| Разрешенное содержимое | Отсутствует — это пустой элемент. |
| Пропуск тега | Так как это пустой элемент, то открывающий тег должен присутствовать, а закрывающий — отсутствовать.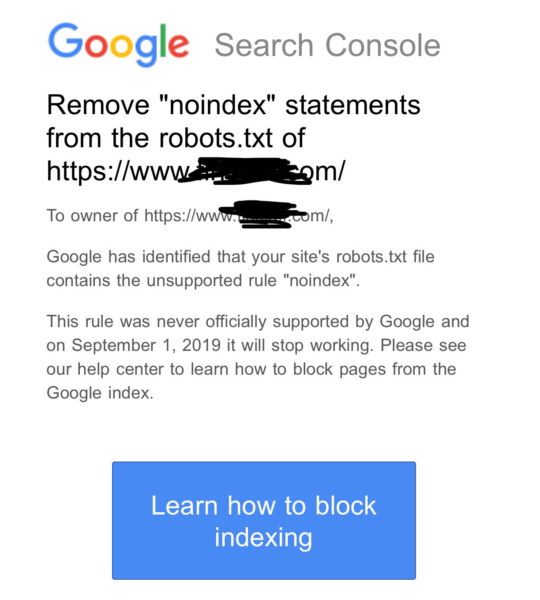 |
| Разрешенные родительские элементы | <meta charset>, <meta http-equiv>: <head> элемент. Если http-equiv это не заявленная декларация, то может быть внутри элемента <noscript> или <head>. |
| Разрешёные роли ARIA | Отсутствуют |
| DOM интерфейс | HTMLMetaElement |
Этот элемент включает в себя глобальные атрибуты.
Примечание: атрибут name имеет особое значение для элемента <meta> и атрибут itemprop не должен быть задан в <meta> элементе в котором уже определены какие-либо name, http-equiv или charset атрибуты.
charset- Этот атрибут задает кодировку символов, используемую на странице. Он должен содержать стандартное имя IANA MIME для кодировки символов. Хотя стандарт не требует определенной кодировки, он рекомендует:
- Авторам рекомендуется использовать
UTF-8. - Не следует использовать ASCII-несовместимые кодировки, чтобы избежать угроз безопасности: браузеры, не поддерживающие их, могут интерпретировать вредоносный контент как HTML. Это относится к семейству кодировок
JIS_C6226-1983,JIS_X0212-1990,HZ-GB-2312,JOHABиEBCDIC.
Примечание: ASCII-несовместимые кодировки — это те, которые не преобразуют 8-битные коды точек
0x20,0x7E,0x0020,0x007Eв коды Unicode точек.- Авторы не должны использовать
CESU-8,UTF-7,BOCU-1и/илиSCSU, так как есть примеры атак межсайтового скриптинга использующих данные кодировки. - Авторам не следует использовать кодировку
UTF-32, потому что не все алгоритмы кодирования HTML5 могут отличить её отUTF-16.
- Указанный набор символов должен соответствовать одной странице.
Нет веских оснований для объявления неточного набора символов. <meta>элемент должен находиться внутри элемента<head>и задаваться в 1024 первых байтах HTML страницы, поскольку некоторые браузеры смотрят только эти байты перед выбором кодировки.- Этот
<meta>элемент — часть алгоритма, определяющего набор символов (algorithm to determine the character set) страницы, который браузер поддерживает. ЗаголовокContent-Typeи любые Byte-Order Marks элементы переопределяют данный элемент. - Настоятельно рекомендуется определить кодировку символов. Если для страницы не определён набор символов, то некоторые cross-scripting тхнологии могут повредить страницу, например такие как UTF-7 fallback cross-scripting technique. Постоянная установка этого элемента будет защищать Вас от этого риска.
- Этот
<meta>элемент это синоним для pre-HTML5<meta http-equiv="Content-Type" content="text/html; charset=IANAcharset">гдеIANAcharsetсоответствует значению эквивалентногоcharsetатрибута.
Этот синтаксис по-прежнему разрешен, хотя и устарел и больше не рекомендуется.
- Авторам рекомендуется использовать
content- Этот атрибут содержит значение для
http-equivилиnameатрибута, в зависимости от контекста. http-equiv- Этот атрибут определяет прагму, которая может изменять поведение серверов и пользователей. Значение прагмы определяется с помощью
contentи может быть следующим:"content-language"Этот API вышел из употребления и его работа больше не гарантируется.- Эта прагма определяет значение языка страницы по умолчанию. Не используйте эту прагму, так как она устарела Используйте глобальный атрибут
<html>элемента вместо этого. "Content-Security-Policy"- Это значение позволит администратору веб-сайта определить политику содержания для обслуживаемых ресурсов. За некоторыми исключениями, политика в основном включают в себя указание происхождения сервера и конечные точки сценария. Это помогает предотвратить атаки межсайтового скриптинга.
"content-type"Этот API вышел из употребления и его работа больше не гарантируется.- Этот атрибут определяет MIME type документа. За ним следует синтаксис такой же как и в поле заголовка объекта содержимого HTTPI, однако как и внутри HTML элемента, большинство этих значений не доступно.
Поэтому допустимым синтаксисом для его содержимого является литеральная строка ‘text/html‘, за которой следует набор символов со следующим синтаксисом: ‘; charset=IANAcharset‘ гдеIANAcharsetэто предпочтительное MIME имя для набора символов, который определяется как IANA. Замечания:- Не используйте эту прагму, так как она устарела. Используйте атибут
charsetв элементе<meta>вместо этого. <meta>не может быть использована для выбора типа документа в XHTML документе, или в HTML5 документе, за которым следует XHTML синтаксис, никогда не задавайте MIME тип как XHTML MIME. Это будет некорректно.- Только HTML документ может использовать контент-тип, так что большинство из них являются неиспользуемыми, поэтому они являются устаревшими и заменяются
charsetатрибутом.
- Не используйте эту прагму, так как она устарела. Используйте атибут
"default-style"- Специализация этой прагмы — предпочтительный стиль таблиц, используемый на странице.
contentатрибут должен содержать заголовок<link>элемента которыйhrefсвязывает атрибут с CSS таблцей стилей, или заголовок<style>элемента, который содержит CSS таблицу стилей. "refresh"- Эта прагма определяет:
- Количество секунд перезагрузки таблицы, если
contentатрибут содержит только положительный целочисленный номер; - Время, в количестве секунд, за которое страница должна быть перенаправлена на другую, если
contentатрибут содержит положительный целочисленный номер, заканчивающийся строкой ‘;url=‘ и корректный URL.
- Количество секунд перезагрузки таблицы, если
"set-cookie"Этот API вышел из употребления и его работа больше не гарантируется.- Эта прагма определяет cookie для страницы. Её содержимое должно заканчиваться синтаксисом, определяемым IETF HTTP Cookie Specification.
Замечание: Не используете эту прагму, так как она устарела. Используйте HTTP header set-cookie вместо этого.
name- Этот атрибут определяет имя уровня документа метаданных.
Его не следует устанавливать, если один из атрибутовitemprop,http-equivилиcharsetтакже указан в наборе.
Имя этого документального уровня метаданных связано со значением, которое содержится вcontentатрибуте.Допустимые значения для имени элемента, со связанными с ними значениями, хранятся посредтвомcontentатрибута:application-name, определяет имя веб-приложения, запущенного на веб-странице; Замечание:- Браузеры могут использовать его для идентификации приложения. Он отличается от
<title>элемента, который обычно состоит из имени приложения, но также может содержать специальную информацию, как например име документа или статус; - Простые веб-страницы не определяют application-name meta.
- Браузеры могут использовать его для идентификации приложения. Он отличается от
авторопределяет в свободном формате имя автора документа;- описание, содержащее краткое и точное резюме содержания страницы. В некоторых браузерах, среди которых Firefox и Opera, этот мета используется как описание страницы по умолчанию в закладке;
- генератор, содержащий в свободном формате идентификатор программного обеспечения, создавшего страницу;;
- Ключевые слова, представленные строками, разделенными запятыми, связанные с содержанием страницы
referrerЭто экспериментальное API, которое не должно использоваться в рабочем коде. контролирует содержимое HTTP. RefererHTTP — заголовок, прикрепленный к любому запросу, отправленному из этого документа:Значения содержимого атрибута <meta name=»referrer»> no-referrerНе отправлять HTTP Refererзаголовок.originОтправить оригинал. no-referrer-when-downgradeОтправить оригинал, как ссылку по умолчанию на безопасный пункт (https->https), но не отправлять ссылку на менее безопасную структуру (https->http). Это поведение по умолчанию. origin-when-crossoriginОтправляет полный URL (удаленный из параметров) при выполнении запроса с тем же источником, или только оригинал документа в других случаях. unsafe-URLОтправляет полный URL (удалённый из параметров), при выполнении запроса того же или перекрестного происхождения. Замечание: Некоторые браузеры поддерживают ключевые слова всегда, по умолчанию и никогда для реферера. Эти значения устарели.
Замечание: Динамическая вставка
<meta name="referrer">(с помощью document.write или appendChild) создаёт недетерминизм, когда дело доходит до отправки рефереров. Также стоит отметить, что когда определяется несколько конфликтующих политик, применяется No-referrer policy.
