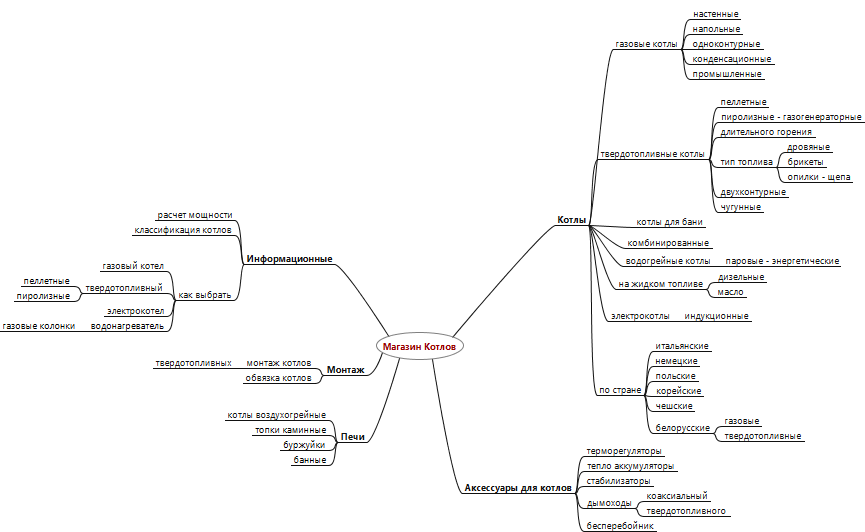
Семантическое ядро — основа продвижения вашего сайта
Перед SEO-продвижением сайта главное что вам нужно — это семантическое ядро. От того, насколько вы грамотно его соберете зависит эффективность дальнейшего продвижения.
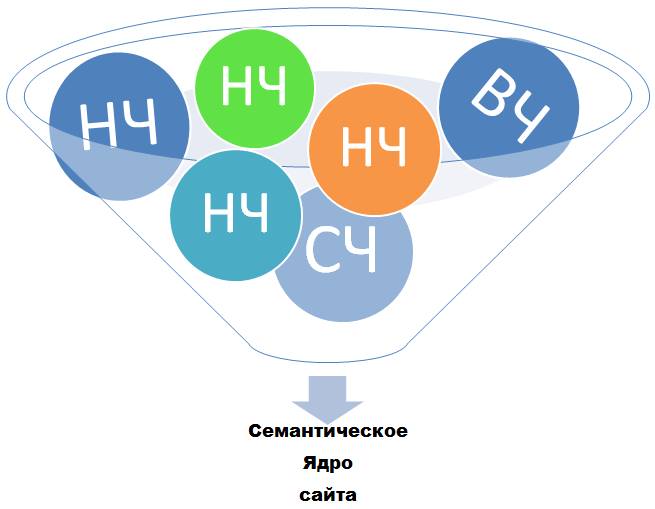
Семантическое ядро (СЯ) — это документ с списком ключевых фраз для вашего сайта, а также их параметров, таких как частотность, конкурентность, геозависимость. Данные ключевые фразы должны наиболее точно передавать суть контента вашего сайта. Для каждой ключевой фразы должна быть определена релевантная страница.
В нашей очередной публикации делимся основами сбора семантического ядра.Но сначала разберем основные источники для фраз для него.
Источники для поисковых запросов
🦄 wordstat.yandex.ru
Сервис по подбору слов от Яндекс. У каждого запроса отображается частотность, можно узнать ее изменение по месяцам на протяжении последних 2-х лет. Все, что нужно для использования, это иметь аккаунт в Яндекс и список маркерных запросов (об этом ниже в статье), знать операторы «» и!.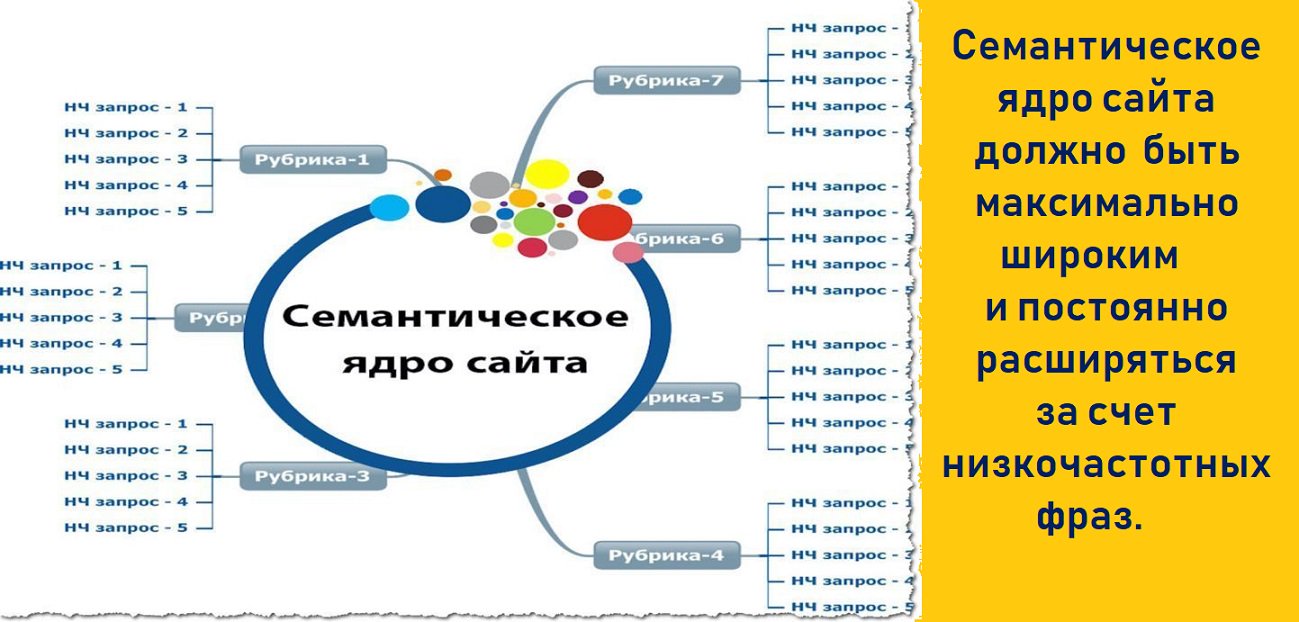
🦄 webmaster.yandex.ru
Личный кабинет для вебмастера, где фиксируются запросы, по которым не только приходят пользователи, но и по которым сайт просто показывался в поисковой выдаче. Получить эти и другие данные можно после регистрации в сервисе сайта.
🦄 metrika.yandex.ru
Сервис аналитики от Яндекс. При условии, что на вашем сайте уже установлен счетчик, здесь можно узнать поисковые запросы, по которым уже приходят пользователи. Часть из них непременно будут обозначать четкое намерение пользователей, которое необходимо вам. Остается только проанализировать их частотность.
🦄 Google Keyword planner
Планировщик ключевых слов от Google. Если предыдущие источники годны только для Яндекс, то здесь вы найдете запросы для второго популярного поисковика, т. е. для Google. Жаль только, что частотности указываются округленные, не точные.
🦄 Google Search console
Аналог webmaster.yandex.ru в Google. Все похоже: регистрируете сайт, получаете среди прочего данные о ключевых запросах, по которым совершены переходы и имеются показы.
🦄 Любой софт, сервисы которые могут парсить wordstat.yandex.ru и /google/keyword-planner/
Например, seranking.ru или key-collector.ru. В них же есть возможность собрать семантику из дополнительных источников, таких как поисковые подсказки или собственные базы ключевых запросов. Поиск ключевиков с помощью подобного софта автоматизирован, есть удобные настройки для их фильтрации от ненужных фраз, слов.
Составьте список маркерных запросов
Итак, с источниками разобрались. Переходим к процессу сбора СЯ. Для начала вам необходимо составить список так называемых маркерных запросов. Маркерные запросы — это фразы, которые в общем смысле описывают ваши услуги /товары, например, «мопеды Suzuki» или же просто «мопеды» (первый пример подойдет к категории каталога, а второй может для главной страницы, если у вас на сайте продажа исключительно мопедов). Как правило такие фразы — это ВЧ запросы в своей тематике.
Маркерные запросы вы можете определить с помощью мозгового штурма: записать все фразы, по которым пользователи ищут ваше предложение.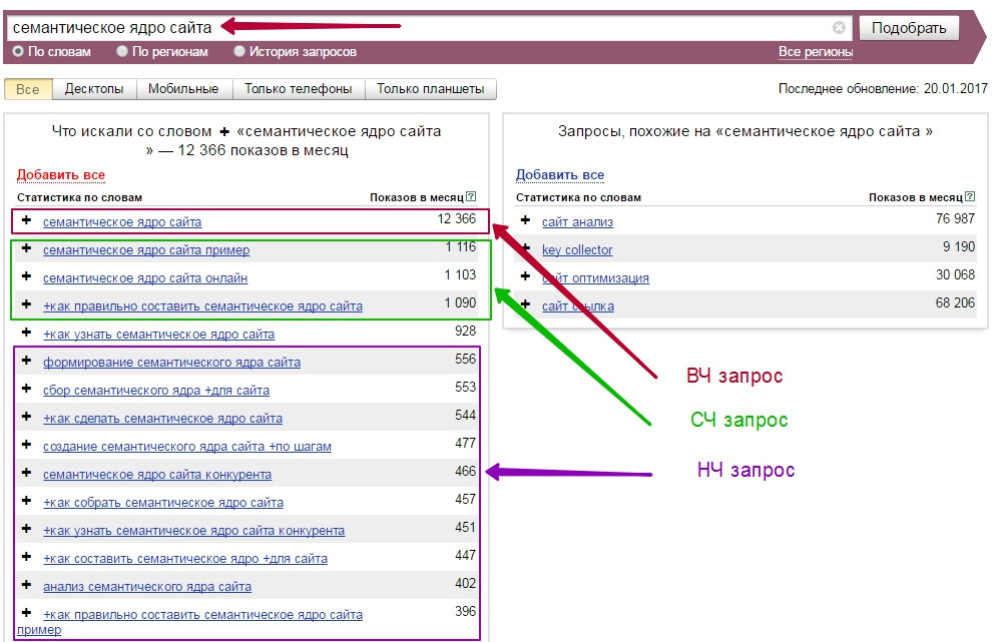 Вы также можете отыскать такие фразы в Яндекс. Вебмастер (если в нем зарегистрирован сайт), подсмотреть у конкурентов (в заголовках страниц, названиях категорий каталога). Для каждого маркерного запроса необходимо определить релевантную страницу на сайте. Далее с полученным списком обратитесь к wordstat.yandex.ru, Google keyword-planner, или любому софту, который работает с этими сервисами.
Вы также можете отыскать такие фразы в Яндекс. Вебмастер (если в нем зарегистрирован сайт), подсмотреть у конкурентов (в заголовках страниц, названиях категорий каталога). Для каждого маркерного запроса необходимо определить релевантную страницу на сайте. Далее с полученным списком обратитесь к wordstat.yandex.ru, Google keyword-planner, или любому софту, который работает с этими сервисами.
Проанализируйте фразы из вашего списка
Каждый такой маркерный запрос, как правило, имеет хвост других запросов, которые содержат дополнительные или уточняющие слова, в случае нашего примера — «мопеды Suzuki цена», «мопеды Suzuki ZZ купить». Такие фразы нам и нужны, потому что именно они являются транзакционными, т. е. они отражают намерение пользователей приобрести мопед.
Список фраз из хвоста можно получить, если вбить в wordstat.yandex.ru маркерный запрос (список будет отображаться в левой колонке) или же применив софт, который упомянут выше.
Если вас интересует только продажа определенного предложения, товара, то нужно отфильтровать полученный список от фраз, которые не отражают четкое намерение покупки пользователя, сконцентрировавшись только на коммерческих запросах. Таким образом, трафик будет целевым. Отфильтрованные фразы типа «обслуживание мопеда Suzuki ZZ» можно оставить для блога на сайте, там они пригодятся, способствуя улучшению поведенческих факторов.
Таким образом, трафик будет целевым. Отфильтрованные фразы типа «обслуживание мопеда Suzuki ZZ» можно оставить для блога на сайте, там они пригодятся, способствуя улучшению поведенческих факторов.
Каждую полученную полезную ключевую фразу из хвоста можно таким же образом снова проанализировать и получить дополнительные фразы. Для интернет-магазинов может быть важным поиск и анализ запросов с вхождением бренда и артикула товара.
Не забудьте для каждой фразы заносить в список их базовую частотность по wordstat.yandex.ru!
Соберите список похожих слов
Обратите внимание при анализе каждой ключевой фразы в wordstat.yandex.ru на правую колонку. В ней список похожих фраз, которые запрашивали пользователи. Здесь вы тоже можете подобрать подходящие ключевики.
Соберите поисковые подсказки
Поисковые подсказки из Яндекса и Google — это источник ультра НЧ запросов, которые имеют низкую конкурентность, а значит по ним легко выйти в топ.
Проанализируйте частотность полученных ключевых запросов
У вас уже получен объемный список фраз, которые, кстати, хорошо хранить в таблице Excel. Теперь нужно проверить хотя бы частотность в фразовом вхождении с помощью оператора «кавычки» в Wordstat. Удобнее это сделать автоматически с помощью софта, например seranking.ru или key-collector.ru, о которых мы уже упоминали.
Теперь нужно проверить хотя бы частотность в фразовом вхождении с помощью оператора «кавычки» в Wordstat. Удобнее это сделать автоматически с помощью софта, например seranking.ru или key-collector.ru, о которых мы уже упоминали.
Финализируйте и сгруппируйте ваши ключевые запросы
Еще раз просмотрите внимательно ваш список слов. Можно удалить запросы, которые вы вряд ли станете продвигать из-за специфики вашей деятельности, вхождения в них названий других городов или конкурентов, или слишком уж «корявой» формы фразы вида «мопед улица фонарь цена».
У вас уже есть маркерные фразы, для которых определены релевантные страницы. Также под каждую маркерную фразу вам необходимо определить группу запросов. Следует знать и то, что для эффективного продвижения сайта необходимо по одной группе запросов продвигать одну страницу. Определение релевантной страницы под определенную группу запросов называется кластеризацией и это отдельная тема для следующей публикации.
В финале вашего труда должна получится примерно такая таблица. Это лайт-версия СЯ без параметров типа геозависимость, сезонность, конкурентность.
Это лайт-версия СЯ без параметров типа геозависимость, сезонность, конкурентность.
Если у вас остались вопросы, пишите нам письма на наш замечательный адрес: [email protected].
Или звоните нам 8 (800) 200 · 69 · 20 и приезжайте в гости (это временно) 😀
Как правильно собрать семантическое ядро сайта для SEO продвижения
1,160 просмотров всего, 1 просмотров сегодня
От качества сборки семантического ядра (сокращённо СЯ) зависит то, насколько эффективно и быстро будет расти сайт в поисковой выдаче. В этой статье мы дадим определение семантике, рассмотрим принципы её работы и кратко расскажем о том, как она собирается.
Определение
Семантическое ядро — это упорядоченный набор слов и их морфологических форм, которые точно характеризуют содержание сайта. После его сборки мы получаем обычный файл-список. В нём содержатся ключевые запросы, основываясь на которые в дальнейшем заполняют страницы.
Не совсем понятно? Разберём простой пример.
У вас сломалась машина. Вы сразу же хватаетесь за ноутбук и берётесь искать ближайший автосервис. В строчке Яндекса вбиваете «ремонт авто Воронеж». Вот эта фраза и является поисковым запросом. А семантическое ядро — это их структурированная совокупность.
СЯ выполняет следующие функции:
1) Помогает найти пользователям нужную информацию.
2) Улучшает видимость сайта в поисковых системах.
3) Используется для создания «каркаса» сайта.
Основы основ
Что это такое и с чем его едят ясно. Поехали дальше. Обратим внимание на базовые правила сборки СЯ.
- Одна страница — одна группа запросов.
Пример — купить двери, купить межкомнатные двери, купить стеклянные межкомнатные двери, деревянные межкомнатные двери и так далее. Но запрос «дверные ручки» сюда включать нельзя.
- Запрос соответствует содержанию.
Допустим, есть ключевик «купить строительные материалы».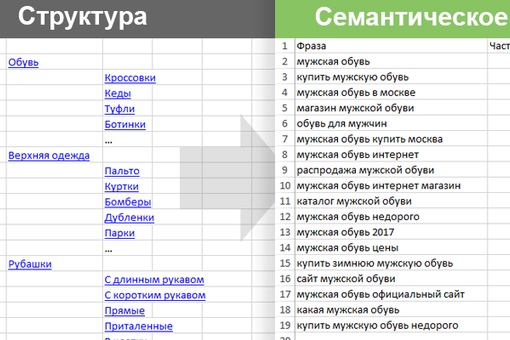
Но в итоге открывается страница, на которой недвусмысленно предлагается заказать строительство дома под ключ. А это уже очень грубое нарушение. Поисковые системы за такое могут понизить сайт в выдаче.
- Стратегия продвижения выбирается в зависимости от частотности запроса.
Очень обширная тема, на которую нужна отдельная статья. Пока просто запомните, что НЧ, СЧ и ВЧ раскручиваются совершенно разными методами.
2 стратегии сборки СЯ
1) С нуля.
Производится глубинный анализ тематики и ниши, продукта, предполагаемых запросов.
Преимущества: сайт быстрее продвигается в топ.
Недостатки: долго, дорого.
2) Запросы конкурентов.
Выбираем нескольких конкурентов. С помощью keyso честно заимствуем у них ядро. Потом чистим его от ненужных запросов.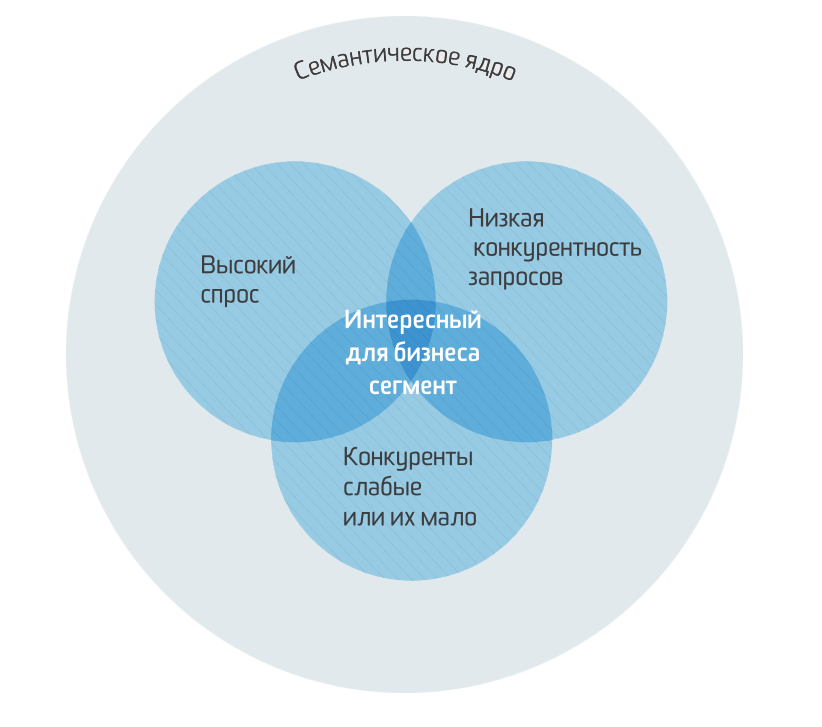 Готово!
Готово!
Преимущества: недолго, дёшево.
Недостатки: есть вероятность того, что конкуренты собрали некачественное СЯ. О последствиях думайте сами.
Типы запросов по цели и частотности
По цели:
1) Информационные.
Используются пользователями для получения некоммерческой информации.
Пример: «Как настроить роутер (название модели) инструкция».
2) Коммерческие.
Направлены на совершение коммерческого действия.
Пример: «Smart TV купить Воронеж».
3) Обобщающие.
Не дают возможности определить цель пользователя.
Пример: «Пластиковые окна».
По частотности:
Высокочастотные — от 1000 в месяц и более.
Пример: Indesit стиральные машинки купить
Среднечастотные — до 1000 в месяц.
Пример: Indesit стиральные машинки купить в рассрочку эльдорадо
Низкочастотные — до 100 в месяц
Пример: Indesit iwub 4085 б/у купить Тамбов недорого
Этапы работы
Итак, в основных моментах разобрались. Теперь переходим непосредственно к процессу сборки. Он состоит из пяти этапов.
Теперь переходим непосредственно к процессу сборки. Он состоит из пяти этапов.
1) Ищем базовые фразы.
2) Расширяем полученную семантику (парсинг).
3) Отсев ненужных ключей.
4) Анализ конкуренции, сезонности и других важных факторов.
5) Группировка запросов.
Вот такой получился алгоритм. Теперь разберём каждый шаг подробнее.
Базовые фразы.
Сначала в уме придумываем как можно больше слов или словосочетаний, которые относятся к нашей тематике. Речь идёт, понятное дело, о поисковых запросах. Сразу записывайте их в документ блокнота, чтобы не забыть.
