Техническая оптимизация с noindex и nofollow – правила и частые заблуждения
Начнем с того, что обозначим разные способы использования noindex и nofollow:
- Тег <noindex> и атрибут rel=»nofollow»
- Метатеги <meta name=»robots» content=»noindex»/> и <meta name=»robots» content=»nofollow»/>
Тег <noindex> и атрибут rel=»nofollow»
Тег <noindex> – это HTML-тег, который запрещает Яндексу индексировать ту или иную область страницы сайта. Для поисковой системы Google этот тег не работает, более того, в Google вообще не предусмотрена возможность исключения части текста страницы из индекса.
Заблуждение №1. Основная ошибка людей, которые используют этот тег, заключается в убеждении, что если часть какого-либо текста помещена между открывающимся и закрывающимся тегом <noindex>, то робот Яндекса не станет читать и анализировать этот текст.
Единственное, что данный тег запрещает – это помещение содержимого в индексную базу, но это содержимое в любом случае будет прочитано и проанализировано роботом.
Пример: На странице вашего сайта расположен некоторый текст, использующий прямые вхождения предложений из других сторонних источников. Следовательно, эти предложения снижают уникальность вашего текста, а вам необходимо, чтобы уникальность была 100%. Вы решаете закрыть эти предложения тегом <noindex>, чтобы Яндекс считал ваш текст уникальным. Это заблуждение.
Абсолютно весь текст вашей страницы будет прочитан и обработан роботом, и ему будет известно, что текст вашей страницы не является уникальным.
Сама суть тега <noindex> – «не индексировать», значит запрета на чтение нет.
Предположим, что поисковый робот зашел на вашу страницу и начал сканировать содержимое. В какой-то момент робот находит открытие тега <noindex>, что является сигналом роботу – дальше текст не индексировать. Но чтобы найти то место кода, где тег <noindex> закрывается, роботу необходимо прочесть содержимое, идущее после открытия данного тега. Следовательно, даже теоретически нельзя запретить роботам читать содержимое с помощью тега <noindex>.
Для чего же тогда нужен тег <noindex>?
Он нужен непосредственно для того, чтобы запретить роботу выдавать в выдаче своей поисковой системы какую-либо информацию. Это могут быть, к примеру, контакты, которые по каким-либо причинам не должны отображаться в выдаче.
Заблуждение №2. Ещё одно заблуждение, которое часто встречается среди владельцев сайтов, – это мнение, что ссылка, помещенная в тег <noindex>, не будет учтена поисковым роботом. Как я говорил ранее, всё, что находится внутри тега <noindex>, будет прочитано и проанализировано роботом Яндекса. И ссылки не являются исключением. Единственное отличие размещенных обычным образом ссылок от ссылок в теге <noindex> – это то, что текст (анкор) ссылки не будет проиндексирован.
На помощь вебмастерам, которым необходимо, чтобы робот всё же не учитывал ссылки со страниц, приходит атрибут rel=»nofollow», который работает как для Яндекса, так и для Google. При использовании этого атрибута ссылка всё равно будет изучена роботом и по ней будет произведён переход, но без nofollow по ссылке будет передан вес адресату, а с nofollow вес будет сгорать.
Пример 1:
<noindex><a href=»http://1ps.ru/»>Создание и продвижение сайтов</a></noindex>
Яндекс не индексирует анкор, но учитывает ссылку на 1ps.ru и передает по ней вес
Пример 2:
<noindex><a href=»http://1ps.ru/» rel=»nofollow»>Создание и продвижение сайтов</a></noindex>
Яндекс не индексирует анкор и не передает вес по ссылке на 1ps.ru
Существует два способа написания тега <noindex> в коде:
1. <noindex>Текст, запрещённый к индексированию</noindex>
2. <!—noindex—>Текст, запрещённый к индексированию<!—/noindex—>
Второй вариант более верный. Так как тег <noindex> не входит в официальную спецификацию языка разметки HTML, то его присутствие в коде может вызвать недопонимание у других поисковых систем, которые будут считать его наличие за ошибку. Чтобы сделать код страницы валидным, для всех поисковых роботов рекомендуется использовать закомментированный вариант написания. Яндекс такое написание распознает, а другие поисковые роботы не будет обращать внимание на его присутствие.
Метатеги <meta name=»robots» content=»noindex»/> и <meta name=»robots» content=»nofollow»/>
Использование метатега noindex в коде страницы запрещает Яндексу (Google, опять же, в данном случае не участвует) индексировать всё текстовое содержимое страницы, ссылки при этом будут проанализированы в полной мере. То есть наличие в коде страницы этого метатега не равнозначно закрытию страницы от индекса в robots.txt.