Атрибут также может иметь значение, взятое из существующего листа определений WHATWG Wiki MetaExtensions page. Хотя ни один из них официально не был принят, в число предложений входят несколько часто используемых имен:
creator, определят в свободном формате имя создателя документа. Это также может быть имя института. Если же имен больше чем одно, то несколько<meta>элементов должны быть использованы;googlebot, синонимrobots, но только следует за Googlebot, сканирует индексы для Google;publisher, определяет в свободном формате имя того, кто опубликовал документ. Это также может быть имя института;robots, определяет поведение, поисковых роботов на странице. Список этих значений представлен ниже:
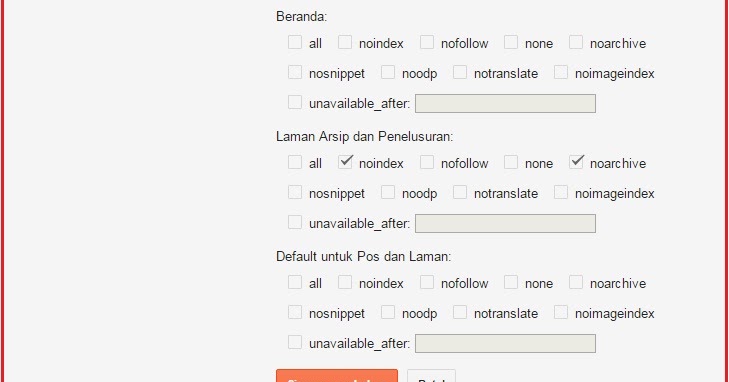
Замечания:Значения для содержимого <meta name=»robots»> Значение Описание Используется indexПозволяет роботу индексировать страницу All noindexОсвобождает робота от идексирования страниц All followПозволяет роботу переходить по ссылкам со страницы All nofollowЗапрещает роботу переходить по ссылкам со страницы All noneЭквивалетно noindex, nofollowGoogle noodpЗапрещает использование Open Directory Project описания, если таковые имеются, как описание страницы на странице результатов поиска Google, Yahoo, Bing
noarchiveЗапрещает поисковой системе кэшировать содержимое страницы. Google, Yahoo, Bing nosnippetЗапрещает отображение любого описания страницы на странице результатов поиска Google, Bing noimageindexЗапрещает отображение этой страницы в качестве ссылающейся страницы индексированного изображения. Google nocacheСиноним noarchiveBing - Только кооперативные роботы будут следовать правилам, определенным именем роботов.
- Роботу необходимо получить доступ к странице, чтобы считать мета значение. Если Вы хотите скрыть от них информацию, то используйте robots.txt файл.
- Если вы хотите удалить страницу индекса, изменение мета в noindex будет работать, но только тогда, когда робот снова посетит страницу. Убедитесь, что файл robots.txt не предотвращает такие посещения. Некоторые поисковые системы имеют инструменты, позволяющие быстро удалить какую-либо страницу.
- Некоторые возможные значения взаимно исключают друг друга, такие как использование индекса и noindex или follow и nofollow одновременно. В этих случаях поведение робота не определено и может варьироваться от одного к другому. Поэтому избегайте этих случаев.
- Некоторые поисковые роботы-роботы, такие как Google, Yahoo Search или Bing, поддерживают те же значения в директиве HTTP, X-Robot-Tags: это позволяет им использовать эту прагму для документов, отличных от HTML, например изображений.
slurp,синонимrobots, но следует только за Slurp, индексирующим роботом от Yahoo Search;
Наконец несколько общих терминов:
viewport, который дает подсказки о размере изначального размера viewport. Эта прагма используется только на некоторых мобильных устройствах.
Замечания:Значения для содержания <meta name="viewport">Значение Допустимые значения Описание widthположительный целочисленный номер или литерал device-widthОпределяет ширину области просмотра в пикселях heightположительный целочисленный номер или литерал device-heightОпределяет высоту области просмотра в пикселях initial-scaleположительное число между 0.и 010.0Определяет соотношение между шириной устройства и размером области просмотра maximum-scaleположительное число между 0.0и10.0Определяет максимальное значение зума; должен быть больше или равен минимальному масштабу или быть неопределенным. minimum-scaleположительное число между 0.0и10.0Определяет минимальное значение зума; должен быть меньше или равен максимальному масштабу или быть неопределенным. user-scalableбулевское значение (да или нет) Если весь набор содержит значения нет, то пользователю не доступен зум на веб-странице. По умолчанию задано значение да. - Хотя и не стандартизирован, этот атрибут используется разными мобильными браузерами, например Safari Mobile, Firefox for Mobile or Opera Mobile.
- Значения по умолчанию могут быть изменены у разных браузеров или устройств..
- Для изучения этой прагмы на Firefox for Mobile, посмотрите статью this article.
- Хотя и не стандартизирован, этот атрибут используется разными мобильными браузерами, например Safari Mobile, Firefox for Mobile or Opera Mobile.
schemeЭтот API вышел из употребления и его работа больше не гарантируется.- Этот атрибут определяет схему, которая описывает метаданные.
Схема — это контекст, ведущий к правильной интерпретацииcontentзначения, например формата.Замечание: Не используйте этот атрибут, так как он устарел. Для него нет никакой замены, поскольку реально он не использовался. Опустите его.
 Он должен содержать стандартное имя IANA MIME для кодировки символов. Хотя стандарт не требует определенной кодировки, он рекомендует:
Он должен содержать стандартное имя IANA MIME для кодировки символов. Хотя стандарт не требует определенной кодировки, он рекомендует: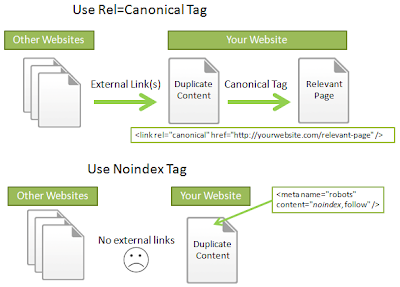
 Постоянная установка этого элемента будет защищать Вас от этого риска.
Постоянная установка этого элемента будет защищать Вас от этого риска. Не используйте эту прагму, так как она устарела Используйте глобальный атрибут
Не используйте эту прагму, так как она устарела Используйте глобальный атрибут  Замечания:
Замечания:
 контролирует содержимое HTTP.
контролирует содержимое HTTP. 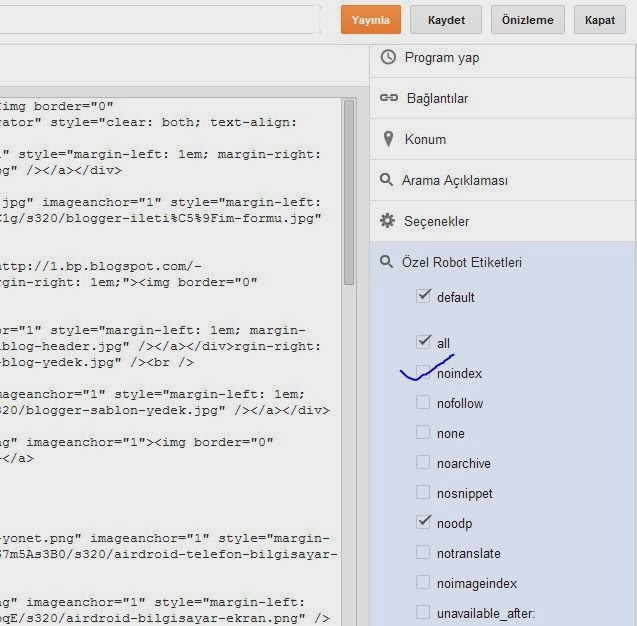
 Это также может быть имя института;
Это также может быть имя института;
 Некоторые поисковые системы имеют инструменты, позволяющие быстро удалить какую-либо страницу.
Некоторые поисковые системы имеют инструменты, позволяющие быстро удалить какую-либо страницу. 0
0
В зависимости от установленных атрибутов, тип метаданных может быть одним из следующих:
- Если в наборе
name, то это document-level metadata, применяемая ко всей странице. - Если в наборе
http-equiv, то это pragma directive,
то есть информация, веб-сервер предоставляет информацию о том, как должна обслуживаться веб-страница. - Если в наборе
charset, то это charset declaration,
то есть кодировка, используемая для сериализованной формы веб-страницы. - Если в наборе
itemprop, то это user-defined metadata,
прозрачна для агента пользователя, поскольку семантика метаданных зависит от пользователя. Это экспериментальное API, которое не должно использоваться в рабочем коде.
<meta charset="utf-8">
<meta http-equiv="refresh" content="3;url=https://www.mozilla.org">
BCD tables only load in the browser
Индексирование поиска блоковс помощью noindex
Вы можете предотвратить отображение страницы в поиске Google, включив метатег noindex в HTML-код страницы или вернув заголовок noindex в HTTP-запросе. Когда робот Googlebot в следующий раз просканирует эту страницу и увидит тег или заголовок, он полностью исключит эту страницу из результатов поиска Google, независимо от того, ссылаются ли на нее другие сайты.
noindex вступила в силу, страница не должна блокироваться файлом robots.txt файл. Если страница заблокирована файлом robots.txt, поисковый робот никогда не увидит директиву noindex , и страница все равно может отображаться в результатах поиска, например, если на нее ссылаются другие страницы. Использование noindex полезно, если у вас нет root-доступа к вашему серверу, так как он позволяет вам контролировать доступ к вашему сайту на постраничной основе.
Реализация
noindex Есть два способа реализовать noindex : как метатег и как заголовок ответа HTTP.У них такой же эффект; выберите способ, более удобный для вашего сайта.
Чтобы большинство поисковых роботов поисковых систем не проиндексировали страницу вашего сайта, поместите следующий метатег в раздел своей страницы:
Чтобы запретить только веб-сканерам Google индексировать страницу:
Вы должны знать, что некоторые поисковые роботы могут интерпретировать директиву noindex по-разному. В результате ваша страница может по-прежнему отображаться в результатах других поисковых систем.
В результате ваша страница может по-прежнему отображаться в результатах других поисковых систем.
Подробнее о метатеге noindex .
Помогите нам определить ваши метатеги
Нам необходимо просканировать вашу страницу, чтобы увидеть ваши метатеги. Если ваша страница по-прежнему отображается в результатах, возможно, мы не сканировали ваш сайт с тех пор, как вы добавили тег. Вы можете запросить у Google повторное сканирование вашей страницы с помощью инструмента проверки URL. Другая причина также может заключаться в том, что ваш файл robots.txt блокирует этот URL для поисковых роботов Google, поэтому мы не видим тег. Чтобы разблокировать свою страницу от Google, вы должны отредактировать файл robots.txt. Вы можете редактировать и тестировать файл robots.txt с помощью инструмента robots.txt Tester .
