Использование тегов noindex и nofollow в продвижении
Рад приветствовать Вас на страницах моего блога barbadosmaney.ru! В данном посте я решил написать о том, как закрыть внешние ссылки от индексации поисковыми системами и зачем все это дело нужно делать.
Статья предназначена в основном для начинающих вебмастеров, которые только недавно начали заниматься продвижением своего сайта. Данную тему, считаю, архиважной при продвижении блога или статьи блога в Топ.
Поэтому я решил осветить несколько вопросов по данной теме:
Для чего нужно закрывать внешние ссылки от индексации.
Закрытие внешних ссылок вручную тегами noindex и rel=”nofollow”.
Автоматическое закрытие внешних ссылок плагином WP-NoExternalLinks.
Сервис для проверки исходящих ссылок.
Разберемся с первым вопросом. Закрывать чужие ссылки со своего сайта следует для того, чтобы не предавать вес вашей страницы другим ресурсам, на которые ссылаетесь. Каждая страница сайта имеет свой вес. Чем больше сайтов на нее ссылаются, тем больше ее вес в глазах поисковых систем.
Практически все вебмастера, занимающиеся продвижением, закрывают внешние ссылки для того, чтобы не дарить авторитет своих вебстраниц чужим ресурсам.
Так же это во многом влияет и на траст сайта. Траст сайта – это некий уровень доверия со стороны поисковых систем к сайту. Вот поэтому нужно следить за исходящими ссылками, дабы попросту не разбазаривать авторитет страниц вашего блога. И впоследствии все это положительно скажется на такие показатели как ТИЦ и PR.
Но это вовсе не говорит о том, что абсолютно все внешние ссылки нужно закрывать. Например, если сайт авторитетный и высокотрастовый почему бы на него не сослаться.
В сети есть такое мнение, что если с сайта не исходит ни одной ссылки, то значит поисковые системы считают его мертвым.
Не знаю, правда это или нет, поэтому спорить не буду. Но то, что огромное количество открытых внешних ссылок молодому блогу в продвижении не поможет – это факт. Кстати, траст своего сайта вы можете проверить на этом сервисе.
Закрываем внешние ссылки тегами noindex и nofollow.
В любом случае, когда никогда придется сослаться на другой вебресурс. Что же делать, чтобы поисковые роботы таких интернет гигантов как Google и Яндекс не индексировали внешние ссылки?
Для робота Яндекса раньше закрывали ссылку атрибутом noindex, а для Google rel=”nofollow”. Но сейчас Яндекс тоже понимает тег
Данный атрибут можно использовать только для ссылок, т.е. в теге <a> и не где больше. Закрытая ссылка будет выглядеть вот так:
<a href=”url” rel=”nofollow”> анкор ссылки </a>
Разберем пример обычной ссылки с названием моего сайта. До закрытия она имеет вот такой вид:
<a href=”http://barbadosmaney.ru” >Заработок в интернете</a>
После закрытия она выглядит так:
<a href=”http://barbadosmaney.ru” rel=”nofollow”>Заработок в интернете</a>
Все, поисковые системы Яши и Гугла не будут ее индексировать. Данный атрибут надо вставлять в статью при ее написании в текстовом редакторе.
Некоторые вебмастера до сих пор используют тег noindex для ссылок, т.е. вот так:
<noindex><a href=”http://barbadosmaney.ru” >Заработок в интернете<a>< /noindex >
Не имеет ни какого смысла сейчас так делать, так как noindex запрещает индексировать только текст. То есть, в данном случае закрыт только анкор ссылки – “Заработок в интернете”, а сама ссылка остается открытой.
К такому выводу я пришел, прочитав статью от самого Яндекса. Хотя некоторые скрипты счетчиков я тегом noindex закрыл.
Автоматически закрываем исходящие ссылки от индексации плагином WP-NoExternalLinks.
Данный плагин пришелся мне по душе. Он очень прост в настройке, а работа его заключается в следующем: он маскирует внешнюю ссылку под внутреннюю. Скачать плагин можно здесь.
После закачивания и активировании его на блоге, переходим к его настройке (редактировать в “Параметрах”). Да там и настраивать особо нечего.

Разделитель ссылок “goto” можно оставить так или изменить на “link”. В пустом окошке нужно прописать адреса сайтов, которые вы не хотите закрывать от индексации. Вот пример его работы: мы хотим сослаться на Яндекса и открытая ссылка выглядит так
После работы плагина она принимает вид (на примере моего сайта)
rel=”nofollow” https://barbadosmaney.ru/goto/ http://www.yandex.ru
Ко всему прочему, по переходу по ссылке сайт открывается в новом окне. Помимо скрытия внешних ссылок в статье, маскируются также ссылки в комментариях и адреса сайтов самих комментаторов.
Самое главное, что мне нравиться в данном плагине – весь процесс автоматизирован.
Сервис для проверки внешних ссылок на сайте.
Очень хороший сервис be1.ru. В нем можно проверить каждую страницу вашего сайта и провести ее анализ на количество исходящих ссылок. Закрытые ссылки помечены красным восклицательным знаком. Он показывает оба тега: noindex и
P.S. Пользоваться или нет рекомендациями данной статьи – дело личное каждого владельца сайта.
