Определение больших данных – Amazon Web Services (AWS)
Несмотря на всю доступную информацию, многие организации не осознают, что сталкиваются с проблемой больших данных, или просто не готовы мыслить такими категориями. Организация может получить преимущества от применения технологий больших данных, если ее существующие приложения и базы данных больше не способны масштабироваться и справляться с внезапными увеличениями объема или разнообразия данных либо требований к скорости их обработки.
Если вовремя не найти правильный подход к работе с большими данными, это может привести к повышению расходов, а также снижению эффективности работы и конкурентоспособности. И напротив, разумная стратегия по работе с большими данными может помочь организации сократить расходы и получить дополнительные эксплуатационные преимущества за счет осуществления текущих крупных рабочих нагрузок с помощью технологий больших данных, а также развертывания новых приложений для выгодного использования открывшихся возможностей.
Сбор данных. Сбор необработанных данных (транзакций, записей журналов, событий мобильных устройств и пр.) – это первая проблема, с которой сталкиваются организации при работе с большими данными. Качественная платформа для работы с большими данными упрощает этот этап, предоставляя разработчикам возможность сбора самых разнообразных данных, структурированных и нет, на любой скорости, от режима реального времени до пакетной обработки.
Хранение. Любая платформа для работы с большими данными должна включать надежный, безопасный и масштабируемый репозиторий для хранения данных как до обработки, так и после таковой. В зависимости от конкретных требований могут понадобиться и временные хранилища для перемещаемых данных.
Обработка и анализ. На этом этапе выполняется преобразование данных из необработанного состояния в пригодный для использования формат. Обычно это достигается за счет сортировки, агрегации, объединения или применения специальных расширенных функций и алгоритмов. После этого итоговые пакеты данных сохраняются для дальнейшей обработки или предоставляются для использования с помощью инструментов бизнес-аналитики и визуализации.
После этого итоговые пакеты данных сохраняются для дальнейшей обработки или предоставляются для использования с помощью инструментов бизнес-аналитики и визуализации.
Визуализация и использование. Основная цель работы с большими данными – получение на их основании ценных аналитических выводов для практического применения. В идеале большие данные должны становиться доступными для всех заинтересованных сторон, чтобы они получали возможность легко и быстро изучать пакеты данных с помощью инструментов бизнес-аналитики и настраиваемой визуализации, рассчитанных на самостоятельное использование. В зависимости от типа аналитики конечным пользователям могут предоставляться готовые результаты в форме данных статических «прогнозов» (в случае прогнозирующей аналитики) или рекомендованных действий (в случае предписывающей аналитики).
Технологии работы с большими данными продолжают активно развиваться. Уже сегодня у организаций есть выбор между разными типами аналитики для реализации различных функций.
Изначально инфраструктуры по работе с большими данными, например Hadoop, поддерживали только пакетные рабочие нагрузки. Крупные пакеты данных загружались для обработки сразу, и процесс ожидания результатов растягивался на часы и даже дни. Но время ожидания результата постепенно стало критическим фактором, и требуемая скорость обработки больших данных послужила толчком к развитию таких новых инфраструктур, как Apache Spark, Apache Kafka, Amazon Kinesis и т. д., способных поддерживать обработку потоковых данных в режиме реального времени.
Amazon Web Services предоставляет разнообразный, полностью интегрированный набор сервисов облачных вычислений, который поможет создать приложения для работы с большими данными, обеспечить их безопасность и выполнить развертывание. При работе с AWS не нужно закупать оборудование или обслуживать инфраструктуру, а значит, можно сконцентрировать усилия на поиске новых подходов и технологий.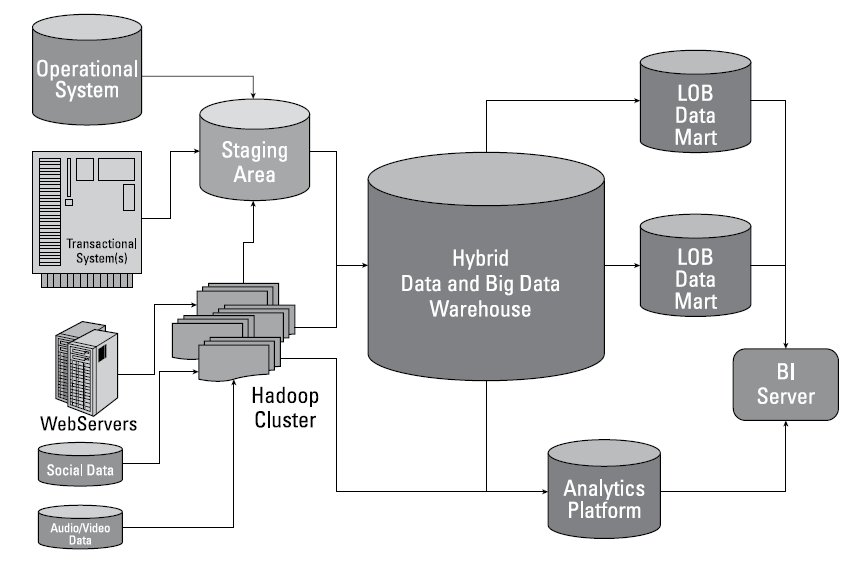
Подробнее о платформе и инструментах AWS для работы с большими данными »
Что такое аналитика больших данных?
Аналитика больших данных – это процесс анализа больших и сложных источников данных для выявления тенденций, моделей поведения клиентов и рыночных предпочтений, что помогает принимать более эффективные бизнес-решения. Сложность анализа больших данных требует новых аналитических инструментов, таких как прогнозирующая аналитика, машинное обучение, потоковая аналитика, и такие методы, как анализ в базе данных и в кластере.
Большие данные обычно определяются четырьмя V:
- Объем: большие объемы данных
- Разнообразие: много разных форм данных, неструктурированных и структурированных
- Скорость: частота входящих данных
- Правдивость: достоверность данных
Помимо огромного объема данных, сложность собираемых данных создает проблемы в управлении данными, их интеграции и анализе. Но компании, которые объединяют неструктурированные источники данных, такие как контент социальных сетей, с существующими структурированными данными, такими как транзакции, могут добавлять контекст и генерировать новые, а зачастую и более богатые идеи.
Но компании, которые объединяют неструктурированные источники данных, такие как контент социальных сетей, с существующими структурированными данными, такими как транзакции, могут добавлять контекст и генерировать новые, а зачастую и более богатые идеи.
Кроме того, большие данные описывают повышенную скорость входящих данных, поступающих из разрастающихся источников, таких как датчики, мобильные устройства, веб-потоки кликов и транзакции, что приводит к необходимости аналитики в реальном времени. Организации, которые могут извлечь выгоду из того, что происходит сейчас, чтобы предотвратить отказ оборудования, рекомендовать предмет для покупки, выявить мошенничество с кредитными картами и многое другое, быстро становятся лидерами в своих отраслях.
Наконец, большие данные относятся к степени точности данных, точности и достоверности. Это не означает, что все данные должны быть тщательно отобранными и чистыми, потому что более сложные источники данных, такие как социальные сети, могут привести к новому пониманию с определенным анализом. Но важно, чтобы организации знали качество, точность и достоверность данных, используемых для формирования понимания и принятия решений.
Но важно, чтобы организации знали качество, точность и достоверность данных, используемых для формирования понимания и принятия решений.
использование QlikView / Qlik Sense для анализа больших данных
Отвечая запросу современного бизнеса иметь доступ к «большим данным», QlikView реализует эту ценность для пользователей, создавая сжатое интеллектуальное представление только той детальной информации, которая актуальна в контексте стоящих перед пользователем проблем.
Пользователям разного уровня требуется информация разной степени детализации. Так, например в крупной сети магазинов топ-менеджеру нужны итоговые показатели эффективности по регионам, менеджеру, ответственному за продукт, может требоваться более 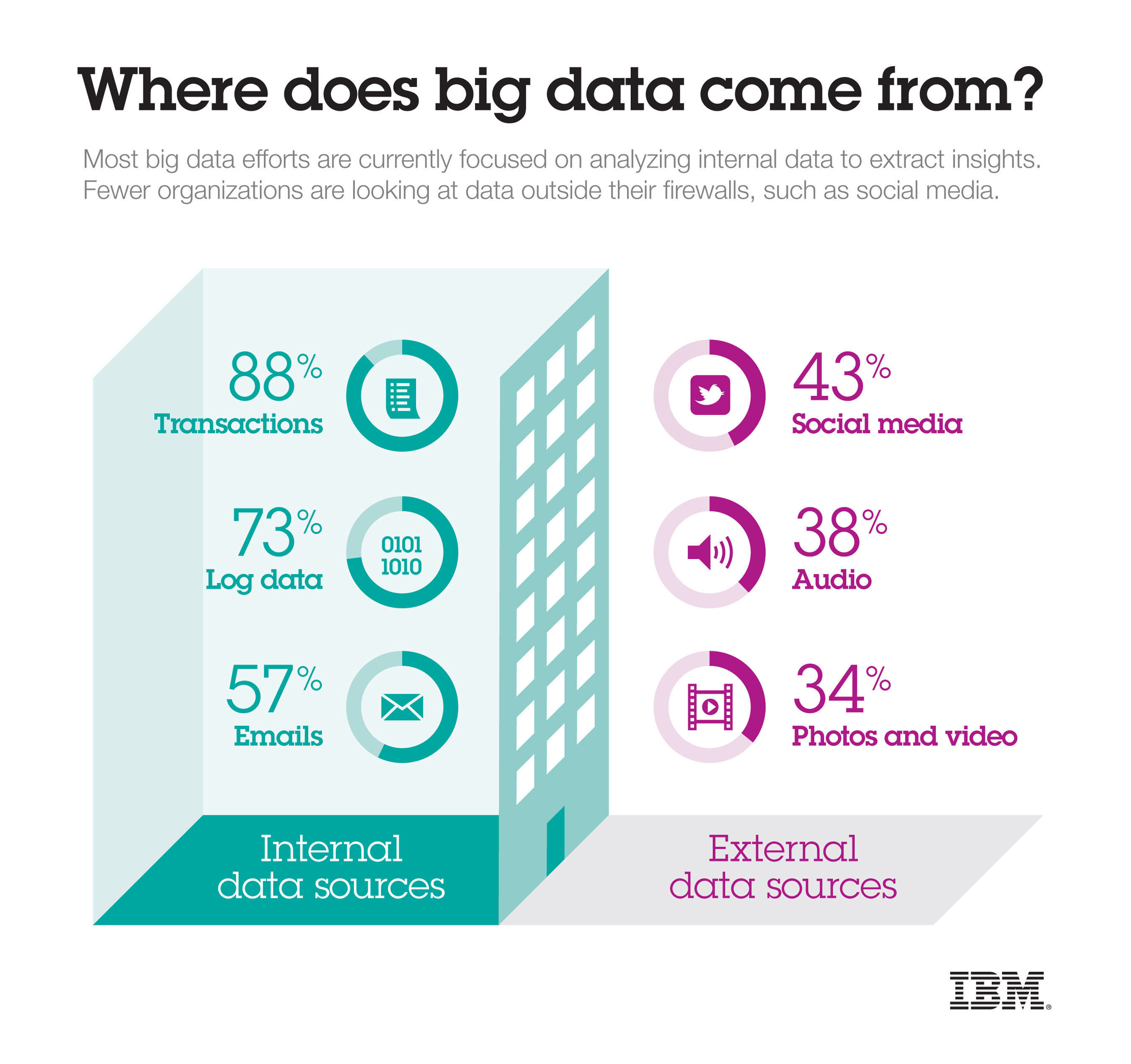
QlikView справляется с этими задачами без создания тяжеловесной и трудозатратой инфраструктуры:
Запатентованный механизм QlikView для обработки данных в оперативной памяти
Многие компании по всему миру уже выбрали именно такой подход к организации анализа терабайт данных, содержащихся в хранилищах и информационных системах.
Инвестировали средства в хранилище? – Воспользуйтесь инструментом QlikView Direct Discovery
Компании, которые вложили средства в создание хранилищ и поэтому не рассматривают возможность загрузки и обработки всех данных в оперативной памяти QlikView, могут применить гибридный подход с использованием инструмента QlikView Direct Discovery.
C коннектором QlikView JDBC Connecto, мы даем возможность поключить QlikView к JDBC источникам данных (базы данных без ODBC/OLEDB драйверов, обычно на Apache Drby / Java DB, источники «больших данных»). A direct database connection may prevented a complex exchange and integration of external files.
Например, вот как можно подключить Hadoop Hive к QlikView.
Furthermore, properties of the JDBC driver are configurable in the connection URL. Especially for installations of QlikView Version 9, a significant reduce of loading time can be achieved with the appropriate use and configuration of the JDBC driver instead of ODBC / OLEDB.
An additional functionality of the QlikView JDBC Connector is the improved support for writing back informations into connected databases. Within the QlikView script the execution of DML statements (eg insert / update / delete) returns a result set with the number of changed rows.
QlikView JDBC Connector лицензируется для QlikView Desktop и QlikView Server/Publisher.
QlikView JDBC Connector поддерживает QlikView Direct Discovery с версии QlikView Version 11.2 (dependent on data sources SQL capability and JDBC driver implementation).
Если вы заинтересованы в данном решение — свяжитесь с нами!
Qlik и Big Data
ВВЕДЕНИЕ
По-прежнему наблюдается огромный интерес к теме Big Data. Он перерос тенденцию просто быть частью IT-лексикона. Для некоторых организаций использование Big Data уже стало реальностью; обеспечивая беспрецедентную способность хранить и анализировать большие объемы разрозненных данных, имеющих решающее важное значение для успеха организации. Это позволило людям выявить новые возможности и решить проблемы, которые им еще не удалось решать.
Для других организаций Big Data по-прежнему является тем, что нужно изучить с точки зрения соответствия текущим и будущим потребностям бизнеса в компании. В этом документе рассматривается, как данные поступают от источника к механизму анализа, а затем обсуждается, как платформа аналитики данных Qlik может помочь компаниям получить максимальную отдачу от работы с Big Data, облегчая доступ и делая данные из Big Data полезными для текущей задачи бизнес-пользователей организации.
В этом документе рассматривается, как данные поступают от источника к механизму анализа, а затем обсуждается, как платформа аналитики данных Qlik может помочь компаниям получить максимальную отдачу от работы с Big Data, облегчая доступ и делая данные из Big Data полезными для текущей задачи бизнес-пользователей организации.
- Преимущества, предоставляемые Big Data, не могут быть использованы, пока не существует способов для простого анализа этих данных бизнесом.
- Способом достижения этой цели является предоставление только необходимых данных для анализа.
- Различные по сложности и объему данные требуют для обработки различных методов или набора методов.
- Qlik предоставляет различные методы у лучшие практики, чтобы предоставить заказчику преимущество во времени, когда нужно обрабатывать Big Data.
РАСТУЩАЯ ПОТРЕБНОСТЬ В АНАЛИТИКЕ BIG DATA
Исторически сложилось так, что использование больших данных фокусировалось в науке, где запускали очень сложные алгоритмы в параллельных вычислительных кластерах для решения основных задач в академических кругах, правительстве и частном секторе. В то время как потребность в науке в решении таких сложных проблем все еще существует, гораздо более необходимо, чтобы конечные пользователи могли использовать возможности аналитики Big Data для решения различных бизнес-задач.
В то время как потребность в науке в решении таких сложных проблем все еще существует, гораздо более необходимо, чтобы конечные пользователи могли использовать возможности аналитики Big Data для решения различных бизнес-задач.
И в отличие от алгоритмической модели, которая стремится найти иглу в стоге сена путем поиска по всем доступным данным, бизнес-пользователи с большей вероятностью будут задавать специальные вопросы, которые сосредоточены на различных срезах данных, относящихся к ним. Они хотят получить новые идеи, чтобы лучше отвечать на реальные бизнес-вопросы, такие как:
- Какие были продажи продукта с тех пор, как мы провели последнюю рекламную кампанию?
- Насколько эффективно моя команда продаж перекрестно продает наши продукты?
- Какой из моих продуктов НЕ продается? Это зависит от региона или отдела продаж?