Вместо метатега вы также можете вернуть заголовок X-Robots-Tag со значением noindex или none в своем ответе. Вот пример HTTP-ответа с
Вот пример HTTP-ответа с X-Robots-Tag , инструктирующим сканеры не индексировать страницу:
HTTP / 1.1 200 ОК (…) X-Robots-Tag: noindex (…)
Подробнее о заголовке ответа noindex .
Что такое Noindex и для чего он нужен? с Гэри Иллисом
В нашем втором виртуальном выступлении с аналитиком Google Webmaster Trends Гэри Иллисом Эрик Энге спросил его о том, как Google обрабатывает различные теги SEO. В этом посте я резюмирую то, что Гэри сказал о теге noindex.
Вы можете посмотреть отрывок, в котором происходит это обсуждение, в этом видео:
Что такое тег noindex?
По словам Эрика Энге, «Тег NoIndex — это инструкция для поисковых систем, что вы не хотите, чтобы страница оставалась в их результатах поиска. Вам следует использовать это, если вы считаете, что у вас есть страница, которую поисковые системы могут посчитать некачественной ».
Вам следует использовать это, если вы считаете, что у вас есть страница, которую поисковые системы могут посчитать некачественной ».
Что делает тег noindex?
- Это директива, а не предложение. То есть Google будет подчиняться ему, а не индексировать страницу.
- Страница все еще может сканироваться Google.
- Страница все еще может накапливать PageRank.
- Страница все еще может передавать PageRank через любые ссылки на странице.
[Твитнуть: «Страницы Noindex все еще собирают и передают PageRank (Гэри Иллис).См. »]
(Гэри отметил, что, хотя Эрик упомянул PageRank, в действительности существует множество других сигналов, которые потенциально могут передаваться через любую ссылку. Лучше сказать« сигналы пройдены », чем« PageRank пройдены ».)
Уменьшается ли частота сканирования страницы noindex со временем?
Частота сканирования — это то, как часто Google возвращается на страницу, чтобы проверить, существует ли еще страница, есть ли какие-либо изменения, накопленные или потерянные сигналы.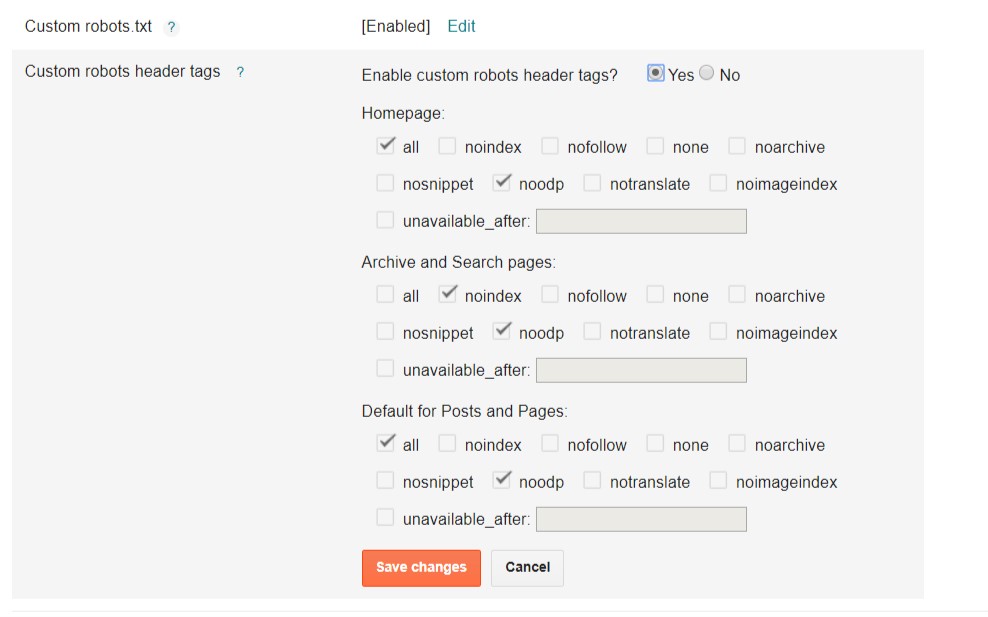
Обычно частота сканирования снижается для любой страницы, которую Google не может проиндексировать по какой-либо причине.Google попытается выполнить повторное сканирование несколько раз, чтобы проверить, исчезли ли или исправлены ли noindex, ошибка или что-то, что блокировало сканирование.
Если инструкция noindex остается, Google начнет постепенно увеличивать время до следующей попытки сканирования страницы, в конечном итоге сокращаясь до проверки примерно каждые два-три месяца, чтобы увидеть, есть ли еще тег noindex.
Эрик заметил, что это означает, что тег noindex — это способ контролировать, как Google сканирует ваш сайт, и Гэри согласился.
[Твитнуть: «Тег Noindex постепенно снижает частоту сканирования страницы Google» (Гэри Илес).См. »]
Узнайте, как реализовать тег noindex на своем сайте.
Узнайте, что Perficient Digital может сделать для SEO вашей компании.
Об авторе
Эрик Энге возглавляет отдел цифрового маркетинга Perficient.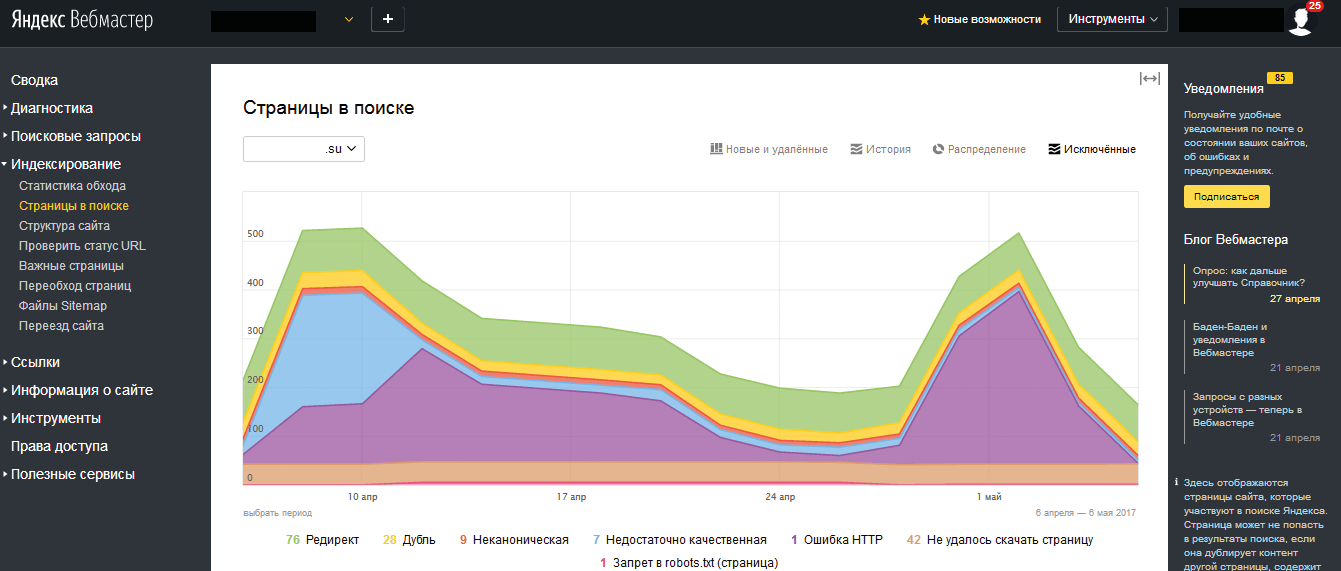 Он разрабатывает исследования и проводит отраслевые исследования, чтобы помочь доказать, опровергнуть или развить предположения о методах цифрового маркетинга и их ценности. Эрик — писатель, блогер, исследователь, преподаватель, основной докладчик и участник крупных отраслевых конференций. В партнерстве с несколькими другими экспертами Эрик был ведущим автором книги «Искусство SEO».
Он разрабатывает исследования и проводит отраслевые исследования, чтобы помочь доказать, опровергнуть или развить предположения о методах цифрового маркетинга и их ценности. Эрик — писатель, блогер, исследователь, преподаватель, основной докладчик и участник крупных отраслевых конференций. В партнерстве с несколькими другими экспертами Эрик был ведущим автором книги «Искусство SEO».
Больше от этого автора
Хотите больше трафика? Деиндексируйте свои страницы.Вот почему.
Большинство людей беспокоятся о том, как заставить Google индексировать их страницы, а не деиндексировать их. Фактически, большинство людей стараются избежать деиндексации, как чумы.
Если вы пытаетесь повысить свой авторитет на страницах результатов поисковых систем, может возникнуть соблазн проиндексировать как можно больше страниц на вашем веб-сайте. И в большинстве случаев это работает.
Но это не всегда может помочь вам получить максимально возможный объем трафика.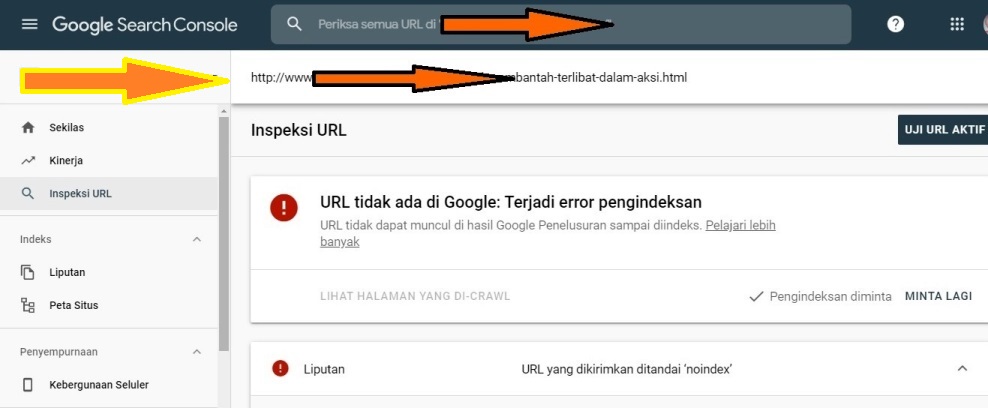
Почему? Это правда, что публикация большого количества страниц, содержащих целевые ключевые слова, может помочь вам получить рейтинг по этим конкретным ключевым словам.