Поделиться «Закрытие внешних ссылок от индексации. noindex и nofollow»
barbadosmaney.ru
nofollow — Википедия
Материал из Википедии — свободной энциклопедии
- Для политики Википедии относительно nofollow см. meta:Nofollow
nofollow — значение атрибута rel тега «a» языка гипертекстовой разметки веб-страниц HTML (rel="nofollow"). Значение предназначено для поисковых систем: оно указывает их роботам, что гиперссылку, не нужно сканировать (переходить по ней). Таким же образом, на практике, помечаются рекламные ссылки, а для поисковых систем Google и Яндекс ссылки с данным атрибутам не передают PR и ТиЦ соответственно
Наиболее популярные поисковые системы, соблюдающие стандарты Консорциума Всемирной паутины, не учитывают ссылки с таким атрибутом при расчёте индекса цитирования веб-сайтов.[2]
Существует также мета-тег nofollow с тем же именем и с похожим назначением. Отличается областью действия (на всю страницу).
Пример атрибута nofollow :
<body> ... <a href="http://www.example.com" rel="nofollow">Попытка рекламы</a>
Пример мета-тега nofollow:
<html> <head> <meta name="robots" content="nofollow" /> <title>Don't index this page</title> </head>
Атрибут nofollow специальным соглашением с 2005 года был постепенно введён в разных разделах Википедии. Это было сделано для уменьшения объёмов заспамливания вики-статей внешними ссылками, которые постоянно добавляются «поисковыми оптимизаторами» и владельцами некоторых сайтов для собственной «раскрутки», поднимая таким образом показатель PageRank и посещаемость своих проектов.
С мая 2010-го года робот Яндекса перестал переходить по ссылкам с атрибутом rel=nofollow
Ссылки с nofollow в панели управления сайтом[править | править код]
Из-за того, что процесс индексации идёт отдельно от расчёта «веса» страницы (и ссылок на ней), что будет учтено при последующем ранжировании — в панели управления сайтом могут отображаться обратные ссылки, которые при этом имеют атрибут rel=»nofollow».
Например, ссылки в панели управления сайтом у Yahoo — включают в себя все найденные его роботами (то есть и с атрибутом nofollow и без), в то время как при расчёте веса каждой из них, имеющие атрибут
Аналогичная ситуация и в панели вебмастеров Google — обратные ссылки с тегом nofollow отображаются и не очищаются. Как правило, в список обратных ссылок c атрибутом nofollow попадают сайты с тематических и трастовых ресурсов. Значение в ранжировании обратных ссылок с тегом nofollow гораздо меньше чем у прямой ссылки.
«Быстроробот» поисковой системы Яндекс также может индексировать подобные ссылки («закрытые» атрибутом nofollow), в результате чего такие ссылки будут в списке внешних ссылок на сайт, однако при очередном обновлении имеющие атрибут nofollow ссылки будут постепенно вычищаться.
Как закрыть ссылки от индексации. Тег nofollow и тег niondex
Всем привет! Сегодня на SEO-mayak.com я расскажу как закрыть ссылки от индексации.
Готовясь к нависанию статьи, я перечитал много разных блогов и понял, что сколько людей, столько и мнений.
Я просто не завидую новичкам, которые ищут ответ на вопрос, как правильно закрывать ссылки.
Непонятно, то ли использовать только один тег nofollow, то ли оба тега вместе, а некоторые веб-мастера считают, что уже нет смысла в закрывании ссылок, так как поисковики все равно игнорируют запреты.

В общем дискуссии идут жаркие, которые создают столько «мутной воды» и кажется, что все с ума посходили, пытаясь докопаться до истины. Я тоже поначалу запутался и решил обратиться к справочникам самих поисковых систем.
Значение и применение nofollow
Почему nofollow относят к тегам? На самом деле это никакой не тег, изначально он был атрибутом для мета тега robots, и распространял запрет индексации ссылок на уровне всей страницы, например:
<meta name="robots" content="nofollow" />
С тех пор много воды утекло и nofollow уже не так часто используют на уровне всей страницы, зато значение nofollow для атрибута rel применяют теперь повсеместно. Но как в России бывает, «кличка» тег за значением nofollow закрепилась на веки вечные.
Для новичков показываю, как правильно закрыть ссылку атрибутом rel=“nofollow“:
<a href="site.com" rel="nofollow"> Текст ссылки</a>
И все же, закрывает ли атрибут rel=“nofollow“ ссылки от индексации? Можете прочитать об этом в справке Google. От себя могу сказать следующее:
Атрибут rel=“nofollow“ запрещает роботу следовать по ссылке, т.е. разрывает связку донор-акцептор. Если связки нет, то PageRank акцептору не передается. НО! Ссылка, на странице донора, прекрасно индексируется поисковыми системами.
Если вспомнить формулу расчета PageRank, то из нее следует, что вес, передаваемый по ссылке, равен весу страницы донора, деленному на все ссылки со страницы. Т.е. вес, который предается по ссылкам с донора, передается и по ссылке с атрибутом nofollow. Только в данном случае перетекает в никуда, вместо того, что бы найти себе полезное применение на сайте.
Но как же Яндекс относится к «буржуйскому» атрибуту? Передается ли по ссылке, помеченной nofollow, показатель Яндекса ВИЦ (взвешенный индекс цитирования) мне неизвестно, так как формула расчета ВИЦ является тайной Яндекса, которая храниться за семью печатями. Но если Яша рекомендует закрывать ненадежные ссылки (спам ссылки) rel=“nofollow“, то из этого можно сделать вывод, что робот Яндекса учтет данные ему «рекомендации» и перехода по ссылке не будет.