Готово? Отлично, теперь запускаем утилиту KeyCollector и копируем туда то, что получилось. Теперь нажимаем кнопку «Парсить с Яндекс.Wordstat». Запаситесь терпением — это может занять до шести часов и более. Всё зависит от размера ядра и параметров парсинга.
Не забывайте о том, что собирать семантику с нуля не обязательно. Можно использовать ядро, которое составляли конкуренты.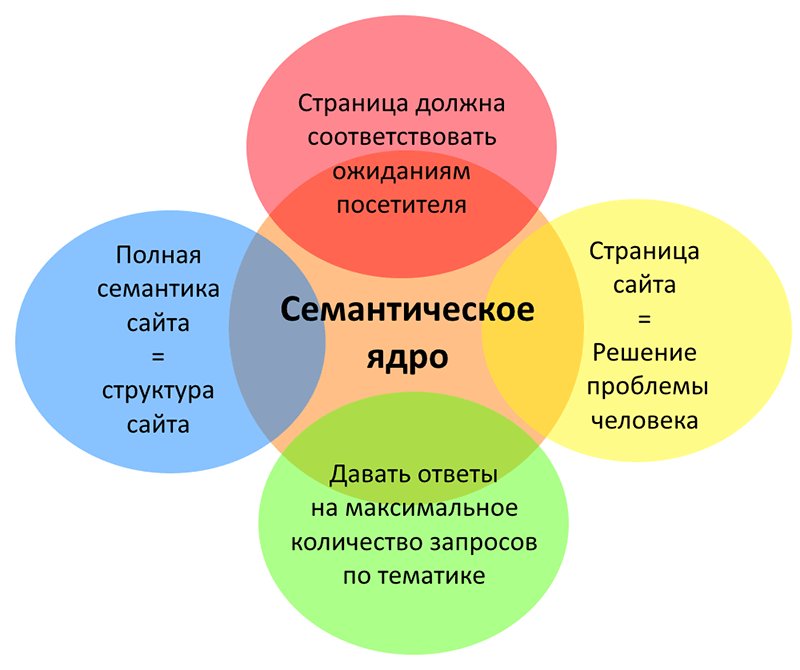 Причём как целиком (не рекомендуется), так и в качестве базы для собственного.
Причём как целиком (не рекомендуется), так и в качестве базы для собственного.
После проводится анализ конкуренции, сезонности и других важных факторов. Это требуется для того, чтобы оставить только нужные ключи и отсеять бесполезные запросы.
Отсев ненужных ключей
Теперь нам нужно избавиться от мусорных запросов, которые нашему сайту никак не помогут. Словосочетаний после парсинга может получиться очень много, но отсеивать их придётся вручную. Есть вариант воспользоваться автоматизированными сервисами, но они не всегда работают корректно.
1) Избавляемся от ключей со сверхнизкой частотностью (меньше 10).
2) Оставляем только подходящие по смыслу фразы. Остальные — удаляем.
3) Проверяем частотность ключевых фраз. Как и в предыдущем случае, лишние запросы удаляем. Нужную себе частотность определяйте самостоятельно.
То, что у нас получилось, экспортируем в таблицу Excel. После этого начинается долгая и нудная, но очень ответственная процедура доработки и группировке семантики.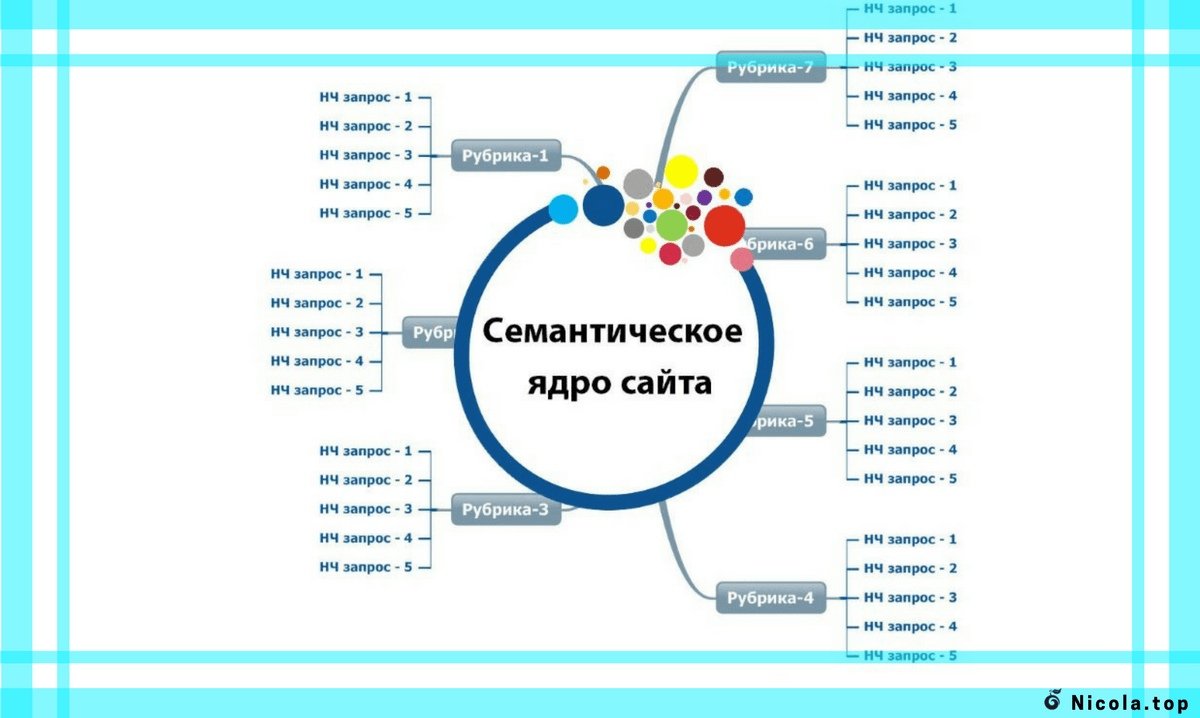
В конце мы получаем несколько групп запросов, которые подходят вам по тематике. На этом сбор семантического ядра заканчивается.
В завершение
Безусловно, это очень обобщенное описание процесса сборки семантического ядра для сайта. В пределах одной статьи всё описать невозможно, но в дальнейшем мы рассмотрим этот вопрос гораздо более подробно.
Как правильно собрать семантическое ядро для сайта ( сео )
Чтобы сайт могли найти посетители, нужно грамотно подобрать ключевые слова. Именно они являются основой семантического ядра. Обычно слова для удобства разделяют по схожим категориям. И сделать это важно не только для продвижения ресурса, но и для создания рекламной кампании. Существует два способа сбора семантики: ручной и автоматический.Контент на сайте бывает информационным и коммерческим. Ключевые слова для семантического ядра выбирают, исходя из тематики контента и анализа конкурентов. При этом следует учитывать региональную принадлежность и сезонность. Все страницы сайта нужно оптимизировать под запросы пользователей.
Составление семантического ядра сайта можно разделить на 3 ступени:
1. Поиск ключевых запросов, на которые будет ориентироваться проект.
2. Группировка ключей по смыслу, категориям и разделам.
3. Оптимизация страниц под определённые запросы.
Ключи тоже разделяют на информационные и коммерческие. Когда посетитель ищет какие-то фразы со словами «купить» или «заказать», значит он уже собирается приобрести товар или воспользоваться услугой. Это коммерческие ключи. Они помогают привлечь на сайт реальных клиентов.
Информационные ключи привлекают посетителей, которые просто проявляют интерес к теме. Они не хотят ничего покупать или заказывать. Хотя некоторые из таких посетителей в будущем тоже становятся клиентами.
Ключи разделяют ещё и по частотности:
— высокочастотные — самые популярные словосочетания, по которым наблюдается наибольшая конкуренция;
— среднечастотные — такие ключи употребляют реже, но они всё равно имеют высокое значение;
— низкочастотные — самые длинные и редкие фразы, которые пользователи набирают в поиске.
Обычно получается так: чем длиннее запрос, тем ниже его частота.
Некоторые считают, что продвижение сайта возможно только с помощью высокочастотных ключей. Но это большая ошибка. Ведь выйти в ТОП по таким запросам гораздо сложнее. Да и не всегда это нужно. Например, фразу «купить диван» набирают много пользователей. Но из такого запроса ничего не понятно. Поэтому гораздо проще и эффективнее использовать другой ключ. Например, «купить угловой диван в Воронеже». Он привлечёт больше целевых посетителей.
Но полностью отбрасывать высокочастотные ключи не стоит. Обычно их располагают на главной странице. Среднечастотные больше подходят для разделов. А для каждого товара используют в основном низкочастотные ключи. Стоит отметить, что какой-то определённой инструкции ранжирования по частотности нет. В одной сфере к высоким показателям относится результат в 1000 запросов в месяц, а в другой — сотни тысяч.
что это такое, зачем оно нужно, как её правильно собрать, примеры
Сайты создают, чтобы получать трафик и прибыль.
Коротко о сути: что такое семантическое ядро и зачем оно нужно
Семантическим ядром принято называть набор слов/словосочетаний по теме сайта. Сеошникам семантическое ядро необходимо потому, что без него не разработать толковую структуру сайта и не выйти в топ. Владельцам бизнеса и маркетологам компании — чтобы понять, какую информацию ищет целевая аудитория, о чем с ней говорить, чтобы вовлечь людей в коммуникацию, повысить их лояльность и продавать.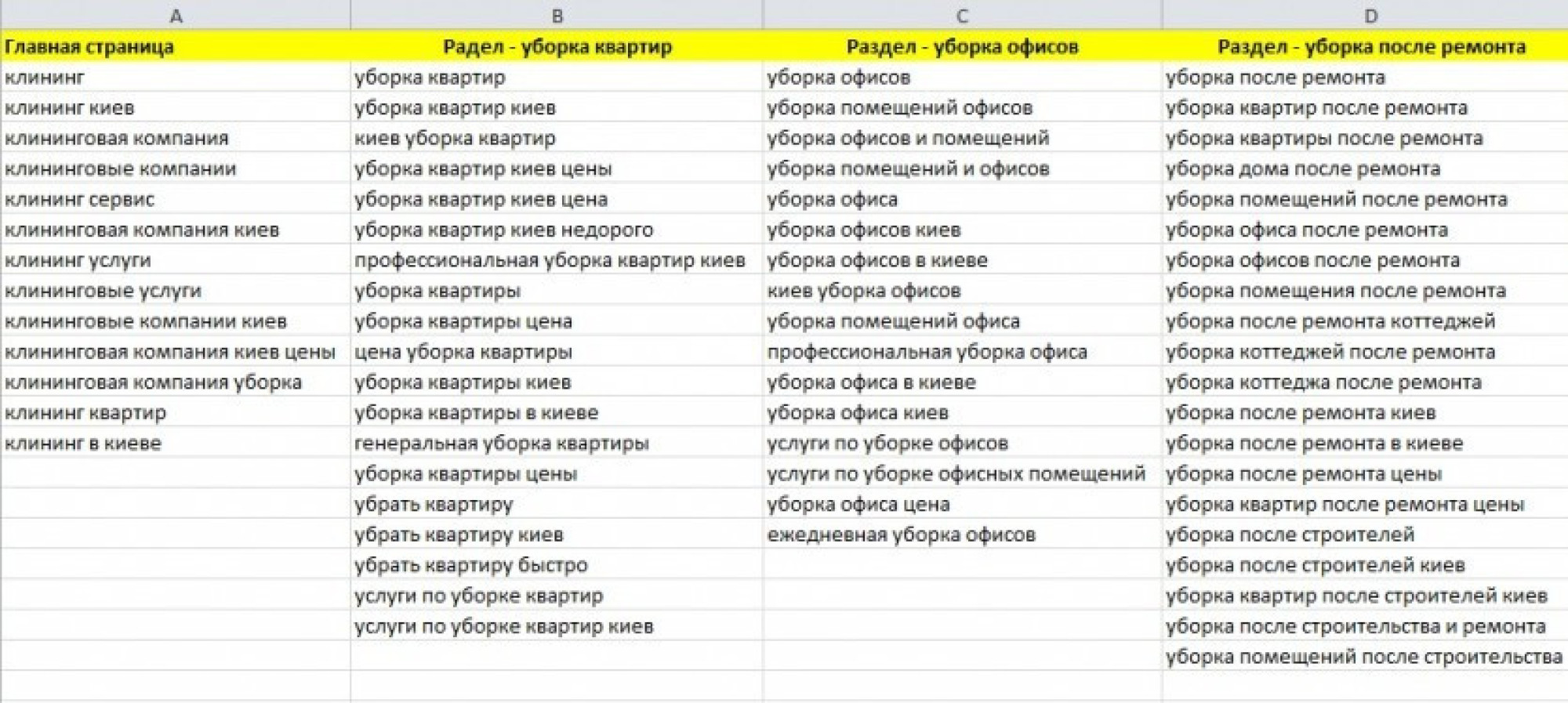
Подробно о задачах семантического ядра
Мы всегда держим в голове 5 вариантов того, как используется семантическое ядро, и что делать после сбора семантического ядра. Мы используем семантику…
…Для разработки структуры сайта. Вот как это выглядит: собирается семантическое ядро, группируются/кластеризируются запросы, и в итоге разработчик и владелец видят, какие категории должны обязательно присутствовать на сайте. Каждая группа ключей — это отдельная категория. Так в структуре сайта будет предусмотрено все необходимое и не окажется ничего лишнего.
…Для поискового продвижения. После разработки структуры сайта ключевые слова распределяются постранично, и каждая страница оптимизируется под свои ключи. Это обеспечивает грамотное продвижение в топ органики, а какой солдат не мечтает стать генералом какой владелец сайта не мечтает видеть его в топе. Если же не распределять ключи, а использовать их хаотично, продвижение затруднится: поисковые роботы просто не поймут, на какую страницу вести людей по каждому конкретному запросу, если он присутствует одновременно на 5-10-15 страницах.
…Для настройки контекстной рекламы. Чтобы рекламная кампания в Яндекс.Директ или Google Ads была результативной, вам тоже необходимо использовать семантическое ядро. Вы выберете те релевантные запросы, по которым хотите продвигаться, и под каждый запрос напишите объявление (а лучше оставите эту работу профессионалам, потому что конверсия точно будет выше). Семантическое ядро поможет увидеть, что пользователи ищут прямо сейчас, и эти знания тоже можно использовать для повышения эффективности контекстной рекламной кампании.
…Для составления контент-плана. Где еще используется семантическое ядро? Оно помогает в работе контент-менеджеру. Статьи в блоги и на сайты-статейники пишутся не «от фонаря», а опираясь на интересы (читай, запросы) пользователей. Поэтому часть ключевых слов — это практически готовые темы для контент-плана, которые нужно только чуть расширить. Например, со словом «велосипеды» вы, сверившись с семантическим ядром, можете запланировать статьи:
- Что такое спортивные велосипеды
- Горные велосипеды: выбираем правильно
- Велосипед для девочки: на что обратить внимание
- Велосипед для мальчика: 5 признаков того, что вы не ошиблись в выборе
- Прогулочные велосипеды: разбираемся в специфике
- Что такое дорожные велосипеды
…Для максимального охвата целевой аудитории. Грамотно составленное семантическое ядро поможет вам не упустить клиентов, максимально охватить людей, которые заинтересованы в вашей продукции. Если с семантикой у вас слабо и вы ограничитесь только просмотром Яндекс.Вордстата, то даже по самому распространенному запросу из одного слова — возьмем все тот же «велосипед» — сервис покажет вам только 2050 вариантов ключей. При этом частотность самого последнего ключа будет 1600, тогда как в принципе Вордстат учитывает запросы с частотностью от 5 в месяц. Получается, что вы теряете аудиторию, которая вводила запросы по теме «велосипеды» с частотностью ниже 1600 — а таких пользователей могут быть в общей сложности тысячи! Полное семантическое ядро такие потери исключает.
Грамотно составленное семантическое ядро поможет вам не упустить клиентов, максимально охватить людей, которые заинтересованы в вашей продукции. Если с семантикой у вас слабо и вы ограничитесь только просмотром Яндекс.Вордстата, то даже по самому распространенному запросу из одного слова — возьмем все тот же «велосипед» — сервис покажет вам только 2050 вариантов ключей. При этом частотность самого последнего ключа будет 1600, тогда как в принципе Вордстат учитывает запросы с частотностью от 5 в месяц. Получается, что вы теряете аудиторию, которая вводила запросы по теме «велосипеды» с частотностью ниже 1600 — а таких пользователей могут быть в общей сложности тысячи! Полное семантическое ядро такие потери исключает.
Итого:
- использовать семантическое ядро можно очень по-разному, но всегда это будет на пользу бизнесу.
Семантика: что собираем?
Почитайте немного о том, из чего в итоге складывается готовое семантическое ядро. Мы учитываем разные виды запросов пользователей и делим их по нескольким критериям.
Мы учитываем разные виды запросов пользователей и делим их по нескольким критериям.
По направленности:
1. Маркерные/базовые вопросы. Это самые очевидные, распространенные, популярные слова, характеризующие вашу тему/продукт/услугу/сферу деятельности. Это базис, набор контрольных точек, вокруг которых будет постепенно наращиваться семантическая масса. Чем точнее вы определили базовые запросы, тем лучше будет результат. Например, при работе с тематикой продажи велосипедов базовыми будут:
- Велосипед купить
- Велосипед сравнить
- Велосипед подобрать
- Велосипед интернет-магазин…
…и еще десяток самых очевидных конструкций.
2. Информационные запросы. Это запросы, по которым пользователи ищут информацию о товаре/услуге ДО ТОГО, как приняли решение о покупке. Например, это могут быть:
- «дорожный велосипед преимущества»
- «дорожный велосипед виды»
- «дорожные велосипед характеристики»
- «ремонт дорожного велосипеда»
3. Транзакционные/коммерческие запросы. Это вид запросов пользователей, который предполагает какое-то действие (транзакцию): забронировать, сравнить, купить, скачать. Например:
Транзакционные/коммерческие запросы. Это вид запросов пользователей, который предполагает какое-то действие (транзакцию): забронировать, сравнить, купить, скачать. Например:
- «скачать руководство по SEO-продвижению сайта»
- «купить зимнюю резину»
- «забронировать отель в Париже»
4. Брендовые запросы. В этом случае пользователи ищут продукт, услуги или информацию по конкретному бренду. Бренды могут быть как крупными и известными, так и совсем небольшими.
Например:
- «новые продукты 1С»
- «приложение Сбермаркет»
- «антивирус Касперский»
- «доставка Самокат»
5. Общие/прочие запросы. Это наиболее общие запросы, которые никак не характеризуют задачи и намерения юзера. Так, если человек вводит в поисковую строку «шоколадный кекс» — он может искать рецепт его изготовления, магазин, который продает шоколадные кексы, или вообще фотографию кекса для своей статьи в блоге.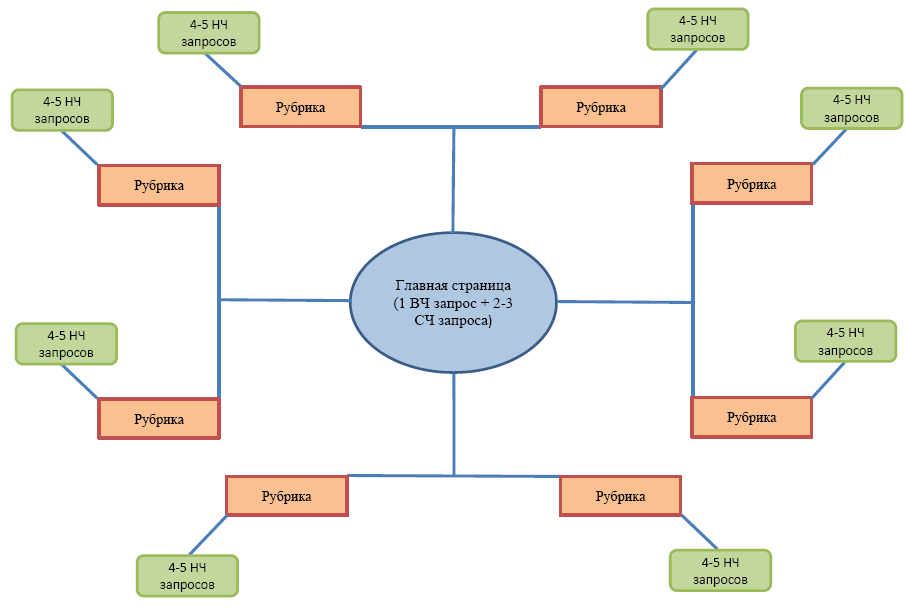
По частотности:
1. Высокочастотные запросы. Это те запросы, которые пользуются особой популярностью. Пользователи вводят их в поисковую строку браузеров в общей сложности больше 10 000 раз в месяц. Это базовые запросы + их несложные разновидности.
