Как и зачем чистить кэш в Google Chrome на Android
Несмотря на то что мобильная версия Google Chrome, в отличие от настольной не перегружает процессор и не расходует всю доступную оперативку, назвать её экономичной довольно сложно. Даже в отсутствие расширений и тем, которые оказывают негативное влияние на “железо” устройства, смартфонная версия браузера имеет обыкновение активно забиваться файлами кэша. Конечно, за несколько недель ничего особенного не произойдёт, но через несколько месяцев объём, который они занимают, может вполне может вырасти до двух, а то и трёх гигабайт. Рассказываем, как с этим бороться.
Кэш в Google Chrome
В последнее время в социальных сетях стало появляться всё больше жалоб от пользователей, которые обнаруживают, что Google Chrome на Android начал активно собирать файлы кэша, засоряя свободное пространство на диске. Пока не очень понятно, что является причиной такой прожорливости, однако факт остаётся фактом. У некоторых пользователей объём кэшированных данных превышает 4 ГБ, что для смартфонов с 8 или даже 16 ГБ встроенного хранилища может оказаться критическим показателем.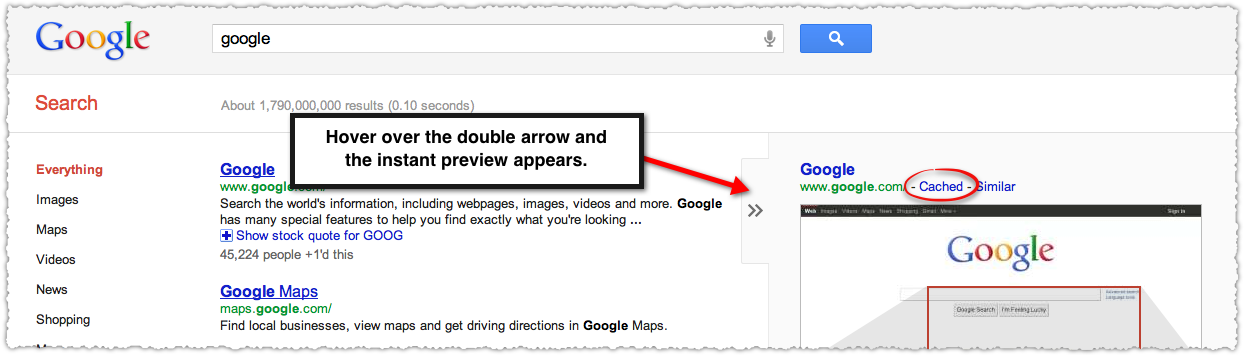
Как удалить кэш браузера
- Для чистки кэша откройте контекстное меню Google Chrome и перейдите в “Настройки”;
- Здесь откройте “Настройки сайтов”, а затем — “Хранилище”;
Как чистить кэш в Chrome
- В открывшемся окне вы увидите кэш, которые сохраняет каждый сайт;
- Вы можете удалить весь кэш сразу или делать это по отдельности для каждого сайта, открывая их поочерёдно.
Читайте также: Как увеличить скорость работы Google Chrome
Лично у меня, как видно на скриншотах, никаких проблем с кэшем нет. Максимальный размер одного файла равен 6,5 МБ. А вот у других пользователей аналогичный файл может весить в десятки раз больше. Из этого можно сделать вывод, что проблема имеет точечный характер и не имеет широкого распространения. С другой стороны, пока не очень понятно, является ли причиной возникшей проблемы ошибка в самом Chrome, который недавно получил обновление, либо специфика сайтов, на которые заходят пользователи.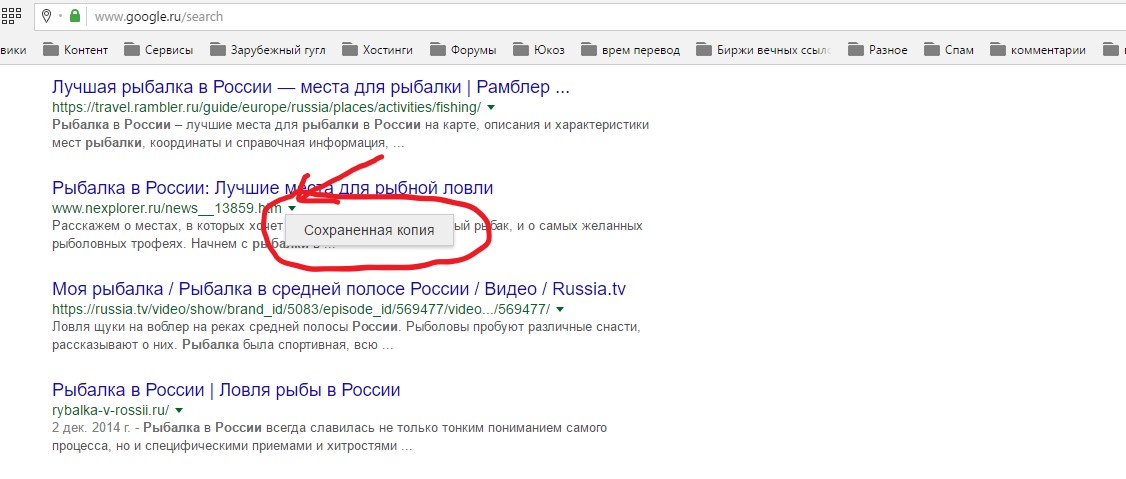
Зачем нужен кэш сайтов
Почему Chrome накапливает много кэша
Я склонен считать, что во всем виноваты сайты, или, если быть до конца точным, форумы. Во всяком случае, на представленных скриншотах видно, что больше всего пространства занимает кэш форумов. Скорее всего, дело в том, что форумы всегда полны разного рода фотографий, видеозаписей и гиф-анимаций. Браузер кэширует эти элементы, чтобы тратить меньше времени на повторную загрузку, вытянув сохранённые файлы из кэша. В результате увеличивается скорость открытия веб-страниц, но при этом страдает внутренний накопитель. А вот чем жертвовать — решать только вам.
Как удалить (очистить) кэш в браузере Google Chrome
В этой статье показаны действия, с помощью которых можно удалить (очистить) кэш в браузере Google Chrome.
Кэш — это различные элементы веб-страниц такие как изображения, стили (css), скрипты и другие файлы которые браузер сохраняет на жесткий диск компьютера при просмотре сайтов.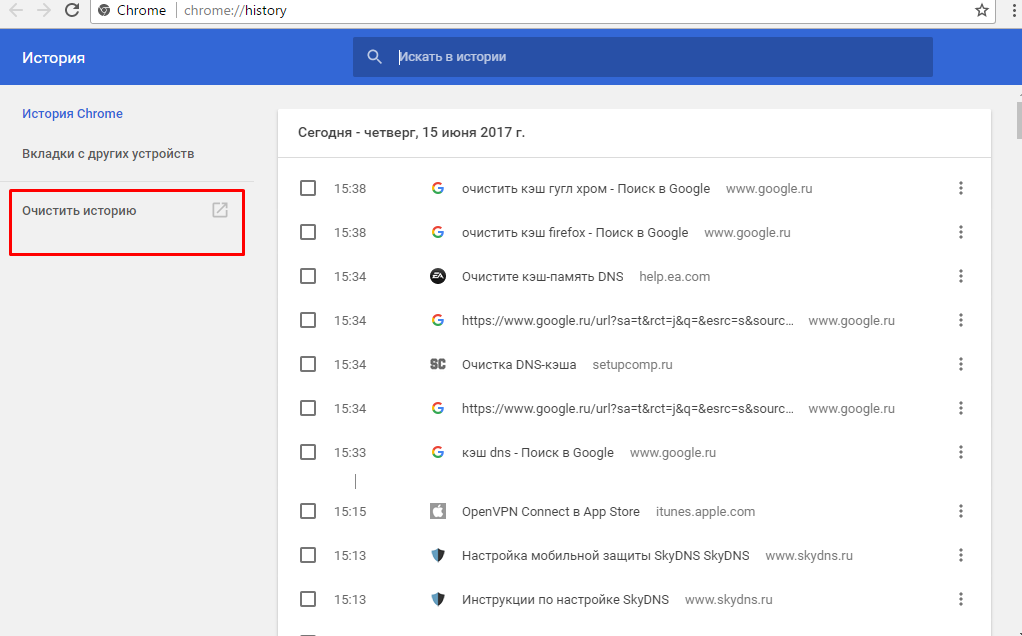
При следующих посещениях ранее просмотренных сайтов, браузер проверит содержимое веб-страницы и загрузит только новую информацию, остальные данные для отображения страницы будут взяты из кэша, тем самым значительно повышается скорость загрузки страниц сайта и экономится ваше время и интернет трафик.
Кэш браузера постоянно увеличивается и может достигать внушительных размеров, поэтому периодически следует удалять (чистить) кэш.
Далее в статье показано как удалить (очистить) кэш в браузере Chrome полностью или для отдельного сайта.
Как удалить (очистить) кэш в Google Chrome
Чтобы полностью удалить (очистить) кэш в браузере Chrome, в правом верхнем углу окна браузера нажмите на значок
В нижней части страницы выберите Дополнительные
В разделе «Конфиденциальность и безопасность» нажмите Очистить историю.
В окне Очистить историю выберите вкладку Дополнительные, затем нажмите на раскрывающийся список Временной диапазон и выберите нужный период времени, например Все время.
Установите (если не установлен) флажок опции Изображения и другие файлы, сохраненные в кеше, и снимите остальные флажки и нажмите кнопку Удалить данные.
Также можно быстро открыть окно Очистить историю, для этого нажмите сочетание клавиш Ctrl+Shift+Del и выполните очистку кэша как показано выше.
Как удалить (очистить) кэш определенного сайта в Google Chrome
Данный способ позволяет очистить кэш на определенном сайте и предполагает, что перед перезагрузкой страницы кэш веб-страницы будет полностью очищен.
Откройте в браузере Chrome нужный сайт и нажмите на клавиатуре клавишу F12, при этом справа откроется панель разработчика с кодом сайта.
Затем нажмите и удерживайте левую кнопку мыши на кнопке Обновить страницу и через 1-2 секунды появится контекстное меню в котором выберите пункт Очистка кеша и жесткая перезагрузка
Также можно обновить текущую страницу без учета кешированного контента, для этого нажмите на клавиатуре сочетание клавиш Ctrl+Shift+R или Shift+F5.
Теперь, используя рассмотренные выше действия, можно легко удалить (очистить) кэш в браузере Google Chrome полностью или для определенной веб-страницы.
Как посмотреть и извлечь файлы из кэша Google Chrome и других браузеров
Приветствую!
В процессе открытия и просмотра сайтов, браузером автоматически сохраняются файлы, которые являются элементами просматриваемых страниц. Это могут быть графические элементы, аудио и видео, таблицы стилей,js файлы, html файлы и так далее.
Все эти файлы сохраняются в кэше браузера, и впоследствии используются для ускорения формирования и отображения страниц сайтов. Принцип работы кэша весьма прост – если тот или иной элемент страницы открываемого сайта сохранён локально, то браузер использует его при формировании страницы, а не запрашивает вновь с Интернет-а. Естественно, извлечение файла из кэша происходит несоизмеримо быстрее, нежели если бы происходила загрузка оного из сети.
 К примеру, это может понадобиться, дабы выяснить, какие сайты просматривались и какой непосредственно контент там отображался. Это можно определить по сохранённым графическим элементам (картинкам, фотографиям) с просматриваемых сайтов, что были сохранены в кэше браузера.
К примеру, это может понадобиться, дабы выяснить, какие сайты просматривались и какой непосредственно контент там отображался. Это можно определить по сохранённым графическим элементам (картинкам, фотографиям) с просматриваемых сайтов, что были сохранены в кэше браузера.Проблема заключается лишь в том, что в браузере Google Chrome и основанных на его «базе» (Яндекс Браузер, Opera и так далее), к файлам кэша напрямую не обратиться. Точнее, если открыть папку с кэшем, то непосредственно сохранённых файлов вы не обнаружите, а увидите лишь файлы с порядковыми номерами. Но вопрос с доступом к кэшу в браузере решаем, о чём и будет поведано в данном материале.
Инструкция по просмотру и извлечению (копированию, сохранению) файлов кэша в Google Chrome, Opera, Яндекс браузер и т.д.
Для решения поставленной задачи мы воспользуемся миниатюрной утилитой под названием «ChromeCacheView», которая работает без установи и имеет поддержку русского языка интерфейса (языковой файл скачивается отдельно и копируется в папку, где находится и сама утилита).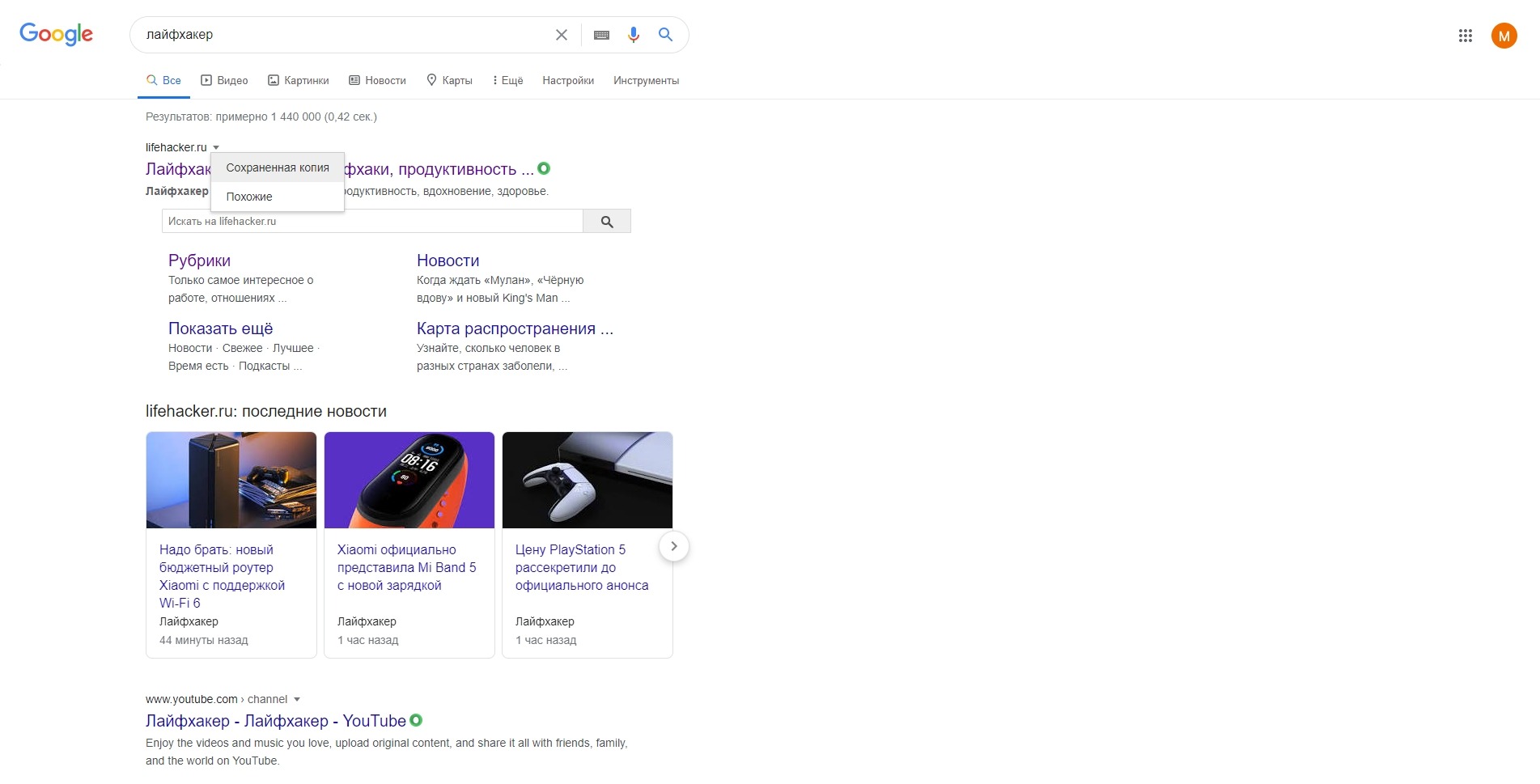
- Зайдя на официальный сайт утилиты, скачайте архив с ней и распакуйте в заранее созданную дня неё папку. Запустите находящийся исполняемый файл программы. Будет открыто основное окно утилиты.