Неужели никак нельзя закрыть ссылку от индексации, чтобы вес страницы никуда не утекал? Можно, но делается это с помощью jQuery AJAX.
Особенно важно закрывать все внешние ссылки для сайтов, которые находятся еще в песочнице, чтобы не отдавать свой «детский» вес, а наоборот стараться накапливать его. Всегда проверяйте шаблон на скрытые внешние ссылки и используйте плагин ТАС для обнаружения закодированных ссылок, вида base64 decode.
У многих новичков наверное возник вопрос. Что такое вес страницы? Я обязательно на него отвечу, но уже в другой раз, так что советую подписаться на обновления блога.
Подошла очередь рассказать о теге noindex, ведь это детище нашего родного Яндекса, которого мы все так любим 🙂
Применение тега noindex
В начале статьи я уже писал о всеобщем «умопомешательстве» при обсуждении nofollow и noindex и в подтверждение своих слов могу привести ситуацию с закрытием тегом noindex имен (анкоров) комментаторов на блогах.
Ведь и я недавно полагал, что заключая ссылку на сайт комментатора в тег noindex, я тем самым запрещаю роботу Яндекса индексировать эту ссылку и переходить по ней, передовая вес страницы.
Но как я уже писал выше, Яша прекрасно распознает атрибут rel=“nofollow“ и использования noindex закрывает только текст (анкор). Следовательно заключать ссылки в тег niondex, совершенно ненужное и бесполезное занятие.
С помощью тега noindex можно закрывать от индексирования участки текста в контенте, которые являются не уникальными, анкоры ссылок, но никак не сами ссылки.
Теперь немного затрону понятие валидности тега noindex. Вообще это довольно обширная тема и я в будущем посвящу ей отдельную статью.
Дело в том, что распространенное написания тега noindex не проходит валидность. Приведу такой пример:
<noindex>текст, который надо закрыть от индексации</noindex>
Так вот, такое написание тега не пройдет валидацию, а Google вообще об этом теге ничего неизвестно.
После шумихи на разных форумах специалисты Яндекс нашли выход из сложившийся ситуации и предложили изменяемое написание тега, которое выполняя те же функции, является валидным.
Валидное написание тега noindex выглядит так:
<!--noindex-->текст, который надо закрыть от индексации<!--/noindex-->
Для новичков скажу, что тег noindex является парным и использовать его надо только так, как показано на примере.
До встречи!
С уважением, Виталий Кириллов
seo-mayak.com
nofollow и noindex | Закрыть ссылку от индексации
nofollow и noindex | Закрыть ссылку от индексации
nofollow и noindex – самые загадочные персонажи разметки html-страницы, главная задача которых состоит в запрете индексирования ссылок и текстового материала веб-страницы поисковыми роботами.

nofollow и noindex – самые загадочные персонажи разметки html-страницы, главная задача которых состоит в запрете индексирования ссылок и текстового материала веб-страницы поисковыми роботами.
nofollow (Яндекс & Google)
|
nofollow – валидное значение в HTML для атрибута rel тега «a» (rel=»nofollow») |
rel=»nofollow» – не переходить по ссылке
Оба главных русскоязычных поисковика (Google и Яндекс) – прекрасно знают атрибут rel=»nofollow» и, поэтому – превосходно управляются с ним. В этом, и Google, и Яндекс, наконец-то – едины. Ни один поисковый робот не пойдёт по ссылке, если у неё имеется атрибут rel=»nofollow»:
<a href=»http://example.ru» rel=»nofollow»>анкор (видимая часть ссылки)</a>
content=»nofollow» – не переходить по всем ссылкам на странице
Допускается указывать значение nofollow для атрибута content метатега <meta>.
В этом случае, от поисковой индексации будут закрыты все ссылки на веб-странице
<meta name=»robots» content=»nofollow»/>
Атрибут content является атрибутом тега <meta> (метатега). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса
Действие атрибутов rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса несколько разное:
- Увидев атрибут rel=»nofollow» у отдельно стоящей ссылки, поисковые роботы Google не переходят по такой ссылке и не индексируют её видимую часть (анкор). Увидев атрибут content=»nofollow» у метатега <meta> в заголовке страницы, поисковые роботы Google сразу «разворачивают оглобли» и катят к себе восвояси, даже не пытаясь заглянуть на такую страницу. Таким образом, чтобы раз и навсегда закрыть от роботов Google отдельно стоящую ссылку (тег <а>) достаточно добавить к ней атрибут rel=»nofollow»:
<a href=»http://example.ru» rel=»nofollow»>Анкор</a>
А, чтобы раз и навсегда закрыть от роботов Google всю веб-страницу,
достаточно добавить в её заголовок строку с метатегом:
<meta name=»robots» content=»nofollow»/> - Яндекс
- Для роботов Яндекса атрибут rel=»nofollow» имеет действие запрета только! на индексацию ссылки и переход по ней. Видимую текстовую часть ссылки (анкор) – роботы Яндекса всё равно проиндексируют.
Для роботов Яндекса атрибут метатега content=»nofollow» имеет действие запрета только! на индексацию ссылок на странице и переходов по них. Всю видимую текстовую часть веб-страницы – роботы Яндекса всё равно проиндексируют.