- Существует ли недостаток резервирования в любой цепочке поставок моего завода? Что произойдет, если стихийное бедствие сократит наши первичные поставки?
- Может ли история звонков для моего региона быть каким-либо шаблоном удовлетворенности или неудовлетворенности клиентов?
Эти типы вопросов были заданы бизнес-пользователями задолго до появления Big Data, но на такие вопросы не давались ответы с высокой степенью уверенности или детализации, поскольку наборы ключевых данных не существовали или были непрактичны для доступа. Бизнес-пользователи не смогли объединить свою интуицию с лучшими данными, чтобы принять оптимальные решения.
Бизнес-пользователи не смогли объединить свою интуицию с лучшими данными, чтобы принять оптимальные решения.
Однако теперь существует технология для расширения доступности источников больших данных для бизнес-пользователей. Qlik (QlikView и Qlik Sense) обеспечивает как быструю гибкую аналитику с одной стороны, так и возможность интеграции данных из нескольких источников (например, хранилищ Hadoop, хранилищ данных, баз данных отделов и электронных таблиц) на одном уровне интерактивной аналитики.
КАК БОЛЬШИЕ ДАННЫЕ ПОСТУПАЮТ ИЗ ИСТОЧНИКА В АНАЛИЗ
Проведем аналогию с добычей металлов, необработанная руда должна быть извлечена из земли, транспортирована на заводы, которые используют механические и химические процессы для получения металла, и только тогда ее можно использовать в ювелирных изделиях или других изделиях.
Аналогичным образом, данные следует от необработанной формы до уровня понимания бизнеса.
- Сбор. Источником бизнес-ориентированных больших данных обычно являются машинные или IoT данные (например, потоки данных, журналы сервера и журналы RFID), данные транзакций (например, активность веб-сайта, данные о точках продаж из физических хранилищ) и данные облака (например, биржевые цены на акции, каналы в социальных сетях).
 Эти данные часто неструктурированы (строки текста или изображений) или полуструктурированы (данные журнала с меткой времени, IP-адресом и другими сведениями). В общем определении больших данных такие данные имеют большой объем (от терабайта до петабайта), высокую скорость роста (много терабайт новых данных в день) и высокий уровень разнообразия (сотни разных типов серверов и приложений, каждый из которых создает информацию в своих собственный форматах).
Эти данные часто неструктурированы (строки текста или изображений) или полуструктурированы (данные журнала с меткой времени, IP-адресом и другими сведениями). В общем определении больших данных такие данные имеют большой объем (от терабайта до петабайта), высокую скорость роста (много терабайт новых данных в день) и высокий уровень разнообразия (сотни разных типов серверов и приложений, каждый из которых создает информацию в своих собственный форматах). - strong>Начальная обработка. Если основной проблемой является стоимость хранения, то данные часто копируются в кластер Hadoop. Распределенная файловая система Hadoop (HDFS) является примером распределенной, масштабируемой и переносимой файловой системы, предназначенной для работы на удобном оборудовании. Hadoop задачи, такие как MapReduce, позволяют осуществлять параллельную обработку данных и агрегацию данных, но это, как правило, достаточно только для интерпретации исходных данных на первом уровне. Ускорительные инструменты, такие как Apache Drill, Spark и Cloudera Impala, предоставляют средства с открытым исходным кодом для внешних систем, таких как Qlik, для лучшего получения данных, хранящихся в Hadoop.
- Уточнение. Довольно часто организации также используют хранилище данных EDW, которое служит в качестве центрального хранилища для структурированных данных, требующих анализа. EDW предназначены не только для хранения, но также имеют надежные возможности ETL (извлечение, преобразование, загрузка), поэтому они играют дополнительную роль с кластерами Hadoop. EDW могут извлекать данные непосредственно из источника данных, сети SAN (сеть хранения данных) или NAS (сетевая система хранения) или кластеров Hadoop. Поскольку данные в EDW структурированы и не являются сырыми, проще запросить и представить более высокий уровень значения, чем исходные данные.
- Анализ. Типичный бизнес-пользователь нуждается в гибкости при получении данных из нескольких источников и должны быть ограждены от подробностей о том, откуда поступают данные или как они организованы. Моделирование данных должно быть быстрым и легко охватывать разные источники данных. Такое окружение (среда) не только снижает нагрузку на ИТ, чтобы соответствовать требованиям бизнеса, но также дает возможность бизнес-пользователям своевременно включать дополнительные данные в свой анализ.
 Эти данные часто неструктурированы (строки текста или изображений) или полуструктурированы (данные журнала с меткой времени, IP-адресом и другими сведениями). В общем определении больших данных такие данные имеют большой объем (от терабайта до петабайта), высокую скорость роста (много терабайт новых данных в день) и высокий уровень разнообразия (сотни разных типов серверов и приложений, каждый из которых создает информацию в своих собственный форматах).
Эти данные часто неструктурированы (строки текста или изображений) или полуструктурированы (данные журнала с меткой времени, IP-адресом и другими сведениями). В общем определении больших данных такие данные имеют большой объем (от терабайта до петабайта), высокую скорость роста (много терабайт новых данных в день) и высокий уровень разнообразия (сотни разных типов серверов и приложений, каждый из которых создает информацию в своих собственный форматах).

ИСПОЛЬЗОВАНИЕ БОЛЬШИХ ДАННЫХ: ВНИМАНИЕ К АКТУАЛЬНОСТИ И КОНТЕКСТУ
Бизнес-пользователям постоянно стараются сделать более эффективным доступ, фильтрацию и анализ данных — и получить представление о них — без использования решений для анализа данных это требует специальных навыков. Им нужны лучшие и простые способы навигации по огромным объемам данных, чтобы найти то, что им подходит, и получить ответы на их конкретные важные вопросы, чтобы они могли принимать более быстрые решения.
Qlik видит несколько распространенных заблуждений о том, как BigData вписывается в общий анализ потребностей бизнес-пользователя. Важно понимать, что:
- Наиболее важные данные могут отсутствовать в репозитории Big Data. Часто данные из хранилища BigData действуют как вспомогательные данные. Например, электронная таблица или небольшая база данных, содержащая результаты опроса удовлетворенности клиентов, могут быть основой для аналитического запроса, а данные из хранилища Big Data позволяют пользователю сопоставлять клиентскую службу, клиента или историю поддержки с оценкой их удовлетворенности.
- Данные, необходимые для анализа, могут быть разбросаны в нескольких хранилищах. Процесс создания хранилища данных предприятия может не только включать копирование данных из операционного источника данных, но также включать в себя моделирование и преобразования метаданных. Поскольку это может быть трудоемким или дорогостоящим, некоторые операционные источники могут оставаться отдельными. Они не требуют затрат и усилий по загрузке в хранилище данных.
Два важных аспекта, которые следует учитывать при работе с большими данными, — это определение необходимости (релевантности) и контекста информации.
Необходимость: правильная (Нужная) информация для нужного человека в нужное время. Подход Qlik всегда заключался в понимании того, что бизнес-пользователи требуют от своего анализа, а не принудительное предложение решения, которое может быть неприемлемым. Доступ к соответствующим данным в нужное время более ценен для пользователей, чем доступ ко всем данным все время.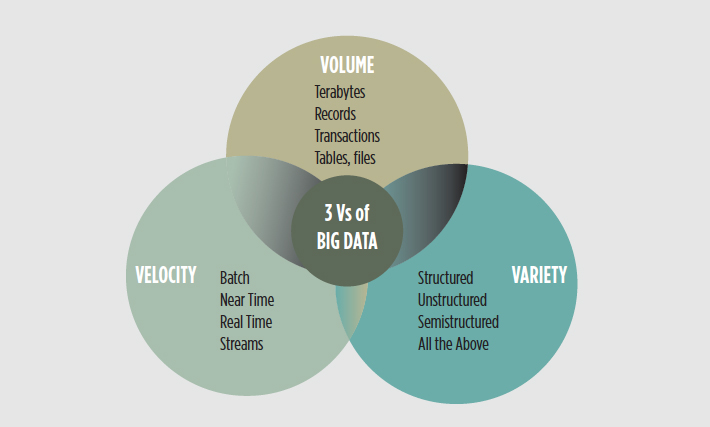 Например, руководители филиалов банков могут захотеть понять (получить) продажи, информацию о клиентах и динамику рынка в своих филиалах, а не всей общенациональной филиальной сети. При таком простом подходе происходит переход от одного большого объема данных к одному из необходимых.
Например, руководители филиалов банков могут захотеть понять (получить) продажи, информацию о клиентах и динамику рынка в своих филиалах, а не всей общенациональной филиальной сети. При таком простом подходе происходит переход от одного большого объема данных к одному из необходимых.
Контекст: что означает «Большие данные» в контексте других источников понимания? Запатентованный инновационный ассоциативный движок Qlik (QlikView и Qlik Sense) разработан специально для интерактивного исследования и анализа в свободной форме, поэтому данные естественным образом «окружены контекстом». Ассоциативный опыт Qlik означает, что каждая часть данных динамически связана с каждой другой частью данных во всех источниках данных. Qlik (QlikView и Qlik Sense) также предлагает мощный «на лету» расчет и агрегацию, которые мгновенно обновляют всю аналитику и выделяют все ассоциации на основе пользовательских взаимодействий. Например, диаграмма Sales by Region может быть окружена соответствующими визуализациями, такими как диаграмма Sales by Product или интерактивные списки, содержащие контекстуальную информацию, такую как дата, местоположение, клиент, история продаж и т. Д. Каждый раз, когда пользователь выбирает одну диаграмму или список, каждый другой список и диаграмма мгновенно обновляются в зависимости от выбора пользователя. Эта уникальная возможность Qlik (QlikView и Qlik Sense) делает невероятно простым для бизнес-пользователя возможность сосредоточиться на (например) конкретном продукте в конкретной географической области, проданному конкретному клиенту, и видеть только те данные, которые имеют к нему отношение.
Д. Каждый раз, когда пользователь выбирает одну диаграмму или список, каждый другой список и диаграмма мгновенно обновляются в зависимости от выбора пользователя. Эта уникальная возможность Qlik (QlikView и Qlik Sense) делает невероятно простым для бизнес-пользователя возможность сосредоточиться на (например) конкретном продукте в конкретной географической области, проданному конкретному клиенту, и видеть только те данные, которые имеют к нему отношение.
Полезность этих ассоциаций еще более очевидна там, где могут быть сотни или тысячи продуктов, клиентов, географические регионы и т. Д. Чрезвычайно большие наборы данных можно нарезать несколькими щелчками, а не прокручивать тысячи строк. С Qlik (QlikView и Qlik Sense) контекст и релевантность идут рука об руку и быстро становятся вполне управляемыми, без каких-либо навыков программирования или расширенной визуализации, что является проблемой больших данных.
РАЗЛИЧНЫЕ МЕТОДЫ ДЛЯ РАЗНЫХ ОБЪЕМОВ ДАННЫХ И СЛОЖНОСТИ
Поскольку Big Data являются относительным термином, а варианты использования и инфраструктура в каждой организации различны, Qlik предлагает несколько методов для обработки сценариев BigData:
- В памяти
- Сегментация
- Цепочка
- Создание по запросу
- Другие методы
В некоторых случаях одного метода может быть достаточно. Другие сценарии могут диктовать использование нескольких методов, работающих вместе.
Каждая ситуация различна. Мы дали механизм (возможность) в руки наших клиентов, чтобы они определили, как они будут управляться ища компромисс между гибкостью, производительностью и типичными характеристиками Big Data: разнообразием и объемом данных.
В этом разделе рассматриваются различные методы Qlik, которые можно использовать в сценариях BigData.
В ПАМЯТИ
Поскольку Qlik Associative Engine оптимизирует скорость работы в оперативной памяти, сжимая данные до 10% от их первоначального размера, многие клиенты Qlik находят, что продукт удовлетворяет требованиям Big Data, сохраняя при этом высокую производительность. Кроме того, объем памяти на стандартном компьютерном оборудовании продолжает расти в размерах и снижается в цене. Это позволило Qlik (QlikView и Qlik Sense) обрабатывать все большие объемы данных в памяти. Например, один сервер 512 ГБ может обрабатывать несжатые наборы данных размером около 4 ТБ. Схема сжатия Qlik означает, что чем больше избыточность в значениях данных, тем больше сжатие.
В отличии от технологий, которые просто «поддерживают» многопроцессорное оборудование, Qlik оптимизирован, чтобы в полной мере использовать всю мощь многопроцессорного оборудования. Он эффективно распределяет расчеты во всех доступных процессорных ядрах, тем самым максимизируя производительность и инвестиции в оборудование. В кластерной среде приложения Qlik (QlikView и Qlik Sense) могут размещаться на разных серверах. Например, приложение, содержащее меньшее количество агрегированных данных, может быть запущено на сервере с меньшим объемом памяти, в то время как приложение с большими объемами подробных данных может быть сконфигурировано для работы на более крупном сервере, причем все это становится невидимым для пользователя.
Кроме того, Qlik может быть развернут таким образом, что один сервер работает в фоновом режиме, извлекает и преобразует большие объемы данных, а другой сервер запускает Приложение, ориентированное на пользователя; без дополнительной нагрузки на обработку фоновых задач. Дополнительным преимуществом для ИТ с этой многоуровневой архитектурой является то, что один из них должен получить доступ к источнику транзакционных данных. Эти данные затем могут быть повторно использованы в нескольких приложениях Qlik без обновления.
Администраторы могут также настроить Qlik (QlikView и Qlik Sense) для загрузки только новых данных или изменившихся с момента последней загрузки, что значительно сокращает пропускную способность, требуемую от любого источника данных.
СЕГМЕНТАЦИЯ
Сегментация — это процесс деления одного приложения Qlik (QlikView и Qlik Sense) на несколько приложений для оптимизации производительности, безопасности, масштабируемости, простоты и сервиса. Данные могут быть сегментированы по регионам или подразделениям. Или пользователь может захотеть сегментировать небольшой dashboard или сводное приложение из другого приложения, содержащего подробные данные. Например, у розничной компании может быть очень большой набор данных и вы хотите представить информацию (и, что еще важнее, информацию) в приложении для розничной торговли по отделам, а также руководителям и нескольким аналитикам, которые выполняют основную часть анализа. Сегментация позволит нам «разбить» большой набор данных, которые будут находиться в приложении, на куски, которые необходимы этим разным группам. Если это будет сделано, каждая из этих групп сможет использовать свое приложение, не требуя мощности ОЗУ и ЦП, необходимых для полной версии приложения. Обратите внимание, что сегментация требует очень небольшого обслуживания или накладных расходов для управления сегментированными версиями.
ЦЕПОЧКА
Цепочка относится к связыванию (или переходу) из одного приложения Qlik (QlikView и Qlik Sense) в другое и поддержанию некоторого «состояния» или выбора, которые пользователь сделал для привязки. Хотя это отдельные приложения Qlik, даже потенциально работающие на разных серверах, они могут совместно использовать состояния выбора. Например, приложение CRM включает в себя несколько различных клиентских зон. Каждая из клиентских зон соответствует отделу внутри компании. Qlik может быть настроен так, чтобы иметь панель инструментов и комплексное приложение общей клиентской базы. Эти приложения затем связаны или привязаны к клиентским зонам, характерным для каждого отдела. Таким образом, цепочка — это еще один метод, который позволяет клиенту управлять приложениями, которые будут содержать слишком много данных для их аппаратного обеспечения для обработки одним гигантским приложением.
Важно отметить, что методы сегментации и цепочки также могут быть использованы вместе, разделяя многогранные представления данных на тематические представления и затем связывая эти отдельные виды с каждым из них.
СОЗДАНИЕ ПО ЗАПРОСУ
Генерация приложений по требованию по требованию (ODAG) — это метод, который позволяет пользователю автоматически создавать целевое приложение для анализа каждый раз, когда они выбирают срез очень большого источника данных.
