10 инструментов, которые помогут найти удалённую страницу или сайт
Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google

Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
Есть и альтернативный способ. Введите в браузерную строку следующий URL:
Сайт Google →
2. Кеш «Яндекса»

Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
Сайт «Яндекса» →
3. Кеш Bing

В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
Сайт Bing →
4. Кеш Yahoo

Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Сайт Yahoo →
Сейчас читают 🔥
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
")
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
Сайт Wayback Machine →
2. Arhive.Today

Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
Сайт Arhive.Today →
3. WebCite

Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Сайт WebCite →
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView

Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
Сайт CachedView →
2. CachedPage

Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
Сайт CachedPage →
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.


Разработчик: Разработчик
Цена: Бесплатно
Читайте также 💻🔎🕸
Как искать информацию в веб-кэше Google (Инструкция)
Полезная ссылка: «Какая кредитная карта — лучшая в 2020 году?У самого значимого в мире поисковика «все ходы записаны» — информация, попавшая в поле зрения поисковых роботов Google, раз и навсегда сохраняется в виде сохранённой копии. Эта копия иногда очень нужна веб-журналистам — чтобы получить важные, но уже удалённые сведения. Но как получить к ним доступ? Как осуществлять поиск по кэшу Google?
Сохраненная копия
Если вы ищете что-то через Google, то найти сохраненную копию можно и через обычный интерфейс поисковика. Нажмите на зелёный треугольничек справа от ссылки на сайт, затем — на надпись «Сохраненная копия». Нажмите на неё — и посмотрите резервную копию имеющейся информации, которая попала в цепкие лапы «гугла».
Поиск через адресную строку
Есть два способа:
Способ №1
Введите в адресную строку своего веб-браузера (Ghrome, Safari, Mozilla, Internet Explorer, Opera и т.д.) следующую информацию:
http://webcache.googleusercontent.com/search?q=cache:http://polezner.ru Вместо polezner.ru подставьте нужный вам сайт.
При желании можно посмотреть версию страницы без графики (только текст, своего рода режим Readability). Для этого достаточно нажать на «Текстовая версия» в правом верхнем углу экрана.
Способ №2
В браузере перед адресом страницы допишите слово «cache: ». В результате вместо самой страницы откроется её копия в кэше Google. Например:
Важно: Google в вашем браузере должен быть поиском по умолчанию. Если у вас не так — вводите «cache: » и адрес страницы в поисковой строке на google.com.
20+ полезных команд для продвинутого поиска в Google
Вот и всё! Теперь вы можете искать в веб-кэше Google всё, что захотите — и когда захотите.
P.S. Хотите, чтобы запрос на кэш Google всегда был под рукой? Добавьте эту страницу в закладки. Как это сделать быстро и эффективно? Для Мас работает сочетание клавиш Cmd + D, для Windows — Ctrl + D.
Читайте также:
Больше полезных новостей — на главной странице блога!Google Cache Browser — просмотр кэша без мучений / Хабр
Бывает так, что нужно походить по страницам сайта, который внезапно лёг или вовсе закрылся, и испокон веков нас здесь выручает Google с его поисковым кэшем. Одна беда — «походить» в этом случае превращается в сплошное мучение: посмотреть страницу, скопировать адрес ссылки, по которой хочется пройти, вставить в поисковую строку и добавить префикс «cache:». Многовато действий ради одного перехода по ссылке. Вот ссылка на решение этой проблемы для нетерпеливых: GCB 2.0.Google Cache Browser 1.0 и его проблемы
Несколько лет назад я уже пытался решить эту проблему, и даже создал небольшой сервис Google Cache Browser, который работал по принципу прокси: скачивал страничку кэша, подменял в ней все ссылки так, чтобы они снова вели на сам сервис, и в таком виде отдавал в браузер пользователю. Однако, он обладал несколькими существенными недостатками:
- Он порядочно расходовал трафик.
- Регулярно попадал в бан гугла.
- В меньшей степени, но все равно заметно грузил процессор (применять регулярные выражения к большим страницам — неблагодарное занятие).