Программа попытается обнаружить папку с кэшем браузера и отобразит сохранённые в нём файлы. Если этого не произошло или у вас в системе установлено несколько браузеров (или используется портативный вариант браузера), то в верхнем меню выберите пункт Файл -> Выбрать папку с кешем.
Там будут доступны варианты быстрого переключения расположения путей для браузеров Opera, Vivaldi, Яндекс Браузер, Google Chrome. Если в вашем случае путь будет отличаться, то существует возможность ручного выбора папки кэша.
- И так, открыв нужный кэш, можете приступить к просмотру файлов в нём находящихся, а также их извлечением (копированием) в любую другую папку.
Делается это просто: выделите файлы, которые должны быть извлечены, а после нажмите в верхнем меню пункт Файл -> Копировать выбранные файлы кэша в… и укажите папку, куда они должны быть скопированы.

- Всё. Интересующие файлы извлечены из кэша, теперь их можно просмотреть и использовать для других задач.
Воспользовавшись столь простым решением, вы с лёгкостью сможете просмотреть и скопировать файлы из кэша браузера Google Chrome, а также других браузеров, основанных на коде Chromium.
Как просмотреть и очистить кэш в браузере Google Chrome
- – Автор: Игорь (Администратор)
Google достаточно часто обновляет свой браузер Chrome. Но, на момент написания этого совета, в нем до сих пор нет настройки для задания ограничения размера кэша. А ведь кэш может очень сильно разрастись, если его периодически не чистить. Вы можете сильно удивиться, узнав сколько места занимает кэш.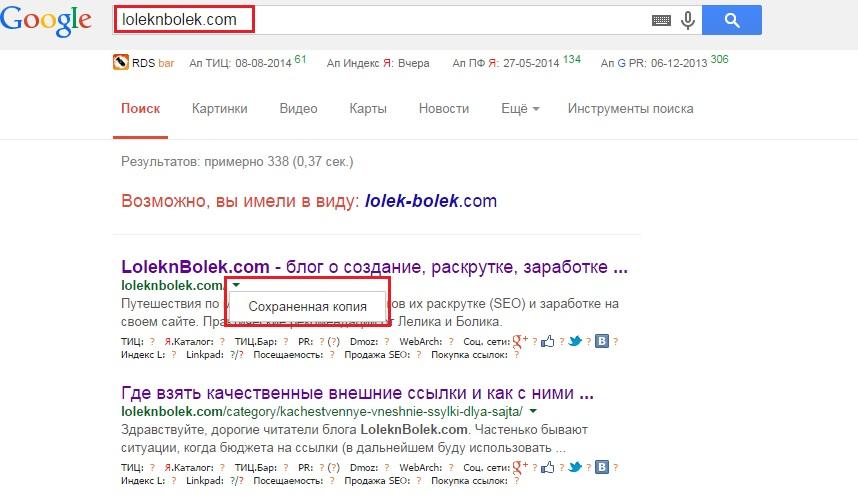
Конечно, ограничить размер можно при помощи специальных параметров, которые необходимо прописать в ярлык для запуска, но это не совсем то, что хотелось бы. Если вам интересно, то сделать это можно при помощи следующих параметров: –disk-cache-dir=”c:\cache” –disk-cache-size=102345678. Где параметр «–disk-cache-dir» — задает место хранения кэша. А параметр «–disk-cache-size» — максимальный размер в байтах.
Примечание: кэш так же стоит чистить в случаях, если у вас возникают проблемы с отображением ваших любимых сайтов. Если не вдаваться в технические подробности, то основная проблема в том, что часть элементов сайта обновилась, но при этом браузер при загрузке сайта по прежнему загружает элементы из кэша.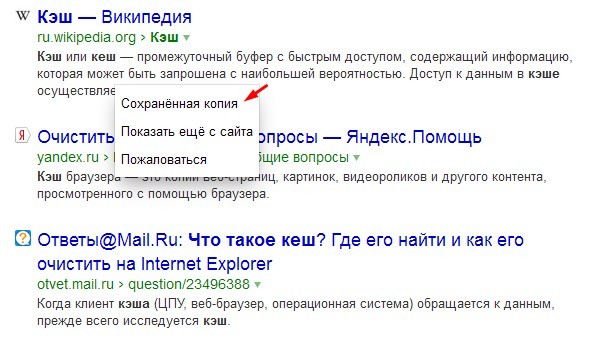
Просмотр кэша при помощи «about:cache»
Есть несколько различных способов для просмотр кэша. Сам браузер имеет специальную команду для просмотра кэша. Введите в адресной строке «about:cache» (без кавычек и без пробелов, но с двоеточием). Содержимое кэша отобразиться в окне браузера. Если у вас достаточно большой кэш, то эта операция может занять некоторое время. Конечно, это не самый удобный способ просмотра, и он больше подойдет технически подкованным пользователям. Но, тем не менее, это все же способ.
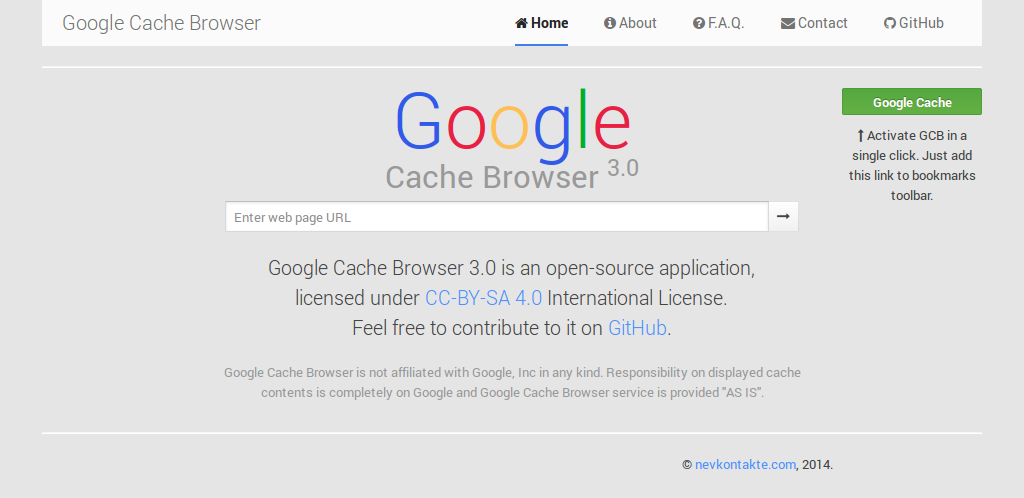
Очистка кэша из браузера
Вы можете очистить кэш за определенный период времени из панели инструментов Chrome.
- Откройте выпадающее меню. Значок из трех полосок
- Наведите мышку на «Инструменты»
- Выберите пункт «Удаление данных о просмотренных страницах…»
- В появившемся меню выберите период, за который необходимо очистить данные
- Выберите необходимые данные для очистки. Для тех данных, которые вы хотите сохранить, снимите галочки
- Нажмите кнопку «Очистить историю»
 Для тех данных, которые вы хотите сохранить, снимите галочки
Для тех данных, которые вы хотите сохранить, снимите галочкиПросмотр кэша с помощью программы ChromeCacheView от NirSoft
ChromeCacheView это небольшая бесплатная утилита, которая позволяет просматривать и выборочно копировать записи кэша браузера Chrome. Она так же позволяет посмотреть информацию о каждом файле кэша. Скачать эту утилиту вы можете по этой ссылке. Программа не требует установки и прекрасно работает в Windows XP, Vista и 7.
☕ Хотите выразить благодарность автору? Поделитесь с друзьями!
- Полезные горячие клавиши в браузере
Добавить комментарий / отзыв
Как увидеть старую страницу вк. Как искать информацию в веб-кэше Google (Инструкция)
Слово кэш можно услышать довольно часто в разных сферах ИТ, сегодня же мы будем разбираться с кэшем страниц сайта. Сам термин означает сохранение поисковыми системами копий страниц от определенного числа, как правило от последнего посещения роботом сайта.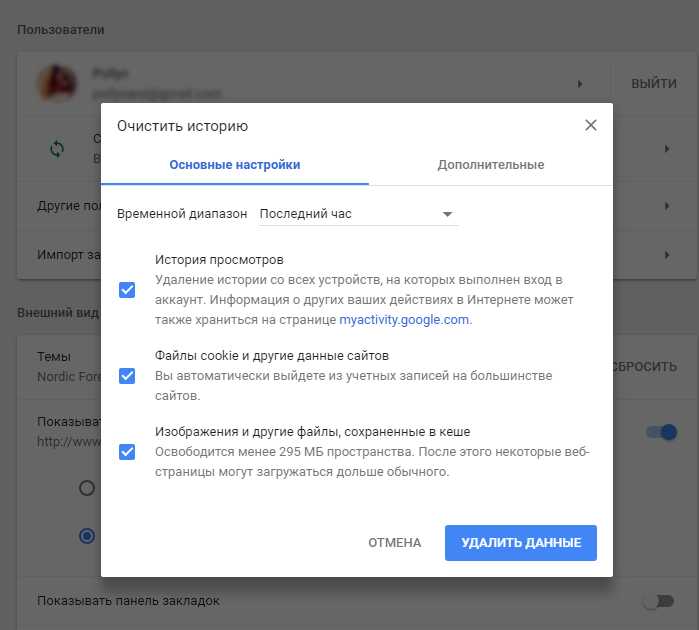 Вы можете в любой момент найти и использовать копию (кэш) страницы для своих потребностей.
Вы можете в любой момент найти и использовать копию (кэш) страницы для своих потребностей.
Это довольно таки хорошо, что поисковики сохраняют на некоторое время страницы на своих серверах и дают нам шанс воспользоваться этим. На хранение кэшированных страниц выделяется много ресурсов и денег, но свою помощь они окупают, так как нам все равно необходимо заходить на их поисковые системы.
Для чего нужен кэш (копии) страниц.
Бывают разные ситуации при работе с сайтами.
Как всегда работы у Вас много, а времени мало и внимательности на все не хватает. Бывают случаи, когда ведутся работы с сайтом, предположим изменение дизайна или мелкие правки по шаблону, тексту. И в один момент понимаете, что где-то допустили ошибку и пропал текст или исчезла часть дизайна сайта. Ну бывает такое и каждый наверное с таким имел дело.
На данный момент, бэкапов у Вас нету, у тоже и не помните как выглядело все изначально. В этом случае помочь сможет копия страницы, которую можно найти в кэше как Яндекса, так и в Гугла, посмотреть как было изначально и поправить.
Или второй случай , Вы изменили немного текст, для того, что бы повысить и хотите посмотреть обновилась страница на которой внесли изменения или нет. Проверить можно с помощью страницы, которая находится в кэше, для этого ищем данную страницу и смотрим на результат.
Так же бывает ситуация, когда сайт не доступен, по той или иной причине, а вам необходимо на него зайти. В этом случае может помочь копия страницы которую можно найти ниже перечисленными способами.
В общем я думаю, стало ясно, что пользоваться кэшем страниц нужно и полезно.
Как найти страницу из кэша Гугла и Яндекса.
Для начала давайте рассмотрим как искать в поисковой системе Google.
Способ №1.
Вы заходите на страницу поисковой системы и прописываете адрес страницы которую хотите найти и посмотреть копию. Я возьму для примера наш сайт:
Прописываем название страницы, сайта в поисковую строку, нажимаем “Enter” и видим , где отображается страница которую вы искали. Смотрим на сниппет и там де УРЛ (адрес) с права от него есть не большая стрелочка вниз, нажимаем на нее и у нас появляется пункт “Сохранённая копия”. Нажимаем на него и нас перекинет на копию страницу от определенного числа.
Смотрим на сниппет и там де УРЛ (адрес) с права от него есть не большая стрелочка вниз, нажимаем на нее и у нас появляется пункт “Сохранённая копия”. Нажимаем на него и нас перекинет на копию страницу от определенного числа.
Способ №2.
Способ можно назвать полуавтоматическим, так как необходимо скопировать адрес, что находится ниже и вместо site.ru подставить домен своего сайта. В результате Вы получите туже самую копию страницы.
http://webcache.googleusercontent.com/search?q=cache:site.ru
Способ №3.
Можно просматривать кэш с помощью плагинов для браузеров или онлайн сервисов. Я использую для этих целей .
Здесь можно посмотреть когда последний раз заходил робот на ресурс, соответственно и копия страницы будет за это число.
Теперь рассмотрим как искать кэш в поисковой системе Яндекс.
Способ №1.
Способ такой же как и для системы Google. Заходим на страницу поисковой системы и прописываете адрес страницы которую хотите найти и посмотреть копию. Снова возьму для примера наш сайт и пропишу:
Снова возьму для примера наш сайт и пропишу:
Прописываем название страницы, сайта в поисковую строку, нажимаем “Enter” и видим поисковую выдачу, где отображается страница которую вы искали. Смотрим на сниппет и там де УРЛ (адрес) с права от него есть не большая стрелочка вниз, нажимаем на нее и у нас появляется пункт “Сохранённая копия”. Нажимаем на него и нас перекинет на копию страницу от определенного числа.
Способ №2.
Используем дополнительные плагины для браузеров. Читайте немного выше всё так же как и для Google.
Если страница не находится в , то большая вероятность того, что ее нету и в кэше. Если страница была ранее в индексе, то возможно она сохранилась в нем.
Как очистить кэш в Яндексе и Гугле.
Бывает необходимо убрать страницу из кэша Яндекса или Гугла или вообще скрыть страницу которая ранее индексировалась и кешировалась от посторонних глаз. Для этого необходимо дождаться пока поисковая система сама выкинет данную страницу естественным путем если Вы ее предварительно удалили.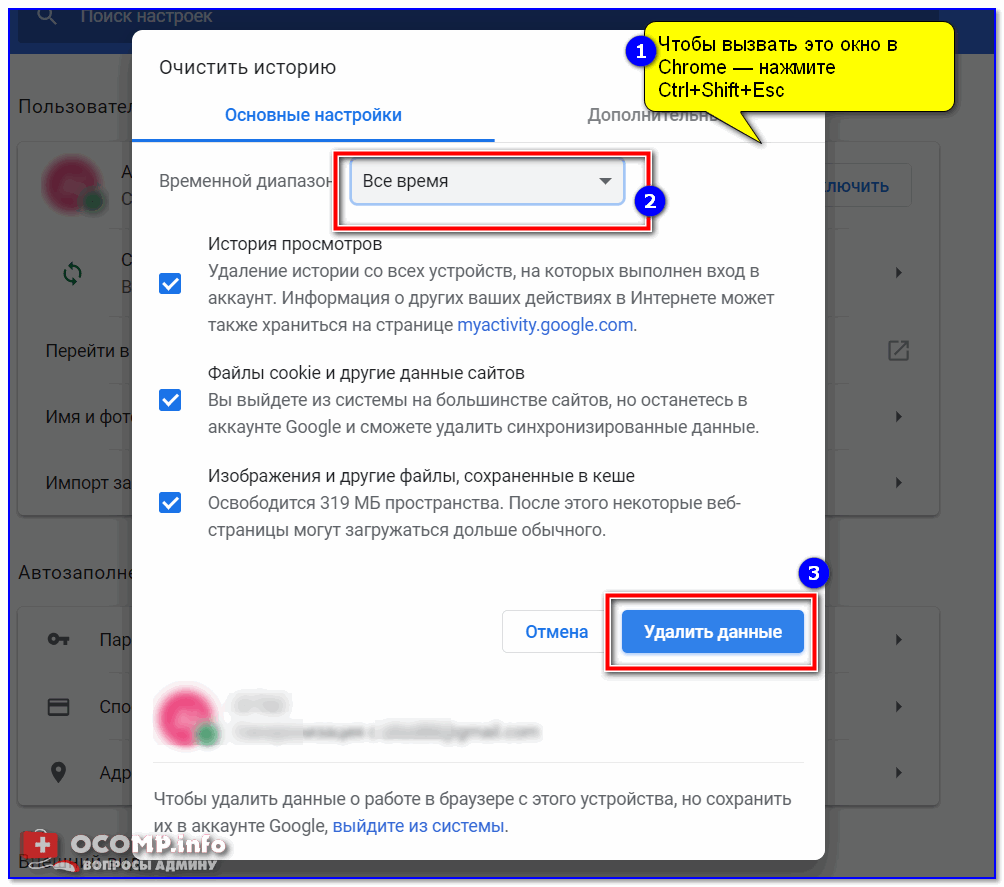 Можно запретить индексировать страницу в файле или использовать тег:
Можно запретить индексировать страницу в файле или использовать тег:
Только смотрите аккуратно с тегом, не поставьте его в общий шаблон сайта ибо будет запрет на кэширование всего сайта. Для этих целей лучше всего используйте дополнительные плагины или программистов которые ранее занимались такой работой.