Наличие в коде страницы метатега nofollow запрещает поисковым системам индексировать ссылки на страницах. Переходить по ссылкам со страницы при наличии этого метатега роботы также не будут. Но вот что написано в помощи Яндекса:
«Робот не посетит документы, если ссылки на них стоят со страницы, содержащей метатег со значением nofollow, тем не менее, они могут быть проиндексированы, если в других источниках на них указаны ссылки без nofollow»
Подведём итоги
Тег <noindex> используем только для того, чтобы запретить роботам Яндекс выдавать информацию в выдаче.
Если мы хотим, чтобы вес ссылки не передавался адресату, то используем атрибут nofollow. При этом не забываем, что робот всё равно может пройти по ссылке (если информация о ней получена из других источников: карта сайта, ссылки) и проанализирует страницу, на которую она ссылается. Метод работает как для Яндекс, так и для Google.
1ps.ru
Noindex и nofollow – надежные помощники оптимизатора
Зачем использовать тег <noindex> и атрибут rel=«nofollow»
Невзирая на то, что мы упоминаем тег <noindex> и атрибут rel=«nofollow» в пределах одной статьи, они являются совершенно разными элементами кода страниц сайта и соответственно используются для различных целей. Для каких именно, читайте далее по тексту.
Тег <noindex>. Значение и условия применения
Тег <noindex> – размещаемый в HTML-коде странички тег, который запрещает боту поисковой системы Яндекс индексировать часть текста (заключенную внутри него). Тег noindex Яндекс ввел по собственной инициативе, которую до сегодняшнего дня разделяет лишь Рамблер.
Поэтому при использовании тега noindex, Google не будет обращать на него внимания.
Если нужно, чтобы не индексировалась ссылка, noindex не сможет помочь.
В данном примере от индексации будет закрыт лишь анкор «Курсы SEO», а сама ссылка все же будет учтена и по ней передастся вес.
Кстати, довольно часто встречающаяся в сети конструкция rel=«noindex» является ошибочной, поскольку это не атрибут, а тег.
Еще один момент, к которому нужно быть готовым – закрывая от робота часть текста, <noindex> приводит к тому, что валидация сайта будет содержать множество ошибок в коде. Причина все та же: среди тех, кто понимает тег noindex – Яндекс и никто более из существенных поисковиков. Кроме того, этот тег не является стандартизированным.
Но выход все же есть. Для того, чтобы исключить ошибки, связанные с использованием этого тега, существует вариант его написания, который устраивает абсолютно всех:
В этом случае тег будет распознан Яндексом, другие поисковики не обратят на него внимания, а проверка кода не будет воспринимать его, как ошибку.
Несмотря на явную пользу от возможности использовать тег noindex, Google так и не принял его и не создал ничего аналогичного.
Кстати о пользе – вот несколько конкретных ситуаций, в которых данный тег незаменим (не забываем, это актуально только для Яндекса):
- Когда нужно спрятать неуникальный текстовый контент.
- Закрыть от глаз поисковых роботов коды различных счетчиков.
- Убрать из индексации текст, который слишком часто меняется и его добавление в индекс является бессмысленным.
rel=«nofollow». Атрибут, который «работает» со всеми поисковиками
Для того чтобы дать роботу поисковика указание о том, что не нужно переходить и передавать вес по ссылке, существует атрибут тега <a> rel=«nofollow». Он является стандартизированным элементом HTML-кода и воспринимается абсолютно всеми поисковиками.
Причем его использование не делает ссылку невидимой, а лишь указывает, что по ней не нужно переходить и заниматься индексацией страницы, на которую она указывает.
Пример использования:
Использование rel=«nofollow» позволяет:
- Исключить передачу веса на «плохой» (с точки зрения поисковых систем) или нетематичный сайт, чтобы не «испортить» свою репутацию.
- Повлиять на перераспределение веса между присутствующими на странице ссылками.
- Управлять количеством учитываемых исходящих ссылок на страничке.
- Закрыть в комментариях ссылки, по которым не предполагается передача веса.
С использованием атрибута rel=«nofollow» важно не переусердствовать: если постоянно скрывать с его помощью ссылки, это может значительно повлиять на уровень доверия поисковиков к Вашему сайту.
Где еще используются noindex и nofollow
Также noindex и его постоянный спутник nofollow могут использоваться совершенно в ином виде – как значения атрибута content в составе мета-тега robots. Последний, в свою очередь, используется в HTML-коде страницы для указания поисковым ботам рекомендаций насчет индексации страничек и переходу по размещенным на них ссылкам.
Приведенный на скриншоте пример трактуется, как пожелание не выполнять индексацию содержимого странички и не анализировать ссылки, размещенные на ней. Наличие подобной конструкции в теле кода страниц может быть возможной причиной, по которой не индексируется сайт.