- Несмотря на все мои ухищрения, он подменял не все ссылки. На некоторых сайтах они были оформлены так, что диву даешься. О валидности этого HTML и речи не шло.
В результате сервис постепенно заглох и однажды я просто не стал продлять домен.
Google Cache Browser 2.0 и JS-фу
Основной проблемой было то, что для моих целей нужно было запускать мой JavaScript в контексте домена webcache.googleusercontent.com, и примерно неделю назад я заметил, что кэшированные страницы по-прежнему грузят и выполняют свои джаваскрипты, при чем не их кэшированные версии, а актуальные версии с сайта. С этого момента осталось только загнать в кэш гугла подходящую страницу с подключённым JS и начать работать в контексте домена гугла.
Все это довольно удачно совпало по времени с SOPA и временным отключением хороших сайтов вроде Википедии, поэтому вчера вечером я таки взялся и довел сервис до ума: теперь он функционирует полностью в браузере (ни единого серверного скрипта), в последних версиях Firefox, Chrome, Opera и в IE8. Проверять в других браузерах у меня времени не хватило, так что шлите баг-репорты! 🙂
И, да, последняя плюшка: все исходники сервиса я опубликовал на GitHub, на условиях GPLv3. Feel free to fork!
Итоги
Человечество осчастливлено возможностью худо-бедно читать Википедию в течение сегодняшнего дня, а я получил массу удовольствия от применения уже подзабытого JS-фу, поскольку на работе я большую часть времени занимаюсь серверной стороной.
ToDo
- Сделать букмарклет для сервиса. При том, букмарклет будет уметь как перекидывать на кэшированную версию страницы, так и довешивать функционал на страницу из кэша, если она уже была открыта.
- Побороть некоторые спонтанные глюки с вёрсткой.
- Подстраховаться от выпадания страницы-точки входа из индекса.
- Более тщательно протестировать кросс-браузерность.
- Возможно, перенести сервис на отдельный, более благовидный домен.
Кстати, вы вполне можете приложить к этому руку — исходники-то лежат на ГитХабе 😉
Достаём потерянные статьи из сетевых хранилищ / Хабр
Решение рассматривается (пока) только для одного сайта — того, на котором мы находимся. Идея появилась в результате того, что один пользователь сделал юзерскрипт, который переадресует страницу на кеш Гугла, если вместо статьи видим «Доступ к публикации закрыт». Понятно, что это решение будет работать лишь частично, но полного решения пока не существует. Можно повысить вероятность нахождения копии выбором результата из нескольких сервисов. Этим стал заниматься скрипт HabrAjax (наряду с 3 десятками других функций). Теперь (с версии 0.859), если пользователь увидел полупустую страницу, с которой можно перейти лишь на главную, в личную страницу автора (если повезёт) и назад, юзерскрипт предоставляет несколько альтернативных ссылок, в которых можно попытаться найти потерю. И тут начинается самое интересное, потому что ни один сервис не заточен на качественное архивирование одного сайта.Кстати, статья и исследования порождены интересным опросом А вас раздражает постоянное «Доступ к публикации закрыт»? и скриптом пользователя dotneter — комментарий habrahabr.ru/post/146070/#comment_4914947.
Требуется, конечно, более качественный сервис, поэтому, кроме описания нынешней скромной функциональности (вероятность найти в Гугл-кеше и на нескольких сайтах-копировщиках), поднимем в статье краудсорсинговые вопросы — чтобы «всем миром» задачу порешать и прийти к качественному решению, тем более, что решение видится близким для тех, кто имеет сервис копирования контента. Но давайте обо всём по порядку, рассмотрим все предложенные на данный момент решения.
Кеш Гугла
В отличие от кеша Яндекса, к нему имеется прямой доступ по ссылке, не надо просить пользователя «затем нажать кнопку „копия“». Однако, все кеширователи, как и известный archive.org, имеют ряд ненужных особенностей.
1) они просто не успевают мгновенно и многократно копировать появившиеся ссылки. Хотя надо отдать должное, что к популярным сайтам обращение у них частое, и за 2 и более часов они кешируют новые страницы. Каждый в своё время.
