Как правильно собрать семантическое ядро для сайта — Маркетинг на vc.ru
Всем привет, наша веб-студия Mad Design готовит презентацию для выступления по seo-оптимизации и продвижению сайта в топ 10 и решили поделиться с вами материалом о том, как собрать семантическое ядро для сайта.
Семантическое ядро сайта – это полный набор ключевых слов, соответствующих тематике веб-ресурса, по которым пользователи смогут найти его в поисковой системе.
К примеру, семантическое ядро для ремонта телефонов iphone будут примерно такими: ремонт iphone X 64 гб, замена стекла iPhone, замена батарейки iPhone X 64 гб, ремонт телефонов iPhone любых моделей и т.д.
Перед началом работ по продвижению вашего сайта сначала необходимо найти все ключевые запросы, по которым его могут искать целевые посетители. На основании семантики составляется структура, распределяются ключи, прописываются мета-теги, заголовки документов, описания к изображениям, а также разрабатывается анкор-лист для работы со ссылочной массой.
При составлении семантического ядра важно решить главную задачу: определить, какую информацию следует опубликовать, чтобы привлечь потенциального клиента.
Составление списка ключевых запросов решает еще одну важную задачу: для каждой поисковой фразы вы определяете релевантную страницу, которая полно сможет ответить на вопрос пользователя.
Данная задача решается следующим образом:
· Вы создаете структуру сайта на основе семантического ядра.
· Вы распределяете подобранные термины по готовой структуре ресурса.
Виды ключевых запросов (КЗ) по количеству просмотров:
· НЧ – низкочастотные. До 100 показов в месяц.
· СЧ – среднечастотные. От 101 до 1 000 показов.
· ВЧ – высокочастотные. Более 1000 показов.
Виды КЗ по типу поиска:
· Информационные нужны при поиске информации. «Как жарить картофель» или «сколько звезд на небе».
· Транзакционные используются для совершения действия. «Заказать пуховый платок», «скачать песни Высоцкого»
· Навигационные используются для поиска связанного с какой-то конкретной фирмой или привязкой к сайту. «Хлебопечь МВидео» или «смартфоны Связной».
· Прочие — расширенный список, по которому невозможно понять конечную цель поиска. К примеру, запрос «торт Наполеон» – возможно, человек ищет рецепт его приготовления, а, возможно, хочет купить торт.
Как составить семантику:
· Необходимо выделить главные термины вашего бизнеса и нужд пользователей. К примеру, клиенты прачечной интересуются стиркой и чисткой.
· Затем следует определить хвосты и спецификацию (более 2 слов в запросе), которые пользователи добавляют к главным терминам. Этим вы увеличите охват целевой аудитории и снизите частотность терминов (стирка пледов, стирка курток и т.п.)
Сбор семантического ядра вручную.
Яндекс Wordstat:
· Выберите регион веб-ресурса.
· Введите ключевую фразу. Сервис выдаст вам количество запросов с данным ключевиком за последний месяц и список «родственных» терминов, которые интересовали посетителей. Имейте ввиду, что если вы вводите, к примеру, «купить окна», то получаете результаты по точному вхождению ключевика. Если вводите данный ключ без кавычек, то получаете общие результаты, и запросы типа «купить окна в воронеже» и «купить окно пластиковое» также будут отражены в данной цифре. Для сужения и уточнения показателя можно воспользоваться оператором «!», который ставится перед каждым словом: !купить !окна. Вы получите число, показывающее точную выдачу по каждому слову. Получится список типа: купить пластиковые окна, купить и заказать окна, при этом слова «купить» и «окна» будут отражаться в неизменном виде. Для получения абсолютного показателя по запросу «купить окна» следует применять следующую схему: вводим в кавычках «!купить !окна». Вы получите самые точные данные.
· Соберите слова из левой колонки и проанализируйте каждое из них. Составьте начальную семантику. Обращайте внимание на правую колонку, содержащую КЗ, которые пользователи вводили до или после поиска слов из левой колонки. Вы найдете еще немало нужных фраз.
· Пройдите по вкладке «История запросов». На графике вы сможете проанализировать сезонность, популярность фраз в каждом месяце. Неплохие результаты дает работа с поисковыми подсказками Яндекса. Каждый КЗ вводится в поисковое поле, и на основе всплывающих подсказок расширяется семантика.
Google-планировщик КЗ:
· Введите главный ВЧ запрос.
· Выберите «Получить варианты».
· Отберите самые релевантные варианты.
Изучение сайтов-конкурентов.
Используйте этот метод как дополнительный, чтобы определить правильность выбора того или иного КЗ. В этом вам помогут инструменты BuzzSumo, Searchmetrics, SEMRush, Адвсе.
Программы для составления семантического ядра.
· Key Collector. Если вы составляете очень объемную семантику, то без этого инструмента вам не обойтись. Программа подбирает семантику, обращаясь к Яндекс Wordstat, собирает поисковые подсказки данного поисковика, фильтрует КЗ со стоп-словами, очень низкой частотой, дублированные, определяет сезонность фраз, изучает статистику счетчиков и соцсетей, подбирает релевантные страницы к каждому запросу.
· SlovoEB. Бесплатный сервис от Key Collector. Инструмент подбирает ключевые слова, группирует и анализирует их.
· Allsubmitter. Помогает подобрать КЗ, показывает сайты-конкуренты.
· KeySO. Анализирует видимость веб-ресурса, его конкурентов и помогает в составлении СЯ.
Что нужно учитывать при подборе ключевых фраз:
· Показатели частотности.
· Большая часть КЗ должна быть НЧ, остальные — СЧ и ВЧ.
· Релевантные поисковым запросам страницы.
· Конкурентов в ТОП.
· Конкурентность фразы.
· Прогнозируемое количество переходов.
· Сезонность и геозависимость.
· КЗ с ошибками.
· Ассоциативные ключи.
Правильное семантическое ядро.
1. Прежде всего, необходимо определиться с понятиями «ключевые слова», «ключи», «ключевые или поисковые запросы» – это слова или фразы, при помощи которых потенциальные клиенты вашего сайта ищут необходимую информацию.
2. Составьте следующие списки: категории товаров или услуг (далее -ТУ), названия ТУ их бренды, коммерческие хвосты ( «купить», «заказать» и т.п.), синонимы, транслитерацию на латинице (или на русском соответственно), профессиональные жаргонизмы ( «клавиатура» – «клава» и т.п.), технические характеристики, слова с возможными опечатками и ошибками ( «оренбуржский» вместо «оренбургский» и т.п.), привязки к местности (город, улицы и т.п.).
3. При работе со списками ориентируйтесь на КЗ из договора по продвижению, структуру веб-ресурса, информацию, прайс-листы, сайты-конкуренты, опыт предшествующего SEO.
4. Приступайте к подбору семантики путем смешения выбранных на предыдущем шаге словосочетаний, используя ручной метод или при помощи сервисов.
5. Сформируйте список стоп-слов и удалите неподходящие КЗ.
6. Сгруппируйте КЗ по релевантным страницам. Под каждый ключ подбирается наиболее релевантная страница или создается новый документ. Желательно данную работу проводить вручную. Для крупных проектов предусмотрены платные сервисы типа Rush Analytics.
7. Идите от большего к меньшему. Сначала распределите ВЧ по страницам. Затем то же самое проделайте с СЧ. НЧ можно добавить к страницам с распределенными по ним ВЧ и НЧ, а также подобрать для них индивидуальные страницы.
После анализа первых результатов работ мы можем увидеть, что:
· продвигаемый сайт не виден по всем заявленным ключевым словам;
· по КЗ выдаются не те документы, которые вы предполагали релевантными;
· мешает неправильная структура веб-ресурса;
· для некоторых КЗ релевантны несколько веб-страниц;
· не хватает релевантных страниц.
При группировке КЗ работайте со всеми возможными разделами на веб-ресурсе, наполняйте каждую страницу полезной информацией, не создавайте дублированный текст.
Распространенные ошибки при работе с КЗ.
· была подобрана только очевидная семантика, без словоформ, синонимов и т.д;
· оптимизатор распределил слишком много КЗ на одну страницу;
· одинаковые КЗ распределены на разные страницы.
При этом ранжирование ухудшается, сайт может быть наказан за «переспам», а если у веб-ресурса неправильная структура, то продвигать его будет очень сложно.
Не важно, каким образом вы будете подбирать семантику. При правильном подходе вы получите правильное СЯ, необходимое для успешного продвижения сайта.
Команда веб-студии Mad Design благодарит вас за внимание. Всем успехов и продаж!)
Материал опубликован пользователем. Нажмите кнопку «Написать», чтобы поделиться мнением или рассказать о своём проекте.
Написатьvc.ru
Как составить семантическое ядро сайта, подбор ключевых слов

Задача подобрать ключевые слова для SEO сайта или контекстной рекламы — это важнейший шаг, который может определить успех всей дальнейшей работы, будь то поисковое продвижение сайта или настройка контекстной рекламы. Как правильно собирать ключевые слова для рекламной кампании мы уже рассказывали. Сейчас мы рассмотрим составление семантического ядра для поискового продвижения сайта. На первый взгляд простая задача найти и собрать ключевые слова на самом деле имеет достаточно глубокий смысл. Нельзя просто так взять ключевые слова и сделать сайт.
Здесь я расскажу не о том, как пользоваться вордстатом или другими вундервафлями для сбора ключевых слов, а о том, зачем вообще собираются ключевые слова, создается семантическое ядро сайта и как это все влияет на ранжирование сайта в поиске.
Ключевые слова для SEO сайта
Ключевые слова или семантическое ядро сайта — это мозг сайта, и чем в нём больше логических связей, тем он «умнее». Проще говоря: если на сайте больше 10 страниц, то страницам сайта нужна логическая организация, иначе возникнет путаница в том, какая страница на какой ключевой запрос отвечает. Каждая страница сайта должна отвечать на определенный запрос, и только одна страница должна быть самой релевантной страницей по конкретному ключевому запросу. Не хватало еще, чтобы страницы сайта конкурировали друг с другом по одним и тем же ключевым словам.
Возьмем тему, например, мы хотим продавать ложки. Мы ищем все возможные ключевые слова про ложки и выделяем из них те, которые необходимы нам в первую очередь, чтобы наши ложки продать. В результате, ключевые слова делятся на две большие группы: тематические ключевые слова, в которые входят торговые запросы, товарные категории, запросы по товарной базе и информационные запросы по теме. Как правило, информационных запросов во много раз больше, чем тематических торговых запросов, однако, именно информационные запросы позволяют описать логику тематики, чтобы продвинуть сайт по торговым запросам.
Более того, одних ключевых слов по теме «ложки» недостаточно, чтобы исчерпывающе дать определение всей тематике ложек, т. к. тематика «ложки» является частью более объемной тематики «столовые приборы» и имеет прямые связи с такими темами, как «вилки» и «ножи». То есть именно в контексте темы «столовые приборы» раскрывается логика темы «ложки». В данном случае, темы «вилки» и «ножи» могут быть смежными запросами ключевым словам по теме «ложки».