Основные выводы
Использование одного из вышеупомянутых элементов (или обоих сразу) зависит от условий, которые преследуются (сокрытие части текста, ссылки или всей страницы при использовании с мета-тегом robots).
Если нужно скрыть от робота Яндекса отдельный текст, noindex это сделает, но когда закрывается ссылка, noindex не поможет. В этом случае следует выбрать атрибут rel=«nofollow», не скрывающий анкор ссылки.
Теперь, когда Вы разобрались с особенностями применения <noindex> и rel=«nofollow», не забудьте поделиться этой важной информацией с теми, кто может в ней нуждаться!
seo-akademiya.com
NOINDEX и NOFOLLOW – что такое и как использовать
Доброго времени суток, уважаемые читатели. Часто сталкиваюсь с тем, что у многих начинающих вебмастеров и блоггеров полная каша в голове по поводу использования noindex и nofollow. Давайте разберемся что это такое, с чем едят и расставим все точки над i.

Стоит начать с того, чтобы в дальнейшем у вас никогда не было путаницы в голове, что и noindex и nofollow используют в двух относительно разных значениях в web-документе.
Первое – это внутри мета-тега ROBOTS (не путайте с файлом robots.txt) в значении атрибута content. Данный мета-тег имеет отношение ко всему документу в целом. Второе, используется только nofollow – внутри тега <a> и имеет отношение к конкретной ссылке. Про тег noindex немного другая история, и о ней мы также сегодня поговорим. Стоит также отметить, что я буду рассматривать использование nofollow и noindex только в двух поисковых системах – Яндекс и Google.
NOINDEX и NOFOLLOW в мета-теге ROBOTS
Мета-тег robots отвечает за всю страницу целиком. Через данный мета-тег можно запрещать или разрешать индексировать контент страницы.
Noindex отвечает за запрет индексации текста на странице.Nofollow отвечает за запрет индексации ссылок на странице.
Используются данные значения следующим образом:
<meta name=»robots» content=»noindex, nofollow» />
что означает – данную страницу нельзя индексировать вообще.Могут быть и такие значения:
<meta name=»robots» content=»index, nofollow» />
можно индексировать контент, но игнорировать ссылки на странице, т.е. не индексировать их.<meta name=»robots» content=»noindex, follow» />
NOFOLLOW в ссылках
Nofollow используется как значение атрибута rel в теге <a>. И отвечает за индексацию каждой конкретной ссылки на странице.
<a href=»url» rel=»nofollow»>ссылка</a>
Атрибут rel показывает отношение данного документа к документу, на который ссылается.
В данном случае, указывая атрибуту rel значение nofollow, мы просим поисковую систему не переходить по внешней ссылке, а также подчеркиваем то, что мы не отвечаем за содержание, на которое ссылаемся.
По ссылкам, оформленным с данным значением, не передается авторитет нашей страницы, другими словами не передается тИЦ и Page Rank. Однако стоит также учитывать и то, что в случае с PR вес все же уходит, но не на сайт, на который мы ссылаемся, а в никуда в прямом смысле этого слова. По поводу тИЦ точной информации о том, уходит вес или остается на сайте — нет.
Итак, абсолютно не важно, сколько ссылок у вас имеют атрибут rel=»nofollow», а сколько без него. Если на странице стоит 10 ссылок, то каждая ссылка получит часть авторитета вашей страницы, и каждая из них передаст этот вес, но если в одном случае вес передастся на конкретный сайт, то в другом случае – вес просто уйдет в никуда.
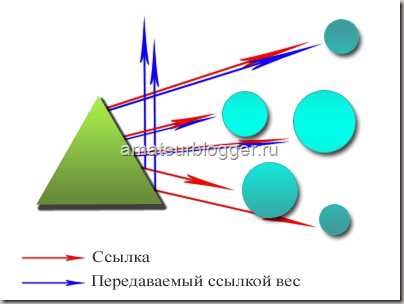
Таким образом цепочка замыкается, все сайты находятся в цикле, и вес, который передает первый сайт всегда возвращается к нему через сотни и тысячи других сайтов. Также не забываем, и я уже писала об этом в статье про перелинковку, что этот вес передается не единожды, а постоянно, при этом с течением времени вес становится только больше, все сильнее увеличивая свой авторитет. Именно на этом принципе строится перелинковка сайта.
Теперь представим, что первый сайт закрыл свои ссылки атрибутом rel=»nofollow». Вес не перейдет на второй сайт, а утечет в никуда, и второй сайт не получит ту часть веса, которую должен был, не сможет передать его дальше по цепочке, и в итоге, пройдя весь цикл, Х-какой-то сайт, который должен был передать вес на первый сайт, передаст его в значительно меньшем количестве, чем мог бы. Итак, каждый раз не получая ту часть веса, которую вы самостоятельно пускаете в никуда, закрывая свои ссылки атрибутом rel=»nofollow», сайт не может передать вам ее, из чего следует, что закрывая свои ссылки, вы сами лишаете себя увеличения веса, и такого показателя, как PR.