Подавляющее большинство пользователей не хотят анализировать весь источник BigData и чаще всего они изначально не знают, какой «срез» данных они хотят проанализировать более подробно. Таким образом, желательным является метод быстрого сканирования BigData для потенциально интересных разделов, которые требуют более подробного анализа. В некоторых случаях эта потребность может быть решена с использованием концепций цепочки и сегментации — краткое приложение будет привязано к другим приложениям, каждое из которых содержит сегмент источника данных более подробно. Но что если слишком много потенциальных сегментов для предварительного определения в качестве приложений? Что делать, если пользователь не знает, какие части базы данных они хотят анализировать? Открытие данных Freeform означает, что пользователь может анализировать в любом направлении. И это может означать, что нужно новое Приложение, каждый раз, когда обнаруживается неизученная область.
Поэтапное создание приложений может быть очень ценным в сценариях, когда пользователь может не знать точно, какую часть базы данных он хочет проанализировать подробно (в деталях). Приложение по требованию обычно состоит из двух разных приложений: первоначально пользователям предоставляется выбор, в котором они из «списка покупок», определенных подмножеств данных, таких как, период времени, сегмент клиента или география. Этот выбор затем можно использовать для запуска немедленного создания целевого приложения для анализа, которое содержит только подробные данные, относящиеся к выбору. Затем пользователь может исследовать выбранные подробные данные в любом направлении, используя возможности Qlik в памяти. Поскольку эти приложения регулируются стандартными правилами безопасности Qlik Sense, можно контролировать, кто может получил доступ к подробным данным и сводной информации.
Теперь у пользователей есть возможность легко исследовать разные фрагменты источника данных без необходимости разработки нового приложения каждый раз, когда он хочет проанализировать набор данных. Это также позволяет администратору предоставлять пользователям доступ к источнику данных огромного размера, поскольку только запрошенный фрагмент подробных данных фактически обрабатывается в памяти в любой момент времени.
ДРУГИЕ МЕТОДЫ
Существуют другие методы, которые можно использовать для доступа к Big Data. Существует множество партнерских технологий и инструментов, которые могут быть интегрированы с платформой Qlik. Более того, можно также разработать собственное аналитическое приложение с использованием JavaScript и API, используемый App-Demand App Generation в фоновом режиме. Подобно стандартным расширениям ODAG, которые поставляются с Qlik Sense, пользовательские приложения генерируют фильтрованный набор данных для анализа через API в Qlik Sense или QMS API / EDX в QlikView. Разработка таких приложений для клиентов, скорее всего, потребует больших технических навыков, но устраняет любые ограничения, налагаемые стандартной функциональностью Qlik. Например, можно разработать единый дизайн пользовательского интерфейса, который содержит приложения для выбора и анализа.
ПОДКЛЮЧЕНИЕ QLIK (QLIKVIEW И QLIK SENSE) К BIG DATA
Qlik разработан как открытая платформа и поставляется с рядом встроенных и сторонних возможностей подключения к хранилищам Big Data.
- Возможность подключения ODBC. Встроенное ODBC-подключение Qlik включает в себя драйверы для Apache Hive, Cloudera Impala и другого программного обеспечения. Дополнительные инструменты BigData могут быть доступны с использованием ODBC-коннектора поставщика. Например, Micro Focus предоставляет драйвер ODBC для Vertica — платформы для анализа данных BigData.
- Возможность подключения к источнику данных. Qlik сотрудничает с несколькими поставщиками, чтобы быть сертификацированным поставщиком драйверов ODBC. Например, MapR сертифицировал Qlik для Apache Drill, и Qlik получили сертификат SAP для своего драйвера HANA ODBC.
- Партнерская связь. Ряд партнеров Qlik разработали коннекторы, предназначенные для работы с определенными источниками данных или приложениями, где Qlik еще не предлагает подключения. Этот растущий список разработанных партнерами коннекторов можно найти на market.qlik.com.
QLIK ПРЕОДОЛЕЛ ПОСЛЕДНЮЮ МИЛЮ BIG DATA
Одной из серьезных проблем в телекоммуникационном секторе является «последняя миля» — доводка телефонного, кабельного или интернет-сервиса до конечной точки дома. Поставщику услуг дорого обходится магистральная сеть — выкопать траншеи и установить линии. В результате, в некоторых случаях провайдеры телекоммуникационных услуг переносят высокие затраты на установку на клиента или вообще игнорируют последнюю милю.
В Big Data также есть проблема «последней мили». Сегодня большинство поставщиков технологий, работающих над проблемами BigData, сосредоточены на обработке данных — они ориентированы на основу, используют аналогию. Но последняя миля — это то, где сосредоточен Qlik. Миссия Qlik заключается в упрощении решений для всех, путем предоставления возможности увидеть всю историю, которая живет в их данных.
Qlik уже делает BigData, и он делает это хорошо. Многие клиенты успешно использовали Qlik для увеличения стоимости своих инвестиций в технологию Big Data, гарантируя, что они не ограничивается только научными данными. Вместо этого Qlik позволяет каждому пользователю получать доступ и взаимодействовать с информацией Big Data в сочетании с традиционными источниками данных, а затем использует мощный ассоциативный опыт Qlik, чтобы получить новое представление.
Большие данные (Big data) · Loginom Wiki
Loginom: Руководство пользователя
В узком смысле — массивы структурированных, слабоструктурированных и неструктурированных данных, объемы которых настолько велики, что их обработка традиционными средствами становится неэффективной или вообще невозможной.
В широком смысле — комплекс средств и методов для обработки и анализа массивов данных, подпадающих под определение больших данных.
Изначально с большими данными связывали три ключевых концепции (правило «трех V»):
- Объем (volume). Данные в компании накапливаются из множества источников в громадном объеме.
- Скорость роста (velocity). Быстрое возрастание объемов данных. Особенно характерно для компаний в области сетевой торговли и электронной коммерции, где ежедневно могут генерироваться сотни терабайт данных.
- Многообразие (variety). Данные из входного потока могут быть разнообразных форматов (таблицы, текст, видео, аудио и пр.), а также быть структурированными и неструктурированными.
Постепенно правило «трех V» обогатилось дополнительными элементами и трансформировалось в: «четыре V» (veracity — достоверность), «пять V» (viability — жизнеспособность и value — ценность) и «семь V» (variability — переменчивость и visualization — визуализация).
В настоящее время понятие «большие данные» связано с использованием предсказательной и поведенческой аналитики и других направлений анализа данных с целью извлечения знаний из огромных массивов данных.
Главными проблемами, с которыми приходится сталкиваться при работе с большими данными, являются возрастание вычислительных затрат — как в плане времени, так и требуемых объемов памяти. Отсюда вытекают задачи оптимизации размещения данных в оперативной памяти, количества обращений к диску и числа проходов по данным.
Если обработка данных невозможна на одном компьютере, то ее алгоритм можно разделить на части и попытаться выполнить на нескольких машинах. Эта идея послужила толчком для появления и развития методологий и инструментов распределенной обработки, например, MapReduce, HDFS, Hive.
Для снижения количества итераций и/или проходов по набору данных при работе аналитических алгоритмов используются их различные вероятностные модификации. Примером такого алгоритма является оптимальное зависимое от данных хеширование для приближенного поиска ближайших соседей.
С большими данными сталкиваются во многих сферах: науке, электронной коммерции, телекоммуникациях, финансовом секторе. Кроме того, для решения бизнес-задач можно привлекать данные из сторонних источников.
Например, информация о пользовательской активности, связях и интересах из социальных сетей может использоваться для обогащения данных при персонализации маркетинговых предложений или при прогнозе платежеспособности заемщика в скоринге.
Термин «большие данные» получил широкое использование начиная с 1990-х годов, а его популяризацию связывают с именем John R. Mashey.
Big Data — ROMI.center
Большие данные или Big Data
Big data — что это такое? В буквальном переводе эта фраза означает большие данные. В традиционном толковании большие данные — это набор огромных объемов информации, настолько сложной и неорганизованной, что она не поддается обработке традиционными инструментами управления базами данных. Big Data просто не вписываются в традиционную структуру из-за своей величины.
Под этим термином также понимают не саму информацию или отдельную технологию, а комбинацию современных и проверенных инструментов работы с гигантскими потоками данных, что помогает получать практическую информацию.
Если суммировать, то биг дата можно определить, как возможность управлять колоссальным объемом разрозненных данных с нужной скоростью и в нужные временные рамки, чтобы обеспечить их обработку и анализ больших данных в реальном времени.
Просто о больших данных
Каждый раз, когда кто-то открывает приложение на смартфоне, посещает сайт, регистрируется в Сети на каком-то ресурсе или даже вводит запрос в поисковую систему, собирается какой-то массив данных.
Пользователи обычно больше сосредоточены на результатах того, что они делают в Интернете. Их не особенно волнует то, что происходит «за кулисами». Например, человек открывает браузер и набирает в поиске «большие данные», а затем переходит по этой ссылке, чтобы прочитать наш глоссарий. Один только этот запрос способствует созданию определенного количества больших данных. Если представить, сколько людей проводят время в Интернете, посещая разные сайты, загружая изображения и так далее, становится понятно, о каких огромных объемах информации может идти речь.
Характеристики больших данных
Есть некоторые термины, связанные с большими данными, которые нужны, чтобы описать их и понять суть. Они называются характеристиками больших данных.
В традиционной трактовке «биг дейта» имеют 3 основных характеристики. В английском языке их обозначают как 3V:
- Volume, Объем: сколько данных. Компании, занимающиеся big data, должны постоянно масштабировать свои решения для хранения данных, поскольку им постоянно требуются большие объемы дискового пространства.
- Velocity, Скорость: насколько быстро обрабатываются данные. Поскольку большие данные генерируются каждую секунду, компаниям необходимо реагировать в режиме реального времени, чтобы справиться с такими потоками.
- Variety, Разнообразие: какие типы данных обрабатываются и сколько их. Большие данные имеют множество форм. Они могут быть структурированными, неструктурированными или представленными в разных форматах — таких, как текст, видео, изображения и так далее.
Хотя сводить большие данные до трех V удобно, современный подход считает, что это — упрощенная схема, которая может вводить в заблуждение. Что является обязательной характеристикой, а что нет? Например, компания может управлять относительно небольшим объемом разнообразных данных или обрабатывать огромные объемы очень простых. И в том, и в другом случае одна из характеристик — или объем, или разнообразие — не совпадает. Тем не менее, речь по-прежнему идет о big data.
Кроме того, чтобы дополнить постоянно развивающиеся технологии в этой области, аналитики ввели дополнительные 2V, которые также относятся к характеристикам big data и применяются для их описания.
- Value, Ценность: имеют ли данные ценность. Сами по себе сбор и хранение больших данных не имеют никакой практической пользы, если они не были проанализированы и не был получен результат.
- Veracity, Правдивость: насколько данные истинны. Большие данные, какими бы большими они ни были, тоже могут содержать неверную информацию. Неопределенность данных — это то, что стоит учитывать при работе с big data.
Последняя характеристика требует некоторых пояснений. Необходимы заранее определенные критерии, по которым собранные big data можно оценивать на предмет их истинности. Тут важно правильно оценить стоящую задачу — собранные данные должны проверяться как на точность, так и в соответствии с контекстом.
Как и в реальной жизни, истина у каждого своя. Например, критерии «правды» для оценки стоимости бизнеса вряд ли совпадут с параметрами оценки ценности конкретного клиента — например, для экспресс-выдачи кредита. В первом случае берутся в расчет финансовые результаты компании и сравнение с другими аналогичными, во втором — индивидуальная кредитная история, наличие просрочек и размер официальных доходов конкретного человека. И в том, и в другом варианте нужны подсказки — какой объем информации это займет, какие признаки информации выделять и по каким критериям анализировать в реальном времени, чтобы это принесло нужный бизнес-результат.
Структурированные и неструктурированные данные
Большие данные включают в себя все разновидности данных, включая информацию из электронной почты, социальных сетей, текстовые потоки и так далее. Управление ими требует использования как структурированных, так и неструктурированных данных.
Структурирование данных — это получение информации, которая имеет определенную длину и формат. Примеры использования структурированных данных включают числа, даты или группы слов и чисел, называемые строками.
Определение неструктурированных данных идет от названия. Они отличаются от структурированных тем, что их структура непредсказуема. Примеры неструктурированных данных включают документы, электронную почту, блоги, цифровые изображения, видео и даже фото со спутника. Они также объединяют некоторые данные, генерируемые машинами или датчиками. Фактически, неструктурированные данные составляют большую часть внутренних данных компании, а также внешних, которые поступают из общедоступных онлайн-источников — таких, например, как соцсети.
В недавнем прошлом большинство компаний не могли ни собирать, ни хранить такой огромный объем неструктурированных данных. Это было слишком дорого или слишком сложно. Даже если удалось бы собрать такую информацию, у них не было инструментов, позволяющих анализировать её и использовать результаты для принятия решений. Существовавшие платформы были сложными в использовании и не давали результатов в разумные сроки, поэтому часто использовались выжимки из данных. Это существенно искажало общую картину, так как критерии отбора информации были субъективными.
Технологии big data (больших данных)
Сегодня разработаны разные технологии, которые используются для обработки больших данных и управления ими. Из них наиболее широко используются фреймворки и платформы, разработанные Apache. По данным MarketsandMarkets, доля этой компании на рынке больших данных составляет 23,5% на конец 2020 года даже с учетом влияния пандемии. Вот что входит в их стартовый набор для управления big data.
- Apache Hadoop — платформа, которая позволяет выполнять параллельную обработку и распределенное хранение данных;
- Apache Spark — среда распределенной обработки данных общего назначения;
- Apache Kafka — платформа потоковой обработки;
- Apache Cassandra — распределенная система управления базами данных NoSQL.
Самая известная парадигма программирования, применяемая сегодня для работы с big data, называется MapReduce. Разработанная Google, модель позволяет выполнять распределенные вычисления с огромными наборами данных в нескольких системах параллельно.
MapReduce состоит из 2х частей:
- Map, Карта данных. Технология сортирует и фильтрует, а затем классифицирует данные, чтобы их было легче анализировать.
- Reduce, Уменьшение. Вычислительная модель объединяет все данные и предоставляет сводку.
Сферы применения больших данных
Большие данные находят множество применений в различных отраслях. Вот некоторые наиболее значимые из них.
Обнаружение мошенничества
Большие данные помогают управлять финансовыми рисками, обнаруживать попытки мошенничества и анализировать подозрительные торговые сделки.
Реклама и маркетинг
Большие данные помогают маркетологам понимать модели поведения пользователей, анализировать их и собирать информацию о мотивах потребления.
Сельское хозяйство
Большие данные в сельском хозяйстве используют для повышения урожайности. Это может быть сделано путем посадки разных семян и саженцев для теста. В big data ведутся записи, обработка и сохранение данных о том, как они реагируют на различные изменения окружающей среды. Затем собранные и проанализированные данные используются для планирования посадки выбранных сельскохозяйственных культур.
Существует также множество аналитических проблем, решить которые ранее было невозможно из-за технологических ограничений. После появления big data компании больше полагаются на этот рентабельный и надежный метод простой обработки и хранения огромных объемов данных. Технологии успешно применяются в сфере HR, здравоохранении, для улучшения городской среды, при проектировании полезных гаджетов и даже электромобилей Tesla.
Профессии в сфере больших данных
Знания о больших данных — один из важных навыков, необходимых для современных профессий, которые сегодня востребованы на рынке — в России и за рубежом. Спрос на этих специалистов вряд ли упадет в ближайшее время — ведь накопление данных со временем будет только расти. Вот некоторые из популярных специальностей.
- Аналитик big data. Анализирует и интерпретирует большие данные, визуализирует их и создает отчеты, помогающие предпринимателям принимать обоснованные бизнес-решения.
- Специалист по работе с большими данными. Ведет сбор данных, оценивая источники и применяя алгоритмы и методы машинного обучения.
- Архитектор данных, Data Architect. Проектирует системы и инструменты баз, способных работать с большими данными.
- Менеджер баз данных. Контролирует производительность системы баз данных, выполняет устранение неполадок и обновляет оборудование и программное обеспечение.
- Инженер big data. Разрабатывает, обслуживает и поддерживает программные решения для обработки больших данных.
Проблемы больших данных
Говоря о современных больших данных, нельзя игнорировать тот факт, что с ними все еще связаны некоторые очевидные проблемы. Вот некоторые из них.