2) далее, возникает такая смешная особенность, что они могут чуть позже закешировать пустую страницу, говорящую о том, что «доступ закрыт».
3) поэтому результат кеширования — как повезёт. Можно обойти все такие кеширующие ссылки, если очень надо, но и оттуда информацию стоит скопировать себе, потому что вскоре может пропасть или замениться «более актуальной» бессмысленной копией пустой страницы.
Кеш archive.org
Он работает на весь интернет с мощностями, меньшими, чем у поисковиков, поэтому обходит страницы какого-то далёкого русскоязычного сайта редко. Частоту можно увидеть здесь: wayback.archive.org/web/20120801000000*/http://habrahabr.ru
Да и цель сайта — запечатлеть фрагменты истории веба, а не все события на каждом сайте. Поэтому мы редко будем попадать на полезную информацию.
Кеш Яндекса
Нет прямой ссылки, поэтому нужно просить (самое простое) пользователя нажать на ссылку «копия» на странице поиска, на которой будет одна эта статья (если её Яндекс вообще успел увидеть).
Как показывает опыт, статья, повисевшая пару часов и закрытая автором, довольно успешно сохраняется в кешах поисковиков. Впоследствии, скорее всего, довольно быстро заменится на пустую. Всё это, конечно, не устроит пользователей веба, который по определению должен хранить попавшую в него информацию.
Yahoo Pipes
pipes.yahoo.com/pipes/search?q=habrahabr+full&x=0&y=0 и прочие.
Довольно интересное решение. Те, кто умеет их настраивать, возможно, полноценно решат задачу архивирования RSS. Из имеющегося, я не нашёл пайпов с поиском статьи по её номеру, поэтому пока нет прямой ссылки на такие сохранённые полные статьи. (Кто умеет с ним работать — прошу изготовить такую ссылку для скрипта.)
Многочисленные клонировщики
Все из них болеют тем, что не дают ссылки на статью по её номеру, не приводят полный текст статьи, а некоторые вообще ограничиваются «захабренным» или «настолько ленивы», что копируют редко (к примеру, раз в день), что актуально не всегда. Однако, если хотя бы один автор копировщика подкрутит движок на сохранение полноценного и актуального контента, он окажет неоценимую услугу интернету, и его сервис займёт главное место в скрипте HabrAjax.
Из живых я нашёл пока что 4, некоторые давно существовавшие (itgator) на данный момент не работали. В общем, пока что они почти бесполезны, потому что заставляют искать статью по названию или ключевым словам, а не по адресу, по которому пользователь пришёл на закрытую страницу (а по словам отлично ищет Яндекс и не только по одному их сайту). Приведены в скрипте для какой-нибудь полезной информации.
Задача
Перед сообществом стоит задача, не утруждая организаторов сайта, довести продукт до качественного, не теряющего информацию ресурса. Для этого, как правильно заметили в комментариях к опросу, нужен архиватор актуальных полноценных статей (и комментариев к ним заодно).
В настоящее время неполное решение её, как описано выше, выглядит так:
Если искать в Яндексе, то подобранный адрес выведет единственную ссылку (или ничего):
Нажав ссылку «копия», увидим (если повезёт) сохранённую копию (страница выбрана исключительно для актуального на данный момент примера):
В Гугле несколько проще — сразу попадаем на копию, если тоже повезёт, и Гугл успел сохранить именно то, что нам надо, а не дубль отсутствующей страницы.
Забавно, что скрипт теперь предлагает «выбор альтернативных сервисов» и в этом случае («профилактические работы»):
Жду предложений по добавлению сервисов и копировщиков (или хотя бы проектов) (для неавторизованных — на почту spmbt0 на известном гуглоресурсе, далее выберем удобный формат).
UPD 23:00: опытным путём для mail.ru было выяснено строение прямой ссылки на кеш:
'http://hl.mailru.su/gcached?q=cache:'+ window.location
Добавил ссылки мейла и ВК в обновление скрипта (habrAjax) (0.861), теперь там — на 2 строчки больше.