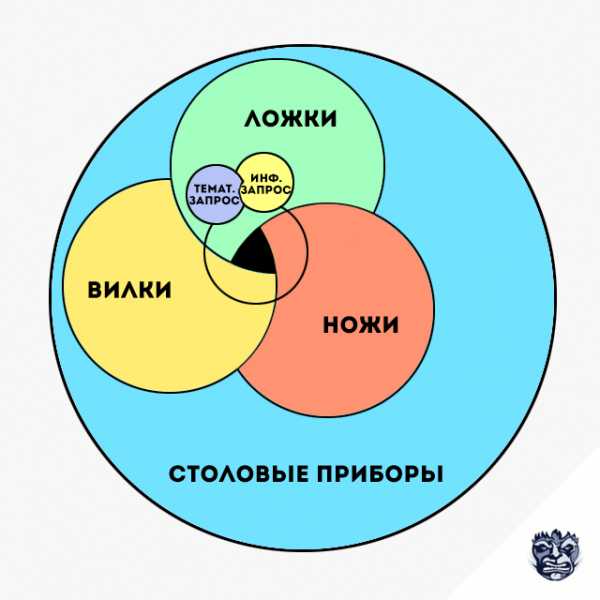
Рис. 1. Чтобы полноценно описать тему «ложки» необходимо частично описать тему «вилки», «ножи» и другие аспекты глобальной темы «столовые приборы».
Замыкаем логику тематики через смежные ключевые запросы
Чтобы заниматься полноценным SEO своего сайта, необходимо усвоить основной принцип: четкая логическая структура всех страниц сайта — это основа поисковой оптимизации. Без жесткого распределения ключевых запросов по страницам и организации связей между страницами вы не сможете объяснить ни людям, ни поисковым системам, где находится та или иная информация на вашем сайте. Без этого оптимизация сайта невозможна. Точность разграничения и полнота охвата тематики играет важную роль в определении релевантности каждой страницы по соответствующему ключевому слову.
Определенная тематика описывается про помощи ключевых слов, характерных для этой тематики, а так же при помощи ключевых слов, позволяющих описать место более узкой тематики в рамках более широкой. Возвращаясь к примеру выше, тематики «вилки» и «ножи» описывают место узкой тематики «ложки» в рамках более широкой тематики «столовые приборы». Все ключевые слова имеют логические связи с другими ключевыми словами как в рамках одной темы, так и с ключевыми словами других тематик разной степени близости.
Ключевые слова близких по смыслу тематик называются смежные запросы. В том же Яндексе, подбор слов позволяет узнать, что еще искали посетители Яндекса, кроме определенного запроса. В случае с нашей темой, с ложками ищут вилки, ножи и, например, тарелки или салфетки. То есть в данном случае, при необходимости охвата тематики «столовые приборы», смежные запросы помогут найти все более узкие тематики. Что касается сервиса wordstat.yandex.ru, то с его помощью можно получить замкнутую последовательность ключевых слов и тематик. Достаточно ввести ключевое слово и следовать по смежным запросам до тех пор, пока в смежных запросах не окажется изначальный запрос. Это особенно важно при описании обширных, нечетких тематик, которые сложно, а порой и вовсе невозможно, описать или выразить в виде ключевого слова или фразы.
Ищем логические синонимы
Кроме смежных запросов и тематик, огромное значение в сборе ключевых слов играют синонимы ключевых запросов. Синонимом ключевого слова «лендинг» может быть landing page или посадочная страница. Все три слова в разной степени востребованности означают одно и то же понятие. Кроме явных синонимов, часто встречаются различные формулировки ключевых запросов или фраз, т. е. логические синонимы. Зачастую, одно и то же понятие можно описать по-разному, что существенно расширяет список потенциальных ключевых слов. Поисковые системы вычисляют логическую связь между синонимами, и релевантнее может оказаться та страница, которая использует все разнообразные формулировки одно ключевого запроса, нежели страница с одной единственной формулировкой ключевого слова.
Собираем минус слова
При подборе ключевых слов необходимо ориентироваться на реальную статистику ключевых слов, которую предоставляют поисковые системы. Сторонние программы, которые собирают ключевые слова на основе собственных внутренних ресурсов не отражают реальную картину запросов пользователей поисковых систем. Поэтому берите ключевые слова и статистику непосредственно из поисковых систем, а не из сторонних ресурсов, которые предоставляют информацию на основании собственных представлений, а не реальных данных из Яндекса или Google. Таким образом, вы изначально не будете забивать себе голову тем, что вам по определению не нужно. А дальше можно начинать фильтровать реальные данные.
Минус слова позволяют исключить ключевые слова, которые однозначно не имеют отношения к специфики вашего сайта. Список ключевых слов, которые нужно отминусовать, может быть огромен, но чем точнее определена тематика, тем проще будет создать логическую структуру сайта. Тем более, что в статистике ключевых слов встречаются как откровенно бредовые запросы, так и запросы, которые могут удовлетворять смыслу сторонних тематик, даже близко не связанных с вашей. Из-за подобных особенностей русского языка, подбор минус слов часто становится достаточно трудоемким процессом, к которому нужно отнестись с особым вниманием.
Собираем все до последнего ключевого слова
При составлении семантического ядра нередко количество ключевых слов ограничивается из-за непопулярности некоторых низкочастотных слов. Происходит это по принципу: зачем мне ключевые слова, которые имеют меньше 100, 50 или 10 запросов в месяц или очень низкочастотные запросы. Все дело в том, что не все понимают, как накапливается статистика запросов ключевых слов и что вообще такое низкочастотные слова. Если коротко, то низкочастотные запросы — это запросы, которые состоят из нескольких слов и имеют очень точную формулировку, например: «купить iPhone 5C 16gb желтый с зеленым чехлом в Москве б/у».
Действительно, именно такой запрос может быть один в месяц, но в целом подобных низкочастотных запросов могут быть тысячи. Но самое главное, эти запросы имеют низкую конкуренцию и очень высокую конверсию, так как в данных запросах люди выражают конкретную потребность, а не абстрактное желание ознакомиться с тем, что такое «iPhone 5C». Подумайте, что для вас проще:
- вывести сайт по 1000 высокоточных низкочастотных запросов, в которых нет конкуренции и получать трафик и заказы сразу, как только страница сайта попадет в поиск;
- вывести сайт по 10 абстрактным ключевым запросам с большой конкуренцией, где большую часть трафика составляют люди, которые ищут информацию, конкуренты или боты.
Безусловно, все зависит от тематики, ресурсов и времени. В итоге решать вам, но тот кто забывает или пренебрегает низкочастотными ключевыми словами, в буквальном смысле, не видит денег у себя под ногами. Поэтому, собирайте все до последнего ключевого слова, даже если у него по статистике всего 1 показ в месяц.
Группируем ключевые запросы
Организация страниц и ключевых слов невозможна без группировка ключевых слов. Группировать ключевые слова можно по частоте, как минимум, на высокочастотные, среднечастотные и низкочастотные. Вообще, группировка ключевых слов должна идти от большего к меньшему, вплоть до отдельных ключевых запросов. В зависимости от группировки ключевых слов могут получиться целые разделы и подразделы сайта, а из некоторых групп ключевых слов может получиться отдельная страница. Например, почему бы не собрать список ключевых слов по какому-нибудь интересному определению в узкой теме, чтобы написать об этом определении статью. Собираем ключевые слова, группируем их по смыслу и получаем готовое содержание статьи, которое даст ответы на 100% запросов, которые были заданы в поиске. Плюс к релевантности.
Итог
- Подбирайте ключевые слова только на основании статистики самих поисковых систем или через сервисы, которые работают непосредственно со статистикой поисковых систем, а не высасывают собственную статистику и ключи из пальца.
- Собирайте все возможные ключевые слова и не пренебрегайте низкочастотными ключевыми словами, мало ключей не бывает.
- Очень внимательно фильтруйте ключевые слова, так как бесполезный трафик не даст вам ничего, кроме траты времени и большого числа отказов на сайте.
- Группируйте ключевые слова, чтобы четче разделять логику связей групп страниц и разделов.
- Продумайте логическую структуру всех страниц сайта и определите каждой странице свое место и свой ключевой запрос, уникальный по смыслу и содержанию страницы.
Каждая страница сайта должна отвечать на свой вопрос. Один вопрос — одна страница. Подбирайте ключевые слова так, чтобы они четко укладывались в тот вопрос, которому посвящена страница сайта. Связывайте страницы ссылками, когда это необходимо по смыслу, чтобы создать логическую связь между страницами. И самое главное — постарайтесь описать свою тематику максимально полно, и тогда — победа!
Пишите в комментариях свое мнение и делитесь постом с друзьями.
Больше вашей активности — больше интересных статей.
convertmonster.ru
Правильно собрать семантическое ядро для продвижения сайта — SEO на vc.ru
Подробная инструкция от руководителя оптимизаторов в «Ашманов и партнёры» Никиты Тарасова.
Семантическое ядро — основа поискового продвижения. Если допустить ошибки на этом этапе, дальнейшая работа по SEO пойдёт под откос. Это руководство поможет собрать семантику для проекта любого масштаба и ничего не упустить.
Этапы работы
Сбор семантического ядра состоит из четырёх последовательных этапов:
*Маркером (или маркерным запросом) называют слово или словосочетание наиболее точно отражающее суть конкретной страницы сайта. Обычно в качестве основного «маркерного» запроса для страницы берётся содержимое заголовка h2. У одной страницы может быть несколько маркерных запросов.
Получение маркеров и работа с ними
На рисунке изображена последовательность действий по подбору и обработке маркеров:
Последовательность подбора и обработки маркеровСобираем список заголовков h2
Собирать заголовки вручную долго и муторно, особенно если сайт состоит из тысяч страниц. Процесс можно автоматизировать и ускорить с помощью «пауков».
«Пауки» — программы, которые эмулируют роботов поисковых систем: обходят все страницы на сайте, получают список URL-адресов и заголовков h2. Список экспортируется в любой удобный формат, например, в Excel. Вот ссылки на наиболее популярные программы:
Корректируем заголовки
Убедитесь, что собранные маркерные запросы обладают частотностью. Если частотность вызывает сомнения, сверьтесь с «Вордстатом», а потом скорректируйте запрос или найдите более частотный.
Не используйте несколько интентов (потребностей пользователей) для продвижения на одной странице. Например, на сайте магазина мебели есть раздел «Кресла и стулья». Но пользователи так не ищут, поэтому эффективней создать два отдельных раздела «Кресла» и «Стулья».
Не проектируйте структуру сайта так, чтобы в разных разделах дублировались одинаковые страницы, как на скриншоте ниже.
Страница «Смесители» дублируется в разделах «Ванная» и «Душ»В примере выше для раздела «Душ» можно оставить ссылку на раздел «Смесители для ванны и душа», но она должна вести на страницу: http://www.domain.ru/catalog/vannaya/smesiteli-dlya-vanny-i-dusha/.
Не создавайте отдельные страницы под синонимичные группы запросов вроде «дешевые матрасы», «недорогие матрасы». Они могут быть восприняты поисковыми системами как нечёткие дубли. Это может привести к проблемам с индексацией сайта: часть страниц будет исключена из поиска.
Чтобы определить, какие запросы можно продвигать на одной странице, а какие — нет, воспользуйтесь сервисом кластеризации*.
*Кластеризация — принцип группировки запросов на основании общего числа URL в поисковой выдаче.
Суть кластеризации в том, чтобы изучить, как распределены запросы у сайтов, уже находящихся в верхней десятке поисковых систем. Для определения совместимости интентов идеально подойдёт такой сервис. А про методы кластеризации подробнее расскажу ниже.
Расширяем заголовки за счёт интентов и дополнительных слов
Когда мы получили маркеры, дальше собираем ключевые слова с помощью «Вордстата». Стоит учесть, что «Вордстат» отображает только 41 страницу со статистикой по запросу.
Если мы имеем дело с частотным маркером (например, «Диван»), то есть вероятность, что весь пул запросов мы не охватим.
Как видно, запросы ещё есть, но на следующей странице результаты не отображаются
Поэтому стоит подготовить список уточняющих запросов, характерных для конкретной тематики: например, «диван купить», «диван цена» и так далее.