Быстрый рост данных
Данные, растущие такими быстрыми темпами, трудно затрудняют получение на их основе понимания. Каждую секунду создается все больше и больше информации, из которой необходимо извлекать действительно актуальные и полезные данные для дальнейшего анализа.
Хранение
Такие большие объемы данных сложно хранить и управлять ими без соответствующих инструментов и технологий.
Синхронизация источников данных
Когда организации импортируют данные из разных источников, данные из одного источника могут быть устаревшими по сравнению с данными из другого.
Безопасность
Огромный объем данных может легко стать мишенью для хакеров и постоянной угрозой компьютерной безопасности. Поэтому перед компаниями, управляющими big data, стоит еще одна проблема — обеспечить безопасность своих данных с помощью надлежащей аутентификации, шифрования данных и так далее.
Ненадежные данные
В силу своих объемов и разности источников большие данные не могут быть точными на 100%. Они могут содержать избыточную или, наоборот, неполную информацию, а также противоречия.
Другие проблемы
Это некоторые другие проблемы, которые возникают при работе с большими данными. Самые известные из них — это корректная интеграция данных, наличие у персонала навыков работы с big data, затраты на профессиональные решения и обработка большого количества данных вовремя и с нужной точностью.
Будущее big data
Данные становятся все более сложными — как в структурированном, так и в неструктурированном виде. Появляются и новые источники — например, датчики на оборудовании или метрики взаимодействия с сайтом в виде потоков кликов. Для удовлетворения этих меняющихся бизнес-требований важно, чтобы нужная информация была доступна в нужное время.
По прогнозам MarketsandMarkets , даже небольшим компаниям в ближайшие 10 лет предстоит освоить практические способы работы с большими данными, чтобы оставаться конкурентоспособными — изучить новые способы сбора и анализа растущего объема информации о клиентах, продуктах, услугах и так далее.
Системы обработки и хранения больших данных
В современных условиях компании сталкиваются с возрастающим потоком информации, поступающей от внутренних подразделений и контрагентов. Чтобы составить общую картину из разрозненных источников информации, с максимальной эффективностью наладить бизнес-процессы, требуется обработка больших массивов данных – централизованная технология анализа информации, представленной в различных форматах.Группа компаний «Паладин», имея более чем 20-летний опыт работы, готова предложить вам лучшее из возможных в заданных условиях решение по организации (модернизации) дата-центров или использованию ресурсов сторонних ЦОД. Наши собственные возможности и развитая партнерская сеть обеспечат выполнение всех ваших требований. У нас есть решения для предприятий, организаций и компаний любого масштаба деятельности. И мы умеем находить самый эффективный вариант для любого бюджета.
Услуги и поддержка в области обработки Больших данных
Эффективное использование данных и повышение организационной гибкости невозможны без подходящей инфраструктуры. Специалисты Группы компаний «Паладин» помогут осуществить необходимые преобразования вашей ИТ-среды. Мы предоставим возможность быстрее добиться результатов в бизнесе с помощью средств анализа и обработки больших данных с учетом существующих инвестиций и процессов.
Оборудование для работы с Большими данными
Расширение Big Data и ускорение темпа роста стало объективной реальностью. Ежесекундно гигантские объемы контента генерируют такие источники, как: социальные сети, информационные сайты, файлообменники — и это лишь сотая часть поставщиков.
Примеры реализации проектов обработки Больших данных в различных отраслях
- Предприятия розничной торговли
Ярким примеров применения систем обработки Больших данных являются розничные сети. Для разработки эффективной стратегии продаж менеджмент сети, в которую входят десятки и сотни торговых точек, нуждается в аналитической информации, описывающей уровень потребительского спроса, движение товаров на складе, прибыльность по тем или иным товарных позициям и многие другие параметры. Применяя системы обработки Больших данных, можно мгновенно создавать детализированные отчеты на основе огромного массива исходной информации.
- Финансовая сфера
Компании, работающие в финансовой отрасли, тратят большую часть вычислительных ресурсов на анализ кредитоспособности заемщиков, расчет нормативных показателей достаточности капитала и другие операции, для которых требуется быстрая обработка данных. В результате использования Big Data существенно сокращается время рассмотрения заявок на получение займа, формирования условий принятия вкладов и других услуг.
- Телекоммуникационная отрасль
Сфера телекоммуникаций традиционно считается одной из наиболее передовых отраслей, в которых новые технологии находят применение раньше остальных. Хранение Больших данных используется в данном случае для формирования и сегментации клиентской базы, создания абонентских профилей и расчета уровня доходности по каждому из них. Владея упорядоченным массивом информации, поставщики телекоммуникационных услуг узнают, какие условия гарантированно заинтересуют клиента и какой результат можно ожидать от внедрения новых технологических решений.
Помимо узкоспециализированных направлений деятельности, также разработаны универсальные программные решения на основе Больших данных. Наши специалисты готовы предоставить подробную консультацию о существующих сценариях использования данной технологии и потенциальных возможностях по их внедрению в бизнес-модель вашей компании.
Стиль архитектуры для обработки больших данных — Azure Application Architecture Guide
- Чтение занимает 10 мин
В этой статье
Архитектура для обработки больших данных позволяет принимать, обрабатывать и анализировать данные, которые являются слишком объемными или слишком сложными для традиционных систем баз данных.A big data architecture is designed to handle the ingestion, processing, and analysis of data that is too large or complex for traditional database systems.
Решения для обработки больших данных обычно предназначены для одного или нескольких из следующих типов рабочей нагрузки:Big data solutions typically involve one or more of the following types of workload:
- пакетная обработка источников неактивных больших данных;Batch processing of big data sources at rest.
- обработка больших данных в динамике в режиме реального времени;Real-time processing of big data in motion.
- интерактивное изучение больших данных;Interactive exploration of big data.
- прогнозная аналитика и машинное обучение.Predictive analytics and machine learning.
Большинство архитектур для обработки больших данных включают некоторые или все перечисленные ниже компоненты.Most big data architectures include some or all of the following components:
Источники данных. Все решения для обработки больших данных начинаются с одного или нескольких источников данных.Data sources: All big data solutions start with one or more data sources. Примеры приведены ниже:Examples include:
- Хранилища данных приложений, например реляционные базы данных.Application data stores, such as relational databases.
- Статические файлы, которые создаются приложениями, например файлы журнала веб-сервера.Static files produced by applications, such as web server log files.
- Источники данных с передачей в режиме реального времени, например устройства Интернета вещей.Real-time data sources, such as IoT devices.
Хранилище данных. Данные для пакетной обработки обычно хранятся в распределенном хранилище файлов, где могут содержаться значительные объемы больших файлов в различных форматах.Data storage: Data for batch processing operations is typically stored in a distributed file store that can hold high volumes of large files in various formats. Этот тип хранилища часто называют озером данных.This kind of store is often called a data lake. Такое хранилище можно реализовать с помощью Azure Data Lake Store или контейнеров больших двоичных объектов в службе хранилища Azure.Options for implementing this storage include Azure Data Lake Store or blob containers in Azure Storage.
Пакетная обработка. Так как наборы данных очень велики, часто в решении обрабатываются длительные пакетные задания. Для них выполняется фильтрация, статистическая обработка и другие процессы подготовки данных к анализу.Batch processing: Because the data sets are so large, often a big data solution must process data files using long-running batch jobs to filter, aggregate, and otherwise prepare the data for analysis. Обычно в эти задания входит чтение исходных файлов, их обработка и запись выходных данных в новые файлы.Usually these jobs involve reading source files, processing them, and writing the output to new files. Варианты: выполнение заданий U-SQL в Azure Data Lake Analytics, использование пользовательских заданий Hive, Pig или Map/Reduce в кластере HDInsight Hadoop и применение программ Java, Scala или Python в кластере HDInsight Spark.Options include running U-SQL jobs in Azure Data Lake Analytics, using Hive, Pig, or custom Map/Reduce jobs in an HDInsight Hadoop cluster, or using Java, Scala, or Python programs in an HDInsight Spark cluster.
Прием сообщений в режиме реального времени. Если решение содержит источники в режиме реального времени, в архитектуре должен быть предусмотрен способ сбора и сохранения сообщений в режиме реального времени для потоковой обработки.Real-time message ingestion: If the solution includes real-time sources, the architecture must include a way to capture and store real-time messages for stream processing. Это может быть простое хранилище данных с папкой, в которую входящие сообщения помещаются для обработки.This might be a simple data store, where incoming messages are dropped into a folder for processing. Но для приема сообщений многим решениям требуется хранилище, которое можно использовать в качестве буфера. Такое хранилище должно поддерживать обработку с горизонтальным масштабированием, надежную доставку и другую семантику очереди сообщений.However, many solutions need a message ingestion store to act as a buffer for messages, and to support scale-out processing, reliable delivery, and other message queuing semantics. Варианты: Центры событий Azure, Центры Интернета вещей и Kafka.Options include Azure Event Hubs, Azure IoT Hubs, and Kafka.
Потоковый обмен сообщениями. После записи сообщений в режиме реального времени в решении нужно выполнить их фильтрацию, статистическую обработку и другие процессы подготовки данных к анализу.Stream processing: After capturing real-time messages, the solution must process them by filtering, aggregating, and otherwise preparing the data for analysis. Затем обработанные потоковые данные записываются в выходной приемник.The processed stream data is then written to an output sink. Azure Stream Analytics предоставляет управляемую службу потоковой обработки на основе постоянного выполнения запросов SQL для непривязанных потоков.Azure Stream Analytics provides a managed stream processing service based on perpetually running SQL queries that operate on unbounded streams. Кроме того, для потоковой передачи можно использовать технологии Apache с открытым кодом, например Storm и Spark Streaming в кластере HDInsight.You can also use open source Apache streaming technologies like Storm and Spark Streaming in an HDInsight cluster.
Хранилище аналитических данных. Во многих решениях для обработки больших данных данные подготавливаются к анализу. Затем обработанные данные структурируются в соответствии с форматом запросов для средств аналитики.Analytical data store: Many big data solutions prepare data for analysis and then serve the processed data in a structured format that can be queried using analytical tools. Хранилище аналитических данных, используемое для обработки таких запросов, может быть реляционной базой данных типа Kimball, как можно увидеть в большинстве традиционных решений бизнес-аналитики (BI).The analytical data store used to serve these queries can be a Kimball-style relational data warehouse, as seen in most traditional business intelligence (BI) solutions. Кроме того, данные можно представить с помощью технологии NoSQL с низкой задержкой, такой как HBase или интерактивная база данных Hive, которая предоставляет абстракцию метаданных для файлов данных в распределенном хранилище.Alternatively, the data could be presented through a low-latency NoSQL technology such as HBase, or an interactive Hive database that provides a metadata abstraction over data files in the distributed data store. Azure Synapse Analytics — это управляемая служба для хранения больших объемов данных в облаке.Azure Synapse Analytics provides a managed service for large-scale, cloud-based data warehousing. HDInsight поддерживает Interactive Hive, HBase и Spark SQL, которые также можно использовать, чтобы предоставлять данные для анализа.HDInsight supports Interactive Hive, HBase, and Spark SQL, which can also be used to serve data for analysis.
Анализ и создание отчетов. Большинство решений для обработки больших данных позволяют получить представление о данных при помощи анализа и отчетов.Analysis and reporting: The goal of most big data solutions is to provide insights into the data through analysis and reporting. Чтобы расширить возможности анализа данных, можно включить в архитектуру слой моделирования, например модель таблицы или многомерного куба OLAP в Azure Analysis Services.To empower users to analyze the data, the architecture may include a data modeling layer, such as a multidimensional OLAP cube or tabular data model in Azure Analysis Services. Также можно включить поддержку самостоятельной бизнес-аналитики с использованием технологий моделирования и визуализации в Microsoft Power BI или Microsoft Excel.It might also support self-service BI, using the modeling and visualization technologies in Microsoft Power BI or Microsoft Excel. Анализ и создание отчетов также может выполняться путем интерактивного изучения данных специалистами по их анализу и обработке.Analysis and reporting can also take the form of interactive data exploration by data scientists or data analysts. Для таких сценариев многие службы Azure поддерживают функции аналитического блокнота, например Jupyter, который позволяет пользователям применять свои навыки работы с Python или R. Для крупномасштабного изучения данных можно использовать Microsoft R Server (отдельно или со Spark).For these scenarios, many Azure services support analytical notebooks, such as Jupyter, enabling these users to leverage their existing skills with Python or R. For large-scale data exploration, you can use Microsoft R Server, either standalone or with Spark.
Оркестрация. Большинство решений для обработки больших данных состоят из повторяющихся рабочих процессов, во время которых преобразуются исходные данные, данные перемещаются между несколькими источниками и приемниками, обработанные данные загружаются в хранилища аналитических данных либо же результаты передаются непосредственно в отчет или на панель мониторинга.Orchestration: Most big data solutions consist of repeated data processing operations, encapsulated in workflows, that transform source data, move data between multiple sources and sinks, load the processed data into an analytical data store, or push the results straight to a report or dashboard. Чтобы автоматизировать эти рабочие процессы, вы можете использовать технологию оркестрации, такую как фабрика данных Azure или Apache Oozie и Sqoop.To automate these workflows, you can use an orchestration technology such Azure Data Factory or Apache Oozie and Sqoop.
Azure предоставляет много служб, которые можно использовать в архитектуре для обработки больших данных.Azure includes many services that can be used in a big data architecture. Их можно условно разделить на две категории:They fall roughly into two categories:
- Управляемые службы, в том числе Azure Data Lake Store, Azure Data Lake Analytics, Azure синапсе Analytics, Azure Stream Analytics, концентратор событий Azure, центр Интернета вещей Azure и фабрика данных Azure.Managed services, including Azure Data Lake Store, Azure Data Lake Analytics, Azure Synapse Analytics, Azure Stream Analytics, Azure Event Hub, Azure IoT Hub, and Azure Data Factory.
- технологии с открытым кодом на платформе Apache Hadoop, включая HDFS, HBase, Hive, Pig, Spark, Storm, Oozie, Sqoop и Kafka.Open source technologies based on the Apache Hadoop platform, including HDFS, HBase, Hive, Pig, Spark, Storm, Oozie, Sqoop, and Kafka. Эти технологии доступны в Azure в службе Azure HDInsight.These technologies are available on Azure in the Azure HDInsight service.
Эти варианты не являются взаимоисключающими, и во многих решениях технологии с открытым объединяются со службами Azure.These options are not mutually exclusive, and many solutions combine open source technologies with Azure services.
Когда следует использовать эту архитектуруWhen to use this architecture
Используйте эту архитектуру для следующих сценариев:Consider this architecture style when you need to:
- хранение и обработка данных в объемах, слишком больших для традиционной базы данных.Store and process data in volumes too large for a traditional database.
- преобразование неструктурированных данных для анализа и создания отчетов;Transform unstructured data for analysis and reporting.
- запись, обработка и анализ непривязанных потоков данных в режиме реального времени или с низкой задержкой;Capture, process, and analyze unbounded streams of data in real time, or with low latency.
- использование службы «Машинное обучение Azure» или Microsoft Cognitive Services.Use Azure Machine Learning or Microsoft Cognitive Services.
ПреимуществаBenefits
- Варианты технологий.Technology choices. Можно комбинировать и сопоставлять управляемые службы Azure и технологии Apache в кластерах HDInsight, чтобы с максимальной выгодой применять существующие навыки и инвестировать в технологии.You can mix and match Azure managed services and Apache technologies in HDInsight clusters, to capitalize on existing skills or technology investments.
- Повышение производительности с помощью параллелизма.Performance through parallelism. В решениях для обработки больших данных используется преимущество параллелизма, что позволяет применять высокопроизводительные решения, которые могут масштабироваться для работы с большими объемами данных.Big data solutions take advantage of parallelism, enabling high-performance solutions that scale to large volumes of data.
- Эластичное масштабирование.Elastic scale. Все компоненты архитектуры для обработки больших данных поддерживают горизонтальное масштабирование, чтобы вы могли адаптировать решение для малых и больших рабочих нагрузок и платить только за те ресурсы, которые используете.All of the components in the big data architecture support scale-out provisioning, so that you can adjust your solution to small or large workloads, and pay only for the resources that you use.