Google Global Cache — для избранных / Хабр
Одна из характеристик Google — предоставление качественный сервисов, бесплатно и с выгодой для себя.Google Global Cache (GGC) — одно из решений по оптимизации огромных объемов своего трафика на базе платформы CDN, да еще и с пользой для пользователей (читай провайдеров).
Но что же все-таки это такое?
Взрыв широкополосного доступа и богатый мультимедийный контент постоянно увеличивает спрос от провайдеров Интернета (ISP). GGC позволяет предоставлять Google контент, в первую очередь видео, из собственной сети (провайдера). Это облегчает нагрузки на сеть и снижает затраты на транзитные линки, тем самым экономя деньги провайдеров, в то же время повышая уровень обслуживания пользователей.
Проект GGC находятся на стадии бета, поэтому соглашение с провайдером является коммерческой тайной, и запрещено использовать упоминания об этой услуги в своих целях.
Обзор системы
Без GGC, каждый запрос пользователя из сети провайдера на видео YouTube, Google Apps, etc. создает транзит этого экземпляра видео по сети, от Google к пользователю.
С GGC, только первая копия видео проходит транзит по всей сети. Если другой пользователь запрашивает то же видео, Google обслуживает его из узла GGC.
Особенности GGC
— сокращение трафика через сети: процент запросов через cache варьирует в зависимости от схемы использования пользователей, но типичная производительность близка к 75%,
— быстрый ответ, прозрачный для пользователей: Google прозрачно обслуживает пользователей запросы из кэша внутри сети,
— простота установки: для установки требуется rack (шкаф), ноутбук, копия CD от Google, а также подключение к Интернету. После того как сервера были настроены и доступны из сети, Google будет делать всю остальную работу и мониторить удаленно,
— надежность: узел имеет несколько уровней избыточности. Если узел GGC недоступен по любой причине, запросы пользователей будут отправлены прозрачно для Google.
Как GGC работает
Когда пользователь запрашивает части содержания — например, видео, веб-страницы или изображения — системы Google определяют, если этот ресурс может быть предоставлен из узла GGC внутри сети, и если пользователь имеет право доступа к узлу GGC.
Если узел GGC уже имеет закэшированую версию запрашиваемого контента в своем локальном кэше, он будет предоставлять контент непосредственно конечному потребителю, улучшая работу пользователей и экономя деньги за Интернет транзит.
Если содержимое не хранится на узле GGC, узел скачивает их из Google, предоставляет его пользователю, и хранит его для будущих запросов.
Диаграмма запросов
1. Пользователь запрашивает по ссылке видео или другой контент размещенный на Google. Компьютер генерирует запрос DNS для адреса хоста.
2. DNS провайдера запрашивает DNS Google на адрес IP хоста с содержанием.
3. DNS Google знает, что у вас есть GGC, так что ответы содержат IP адреса GGC узла провайдера.
Это известно, потому что провайдер анонсировал IP адреса DNS резолвера узлу GGC (через BGP) и Google обновил информацию в свой DNS.
4. DNS провайдера отвечает IP-адрес GGC узла пользователю.
5. Компьютер пользователя отправляет запрос на IP адрес который маршрутизируется на GGC узел.
6. Узел подтверждает, что пользователь имеет доступ к этому узлу (делается путем сопоставления IP-адресa пользователя в список блоков IP анонсированных через узел BGP.) Если адрес не является в списке, пользователь перенаправляется на кэш в сети Google.
7. Если контент не содержится на узле GGC, узел запрашивает контент из Google и кэширует его.
8. После того как узел GGC содержит контент, отдает его пользователю. Контент содержится на узле, так что следующий запрос может быть отдан без запроса к Google.
Предоставляемое оборудование от Google
Google предоставляет необходимое оборудование, провайдер должен обеспечить размещение с своем помещении, питание от электросети и подключение к Интернету.
GGC работает на стоечных серверах (rack mountable), по 3-8 в каждом кластере.
Характеристики серверов
• 2 RU Rack-mountable chassis
• 74см Д x 44см Щ x 8.64см В
• Вес: 28 КГ
• Блок питания: 2x 110/220 VAC.