Для запрета индексации видимой текстовой части ссылки или страницы для роботов Яндекса – ещё потребуется добавить его любимый тег или значение noindex
noindex – не индексировать текст
(тег и значение только для Яндекса)
Тег <noindex> не входит в спецификацию HTML-языка.
Тег <noindex> – это изобретение Яндекса, который предложил в 2008 году использовать этот тег в качестве маркера текстовой части веб-страницы для её последующего удаления из поискового индекса. Поисковая машина Google это предложение проигнорировала и Яндекс остался со своим ненаглядным тегом, один на один. Поскольку Яндекс, как поисковая система – заслужил к себе достаточно сильное доверие и уважение, то придётся уделить его любимому тегу и его значению – должное внимание.
Тег <noindex> – не признанное изобретение Яндекса
Тег <noindex> используется поисковым алгоритмом Яндекса для исключения служебного текста веб-страницы поискового индекса. Тег <noindex> поддерживается всеми дочерними поисковыми системами Яндекса, вида Mail.ru, Rambler и иже с ними.
Тег noindex – парный тег, закрывающий тег – обязателен!
Учитывая не валидность своего бедного и непризнанного тега,
Яндекс соглашается на оба варианта для его написания:
Не валидный вариант – <noindex></noindex>,
и валидный вариант – <!— noindex —><!—/ noindex —>.
Хотя, во втором случае – лошади понятно, что для гипертекстовой разметки HTML, это уже никакой не тег, а так просто – html-комментарий на веб-странице.
Тег <noindex> – не индексировать кусок текста
Как утверждает справка по Яндекс-Вебмастер, тег <noindex> используется для запрета поискового индексирования служебных участков текста. Иными словами, часть текста на странице, заключённая в теги <noindex></noindex> удаляется поисковой машиной из поискового индекса Яндекса. Размеры и величина куска текста не лимитированы. Хоть всю страницу можно взять в теги <noindex></noindex>. В этом случае – останутся в индексе одни только ссылки, без текстовой части.
Поскольку Яндекс подходит раздельно к индексированию непосредственно самой ссылки и её видимого текста (анкора), то для полного исключения отдельно стоящей ссылки из индекса Яндекса потребуется наличие у неё сразу двух элементов – атрибута rel=»nofollow» и тега <noindex>. Такой избирательный подход Яндекса к индексированию ссылок даёт определённую гибкость при наложении запретов.
Так, например, можно создать четыре конструкции, где:
- Ссылка индексируется полностью
- <a href=»http://example.ru»>Анкор (видимая часть ссылки)</a>
- Индексируется только анкор (видимая часть) ссылки
- <a href=»http://example.ru» rel=»nofollow»>Анкор</a>
- Индексируется только ссылка, без своего анкора
- <a href=»http://example.ru»><noindex>Анкор</noindex></a>
- Ссылка абсолютно НЕ индексируется
- <a href=»http://example.ru» rel=»nofollow»><noindex>Анкор</noindex></a>
Для справки: теги <noindex></noindex>, особенно их валидный вариант <!— noindex —><!—/ noindex —> – абсолютно не чувствительны к вложенности. Их можно устанавливать в любом месте HTML-кода. Главное, не забывать про закрывающий тег, а то – весь текст, до самого конца страницы – вылетит из поиска Яндекса.
Метатег noindex – не индексировать текст всей страницы
Допускается применять noindex в качестве значения для атрибута метатега content –
в этом случае устанавливается запрет на индексацию Яндексом текста всей страницы.
Атрибут content является атрибутом тега <meta> (метатег). Метатеги используются для хранения информации, предназначенной для браузеров и поисковых систем. Все метатеги размещаются в контейнере <head>, в заголовке веб-страницы.
Абсолютно достоверно, ясно и точно, что использование noindex в качестве значения атрибута content для метатега <meta> даёт очень хороший результат и уверенно «выбивает» такую страницу из поискового индекса Яндекса.
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом в заголовке –
Яндекс совершенно не индексирует, но при этом он –
проиндексирует все ссылки на ней.
Разница в действии тега и метатега noindex
Визуально, разница в действии тега и метатега noindex заключается в том, что запрет на поисковую индексацию тега noindex распространяется только на текст внутри тегов <noindex></noindex>, тогда как запрет метатега – сразу на текст всей страницы.
Пример: <noindex>Этот текст будет не проиндексирован</noindex>
<meta name=»robots» content=»noindex»/>
Текст страницы, с таким метатегом – Яндекс полностью не индексирует
Принципиально, разница в действии тега и метатега проявляется в различиях алгоритма по их обработке поисковой машиной Яндекса. В случае с метатегом noindex, робот просто уходит со страницы, совершенно не интересуясь её содержимым (по крайней мере – так утверждает сам Яндекс). А, вот в случае с использованием обычного тега <noindex> – робот начинает работать с контентом на странице и фильтровать его через своё «ситечко». В момент скачивания, обработки контента и его фильтрации возможны ошибки, как со стороны робота, так и со стороны сервера. Ведь ни что не идеально в этом мире.
Поэтому, кусок текста страницы, заключённого в теги <noindex></noindex> – могёт запросто попасть Яндексу «на зуб» для дальнейшей поисковой индексации. Как утверждает сам Яндекс – это временное неудобство будет сохраняться до следующего посещения робота. Чему я не очень охотно верю, потому как, некоторые мои тексты и страницы, с тегом и метатегом noindex – висели в Яндексе по нескольку месяцев.