Примеры:
«купить авто» — 2 526 169 запросов в месяц
«ремонт квартир» — 842 936 запросов в месяц
А вот как выглядит вариант с расширением базовых запросов:
Базовый запрос: «пластиковые окна» — 1 485 530 запросов в месяц
2. Среднечастотные ключевые запросы. Это запросы с частотой показов от 500 до 5000-10000 (совсем точной градации, которую никто не оспаривает, нет). Это всегда уточненные запросы, часто с географической привязкой.
Примеры:
«Купить велосипед в Омске» — 1535 показов
«Установка пластиковых окон в Челябинске» — 528 показов
3. Низкочастотные ключевые запросы. Это запросы, которые вводятся до 300-500 раз в месяц.
Низкочастотные ключевые запросы. Это запросы, которые вводятся до 300-500 раз в месяц.
Примеры:
«Купить велосипед для девочки в Омске» — 15 показов.
«Установка пластиковых окон в дом в Челябинске» — 9 показов
Как собрать семантическое ядро: важное об этапах работы
Теперь мы расскажем, как собирать и готовить семантическое ядро на примере того, как это происходит в SoldiMarketing. Если говорить коротко, то схема такова: «собираем базу => кластеризируем => расширяем семантику => сужаем семантику/чистим семантическое ядро». Подробности далее.
Этап 1. Выписываем все слова, словоформы, синонимы, характеризующие продукт/услугу. Так мы получаем список базовых ключевых слов. Используем для этого здравый смысл, брейншторм и синонимайзеры.
Этап 2. Кластеризация семантического ядра. Поисковые фразы, по которым пользователи будут приходить на ваш ресурс, мы объединяем в отдельные кластеры. Это группы запросов, близких по смыслу. Например, если у вас кондитерская, то семантический кластер «кекс» будет включать целую группу запросов, от «рецепт кекса» до «шоколадный кекс» и «ванильный кекс».
Это группы запросов, близких по смыслу. Например, если у вас кондитерская, то семантический кластер «кекс» будет включать целую группу запросов, от «рецепт кекса» до «шоколадный кекс» и «ванильный кекс».
- Мы проводим кластеризацию вторым этапом потому, что если сначала расширить семантическое ядро, а затем кластеризировать, то придется работать с очень большим количеством ключей. В нашем случае мы сначала формируем кластеры, а затем они «обрастают» дополнительной, расширяющей, уточняющей и связанной семантикой.
Этап 3. Расширяем список запросов. Мы изучаем сайты конкурентов, смотрим тематические картинки в Яндексе и Google, изучаем подсказки Яндекса и особенно внимательно анализируем левую колонку сервиса Яндекс.Вордстат. Настойчиво советуем не пренебрегать Вордстатом, потому что он может выдать вам все варианты каждого слова, вводимого пользователям. Особенно если это слово семантически сложное, как, например, название площадки для e-commerce Wildberries.
Не факт, что нужно использовать все словоформы, потому что поисковые системы уже умеют (и продолжают учиться) определять правильно даже аббревиатуры и слова, написанные с ошибками. Например, подсказки Яндекса покажут нам эту площадку и на запрос «вб», и на запрос «валтб», и на запрос «валбери», и даже просто на «wi». Но понимать, как ищут пользователи, нужно.
Так мы проходимся по каждому кластеру — не ленимся, чтобы не упустить аудиторию.
Этап 4. Продолжаем расширение. Используем метод гипонимов, или тезаурус. Это так называемые смежные слова, связанные с вашим товаром или услугой. Например, для слова «компьютер» гипонимы — это «монитор», «процессор», «мышь», «клавиатура», «жесткий диск» и даже «коврик для мыши». Собираем все словосочетания с этими ключевыми словами, отвечая на вопрос «А что еще ищут пользователи, которым интересны компьютеры?». Здесь наш верный помощник — правая колонка Яндекс. Вордстата «Запросы, похожие на…» и блок в Яндексе «Люди ищут…».
Вордстата «Запросы, похожие на…» и блок в Яндексе «Люди ищут…».
Этап 5. Используем веб-аналитику. Дополнительно, если мы собираем семантическое ядро для уже действующего сайта, то используем данные веб-аналитики от Яндекс.Метрики или Google Analytics. Они помогают нам понять, по каким запросам приходит уже существующая аудитория.
Этап 6. Сужаем/чистим семантическое ядро. Теперь, когда мы собрали максимум семантики по теме сайта, начинаем, как скульпторы, отсекать лишнее. И лишнее — это вовсе не низкочастотники. Так, по некоторым ключам с прогнозом показа 5-7 в месяц может прийти самая горячая аудитория, которая купит с первого касания. Мы проводим чистку семантического ядра от…
…брендовых запросов конкурентов. Если компания «Ромашка» продает ноутбуки, а пользователь набирает «купить ноутбук Связной» — это нетематический запрос в нашем случае; пользователь уже сделал выбор. (Заметим, работать можно и с такими запросами, но это удел крупного бизнеса, планирующего тотальный захват рынка).
…запросов со стоп-словами. Это запросы «дешево» или «со скидкой», если вы не планируете демпинговать и привлекать аудиторию, считающую каждую копейку. Или запросы вида «скачать шаблон коммерческого предложения» в случае, если вы предлагаете его разработку; запросы «установить пластиковое окно самостоятельно», если вы предлагаете монтаж таких окон.
…запросов на товары/услуги, которых нет в ассортименте. Если вы продаете велосипеды для взрослых, то даже коммерческие запросы «велосипед для девочки купить» или «велосипед для мальчика трехколесный подобрать» будут для вас нетематическими.
…дублирующих запросов. Например, нет смысла оставлять два ключа «букеты купить», «букет купить; если речь идет о продвижении сайта в Яндексе, то лучше их склеить. Для продвижения в Google такие ключи не склеиваем: эта поисковая система не воспринимает их как дубль.
…неподходящих географических запросов. Если у вас локальный бизнес по продаже велосипедов в Омске, то запрос «купить велосипед + Москва» для вас точно нетематический.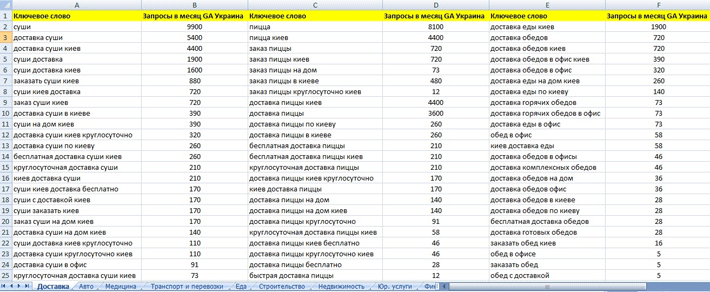 Если у вас интернет-магазин ковров с доставкой по России, то запрос «купить ковер + доставка в Беларусь» вам ничего не даст.
Если у вас интернет-магазин ковров с доставкой по России, то запрос «купить ковер + доставка в Беларусь» вам ничего не даст.
Таким образом, на выходе у нас получается максимально полное, грамотно кластеризированное, тщательно очищенное семантическое ядро — просто конфетка! И это то, что мы «посеем», чтобы у владельцев бизнеса все «заколосилось», и они получили хороший «урожай» трафика и продаж.
Важно:- Программами для автоматического сбора семантического ядра мы пользуемся факультативно, для сведения и для разгона. У них есть свои плюсы, но мы намного больше полагаемся на наши головы, руки и опыт, чем на обезличенные программные алгоритмы. Ценность программного сбора семантического ядра без крайне тщательной ручной обработки результатов невысока. Только человеческий, а не искусственный, интеллект может не просто оценить технические характеристики каждого запроса, а учесть уровень конкуренции, специфику работы и ассортимента конкретной компании.
 Только человек может включить чуйку, которая приходит с опытом. И уже на основе этого продолжить работу по сбору и чистке семантического ядра.
Только человек может включить чуйку, которая приходит с опытом. И уже на основе этого продолжить работу по сбору и чистке семантического ядра.
 Только человек может включить чуйку, которая приходит с опытом. И уже на основе этого продолжить работу по сбору и чистке семантического ядра.
Только человек может включить чуйку, которая приходит с опытом. И уже на основе этого продолжить работу по сбору и чистке семантического ядра.…Вот только теперь мы готовы приступить к разработке сайта, составлению контент-плана или настройке и ведению контекстной рекламной кампании. Иначе вся работа, которую важно делать после составления семантического ядра, будет проделана впустую, а это неинтересно ни нам, ни нашим заказчикам.
что это и как правильно собрать? Подбор ключевых слов для сео продвижения
Даже если сайт имеет красивый дизайн, наполнен интересным контентом и яркими фотографиями, это ещё не значит, что он будет привлекать клиентов и приносить прибыль компании. Он просто затеряется среди сотен других.
Чтобы сайт занимал верхние строчки поисковых систем, необходимо его оптимизировать и умело продвинуть. Как же это сделать? Для начала – собрать ключевые слова и составить семантическое ядро.
Что такое семантическое ядро?
Чтобы сайт привлекал как можно больше посетителей, приносил хороший трафик и потенциальных клиентов, его должны «полюбить» поисковые системы Google и Яндекс.
Поисковики представляют собой довольно сложные системы, которые работают по отлаженному алгоритму. 4 «работника» – поисковых робота – выполняют определённую задачу:
- Пауки. Всего пауков 2. Первый загружает все страницы из сети Интернет, другой пробегает по всем ссылкам и ищет новые страницы.
- Индексатор. Этот инструмент отбирает все страницы по наибольшей релевантности, загружает в свою базу и после индексирует.
- База данных. Представляет собой хранилище, куда индексатор направляет страницы после тщательного отбора.
- Система выдачи. Конечный этап процесса – выдача результатов по запросам пользователей в Яндексе и Google. Простыми словами, это то, что мы с вами видим на экране, когда делаем запрос в поиске.
Когда в интернете размещается новая информация, требуется некоторое время, чтобы робот обошёл и проиндексировал страницу.
Поисковики отбирают полезные сайты по сотням критериев, поэтому очень важно им «понравиться».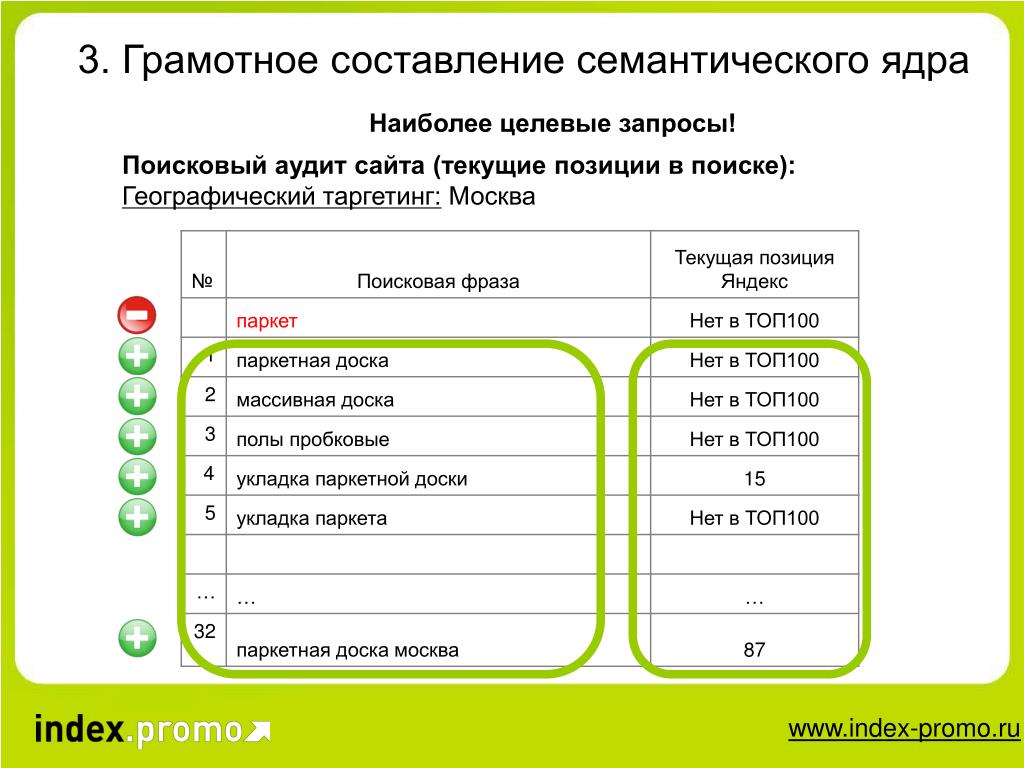 Для этого необходимо провести целый комплекс процедур по SEO-оптимизации, самым первым этапом которой является сбор семантического ядра. Он же считается и самым важным, так как грамотно составленное семантическое ядро выделит веб-ресурс среди конкурентов и поднимет его в ТОП-выдаче поисковиков.
Для этого необходимо провести целый комплекс процедур по SEO-оптимизации, самым первым этапом которой является сбор семантического ядра. Он же считается и самым важным, так как грамотно составленное семантическое ядро выделит веб-ресурс среди конкурентов и поднимет его в ТОП-выдаче поисковиков.
Семантическое ядро – это список ключевых фраз, которые пользователь вводит в поисковую строку, чтобы найти необходимую информацию, товар или услугу. Именно семантическое ядро берётся за основу при разработке ресурса для его дальнейшего продвижения.
Перед началом работ по SEO-оптимизации необходимо собрать все ключевые запросы, по которым пользователи ищут нужную информацию. На основании семантики:
- Составляется структура сайта. Благодаря чёткой структуре веб-ресурса, поисковые роботы быстрее обходят сайт, а пользователь легко перемещается по его страницам.
- Ключи органически распределяются по странице. Чтобы страница выдавалась в поиске, она должна соответствовать запросам пользователя. А чтобы пользователю было комфортно читать текст, а ключи не бросались в глаза и не резали слух, их необходимо грамотно вписать и распределить по тексту.
- Настраиваются мета-теги, заголовки и описания к изображениям. Мета-теги – это куски кода, которые содержат информацию о странице и передают её поисковикам и браузерам. Они сообщают, по каким запросам пользователей необходимо показывать страницу. Отсутствие или некорректное обозначение мета-тегов негативно отражается на продвижении сайта.
- Составляется анкор. Анкор – это видимый текст ссылки, который содержит ключевые слова и помогает комфортно перемещаться по веб-ресурсам. Ошибки в составлении анкора понизят позиции сайта в выдаче.
- Публикуется контент. На любом сайте содержатся блоки информации. На основании ключевых слов составляется ТЗ копирайтеру, который будет наполнять сайт свежими текстами. Статьи, которые максимально релевантны запросам пользователей, занимают более высокие позиции в выдаче и собирают больше трафика.
 Чтобы страница выдавалась в поиске, она должна соответствовать запросам пользователя. А чтобы пользователю было комфортно читать текст, а ключи не бросались в глаза и не резали слух, их необходимо грамотно вписать и распределить по тексту.
Чтобы страница выдавалась в поиске, она должна соответствовать запросам пользователя. А чтобы пользователю было комфортно читать текст, а ключи не бросались в глаза и не резали слух, их необходимо грамотно вписать и распределить по тексту. Статьи, которые максимально релевантны запросам пользователей, занимают более высокие позиции в выдаче и собирают больше трафика.
Статьи, которые максимально релевантны запросам пользователей, занимают более высокие позиции в выдаче и собирают больше трафика.Какие бывают ключевые слова?
Чтобы составить семантическое ядро, необходимо собрать ключевые фразы. Ключи – это одно или несколько слов, которые используют пользователи, когда ищут информацию в интернете.
Например: пользователь хочет приготовить пирог. В поиске он вводит запрос: «Рецепты пирогов с фото». Это и будет ключ.
Ключевые запросы классифицируют по многим признакам, однако есть два основных: частотность и цель запроса.
По популярности ключи бывают:
- Низкочастотные – менее 100 показов в месяц
- Среднечастотные – менее 1000 показов в месяц
- Высокочастотные – от 1000 показов в месяц и выше
Популярность запросов – относительный показатель, который напрямую связан с тематикой сайта. Например, для магазина мобильных телефонов и аксессуаров, запрос «купить телефон Huawei» с частотностью показов около 7 000 в месяц будет являться средним. Для кружка изобразительного искусства запрос «уроки рисования» с 2 000 показов – высокочастотным.
Для кружка изобразительного искусства запрос «уроки рисования» с 2 000 показов – высокочастотным.
По статистике, более 60% запросов относится к низко- или среднечастотным, поэтому при составлении семантического ядра следует выбирать не только запросы с высокой популярностью, а максимально расширить список низкочастотников. Продвижение по ним будет проще, дешевле, а также поможет привлечь дополнительных клиентов.
В зависимости от целей поиска выделяют следующие ключи:
- Информационные. Их вводят для того, чтобы узнать какую-то информацию («как приготовить торт», «что такое семантика»).
- Транзакционные. Считаются запросами коммерческого характера. По ним переходят, если хотят совершить какое-то действие («купить квартиру в Минске», «заказать авиабилет»).
- Витальные. Такие запросы вбивают в поиск, если хотят целенаправленно найти какой-то сайт («Facebook», «VK»).
- Прочие. Иногда по запросам пользователей сложно определить, что именно он ищет. Например, запрос «шуба» не несёт информации о том, хочет человек купить шубу или посмотреть, какие модели сейчас в моде.
 Например, запрос «шуба» не несёт информации о том, хочет человек купить шубу или посмотреть, какие модели сейчас в моде.
Например, запрос «шуба» не несёт информации о том, хочет человек купить шубу или посмотреть, какие модели сейчас в моде.Перед тем, как приступать к сбору семантического ядра, необходимо чётко понимать цели своего бизнеса и нужды аудитории. Все информационные разделы должны соответствовать информационным запросам.
Как собрать семантическое ядро для СЕО?
SEO-оптимизация сайта начинается с формирования семантического ядра. Необходимо определиться с основными направлениями веб-ресурса, сферой деятельности компании и продумать, какие ключевые запросы максимально точно характеризуют его.
Сам процесс подборки семантического ядра можно разделить на несколько главных этапов:
- Подбор маркеров
- Подбор семантического ядра через Яндекс Вордстат
- Сбор частотности в Key Collector или Slovoeb
- Кластеризация запросов семантического ядра
- Заключительный анализ
Шаг 1. Подбор маркеров
Маркерные запросы или маркеры – это слова и словосочетания, которые максимально точно определяют тематику и характеризуют сайт. От маркеров зависит, насколько полным и точным будет СЯ.
От маркеров зависит, насколько полным и точным будет СЯ.
Собрать маркерные запросы можно несколькими способами:
- Мозговой штурм. Цель мозгового штурма – составить первичный перечень ключевых фраз, которые ещё называют базовыми. Чтобы понять, какие запросы могут подойти, необходимо ответить на вопрос: «что я предлагаю?». Для охвата широкого спектра маркеров ищите не только слова, связанные с деятельностью компании. Подбирайте синонимы, топонимы, сокращения, аббревиатуры, сленг, используйте транслитерацию, двойные слова.
- Анализ ядра конкурентов. Если закончилась фантазия, можно прибегнуть к хитрости и узнать, какие ключи используют конкуренты, работающие в той же сфере, что и вы. Сделайте ТОП-выгрузку и загляните в Title и сниппеты конкурирующих сайтов. К тому же, так вы сможете узнать о позициях других веб-ресурсов в вашей нише.
- Разделы и категории сайта. Если ваш сайт уже готов, используйте названия разделов, рубрик для подбора маркеров.
- Яндекс Метрика/Google Search Увеличить семантическое ядро можно с помощью этих инструментов. При наличии готового сайта проанализируйте, по каким ключам пользователи чаще всего приходят к вам на сайт, и используйте их в качестве маркеров.
- Сбор AdWords. Используйте базу AdWords для сбора ключей.
- Сбор подсказок. Также можно воспользоваться подсказками – LSI-запросами из поиска Google и Яндекс. Помимо самих запросов они помогают подобрать синонимы и связанные слова, проверить блоки «Вместе с этим искали».
Шаг 2. Подбор семантического ядра через Яндекс Вордстат
Яндекс Wordstat – бесплатный сервис для подбора ключей вручную, который отображает все поисковые запросы в Яндекс за последний месяц. Для того, чтобы начать работу, необходимо иметь аккаунт в Яндекс и зарегистрироваться.
С помощью Вордстата можно спарсить ключи, которые . Введите запрос в верхней строке сервиса и сделайте выгрузку. Перед вами появится две таблицы:
Перед вами появится две таблицы:
- Левая таблица показывает разные формы и словосочетания запроса, по которому пользователи ищут информацию в Яндексе. Напротив каждой фразы стоит число – столько раз данный запрос был введён в поиске за последние 30 дней.
- Правая таблица содержит слова и словосочетания, которые косвенно связаны с вашим запросом. Вы можете их использовать в качестве подсказок для расширения семантики.
Чтобы запросы были максимально информативными и полезными, не лишним будет применить базовые операторы Wоrdstat:
- Кавычки. Фраза, взятая в «» отображает показы только данного запроса, которое может иметь разное склонение и порядок слов.
- Восклицательный знак. «!» фиксирует окончание, и вам выдаются запросы без склонения. Позволяет подобрать запросы с нужной словоформой.