• 4 x 1000Base-T copper Gigabit Ethernet
• IP адресация: выделенная подсеть (один широковещательный домен).
Возможные конфигурации:
3 сервера — 6RU 1200W
4 сервера — 8RU 1600W
6 сервера — 12RU 2400W
8 сервера — 16RU 3200W
Администрирование
Используется сайт ggcadmin.google.com, для конфигурации узла и информации о доставке. Первоначальный пользователь получает доступ к порталу от группы GGC.
После принятия бета-соглашения, пользователь может пригласить дополнительных пользователей.
Остальные детали
— Google сохраняет право собственности на оборудование и программное обеспечение, из которого составлен узел. Google будет отвечать за техническое обслуживание, поддержку и транспортные расходы, связанные с серверным оборудованием,
— По уверениям Google, конфиденциальность пользователей имеет первостепенное значение.
Личная информация (Personally Identifiable Information) или частный контет пользователей не сохраняется на узле GGC,
— Google сохраняет право требовать от провайдеров заверений о неразглашении использования услуги, так как проект находится в стадии бета.
Почему для избранных спросите вы?
Дело в том что Google обычно предлагает сам такие услуги только тем провайдерам, которые присутствуют в крупнейших точках обмена трафиком и если трафик на ресурсоемкие услуги Google (youtube, maps) составляют значительный процент от трафика (>70%).
Ссылки по теме:
Google @ Peering DB
Региональное кеширование от Google и реакция на него СМИ
Вот пример
Как посмотреть кэш гугла и Google Cache Browser
Как посмотреть кеш гугла отдельной страницы:
Если вам нужно посмотреть предыдущее состояние сайта или какой-либо странички (например страничка удалилась, или на ней исчезла какая-либо информация), то вам в этом поможет кеш google.
В каких случаях может пригодится кэш гугла:
- страницу или сайт удалили
- на странице изменилась или пропала информация
- сайт слишком перегружен, под ддос-атакой или проводятся какие-либо регламентные работы
- интересно узнать когда в последний раз поисковик индексировал страницу
Посмотреть кэш гугла очень легко:
Если у вас браузер chrome, то просто добавьте перед адресом страницы слово «cache:», пример для этой страницы: «cache:elims.org.ua/blog/android-podborka-interesnyx-prilozhenij/». Если у вас другой браузер, то делаем следующее:
- Введите в гугле интересующий запрос — название сайта, статьи или просто адрес странички которую хотите посмотреть в кеше гугла.

- Нажмите напротив нужной ссылки на маленький треугольник смотрящий вниз
- Нажмите на «Сохраненная копия»
- Ниже на рисунке показан пример страницы из кеша гугла. Как видите на сером фоне указана информация о адресе закешированной версии страницы и точно время до секунды когда эта страница была внесена в кэш.

Если вы наблюдательны, то можете заметить что страница внесена в кеш была 21-го октября, а дата поста за 22-е октября. Это из-за разницы времени между поясами в которых находится гугл и сайт.
Также стоит знать что гугл заносит в кеш только текстовую информацию (как я знаю). Если картинка была физически удалена из сервера на котором она находилась, то вместо нее гугл просто покажет пустое место. В данном примере он отобразил картинку, так как она автоматом «подсосалась».
Еще один способ посмотреть кэш гугла:
Придется поработать ручками. Теперь, для того, чтоб посмотреть, страницу elims.org.ua/pritchi в кеше гугла, вам придется перед ее адресом добавить вот это:
webcache.googleusercontent.com/search?q=cache:
В результате получится вот это:
webcache.googleusercontent.com/search?q=cache:elims.org.ua/pritchi
По такому адресу вы и увидите кеш страницы elims.org.ua/pritchi. Для своих страниц делайте по аналогии.