Чтобы было проще это понять, представим, что каждая ссылка передает вес, равным единице.
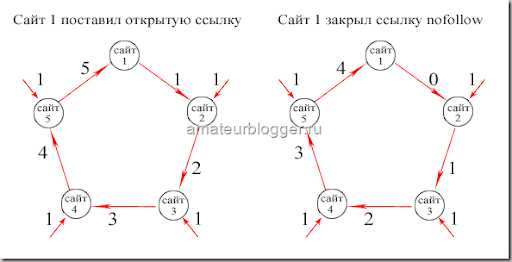
Таким образом, если первый сайт не закрыл ссылку атрибутом rel=»nofollow», то в конце цикла получит больший вес от входящих ссылок, чем в случае, если исходящие ссылки будут закрыты.
Получается, закрывать ссылки не выгодно?
Это действительно так, но только в том случае, если мы ссылаемся на качественные авторитетные ресурсы.
Закрывать ссылку невыгодно, если вы действительно, по настоящему рекомендуете своим читателям статью, на которую ссылаетесь, свою страничку в социальной сети, на свою ленту RSS. Глупо закрывать ссылки на свои же страницы в социальных сетях, когда рекомендуете своим читателям подписаться на обновления блога через них. Ведь это же ваши собственные страницы, ваша собственная RSS лента, в которой транслируется ваше же содержание. Разве вы сами не отвечаете за него?
Но есть ситуации, когда действительно необходимо закрывать ссылки значением nofollow. Обратимся к источникам, Яндекс и Google, что они говорят по этому поводу?
Мы должны закрывать ссылки в тех разделах своего сайта, где любой пользователь может оставить свою ссылку, за которую мы не сможем поручиться, гарантировать, что там качественное содержание.
Дополнительно к этому Google рекомендует обозначать продажные ссылки атрибутом rel=»nofollow». Также Google пишет, что с помощью nofollow мы можем указать роботу на закрытые разделы нашего сайта, но уточняет, что есть и другие способы указывать на это.
Также мне хотелось бы уделить внимание ещё одному моменту. Некоторые ярые борцы за закрытые ссылки ставят rel=»nofollow» не только в самих ссылках, т.е. в теге <a>, но и везде, на что только хватает фантазии. И в теге <iframe>, и <script>, и в теге <img>.
Давайте не будем выдумывать свои собственные стандарты, а обратимся к существующим, которые разрабатывает международная организация W3C.
Значение rel=»nofollow» можно использовать только в теге <a>, и в других тегах его использовать нельзя!
Итак, мы выяснили, когда стоит пользоваться атрибутом ссылки rel=»nofollow», а когда это не целесообразно. Также мы больше не будем вставлять его никуда, кроме одного единственного тега, обозначающего ссылку. Теперь уделим внимание тегу noindex.
NOINDEX – рудимент от Яндекса
Когда-то Яндекс не понимал значение nofollow, и поэтому придумал свой собственные тег
<noindex>что-то внутри</noindex>
для того, чтобы можно было закрывать неугодные ссылки с его помощью. Все, что находилось внутри данного тега игнорировалось роботом Яндекса. Но с тех пор утекло немало воды, Яндекс повзрослел и начал понимать атрибут rel=»nofollow». Случилось это ещё весной 2010 года. Именно тогда тег noindex потерял свое значение в качестве инструмента для закрытия ссылок. Но при этом осталось другое значение – скрывать текстовый контент. Выдержка из раздела Помощь Яндекса:Им рекомендуется скрывать служебные участки текста. О каких служебных участках идет речь – не совсем ясно, но совершенно очевидно, что к ссылкам этот тег теперь не имеет никакого отношения. Т.е. получается, если мы поместим ссылку в данный тег:
<noindex><a href=»url»>анкор ссылки</a></noindex>
то Яндекс учтет все, кроме анкора ссылки. Т.е. ссылка будет учтена, не будет учтен только текст. Таким образом скрывать ссылки тегом noindex не имеет никакого значения.
Можно смело отказаться от использования данного тега, тем более, учитывая ещё и его невалидность. Ведь по сути такого тега вообще не существует. Как мы знаем, стандарты HTML разрабатывает международная организация W3C, и в спецификации к языку HTML нет такого тега, это полностью выдумка Яндекса.
Остался ещё один вопрос, на который мне хотелось бы обратить ваше внимание. Часто, когда я пытаюсь объяснить то, о чем написала в данной статье, мне возражают:
«Я делаю анализ сайта таким-то инструментом, и он показывает мне, что у меня ссылки не закрыты…
или
инструмент такой-то рекомендует закрыть ссылки тегом noindex.