Теперь давайте посмотрим как средствами поисковой системы Google и Яндекс можно очистить кэш (очистить, удалить страницу).
Поисковая система Google к этому вопросу подошла с правильной стороны и создала такой инструмент как «Удалить URL-адреса » в Webmaster Tools. Что бы им воспользоваться необходимо зайти в инструменты вебмастера по адресу:
www.google.com/webmasters/
Для того, что бы очистить кеш или удалить полностью страницу (а так же можно сразу удалить и очистить кэш вместе), необходимо нажать на кнопку «Временно скрыть » и ввести url адрес страницы которую необходимо очистить и нажать кнопку «Продолжить «.
Теперь в данном окне при нажатии на список «Тип запроса » можно увидеть несколько способов удаления и очистки как страницы с индекса гугла так и очистки кєша.
- Если Вам необходимо полностью удалить страницу и cache, то используем первый способ.
- Если необходимо просто очистить его, то используем второй способ. Как правило для нашего примера нужно использовать именно его. Страница остается в индексе, но кэш удаляется и при следующем приходе робота, она снова появится там.
- Если необходимо временно скрыть, то используем третий способ. Используется в том случае когда не успевают наполнятся страницы качественным контентом. В данном случае скрыть ее на некоторое время будет лучше.
Как только выбираете один из способов, в данном случае 2й, нажимаем на кнопку «Отправить запрос «.
После нажатия получаем страницу, где можно увидеть, что данная страница добавлена на удаление из кэша и находится в статуже «Ожидание «. Теперь остается только ждать. Как правило данная процедура занимает от нескольких минут до нескольких часов.
Теперь остается только ждать. Как правило данная процедура занимает от нескольких минут до нескольких часов.
Если Вы не правильно указали страницу и хотите сделать отмену, то можно нажать на кнопку «Отмена «.
После того как вы через некоторое время зайдете в инструмент «Удалить URL-адреса», можно будет увидеть статус «Выполнено». Это означает, что робот Гугл зашел на страницу и очистил ее историю.
Очистить (удалить) страницу в Yandex
У поисковой системы Яндекс есть похожий инструмент в инструментах для вебмастеров, но здесь есть одно «НО». Очистки кэша как такового нету, можно целиком удалить страницу из индекса ПС и при этом удалится вся ее история.
Для того, что бы воспользоваться данным инструментом необходимо зайти в Yandex webmaster по ссылке:
webmaster.yandex.ua/delurl.xml
и в строку ввести необходимый урл.
Поисковая система исключит данный адрес через некоторое время «АП». Как правило у Яндекса на это уходит пару ней, поэтому необходимо будет подождать.
Как правило у Яндекса на это уходит пару ней, поэтому необходимо будет подождать.
Если у Вас есть вопросы задавайте их в комментариях, мы всегда на связи!
Иногда, зайдя на одну из ранее посещаемых страниц в сети Интернет, мы получаем 404 ошибку — страница не найдена. Возможно, что эта страница была удалена, возможно, что сайт на данный момент не доступен и т.д., но нам от этого не тепло и не холодно. Возникает закономерный вопрос: как просмотреть удалённую страницу? В данной статье я попробую дать ответ на этот вопрос и предложить Вам четыре готовых варианта решения данной задачи. Приступим?
Вариант 1: автономный режим браузера
Для экономии трафика и увеличения скорости загрузки страниц, многие современные браузеры используют, так называемый, кэш. Что это такое? Кэш (от англ. cache ) — это дисковое пространство на Вашем компьютере, выделенное специально под временные файлы, к которым относятся и веб-страницы.
Так что если страница удалена или Интернет Вам не доступен, Вы можете воспользоваться данными из кэша браузера.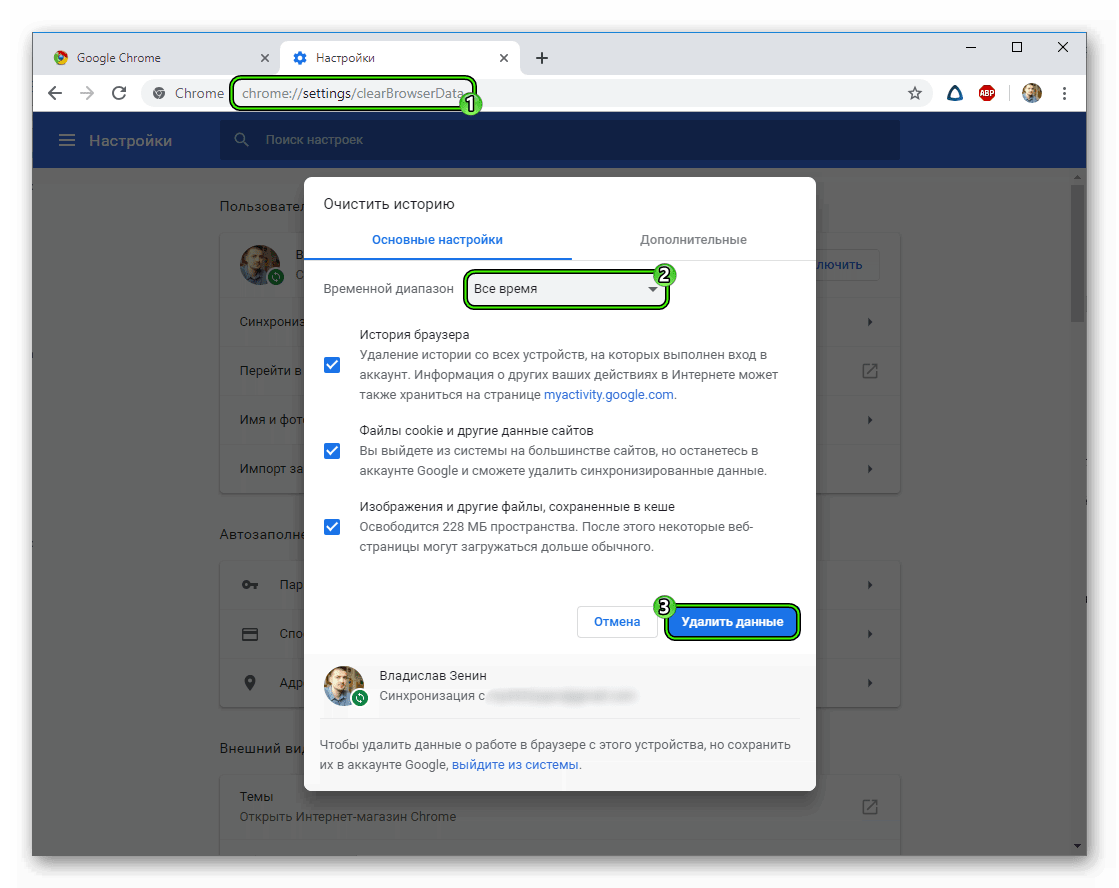 Для этого Вам нужно перейти в, так называемый, автономный режим работы браузера. Как это сделать?
Для этого Вам нужно перейти в, так называемый, автономный режим работы браузера. Как это сделать?
Примечание : для просмотра удалённой страницы в автономном режиме, она должна присутствовать в кэше браузера. Это происходит только в том случае, если Вы ранее уже посещали эту страницу. Но нужно помнить, что кэш периодически подчищается самим браузером. Многое здесь зависит от выделенного под кэш дискового пространства в настройках браузера.
Как включить автономный режим работы браузера?
Для браузером на движке Chromium , а это Google Chrome , Яндекс.Браузер , браузерИнтернет от Mail.ru, Рамблер Браузер и др., автономного режима не существует. Точнее он есть, но только в качестве эксперимента. Для его активизации перейдите на системную страницу: chrome://flags/ — и найдите там «Автономный режим кеша», а потом кликните в нём ссылку «Включить ».
Включение и выключение автономного режима в браузере Google Chrome
В браузере Firefox (версия 29 и старше)
нужно открыть меню (кликнув по кнопке с тремя полосками, она обычно находится в верхнем правом углу окна браузера)
и кликнуть в нём пункт «Разработка» (в виде гаечного ключа)
, а потом пункт «Работать автономно ».
Включение и выключение автономного режима в браузере Firefox
В браузере Opera кликните кнопку «Opera», найдите в меню пункт «Настройки», а потом кликните пункт «Работать автономно ».
Как включить или отключить автономный режим в Opera?
В Internet Explorer нужно нажать кнопку Alt , выбрать пункт «Файл » (в появившемся меню) и кликнуть пункт меню «Автономный режим ».
Как отключить автономный режим в Internet Explorer 11?
Стоит уточнить, что в IE 11 разработчики удалили возможность включения и отключения автономного режима. Здесь возникает другая проблема: как отключить автономный режим в Internet Explorer 11? Тут проделать обратные действия не получится, нужно сбрасывать настройки браузера.
Для этого закройте все приложения, в том числе и браузер. Дальше нажмите комбинацию клавиш Win
+R
и введите: inetcpl.cpl — в открывшемся окне «Выполнить», нажмите кнопку Enter
. В открывшемся окне «Свойства: Интернет» перейдите на вкладку «Дополнительно ». На открывшейся вкладке найдите и кликните кнопку «Восстановить дополнительные параметры », а потом и появившуюся кнопку «Сброс… ». В окне подтверждения установите галочку «Удалить личные настройки » и нажмите кнопку «Сброс ».
На открывшейся вкладке найдите и кликните кнопку «Восстановить дополнительные параметры », а потом и появившуюся кнопку «Сброс… ». В окне подтверждения установите галочку «Удалить личные настройки » и нажмите кнопку «Сброс ».
Вариант 2: копии страниц в поисковых системах
Я уже как-то отмечал , что пользователям поисковых систем нет смысла заходить на сайты, ведь можно просматривать копии их страниц в самой поисковой системе. Так или иначе, но это хороший способ просмотреть удалённую страницу.
Google , Вы можете использовать оператор поискового запроса info: , с указанием нужного URL-адреса, например:
В случае с поисковой системой Яндекс , Вы можете использовать оператор поискового запроса url: , с указанием нужного URL-адреса, например:
Здесь нам нужно навести курсор мыши на (зелёный)
URL-адресс в сниппете, а потом кликнуть появившуюся ссылку «копия » и мы получим последнюю сохранённую в Яндекс версию удалённой страницы.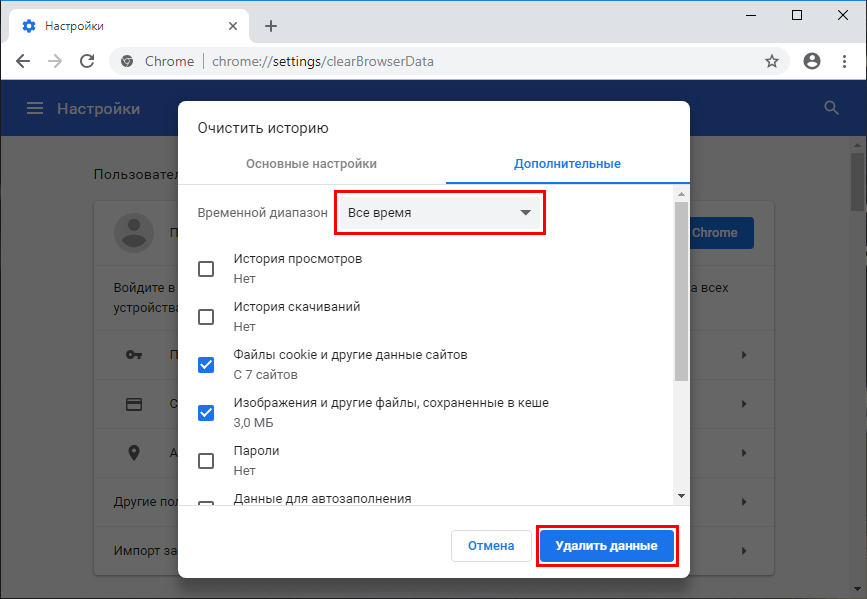
Проблема в том, что поисковые системы хранят только последние проиндексированные копии страниц. В том случае если страница была удалена, со временем она может стать недоступной и в кэше поисковых систем.
Вариант 3: WayBack Machine
Есть в сети Интернет и такой замечательный сервис, как WayBack Machine , рекомендую взять его на заметку. Фактически, это целый Интернет архив, который содержит историю существования многих сайтов.
Просмотр истории сайта на WayBack Machine
Суть его проста. Вы вводите нужный вам URL-адрес, а сервис пытается найти его копии в своей базе с привязкой к дате. К сожалению, сервис индексирует далеко не все сайты и тем более их страницы, но тем не менее. Это реальный способ восстановить ранее удалённую страницу.
Вариант 4: Archive.today
Достаточно простым и (к сожалению)
пассивным сервис для создания копий веб-страниц сайтов является сервис Archive.today . Другими словами, для того, чтобы получить доступ к удалённой странице, нужно чтобы ранее она была кем-то скопирована в сервис. Для этого нужно ввести URL-адрес в первую (красную)
форму и нажать кнопку «submit url ».
После этого вы можете попробовать найти нужную страницу, используя вторую (синюю) форму. В результате Вы увидите имеющиеся в архиве копии страниц.
Возможно, что существуют и другие варианты решения поставленной задачи с просмотром удаленных страниц, но думаю и того, что было сказано будет вполне достаточно. На этом у меня всё. Спасибо за внимание. Удачи!
Полезная ссылка: Московский юрист бросил крутую работу и преподает медитацию онлайн. Обучил — БЕСПЛАТНО! — уже 20 000 человек. Попробуйте и Вы!
У самого значимого в мире поисковика «все ходы записаны» — информация, попавшая в поле зрения поисковых роботов Google, раз и навсегда сохраняется в виде сохранённой копии. Эта копия иногда очень нужна веб-журналистам — чтобы получить важные, но уже удалённые сведения. Но как получить к ним доступ? Как осуществлять поиск по кэшу Google?
Сохраненная копия
Если вы ищете что-то через Google, то найти сохраненную копию можно и через обычный интерфейс поисковика. Нажмите на зелёный треугольничек справа от ссылки на сайт, затем — на надпись «Сохраненная копия». Нажмите на неё — и посмотрите резервную копию имеющейся информации, которая попала в цепкие лапы «гугла».
Нажмите на зелёный треугольничек справа от ссылки на сайт, затем — на надпись «Сохраненная копия». Нажмите на неё — и посмотрите резервную копию имеющейся информации, которая попала в цепкие лапы «гугла».
Поиск через адресную строку
Есть два способа:
Способ №1
Введите в адресную строку своего веб-браузера (Ghrome, Safari, Mozilla, Internet Explorer, Opera и т.д.) следующую информацию:
http://webcache.googleusercontent.com/search?q=cache:http://сайт Вместо сайт подставьте нужный вам сайт.
При желании можно посмотреть версию страницы без графики (только текст, своего рода режим Readability). Для этого достаточно нажать на «Текстовая версия» в правом верхнем углу экрана.
Способ №2
В браузере перед адресом страницы допишите слово «cache: ». В результате вместо самой страницы откроется её копия в кэше Google. Например:
Важно: Google в вашем браузере должен быть поиском по умолчанию. Если у вас не так — вводите «cache: » и адрес страницы в поисковой строке на google.com.
Если у вас не так — вводите «cache: » и адрес страницы в поисковой строке на google.com.
Вот и всё! Теперь вы можете искать в веб-кэше Google всё, что захотите — и когда захотите.
P.S. Хотите, чтобы запрос на кэш Google всегда был под рукой? Добавьте эту страницу в закладки. Как это сделать быстро и эффективно? Для Мас работает сочетание клавиш Cmd + D, для Windows — Ctrl + D.