Если же вы хотите посмотреть кеш только текстовой версии, то есть без изображений, flash и прочего, то в конец добавьте «&strip=1», на нашем примере получится:
webcache.googleusercontent.com/search?q=cache:elims.org.ua/pritchi&strip=1
В браузере Google Chrome достаточно перед адресом ввести cache:
cache:elims.org.ua/pritchi
Как посмотреть кеш гугла нескольких страничек перемещаясь по ним:
Google Cache Browser
Бывает необходимо полазить по сайту, который перестал открываться, а может и окончательно закрылся, тут конечно, как вы догадались на выручку придет кэш от Google. Но есть проблема — «лазить» по сайту в кеше очень неудобно, так как нужно посмотреть страницу в кеше, увидеть ссылку на которую вы хотите дальше перейти, скопировать ее, вставить в поиск с префиксом «cache:». Слишком много ручной работы, правда? В таких случаях нам на помощь приходит сервис с помощью которого можно легко и быстро лазить по сайту без каких-либо вышеописанных ручных действий — cache.nevkontakte.com (upd: у меня перестал работать)
Понравилось? =) Поделись с друзьями:
Опубликовано в рубрике СайтыУдаление Кэша Отдельного Сайта И Полная Очистка Истории
Для тех, кто не в курсе: браузер многое кэширует. Что это, поясню на примере: при первом посещении сайта, браузером загружаются картинки с сайта, видео, другие файлы (стили, скрипты). Все эти файлы имеют размер и чтобы при переходе со страницы на страницу не загружать одинаковые файлы, браузер сохраняет их в своей памяти (на диске компьютера) и в дальнейшем берет их от туда. Такая процедура называется кэшированием.
Иногда нужно очистить кэш сайта, например, это нужно, когда над сайтом проводятся работы и меняются статические файлы. Внесенные изменения не видны из-за того, что вы видите не реальный файл а файл из кэша браузера. Чтобы видеть реальную картину, нужно очистить кэш. В Google Chrome есть возможность очистить кэш полностью. При такой очистке удаляется кэш всех сайтов которые вы посещали. Обычно при такой очистке удаляются все данные: куки, сохраненные с сайта картинки и другие статические файлы, история посещений и прочее.
Полная очистка кэша браузера Google Chrome
Чтобы полностью очистить кэш Google Chrome нужно зайти в историю (Ctrl+H), затем нажать «очистить историю», в появившемся окне нажать «Очистить историю» (в этом же окне можно выбрать что именно очищать):
Очистка кэша отдельного сайта в Google Chrome (выборочная очистка)
Иногда нет необходимости очищать весь кэш, в нем все-таки многое сохраняется и это многое создает много удобства. Например, авторизация на некоторых сайтах, история поиска и т.д. Но при этом нужно удалить кэш отдельного сайта. Сделать это можно так:
- Откройте инструменты разработчика: Ctrl+Shift+I
- Теперь, оставив панель открытой, кликните левой кнопкой мыши на кнопку «Обновить» (рядом со строкой адреса) и не отпускайте кнопку.
- Через несколько секунд вы увидите выпадающее меню в котором будет пункт: Очистка кэша и аппаратная перезагрузка.
Чтобы перезагрузить страницу без использования файлов кэша, можно воспользоваться комбинацией клавиш Ctrl+F5 или Ctrl+Shift+R.
Удаление файлов cookies (куков) отдельной страницы
Для того, чтобы удалить куки отдельного сайта из истории:
- Наберите в адресной строке: chrome://settings/cookies;
- Введите в поле поиска часть домена сайта;
- Удалите найденные куки;
В этом же окне можно удобно удалять куки по отдельности а не все сразу:
Удаление отдельной куки отдельного сайта
Просмотр кеша всех сайтов 🗄 Cache.pw
Просмотр кеша веб-сайта
Введите URL с https: // или http: // и нажмите кнопку.
Как это работает
Когда вы вставляете URL-адрес и нажимаете любую кнопку, вы будете перенаправлены на кэшированную страницу этой страницы в службе, которую вы нажали.
Да, все просто.
Твиттер
Вконтакте
Телеграмма
Страница в кэше Google
Google Cache обычно называется копиями веб-страниц, кэшированных Google.Google сканирует Интернет и делает снимки каждой страницы в качестве резервной на случай, если текущая страница недоступна. Затем эти страницы становятся частью кеша Google. Эти кэшированные страницы Google могут быть чрезвычайно полезны, если сайт временно не работает. Вы всегда можете получить доступ к этим страницам, посетив кешированную версию Google.