Готовые тематические подборки можно найти на этой странице.
Получить маркеры, сцепленные с дополнительными словами, можно при помощи формулы =СЦЕПИТЬ(A1;» «;$E$1).
Маркеры не должны содержать символы .,»?!()- и другие знаки. Замените символы в Excel на пробел, используя сочетание клавиш Ctrl и H, а затем проверьте список маркерных запросов на орфографию.
Собираем заголовки с сайтов конкурентов
Проанализируйте сайты конкурентов, находящиеся в топе выдачи по интересующим вас запросам. В ходе анализа особенно интересно получить заголовки «теговых страниц», которые заточены под конкретный пользовательский интент.
Заголовки сайтов-конкурентов можно просканировать «пауками», о которых говорилось выше (например, Screaming frog SEO spider).
Этот подход поможет расширить структуру сайта и подобрать новые запросы для семантического ядра.
Нормализуем запросы
Под нормализацией понимается определение наиболее частотной формы запроса. Это нужно, чтобы не упустить запросы с высокой частотой, приносящие больше трафика на сайт.
Если запросов немного, они состоят из двух слов, то определить наиболее частотный запрос можно в «Вордстате» при помощи операторов: «[!поисковый !запрос]».
Например:
Если запрос состоит из трех и более слов, а запросов больше ста, проверка вручную займёт много времени. Чтобы автоматически выявлять наиболее частотную словоформу, я сделал специальный парсер на базе А-parser.
Логика работы парсера в следующем:
- в «Вордстате» запросы выводятся в порядке убывания частоты;
- каждый запрос, подаваемый на вход, заключается в кавычки, тем самым анализируются все словоформы запроса;
- в качестве результата берётся первый запрос из левой колонки, то есть наиболее частотная из словоформ.
Как видно из примера ниже, наиболее частотной словоформой является «купить диван», что подтверждается точной частотой запросов из примеров выше.
Когда мы провели работы, описанные в разделе, у нас получается список маркерных запросов, удовлетворяющий следующим критериям:
- нет опечаток;
- нет символов и знаков препинания;
- все маркерные запросы частотные;
- часть маркеров содержит дополнительные слова и словосочетания, характерные для конкретной тематики;
- в списке присутствуют наиболее частотные словоформы запросов;
Парсинг запросов
Список маркеров, который мы получили, нужно расширить дополнительными словами — «хвостами». Это поможет нам максимально охватить семантику в поисковой нише, в которой продвигается сайт. Дополнительные слова можно взять из источников, указанных на схеме ниже.
Наиболее популярные источники для парсинга поисковых запросовКоротко разберу особенности некоторых источников.
Поисковые подсказки «Яндекса» и Google
Основное преимущество подсказок в том, что их база намного больше, чем база того же «Вордстата».
В подсказки попадают запросы, обладающие частотой, которые реально запрашивают пользователи. В «Вордстате» же есть доля мусорных и автосгенерированных запросов, не обладающих реальным поисковым спросом.
Подсказки в «Яндексе» можно получать в формате json. В этом случае каждой поисковой подсказке присваивается определенный тип.
Ниже приведены наиболее часто встречающиеся типы подсказок:
- B и T обозначают «обычные» подсказки;
- W — это перестановка слов;
- In — автодополнение;
- Pb — порно-подсказка;
- Nav — навигационный запрос;
- Rich — расширенная подсказка-сниппет, появляется для «Википедии»;
- Tail_word — как правило, означает, что подсказка дополняется не с конца, а с начала;
- Art, Fast_w, Fresh_console, Fast — неизвестные типы.
Например, после сбора можно сразу удалить все подсказки с типом «In», что существенно уменьшит число мусорных запросов. Для сбора подсказок с указанием типов я использую парсер.
«Яндекс.Вебмастер»
В «Вебмастере» есть раздел, в котором можно получить рекомендованные поисковые запросы. Достаточно нажать на кнопку и через некоторое время список будет доступен для скачивания.
Рекомендованные поисковые запросы в «Яндекс.Вебмастере»«Яндекс.Метрика» и Google Analytics
Часть запросов можно выгрузить из отчёта «Яндекс.Метрики»: «Стандартные отчеты» → «Источники» → «Поисковые запросы».
Выгрузка поисковых запросов из «Яндекс.Метрики»В Google Analytics также есть данные о запросах, но с 2011 года Google начал шифровать запросы пользователей, поэтому собрать большой объём информации из данного источника не получится.
Выгрузка поисковых запросов из Google AnalyticsГотовые базы ключевых слов
На рынке есть готовые базы ключевых слов для различных тематик. Например:
У готовых баз есть два недостатка: они обновляются нерегулярно и содержат много мусорной и автосгенерированной семантики.
Тем не менее предпочтительнее использовать базу «Букварикс». Как показали исследования коллег из Rush Analytics, она содержит минимум мусорных запросов и к тому же бесплатная.
SaaS-решения
SaaS-решения (software as a service) помогают выгружать списки запросов, по которым находится в выдаче ваш сайт или сайты конкурентов. Ниже список наиболее популярных сервисов:
Когда получим «хвосты» для маркерных запросов, нужно объединить данные из всех источников в один список и избавиться от дублей.
Для автоматизации сбора запросов можно воспользоваться программами:
И сервисами:
Чистка запросов
Удаляем мусорные фразы
В процессе сбора хвостов в списки неизбежно попадают мусорные запросы. Избавится от них можно с помощью функции «Стоп слова» программы Key collector.
В качестве стоп-слов можно использовать готовые тематические подборки.
С помощью функции «Анализ групп» можно найти и удалить нецелевую семантику.
Удаление низкочастотных запросов
Часть собранных запросов может быть автосгенерированными или низкочастотными (менее трех запросов). Если такие запросы попадут в семантическое ядро, то с высокой вероятностью для них будут созданы отдельные страницы на сайте. Значимого объема трафика они не принесут, но будут отнимать краулинговый бюджет.
Краулинговый бюджет — количество страниц, которые поисковый бот может обойти за период времени.
Нижний порог частоты запроса определяется отдельно для каждой тематики. Брать в работу микро- и низкочастотные запросы стоит лишь в исключительных ситуациях (например, если продукт супермаржинальный). Пример: разработка и внедрение ERP-систем, продажа нефтеперерабатывающего оборудования и так далее.
Для определения точной частоты запросов можно воспользоваться одной из программ — Key collector или A-parser, либо сервисами:
После чистки вы получите список целевых запросов, обладающих достаточной частотой.
Распределение запросов и кластеризация
Основная идея кластеризации — выяснить, как распределены запросы у сайтов, находящихся в первой десятке поисковой выдачи.
Наиболее широкое распространение данная методология получила около четырёх лет назад. Правда, некоторые оптимизаторы до сих пор предпочитают распределять запросы вручную, а зря.
Кластеризация позволяет решить ряд проблем при распределении запросов по страницам сайта. Она особенно полезна на больших объемах — от 1000 запросов и более.
Определяем тип запроса (коммерческий, информационный)
Запросы «пудра» и «пудра купить» на первый взгляд про одно и тоже. Но в первом случае поисковая выдача заполнена преимущественно информационными сайтами.
Исключение составляют два сайта: pudra.ru и «Подружка»: https://www.podrygka.ru/catalog/makiyazh/litso-1/pudra/. Их в расчет не берем, так как первый ранжируется за счет вхождения запроса в домен. А второй — за счёт своей популярности и больших объёмов прямого трафика на сайт.
По запросу «пудра» лидируют в основном информационные сайтыПо запросу «пудра купить» десятку результатов поисковой выдачи занимают в основном интернет-магазины.
Можно сделать вывод, что продвинуть оба запроса на одной странице не получится. Для продвижения запроса «пудра» нужна информационная статья с достаточным объемом текста и иллюстрациями. А для продвижения запроса «пудра купить» — небольшой текст и каталог товаров с ценами.
Результаты выдачи поисковых систем — особенно «Яндекса» — достаточно сильно типизированы. Выдача состоит либо преимущественно из коммерческих сайтов, либо из информационных. Кластеризация позволяет с большой точностью отделить коммерческие запросы от информационных.
Определяем типы страниц (главная, внутренняя)
Теперь проанализируем выдачу по запросы «люстры купить» и «люстры интернет-магазин», которые также похожи. Видно, что по запросу «люстры купить» топ занимают внутренние страницы сайтов, а по запросу «люстры интернет-магазин» — главные страницы.
По запросу типа «люстры купить» приоритет отдается внутренним страницам сайтовСледовательно, по запросу «люстра купить» продвигаем внутренние страницы с каталогом люстр, а по запросу «люстры интернет магазин» — главную страницу сайта.
Определяем совместимость продвижения запросов на одной странице
На скриншоте ниже видно, что запросы «угловые диваны» и «недорогие диваны» не имеют между собой ни одного общего URL. Для достижения лучших результатов эти запросы стоит продвигать на отдельных страницах.
Кластеризация — инструмент аналитики, который не даёт готового решения. Он собирает данные в удобном отображении для дальнейшей постобработки и анализа.
Существует два метода кластеризации:
- Hard — используется для продвижения по позициям, а также для продвижения в конкурентных тематиках. Количество запросов в кластере меньше, но точность выше.
Условие, соблюдаемое при hard-кластеризации, — у всех запросов в кластере должен быть общий набор URL.
- Soft — в основном используется для трафикового продвижения. Количество запросов в кластере больше, но точность ниже.
Условие, соблюдаемое при soft-кластеризации, — запросы сравниваются на предмет общих URL у всех запросов в группе. Например, у запроса А есть общий набор URL с запросом В, у запроса В есть общий набор URL с запросом С.
Схематичное изображение методов hard- и soft-кластеризацииПриведу несколько популярных сервисов кластеризации:
Для постобработки кластеризованной семантики можно воспользоваться бесплатной надстройкой для Excel.
Сбор семантики для больших проектов
Если проект содержит тысячи посадочных страниц, лучше собирать семантику отдельно для каждого раздела, учитывая приоритеты бизнеса и сезонность. А затем последовательно собирать семантическое ядро для двух–трёх разделов за каждую итерацию. Такой подход позволит собрать качественное семантическое ядро и не упустить целевые запросы
Если же собирать семантическое ядро сразу под весь проект, то на выходе получатся тысячи или даже десятки тысяч кластеров запросов, которые будет сложно обработать.
Как сохранить наследственность «Маркерный запрос — URL»
На первом шаге, описанном в статье, мы выгружали табличный список «Маркерный запрос — URL». Если сохранить URL после всех корректировок с маркерными запросами, то с помощью функции ВПР в Excel можно привязать часть URL-адресов к уже раскластеризованной семантике.
То есть — если маркерный запрос находится в кластере с другими запросами и у маркерного запроса уже известен URL, то можно считать, что все запросы кластера принадлежат к этому URL.
Не стоит бояться развивать структуру сайта. Если по результатам сбора запросов и их кластеризации вы понимаете, что под часть запросов не хватает посадочных страниц, лучше создать их или в крайнем случае отказаться от продвижения части запросов. Это будет эффективнее, чем вести несколько групп запросов (часто с несовместимыми интентами) на одну страницу сайта.
Материал опубликован пользователем. Нажмите кнопку «Написать», чтобы поделиться мнением или рассказать о своём проекте.
Написатьvc.ru
подробный гайд для новичков — Блог — Линкбилдер
Составление семантического ядра — это первый и очень важный этап перед стартом продвижения любого сайта. При этом не имеет значения, готовите ли вы рекламную кампанию в контекстной рекламе или собираетесь продвигать сайт в поисковых системах естественными ссылками, уже на начальном этапе очень важно понимать как потенциальные клиенты будут искать ваши товары и услуги в Интернете.