Особенности метатега noindex
Равно, как и в случае с тегом <noindex>, действие метатега noindex позволяет гибко накладывать запреты на всю страницу. Примеры метатегов для всей страницы сдерём из Яндекс-Вебмастера:
- не индексировать текст страницы
- <meta name=»robots» content=»noindex»/>
- не переходить по ссылкам на странице
- <meta name=»robots» content=»nofollow»/>
- не индексировать текст страницы и не переходить по ссылкам на странице
- <meta name=»robots» content=»noindex, nofollow»/>
- что, аналогично следующему:
- запрещено индексировать текст и переходить
по ссылкам на странице для роботов Яндекса - <meta name=»robots» content=»none»/>
Вот такой он, тег и значение noindex на Яндексе :):):).
Тег и метатег noindex для Google
Что-же касается поисковика Google, то он никак не реагирует на присутствие выражения noindex, ни в заголовке, ни в теле веб-страницы. Google остаётся верен своему валидному «nofollow», который он понимает и выполняет – и для отдельной ссылки, и для всей страницы сразу (в зависимости от того, как прописан запрет). После некоторого скрипения своими жерновами, Яндекс сдался и перестал продвижение своего тега и значения noindex, хотя – и не отказывается от него полностью. Если роботы Яндекса находят тег или значение noindex на странице – они исправно выполняют наложенные запреты.
Универсальный метатег (Яндекс & Google)
С учётом требований Яндекса, общий вид универсального метатега,
закрывающего полностью всю страницу от поисковой индексации,
выглядит так:
- <meta name=»robots» content=»noindex, nofollow»/>
- – запрещено индексировать текст и переходить по ссылкам на странице
для всех поисковых роботов Яндекса и Google
nofollow и noindex | Закрываемся от индексации на tehnopost.info
- nofollow (Яндекс & Google)
- rel=»nofollow» – не переходить по ссылке
- content=»nofollow» – не переходить по всем ссылкам
- Действие rel=»nofollow» и content=»nofollow»
на поисковых роботов Google и Яндекса
- noindex – не индексировать текст
(тег и значение только для Яндекса)- Тег <noindex> – не признанное изобретение Яндекса
- Тег <noindex> – не индексировать кусок текста
- Метатег noindex – не индексировать текст всей страницы
- Разница в действии тега и метатега noindex
- Особенности метатега noindex
- Тег и метатег noindex для Google
- Универсальный метатег (Яндекс & Google)
tehnopost.info
Использование nofollow и noindex для внутренней перелинковки страниц — Devaka SEO Блог
Из-за возникновения в последнее время у владельцев сайтов вопросов, связанных с использованием тега noindex и атрибута ссылки nofollow при перелинковке страниц, следует разобраться в этих вещах немного подробнее.
Внутренней перелинковкой сайта можно назвать манипуляцию ссылками на его страницах, которыми, в плане веса, мы можем “сделать акцент” на определенные разделы своего ресурса. При перелинковке часто возникают такие случаи, когда ссылку необходимо показать пользователю, но от робота скрыть, либо указать ему как-то, чтобы он её не учитывал. Таким образом, мы смогли бы сделать акцент на наиболее важных ссылках.
Ранее, для решения этой задачи, при продвижении в Google использовали атрибут ссылки rel=nofollow, а для Яндекса тег <noindex>. Но со временем мир меняется и Google поменял алгоритм при пересчете весов страниц, а Яндекс стал учитывать атрибут nofollow (по аналогии с Google). Помимо этого, ссылки в noindex все же учитываются и могут появляться в панели для вебмастеров, не учитывается лишь их текст.
Если схематически представить работу noindex и nofollow, то это будет выглядеть примерно так:
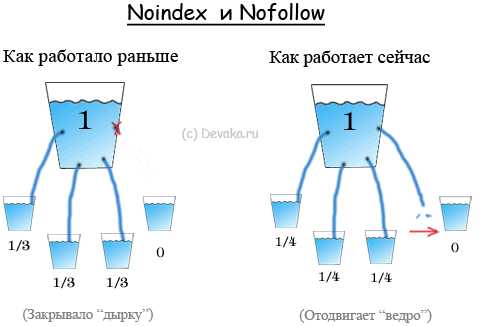
Ведра здесь отображают страницы,
дырки в ведре – наличие ссылки на странице,
струйки – перетекание веса от страницы-донора к странице-акцептору,
цифры обозначают примерный вес страниц.
Если раньше nofollow в Google и noindex в Яндексе (для ссылок) убирали “дырки в ведре” и акцептор не получал веса из этого “ведра”, то сейчас “дырки” остаются и передвигается лишь “ведро-акцептор”, чтобы в него не попала “струйка” веса 🙂
Другими словами, использование noindex и nofollow не закрывает дыр вашего сайта и из-за них другие страницы получат меньше веса, чем могли бы. Поэтому, для решения поставленной в начале статьи задачи необходимо убирать ненужные ссылки со страниц совсем.
Отсюда возникает ряд вопросов, своими ответами на которые делюсь ниже.
Стоит ли использовать noindex и/или nofollow для внутренней перелинковки?
Не рекомендую! Для внутренней перелинковки они вам не помогут, лучше, в данном случае, от них отказаться (прямым текстом).
Откуда информация по noindex для Яндекса?