Однако на самом деле может быть более полезным для вашего рейтинга, если некоторые страницы вашего сайта не попадут в индекс поисковой системы.
Вместо этого он направляет трафик на релевантные страницы и предотвращает появление неважных страниц, когда пользователи ищут контент на вашем сайте с помощью Google.
Вот почему (и как) вам следует деиндексировать свои страницы, чтобы привлечь больше трафика.
Для начала давайте рассмотрим разницу между сканированием и индексированием.
Объяснение сканирования и индексирования
В мире SEO сканирование сайта означает следование по пути.
Под сканированием понимается поисковый робот (также известный как паук), который следует по вашим ссылкам и просматривает каждый дюйм вашего сайта.
Сканерымогут проверять HTML-код или гиперссылки. Они также могут извлекать данные с определенных веб-сайтов, что называется веб-парсингом.
Когда боты Google заходят на ваш сайт, чтобы сканировать, они переходят по другим связанным страницам, которые также есть на вашем сайте.
Затем боты используют эту информацию для предоставления поисковикам актуальных данных о ваших страницах.Они также используют его для создания алгоритмов ранжирования.
Это одна из причин, почему карты сайта так важны. Файлы Sitemap содержат все ссылки на вашем сайте, поэтому боты Google могут легко изучить ваши страницы.
Индексирование, с другой стороны, относится к процессу добавления определенных веб-страниц в индекс всех страниц, доступных для поиска в Google.
Если веб-страница проиндексирована, Google сможет сканировать и проиндексировать эту страницу. После деиндексации страницы Google больше не сможет ее индексировать.
По умолчанию индексируются все записи и страницы WordPress.
Хорошо проиндексировать релевантные страницы, потому что присутствие в Google может помочь вам заработать больше кликов и привлечь больше трафика, что приведет к увеличению доходов и увеличению узнаваемости бренда.
Но если вы позволите проиндексировать части вашего блога или веб-сайта, которые не являются жизненно важными, вы можете принести больше вреда, чем пользы.
Вот почему деиндексирование страниц может увеличить трафик.
Почему удаление страниц из результатов поиска может увеличить посещаемость
Вы можете подумать, что чрезмерно оптимизировать свой сайт невозможно.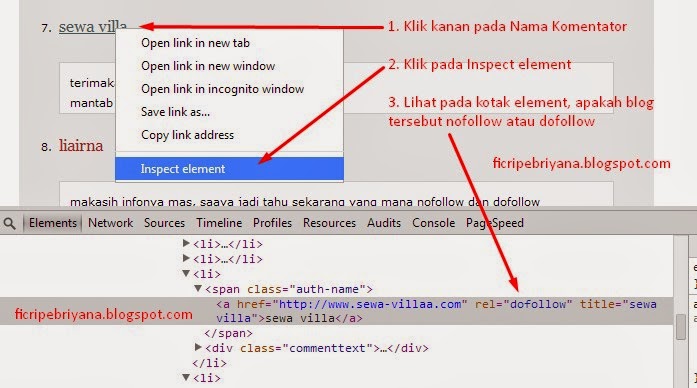
Но это так.
Слишком много SEO может помешать вашему сайту занимать высокие позиции. Не переусердствуйте.
Есть много разных случаев, когда вам может потребоваться (или вы захотите) исключить веб-страницу (или, по крайней мере, ее часть) из индексации и сканирования поисковой системой.
Очевидная причина — предотвратить индексирование дублированного контента.
Дублированный контент означает, что существует более одной версии одной из ваших веб-страниц. Например, одна версия может быть удобной для печати, а другая — нет.
Обе версии не должны появляться в результатах поиска. Только один. Деиндексируйте версию для печати и сохраните индексируемую обычную страницу.
Еще один хороший пример страницы, которую вы, возможно, захотите деиндексировать, — это страница с благодарностью — страница, на которую посетители переходят после выполнения желаемого действия, такого как загрузка вашего программного обеспечения.
Обычно на этой странице посетитель сайта получает доступ ко всему, что вы ему обещали, в обмен на их действия, например, к электронной книге.
Вы хотите, чтобы люди попали на ваши страницы с благодарностью только потому, что они выполнили действие, которое вы хотите, чтобы они предприняли, например, приобрели продукт или заполнили форму для потенциальных клиентов.
Не потому, что они нашли вашу страницу благодарности через поиск Google. Если они это сделают, они получат доступ к тому, что вы предлагаете, без необходимости выполнять желаемое.
Это не только бесплатная раздача вашего самого ценного контента, но также может испортить аналитику всего вашего сайта из-за неточных данных.
Если эти страницы проиндексированы, вы подумаете, что привлекаете больше потенциальных клиентов, чем на самом деле.
Если на ваших страницах благодарности есть ключевые слова с длинным хвостом, и вы не деиндексировали их, они могут иметь довольно высокий рейтинг, хотя в этом нет необходимости.
Что делает еще проще для того, чтобы их находило все больше и больше людей.
Вам также необходимо деиндексировать страницы профилей сообщества, распространяющие спам.
Удалить спам на страницах профиля сообщества
Бритни Мюллер из Moz недавно деиндексировала 75% веб-сайта Moz и добилась огромного успеха.
Большинство типов страниц, которые она деиндексировала? Страницы профилей сообщества, рассылающие спам.
Она заметила, что при поиске по сайту: moz.com более 56% результатов приходилось на страницы профилей сообщества Moz.
Были тысячи этих страниц, которые ей нужно было деиндексировать.
Профили сообществаMoz работают по системе баллов. Пользователи зарабатывают больше очков, называемых MozPoints, за выполнение действий на сайте, например, за комментирование сообщений или публикацию блогов.
Поговорив с разработчиками, Бритни решила деиндексировать страницы профиля, набрав менее 200 баллов.
Мгновенно органический трафик и рейтинг выросли.
Деиндексируя страницы профилей сообщества таких пользователей, как этот, с небольшим количеством очков MozPoints, нерелевантные профили остаются вне страниц результатов поисковой системы.
Таким образом, только наиболее известные пользователи сообщества Moz с тоннами MozPoints, такие как Бритни, будут отображаться в результатах поиска.
Затем профили с наибольшим количеством комментариев и действий появляются, когда кто-то их ищет, так что на сайте легко найти влиятельных людей.
Если вы предлагаете профили сообщества на своем веб-сайте, следуйте примеру Moz и деиндексируйте профили, которые не принадлежат влиятельным или известным пользователям.
Вы можете подумать, что отключения «видимости для поисковых систем» в WordPress достаточно, чтобы уменьшить видимость для поисковых систем, но это не так.
На самом деле поисковые системы должны выполнить этот запрос.
Вот почему вам нужно деиндексировать их вручную, чтобы убедиться, что они не появятся на странице результатов.Во-первых, вы должны понять разницу между тегами noindex и nofollow.
Объяснение тегов Noindex и nofollow
Вы можете легко использовать метатег, чтобы страница не отображалась в поисковой выдаче.
Все, что вам нужно знать, это копировать и вставлять.
Теги, позволяющие удалять страницы, называются «noindex» и «nofollow».
Прежде чем мы перейдем к тому, как вы можете добавлять эти теги, вам необходимо знать разницу между тем, как работают эти два тега.
Это два разных тега, но их можно использовать по отдельности или вместе.
Когда вы добавляете на страницу тег noindex, он сообщает поисковым системам, что, хотя они все еще могут сканировать страницу, они не могут добавить страницу в свой индекс.
Любая страница с директивой noindex не попадает в индекс поисковой системы, а это означает, что она не будет отображаться на страницах результатов поисковой системы.
Вот как выглядит тег noindex в HTML-коде сайта:
Когда вы добавляете на веб-страницу тег nofollow, он запрещает поисковым системам сканировать любые ссылки на странице.
Это означает, что любой рейтинг, присвоенный странице, не будет передан страницам, на которые она ссылается.
Тем не менее, любая страница с тегом nofollow может индексироваться в поиске. Вот как выглядит тег nofollow в коде веб-сайта:
Вы можете добавить тег noindex отдельно или с тегом nofollow.
Вы также можете добавить тег nofollow отдельно. Добавляемые вами теги будут зависеть от ваших целей для конкретной страницы.
Добавьте только тег noindex, если вы не хотите, чтобы поисковая система индексировала вашу веб-страницу в результатах поиска, но вы хотите, чтобы она продолжала переходить по ссылкам на этой странице.
Если у вас есть платные целевые страницы, может быть хорошей идеей добавить к ним тег noindex.
Вы не хотите, чтобы поисковые системы приводили к ним посетителей, поскольку люди должны платить за их просмотр, но вы можете захотеть, чтобы связанные страницы извлекали выгоду из его авторитета.
Добавьте только тег nofollow, если вы хотите, чтобы поисковая система проиндексировала определенную страницу на страницах результатов, но вы не хотите, чтобы она переходила по ссылкам, имеющимся на этой конкретной странице.
Добавьте на страницу теги noindex и nofollow, если вы не хотите, чтобы поисковые системы индексировали страницу или могли переходить по ссылкам на ней.
Например, вы можете добавить теги noindex и nofollow к страницам благодарности.
Теперь, когда вы знаете, как работают теги noindex и nofollow, вот как добавить их на свой сайт.
Как добавить метатег «noindex» и / или «nofollow»
Если вы хотите добавить тег noindex и / или nofollow, первым делом нужно скопировать желаемый тег.