Веб-сайт Google обычно обновляется в течение нескольких дней. Фактическое время обновлений зависит от частоты обновления самого веб-сайта.


Кешированная страница Яндекса
Яндекс Кэш — это копии веб-страниц, кэшированные Яндексом.Яндекс сканирует Интернет и делает снимки каждой страницы в качестве резервной на случай, если текущая страница недоступна. Затем эти страницы становятся частью кеша Яндекса. Эти кешированные страницы Яндекса могут быть чрезвычайно полезны, если сайт временно не работает. Вы всегда можете получить доступ к этой странице, посетив кешированную версию Яндекса.
Веб Яндекс обычно обновляется в течение нескольких дней. Фактическое время обновлений зависит от частоты обновления самого веб-сайта.
Archive.org Кэш
Архив.org, также известная как Wayback Machine, представляет собой цифровой архив Всемирной паутины и другой информации в Интернете, созданный некоммерческой организацией Internet Archive, расположенной в Сан-Франциско, Калифорния. Он был создан Брюстером Кале и Брюсом Гиллиатом и поддерживается контентом из Alexa Internet. Служба позволяет пользователям просматривать архивные версии веб-страниц с течением времени, что в архиве называется трехмерным индексом.

Твиттер
Вконтакте
Телеграмма
Как добавить сайт в кеш
Хочу добавить свой сайт в гугл, яндекс и архив.орг кеш?
Просто добавьте в Консоль поиска Google и Яндекс Вебмастер и ждите.
.Получить возраст кэша Google URL веб-страницы
Возможно, вы знаете, что Google хранит кеш-память веб-сайтов и страниц на регулярной основе, сохраняя их в доступном хранилище веб-кешей Google. Эти кеши могут быть чрезвычайно полезны по целому ряду причин, но особенно часто они используются, если сайт медленно загружается или страдает от временного простоя, вы, как правило, все еще можете получить доступ к соответствующей странице или сайту, перейдя в кэшированный сайт Google. версия страницы.Это связано с тем, что эта альтернативная версия хранится на серверах Google, а не на веб-серверах доменов, что делает страницу доступной независимо от того, работает ли исходный сайт или нет. Конечно, большой вопрос заключается в том, насколько актуален этот кеш, и это сводится к возрасту кеша , поскольку не слишком полезно просматривать старый кеш сайта, который слишком устарел, чтобы иметь отношение к чему-то вроде новостного сайта. Именно об этом мы и поговорим, быстро найдя возраст моментального снимка Google Web Cache для любого URL-адреса, хранящегося на их серверах.
Этот трюк работает одинаково в любом веб-браузере и в любой операционной системе. Это означает, что вы можете использовать этот совет независимо от того, используете ли вы Safari, Chrome, Firefox, Mac OS X, iOS, Android или Windows. Также нет необходимости отключать терминал и начинать опрашивать домены с помощью curl, чтобы получить информацию о заголовке, решение намного проще, чем это, и выполняется полностью через Интернет с использованием простой модификации URL.
Это несколько странно, что делает его наиболее полезным для веб-работников, веб-разработчиков и администраторов серверов.Но это также действительно полезно для читателей, которые пытаются посмотреть на сайт, который в противном случае не работает из-за загрузки или по другой причине.