- Оба оператора. Совместное использование кавычек и восклицательного знака фиксирует не только окончание, но и сам запрос. В данном случае, меняться может только порядок слов.
 В данном случае, меняться может только порядок слов.
В данном случае, меняться может только порядок слов.Кроме базовых существуют также вспомогательные операторы:
- Или. Графически обозначается с помощью «|». Помогает быстро собрать семантику в случае, когда необходимо сравнить несколько фраз.
- Квадратные скобки. Задаётся знаком «[]» и фиксирует порядок слов в запросе.
- Плюс. «+» – полезен при поиске запросов со стоп-словами (частицами, предлогами и т.п.).
- Минус. Используйте оператор «-», чтобы исключить из запроса определённые слова.
- Группировка. Используя символ «()», можно объединить действия всех вспомогательных операторов.
Кроме того, сервис имеет набор инструментов, которые позволят отфильтровать запросы по регионам, сезонности, популярности поиска на мобильных устройствах или компьютерах. Чем больше запросов вы сможете собрать, тем лучше. И не забывайте использовать стоп-слова, которые помогут отфильтровать ненужные и нетематические запросы.
Перед тем как приступить к следующему шагу, скачайте расширение Yandex Wordstat Assistant. После этого на экране Вордстата появится окошко в левом углу, куда вы сможете добавлять подходящие запросы. Для этого нажмите на + рядом с ключевой фразой – она автоматически появится в этом окошке.
Шаг 3. Сбор частотности в Key Collector или Slovoeb
Как только все запросы будут собраны, приступайте к сбору частотности – количеству показов в поисковиках за месяц.
Чаще всего для данной цели используют программу Key Collector, с помощью которой можно:
- Собрать ключи через Wordstat
- Подобрать подсказки
- Очистить ненужные запросы через встроенный фильтр
- Отсортировать запросы по разным частотностям
- Определить дубли
- Разграничить сезонные запросы
- Собрать данные из разных сервисов: Яндекс.Метрика, Вконтакте, Google Аналитика и т.п.
Инструментарий Key Collector достаточно разнообразен, но следует учитывать, что доступ к нему платный.
В качестве бесплатного аналога используют сервис Slovoeb. По качеству сбора частотностей он ни в чём не уступает Key Collector, однако, может выполнить более скудный спектр задач. Чтобы начать работу в Slovoeb:
- Зайдите в настройки и укажите логин и пароль от аккаунта в Яндекс. Из-за большого количества запросов программа часто блокирует аккаунт, поэтому не используйте свой реальный, а создайте дополнительный.
- В меню выберите «Создать проект», «Данные», «Добавить фразы» и добавьте список подобранных ранее маркеров.
- На панели выберите раздел «Сбор ключевых слов и статистики» и отметьте необходимую частотность запросов.
После того, как частотность собрана, для удобства выгрузите её в таблицу Exel.
Шаг 4. Кластеризация запросов СЯ
Кластеризация – это объединение сочетающихся ключей в смысловые кластеры – группы, которые будут соответствовать определённым страницам сайта. Один кластер – одна веб-страница. Кластеризация необходима для того, чтобы упорядочить структуру запросов и распределить их по страницам таким образом, чтобы их продвижение происходило одновременно.
Если не проводить кластеризацию, собранное семантическое ядро принесёт пользу, но не сможет полностью раскрыть свой потенциал и показать эффективность. Это может привести к:
- Потере позиций в ТОП-выгрузке
- Созданию дублей
- Потере денежных средств и времени на создание ненужного контента
- Неравномерному продвижению страниц веб-ресурса
Провести кластеризацию можно как вручную, так и с помощью специальных программ.
Ручной способ
Бесплатные программы Excel, LibreOffice, OpenOffice прекрасно справятся с задачей ручной структуризации, так как имеют базовые функции: фильтрацию и сортировку.
Самостоятельная кластеризация займёт у вас гораздо больше времени, чем автоматизированная, а также потребует больше внимания и сил. Но это не значит, что этот способ неэффективный.
Автоматизированный способ
Чаще всего для автоматизированной кластеризации используют программы:
- Key Collector
- Rush Analytics
- Overlid
- Топвизор
- Пискель тулс
Самым лучшим считается уже известный вам Key Collector. Сервис не только быстро и эффективно разобьёт ключи на кластеры, но также оценит конкурентность и эффективность запросов и проверит веб-ресурс на соответствие контента семантическому ядру.
Сервис не только быстро и эффективно разобьёт ключи на кластеры, но также оценит конкурентность и эффективность запросов и проверит веб-ресурс на соответствие контента семантическому ядру.
Инструкция по работе с Key Collector проста. В меню необходимо выбрать опцию «Анализ групп» и указать режим разбивки:
- По отдельным словам – формирует группы из фраз, которые совпадают хотя бы одним словом.
- По составу фраз – позволяет провести кластеризацию по огромному количеству запросов.
- По ключевой выдаче – группирует ключи по количеству ссылок, которые совпали в поиске.
- По составу фраз и поисковой выдаче – совмещает два последних режима.
Шаг 5. Заключительный анализ
После того, как вы составите семантическое ядро сайта, проверьте, правильно ли вы распределили запросы по группам, отсеяли ли ненужные ключи. Даже если вам показалось, что составление семантического ядра прошло безупречно, вы можете обнаружить некоторые ошибки.
Теперь на основании семантического ядра можно приступать к оптимизации сайта, составлению title, description, заголовков страниц и т.п.
О чём необходимо помнить при составлении семантического ядра?Составление семантического ядра – основа любых процессов по оптимизации и продвижению сайта. Чтобы не потратить время зря и сделать результат максимально эффективным учитывайте следующее:
- Тщательно изучите специфику сайта и компании
- Научитесь работать с SEO-программами
- Изучайте конкурентов
- Отсеивайте ненужные запросы
- Структурируйте и анализируйте информацию
Семантическое ядро – это просто список запросов пользователей. Но в опытных руках SEO-специалиста СЯ может стать выигрышным козырем: поможет оптимизировать сайт и вывести его на первые позиции поисковой выдачи.
Семантическое ядро сайта: как собрать и почему важно не ошибиться
Семантическое ядро сайта: как собрать и почему важно не ошибиться
Что это такое?
Семантическое ядро — это мозг сайта. Его можно сравнить с зубами дракона, которые волшебник из сказки бросает в землю. Чем больше зубов дракона (ключевых запросов) будет посеяно, тем больше воинов поднимется из-под земли.
Его можно сравнить с зубами дракона, которые волшебник из сказки бросает в землю. Чем больше зубов дракона (ключевых запросов) будет посеяно, тем больше воинов поднимется из-под земли.
Википедия дает следующее определение семантического ядра: это набор поисковых слов, их морфологических форм и словосочетаний, которые наиболее точно характеризуют вид деятельности, товара или услуги, которые продвигает сайт.
Правильно подобрать ключевые запросы часто не так легко, как кажется: сбор семантики — это сложная аналитическая работа, которая в идеале занимает 3-4 дня, а иногда и этого не достаточно. Чтобы собрать семантическое ядро, специалист анализирует деятельность компании, статистику поисковых систем, статистику сайта, сайты конкурентов и сезонные ключевые слова.
Как это работает
Суть сбора семантического ядра состоит в том, что специалист должен просчитать все варианты запросов, чтобы деньги, выделенные на рекламную кампанию, были потрачены максимально эффективно.
При этом цели сбора семантического ядра для SEO-продвижения и контекстной рекламы отличаются. Для SEO-продвижения нужно найти максимальное число запросов всех уровней (высокочастотных, среднечастотных и низкочастотных), по которым сайт поднимется в ТОП-10. В контекстной рекламе корректно подобранное семантическое ядро помогает снизить цену за клик.
Сбор семантического ядра решает и еще одну задачу. С его помощью можно изучить рынок, потребности клиентов и построить бизнес с учетом этих данных. Статистика поисковых запросов — это драгоценная информация о желаниях и интересах людей, которую опытный маркетолог проконвертирует в новый бизнес-план.
Что ищут люди? Что их волнует? Какие нюансы их интересуют? Человек, обладающий этими сведениями, поймет потребности своих клиентов до мельчайших деталей и обеспечит себе процветание на долгие годы.
Что посеешь, то и пожнешь
Сегодня на рынке продвижения интернет-сайтов существует жесткая конкуренция. Некоторые игроки этого рынка недооценивают важность этапа сбора семантического ядра. Чем это грозит? Деньги клиентов, выделенные на рекламную кампанию, будут расходоваться бездарно. Результат будет в разы меньше запланированного.
Некоторые игроки этого рынка недооценивают важность этапа сбора семантического ядра. Чем это грозит? Деньги клиентов, выделенные на рекламную кампанию, будут расходоваться бездарно. Результат будет в разы меньше запланированного.
Если ключевые запросы будут определены неправильно, сайт будет заточен под потребности пользователей, сформулированные неточно. Поисковые системы будут продвигать такой сайт, но потенциальные клиенты не зайдут на него и не превратятся в клиентов. В результате сайт опустится в поисковой выдаче.
В случае с контекстной рекламой цена за один клик будет неоправданно высока.
Реклама “не выстрелит”, объявления будут показываться не тем пользователям, которых могли бы заинтересовать услуги компании. Большая часть целевой аудитории останется за бортом этой рекламной кампании.
Семантическое ядро сайта — это фундамент, на котором мы будем строить SEO-продвижение и контекстную рекламу. Ошибки здесь недопустимы. Если же они были допущены, клиент надолго разочаруется в возможностях интернет-маркетинга, потому что его ожидания не оправдались. Итог непрофессионального или некорректного сбора семантического ядра — это недозаработанные деньги клиента.
Итог непрофессионального или некорректного сбора семантического ядра — это недозаработанные деньги клиента.
Алгоритм действий
Сбор семантического ядра начинается с определения базовых и рекламных запросов. Например, если сайт занимается продажей сельскохозяйственной техники, базовыми запросами будут “комбайн” или “трактор”. Рекламные запросы — “купить комбайн” и “аренда трактора”.
Для поиска рекламных запросов используется сервис Wordstat Yandex.ru. Также специалист найдет все сленговые слова, аббревиатуры и обратит внимание на транслит (написание брендов русскими буквами). Все это будет использовано для генерации запросов.
Для работы с семантическим ядром используются программы: KeyCollector, Slovoeb, Магадан (а также могут использоваться другие).
Программа Key Collector способна собрать запросы для семантического ядра и оценить их конкурентность, стоимость и эффективность.
Существует еще один важный параметр — трендовость запроса. С помощью сервиса Wordstat.yandex.ru можно увидеть график, иллюстрирующий историю показов ключевого запроса. Google Trends отражает внимание к темам и запросам. Оба сервиса демонстрируют графики по времени. Чем больше показов ключевого запроса, тем больше у компании потенциальных клиентов.
С помощью сервиса Wordstat.yandex.ru можно увидеть график, иллюстрирующий историю показов ключевого запроса. Google Trends отражает внимание к темам и запросам. Оба сервиса демонстрируют графики по времени. Чем больше показов ключевого запроса, тем больше у компании потенциальных клиентов.
После того, как ключевые запросы были определены, специалист переходит к чистке семантического ядра. В случае с контекстной рекламой вся семантика делится на две части: для поиска и для РСЯ (рекламная сеть Яндекса) и для КМС (контекстно-медийная сеть в Google). Чистка семантического ядра проводится как в рекламных кампаниях, которые предназначены для поиска, так и в предназначенных для РСЯ и КМС. Отсекаются ключевые запросы, которые не соответствуют смыслу или тематике.
Если наша цель — SEO-продвижение, нужно вычистить из семантического ядра все запросы, по которым WordStat демонстрирует статистику, близкую к нулю.
Специалист также должен отсечь минус-слова — например, такие как “бесплатно” или “своими руками”.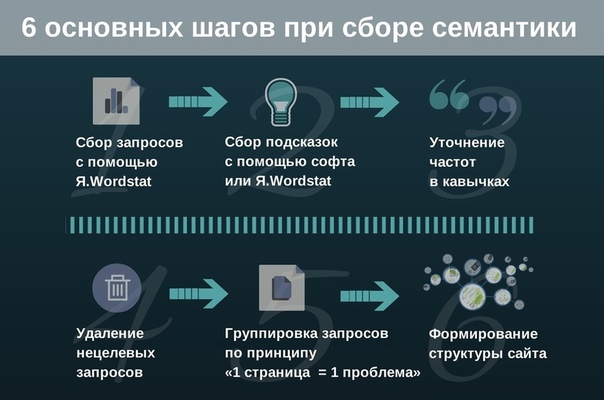 Это сведет на нет “мусорные показы”. Но в некоторых случаях, когда слово “бесплатно” может принести определенное количество клиентов, его оставляют. Например, “пройти бесплатный тест по английскому языку”. В этом случае пользователь после бесплатного теста станет клиентом курсов английского языка.
Это сведет на нет “мусорные показы”. Но в некоторых случаях, когда слово “бесплатно” может принести определенное количество клиентов, его оставляют. Например, “пройти бесплатный тест по английскому языку”. В этом случае пользователь после бесплатного теста станет клиентом курсов английского языка.
В случае с SEO после того, как семантическое ядро собрано, оно отдается специалисту по продвижению. Он определяет структуру сайта, выделяет типовые страницы, подбирает целевые запросы под каждую страницу. После этого составляется ТЗ для копирайтера, в котором указывается, как именно должны быть включены в тексты статей ключевые слова. Тексты пишутся и публикуются на сайте и он начинает свой путь наверх в поисковой выдаче.
Контекстная реклама настраивается таким образом, чтобы показываться пользователю, который набирает в поисковике один из ключевых запросов семантического ядра. Чем больше будет таких запросов, тем точнее можно показать, чего специалист хочет от поисковой машины, тем меньше будет стоимость одного клика. И тем эффективнее будет рекламная кампания, за которую заплатил клиент.
И тем эффективнее будет рекламная кампания, за которую заплатил клиент.
Никакого волшебства
Задумываясь о разработке сайта, нужно задать себе вопрос “Зачем?” Ответ прост — “Для рекламы моего бизнеса”. А это значит, что сайт будет существовать в поисковой среде, в которой есть свои правила и законы. Для того, чтобы добиться в этой среде успеха (подняться в поисковой выдаче), нужно соблюдать эти законы. Это очень серьезные задачи, и решить их могут профессионалы высокого уровня.
Если клиент только собирается запустить свой сайт, ему необходимо собрать семантическое ядро до разработки ресурса. Во-первых, это поможет ему в построении бизнеса, решит маркетинговые задачи. Во-вторых, опираясь на ключевые запросы, можно правильно выстроить структуру сайта и распределить ее по страницам. Чем раньше будут учтены законы поисковой выдачи при разработке сайта, тем лучше будет результат. Если клиент сначала обращается в агентство для сбора семантического ядра, специалисты могут курировать разработку сайта, которая делается на стороне.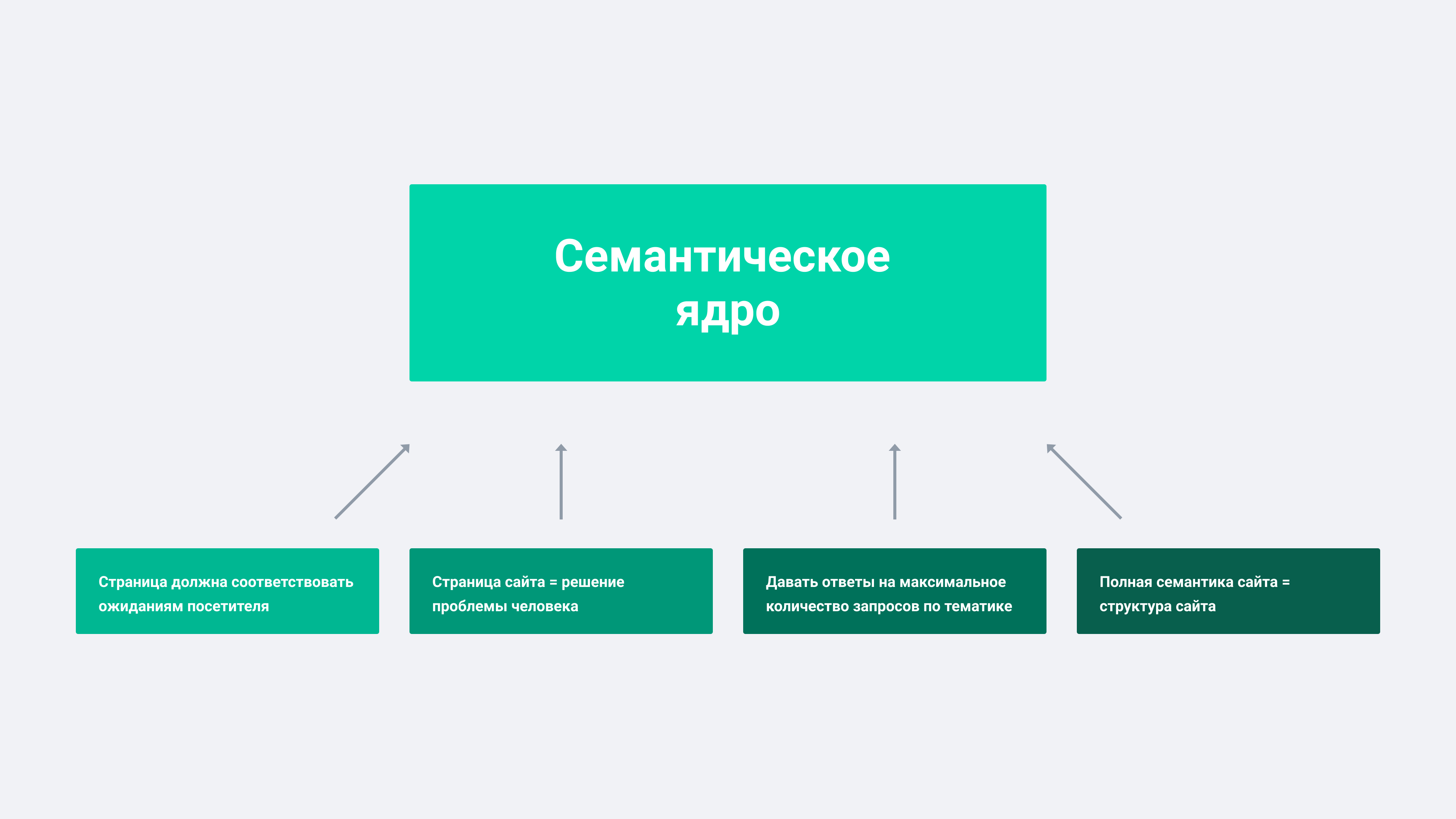
Специалисты знают: в любой сфере бизнеса можно сгенерировать десятки и сотни тысяч запросов, по которым на сайт компании придут тысячи клиентов. Большое количество ключевых запросов, размещенных на сайте, повышает его шансы подняться в ТОП-10 в поисковой выдаче.
Сколько пользователей придет на сайт, превратятся ли они в клиентов, найдут ли на сайте решение своей проблемы — все это зависит от правильно составленного семантического ядра. Никакой магии здесь нет — только четкий кропотливый труд и знание алгоритмов работы поисковых систем.
Как собрать семантическое ядро для веб-ресурса
Если Вы грамотно соберёте семантическое ядро, это не будет гарантией покорения вершин ТОПа, но, если Вы не сделаете эту работу достаточно грамотно с точки зрения поискового робота и достаточно корректно и качественно сточки зрения читателя, гарантия того, что статья не продвинется в ТОП будет достаточно большая.
Это, пожалуй, главная и основная причина того, почему каждый, кто занимается написанием статей для интернета, должен как минимум представлять, что такое семантическое ядро, как его видят поисковые роботы, как его быстро и правильно собрать.
Что такое семантическое ядро?
В сущности семантическое ядро – это набор запросов, по которым читатели с помощью поискового робота найдут на необъятных просторах интернета статью, которую Вы, возможно, ещё и не написали. Во всяком случае именно так поступают опытные авторы статей для сайтов.
Собрав ядро, становиться совершенно понятно, что именно интересует читателя. Но самое главное – понятно ещё, какие запросы интересуют в большей или меньшей мере. Разумеется, чем выше частотность, тем сложнее выйти по этим запросам в топ. Но это уже относится скорее к использованию семантического ядра. Единственное, что нужно учитывать, это ранжирование запросов по частотности.
Самый простой вариант сбора семантического ядра
Сам процесс сбора ключевых запросов, на первый взгляд, не представляет трудностей. Достаточно перейти на сервис wordstat от Yandex, ввести ключевое слово или фразу и Яндекс тут же выдаст количество запросов в месяц, плюс другие слова, с которыми ищут это слово. Если использовать для поиска и их, получим ещё больше фраз. По сути это и есть простейшее семантическое ядро.
Достаточно перейти на сервис wordstat от Yandex, ввести ключевое слово или фразу и Яндекс тут же выдаст количество запросов в месяц, плюс другие слова, с которыми ищут это слово. Если использовать для поиска и их, получим ещё больше фраз. По сути это и есть простейшее семантическое ядро.