Вы можете верить всем этим инструментам, это ваше полное право, но не лучше ли верить официальной документации поисковиков, и не лучше ли думать собственной головой?
Удачи в оптимизации сайтов.
amateurblogger.ru
что это такое за тег для Яндекса
Noindex – это тег, с помощью которого можно управлять функцией индексации поискового робота. Если выделить отдельный фрагмент текста и закрыть его тегом noindex, он не будет проиндексирован поисковой системой и, соответственно, не попадет в ее кэш. Впервые данный инструмент был предложен специалистами Яндекса, чтобы у веб-мастеров появился простой способ отделения части текстового контента, которая не несет смысловой нагрузки и не должна учитываться при оценке страницы.
Вторая, не менее важная функция тега noindex, состоит в том, чтобы блокировать индексацию отдельных страниц сайта, предназначенных для публикации пользовательского контента. К таким относятся страницы с отзывами, комментариями, сообщениями и др. В данном случае noindex позволяет избежать распространения нежелательной информации и использовать менее жесткий режим модерирования пользовательских сообщений.
Тег noindex учитывает только Яндекс. Google игнорирует его присутствие и проводит полную индексацию текстового содержания страницы. Для задействования блокировки индексации, актуальной для всех поисковиков, следует прописывать соответствующий метатег для отдельных страниц или всего сайта в файле robots.txt. Недостаток данного способа очевиден: запрет на индексацию возможен только по отношению ко всей странице, но не отдельному текстовому фрагменту.
Преимущества тега noindex
- Сокрытие второстепенной информации позволяет повысить релевантность индексируемой страницы за счет возрастания относительной плотности ключевых фраз.
- С помощью noindex можно спрятать содержимое сквозных блоков, информация в которых будет дублироваться на нескольких страницах, что отразится на пессимизации сайта в поисковой выдаче Yandex.
- В некоторых случаях в сниппет может попасть нежелательная или служебная информация, которую проще всего скрыть тегом noindex.
Принцип действия
Noindex может находиться в любом месте HTML-кода вне зависимости от уровня вложенности. Для сохранения валидности кода тег следует использовать в следующем формате:
<!—noindex—>Здесь находится закрытый для индексации текст<!—/noindex—>.
Несмотря на тот факт, что noindex был изначально предложен разработчиками Yandex, использование данного инструмента может быть расценено в качестве серого метода оптимизации. Это связано с тем, что некоторые веб-мастера применяют его не по прямому назначению. В частности, от робота прячется неуникальный контент или качественный текст, не содержащий ключевых слов, рассчитанный на прочтение посетителем сайта. Одновременно поисковику предлагается насыщенный ключевыми фразами текст, тяжелый для восприятия человека.
Для борьбы с подобными методами оптимизации Yandex анализирует текст, закрытый тегом noindex, проводя его индексацию, но впоследствии отфильтровывая скрытое содержимое. В результате изучения контента страницы поисковик может принять решение о наложении санкций на сайт, если сочтет, что его владелец использует неправомерные способы влияния на результаты поисковой выдачи.
wiki.rookee.ru
Теги noindex и nofollow: как использовать

Тег noindex и атрибут nofollow – это различные элементы, использующиеся в коде страницы. Они предназначены для различных целей и применяются по-разному, но для лучшего понимания их стоит рассматривать вместе.
Тег noindex
Noindex применяется для того, чтобы сообщить роботу «Яндекса» о том, что нельзя индексировать определенные части веб-страницы. Тег размещается в HTML-коде и имеет закрывающий тег. Контент, оказавшийся между открывающим и закрывающим тегами, будет игнорироваться ботом.
Тег noindex был придуман «Яндексом», и в настоящее время только два поисковика учитывают его: «Яндекс» и «Рамблер». Боты других поисковых систем игнорируют тег и все равно индексируют всю веб-страницу полностью. Кроме того, тег не может запретить индексировать гиперссылки и передавать по ним вес другому веб-ресурсу.

Валидность
Тег <noindex> не стандартизирован, поэтому его применение может привести к появлению ошибок в коде. Вследствие этого его записывают немного по-другому. В коде страницы этот тег выглядит так:
<!—noindex—>
«Текст, который не должен индексироваться Яндексом»
<!—/noindex—>
Восклицательные знаки и дефисы применяются для валидации кода. Если не использовать эти символы (а писать без них, как это бывает с обычными тегами), то проверка на валидность будет показывать ошибку.
При верном использовании этого тега страница будет правильно восприниматься «Яндексом», Google и другими поисковыми роботами. При этом «Яндекс» поймет, что часть контента надо исключить из индексации, а Google сделает вывод, что в коде нет ошибок, и будет индексировать полностью. У поисковой системы «Гугл» нет аналогичного тега, несмотря на то, что у такого элемента есть много плюсов.