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кеша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.iphones.ru/
Где http://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета
6. Archive.is, для собственного кэша
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).![]()
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari .
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на
Сервис социальных сетей позволяет пользователям выкладывать на свою страницу фотографии и прочие материалы, чем часто пользуются для их хранения, быстрой передачи и прочего. Однако иногда бывает и так, что пользователь случайно удаляет очень важное изображение, не имея к ней никакой копии. То есть она пропадает навсегда.
Однако иногда бывает и так, что пользователь случайно удаляет очень важное изображение, не имея к ней никакой копии. То есть она пропадает навсегда.
Прежде чем предпринимать какие-то действия, необходимо проверить, не сохранилось ли изображение в каком-нибудь другом месте — на карте памяти фотоаппарата, в загрузках телефона, на компьютере. Таким образом можно сэкономить время и нервы.
Итак, Вконтакте сохраняет на серверах все удаленные с аккаунтов фотографии.
Следует понимать, что не существует никакого удобного способа просмотра удаленных фотографии, сервисы социальных сетей не предусматривают такого. Например, на компьютере существует корзина, в которой содержатся все удаленные файлы и с помощью которой их можно легко восстановить, но в Интернете аналогичной папки просто не существует.
Итак, особую сложность вызывает тот факт, что на фото не осталось конкретной ссылки, иначе можно было бы просто найти изображение через поисковую систему, если альбом с фотографиями и сама страница не были ограничены для просмотра.
Чтобы найти удаленное фото, следует скопировать ссылку на аккаунт и вставить её в поиск. Появятся несколько ссылок. Под первой из них нужно нажать на маленький треугольник и выбрать вкладку «Сохраненная копия». Откроется сохраненная копия аккаунта, на которой возможно найти удаленное изображение и скопировать на компьютер при помощи «Сохранить как…».
Восстановить удаленное фото также возможно, если оно недавно было просмотрено в полном размере, что означает её временное сохранение в кеше браузера. Чтобы его найти, необходима специальная программа для просмотра кеша в браузере — каждому из них соответствует специальная программа. Следует использовать пакет приложений Web Browser Tools, в котором содержится необходимая утилит.
После активации приложения откроется список всех удаленных фотографий, в котором есть возможность восстановления. Логично искать файлы формата jpeg или jpg и обращать внимание на объем файла..
Если ничего из вышеописанного не дало успеха, то есть смысл написать техподдержке социальной сети и попросить помощи с восстановлением. Если вопрос заключается в действительно важной фотографии, то модераторы наверняка обратят на него внимание.
Если вопрос заключается в действительно важной фотографии, то модераторы наверняка обратят на него внимание.
Важно, что нет никакого способа восстановить альбом с изображениями. После подтверждения об удалении альбом исчезнет без всякой возможности на восстановление.
В заключении важно сказать, что самый простой способ не терять важные фото — не хранить их в одном месте и тем более в социальных сетях, в которых могут взломать аккаунт или же просто случится ошибка, которая удалит некоторую информацию.
Кнопка «Восстановить» при удалении фотографии
Также прежде всего стоит думать об удалении каждой из фотографий. Если фото было удалено случайно, то сразу же можно его восстановить, пока страница не была обновлена.
Как получить доступ к веб-странице, когда она закрыта
- Подробности
- мая 07, 2017
- Просмотров: 14386
Ничто не исчезает полностью из Интернета.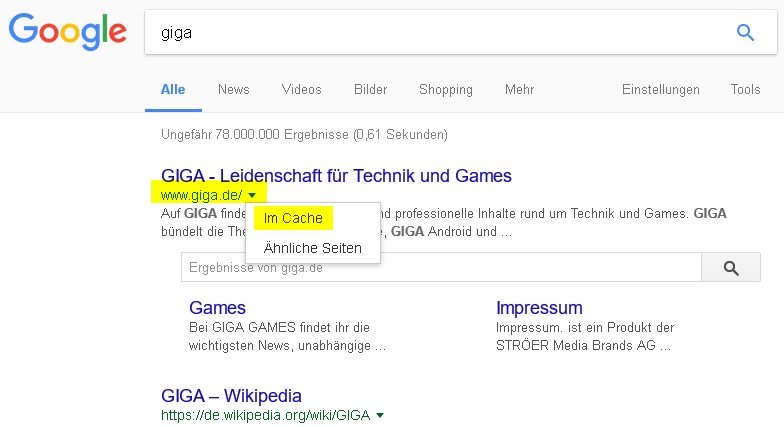 Если веб-страница не работает в течение нескольких минут или нескольких лет, вы можете просмотреть ее содержимое в любом случае.
Если веб-страница не работает в течение нескольких минут или нескольких лет, вы можете просмотреть ее содержимое в любом случае.
Вариант 1. Кэш Google
Google и другие поисковые системы загружают и сохраняют копии проиндексированных веб-страниц. Если веб-страница не работает, вы можете легко просмотреть последнюю копию, сохраненную в кеше Google.
Если вы пытаетесь получить доступ к веб-странице из поиска Google, доступ к кешированной копии получить довольно легко. Просто нажмите кнопку «Назад» в веб-браузере, когда веб-страница не загружается. Нажмите стрелку справа от адреса веб-страницы и нажмите «Сохраненная копия», чтобы просмотреть старую копию.
Если страница загружается долго, вы можете нажать ссылку «Только текст» в верхней части кешированной страницы. Веб-страница загрузится мгновенно, но вы не увидите никаких изображений. Это необходимо, когда сервер веб-сайта отключен, и ваш браузер не может загружать изображения веб-страницы.
Вы также увидите дату и время, когда Google создала эту кэшированную копию, отображаемую в верхней части страницы.
Также есть быстрый способ просмотра кэшированной копии Google любой веб-страницы без предварительного поиска в Google.
Просто подключите следующий адрес в адресную строку, заменив site.ru/page.htm полным адресом веб-страницы, которую вы хотите.
http://webcache.googleusercontent.com/search?q=cache: site.ru/page.htm
Не забудьте убрать «http: //» или «https: //» из начала адреса веб-страницы. Итак, если вы хотите посмотреть копию данной страницы, просто скопируйте в адресную строку следующий адрес (предварительно убрав пробел и копирайт):
http://webcache.googleusercontent.com/search?q=cache: juice-health.ru/internet/606-dostup-k-veb-stranice
Если вы получаете ошибку 404 значит такой страницы в кэше пока нет.
Хотя тут я рассказал про Google Cache, поисковая система Яндекс также имеет свою подобную функцию. Если вы используете Яндекс, вы также можете щелкнуть стрелку справа от адреса и нажать «Сохраненная копия», чтобы просмотреть копию из кеша Яндекс.
Если вы используете Яндекс, вы также можете щелкнуть стрелку справа от адреса и нажать «Сохраненная копия», чтобы просмотреть копию из кеша Яндекс.
Вариант второй: Wayback Machine или CoralCDN
Интернет-архив Wayback Machine также позволяет просматривать старые копии веб-страницы. В тех случаях, когда Google Cache предлагает вам только одну, самую последнюю сохраненную копию, Wayback Machine предлагает несколько старых версий веб-страницы, возвращающихся гораздо дальше, чтобы вы могли видеть, как выглядела веб-страница несколько лет назад.
Чтобы использовать Wayback Machine, перейдите на страницу https://web.archive.org. Вставьте полный адрес веб-страницы, которую вы хотите просмотреть, в поле и нажмите «Обзор истории». Например, вы можете скопировать и вставить этот адрес из адресной строки вашего браузера, если веб-страница не загружается.
Если вы просто хотите просмотреть последнюю сохраненную в кэше копию веб-страницы, вы можете нажать на дату в верхней части страницы архива.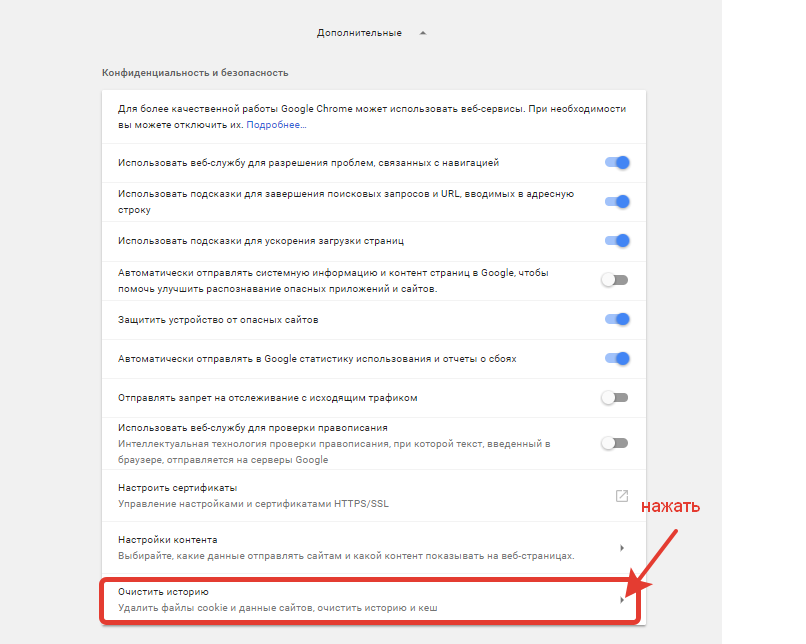
Если вам нужна более старая копия, вы можете выбрать год и нажать дату в календаре, чтобы просмотреть веб-страницу, как она выглядела в эту дату.
Вы можете щелкнуть ссылки, которые появляются на странице после загрузки, чтобы просмотреть другие веб-страницы по мере их появления в эту дату. Этот инструмент позволяет просматривать целые веб-сайты, которые исчезли или сильно изменились.
Возможно, вы также слышали о CoralCDN (в последнее время не всегда работает). CoralCDN особенно полезен для просмотра кэшированных копий веб-страниц, которые оказались недоступны из-за внезапного высокого трафика. Вышеупомянутые два инструмента должны помочь вам получить копию любой страницы за любое время.
Читайте также
Очистка кэш редиректов в Google Chrome браузере и не только
В веб-разработке бывают моменты, когда ты, вроде бы, все делаешь правильно, но глюк на сайте не проходит. Кэш браузера – наверное, один из самых популярных подобных нюансов. Недавно я столкнулся с некой вариацией этой проблемы – оказывается Chrome и остальные веб-браузеры, кэшируют информацию о редиректах. Так что, если вы настраиваете 301 редирект, а ничего не происходит, возможно, проблема именно в этом. Сегодня разберемся как очистить кэш редиректов Google Chrome без удаления всех данных.
Недавно я столкнулся с некой вариацией этой проблемы – оказывается Chrome и остальные веб-браузеры, кэшируют информацию о редиректах. Так что, если вы настраиваете 301 редирект, а ничего не происходит, возможно, проблема именно в этом. Сегодня разберемся как очистить кэш редиректов Google Chrome без удаления всех данных.
Само по себе автоматическое кэширование в браузерах – штука полезная, но в ходе разработки вебсайтов, есть смысл его отключать, т.к. ты постоянно вносишь какие-то правки, и каждый раз чистить кэш хлопотно. Обычно в таких ситуациях хватает нажатия Ctrl+F5 (для CSS-стилей так точно), но с редиректами эта фишка, почему-то не прокатывает. Chrome и другие локально сохраняют информацию о них на какое-то время и повторный HTTP запрос не будет отправляться для того же URL.
В общем, столкнувшись в очередной раз с этой проблемой, нашел полезную статью по теме где собраны все возможные варианты решения текущей задачи. Ими и поделюсь ниже.
Режим Инкогнито
Наиболее простой подход – использовать Incognito Mode, очищающий кэш браузера каждый раз после его закрытия. Преимуществом метода можно назвать то, что он применим для всех популярных нынче программных продуктов, т.к. есть и в Opera, и Firefox.
Преимуществом метода можно назвать то, что он применим для всех популярных нынче программных продуктов, т.к. есть и в Opera, и Firefox.
В Хроме его включить можно следующим образом:
К сожалению, работа в данном формате не решает проблему в “основном” веб-браузере. В таком случае есть смысл рассмотреть какой-то из вариантов ниже. Кстати, Incognito-режим можно использовать для посещения сайтов по типу TopCasinoExpert и других из этой тематики, которые недоступны в некоторых странах.
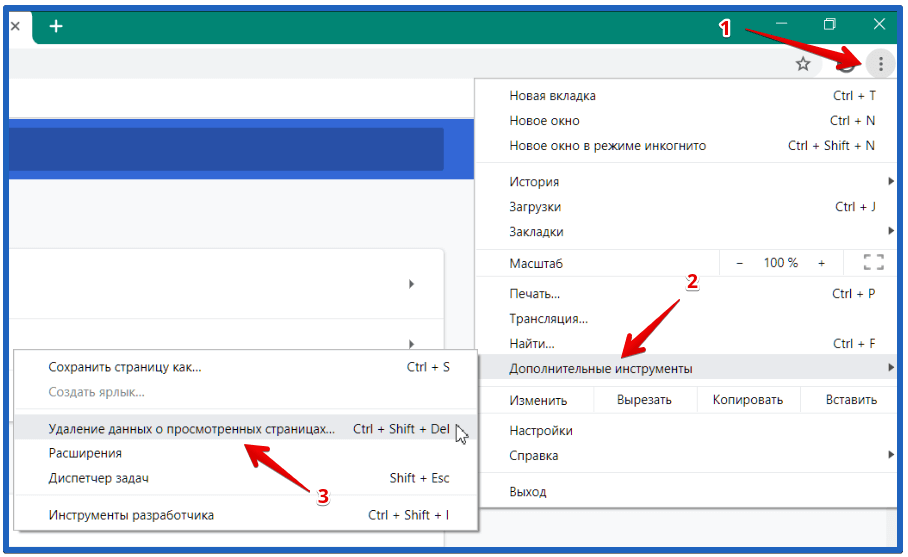
Очистка всего кэша
Самый радикальный метод – вообще удалить весь кэш. Для его реализации в Google Chrome нужно:
1. Зайти в меню – выбрать “Настройки” (Settings) – в самом низу страницы будет опция “Дополнительные” (Show advanced settings).
2. После клика увидите доп.параметры, где в блоке «Конфиденциальность и безопасность» (Privacy) ищете опцию «Очистить историю» (Clear browsing data…).
3. При нажатии на этот пункт меню появится всплывающее окно, в котором обязательно надо отметить пункт “Изображения и другие файлы, сохраненные в кеше” (Cached images and files).
Остальные отметки активируете по желанию в зависимости от того, какую именно инфу вы хотите удалить. Также разрешается выбрать временной диапазон: последний час, 24часа, 7дней, 4недели или за всем время.
4. После задания параметров нажимаете на кнопку “Удалить данные”.
В данном случае вместе с очисткой кэша редиректов в Google Chrome удалится и другая информация, отмеченная вами. Кроме того, действие применится ко всем абсолютно сайтам, а не только к тому, над которыми работаете. Поэтому есть смысл использовать более “тонкий” подход.
Удаление кэша браузера для отдельного URL
Кроме Chrome метод подходит и для Firefox, IE, Edge (алгоритм действий там аналогичный). Преимущества также в том, что все изменения применяются только к конкретному сайту/URL. Вот что нужно сделать:
1. Нажимаете SHIFT+CTRL+I дабы открыть инструменты разработчика Chrome Devtools (о которых я уже когда-то рассказывал).
2. Переходим во вкладку “Network”, где отмечаем галочку “Disable cache”. Важно! Инструмент должен быть открытым все это время иначе выполнить следующие шаги у вас не получится.
Важно! Инструмент должен быть открытым все это время иначе выполнить следующие шаги у вас не получится.
3. Затем в адресной строке браузера вводите URL-адрес сайта и нажимаете Enter.
4. Нажимаете на иконку обновления страницы и удерживаете ее пока не появится всплывающее окно. В нем кликаете по пункту “Очистка кэша и жестка перезагрузка” (Empty Cache and Hard Reload).
5. Сразу после того, как страница веб-сайта будет перезагружена, вы можете снять метку возле опции “Disable cache” в инструментах разработчика.
Используем Chrome Fetch API
Это слегка “экзотический подход”, но тоже работает. Вам надо:
1. Перейти на сайт www.google.com или любой другой с non-restrictive CORS policy (если честно хз, что это, поэтому остановлю выбор на Гугле).