- Взаимодействие с существующими решениями.Interoperability with existing solutions. Компоненты архитектуры для обработки больших данных также используются в соответствующих решениях Интернета вещей и корпоративных решениях бизнес-аналитики, что позволяет создавать интегрированные средства для рабочих нагрузок обработки данных.The components of the big data architecture are also used for IoT processing and enterprise BI solutions, enabling you to create an integrated solution across data workloads.
СложностиChallenges
- Сложность.Complexity. Решения для обработки больших данных могут быть очень сложными и содержать множество компонентов для приема данных из нескольких источников.Big data solutions can be extremely complex, with numerous components to handle data ingestion from multiple data sources. Создание, тестирование и устранение неполадок процессов обработки больших данных может стать непростой задачей.It can be challenging to build, test, and troubleshoot big data processes. Более того, в нескольких системах может существовать большое количество параметров конфигурации для оптимизации производительности.Moreover, there may be a large number of configuration settings across multiple systems that must be used in order to optimize performance.
- Набор навыков.Skillset. Многие технологии для обработки больших данных являются узкоспециализированными. В них используются платформы и языки, которые не являются стандартными для более общих архитектур приложений.Many big data technologies are highly specialized, and use frameworks and languages that are not typical of more general application architectures. С другой стороны, технологии для обработки больших данных способствуют развитию новых интерфейсов API на основе более традиционных языков.On the other hand, big data technologies are evolving new APIs that build on more established languages. Например, язык U-SQL в Azure Data Lake Analytics построен на комбинации Transact-SQL и C#.For example, the U-SQL language in Azure Data Lake Analytics is based on a combination of Transact-SQL and C#. Аналогичным образом, API на основе SQL доступны для Hive, HBase и Spark.Similarly, SQL-based APIs are available for Hive, HBase, and Spark.
- Зрелость технологий.Technology maturity. Многие из технологий, используемых для обработки больших данных, находятся в развитии.Many of the technologies used in big data are evolving. Основные технологии Hadoop, например Hive и Pig, уже сформированы. Но в новые технологии, такие как Spark, с каждым выпуском вносятся значительные изменения и усовершенствования.While core Hadoop technologies such as Hive and Pig have stabilized, emerging technologies such as Spark introduce extensive changes and enhancements with each new release. Управляемые службы, такие как Azure Data Lake Analytics и фабрика данных Azure, являются относительно молодыми по сравнению с другими службами Azure и, скорее всего, с течением времени будут изменяться.Managed services such as Azure Data Lake Analytics and Azure Data Factory are relatively young, compared with other Azure services, and will likely evolve over time.
- Безопасность.Security. В решениях для обработки больших данных все статические данные обычно хранятся в централизованном озере данных.Big data solutions usually rely on storing all static data in a centralized data lake. Защита доступа к этим данным —непростая задача, особенно если данные должны приниматься и использоваться несколькими приложениями и платформами.Securing access to this data can be challenging, especially when the data must be ingested and consumed by multiple applications and platforms.
РекомендацииBest practices
Использование параллелизма.Leverage parallelism. В большинстве технологий для обработки больших данных рабочая нагрузка распределяется между несколькими единицами обработки.Most big data processing technologies distribute the workload across multiple processing units. Поэтому статические файлы данных создаются и хранятся в формате, доступном для разбивки.This requires that static data files are created and stored in a splittable format. Распределенные файловые системы, такие как HDFS, могут обеспечить оптимизацию производительности чтения и записи. При этом фактическая обработка параллельно выполняется на нескольких узлах кластера. Это сокращает общее время выполнения заданий.Distributed file systems such as HDFS can optimize read and write performance, and the actual processing is performed by multiple cluster nodes in parallel, which reduces overall job times.
Секционирование данных.Partition data. Пакетная обработка обычно выполняется регулярно — например, еженедельно или ежемесячно.Batch processing usually happens on a recurring schedule — for example, weekly or monthly. Секционированные файлы и структуры данных, такие как таблицы, основаны на темпоральных периодах, которые соответствуют расписанию обработки.Partition data files, and data structures such as tables, based on temporal periods that match the processing schedule. Это упрощает прием данных, планирование заданий и устранение ошибок.That simplifies data ingestion and job scheduling, and makes it easier to troubleshoot failures. Кроме того, таблицы разделов, которые используются в запросах Hive, U-SQL или SQL, могут значительно повысить их производительность.Also, partitioning tables that are used in Hive, U-SQL, or SQL queries can significantly improve query performance.
Применение семантики схемы при считывании.Apply schema-on-read semantics. Озеро данных позволяет объединять в хранилище файлы в разных форматах — структурированные, частично структурированные и неструктурированные.Using a data lake lets you to combine storage for files in multiple formats, whether structured, semi-structured, or unstructured. Используйте семантику схемы при считывании, которая проецирует схему на данные при обработке, а не при хранении.Use schema-on-read semantics, which project a schema onto the data when the data is processing, not when the data is stored. Это повышает гибкость решения и предотвращает образование узких мест во время приема данных в результате проверки данных и типов.This builds flexibility into the solution, and prevents bottlenecks during data ingestion caused by data validation and type checking.
Обработка данных на месте.Process data in-place. В традиционных решениях бизнес-аналитики для перемещения данных в хранилище часто используется процесс извлечения, преобразования и загрузки (ETL).Traditional BI solutions often use an extract, transform, and load (ETL) process to move data into a data warehouse. Для больших объемов данных и разнообразных форматов в решениях для обработки больших данных обычно используются различные вариации ETL, например преобразование, извлечение и загрузка (TEL).With larger volumes data, and a greater variety of formats, big data solutions generally use variations of ETL, such as transform, extract, and load (TEL). При таком подходе данные обрабатываются в распределенном хранилище данных. Они преобразуются в требуемую структуру перед перемещением в хранилище аналитических данных.With this approach, the data is processed within the distributed data store, transforming it to the required structure, before moving the transformed data into an analytical data store.
Регулирование затрат при тарификации на основе объема и времени использования.Balance utilization and time costs. Для заданий пакетной обработки очень важно учитывать два фактора: расходы на единицу вычислительных узлов и поминутная стоимость использования этих узлов для выполнения задания.For batch processing jobs, it’s important to consider two factors: The per-unit cost of the compute nodes, and the per-minute cost of using those nodes to complete the job. Например, выполнение пакетного задания может занять восемь часов при использовании четырех узлов кластера.For example, a batch job may take eight hours with four cluster nodes. Но может оказаться, что все четыре узла используются для задания только в течение первых двух часов, а после этого достаточно двух узлов.However, it might turn out that the job uses all four nodes only during the first two hours, and after that, only two nodes are required. В таком случае выполнение всего задания на двух узлах увеличит общее время, но не удвоит его. Поэтому совокупная стоимость будет меньше.In that case, running the entire job on two nodes would increase the total job time, but would not double it, so the total cost would be less. В некоторых бизнес-сценариях более длительное время обработки может быть более выгодным, чем использование ресурсов кластера с недостаточным использованием.In some business scenarios, a longer processing time may be preferable to the higher cost of using underutilized cluster resources.
Разделение кластерных ресурсов.Separate cluster resources. При развертывании кластеров HDInsight обычно можно повысить производительность, подготовив отдельные кластерные ресурсы для каждого типа рабочей нагрузки.When deploying HDInsight clusters, you will normally achieve better performance by provisioning separate cluster resources for each type of workload. Например, кластеры Spark включают Hive, но при масштабной обработке с использованием Hive и Spark рекомендуем развернуть отдельные выделенные кластеры Spark и Hadoop.For example, although Spark clusters include Hive, if you need to perform extensive processing with both Hive and Spark, you should consider deploying separate dedicated Spark and Hadoop clusters. Аналогичным образом, при использовании HBase и Storm для потоковой обработки с низкой задержкой и Hive для пакетной обработки рекомендуем развернуть отдельные кластеры для Storm, HBase и Hadoop.Similarly, if you are using HBase and Storm for low latency stream processing and Hive for batch processing, consider separate clusters for Storm, HBase, and Hadoop.
Оркестрация приема данных.Orchestrate data ingestion. Иногда существующие бизнес-приложения могут записывать файлы данных для пакетной обработки непосредственно в контейнеры больших двоичных объектов в хранилище Azure, где они могут использоваться службами HDInsight или Azure Data Lake Analytics.In some cases, existing business applications may write data files for batch processing directly into Azure storage blob containers, where they can be consumed by HDInsight or Azure Data Lake Analytics. Тем не менее часто требуется выполнять оркестрацию приема данных из локального или внешнего источника в озере данных.However, you will often need to orchestrate the ingestion of data from on-premises or external data sources into the data lake. Наиболее прогнозируемый и централизованно управляемый подход для этого — рабочий процесс или конвейер оркестрации, например поддерживаемый фабрикой данных Azure или Oozie.Use an orchestration workflow or pipeline, such as those supported by Azure Data Factory or Oozie, to achieve this in a predictable and centrally manageable fashion.
Очистка конфиденциальных данных на ранней стадии.Scrub sensitive data early. При приеме данных необходимо очищать конфиденциальные данные на ранней стадии, чтобы они не сохранялись в озере данных.The data ingestion workflow should scrub sensitive data early in the process, to avoid storing it in the data lake.
Архитектура Интернета вещейIoT architecture
Интернет вещей (IoT) — это набор специализированных решений для обработки больших данных.Internet of Things (IoT) is a specialized subset of big data solutions. На следующей схеме представлены возможные варианты логической архитектуры для Интернета вещей.The following diagram shows a possible logical architecture for IoT. Особое внимание в этой схеме уделяется компонентам архитектуры для потоковой передачи событий.The diagram emphasizes the event-streaming components of the architecture.
Облачный шлюз принимает события от устройств на границе облака, используя надежную службу сообщений с низкой задержкой.The cloud gateway ingests device events at the cloud boundary, using a reliable, low latency messaging system.
Устройства могут отправлять события в облачный шлюз напрямую или через полевой шлюз.Devices might send events directly to the cloud gateway, or through a field gateway. Полевой шлюз — это специальное устройство или программа, обычно размещаемые рядом с устройствами, которые получают события и пересылают их в облачный шлюз.A field gateway is a specialized device or software, usually colocated with the devices, that receives events and forwards them to the cloud gateway. Полевой шлюз может выполнять некоторую предварительную обработку событий, собираемых с устройств, например фильтрацию, статистическую обработку или преобразование протоколов.The field gateway might also preprocess the raw device events, performing functions such as filtering, aggregation, or protocol transformation.
Полученные события проходят через один или несколько обработчиков потока, которые передают данные в другие системы (например, хранилище данных) или выполняют аналитическую или другую обработку.After ingestion, events go through one or more stream processors that can route the data (for example, to storage) or perform analytics and other processing.
Ниже приводятся примеры типичных процессов обработки.The following are some common types of processing. (Очевидно, что этот список не является исчерпывающим.)(This list is certainly not exhaustive.)
Сохранение данных о событиях в «холодное» хранилище для архивации или пакетной аналитики.Writing event data to cold storage, for archiving or batch analytics.
Аналитика критического пути, то есть анализ потока событий почти в режиме реального времени для обнаружения аномалий, выявления закономерностей в скользящих диапазонах времени или создания оповещений при выполнении определенных условий в потоке.Hot path analytics, analyzing the event stream in (near) real time, to detect anomalies, recognize patterns over rolling time windows, or trigger alerts when a specific condition occurs in the stream.
Обработка специальных типов сообщений, не относящихся к телеметрии, например уведомлений и тревожных сигналов.Handling special types of non-telemetry messages from devices, such as notifications and alarms.
Машинное обучение.Machine learning.
Серые блоки обозначают компоненты системы Интернета вещей, не связанные напрямую с потоковой передачей событий. Они включены в схему для полноты представления.The boxes that are shaded gray show components of an IoT system that are not directly related to event streaming, but are included here for completeness.
Реестр устройств — это база данных о подготовленных устройствах, которая содержит идентификаторы устройств и некоторые метаданные, например расположение.The device registry is a database of the provisioned devices, including the device IDs and usually device metadata, such as location.
API подготовки — это общий внешний интерфейс для подготовки и регистрации новых устройств.The provisioning API is a common external interface for provisioning and registering new devices.
В некоторых решениях Интернета вещей допускается отправка управляющих сообщений на устройства.Some IoT solutions allow command and control messages to be sent to devices.
В этом разделе представлен общий обзор Интернета вещей, и в нем не упоминается множество тонкостей и проблем, которые необходимо учитывать.This section has presented a very high-level view of IoT, and there are many subtleties and challenges to consider. Подробный пример использования архитектуре вы найдете в PDF-документе с описанием эталонной архитектуры Центра интернета вещей Microsoft Azure.For a more detailed reference architecture and discussion, see the Microsoft Azure IoT Reference Architecture (PDF download).
Следующие шагиNext steps
Источники больших данных: откуда они берутся?
За последние пять лет росло понимание роли, которую большие данные могут играть в предоставлении организации бесценной информации, выявлении сильных и слабых сторон и расширении возможностей компаний для улучшения своей практики. У больших данных нет повестки дня, они непредвзяты и беспристрастны — они просто представляют собой моментальный снимок активности.
Тем не менее, хотя многие организации понимают важность данных, очень немногие видят их влияние.Новое исследование под названием Broken Links: Почему аналитика еще не окупилась. утверждает, что 70% руководителей предприятий признают важность продаж и маркетинговой аналитики, но только 2% говорят, что их аналитика достигла широкого положительного результата. влияние. Этот вывод указывает на необходимость того, чтобы большие данные обрабатывались внешними фирмами, которые специализируются на анализе данных, генерируемых компаниями, и которые могут предложить реальные практические идеи. В предисловии к своему отчету Дэн Уэзерилл пишет: «Наш опрос и последующие интервью с почти 450 U.Руководители высшего звена, работающие на основе S, из таких отраслей, как фармацевтика, медицинское оборудование, ИТ, финансовые услуги, телекоммуникации, путешествия и гостиничный бизнес, подтвердили одну вещь, которую мы уже знали: немногие организации смогли понять это правильно и оказать такое влияние на бизнес, которое они на что надеялся.
Этот термин является всеобъемлющим и используется для описания огромного количества данных, которые генерируются организациями в современной деловой среде.Мысль о сборе больших данных была сосредоточена на 3V, то есть на объеме, скорости и разнообразии данных, поступающих в систему. В течение многих лет этого было достаточно, но по мере того, как компании переходят и все больше и больше процессов работают в режиме онлайн, это определение было расширено и теперь включает изменчивость — увеличение диапазона значений, типичных для большого набора данных — и значение , которое относится к необходимость оценки корпоративных данных ».
Большая часть генерируемых больших данных поступает из трех основных источников: социальных данных, машинных данных и транзакционных данных.Кроме того, компаниям необходимо проводить различие между данными, которые генерируются внутри, то есть хранятся за межсетевым экраном компании, и внешними данными, которые необходимо импортировать в систему.
То, являются ли данные неструктурированными или структурированными, также является важным фактором. Неструктурированные данные не имеют предопределенной модели данных и, следовательно, требуют больше ресурсов, чтобы разобраться в них.
Социальные данные поступают из лайков, твитов и ретвитов, комментариев, загрузок видео и общих медиа, которые загружаются и распространяются через популярные в мире социальные сети.Такие данные дают бесценную информацию о поведении и настроениях потребителей и могут иметь огромное влияние на маркетинговую аналитику. Общедоступный Интернет — еще один хороший источник социальных данных, и такие инструменты, как Google Trends, можно использовать с большим успехом для увеличения объема больших данных.
Машинные данные — это информация, генерируемая промышленным оборудованием, датчиками, установленными в машинах, и даже веб-журналами, которые отслеживают поведение пользователей. Ожидается, что этот тип данных будет расти в геометрической прогрессии по мере того, как Интернет вещей становится все более распространенным и распространяется по всему миру.Такие датчики, как медицинские устройства, интеллектуальные счетчики, дорожные камеры, спутники, игры и быстрорастущий Интернет вещей, будут обеспечивать высокую скорость, ценность, объем и разнообразие данных в самом ближайшем будущем.