Для тега noindex скопируйте следующий тег:
Для тега nofollow скопируйте следующий тег:
Для обоих тегов скопируйте следующий тег:
Добавить теги так же просто, как добавить тег, который вы скопировали, в раздел
HTML-кода вашей страницы.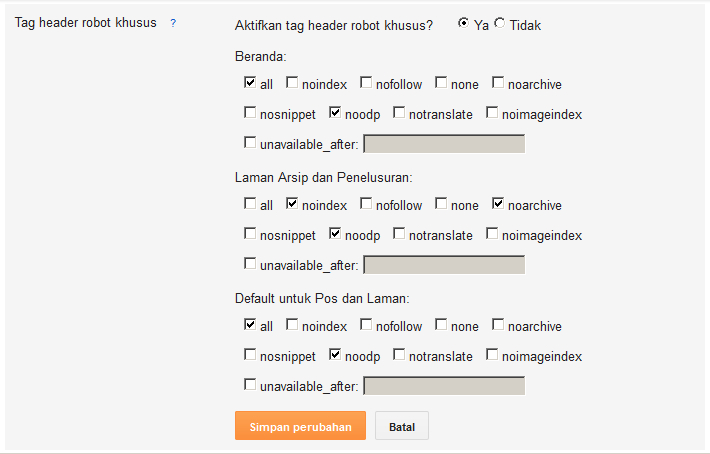 Он также известен как заголовок страницы.
Он также известен как заголовок страницы.Просто откройте исходный код веб-страницы, которую вы хотите деиндексировать. Затем вставьте тег в новую строку в разделе
HTML.Вот как выглядит тег для noindex и nofollow в заголовке.
Имейте в виду, что тег обозначает конец заголовка. Никогда не вставляйте теги noindex или nofollow за пределами этой области.
Сохраните обновления кода, и все готово.Теперь поисковая система исключит вашу страницу из результатов поиска.
Вы можете сделать невозможным сканирование нескольких страниц, изменив файл robots.txt.
Что такое robots.txt и как получить к нему доступ?
Robots.txt — это просто текстовый файл, который веб-мастера могут создать, чтобы сообщить роботам поисковых систем, как именно они хотят сканировать свои страницы или переходить по ссылкам.
Файлы Robots.txt просто указывают, разрешено ли определенному программному обеспечению для веб-сканирования сканировать определенные части веб-сайта.
Если вы хотите «nofollow» сразу нескольких веб-страниц, вы можете сделать это из одного места, открыв файл robots.txt на своем сайте.
Во-первых, неплохо бы выяснить, есть ли на вашем сайте файл robots.txt. Чтобы в этом разобраться, зайдите на свой веб-сайт и добавьте robots.txt.
Это должно выглядеть примерно так: www.yoursitehere.com/robots.txt.
Вот как выглядит наш файл robots.txt.
На наш сайт добавлена задержка сканирования 10, из-за которой роботы поисковых систем не будут сканировать ваш сайт слишком часто.Это предотвращает перегрузку серверов.
Если при переходе по этому адресу ничего не появляется, значит, на вашем веб-сайте нет файла robots.txt. На Disney.com нет файла robots.txt.
Вместо пустой страницы вы также можете увидеть ошибку 404.
Вы можете создать файл robots.txt практически в любом текстовом редакторе. Чтобы узнать, как именно добавить его, прочтите это руководство.
Чистый костяк файла robots. txt должен выглядеть примерно так:
txt должен выглядеть примерно так:
User-agent: *
Disallow: /
Затем вы можете добавить конечные URL всех страниц, сканирование которых робот Googlebot не должен сканировать.
Вот несколько кодов robots.txt, которые могут вам понадобиться:
Разрешить индексирование всего:
User-agent: *
Disallow:
или
User-agent: *
Allow: /
Запретить индексирование:
Пользовательский агент: *
Запретить: /
Деиндексировать определенную папку:
User-agent: *
Disallow: / folder /
Запретить роботу Googlebot индексировать папку, кроме одного определенного файла в этой папке:
User-agent: Googlebot
Disallow: / folder1 /
Allow: / folder1 / myfile.html
Google и Bing позволяют людям использовать подстановочные знаки в файлах robots.txt.
Чтобы заблокировать доступ к URL-адресам, которые содержат специальный символ, например вопросительный знак, используйте следующий код:
User-agent: *
Disallow: / *?
Google также поддерживает использование noindex в файле robots.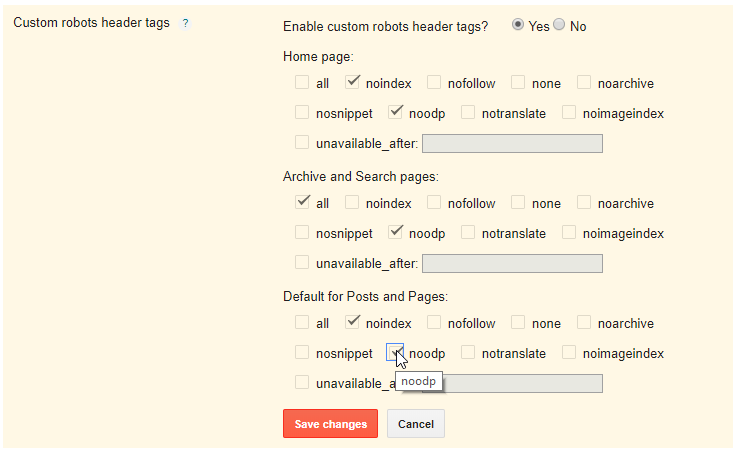 txt.
txt.
Для noindex из robots.txt используйте этот код:
User-agent: Googlebot
Disallow: / page-uno /
Noindex: / page-uno /
Вместо этого вы также можете добавить заголовок X-Robots-tag на определенную страницу.
Вот как выглядит тег X-Robots, запрещающий сканирование:
HTTP / 1.1 200 OK
(…)
X-Robots-Tag: noindex
(…)
Этот тег можно использовать как для кодов nofollow, так и для noindex.
Могут быть случаи, когда вы добавляли теги nofollow и / или noindex или изменяли файл robots.txt, но некоторые страницы все еще отображаются в поисковой выдаче. Это нормально.
Вот как это исправить.
Почему ваши страницы все еще могут отображаться в поисковой выдаче (сначала)
Если ваши страницы по-прежнему отображаются в результатах поиска, возможно, это связано с тем, что Google не сканировал ваш веб-сайт с тех пор, как вы добавили тег.
Отправьте запрос на повторное сканирование вашего сайта в Google с помощью инструмента «Просмотреть как Google».
Просто введите URL своей страницы, нажмите, чтобы просмотреть результаты Fetch, и проверьте статус отправки URL.
Другая причина того, что ваши страницы все еще отображаются, заключается в том, что в вашем файле robots.txt могут быть ошибки.
Вы можете отредактировать или протестировать файл robots.txt с помощью инструмента robots.txt Tester. Выглядит это примерно так:
Никогда не используйте теги noindex вместе с тегом disallow в robots.текст.
Не использовать мета-индекс noindex И запретить в robots.txt
Когда вы используете метатег noindex для нескольких страниц, но по-прежнему запрещаете их использование в файле robots.txt, боты проигнорируют ваш метатег noindex.
Никогда не используйте оба тега одновременно. Также рекомендуется оставить карты сайта на некоторое время, чтобы поисковые роботы их видели.
Когда Moz деиндексировал несколько страниц своего профиля сообщества, они оставили карту сайта профиля сообщества на месте на пару недель.
Было бы неплохо сделать то же самое.
Также есть возможность запретить сканирование вашего сайта вообще, при этом позволяя Google AdSense работать на страницах.
Подумайте об одной из своих страниц, например, о странице «Свяжитесь с нами» или даже о странице политики конфиденциальности. Вероятно, он связан с каждой страницей вашего веб-сайта либо в нижнем колонтитуле, либо в главном меню.
На эти страницы идет огромное количество ссылок. Вы не хотите просто выбросить его. Особенно, когда он появляется прямо из главного меню или нижнего колонтитула.
Имея это в виду, вы никогда не должны включать страницу, которую вы блокируете, в robots.txt в карту сайта XML.
Не включать эти страницы в карты сайта XML
Если вы заблокируете страницу в файле robots.txt, но затем включите ее в карту сайта XML, вы просто дразните Google.
В карте сайта написано: «Вот блестящая страница, которую нужно проиндексировать, Google».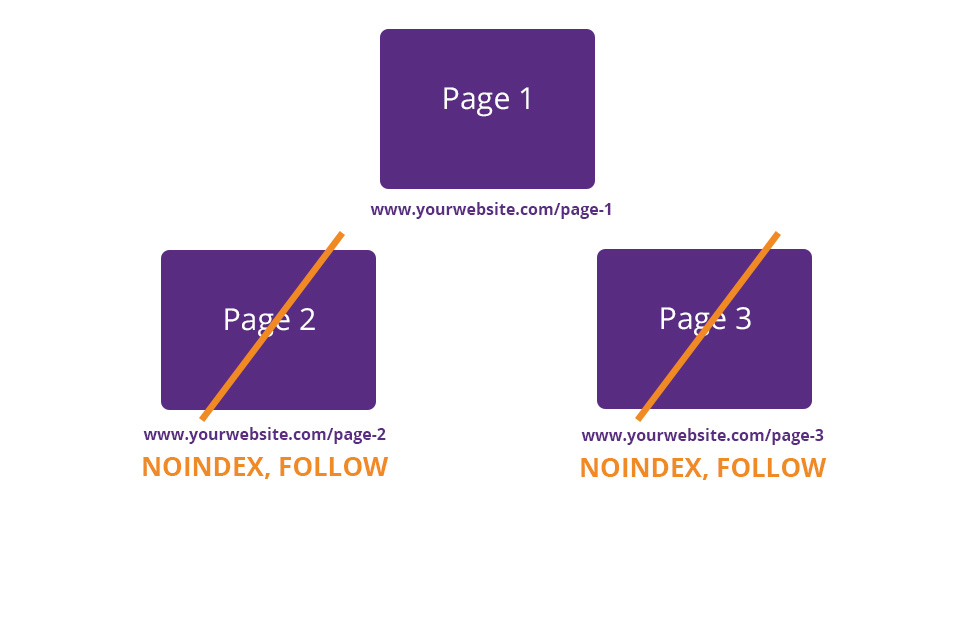 Но затем ваш файл robots.txt удалит эту страницу.