Вебмастерам Платон из службы поддержки отвечает, что <noindex> исключит из индексирования часть текста, но ссылки при этом будут проиндексированы. Это же подтверждается наличием подобных ссылок в панели для вебмастеров. Подробнее в Яндекс.Помощи…
Зачем введены эти новшества в перерасчете веса поисковиками?
Возможно для того, чтобы корректно расчитывать веса страниц.
Как закрыть ссылку от поисковика другим способом?
Для яндекса пока работает JavaScript, но это ненадолго. Google поймёт любую ссылку, даже во Flash 🙂 Не старайтесь скрывать что-то от кого-то, просто делайте грамотную навигацию, юзабельную и без излишеств.
Как закрыть часть текстового контента от Google?
Noindex для гугла не работает, официальных тегов для этого Google не предоставляет. Контент, который необходимо закрыть, можете попробовать загружать аджаксом (ajax).
А вы используете nofollow или noindex для внутренних ссылок?
devaka.ru
Заблуждения о теге и атрибуте rel=»nofollow»
 Уж сколько раз говорено-переговорено про всем известные запрещающие теги, позволяющие закрыть ссылки от индексации! Однако многие вебмастера так и не удосужились правильно понимать их суть и назначение. Давайте освежим память ( а новичкам сделаем в ней «зарубку») и рассмотрим, ЗАЧЕМ, КАК И ПОЧЕМУ, ОТЧЕГО и ДЛЯ ЧЕГО, В КАИХ СЛУЧАЯХ и КАК ЭТО БУДЕТ ПРАВИЛЬНО ДЕЛАТЬ, когда появиться необходимость использовать эти теги. Главное — выявить заблуждения, которыми страдают вебмастера, используя их.
Уж сколько раз говорено-переговорено про всем известные запрещающие теги, позволяющие закрыть ссылки от индексации! Однако многие вебмастера так и не удосужились правильно понимать их суть и назначение. Давайте освежим память ( а новичкам сделаем в ней «зарубку») и рассмотрим, ЗАЧЕМ, КАК И ПОЧЕМУ, ОТЧЕГО и ДЛЯ ЧЕГО, В КАИХ СЛУЧАЯХ и КАК ЭТО БУДЕТ ПРАВИЛЬНО ДЕЛАТЬ, когда появиться необходимость использовать эти теги. Главное — выявить заблуждения, которыми страдают вебмастера, используя их.
Существуют запрещающие теги
Тег noindex и атрибут rel=»nofollow»
Метатеги <meta name=»robots» content=»noindex»/> и <meta name=»robots» content=»nofollow»/>
Давайте-ка немного вних разберемся.
Суть тега <noindex>
Тег <noindex> – это HTML-тег, который запрещает Яндексу индексировать ту или иную область страницы сайта. Для поисковой системы Google этот тег не работает, более того, в Google вообще не предусмотрена возможность исключения части текста страницы из индекса.
Заблуждение №1. Основная ошибка людей, которые используют этот тег, заключается в убеждении, что если часть какого-либо текста помещена между открывающимся и закрывающимся тегом <noindex>, то робот Яндекса не станет читать и анализировать этот текст.
Единственное, что данный тег запрещает – это помещение содержимого в индексную базу, но это содержимое в любом случае будет прочитано и проанализировано роботом.
Пример: На странице вашего сайта расположен некоторый текст, использующий прямые вхождения предложений из других сторонних источников. Следовательно, эти предложения снижают уникальность вашего текста, а вам необходимо, чтобы уникальность была 100%. Вы решаете закрыть эти предложения тегом <noindex>, чтобы Яндекс считал ваш текст уникальным. Это заблуждение.
Абсолютно весь текст вашей страницы будет прочитан и обработан роботом, и ему будет известно, что текст вашей страницы не является уникальным.
Сама суть тега <noindex> – «не индексировать», значит запрета на чтение нет.
Предположим, что поисковый робот зашел на вашу страницу и начал сканировать содержимое. В какой-то момент робот находит открытие тега <noindex>, что является сигналом роботу – дальше текст не индексировать. Но чтобы найти то место кода, где тег <noindex> закрывается, роботу необходимо прочесть содержимое, идущее после открытия данного тега. Следовательно, даже теоретически нельзя запретить роботам читать содержимое с помощью тега <noindex>.
Для чего же тогда нужен тег <noindex>?
Он нужен непосредственно для того, чтобы запретить роботу выдавать в выдаче своей поисковой системы какую-либо информацию. Это могут быть, к примеру, контакты, которые по каким-либо причинам не должны отображаться в выдаче.
Заблуждение №2. Ещё одно заблуждение, которое часто встречается среди владельцев сайтов, – это мнение, что ссылка, помещенная в тег <noindex>, не будет учтена поисковым роботом. Как я говорил ранее, всё, что находится внутри тега <noindex>, будет прочитано и проанализировано роботом Яндекса. И ссылки не являются исключением. Единственное отличие размещенных обычным образом ссылок от ссылок в теге <noindex> – это то, что текст (анкор) ссылки не будет проиндексирован.
Существует два способа написания тега <noindex> в коде:
- <noindex>Текст, запрещённый к индексированию</noindex>
- <!—noindex—>Текст, запрещённый к индексированию<!—/noindex—>
Второй вариант более верный. Так как тег <noindex> не входит в официальную спецификацию языка разметки HTML, то его присутствие в коде может вызвать недопонимание у других поисковых систем, которые будут считать его наличие за ошибку. Чтобы сделать код страницы валидным, для всех поисковых роботов рекомендуется использовать закомментированный вариант написания. Яндекс такое написание распознает, а другие поисковые роботы не будет обращать внимание на его присутствие.