Чтобы эффективно использовать полученные фразы, нужно определиться с темой и подобрать наиболее подходящие ключевые слова или фразы. Всё должно строится вокруг основного самого высокочастотного запроса, который, однако, нельзя рекомендовать слишком высокочастотным. Гораздо более эффективно выбрать более реальные цели. Так, к примеру, если Вы решили основным сделать фразу или слово с частотой запроса 20000 в месяц, то в тексте будет наиболее эффективно использовать несколько ключевых фраз с частотой 4000 запросов в месяц. При этом должно быть учтено то простое обстоятельство, что все эти фразы должны быть объединены в статье в единую тему и встречаться определённое количество раз.
Как правильно использовать семантическое ядро?
Что же будет правильным: написать статью и уже потом её оптимизировать на основе имеющегося текста или, наоборот, составить план статьи, определиться с количеством ключевых слов и/или фраз и потом писать текст. Технически приемлемы оба способа. Особенно, если есть опыт написания СЕО текстов. Вариант с предварительным определением Семантического ядра хорош для различных продающих текстов, также незаменим, если написание текста поручается копирайтерам. Здесь хорошее семантическое ядро и представление заказчиком структуры текста будет гарантом, что копирайтер выполнит свою работу с учётом всех нюансов, которые в полной мере может и не знать.
Технически приемлемы оба способа. Особенно, если есть опыт написания СЕО текстов. Вариант с предварительным определением Семантического ядра хорош для различных продающих текстов, также незаменим, если написание текста поручается копирайтерам. Здесь хорошее семантическое ядро и представление заказчиком структуры текста будет гарантом, что копирайтер выполнит свою работу с учётом всех нюансов, которые в полной мере может и не знать.
Что может помочь в сборе и семантического ядра?
Для составления семантического ядра можно использовать как тяжёлую артиллерии (специализированные программы, такие как Key Collector), так и различные приложения попроще. Если заниматься профессионально, конечно, Key Collector — это мощное и качественное орудие. Если объёмы недостаточно велики, работу достаточно качественно можно выполнить и вручную. Неплохим помощником для отбора будет бесплатное браузерное приложение Yandex Wordstat Assistant.
Осознавая важность составления семантического ядра на самых ранних стадиях по работе с сайтом, команда LESL. RU закладывает хорошую базу еще при создании сайта, чтобы в дальнейшем он был готов к профессиональному и эффективному продвижению. Заказывая продвижение сайта или его администрирование у нас, Вы можете быть уверены в правильном выборе надежного помощника Вашему онлайн-бизнесу.
RU закладывает хорошую базу еще при создании сайта, чтобы в дальнейшем он был готов к профессиональному и эффективному продвижению. Заказывая продвижение сайта или его администрирование у нас, Вы можете быть уверены в правильном выборе надежного помощника Вашему онлайн-бизнесу.
3 шага к построению семантического ядра | Манолис Симиониди | Блог ASOdesk 🚀
Прежде чем мы углубимся в этапы создания (построения) вашего семантического ядра, давайте сначала узнаем, что такое семантическое ядро на самом деле.
Семантическое ядро — набор ключевых слов (ключевых фраз), наиболее ясно описывающих приложение. Как вы, наверное, уже поняли, это одна из самых важных задач в ASO, потому что после создания семантического ядра мы выбрали, какие ключевые слова использовать или пропустить.
Теперь, когда мы получили определение семантического ядра, давайте посмотрим на этапы его создания.
Выбор ключевых слов — это первый и наиболее важный шаг в создании семантического ядра. Перед запуском спросите себя «Кто будет использовать мое приложение?» . После ответа на этот простой (но иногда сложный) вопрос мы можем начать с добавления нескольких ключевых слов. Ключевые слова будут отличаться в зависимости от темы вашего приложения (тема, идея). Давайте возьмем приложение и возьмем его в качестве примера. мы будем использовать приложение WhatsApp .Для этого приложения мы можем выбрать ключевые слова, такие как мессенджер, звонки, текстовые сообщения, видеозвонки и т. Д. , чтобы создать высококачественное семантическое ядро, вы можете поместить что-то, что едва ли актуально для вашего приложения, но имеет высокая посещаемость.
Перед запуском спросите себя «Кто будет использовать мое приложение?» . После ответа на этот простой (но иногда сложный) вопрос мы можем начать с добавления нескольких ключевых слов. Ключевые слова будут отличаться в зависимости от темы вашего приложения (тема, идея). Давайте возьмем приложение и возьмем его в качестве примера. мы будем использовать приложение WhatsApp .Для этого приложения мы можем выбрать ключевые слова, такие как мессенджер, звонки, текстовые сообщения, видеозвонки и т. Д. , чтобы создать высококачественное семантическое ядро, вы можете поместить что-то, что едва ли актуально для вашего приложения, но имеет высокая посещаемость.
Если ваше приложение — игра, то ваше семантическое ядро будет намного больше, чем неигровое приложение. Зачем? Просто потому, что в играх есть гораздо более широкий выбор ключевых слов, которые можно использовать. Например, если у кого-то, у кого есть приложение для путешествий на первых этапах создания семантического ядра, будет 100 ключевых слов, у того, кто создает семантическое ядро игр, будет 300 ключевых слов, большая разница, верно?
Теперь вы можете подумать, откуда у ASO-маркетологов тысячи ключевых слов в семантическом ядре? Что ж, используя инструменты ASOdesk , такие как отчет Organic report или Автоматические предложения ключевых слов , вы можете просто добавить множество релевантных ключевых слов в свое приложение. Organic report Инструмент , например, может показать 30 самых популярных ключевых слов, которые используются для поиска вашего приложения, а Автоматические предложения ключевых слов покажет вам ключевые слова с высоким трафиком, релевантные вашему приложению.
Organic report Инструмент , например, может показать 30 самых популярных ключевых слов, которые используются для поиска вашего приложения, а Автоматические предложения ключевых слов покажет вам ключевые слова с высоким трафиком, релевантные вашему приложению.
При создании семантического ядра вы должны задать себе еще один вопрос. «С кем конкурирует наше приложение?» . При таком большом росте мобильного рынка вы можете задавать этот вопрос каждый день, но если серьезно, выберите основных конкурентов для своих приложений, рынок может меняться каждый день, поэтому лучше обновлять их хотя бы раз в неделю.
Если вы используете ASOdesk, , вы можете посмотреть их Органический отчет и узнать, какие 30 запросов ключевых слов у них наиболее часто встречаются. На основе трафика ключевых слов вы можете добавить несколько ключевых слов от ваших конкурентов, которые будут полезны для вашего семантического ядра.
Несколько дней назад я проводил вебинар по ASO, в качестве примера я использовал игру The Elder Scrolls: Legends , , используя отчет Organic его конкурентов. Я успешно создал семантическое ядро этого приложения всего за несколько секунд. несколько минут.
Наконец, мы переходим к третьему этапу — анализу вашего семантического ядра. Используя инструмент ASOdesks Keywords Analytics , мы можем отслеживать оценку трафика для каждого ключевого слова в нашем семантическом ядре. Трафик отображается в виде точного значения, поэтому вам не нужно сидеть и смотреть на оценочную стоимость, чтобы понять, сколько людей выполняет конкретный поисковый запрос.
Удалите бесполезные ключевые слова; это ключевые слова, у которых слишком мало трафика. В процессе анализа вашего семантического ядра вы всегда можете использовать функцию предложений по ключевым словам , чтобы добавить больше разновидностей ключевого слова, тем самым увеличив ваше семантическое ядро.
Теперь, если вы прочитали эту статью, у вас не должно возникнуть проблем с созданием вашего первого семантического ядра и вы должны быть готовы к успеху благодаря нашему анализу ключевых слов! Но об этом мы напишем более подробно в отдельной статье.
Чтобы узнать больше об ASO и о том, как работают все инструменты в ASOdesk, перейдите по следующему адресу: www.asodesk.com Создайте учетную запись и запланируйте живую демонстрацию или задайте любые вопросы по ASO нашей команде поддержки по внутренней связи, они будут более чем счастливы чтобы помочь вам! : wink:
Хорошего дня!
пошаговое руководство — ASO Blog by ASOdesk
Построение семантического ядра — важнейшая часть оптимизации App Store, от которой зависит эффективность дальнейшего продвижения.Вам нужно найти определенные ключевые слова, которые принесут вам установки из поиска. В этой статье мы подробно расскажем, как правильно построить семантическое ядро.
Это серия статей, основанная на материалах лекций ASOdesk Academy, в которых мы рассмотрели все аспекты оптимизации App Store.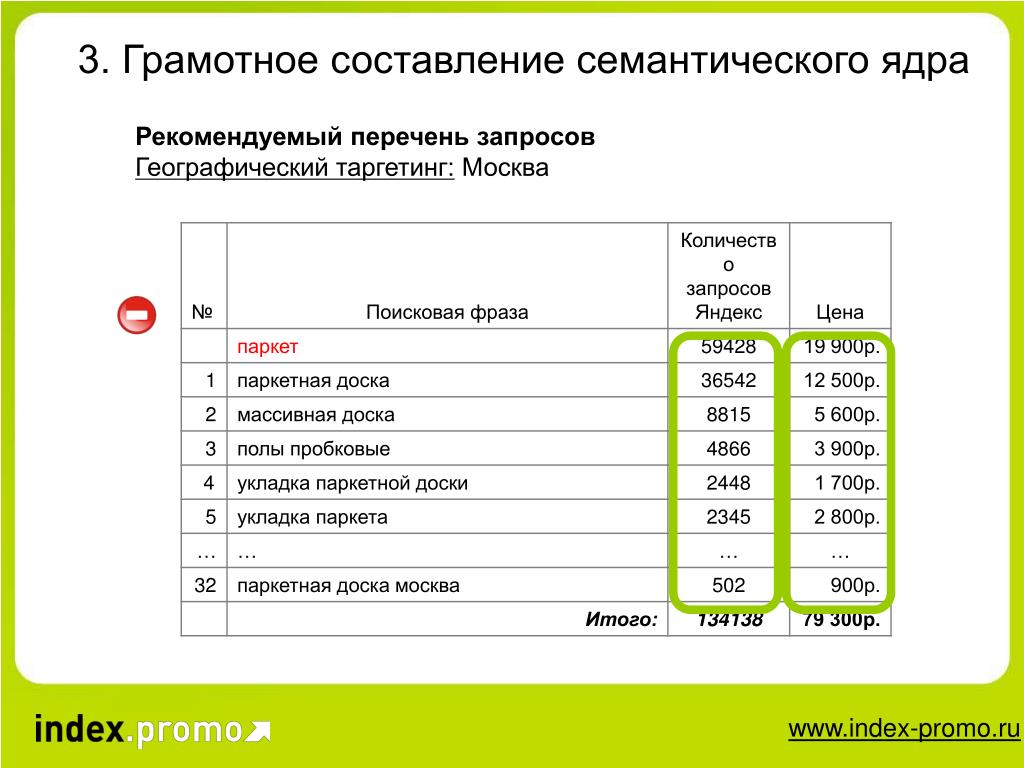 Мы уже отметили, как конкурентный анализ помогает в оптимизации App Store, как работать с итерациями в ASO и что важно учитывать при оптимизации приложения для иностранных языков.Посмотреть оригинал лекции можно здесь:
Мы уже отметили, как конкурентный анализ помогает в оптимизации App Store, как работать с итерациями в ASO и что важно учитывать при оптимизации приложения для иностранных языков.Посмотреть оригинал лекции можно здесь:
Перед построением ядра проанализируйте рынок и убедитесь, что вам нужна ASO. Чтобы проверить, нужно ли вам это, воспользуйтесь этой статьей. Вы найдете процент поискового трафика в разных категориях и получите инструкции, как проверить процент брендированного трафика в вашей нише. После того, как вы определили, в какой степени вашему приложению требуется ASO, можно переходить к построению семантического ядра.
Результатом анализа поисковых запросов будет семантическое ядро; вы будете использовать запросы ядра в текстовых метаданных. Мы выделяем следующие этапы построения семантического ядра:
Мы выделяем следующие этапы построения семантического ядра:
Обычно специалист по ASO вносит изменения в семантическое ядро перед каждой итерацией (циклом оптимизации). Чтобы вывести приложение в топ, нужно не менее 6-8 итераций. Подробнее о работе с итерациями читайте в этой статье.
Мы рассмотрим, как построить семантическое ядро на примере приложения «Workout for Women: Fit at Home».
Разработчик и специалист по мобильному маркетингу должны хорошо знать свое приложение и проблемы, которые оно решает.Перед тем, как начать продвижение, ASO-специалист также должен разбираться в продукте и знать, кому он нужен и зачем.
Поисковые запросы исходят из задач, с которыми может помочь приложение. Поэтому, прежде чем прибегать к поисковым предложениям, запишите все запросы, которые, по вашему мнению, пользователи используют для поиска похожих приложений.
Перейдите в ASOdesk Keyword Analytics и введите запросы, относящиеся к вашему приложению, в поле Добавить ключевые слова.
Если у вас фирменное приложение, начните с брендированных ключевых слов.А затем введите все общие запросы. На первом этапе у нас было 43 ключевых слова.
Добавьте ключевые слова в Keyword AnalyticsВы можете самостоятельно найти от 20 до 100 поисковых запросов. Но самостоятельно придумать все комбинации ключевых слов невозможно. Автоматические сервисы увеличат количество ключевых слов в 3-10 раз.
Автоматические предложения в аналитике ключевых словИнструмент автоматического предложения в ASOdesk находит все поисковые запросы, относящиеся к приложению.Лента поисковых предложений постоянно обновляется, и если вы добавили все перечисленные запросы, система предложит новые.
Благодаря поисковым подсказкам мы нашли еще 265 слов для нашего приложения.
Автоматические предложения в аналитике ключевых слов Отсутствует ранжированное ключевое слово Этот инструмент показывает поисковые запросы, которых еще нет в семантическом ядре, но приложение уже ранжировано по ним. Если популярность поисковой рекламы и ежедневные показы высоки, есть смысл добавить их в семантическое ядро.
Если популярность поисковой рекламы и ежедневные показы высоки, есть смысл добавить их в семантическое ядро.
Search Ads Popularity (SAP) — это показатель популярности запроса, который Apple предоставляет при настройке рекламных кампаний в Apple Search Ads. Лучше не использовать низкочастотные запросы с числом SAP менее 5.
ежедневных показов — это количество пользователей, которые ищут приложение по определенному запросу.
Мы нашли 39 слов с помощью инструмента «Недостающие ключевые слова».
Отсутствующие ранжированные ключевые слова в аналитике ключевых слов Ключевые слова с длинным хвостомОколо 70% поискового трафика приходится на запросы с длинным хвостом.Здесь вы найдете очень целевые запросы, по которым у приложения будет низкая конкуренция.
С помощью этого инструмента мы добавили еще 29 ключевых слов для приложения тренировки.
Ключевые слова с длинным хвостом в автоматических предложениях ключевых слов Шаг 3.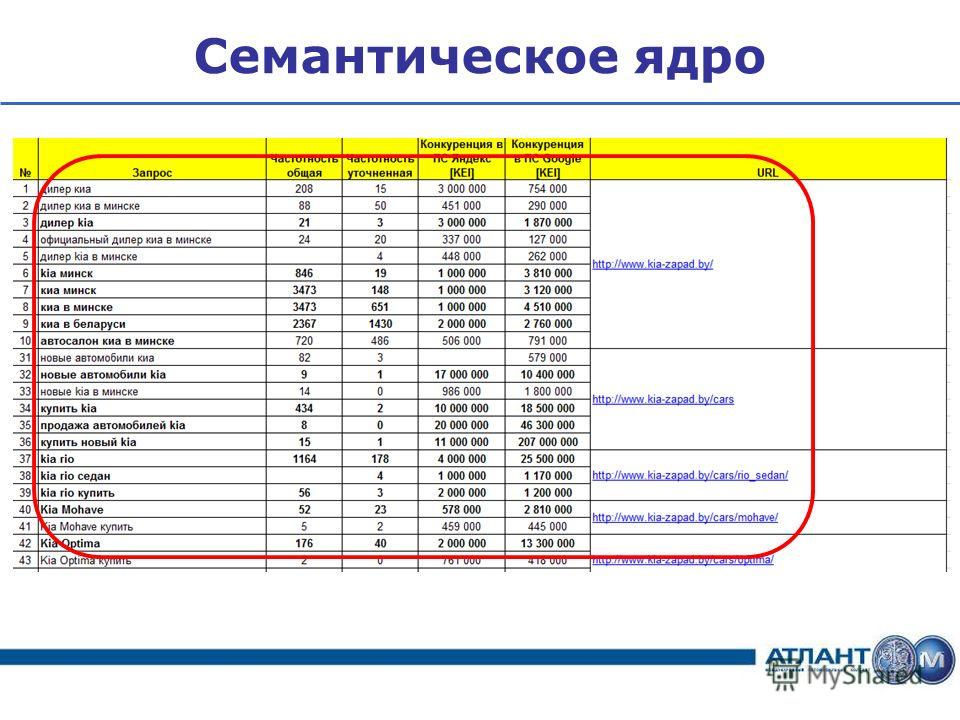 Анализ поисковых предложений в App Store
Анализ поисковых предложений в App Store При поиске приложения пользователь не вводит весь запрос, а щелкает по предложению поиска, которое предлагает магазин приложений.
Наша задача — попробовать восстановить весь путь поиска приложения.
Этот метод очень полезен для 2-4 итераций, когда вы уже используете большую часть запросов, но продолжаете искать точки роста.
С помощью предложений магазина приложений вы можете увидеть картину глазами пользователей и сузить ядро.
Например, вы работали над охватом и используете широкие запросы («фитнес», «тренировка», «похудеть»). Тогда стоит поискать более узкие поисковые запросы, подходящие под специфику приложения: «фитнес для женщин», «для начинающих», «похудеть за 30 дней» и т. Д.
Чтобы проверить свои поисковые предложения, введите ключевое слово и посмотрите, что предлагает вам магазин приложений.
Вы можете перейти к более подробной информации и ввести слова посимвольно в App Store или Google Play.
ASOdesk также поможет вам найти варианты поиска по вашим запросам. Они отображаются в таблице ключевых слов в столбце «Предложения». Мы добавили 25 слов из предложений для нашего приложения.
Таблица ключевых слов в Keyword Analytics Предложения по ключевым словам для «потери веса»Вы также можете проверить предложения с помощью инструмента Keyword Explorer.
Результаты поиска по запросу «тренировка» в проводнике ключевых словВедущие конкуренты предоставляют информацию о ключевых словах и метаданных. Вы можете увидеть прогноз количества установок, которые получат конкуренты по различным ключевым словам. А также оцените, какие слова и фразы проходит модерация.
Для анализа нужно найти конкурентов по поисковым запросам из вашей ниши. Это можно сделать через обозреватель ключевых слов в ASOdesk.
Результаты поиска по запросу «тренировка» в Keyword Explorer На этом этапе мы также проверяем релевантность ваших поисковых запросов. Если при вводе запроса в поиск вы видите похожие приложения конкурентов, это ключевое слово можно добавить в семантическое ядро. Если по этому запросу ранжируются совершенно разные приложения, вам не следует использовать этот запрос.
Если при вводе запроса в поиск вы видите похожие приложения конкурентов, это ключевое слово можно добавить в семантическое ядро. Если по этому запросу ранжируются совершенно разные приложения, вам не следует использовать этот запрос.
Например, в результатах поиска по запросу «тело» много приложений и игр для редактирования фотографий, но не фитнес-приложений. Поэтому нам нужно удалить это ключевое слово из семантического ядра или использовать его только в сочетании с другими словами (идеальное тело, здоровое тело).
Результаты поиска по запросу «body» в Keyword ExplorerВ ASOdesk вы можете найти и проанализировать до 9 конкурентов одновременно, используя следующие инструменты:
Органический отчетПоказывает прогноз установок по поисковым запросам, по которым оценивается приложение конкурента (оценка установок).
Мы проанализировали конкурента и нашли поисковые запросы. Теперь добавим в семантическое ядро самые актуальные.
Инструмент на основе приложений конкурентов показывает запросы, которых нет в нашем ядре.По этим запросам похожие приложения входят в топ-1, топ-2–5 и т. Д.
В ходе анализа мы добавили 73 запроса к приложению тренировки.
Отсутствующие ключевые слова конкурентов в аналитике ключевых слов Конкуренты Лучшие ключевые словаНаходит самые популярные запросы, по которым установки у ваших конкурентов. Вы можете добавить эти запросы в свое семантическое ядро. Мы добавили 24 ключевых слова для нашего приложения.
Конкуренты Лучшие ключевые слова в ключевых словах Автоматические предложения Наименее конкурентоспособные ключевые слова Если приложение еще не пользуется популярностью, по высокочастотным запросам попасть в топ будет невозможно.Следовательно, вам нужно ранжироваться по запросам с низкой конкуренцией.
В результате анализа мы нашли 30 ключевых слов для приложения для тренировки.