2. Нажимаете сочетание клавиш SHIFT+CTRL+J для открытия консоли Google Chrome.
3. Далее в ней пишете следующий код:
fetch('https://www.вашсайт.com', {method: 'post'}). |
 then(() => {})
then(() => {})fetch(‘https://www.вашсайт.com’, {method: ‘post’}).then(() => {})
Разумеется, в данном примере нужно заменить URL сайта на свой (обратите внимание, что ссылка пишется полностью с https/http.
Итого. Если говорить о текущей задаче, то очистить кэш в Google Chrome для редиректов мне помог третий вариант. Последний не пробовал, но пару человек из оригинальной статьи подтвердили его работоспособность. Что касается всех остальных ситуаций (обновить CSS файлы, например), то для этого хватает классического Ctrl+F5. Хотя, мне кажется, есть смысл вообще отключать кэширование браузера в ходе веб-разработки. Что думаете по этому поводу?
Как кэшировать сайт в Google | Small Business
Поисковая система Google основана на результатах, которые Googlebot или пауки генерируют при сканировании Интернета. Ссылки на ваш сайт или ссылки на вашем сайте на другие сайты помогают Google найти ваш сайт и кэшировать его «естественным образом», чтобы они могли его проиндексировать.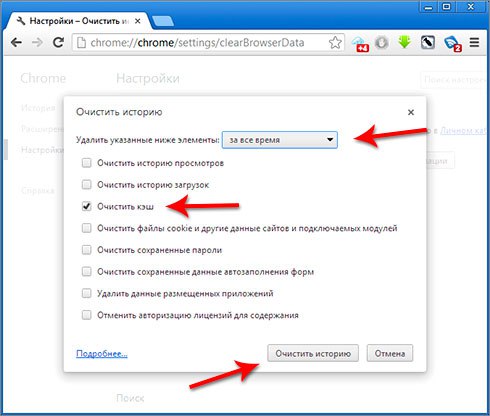 Чтобы ускорить этот процесс или обновить кеш для вашего веб-сайта, потому что вы изменили много контента, Google предлагает способ отправить им свой сайт, чтобы индексация и кеширование происходили быстрее.Таким образом клиенты могут получить доступ к текущей информации на вашем сайте через кеш Google, даже если ваш сервер временно отключится.
Чтобы ускорить этот процесс или обновить кеш для вашего веб-сайта, потому что вы изменили много контента, Google предлагает способ отправить им свой сайт, чтобы индексация и кеширование происходили быстрее.Таким образом клиенты могут получить доступ к текущей информации на вашем сайте через кеш Google, даже если ваш сервер временно отключится.
Использование Google’s Webmaster Tools
Войдите на веб-страницу Google Webmaster Tools, используя свою учетную запись Google (ссылка в разделе «Ресурсы»).
Щелкните сайт в списке, который вы хотите, чтобы Google кэшировал. Если у вас нет сайта в вашем списке, нажмите кнопку «Добавить сайт» и введите сайт в поле всплывающего диалогового окна.Нажмите кнопку «Продолжить» и пройдите один из процессов проверки, чтобы доказать, что вы управляете этим сайтом или являетесь его владельцем.
Щелкните раскрывающееся меню «Состояние», выберите «Просмотреть как Google» и введите в поле страницу своего веб-сайта, которую Google должен сканировать. URL сайта уже напечатан перед полем. Чтобы Google кэшировал главную страницу вашего сайта, оставьте поле пустым.
URL сайта уже напечатан перед полем. Чтобы Google кэшировал главную страницу вашего сайта, оставьте поле пустым.
Нажмите кнопку «Получить» и разрешите роботу Googlebot сканировать сайт. После успешного сканирования нажмите кнопку «Отправить в индекс» и «ОК» в появившемся диалоговом окне.Google обновляет кеш для новых страниц, которые еще не просканированы, и страниц, которые изменились с момента последнего сканирования. Таким образом Google позволяет получать 500 страниц в неделю и 10 страниц с включенными ссылками.
Использование Google’s Public Site Submission
Перейдите на веб-страницу Google Crawl URL (ссылка в разделе «Ресурсы»).
Введите полный URL-адрес сайта, включая «http: //», в поле.
Введите два слова в поле CAPTCHA и нажмите кнопку «Отправить запрос».
Ссылки
Ресурсы
Советы
- Если у вас есть новый сайт, который Google должен добавить в свой индекс, вы также можете отправить для него карту сайта в Инструментах Google для веб-мастеров.

Предупреждения
- Google не дает никаких гарантий относительно того, сколько времени потребуется для индексации и кеширования вашего сайта.
Писатель Биография
Марисса Роберт окончила Университет Бригама Янга по специальности английский язык и литература.Она имеет большой опыт написания маркетинговых кампаний, бизнес-справочников и руководств, а также написания, корректуры и редактирования внештатных писем. Живя во Франции, она переводила рукописи на английский язык. Она публиковала статьи на различных веб-сайтах, а также периодически ведет два блога.
Как найти старые веб-сайты и выполнить поиск по кешированным страницам Google
Что нужно знать
- Способ 1. Найдите слово или веб-сайт. В результатах поиска щелкните треугольник над заголовком страницы и выберите в меню Кэшировано .
- Метод 2: Введите cache: [название сайта] в поле поиска строчными буквами без пробелов и нажмите Введите .

Есть два способа просмотреть кешированную версию страницы в Google. Выполните регулярный поиск на сайте для настольных компьютеров, а затем откройте оттуда кешированную версию или добавьте одно слово в поиск Google на настольных или мобильных сайтах, чтобы немедленно открыть кешированную версию.
Выполните обычный поиск в Google
Использовать обычный поиск Google для поиска кэшированной страницы так же просто, как выполнить обычный поиск и затем щелкнуть ссылку в результатах поиска, чтобы открыть кешированную страницу.
Найдите слово, фразу или весь веб-сайт.
Найдите в результатах конкретную страницу, для которой вам нужна кешированная версия.
Щелкните треугольник над заголовком страницы и выберите Кэшировано .
При нажатии на ссылку Cached часто отображается страница в том виде, в котором она была в последний раз проиндексирована в Google, но с выделенными ключевыми словами для поиска.![]() Этот метод чрезвычайно полезен, если вы хотите найти конкретную информацию без необходимости сканировать всю страницу.
Этот метод чрезвычайно полезен, если вы хотите найти конкретную информацию без необходимости сканировать всю страницу.
Если поисковый запрос не выделен, используйте сочетание клавиш Ctrl + F (Windows) или Command + F (Mac), чтобы найти слово (слова).
Прямо в кэш
Вместо этого вы можете перейти к делу и перейти непосредственно к кэшированной странице, добавив cache: непосредственно перед поиском Google.
Откройте новое поле поиска Google и введите cache: (включая двоеточие).
Введите URL-адрес страницы, для которой вы хотите увидеть кешированную версию. Например, введите cache: lifewire.com строчными буквами без пробелов. Не используйте стандартные «http» или «https», которые появляются в начале URL-адресов.
Нажмите Введите , чтобы сразу открыть кешированную страницу.

Когда Google индексирует веб-страницы, он сохраняет снимки их содержания, известные как кэшированные страницы.URL-адреса периодически обновляются новыми кэшированными изображениями. Используйте этот трюк с мощным поиском Google, чтобы открыть кэшированное изображение страницы и найти нужную информацию.
Ограничения кешей
Имейте в виду, что в кеше отображается время последней индексации страницы, поэтому иногда изображения не отображаются, и информация будет устаревшей. Однако, в зависимости от того, что вы ищете, это может не вызывать беспокойства.
Некоторые страницы инструктируют Google с помощью протокола, называемого robots.txt, чтобы сделать исторические страницы недоступными. Дизайнеры веб-сайтов также могут сделать страницы закрытыми от результатов поиска Google, удалив их из индекса сайта (также известное как «запрет на индексирование»).
Google хранит только самый последний кеш страницы, поэтому, если вы пытаетесь получить доступ к действительно старой странице — возможно, к той, которая сильно изменилась или долгое время находилась в автономном режиме, — попробуйте Wayback Machine.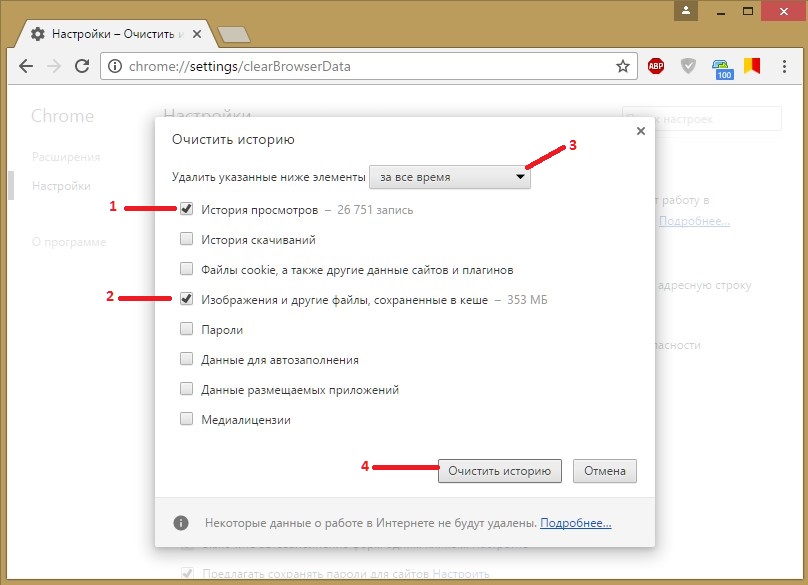
Спасибо, что сообщили нам!
Расскажите, почему!
Другой Недостаточно подробностей Сложно понятьКак использовать кеш Google для восстановления веб-страницы
В случае, если вам нужно восстановить файл, а у вас нет локальной резервной копии, вы можете использовать кеш Google в качестве альтернативы.
Когда Google сканирует ваш сайт, он делает снимок вашей страницы. Этот снимок показывает, как выглядел ваш сайт, когда Google его просканировал, и доступен для просмотра с помощью ссылки «Сохранено в кеше» в результатах поиска Google. Короче говоря, при восстановлении страницы с использованием кеша Google используется HTML-код, сохраненный Google при сканировании вашего сайта, для восстановления файла, который вам нужно восстановить.
Обратите внимание: :
Действия, описанные ниже, не гарантируются. Этот метод рекомендуется использовать только в крайнем случае.Кеш Google не будет работать на php или других страницах с использованием сценариев на стороне сервера, поскольку Google не может видеть ваш php-код, а только сгенерированный html.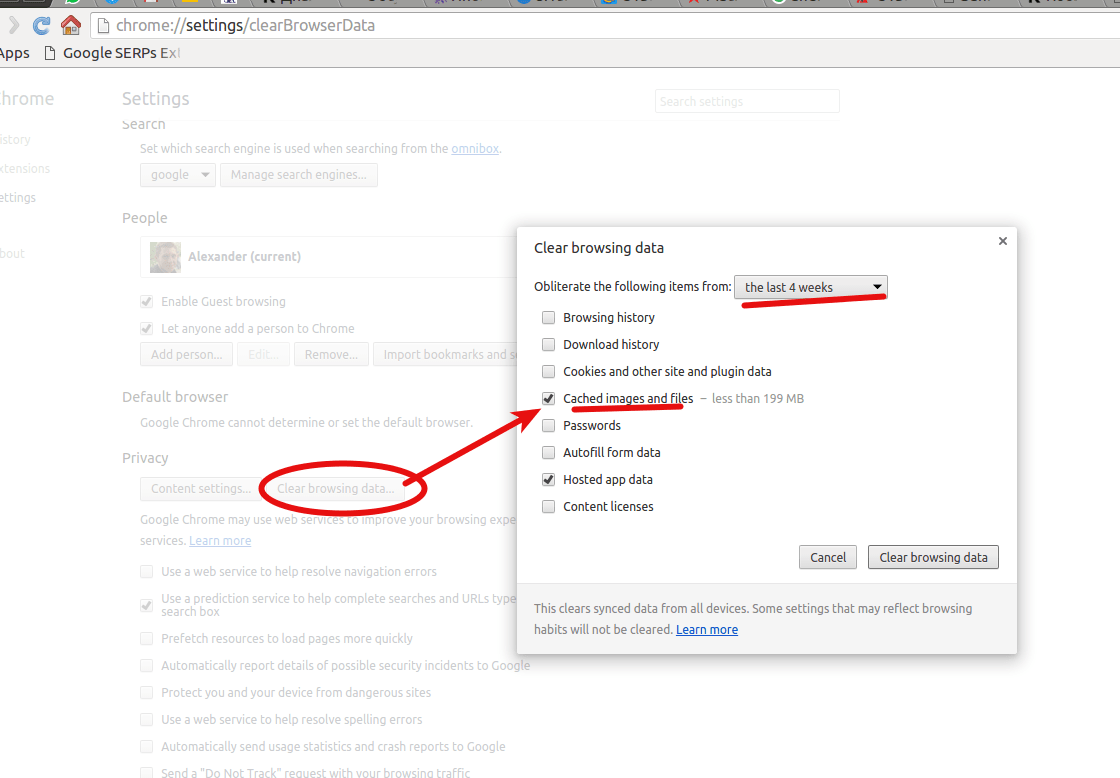
- Найдите в Google site: example.com . Обязательно замените example.com своим доменным именем и не вставляйте пробелов между site: и example.com.
- Вы увидите список всех страниц, просканированных Google и находящихся на сайте example.com. Щелкните ссылку Cached рядом со страницей, которую необходимо восстановить.
- Вверху страницы Google отобразит сообщение, подобное следующему:
- Протестируйте новый файл в своем браузере. В этом примере вы хотите протестировать example.com/index_test.html. Если эта версия вашей страницы в кеше Google подойдет вам, переместите исходный файл в сторону и вместо этого поместите тестовый файл на место. В этом примере вы должны переименовать index.html во что-нибудь еще, например index.html.bak, а затем переименовать тестовый файл index_test.html в index.html.
Это кеш Google https://www.example.com/. Это снимок страницы, появившейся 14 декабря 2009 г. в 22:29:21 по Гринвичу.
Указанная дата снимка — это дата, когда Google просканировал ваш сайт. Если ваша страница правильно отображается под этим сообщением, вы можете использовать HTML-код в кеше Google, чтобы попытаться восстановить файл.
Посмотреть исходный код страницы.В большинстве браузеров вы можете щелкнуть правой кнопкой мыши и выбрать View Page Source. Исходный код — это HTML-код, который используется для отображения вашего веб-сайта. Выберите весь код в источнике страницы и скопируйте / вставьте его в тестовый файл в своей учетной записи. Например, если вы пытаетесь восстановить index.html, поместите код в файл с именем index_test.html. Google добавляет несколько строк вверху страницы, поэтому вам нужно удалить первые несколько строк кода вверху. Эти первые несколько строк — это то, что Google использует для отображения информации вверху кэшированной страницы, например, даты снимка.
Выберите весь код в источнике страницы и скопируйте / вставьте его в тестовый файл в своей учетной записи. Например, если вы пытаетесь восстановить index.html, поместите код в файл с именем index_test.html. Google добавляет несколько строк вверху страницы, поэтому вам нужно удалить первые несколько строк кода вверху. Эти первые несколько строк — это то, что Google использует для отображения информации вверху кэшированной страницы, например, даты снимка.
Обзор кэширования | Cloud CDN | Google Cloud
Кэшируемый ответ — это HTTP-ответ, который Cloud CDN может хранить и быстро
извлекать, что позволяет ускорить загрузку.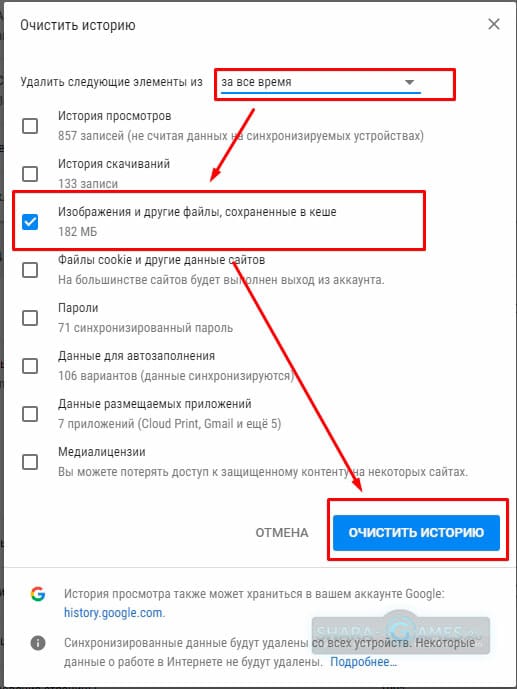 Не все ответы HTTP
кешируемый.