Назначение тега rel=»nofollow»
На помощь вебмастерам, которым необходимо, чтобы робот всё же не учитывал ссылки со страниц, приходит атрибут rel=»nofollow», который работает как для Яндекса, так и для Google. При использовании этого атрибута ссылка всё равно будет изучена роботом и по ней будет произведён переход, но без nofollow по ссылке будет передан вес адресату, а с nofollow вес будет просто сгорать.
Пример 1:
<noindex><a href=»http://prt56.ru/»>Создание и продвижение сайтов</a></noindex>
Яндекс не индексирует анкор, но учитывает ссылку на prt56.ru и передает по ней вес
Пример 2:
<noindex><a href=»http://prt56.ru//» rel=»nofollow»>Создание и продвижение сайтов</a></noindex>
Яндекс не индексирует анкор и не передает вес по ссылке на prt56.ru. Кроме того, атрибут rel=»nofollow» дает поисковым ситемам сигнал о том, что данная ссылка не продажная и это немаловажно для оценки сайта со стороны поисковых ситем.
Метатеги <meta name=»robots» content=»noindex»/> и <meta name=»robots» content=»nofollow»/>
Использование метатега noindex в коде страницы запрещает Яндексу (Google, опять же, в данном случае не участвует) индексировать всё текстовое содержимое страницы, ссылки при этом будут проанализированы в полной мере. То есть наличие в коде страницы этого метатега не равнозначно закрытию страницы от индекса в robots.txt.
Наличие в коде страницы метатега nofollow запрещает поисковым системам индексировать ссылки на страницах. Переходить по ссылкам со страницы при наличии этого метатега роботы также не будут. Но вот что написано в помощи Яндекса:
«Робот не посетит документы, если ссылки на них стоят со страницы, содержащей метатег со значением nofollow, тем не менее, они могут быть проиндексированы, если в других источниках на них указаны ссылки без nofollow». Это тоже нужно учитывать.
Источник
(Visited 9 times, 1 visits today)
prt56.ru
Noindex, nofollow для Google — как и когда использовать с пользой для SEO продвижения
Существуют три разных понятия:
- метатег “robots” со значением”noindex”;
- тег <noindex>;
- атрибут rel=”nofollow”.
Noindex
Noindex – это директива для поисковых систем, которая запрещает отображать страницу либо часть текста в результатах поиска. Давайте рассмотрим подробнее – где и в каких случаях используется эта директива?
Mетатег “robots” со значением “noindex”
Чтобы не допустить определенную страницу к индексированию поисковыми системами используется метатег robots с добавлением значения “noindex”.
В разделе <head> страницы размещается следующая конструкция:
<head>
<meta name="robots" content="noindex" />
…
</head>
Данный метатег распространяется на всех роботов поисковых систем. Но иногда может использоваться только для определенных роботов, в зависимости от целей. Например, можно запретить индексацию только лишь определенной поисковой системе, указав в значении для атрибута “name” название робота (например – Googlebot, для Google):
<meta name="googlebot" content="noindex" />
Пример: Вы не хотите, чтобы ваши изображения были найдены через поиск по изображениям и использованы кем-то в личных целях.
Решение: Можно запретить индексацию страницы с данными изображениями только в поиске по изображениям, используя робот Googlebot-Image:
<meta name="googlebot-image" content="noindex" />
Таким образом, страница появится в результатах обычного поиска, но её содержимое не будет индексироваться для поиска по изображениям.
Тег <noindex> – для закрытия от индексации части контента
Для того, чтобы закрыть от индексации часть текста используется тег <noindex>, который может быть помещен в любые элементы html-кода страницы:
<noindex>текст, который будет запрещен к индексированию</noindex>
Однако, данный тег будет восприниматься только поисковиком Яндекс, так как он не является стандартизированным и был введен только этой поисковой системой.
Если мы разместим текст внутрь тега, то он не будет индексироваться при сканировании роботом Яндекс и при этом будет попадать в индекс всех остальных поисковиков.
Валидность
Так как тег <noindex> не является стандартизированным, то могут возникать ошибки валидации. Чтобы код оставался валидным, рекомендуется использование тега в таком виде:
<!--noindex-->текст, который будет запрещен к индексированию<!--/noindex-->
Варианты использования meta robots noindex
Мета-тег “Robots” содержит директивы, разделенные запятыми:
- Index/Noindex задает правило индексации страницы;
- Follow/Nofollow разрешает или запрещает переходить по ссылкам со страницы. Значения по умолчанию – Index и Follow.
Существуют следующие варианты использования метатега:
| <meta name=“robots” content=“index,follow”> | Разрешено индексировать страницу и переходить по ссылкам на ней. |
| <meta name=“robots” content=“noindex,follow”> | Запрещено индексировать страницу, но можно переходить по ссылкам на ней. |
| <meta name=“robots” content=“index,nofollow”> | Разрешено индексировать страницу, но нельзя переходить по ссылкам на странице. |
| <meta name=“robots” content=“noindex,nofollow”> | Запрещено индексировать страницу и переходить по ссылкам на ней. |
Как показывает практика (см. эксперимент С. Кокшарова), Google обычно корректно воспринимает данные правила. Что касается Яндекс, то он может не всегда следовать правилу “noindex, nofollow” и переходит по ссылкам, чтобы проверить их качество (под такими директивами иногда прячутся недобросовестные сайты).