Транзакционные данные генерируются из всех ежедневных транзакций, которые происходят как онлайн, так и офлайн. Счета, платежные поручения, записи о хранении, квитанции о доставке — все это данные о транзакциях, но сами по себе данные практически бессмысленны, и большинству организаций сложно понять, какие данные они генерируют, и как их можно найти с пользой.
Получение реальной ценности из данных
Реальная ценность для бизнеса проистекает из способности комбинировать эти данные таким образом, чтобы генерировать идеи, решения и действия. CloudMoyo помогает компаниям разработать комплексную, последовательную и устойчивую аналитическую стратегию, которая дает им инструменты для дифференциации с помощью действенных идей и поддерживает сотрудников и сам бизнес. Ряд факторов указывает на ценность ниши, которую заполняют такие компании, как CloudMoyo.Недавнее исследование показало, что две трети компаний с самыми передовыми технологиями в этой области не могут нанять достаточно людей для использования этих возможностей . Кроме того, аналитика требует значительных ресурсов.
Крупным компаниям сложно выделить достаточно ресурсов, но для небольших компаний немыслимо, чтобы они могли выделить все, что необходимо для эффективного анализа. В обоих случаях аутсорсинг является неоценимым преимуществом.
Несмотря на общепризнанное понимание того, что большие данные могут обеспечить конкурентное преимущество, у тех, кто сотрудничает с опытными сторонними поставщиками, гораздо больше шансов извлечь выгоду из высококачественной и доступной аналитической информации.Эра больших данных действительно наступила, и вопрос уже не в том, должны ли предприятия работать с большими данными, а в том, как это сделать. Технологический гигант Cisco прогнозирует, что объем данных, производимых в 2020 году, будет в 50 раз больше, чем сегодня. Неудивительно, что компании чувствуют себя подавленными и отчаянно нуждаются в надежных советах специалистов, которые разбираются в своем бизнесе и могут сочетать его с технологиями для достижения результатов.
Проактивность — ключ к успеху
Традиционная отчетность и бизнес-аналитика уступают место расширенной аналитике.Уже недостаточно активно анализировать, что произошло и почему. Вместо этого необходимо создать системы и партнерства, которые будут использовать высококачественные данные и интерпретировать данные, чтобы делать прогнозы относительно того, что может произойти дальше, с конкретными доказательствами, подтверждающими утверждения.
Организации могут удовлетворить потребности бизнеса по всему спектру аналитических требований с помощью облачных больших данных как услуги — от доставки и управления данными до использования данных. Разрабатывая комплексную облачную стратегию больших данных, они могут определить структуру понимания и оптимизировать общую ценность корпоративных данных.Однако облачная аналитика больших данных не является универсальным решением, и опытный ИТ-партнер, такой как CloudMoyo, может помочь вам в этом путешествии.
Объяснение примеров, источников и технологий
В течение многих лет люди спрашивали всезнающего Google, как большие данные могут помочь бизнесу добиться успеха, какие технологии больших данных являются лучшими, и другие важные вопросы. О больших данных уже много написано и сказано, но сам термин остается необъяснимым. Честно говоря, мы не принимаем в расчет широко распространенное определение «большие данные — это большие данные».Эта концепция вызывает другой вопрос: каковы меры для «большого» — 1 терабайт, 1 петабайт, 1 эксабайт или более?
Здесь наша команда консультантов по большим данным определяет концепцию больших данных, описывая их ключевые особенности. Чтобы дать полную картину, мы также делимся обзором примеров больших данных из разных отраслей, перечисляем разные источники больших данных и фундаментальные технологии.
Определение больших данных
Вот наше определение:
Большие данные — это данные, которые характеризуются такими информационными характеристиками, как характер журнала событий и статистическая корректность, и которые предъявляют такие технические требования, как распределенное хранилище, параллельная обработка данных и простая масштабируемость решения.
Более подробно об этих функциях и требованиях можно прочитать ниже.
Информационные особенности : В отличие от традиционных данных, которые могут измениться в любой момент (например, банковские счета, количество товаров на складе), большие данные представляют собой журнал записей , каждая из которых описывает какое-либо событие (например, покупку в магазине, просмотр веб-страницы, значение датчика в данный момент, комментарий в социальной сети). Данные о событиях не меняются по самой своей природе.
Кроме того, больших данных могут содержать пропуски и ошибки , что делает их плохим выбором для задач, где абсолютная точность имеет решающее значение. Таким образом, нет смысла использовать большие данные для бухгалтерского учета. Однако больших данных является статистически правильным и может дать четкое представление об общей картине, тенденциях и зависимостях. Еще один пример из Финансов: большие данные могут помочь выявлять и измерять рыночные риски на основе анализа поведения клиентов, отраслевых показателей, производительности портфеля продуктов, истории процентных ставок, изменений цен на сырьевые товары и т. Д.
Технические требования : объем больших данных требует параллельной обработки и особого подхода к хранилищу : одного компьютера (или одного узла, как его называют гуру ИТ) недостаточно для выполнения этих задач — нам нужно много, обычно от 10 до 100.
Кроме того, решение для больших данных требует масштабируемости . Чтобы справиться с постоянно растущим объемом данных, нам не нужно вносить какие-либо изменения в программное обеспечение каждый раз, когда объем данных увеличивается.Если это произойдет, мы просто задействуем больше узлов, и данные будут автоматически перераспределены между ними.
Примеры больших данных
Чтобы лучше понять, что такое большие данные, давайте выйдем за рамки определения и рассмотрим несколько примеров практического применения в различных отраслях.
1. Клиентская аналитика
Чтобы создать 360-градусное представление о клиенте, компаниям необходимо собирать, хранить и анализировать огромное количество данных. Чем больше источников данных они используют, тем более полную картину они получат.Скажем, для каждого из своих 10+ миллионов клиентов они могут проанализировать 5 типов больших данных о клиентах:
- Демографические данные (заказчик — женщина, 35 лет, двое детей и т. Д.).
- Данные транзакции (продукты, которые она покупает каждый раз, время покупки и т. Д.)
- Данные о поведении в сети (продукты, которые она кладет в корзину, когда делает покупки в Интернете).
- Данные из текстов, созданных клиентами (комментарии о компании, которые эта женщина оставляет в Интернете).
- Данные об использовании товара / услуги (отзывы о качестве заказанного товара, скорости доставки и т. Д.).
Клиентская аналитика одинаково полезна для компаний и клиентов. Первые могут корректировать свой продуктовый портфель, чтобы лучше удовлетворять потребности клиентов и организовывать эффективную маркетинговую деятельность. Последние могут наслаждаться любимыми товарами, актуальными акциями и индивидуальным общением.
2. Промышленная аналитика
Чтобы избежать дорогостоящих простоев, влияющих на все связанные процессы, производители могут использовать данные датчика для упреждающего обслуживания.Представьте, что аналитическая система собирала и анализировала данные датчиков в течение нескольких месяцев, чтобы сформировать историю наблюдений. Основываясь на этих исторических данных, система определила набор закономерностей, которые могут привести к поломке машины. Например, система распознает, что изображение, сформированное датчиками температуры и нагрузки, похоже на предаварийную ситуацию № 3, и предупреждает бригаду технического обслуживания о необходимости проверки оборудования.
Важно отметить, что профилактическое обслуживание — не единственный пример того, как производители могут использовать большие данные.В этой статье вы найдете подробное описание других реальных случаев использования больших данных.
3. Аналитика бизнес-процессов
Компании также используют аналитику больших данных для мониторинга производительности своих удаленных сотрудников и повышения эффективности процессов. Возьмем, к примеру, транспорт. Компании могут собирать и хранить данные телеметрии, поступающие от каждого грузовика, в режиме реального времени, чтобы определить типичное поведение каждого водителя. После определения шаблона система анализирует данные в реальном времени, сравнивает их с шаблоном и сигнализирует о несоответствии.Таким образом, компания может обеспечить безопасные условия труда (так как водители должны переодеваться, чтобы отдыхать, но они иногда пренебрегают правилом).
4. Аналитика для выявления мошенничества
Банки могут обнаруживать необычное поведение карты в режиме реального времени (если ее использует кто-то другой, а не владелец) и блокировать подозрительные действия или, по крайней мере, откладывать их, чтобы уведомить владельца. Например, если пользователь пытается снять деньги в Испании, пока он проживает в Техасе, прежде чем отклонить транзакцию, банк может проверить информацию пользователя в социальной сети — возможно, они просто в отпуске.Кроме того, банк может проверить, имеет ли этот пользователь какую-либо связь со счетами, связанными с мошенничеством, или действиями по всем другим каналам.
Источники больших данных: внутренние и внешние
Есть два типа источников больших данных: внутренние и внешние. Данные: внутренние , если компания их производит, владеет и контролирует. Внешние данные — это общедоступные данные или данные, созданные вне компании; соответственно, компания им не владеет и не контролирует.
Давайте рассмотрим несколько очевидных примеров источников данных.
Автономная система или часть традиционной BI?
Большие данные могут использоваться как в составе традиционной бизнес-аналитики, так и в независимой системе. Вернемся снова к примерам. Компания анализирует большие данные, чтобы определить модели поведения каждого клиента. Основываясь на этих выводах, он относит клиентов с похожими моделями поведения к определенному сегменту. Наконец, традиционная система бизнес-аналитики использует сегменты клиентов в качестве еще одного атрибута для отчетности.Например, пользователи могут создавать отчеты, которые показывают продажи по сегментам клиентов или их реакцию на недавнюю рекламную акцию.
Другой пример: представьте себе веб-сайт электронной коммерции, поддерживаемый аналитической системой, которая определяет предпочтения каждого пользователя, отслеживая продукты, которые они покупают или в которых они заинтересованы (в зависимости от времени, проведенного на странице продукта). Основываясь на этой информации, система рекомендует товары, которые вам могут понравиться. Это независимая система.
Технологии больших данных: обзор общеизвестных имен и терминов
Мир больших данных говорит на своем языке.Давайте посмотрим на некоторые полезные термины и самые популярные технологии:
- Сloud — это предоставление вычислительных ресурсов по запросу на условиях оплаты по факту использования. Этот подход широко используется в больших данных, поскольку последний требует быстрой масштабируемости. Например, администратор может добавить 20 компьютеров за несколько кликов.
- Hadoop — это фреймворк, используемый для распределенного хранения огромных объемов данных (его компонент HDFS ) и параллельной обработки данных ( Hadoop MapReduce ).Он разбивает большой фрагмент на более мелкие, которые обрабатываются отдельно на разных узлах данных (компьютерах), и автоматически собирает результаты на нескольких узлах для получения единого результата. Довольно часто Hadoop означает экосистему, которая охватывает несколько технологий больших данных, например Apache Hive , Apache HBase , Apache Zookeeper и Apache Oozie .
- Apache Spark — это платформа, используемая для параллельной обработки данных в памяти, которая делает возможной аналитику больших данных в реальном времени.Например, аналитическая система может определить, что посетитель довольно долго просматривал страницы определенных товаров, но еще не добавил их в корзину. Чтобы мотивировать покупку, система может предложить купон на скидку на интересующий товар.
Подробнее:
Теперь вы знаете, что такое большие данные, не так ли?
Наши консультанты по большим данным создали небольшую викторину. У вас есть пять вопросов, чтобы проверить, насколько вы узнали о больших данных:
- Какая обработка данных требуется для больших данных?
- Являются ли большие данные на 100% надежными и точными?
- Если ваша цель — создать уникальный клиентский опыт, какая аналитика больших данных вам нужна?
- Назовите не менее трех внешних источников больших данных.
- Есть ли сходство между Hadoop и Apache Spark?
Молодец! Мы надеемся, что эта статья была для вас полезной и, прочитав ее, вы сочли викторину легкой.
Услуги по работе с большими данными от ScienceSoftБольшие данные — еще один шаг к успеху вашего бизнеса. Мы поможем вам применить передовой подход к большим данным, чтобы полностью раскрыть их потенциал.
4 скрытых источника больших данных и где их найти
Большие данные повсюду вокруг вас, включая места, куда вы, возможно, даже не подумаете смотреть.Ваша организация упускает из виду скрытые наборы данных, которые могут способствовать аналитике и аналитике? Читайте дальше, чтобы ознакомиться с четырьмя источниками больших данных, которые вы могли упустить.
Некоторые источники больших данных очевидны. Файлы журналов программного обеспечения, базы данных, в которых хранятся записи о клиентах, и т.п. предназначены для конкретной цели сбора и хранения данных.
В результате именно на эти места организации в первую очередь обращают внимание при поиске источников данных для аналитики.
Скрытые источники больших данных
Тем не менее, чтобы максимально использовать большие данные, нужно мыслить помимо очевидного.
Рассмотрите также следующие источники больших данных, которые могут дать ценную информацию для бизнес-операций, маркетинга и не только:
1. Электронная почта
В среднем офисный служащий отправляет 40 деловых писем в день и получает 121. Это много данных, особенно если вы считаете вложения, которые включены во многие сообщения.
Mining данных из учетных записей электронной почты вашей организации может дать представление обо всем: от уровня производительности сотрудников и состояния вашего бизнеса до времени суток, когда ваши клиенты с наибольшей вероятностью ответят на электронные письма (и, возможно, о других формах взаимодействия , тоже).
2. Социальные сети
Между твитами, публикациями в Facebook, изображениями в Instagram и всеми другими потоками данных в социальных сетях платформы социальных сетей предлагают множество информации, которую вы можете проанализировать, чтобы узнать больше, например, о том, как люди говорят о вашем бизнесе и о каких актуальны для вашего бизнеса темы.
Прочтите нашу электронную книгу
Успешная работа с большими данными — одна из самых сложных частей работы ИТ-отдела.Эта электронная книга проведет вас через тонкости построения успешных проектов больших данных на прочной основе интеграции данных.
3. Открытые данные
Есть много гигабайт «открытых» данных, которые можно взять бесплатно. Многие из них предоставляются государственными учреждениями, такими как город Нью-Йорк и федеральное правительство США, которые публикуют открытые наборы данных, которые могут использоваться кем угодно. Конечно, вы не можете контролировать, какие данные собираются и сообщаются.
Но есть большая вероятность, что в этих наборах данных вы найдете информацию, имеющую отношение к вашему бизнесу. В качестве бонуса многие открытые наборы данных поддерживаются в относительно хорошем состоянии и готовы к немедленному анализу.
4. Данные датчика
Традиционно источниками машинных данных были файлы журналов, создаваемые такими устройствами, как серверы и сетевые коммутаторы. Однако организации все чаще добавляют устройства Интернета вещей (IoT) в свою инфраструктуру.Устройства IoT также генерируют машинные данные, которые могут или не могут быть записаны в обычные журналы. Если вы используете датчики или другие интеллектуальные устройства, не упускайте из виду огромные объемы данных, которые они производят.
Короче говоря, источники больших данных есть везде. Вам просто нужно заглянуть под поверхность, чтобы найти богатые источники данных, которые в противном случае могли бы отсутствовать.
Загрузите нашу электронную книгу, чтобы узнать больше о создании успешных проектов больших данных на прочной основе интеграции данных.
70 удивительных бесплатных источников данных, о которых вы должны знать
Овен Чау, Octoparse .
Каждая отличная визуализация данных начинается с хороших и чистых данных. Большинство людей считает, что сбор больших данных — непростая задача, но это неправда. В Интернете доступны тысячи бесплатных наборов данных, готовых для анализа и визуализации кем угодно. Здесь мы собрали 70 бесплатных источников данных за 2017 год по правительству, преступности, здравоохранению, финансовым и экономическим данным, маркетингу и социальным сетям, журналистике и СМИ, недвижимости, каталогам и обзорам компаний и многому другому.
Мы надеемся, что вам это понравится, и вы сэкономите много времени и сил на поиске в Интернете вслепую.
Источник бесплатных данных: Правительство
- Data.gov : Это первая стадия, которая действует как портал для всех видов удивительной информации по всем, от климата до преступности, свободно от правительства США.