Под семантическим ядром понимается структурированный набор фраз, выражений, синонимов и вообще любых словосочетаний, которые максимально подробно описывают товары и услуги вашего сайта. Говоря простым языком, семантическое ядро — это те самые запросы, которые пользователи будут вводить в поисковую строку, чтобы попасть на ваш сайт, а если не повезет — то на сайт конкурентов.
Конечно, по-хорошему, прорабатывать «семантику» (так очень часто SEO-специалисты сокращают термин семантическое ядро) необходимо еще до создания сайта. Так, вы сможете заранее создать правильную структуру сайта и необходимые посадочные страницы (страницы, связанные с конкретными запросами). Это в значительной степени облегчит дальнейшее продвижение сайта и снизит трудозатраты на разработку. Но по естественным причинам, когда речь идет о первом опыте продвижения и тем более первом опыте создания сайта, вопросы о «семантически правильной» структуре проекта возникают далеко не сразу.
Основные виды запросов
Чтобы правильно собрать семантическое ядро, важно понимать, что не все запросы могут привести нужную аудиторию, поэтому их принято делить на три основные группы:
- Транзакционные (коммерческие)
- Информационные (некоммерческие)
- Навигационные
Для продвижения коммерческого сайта (интернет-магазина, сайта услуг) нам необходимо выбирать запросы, которые смогут привести на сайт клиентов, т. е. транзакционные запросы. К ним относятся фразы, в основе которых лежит покупательский интерес. Например, «квартиры до 3 млн», «магазин сантехники», «ламинирование волос в Москве». Такие фразы также часто содержат слова «купить», «цена», «заказать», «доставка», «недорого» и т. п. Например, доставка пиццы, заказать суши, ремонт холодильника недорого.
В отличие от транзакционных, информационные запросы имеют под собой другую основу и хоть и могут привести посетителей на ваш сайт, покупать они, скорее всего, ничего не будут. Такие запросы связаны с поиском информации и, как правило, не подразумевают транзакций. Например, «как поменять кран в ванной», «как удалить программу с компьютера», «как сварить кисель без комочков» и т.п. Если, конечно, вы мастер слова и можете продать снег даже эскимосу, то при определенном подходе вы сможете превратить посетителя, пришедшего по информационному запросу в вашего клиента, но! Здесь важно понимать, что поисковая система никогда не будет ранжировать коммерческий сайт (или страницу) по информационным запросам. Поэтому вам придется либо создавать на сайте отдельный блог, либо договариваться о размещении нужных статей с профильными блогерами, но это уже совсем другая история.
Наконец, третий тип запросов (навигационные запросы) — это запросы, связанные с поиском конкретного места или бренда. Например, «Кафе Му-му адрес на бауманской» или «адреса всех магазинов Летуаль», «сервис Линкбилдер». Чтобы попасть в ТОП по названию вашего бренда достаточно указать его в заголовках страниц, а также составить подробную страницу контактов, с указанием адреса, схемы проезда и т.д. Не лишним будет добавить вашу организацию в справочник организаций Яндекс и Google, а также популярные сервисы отзывов, наподобие https://www.yell.ru. В этом случае, даже если пользователь промахнется мимо вашего сайта и выберет сайт популярного «отзовика», он сможет получить достоверную и правильную информацию о вашем бизнесе.
Частотность запросов
Частотность запроса отражает количество раз, которое запрос был набран в поисковой системе за месяц. Особенно подчеркиваем, что речь идет именно про показы запроса, а не про трафик. Наличие вашего сайта даже на первом месте не гарантирует, что 100% пользователей, набравших этот запрос, перейдут на ваш сайт. Некоторые пользователи могут уйти по контекстной рекламе, некоторые на другие сайты, потому что у конкурента, например, указана привлекательная цена в заголовке. Кроме того, часть статистики накручена различным SEO-софтом по сбору позиций и т.д., поэтому при прогнозе трафика старайтесь избегать завышенных ожиданий. Различные исследования показывают, что сайты, стоящие на первой строчке поисковой выдачи собирают не более 25% всего трафика по запросу, последним же (на 9-10-ом местах) достается 2-3%, не более. На второй и тем более третьей странице выдачи живут одни боты, реальных людей там практически нет.
Проверить частотность запроса можно в сервисе https://wordstat.yandex.ru/
Как правило, по частотности запросы также делят на три группы:
- Высокочастотные (ВЧ)
- Среднечастотные (СЧ)
- Низкочастотные (НЧ)
Точного деления по частотности не существует, для каждой тематики эти показатели свои. Например, для фильмов онлайн, низкочастотными можно назвать запросы ниже 1000 показов в месяц, а для условных глубоководных сварочных аппаратов запросы выше 100 показов — уже запредельная радость.
Также учитывайте, что по умолчанию, Wordstat выдает цифру, которая включает в себя статистику показов всех словоформ искомого запроса. Если вы запросите данные, например, по слову «смартфон» (без кавычек), то узнаете суммарное количество раз, где это слово было использовано, например, в запросах «купить смартфон», «смартфоны эппл» и т.д. Чтобы получить «чистый» показатель, запрос необходимо взять в кавычки и добавить восклицательный знак, т.е. вот так: «!смартфон».
Почему важно собрать полное семантическое ядро?
Полное семантическое ядро даже среднего по величине интернет-магазина может достигать десятки тысяч фраз. Соберите воедино все товарные группы, сами товары, артикулы, фильтры по цвету / году / размеру / полу и т.д., популярные теги и вы поймете, откуда берутся такие масштабы. Безусловно, в зависимости от тематики эти цифры могут сильно разниться.
Имея в своем распоряжении полную «семантику», вы будете видеть:
- Общую динамику роста сайта по запросам (сайт растет или падает).
- Какие группы товаров получают мало трафика (точки роста).
- Тренды и сезонность спроса.
- Возможные проблемы на сайте (просели позиции по определенным группам запросов).
- Товары (услуги), на которые есть стабильный спрос, но у вас они не продаются (но могут).
Эти данные, во-первых, помогут раскрыть потенциал вашего сайта, слабые места над которыми стоит поработать в первую очередь, во-вторых, вовремя зафиксировать и устранить проблемы. Мы практически ежедневно сталкиваемся с ситуациями, когда по ошибке разработчиков на сайте пропадают целые разделы, что непременно сказывается на позициях и трафике по определенным группам товаров. Поисковые системы реагируют достаточно быстро и удаляют из выдачи пустые (битые) страницы. Имея перед собой полную картину видимости сайта по запросам, вы сможете понять, где следует «копать» в первую очередь.
Как собирать запросы для семантического ядра
Сбор полного ядра — процесс не быстрый и требует значительных временных затрат и концентрации. Старайтесь не поручать работу одному человеку или делать все самому. Лучшим решением будет разделить задания между несколькими людьми по товарным категориям и желательно, чтобы каждый специалист обладал хорошими знаниями в той области, которую ему доверяют. Часто бывает, что сотрудник с низкой компетенцией может пропустить или удалить важный запрос. Например, запрос «смартфоны nfc» неподготовленный человек может отнести к какому-нибудь китайскому бренду и исключить его из списка, поскольку на сайте такого бренда нет. Но на деле под этим запросом понимаются смартфоны, имеющие на борту чип для бесконтактной оплаты NFC. И таких смартфонов в любом специализированном интернет-магазине наберется ни один десяток. Возможно, пример с NFC и не самый показательный, но думаем, что суть вы уловили. Особенно будьте осторожны, когда доверяете сбор семантики фрилансерам и вдвойне осторожней, когда речь идет о сложных B2B-тематиках, где без специальных знаний совсем тяжело.
Теперь мы пробежимся по наиболее распространенным способам сбора «семантики».
Wordstat
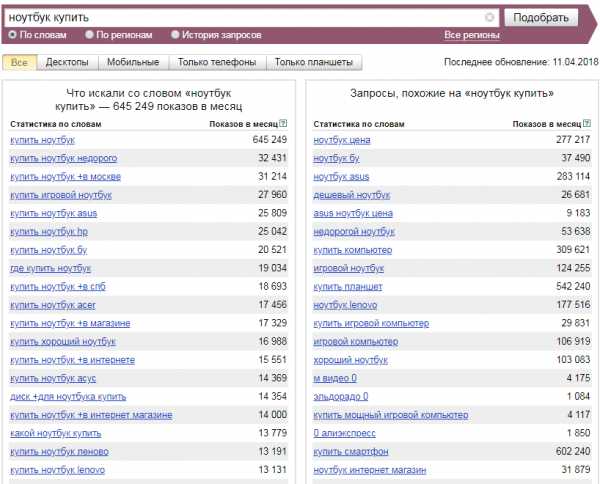
Сервис https://wordstat.yandex.ru/ можно считать первоисточником, любые другие инструменты так или иначе взаимодействуют с данными «поисковика». Для начала выберите несколько запросов, которые характеризуют ваш бизнес максимально точно. Предположим, вы владелец интернет-магазина смартфонов. Отталкивайтесь от того, как бы вы сами искали любой подобный магазин в поисковой системе. Возьмем для примера запрос «купить смартфон».
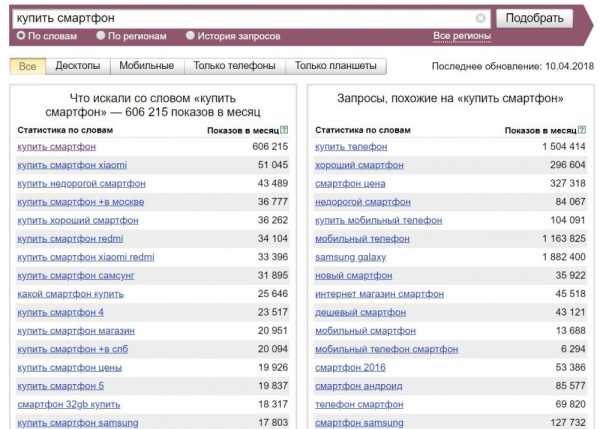
В левой колонке мы видим фразы, которые пользователи искали вместе со словом «купить смартфон».
Помните, что из списка полученных фраз необходимо исключить все некоммерческие запросы, например, «какой смартфон купить в 2018 году», а также запросы, несвязанные с вашим бизнесом, для примера, «мтс купить смартфон по акции» (если, конечно, вы не сотрудник МТС).
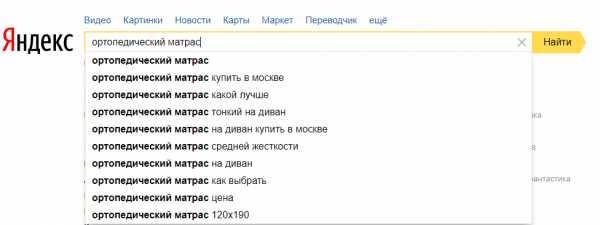
Если вы сомневаетесь к какому типу относится запрос (коммерческий или нет), просто «вбейте» его в «поисковик» и посмотрите на результаты выдачи. Если в выдаче преобладают блоги и журналы, то запрос, скорее всего, информационный.

Выдача по запросу «какой смартфон купить в 2018 году», одни информационные сайты
В правой колонке «Яндекс» показывает нам фразы, похожие на искомый запрос, но мусора здесь однозначно больше. Используйте только те фразы, которые реально отражают суть вашего бизнеса, естественно также, исключая информационные запросы, вроде «хороший смартфон». Правую колонку хорошо использовать для поиска синонимов. Например, редкий человек может сходу правильно написать бренд китайской компании Xiaomi. Можно встретить и «ксиоми», и «сиаоми» и «сяоми». Все эти варианты также следует включить в состав ядра.