Отличия meta robots noindex от noindex в robots.txt
Есть 2 способа скрыть страницу от индексирования:
- Закрыть страницу в robots.txt с помощью Disallow.
- Добавить на страницу в <head> метатег:
<meta name="robots" content="noindex" />
Основные отличия:
- В robots.txt можно закрыть от индекса не только страницу, а и папку, тип файла, служебные страницы сайта, результаты поиска по сайту и т.д. – то есть можно работать массово с группами страниц.
- <meta name=”robots” content=”noindex, follow”> позволяет закрывать страницы точечно, а также передавать ссылочный вес.
Если необходимо закрыть определенную страницу, лучше все-же воспользоваться метатегом чтобы не перегружать robots.txt лишними строками. Кроме того, выше вероятность того, что правило сработает (по сравнению с robots.txt).
Помните, что robots.txt – это всего лишь рекомендации, то есть поисковые системы могут игнорировать его — индексировать и сканировать запрещенные URL. Поэтому, если вы хотите скрыть URL с гарантией, лучше это сделать через метатег. А если уж наверняка – то можно, например, закрыть директории паролем.
Распространенные ошибки
Страница закрыта через метатег, но все равно находится в поиске
Возможные причины:
- Страница закрыта также robots.txt и робот не заходит на неё, соответственно не может прочитать директиву в метатеге noindex.
- Робот еще не успел посетить страницу (на сайте много страниц).
Решение: Чтобы закрыть страницу через метатег, необходимо, чтобы она была открыта в robots.txt. Если на сайте много страниц, а страницу нужно срочно закрыть – лучше воспользоваться панелью вебмастера.
Внедрение одновременно noindex и rel canonical на страницах (например, пагинации)
Это частая ошибка вебмастеров, ведь эти два тега противоречат друг другу. Google дает четкий ответ по этому поводу тут: https://www.seroundtable.com/noindex-canonical-google-18274.html .
Решение для страниц пагинации:
- canonical не использовать,
- на страницах пагинации прописать: <meta name=”robots” content=”noindex, follow” />, а также link rel=”prev” и link rel=”next”.
На сайте есть не закрытые метатегом служебные страницы – версии страниц «для печати», а также служебные/шаблонные страницы, которые создаются динамически. Это частая проблема, так как в индекс могут попасть сотни ненужных страниц. В дальнейшем эти «мусорные» страницы могут ранжироваться в поиске вытесняя полезные продвигаемые страницы. Закрытие через robots.txt может не решить проблему.
Решение: Google советует закрыть такого рода страницы через метатег <meta name="robots" content="noindex, nofollow" />.
Атрибут rel-nofollow
Значение rel=”nofollow” запрещает поисковой системе переходить по конкретной ссылке.
Пример использования: <a href="test.com" rel="nofollow">Ссылка</a>
Google утверждает: «…Как правило, переход не производится. Это означает, что по этим ссылкам Google не передает ни PageRank, ни текст ссылки…»
Однако, «как правило» предполагает, что бывают исключения. Также, например, ссылки с nofollow могут быть проиндексированы, если на страницу ссылаются другие сайты без использования nofollow, либо страница есть в Sitemap.
Как и где использовать
Рекомендуется использовать rel=”nofollow”:
- для закрытия ссылок на некачественный контент или контент, которому вы не доверяете,
- для закрытия неуникального контента,
- для закрытия платных ссылок,
- для корректной индексации (например, чтобы скрыть технические страницы и не тратить ресурсы робота на их сканирование).
Помимо этих случаев, многие оптимизаторы используют rel=”nofollow”, когда хотят, чтобы внешняя ссылка не передавала вес.
Передает ли nofollow вес
По словам Google, rel=”nofollow” не передает ссылочный вес. Однако, есть свидетельства, что Google учитывает ссылки социальных сетей Facebook, Twitter не смотря на nofollow.
Что касается Яндекс, то с 2010 года он не учитывает ссылки с nofollow и, соответственно ссылка не передает вес. Это официальная версия Яндекс. Однако, есть подтверждения экспериментов, что Яндекс учитывает анкоры таких ссылок.
Как бы там ни было, ваш ссылочный профиль должен быть разнообразным и рекомендуется разбавлять анкор-лист ссылками с rel=”nofollow”.
Распространенные ошибки
Использование rel=”nofollow” для внутренней перелинковки.
Google так делать не советует (https://www.searchengines.ru/mett_katts_ne_nofollow_int_links.html )
Использовать rel nofollow на каждый язык языковой версии чтобы «сегментировать» их, не передавая вес друг-другу.
Не нужно с помощью rel nofollow пытаться манипулировать весом. Если сайт целостный, все равно в рамках внутренней перелинковки вес будет переходить. Как уже говорилось выше – Google не приветствует rel nofollow для внутренней перелинковки. Но не забудьте об использовании hreflang.
Использовать rel nofollow для ссылок на страницы фильтра.
Рекомендуется не использовать атрибут nofollow, а реализовать фильтры с помощью JS или закрывать страницы метатегом noindex, nofollow.
Надеемся, что данная статья ответила на основные вопросы по использованию тегов noindex, nofollow. Желаем успешного продвижения!
proposition.com.ua