- Data.gov.uk : Есть наборы данных из всех центральных департаментов Великобритании и ряда других государственных и местных органов власти. Он действует как портал для всевозможной информации обо всем, включая бизнес и экономику, преступность и правосудие, оборону, образование, окружающую среду, правительство, здравоохранение, общество и транспорт.
- США. Бюро переписи : Веб-сайт посвящен официальной статистике жизни граждан США, включая население, экономику, образование, географию и многое другое.
- The CIA World Factbook : Факты по каждой стране мира; фокусируется на истории, правительстве, народонаселении, экономике, энергетике, географии, коммуникациях, транспорте, военных и транснациональных проблемах 267 стран.
- Socrata : Socrata — это компания, занимающаяся разработкой программного обеспечения, которая является еще одним интересным местом для изучения правительственных данных с помощью некоторых встроенных инструментов визуализации.Его данные как услуга были приняты более чем 1200 правительственными учреждениями для открытых данных, управления эффективностью и управления на основе данных.
- Портал открытых данных Европейского союза : это единая точка доступа к растущему диапазону данных от учреждений и других органов Европейского Союза. Увеличение объемов данных включает экономическое развитие в ЕС и прозрачность институтов ЕС, включая географические, геополитические и финансовые данные, статистику, результаты выборов, правовые акты, а также данные о преступности, здоровье, окружающей среде, транспорте и научных исследованиях.Их можно было повторно использовать в разных базах данных и отчетах. Более того, различные цифровые форматы доступны в учреждениях ЕС и других органах ЕС. Портал предоставляет стандартизированный каталог, список приложений и веб-инструментов, повторно использующих эти данные, редактор запросов к конечной точке SPARQL и доступ к rest API, а также советы о том, как наилучшим образом использовать сайт.
- Canada Open Data — пилотный проект с множеством правительственных и геопространственных наборов данных. Это может помочь вам изучить, как правительство Канады обеспечивает большую прозрачность, подотчетность, увеличивает участие граждан и стимулирует инновации и экономические возможности с помощью открытых данных, открытой информации и открытого диалога.
- Datacatalogs.org : он предлагает открытые правительственные данные из США, ЕС, Канады, CKAN и других стран.
- Национальный центр статистики образования США : Национальный центр статистики образования (NCES) является основным федеральным органом, занимающимся сбором и анализом данных, связанных с образованием в США и других странах.
- UK Data Service : Коллекция UK Data Service включает в себя основные опросы, спонсируемые правительством Великобритании, межнациональные опросы, лонгитюдные исследования, данные переписи населения Великобритании, международные агрегированные данные, коммерческие данные и качественные данные.
Источник свободных данных: Crime
- Единое сообщение о преступности : Программа UCR была отправной точкой для руководителей правоохранительных органов, студентов, исследователей, представителей СМИ и общественности, ищущих информацию о преступности в США.
- Статистика преступности ФБР : Статистические отчеты и публикации о преступлениях с подробным описанием конкретных преступлений и тенденциями для понимания угроз преступности как на местном, так и на национальном уровнях.
- Бюро статистики юстиции : Информация обо всем, что связано с У.S. Система правосудия, включая случаи смерти, связанные с арестом, перепись заключенных в тюрьмах, национальное обследование лабораторий по анализу ДНК, опросы группировок правоохранительных органов и т. Д.
- Национальный поиск сексуальных преступников : Это беспрецедентный ресурс общественной безопасности, который предоставляет общественности доступ к данным о сексуальных преступниках по всей стране. В нем представлена самая последняя информация, предоставленная каждой юрисдикцией.
Источник бесплатных данных: Health
- Управление по санитарному надзору за качеством пищевых продуктов и медикаментов США : Здесь вы найдете сжатый файл данных базы данных Drugs @ FDA.Drugs @ FDA, обновляется ежедневно, этот файл данных обновляется раз в неделю, во вторник.
- ЮНИСЕФ : ЮНИСЕФ собирает данные о положении детей и женщин во всем мире. Наборы данных включают точные, репрезентативные на национальном уровне данные из обследований домашних хозяйств и других источников.
- Всемирная организация здравоохранения : статистика питания, болезней и здоровья в более чем 150 странах.
- Healthdata.gov : 125 лет данных о здравоохранении в США, включая данные Medicare на уровне заявлений, эпидемиологию и статистику населения.
- Информационный центр здравоохранения и социального обеспечения NHS : Наборы данных о состоянии здоровья от Национальной службы здравоохранения Великобритании. Организация выпускает более 260 официальных и национальных статистических публикаций. Сюда входят национальные сравнительные данные по вторичному использованию, разработанные на основе долгосрочной статистики больничных эпизодов, которые могут помочь местным руководителям повысить качество и эффективность оказания первой медицинской помощи.
Источник бесплатных данных: финансово-экономические данные
- Всемирный банк Открытые данные : статистика образования обо всем, от финансов до показателей предоставления услуг по всему миру.
- Экономические данные МВФ : невероятно полезный источник информации, который включает отчеты о глобальной финансовой стабильности, региональные экономические отчеты, международную финансовую статистику, курсы валют, направления торговли и многое другое.
- База данных UN Comtrade : бесплатный доступ к подробным данным о мировой торговле с визуализацией. UN Comtrade — это хранилище официальной статистики международной торговли и соответствующих аналитических таблиц. Все данные доступны через API.
- Global Financial Data : Global Financial Data содержит данные о более чем 60 000 компаний за 300 лет и является уникальным источником для анализа перипетий мировой экономики.
- Google Finance : котировки акций и графики в реальном времени, финансовые новости, конвертация валют или отслеживание портфелей.
- Google Public Data Explorer : Google Public Data Explorer предоставляет общедоступные данные и прогнозы от ряда международных организаций и академических институтов, включая Всемирный банк, ОЭСР, Евростат и Денверский университет.Они могут отображаться в виде линейных графиков, гистограмм, диаграмм поперечного сечения или на картах.
- Бюро экономического анализа США : официальная макроэкономическая и отраслевая статистика США, в первую очередь отчеты о валовом внутреннем продукте (ВВП) США и его различных единицах. Они также предоставляют информацию о личном доходе, корпоративной прибыли и государственных расходах в своих счетах национального дохода и продуктов (NIPA).
- Finder Financial Data Finder в OSU : многочисленные ссылки на все, что связано с финансами, независимо от степени неясности, включая показатели мирового развития в Интернете, открытые данные Всемирного банка, глобальные финансовые данные, статистические базы данных Международного валютного фонда и EMIS Intelligence.
- Национальное бюро экономических исследований : макроданные, отраслевые данные, данные о производительности, данные о торговле, международные финансы, данные и многое другое.
- Комиссия по ценным бумагам и биржам США : Ежеквартальные наборы данных извлеченной информации из экспонатов в корпоративные финансовые отчеты, поданные в Комиссию.
- Визуализация экономики : Визуализация данных об экономике.
- Financial Times : Financial Times предоставляет широкий спектр информации, новостей и услуг для глобального бизнес-сообщества.
Источник бесплатных данных: маркетинг и социальные сети
- Amazon API : Просмотрите общедоступные наборы данных Amazon Web Services по категориям для получения огромного объема информации. Amazon API Gateway позволяет разработчикам безопасно подключать мобильные и веб-приложения к API, которые работают в Amazon Web (AWS) Lambda, Amazon EC2 или других общедоступных веб-сервисах, размещенных за пределами AWS.
- Американское общество туристических агентств : ASTA — крупнейшая в мире ассоциация профессионалов в области путешествий.Он предоставляет участникам информацию, включая туристических агентов и компании, продукты которых они продают, например туры, круизы, отели, прокат автомобилей и т. Д.
- Social Mention : Social Mention — это платформа для поиска и анализа в социальных сетях, которая объединяет созданный пользователями контент со всей вселенной в единый поток информации.
- Google Trends : Google Trends показывает, как часто вводится конкретный поисковый запрос по отношению к общему объему поиска в различных регионах мира на разных языках.
- Facebook API : узнайте, как публиковать и получать данные из Facebook с помощью Graph API.
- Twitter API : Платформа Twitter соединяет ваш веб-сайт или приложение с мировым сообществом, происходящим в Twitter.
- Instagram API : платформу Instagram API можно использовать для создания неавтоматических, аутентичных, высококачественных приложений и сервисов.
- Foursquare API : Foursquare API дает вам доступ к нашей базе данных мест мирового класса и возможность взаимодействия с пользователями и продавцами Foursquare.
- HubSpot : большое хранилище маркетинговых данных. Здесь вы можете найти последнюю маркетинговую статистику и тенденции. Он также предоставляет инструменты для маркетинга в социальных сетях, управления контентом, веб-аналитики, целевых страниц и поисковой оптимизации.
- Moz : Анализ SEO, который включает исследование ключевых слов, создание ссылок, аудит сайтов и анализ оптимизации страниц, чтобы помочь компаниям лучше понять свое положение в поисковых системах и способы повышения их рейтинга.
- Институт контент-маркетинга : Последние новости, исследования и исследования в области контент-маркетинга.
Источник бесплатных данных: Журналистика и СМИ
- Сеть разработчиков New York Times — статьи Search Times с 1851 года по сегодняшний день, получение заголовков, рефератов и ссылок на связанные мультимедийные материалы. Вы также можете искать обзоры книг, списки событий Нью-Йорка, обзоры фильмов, главные новости с изображениями и многое другое.
- Associated Press API : AP Content API позволяет вам искать и загружать контент с помощью ваших собственных редакционных инструментов, без необходимости посещать порталы AP.Он обеспечивает доступ к изображениям, принадлежащим AP, участникам и сторонним организациям, а также видео, созданным AP и выбранной третьей стороной.
- Google Книги Ngram Viewer : это онлайн-поисковая система, которая составляет график частот любого набора разделенных запятыми поисковых строк, используя годовое количество n-граммов, найденных в источниках, напечатанных между 1500 и 2008 годами в текстовых корпусах Google.
- База данных Википедии : Википедия предлагает бесплатные копии всего доступного содержания заинтересованным пользователям.
- FiveThirtyEight : это веб-сайт, посвященный анализу опросов общественного мнения, политике, экономике и спортивным блогам. Данные и код на Github лежат в основе историй и интерактивов FiveThirtyEight.
- Google Scholar : Google Scholar — это свободно доступная поисковая система в Интернете, которая индексирует полный текст или метаданные научной литературы по множеству форматов публикации и дисциплин. Он включает большинство рецензируемых академических онлайн-журналов и книг, доклады конференций, тезисов и диссертаций, препринты, рефераты, технические отчеты и другую научную литературу, включая судебные заключения и патенты.
Источник бесплатных данных: Недвижимость
- Замки : Замки — успешное частное независимое агентство. Основанная в 1981 году, она предлагает комплексные услуги, включая продажу жилья, сдачу внаем и управление, а также обследования и оценки.
- Realestate.com : RealEstate.com служит основным ресурсом для начинающих покупателей жилья, предлагая простые для понимания инструменты и советы экспертов на каждом этапе процесса.
- Gumtree : Gumtree — это первый сайт бесплатных объявлений в Великобритании. Купить и продать предметы, автомобили, недвижимость, а также найти или предложить работу в вашем районе — все это доступно на веб-сайте.
- Джеймс Хейворд : Он обеспечивает новаторский подход к базам данных для продаж, сдачи в аренду и управления жилыми помещениями.
- Lifull Home ’ s : веб-сайт недвижимости в Японии.
- Immobiliare.it : сайт недвижимости Италии.
- Subito : веб-сайт недвижимости Италии.
- Immoweb : ведущий веб-сайт о недвижимости Бельгии.
Источник бесплатных данных: Business Directory and Review
- LinkedIn : LinkedIn — это социальная сеть, ориентированная на бизнес и занятость, которая работает через веб-сайты и мобильные приложения. У него 500 миллионов членов в 200 странах, и вы можете найти бизнес-каталог здесь.
- OpenCorporates : OpenCorporates — это крупнейшая открытая база данных компаний и данных компаний в мире, насчитывающая более 100 миллионов компаний в столь же большом количестве юрисдикций.Наша основная цель — сделать информацию о компаниях более удобной и доступной для общества, в частности, для решения проблемы использования компаний в преступных или антиобщественных целях, например, с коррупцией, отмыванием денег и организованной преступностью.
- Yellowpages : Первоисточник для поиска и связи с местными водопроводчиками, разнорабочими, механиками, адвокатами, дантистами и т. Д.
- Craigslist : Craigslist — это американский веб-сайт классифицированных объявлений с разделами, посвященными вакансиям, жилью, знакомствам, продаже, необходимым товарам, услугам, сообществу, выступлениям, резюме и дискуссионным форумам.
- GAF Master Elite Contractor : Основанная в 1886 году компания GAF стала крупнейшим производителем кровли для коммерческих и жилых помещений в Северной Америке (Источник: исследование Fredonia Group). Наш успех в увеличении продаж компании до почти 3 миллиардов долларов стал результатом нашего неустанного стремления к качеству в сочетании с ведущим в отрасли опытом и комплексными решениями для кровли. Джим Шнеппер — президент GAF, дочерней компании Standard Industries. Если вы хотите защитить то, что вам больше всего нравится, вот лишь некоторые из причин, по которым мы считаем, что вам следует выбрать GAF.
- CertainTeed : Здесь вы можете найти подрядчиков, специалистов по ремонту, монтажников или строителей в США или Канаде по вашему жилому или коммерческому проекту.
- Компании в Калифорнии : Вся информация о компаниях в Калифорнии.
- Manta : Manta — один из крупнейших онлайн-ресурсов, предлагающих продукты, услуги и возможности для обучения. Каталог Manta может похвастаться миллионами уникальных посетителей каждый месяц, которые ищут в обширной базе данных по отдельным предприятиям, отраслевым сегментам и географическим спискам.
- EU-Startups : Справочник о стартапах в ЕС.
- Канзасская коллегия адвокатов : Справочник юристов. Канзасская ассоциация адвокатов (KBA) была основана в 1882 году как добровольная ассоциация преданных своему делу профессиональных юристов и насчитывает более 7000 членов, включая юристов, судей, студентов-юристов и помощников юристов.
Источник бесплатных данных: другие сайты портала
- Capterra : Справочник о программном обеспечении для бизнеса и обзоры.
- Monster : источник данных о вакансиях и возможностях карьерного роста.
- Glassdoor : Справочник о вакансиях и информация о компаниях изнутри с отзывами сотрудников, персонализированными инструментами заработной платы и т. Д.
- Схема хорошего гаража : Справочник по автосервису, ТО или ремонту автомобилей.
- ОСМОЗ : Информация об аромате.
- Octoparse : бесплатный инструмент для извлечения данных для сбора всех упомянутых выше веб-данных в режиме онлайн.
Знаете ли вы какие-нибудь отличные источники данных? Свяжитесь с нами по адресу [email protected], чтобы сообщить нам об этом и помочь нам поделиться своими данными.
Другие источники по теме:
30 лучших инструментов больших данных для анализа данных
Топ 30 бесплатных программ для парсинга веб-страниц
Связанные
Топ-10 категорий источников больших данных и технологий майнинга
Этот гостевой пост принадлежит Джеффу Моррису, вице-президенту по маркетингу продуктов в Actuate Corporation, компании, стоящей за популярным продуктом для создания отчетов с открытым исходным кодом BIRT.
Большинство дискуссий по организации центра больших данных на фреймворках репозиториев, в частности, кластерах Hadoop и фреймворках MapReduce. Этот ориентированный на технологии взгляд часто упускает из виду самый важный вопрос: «Что вы планируете делать с данными, которые собираете?»
Поскольку все ответы будут разными, это означает, что универсального решения не существует. Успех заключается в распознавании различных типов источников больших данных, использовании надлежащих технологий добычи полезных ископаемых для поиска сокровищ в каждом типе, а затем в интеграции и представлении этих новых идей в соответствии с вашими уникальными целями, чтобы ваша организация могла принимать более эффективные управленческие решения. .
Таксономия источников и технологий больших данных
Для этого процесса давайте определим два сегмента для организации ваших больших данных — источники для больших данных и технологии для добычи этих источников.