Когда применяется noindex
Этот тег приносит неоспоримую пользу веб-ресурсу. Его применяют, когда надо:
-
скрыть от ботов часть HTML-кода, например коды счетчиков;
-
запретить индексировать часто меняющийся текст веб-страницы, который бессмысленно добавлять в индекс;
-
скрыть неуникальные фрагменты текста, чтобы не терять позиции в поисковой выдаче из-за неуникальности.
Атрибут nofollow
Nofollow – это не тег, а атрибут, использующийся в теге гиперссылки <a>. Этот атрибут, понятный для всех поисковых роботов, используется для того, чтобы запретить переходить по ссылке и передавать вес по ней.
В коде это выглядит так:
<a href=”гиперссылка” rel=”nofollow”> Текст ссылки </a>
Этот атрибут стандартизирован в HTML, поэтому все поисковые боты правильно воспринимают его и выполняют инструкции: не переходят и не передают вес. При этом ссылка не становится невидимой.

Когда применяется nofollow
Существует много ситуаций, в которых этот атрибут незаменим. Nofollow используется, когда требуется:
-
перераспределить вес между несколькими ссылками на одной веб-странице;
-
поставить ссылку на сайт, у которого другая тематика;
-
запретить передачу веса на веб-ресурс, который поисковики считают некачественным;
-
управлять количеством ссылок, которые должны учитываться поисковыми системами;
-
не допустить передачу веса по множеству ссылок в комментариях.
При использовании nofollow нужно знать меру, потому что сайты, на которых все ссылки закрыты с помощью этого атрибута, не вызывают доверия у поисковиков.
Теги noindex и nofollow могут применяться в качестве значения для атрибута content. Это нужно для того, чтобы в метатеге robots дать указание роботам, что на данной странице не нужно ничего индексировать или переходить по ссылкам, размещенным на ней.
Таким образом, применение nofollow или noindex зависит от целей, которых нужно достичь. В качестве таких целей может быть необходимость скрыть часть текста, ссылки или запретить индексировать всю страницу. При этом noindex работает только для «Яндекса», а nofollow – для всех поисковиков.
Noindex является тегом, а nofollow – атрибутом тега <a>. Noindex используется для того, чтобы запретить индексацию контента, а nofollow предназначен для запрета перехода по ссылке и передачи веса.
www.rookee.ru
| HTML | WebReference
Поисковый робот Яндекса «ходит» по сайтам, просматривает и анализирует их содержимое, после чего сохраняет указатель на текст и изображения в поисковую базу данных Яндекса. Такой процесс называется индексированием. Часть веб-страницы можно закрыть от индексирования, поместив её внутрь элемента <noindex>. Тогда при следующем посещении веб-страницы поисковый робот проигнорирует такое содержимое и не станет добавлять его в свою базу данных. Это делается по разным причинам, к примеру, закрытые от индексации ссылки не передают ТИЦ (тематический индекс цитирования).
Важно понимать, что это нестандартный элемент и придуман Яндексом для своих целей. Браузеры никак не поддерживают <noindex> и просто выводят его содержимое как обычно.
Если вам нужно закрыть ссылку для поисковиков, добавьте к ней атрибут rel со значением nofollow:
<a href="//webref.ru" rel="nofollow">Ссылка не индексируется</a>Если требуется закрыть для поисковиков всю страницу используйте элемент <meta>, добавив его в код HTML:
<meta name="robots" content="noindex">Или добавьте в файл robots.txt следующую строку:
Disallow: /private.htmlГде private.html адрес страницы.
Закрывающий тег
Пример
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>noindex</title> </head> <body> <noindex> <p>Данный текст Яндекс не будет индексировать.</p> </noindex> </body> </html>
Браузеры
В таблице браузеров применяются следующие обозначения.
- — элемент полностью поддерживается браузером;
- — элемент браузером не воспринимается и игнорируется;
- — при работе возможно появление различных ошибок, либо элемент поддерживается с оговорками.
Число указывает версию браузреа, начиная с которой элемент поддерживается.
×Автор и редакторы
Автор: Клим Щербаков
Последнее изменение: 30.08.2018
Редакторы: Влад Мержевич
webref.ru
что это такое, как правильно использовать

Nofollow – это атрибут, который прописывается для определенной ссылки или всех ссылок на странице в мета-теге robots с целью запрета поисковым роботам на переход по ним и передачу веса.
Noindex – это атрибут, который закрывает от индексации текст на странице.
То есть, noindex отвечает за контент в документе, в то время как nofollow – за ссылки.
Правила применения и зачем нужен nofollow?