Не все ответы HTTP
кешируемый.
Режимы кэширования
В режимах кэширования вы можете контролировать факторы, определяющие, Cloud CDN кэширует ваш контент.
Cloud CDN предлагает три режима кеширования, которые определяют, как кэшируются, соблюдает ли Cloud CDN директивы кеширования, отправленные origin и как применяются TTL кеша.
Доступные режимы кэширования показаны в следующей таблице:
| Режим кэширования | Поведение |
|---|---|
CACHE_ALL_STATIC | Автоматически кэширует статический контент, который
не имеет директивы no-store или private .Ответы источника, которые устанавливают действительные директивы кеширования, также кэшируются. Это поведение по умолчанию для для Cloud CDN.
бэкэнды, созданные с помощью инструмента командной строки |
USE_ORIGIN_HEADERS | Требуются ответы источника для установки допустимых директив кеширования и допустимых
кеширование заголовков. Ответы без этих директив
пересылаются из источника. |
FORCE_CACHE_ALL | Безоговорочно кэширует ответы, игнорируя любые директивы кеширования, установленные Происхождение.Убедитесь, что вы не кэшируете частный контент для каждого пользователя (например, динамический HTML или ответы API), если в этом режиме используется общий сервер. настроен. |

FORCE_CACHE_ALL , время по умолчанию
live (TTL) для кэширования контента составляет 3600 секунд (1 час), если вы явно не
установить другой TTL. Принятие нового значения TTL по умолчанию, равного 1 часу, может вызвать некоторые
записи, которые ранее считались свежими (из-за более длинных TTL от
исходные заголовки) теперь считаются устаревшими. Внимание: Режим
Внимание: Режим FORCE_CACHE_ALL переопределяет директивы кеширования ( Cache-Control и Истекает ), но не отменяет другие заголовки ответа источника. В
в частности, заголовок Vary по-прежнему соблюдается и может подавлять кеширование даже
в наличии FORCE_CACHE_ALL . Для получения дополнительной информации см. Vary
заголовки. Примечание: Режим FORCE_CACHE_ALL отменяет максимальный возраст, указанный для любого
подписанные URL-адреса или подписанные файлы cookie через
Максимальный возраст записи в кэше — параметр в консоли Google Cloud Console или gcloud.
Параметр --signed-url-cache-max-age .Инструкции по настройке см. В разделе Настройка кеша. режим.
Статическое содержимое
Статический контент — это контент, который всегда один и тот же, даже когда к нему обращается разные пользователи. CSS, который вы используете для стилизации своего сайта, JavaScript для предоставления интерактивность, видео и графическое содержание обычно не меняются для каждого пользователя в течение заданный URL ( ключ кеша ), и, таким образом, получить выгоду от кеширования через Глобальная пограничная сеть Cloud CDN.
Когда вы устанавливаете режим кеширования для кэширования всего статического контента, Cloud CDN автоматически кэширует ответы для следующего:
- веб-ресурсов, включая CSS (
текст / css), JavaScript (application / javascript) и все веб-шрифты, включая WOFF2 (font / woff2) - изображений, включая JPEG (
изображения / jpg) и PNG (изображения / png) - видео, включая H.264, H.265 и MP4 (
видео / MP4) +. Аудиофайлы, включая MP3 (изображения / MPEG) и MP4 (аудио / MP4) - Отформатированные документы, включая PDF (заявка
/ pdf)
В следующей таблице приведены сводные данные.
| Категория | Типы MIME |
|---|---|
| Веб-ресурсы | текст / текст CSS / текст ecmascript / приложение JavaScript / JavaScript |
| Шрифты | Любой Content-Type соответствующий шрифт / * |
| Изображения | Любой Content-Type соответствует image / * |
| Видео | Любой Content-Type соответствует video / * |
| Аудио | Любой Content-Type соответствует audio / * |
| Типы форматированных документов | Заявка / pdf и заявка / постскриптум |
Cloud CDN проверяет заголовок HTTP-ответа Content-Type , который
отражает MIME
тип
обслуживаемого контента.
Обратите внимание на следующее:
Программное обеспечение веб-сервера вашего источника должно установить
Content-Typeдля каждого отклик. Многие веб-серверы автоматически устанавливают заголовокContent-Type, включая NGINX, Varnish и Apache.Cloud Storage автоматически устанавливает заголовок
Content-Typeзагружать, когда вы используете Облачная консоль или инструментgsutilдля загрузки контента.Если ответ кэшируется на основе его типа MIME, но имеет
Cache-Controlзаголовок ответаprivateилиno-store, илиSet-Cookieзаголовок (см. полный список правил), он не кешируется.
text / html ) и JSON.
( application / json ) по умолчанию не кэшируются. Эти типы ответов
обычно динамический (на пользователя). Примеры: тележки для покупок, страницы продуктов.
с персонализацией пользователя и аутентифицированными ответами API.Cloud CDN не использует расширения файлов в пути URL для определения является ли ответ кешируемым, потому что многие действительные кешируемые ответы не отражены в URL-адресах.
Если вы хотите кэшировать типы содержимого text / html и application / json , вы должны
установить явные заголовки Cache-Control в ответ, будучи
осторожно, чтобы случайно не кэшировать данные одного пользователя и не передать их всем пользователям.
Кэшируемое содержимое
Cloud CDN кэширует ответы, которые соответствуют всем требованиям в эта секция. Некоторые из этих требований указаны в RFC. 7234, и другие специфичен для Cloud CDN.
Cloud CDN может периодически изменять точный набор условий при который кэширует содержимое.Если вы хотите явно запретить Cloud CDN от кэширования вашего контента, следуйте рекомендациям в RFC 7234, чтобы определить, как указать гарантированно некэшируемый ответ. Также некэшируемый контент на основе раздела исходных заголовков.
Текущая реализация Cloud CDN сохраняет ответы в кеше, если все следующее верно.
| Атрибут | Требование |
|---|---|
| Обслуживает | Backend service, backend bucket или настраиваемый источник с Cloud CDN включен |
| В ответ на | GET запрос |
| Код состояния | 200 , 203 , 204 , 206 , 300 , 301 , 302 , 307 , 308 , 404 , 405 , 410 , 421 , 451 или 501 |
| Директива кэширования | В режиме кеширования В режиме кеширования В режиме кэширования |
| Свежесть | В режиме кэширования В режиме кэширования С режимом кеширования |
| Содержание | Содержит действительную длину содержимого Например, заголовок |
| Размер | Меньше или равно максимальному размеру. Ответы размером от 10 МБ до 5 ТБ см. В дополнительном ограничения кэшируемости, описанные в запросы диапазона байтов. |
Для серверных сегментов облачного хранилища следующие способы удовлетворить эти требования:
Сделайте вашу корзину общедоступной.Это подход, который мы рекомендуем для общедоступного контента. С этим настройки, любой в Интернете может просматривать и перечислять ваши объекты и их метаданные, исключая ACL. Рекомендуемая практика — посвящать конкретные ведра для общественных объектов. Для получения дополнительной информации см. Рекомендуемая архитектура корзины.
Сделайте личность общедоступные объекты. Мы не рекомендуем такой подход.
По умолчанию, когда вся корзина является общедоступной или отдельные объекты
общедоступные и отдельные объекты не указывают метаданные Cache-Control ,
Cloud Storage назначает заголовок Cache-Control: public, max-age = 3600 объект.Вы можете установить разные значения, используя Cache-Control метаданные.
Для примера, показывающего, как настроить внешний балансировщик нагрузки HTTP (S) с серверной частью ведро, см. Настройка Cloud CDN с помощью серверной части. ведро.
Примечание. Альтернативой общедоступному контенту является сохранение его приватности и вместо этого используйте подписанные URL-адреса.Максимальный размер
Cloud CDN устанавливает максимальный размер для каждого ответа. Любой ответ с тело больше максимального не кэшируется, но доставляется в клиент.
Максимальный размер зависит от того, поддерживает ли исходный сервер байт. диапазон запросов.
| Исходный сервер поддерживает запросы диапазона байтов | Исходный сервер не поддерживает запросы диапазона байтов |
|---|---|
| 5 ТБ (5,497,558,138,880 байт) | 10 МБ (10 485 760 байт) |
Почти все современные веб-серверы (включая NGINX, Apache и Varnish) поддерживают запросы диапазона байтов.
Некэшируемый контент на основе исходных заголовков
Есть проверки, блокирующие кеширование ответов.Cloud CDN может периодически менять точный набор условий, при которых он кэширует контент, поэтому, если вы хотите явно запретить Cloud CDN от кеширования вашего контента, следуйте рекомендациям стандарта (RFC 7234), чтобы определить, как указать гарантированно-некэшируемый ответ.
Текущая реализация Cloud CDN не кэширует ответ, если он не соответствует требованиям к кэшируемому контенту или, если есть из следующего верно.
| Атрибут | Требование |
|---|---|
| Обслуживает | Серверная служба или пользовательское происхождение, не имеющее Cloud CDN включен |
| Печенье | Имеет заголовок Set-Cookie |
Различный Заголовок | Имеет значение, отличное от Принять , Accept-Encoding или Origin |
| Директива реагирования | Ответ имеет заголовок Cache-Control с без магазина или частный директива (если не используется режим кеширования FORCE_CACHE_ALL , в
в этом случае заголовок Cache-Control игнорируется) |
| Директива запроса | Запрос содержит директиву Cache-Control: no-store |
| Запрос авторизации | Запрос имеет заголовок Authorization , если только
отменено ответом
Кэш-контроль. |
| Размер | Больше максимального размера |
Если Cache-Control: no-store или private присутствует, но
содержимое все еще кэшируется, это происходит по одной из следующих причин:
- Подпись URL настроена.
- Режим кеширования Cloud CDN настроен на принудительное кэширование всех ответов.
Предотвращение кеширования
Для предотвращения кэширования личной информации в Cloud CDN кеши, выполните следующие действия:
- Убедитесь, что режим кеширования Cloud CDN не установлен на
FORCE_CACHE_ALL Режим, который безусловно кэширует все ответы. - Включите заголовок
Cache-Control: privateв ответы, которые не должны хранится в кэше Cloud CDN или в Cache-Control: no-storeзаголовок в ответах, который не должен храниться ни в каком кэше, даже в веб- кеш браузера. - Не подписывать URL-адреса, которые предоставляют доступ к частным
Информация. Когда доступ к контенту осуществляется с помощью подписанного URL-адреса, он потенциально
подходит для кэширования независимо от директив
Cache-Controlв отклик. - Для запросов источника (заполнения кеша), которые включают запрос авторизации
необходимо повторно проверить директивы управления кешемилиs-maxage, когда режим кеширования установлено значениеUSE_ORIGIN_HEADERSилиCACHE_ALL_STATIC.Это предотвращает случайное кэширование пользовательского контента и / или контента, который требует аутентификация. Режим кешированияFORCE_CACHE_ALLне имеет этого ограничение.
С помощью настраиваемых заголовков ответов вы можете указать заголовки, которые внешний балансировщик нагрузки HTTP (S) добавляет к проксируемым ответам. Пользовательские заголовки ответов позволяют отразить кеш статус для ваших клиентов, географические данные клиентов и ваш собственный статический ответ заголовки.
Список заголовков см. В разделе «Переменные, которые могут отображаться в заголовке». значение.
Инструкции см. В разделе Работа с настраиваемым ответом. заголовки.
Ключи кэша
Каждая запись в кэше Cloud CDN идентифицируется кешем ключ . Когда запрос поступает в кеш, кеш преобразует URI запрос в ключ кеша, а затем сравнивает его с ключами кэшированных записей. Если он находит совпадение, кеш возвращает объект, связанный с этим ключом.
Для серверных сервисов Cloud CDN
по умолчанию в качестве ключа кеша используется полный URI запроса.Например, https://example.com/images/cat.jpg — это полный URI для определенного
запрос на объект cat.jpg . Эта строка используется как ключ кеша по умолчанию.
Только запросы с этим точным совпадением строки. Запросы на http://example.com/images/cat.jpg или https://example.com/images/cat.jpg?user=user1 не совпадают.
Вы можете изменить, какие части URI используются в ключе кеша. В то время как имя файла и путь всегда должны быть частью ключа, вы можете включать или опускать любые комбинация протокола, хоста или строки запроса при настройке ключа кеша.Использование ключей кеширования описывает, как настроить ваш ключи кеша.
| URI часть | Настройка | Примеры URL-адресов с одинаковым ключом кеша |
|---|---|---|
| Протокол | Опустить протокол из ключа кэша. |
|
| Хост | Не указывать хост в кэше кеша. |
|
| Строка запроса | Пропустить строку запроса из ключа кеша. Выборочно пропускать или включать части строки запроса. |
|
В дополнение к включению или исключению всей строки запроса вы можете использовать части строки запроса с помощью списков включения и списков исключения.
Для серверных сегментов ключ кеша состоит из URI без протокола, хоста или строки запроса.
Таким образом, для заданного сегмента серверной части следующие URI разрешаются в один и тот же кэшированный объект:
-
http://example.com/images/cat.jpg -
https://example.com/images/cat.jpg -
https://example.com/images/cat.jpg?user=user1 -
http://example.com/images/cat.jpg?user=user1 -
https://example.com/images/cat.jpg?user=user2 -
https://media.example.com/images/cat.jpg -
https://www.example.com/images/cat.jpg
Строка запроса включает список
Вы можете выборочно контролировать параметры строки запроса Cloud CDN
включается в ключи кеша.Например, если вы создаете список включения пользователь , затем https://example.com/images/cat.jpg?user=user1&color=blue создает ключ кеша https://example.com/images/cat.jpg?user=user1 , который
также соответствует https://example.com/images/cat.jpg?user=user1&color=red .
Чтобы использовать эту опцию, вы должны включить строку запроса, указать непустой список включения, а не задают список исключения.
URL с разным порядком одинаковых параметров запроса приводят к разным ключи кеша.Следующие два URL-адреса имеют разные ключи кеша, даже если они одинаковые параметры запроса:
-
https://example.com/images/cat.jpg?user=user1&color=red -
https://example.com/images/cat.jpg?color=red&user=user1
Строка запроса исключает список
Вы можете выборочно контролировать параметры строки запроса Cloud CDN
игнорирует, используя список исключений. Например, если вы создаете список исключений из пользователя ,
все параметры строки запроса , кроме пользователя , используются в ключе кеша.
С настроенным списком исключений и входом https://example.com/images/cat.jpg?user=user1&color=blue , Cloud CDN
создает ключ кеша https://example.com/images/cat.jpg?color=blue , который также
соответствует https://example.com/images/cat.jpg?user=user2&color=blue , но не https://example.com/images/cat.jpg?user=user1&color=red .
Чтобы использовать эту опцию, вы должны включить строку запроса, указать непустой список исключений, а не задают список включения.
Директивы управления кешем
директивы управления кешем HTTP влияют на поведение Cloud CDN, как описано в следующей таблице.