Перебирая запрос за запросом, вы непременно заметите, что потенциальные клиенты ищут смартфоны по нескольким критериям:
- Цена (купить недорогой смартфон)
- Бренд (купить смартфон xiaomi, купить смартфон samsung)
- Модель (купить смартфон xiaomi redmi)
- Характеристики (смартфон 32gb купить)
- Регион (купить смартфон в москве, купить смартфон в спб)
Благодаря этим данным, вы можете составить так называемые маски запросов, такие как:
- Смартфон + действие (купить, заказать, с доставкой по России).
- Смартфон + цена (недорого, дешево, по акции, до 10 тыс, до 20 тыс, до 30 тыс).
- Смартфон + бренд (Samsung, Apple).
- Смартфон + бренд + модель (Samsung Galaxy S9+, Apple iPhone X).
- Смартфон + характеристика (32 гб, с NFC, 6 дюймов, с 2мя sim-картами).
- Смартфон + что-то еще (для бабушки, с большой автономностью и т.п.).
Выделив основные маски запросов, вы сможете:
- Корректно распределить посадочные страницы на сайте по группам товаров и их характеристикам.
- Создать страницы под популярные поисковые запросы (как, например, смартфон для бабушки).
- Тиражировать выбранные маски запросов на все остальные товарные категории.
- Шаблонизировать сбор семантического ядра.
На данном этапе мы не рекомендуем придавать особое значение частотности запроса, включайте в список любые непустые фразы (с частотой от 1), которые связаны с вашим бизнесом. Какие фразы вы используете непосредственно для продвижения и рекламы — вопрос вторичный. На первом этапе главное собрать полноценное семантическое ядро, почему это важно мы уже сказали ранее.
Rush Analytics
Сервис Rush Analytics позволяет в значительной степени автоматизировать сбор запросов из левой колонки Wordstat и выгрузить данные в таблицу Excel.
Для нашего примера достаточно запустить сбор ключевых слов по запросам «смартфон» и «телефон». Правда, здесь есть один важный нюанс. По умолчанию, Wordstat отдает всего 41 страницу результатов. Как вы понимаете, все запросы таким методом мы не получим. Чтобы обойти ограничение, существует метод сбора частотности для запросов заданной длины (до 7 слов).
Для этого добавляем запросы в сервис следующим образом (кавычки обязательны):
- «смартфон смартфон»
- «смартфон смартфон смартфон»
- «смартфон смартфон смартфон смартфон»
и так далее до 7 слов.
Тоже самое следует проделать и с запросом «телефон».
С помощью этого метода вы сможете собрать максимальное количество запросов в вашей тематике.
Мы не будем подробно останавливаться на интерфейсе сервиса, для этого наши коллеги подготовили понятную инструкцию вместе с видео: https://www.rush-analytics.ru/faq/sbor-yandex-wordstat-rukovodstvo
Spywords.ru
Сервис spywords.ru позволяет немного схитрить и собрать семантику не с нуля, а с помощью ваших конкурентов.
Суть работы предельно проста: вы выбираете 3-4 лидера в нише и собираете все фразы, по которым они ранжируются в поисковых системах в пределах ТОП100.
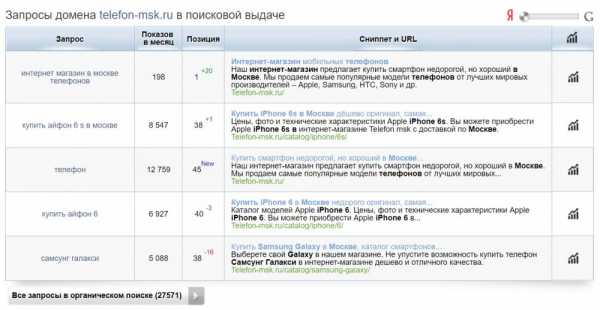
Запросы конкурента в ПС Яндекс
Безусловно, таким образом, вы вряд ли соберете полноценное семантическое ядро, но процентов 60 охватить вполне возможно и для старта этого может быть достаточно.
Где еще можно подсмотреть запросы?
В прошлой статье ТОП-10 ошибок на старте продвижения сайта мы уже говорили, что нужно не пренебрегать статистикой собственного сайта. Если ваш проект уже запущен и собирает небольшой трафик, изучите статистику переходов из поисковых систем и включите эти запросы в семантическое ядро.
Узнать по каким запросам ранжируется ваш сайт можно в системах Яндекс.Метрика или Google Analytics, а также в сервисах Яндекс.Вебмастер и Google Search Console.
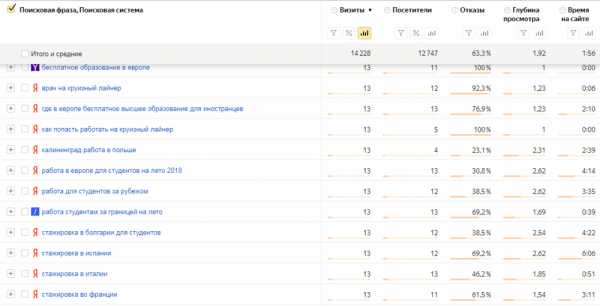
Статистика переходов по поисковым фразам из Яндекс.Метрики
Статистика поисковых запросов из панели Яндекс.Вебмастер
Если на вашем сайте также есть поиск, попросите ваших разработчиков сохранять историю запросов ваших клиентов.
Кластеризация запросов
Предположим, что вы собрали все необходимые фразы, почистили дубли, избавились от лишних запросов. Теперь перед вами огромный файл с тысячами ключевых слов. Все эти ключевые фразы нужно распределить по группам.
Последние годы широкую популярность получил метод автоматизированной кластеризации запросов на основе сравнения поисковой выдачи. Говоря простым языком, кластеризация показывает, какие запросы можно продвигать на одну страницу, а какие нет. С помощью кластеризации вы увидите, что, например, запросы «мобильные телефоны» и «сотовые телефоны» можно продвигать на одну страницу, а запросы «смартфоны Apple» и «дешевые смартфоны» не стоит.
Произвести кластеризацию можно с помощью все того же сервиса Rush Analytics. Интерфейс данного функционала также очень простой, но если что инструкция прилагается: https://www.rush-analytics.ru/faq/klasterizaciya-zaprosov-semanticheskogo-yadra-rukovodstvo
Что делать дальше?
Теперь, когда ядро собрано, а запросы разделены по группам, самое время заняться оптимизацией вашего сайта. Ваша цель — обеспечить каждой группе запросов посадочную страницу. Позаботьтесь, чтобы на сайте была четкая структура каталога и понятная навигация по разделам. Каждый бренд, товар, фильтр и интерес пользователя должны получить отдельную посадочную страницу с уникальными мета-тегами и описанием. В ближайших статьях мы обязательно поговорим о том, как создать идеальную, с точки зрения поисковой системы, посадочную страницу.
Заключение
Важно понимать, что ежедневно появляются новые товары, меняются интересы и предпочтения пользователей, поэтому очень важно оставаться на гребне волны и вовремя реагировать на новые тренды. Понятно, что в ежедневном потоке дел не всегда удается посветить все время аналитике, но собрать «семантику» лишь один раз и не работать дальше в этом направлении — решение без перспектив.
Старайтесь больше внимания обращать на ваших конкурентов. Как на тех, кто уже присутствует на рынке давно, так и на новичков. На последних мы бы рекомендовали смотреть даже более пристально, ведь им приходится заходить на конкурентный рынок и сделать это без каких-либо даже минимальных инноваций крайне сложно. Конкурировать одной лишь ценой крайне сложно. На том же рынке смартфонов появляется все больше игроков, которые предлагают Trade-In (обмен старого смартфона на новый с доплатой), а также продажу смартфона по подписке. Постепенно потенциальные покупатели привыкнут к новым сервисам, а игрокам, которые не пожелают модернизировать бизнес, придется уйти с рынка. Надеемся, что вы будете не из их числа.
Успешного продвижения!
linkbuilder.su
Собираем семантическое ядро – Инструкция для новичков

Автор: Татьяна Бикаева, маркетолог CPA-сети Admitad и проекта GetDirect
Под семантическим ядром принято понимать набор ключевых запросов, их форм и словосочетаний, которые всеобъемлюще описывают и характеризуют товар или услугу. Подбор поисковых запросов для SEO или для настройки контекстной рекламы – один из важнейших шагов, который определяет успех дальнейшей работы.
При сборе семантического ядра важно ответить себе на два вопроса:
• Какую полезную информацию пользователь может найти на моем сайте?
• С помощью каких поисковых запросов пользователи ищут ту информацию, которая опубликована у меня на сайте?
Сбор семантического ядра, как и любой другой маркетинговый процесс, имеет свои правила, которыми не следует пренебрегать:
• По одному запросу следует продвигать только одну страницу.
• Продвигаемая (в SEO или в контекстной рекламе) страница, должна отвечать на запрос пользователя. Следует убедиться, что страница содержит релевантный контент.
• Семантическое ядро должно включать в себя высокочастотные, среднечастотные и низкочастотные запросы. При этом стратегия продвижения запросов разной частотности будет различаться (как для SEO, так и для контекстной рекламы).
Каким должен быть объем семантического ядра:
• Максимальное число запросов не может быть точно определено и сильно зависит от тематики. В семантическое ядро должны быть включены все запросы, которые есть в вашей тематике и являются релевантными предлагаемому товару или услуге.
• В среднем размер семантического ядра для небольших и средних сайтов составляет от нескольких сотен до нескольких тысяч запросов. Семантическое ядро для крупного сайта варьируется в пределах от нескольких десятков тысяч до нескольких сотен тысяч. Однако, следует понимать, что при схожих размерах сайты разных тематик могут иметь принципиально разный размер семантического ядра.
Существуют два принципа сбора семантического ядра:
1. Копирование запросов у конкурентов. Здесь механика предельна проста: выбираем 2-4 конкурента, которые являются лидерами сегмента, с помощью специальных сервисов (spywords.ru, seopult.ru) собираем семантические ядра конкурентов. Далее сегментируем полученные данные и «чистим» от нерелевантных запросов. Этих шагов достаточно для получения качественного ядра.
Плюсы метода: экономия времени и денег, относительная простота.
Минусы метода: есть риск повторения ошибок конкурентов (всегда сохраняется вероятность того, что семантическое ядро конкурентов собрано некорректно), также выпадают те, возможно целевые и эффективные, запросы, которым «не уделили внимания» конкуренты.
2. Создание семантического ядра «с нуля». Семантика формируется исходя из глубокого анализа тематики, сайта, товара/услуги и предполагаемых продающих запросов.
Плюсы метода: максимально эффективное семантическое ядро, и, как следствие, наиболее успешное продвижение.
Минусы метода: высокие временные, а также и финансовые затраты.
Ключевые запросы принято разделять на:
• Информационные — запросы пользователей, желающих получить некоммерческую информацию.
Например: [как правильно собирать шкаф].
• Продающие — те, которые пользователи вводят, желая совершить какое-то транзакционное действие.
Например: [купить деревянный шкаф].
• Прочие запросы — те, по которым нельзя определить намерения пользователя.
Например: [деревянный шкаф].
Также запросы разделяют по частотности:
• Сверхвысокочастотные: те, которые пользователи задают свыше 10000 раз в месяц- [купить шкаф]
• Высокочастотные — те, которые пользователи задают свыше 1000 раз в месяц — купить деревянный шкаф]
• Среднечастотные — те, которые пользователи задают до 1000 раз в месяц — [купить полированный шкаф из красного дерева]
• Низкочастотные — те, которые пользователи задают до 100 раз в месяц — [купить полированный шкаф из красного дерева в твери]
• Сверхнизкочастотные — те, которые пользователи задают до 10 раз в месяц — [купить полированный шкаф из красного дерева 2000 года выпуска в твери]
При этом не забываем про «анатомию поискового запроса»:
• Тело запроса
• Спецификатор (намерения пользователя) запроса
• Хвост запроса
При этом важно отметить, что чем больше «хвост» запроса, тем ниже его частотность.