Определение возраста веб-кэша Google из любого браузера
Используйте следующий формат URL:
http://webcache.googleusercontent.com/search?q=cache:URLGOESHERE
Обязательно замените «URLGOESHERE» на правильный веб-адрес страницы или сайта, чей кэш вы хотите получить, и посмотреть время. Например, чтобы проверить возраст Google Webcache OSXDaily.com, вы должны использовать следующий URL:
http://webcache.googleusercontent.com/search?q=cache:osxdaily.com
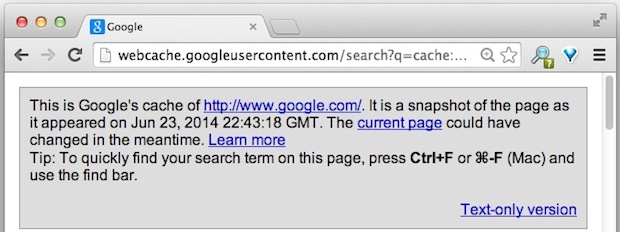
После загрузки вы сможете найти возраст кеша в самом верху URL. Большинство людей не замечают этого, потому что оно напечатано мелким шрифтом, но именно там вы найдете дату и время последнего захвата страницы службой кеширования Google:
Это кеш Google http: // (DOMAIN) /. Это снимок страницы, появившейся 24 июня 2014 г. в 07:03:32 по Гринвичу.Текущая страница за это время могла быть изменена. Узнать больше
Совет. Чтобы быстро найти поисковый запрос на этой странице, нажмите Ctrl + F или ⌘-F (Mac) и используйте панель поиска. - См. Дополнительную информацию по адресу: http://webcache.googleusercontent.com/search?q=cache:DOMAIN
Этот тип заголовка показан в верхней части этого изображения в сером поле над типичной страницей. Для тех, кто использует его, чтобы поэкспериментировать, это обычно первый div, который появляется в HTML:

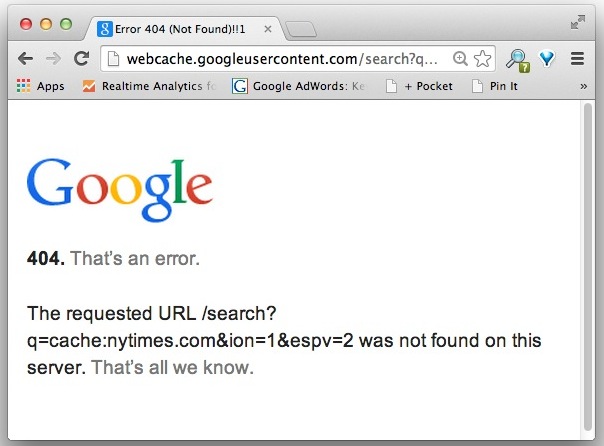
Google заботливо сохраняет такие кеши для большинства URL-адресов, но некоторые сайты либо не разрешают это, либо просто не покрываются.Например, у New York Times и NYTimes.com нет кеша, что приведет к появлению такой страницы с ошибкой:
Определение возраста кэша Google из браузера Chrome
Если вы используете Google Chrome, эта задача еще проще, потому что вы можете просто ввести следующий URL в адресную строку, чтобы получить кешированную версию:
кеш: URL-GOES-HERE
(обратите внимание, что это не cache: //, а cache: без двойной косой черты)
Например, из Chrome вы можете получить файл OSXDaily.com с такой структурой URL:
кеш: osxdaily.com
Это вызовет версию страницы веб-кеша Google (переход по тому же URL-адресу webcache.googleusercontent.com, что и в предыдущем примере), и это когда определение возраста кеша чрезвычайно просто, просто посмотрите на верхнюю часть, чтобы найти его, он скажет что-то вроде:
"Это кеш Google на https://osxdaily.com/. Это снимок страницы, которая появилась 24 июня 2014 г., 07:03:32 GMT"
Обратите внимание, что дата и время после части «снимок страницы в том виде, в котором она появилась» — это то, что вы ищете, когда был захвачен веб-кеш Googles для определенного URL.
Итак, в следующий раз, когда вы не сможете перейти на конкретный веб-сайт, но все равно захотите его проверить, версия Google Cache может быть потенциальным источником, просто не забудьте сначала проверить возраст, чтобы вы знали, актуальна она или нет. Удачного просмотра.
Связанные
.html — Как я могу узнать возраст кеша Google любого URL-адреса или веб-страницы?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
- Реклама Обратитесь к разработчикам и технологам со всего мира
- О компании
html — Где найти кешированные файлы ранее посещенных веб-страниц — Google Chrome
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- Вакансии Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
- Реклама Обратитесь к разработчикам и технологам со всего мира
- О компании