Н / Д означает, что директива не применима к запросу или ответу.
| Директива | Запрос | Ответ |
|---|---|---|
без магазина | Если Cloud CDN присутствует в запросе, это учитывается и не сохраняет ответ в кеше. | Ответ с Это можно изменить для каждого маршрута с помощью параметра |
без кеширования | Директива запроса no-cache игнорируется, чтобы клиенты не
потенциально инициируя или заставляя повторную валидацию в источнике. | Ответ с Это можно изменить для каждого маршрута с помощью параметра |
общественный | НЕТ | Ответ с публичной директивой При использовании кеша |
частный | НЕТ | Ответ с частной директивой Это можно изменить для каждого маршрута с помощью параметра |
max-age = секунд | Директива запроса max-age игнорируется. Кешированный ответ
возвращается, как если бы этот заголовок не был включен в запрос. | Ответ с директивой max-age кэшируется до определенного секунд . |
s-maxage = секунд | НЕТ | Ответ с директивой Если присутствуют и Ответы с этой директивой не обслуживаются устаревшими. |
min-fresh = секунд | Директива запроса min-fresh игнорируется. Кешированный ответ
возвращается, как если бы этот заголовок не был включен в запрос. | НЕТ |
max-stale = секунд | Директива запроса Cloud CDN учитывает это и возвращает устаревший кэшированный
ответ только в том случае, если устаревший ответ меньше, чем | НЕТ |
stale-while-revalidate = секунд | НЕТ | Ответ с Это поведение можно включить для всех ответов, установив |
stale-if-error = секунд | Директива запроса stale-if-error игнорируется. Кэшированный
ответ возвращается, как если бы этот заголовок не был включен в запрос. | Этот заголовок ответа не действует. Это поведение можно включить для всех ответов, установив |
необходимо перевалидировать | НЕТ | Ответ с Ответы с этой директивой не обслуживаются устаревшими. |
прокси-ревалидат | Ответ с Ответы с этой директивой не обслуживаются устаревшими. | |
неизменяемый | НЕТ | Без эффекта. Это передается клиенту в ответе. |
без преобразования | НЕТ | Cloud CDN не применяет преобразования. |
только при кэшировании | Директива запроса «только если кэшируется» игнорируется.Кэшированный
ответ возвращается, как если бы этот заголовок не был включен в запрос. | НЕТ |
Там, где это возможно, Cloud CDN старается соответствовать RFC (HTTP RFC 7234), но поддерживает оптимизацию для разгрузки кеша и минимизирует влияние, которое клиенты могут иметь процент попаданий и / или общую исходную нагрузку.
Для ответов, использующих заголовок HTTP / 1.1 Expires :
- Значение заголовка
Expiresдолжно быть действительной HTTP-датой, как определено в RFC 7231. - Значение даты в прошлом, недопустимая дата или значение
0указывает, что содержание уже истекло и требует повторной валидации. - Если в ответе присутствует заголовок
Cache-Control, Cloud CDN игнорирует заголовокExpires.
Наличие действительного, будущего заголовка Expires в ответе позволяет
ответ кэшируется и не требует указания других директив кеширования.
Протокол HTTP / 1.0 Заголовок Pragma , если он присутствует в ответе, игнорируется и
передается клиенту как есть. Клиентские запросы с этим заголовком
передаются источнику и не влияют на то, как ответ обслуживается
Облачный CDN.
Модель Vary заголовок указывает, что ответ варьируется в зависимости от клиента
заголовки запросов. Помимо URI запроса Cloud CDN учитывает Разные заголовки , которые исходные серверы включают в ответы. Например, если
в ответе указано Vary: Accept , Cloud CDN использует одну запись кеша для
запросы, которые указывают Accept: image / webp, image / *, * / *; q = 0.8 и еще один для
запросы с указанием Принять: * / * .
Стол в
Списки разделов некэшируемого содержимого
заголовки Vary , которые позволяют кэшировать контент. Другое Изменение значений заголовка предотвратить кэширование содержимого.
Режим кэширования FORCE_CACHE_ALL не , а отменяет это поведение. Модель Vary заголовки важны, чтобы избежать заражения кеша между несколькими возможными источниками
ответы сервера.Для FORCE_CACHE_ALL было бы опасно вызывать эти
ответы для кеширования.
Различные заголовки иногда используются при обслуживании сжатого содержимого.
Cloud CDN не сжимает и не распаковывает ответы, но может
обслуживать ответы, сжатые исходным сервером. Если ваш исходный сервер выбирает
следует ли обслуживать сжатый или несжатый контент в зависимости от значения Accept-Encoding Заголовок запроса , убедитесь, что в ответе указано Vary: Accept-Encoding .
Срок действия и запросы на проверку
В режиме кэширования USE_ORIGIN_HEADERS каждая запись в кэше
Срок действия кэша Cloud CDN определяется параметром Cache-Control:
s-maxage , Cache-Control: max-age и / или Срок действия истекает заголовки в соответствии с RFC 7234.
Если присутствует более одного, Cache-Control: s-maxage имеет приоритет над Cache-Control: max-age и Cache-Control: max-age имеет приоритет над Срок действия истекает .
В режиме кэширования CACHE_ALL_STATIC к исходным заголовкам обращается
по умолчанию для определения свежести. Если их нет, любой статический контент
считается свежим.
В режиме кэширования FORCE_CACHE_ALL все ответы серверной части
считается свежим.
Когда Cloud CDN получает запрос, он ищет соответствующий запись в кеше и проверяет ее возраст. Если запись в кеше существует и достаточно свежа, ответ может быть получен из кеша.Однако, если срок годности пройден, Cloud CDN пытается повторно проверить запись в кеше, связавшись с один из ваших бэкэндов. Это делается перед отправкой ответа, если вы включить службу во время устаревания, в в этом случае повторная проверка выполняется асинхронно.
Cloud CDN повторно проверяет кэшированные объекты старше 30 дней.
Это позволяет автоматически аннулировать и удалять устаревшие, созданные пользователем
кешированный контент. Когда значение max-age или s-maxage превышает 30 дней (2,592,000
секунд), Cloud CDN обрабатывает значение, как если бы оно было 2,592,000
секунд.Нижестоящие клиенты по-прежнему видят точные значения max-age и s-
maxage , даже если они превышают 30 дней.
Cloud CDN может попытаться использовать информацию из кешированного ответа заголовки для проверки записи кэша с помощью серверной части. Это случается, когда верны оба следующих утверждения:
- Ранее кэшированный ответ имеет заголовок
Last-ModifiedилиETag. - Клиентский запрос — это запрос
GET, который не содержитIf-Modified-SinceилиIf-None-Matchheader.
Cloud CDN выполняет эту проверку немного по-разному в зависимости от был ли ответ кэширован с использованием диапазона байтов запросов:
- Если ответ был кэширован с помощью запросов диапазона байтов, Cloud CDN
инициирует отдельный запрос проверки, который включает
If-Modified-Sinceи / илиIf-None-Match заголовки. - В противном случае Cloud CDN добавляет
If-Modified-Sinceи / илиIf-None-Match Заголовкисоответствуют запросу клиента и пересылают измененный запрос на бэкэнд.
Если кешированная копия все еще актуальна, серверная часть может проверить существующую
запись в кэш, отправив ответ 304 Not Modified . В этом случае серверная часть
отправляет только заголовки ответа, но не тело ответа. Облачный CDN
вставляет новые заголовки ответов в кеш, обновляет срок действия,
и передает клиенту новые заголовки и кешированное тело ответа.
Если ранее кэшированный ответ не имеет Last-Modified или ETag заголовок, Cloud CDN игнорирует запись в кеше с истекшим сроком действия и пересылает
клиентский запрос к бэкэнду без изменений.
Срок действия записи в кэше — это верхняя граница того, как долго запись в кэше остается действительной. Нет гарантии, что запись в кеше останется. в кеше до истечения срока его действия. Записи в кеше для непопулярного контента могут быть выселены, чтобы освободить место для нового контента. Независимо от указанного срока время, записи кеша, к которым нет доступа в течение 30 дней, автоматически удаляются.
Для получения дополнительной информации см. Выселение и истечение срока.
Настройки TTL и отменяют
Вы можете точно настроить поведение Cloud CDN в зависимости от того, как долго Cloud CDN ждет перед повторной проверкой содержимого.
Для получения дополнительной информации см. Использование настроек TTL и отменяет.
Поддержка запросов диапазона байтов
Ответ, удовлетворяющий следующим критериям, указывает, что источник сервер поддерживает запросы диапазона байтов:
- Код состояния:
200 OKили206 Частичное содержимое - Заголовок:
Диапазон приема: байты - Заголовок:
Content-Lengthи / илиContent-Range - Заголовок:
ETagс сильным валидатором - Заголовок:
Последнее изменение
Cloud Storage поддерживает запросы диапазона байтов для большинства объектов.Тем не мение,
Облачное хранилище не поддерживает запросы диапазона байтов для объектов с Content-Encoding: gzip метаданные, если клиентский запрос не содержит Accept-
Кодировка: заголовок gzip . Если у вас есть объекты Cloud Storage размером более
10 МБ, убедитесь, что у них нет Content-Encoding: gzip метаданные. Для получения информации о том, как редактировать метаданные объекта, см. Просмотр и
редактирование метаданных объекта.
Популярное программное обеспечение веб-сервера также поддерживает запросы диапазона байтов.Проконсультируйтесь со своим веб-сайтом документацию по серверному программному обеспечению для получения подробной информации о том, как включить поддержку. Для большего информацию о запросах диапазона байтов см. HTTP Технические характеристики.
Когда исходный сервер поддерживает запросы диапазона байтов, Cloud CDN кеш отказывается сохранить кешируемый ответ, когда он запрашивается, если выполняется одно из следующих условий:
- Тело ответа неполное, поскольку клиент запросил только часть содержание.
- Тело ответа превышает 1 МБ (1 048 576 байт).
Когда это происходит, и в противном случае ответ удовлетворял бы нормальному требования к кэшируемости, кеш записывает, что источник сервер поддерживает запросы диапазона байтов для этого ключа кеша и пересылает источник ответ сервера клиенту.
При промахе кэша кеш проверяет, известно ли, что исходный сервер поддерживает
запросы диапазона байтов. Если известно, что запросы диапазона байтов поддерживаются для
ключ кеша, кеш не пересылает клиентский запрос внешнему балансировщику нагрузки HTTP (S).Вместо этого кеш запускает собственное заполнение кеша диапазона байтов.
запросы недостающих частей контента. Если ваш исходный сервер возвращает
запрошенный диапазон байтов в ответе 206 Partial Content , кеш может
сохраните этот диапазон для будущих запросов.
Кэш хранит ответ 206 Partial Content только тогда, когда он получен в
ответ на запрос диапазона байтов, инициированный кешем. Потому что кеш
не инициирует запрос диапазона байтов, если ранее не было записано, что
исходный сервер поддерживает запросы диапазона байтов для этого ключа кеша, данного кеша
не хранит контент размером более 1 МБ до второго раза, когда
доступ к контенту.
Запрос свертывания (объединения)
Сворачивание запроса (также называемое объединением ) активно сворачивается несколько
управляемые пользователем запросы на заполнение кеша для одного и того же ключа кеша в одном источнике
запрос на граничный узел. Это может значительно снизить нагрузку на источник, и
применяется как к запросам элемента , так и к запросам (ответы получены напрямую) и чанк запросов, где
Cloud CDN использует запросы Range для получения более крупных объектов.
эффективно.
Свертывание запроса включено по умолчанию.
Свернутые запросы ведут себя следующим образом:
- Свернутые запросы регистрируют как клиентский запрос, так и (свернутый) запрос на заполнение кеша.
- Лидер свернутого сеанса используется для создания запрос на исходное заполнение.
- Запросить атрибуты, не являющиеся частью ключа кеша,
такие как
User-AgentилиAccept-Encodingзаголовок, отражают только лидер свернувшейся сессии. - Запросы, у которых нет того же ключа кеша, не могут быть свернуты.
На следующей диаграмме показано, как объединяются запросы:
Cloud CDN с включенным сворачиванием запросов (щелкните, чтобы увеличить)Для сравнения, с отключенным сворачиванием запросов или для запросов, которые не могут быть объединенных, количество исходных запросов и ответов может быть равно количество клиентов, пытающихся получить объект, который в данный момент не кэширован.
Облачная CDN без сворачивания запросов включена (нажмите, чтобы увеличить)Для всех типов запросов сворачивание включено по умолчанию.Для запроса товара типов можно отключить сворачивание. Мы рекомендуем отключить сворачивание для элемента запросы в сценариях с высокой задержкой, например при показе рекламы, если источник нагрузка не рассматривается.
В следующей таблице обобщены поведение и возможности настройки по умолчанию для разные типы запросов.
| Тип запроса | Поведение по умолчанию | настраиваемый | Преимущества сворачивания |
|---|---|---|---|
| Запросы фрагментов | Включено | № | Может значительно снизить исходную полосу пропускания |
| Запросы о товаре | Включено | Есть | Может уменьшить объем запросов на отправку |
Для отключить сворачивание запроса элемента с помощью Cloud SDK для серверной корзины ссылающийся на сегмент Cloud Storage:
Примечание: добавлена поддержка Cloud SDK для флага --request-coalescing .
в Cloud SDK версии 330.0.0.gcloud
Используйте gcloud compute backend-services или backend-buckets Команда :
gcloud compute backend-services update BACKEND_SERVICE_NAME \
--no-request-coalescing
Чтобы включить сворачивание запроса элемента в серверной корзине с помощью Cloud SDK:
gcloud
Используйте команду gcloud compute backend-buckets :
gcloud compute backend-buckets update BACKEND_BUCKET_NAME \
--request-coalescing
Чтобы включить сворачивание запроса элемента с помощью Cloud SDK для серверной службы, включая группы виртуальных машин и настраиваемые источники:
gcloud
Используйте команду gcloud compute backend-services :
gcloud compute backend-services update BACKEND_SERVICE_NAME \
--request-coalescing
Запросы, инициированные Cloud CDN
Если исходный сервер поддерживает запросы диапазона байтов, Cloud CDN может отправлять несколько запросов на ваш исходный сервер в ответ на один запрос клиента.Cloud CDN может инициировать два типа запросы: запросы проверки и запросы диапазона байтов.
Если ответ, указывающий, что исходный сервер поддерживает запросы диапазона байтов
для определенного ключа кеша истек срок действия, Cloud CDN инициирует
запрос на проверку, чтобы подтвердить, что контент не изменился и что ваш
исходный сервер по-прежнему поддерживает запросы диапазона для содержимого. Если ваше происхождение
сервер отвечает ответом 304 Not Modified , Cloud CDN
переходит к обслуживанию содержимого, используя диапазоны байтов.Иначе,
Cloud CDN перенаправляет ответ вашего исходного сервера на
клиент. Вы контролируете время истечения срока действия с помощью Cache-Control и Expires .
заголовки ответов.
При промахе кеша Cloud CDN инициирует запросы на заполнение кеша для набор диапазонов байтов, которые перекрывают клиентский запрос. Если некоторые диапазоны контент, запрошенный клиентом, присутствует в кеше, Cloud CDN обслуживает все, что может, из кеша и отправляет байт диапазон запрашивает только отсутствующие диапазоны на ваш исходный сервер.
Каждый запрос диапазона байтов, инициированный Cloud CDN, указывает диапазон который начинается со смещения, кратного 2 097 136 байтам. С возможным За исключением последнего диапазона, каждый диапазон также составляет 2 097 136 байт. Если содержание не кратно этому размеру, окончательный диапазон меньше. В размер и смещения, используемые в запросах диапазона байтов, могут измениться в будущем.
В качестве примера рассмотрим запрос клиента на байты от 1 000 000 до 3 999 999. содержимого, которого нет в кеше.В этом примере Cloud CDN может инициировать два запроса GET, один для первого. 2 097 136 байт содержимого и еще 2 097 136 байт для вторых. Этот приводит к заполнению кэша 4 194 272 байта, даже если клиент запросил только 3 000 000 байт.
Когда вы используете корзину Cloud Storage в качестве источника, каждый запрос GET оплачивается как отдельная операция класса B. С вас взимается плата за все запросы GET, обрабатываемые облачным хранилищем, включая любые запросы, инициированные Cloud CDN. Когда ответ обслуживается полностью из кеша Cloud CDN, запросы GET не отправляются Облачное хранилище, и вы не платите ни за какое облачное хранилище операции.
Когда Cloud CDN инициирует запрос проверки или диапазон байтов
запрос, он не включает специфичные для клиента заголовки, такие как Cookie или Пользовательский агент .
В облачном ведении журнала httpRequest.userAgent поле , Cloud-CDN-Google означает, что запрос инициирован Cloud CDN.
Обход кеша
Обход кэша позволяет запросам, содержащим определенные заголовки, обходить кеш, даже если содержимое было ранее кэшировано.
В этом разделе представлена информация об обходе кеша с заголовками HTTP,
например, Pragma и Авторизация . Эта функция полезна, когда вы хотите
убедитесь, что ваши пользователи или клиенты всегда получают последний контент
только что с исходного сервера. Возможно, вы захотите сделать это для тестирования, настройки
промежуточные каталоги или скрипты.