Но затем ваш файл robots.txt удалит эту страницу.
Вы должны поместить весь контент на своем сайте в две разные категории:
- Качественные поисковые целевые страницы
- Служебные страницы, которые полезны для пользователей, но не обязательно должны быть целевыми страницами поиска
Нет необходимости блокировать что-либо в первой категории в robots.текст. Этот контент также никогда не должен иметь тега noindex. Включите все эти страницы в карту сайта XML, несмотря ни на что.
Вам следует заблокировать все, что находится во второй категории, с помощью тегов noindex, nofollow или robots.txt. Вы действительно не хотите включать это содержание в карту сайта.
Google будет использовать все, что вы отправляете в свою XML-карту сайта, чтобы понять, что должно или не должно быть важным для инструмента на вашем сайте.
Но то, что чего-то нет в вашей карте сайта, не означает, что Google полностью проигнорирует это.
Сделайте сайт: выполните поиск, чтобы увидеть все страницы, которые Google в настоящее время индексирует с вашего сайта, чтобы найти любые страницы, которые вы, возможно, пропустили или забыли.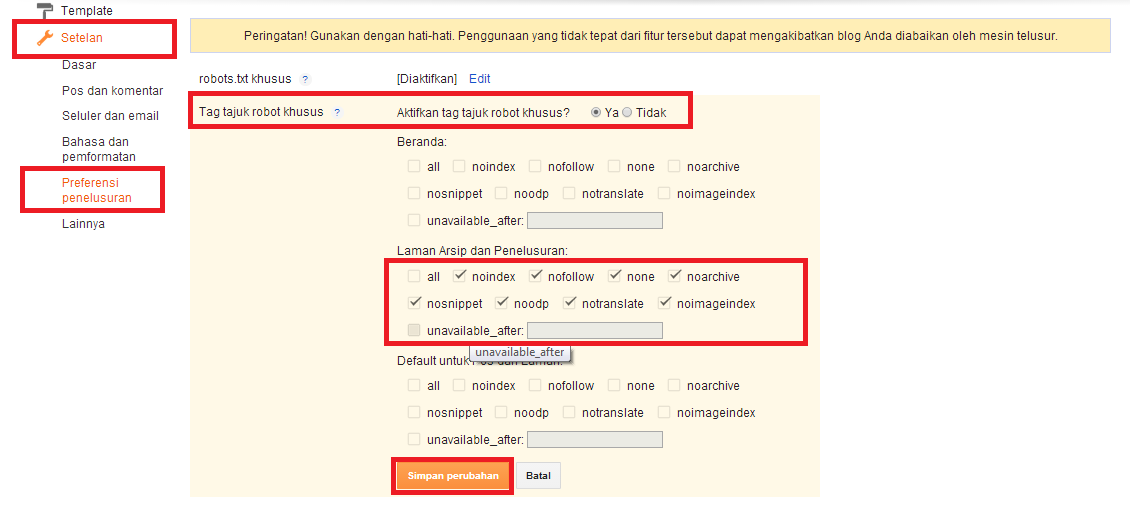
Самые слабые страницы, которые Google все еще индексирует, будут перечислены последними на вашем сайте: search.
Вы также можете легко просмотреть количество отправленных и проиндексированных страниц в Инструментах Google для веб-мастеров.
Заключение
Большинство людей обеспокоены тем, как они могут индексировать свои страницы, а не деиндексировать их.
Но индексирование слишком большого количества неправильных страниц может действительно повредить вашему общему рейтингу.
Для начала вы должны понять разницу между сканированием и индексированием.
Сканирование сайта означает сканирование ботов по всем ссылкам на каждой веб-странице, принадлежащей сайту.
Индексирование означает добавление страницы в индекс Google для всех страниц, которые могут отображаться на страницах результатов Google.
Удаление ненужных страниц со страниц результатов, таких как страницы с благодарностями, может увеличить трафик, потому что Google будет сосредоточиваться только на ранжировании релевантных страниц, а не незначительных.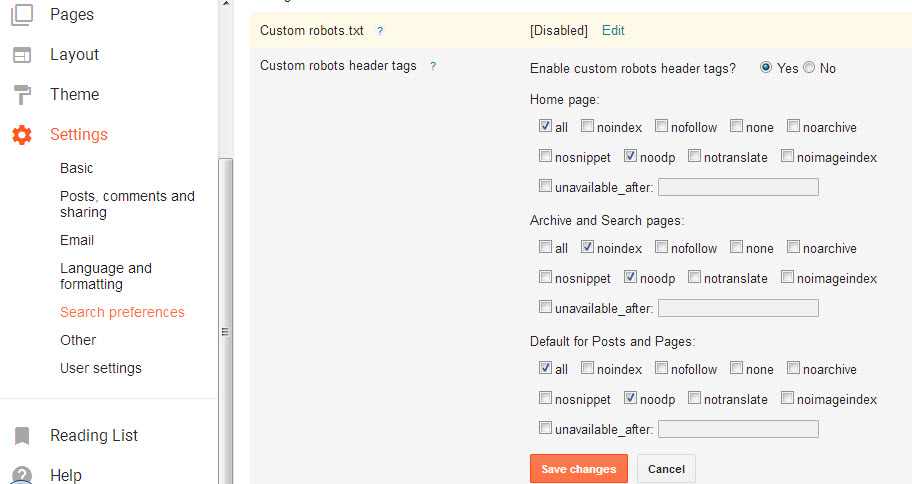
Удалите страницы профилей сообщества, содержащие спам, если они у вас есть. Moz деиндексировал страницы профилей сообщества, набравшие менее 200 баллов, и это быстро увеличило их посещаемость.
Затем выясните разницу между тегами noindex и nofollow.
Теги Noindex удаляют страницы из индекса Google, доступных для поиска. Теги Nofollow не позволяют Google сканировать ссылки на странице.
Вы можете использовать их вместе или по отдельности. Все, что вам нужно сделать, это добавить код для одного или каждого тега в HTML-заголовок вашей страницы.
Затем узнайте, как работает ваш файл robots.txt. Вы можете использовать эту страницу, чтобы заблокировать сканирование Google нескольких страниц одновременно.
Ваши страницы могут по-прежнему отображаться в поисковой выдаче, но используйте инструмент «Просмотреть как Google», чтобы решить эту проблему.
Не забудьте никогда не индексировать страницу и не разрешать ее в robots.txt. Кроме того, никогда не включайте страницы, заблокированные в файле robots. txt, в карту сайта XML.
txt, в карту сайта XML.
Какие страницы вы собираетесь деиндексировать в первую очередь?
Узнайте, как мое агентство может привлечь огромное количество трафика на ваш веб-сайт
- SEO — разблокируйте огромное количество SEO-трафика.Смотрите реальные результаты.
- Контент-маркетинг — наша команда создает эпический контент, которым будут делиться, получать ссылки и привлекать трафик.
- Paid Media — эффективные платные стратегии с четкой окупаемостью инвестиций.
Заказать звонок
Тест тегов Noindex | SEO Site Checkup
Проверьте, использует ли ваша веб-страница метатег robots или X-Robots-Tag HTTP-заголовок , чтобы дать указание поисковым системам не показывать ваш сайт на страницах результатов поиска.
Проверить все факторы
Тест мета-заголовка
Мета-описание Тест
Предварительный просмотр результатов поиска Google
Тест наиболее распространенных ключевых слов
Тест использования ключевых слов
Ключевые слова Cloud Test
Проверка связанных ключевых слов
Тестирование доменов конкурентов
Тест тегов заголовков
Роботы. txt Test
Sitemap Test
SEO дружественный URL-тест
Image Alt Test
Встроенный тест CSS
Тест устаревших HTML-тегов
Тест Google Analytics
Favicon Test
Тест обратных ссылок
Проверка ошибок JS
Тест в социальных сетях
Тест размера страницы HTML
Сжатие HTML / тест GZIP
Тест скорости загрузки сайта
Тест объектов страницы
Тест кэша страницы (кеширование на стороне сервера)
Флэш-тест
Тест использования CDN
Тест кеширования изображений
Тест кеширования JavaScript
Тест кеширования CSS
Тест минификации JavaScript
Тест минификации CSS
Тест вложенных таблиц
Тест набора фреймов
Doctype Test
Проверка переадресации URL
Тест канонизации URL
HTTPS тест
Тест безопасного просмотра
Проверка подписи сервера
Тест просмотра каталогов
Проверка электронных писем с открытым текстом
Тест адаптивного медиа-запроса
Тест мобильных снимков
Структурированные данные
Пользовательский тест страницы ошибки 404
Тест тегов Noindex
Канонический тест тегов
Тест тега Nofollow
Тест запретить директиву
SPF Records Test
txt Test
Sitemap Test
SEO дружественный URL-тест
Image Alt Test
Встроенный тест CSS
Тест устаревших HTML-тегов
Тест Google Analytics
Favicon Test
Тест обратных ссылок
Проверка ошибок JS
Тест в социальных сетях
Тест размера страницы HTML
Сжатие HTML / тест GZIP
Тест скорости загрузки сайта
Тест объектов страницы
Тест кэша страницы (кеширование на стороне сервера)
Флэш-тест
Тест использования CDN
Тест кеширования изображений
Тест кеширования JavaScript
Тест кеширования CSS
Тест минификации JavaScript
Тест минификации CSS
Тест вложенных таблиц
Тест набора фреймов
Doctype Test
Проверка переадресации URL
Тест канонизации URL
HTTPS тест
Тест безопасного просмотра
Проверка подписи сервера
Тест просмотра каталогов
Проверка электронных писем с открытым текстом
Тест адаптивного медиа-запроса
Тест мобильных снимков
Структурированные данные
Пользовательский тест страницы ошибки 404
Тест тегов Noindex
Канонический тест тегов
Тест тега Nofollow
Тест запретить директиву
SPF Records Test
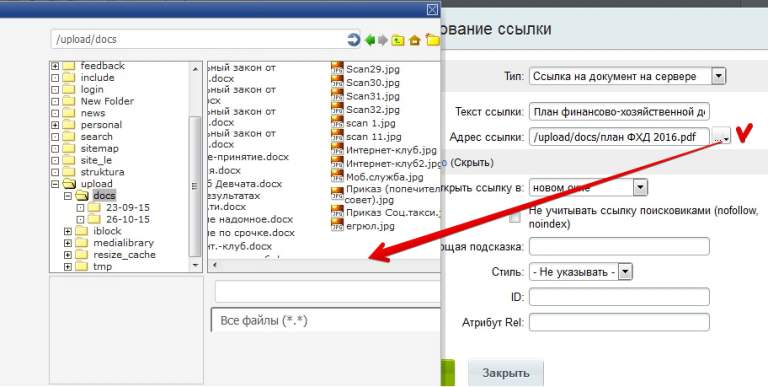 youtube.com/embed/kgXIwAIclmQ?showinfo=0″ frameborder=»0″ webkitallowfullscreen=»» mozallowfullscreen=»» allowfullscreen=»»/>
youtube.com/embed/kgXIwAIclmQ?showinfo=0″ frameborder=»0″ webkitallowfullscreen=»» mozallowfullscreen=»» allowfullscreen=»»/>
В чем разница между NoIndex и NoFollow?