Основные этапы сбора семантического ядра для тех, кто хочет сделать это «с нуля»:
1. Первоначально необходимо провести глубокий анализ тематики и основных конкурентов.
2. Далее следует составить первичный список запросов. Для этого анализируем страницы своего сайта и ищем типичные словосочетания. Например, для магазина бытовой техники, это: «электрочайник», «утюг», «пароварка», «микроволновая печь». Также, бывает полезно для этого изучить заголовки страниц, потому что, зачастую, в 4-5 словах сказано, какая информация содержится на странице.
Например, сайт mvideo.ru, категория «Системные блоки». Основной запрос находится в заголовке страницы:
Там где возможно, следует включать в список синонимичные сочетания.
Например:
• мобильный телефон, сотовый телефон
• шубы женские, шубы для женщин
• джинсы детские, джинсы для детей
• смарт часы, умные часы и т.д.
Для e-commerce не лишним будет включить в первичный список запросы с добавлением слова «купить». Например: [купить системный блок], [купить ноутбук], [купить утюг] и так далее.
3. Далее собираем расширения для каждой найденной нами фразы через wordstat.yandex.ru. Например, [купить смарт часы]:
В левой колонке мы видим запросы, связанные с исходной фразой, а в правой — запросы, похожие на исходную фразу.
4. После этого нужно логически сгруппировать запросы и распределить их по страницам сайта (существующим или тем, которые ещё предстоит создать). Здесь важен принцип: одна страница – одна «проблема».
Например, запросы [купить смарт часы], [купить фитнес часы], [умные часы] — следует отнести к одной странице, а запросы [фитнес часы Android] и [фитнес часы iOS] — к разным.
Рассмотрим, как применить эту схему на примере магазина квадрокоптеров:
• Анализируем тематику и основных конкурентов.
• Проводим аналитику заголовков листингов и товарных фильтров, собираем названия групп товаров и их характеристики. Например, листинг «Квадрокоптеры», свойства:
— радиоуправляемый
— WLToys
— wi-fi
— FPV-камера
— 6 осей
— пилотаж
— для мальчиков
— белый
— 4 канала
— электро
— с камерой
— китай
• «Склеиваем» название товара в единственном числе и свойство в excel, получаем:
— Квадрокоптер радиоуправляемый
— Квадрокоптер WLToys
— Квадрокоптер для мальчиков и т.д.
• Cобираем расширения каждой найденной фразы через wordstat.yandex.ru
• Далее логически группируем запросы и распределяем их по страницам сайта (существующим, либо тем, которые ещё предстоит создать).
ТОП-3 популярных сервисов для сбора качественного семантического ядра:
Wordstat.yandex.ru. Это бесплатный сервис Яндекса, которым пользуются SEO специалисты и специалисты по контекстной рекламе.
Сервис предоставляет данные о частотности запросов (числе показов в месяц), а также позволяет получить дополнительные запросы к тем, которые были введены.
Помимо этого, здесь мы можем получить статистку изменения частотности любого запроса в зависимости от региона и от временного периода.
Например, статистика изменения частотности по регионам запроса [квадракоптеры]:
 KeyCollector. Программа, автоматически собирающая данные из нескольких десятков источников. Помимо сбора всё тех же фраз и статистики из wordstat.yandex.ru, она собирает данные из поисковой и рекламной выдачи Яндекса и Google, статистку фраз из Яндекс.Директа, информацию из различных специализированных сервисов (megaindex, seopult), статистку из ВКонтакте и проч.
KeyCollector. Программа, автоматически собирающая данные из нескольких десятков источников. Помимо сбора всё тех же фраз и статистики из wordstat.yandex.ru, она собирает данные из поисковой и рекламной выдачи Яндекса и Google, статистку фраз из Яндекс.Директа, информацию из различных специализированных сервисов (megaindex, seopult), статистку из ВКонтакте и проч.
Есть возможность бесплатного использования сервиса, однако, полная лицензионная версия платная.
Spywords.ru. Позволяет получить данные практически о любом сайте. В первую очередь его используют для анализа сайтов конкурентов.
В частности сервис позволяет:
• выгрузить поисковые фразы, по которым сайт находится в пределах ТОП-100 выдачи Яндекса и Google.
• Выгрузить рекламные фразы и объявления сайтов конкурентов.
www.searchengines.ru
Семантическое ядро в 2 раза быстрее: инструкция по автоматизации
Типичный сбор семантического ядра начинается с парсинга Wordstat или сбора ключевиков со всевозможных сервисов в KeyCollector. Затем наступает черед ручной кластеризации в Excel или KeyCollector. Весь процесс отнимает дюжину времени, а именно порядка 16–24 человекочасов seo-специалиста. Можно ли ускорить этот процесс без потери качества? Да, и мы расскажем, как это сделать.
Этап 1. Подготовительный
Шаг 1. Забыть про сбор максимального полного семантического ядра через парсеры Wordstat или KeyCollector и тем более руками. Вам не нужно тратить время seo-специалиста напрасно. Подробнее — ниже.
Шаг 2. Создать черновую структуру сайта, отталкиваясь от которой собрать семантическое ядро и, собственно, структуру сайта. Для этого даем клиенту заполнить бриф. В нем он должен описать, чем занимается компания, какие проблемы решает будущих пользователей, кто конкуренты, основные группы товаров или ключевые услуги. Посмотрите шаблон полного брифа. Если же вы владелец сайта, то ответьте на такие же вопросы для структуризации мыслей.
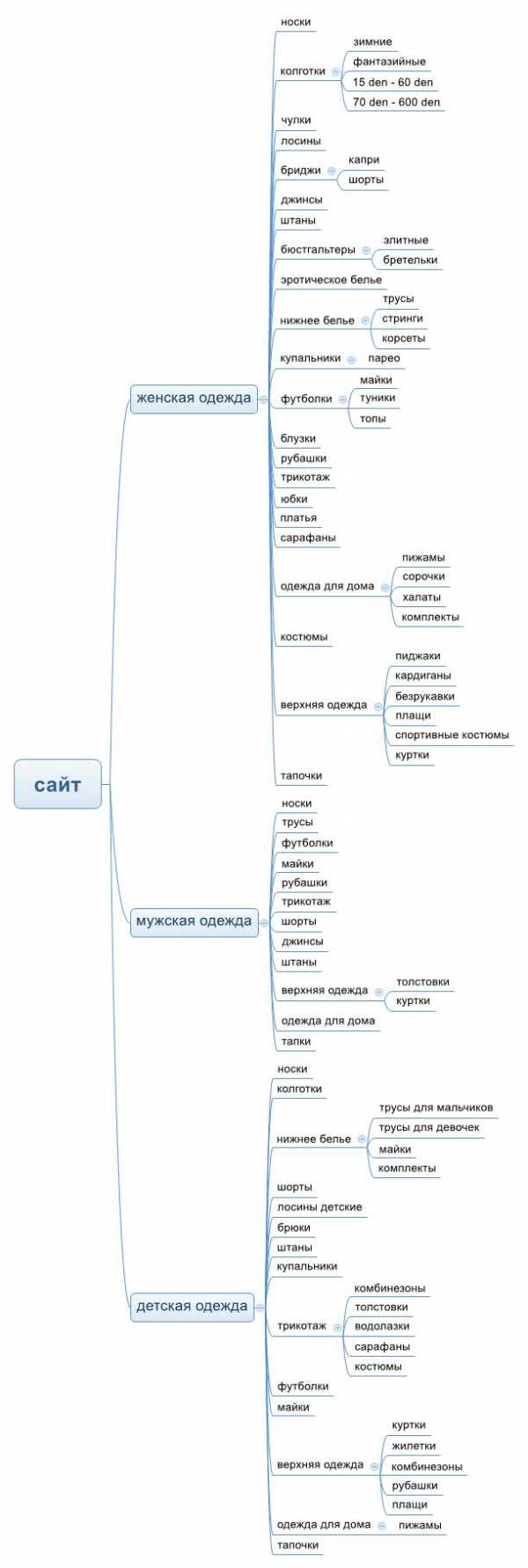
Шаг 3. После изучения брифа устраиваем мозговой штурм и делаем список общих ключевых фраз, которые характеризуют бизнес. Главное не прерывать мыслительный поток и записывать все фразы, даже нелепые на первый взгляд. Например, у нас интернет-магазин по продаже ортопедических матрасов, стульев и подушек. Тогда короткий список определяющих фраз будет такой:
- ортопедические матрасы
- ортопедические подушки
- ортопедические кресла
- ортопедические стулья
- стулья для осанки
- анатомические подушки
- матрасы для спины
- подушки для стульев.
Каждая фраза из этого списка — высокочастотник в тематике и определяет только тип товара. Дальше нужно расширять семантическое ядро средне- и низкочастотниками, а затем кластеризовать (разбивать всю семантику на подкатегории). На этих этапах мы и сэкономим время с помощью автоматизации.
Этап 2. Автоматизация уровень новичок
Сбор семантики
Выгрузить семантику с последующей кластеризацией можно с помощью Serpstat, поэтому шаги по работе в сервисах покажем на его примере. Также для сбора семантического ядра можно использовать SEMrush.
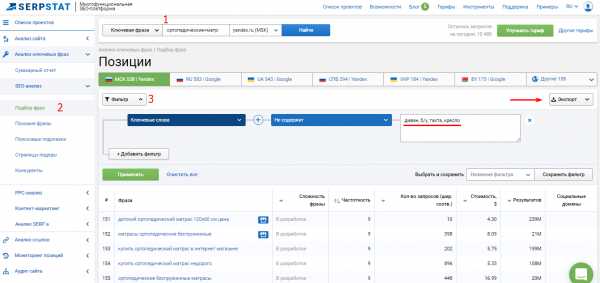
Шаг 1. Поочередно вводим ключевые фразы в сервис, выбираем регион поиска, под которое будет продвигаться сайт, и экспортируем все фразы из инструмента “Подбор фраз”. Также если у вас заготовлен список стоп-слов, вы можете добавить его в фильтр “Ключевые слова — не содержит” через запятую и выгрузить уже “чистую” семантику.
Процесс сбора семантики по одной ключевой фразе занимает до 3 минут.
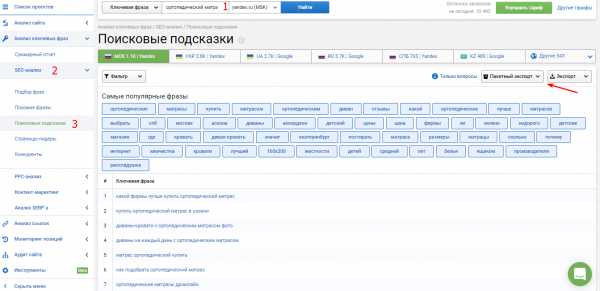
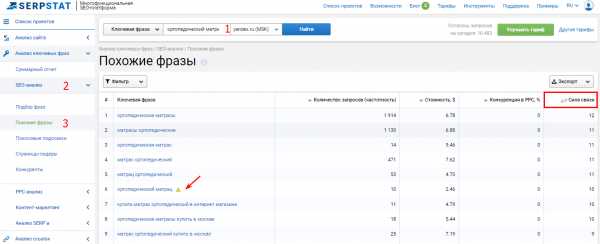
Шаг 2. Продолжаем расширять семантику, используя инструмент “Похожие фразы”, который находит синонимы фразы и сленговые выражения. Внедряя ключевики из этого отчета, вы максимально охватите запросы аудитории. А параметр “Сила связи” подскажет вам, используют ли эту фразу в своем семантическом ядре ваши конкуренты из топ-20. Чем выше число, тем больше сайтов используют исследуемую фразу и предложенный синоним.