Ключевые слова наименее конкурентов в автоматических предложениях ключевых слов Сравнительный отчет ASOЭтот инструмент позволяет вам видеть ключевые слова, по которым у конкурентов растут или падают позиции в поиске, а также недавно добавленные ключевые слова.
Ключевые слова можно фильтровать с помощью движения. Мы добавили 27 ключевых слов.
Начните оптимизацию своего приложения с ASOdesk
Кредитная карта не требуется
Шаг 5. Очистите ядро от нерелевантных и низкочастотных запросов Все запросы, которые мы собрали в ходе анализа, отображаются в таблице ключевых слов. В результате построения семантического ядра приложения для тренировок мы получили 439 ключевых слов.
Количество метаданных ограничено. Поэтому мы не можем включить все указанные запросы в заголовок, описание и ключевые слова. Вам нужно выбрать именно те ключевые слова, которые принесут установки. Поэтому важно очистить ядро от нерелевантных и низкочастотных запросов.
Удалить нерелевантные запросы из семантического ядраВаше приложение должны найти только те, кто заинтересован в его использовании.
Например, в вашем приложении есть только упражнения для похудения и наращивания мышц, но в нем отсутствуют функции диеты и подсчета калорий.
В этом случае не следует добавлять в семантическое ядро ключевые слова «диета», «кето-диета» или «подсчет калорий». Если пользователи загрузят приложение, а затем поймут, что искали что-то совершенно другое, вы получите отрицательные отзывы.
Количество удалений будет расти, а жизненный цикл и коэффициент удержания пользователей упадут. Поэтому выбирайте только релевантные запросы, чтобы приложение находили те пользователи, которым оно действительно нужно.
Поэтому выбирайте только релевантные запросы, чтобы приложение находили те пользователи, которым оно действительно нужно.
Например, модерация не будет проходить запросы «Nike training», «GetFit», «BetterMe» для приложения «Workout for Women: Fit at Home».
Но мы можем добавить фирменный запрос с ошибкой: «get fitt», «beterme» и т. Д. Такие запросы иногда можно проиндексировать.
IOS 14 добавила функцию автокоррекции, которая автоматически исправляет опечатки. Чтобы узнать, следует ли использовать фирменный запрос с ошибкой, попробуйте ввести его в строку поиска App Store и посмотрите, исправляет ли его магазин приложений.
Используйте бренд, если приложение связано с другим приложением. Например, мы можем вставить «WhatsApp» в заголовок, если будем делать стикеры для этого мессенджера.
Анализ имен конкурентов Остальные запросы разбить на группы После декайтинга всех нерелевантных ключевых слов у нас осталось 411 ключевых слов.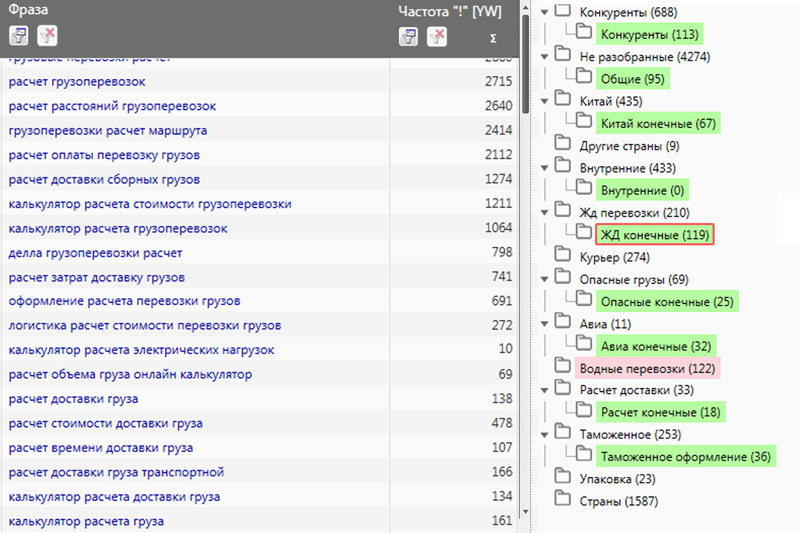 С помощью умного флажка вы можете сортировать ключевые слова по популярности Search Aps, ежедневным показам и другим параметрам. Вы можете установить желаемые значения или просто нажать на желаемый индикатор, и система автоматически покажет ключевые слова для максимального или минимального значения. Например, на скриншоте мы отфильтровали ключевые слова в порядке возрастания: от самого низкого SAP до самого высокого.
С помощью умного флажка вы можете сортировать ключевые слова по популярности Search Aps, ежедневным показам и другим параметрам. Вы можете установить желаемые значения или просто нажать на желаемый индикатор, и система автоматически покажет ключевые слова для максимального или минимального значения. Например, на скриншоте мы отфильтровали ключевые слова в порядке возрастания: от самого низкого SAP до самого высокого.
Для удобства анализа запросов разделим их на 4 группы:
Низкочастотные поисковые запросы: Популярность поисковых объявлений от 5 до 15Мы не будем включать запросы с SAP 5 в метаданные.Они будут занимать много места, но мы не получим с них установок, так как их практически не ищут в любой день.
Запросы от SAP выше 5 перейдут в дополнительную локаль. Например, если вторичный языковой стандарт предназначен только для Испании, поле ключевых слов может содержать запросы на испанском языке, которые не подходят к основному языку.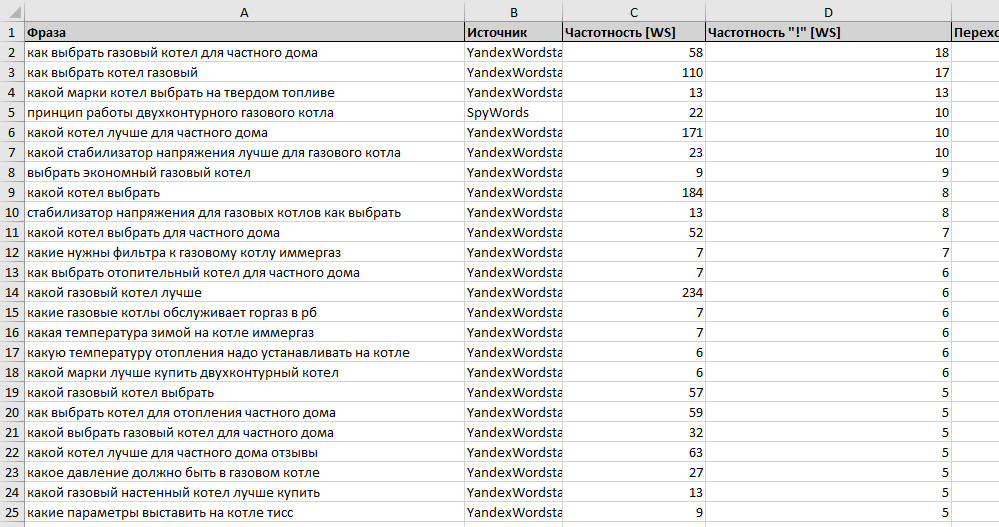
Мы также добавим их в отдельную категорию и посмотрим, как меняются популярность поисковой рекламы и количество показов в день для этих ключевых слов.Давайте отфильтруем запросы по популярности Search Aps и выделим их синим цветом.
Мы также удалили ключевые слова, у которых ежедневный показ равен 0. Теперь у нас осталось 319 слов.
Низкочастотные запросы в таблице ключевых слов Запросы, для которых система в настоящее время подсчитывает трафик: Расчет популярности поисковой рекламыЕсли вы видите слово «Расчет», значит, вы нашли новый запрос. Ранее пользователи ASOdesk не искали такие запросы, поэтому у нас пока нет данных об их популярности.
Добавьте их в отдельную группу. Вам нужно подождать, пока система рассчитает популярность поисковых объявлений и ежедневные показы для этих запросов, а затем решить, сохранить их или удалить.
Запросы, по которым учитывается трафик Высокочастотные поисковые запросы: Популярность поисковой рекламы более 40 Популярные запросы не работают для приложений, которые только появляются на рынке. Конкуренция за них уже высока, и вы не получите позиций. Поэтому не сосредотачивайтесь исключительно на популярных поисковых запросах.На первых итерациях лучше не использовать ключевые слова с популярностью поисковой рекламы более 40.
Конкуренция за них уже высока, и вы не получите позиций. Поэтому не сосредотачивайтесь исключительно на популярных поисковых запросах.На первых итерациях лучше не использовать ключевые слова с популярностью поисковой рекламы более 40.
Кроме того, высокочастотные запросы все равно будут отображаться в ваших метаданных. Например, метаданные нашего приложения будут включать запросы «тренировка», «домашняя тренировка». Вам просто нужно отслеживать такие запросы в процессе оптимизации.
Высокочастотные поисковые запросы в таблице ключевых слов Среднечастотные запросы: Популярность поисковых объявлений от 15 до 40Если ваше приложение только выходит на рынок, добавьте в семантическое ядро поисковые запросы с популярностью от 16 до 40.
Среднечастотные запросы в таблице ключевых слов Необходимо изучать поисковые запросы перед каждой итерацией и включать их в семантические когорты. Например, во время итерации сужения ядра мы видим, что запросы с «потерей веса» набирают популярность в поиске. Тогда стоит добавить в метаданные больше похожих ключевых слов.
Тогда стоит добавить в метаданные больше похожих ключевых слов.
Для построения семантического ядра нужно 5 простых шагов:
1. Добавьте все поисковые запросы, относящиеся к приложению, исходя из вашего мнения.
2. Расширьте семантическое ядро с помощью автоматизированных предложений ASO-сервисов.
3. Добавьте ключевые слова из автопредложений магазина приложений.
4. Проанализируйте своих конкурентов. Найдите запросы, по которым приложения конкурентов: поднимаются в поиске, получают наибольшее количество установок, находятся в верхней части результатов поиска.
5. Очистите ядро от неконкурентоспособных и нерелевантных запросов. Мы должны оставить только те ключевые слова, которые принесут нам установки.
На основе построенного семантического ядра подготовьте метаданные.При этом учитывайте правила App Store и Google Play, а также факторы ранжирования приложений в магазине. Подробнее об этих факторах читайте в нашей статье.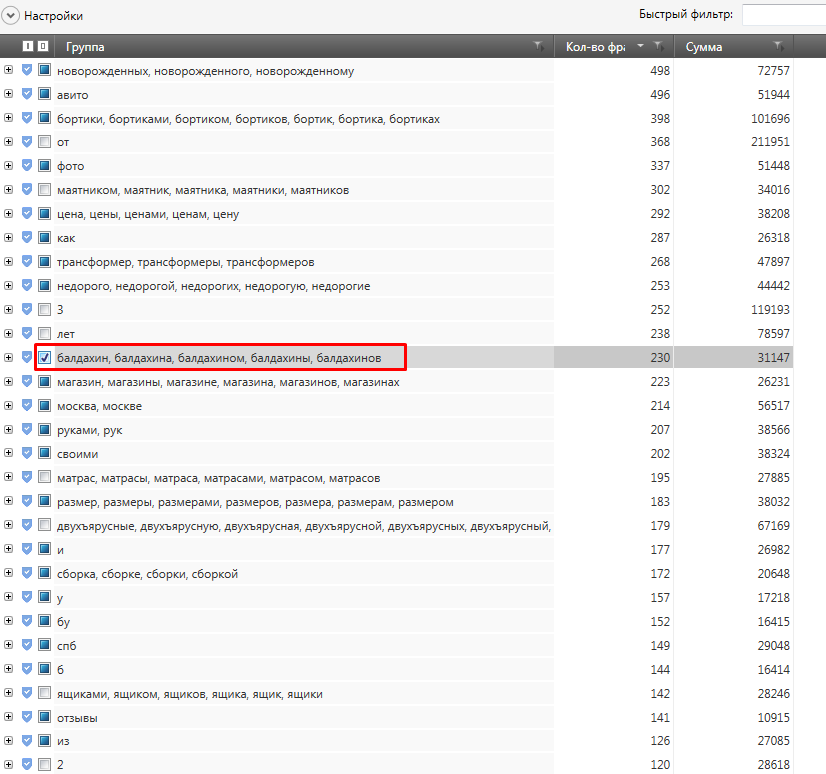
Как сгруппировать фразы для смыслового ядра сайта
И вот мы пытаемся разобраться, что такое семантическое ядро и как его собирать. Но эта информация абсолютно бесполезна без знания правил группировки и кластеризации фраз.
Почему групповая фраза?
Важно, что семантическое ядро должно учитывать не сколько основных факторов, а именно желание, интересы пользователей и соответствие бизнес-целям проекта.Необходимо семантическое ядро группировки фраз:
- создание семантического ядра структуры сайта помогает определить форму, в которой необходимо организовать меню сайта и внутренние ссылки на страницы;
- маркетинговый анализ — проанализировать текущий спрос на товары и услуги; ,
- создать контент-план — выбор интересующих пользователя тем, а также выбор запросов для оптимизации конкретных страниц сайта;
- создать правильную перелинковку сайта;
- разделение запросов на коммерческие и информационные, которые запрашивает пользователь, лучше всего соответствуют бизнес-целям веб-сайта.
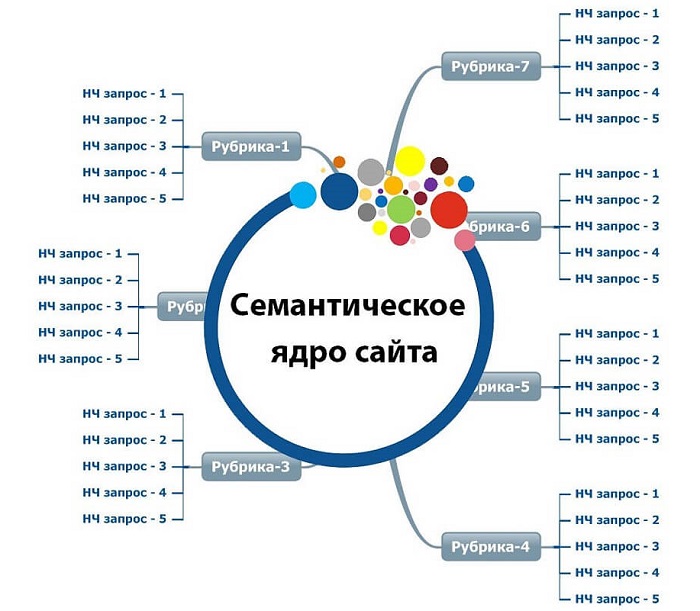
Грамотная группа поисковых запросов позволяет максимально увеличить посещаемость поисковых систем.
Существует несколько способов кластеризации ключевых фраз в семантическом ядре.
Группировка также может выполняться по типу
Информационные запросы следует сразу выделить в отдельную группу. Когда человек вводит запрос, он хочет найти информацию для решения конкретной проблемы. Такие запросы характерны для информационных порталов, новостных изданий, в целом для информационных, научно-популярных, образовательных сайтов.
К информационным запросам можно отнести ключевые фразы «что», «когда», «где», «как» и «инструкция», «обратная связь», «форум» и так далее.
Например:
- качественных обзоров трафика
- индивидуальный график трафика до и после
- трафик есть пробок
- сделать самому
- форум качественных обзоров трафика
Транзакционные (коммерческие) запросы помогают пользователю выполнить какое-либо действие — скачать, купить, скачать. Для интернет-магазинов это транзакционные запросы, в результате которых получается целевая и эффективная аудитория.
Для интернет-магазинов это транзакционные запросы, в результате которых получается целевая и эффективная аудитория.
Примеры:
- цена трафика
- сколько стоит посещаемость на сайт
- стоимость трафика
- стоимость трафика по гео
В отдельную группу выделены геозависимые запросы. Это запросы, по которым пользователь ожидает увидеть местные или региональные сайты.
Например:
- ремонтные услуги
- внутренняя отделка дома
- специалистов по ремонту
Общие или нечеткие запросы могут быть как информационными, так и транзакционными.В этом случае неясна цель пользователя. Конверсия для этого типа запросов намного меньше, чем для транзакционного.
Примеры:
- посещаемость бизнес-сайта
- посещаемость сайта
- быстро увеличить посещаемость сайта
- варианты трафика
Продвигать сайт по запросам сложно, так как непонятно, что нужно пользователю: информация о «посещаемости» или заказ услуги.
Необходимо определить синонимичный запрос:
- заказ трафика
- для заказа посетителей на сайт
И профессионализм:
- цена трафика
- цена быстрого трафика
Группировка по значению в первую очередь предназначена для удобства пользователя. Мы должны понимать требования к уровню продукта или услуги и вести к цели.
Группировка запросов по типу страницы
Основные типы страниц:
- main — слова и фразы, которые в целом характерны для сайта, например: качественный трафик на сайт из Эстонии;
- категорий / подкатегорий товаров и услуг — общее количество запросов на товары и услуги, например: цена трафика, трафик из Эстонии;
- карта товаров / услуг — группируйте запросы, относящиеся к конкретному товару или услуге, например: CPC, CPM;
- информационных страниц (блог / статья), которые будут отвечать на конкретный информационный запрос, например: что такое SEO и почему это важно; для других страниц.

Правила группировки ключевых слов:
1. Один токен-запрос перемещает одну страницу веб-сайта. Это не значит, что для каждого запроса сайт должен быть отдельной страницей. Просто одним и тем же запросом нельзя оптимизировать несколько страниц. В противном случае на сайте появится похожая по смыслу страница, что приведет к затруднениям в навигации.
2. Выбранные ключевые слова для страницы должны давать исчерпывающий ответ пользователю. Например, появление слова «купить» в запросе должно привести к покупке продукта на сайте.По запросу «цена» пользователь должен увидеть прайс-лист.
3. Высокочастотные запросы не должны быть дальше одного-двух кликов от домашней страницы по категориям.
4. На главной странице рекомендуется делать общие запросы, более конкретные запросы товаров, услуги должны быть отнесены к категориям страниц и товаров.
5. Недопустимо совмещение коммерческого и информационного запроса посещения.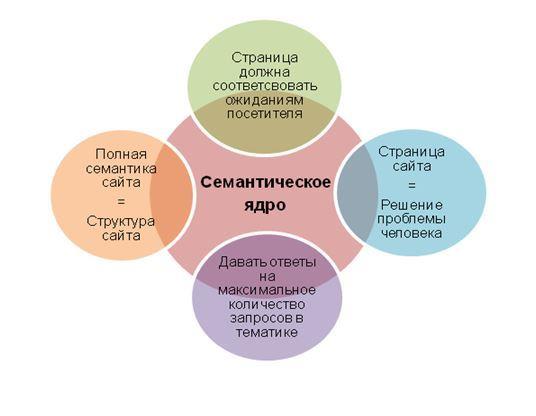 Коммерческие запросы — каталоги, прайс-листы, страницы, услуги, информация, статьи, новости, сообщения в блогах.
Коммерческие запросы — каталоги, прайс-листы, страницы, услуги, информация, статьи, новости, сообщения в блогах.
6. В одну группу лучше всего добавлять слова, очень близкие по значению и структуре к другим в пределах слов запроса. Например, такими запросами могут быть «посещаемость сайта», «быстрый трафик», «качество трафика».
Что обычно делают ошибки при группировке фраз
1. Не используйте низкочастотные запросы
Создание фильтра для низкочастотных запросов позволяет сделать страницу более полезной и удобной. Низкочастотные запросы более точны и указывают на конкретный продукт или услугу, которые, в свою очередь, приводит к дальнейшим успешным преобразованиям.
Например:
- мастер по дизайну интерьера дома
- внутренняя отделка без мастера
2. Смешение коммерческих и информационных запросов
Эти два типа запросов имеют разные цели — привлечение готовых к покупке клиентов и расширение диапазона запросов, которые могут обнаружить сайт.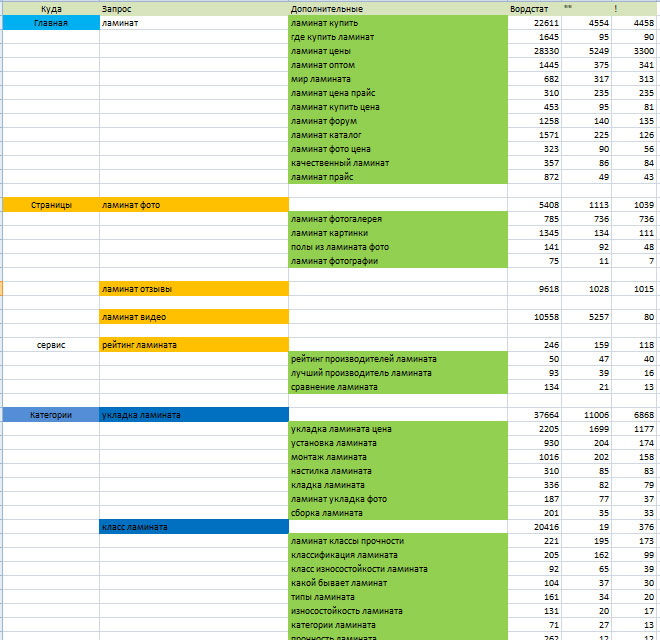
3. Объединить разные группы на одной странице
Вернемся к тому, что для каждой группы запросов должна быть своя посадочная страница.