Вот 10 основных типов источников больших данных и соответствующие методы добычи, которые могут быть применены для поиска ваших золотых самородков.
1. Профили в социальных сетях —Подключение к профилям пользователей из Facebook, LinkedIn, Yahoo, Google, а также из социальных сетей или туристических сайтов по конкретным интересам, чтобы отбирать профили людей и демографическую информацию и расширять ее, чтобы фиксировать их, надеюсь, похожие мыслящих сетей.(Это требует довольно простой интеграции API для импорта предопределенных полей и значений — например, интеграция API социальной сети, которая собирает всех маркетологов B2B в Twitter.)
2. Социальные влиятельные лица — Комментарии в блогах редактора, аналитика и профильных экспертов, форумы пользователей, лайки в Twitter и Facebook, сайты каталогов и обзоров в стиле Yelp и другие сайты, ориентированные на обзоры, такие как Apple App Store, Amazon, ZDNet и т. Д. (Доступ к этим данным требует обработки естественного языка и / или возможности поиска на основе текста для оценки положительного / отрицательного характера слов и фраз, определения значения, индексации и записи результатов).
3. Данные об активности — файлы журналов компьютеров и мобильных устройств, также известные как «Интернет вещей». Эта категория включает в себя информацию отслеживания веб-сайтов, журналы приложений и данные датчиков, такие как чекины и другое отслеживание местоположения, среди прочего, созданного машиной контента. Но обратите внимание также на данные, генерируемые процессорами автомобилей, видеоигр, кабельных коробок или, скоро, бытовых приборов. (Технологии синтаксического анализа, такие как Splunk или Xenos, помогают разобраться в этих типах полуструктурированных текстовых файлов и документов.)
4. Программное обеспечение как услуга (SaaS) и облачные приложения — Такие системы, как Salesforce.com, Netsuite, SuccessFactors и т. Д., Представляют данные, которые уже находятся в облаке, но их сложно переместить и объединить с внутренними данными. (Здесь могут быть уместны технология интеграции распределенных данных, технология кэширования в памяти и интеграция API.)
5. Public —Microsoft Azure MarketPlace / DataMarket, The World Bank, SEC / Edgar, Wikipedia, IMDb и т. Д.- данные, которые общедоступны в Интернете, что может улучшить типы анализа, который можно выполнить. (Используйте те же типы синтаксического анализа, использования, поиска и категоризации, что и для трех ранее упомянутых источников.)
6. Результаты приложения Hadoop MapReduce — Технологические архитектуры следующего поколения для обработки и параллельного анализа данных из журналов, веб-сообщений и т. Д. Обещают создать новое поколение предварительно и постобработанных данных. Мы предвидим массу новых продуктов, которые будут рассматривать варианты использования приложений для любых видов больших данных — достаточно взглянуть на списки партнеров Cloudera и Hortonworks.На самом деле, мы не удивимся, если слои приложений MapReduce, сочетающие в себе все, что упомянуто выше (консолидация, «сокращение» и агрегирование больших данных в многоуровневом или иерархическом подходе), скорее всего, станут собственными «большими данными».
7. Устройства хранилища данных —Teradata, IBM Netezza, EMC Greenplum и т. Д. Собирают из операционных систем внутренние транзакционные данные, которые уже подготовлены для анализа. Они, вероятно, станут целью интеграции, которая поможет улучшить анализируемые и сокращенные результаты вашей установки больших данных.
8. Источники данных Columnar / NoSQL —MongoDB, Cassandra, InfoBright и т. Д. — примеры нового типа репозитория и агрегатора данных map reduce. Это специальные приложения, которые заполняют пробелы в средах на основе Hadoop, например, использование Cassandra для сбора больших объемов распределенных данных в реальном времени.
9. Технологии сетевого и поточного мониторинга — Приложения для оценки пакетов и распределенной обработки запросов, а также анализаторы электронной почты также являются областями, которые, вероятно, будут активно развиваться с появлением новых технологий запуска.
10. Устаревшие документы —Архивы выписок, страховых форм, медицинских карт и корреспонденции с клиентами все еще остаются неиспользованным ресурсом. (Многие архивы заполнены старыми документами PDF и файлами потоков печати, которые содержат оригинальные и единственные системы записи между организациями и их клиентами. Анализ этого полуструктурированного устаревшего контента может оказаться сложной задачей без специальных инструментов, таких как Xenos.)
Как вы это используете
Мы еще не слышали разговоров о том, чтобы рассматривать управление большими данными в организации как многоуровневый процесс, которым оно и является.Наша лакмусовая бумажка будет не только в том, насколько хорошо мы фиксируем большие данные, но и в том, как мы их организуем, визуализируем и вводим в действие, чтобы получить большую отдачу от инвестиций в большие данные. Выбор правильных технологий для извлечения ценности из разнообразных источников больших данных — это следующее обсуждение, которое нам необходимо провести, как только мы выйдем за рамки одобрения друг друга, потому что «это работает с Hadoop!»
Конечно, BIRT (Business Intelligence and Reporting Tools), проект с открытым исходным кодом Eclipse, который служит основой для набора продуктов ActuateOne, поддерживает Hadoop.Но настоящий вопрос, который нужно задать: «Для чего?» Здесь начинается настоящее интересное обсуждение, поскольку оно знаменует собой точку пересечения традиционной бизнес-аналитики и больших данных.
Сегодня архитектор данных является экспертом по большим данным, но представьте, что произойдет, когда мы с вами пожинаем личную выгоду от больших данных, которые влияют на нашу жизнь — заторы на дорогах могут уменьшиться ; купоны на товары, которые нам нужны, будут приходить на наши телефоны, когда мы войдем в Target или WalMart; наши продуктовые магазины могут предупредить нас, чтобы мы выбросили молоко, прежде чем мы его понюхаем; или мы могли бы открыть основы Большого взрыва.
При правильном управлении большими данными его потенциал безграничен. И дело не в технологическом «будущем»… это происходит прямо сейчас.
Big Data: что это такое и почему это важно
История больших данных
Термин «большие данные» относится к данным, которые настолько большие, быстрые или сложные, что их сложно или невозможно обработать традиционными методами. Акт доступа и хранения больших объемов информации для аналитики существует уже давно.Но концепция больших данных набрала обороты в начале 2000-х, когда отраслевой аналитик Дуг Лэйни сформулировал ныне распространенное определение больших данных как три V:
.Том : Организации собирают данные из различных источников, включая бизнес-транзакции, интеллектуальные (IoT) устройства, промышленное оборудование, видео, социальные сети и многое другое. В прошлом его хранение было проблемой, но более дешевое хранилище на таких платформах, как озера данных и Hadoop, облегчило бремя.
Скорость : С развитием Интернета вещей потоки данных поступают на предприятия с беспрецедентной скоростью и должны обрабатываться своевременно. RFID-метки, датчики и интеллектуальные счетчики вызывают необходимость иметь дело с этими потоками данных в режиме, близком к реальному времени.
Разнообразие : Данные поступают во всех форматах — от структурированных числовых данных в традиционных базах данных до неструктурированных текстовых документов, электронных писем, видео, аудио, данных биржевых котировок и финансовых транзакций.
В SAS мы рассматриваем два дополнительных аспекта, когда дело доходит до больших данных:
Вариативность:
Помимо увеличения скорости и разнообразия данных, потоки данных непредсказуемы — часто меняются и сильно различаются. Это сложно, но предприятиям необходимо знать, когда в социальных сетях что-то происходит, и как управлять ежедневными, сезонными и вызванными событиями пиковыми нагрузками данных.
Верность:
Под достоверностью понимается качество данных.Поскольку данные поступают из множества разных источников, сложно связать, сопоставить, очистить и преобразовать данные между системами. Компаниям необходимо соединить и соотнести отношения, иерархии и множественные связи данных. В противном случае их данные могут быстро выйти из-под контроля.
источников BigData — BigData
Я всегда подчеркиваю, что данные есть везде.
Большие данные часто сводятся к нескольким разновидностям, включая социальные данные, машинные данные и транзакционные данные.Данные социальных сетей предоставляют компаниям замечательную информацию о поведении и настроениях потребителей, которые могут быть интегрированы с данными CRM для анализа: 230 миллионов твитов , размещаемых в Twitter в день, 2,7 миллиарда лайков, и комментариев, добавленных в Facebook. каждый день и 60 часов видео загружается на YouTube каждую минуту (это то, что мы подразумеваем под скоростью передачи данных).
Данные о машинах состоят из информации, генерируемой промышленным оборудованием, данных в реальном времени от датчиков, отслеживающих детали и контролирующих механизмы (часто также называемых Интернетом вещей), и даже веб-журналов, которые отслеживают поведение пользователей в Интернете.В клиентском центре arcplan CERN, крупнейшем в мире центре исследований физики элементарных частиц, Большой адронный коллайдер (LHC) генерирует 40 терабайт данных каждую секунду во время экспериментов. Что касается данных о транзакциях, крупные розничные торговцы и даже компании B2B могут на регулярной основе генерировать множество данных, учитывая, что их транзакции состоят из одного или нескольких элементов, идентификаторов продуктов, цен, информации о платежах, данных производителя и дистрибьютора и многого другого. Крупные розничные торговцы, такие как Amazon.com, продажи которого в третьем квартале 2011 года составили 10 миллиардов долларов, и такие рестораны, как американская сеть пиццерий Domino’s, обслуживающая более 1 миллиона клиентов в день, генерируют петабайты больших транзакционных данных. Следует отметить, что большие данные могут напоминать традиционные структурированные данные или неструктурированная высокочастотная информация .
При определении больших данных также важно понимать сочетание неструктурированных и многоструктурированных данных, составляющих объем информации.
Неструктурированные данные поступают из информации, которая не организована и не легко интерпретируется традиционными базами данных или моделями данных, и, как правило, содержит много текста.Метаданные, твиты в Twitter и другие сообщения в социальных сетях — хорошие примеры неструктурированных данных.
Многоструктурированные данные относятся к различным форматам и типам данных и могут быть получены в результате взаимодействия между людьми и машинами, например веб-приложениями или социальными сетями. Отличным примером являются данные веб-журнала, которые включают комбинацию текста и визуальных изображений вместе со структурированными данными, такими как информация о форме или транзакциях. По мере того, как цифровой прорыв преобразует каналы связи и взаимодействия, а также по мере того, как маркетологи улучшают качество обслуживания клиентов на различных устройствах, веб-ресурсах, личных взаимодействиях и социальных платформах, многоструктурированные данные будут продолжать развиваться.
Лидеры отрасли, такие как глобальная аналитическая компания Gartner , используют такие фразы, как «объем» (объем данных), «скорость» (скорость информации, генерируемой и поступающей в предприятие) и «разнообразие» (вид данных доступно), чтобы начать обсуждение больших данных. Другие сосредоточились на дополнительных V, таких как «достоверность» и «ценность» больших данных.
Ясно одно: каждое предприятие должно полностью понимать большие данные — что они для них значат, что они делают для них, что они значат для них — и потенциал маркетинга, основанного на данных , начиная с сегодня. Не ждите. Ожидание только отсрочит неизбежное и еще больше усложнит разгадку неразберихи.
Как только вы начнете работать с большими данными, вы узнаете то, чего не знаете, и получите вдохновение, чтобы предпринять шаги для решения любых проблем. Лучше всего то, что вы можете использовать идеи, которые собираете на каждом этапе, чтобы начать улучшать свои стратегии взаимодействия с клиентами; Таким образом вы сможете задействовать в маркетинге больших данных и сразу же повысить ценность как офлайн, так и онлайн-взаимодействий.
Есть несколько источников BigData:
- Датчики / счетчики и записи активности с электронных устройств: Такая информация создается в режиме реального времени, количество и периодичность наблюдений за наблюдениями будет изменяться, иногда это будет зависеть от отрезка времени, от других наступления одного события (например, автомобиля, проезжающего под углом обзора камеры), а в других случаях будет зависеть от ручных манипуляций (со строгой точки зрения, это будет то же самое, что и возникновение события).Качество такого источника зависит, главным образом, от способности датчика проводить точные измерения ожидаемым образом.
- Социальные взаимодействия: Это данные, полученные в результате взаимодействия людей через сеть, например Интернет. Наиболее распространены данные, полученные в социальных сетях. Этот вид данных подразумевает качественные и количественные аспекты, которые представляют определенный интерес для измерения. Количественные аспекты легче измерить, чем качественные: первые подразумевают подсчет количества наблюдений, сгруппированных по географическим или временным характеристикам, тогда как качество вторых в основном зависит от точности алгоритмов, применяемых для извлечения смысла содержания, которое обычно найденный как неструктурированный текст, написанный на естественном языке, примерами анализа, сделанного на основе этих данных, являются анализ настроений, анализ тем тенденций и т. д.;
- Деловые операции: Данные, полученные в результате деловой активности, могут быть записаны в структурированных или неструктурированных базах данных. При записи в структурированные базы данных наиболее распространенной проблемой для анализа этой информации и получения статистических показателей является большой объем информации и периодичность ее производства, потому что иногда эти данные производятся в очень быстром темпе, тысячи записей могут быть созданы за один раз. во-вторых, когда крупные компании, такие как сети супермаркетов, регистрируют свои продажи.Но данные такого типа не всегда создаются в форматах, которые можно напрямую хранить в реляционных базах данных, электронный счет является примером этого случая источника, он имеет более или менее структуру, но если нам нужно поместить данные, которые он содержит в реляционной базе данных нам нужно будет применить некоторый процесс для распределения этих данных по разным таблицам (чтобы нормализовать данные в соответствии с теорией реляционных баз данных) и, возможно, не в виде простого текста (это может быть изображение, PDF-файл, Запись в Excel и т. Д.), одна проблема, которая может возникнуть здесь, заключается в том, что процессу требуется время, и, как было сказано ранее, данные, возможно, производятся слишком быстро, поэтому нам понадобятся разные стратегии для использования данных, обрабатывая их как есть, не добавляя их. реляционная база данных, отбрасывающая некоторые наблюдения (какие критерии?), использующая параллельную обработку и т. д. Качество информации, полученной в результате бизнес-транзакций, тесно связано со способностью получать репрезентативные наблюдения и обрабатывать их;
- Электронные файлы: Это относится к неструктурированным документам, статически или динамически создаваемым, которые хранятся или публикуются в виде электронных файлов, таких как Интернет-страницы, видео, аудио, файлы PDF и т. Д.Они могут иметь содержимое, представляющее особый интерес, но их трудно извлечь, могут использоваться различные методы, такие как интеллектуальный анализ текста, распознавание образов и т. Д. Качество наших измерений в основном зависит от способности извлекать и правильно интерпретировать всю репрезентативную информацию из этих документов;
- Вещания: В основном речь идет о видео и аудио, создаваемых в реальном времени, получение статистических данных из содержимого такого рода электронных данных в настоящее время слишком сложно и требует больших вычислительных и коммуникационных мощностей, которые когда-то решали проблемы преобразования «цифрового- аналоговое »содержимое к содержимому« цифровых данных », мы столкнемся с такими же сложностями при его обработке, как и те, которые мы можем найти при социальных взаимодействиях.
Какие наборы данных считаются большими данными?
Использование больших данных почти так же разнообразно, как и велико. Яркие примеры, с которыми вы, вероятно, уже знакомы, включая социальные сети, которые анализируют данные своих участников, чтобы узнать о них больше и связывать их с контентом и рекламой, имеющими отношение к их интересам, или поисковые системы, просматривающие взаимосвязь между запросами и результатами, чтобы дать более точные ответы. на вопросы пользователей.
Но потенциальное использование идет гораздо дальше! Двумя крупнейшими источниками данных в больших объемах являются данные о транзакциях, включая все, от цен на акции до банковских данных и историй покупок отдельных продавцов; и данные датчиков, большая часть которых поступает из так называемого Интернета вещей (IoT) .Эти данные датчика могут быть любыми: от измерений, сделанных от роботов на производственной линии автопроизводителя, до данных о местоположении в сети сотовой связи , до мгновенного использования электроэнергии в домах и на предприятиях, до информации о посадке пассажиров, полученной во время транзита.