Выраженный результат показывается на товарах, которые люди могут искать по-всякому. Например, подушки для спины.
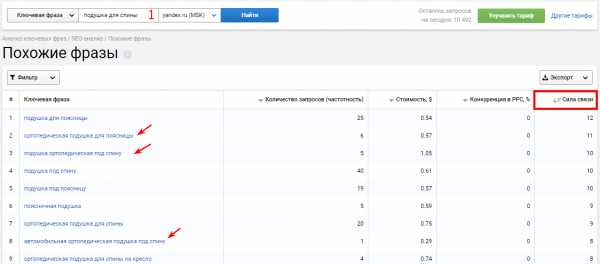
Шаг 3. Последний шаг в расширении семантики — это сбор поисковых подсказок поисковой системы. Преимущество в том, что сервисы собирают информацию в режиме реального времени и вытаскивают сразу все поисковые подсказки, которые может предложить Яндекс/Google. Поисковики же предлагают только до 12 подсказок на фразу.
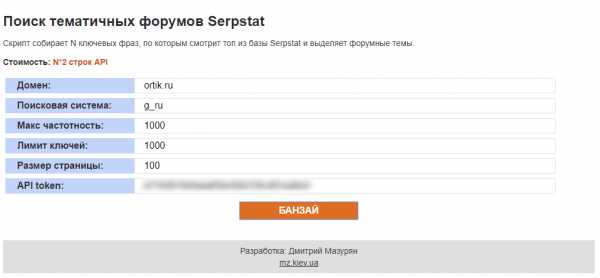
Чтобы выгрузить все подсказки, переходим в инструмент “Поисковые подсказки” и выгружаем список.
Обратите внимание на облако популярных фраз, именно такие слова чаще всего ищут люди со словосочетанием “ортопедические матрасы”. Если среди фраз есть определенные размеры, бренды или тип изделия, то стоит включить их в ассортимент интернет-магазина.
Также под информационный тип ключевиков, как “лучшие матрасы для проблем с позвоночником”, вы можете подготовить статью к вам в блог, что станет дополнительным источником трафика и продаж.
Шаг 4. Сводим все отчеты в единую таблицу и чистим дубли с помощью плагина Remove Duplicate.

Потраченное время — до 5 минут. Зависит от количества ключевых запросов.
Пользуюсь сервисами вы уже выигрываете время перед теми, кто собирает, чистит и кластеризует семантику вручную. Чтобы понять разницу, попробуйте провести все описанные шаги, вытаскивая ключевые фразы и поисковые подсказки в Wordstat, а затем повторите инструкцию.
Кластеризация
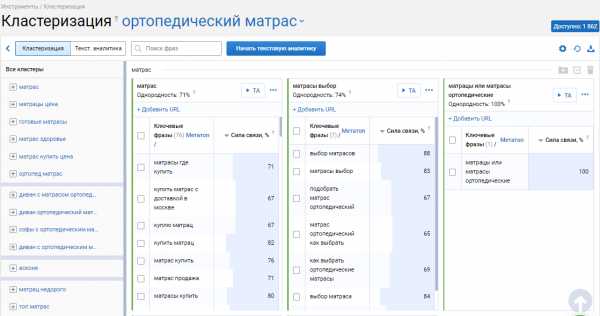
Также экономит до 8 часов автоматическая кластеризация. Это разбивка всех ключевых фраз на смысловые группы, под которые создается структура сайта, посадочные страницы, фильтры, категории товаров и так далее.
Для этого загрузите ваш файл со всеми ключевыми фразами в инструмент кластеризации и в течение 10–30 минут, в зависимости от количества ключевиков, вы получите отчет.
Если группировка не удовлетворяет качеством, не выходя из проекта, щелкните по значку “настройки” и поставьте силу связи сильнее/слабее. Изменение настроек в пределах одного проекта бесплатное, перегруппировка семантики длится не больше 1 минуты.
Этап 3. Автоматизация уровень профи
Если вы уже собираете семантику с помощью сервисов через интерфейс, пришло время познакомить вас с API. Это набор функций, позволяющих пользователям получать доступ к данным или компонентам сервиса, в нашем случае — Serpstat. Преимущество работы по API:
- Можете комбинировать разные отчеты в один, не заходя в сервис. При этом данные будут выгружаться со скоростью 10 запросов в секунду. Реально ли повторить такое руками? Конечно, нет 🙂
- Лимиты API (юниты) и лимиты в интерфейсе отличаются, по API вы получаете гораздо больше данных и дешевле. Даже если у вас закончились лимиты на сбор ключевых слов в интерфейсе, вы можете выгружать фразы, используя API.
- Вы можете не покупать подписку на сервис, а просто купить нужное вам количество API-юнитов и получать данные, не заходя в интерфейс.
- Можете написать любой скрипт для API и получать любые данные в один клик, которые не смогут добыть ваши конкуренты. Например, этот бесплатный скрипт ищет ветки форумов, которые ранжируются в топ-100 поисковой системы по тем же ключевым словам, что и ваш сайт. В результате вы получите список всех найденных URL-ов, их ключевые фразы, а также их позиции.

А теперь повторим все действия по сбору семантики со второго этапа с помощью API.
Шаг 1. Скопируйте эту таблицу со скриптом в свой Google Диск.
Шаг 2. Скопируйте свой токен в личном профиле Serpstat и вставьте в соответствующее поле в таблице. Также выберите нужную базу поисковика и заполните параметры отбора ключевых фраз, добавьте список ключевых фраз, по которым вы хотите выгрузить отчеты.
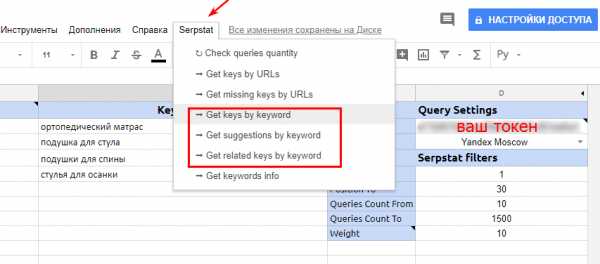
Запустите скрипт, парся по очереди отчеты по подбору фраз, поисковых подсказок и похожих/сленговых фраз (см. скрин):
Программа попросит залогиниться через gmail-аккаунт и запросит доступ на разрешение работы. Подтвердите запуск скрипта, минуя предупреждение о небезопасности.
Шаг 3. Через 30–60 секунд скрипт завершит работу и соберет ключевые слова в рамках заданных параметров.
Также в этом скрипте можно настроить фильтр по минус-словам и любые другие.
Итого мы сэкономили еще несколько часов работы seo-специалиста на сведении всех отчетов в один и сборе данных по каждому ключевому слову в интерфейсе.
Скрипты для работы по API могут писать ваши seo-специалисты, а можно найти официальные в открытом доступе.
Выводы
Максимально ускоряют сбор семантического ядра без потери качества такие действия:
- Кластеризация с помощью специальных сервисов.
- Парсинг ключевых слов, подсказок и сленговых выражений по API seo-платформ.
Помните, что ваши лидирующие конкуренты в лице других бизнесов или агентств по поисковому продвижению уже используют различные сервисы автоматизации и обгоняют сборщиков семантики руками на десять шагов. Поэтому осваивайте новые решения и будьте в топе! Начать можно с seo аудита:
Получить предложение!
Подпишись и следи за выходом новых статей в нашем монстрограмме.
convertmonster.ru
Как собрать семантическое ядро сайта в Wordstat через Key Collector
Головная боль любого профессионального сеошника — это собрать хорошую семантику. Как раз мне пришел новый проект на продвижение, и в этом посте я покажу реальный сбор большого семантического ядра для сайта.
Хотя этот пример я буду делать на основе интернет магазина, но сам принцип можно вполне применять для любого типа сайта — корпоративного, сайта услуг, информационного проекта.
Как собрать семантическое ядро для интернет магазина
Начинается все с анализа клиентского проекта, сайтов конкурентов и составления первичной структуры. Цель этой задачи — понять, по каким направлениям нужно собирать семантику.
Я отрисовываю первичную структуру в Xmind, у меня получилась вот такая схема.
Теперь начинается самое интересное.
Как собрать семантическое ядро с помощью кей коллектор
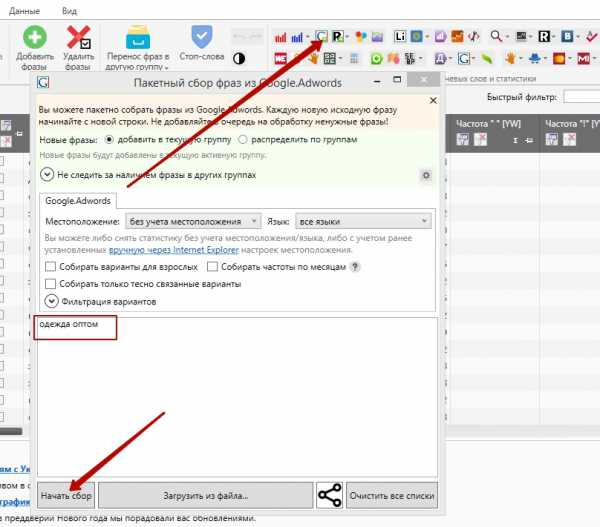
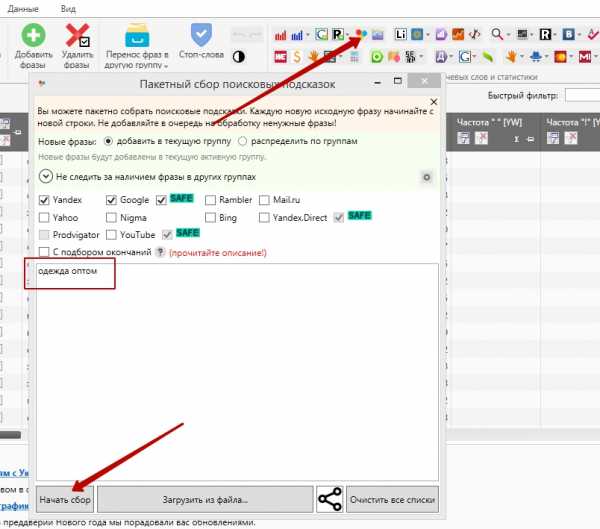
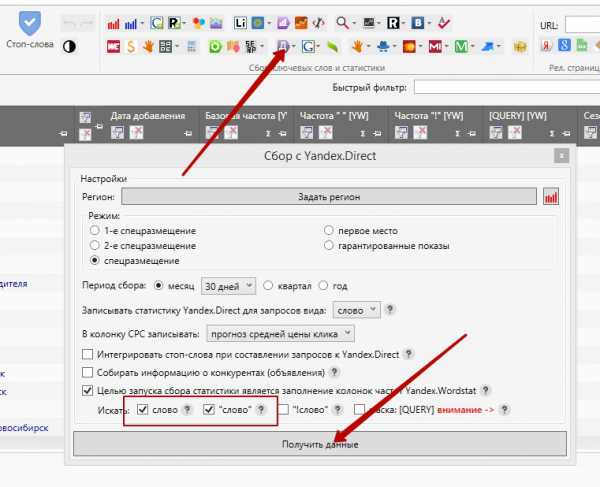
На мой взгляд key collector — это просто незаменимая программа для автоматического сбора семантики. Я закидываю все запросы, которые у меня получились в структуре в яндекс wordstat, google adwords, а также в подсказки яндекс и google.