Первый и второй запросы — сгруппировать и разместить на одной целевой странице, четвертую и пятую — на другой. У каждого последующего запроса должна быть своя целевая страница.
Так пользователь увидит страницу с необходимой информацией.
Статистика
- Семантическое ядро должно полностью определять объем проекта.
- Группа ключевых слов нужна для многих целей — от анализа рынка товаров и услуг до создания оптимальной структуры сайта;
- При группировании запросы должны начинаться с бизнес-целей проекта;
Основные правила при группировании ключевых слов:
- одна группа поисковых запросов на одной целевой странице;
- целевая страница должна соответствовать запросам пользователя и давать исчерпывающий ответ;
- Не нужно продвигать проект в общих чертах, а также смешивать в одной группе информационные и коммерческие запросы.

Правильно группируйте запросы и привлекайте максимум трафика с поисковых систем.
(PDF) Скажите больше, чем просто сборка! Обращение киберфизической семантики исполнения двоичных файлов встроенного контроллера Интернета вещей
преобразует его с дополнительной информацией времени выполнения и генерирует
повторно используемых программных компонентов. Однако TOP не может гарантировать семантическое восстановление
для алгоритмов контроллера, поскольку не может заполнить семантический пробел
между восстановленным исходным кодом и соответствующими абстрактными алгоритмическими концепциями
, т.е.е., параметры
,и математические операции. Методы двоичного обратного проектирования —
niques [18], [36], [35], [49], [53] могут точно извлекать типы данных из
двоичных файлов. Недавние работы [36], [53] восстанавливают только информацию
, которая исходит из семантики параметров системных вызовов
.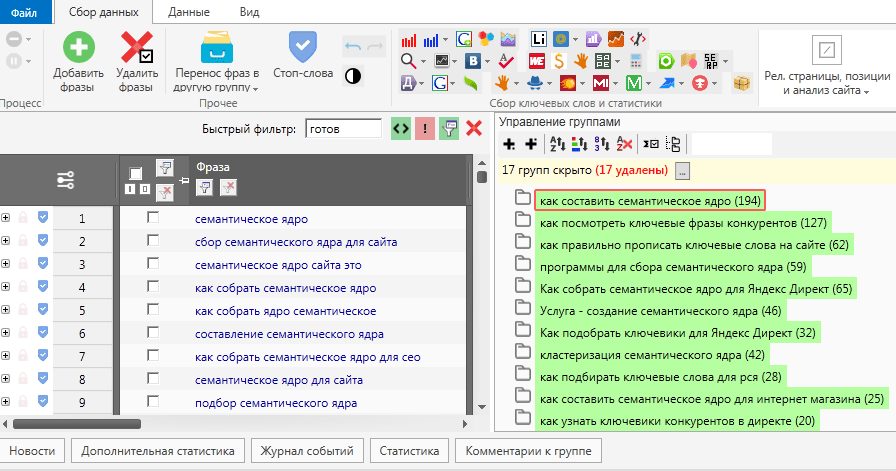 Хотя информация о типе полезна при проектировании двоичного обратного
Хотя информация о типе полезна при проектировании двоичного обратного
, она все же не обеспечивает семантику высокого уровня алгоритма
для двоичного кода и сегментов данных.
Низкоуровневая проверка подобия. Множество алгоритмов подобия кода
на основе CFG было предложено ранее [32], [50],
[55], но не было никакой работы по сравнению двоичных инструкций
низкого уровня с математическими алгоритмическими командами высокого уровня.
выражений. Дифференциальное тестирование представляет собой эффективный способ обнаружения
низкоуровневых различий между независимыми реализациями
с аналогичными предполагаемыми функциями.BINDIFF [19],
[25] широко используется и заработал репутацию
как отраслевой стандарт для двоичной дифференциации. BINDI FF
начинается с восстановления графов управляющих потоков (CFG) двух двоичных файлов
и использует эвристику для нормализации и сопоставления вершин
из двух графов. BINJUICE [34] извлекает синтаксические
BINJUICE [34] извлекает синтаксические
уравнений из базовых блоков для измерения сходства между двумя базовыми блоками
. BLEX [21] использует динамический подход для поиска двоичного кода
.Поиск зависит от двух похожих кодов
, имеющих синтаксически похожее низкоуровневое поведение выполнения. Сюй
и др. [56] используют нейронные сети для поиска сходства
между исполняемыми файлами на основе теоретико-графического анализа их графов управляющих потоков
. Для нашей проблемы одна из основных проблем с
вышеупомянутыми решениями заключается в том, что большинство программного обеспечения контроллера
имеет индивидуальные реализации связанных алгоритмов.
Следовательно, прямое сравнение скомпилированной реализации алгоритма
с отдельной реализацией будет бесполезным
в разных реализациях.
VII. ВЫВОДЫ
Мы представили MISMO, общую структуру для извлечения
семантической информации встроенных двоичных файлов микропрограммного обеспечения с
относительно связанного с ним высокоуровневого алгоритма управления. Мы
Мы
оценили MISMO на 2263 двоичных файлах коммерческого микропрограммного обеспечения
30 отраслевыми поставщиками из 6 реальных киберфизических доменов приложений IoT
. Нам удалось извлечь их семантическую
информации относительно алгоритма.Мы использовали MISMO
для обнаружения уязвимости нулевого дня в последней версии ядра Linux
и обеспечили детализированную защиту конфиденциальных данных
в приложении для самоуправляемых автомобилей.
БЛАГОДАРНОСТИ
Мы признательны Office of Naval Research (ONR) и Национальному научному фонду Na-
(NSF) за поддержку нашего проекта
.
ССЫЛКИ
[1] «Статический анализатор Clang; доступно по адресу http: // clang-analyzer.llvm.org/ ».
[2] «Средство для очистки потоков данных; доступно по адресу http://clang.llvm.org/docs/
DataFlowSanitizerDesign.html ».
[3] «Ollydbg; доступно на http://www.ollydbg.de ».
[4] «Модель Simulink для изучения фильтра Калмана для гауссовских процессов;
доступно на http://www.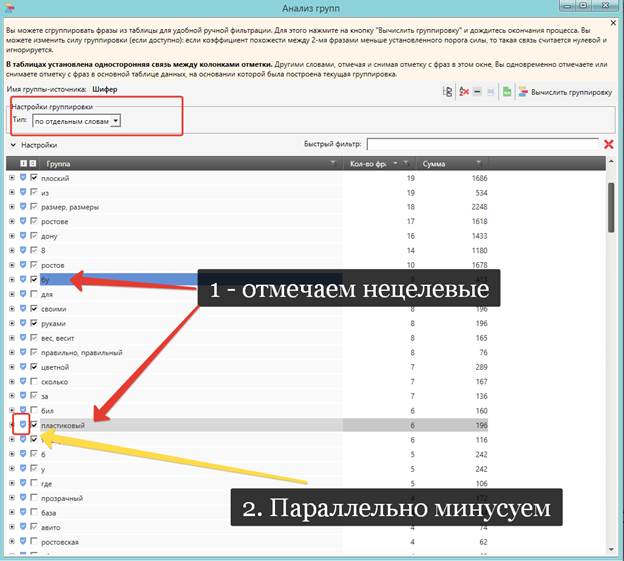 mathworks.com ».
mathworks.com ».
[5] «Snowman: собственный код декомпилятора c / c ++; доступно по адресу http:
//derevenets.com/ ».
[6] М. Абади, М. Будиу, ´
U.Эрлингссон и Дж. Лигатти, «Принципы, реализации и приложения целостности Controlflow
», ACM Transac-
tions on Information and System Security (TISSEC), vol. 13, нет. 1, стр. 4,
2009.
[7] К. Ангриши, «Превращение Интернета вещей (iot) в Интернет уязвимостей-
уязвимостей (iov): бот-сети Интернета», препринт arXiv arXiv: 1702.03681, 2017.
[ 8] M. Antonakakis, T. April, M. Bailey, M. Bernhard, E. Bursztein,
J. Cochran, Z.Дурумерик, Дж. А. Халдерман, Л. Инверницци, М. Каллицис
и др., «Понимание ботнета mirai», в симпозиуме по безопасности USENIX,
2017, стр. 1092–1110.
[9] Ф. Беллард, «Qemu, быстрый и портативный динамический переводчик». в Ежегодной технической конференции USENIX
, FREENIX Track, 2005, стр. 41–46.
[10] К. Кадар, Д. Данбар, Д. Р. Энглер и др., «Клее: автоматическое и автоматическое создание
Кадар, Д. Данбар, Д. Р. Энглер и др., «Клее: автоматическое и автоматическое создание
автоматических тестов с высоким уровнем покрытия для сложных системных программ.”
в OSDI, vol. 8. 2008. С. 209–224.
[11] А. А. Карденас, С. Амин и С. Састри, «Безопасный контроль: к
живучестикиберфизических систем», в 2008 г. 28-я Международная конференция
по распределенным вычислительным системам. IEEE, 2008,
, с. 495–500.
[12] О. Сертик и др., «Sympy python library for symbolic Mathematics»,
2008.
[13] Б. Чен, X. Лю, Х. Чжао и JC Pr´
ıncipe, «Максимальный коррентропный фильтр
Калмана», Автоматика, т.76, pp. 70–77, 2017.
[14] Э. Чиен, Л. Омерчу и Н. Фальер, «W32.Duqu — предшественник
следующего Stuxnet», Symantic Security Response, Tech. Rep., 2011.
[15] В. Чипунов, В. Кузнецов, Г. Кандеа, «S2e: платформа для многопутевого анализа программных систем in-
vivo», ACM SIGPLAN Notices,
vol. . 46, нет. 3, pp. 265–278, 2011.
. 46, нет. 3, pp. 265–278, 2011.
[16] H. Choi, W.-C. Ли, Я. Аафер, Ф. Фэй, З. Ту, Х. Чжан, Д. Сюй и
X. Синьян, «Обнаружение атак против роботизированных транспортных средств: подход, контролирующий инвариант
,» в Proceedings of the Конференция ACM SIGSAC 2018 по
компьютерной и коммуникационной безопасности.ACM, 2018. С. 801–816.
[17] В. Костан и С. Девадас, «Intel sgx объяснил». IACR Cryptology ePrint
Архив, т. 2016, вып. 086, pp. 1–118, 2016.
[18] А. Коззи, Ф. Стрэттон, Х. Сюэ и С. Т. Кинг, «Поиск данных
структур». в OSDI, т. 8. 2008. С. 255–266.
[19] Т. Дуллиен и Р. Роллес, «Графическое сравнение исполняемых объектов
(английская версия)», SSTIC, vol. 5, pp. 1–3, 2005.
[20] К. Игл, Профессиональная книга IDA: неофициальное руководство по самому популярному дизассемблеру
в мире.No Starch Press, 2011.
[21] М. Эгеле, М. Ву, П. Чепмен и Д. Брамли, «Бланкетное выполнение:
Динамическое тестирование подобия для двоичных файлов и компонентов программ». в
в
Usenix Security, 2014, стр. 303–317.
[22] М. Эммерик и Т. Уоддингтон, «Использование декомпилятора для восстановления исходного кода
в реальном мире», в Reverse Engineering, 2004. Proceedings. 11-я
Рабочая конференция по. IEEE, 2004, стр. 27–36.
[23] F-Secure Labs, «BLACKENERGY и QUEDAGH: конвергенция
криминального ПО и APT-атак», 2016 г.
[24] Н. Фальер, Л. О. Мурчу, Э. Чиен, «W32. досье stuxnet », Белая бумага
, Symantec Corp., Security Response, vol. 5, вып. 6, стр. 29, 2011.
[25] Х. Флаке, «Структурное сравнение исполняемых объектов», DIMVA 2004,
6-7 июля, Дортмунд, Германия, 2004.
[26] Л. Гарсия и С. А. Зонуз, « Эй, моя зловреда знает физику! атака
ПЛК с помощью руткита, учитывающего физическую модель », 2017.
[27] M. Gowda, J. Manweiler, A. Dhekne, R.Р. Чоудхури и Дж. Д. Вайс,
«Отслеживание ориентации дрона с помощью нескольких GPS-приемников», в материалах
22-й ежегодной международной конференции по мобильным вычислениям и
сети. АКМ, 2016, с. 280–293.
[28] Hex-Rays, «Дизассемблер Ida pro; доступно на http://wiki.ros.org/ros
Arduino Bridge ».
[29] А. П. М. Хинкканен, «Защита промышленного привода переменного тока от кибер-саботажа
», доктор философии. диссертация, Университет Аалто, 2013.
12
Работа с семантической моделью .NET Compiler Platform SDK
- 3 минуты на чтение
В этой статье
Синтаксические деревья представляют лексическую и синтаксическую структуру исходного кода. Хотя одной этой информации достаточно для описания всех деклараций и логики в источнике, ее недостаточно для определения того, на что делается ссылка.Имя может представлять:
- тип
- поле
- метод
- локальная переменная
Хотя каждый из них уникально отличается, определение того, к какому идентификатору фактически относится, часто требует глубокого понимания языковых правил.
Есть программные элементы, представленные в исходном коде, и программы также могут ссылаться на ранее скомпилированные библиотеки, упакованные в файлы сборки. Хотя для сборок нет исходного кода и, следовательно, нет синтаксических узлов или деревьев, программы все же могут ссылаться на элементы внутри них.
Для этих задач вам понадобится семантическая модель .
В дополнение к синтаксической модели исходного кода семантическая модель инкапсулирует правила языка, давая вам простой способ правильно сопоставить идентификаторы с правильным элементом программы, на который ссылаются.
Сборник
Компиляция — это представление всего, что необходимо для компиляции программы на C # или Visual Basic, включая все ссылки на сборки, параметры компилятора и исходные файлы.
Поскольку вся эта информация находится в одном месте, элементы, содержащиеся в исходном коде, могут быть описаны более подробно. Компиляция представляет каждый объявленный тип, член или переменную в виде символа. Компиляция содержит множество методов, которые помогут вам найти и связать символы, которые были либо объявлены в исходном коде, либо импортированы как метаданные из сборки.
Подобно синтаксическим деревьям, компиляции неизменяемы. После создания компиляции вы или кто-либо другой, с кем вы можете поделиться ею, не можете изменить ее.Однако вы можете создать новую компиляцию из существующей компиляции, указав при этом изменения. Например, вы можете создать компиляцию, которая во всех отношениях будет такой же, как и существующая компиляция, за исключением того, что она может включать дополнительный исходный файл или ссылку на сборку.
Символы
Символ представляет отдельный элемент, объявленный исходным кодом или импортированный из сборки как метаданные. Каждое пространство имен, тип, метод, свойство, поле, событие, параметр или локальная переменная представлены символом.
Разнообразные методы и свойства типа «Компиляция» помогают находить символы. Например, вы можете найти символ объявленного типа по его общему имени в метаданных. Вы также можете получить доступ ко всей таблице символов как к дереву символов, основанному на глобальном пространстве имен.
Вы также можете получить доступ ко всей таблице символов как к дереву символов, основанному на глобальном пространстве имен.
Символы также содержат дополнительную информацию, которую компилятор определяет из источника или метаданных, например, другие символы, на которые есть ссылки. Каждый тип символа представлен отдельным интерфейсом, производным от ISymbol, каждый со своими собственными методами и свойствами, детализирующими информацию, собранную компилятором.Многие из этих свойств напрямую ссылаются на другие символы. Например, свойство IMethodSymbol.ReturnType сообщает вам фактический символ типа, который возвращает метод.
Символы представляют собой общее представление пространств имен, типов и членов между исходным кодом и метаданными. Например, метод, объявленный в исходном коде, и метод, который был импортирован из метаданных, представлены IMethodSymbol с одинаковыми свойствами.
Символы похожи по концепции на систему типов CLR, представленную System. Reflection API, но они богаче тем, что моделируют больше, чем просто типы. Пространства имен, локальные переменные и метки — все символы. Кроме того, символы представляют собой концепции языка, а не концепции CLR. Есть много совпадений, но есть и много значимых различий. Например, метод итератора в C # или Visual Basic — это отдельный символ. Однако, когда метод итератора переводится в метаданные CLR, это тип и несколько методов.
Reflection API, но они богаче тем, что моделируют больше, чем просто типы. Пространства имен, локальные переменные и метки — все символы. Кроме того, символы представляют собой концепции языка, а не концепции CLR. Есть много совпадений, но есть и много значимых различий. Например, метод итератора в C # или Visual Basic — это отдельный символ. Однако, когда метод итератора переводится в метаданные CLR, это тип и несколько методов.
Семантическая модель
Семантическая модель представляет всю семантическую информацию для одного исходного файла.Вы можете использовать его, чтобы обнаружить следующее:
- Символы, на которые есть ссылка в определенном месте в источнике.
- Результирующий тип любого выражения.
- Вся диагностика, представляющая собой ошибки и предупреждения.
- Как переменные попадают в регионы источника и из них.
- Ответы на более умозрительные вопросы.
Введение в ARIA | Основы Интернета | Разработчики Google
Меггин — технический писатель
Дэйв — технический писатель
Алиса является соавтором Web Fundamentals
До сих пор мы поощряли использование собственных HTML-элементов, потому что они дают вам фокус,
поддержка клавиатуры и встроенная семантика, но бывают случаи, когда простой
макет и собственный HTML не помогут. Например, сейчас нет
стандартизированный элемент HTML для очень распространенной конструкции пользовательского интерфейса — всплывающего меню. Ни
есть ли элемент HTML, который обеспечивает семантическую характеристику, такую как »
пользователь должен узнать об этом как можно скорее ».
Например, сейчас нет
стандартизированный элемент HTML для очень распространенной конструкции пользовательского интерфейса — всплывающего меню. Ни
есть ли элемент HTML, который обеспечивает семантическую характеристику, такую как »
пользователь должен узнать об этом как можно скорее ».
В этом уроке мы исследуем, как выразить семантику, которую HTML не может выразить самостоятельно.
Доступные многофункциональные Интернет-приложения Инициативы по обеспечению доступности Интернета спецификация (WAI-ARIA или просто ARIA) хорош для преодоления проблем доступности, с которыми невозможно справиться с собственным HTML.Он работает, позволяя вам указывать атрибуты, которые изменяют способ перевода элемента в дерево доступности. Давайте посмотрим на пример.
В следующем фрагменте мы используем элемент списка как своего рода настраиваемый флажок. В Класс CSS «checkbox» придает элементу требуемые визуальные характеристики.
Получать рекламные предложения
Хотя это нормально работает для зрячих пользователей, программа чтения с экрана не покажет
что элемент должен быть флажком, поэтому пользователи с ослабленным зрением могут пропустить
элемент целиком.
Однако, используя атрибуты ARIA, мы можем дать элементу недостающую информацию.
чтобы программа чтения с экрана могла правильно его интерпретировать. Здесь мы добавили роль и aria-checked атрибутов для явной идентификации элемента как флажка и
чтобы указать, что он установлен по умолчанию. Теперь элемент списка будет добавлен в
дерево специальных возможностей и программа чтения с экрана правильно отметят это как флажок.
Получать рекламные предложения
Примечание: Мы рассмотрим список атрибутов ARIA и когда их использовать позже.ARIA работает, изменяя и дополняя стандартное дерево доступности DOM.
Хотя ARIA позволяет нам тонко (или даже радикально) изменять доступность
дерево для любого элемента на странице, это единственное, что он меняет. ARIA
не усиливает присущее элементу поведение ; это не сделает
элемент или дать ему прослушиватели событий клавиатуры. Это все еще часть нашего
задача развития.
Важно понимать, что нет необходимости переопределять значение по умолчанию.
семантика.Независимо от его использования стандартный HTML элементу не нужен дополнительный атрибут role = "checkbox" ARIA, чтобы быть
правильно объявлено.
Также стоит отметить, что некоторые элементы HTML имеют ограничения на то, что ARIA
на них можно использовать роли и атрибуты. Например, стандартный может не иметь каких-либо дополнительных ролей / атрибутов.
См. Спецификацию ARIA в HTML за дополнительной информацией.
Давайте посмотрим, какие еще возможности может предложить ARIA.
Что умеет ARIA?
Как вы видели на примере флажка, ARIA может изменять семантику существующего элемента. или добавить семантику к элементам, для которых нет собственной семантики. Он также может
выражать семантические шаблоны, которых вообще нет в HTML, например меню или вкладку
панель. Часто ARIA позволяет нам создавать элементы типа виджетов, которые были бы невозможны
с простым HTML.
или добавить семантику к элементам, для которых нет собственной семантики. Он также может
выражать семантические шаблоны, которых вообще нет в HTML, например меню или вкладку
панель. Часто ARIA позволяет нам создавать элементы типа виджетов, которые были бы невозможны
с простым HTML.
- Например, ARIA может добавить дополнительную метку и текст описания, который
доступ к вспомогательным технологиям API.
- ARIA может выражать семантические отношения между элементами, которые расширяют стандартное родительско-дочернее соединение, такое как настраиваемая полоса прокрутки, которая управляет конкретный регион.
. . .