Если указанный заголовок совпадает, кеш обходится для всех режимов кеширования.
настройки, даже FORCE_CACHE_ALL .Обход кеша приводит к большому количеству
кеш промахивается, если указанные заголовки являются общими для многих запросов.
Прежде чем начать
Убедитесь, что Cloud CDN включен; инструкции см. Использование Cloud CDN.
При необходимости обновите до последней версии Cloud SDK:
обновление компонентов gcloud
Примечание. Убедитесь, что вы используетеgcloudSDK версии324.0.0или более поздней версии.
Настройка обхода кеша
Можно указать до пяти имен заголовков HTTP.Значения нечувствительны к регистру. Имя заголовка должно быть допустимым полем заголовка HTTP. токен. Имя заголовка не должно появляться более одного раза в списке добавленных заголовков. Для правила о допустимых именах заголовков, см. Как настраиваемые заголовки Работа.
Консоль
- В консоли Google Cloud перейдите на страницу балансировки нагрузки .
Перейти на страницу балансировки нагрузки
- Щелкните имя внешнего балансировщика нагрузки HTTP (S).
- Щелкните Редактировать Редактировать.
- В конфигурации Backend выберите backend и нажмите Edit редактировать.
- Убедитесь, что выбрано Включить облако CDN .
- В нижней части окна щелкните Дополнительные конфигурации .
- В разделе Обход кеша в заголовке запроса щелкните Добавить заголовок .
- Введите имя заголовка, например
PragmaилиAuthorization. - Нажмите Обновить .
- Нажмите Обновить еще раз.
gcloud
Для серверных сегментов используйте серверные сегменты gcloud compute
создать или
подсистемы вычислений gcloud
команда обновления
с флагом --bypass-cache-on-request-headers .
Для серверных служб используйте серверные службы gcloud compute.
создать или
серверные службы gcloud для вычислений
команда обновления
с флагом --bypass-cache-on-request-headers .
gcloud compute backend-buckets (create | update) BACKEND_BUCKET_NAME
--bypass-cache-on-request-headers = BYPASS_REQUEST_HEADER
gcloud compute backend-services (создать | обновить) BACKEND_SERVICE_NAME
--bypass-cache-on-request-headers = BYPASS_REQUEST_HEADER
Например:
gcloud compute backend-services обновить my-backend-service
--bypass-cache-on-request-headers = Прагма
--bypass-cache-on-request-headers = Авторизация
api
Для серверных сегментов используйте Метод: backendBuckets.вставлять, Метод: backendBuckets.update, или Метод: backendBuckets.patch Вызов API.
Для серверных служб используйте Метод: backendServices.insert, Метод: backendServices.update, или Метод: backendServices.patch Вызов API.
Например:
ПАТЧ https://compute.googleapis.com/compute/v1/projects/ PROJECT_ID / global / backendBuckets
Добавьте следующий фрагмент в тело запроса JSON:
"cdnPolicy": {
"bypassCacheOnRequestHeaders": [
{
"headerName": строка
}
]
}
Отключение обхода кеша
Что дальше
Как загрузить весь сайт из Google Cache?
Новая версия CMS стала более удобной и понятной для веб-мастеров со всего мира. — Полная локализация Archivarix CMS на 13 языков (английский, испанский, итальянский, немецкий, французский, португальский, польский, турецкий, японский, китайский, русский, украинский, белорусский).
— Экспорт всех текущих данных сайта в zip-архив для сохранения резервной копии или передачи на другой сайт.
— Показать и удалить поврежденные zip-архивы в инструментах импорта.
— Проверка версии PHP при установке.
— Информация по установке CMS на сервере с NGINX + PHP-FPM.
— В поиске при включенном экспертном режиме отображается дата / время страницы и ссылка на ее копию в WebArchive.
— Улучшения пользовательского интерфейса.
— Оптимизация кода.
Если вы являетесь носителем языка, на который наша CMS еще не переведена, мы приглашаем вас сделать наш продукт еще лучше. Через сервис Crowdin вы можете подать заявку и стать нашим официальным переводчиком на новые языки.
Новая версия Archivarix CMS.
— Поддержка интерфейса командной строки для развертывания веб-сайтов прямо из командной строки, импорта, настроек, статистики, очистки истории и обновления системы.
— Поддержка зашифрованных паролей password_hash (), которые можно использовать в CLI.
— Экспертный режим для включения дополнительной отладочной информации, экспериментальных инструментов и прямых ссылок на сохраненные в WebArchive снимки состояния.
— Инструменты для неработающих внутренних изображений и ссылок теперь могут возвращать список всех отсутствующих URL-адресов вместо удаления.
— Инструмент импорта показывает поврежденные / неполные zip-файлы, которые можно удалить.
— Улучшена поддержка файлов cookie, чтобы соответствовать требованиям современных браузеров.
— Параметр для выбора редактора по умолчанию для HTML-страниц (визуальный редактор или код).
— Вкладка «Изменения», отображающая различия текста, по умолчанию отключена, может быть включена в настройках.
— Вы можете вернуться к определенному изменению на вкладке «Изменения».
— Исправлен URL-адрес карты сайта XML для веб-сайтов, созданных с субдоменом www.
— Исправлено удаление временных файлов, которые были созданы в процессе установки / импорта.
— Более быстрая очистка истории.
— Удалены неиспользуемые фразы локализации.
— Переключатель языка на экране входа в систему.
— Обновлены внешние пакеты до последних версий.
— Оптимизировано использование памяти для вычисления различий текста на вкладке «Изменения».
— Улучшена поддержка старых версий расширения php-dom.
— экспериментальный инструмент для исправления размеров файлов в базе данных, если вы редактировали файлы непосредственно на сервере.
— экспериментальный и очень сырой инструмент экспорта плоской структуры.
— экспериментальная поддержка открытого ключа для будущих функций API.
Первое июньское обновление Archivarix CMS с новыми удобными функциями.
— Исправлено: раздел истории не работал, если в php не было включено расширение zip.
— Новая вкладка «История» с подробностями об изменениях при редактировании текстовых файлов.
— Инструмент редактирования .htaccess.
— Возможность очистки резервных копий до нужной точки отката.
— Раздел «Отсутствующие URL-адреса» удален из инструментов, поскольку он доступен из панели управления.
— Мониторинг и отображение свободного места на диске в панели управления.
— Улучшена проверка необходимых расширений PHP при запуске и начальной установке.
— Незначительные косметические изменения.
— Все внешние инструменты обновлены до последних версий.
Обновление, которое оценят веб-студии и те, кто использует аутсорсинг.
— Отдельный пароль для безопасного режима.
— Расширенный безопасный режим. Теперь вы можете создавать собственные правила и файлы, но без исполняемого кода.
— Переустановка сайта из CMS без необходимости вручную удалять что-либо с сервера.
— Возможность сортировки пользовательских правил.
— Улучшенный поиск и замена для очень больших сайтов.
— Дополнительные настройки для инструмента «Метатег видового экрана».
— Поддержка доменов IDN на хостинге со старой версией ICU.
— При первоначальной установке с паролем добавлена возможность выхода.
— Если при интеграции с WP будет обнаружен .htaccess, то правила Archivarix будут добавлены в его начало.
— При загрузке сайтов по серийному номеру используется CDN для увеличения скорости.
— Прочие мелкие улучшения и исправления.
— Новая панель для просмотра статистики, настроек сервера и обновлений системы.
— Возможность создавать шаблоны и удобно добавлять новые страницы на сайт.
— Интеграция с WordPress и Joomla в один клик.
— Теперь в Search & Replace дополнительная фильтрация выполняется в виде конструктора, куда можно добавить любое количество правил.
— Теперь вы можете фильтровать результаты по домену / поддоменам, дате и времени, размеру файла.
— Новый инструмент для сброса кеша в Cloudlfare или включения / отключения режима разработки.
— Новый инструмент для удаления версий в URL-адресах, например, «? Ver = 1.2.3» в css или js. Позволяет восстановить даже те страницы, которые в WebArchive выглядели криво из-за отсутствия стилей с разными версиями.
— Инструмент robots.txt позволяет сразу включать и добавлять карту сайта.
— Автоматическое и ручное создание точек отката для изменений.
— Импорт может импортировать шаблоны.
— Сохранение / Импорт настроек загрузчика содержит созданные кастомные файлы.
— Для всех действий, которые могут длиться дольше тайм-аута, отображается индикатор выполнения.
— Инструмент для добавления метатега области просмотра на все страницы сайта.
— Инструменты для удаления битых ссылок и изображений имеют возможность учитывать файлы на сервере.
— Новый инструмент для исправления неправильных ссылок urlencode в html-коде. Редко, но может пригодиться.
— Улучшен инструмент отсутствующих URL-адресов. Вместе с новым загрузчиком теперь подсчитывает обращения к несуществующим URL.
— Советы по регулярным выражениям в поиске и замене.
— Улучшена проверка отсутствующих расширений php.
— Обновлены все используемые js-инструменты до последних версий.
Это и многие другие косметические улучшения и оптимизации скорости.
Веб-сайт показывает ошибку 404 в кэше Google
Если вы один из тех владельцев веб-сайтов, которым трудно просматривать кешированную версию в Google, то этот пост для вас.К концу этого поста вы узнаете, как просмотреть точную дату сканирования, несмотря на то, что на вашем веб-сайте появляются ошибки 404 в веб-кеше Google.
Прежде чем перейти к обещанному решению, давайте рассмотрим некоторые вопросы, найденные в различных новостях, на форумах и в списках форумов, с широким диапазоном мыслей и аргументов.
- Ошибка 404 кэша Google будет влиять на ваш рейтинг поиска или нет.
- Как исправить ошибку 404 кеша Google.
- Как решить ошибку 404 кеша Google.
- Я получаю ошибку 404 при проверке кеширования старых веб-сайтов.
- Мой веб-сайт не показывает «опцию кеширования» в результатах поиска.
- Мой сайт не отображается в поиске Google, но мои результаты были очень хорошими для поиска по определенному ключевому слову.
- Что мне делать, чтобы мой сайт вернулся на первое место в Google?
Прежде чем продолжить, хотим вас заверить, ребята —
Это может случиться.
И кеш Google 404 — это проблема Google, а не вашего сайта! Вы, должно быть, заметили, что эти ошибки не появляются в Yahoo или Bing.Это только в Google. И это не повлияет на ваш рейтинг в поисковых системах.
Согласно недавнему обсуждению с Reddit, Джон Мюллер из Google сказал: «если ваша ссылка на кеш в Google возвращает ошибку 404, это не означает, что ваш рейтинг в Google будет поврежден». Кроме того, он поясняет, что поиск 404-й ошибки в Google Cache является внутренней проблемой сервера Google Cache и не влияет на индексацию или ранжирование веб-страницы.
И, с точки зрения Google, отсутствие ссылки кеша не является фактором низкого качества или фактором ранжирования.
Все еще есть сомнения!
Позвольте нам помочь вам увидеть точные данные кеша независимо от того, возникает ли у вас ошибка кеширования 404 для вашего веб-сайта. Выполните следующие действия:
Мы также получаем ошибку кеширования Google 404, и мы искали метод, чтобы узнать, действительно ли это ухудшает наш рейтинг или страницы нашего сайта деиндексируются из базы данных Google. Мы провели исследование и обнаружили, что эти ошибки не имеют ничего общего с индексированием или рейтингом ключевых слов; это просто проблема с кеширующим сервером Google.И мы нашли способ узнать дату последнего кеширования и версию наших страниц.
Так что держитесь крепче и следуйте этим простым шагам.
Шаг 1
В поиске Google.com
Шаг 2
Мы искали
Шаг 3
Перейдите к URL / URL, для которых вы хотите увидеть последнюю версию сканирования и дату
Шаг 4
Мы проверяем дату и версию последнего сканирования для одного из URL-адресов нашего веб-сайта —
Шаг 5
Выберите раскрывающийся список рядом с URL-адресом — см. Пример ниже
Step 6
Вы получите этот URL, внимательно проверьте эту ошибку —
Шаг 7
Теперь найдите <«J:»>
Шаг 8
Удалить коды / фразы после <«J:»>
Шаг 9
И добавьте к нему
Шаг 10
Конечный URL будет примерно таким —
Step 11
А вот детали, которые вы искали
Надеюсь, он решит некоторые из ваших вопросов.
Если вам понравились наши выводы, поделитесь своими мыслями в комментариях ниже и поделитесь с друзьями, которые все еще сомневаются и находят решение, как исправить ошибки 404 кеша.
Как окупить Google Cache в вашем генеалогическом исследовании
Что вы делаете, когда вы что-то гуглите, нажимаете на URL-адрес результата поиска, и он говорит «страница не найдена» или «ошибка?» Дебби недавно нашла ответ в своей новой копии недавно отредактированного и обновленного The Genealog’s Google Toolbox (2-е издание).
Она написала нам: «Я заказала свою книгу на прошлой неделе и сегодня нашла ее в своем почтовом ящике! Я тут же пролистал его, прочитал заголовки и посмотрел на картинки.Мне нравится, как он читается… не «по учебникам», а более приятным и более таким, как если бы кто-то только что со мной разговаривал. Не могу дождаться, чтобы попробовать все советы и посмотреть, что я могу открыть! Фактически, я уже обнаружил то, чего не знал… поиск t в кеше, когда вы получаете страницу с надписью «не найден» или «ошибка». Если бы я только мог вспомнить все случаи, когда видел это. Большое спасибо! Я очень рада, что добавила эту книгу в свою маленькую генеалогическую библиотеку! »
Google Cache: вот как это работает
Как вы знаете, Google «сканирует» Интернет, постоянно индексируя веб-сайты.Он также делает снимок каждой просматриваемой страницы и кэширует или сохраняет изображение в качестве резервной копии. Это скрытая информация, которую Google использует, чтобы определить, соответствует ли страница вашим поисковым запросам.
В случае веб-сайта, который больше не существует, копия кэша предоставляет моментальный снимок веб-сайта, когда он был еще активен. Практически каждый результат поиска включает ссылку Cached .
Как получить кэшированную веб-страницу:
- Когда вы попадаете на страницу с ошибкой «Обнаружена заметка о файле», нажмите кнопку «Назад» в браузере, чтобы вернуться на страницу результатов поиска Google.
- Прямо под заголовком сайта находится его URL. Щелкните маленькую стрелку вниз рядом с этим адресом.
- «Кэшировано» будет одним из вариантов, представленных во всплывающем меню. Щелкнув ссылку Cached , вы перейдете к кэшированной Google версии этой веб-страницы, а не к текущей версии страницы.
Кэшированные версии веб-сайтов также могут быть полезны, если исходная веб-страница недоступна, потому что:
- перегрузки интернета;
- веб-сайт не работает, перегружен или просто работает медленно.Поскольку серверы Google обычно работают быстрее, чем многие веб-серверы, часто вы можете получить доступ к кэшированной версии страницы быстрее, чем сама страница; и
- владелец веб-сайта недавно удалил страницу из Интернета.
Если Google возвращает ссылку на страницу, которая, кажется, не имеет ничего общего с вашим запросом, или если вы не можете найти информацию, которую ищете на текущей версии страницы, взгляните на кешированную версию, щелкнув закешированная ссылка. После этого вы увидите веб-страницу в том виде, в котором она выглядела, когда Google в последний раз проиндексировал ее.
Вы заметите, что вверху страницы появится серый заголовок. Это предоставит вам следующую информацию о кэшированной странице, которую вы просматриваете:
- Исходный веб-адрес страницы.
- Дата и время, когда просматриваемая страница была кэширована.
- Ссылка на текущую версию этой страницы.
Если вы не видите кешированную ссылку в результатах поиска, возможно, она была пропущена, потому что владелец веб-сайта попросил Google удалить кешированную версию или попросил Google не кэшировать их содержание.Кроме того, все сайты, которые Google еще не проиндексировали, не будут иметь кешированной версии.
Имейте в виду, что если исходная страница содержит более 101 килобайт текста, кешированная версия страницы будет состоять только из первых 101 килобайт (120 килобайт для файлов PDF).
Хотите узнать больше о кешировании?
ВИДЕО: Кэширование HTTP