В чем разница между NoFollow и NoIndex?
Цифровые маркетологи тратят много времени и энергии на совершенствование каждой страницы контента на веб-сайте. У каждой страницы есть цель, с хорошо проработанным и стратегически сформулированным содержанием, ориентированным на целевого пользователя. Контент создается для привлечения потенциальных клиентов и повышения авторитета веб-страниц и их соответствующих доменов.Затем эти страницы отправляются для индексации поисковым системам, чтобы их можно было сканировать и в конечном итоге сохранять для того, чтобы их нашел конечный пользователь.
Однако есть страницы, сканирование которых запрещено. Эти страницы могут помешать вашей тяжелой работе по созданию этого красивого и индивидуального контента. Помня об этом, вам нужно знать, как правильно сообщить сканерам поисковых систем, что вы не хотите, чтобы ваш контент индексировался или сканировался.
Что такое NoIndex?NoIndex — это метатег, который добавляется в код заголовка веб-страницы, чтобы сообщить поисковым системам, что, хотя они могут сканировать страницу, чтобы понять ее содержание, они не могут проиндексировать страницу, чтобы она отображалась в результатах поиска.Это пример того, как NoIndex отображается в исходном коде веб-страницы:
Что такое NoFollow? NoFollow — это метатег, добавляемый в код заголовка веб-страницы, который сообщает поисковым системам не переходить по ссылкам на этой странице. По сути, это дезавуирует ссылки на этой странице и информирует поисковую систему, чтобы она не передавала никаких полномочий или «ссылочного веса» страницам, на которые есть ссылки в вашем контенте. Это пример того, как NoFollow отображается в исходном коде веб-страницы:
Это пример того, как NoFollow отображается в исходном коде веб-страницы:
NoIndex и NoFollow сильно различаются по полезности.Вы будете использовать NoIndex при указании поисковой системе не сохранять вашу веб-страницу для отображения в результатах поиска, в то время как вы будете использовать NoFollow, когда вы дадите указание сканерам поисковой системы не переходить по ссылкам на вашей странице. Следовательно, NoIndex предназначен для вашей веб-страницы , а NoFollow — для ссылок , которые существуют на вашей веб-странице.
Когда следует использовать каждый? Примером метатега NoIndex является страница с благодарностью. Вы не хотели бы, чтобы поисковая система отображала страницу с благодарностью на странице результатов поисковой системы, поскольку это обычно страница, на которую пользователь попадает после того, как он заполнил вашу форму генерации лидов. Чтобы поисковые системы знали, что эту страницу хранить нельзя, вы должны указать метатег NoIndex в коде заголовка вашей веб-страницы. Другие примеры страниц, которые вы не хотели бы индексировать поисковыми системами, включают Политику конфиденциальности, Условия и положения и страницы Страница не найдена.
Чтобы поисковые системы знали, что эту страницу хранить нельзя, вы должны указать метатег NoIndex в коде заголовка вашей веб-страницы. Другие примеры страниц, которые вы не хотели бы индексировать поисковыми системами, включают Политику конфиденциальности, Условия и положения и страницы Страница не найдена.
Примером метатега NoFollow также является целевая страница. Если ваша целевая страница содержит ссылку на ваше предложение, скажем, электронную книгу «10 советов, как максимально использовать ваши усилия в цифровом маркетинге», вы должны убедиться, что сканер поисковой системы не просканирует эту ссылку и не начнет индексировать этот контент.
Изучение ресурсов для защиты и оптимизации вашего контента для поисковых систем является важной частью ваших инициатив по контент-маркетингу и привлечению потенциальных клиентов. Правильное использование метатегов NoFollow и NoIndex поможет вам максимально эффективно использовать свою контент-стратегию и убедиться, что вы не теряете ценных потенциальных клиентов.
Как мне реализовать NoIndex или NoFollow на моем веб-сайте?
Если вы используете WordPress, мы рекомендуем бесплатный инструмент Yoast SEO для управления вашими усилиями по SEO на странице.Чтобы активировать функции NoIndex и NoFollow, вы должны включить «расширенные настройки» на панели настроек Yoast.
Оттуда вы найдете варианты для реализации правил NoIndex и NoFollow на каждой странице вашего веб-сайта.
Легко, как пирог!
полное справочное руководство от ContentKing
Коротко о мета-тегах роботов
Узнайте, что такое метатег robots и как вы можете использовать его для улучшения сканирования, индексации и ранжирования поисковой системой.
Чего можно ожидать от этой статьи
Метатег robots указывает поисковым системам, какие страницы вы хотите, чтобы они проиндексировали и как. В этой статье подробно рассматриваются некоторые тонкости этого тега и, что более важно, показано, как заставить его работать на вас сегодня.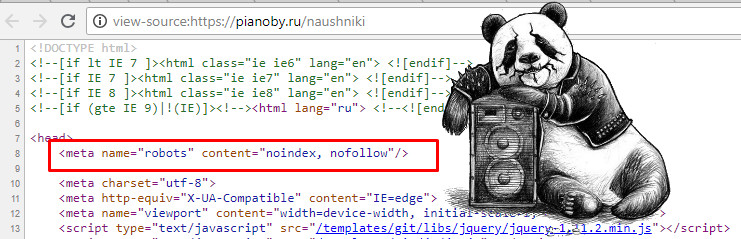
Мета-тег роботов позволяет точно настроить, какой контент поисковые системы должны индексировать и отображать пользователям в пределах SERP (страниц результатов поисковой системы). Метатег robots находится в исходном HTML-коде страницы и выглядит примерно так:
В этом конкретном примере всем поисковым системам указывается не индексировать страницу, а следовать по ссылкам, которые они находят на странице, и передавать полномочия ссылки .Эти инструкции ( noindex, следуйте за ) называются директивами поисковой системы и будут вскоре объяснены
Мета-теги роботов относятся к элементам HTML, известным как метатеги, которые помогают браузерам и поисковым системам определять, как вести себя на вашей странице, а также как отображать ваш контент на странице результатов поисковой системы.
Независимо от того, являетесь ли вы владельцем веб-сайта или специалистом по поисковой оптимизации, вам необходимо четко сигнализировать поисковым системам, как вы хотите индексировать свои веб-сайты. Это возможно благодаря метатегу robots.
Это возможно благодаря метатегу robots.
Несмотря на то, что поисковые системы прошли долгий путь в понимании веб-сайтов, когда дело доходит до индексации, вы не хотите оставлять на усмотрение их алгоритмов, какие страницы должны быть проиндексированы, а какие нет. Уже одного этого достаточно, чтобы сделать мета-теги роботов неотъемлемой частью вашего инструментария SEO.
Метатег robots часто используется для борьбы с дублированием контента. Дублированный контент — это одинаковые или очень похожие страницы, которые доступны по нескольким URL-адресам, что дает поисковым системам противоречивые сигналы, существенно сбивая их с толку.
Тем не менее, следует отметить, что существуют другие, зачастую более эффективные, механизмы для предотвращения проблем с дублированием контента, такие как канонические URL-адреса и robots.txt. Однако есть несколько конкретных вариантов использования метатега robots, на которые мы сейчас рассмотрим. Но сначала давайте узнаем, какие директивы доступны для поисковых систем.
Одна вещь, которая делает метатег роботов таким эффективным, — это его универсальность. Вот список всех имеющихся в вашем распоряжении директив, сигнализирующих о ваших предпочтениях индексирования поисковым системам:
noindex
Директива noindex сигнализирует роботам поисковых систем не возвращать страницу в результатах поиска при запросе.
nofollow
Директива nofollow указывает роботам поисковых систем, что не следует переходить по всем ссылкам на странице и не следует передавать полномочия по ссылкам.
нет
Директива none сигнализирует роботам поисковых систем о том, что эту страницу в основном следует игнорировать. Иногда его также используют как ярлык для директив noindex и nofollow .
Совет: когда вы используете директиву none или noindex, nofollow , рекомендуется запретить доступ к этой странице вместе с помощью ваших роботов.txt файл.
noarchive
Директива noarchive запрещает поисковым системам отображать кэшированную версию указанной страницы.
nosnippet
Директива nosnippet запрещает поисковым системам отображать фрагменты в результатах поиска и дополнительно предотвращает кэширование страницы поисковыми системами.
noimageindex
Директива noimageindex запрещает поисковым системам индексировать изображения на странице.Обратите внимание, что если изображение размещено на другой странице, не имеющей директивы noimageindex , оно все равно будет проиндексировано. Об этом важно знать при SEO-оптимизации изображений.