- А ARIA может сделать части страницы «живыми», чтобы они сразу сообщали
вспомогательные технологии, когда они меняются.
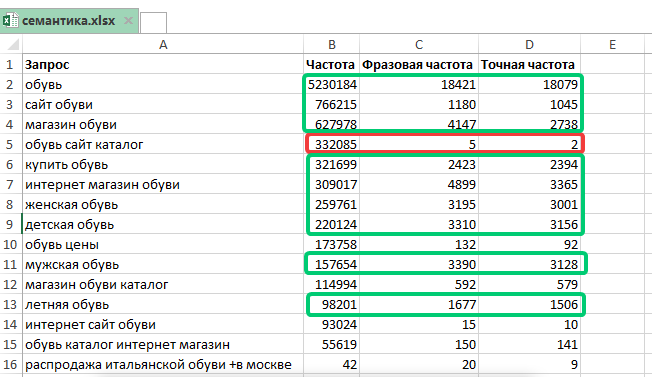
GOOG: 400 долларов
Одним из основных аспектов системы ARIA является набор из ролей . Роль
с точки зрения доступности представляет собой сокращенный индикатор для определенного пользовательского интерфейса
шаблон. ARIA предоставляет словарь шаблонов, которые мы можем использовать через роль атрибут любого HTML-элемента.
Когда мы применили role = "checkbox" в предыдущем примере, мы говорили
вспомогательная технология, согласно которой элемент должен следовать шаблону «флажок».Это
есть, мы гарантируем, что он будет иметь проверенное состояние (проверено или нет
отмечен), и что состояние можно переключать с помощью мыши или клавиши пробела,
как стандартный элемент флажка HTML.
Фактически, поскольку взаимодействие с клавиатурой занимает важное место в программе чтения с экрана
использования, очень важно убедиться, что при создании пользовательского виджета роль атрибут всегда применяется в том же месте, что и tabindex атрибут; это гарантирует, что события клавиатуры попадут в нужное место и когда
фокус направлен на элемент, его роль точно передана..jpg)
Спецификация ARIA описывает
таксономия возможных значений атрибута роли и связанного с ним ARIA
атрибуты, которые могут использоваться вместе с этими ролями. Это лучшее
источник исчерпывающей информации о том, как работают роли и атрибуты ARIA
вместе и как их можно использовать таким образом, который поддерживается браузерами и
вспомогательные технологии.
Однако спецификация очень плотная; более доступное место для начала — ARIA Документ по методам разработки , который исследует передовой опыт использования доступных ролей ARIA и свойства.
ARIA также предлагает ключевые роли, расширяющие возможности HTML5. Увидеть Знаменитый дизайн ролей Узоры spec для получения дополнительной информации.
Обратная связь
Была ли эта страница полезной?
Есть
Что было самым лучшим на этой странице?
Это помогло мне выполнить мои цели
Спасибо за ваш отзыв! Если у вас есть конкретные идеи, как улучшить эту страницу, пожалуйста, создать проблему.
Это была информация, которая мне нужна
Спасибо за ваш отзыв! Если у вас есть конкретные идеи, как улучшить эту страницу, пожалуйста, создать проблему.Имеет точную информацию
Спасибо за ваш отзыв! Если у вас есть конкретные идеи, как улучшить эту страницу, пожалуйста, создать проблему.Легко читалось
Спасибо за ваш отзыв!Если у вас есть конкретные идеи, как улучшить эту страницу, пожалуйста, создать проблему.Что-то еще
Спасибо за ваш отзыв! Если у вас есть конкретные идеи, как улучшить эту страницу, пожалуйста, создать проблему.№
Что было хуже всего на этой странице?
Это не помогло мне выполнить мои цели
Спасибо за ваш отзыв!Если у вас есть конкретные идеи, как улучшить эту страницу, пожалуйста, создать проблему.
Отсутствовала необходимая мне информация
Спасибо за ваш отзыв! Если у вас есть конкретные идеи, как улучшить эту страницу, пожалуйста, создать проблему.Он имел неточную информацию
Спасибо за ваш отзыв! Если у вас есть конкретные идеи, как улучшить эту страницу, пожалуйста, создать проблему.Трудно было прочитать
Спасибо за ваш отзыв! Если у вас есть конкретные идеи, как улучшить эту страницу, пожалуйста, создать проблему.Что-то еще
Спасибо за ваш отзыв! Если у вас есть конкретные идеи, как улучшить эту страницу, пожалуйста, создать проблему.Что такое универсальный семантический уровень? Зачем вам один?
Я инженер-программист и люблю абстракции.Мне нравятся абстракции, потому что, сделанная правильно, абстракция снизит сложность до уровня, на котором мне не придется тратить время на размышления об этом. Абстракция позволяет мне работать с хорошо продуманным интерфейсом, который позволяет мне добиваться большего без необходимости всегда рассматривать систему на молекулярном уровне.
Абстракция позволяет мне работать с хорошо продуманным интерфейсом, который позволяет мне добиваться большего без необходимости всегда рассматривать систему на молекулярном уровне.
Оказывается, деловые люди тоже любят абстракцию. Это не должно вызывать удивления, поскольку компании моделируют сложные концепции реального мира, где важны детали. От расчета до контекстного значения абстракция помогает в правильности и понимании.
Возьмем, к примеру, простое определение, такое как «Сотрудник». Это включает в себя подрядчиков? Удаленные люди? Как насчет известной простой формулы для расчета приведенной стоимости с компаундированием:
Что такое «чистый объем продаж»? Это за вычетом затрат на отдельные позиции счета и / или за вычетом скидок? Небольшой вариант использования может содержать десятки таких вычислений, в то время как модель отдела может содержать сотни. Без некоторого уровня абстракции бизнес обязан перед ИТ-отделом создавать и запускать отчеты или рискует совершить большие, дорогостоящие и худшие из всех скрытых ошибок. Можете ли вы позволить себе, чтобы каждый из ваших сотрудников независимо пытался правильно воспроизвести эту логику в своих таблицах и отчетах? Сможете ли вы отловить незаметные, но серьезные ошибки?
Можете ли вы позволить себе, чтобы каждый из ваших сотрудников независимо пытался правильно воспроизвести эту логику в своих таблицах и отчетах? Сможете ли вы отловить незаметные, но серьезные ошибки?
В бизнес-аналитике (BI), также иногда называемой аналитикой, ключевая абстракция, используемая в большинстве реализаций, называется «семантическим слоем».
Семантика в контексте данных и хранилищ данных означает « с точки зрения пользователя »; что звучит как хорошее чистое решение неприятной проблемы неограниченной сложности.
Семантический слой не совсем новый. Фактически, эта концепция была первоначально запатентована в 1991 году компанией Business Objects, а в 2003 году была успешно оспорена Microstrategy.
Итак, семантический уровень звучит здорово, в чем загвоздка?
Посмотрите этот простой поиск, который я выполнил для «семантического слоя»
Сколько семантических слоев вам нужно? (Подсказка: правильный ответ — 1).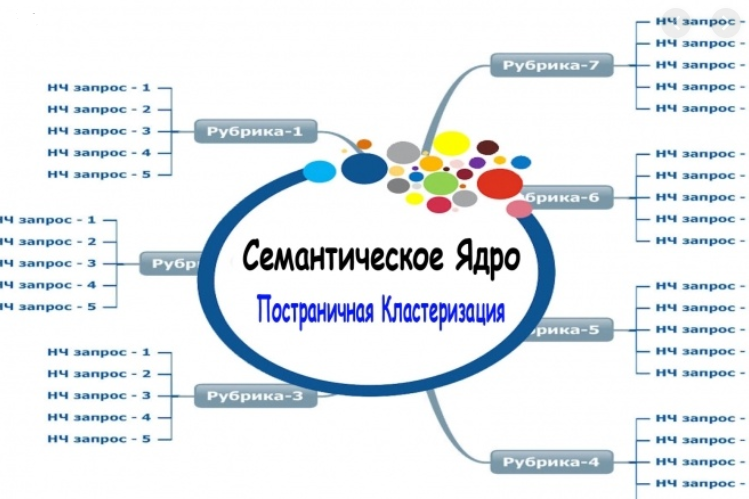 Помните, что семантический уровень — это абстракция, и хотя наличие нескольких абстракций для одной и той же концепции иногда является правильным и полезным, в большинстве случаев это противоречит инженерной мантре DRY (не повторяйтесь).
Помните, что семантический уровень — это абстракция, и хотя наличие нескольких абстракций для одной и той же концепции иногда является правильным и полезным, в большинстве случаев это противоречит инженерной мантре DRY (не повторяйтесь).
Что изменилось?
Чтобы оставаться великими, великие идеи должны развиваться. Концепции семантической модели бизнес-аналитики, представленные почти 25 лет назад, были в основном статичными. AtScale считает, что ценность современной платформы бизнес-аналитики заключается в устранении известных недостатков и внедрении инноваций в том, что изначально сделало семантический уровень отличным: это умножитель силы для потребителей данных. Глубокие знания расчетов и базовой структуры данных отошли на второй план по сравнению с поколениями полезных операционных отчетов, информационных панелей и другого анализа, созданного людьми, которые разбираются в бизнес-областях, а не в математике.
Большие изменения за последние 10 лет, которые повлияли на данные и их семантический слой, произошли в:
- Объем
Создается больше данных. Большинство компаний в США имеют 100 терабайт данных. По оценкам, в 2020 году будет создано 40 зеттабайт данных. Это большие цифры, которые быстро растут. Ценность объединения с агрегатами (тема, которую я расскажу в следующем блоге) заключается как в сокращении затрат на обслуживание (отсутствие необходимости постоянно работать с конвейерами ETL), так и в возможности более быстрого анализа этих огромных объемов данных.Данные не собираются атрофироваться, они будут только расти. Готовы ли вы справиться с приходящей на вас громкостью? - Скорость
Все больше данных поступает все быстрее и быстрее. Подходы на более старом семантическом уровне, у которых была фаза статической сборки, слишком медленны, чтобы справляться с натиском данных сегодня и в будущем. Работая с крупнейшими компаниями в мире, мы разработали Adaptive Cache (подход ИИ к агрегатам), который может автоматически сопоставляться от источника к агрегату и имеет возможность выполнять инкрементные обновления. Конечным результатом является то, что бизнес имеет доступ к самым последним данным, собранным без нагрузки на ИТ или ожидания бизнеса. Дело в скорости; как быстро ты сможешь ответить? - Разнообразие
Каждый день добавляются новые типы данных. Современный семантический уровень может сделать полуструктурированные данные структурированными; как если бы он был относительным за своими абстракциями. Это означает, что бизнес-пользователи могут продолжать использовать ваши стандартные инструменты визуализации, которые не имеют понятия о новых или созданных компьютером базовых форматах, таких как JSON или пары ключ-значение, без необходимости в сложном, трудном в обслуживании, повторяющемся перемещении данных, не добавляющем ценности. / ETL.Нет необходимости переучивать конечных пользователей новому UX визуализации. они могут продолжать использовать свои Tableau, Excel, Qlik и другие инструменты, от которых они откажутся, только когда вы вырвете их из их холодных мертвых рук. - Верность
Это говорит о самой сути семантического уровня. Неопределенность проявляется во многих формах, и бизнес-пользователи потеряли веру в данные, которые они используют для принятия решений. Абстракции предоставляют проверенные, проверенные структуры и вычисления, которым потребители могут доверять.
 Конечным результатом является то, что бизнес имеет доступ к самым последним данным, собранным без нагрузки на ИТ или ожидания бизнеса. Дело в скорости; как быстро ты сможешь ответить?
Конечным результатом является то, что бизнес имеет доступ к самым последним данным, собранным без нагрузки на ИТ или ожидания бизнеса. Дело в скорости; как быстро ты сможешь ответить?
Вверх
Семантический уровень — это не единая абстракция, это группа абстракций, используемых для решения различных проблем.Семантический уровень позволяет улучшить следующее:
- Удобство использования / понимание / приемлемость
Одна из самых больших жалоб со стороны бизнеса заключается в том, что ИТ-специалистам требуется слишком много времени для создания или изменения отчетов для них. Они хотят встать у руля и распоряжаться своей судьбой. Хорошо спроектированный семантический слой с гибкими инструментами позволяет пользователям понять, как изменение их запроса приведет к различным результатам, и в то же время дает им независимость от ИТ — свободу от ИТ, но при этом остается уверенность в том, что их результаты будут правильными. - Безопасность и управление
В наши дни у предприятия есть строгие, а иногда и нормативные требования, чтобы они отслеживали и знали, «кто» видел «какие» данные и «когда». Наш продукт «Настоящее делегирование» возник в результате партнерства с нашими фантастическими клиентами и позволяет им знать, кто, что и когда находится в надежно защищенном озере данных. Предыдущие воплощения семантического уровня не имели возможности отслеживать происхождение данных от уровня строк до каждого агрегата, управляемого программным обеспечением. - Возможности
Более зрелая и сложная аналитика + современные поставщики BI, внедряющие расширенные возможности = требуется абстракция. По мере того, как мы завершаем наше видение современной платформы бизнес-аналитики, мы обнаруживаем, что втягиваем концепции, которые когда-то были в сфере науки о данных. Это новое поколение прогнозной аналитики и аналитики с машинным обучением не поддерживается инструментами бизнес-аналитики и слишком сложна, чтобы бизнес-пользователи понимали ее реализацию, а не только желаемый результат. - Корректность
Семантический уровень выделяется тем, что может создавать сложный SQL и часто несколько операторов SQL в ответ на очень упрощенный набор жестов пользователя. Семантический уровень должен понимать, как работать с циклами базы данных, сложными объектами, сложными наборами (объединение, пересечение), навигацией по агрегированной таблице и сочетаниями клавиш. Применяя правила для определения сложности и неоднозначности базы данных, генерация SQL гарантирует, что если два пользователя запросят одну и ту же информацию, они получат одинаковые результаты — это наиболее важный аспект семантического уровня, позволяющий организации определить единый версия правды. - Снижение задержки
Задержка, также называемая «временем понимания», — это то, через какое время после того, как данные куда-то попадают, их можно использовать для принятия решений. В устаревших решениях бизнес-аналитики часто был процесс сборки, который мог занять от нескольких минут для небольших данных до дней / недель для больших данных. Мы потратили много времени на создание интегрированного набора технологий, который позволяет новым данным, поступающим в ваше хранилище данных, запрашивать их с помощью инструмента бизнес-аналитики в течение нескольких минут независимо от размера.Нет времени ожидания полной сборки или полной перестройки, а также нет ручных процессов ETL. Метаданные семантического уровня включают в себя происхождение данных, которое может использоваться как для управления, как обсуждалось, так и для сопоставления исходных таблиц фактов со всеми последующими временными структурами данных, которые используются для повышения производительности путем их постепенного обновления. - Производительность и масштабирование
Одна из причин, по которой Microsoft представила табличную модель, заключалась в устранении проблем с производительностью, но это усложняло работу.Какую модель мне следует использовать? По словам Microsoft:


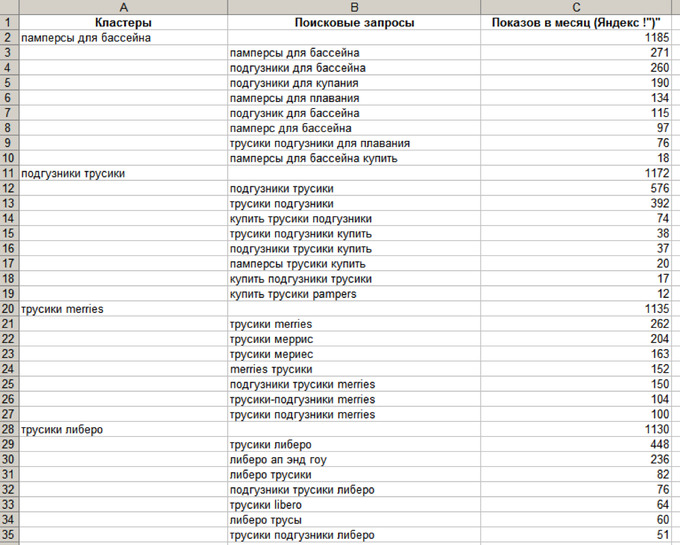 Мы потратили много времени на создание интегрированного набора технологий, который позволяет новым данным, поступающим в ваше хранилище данных, запрашивать их с помощью инструмента бизнес-аналитики в течение нескольких минут независимо от размера.Нет времени ожидания полной сборки или полной перестройки, а также нет ручных процессов ETL. Метаданные семантического уровня включают в себя происхождение данных, которое может использоваться как для управления, как обсуждалось, так и для сопоставления исходных таблиц фактов со всеми последующими временными структурами данных, которые используются для повышения производительности путем их постепенного обновления.
Мы потратили много времени на создание интегрированного набора технологий, который позволяет новым данным, поступающим в ваше хранилище данных, запрашивать их с помощью инструмента бизнес-аналитики в течение нескольких минут независимо от размера.Нет времени ожидания полной сборки или полной перестройки, а также нет ручных процессов ETL. Метаданные семантического уровня включают в себя происхождение данных, которое может использоваться как для управления, как обсуждалось, так и для сопоставления исходных таблиц фактов со всеми последующими временными структурами данных, которые используются для повышения производительности путем их постепенного обновления.«Сегодня и с несколькими таблицами, и с таблицами есть свои сильные и слабые стороны, и одно явно не превосходит другое».
Мы использовали другой подход и изобрели технологию адаптивного кэша, которая обеспечивает производительность независимо от базовой структуры, нам все равно, является ли ваша модель снежинкой, звездой или чисто OLTP. Вы разрабатываете свои данные, а мы обеспечиваем их работоспособность, всегда генерируя наилучший возможный SQL и используя наиболее подходящие агрегаты.Это означает меньше проблем с ETL и данными, а также больше отчетов и анализа. Каждый случай использования больших данных в реальном мире, с которым мы сталкиваемся, дает нам больше информации о том, как сделать данные более быстрыми и доступными.
 — Технет
— ТехнетОбратная сторона семантического уровня
Самым большим недостатком семантического уровня является то, что вы должны создавать, поддерживать и управлять им. Слой необходимо синхронизировать с любыми происходящими изменениями базы данных. Однако, в конце концов, поддерживать семантический уровень определений намного проще, чем поддерживать 1000 отчетов.
Второй недостаток заключается в том, что данные часто существуют в нескольких серверных системах или операционных хранилищах данных (ODS). Таким образом, вам необходимо создать и поддерживать несколько семантических слоев; один семантический уровень на систему или на инструмент бизнес-аналитики.
Примечательно, что, по нашему мнению, мир движется к озерам данных и виртуализации данных, которая позволит создавать и поддерживать единый семантический слой. Это станет решенной проблемой в 2017 году.
Тренд
В ответ на недостаточное удобство использования, сложность и неспособность ИТ-служб обслуживать запросы в разумные сроки предыдущих поколений платформ семантического уровня рынок перешел на использование набора инструментов для обнаружения данных: Tableaus, Qliks и т. Д., которые полностью отказались от централизованных семантических слоев. Эти инструменты упрощают подключение к реляционным источникам данных. Последствия этого заключаются в том, что бизнес-пользователям потребуется лучшее понимание построения запросов, в котором, возможно, не было необходимости при хорошем семантическом уровне.
Пользователи бизнес-аналитики, проводящие остальные 20% анализа с помощью этих инструментов обнаружения данных, обошли старую модель фиксированного хранилища данных. Логика теперь распределяется и дублируется, возникают сложные персональные модели, включающие комбинации данных из хранилища и других систем.В конце концов, это уступило место моделям «ступица и спица», и управление данными стало серьезной проблемой. Пользователям выдавали достаточно веревки, чтобы прострелить себе ногу.
Нам нравятся инструменты обнаружения данных, однако мы считаем, что они были разработаны для обнаружения, а не обязательно для базовой бизнес-аналитики. Использование возникло потому, что искушенные пользователи обладали свободой и властью, которые не могли исключить корпоративные ИТ.
Современное решение
Наше решение проблем, с которыми сталкиваются пользователи с предыдущим поколением и подходом, состоит в том, чтобы сделать крупномасштабную аналитику более гибкой. Мы спросили себя:
Мы спросили себя:
Поскольку AtScale ведет современную эпоху бизнес-аналитики, семантический уровень становится более важным, поскольку мы увеличиваем количество элементов, которые мы можем указать.
Нужен ли вам универсальный семантический уровень?
Компании должны будут определить семантический слой, несмотря ни на что. Если у вас нет экспертов, все ваши конечные пользователи будут делать это сами в Tableau, Qlik, Excel или в любом другом интерфейсе, который они используют. Для устоявшихся и часто используемых моделей снижение уровня определений увеличит принятие, время на анализ и точность.
Текущие инструменты бизнес-аналитики сфокусированы на предоставлении пользователям гибкости, а это часто означает, что модель управления «не требует управления». Многие люди, с которыми мы говорим, пришли из мира, где они пишут и поддерживают сложные конвейеры ETL для генерации множества извлечений, которые передаются в инструменты бизнес-аналитики. Это не только головная боль, связанная с обслуживанием, но и серьезный инфаркт миокарда.