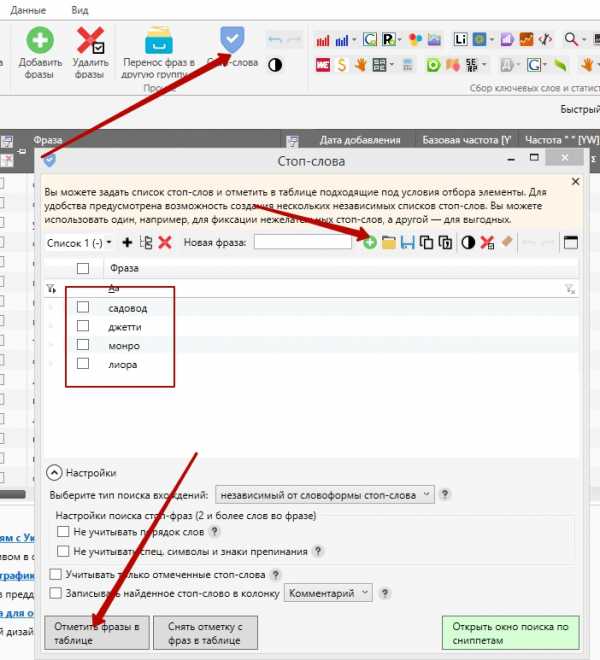
сбор семантики в wordstat
сбор семантики в google adwords
сбор семантики в подсказках яндекс и google
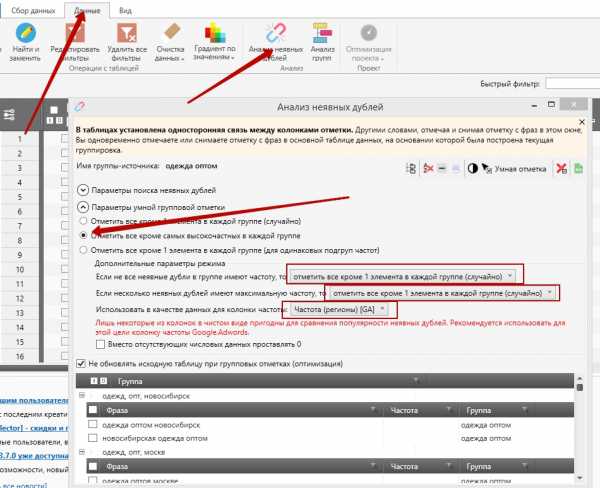
На выходе получается просто огромное ядро, которое нужно хорошо почистить.
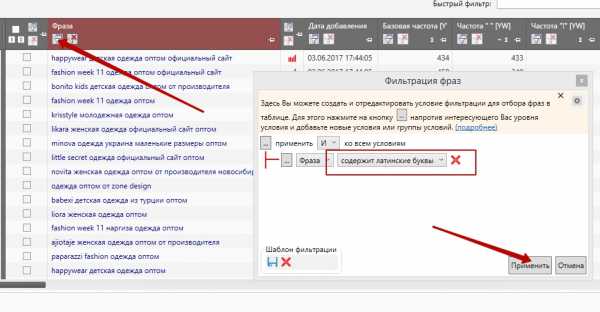
Чистку я делаю на уровнях частотности (удаляю нулевки), дублей явных или неявных, стоп слов и разного мусора через фильтры.
чистка ядра по частотности
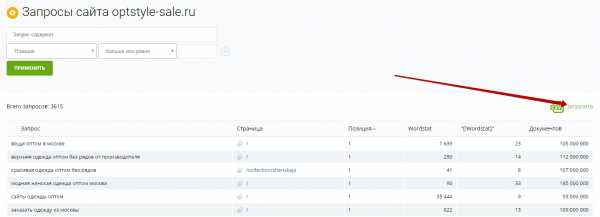
чистка неявных дублей
чистка стоп слов
чистка через фильтры
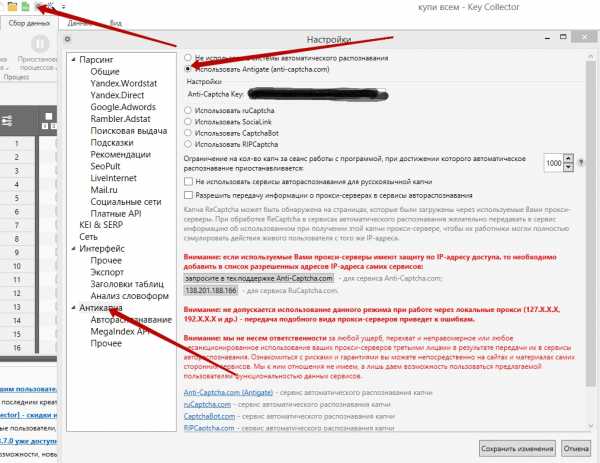
Конечно, мне здесь сильно помогает антикапча, иначе я бы просто замудохался все время вводить эти буквы и цифры. Я использую сервис anti-captcha.com.
После того, как ядро почищено, я делаю новую итерацию — закидываю ключи снова на парсинг в wordstat, adwords и подсказки, потом опять чищу и получается готовое ядро.
Для данного проекта итерацию я делать не стал, так как проект достаточно большой и запросов вполне хватает, чтобы обеспечить прогнозируемые результаты.
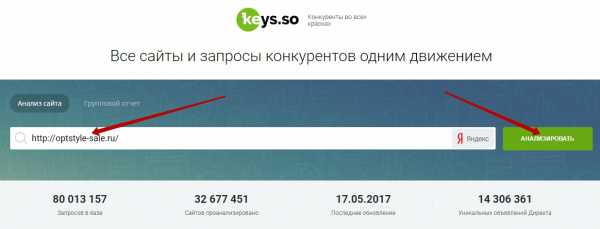
Сбор семантического ядра конкурентов
Следующий шаг — это собрать семантику конкурентов с помощью сайта keys.so. На мой взгляд, это просто офигенный сервис для парсинга чужих запросов, у него мало мусора и очень большая база.
Просто нахожу несколько сайтов конкурентов (3-4 достаточно) по самым жирным запросам, загоняю их в сервис, и он выдает ВСЕ ключи, по которым они продвигаются.
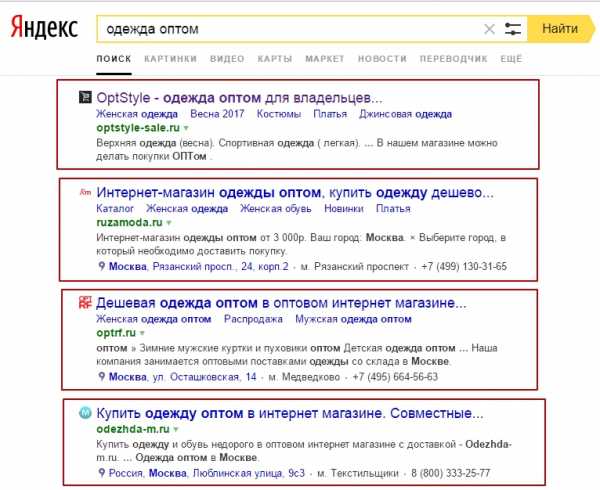
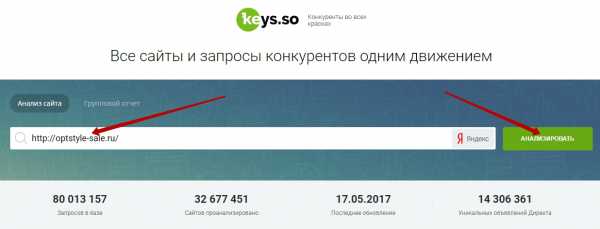
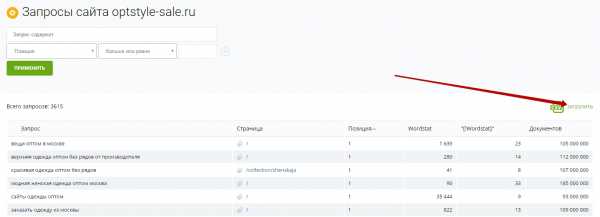
Затем также загоняю их в кейколлектор, чищу от разного мусора аналогично вышеописанному, и получается отличное семантическое ядро конкурентов плюсом к уже собранному ядру.
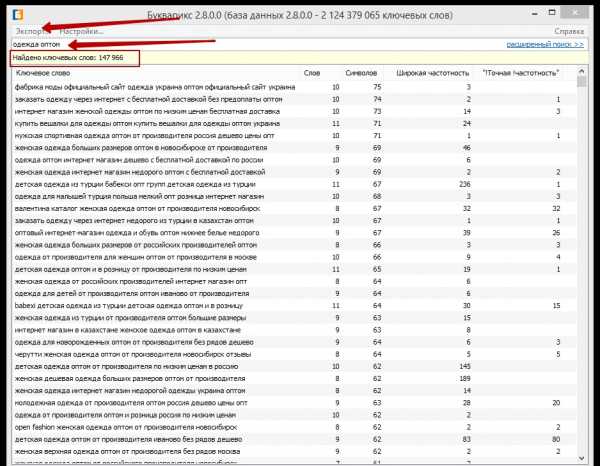
Сбор семантики в букварикс
Еще одна программа, которую я использую в работе — это bukvarix.com. Отличная прога, мало мусора, очень большая база. Единственный минус — весит просто до хера. Только в сжатом виде около 40 Гб, а в распакованном более 170.
Также загоняю в нее все слова из структуры.
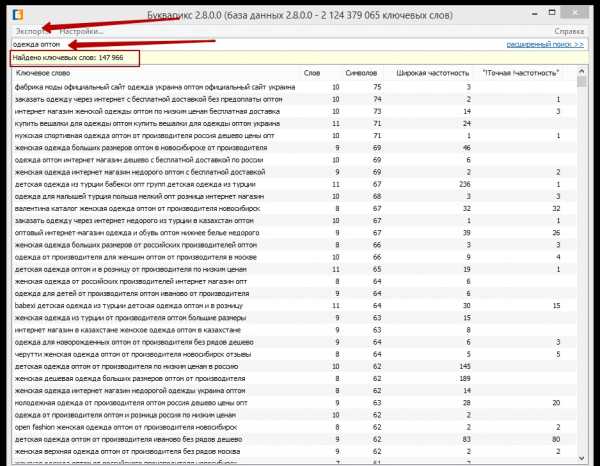
Результат парсинга аналогично чищу через кейколлектор. На выходе получаю еще одно семантическое ядро.
Теперь заключительный момент — нужно все это скомпоновать (первичный парсинг кейколлектора, конкурентов из key.so и букварикс), почистить от дублей и вот она — готовая семантика для интернет магазина.
После сбора семантическое ядро нужно кластеризовать, но это уже совсем другая история.
По времени, в среднем, в моем не спешащем темпе такое ядро я собираю где-то за 2 недели. Долго это или быстро, не знаю, у меня вот такой темп.
Повторюсь, что такая схема подойдет для любого типа сайта, и для своих информационных проектов я собираю семантику точно таким же способом.
Конечно, можно быстро вручную собрать базовое семантическое ядро для сайта бесплатно и онлайн с помощью того же сервиса yandex.wordstat.ru, но оно получится однобоким, очень маленьким, и у вас просто будет мало возможностей его расширить.
В этом видео вы можете посмотреть основы работы с яндекс вордстат и кей коллектор.
Если вам понравилась статья или была полезной, то пишите ваши комментарии, вопросы.
Загрузка…
mydaoseo.ru