Чтобы понять, в каких случаях может вообще пригодиться этот атрибут, рассмотрим, как к нему относятся популярнейшие поисковые системы.
- Яндекс. Когда на вашем ресурсе содержатся разделы, предназначенные специально для обсуждения записей, написания комментариев к статьям или форум, важно следить за тем, какие исходящие ссылки оставляют в них посетители. Желательно модерировать каждый комментарий. Благодаря этому владелец сайта сможет предотвратить размещение различных вредоносных ссылок от спамеров. Хотя поисковик и не учитывает их, спам сильно влияет на репутацию веб-ресурса и к нему может быть применен фильтр. В связи с этим следует проверять все комментарии, и если есть какие-то сомнения относительно качества размещаемой ссылки, пропишите для них атрибут rel=”nofollow”. Сейчас, в измененном руководстве Яндекс, данный текст был удален и осталось только правило применения rel=»nofollow» Руководство Яндекс о nofollow
- Google. Если у вашего сайта есть раздел, где пользователи могут комментировать записи, есть большой риск, что в комментариях появятся ссылки на вредоносные страницы. Спамеры «любят» сайты с комментариями без модерации. Атрибут nofollow для спам-ссылок спасет ваш ресурс и сохранит его чистую репутацию в глазах поисковой системы. Если же вы доверяете сайту, на который ссылается посетитель или вы сами ссылаетесь, то нет необходимости прописывать nofollow. Руководство Google о nofollow
Эти сообщения взяты с официальных сайтов поисковиков. Как видите, в Яндекс и Google написаны аналогичные вещи: значение nofollow нужно использовать в тех случаях, когда вы хотите сообщить ботам о недоверии в отношении сайта, на который ведет ссылка.
Рассмотрим более конкретные примеры, когда для ссылки требуется прописать запрещающий атрибут:
- Ссылка коммерческого характера. Поисковые системы при ранжировании ресурсов в результатах выдачи нередко анализируют качество ссылающихся на них сайтов. Поэтому для платных ссылок стоит применять nofollow, чтобы они не сказывались на дальнейших позициях ресурса в поисковой выдаче. Согласно правилам поисковых систем, пользователи должны различать информационный контент от коммерческого, поэтому вебмастера обязаны предоставлять информацию о продающих ссылках, которая будет считываться автоматически.
- Материал сомнительного качества. Если вам не нравится содержание страницы, на которую посетитель оставляет ссылку в комментарии, и вы не желаете жертвовать репутацией своего сайта, прописывайте в теги данной ссылки значение rel=”nofollow”. Спамеры, заметив на вашем ресурсе тенденцию, когда к непроверенным ссылкам добавляется блокирующий атрибут, вскоре прекратят попытки навредить сайту. Если же вы видите, что пользователь оставляет ссылку на качественный материал, вручную или автоматически nofollow можно удалить.
- Приоретирезация считывания информации. Поисковые роботы не способны регистрироваться на сайтах и входить в аккаунты. Поэтому есть смысл применить nofollow для таких ссылок как «Войти», «Зарегистрироваться» и ведущих на прочие страницы, которые не несут пользу находясь в выдаче поисковой системы. Это позволит роботу не тратить краулинговый бюджет и сканировать прежде всего самые важные документы для их добавления в индекс. Также важно обеспечить простую навигацию, удобные URL для поисковых машин и пользователей и так далее.
Как правильно прописать nofollow?
Это сейчас nofollow позволяет управлять каждой ссылкой отдельно, но когда-то данное значение можно было задействовать только в мета-теге, который закрывал от поисковой системы абсолютно все ссылки на странице. И для запрета перехода по отдельным ссылкам вебмастерам приходилось блокировать их URL в robots.txt.
Robots Nofollow
Эти мета-теги так и остались по сей день. Если вы хотите закрыть от индексации все ссылки, содержащиеся на определенной странице, то на этой странице нужно прописать такой код:

<meta name=”robots” content=”nofollow” />Важно не путать данный тег с двумя нижеприведенными кодами, content=»none» и content=”noindex, nofollow” блокируют доступ ботов ко всей странице, а не только к ее ссылкам. Поэтому, если вы хотите чтобы страницы индексировались, то ни в коем случае не прописывайте для них два вот этих тега:
<meta name=”robots” content=”none” /><meta name =”robots” content=”noindex, nofollow” />Rel Nofollow
Выше мы рассмотрели варианты, как запретить переход поисковых роботов по всем ссылкам на страницах. Но еще можно назначить запрет на переход к конкретной ссылке.
Чтобы запретить для индексации и переход робота по ссылке, к ней надо прописать атрибут rel=”nofollow”, в коде это выглядит так:
<a href=”URL” rel=”nofollow”>анкор гиперссылки</a>Утекает ли вес ссылки через nofollow?