лапша
Исторически директива noodp использовалась для того, чтобы поисковые системы не извлекали описание страницы в DMOZ (открывается в новой вкладке) (каталог открытого содержимого ссылок, поддерживаемых добровольцами) в качестве фрагмента для вашей страницы в поисковой выдаче. .По состоянию на май 2017 года DMOZ был закрыт, поэтому этот метатег робота больше нельзя использовать.
notranslate
Директива notranslate предписывает поисковым системам не предлагать переведенную версию страницы в поисковой выдаче.
Директива unavailable_after указывает поисковым системам не отображать страницу по истечении заданного времени. Дата / время должны быть отформатированы в формате RFC 850.
index и все
Индекс , и все директивы сигнализируют роботам поисковых систем о том, что вы хотите, чтобы они проиндексировали страницу.Указывать это необязательно, так как это значение по умолчанию для поисковых систем: если вы не укажете другую директиву, поисковые системы будут индексировать страницу и переходить по ее ссылкам.
следовать и все
Директивы следуют за и , все директивы предписывают поисковым системам переходить по ссылкам на странице и передавать полномочия ссылки. Как и директива index , она используется по умолчанию, поэтому указывать ее нет необходимости.
Если честно: хотя метатег роботов — это мощный способ указать поисковым системам, как обращаться с вашим контентом, обычно это не тот механизм, к которому можно обратиться.Если вы не хотите, чтобы страница индексировалась поисковыми системами, обычно рекомендуется использовать каноническую ссылку или полностью запретить доступ к странице через robots.txt. Однако, если по какой-либо причине вы не можете использовать эти решения, метатег robots — хороший метод для достижения той же цели: предотвращения проблем с дублированным контентом.
Кроме того, особый вариант использования метатега robots — это работа со страницами-заполнителями. Иногда вам нужно опубликовать страницу, которая еще не доработана и пока содержит «тонкий контент».В этих случаях вы, возможно, еще не захотите, чтобы страница проиндексировалась, и метатег robots — подходящее решение для предотвращения этого.
Довольно часто возникает необходимость передать несколько команд поисковым системам, которые посещают вашу страницу. И объединение директив мета-тегов роботов — безусловно, лучший способ сделать это. Вы можете начать с создания многодирективной инструкции, используя директивы мета-тегов роботов, которые позволяют одновременно выполнять одновременные действия.
Пример:
Кроме того, существуют ситуации, при которых необходимо передавать разные директивы разным сканерам.Директивы ниже, например, дают директиву noindex , nofollow при сканировании Google и Bing, а другие поисковые системы решат полностью игнорировать директиву noindex .
Обратите внимание, что если возникает сценарий, в котором есть конкурирующие директивы, поисковые роботы по умолчанию будут использовать наиболее строгую директиву (аналогично robots.txt файл).
HTTP-заголовок
X-Robots-TagКогда вы имеете дело с файлами, отличными от HTML, такими как изображения и PDF-файлы, которые не должны индексироваться поисковыми системами, лучше всего подойдет HTTP-заголовок X-Robots-Tag. Когда веб-сервер отвечает на запрос браузера или поисковой системы посетителя, он отправляет не только «основной контент», но и HTTP-заголовки. Отправляя HTTP-заголовок X-Robots-Tag, веб-сервер может давать определенные директивы индексирования поисковым системам, даже для файлов, отличных от HTML.
Например, если вы используете веб-сервер Apache и хотите добавить noindex, nofollow X-Robots-Tag к HTTP-ответу для всех ваших файлов .PDF, вы должны установить конфигурацию следующим образом :
<Файлы ~ "\ .pdf $">
Заголовочный набор X-Robots-Tag "noindex, nofollow"
В качестве альтернативы вы можете сделать то же самое для изображений типов файлов png, jpg и gif:
<Файлы ~ "\. (Png | jpe? G | gif) $">
Заголовочный набор X-Robots-Tag "noindex"
Обратите внимание, что настройка заголовка X-Robots-Tag обычно требует изменений в конфигурации вашего веб-сервера, и при неправильной настройке может негативно повлиять на весь ваш веб-сайт.Если вы не хотите вносить изменения в конфигурацию своего веб-сервера, рекомендуется оставить эти изменения администратору сервера.
Итак, есть несколько разных способов сообщить поисковой системе о ваших предпочтениях в отношении индексации, и каждый служит своей цели. Но когда использовать какой? Чтобы помочь с этим вопросом, вот краткое изложение каждого метода (метатег robots, заголовок X-Robots и файл robots.txt) и где его имеет смысл использовать.
Мета-тег роботов : используйте метатег роботов, чтобы указать свои предпочтения в отношении , индексируя ваших страниц.Исходя из этого, роботы поисковых систем могут полностью игнорировать страницу или даже определять, по каким ссылкам переходить, а по каким ссылкам не переходить на вашем веб-сайте, используя этот тег.
X-Robots-Header : X-Robots-Header похож на метатег robots, но вместо указания инструкций в исходном HTML-коде страниц вы указываете его на уровне веб-сервера. Для файлов, отличных от HTML, таких как PDF-файлы и изображения, это единственный способ указать настройки индексации, поэтому в основном он используется именно для этого.
Robots.txt : файл robots.txt используется для обозначения ваших предпочтений около доступа к вашим страницам для поисковых систем. Важно понимать, что если вы заблокируете доступ к своим страницам, поисковые системы никогда не смогут правильно проиндексировать это содержание.
Часто задаваемые вопросы о мета-тегах роботов
Некоторые часто задаваемые вопросы о мета-тегах роботов:
- Что делать, если в мета-теге robots нет пробелов между командами?
- Что делать, если в метатеге robots нет запятых?
- Учитываются ли в командах регистр?
- Как мне увидеть заголовок X-Robots?
- Будут ли поисковые системы по-прежнему сканировать страницы с метатегом robots?
1.Что делать, если между командами в метатеге robots есть пробелы?
Не беспокойтесь - все основные поисковые системы автоматически пропускают интервалы в командах. Это означает, что это не фактор в директиве тега (см. Пример ниже):
совпадает с
2. Что делать, если в метатеге robots нет запятых?
В метатеге robots лучше всего использовать запятые.Bing утверждает, что им все равно, в отличие от Google. И для этого есть достаточно причин для их использования (вот пример КАК НЕ ДЕЛАТЬ ):
3. Учитываются ли в командах регистр?
Нет. Google, Yahoo и Bing могут распознать, какая команда находится в директиве, даже если она случайным образом в верхнем или нижнем регистре. Показательный пример:
4.Как мне увидеть заголовок X-Robots-Tag?
Заголовок X-Robots-Tag можно просмотреть в заголовках HTTP. Это довольно техническая задача, которую нужно выполнить в вашем браузере, поэтому рекомендуется использовать такой инструмент, как ContentKing, чтобы увидеть это.
5. Будут ли поисковые системы по-прежнему сканировать страницы с метатегом robots?
Да, если вы не разместите другую директиву, предписывающую ботам НЕ сканировать определенные страницы вашего сайта через ваш файл robots.txt.
В заключение…
Метатег robots - один из нескольких механизмов борьбы с дублированием контента.Если вы не имеете дело с содержанием-заполнителем, обычно лучше использовать канонический URL или методы robots.txt. Но если эти параметры по какой-либо причине исключены, метатег роботов - верный способ получить больший контроль над тем, как поисковые системы индексируют и представляют ваш веб-сайт.
Мета-индекс
Что такое метатег noindex?
Мета-тег noindex используется для того, чтобы поисковые системы не включали страницу, на которой он используется, в индекс поисковой системы.Это метатег, который помещается в
веб-страницы.Meta noindex является частью тега meta = robots, который является необязательным тегом для включения на каждую страницу вашего веб-сайта.
Формат Meta Noindex
Вот формат мета-тега noindex:
Тег noindex часто сопровождается директивой follow / nofollow, хотя это необязательная директива для включения.Если он не включен, по умолчанию установлено «следовать», таким образом, если вы не хотите, чтобы поисковые системы считали ссылки на странице как голоса за страницы, на которые они также ссылаются.
Все следующие допустимые форматы мета-тега noindex:
Meta Noindex использует
Тег noindex используется для удаления определенных страниц из индекса поисковой системы.Это часто происходит из-за того, что страница является копией другой страницы (в этом случае она должна быть либо перенаправлена 301, либо канонически настроена на другую страницу), имеет низкое качество и, таким образом, кажется вредной для общих целей SEO вашего сайта (в которых в случае, если вам, вероятно, следует обновить страницу и сделать ее качественной), или это страница, на которую вы вошли или иным образом доступна, и вы не хотите, чтобы люди находили ее в поисковых системах.
Что делает мета noindex
, а неОчень важно понимать, что делает метатег noindex , а не , потому что в Интернете много ложной информации.
Мета тег noindex делает , а не :
- Защитите свою страницу от сканирования поисковыми системами;
- Удалите вашу страницу из внутреннего поиска по сайту или из списка других возможных вариантов;
- Передать значение ссылки на повторяющуюся страницу;
- Прямая помощь в повышении рейтинга.
Чтобы прояснить пункт 4, может быть вредно иметь много страниц низкого качества на вашем веб-сайте. В этом и заключалась вся цель алгоритма Google Panda, который нацеливался на информационные сайты, которые массово производили тонкий контент, специально предназначенный для ранжирования в поисковых системах для продажи рекламы.Однако простое отсутствие индексации большого количества страниц низкого качества - это лишь один из многих факторов, которые поисковые системы принимают во внимание при определении высокого качества вашего сайта. Таким образом, если у вас есть проблемы с ранжированием в поисковых системах, не рекомендуется просто использовать noindex страницы, которые, по вашему мнению, могут не понравиться поисковым системам.
Поиск тегов noindex на вашем сайте
Раньше я обнаруживал, что страница не ранжировалась из-за мошеннического тега noindex. Фактически, это произошло с локальной страницей SEO на Credo ранее в 2017 году.
Чтобы найти теги noindex на вашем сайте, самый простой способ - использовать SEO Spider Screaming Frog для сканирования вашего сайта, затем перейти на вкладку «Директивы» и отфильтровать по желанию:
.