Хотя Google в своих заявлениях позиционирует применение атрибута nofollow как непреодолимый барьер для поисковых роботов, у каждого правила есть исключения. И это подтвердило обращение бывшего главы компании по борьбе с поисковым спамом, Мэтта Катса. Он заявил, что «Google может учитывать ссылки из социальных сетей, даже несмотря на nofollow».
С Яндексом вопрос еще более явный. Если раньше в справке по Яндекс.Вебмастеру было упоминание о nofollow-ссылках, то сейчас его нету.

Но, раньше можно было это проверить, если применить в поиске такую конструкцию url: ваш урл << inlink:(“анкор ссылки”), и Яндекс нам отображал только те страницы, где содержится наш искомы анкор ссылки. Сейчас же этот метод не работает, поисковая система Яндекс запретила использовать такую конструкцию в поиске. Поэтому можно с большей долью вероятностью сказать, что Яндекс может учитывать такие ссылки.
А вот что касается крупных сайтов, то видно, например, что Яндекс учитывает ссылки с Твиттера, даже если они отдаются через редирект и закрыты nofollow.
В целом можно сказать, что применение данного атрибута для поисковых роботов не всегда является запретом, если особенно сайт авторитетный.
Стоит ли закрывать внутренние ссылки в nofollow?
В прошлом, seo оптимизаторы сильно злоупотребляли rel=»nofollow» тем самым манипулирую передаваемым весом внутри сайта. Поэтому поисковая система Google заявила, что все внутренние ссылки отмеченные rel=»nofollow» будут отдавать вес вникуда.
То есть со страницы где стоит такая ссылка будет уходить вес, но на страницу на которую стоит ссылка он не будет передаваться, получается он будет обнуляться.
Атрибут noindex: что это и чем отличается от nofollow?
Многие начинающие вебмастера ломают голову, не понимая, чем noindex отличается от nofollow. Все просто:
- nofollow — применяется к ссылкам
- noindex — применяется к тексту
Если вы хотите запретить текст на всей странице сайта для индексации, но при этом учитывать ссылки, на странице нужно прописать следующий код:
<meta name=”robots” content=”noindex, follow: />Если вы хотите закрыть часть текста, то в Google нет такого атрибута, но в Яндексе это возможно. Тег noindex был внедрен поисковиком Яндекс, так как раньше он не понимал nofollow, а ненужные ссылки нужно было как-то закрывать от роботов.
Но в 2010 году поисковая система начала работать с атрибутом rel=”nofollow”, при этом noindex не исчез, а остался отвечать за скрытие текста. Теперь, если вы хотите закрыть от индексации текст или например анкор ссылки, пропишите команду:
<noindex><a href=”url”>анкор ссылки</a></noindex>
Сама ссылка будет открыта для индексации, не учтется только ее текст (анкор). Так же можно закрывать не только анкоры ссылок, но и контент.
Например это удобно было, когда Яндекс ввел новый алгоритм Баден-Баден, который накладывал санкции за seo тексты. Стоило закрыть портянки текста в noindex, и можно было выйти из под этого фильтра, причем не потерять позиции в Google, так как поисковая система Google не учитывает тег <noindex></noindex>.
Выводы
Nofollow отвечает за скрытие ссылок, как на всей странице, так и для определенное ссылки. Ранее noindex тоже выполнял аналогичную функцию, но только по отношению к Яндексу, который со временем начал понимать nofollow, в результате чего значением noindex начали закрывать от индексации контент на странице.
Владелец сайта должен грамотно использовать атрибут nofollow и понимать, в каких именно случаях это делать:
- Когда ссылка ведет на веб-ресурсы с некачественным контентом.
- Когда вы размещаете на странице коммерческий контент.
- Для разделов с комментариями в блогах и на форумах, которые чаще всего атакуют спамеры.
По заявлениям, поисковые машины по nofollow-ссылкам не передают вес ссылки, но бывают и исключения.
Главная задача использования nofollow — помочь указать приоритетные для сканирования ссылки, разделить продающие статьи от информационных, а также защитить сайт от спама, который, если не контролировать, может привести к снижению ранжирования или куда хуже, вылету ресурса из индекса.
Для всех других ситуаций можете смело применять dofollow ссылки, открытые для поисковых роботов. Репутация сайта ничуть не ухудшится, а даже улучшится, если вы будете оставлять ссылки на полезные для вашей целевой аудитории страницы. И никакой вес ваши документы не потеряют, а наоборот даже могут приобрести за счет обратного PageRank.
Пожалуйста, оцените эту статью. Чтобы мы могли делать лучший контент! Напишите в комментариях, что вам понравилось и не понравилось!
ПолезноРейтинг статьи: / 5. Кол-во оценок:
webmasterie.ru